
Abstract
While embracing digitalization that is further accentuated by the Covid-19 pandemic, the real business outcome is achieved through a robust and well-crafted ‘Data Science Strategy’ (DSS), as significant constituent of Enterprise Digital Strategy. Extant literature has studied the challenges in adoption of components of ‘Data Science’ in discrete for various industry sectors and domains. There is dearth of studies on comprehensive ‘Data Science’ adoption as an umbrella constituting all of its components. The study conducts a “Systematic Literature Review (SLR)” on enablers and barriers affecting the implementation and success of DSS in enterprises. The SLR comprised of 113 published articles during the period 1998 and 2021. In this SLR, we address the gap by synthesizing and proposing a novel framework of ‘Enablers and Barriers’ influencing the success of DSS in enterprises. The proposed framework of ‘Data Science Strategy’ can help organizations taking the right steps towards successful implementation of ‘Data Science’ projects.
Similar content being viewed by others


1 Introduction
There is a digital revolution in businesses across sectors and geographies. There is a need for both traditional and new business models to capitalize on the digital technologies to overcome existential threats and gain access to game-changing opportunities. The digitalization revolution has gained momentum on the back of the Covid-19 pandemic which has forced businesses to reshape their business models. The availability of digital technologies and vastly spread Internet connectivity is leading to large-scale digital transformations, enabling organizations to redefine their business models (Van Tonder et al. 2020). Digital transformation involves two steps, namely, digitization and digitalization (Verhoef et al. 2021). Digitization is the process of transforming information from analogue to the digital mode. Digitalization refers to the process of leveraging digital technologies to redefine business models to benefit from digital business opportunities.
For successful implementation of digital transformation initiatives in shaping the next generation of products and services, organizations need a coherent and well-crafted digital strategy supported by technology and customer experience (Erceg and Zoranović 2020; Pappas et al. 2018; Sebastian et al. 2017; Zaki 2019). This strategy has to be enabled by digital capabilities (Westerman 2018). Any digital strategy encompasses the exploration, application, and large-scale adoption of technologies, such as Social, Mobile, Analytics, Cloud, and IoT (SMACIT), Virtual Reality, Blockchain, 3D Printing, Drones, and Augmented Reality. Adopting the right digital strategy will enable organizations in remaining competitive, overcoming the challenges of digitalization, and taking advantage of opportunities (Becker and Schmid 2020).
The digital strategy augments the organizational strategy by transitioning from predicting and planning to experimenting and responding. It also helps in agile planning, inclusive responsibilities, and utilization of IT capabilities. Digital solutions strategy often includes establishing ‘Data Science’ capabilities (Dremel et al. 2017). The rapid increase in digitization is opening up avenues for the large-scale capture, storage, and analysis of business data, which if optimally used with ‘Data Science’ tools and technologies can unlock significant business benefits. ‘Data Science’ plays a vital role in harnessing data from all organizational touchpoints and analyzing it to generate business insights across the domains of R&D, manufacturing, marketing, operations, supply chain, customer relationship management, strategy formulation, finance, human resource management, and others.
Driven by technological advancements, the increased ability to collect and process large amounts of data to extract business insights has led to a rush towards the implementation of ‘Data Science’ initiatives. It is expected that early adopters of Artificial Intelligence (AI) will share a global profit pool of $1 trillion by 2030 (Bughin 2018). Though the importance of ‘Data Science’ is widely acknowledged, most organizations are still in the early stages of adoption. About 75% to 80% of organizations (Deloitte’s Analytics Advantage Survey, 2013; Forbes report, 2015) have failed to successfully deploy ‘Data Science’ (Ghasemaghaei et al. 2018; Mazzei and Noble 2017).
In 2015, more than 75% of organizations either invested or planned to invest in ‘Data Science’ (Sun et al. 2020). However, more than 95% (2017 survey by McKinsey Global Institute and Digital@McKinsey) of the companies across domains and geography have not embraced AI to reinventing their business operations (Bughin 2018). As of 2017, while more than 80% of the organizations see an opportunity in adopting AI strategically, only 23% of them have adopted AI, and another 23% have started with pilot projects in AI (Ransbotham et al. 2017). By 2019, though AI adoption grew by 270% over the last four years (2015–2018), only 37% of the organizations have actually deployed AI or at least have short-term plans of embracing it (Rowell- Jones and Howard, 2019: 2019 Gartner CIO Survey). Amongst the ‘Data Science’ technology adopters, a large section has not achieved the desired Return on Investments (ROI) or repeated success from adoption (Braganza et al. 2017).
In the recent past, GE failed to implement a digital strategy planned towards digital transformation and as a result, had to lay off employees supporting its digital strategy (Colvin 2018). In similar lines, Nike could not reap benefits from customer digital data that was intended to provide feedback and suggestions on consumer lifestyle (de Swaan Arons et al. 2014). Nike had to discontinue its Nike + products (Correani et al. 2020). This implies that despite much hype (Fox and Do 2013) about ‘Data Science’ and its benefits, the successful implementation in organizations and in public sector (Vydra and Klievink 2019), and achieving the desired outcomes remain a challenge (Tabesh et al. 2019). We attribute this challenge to the lack of a well-crafted, holistic, distinct and robust 'Data Science Strategy' and/or failure in its implementation.
The evidence from reviewed articles suggests a lack of concise framework for understanding the enablers and barriers of ‘Data Science Strategy’ in enterprises. Therefore, the main purpose of this article is to synthesize all the enablers and barriers affecting the formulation and implementation of ‘Data Science Strategy’ in organizations across different industries, sectors, and geographies. To begin with, the structured literature survey is carried out to summarize the learnings from extant literature. The literary content is then segmented under appropriate themes. The study also proposes a conceptual framework for the successful implementation of ‘Data Science’ projects which would also be of use to future researchers with significant agenda for ‘Data Science Strategy’ research.
The learnings from this “Systematic Literature Review (SLR)” can be used by both academic researchers and practitioners in the field of ‘Data Science’ and ‘Information System’ Strategy. Academic researchers can explore the gap in existing literature in the area of ‘Data Science Strategy’ and attempt empirical studies on areas where the gaps have been identified. Practitioners such as ‘Data Science’ management, ‘Chief Data Science Officers’ can use our findings to understand the challenges, issues, best practices, and the possibilities of implementing ‘Data Science Strategy’ in their organizations.
Specifically, this paper focuses on the following research questions with respect to Data Science: What are the enablers and barriers that affect the strategic implementation and success of ‘Data Science’ in organizations?
The remaining sections of the paper are organized as follows: The background section presents the contextual information on ‘Data Science’ and its constituents, ‘Data Science Strategy’, and Contexts and associated factors. The research method section then discusses the methodology used in our literature review. This is followed by the results section, which presents the synthesized findings and conceptual framework. The discussion section details the various organizational approaches to ‘Data Science’ adoption, theoretical contributions and managerial implications. The limitations and future research section details the limitations of the study and the avenues for future research. Finally, the conclusion section summarizes the findings of the study.
2 Background
The definition of ‘Data Science’ is constantly evolving with the continuous advancement in technological trends. ‘Data Science’ is a cyclical process of capturing the business needs and acquiring the relevant data, storage, security, privacy, preparation, pre-processing, analytics; generating and communicating insights; and finally, actuating these actionable insights (Jägare 2019). ‘Data Science’ is an umbrella term that cuts across constituents such as Artificial Intelligence (AI), Machine Learning (ML), Big Data (BD), Big Data Analytics (BDA), Visualization, and Business Intelligence & Analytics (BI&A), Mathematics, Computer Science & Programming Skills, and Domain Knowledge (Fig. 1).

‘Data Science’ constituents. The size and shape of each circle (or oval) in Fig. 1 is only representative, drawn in convenience to adjust the text and not indicative of any weightage to the ‘Data Science Constituents.’
‘Data Science Strategy (DSS)’ refers to the overall organizational strategy signifying its ‘Data Science' investment. It includes the overall Data Science objectives, strategic choices, regulatory requirements, data strategy (data management including, acquisition, storage, security, privacy, ethics, and data governance), resource management, competency build-up, infrastructure planning. This strategy also defines the means to track Key Performance Indicators (KPI) and Return on Investments (ROI) (Jägare 2019).
The adoption and successful implementation factors of ‘Data Science Strategy’ vary between industries and, more importantly, on the aligned business objectives. Currently, the Covid-19 pandemic is testing the resilience of organizations by challenging organizational design and work practices. In giant organizations (viz. Amazon, Google, AirBnB), Small and Medium Enterprises (SMEs), and start-ups, the key focus is on refining the current organizational strategy to integrate digital-enabled exponential systems (George et al. 2020). In context of the growing debate on automation replacing jobs, Soto-Acosta (2020) note that only 20% of activities are automated and the rest are augmented by digitalization. To make automation possible, more jobs need to be created in the area of ‘Data Science’ in order to perform the majority of tasks remotely. The Covid-19 pandemic is acting as a catalyst for the digital transformation of established firms as well as startups, forcing them to innovate in order to survive. Even traditional companies with no or limited digital experiences are adopting digital technologies in order to stay relevant in the market. This acceleration in the adoption of digital technologies finds reflection in the revised way of techniques for data collection, online appointments and therapies, work-from-home, smart-homes, schooling, learning and social interconnect activities (Hantrais et al. 2020; Maalsen and Dowling 2020).
Extant literature has studied ‘Data Science Strategy’ in the contexts of dynamic market places, organizational and dynamic capabilities (Knabke & Olbrich, 2018), innovations (Mikalef et al. 2018, 2019a), and new product development processes (Johnson et al. 2017). Studies have been conducted in the context of but not limited to healthcare (Chen and Banerjee 2020; Kamble et al. 2019; Kemppainen et al. 2019; Li et al. 2021; Newlands et al. 2020; Ramnath et al. 2020; Yang et al. 2015; Wang and Hajli 2017), B2B (Hallikainen et al. 2020), construction (Ahmed et al. 2018; Ram et al. 2019; Sang et al. 2020), supply chain management (Ali et al. 2020; Arunachalam et al. 2018; Brinch et al. 2018; Dubey et al. 2019a; Khan 2019; Lai et al. 2018; Lamba and Singh 2018; Mandal 2019; Singh and Singh 2019; Wang et al. 2018c), manufacturing (Popovič et al. 2018; Verma 2017), consumer goods (Rialti et al. 2018); e-commerce (Behl et al. 2019; Wamba et al. 2017), telecommunications (Saldžiūnas and Skyrius 2017; Walker and Brown 2019), banking and financial services (Lee et al. 2017; Lautenbach et al. 2017; Gregory 2011), automotive (Dremel et al. 2017), and airlines (Holland et al. 2020).
Attempts have also been made in the past to conduct SLR to identify various components of Data Science from a strategy point of view. These review articles from the strategic adoption point have focused highly on individual components of ‘Data Science’. In the recent past ‘Big Data’ (Ciampi et al. 2020; Günther et al. 2017; Mikalef et al. 2016, 2020a; Nelson and Olovsson 2016; Olszak and Mach-Król 2018; Wamba et al. 2015; Zhao-hong et al. 2018), ‘Big Data and dynamic capabilities’ (Rialti et al. 2019), ‘Big Data business models’ (Huberty 2015; Wiener et al. 2020), and ‘Big Data assessment models’ (Adrian et al. 2016) have been explored. Researchers have also focused upon ‘Big Data Analytics’ (Adrian et al. 2017; Al-Sai et al. 2020; Bogdan and Lungescu 2018; Inamdar et al. 2020; Maroufkhani et al. 2019; Mikalef et al. 2019a; Singh et al. 2021; Sivarajah et al. 2017), Artificial Intelligence (Alsheiabni et al. 2020; Borges et al. 2021; Keding 2020; Kitsios and Kamariotou 2021; Markus 2017), Business Analytics (Cao and Duan 2017), and Business Intelligence and Analytics (BI&A) (Chen et al. 2012; Eggert and Alberts 2020; Lautenbach et al. 2017; Llave 2017; Moreno et al. 2019; Sang et al. 2020).
The literature on ‘Data Science Strategy’ under single-unified umbrella term that cuts across different technologies, such as ‘Big Data’, ‘Data Analytics’, ‘Artificial Intelligence’, ‘Machine Learning’, ‘Deep Learning’, ‘Visualization’, and ‘Business Intelligence’ is considerably scarce. In contrast, studies on ‘Data Science’ adoption and implementation in enterprises with corresponding barriers and enablers across various industry sectors and domains are limited. The conceptual framework for holistic ‘Data Science Strategy’ is absent to our limited understanding. To be successful in deriving desired business outcomes organizations need to recognize the need for a well-crafted and all-encompassing ‘Data Science Strategy’ augmenting digitalization and digital transformation.
3 Research method: a systematic literature review
The SLR is focused on identifying and synthesizing the knowledge on enablers and barriers influencing ‘Data Science Strategy’ in organizations. It takes into consideration the accessible scholarly business management research articles in the English language from four databases, namely, EBSCO business source ultimate, Scopus, Science Direct, and Pro-Quest databases. These databases are chosen since they have the most relevant and reputed peer-reviewed list of journals (by renowned publications like Springer, Emerald, IEEE, Elsevier, Taylor and Francis, etc.) where ‘Data Science Strategy’ research is traditionally published. Also, the large number of past SLRs (Mikalef et al., 2018; Dam et al., 2019; Sivarajah et al., 2017; Eggert and Alberts, 2020; Arunachalam et al., 2018) focused on the AI, ML, BDA domains too have considered these scholarly databases. The articles were identified based on the keyword search in title, abstract, and article keywords sections. In total, the search yielded 573 documents. The duplicates were excluded leaving a total of 480 articles for consideration. In the next step, the number of relevant articles was further narrowed down based on examination of title and abstracts and this brought down the number to 158 articles. The examination was focused towards characterizing factors influencing the ‘Data Science Strategy’ implementation in organizations. The systematic process (Fig. 2), based on further in-depth analyses for relevance and quality of articles, resulted in a final literature base comprising of 113 articles, leading to analyses of findings, synthesis, conceptual framework and research agenda for future studies.

Methodology and output
4 Results
4.1 Findings
This article summarizes the research in the field during the period 1998–2021.However, there have been more articles published on the subject during 2015–2021., Driven by the advancements in ‘Information Technology Capabilities’ and reduction in cost of computations, organizations of all sizes and types in the last quarter of twentieth century began to adopt digital technology to increase their competitiveness (Khosrowpour, 1990). Their focus was to implement business applications evolving from technological advancements in data associated fields. The ‘Big Data’ and ‘Data Science’ terms were coined in the year 2007 and 2008, respectively, and ‘Big Data Analytics’ gained importance in the year 2011 (Nguyen et al. 2018). As a result, both academic and practitioners shifted attention to the adoption and implementation of ‘Data Science’ strategies.
After the systematic process, as described in the research methodology section, this paper included 79 distinct journals in this literature review. Out of the 113 articles selected for the review, 17 were from A*-category (according to the 2019 ABDC journal quality list), followed by 37 in A category, 15 in B category, and 17 in C category journals. Likewise, 16 articles were indexed in the Scopus database. Further, 11 articles belonged neither to the ABDC quality list nor the Scopus database (Fig. 3).

Year-wise distribution of articles with publication ranking
Figure 3 also represents the distribution of articles between the years 1998 and 2021 (till the date of search). The number of articles on ‘Data Science Strategy’ have increased over the years. The year 2019 recorded a maximum number of 31 papers. The steep increase in the number of articles over the past five years is testimony to the importance of the subject and the interest it is generating amongst academicians and practitioners worldwide. With more and more businesses investing in data-driven technologies, clear-cut business objectives are still far from realization. Hence, despite the increased number of articles, this research domain is still an emerging one.
Figure 4 shows the distribution of articles based on the industry type with corresponding research methods. The maximum number of articles, that is 48 articles, deal with multiple industries. Of these, 28 are empirical studies. Individually, the ‘Healthcare’ industry dominates the publications with 09 articles, out of which four are empirical studies, four are case study articles, and one SLR. ‘Financial Services’ and ‘Construction’ industries have received attention in 06 and 05 articles, respectively.

Industry-wise distribution of articles with research methods. *Multi-Industry in the above plot refers to data collected from respondents (by means of interviews, case studies, and empirical investigations) belonging to multiple industries such as Technology & Entertainment, Web Service, Healthcare, Insurance, Manufacturing, Retail, Telecommunications, Agriculture, Banking, Transportation, Oil & Gas, Media, Consumer Goods, and many more
Figure 5 showcases the distribution of articles based on the domain of work with corresponding research methods. The supply chain management domain leads with 15 articles, of which eight articles are empirical studies. Manufacturing and policy studies are credited with 4 articles each Other domains with corresponding articles are also listed.

Domain-wise distribution of articles with research methods
The distinct ‘Enablers and Barriers’ of ‘Data Science Strategy’ for different industry sectors, and domains are segregated in supplementary Table S1. The applicability and intensity of each barrier towards ‘Data Science’ adoption and its success varies based on the industry sector and the domain areas. Table S1 provides a comprehensive list of barriers in each of the major industries and domains varying from airlines to construction, healthcare to financial services, manufacturing to e-commerce, and so on. The underpinning theories used in the reviewed literature along with the key enablers of ‘Data Science Strategy’ implementation are documented in supplementary Table S2. Reviewed literature has drawn upon many theories including Resource-Based View (RBV), Dynamic Capability View (DCV), Knowledge-Based View (KBV), Technology-Organization- Environment (TOE) framework, Organizational Learning Theory (OLT), Diffusion of Innovation Theory (DIT), Technology Acceptance Model (TAM), Task-Technology Fit (TTF), Information Systems Success Model (ISSM), Agency Theory (AT), Stakeholders Theory (ST), Institutional Theory (ITh), and many more.
Different research methods adopted by the reviewed articles are graphically summarized in supplementary Fig. S1. The findings imply that nine different research methods are used in general. The majority of studies involved ‘Analytical or Empirical’ studies followed by ‘Case Study-based’ methodologies and ‘Interviewing’. The other research methods include Theoretical, Conceptual, Focus Group Discussions, Delphi Studies and Expert Viewpoints. The article search on the subject area resulted in articles from 79 distinct reputed journal publications. The journal publications with more than one article are documented in supplementary Fig. S2.’British Journal of Management ‘ has a maximum six number of articles published in the research area followed by five articles each in’Engineering, Construction and Architectural Management’, and’Industrial Marketing Management Journals ‘. Four articles are published in’Information and Management Journal ‘ followed by three articles each in’Information Systems & e-Business Management ‘,’Information Systems Frontiers ‘, and’International Journal of Logistics Management.’ The underpinning theories (49 numbers) for the reviewed articles on ‘Data Science Strategy’ is highlighted in supplementary Fig. S3. Resource-Based View is extensively used by 26% of the published research articles. Dynamic Capability Theory (19%) is the next prominent theory followed by Technology-Organization-Environment, which finds a place in 7% of the articles. Around 39% of the articles are drawn upon by different other theories as highlighted in supplementary Table S2. The study region of reviewed articles is spread across different geographies, as documented in supplementary Fig. S4. The United States of America dominates the list with 15 articles followed by 8 studies based on Indian industries. Europe and China follow the list with 7 articles each studied in the respective regions. Other regions including Asia, Singapore, Canada, Slovenia, Saudi Arabia, Pakistan, Norway, Iran, Finland, Dutch, and Brazil contribute one article each.
4.2 Synthesis of ‘data science’ components
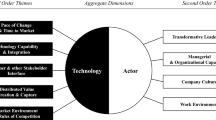
The reviewed articles categorize the ‘Data Science’ components based on underlying theoretical frameworks. Under the lens of RBV, they are classified under Tangible, Human, and Intangible resources (Gupta and George 2016; Mikalef and Gupta 2021). Tangible resources comprise of data (internal, external, and combined data), technology (Hadoop, NoSQL, etc.), and basic resources, such as time and investments. The technical (pertaining to data-specific) and managerial (analytical and business acumen) skills include human resources. The intangible resources indicate organization culture and learning abilities, which include data-driven approaches and Knowledge-Management Systems. Few studies (Sun et al. 2020; Verma and Bhattacharyya 2017) have adopted the TOE framework to categorize the ‘Data Science’ components under the context of technology (resources, competence, complexity, compatibility, and relative advantage), organization (Firm size, perceived costs, and organizational support), and environment (competition, partner readiness, industry type, and regulations). Few more studies are carried out under the Motivation-Opportunity-Ability (MOA) theoretical framework (Wang et al. 2018c). Motivation comprises of perceived ease and usefulness, external pressure, corporate culture and leadership support. Regulatory mechanisms, policies, information level, and associated risk define the opportunity aspect. The ability aspect points toward management capability, data talent, and infrastructure. Considering the merits of all these theoretical foundations and corresponding literature, in this SLR, the factors are synthesized (Fig. 6) into the following themes: 'Content' referring to Data Characteristics and Data Governance; 'Context' in technology and environmental aspects; 'Intent' toward aligning with the core strategy of the organization, managerial willingness, organizational agility, leadership, cultural aspects; and 'Outcome' as a business value in terms of 'Key Performance Indicators' (KPIs) and 'Return on Investments’ (RoI).

Synthesized factors associated with ‘Data Science Strategy’ in organizations
4.2.1 Data characteristics
In the successful implementation of ‘Data Science’ in an organization, data characteristics can add value to the firm. Transforming these data characteristics into a valuable proposition relies upon the firms’ understanding of these characteristics and how to deliver value through their use (Wright et al. 2019). Ranjan (2019) analyzed the problems presented by data characteristics under the context of 10 Vs—Volume, Variety, Velocity, Veracity, Variability, Validity, Visualization, Vulnerability, Volatility, and Value. Whereas Ghasemaghaei et al. (2018) and Wamba et al. (2015) characterized data using 7Vs, namely Volume, Velocity, Variety, Veracity, Value, Variability, and Visualization. Each of these characteristics is important under different contexts including the industry sector. It is necessary to keep data as driver. Keeping data as driver demands certain business processes to be able to effectively use the data (de Medeiros et al. 2020). These business processes and procedures used in collecting and analyzing ‘data’ take the implementation of ‘Data Science Strategy’ further ahead (Rialti et al. 2019).
The characteristic of an incidence reflecting the raw facts defines the data quality. The data quality comprises of correctness, completeness, relevancy, timeliness, clarity, consistency, ease of understanding, and accessibility. It greatly affects the results of ‘Data Science’ (Ghasemaghaei et al. 2018). The application of ‘Data Science’ would positively influence the business value, once data quality challenges are addressed (Wamba et al. 2019). Intention to adopt ‘Data Science’ is positively affected by data quality and an understanding of the benefits of data.
4.2.2 Governance
For warranting the data quality and leveraging its value, data governance is a potential approach (Gregory 2011; Grover et al. 2018; Mir et al. 2020; Braganza et al. 2017; Wiener et al. 2020). Governance includes areas such as organizational strategy, data quality & security, innovation applications, ‘Data Science’ architecture, and lifecycle (Fakhri et al. 2020). Data policies are deployed by organizations to support product innovation (Lacam 2020).
The data governance aims at adding value to the enterprise through risk mitigation plans and helps achieving compliance (Gregory 2011). Bertot et al. (2014) highlight the need to develop a data governance model with respect to ‘Data Science’ in the context of privacy, reuse, accuracy, archival, curation, platforms, architecture, and sharing policies across sectors. In the finance sector, in protecting the consumer rights and interests, it is conducive to regulate the use of personal information (Li & Yu 2020). The magnitude of influence of data security, privacy, and accuracy are in descending order on ‘Data Science’ adoption and are 54%, 36%, and 8%, respectively in the total measurement (Latif et al. 2019). Effective data exchange within and among network partners is a necessity to benefit from ‘Data Science’. Due to security and privacy challenges, the organizations can be hesitant in sharing data with partners (Günther et al. 2017). To establish close connections and harmonization with partners there needs to be balanced and controlled sharing of data (Coombs et al. 2020; Sivarajah et al. 2017). There exists a positive interplay between governance of BDA infrastructure and BDA capabilities (Bertello et al. 2020).
4.2.3 Technology
Over the last few years, immense progress is observed in the technology related to ‘Data Science’ (Gupta and George 2016). The ‘Data Science’ concept emphasizes effective deployment of technology and talent to capture and manage data in order to generate insights (Mikalef et al. 2020b). ‘Data Science’ technology capability includes infrastructure and human talent.
The core themes of technology capability in terms of infrastructure are connectivity, compatibility, and modularity (Akter et al. 2016). In import and export business enterprises, with the introduction of a new IT system, it is necessary to build an internal management system to improve operational efficiencies (Zhang 2021). Investing in infrastructure, such as data lake, analytics portfolio, and human talent generates business value (Grover et al. 2018). Bendre and Thool (2016) have highlighted the use of ‘Data Science’ in different domains and emphasized the need for technological platforms covering lifecycle management including data acquisition, processing and visualization challenges. The challenges arising from data characteristics in computing methods require different strategies and advanced techniques including technology usage on data segregation and accumulation, high-performance computing, incremental learning, scalability, and heuristics (Choi et al. 2018; Wang et al. 2018b).
Amongst large and diverse firms, it is observed that investing in ‘Data Science’ which is IT-intensive and with a highly competitive nature leads to improvement in productivity (Müller et al. 2018). Many organizations have transitioned from traditional analytics (Analytics 1.0—business intelligence) to ‘Big Data Analytics’ (Analytics 2.0). Using the ‘Data Science’ platform that can combine the traditional analytics and ‘Big Data’ organizations are transitioning to a new synthesis, known as the Analytics 3.0- data enriched offering (Davenport 2013; Harlow 2018).
Human talent is arguably the most important and critical element in leveraging ‘Data Science’ investments (Grover et al. 2018; Wamba et al. 2015). Talent capability includes technical, relational, and business knowledge, along with the ability to manage technology (Akter et al. 2016). The challenges in talent management include cognitive and behavioural limitations, and lack of educational programs for the development of both analytical and communication skills with regards to translating data into business insights (de Medeiros et al. 2020).
The implementation of a ‘Data Science’ value chain is driven by overall business directions and strategy, including the knowledge management strategy. In this context, ‘knowledge management’ refers to the process of sharing internally held information in an easy and systematic approach for the benefit of the organization. Developing a strategic intent and knowledge management system for ‘Data Science’ will lead to a long-term sustainable competitive advantage by allowing enterprises to implement new business models and develop large-scale ability to experiment (Harlow 2018). Relative performance in firms that develop more ‘Data Science’ capabilities than others is higher. Further, knowledge management orientation plays a significant role in amplifying the effect of ‘Data Science’ capabilities (Ferraris et al. 2019). Knowledge management capabilities and organizational ambidexterity (exploration and exploitation) influence the relationship between ‘Data Science’ and strategic flexibility (Rialti et al. 2020). The synergy between organizational resources and capabilities in complementing ‘Data Science’, improves organizational objectives and outcomes (Wang et al. 2019). Poeppelbuss et al. (2011) studied maturity models describing organizational capabilities from the research, publication and practitioner’s perspectives. Grossman (2018) introduced the Analytic Processes Maturity Model (APMM) framework to evaluate the analytic maturity of an organization.
4.2.4 Business environment
The business environment reflects industry characteristics and government regulations. The industry is characterized by the firms' partners and competitors, and the government policies influence the macroeconomics context and the regulations (Sun et al. 2020). A favourable industry and regulatory environment (infrastructure, legal, regulations, directives, support, competitive pressure, and trading partner readiness) positively affects the ‘Data Science’ adoption intent (Sun et al. 2020; Wiener et al. 2020). Dubey et al. (2019b) developed and tested the model describing the relation between resources, talent, culture, cost, and operational performance with institutional pressures (coercive, normative, and mimetic).
To successfully adopt ‘Data Science’ in the organizational context, firms should take the internal teams onboard the digital transformation journey, while reinforcing strategic initiatives and influencing employee behaviour towards their successful implementation (Boldosova 2019). In addition to its technical capacity, the power dynamics within a firm and its competitive landscape play a significant role in ‘Data Science’ build-up (Jha et al. 2020). An organization’s relationships with its stakeholders, including the public sector, and assimilation of social media facilitate organizational learning (Okwechime et al. 2018). This further leads to the absorption of ‘Data Science’ technologies (Bharati and Chaudhury 2019). Investment in ‘Data Science’ not only affects firms’ equilibrium price, market share, and profit but also the rivals’ performances (Wu et al. 2017). With ‘Data Science’ investments, market outcomes also vary based on the competition strategy used, either conservative or expansive. Depending on a fully covered or partially covered market structure, the impact on firms’ competition varies when consumer’s preference of ‘Data Science Strategy’ is heterogeneous.
There are limited studies exploring the factors for adoption of ‘Data Science’ in the start-up environment. These studies bring to light the fact that the key factors affecting adoption are different from established firms (Behl et al. 2019). Different enablers of ‘Data Science’ in start-ups are technical support from the vendors, attitude of the top management, competitive environment, infrastructure, skill enhancement, data access, quality of data, and perceived usefulness. Higher performance can be derived from firms when the Strategic Factor Market (SFM) is imperfect due to the differences in the expectation of the future value of strategic resources. The Information Management Capability (IMC) allows the firm to manage market needs and directions in line with core strategy (Macada et al. 2019).
4.2.5 Alignment with core strategy
‘Digital strategy’ being the superset of ‘Data Science Strategy’ needs to be aligned with the core organizational strategy. Most ‘digital strategies’ fail because they fail to re-imagine the vision of the organization and the journey of digitization. Alignment of digital strategy with core business strategy needs to be accompanied by the way the organization drives its vision (Trompenaars and Woolliams 2016). The digital strategy that an organization should embrace needs to be unique and be difficult enough for the competitors to replicate (Ross et al. 2017). Managerial and operational capabilities are necessary for realizing a digital business strategy (Ukko et al. 2019).
Adopting ‘Data Science Strategy’ in an organization does not mandatorily require building a new strategy. Rather, it requires a coherent alignment with the planned business objectives (Keding 2020). While formulating long-term business strategy, the inclusion of ‘Data Science Strategy’ facilitates business alignment and eventually leads to success (Grover et al. 2018).
Successful deployment of ‘Data Science Strategy’ requires good collaboration and alignment between the IT and business departments. This collaboration and alignment require diverse mechanisms of organizational governance (Dremel et al. 2017). Several stakeholders within and outside the organization mutually benefit either by combining and/or sharing data (Günther et al. 2017). Hence, it is important to align the ‘Data Science Strategy’ of an organization with that of core strategy (Biazzin and Castro-Carvalho 2019).
4.2.6 Managerial willingness
Behavioural intention to use ‘Data Science’ in organizations is determined by outcome expectations, social perception, enabling conditions, and resistance to change. Though ‘Data Science’ is perceived to be difficult (effort expectation), the influence of this perception on ‘Data Science’ adoption intention is small. The ‘Data Science’ adoption intention is contained to the relationship between facilitation conditions on behavioural intention (Cabrera-Sánchez and Villarejo-Ramos 2019). Based on the understanding of ‘Data Science’, the record of its success, and the logical reasoning provided by the technology itself, the managers' willingness to trust ‘Data Science’ varies (Keding 2020). Instead of working in business units in silos, leveraging ‘Data Science’ as a horizontal facilitator leads to an increased awareness at managerial levels. There is a different level of acceptance of ‘Data Science’ based on hierarchical layers in an organization. By customized design of algorithms, the acceptance level can be increased.
Leadership team support is a necessary ingredient in adopting ‘Data Science’. It provides the needed resources by actively promoting, endorsing, and fostering its use. Also, this helps manage change and remove organizational barriers related to Data Science usage (Lautenbach et al. 2017). An organization’s ‘Data Science’ adoption decision can be greatly influenced by highly motivated top managers inclined towards innovations. This happens because such personnel can only provide strategic direction, authority, and resources (Sun et al. 2020).
4.2.7 Organizational agility
Agility positively mediates the relationship between ‘Data Science’ and firm performance (Rialti et al. 2019). Organizational agility must be developed in order to contribute to the emergence of an overall ‘Data Science’ capability (Mikalef and Gupta 2021). Agility is often connected to an organization's dynamic capabilities (Rialti et al. 2019). For all the business processes including product development, resource allocation, knowledge creation, and/or ‘Data Science’ cycle, there is an association of organizational dynamic capabilities (Božič and Dimovski, 2020; Braganza et al. 2017). In a highly dynamic business environment, adopting ‘Data Science’ creates competitive advantage (Sun et al. 2020).
Work practices need to be realigned continuously to gain from ‘Data Science’ (Günther et al. 2017). At the work-practice level, organizations work with ‘Data Science’ in inductive (bottom-up) and deductive (top-down) approaches. For ‘Data Science’ success, both these approaches need to intertwine and complement each other. The intensity of organizational learning is one of the critical intangible resources needed to build ‘Data Science’ capability (Gupta and George 2016; Mikalef et al. 2020b).
4.2.8 Leadership and culture
Cultural differences are a prime aspect in firms' managers' willingness for and resistance to ‘Data Science’ adoption (Keding 2020). Leadership with a clear ‘Data Science Strategy’ and vision can articulate the business cases that are likely to succeed (Grover et al. 2018).
In capitalizing on ‘Data Science’ capabilities, firms need power shift in the organization structure. The new teams of data and analytics need support from top management teams and also an inclusive data-based decision process (GalbRaith 2014). Behavioural change too is required in order to make data-driven decision and stimulating organizational readiness for capability restructuring is the need of the organizations (de Medeiros et al. 2020).
Along with increasing proficiency in sustainable design, 'Data Science' capability also directly enhances sustainable growth and performance (Zhang et al. 2020). ‘Data Science’ increases sustainable innovativeness in organizations as a measure of successful new product development (Song et al. 2020). For sustainable development, assessing the readiness of organizations to adopt 'Data Science' on the temporal dimension is important (Olszak and Mach-Król 2018).
As an antecedent of agility, ambidexterity improves organizations’ ability to respond effectively to market changes (Rialti et al. 2019). Ambidextrous organizational culture acts as a mediator between ‘Data Science’ capabilities and firm performance. Exploration orientation of a firm has a positive effect on ‘Data Science’ leading to long-term results such as generation of new product revenues (Johnson et al. 2017). Organizations can choose strategic pathways based on an assessment of their technical (exploiting suppliers) and analytical (exploring data) capabilities (Najjar and Kettinger 2013). ‘Data Science’ capability has a positive and significant effect on innovative capabilities, both incremental and radical. Moderation effect by information governance is significant on radical innovation than on incremental innovation (Mikalef et al. 2020a). Increased exploration and exploitation capabilities of organizations may be considered related to implementing a 'Data Science capable’ business process management system within ambidextrous organizations (Rialti et al. 2018). Firms can realize organizational creativity and performance by fostering ‘Data Science’ (Mikalef and Gupta 2021). Organizational ambidexterity, which is data-driven with real-time responsiveness, increases firms’ ability toward new market opportunities.
4.2.9 Business value
‘Data Science’ has the potential to provide companies with high business value in terms of financial/market performance or customer satisfaction (Raguseo and Vitari 2018). The outcome of the 'Data Science' project lies in realizing business value, which could be transactional, strategic, and/or transformational (Ji-fan Ren et al. 2017). In enhancing business value, system quality and information quality are key factors (Ji-fan Ren et al. 2017). The strategic value of ‘Data Science’ could be functional (tangible: financial performance, market performance) and/or symbolic (intangible: reputation, brand image) (Grover et al. 2018). Based on industry characteristics and business goals, organizations need to have measures of Key Performance Indicators (KPIs) and RoIs.
The KPIs typically would involve data governance, decision quality, process efficiency, innovation contributions, business expansion, and stakeholder satisfaction (Chakravorty 2020; Grover et al. 2018). It is equally important to track the intermediate indicators, such as stakeholder sentiment and engagement, along with co-creation and value sharing (Libert et al. 2016). RoI refers to revenue, profitability, return on assets, share value, reduced costs, design-cycle optimization, symbolic value (image, reputation, first-mover), forecasting, and prediction (Grover et al. 2018; Shim et al. 2015). Early adopters of’Data Science', focused on the execution of projects as they knew that they had value to offer (Shim et al. 2015). With the integration of 'Data Science' into the mainstream, organizations need to devise the mechanism to substantiate the investments. To derive competitive advantage and add business value to organizations, ‘Data Science’ needs to be an integral part of the entire digital transformation journey and each organization needs a distinct ‘Data Science Strategy’ (DSS).
4.3 Conceptual framework of ‘Enablers and Barriers’ of successful ‘Data Science Strategy’
The SLR summarizes the status of research in the field of ‘Data Science Strategy’. Considering the fact that there is little effort so far in providing an eagle’s eye view on research in ‘Data Science’ encompassing the domains of ‘Big Data’, ‘Artificial Intelligence’, ‘BI&A’, and relevant technologies, this effort is a considerable leap in synthesizing all the enablers and barriers of ‘Data Science Strategy’ adoption in organizations. We propose a conceptual framework for developing and implementing successful ‘Data Science Strategy’ for enterprises (Refer Fig. 7).

Conceptual framework for enterprise ‘Data Science Strategy’
The synthesized ‘Data Science’ components under the themes 'Content', 'Context', 'Intent' and 'Outcome' led to the development of a conceptual framework influenced by the 4I model by Crossan et al. (1999). The 4Is: Intuition, Interpretation, Integration and Institutionalization, take place across individual and organizational levels. Okwechime et al. (2018) have made use of the 4I model in deploying and integrating ‘Big Data’ and ‘Smart Cities’ from the organizational learning perspective. Mandlik and Kadirov (2018) studied the ‘Big Data’ ecosystem at the micro-level (Individual behavior), meso-level (Network of firms), and the macro-level (Institutional, Socio-political). The conceptual framework proposed for ‘Data Science’ success, connects the construct ‘Resources’ as the business input leading to ‘Strategic Business Value’ as the outcome. This transformation of input to outcome is driven by the enterprise ‘Data Science Strategy’. The strategy rests on the balancing of two competing constituents of the same continuum, which are ‘Barriers’ and ‘Enablers’ of ‘Data Science’ success. Drawn upon the Stimulus-Organism-Response (S-O-R) model (Mehrabian and Russell 1974), Contingency model (Fiedler 1964), and Institutional theory (Meyer and Rowan 1977), the constituents ‘Barriers’ and ‘Enablers’ are grouped under the themes Individual, Organizational and Institutional. The S-O-R model describes the influence of factors affecting individual, organizational and institutional behaviors that translate inputs in to business outcomes. The contingency model is appropriate in defining the optimal approach to balance the barriers and enablers of ‘Data Science Strategy’. The reference to the institutional theory is appropriate in emphasizing the role of institutional setup beyond the limited individual and organizational functional considerations.
At the individual-level, the tendency of resistance to ‘Data Science’ project execution either by an employee or by a mid-level manager is either due to fear of ‘failure’ or ‘loss of control’ or ‘operational disruption’ (Mikalef et al. 2020c; Shahbaz et al. 2019). The enablers in the form of developing dynamic capability, such as experience in ‘dealing with complexity’, ‘high tolerance for complexity’ (Gong and Janssen 2021; Walker and Brown 2019) and ‘Top-management-Team’ support (Alaskar et al. 2020; Behl et al. 2019; Chaurasia and Verma 2020; Foshay et al. 2015; Halaweh and Massry 2015; Lai et al. 2018; Lamba and Singh 2018; Lautenbach et al. 2017; Popovič et al. 2018; Ransbotham et al. 2017; Verma and Bhattacharyya 2017; Walker and Brown 2019; Wang et al. 2018c) are a must to address the barriers to considerable extent. Organizational environment for an individual in communicating the benefits of ‘Data Science’ (Chakravorty 2020; Gong and Janssen 2021; Verma 2017) is also a barrier for ‘Data Science’ project success. Creating opportunities to interact with leadership team and adopting a deliberate storytelling technique (Boldosova 2019) would be helpful in overcoming the communication gap barriers. There is a significant effect of communicating to internal teams with deliberate storytelling, and reinforcing the strategic initiatives. This in turn influences employee behaviour towards ‘Data Science’ initiatives.
At organization-level barriers for ‘Data Science’ success range from data-related challenges to huge investment requirements to internal politics. Establishing ‘Data Science’ projects require huge investments on skills and infrastructure (Behl et al. 2019; De Luca et al. 2020; Holland et al. 2020; Lee et al. 2017; Wu et al. 2017), which is quite a big challenge for most organizations. Though it may not be avoided completely, infrastructure flexibility in identifying and using of compatible and complementary resources (Alaskar et al. 2020; Chaurasia and Verma 2020; Mikalef and Gupta 2021; Moreno et al. 2019; Shokouhyar et al. 2020; Verma and Bhattacharyya 2017; Walker and Brown 2019) already existing in the organization can considerably reduce the burden on new investments. Lack of skills and knowledge (Ahmed et al. 2018; Behl et al. 2019; Dubey et al. 2019b; Lamba and Singh 2018; Foshay et al. 2015; GalbRaith 2014; Mikalef et al. 2020a, 2019b, 2020c; Rialti et al. 2019) required to execute the ‘Data Science’ projects can be addressed by setting up ‘Training & Knowledge Management’ capabilities and processes (Calvard 2016; Dam et al. 2019; Ferraris et al. 2019; Harlow 2018; Rialti et al. 2020). Acquiring and retaining the right talent in the field of ‘Data Science’ is another challenge (Holland et al. 2020; Ransbotham et al. 2017) and needs to be addressed by rewarding and recognizing (GalbRaith 2014) the contributions in regular and timely manner.
The divergent actions towards ‘Data Science’ projects by different business units, including IT, in the same organization due to working in silos, and non-alignment (Calvard 2016; Foshay et al. 2015; Walker and Brown 2019) to business objectives are barriers for success. “Data Science Strategy’ must be aligned (Biazzin and Castro-Carvalho 2019; Comuzzi and Patel 2016; GalbRaith 2014; Ross et al. 2017; Mithas et al. 2013; Moreno et al. 2019; Trompenaars and Woolliams 2016; Ukko et al. 2019; Zaki, 2019) with ‘Digital Business Strategy’ which, in turn, should be aligned with ‘Organizational Strategy’. Further, there has to be seamless collaboration across the organization (Kache and Seuring 2017) to enable desired outcomes. Organizational inertness (Biazzin and Castro-Carvalho 2019), resistance to organizational flexibility (Ahmed et al. 2018; Cabrera-Sánchez and Villarejo-Ramos 2019; Dubey et al. 2019a; Mikalef et al. 2019a, 2020c; Wang et al. 2018b) and denial (no support) to experimentation (Alaskar et al. 2020; Mikalef et al. 2020c; Walker and Brown 2019) are other sets of organizational barriers. These challenges need to be addressed with a cultural shift within the enterprise. Organizations developing ability to absorb paradigm shifts (Walker and Brown 2019), by developing dynamic capabilities, such as dealing with complexity, facilitating reuse, enabling interoperability, client orientation, creating flexibility, adherence to privacy, facilitating communication, impact evaluation, decision-making support, and migration strategy (Gong and Janssen 2021) can overcome organizational inertness. Organizational agility (Dam et al. 2019; Verhoef et al. 2021) in learning and developing ambidextrous culture in exploring and exploiting the new technological advancements with strong data-driven analytics culture will help overcome the resistance to flexibility and lack of experimentation. The intensity of organizational learning is one of the critical intangible resources needed to build ‘Data Science’ capabilities. Barriers in the form of ‘data challenges’ (Brinch et al. 2018; Chakravorty 2020; Devasia 2018; Fakhri et al. 2020; Halaweh and Massry 2015; Lamba and Singh 2018; Lautenbach et al. 2017; Mikalef et al. 2020a; Shahbaz et al. 2019; Saldžiūnas and Skyrius 2017; Sivarajah et al. 2017; Zaki 2019), such as collection, extraction, relevance, refinement, handling, ownership, documentation, communication, management, quality, trust, security, and privacy must be dealt with utmost care and by making deliberate use of characteristics of data (Behl et al. 2019; Choi et al. 2018; Ranjan 2019; Lacam 2020; Rialti et al. 2018; Sarker et al. 2019; Schroeder 2016; Wright et al. 2019; Yadav 2017). A proper data and information governance model (Bertot et al. 2014; Chakravorty 2020; Fakhri et al. 2020; Foshay et al. 2015; Gregory 2011; Mikalef et al. 2020a; Wang et al. 2018a) would help overcome these challenges to a significant effect. The intra-firm power dynamics (Jha et al. 2020; Schroeder 2016) also play a significant role in the success of ‘Data Science’ projects. The adverse effects must be handled in organizations by encouraging formal and informal network creation amongst the management team and ‘Data Science’ teams.
Barriers at the institutional-level are equally important to be addressed as much as individual and organizational-level in the success of ‘Data Science’ projects. Institutional pressures namely coercive, normative, and mimetic (Dubey et al. 2019b) can act both as barriers and enablers based on the context and industry characteristics. Awareness of the institutional pressures help in the selection of tangible (infrastructure), intangible (culture), and human resources (‘Big Data’ skills). The competing business models with lack of transparency require compliance requirements (Lautenbach et al. 2017; Mikalef et al. 2020c) to be established by industry-level collaborations along with a clear ‘target market’ definition (Holland et al. 2020). Creating effective institutional arrangement in facilitating innovative technologies enables organizations to benefit from ‘Data Science’ (Sang et al. 2020). External market factors (Lautenbach et al. 2017) adversely affecting the ‘Data Science’ projects need to be dealt by industry-government engagement by formulating a national-level strategy for the ‘Data Science’ domain. Information Management Capability (IMC) of an organization plays an important role in effectively handling external market factors (Macada et al, 2019). Lack of competency and support by vendors and alignment between client and service provider (Behl et al. 2019; Walker and Brown 2019) needs institutional arrangement in addressing the issue. There is also need to create a competence pool in the domain of ‘Data Science’. Dearth of adequate talent in the core domains, along with ‘Data Science’ skillsets (Akter et al. 2016; Chatterjee 2020; Devasia 2018; Halaweh and Massry 2015; Jha et al. 2020; Kache and Seuring 2017; Lautenbach et al. 2017; Mikalef et al. 2019a; Ransbotham et al. 2017; Wang et al. 2018c), is another challenge that organizations face in implementing ‘Data Science’. Collaboration between industry and academia on ‘Data Science’ topics would lead to the development of skilled talent during university education. This would help to address the above-mentioned institutional concerns to a considerable extent.
The proposed conceptual framework was validated and refined through an iterative feedback process based on expert opinions. The conceptual model was shared with ten different experts leading ‘Data Science’ initiatives in their organizations at senior executive levels. These organizations work in the Retail, Media, Healthcare, Fintech, Manufacturing, Automobile, Aerospace, and Telecommunications sectors. Their opinions were given due consideration and the model was appropriately modified.
5 Discussion
In adopting ‘Data Science’, organizational approaches can be either deductive (top-down) or inductive (bottom-up). The traditional approach is the top-down approach where the business problem is defined first followed by a search for the required data. With this approach, there could be challenges with the accessibility of data and a feeble understanding of data collection methods and processes. Unless there exists high data analysis competency in the organization, this approach could be risky. With limited exposure to ‘Data Science’, a bottom-up approach is suggested where available data is first analyzed, and further, the business problem is accordingly defined based. This approach would have the following steps: (i) control of data hygiene, (ii) staff training, (iii) data value estimation, (iv) development of new dimensions for data sets, (v) evaluation of data analysis consequences, and (vi) use of insights (Saldžiūnas and Skyrius 2017). On the contrary, Lautenbach et al. (2017) suggest organizations drive BI&A usage with the top-down approach. The leadership team must keep the employees informed of the value and benefits derived through BI&A use (Lautenbach et al. 2017).
‘Data Science Strategy’ by its very nature leads to asymmetric information in the technology market (Mandlik and Kadirov 2018). In equity markets, information on firms’ investment in ‘Data Science’ leads to positive stock market reactions. Moreover, investments in small vendors tend to bring in higher returns than big vendors. Also, investors assess ‘Data Science’ investments of big firms as compared to those of small firms (Lee et al. 2017). There is a different impact on the size of returns depending on firm size and vendor size. Reliability, ROI, real-time analytics must be kept in mind while dealing with ‘Data Science’ adoption from a business perspective (Yadav 2017).
This SLR provides an eagle’s eye view of enablers and challenges of adopting ‘Data Science’ in organizations. In harnessing the power of ‘Data Science’, policies are required that are collaborative and complementary across organizations in creating a stakeholder marketplace, facilitating the generation of annotated data sets, spreading awareness relating to the contribution of AI, and supporting the start-ups (Chatterjee 2020).
5.1 Theoretical contributions
The article makes quite a significant contribution to theory in the field of ‘Data Science Strategy’.
-
This SLR recognizes that prior studies have focused upon different aspects of ‘Data Science’ adoption in organizations predominantly focusing upon ‘Big Data Analytics’ and ‘Artificial Intelligence’. The dearth of studies on ‘Data Science’ as an umbrella term that cuts across different technologies, such as Big Data, Data Analytics, AI, ML, Deep Learning (DL), Visualization, and Business Intelligence (BI) is evident. This SLR has reviewed the most relevant articles and synthesized the knowledge on ‘Data Science’ strategies. The findings and synthesized components are further developed into a conceptual framework. Developing this conceptual framework is the main theoretical contribution of this article. The findings, therefore, contribute to answering the research question ‘What are the enablers and challenges that affect the strategic implementation and success of ‘Data Science’ (AI/ML/BD) in organizations?’ and fulfil a significant gap in the literature.
-
The existing literature on ‘Big Data Analytics’ and ‘Artificial Intelligence’ draws upon strong theoretical backgrounds (Refer Table S2). ‘Data Science’ adoption in organizations has extensive opportunity in generating novel theory, along with new management practices. This article contributes to the theories by drawing upon Stimulus-Organism-Response (S–O-R) model, Contingency model, and Institutional theory in formulation of the proposed conceptual framework.
-
The proposed framework sets the agenda for further research in ‘Data Science’ strategy. This SLR article could serve as reference for practitioners as well as research scholars. Through the proposed framework, literature can be further enriched by developing the constructs grouped under ‘barriers’ and ‘enablers’, and developing them into propositions and hypotheses. Research contributions towards validating these propositions and/or hypotheses using appropriate qualitative and quantitative techniques can add to the knowledge body.
5.2 Managerial implications
Managers need to note that ‘Data Science’ is a part of the wider ecosystem including ‘Big Data’, ‘Data Analytics’, ‘Machine Learning’, ‘Artificial Intelligence’, and ‘Business Intelligence’. It also provides significant benefits over traditional analytics (Business Intelligence) systems. The considerable effect of ‘Data Science’ on the workforce is quite eminent in the next few years both at the organizational and the personal levels.
The proposed framework of ‘Data Science Strategy’ can help organizations from various industries and domains in taking the right steps towards the successful implementation of ‘Data Science’ projects. We summarize the implications to managers below.
-
Every enterprise’s ‘Data Science’ journey should start with the right business questions. Be sure of a clear business strategy and an expected value that the ‘Data Science Strategy’ can relate to. In answering the business questions pertaining to ‘Data Science’, choose the strategic choices necessary to drive the ‘Data Science’ transformation forward with resources, such as Data, Technology, Infrastructure and Human talent (skills and knowledge). Without business-appropriate choice of these resources, the desired outcome would hardly be achieved.
-
For ‘Data Science’ project to successfully lead to business outcomes, managers need to be cognizant of the barriers. Though it may not be possible to completely eliminate them, they can be minimized. The proposed framework summarizes the comprehensive list of barriers that managers need to keep their focus upon. Prior analyses of these barriers much before implementation of ‘Data Science’, would help in the planning and distribution of resources. The barriers summarized in the framework are a result of our review on multiple industry sectors and domains. We believe many organizations would almost face all or few of these barriers. Depending on the specific industry and domain, specifically applicable barriers should be considered by the managers (also refer to Supplementary Table S1). In summary, good overview of barriers at the early stages of planning and implementation of ‘Data Science’ projects will help managers to overcome hindrances and realize expected outcomes.
-
Along with barriers to ‘Data Science’, the proposed framework also summarizes the comprehensive list of enablers which intend to minimize the barriers. Enablers and barriers of ‘Data Science’ projects are inversely related. The summary of enablers for various industry sectors and domains is presented in Supplementary Table S2. Detailed prior research on all the enablers and specific attention to the ones relevant to their industry would help them to optimize the resources and accelerate the ‘Data Science’ journey to realizing ‘business value’.
-
The outcomes of ‘Data Science’ projects can be either functional or symbolic. Organizations must focus upon clearly targeted outcomes which can be measured using process KPIs and business value in terms of profits and cost savings (RoI). The value in the form of competitive advantage and structural transformation must also be monitored as indicated in the framework. Managers must also recognize the importance of ‘Data Science’ adoption in the form of symbolic value add. As a symbolic business value, ‘Data Science’ adds to the organizations’ brand value, and recognition as technology-driver. ‘Data Science’ projects can also enhance and lead social, environmental and corporate friendly initiatives within the organization. Managers must realize that the business outcomes in most ‘Data Science’ project initiatives are iterative and prone to initial hiccups. Awareness and balance of barriers and enablers from the proposed framework will help to realize the desired results in a stipulated time span. Therefore, early-stage setbacks on ‘Data Science’ projects should not deter the purpose of successful utilization of ‘Data Science’. Despite the mentioned barriers, managers in organizations need to keep up their motivations and convince the stakeholders (sub-ordinates, partners, vendors and management teams), and count on the ‘Data Science’ enablers.
Knowledge acquired from the learnings of the proposed framework in the form of resources, barriers, enablers, and strategic business value would help organizations in adopting ‘Data Science’ and exploit new business opportunities.
6 Limitations and future research
We acknowledge the limitations of our study and the readers should interpret the content of this SLR article in the context of these limitations. Primarily, the SLR has been reliant on accessible research articles from four databases, namely, EBSCO Business Source Ultimate, Scopus, Science Direct, and Pro-Quest databases, in English language. Though we have conducted SLR by identifying all possible articles relevant, we could have missed some from other leading databases (Web of Science). In addition, the interpretation of findings and synthesis are subjective, a fact which we (authors) have attempted to overcome by examining the articles independently. Secondly, amongst the mentioned databases used, the articles are identified based on ‘keyword search’ in the Title, Abstract, and Article keywords sections. We could have failed to consider the relevant articles where the subject area of interest is embedded in the main text. Thirdly, the proposed conceptual framework needs to be developed into an hypotheses and validated with empirical studies.
In addressing the first and second limitations mentioned, it is recommended further to conduct literature reviews from other databases including keyword search throughout the article (not limiting only to Title, Abstract, and Article keywords). To address the third limitation mentioned above, the proposed framework could help future researchers push significant agenda for ‘Data Science Strategy’ research.
We have identified the following future research opportunities:
-
Developing constructs for each of the constituents in the framework, formulating and empirically validating hypotheses.
-
As highlighted in motivation for this SLR, the literature articles have focused highly on certain individual components of ‘Data Science Strategy’ in discrete (viz. Big Data Strategy, Big Data Analytics Strategy, Artificial Intelligence Strategy, and BI&A Strategy). Considerably less research attention is paid to other individual components of ‘Data Science strategies’ including data visualization strategies, Machine Learning and Deep Learning strategies in enterprises, and ‘Data Science’ strategies with ‘Small Data’. Data visualization is an important component in persuading the top management stakeholders. Future studies could focus upon examining the ‘Data Science’ strategies in these neglected areas.
-
A large number of ‘Data Science Strategy’ studies have been dedicated to ‘Big Data Analytics’. Apart from ‘Big Data Analytics’, there also exists relevance for ‘Small Data’ analytics. For many small and medium businesses, ‘Small Data’ also provides great business insights. There is dearth of studies on enablers, barriers and impact of ‘Small Data’ implementation and strategic constituents. Future researchers can focus upon this direction.
-
Extant literature predominantly examines the enablers and barriers of ‘Data Science’ adoption in certain industry sectors and business domains (viz. Healthcare, Manufacturing, Construction, E-commerce, Telecommunications, Banking and Finance, Automotive, Aerospace, and Entertainment) (Ahmed et al. 2018; Dremel et al. 2017; Holland et al. 2020; Lee et al. 2017; Saldžiūnas and Skyrius 2017; Yang et al. 2015; Wang and Hajli 2017; Wamba et al. 2017). However, many sectors are yet to be explored (viz. Offline and Online Education, Disaster management) in this context. Researchers could pay attention to these unexplored areas.
-
Sector-wise comparative analysis between enablers and barriers of ‘Data Science’ Strategy between enterprises has also not been attempted in extant literature. Studies in such direction can bring in key insights which can be used for peer-to-peer learning among industries. Owing to the current Covid-19 pandemic situation, organizations are speeding up their digital transformation journeys. As a result, they are capturing large amounts of data which is unprecedented and new AI use cases are also evolving. The impact of Covid-19 pandemic on the overall ‘Data Science’ ecosystem including strategic dimensions needs investigation.
-
‘Data Science Strategy’ studies have largely focused on industry sectors in countries such as the USA, India, China and Europe (Refer to Fig. S4). Except India and China, the industries in other Asia–Pacific regions have not been examined extensively. Future studies can be devoted to this aspect. Additionally, market-specific condition combination (developed & developing economies) along with organizational culture (explorative and exploitative, flexibility) can further be explored. The adoption of ‘Data Science’ in internationalization is still an emerging research interest. The organizational variables affecting the relationship between ‘Data Science’ and internationalization could be of interest to future researchers.
-
With many start-up companies mushrooming, studies exploring the factors associated with ‘Data Science’ adoption and success, and contrasting them with that of established firms is an area can be researched. Further research should be conducted to understand the role of ‘Data Science’ in digital transformation.
-
There may be scenarios, wherein the Human Resource Management (HRM) dimension has led to a failure in the ‘Data Science’ implementation. This dimension has not been studied extensively. Studies can be conducted specifically on the HRM dimension of the ‘Data Science’ implementation.
-
Consideration towards growing diversity of consumer preferences ethically is strategically relevant to deploy the ‘Data Science’ business models (Wiener et al. 2020). On the contrary, Biazzin and Castro-Carvalho (2019) studied the impact of buyers’ current behaviour and found it does not significantly impact their deployment. Societal impacts of different ‘Data Science’ strategies should involve the proper implementation of rules and policies to ensure ethical use. This could also be direction for future research.
-
Studies are also limited on the implementation of ‘Data Science Strategy’ in government sector organizations. As an example, the citizens’ data collected by Government of India through ‘Aadhar’ unique identification number, ‘Aarogya Sethu’, and ‘CoWIN’ can be used for building social welfare and health infrastructure development programs. The benefits and the intertwined challenges with ‘Data Science Strategy’ in the government sector offer further opportunities for research.
7 Conclusion
The SLR aimed at synthesizing the enablers and barriers of 'Data Science Strategy' adoption in different industries, sectors, and business domains. The review conducted an in-depth study of 113 published articles (1998- 2021) sourced from four different databases, namely, EBSCO Business Source Ultimate, Scopus, Science Direct, and Pro-Quest databases, respectively. The findings show that the enablers of ‘Data Science’ and barriers for adoption of ‘Data Science Strategy’ are synthesized. The SLR identified four themes namely ‘Content’ (Data Quality & Governance), ‘Context’ (Technology and Environmental), ‘Intent’ (Culture, Alignment, Agility), and ‘Outcomes’ (Functional and Symbolic business value) that influence the development of ‘Data Science Strategy’ in organizations.
The key lessons learnt are formulated in to a conceptual framework linking ‘Data Science’ resources to business outcomes, influenced by ‘barriers’ and ‘enablers’. In summary, the barriers and enablers are segregated under individual, organizational and institutional contexts. Organizations may not completely be able to eliminate the ‘barriers’, but capitalizing on ‘enablers’ would mitigate the risks of ‘Data Science’ adoption and success of projects leading to desired business outcomes. The study also summarizes the ‘barriers’ and ‘enablers’ of ‘Data Science Strategy’ in organizations depending on industry sectors and domains. Although most of the barriers and enablers might be common across businesses, organizations should prioritize those relevant to their areas of expertise.
The study also emphasizes on the significant role of 'Data Science Strategy' in organizations augmenting 'Data Strategy', 'digitalization' and, eventually 'digital transformation' leading to business success. Research gaps are identified for future attention. The academic and practitioner community should focus their efforts on promoting the development and implementation of a well-crafted, outcome-based, holistic 'Data Science Strategy' so as to reap the benefits of the digital revolution that’s happening globally. Additionally, the onset of Covid-19 pandemic has accentuated the challenges faced by enterprises across various domains which further pushes for a need for a ‘Data Science Strategy’ to aid in the development of a ‘Digital Strategy’ for an organization.
References
Adrian C, Abdullah R, Atan R, Jusoh YY (2016) Towards developing strategic assessment model for big data implementation: a systematic literature review. Int J Adv Soft Comput Appl 8(3):173–192
Adrian C, Abdullah R, Atan R, Jusoh YY (2017) Factors influencing to the implementation success of big data analytics: a systematic literature review. In: 2017 International conference on research and innovation in information systems (ICRIIS). IEEE, pp 1–6
Ahmed V, Aziz Z, Tezel A, Riaz Z (2018) Challenges and drivers for data mining in the AEC sector. Eng Constr Archit Manag 25(11):1436–1453. https://doi.org/10.1108/ECAM-01-2018-0035
Akter S, Wamba SF, Gunasekaran A, Dubey R, Childe SJ (2016) How to improve firm performance using big data analytics capability and business strategy alignment? Int J Prod Econ 182:113–131. https://doi.org/10.1016/j.ijpe.2016.08.018
Alaskar TH, Mezghani K, Alsadi AK (2020) Examining the adoption of Big data analytics in supply chain management under competitive pressure: evidence from Saudi Arabia. J Decis Syst. https://doi.org/10.1080/12460125.2020.1859714
Ali Q, Salman A, Yaacob H, Zaini Z, Abdullah R (2020) Does big data analytics enhance sustainability and financial performance. The case of ASEAN banks. J Asian Finance Econ Bus 7(7):1–13. https://doi.org/10.13106/jafeb.2020.vol7.no7.001
Al-Sai ZA, Abdullah R, Husin MH (2020) Critical success factors for big data: a systematic literature review. IEEE Access 8:118940–118956. https://doi.org/10.1109/access.2020.3005461
Alsheiabni S, Messom C, Cheung Y, Alhosni M (2020) Winning AI strategy: six-steps to create value from artificial intelligence. AMCIS 2020 Proceedings. 1. https://aisel.aisnet.org/amcis2020/adv_info_systems_research/adv_info_systems_research/1
Arunachalam D, Kumar N, Kawalek JP (2018) Understanding big data analytics capabilities in supply chain management: unravelling the issues, challenges and implications for practice. Trans Res E Log Trans Rev 114:416–436. https://doi.org/10.1016/j.tre.2017.04.001
Becker W, Schmid O (2020) The right digital strategy for your business: an empirical analysis of the design and implementation of digital strategies in SMEs and LSEs. Bus Res. https://doi.org/10.1007/s40685-020-00124-y
Behl A, Dutta P, Lessmann S, Dwivedi YK, Kar S (2019) A conceptual framework for the adoption of big data analytics by e-commerce startups: a case-based approach. IseB 17(2):285–318. https://doi.org/10.1007/s10257-019-00452-5
Bendre MR, Thool VR (2016) Analytics, challenges and applications in big data environment: a survey. J Manage Anal 3(3):206–239. https://doi.org/10.1080/23270012.2016.1186578
Bertello A, Ferraris A, Bresciani S, De Bernardi P (2020) Big data analytics (BDA) and degree of internationalization: the interplay between governance of BDA infrastructure and BDA capabilities. J Manage Governance. https://doi.org/10.1007/s10997-020-09542-w
Bertot JC, Gorham U, Jaeger PT, Sarin LC, Choi H (2014) Big data, open government and e-government: issues, policies and recommendations. Inform Polity 19(1,2):5–16. https://doi.org/10.3233/IP-140328
Bharati P, Chaudhury A (2019) Assimilation of big data innovation: investigating the roles of IT, social media, and relational capital. Inf Syst Front 21(6):1357–1368
Biazzin C, Castro-Carvalho L (2019) Big data in procurement: the role of people behavior and organization alignment. Dimensión Empresarial 17(4):10–28
Bogdan M, Lungescu DC (2018) Is strategic management ready for big data? A review of the big data analytics literature in management research. Manage Chall Contemp Soc Proc 11(2):65
Boldosova V (2019) Deliberate storytelling in big data analytics adoption. Inf Syst J 29(6):1126–1152. https://doi.org/10.1111/isj.12244
Borges AF, Laurindo FJ, Spínola MM, Gonçalves RF, Mattos CA (2021) The strategic use of artificial intelligence in the digital era: systematic literature review and future research directions. Int J Inf Manage 57(2021):102225. https://doi.org/10.1016/j.ijinfomgt.2020.102225
Božič K, Dimovski V (2020) The relationship between business intelligence and analytics use and organizational absorptive capacity: applying the DeLone & mclean information systems success model. Econ Bus Rev Central South-Eastern Eur 22(2):191–232. https://doi.org/10.15458/ebr99
Braganza A, Brooks L, Nepelski D, Ali M, Moro R (2017) Resource management in big data initiatives: processes and dynamic capabilities. J Bus Res 70:328–337. https://doi.org/10.1016/j.jbusres.2016.08.006
Brinch M, Stentoft J, Jensen JK, Rajkumar C (2018) Practitioners understanding of big data and its applications in supply chain management. Int J Log Manage 29(2):555–574. https://doi.org/10.1108/IJLM-05-2017-0115
Bughin J (2018) Wait and see could be a costly AI Strategy. MIT Sloan Management Review. https://www.kungfu.ai/wp-content/uploads/2019/01/Wait-and-See-Could-Be-a-Costly-AI-Strategy.pdf
Cabrera-Sánchez JP, Villarejo-Ramos AF (2019) Factors affecting the adoption of big data analytics in companies. Revista De Administração De Empresas 59(6):415–429
Calvard TS (2016) Big data, organizational learning, and sensemaking: Theorizing interpretive challenges under conditions of dynamic complexity. Manag Learn 47(1):65–82. https://doi.org/10.1177/1350507615592113
Cao G, Duan Y (2017) How do top-and bottom-performing companies differ in using business analytics? J Enterp Inf Manag 30(6):874–892. https://doi.org/10.1108/JEIM-04-2016-0080
Chakravorty R (2020) Common challenges of data governance. J Securit Oper Custody 13(1):23–43
Chatterjee S (2020) AI strategy of India: policy framework, adoption challenges and actions for government. Transf Govern People Process Policy 14(5):757–775. https://doi.org/10.1108/TG-05-2019-0031
Chaurasia SS, Verma S (2020) Strategic determinants of big data analytics in the AEC sector: a multi-perspective framework. Constr Econ Build 20(4):63–81
Chen Y, Banerjee A (2020) Improving the digital health of the workforce in the COVID-19 context: an opportunity to future-proof medical training. Future Healthcare J 7(3):189. https://doi.org/10.7861/fhj.2020-0162
Chen H, Chiang RH, Storey VC (2012) Business intelligence and analytics: from big data to big impact. MIS Q 36(4):1165–1188. https://doi.org/10.2307/41703503
Choi TM, Wallace SW, Wang Y (2018) Big data analytics in operations management. Prod Oper Manag 27(10):1868–1883. https://doi.org/10.1111/poms.12838
Ciampi F, Marzi G, Demi S, Faraoni M (2020) The big data-business strategy interconnection: a grand challenge for knowledge management. A review and future perspectives. J Knowl Manag 24(5):1157–1176. https://doi.org/10.1108/JKM-02-2020-0156
Colvin G (2018) What the Hell Happened at GE? Fortune Magazine. 177/6, http://fortune.com/longform/ge-decline-what-the-hell-happened/
Comuzzi M, Patel A (2016) How organisations leverage big data: a maturity model. Ind Manag Data Syst 116(8):1468–1492. https://doi.org/10.1108/IMDS-12-2015-0495
Coombs C, Hislop D, Taneva SK, Barnard S (2020) The strategic impacts of Intelligent automation for knowledge and service work: an interdisciplinary review. J Strateg Inf Syst 29(4):101600. https://doi.org/10.1016/j.jsis.2020.101600
Correani A, De Massis A, Frattini F, Petruzzelli AM, Natalicchio A (2020) Implementing a digital strategy: learning from the experience of three digital transformation projects. Calif Manage Rev 62(4):37–56. https://doi.org/10.1177/0008125620934864
Crossan MM, Lane HW, White RE (1999) An organizational learning framework: from intuition to institution. Acad Manag Rev 24(3):522–537. https://doi.org/10.5465/amr.1999.2202135
Dam NAK, Le Dinh T, Menvielle W (2019) A systematic literature review of big data adoption in internationalization. Journal of Marketing Analytics 7(3):182–195. https://doi.org/10.1057/s41270-019-00054-7
Davenport TH (2013) Analytics 3.0. Harvard Bus Rev 91(12):64–72, available at: https://hbr.org/2013/12/analytics-30#. Accessed 28 April 2021
De Luca LM, Herhausen D, Troilo G, Rossi A (2020) How and when do big data investments pay off? The role of marketing affordances and service innovation. J Acad Mark Sci 2020:1–21. https://doi.org/10.1007/s11747-020-00739-x
de Medeiros MM, Hoppen N, Maçada ACG (2020) Data science for business: benefits, challenges and opportunities. The Bottom Line 33(2):149–163. https://doi.org/10.1108/BL-12-2019-0132
Devasia R (2018) Data strategy to excel through disruptions in CADS. Sansmaran Res J, pp 1–2
de Swaan Arons M, van den Driest F, Weed K (2014) The ultimate marketing machine. Harvard Business Review.
Downes L, Mui C (1998) The end of strategy. Strat Lead 26(5):4
Dremel C, Wulf J, Herterich MM, Waizmann JC, Brenner W (2017) How AUDI AG established big data analytics in its digital transformation. MIS Q Exec 16(2):81–100
Dubey R, Gunasekaran A, Childe SJ (2019a) Big data analytics capability in supply chain agility. Manag Decis 57(8):2092–2112. https://doi.org/10.1108/MD-01-2018-0119
Dubey R, Gunasekaran A, Childe SJ, Blome C, Papadopoulos T (2019b) Big data and predictive analytics and manufacturing performance: integrating institutional theory, resource-based view and big data culture. Br J Manag 30(2):341–361. https://doi.org/10.1111/1467-8551.12355
Eggert M, Alberts J (2020) Frontiers of business intelligence and analytics 3.0: a taxonomy-based literature review and research agenda. Bus Res 13(2):685–739. https://doi.org/10.1007/s40685-020-00108-y
Erceg V, Zoranović T (2020) Required competencies for successful digital transformation. Ekonomika 66(3):47–54. https://doi.org/10.5937/ekonomika2003047E
Fakhri AB, Mohammed SL, Khan I, Sadiq AS, Alkazemi B, Pillai P, Choi BJ (2020) Industry 4.0: architecture and equipment revolution. Comput Mater Continua 66(2):1175–1194. https://doi.org/10.32604/cmc.2020.012587
Ferraris A, Mazzoleni A, Devalle A, Couturier J (2019) Big data analytics capabilities and knowledge management: impact on firm performance. Manag Decis 57(8):1923–1936. https://doi.org/10.1108/MD-07-2018-0825
Fiedler FE (1964) A contingency model of leadership effectiveness. In: Advances in experimental social psychology. Academic Press, vol 1, pp 149–190. doi: https://doi.org/10.1016/S0065-2601(08)60051-9
Foshay N, Yeoh W, Boo YL, Ong KL, Mattie D (2015) A comprehensive diagnostic framework for evaluating business intelligence and analytics effectiveness. Australas J Inf Syst 19:S37–S54. https://doi.org/10.3127/ajis.v19i0.1178
Fox S, Do T (2013) Getting real about big data: applying critical realism to analyse big data hype. Int J Manag Proj Bus 6(4):739–760. https://doi.org/10.1108/IJMPB-08-2012-0049
GalbRaith JR (2014) Organizational design challenges resulting from big data. J Org Des 3(1):2–13. https://ssrn.com/abstract=2458899
George G, Lakhani KR, Puranam P (2020) What has changed? The impact of Covid pandemic on the technology and innovation management research agenda. J Manage Stud 57(8):1754–1758. https://doi.org/10.1111/joms.12634
Ghasemaghaei M, Ebrahimi S, Hassanein K (2018) Data analytics competency for improving firm decision making performance. J Strateg Inf Syst 27(1):101–113. https://doi.org/10.1016/j.jsis.2017.10.001
Gong Y, Janssen M (2021) Roles and capabilities of enterprise architecture in big data analytics technology adoption and implementation. J Theor Appl Electron Commer Res 16(1):37–51. https://doi.org/10.4067/S0718-18762021000100104
Gregory A (2011) Data governance—protecting and unleashing the value of your customer data assets. J Direct Data Digit Mark Pract 12(3):230–248. https://doi.org/10.1057/dddmp.2010.41
Grossman RL (2018) A framework for evaluating the analytic maturity of an organization. Int J Inf Manage 38(1):45–51. https://doi.org/10.1016/j.ijinfomgt.2017.08.005
Grover V, Chiang RH, Liang TP, Zhang D (2018) Creating strategic business value from big data analytics: a research framework. J Manag Inf Syst 35(2):388–423. https://doi.org/10.1080/07421222.2018.1451951
Günther WA, Mehrizi MHR, Huysman M, Feldberg F (2017) Debating big data: a literature review on realizing value from big data. J Strateg Inf Syst 26(3):191–209. https://doi.org/10.1016/j.jsis.2017.07.003
Gupta M, George JF (2016) Toward the development of a big data analytics capability. Inf Manage 53(8):1049–1064. https://doi.org/10.1016/j.im.2016.07.004
Halaweh M, Massry AE (2015) Conceptual model for successful implementation of big data in organizations. J Int Technol Inf Manage 24(2):2
Hallikainen H, Savimäki E, Laukkanen T (2020) Fostering B2B sales with customer big data analytics. Ind Mark Manage 86:90–98. https://doi.org/10.1016/j.indmarman.2019.12.005
Hantrais L, Allin P, Kritikos M, Sogomonjan M, Anand PB, Livingstone S (2020) Covid-19 and the digital revolution. Contemp Soc Sci 16(2):256–270. https://doi.org/10.1080/21582041.2020.1833234
Harlow HD (2018) Developing a knowledge management strategy for data analytics and intellectual capital. Meditari Account Res 26(3):400–419. https://doi.org/10.1108/MEDAR-09-2017-0217
Holland CP, Thornton SC, Naudé P (2020) B2B analytics in the airline market: harnessing the power of consumer big data. Ind Mark Manage 86:52–64. https://doi.org/10.1016/j.indmarman.2019.11.002
Huberty M (2015) Awaiting the second big data revolution: from digital noise to value creation. J Ind Compet Trade 15(1):35–47
Inamdar Z, Raut R, Narwane VS, Gardas B, Narkhede B, Sagnak M (2020) A systematic literature review with bibliometric analysis of big data analytics adoption from period 2014 to 2018. J Enterp Inf Manag 34(1):101–139. https://doi.org/10.1108/JEIM-09-2019-0267
Jägare U (2019) Data science strategy for dummies. John Wiley and Sons, Incorporated
Jha AK, Agi MA, Ngai EW (2020) A note on big data analytics capability development in supply chain. Decis Support Syst 138:113382. https://doi.org/10.1016/j.dss.2020.113382
Ji-fan Ren S, Fosso Wamba S, Akter S, Dubey R, Childe SJ (2017) Modelling quality dynamics, business value and firm performance in a big data analytics environment. Int J Prod Res 55(17):5011–5026. https://doi.org/10.1080/00207543.2016.1154209
Johnson JS, Friend SB, Lee HS (2017) Big data facilitation, utilization, and monetization: exploring the 3Vs in a new product development process. J Prod Innov Manag 34(5):640–658. https://doi.org/10.1111/jpim.12397
Kache F, Seuring S (2017) Challenges and opportunities of digital information at the intersection of Big Data Analytics and supply chain management. Int J Oper Prod Manag 37(1):10–36. https://doi.org/10.1108/IJOPM-02-2015-0078
Kamble SS, Gunasekaran A, Goswami M, Manda J (2019) A systematic perspective on the applications of big data analytics in healthcare management. Int J Healthcare Manage 12(3):226–240. https://doi.org/10.1080/20479700.2018.1531606
Keding C (2020) Understanding the interplay of artificial intelligence and strategic management: four decades of research in review. Manage Rev Quart 71:91–134. https://doi.org/10.1007/s11301-020-00181-x
Kemppainen L, Pikkarainen M, Hurmelinna-Laukkanen P, Reponen J (2019) Connected health innovation: data access challenges in the interface of AI companies and hospitals. Technol Innov Manag Rev 9(12):43–55
Khan M (2019) Challenges with big data analytics in service supply chains in the UAE. Manag Decis 57(8):2124–2147. https://doi.org/10.1108/MD-06-2018-0669
Khosrowpour M (1990) The changing role of information technology services. Rev Bus 11(4):11
Kitsios F, Kamariotou M (2021) Artificial intelligence and business strategy towards digital transformation: a research Agenda. Sustainability 13(4):2025. https://doi.org/10.3390/su13042025
Knabke T, Olbrich S (2018) Building novel capabilities to enable business intelligence agility: results from a quantitative study. Inf Syst E-Bus Manage 16(3):493–546. https://doi.org/10.1007/s10257-017-0361-z
Lacam JS (2020) Data: a collaborative? J High Technol Managem Res 31(1):100370. https://doi.org/10.1016/j.hitech.2020.100370
Lai Y, Sun H, Ren J (2018) Understanding the determinants of big data analytics (BDA) adoption in logistics and supply chain management. Int J Logist Manage 29(2):676–703. https://doi.org/10.1108/IJLM-06-2017-0153
Lamba K, Singh SP (2018) Modeling big data enablers for operations and supply chain management. Int J Logist Manage 29(2):629–658. https://doi.org/10.1108/IJLM-07-2017-0183
Latif Z, Lei W, Latif S, Pathan ZH, Ullah R, Jianqiu Z (2019) Big data challenges: prioritizing by decision-making process using Analytic Network Process technique. Multimed Tools Appl 78(19):27127–27153. https://doi.org/10.1007/s11042-017-5161-4
Lautenbach P, Johnston K, Adeniran-Ogundipe T (2017) Factors influencing business intelligence and analytics usage extent in South African organisations. South Afric J Bus Manage 48(3):23–33. https://hdl.handle.net/10520/EJC-97b9b0316
Lee H, Kweon E, Kim M, Chai S (2017) Does implementation of big data analytics improve firms’ market value? Investors’ Reaction in Stock Market. Sustainability 9(6):978. https://doi.org/10.3390/su9060978
Li S, Yu H (2020) Big data and financial information analytics ecosystem: strengthening personal information under legal regulation. Inf Syst E-Bus Manage 18(4):891–909. https://doi.org/10.1007/s10257-019-00404-z
Li X, Zhang Y, Li Y, Yu K, Du Y (2021) Study of E-business applications based on big data analysis in modern hospital health management. Inf Syst E-Bus Manage 19:621–640. https://doi.org/10.1007/s10257-021-00520-9
Libert B, Beck M, Wind Y (2016) Questions to ask before your next digital transformation. Harv Bus Rev 60(12):11–13
Llave MR (2017) Business intelligence and analytics in small and medium-sized enterprises: a systematic literature review. Proc Comput Sci 121:194–205. https://doi.org/10.1016/j.procs.2017.11.027
Maalsen S, Dowling R (2020) Covid-19 and the accelerating smart home. Big Data Soc 7(2):2053951720938073. https://doi.org/10.1177/2053951720938073
Macada ACG, Brinkhues RA, Freitas JCDS (2019) Information management capability and big data strategy implementation. Revista De Administração De Empresas 59(6):379–388. https://doi.org/10.1590/S0034-759020190604
Mandal S (2019) The influence of big data analytics management on capabilities on supply chain preparedness, alertness and agility. Inf Technol People 32(2):297–318. https://doi.org/10.1108/ITP-11-2017-0386
Mandlik MA, Kadirov D (2018) Big data approaches and outcome of information asymmetry: opportunities for future research. Int J Bus Contin Risk Manage 8(4):303–318. https://doi.org/10.1504/IJBCRM.2018.095287
Markus ML (2017) Datification, organizational strategy, and IS research: what’s the score? J Strateg Inf Syst 26(3):233–241. https://doi.org/10.1016/j.jsis.2017.08.003
Maroufkhani P, Wagner R, Wan Ismail WK, Baroto MB, Nourani M (2019) Big data analytics and firm performance: a systematic review. Information 10(7):226. https://doi.org/10.3390/info10070226
Mazzei MJ, Noble D (2017) Big data dreams: a framework for corporate strategy. Bus Horiz 60(3):405–414. https://doi.org/10.1016/j.bushor.2017.01.010
Mehrabian A, Russell JA (1974) An approach to environmental psychology. The MIT Press.
Meyer JW, Rowan B (1977) Institutionalized organizations: formal structure as myth and ceremony. Am J Soc 83(2):340–363
Mikalef P, Gupta M (2021) Artificial intelligence capability: Conceptualization, measurement calibration, and empirical study on its impact on organizational creativity and firm performance. Inf Manage 58(3):103434. https://doi.org/10.1016/j.im.2021.103434
Mikalef P, Pappas IO, Krogstie J, Giannakos M (2018) Big data analytics capabilities: a systematic literature review and research agenda. Inf Syst E-Bus Manage 16(3):547–578. https://doi.org/10.1007/s10257-017-0362-y
Mikalef P, Boura M, Lekakos G, Krogstie J (2019a) Big data analytics capabilities and innovation: the mediating role of dynamic capabilities and moderating effect of the environment. Br J Manag 30(2):272–298. https://doi.org/10.1111/1467-8551.12343
Mikalef P, Boura M, Lekakos G, Krogstie J (2019b) Big data analytics and firm performance: findings from a mixed-method approach. J Bus Res 98:261–276. https://doi.org/10.1016/j.jbusres.2019.01.044
Mikalef P, Boura M, Lekakos G, Krogstie J (2020a) The role of information governance in big data analytics driven innovation. Inf Manage 57(7):103361. https://doi.org/10.1016/j.im.2020.103361
Mikalef P, Krogstie J, Pappas IO, Pavlou P (2020b) Exploring the relationship between big data analytics capability and competitive performance: the mediating roles of dynamic and operational capabilities. Inf Manage 57(2):103169. https://doi.org/10.1016/j.im.2019.05.004
Mikalef P, van de Wetering R, Krogstie J (2020c) Building dynamic capabilities by leveraging big data analytics: The role of organizational inertia. Inf Manage. https://doi.org/10.1016/j.im.2020.103412
Mikalef P, Pappas IO, Giannakos MN, Krogstie J, Lekakos G (2016) Big data and strategy: a research framework. In: MCIS
Mir UB, Sharma S, Kar AK, Gupta MP (2020) Critical success factors for integrating artificial intelligence and robotics. Digit Policy Regul Govern 22(4):307–331. https://doi.org/10.1016/j.jjimei.2021.100017
Mithas S, Tafti A, Mitchell W (2013) How a firm's competitive environment and digital strategic posture influence digital business strategy. MIS Quart, pp 511–536. http://www.jstor.org/stable/43825921
Moreno V, da Silva FELV, Ferreira R, Filardi F (2019) Complementarity as a driver of value in business intelligence and analytics adoption processes. Revista Ibero-Americana De Estrategia 18(1):57. https://doi.org/10.5585/ijsm.v18i1.2678
Müller O, Fay M, Vom Brocke J (2018) The effect of big data and analytics on firm performance: an econometric analysis considering industry characteristics. J Manag Inf Syst 35(2):488–509. https://doi.org/10.1080/07421222.2018.1451955
Najjar MS, Kettinger WJ (2013) Data monetization: lessons from a Retailer’s Journey. MIS Q Exec 12(4):213–225
Nelson B, Olovsson T (2016) Security and privacy for big data: a systematic literature review. In: 2016 IEEE international conference on big data (big data). IEEE, pp 3693–3702. doi: https://doi.org/10.1109/BigData.2016.7841037.
Newlands G, Lutz C, Tamò-Larrieux A, Villaronga EF, Harasgama R, Scheitlin G (2020) Innovation under pressure: Implications for data privacy during the Covid-19 pandemic. Big Data Soc 7(2):2053951720976680. https://doi.org/10.1177/2053951720976680
Nguyen T, Li ZHOU, Spiegler V, Ieromonachou P, Lin Y (2018) Big data analytics in supply chain management: a state-of-the-art literature review. Comput Oper Res 98:254–264. https://doi.org/10.1016/j.cor.2017.07.004
Okwechime E, Duncan P, Edgar D (2018) Big data and smart cities: a public sector organizational learning perspective. Inf Syst E-Bus Manage 16(3):601–625. https://doi.org/10.1007/s10257-017-0344-0
Olszak CM, Mach-Król M (2018) A conceptual framework for assessing an organization’s readiness to adopt big data. Sustainability 10(10):3734. https://doi.org/10.3390/su10103734
Pappas IO, Mikalef P, Giannakos MN, Krogstie J, Lekakos G (2018) Big data and business analytics ecosystems: paving the way towards digital transformation and sustainable societies. Inf Syst E-Bus Manage 16:479–491. https://doi.org/10.1007/s10257-018-0377-z
Poeppelbuss J, Niehaves B, Simons A, Becker J (2011) Maturity models in information systems research: literature search and analysis. Commun Assoc Inf Syst 29(27):505–532. https://doi.org/10.17705/1CAIS.02927
Popovič A, Hackney R, Tassabehji R, Castelli M (2018) The impact of big data analytics on firms’ high value business performance. Inf Syst Front 20(2):209–222. https://doi.org/10.1007/s10796-016-9720-4
Raguseo E, Vitari C (2018) Investments in big data analytics and firm performance: an empirical investigation of direct and mediating effects. Int J Prod Res 56(15):5206–5221. https://doi.org/10.1080/00207543.2018.1427900
Ram J, Afridi NK, Khan KA (2019) Adoption of Big Data analytics in construction: development of a conceptual model. Built Environ Project Asset Manage 9(4):564–579. https://doi.org/10.1108/BEPAM-05-2018-0077
Ramnath VR, Kairaitis K, Malhotra A (2020) The challenge of COVID-19 has accelerated the use of new data-sharing technologies. Respirology 25(8):800. https://doi.org/10.1111/resp.13894
Ranjan J (2019) The 10 Vs of Big Data framework in the Context of 5 Industry Verticals. Productivity 59(4):324–342
Ransbotham S, Kiron D, Gerbert P, Reeves M (2017) Reshaping business with artificial intelligence: Closing the gap between ambition and action. MIT Sloan Manag Rev 59(1):1–17
Rialti R, Marzi G, Silic M, Ciappei C (2018) Ambidextrous organization and agility in big data era. Bus Process Manag J 24(5):1091–1109. https://doi.org/10.1108/BPMJ-07-2017-0210
Rialti R, Marzi G, Ciappei C, Busso D (2019) Big data and dynamic capabilities: a bibliometric analysis and systematic literature review. Manag Decis 57(8):2052–2068. https://doi.org/10.1108/MD-07-2018-0821
Rialti R, Marzi G, Caputo A, Mayah KA (2020) Achieving strategic flexibility in the era of big data. Manag Decis 58(8):1585–1600. https://doi.org/10.1108/MD-09-2019-1237
Ross JW, Beath CM, Sebastian IM (2017) How to develop a great digital strategy. MIT Sloan Manag Rev 58(2):7
Saldžiūnas K, Skyrius R (2017) The challenges of big data analytics in the mobile communications sector. Ekonomika 96(2):110–121
Sang L, Yu M, Lin H, Zhang Z, Jin R (2020) Big data, technology capability and construction project quality: a cross-level investigation. Eng Constr Archit Manag 28(3):706–727. https://doi.org/10.1108/ECAM-02-2020-0135
Sarker KU, Deraman AB, Hasan R, Abbas A (2019) Ontological practice for big data management. International Journal of Computing and Digital Systems 8(03):265–273. https://doi.org/10.12785/ijcds/080306
Schroeder R (2016) Big data business models: Challenges and opportunities. Cogent Soc Sci 2(1):1166924. https://doi.org/10.1080/23311886.2016.1166924
Sebastian IM, Ross JW, Beath C, Mocker M, Moloney KG, Fonstad NO (2017) How big old companies navigate digital transformation. MIS Q Exec 16(3):197–213
Shahbaz M, Gao C, Zhai L, Shahzad F, Hu Y (2019) Investigating the adoption of big data analytics in healthcare: the moderating role of resistance to change. J Big Data 6(1):1–20. https://doi.org/10.1186/s40537-019-0170-y
Shim JP, French AM, Guo C, Jablonski J (2015) Big data and analytics: Issues, solutions, and ROI. Commun Assoc Inf Syst 37(1):39. https://doi.org/10.17705/1CAIS.03739
Shokouhyar S, Seddigh MR, Panahifar F (2020) Impact of big data analytics capabilities on supply chain sustainability. World J Sci Technol Sustain Dev 17(1):33–57. https://doi.org/10.1108/WJSTSD-06-2019-0031
Singh RK, Agrawal S, Sahu A, Kazancoglu Y (2021) Strategic issues of big data analytics applications for managing health-care sector: a systematic literature review and future research agenda. TQM J Ahead of Print. doi: https://doi.org/10.1108/TQM-02-2021-0051
Singh NP, Singh S (2019) Building supply chain risk resilience. Benchmark Int J 26(7):2318–2342. https://doi.org/10.1108/BIJ-10-2018-0346
Sivarajah U, Kamal MM, Irani Z, Weerakkody V (2017) Critical analysis of Big Data challenges and analytical methods. J Bus Res 70:263–286. https://doi.org/10.1016/j.jbusres.2016.08.001
Song M, Zhang H, Heng J (2020) Creating sustainable innovativeness through big data and big data analytics capability: from the perspective of the information processing theory. Sustainability 12(5):1984. https://doi.org/10.3390/su12051984
Soto-Acosta P (2020) COVID-19 pandemic: Shifting digital transformation to a high-speed gear. Inf Syst Manag 37(4):260–266. https://doi.org/10.1080/10580530.2020.1814461
Sun S, Hall DJ, Cegielski CG (2020) Organizational intention to adopt big data in the B2B context: an integrated view. Ind Mark Manage 86:109–121. https://doi.org/10.1016/j.indmarman.2019.09.003
Tabesh P, Mousavidin E, Hasani S (2019) Implementing big data strategies: a managerial perspective. Bus Horiz 62(3):347–358. https://doi.org/10.1016/j.bushor.2019.02.001
Trompenaars F, Woolliams P (2016) Going digital internationally. Organ Dev J 34(1):11–35
Ukko J, Nasiri M, Saunila M, Rantala T (2019) Sustainability strategy as a moderator in the relationship between digital business strategy and financial performance. J Clean Prod 236:117626. https://doi.org/10.1016/j.jclepro.2019.117626
Van Tonder C, Schachtebeck C, Nieuwenhuizen C, Bossink B (2020) A framework for digital transformation and business model innovation. Manage J Contemp Manage 25(2):111–132. https://doi.org/10.30924/mjcmi.25.2.6
Verhoef PC, Broekhuizen T, Bart Y, Bhattacharya A, Dong JQ, Fabian N, Haenlein M (2021) Digital transformation: a multidisciplinary reflection and research agenda. J Bus Res 122:889–901. https://doi.org/10.1016/j.jbusres.2019.09.022
Verma S (2017) The adoption of big data services by manufacturing firms: an empirical investigation in India. JISTEM-J Inf Syst Technol Manage 14(1):39–68. https://doi.org/10.4301/S1807-17752017000100003
Verma S, Bhattacharyya SS (2017) Perceived strategic value-based adoption of big data analytics in emerging economy. J Enterp Inf Manag 30(3):354–382. https://doi.org/10.1108/JEIM-10-2015-0099
Vydra S, Klievink B (2019) Techno-optimism and policy-pessimism in the public sector big data debate. Gov Inf Q 36(4):101383. https://doi.org/10.1016/j.giq.2019.05.010
Walker RS, Brown I (2019) Big data analytics adoption: a case study in a large South African telecommunications organisation. South Afr J Inf Manage 21(1):1–10. https://doi.org/10.4102/sajim.v21i1.1079
Wamba SF, Akter S, Edwards A, Chopin G, Gnanzou D (2015) How ‘big data’ can make big impact: Findings from a systematic review and a longitudinal case study. Int J Prod Econ 165:234–246. https://doi.org/10.1016/j.ijpe.2014.12.031
Wamba SF, Gunasekaran A, Akter S, Ren SJF, Dubey R, Childe SJ (2017) Big data analytics and firm performance: effects of dynamic capabilities. J Bus Res 70:356–365. https://doi.org/10.1016/j.jbusres.2016.08.009
Wamba SF, Akter S, Trinchera L, De Bourmont M (2019) Turning information quality into firm performance in the big data economy. Manag Decis 57(8):1756–1783. https://doi.org/10.1108/MD-04-2018-0394
Wang Y, Hajli N (2017) Exploring the path to big data analytics success in healthcare. J Bus Res 70:287–299. https://doi.org/10.1016/j.jbusres.2016.08.002
Wang Y, Kung L, Byrd TA (2018a) Big data analytics: Understanding its capabilities and potential benefits for healthcare organizations. Technol Forecast Soc Chang 126:3–13. https://doi.org/10.1016/j.techfore.2015.12.019
Wang Y, Kung L, Wang WYC, Cegielski CG (2018b) An integrated big data analytics-enabled transformation model: Application to health care. Inf Manage 55(1):64–79. https://doi.org/10.1016/j.im.2017.04.001
Wang L, Yang M, Pathan ZH, Salam S, Shahzad K, Zeng J (2018c) Analysis of influencing factors of big data adoption in Chinese enterprises using DANP technique. Sustainability 10(11):3956. https://doi.org/10.3390/su10113956
Wang Y, Kung L, Gupta S, Ozdemir S (2019) Leveraging big data analytics to improve quality of care in healthcare organizations: A configurational perspective. Br J Manag 30(2):362–388. https://doi.org/10.1111/1467-8551.12332
Westerman G (2018) Your company doesn’t need a digital strategy. MIT Sloan Manag Rev 59(3):1–5
Wiener M, Saunders C, Marabelli M (2020) Big-data business models: A critical literature review and multiperspective research framework. J Inf Technol 35(1):66–91. https://doi.org/10.1177/0268396219896811
Wright LT, Robin R, Stone M, Aravopoulou DE (2019) Adoption of big data technology for innovation in B2B marketing. J Bus Bus Mark 26(3–4):281–293. https://doi.org/10.1080/1051712X.2019.1611082
Wu J, Li H, Lin Z, Goh KY (2017) How big data and analytics reshape the wearable device market–the context of e-health. Int J Prod Res 55(17):5168–5182. https://doi.org/10.1080/00207543.2015.1059521
Yadav J (2017) Confronts of big data and its tools. Int J Adv Res Comput Sci 8(1):215–218
Yang H, Kundakcioglu OE, Zeng D (2015) Healthcare data analytics. Inf Syst E-Bus Manage 13:595–597. https://doi.org/10.1007/s10257-015-0297-0
Zaki M (2019) Digital transformation: harnessing digital technologies for the next generation of services. J Serv Mark 33(4):429–435. https://doi.org/10.1108/JSM-01-2019-0034
Zhang F (2021) Construction of internal management system of business strategic planning based on Artificial Intelligence. Inf Syst E-Bus Manage. https://doi.org/10.1007/s10257-021-00510-x
Zhang H, Song M, He H (2020) Achieving the success of sustainability development projects through big data analytics and artificial intelligence capability. Sustainability 12(3):949. https://doi.org/10.3390/su12030949
Zhao-hong Y, Hui-yu W, Bin Z, Zhi-he H, Wan-lin L (2018) A literature review on the key technologies of processing big data. In: 2018 IEEE 3rd International conference on cloud computing and big data analysis (ICCCBDA). IEEE, pp 202–208. doi: https://doi.org/10.1109/ICCCBDA.2018.8386512.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Reddy, R.C., Bhattacharjee, B., Mishra, D. et al. A systematic literature review towards a conceptual framework for enablers and barriers of an enterprise data science strategy. Inf Syst E-Bus Manage 20, 223–255 (2022). https://doi.org/10.1007/s10257-022-00550-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10257-022-00550-x