
Abstract
Spatial memory is a cognitive skill that allows the recall of information about the space, its layout, and items’ locations. We present a novel application built around 3D spatial audio technology to evaluate audio-spatial memory abilities. The sound sources have been spatially distributed employing the 3D Tune-In Toolkit, a virtual acoustic simulator. The participants are presented with sequences of sounds of increasing length emitted from virtual auditory sources around their heads. To identify stimuli positions and register the test responses, we designed a custom-made interface with buttons arranged according to sound locations. We took inspiration from the Corsi-Block test for the experimental procedure, a validated clinical approach for assessing visuo-spatial memory abilities. In two different experimental sessions, the participants were tested with the classical Corsi-Block and, blindfolded, with the proposed task, named Audio-Corsi for brevity. Our results show comparable performance across the two tests in terms of the estimated memory parameter precision. Furthermore, in the Audio-Corsi we observe a lower span compared to the Corsi-Block test. We discuss these results in the context of the theoretical relationship between the auditory and visual sensory modalities and potential applications of this system in multiple scientific and clinical contexts.
Similar content being viewed by others


1 Introduction
In behavioral testing, technological innovations allow researchers to disclose cognitive processes’ properties otherwise difficult to be isolated and adequately investigated. In this context, testing of visually impaired people strongly benefits from using systems capable of delivering auditory stimulation. Early visual deprivation might delay the development of specific auditory spatial skills and negatively impact the ability to engage in positive social interactions [46, 61, 65]. Thus, the development of audio-technological tools is fundamental for the assessment of such cognitive skills, such as working memory (WM) abilities.
Furthermore, clinical evaluation and intervention are especially crucial in the first period of life to support the development of perceptual and cognitive skills and guarantee improvements in independence and increment of opportunities. Here we present a novel solution, based on auditory stimuli generated through a 3D audio simulation, to convey spatial information. In this study, we tested such a system with sighted adults.
WM is a limited-capacity store system for the online maintenance, update, and manipulation of information for a short time [7, 33]. This component is actively involved during complex and demanding tasks [8, 70] such as memorization and processing of visuo-spatial material [38, 43]. Indeed, its functions include the storage of visual inputs, spatial configurations, and visual images [59]. The first WM model was proposed by Alan Baddeley [7]. According to the latter, WM consists of a central executive component and two subsystems: the visuo-spatial sketchpad and the phonological loop for the maintenance and manipulation of visual and acoustic information, respectively. Measurement of WM capacity is an accurate predictor of cognitive abilities in childhood [20, 21, 23] and is widely used within educational psychology to infer children’s academic attainment [2, 25]. Deficits in WM have been observed in several brain disorders and psychiatric diseases such as autism, schizophrenia, dementia, or Parkinson’s disease [9, 24, 26, 53].
As regards the processing of spatial material, at a cortical level, previous studies highlighted the presence of a distinction between two neural pathways for the visual processing of object features and its spatial information: the ventral what and the dorsal where pathways [27] respectively. Several studies on congenitally blind (CB) individuals demonstrated that large parts of the visual system are task-specific modality invariant in nature and can be accessed, via cross-modal mechanisms, by the processing of other sensory modalities [44, 58, 60, 71].
The same segregation between what and where is valid in the context of auditory perception, with some differences to the visual modality. First, in the visual system, information from one hemifield is sent to the contralateral hemisphere. On the contrary, in the auditory modality, both regions receive information from both ears [62]. The visual cortex has a topographic organization, with adjacent neurons, responding to nearby stimuli in the retina [10, 39]. Sound frequency is represented in a tonotopic map, and this representation is maintained across the whole auditory pathway, including the auditory cortex [47]. Previous works on spatial WM pointed out that the dorsal visual pathway (prefrontal and post parietal cortices) is also involved in WM processing of both visual and auditory locations [5, 19, 30, 45, 55]. However, it is still an open debate about whether auditory and visual information is processed in separate brain networks or in a shared neuronal network integrating the two information. Furthermore, very few studies investigated how spatialized stored auditory stimuli are processed in WM [66, 72, 73]. In a previous work [66], we designed an audio-spatial memory test to explore memory abilities in sighted and blind individuals. Both groups were asked to learn and process complex semantic and non-semantic auditory structures and memorize sequences of sounds increasing in length. Although all participants were able to accomplish the task and generate an appropriate mental representation of sounds’ dispositions, only the sighted group could benefit from the semantic relationship between the auditory structure elements in recalling the sequences.
However, WM abilities are nowadays still mostly assessed in the visual modality, with a wide range of procedures [51], primarily based on span methods, either verbal [12] or spatial [11]. The memory span is used as a neuropsychological parameter for identifying short-term spatial memory dysfunctions and memory capacity in general regardless of the input sensory modality [8, 34]. In the span tasks, participants are asked to maintain information in memory for later recall or manipulation [70]. One of the methods most used in this context is the Corsi-Block test [48]. In its original version, the Corsi-Block consists of a wooden board (\(28 \times 28\ \hbox {cm}^2\)) with 9 blocks irregularly arranged on its top (see Fig. 6). The experimenter taps to a predetermined sequence of blocks, and the participant is asked to recall the sequence in the same order of presentation or reverse. If at least one out of the total number of sequences for a specific length is correctly recalled, the test goes on with the presentation of a longer sequence. Otherwise, the procedure ends. The longest series of blocks above which the participant can no longer recall sequences is taken as the individual’s span. The memory span and the number of sequences correctly recalled are extracted from the test as the interest parameters. According to the normative data, the average visuo-spatial memory span is equal to a value between 6 and 7 [33]. Individuals of every age, from preschoolers to octogenarians [11], can be tested with the Corsi-Block procedure. This paradigm is widely used to assess learning disabilities in children, dementia, and other neurological diseases [11]. Additionally, the Corsi-Block serves as an investigation tool for developmental changes and gender differences in spatial and memory abilities [16, 52]. This methodology has also been used to verify the theoretical assumptions of the model of Baddeley.
Beside the physical versions of this test, several computer based-forms of the Corsi-Block have been designed [40, 49, 50, 68]. In these versions, the blocks are replaced by squares that flash on a computer screen. Thus, the subject reproduces the presented sequences by tapping the screen or using the computer mouse to click on the virtual blocks. Other versions of the Corsi-Block are the walking Corsi [56], the eCorsi [15], which is a software developed for the rendering of a tablet-based version of the test, and the haptic Corsi proposed for the first time by Ruggiero and colleagues [63] and designed to evaluate the effect of blindness on spatial memory. However, there is a lack of proper technological solutions to investigate spatial WM skills in the auditory modality. Studying auditory cognition often requires more specific hardware or software than visual cognition research. For example, in studying cognitive functions that involve auditory spatial information, multiple acoustic spatial locations are necessary, such as numerous speakers [67] or dedicated virtual acoustics.
In this study, we tested sighted adults with a novel task, named Audio-Corsi, to evaluate their audio-spatial WM skills. This experimental procedure, takes inspiration from the Corsi-Block test. All the subjects involved in the current research, were also tested with the Corsi-Block to compare the memory spans in the two sensory modalities (i.e., vision and audition). We aimed to shed light on the WM processing of spatial information for audition and to provide a novel methodological solution to test audio-spatial memory abilities. Like the classical Corsi-Block procedure, the subjects listened to sequences of spatialized sounds and recalled them using a custom-made dedicated keyboard. Since vision is the most accurate sense for spatial perception [22], we expected a higher memory span in the visual rather than auditory modality. With the current study, we were also interested in seeing the pros and cons of using a system based on acoustic sources spatially arranged around listener’s head. Indeed, the technological system here presented might eventually open new ways to evaluate cognitive skills to intervene in the first period of life, especially in congenital blindness.
2 Material and methods
2.1 Participants
The current research involved 20 healthy participants (7 males, mean age ± standard deviation: \(25.05 \pm 2.91\)). None of the subjects reported any sensory or cognitive impairment. Whereas they were informed about the procedures to be used and the purpose of the experiment, the underlying research questions were not revealed. The experiments were approved by the local health service (Comitato Etico, ASL 3, Genoa, Italy). Adult informed written consent for the study was obtained in all cases, and all the experiments were carried out following the declaration of Helsinki. The whole session did not have a fixed duration since it depended on the ability of the participant. However, it lasted \(\sim 25\) min on average.
2.2 Equipment and sound spatialisation
The sound spatialisation was performed using the 3D Tune-In Toolkit, an open-source library for audio spatialization and simulation of hearing loss and hearing aids, developed by researchers from Imperial College London and the University of Málaga [17, 18, 42]. It performs real-time binaural spatialization, which allows the creation of three-dimensional soundscapes using a simple pair of headphones as a playback device. The generation of binaural signals is based on the convolution of a monaural signal with head-related transfer functions (HRTFs), which model the directional filtering of the incoming signal due to the characteristics of the listener’s ears and body shape (i.e., torso, shoulders, head, and pinnae) [1]. Furthermore, the Toolkit integrates a near-field sources simulator, which is based on ILD corrections applied when the source is closer than the distance at which the HRTF was measured (in this case, 2 metres). For more details about the implementation, please see [18]. For this study, an HRTF measured from a Kemar dummy head mannequin was used, and no reverberation was added to the rendering. The signal used for the various sources, both in the pilot and test stages, is a pink noise with a duration of 2.5s. The audio was played back using a pair of Sennheiser HD650 headphones, and the sound pressure levels A-weighted measured at the ears is reported in Table 1. We did not use any head tracker. According to the pilot studies with the acoustic configuration with six sounds, we found that the use of the head tracker did not influence localization abilities (see Fig. 2). The spatialisation was performed in real time using the Toolkit’s Test Application; a screenshot of the interface can be found in Fig. 1.
2.3 Communication protocol
Starting from the already developed 3D Tune-In Toolkit, we designed an application for testing audio-spatial memory abilities by implementing the communication between Matlab (Matlab2017, The Mathworks) and the Toolkit. The 3D Tune-In Toolkit’s test application receives instructions with OSC messages [74], based on wireless (WLAN) communication. The latter is a protocol for data exchange among devices based on the UDP communication protocol, which uses the IP addresses and the port of the communication units. The UDP communication was established in Matlab by creating an UDP object (udp() function). Using the oscsend() Matlab function instead, it was possible to pilot the sounds when needed (e.g., start-stop individual sources, modify source positions according to head rotations, etc.), with instructions compatible with the toolkit.
2.4 Choice of stimuli positions
Once Matlab and the Toolkit communication was established, we set the positions of the auditory sources to be rendered through headphones. Our goal was to define a maximum number of sounds that could be easily perceived as coming from different locations. In other words, we wanted to deliver acoustic stimuli that could be easily distinguishable in terms of their locations around the user’s head.
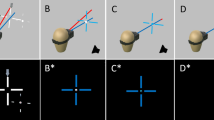
In the Toolkit, each source is represented with two white dots (which turn to pink when audio is playing). The larger dot is connected to the listener with a white line (see Fig. 1). The angle between the connection line and the chart’s horizontal axis indicates the azimuth angle, from 0.0 to 359.9 degrees anti-clockwise. The smaller dot represents the elevation of the source. The angle between the line that connects the two white dots and the horizontal axis of the chart represents the relative elevation of the source. The elevation varies between 0 and 90 degrees anti-clockwise (top-right quadrant), and clockwise from 360 to 270 (bottom-right quadrant).

Binaural Test App. The picture, represents the layout of the binaural test app. The app allows the spatialization of sound sources for binaural (headphones) listening. The app is also provided with some algorithms for simulating near-field and far-field auditory sources and reverberation in a 3D binaural context. Moreover, the test app allows the integration of hearing loss and hearing aid simulators (http://www.3d-tune-in.eu/)
2.4.1 Pilot studies
To choose sounds locations (i.e., the maximum number of acoustic stimuli to respect the criteria mentioned above), we carried out pilot studies with twenty-five sighted adults. We first decided the sound duration by looking at the ability to localize the stimuli. We observed that longer time lengths allowed the participants to localize the sounds better, especially when they were close to each other (e.g., north-west and west locations). We chose 2.5 seconds as time length, in line with a previous work [66]. In the pilot tests, the participants were provided with four configurations, which differed from each other in the number of acoustic sources and their positions around the head (Fig. 2). The experimental request was to localize the stimuli presented around their heads. Compared to the experimental session, the participants did not listen to sequences of sounds. Conversely, they only had to localize the stimuli. Furthermore, while listening to the sounds, they were instructed to fix their gaze at the drawing of their locations.
On each trial, the sounds were presented one by one. After each emission, the participant was asked to indicate the position of the stimulus on the drawing. The percentage of correct responses for each configuration was extracted to quantify the ability to localize the sounds. The number of attempts for each design was equal to the number of the auditory sources employed (e.g., in the design with six sounds, the number of trials was equal to six). As shown in Fig. 2, the greater number of correct responses was achieved in the design shown in panel D of the figure (6 sounds, arranged onto 2 circles). Table 1 lists the features of the single sources in this configuration. The frontal and rear sounds differed in their elevations. From the pilot studies, we obtained that the choice to set greater elevations for the frontal and lower elevations for the rear sounds significantly improved localization abilities, thus increasing the distinctiveness between these stimuli.

Results of the pilot tests. The filled circles represent the positions of the virtual sources. Participants listened to the sounds one by one, in random order, while looking at the configuration printed on a paper placed in front of them. In A C and D, the sounds were distributed on two circles: one closer to participants’ head (perceived at a higher volume), the other further (perceived at a lower volume). Circle’s colors represent the percentage of participants that correctly indicated the position of the sounds

Spatial configuration of the virtual environment. The final design includes 6 auditory sources. This choice is based on the results of pilot experiments
2.5 Arduino-based keyboard
To register the experimental session responses, we designed an Arduino-based keyboard (see Fig. 4).The buttons of the keyboard replicate the positions of the six virtual sources to let the user know sound arrangements through haptic exploration (Fig. 3). The blue button on the top matches the position of participant’s heads in the Toolkit. Therefore, to guarantee an exact correspondence between the Toolkit and the sources, we placed the blue button at the keyboard’s center. The keyboard, designed in AutoCAD, was built as a laser-cut wooden box of \(30 \times 30\ \hbox {cm}^2\) with a set of buttons on the top surface, which also hosted the needed electronic components (see Figs. 5 and 4). The system is controlled by an Arduino UnoFootnote 1, connected to the computer via USB that allows for serial communication and also powers the device. Arduino Uno logs the button, connected through tinned copper wires, pressed by the user with a pull-down resistor configuration (Fig. 5). We used the Matlab support package for Arduino to enable communication between the readout and recording of participants’ responses. This package enables the user to acquire analog and digital data from the board over a USB connection or wirelessly over Wi-Fi. The arduino() function was used to connect the Arduino Uno hardware to Matlab, by giving the port and board names as input data in the function. Once the arduino object is created, the user can program the hardware and employ custom add-on libraries.

Assembled keyboard. The red buttons represent the positions of the six virtual sounds while the central blue button is the reference point

Keyboard circuit schematic
3 Task and procedure
3.1 Standard Corsi-Block task
In the Corsi-Block test, the participants have to recall sequences of spatialized blocks presented by the experimenter. The subjects sat in front of the experimenter with the board in between them. We used a wooden board like the one used by Kessels [33, 35] (Fig. 6 for details). The board and the blocks were brown. A number ranging from 1 to 9 was printed on the side of the blocks directed towards the experimenter. Participants were instructed to tap the blocks in the same serial order of presentation (three sequences per each length from 1 to 9 blocks). The experimenter explained to them that if at least one out of three sequences was correctly recalled, the test went on. During the sequence presentation, the experimenter tapped the blocks at a rate of one block per second. The experimental session stopped when the participant did not correctly recall none of the three presented sequences. The number of the sequences correctly memorized was not communicated. According to normative standards, the sequences administrated in the Corsi-Block paradigm were the same used in clinical settings, according to normative standards [69].
3.2 Audio-Corsi
After the Corsi-Block, the subjects were blindfolded, and the experimenter replaced the set of blocks with the keyboard described in 2.5. At the beginning of the auditory experiment, participants were asked to haptically explore the keyboard (Fig. 4). When they felt confident with the task, the experimenter explained sources’ dispositions and the test procedure. The auditory stimuli were presented binaurally through headphones from the locations shown in Fig. 3. The sound pressure level, A-weighted, measured at each ear for each stimulus in each location is reported in the last two columns of Table 1. The Audio-Corsi was divided into two phases: the training and experimental sessions.

Original apparatus of the Corsi-Block paradigm. This apparatus was used in the current research to compare the performances between the Corsi-Block test and our Audio-Corsi paradigm
3.2.1 Training session
Before starting the test, participants performed a 3-minute training to familiarize themselves with the system. The training served the participant to understand how the sounds were reproduced from the six positions and assure that the sources’ localization would have been optimal. In other words, the goal was to let the participants understand how the sounds were spatially arranged even without seeing them. Without this preliminary phase, there could have been errors in sequence recalling due to perceptual and localization errors rather than memory capacity. The participants explored the keyboard while pressing the red buttons and listening to the corresponding sounds. After the listening phase, they were asked to identify each sound position by pressing the corresponding button on the keyboard. They were presented with the six stimuli one by one, randomly. After each sound presentation, the participants pressed the corresponding button. This phase resembled the pilot studies. Then the test started, following the rules of the Corsi-Block test.
3.2.2 Experimental session
The participants listened to sequences of increasing lengths, from 1 to 9 sounds, three sequences per length. During the listening phase, the participants placed the dominant hand’s index finger on the reference button. In the recalling phase, they pressed the buttons with the same finger, following sequence presentations. Afterward, they moved the index finger back on the reference point while waiting for the following sequence. In the encoding phase, the sounds were presented through the same headphones employed in the pilot studies. Participants were instructed not to move their heads during the listening phase. If it occurred, the experimenter played the trial again. During the recalling phase, instead, they were allowed to move the head.
4 Data and statistical analyses
The parameters evaluated in both the visual and auditory tasks were:
-
The memory span;
-
The number of sequences to end the task;
-
The product between the two parameters mentioned above (total score);
The memory span corresponds to the length of the longest sequence correctly recalled. The second parameter refers to the number of correctly recalled sequences out of the total (n=24). Finally, the product between the two was also calculated (the total score) [34, 35]. The total score is more reliable than the memory span alone since it considers the performance of all the trials of a given length.
To assess the goodness of the measurement, we calculated for each of the three parameters the coefficient of variation (CV), that is, the ratio between the standard deviation (SD) and the mean of the sample; the lower the value of CV, the more precise the estimate. In detail, distributions with a coefficient of variation less than one are considered low-variance, whereas those with a CV greater than one are considered high variance. Thus, the lower the CV, the closer the points are to the average.
We were interested in seeing whether the variability in the memory span in the two experiments was similar across participants to assess the system’s validity. Indeed, if the measurement provided by a system is on average the same and close to the mean, we might infer that this system allows a stable measure. Validation studies using the Corsi-Block apparatus identified a visuo-spatial memory span with a value ranging between 6 and 7 [35], which is the standard range in the absence of cognitive delays. In other words, healthy subjects can maintain in memory, on average, six or at maximum seven items, with low variability. We checked if in the Audio-Corsi the participants recalled the sequences up to a certain length as well, to verify whether the toolkit and this specific sounds’ configuration can be employed to evaluate audio-spatial memory abilities by measuring an acoustic memory span.
4.1 Statistical analyses
Statistical analyses were carried out in Matlab (R2017b) and RStudio. Firstly, the normality of the data was checked with the Jarque-Bera test (jbtest() Matlab function). Then, the parameters listed above were compared between the two experiments by running paired Student’s t-tests (ttest() Matlab function) in case of data normally distributed. Otherwise we ran the Wilcoxon signed rank test (signrank() Matlab function). Cohen’s value was determined to quantify the effect size (Cohen’s d).
5 Results
5.1 Training results
The time length of the training (three minutes) was chosen to be sure participants could remember sounds positions. In fact, in [66], the authors set a five minutes exploration to let the subjects explore an acoustic spatial layout composed of fourteen distinct semantic sounds. In the Audio-Corsi we used six equal sounds (pink noise from all the locations). Therefore, we hypothesized three minutes were enough for the participant to understand sounds positions. In line with our hypothesis, we found that the accuracy in sequence recalling after the training was, on average, more than 95 %.
5.2 Performance results
The performances were compared between the Corsi-Block test and the Audio-Corsi in terms of memory span, number of sequences correctly recalled, and total score. In Table 2, means (M), standard deviations (SD) and coefficient of variations (CV) are shown. The values presented in Table 2 highlight that the participants’ performances were different between the two tests. Only the data referring to the memory span and the number of correct sequences followed a normal distribution. For the latter, also the homogeneity of variance was guaranteed (Bartlett’s statistic for the span: 0.8, \(\hbox {df} = 1\), \(p = 0.37\). Bartlett’s statistic for the number of correct sequences: 0.623, \(\hbox {df} = 1\), \(p = 0.43\)). Thus, for these two factors, we ran paired Student’s t-tests (see Fig. 7 for the details). The results highlighted that the performances were greater in the Corsi-Block rather than in the Audio-Corsi for both the memory span (paired Student’s t-test: \(\hbox {t} = 4.26\), \(\hbox {df} = 19\), \(p < 0.01\), Cohen’s \(\hbox {d} = 0.95\)) and the number of correct sequences recalled (paired Student’s t-test: \(\hbox {t}= 3.47\), \(\hbox {df} = 19\), \(p < 0.001\), Cohen’s \(\hbox {d}=0.78\)). As regards the total score instead, the data did not follow a normal distribution. We thus ran the Wilcoxon signed rank test to compare the results. As for the other two parameters, we found that the total score was greater in the Corsi-Block rather than the Audio-Corsi (\(\text {z-val} = 2.95\), \(p < 0.01\), Cohen’s value: 0.78). To verify the gender’s effect on the overall results, we ran the same analyses after removing the 7 males from the two groups. The significant difference between the experiments was maintained for the span (paired Student’s t-test: \(\hbox {t} = 3.09\), \(\hbox {df} =19\), \(p < 0.01\), Cohen’s \(\hbox {d} = 0.85\)), the number of correct sequences (paired Student’s t-test: \(\hbox {t} = 5.06\), \(\hbox {df} = 19\), \(p < 0.001\), Cohen’s \(\hbox {d} = 1.4\)) and the total score (\(\text {z-val} = 1.84\), \(p < 0.01\), Cohen’s value: 0.98).

Performances in the Corsi-Block and the Audio-Corsi. The panel on the left refers to the memory span, the middle panel to the number of sequences correctly recalled, the panel on the right to the total score. Three asterisks (***) indicate \(p < 0.001\). The label CB indicates the performances in the Corsi-Block, while AC in the Audio-Corsi. As shown in the figure, the subjects outperformed in the Corsi-Block paradigm
6 Discussion
This article presents a novel application of a system based on the 3D spatial audio technology, named Audio-Corsi, to evaluate audio-spatial WM abilities. We administered the Corsi-Block paradigm [35] and the proposed Audio-Corsi to twenty sighted individuals, and their performances were compared between the two experiments. The memory span, the number of correct sequences, and the total score were extracted. In the Corsi-Block test, the participants reached a greater memory span and recalled more sequences (Fig. 7) than the Audio-Corsi.
It is crucial to consider that the Corsi-Block and the Audio-Corsi differ among each other, besides the stress on two distinct sensory modalities, and have to be considered as two different experiments. The first difference between the two lies in the number of stimuli employed: nine blocks vs. six sounds. Although this aspect should not have influenced performance as most participants did not reach the maximum number of recalled items, their disposition changed systematically between the two experiments, especially regarding the encoding and response phases. In the Corsi-Block, the nine blocks were in front of the participant during both stimuli presentation and recall. In the Audio-Corsi, the sounds were presented around the participants’ heads while their dominant index fingers were kept on the reference button. Therefore, in the Audio-Corsi, there was a transfer from the head as a reference frame when listening, to the button as a reference in the recalling. Furthermore, it is possible that sequences with stimuli only in front of the participant led to fewer errors than those sequences where the sounds were spread around the subject’s head. The reproduction of stimuli in the rear hemisphere indeed rests on a change of reference frame.
Consequently, this paradigm could have led the subject to refer to a head- or hand-centered reference frame, and spatial representation might have been anchored to different body parts depending on individual participant strategy [4]. Indeed, a head-centered representation differs significantly from a hand-centered representation, especially for auditory perception, since the ears are on the head and not on the hands (see for example [29]). Further studies might better investigate the contribution of head- and hand-centered frames of reference in auditory spatial memory skills. Nevertheless, in our case, the training before the Audio-Corsi was performed to make sure participants learned the correspondence between the spatial disposition of the buttons and the sounds.
Another difference between the two experiments is that one is based on a direct motor reproduction, the other one is not. In the case of the Corsi-Block test indeed, the participant is asked to observe the experimenter indicating the cubes to be memorized. This procedure might induce a motor priming effect that influences performance. The observation of a finger movement might elicit an analogous motor planning response in the observer; that is, the observed actions are automatically mapped onto the observer’s internal motor repertoire [32]. This phenomenon might lead to facilitation when the observed and executed movements are congruent (e.g., [13, 14]). In the Corsi-Block paradigm, finger movements of the experimenter and the participant are not equal but mirrored. Thus their overall congruence could have led to a motor priming effect. This phenomenon leads to a slight reduction of the memory load, from which the subjects could have benefit in the recalling phase of the sequences in the Corsi-Block.
Finally, the Audio-Corsi could have automatically required verbal coding compared to the Corsi-Block procedure. The participants might have recalled the sequences by verbalizing the buttons’ order or associating each button with a number. However, at the end of the experimental session, only a few participants (less than 3) reported the attempt to recall the sequences by verbalizing them with the strategies described above, similar to previous observation with a haptic adaptation of the Corsi-Block test [64]. Furthermore, in our task, the time interval between the memorization and recalling of the sequence was quite short, suggesting that participants would be unlikely to code the items verbally if the verbal strategy were adopted.
For the reasons listed above, the two paradigms have been considered as two different experiments.
However, the Audio-Corsi presents several advantages compared to the Corsi-Block test. From a methodological perspective, the Audio-Corsi allows the experimenter to control the Inter-Stimulus Interval (ISI) and the presentation time for each stimulus. Contrary, in the Corsi-Block test, there is no fixed timing since the procedure is not automatic but depends on the experimenter’s ability. A solution to this issue has been proposed by developing a tablet-like version of the Corsi-Block test [15]. The authors pointed out several limitations of the Corsi-Block test, such as the possibility of the examiner to change the finger used to show the stimuli and the pace at which the tapping is performed. Along these lines, our Audio-Corsi provides a solution to these issues in the context of audio-spatial memory. The possibility to manipulate temporal stimulus properties provides the researcher with the means to investigate the role of presentation time in spatial memory, such as the duration of the stimulus or the ISI.
The validity of the Audio-Corsi was tested by looking at the variability in the responses. By considering the coefficient of variation (CV), we measured each test’s overall accuracy in providing the memory span in the group of tested participants. As reported in Table 2, the CVs for both experiments were less than 1, thus indicating that the estimate provided by both tests was quite precise. Furthermore, the low CVs confirm that the auditory sources were memorized and recalled similarly across participants (i.e., low variability in the responses). The rationale behind this measurement relies on providing a reliable and robust task to measure audio-spatial memory. Although the two experiments are not directly comparable, the high precision reached in the Audio-Corsi, equivalent to the Corsi-Block test, strongly suggests that our methodology can be used in the context of audio-spatial memory abilities.
As mentioned, we observed a difference in the span between the two experiments. In the Corsi-Block test, the participants reached, on average, a visual span between six and seven, in line with previous literature [35]. In the Audio-Corsi instead, we measured a memory span between five and six. In other words, the audio-spatial memory span is lower than the visual spatial-memory span. Even though we cannot be sure the two experiments stress on the same memory components, we might conclude this difference can be ascribed to the roles of vision and audition on spatial location processing and on spatial memory in general. Some studies already demonstrated that localization abilities are worse for sounds than visual objects [75], mostly because of the different spatial resolution of the two sensory systems. While spatial processing is mostly achieved through vision, on the other end of the continuum, auditory processing is mainly related to the processing of temporal information, such as rhythm [31]. In this context, it has been argued that vision dominates spatial processing not only for localization but also for memory [36, 37, 57].
Conversely, audition dominates temporal processing [28]. Along these lines, Lehnert and Zimmer demonstrated that visual stimuli are better localized than the auditory stimuli, even if presented in the same spatial layout [41].
Furthermore, visual inputs lead to more accurate spatial representations than do auditory inputs [54]. However, in our task, all participants could localize sounds after the training because the stimuli were distributed ad-hoc to eliminate perceptual errors as much as possible. In other words, localization ability itself did not influence performance. The different performance in the two experiments might help to shed light on the role played by vision in the storage and manipulation of acoustic spatial information. The methodology here proposed indeed would be useful and appropriate to further investigate this topic by testing sensory deprived participants, thus informing about the role of the missing sensory modality in spatial memory.
Previous research has proposed the existence of modality unspecific memory chunks, namely, object files [54]. This hypothesis comes from the observation of no memory decay, nor improvement, when spatial locations to be memorized are coded both visually and auditory. Although we did not test participants with multisensory stimuli in our study, we observed the same effect of the cognitive load on both tests’ performance. In particular, memorization worsened with increasing sequence length. This parallelism between the memory decays supports, on the one hand, the hypothesis that locations of auditory and visual items are stored in a common memory instead of two modality-specific storages [41], as memorization of both types of items is affected by the same factor. Considering the multi-component model proposed by Baddeley [6], it has been proposed that the episodic buffer guarantees the binding of information in a single multimodal object file. However, the pattern of results does not exclude the possibility that the visual and auditory information are stored separately but follow the same task-dependent and sensory independent mechanism [3]. In this sense, the system proposed in the current research can be potentially integrated with a visual VR headset, thus allowing further research to investigate the multimodality of memory processes by combining surrounding visual and auditory spatial stimuli.
To conclude, in the current research, we employed a system based on an acoustic simulation to evaluate audio-spatial memory abilities in sighted individuals. From this procedure, named Audio-Corsi, we extracted an audio-spatial memory span that was compared to the visuo-spatial memory span obtained through the Corsi-Block paradigm. The performance was higher in the Corsi-Block test, in terms of memory span, sequences correctly recalled, and the total score (see Fig. 7). The low variability observed in both tasks (see Table 2) strongly supports the proposed system as an efficient methodology to measure audio-spatial memory skills and may also constitute the starting point for the design of novel clinical procedures, addressed to evaluate cognitive skills in blind and visually impaired individuals. Nevertheless, given all the differences between the two apparatus, we cannot be sure that the Corsi-Block, and Audio-Corsi measure the same components of memory. Further studies are thus needed to explore more which type of spatial memory the task measures and the influence of the different frames of reference employed in the encoding and recalling of the acoustic stimuli. However, the current research, provides a novel methodology for the assessment of audio-spatial memory abilities, easily implementable and reproducible by researchers in basic and clinical neuroscience. Moreover, this result provides an important reference for future evaluation of audio-spatial memory, usually not studied for the lack of proper technologies.
Notes
References
Algazi VR, Duda RO (2010) Headphone-based spatial sound. IEEE Signal Process Mag 28(1):33–42
Alloway TP, Gathercole SE, Pickering SJ (2006) Verbal and visuospatial short-term and working memory in children: Are they separable? Child Dev 77(6):1698–1716
Amedi A, Stern WM, Camprodon JA, Bermpohl F, Merabet L, Rotman S, Hemond C, Meijer P, Pascual-Leone A (2007) Shape conveyed by visual-to-auditory sensory substitution activates the lateral occipital complex. Nature Neurosci 10(6):687
Arbib MA (1991) Interaction of multiple representations of space in the brain
Arnott SR, Binns MA, Grady CL, Alain C (2004) Assessing the auditory dual-pathway model in humans. Neuroimage 22(1):401–408
Baddeley A (2000) The episodic buffer: a new component of working memory? Trends Cognit Sci 4(11):417–423
Baddeley, Hitch G (1974) Working memory. In: Psychology of learning and motivation, volume 8, pp 47–89. Elsevier
Baddeley, Logie R, Bressi S, Sala SD, Spinnler H (1986) Dementia and working memory. Q J Exp Psychol Sect A 38(4):603–618
Barendse EM, Hendriks MP, Jansen AP (2013) Working memory deficits in high-functioning adolescents with autism spectrum disorders: neuropsychological and neuroimaging correlates. J Neurodev Disord 5(1):14
Baseler HA, Morland AB, Wandell BA (1999) Topographic organization of human visual areas in the absence of input from primary cortex. J Neurosci 19(7):2619–2627
Berch DB, Krikorian R, Huha EM (1998) The corsi block-tapping task: methodological and theoretical considerations. Brain Cognit 38(3):317–338
Blankenship AB (1938) Memory span: a review of the literature. Psychol Bull 35(1):1
Brass M, Bekkering H, Prinz W (2001) Movement observation affects movement execution in a simple response task. Acta Psychol 106(1–2):3–22
Brass M, Bekkering H, Wohlschläger A, Prinz W (2000) Compatibility between observed and executed finger movements: comparing symbolic, spatial, and imitative cues. Brain Cognit 44(2):124–143
Brunetti R, Del Gatto C, Delogu F (2014) ecorsi: implementation and testing of the corsi block-tapping task for digital tablets. Front Psychol 5:939
Capitani E, Laiacona M, Ciceri E et al (1991) Sex differences in spatial memory: a reanalysis of block tapping long-term memory according to the short-term memory level. Ital J Neurol Sci 12(4):461–466
Cuevas-Rodríguez M, González-Toledo D, De La Rubia-Cuestas E, Garre C, Molina-Tanco L, Reyes-Lecuona A, Poirier-Quinot D, Picinali L (2018) The 3d tune-in toolkit–3d audio spatialiser, hearing loss and hearing aid simulations. In: 2018 IEEE 4th VR workshop on sonic interactions for virtual environments (SIVE), pp 1–3. IEEE
Cuevas-Rodríguez M, Picinali L, González-Toledo D, Garre C, de la Rubia-Cuestas E, Molina-Tanco L, Reyes-Lecuona A (2019) 3d tune-in toolkit: an open-source library for real-time binaural spatialisation. PloS One 14(3):e0211899
Curtis CE, DEsposito M (2003) Persistent activity in the prefrontal cortex during working memory. Trends Cognit Sci 7(9):415–423
Daneman M, Carpenter PA (1980) Individual differences in working memory and reading. J Verbal Learn Verbal Behav 19(4):450–466
Daneman M, Merikle PM (1996) Working memory and language comprehension: A meta-analysis. Psychon Bull Rev 3(4):422–433
de Beni R, Cornoldi C (1988) Imagery limitations in totally congenitally blind subjects. J Exp Psychol Learn Mem Cognit 14(4):650
Engle RW, Tuholski SW, Laughlin JE, Conway AR (1999) Working memory, short-term memory, and general fluid intelligence: a latent-variable approach. J Exp Psychol Gen 128(3):309
Forbes N, Carrick L, McIntosh A, Lawrie S (2009) Working memory in schizophrenia: a meta-analysis. Psychol Med 39(6):889–905
Gathercole S, Alloway TP (2008) Working memory and learning: a practical guide for teachers. Sage, California
Germano C, Kinsella GJ (2005) Working memory and learning in early alzheimers disease. Neuropsychol Revi 15(1):1–10
Goodale MA, Humphrey GK (1998) The objects of action and perception. Cognition 67(1–2):181–207
Guttman SE, Gilroy LA, Blake R (2005) Hearing what the eyes see: auditory encoding of visual temporal sequences. Psychol Sci 16(3):228–235
Hanneton S, Hoellinger T, Forma V, Roby-Brami A, Auvray M (2020) Ears on the hand: reaching three-dimensional targets with an audio-motor device. Multisens Res 33(4–5):433–455
Hecker R, Mapperson B (1997) Dissociation of visual and spatial processing in working memory. Neuropsychologia 35(5):599–603
Henneman RH (1952) Vision and audition as sensory channels for communication. Q J Speech 38(2):161–166
Iacoboni M, Woods RP, Brass M, Bekkering H, Mazziotta JC, Rizzolatti G (1999) Cortical mechanisms of human imitation. Science 286(5449):2526–2528
Kessels RP, Postma A (2018) The box task: a tool to design experiments for assessing visuospatial working memory. Behav Res Methods 50(5):1981–1987
Kessels RP, van Den Berg E, Ruis C, Brands AM (2008) The backward span of the corsi block-tapping task and its association with the wais-iii digit span. Assessment 15(4):426–434
Kessels RP, Van Zandvoort MJ, Postma A, Kappelle LJ, De Haan EH (2000) The corsi block-tapping task: standardization and normative data. Appl Neuropsychol 7(4):252–258
King AJ, Parsons CH, Moore DR (2000) Plasticity in the neural coding of auditory space in the mammalian brain. Proc Natl Acad Sci 97(22):11821–11828
Kitagawa N, Ichihara S (2002) Hearing visual motion in depth. Nature 416(6877):172
Klauer KC, Zhao Z (2004) Double dissociations in visual and spatial short-term memory. J Exp Psychol Gen 133(3):355
Kosslyn SM, Alpert NM, Thompson WL, Maljkovic V, Weise SB, Chabris CF, Hamilton SE, Rauch SL, Buonanno FS (1993) Visual mental imagery activates topographically organized visual cortex: pet investigations. J Cognit Neurosci 5(3):263–287
LeFevre J-A, Fast L, Skwarchuk S-L, Smith-Chant BL, Bisanz J, Kamawar D, Penner-Wilger M (2010) Pathways to mathematics: longitudinal predictors of performance. Child Dev 81(6):1753–1767
Lehnert G, Zimmer HD (2006) Auditory and visual spatial working memory. Mem Cognit 34(5):1080–1090
Levtov Y, Picinali L, DCruz M, Simeone L (2016) 3d tune-in: the use of 3d sound and gamification to aid better adoption of hearing aid technologies. In: Audio Engineering Society Convention 140. Audio Engineering Society
Logie RH, Marchetti C (1991) Visuo-spatial working memory: visual, spatial or central executive? In: Advances in psychology, volume 80, pp 105–115. Elsevier
Mahon BZ, Anzellotti S, Schwarzbach J, Zampini M, Caramazza A (2009) Category-specific organization in the human brain does not require visual experience. Neuron 63(3):397–405
Martinkauppi S, Rämä P, Aronen HJ, Korvenoja A, Carlson S (2000) Working memory of auditory localization. Cereb Cortex 10(9):889–898
McConnell SR, Odom SL (1999) A multimeasure performance-based assessment of social competence in young children with disabilities. Top Early Child Spec Educ 19(2):67–74
Middlebrooks JC (2002) Auditory space processing: here, there or everywhere? Nature Neurosci 5(9):824–826
Milner B (1971) Interhemispheric differences in the localization of psychological processes in man. British medical bulletin
Morris RG, Baddeley AD (1988) Primary and working memory functioning in alzheimer-type dementia. J Clin Exp Neuropsychol 10(2):279–296
Nelson RE, Dickson AL, Baños JH (2000) An automated administration of corsis block-tapping test. Percept Motor Skills 91(2):578–580
Oberauer K, Schulze R, Wilhelm O, Süß H-M (2005) Working memory and intelligence–their correlation and their relation: comment on ackerman, beier, and boyle (2005)
Orsini A, Chiacchio L, Cinque M, Cocchiaro C, Schiappa O, Grossi D (1986) Effects of age, education and sex on two tests of immediate memory: a study of normal subjects from 20 to 99 years of age. Percept Motor Skills 63(2):727–732
Pagonabarraga J, Kulisevsky J (2012) Cognitive impairment and dementia in parkinsons disease. Neurobiol Dis 46(3):590–596
Paivio A (1991) Dual coding theory: retrospect and current status. Can J Psychol Rev Can Psychol 45(3):255
Pasternak T, Greenlee MW (2005) Working memory in primate sensory systems. Nature Rev Neurosci 6(2):97–107
Piccardi L, Iaria G, Ricci M, Bianchini F, Zompanti L, Guariglia C (2008) Walking in the corsi test: which type of memory do you need? Neurosci Lett 432(2):127–131
Pouget A, Deneve S, Duhamel J-R (2002) A computational perspective on the neural basis of multisensory spatial representations. Nature Rev Neurosci 3(9):741
Ptito M, Matteau I, Gjedde A, Kupers R (2009) Recruitment of the middle temporal area by tactile motion in congenital blindness. Neuroreport 20(6):543–547
Quinn J, McConnell J (1999) Manipulation of interference in the passive visual store. Eur J Cognit Psychol 11(3):373–389
Reich L, Szwed M, Cohen L, Amedi A (2011) A ventral visual stream reading center independent of visual experience. Curr Biol 21(5):363–368
Rettig M (1994) The play of young children with visual impairments: characteristics and interventions. J Vis Impair Blind
Romand R, Varela-Nieto I (2014) Development of auditory and vestibular systems. Academic Press, Cambridge
Ruggiero G, Iachini T (2010) The role of vision in the corsi block-tapping task: evidence from blind and sighted people. Neuropsychology 24(5):674
Ruggiero G, Ruotolo F, Iachini T (2009) The role of vision in egocentric and allocentric spatial frames of reference. Cognitive processing 10(2):283–285
Sacks S, Kekelis L, Gaylord-Ross R (1992) The development of social skills by blind and visually impaired students: Exploratory studies and strategies. American Foundation for the Blind
Setti W, Cuturi LF, Cocchi E, Gori M (2018) A novel paradigm to study spatial memory skills in blind individuals through the auditory modality. Sci Rep 8(1):13393
Setti W, Cuturi LF, Maviglia A, Sandini G, Gori M (2019) Arena: a novel device to evaluate spatial and imagery skills through sounds. In: 2019 IEEE international symposium on medical measurements and applications (MeMeA), pp 1–6. IEEE
Smyth MM, Scholey KA (1994) Interference in immediate spatial memory. Mem Cognit 22(1):1–13
Spinnler H (1987) Standardizzazione e taratura italiana di test neuropsicologici. Ital J Neurol Sci 6:21–120
St Clair-Thompson H, Sykes S (2010) Scoring methods and the predictive ability of working memory tasks. Behav Res Methods 42(4):969–975
Striem-Amit E, Dakwar O, Reich L, Amedi A (2012) The large-scale organization of visual streams emerges without visual experience. Cereb Cortex 22(7):1698–1709
Taevs M, Dahmani L, Zatorre RJ, Bohbot VD (2010) Semantic elaboration in auditory and visual spatial memory. Front Psychol 1:228
Vuontela V, Steenari M-R, Carlson S, Koivisto J, Fjällberg M, Aronen ET (2003) Audiospatial and visuospatial working memory in 6–13 year old school children. Learn Mem 10(1):74–81
Wright M (2005) Open sound control: an enabling technology for musical networking. Organ Sound 10(3):193–200
Zimmer H, De Vega M (1996) The medium and the message in spatial communication. Researching technical documents, pp 153–180
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Setti, W., Engel, I.AM., Cuturi, L.F. et al. The Audio-Corsi: an acoustic virtual reality-based technological solution for evaluating audio-spatial memory abilities. J Multimodal User Interfaces 16, 207–218 (2022). https://doi.org/10.1007/s12193-021-00383-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12193-021-00383-x