
Abstract
The characterisation of Quantum Channel Discrimination (QCD) offers critical insight for future quantum technologies in quantum metrology, sensing and communications. The task of multi-channel discrimination creates a scenario in which the discrimination of multiple quantum channels can be equated to the idea of pattern recognition, highly relevant to the tasks of quantum reading, illumination and more. Although the optimal quantum strategy for many scenarios is an entangled idler-assisted protocol, the extension to a multi-hypothesis setting invites the exploration of discrimination strategies based on unassisted, multipartite probe states. In this work, we expand the space of possible quantum-enhanced protocols by formulating general classes of unassisted multi-channel discrimination protocols which are not assisted by idler modes. Developing a general framework for idler-free protocols, we perform an explicit investigation in the bosonic setting, studying prominent Gaussian channel discrimination problems for real-world applications. Our findings uncover the existence of strongly quantum advantageous, idler-free protocols for the discrimination of bosonic loss and environmental noise. This circumvents the necessity for idler assistance to achieve quantum advantage in some of the most relevant discrimination settings, significantly loosening practical requirements for prominent quantum-sensing applications.
Similar content being viewed by others
Introduction
As the development of practical quantum technologies accelerates1,2,3, the field of quantum sensing is already the most mature and already obtaining quantum advantage in a variety of applications4. Critical theoretical underpinnings in quantum metrology and hypothesis testing5,6,7,8,9,10 have led to quantum-enhanced protocols with fundamental applications in quantum illumination11,12,13,14,15,16,17,18,19,20,21,22,23,24 and quantum reading25,26,27,28,29,30,31,32,33, with particular interest in the continuous variable (CV) domain34,35,36.
The fundamental task of Quantum Channel Discrimination (QCD) models many of these applications. In QCD, a user is tasked with classifying an ensemble of quantum channels through the use of an input quantum state (probe state) and a discriminatory measurement. Locating an optimal discrimination protocol is very difficult, as it embodies a double optimisation problem of both the probe state and the output measurement. Nonetheless, significant progress has been made in recent years in a variety of contexts37,38.
Until recently, QCD has been mostly limited to the problem of binary classification. However, advances in multi-channel discrimination and the formulation of channel position finding (CPF)39,40 have brought with them new insight and opportunities for more complex multi-hypothesis classification problems. These multi-channel discrimination problems are highly relevant in a number of fascinating settings, such as data readout from optical memories, quantum-enhanced optical/thermal pattern recognition41,42 and target detection43.
Within these applications (and many more in quantum sensing), the assistance of idler modes has been a crucial feature in order to attain quantum-enhanced performance39,44. Idler modes refer to perfectly preserved, ancillary quantum systems which share entanglement with input probe states throughout a sensing protocol. In the bosonic setting, these protocols consist of using one mode of a two-mode squeezed vacuum (TMSV) state to probe a target, whereas the remaining mode (the idler) is kept by the user. Idler-assisted protocols have been shown to be optimal for a number of important discrimination tasks and offer significant advantage for many more.
Yet, the necessity for idler modes is problematic, due to the requirement that they need to be perfectly protected. In practice, this is not possible, as some decoherence will always be imparted on the idler while the probe mode is interacting with a target. To combat this, idlers are either contained in delay lines (e.g., very low-loss fibre optics) or stored in quantum memories until required for measurement. This preservation requirement causes serious practical difficulties due to the challenging nature of creating stable quantum memories with adequate storage time45,46,47,48. In some settings, it may be much more practical to use unassisted protocols limited to signal-only probe modes, especially for near-term quantum technologies.
Research on unassisted protocols has been primarily limited to single-channel sensing problems, motivating the use of coherent states to formulate classical benchmarks and even to search for quantum enhancements beyond entanglement49,50. However the multi-channel discrimination picture invites us to explore different unassisted protocols. In particular, it is now possible to construct protocols that distribute entanglement over multiple quantum channels using multipartite entangled states. Without additional idler modes to defend entanglement, input states must be cleverly designed to preserve quantum correlations in the face of increased decoherence. Recently, Pereira et al.51 have explored the use of a block protocol with entangled bosonic states for discriminating small collections of Gaussian quantum channels, proving that there do exist idler-free protocols capable of exceeding the best known classical strategies.
Motivated by this, we arrive at our key research objectives: To generalise the theory of unassisted protocols for multi-channel discrimination, and to ask: Can we design unassisted multi-channel discrimination protocols that achieve significant quantum advantage?
Hence, in this work, we construct general classes of unassisted protocols for multi-channel discrimination. These are block protocols that utilise (generally entangled) multipartite quantum states as probe states. Multipartite states (and thus entanglement) can now be distributed across multiple quantum channels in many inequivalent ways, leading to two distinct, broad classes of discrimination protocols. Via multi-mode entanglement and carefully designed probe distributions, we present unassisted protocols that are able to attain performances on par with that of idler assistance. This circumvents the necessity for idler assistance in some of the most relevant discrimination settings, loosening practical requirements for quantum-enhanced pattern recognition.
This study is structured as follows: in ‘Results’, after first reviewing the model of quantum pattern recognition, we present our main findings. We introduce the general framework of block protocols using unassisted multipartite quantum probe states. We then identify two distinct classes of unassisted protocol that emerge from this framework, discuss their operational interpretations and devise a diagrammatic language for describing such protocols. We corroborate these general findings by demonstrating the efficacy of idler-free protocols for the discrimination of multiple bosonic Gaussian quantum channels. In ‘Discussion’, our results are summarised and we identify future investigative paths. Finally, the ‘Methods’ section contains a number of useful theoretical tools and insights used within this research.
Results
Quantum pattern recognition
In this work, we study the discrimination of quantum multi-channels that we call quantum channel patterns. A binary channel pattern is defined as an m-length sequence of quantum channels, such that each channel in the sequence admits the properties of a target channel \({{{{\mathcal{E}}}}}_{\mathrm{T}}\) or background channel \({{{{\mathcal{E}}}}}_{\mathrm{B}}\) (identified by the labels T, B respectively). It is useful to convert this sequence into a multi-set of binary variables, which represents the channel pattern i = {i1, i2, …, im}, where ij ∈ {B, T} for all j ∈ {1,…, m}. We can then more precisely denote an m-length channel pattern as tensor product
Throughout this work, we refer to a channel pattern simply by its binary string i, unless \({{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}}\) is formally required. Background and target channels can be used to encode physical properties of a multipartite system. For instance, one can associate each pixel of an m-pixel binary thermal image with a cold (background) or hot (target) temperature. Quantum mechanically, one may attribute each pixel to a quantum channel that describes how a quantum probe may interact with either pixel.
A channel pattern i represents only a single instance of a possible binary arrangement. More generally, these instances belong to a larger space of multi-channels we may call an image space. We label an arbitrary N-element image space as the set \({{{\mathcal{U}}}}=\{{{{{\boldsymbol{i}}}}}_{1},{{{{\boldsymbol{i}}}}}_{2},\ldots ,{{{{\boldsymbol{i}}}}}_{N}\}\) containing N unique channel patterns. As we are considering binary patterns, the most general image space we can consider is the set of all m-length binary strings \({{{{\mathcal{U}}}}}_{m}=\{{{{{\boldsymbol{i}}}}}_{1},{{{{\boldsymbol{i}}}}}_{2},\ldots ,{{{{\boldsymbol{i}}}}}_{{2}^{m}}\}\), of which all other binary image spaces are a subset. Image spaces can be used to specify important, physical problem settings such as those defined by the task of CPF, which is concerned with locating target channels hidden among collections of background channels (see ‘Methods’ for more details).
The challenge of multi-channel discrimination may now be presented: consider an m-length pattern of unidentified quantum channels. Suppose that the sequence of channels belongs to a pattern from a known image space \({{{\mathcal{U}}}}\). Each pattern in the image space possesses a unique probability of existing, πi. The task of discrimination then consists of distinguishing between all the multi-channels in the statistical ensemble \({\{{\pi }_{{{{\boldsymbol{i}}}}};{{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}}\}}_{{{{\boldsymbol{i}}}}\in {{{\mathcal{U}}}}}\), which describes an ensemble of multi-channels \({\{{{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}}\}}_{{{{\boldsymbol{i}}}}\in {{{\mathcal{U}}}}}\) distributed according to the classical probability distribution \({\{{\pi }_{{{{\boldsymbol{i}}}}}\}}_{{{{\boldsymbol{i}}}}\in {{{\mathcal{U}}}}}\).
The most general multi-channel discrimination protocol is a general adaptive protocol, \({{{\mathcal{P}}}}\). This is best described by a quantum comb52,53,54; a quantum circuit board with an arbitrary number of registers, with M slots in which channel patterns \({{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}}\) are placed. There is no limit to the amount of entanglement that can be used to construct a quantum comb and a general adaptive protocol can make use of adaptive operations and feedback-based state preparation. Due to their generality, these protocols are very difficult to characterise and optimise. Therefore, it is often much more beneficial to consider simpler protocols.
Of such, block protocols \({{{\mathcal{B}}}}\) represent a very important class of non-adaptive discrimination strategy. Channel patterns are probed using M identical and independent copies of some input probe state, \({\rho }^{\otimes M}\to {\rho }_{{{{\boldsymbol{i}}}}}^{\otimes M}:= {{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}}{(\rho )}^{\otimes M}\). After M pattern interactions, an optimised POVM \({\{{{{\Pi }}}_{{{{\boldsymbol{i}}}}}\}}_{{{{\boldsymbol{i}}}}\in {{{\mathcal{U}}}}}\) is used to perform the classification. Given an image space \({{{\mathcal{U}}}}\) with the pattern probability distribution \({\{{\pi }_{{{{\boldsymbol{i}}}}}\}}_{{{{\boldsymbol{i}}}}\in {{{\mathcal{U}}}}}\), the average error probability of misclassification is given by
where this sum runs over all pairs of unequal channel patterns throughout the image space. In order to benchmark this discrimination performance without specifying precise measurements, the following fidelity-based bounds from can be used55,56,
where \(F(\rho ,\sigma )={{{\rm{Tr}}}}\left[\sqrt{\sqrt{\rho }\sigma \sqrt{\rho }}\right]\) denotes the Bures fidelity. These bounds are completely general and do not depend on the channel dimension. Hence, they may be utilised for both finite and infinite dimensional input states (provided that we use energy-constrained quantum states).
These non-adaptive block protocols have been shown to offer high performance in a number of discrimination settings and, in some cases, are optimal37. If a block protocol makes use of entangled, ancillary quantum systems (idlers), then it is known as a block-assisted protocol \({{{{\mathcal{B}}}}}^{{{{\rm{a}}}}}\). Idler-based entanglement can induce quantum enhancements in many different discrimination settings41,42. Without additional idler modes, we are left with an unassisted block protocol, \({{{{\mathcal{B}}}}}^{{{{\rm{u}}}}}\). Much less is known about unassisted protocols in a multi-channel setting, which we rectify in the following sections.
Fixed unassisted block protocols
Consider an image space \({{{\boldsymbol{i}}}}\in {{{\mathcal{U}}}}\) of m-length multi-channels, each of which occur with probability πi, generating the channel pattern ensemble \({\{{\pi }_{{{{\boldsymbol{i}}}}};{{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}}\}}_{{{{\boldsymbol{i}}}}\in {{{\mathcal{U}}}}}\). Unassisted discrimination involves developing a strategy for accurately distinguishing patterns from the image space without utilising entangled idler modes or ancillary quantum systems. Unlike in an assisted protocol, entanglement is now only permitted between probe modes. We proceed in this practical direction by investigating how inter-probe entanglement can play a role in constructing quantum-enhanced, unassisted block protocols.
Consider an m-length channel pattern. An unassisted block protocol \({{{{\mathcal{B}}}}}^{{{{\rm{u}}}}}\) using multipartite states will assign an M-copy, n ≤ m multi-mode state to interact with some region of the channel pattern, defined by a set of channel labels s = {s1, …, sn} for si ∈ {1, …, m}. This channel region s, which we aptly call a probe domain, defines a sub-pattern of the total channel pattern over which a multipartite state \({\sigma }_{{{{\boldsymbol{s}}}}}^{\otimes M}\) can be irradiated. Hence, a probe domain s is a subset of channel labels s ⊆ {1, …, m}, which designates a region of the channel pattern over which probe modes are permitted to be entangled. Input modes that are incident in the domain s can be entangled but are fully separable with respect to any modes outside of this region. Furthermore, each M-copy probe state \({\sigma }_{{{{\boldsymbol{s}}}}}^{\otimes M}\) can be different for its respective probe domain.
In order to completely interact with all m-channels in the pattern, it is necessary to define a discrete probe-domain distribution. This is a collection of distinct channel pattern sub-regions {s1, s2, …, sN} over which an associated N length collection M-copy multipartite states \(\{{\sigma }_{{{{{\boldsymbol{s}}}}}_{1}}^{\otimes M},{\sigma }_{{{{{\boldsymbol{s}}}}}_{2}}^{\otimes M},\ldots ,{\sigma }_{{{{{\boldsymbol{s}}}}}_{N}}^{\otimes M}\}\) are irradiated. More precisely, we can define a probe-domain distribution as
In Eq. (6), we demand that every channel index 1,…, m is accounted for in at least one subset \({{{\boldsymbol{s}}}}\in {{{\mathcal{S}}}}\), so that no channels are left unprobed. Using \({{{\mathcal{S}}}}\), we can define a global probe state irradiated over a channel pattern, constructed as the tensor product of all the local sub-states.
It is not immediately clear how one should design this probe-domain distribution. However, the most intuitive way to construct \({{{\mathcal{S}}}}\) is to devise a distribution such that each channel is only associated with a single probe domain. A probe-domain distribution disjoint if it satisfies this property. Suppose one constructs an N-partite probe-domain distribution that is disjoint, \({{{{\mathcal{S}}}}}_{{{{\rm{d}}}}}\). Formally, we can define this as,
where disjointedness is demanded on the right-hand side of this equation, such that no two probe domains sj and sk are permitted to share the same channel label, for all j,k. Again, we demand that all channels 1,…, m are accounted for in this distribution, as in Eq. (6). We may then choose an N-element set of multipartite probe states in accordance with this disjoint structure \({\{{\sigma }_{{{{{\boldsymbol{s}}}}}_{j}}\}}_{j = 1}^{N}\), where each \({\sigma }_{{{{{\boldsymbol{s}}}}}_{j}}\) can be unique. Assuming M-copies of each sub-state, we can define a global probe state
In this way, each channel in the pattern is probed exactly M times per total round of discrimination. Furthermore, as all probe domains are disjoint, there are no overlaps between any multipartite states; each channel in the pattern is always probed within the same probe domain and within the same collection of channels.
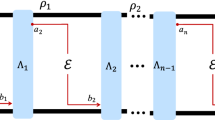
From an operational point of view, the disjointedness of \({{{{\mathcal{S}}}}}_{{{{\rm{d}}}}}\) and lack of probe domain overlaps means that each sub-state \({\sigma }_{{{{{\boldsymbol{s}}}}}_{j}}^{\otimes M}\) can interact simultaneously with the multi-channel. As such, each probe state can be considered to be static (or fixed) over a sub-region of the channel pattern throughout the entire discrimination protocol. For this reason, we describe an unassisted protocol using a disjoint probe-domain distribution as a fixed block protocol, \({{{{\mathcal{B}}}}}_{{{{\rm{fix}}}}}^{{{{\rm{u}}}}}\) (see Fig. 1a for an example).

a Disjoint vs. b non-disjoint multipartite probe-domain distributions assuming the use of single-copy probe states, M = 1. In a, there are clearly no overlapping probe domains and it therefore generates a fixed block protocol. Contrarily, the overlapping probe domains in b gives rise to a dynamic block protocol.
Fixed block protocols are very intuitive, thanks to their simple, static format. Indeed, classical block protocols can inherently be considered to be fixed protocols, where separable collections of coherent states are irradiated upon a channel pattern. Using our previous formalism and considering m-length channel patterns, one may define a trivial probe-domain distribution \({{{{\mathcal{S}}}}}_{{{{\rm{d}}}}}=\{\{1\},\{2\},\ldots ,\{m\}\}\) and a corresponding set of single-mode coherent states \({\{{\alpha }_{j}\}}_{j = 1}^{m}\), which produces the global state \({\sigma }_{{{{{\mathcal{S}}}}}_{{{{\rm{d}}}}}}^{\otimes M}{ = \bigotimes }_{j = 1}^{m}{\alpha }_{j}^{\otimes M}\). Larger probe domains invite the potential for entangled probe states over fixed probe domains and can provide an easy route for potential quantum enhancements in many settings. In general, the performance of fixed block protocols can always be assessed through the average error probability by substituting \({\sigma }_{{{{{\mathcal{S}}}}}_{{{{\rm{d}}}}}}\) into Eq. (2).
Dynamic unassisted block protocols
Interestingly, we need not restrict ourselves to probe-domain distributions which are disjoint. Departing the rigidity of disjoint probe-domain distributions offers a fascinating route for quantum-enhanced, unassisted protocols. Although this path is less intuitive, it unveils a rich and flexible class of discrimination protocols with rewarding features.
Consider now a non-disjoint, N-partite probe-domain distribution \({{{{\mathcal{S}}}}}_{{{{\rm{nd}}}}}=\mathop{\bigcup }\nolimits_{j = 1}^{N}\{{{{{\boldsymbol{s}}}}}_{j}\}\), meaning that probe domains are free to overlap and share similar channel labels, i.e. the overlap of two probe domains is no longer the empty set \({{{{\boldsymbol{s}}}}}_{j}\cap {{{{\boldsymbol{s}}}}}_{k}\ne \varnothing\). This renders a much larger and more general space of possible distributions. A global quantum probe state \({\sigma }_{{{{{\mathcal{S}}}}}_{{{{\rm{nd}}}}}}\) associated with such a distribution is again found as the tensor product of all local sub-states; however, its interpretation is less obvious. We begin by describing the physical interpretation of a non-disjoint probe-domain distribution within a discrimination protocol.
Any non-disjoint discrete distribution \({{{{\mathcal{S}}}}}_{{{{\rm{nd}}}}}\) can be decomposed into a sequence of r disjoint distributions,
where \({{{{\mathcal{S}}}}}_{{{{\rm{d}}}}}^{k}\) is a disjoint sub-collection of probe domains in accordance with Eq. (7). In this case, each \({{{{\mathcal{S}}}}}_{{{{\rm{d}}}}}^{k}\) need not contain all the channel labels but all m-channels must be accounted for in the global distribution \({{{{\mathcal{S}}}}}_{{{{\rm{nd}}}}}\). This allows us to rewrite the global, single-copy probe state in a more meaningful way
That is, it is the tensor product of r disjointly distributed multipartite input states.
Therefore, the utilisation of a non-disjoint probe-domain distribution corresponds to a block protocol with r rounds of disjoint pattern interaction. At each round, the user interacts with the channel pattern by irradiating unassisted multipartite states and over the course of r rounds the probe-domain distribution ‘moves’ around the channel pattern. For this reason, it can be intuitively called a dynamic block protocol, \({{{{\mathcal{B}}}}}_{{{{\rm{dy}}}}}^{{{{\rm{u}}}}}\). Figure 1b depicts an m = 4 × 6 = 24 channel pattern which is being non-disjointly probed. The dynamic ‘movement’ of probe domains throughout its r = 4 rounds of disjoint pattern interaction is visualised in Fig. 2a.

a Non-disjoint probe-domain distributions can be decomposed into multiple rounds of disjoint pattern interaction, generating a dynamic discrimination protocol. This dynamic protocol can be equivalently represented by a fixed block protocol on a modified image space, as shown in b. The original (6 × 4)-channel pattern i is transformed into a (8 × 4)-pattern νi, which has been appropriately modified in accordance with the non-disjoint probe-domain distribution \({{{{\mathcal{S}}}}}_{{{{\rm{nd}}}}}\) using Eq. (13). Here we have assumed the use of single-copy probe states, M = 1.
The number of disjoint rounds r required to construct a dynamic protocol depends on the number of overlaps that occur within the decomposition in Eq. (9). An overlap simply refers to an instance of a channel label that is contained in more than one probe domain. We can define the number of overlaps mov as the total number of additional channel labels contained in the non-disjoint distribution
If there are many probe-domain overlaps, then r may be very large; if there are no overlaps, then r = 1 and we return to a fixed protocol.
In order to fairly compare dynamic and fixed block protocols, one must also be careful when distributing the number of probe copies M; a dynamic protocol with r rounds of disjoint pattern interaction and M-copy input states will clearly use more than M total probe modes. It is useful to define a resource metric known as the average channel use,
which describes the average number of probe copies applied per channel within a dynamic block protocol. When comparing the performance of fixed/dynamic block protocols, we must ensure they have the same average channel use.
Dynamic/fixed block protocol transformation
Consider a dynamic block protocol that follows a non-disjoint probe-domain distribution \({{{{\mathcal{S}}}}}_{{{{\rm{nd}}}}}\). Now, any channel \({{{{\mathcal{E}}}}}_{{i}_{j}}\) within the global pattern \({{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}}\) may be probed as part of several different multipartite domains. This more general scenario requires a mathematical model that allows us to quantitatively investigate the performance of dynamic protocols.
To achieve this, we find a simple relationship between dynamic and fixed block protocols, corresponding to an appropriate transformation on a channel pattern image space, \({{{\mathcal{U}}}}\). When two probe domains overlap, the overlapping channels are probed twice, but by independent probe states. Therefore, we attribute a unique Hilbert space to each independent probe mode and channel in each disjoint round throughout the protocol, while retaining the characteristics of the original channels. This can be done by considering a modified channel pattern which has been concatenated with copies of the channels that are overlapped.
Figure 2 depicts how this pattern modification takes place. Given that \({{{{\mathcal{S}}}}}_{{{{\rm{nd}}}}}\) contains mov overlapping channels, an originally m-length channel pattern i can be mapped to a (m + mov)-length pattern, where the additional copies of overlapping channels are concatenated with the multi-channel. These copy channels directly obey the behaviour of their originals. In this way, a dynamic protocol over m-length channel patterns can be equivalently studied as a fixed block protocol over an appropriately modified (m + mov)-length channel pattern space.
Let us more precisely express this transformation. A \({{{{\mathcal{S}}}}}_{{{{\rm{nd}}}}}\) dynamic protocol invokes the following transformation on a generic m-length channel pattern i into an extended channel pattern νi. As νi contains repeated elements, it is formally treated as a multi-set rather than a traditional set57. Then, the transformation can be explicitly written as
where ⊎ is the multi-set union operator, which concatenates each subset of channel labels, e.g., if we consider m = 3 length channel patterns and a probe-domain distribution \({{{{\mathcal{S}}}}}_{{{{\rm{nd}}}}}=\{\{1,2\},\{2,3\}\}\) then modified channel patterns take the form νi = {i1, i2}⊎{i2, i3} = {i1, i2, i2, i3}. From a channel perspective, this transformation can be equivalently portrayed as
By iterating this concatenation process over all patterns in an image space \({\{{{{{\boldsymbol{\nu }}}}}_{{{{\boldsymbol{i}}}}}\}}_{{{{\boldsymbol{i}}}}\in {{{\mathcal{U}}}}}\), one can easily convert a dynamic protocol into a fixed representation. Furthermore, it is expedient to write the global output states of these protocols in this format, such that
This transformation greatly simplifies the complication of overlapping probe domains and allows for an investigation of error probabilities. By abstracting our set of discriminatory POVMs to the modified image space \({\{{{{\Pi }}}_{{{{{\boldsymbol{\nu }}}}}_{{{{\boldsymbol{i}}}}}}\}}_{{{{\boldsymbol{i}}}}\in {{{\mathcal{U}}}}}\) and using an M-copy global probe state, then the average error probability of classification can be succinctly given by
Without explicit knowledge of these POVMs, we can simply utilise the fidelity bounds from Eqs. (3) and (4). These fidelity-based bounds can be readily computed, thanks to this fixed protocol transformation, by iterating over all unequal channel patterns in the modified image space (see ‘Methods’ for more details).
Correspondence with error correction
This dynamic to fixed block protocol mapping identifies a fascinating feature. In essence, a dynamic protocol invokes an encoding of quantum channel patterns, wherein m-length patterns from some image space \({{{\boldsymbol{i}}}}\in {{{\mathcal{U}}}}\) are encoded into an extended counterpart \({\{{{{{\boldsymbol{\nu }}}}}_{{{{\boldsymbol{i}}}}}\}}_{{{{\boldsymbol{i}}}}\in {{{\mathcal{U}}}}}\). This modified image space is a function of the non-disjoint probe-domain distribution \({{{{\mathcal{S}}}}}_{{{{\rm{nd}}}}}\). Thus, we make the crucial observation: Using entangled probe states, one can design a dynamic block protocol which encodes a quantum image space into a more distinguishable form.
Consider a single-channel \({{{{\mathcal{E}}}}}_{{i}_{{{{\rm{ov}}}}}}\) within a larger-channel pattern which happens to fall within the domain of two entangled sub-states of a global probe, \({\sigma }_{{{{{\mathcal{S}}}}}_{{{{\rm{nd}}}}}}={\sigma }_{{{{\boldsymbol{s}}}}}\otimes {\sigma }_{{{{{\boldsymbol{s}}}}}^{\prime}}\). Because of this, the probe states must be applied at different disjoint rounds in a dynamic protocol. In one round, the probe state σs is being used to determine the classification of all the channels \({{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}[{{{\boldsymbol{s}}}}]}:= {\{{{{{\mathcal{E}}}}}_{{i}_{k}}\}}_{k\in {{{\boldsymbol{s}}}}}\). In another round, the probe state \({\sigma }_{{{{{\boldsymbol{s}}}}}^{\prime}}\) is being used to classify the channels in the region \({{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}[{{{{\boldsymbol{s}}}}}^{\prime}]}={\{{{{{\mathcal{E}}}}}_{{i}_{k}}\}}_{k\in {{{{\boldsymbol{s}}}}}^{\prime}}\). As these probe sub-states are entangled over their domains, then the distinguishability of their output states \({{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}[{{{\boldsymbol{s}}}}]}({\sigma }_{{{{\boldsymbol{s}}}}})\) and \({{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}[{{{{\boldsymbol{s}}}}}^{\prime}]}({\sigma }_{{{{{\boldsymbol{s}}}}}^{\prime}})\) are correlated with the precise collection of quantum channels in each region. Dependent upon the size of entangled probe domains and the physical setting of discrimination, some collections of channels are easier to discriminate than others.
We arrive at the key insight: As \({{{{\mathcal{E}}}}}_{{i}_{{{{\rm{ov}}}}}}\) is contained in both probe domains, we are able to gather two potentially unique opinions on its classification; one from the perspective of σs in the pattern region s and another from \({\sigma }_{{{{{\boldsymbol{s}}}}}^{\prime}}\) in its region \({{{{\boldsymbol{s}}}}}^{\prime}\). On their own, these states may not be very effective at discriminating the channel \({{{{\mathcal{E}}}}}_{{i}_{{{{\rm{ov}}}}}}\), i.e., one of the output states may not be very distinguishable from other potential output states in that region. However, by probing \({{{{\mathcal{E}}}}}_{{i}_{{{{\rm{ov}}}}}}\) in conjunction with two different probing domains, it is more likely that at least one of the sub-regions will be a more distinguishable collection of channels, thus providing a greater chance of correct classification.
In this way, dynamic block protocols implicitly possess a form of error-correcting behaviour. By varying the spatial probe-domain distributions throughout the protocol, channels are probed from various perspectives, correlated with different sub-regions of the channel pattern. Poorly distinguishable channels in one sub-region may be significantly more distinguishable when probed within a different sub-region. Over the course of r disjoint rounds of pattern interaction, each entangled multipartite sub-state can help to correct errors that would arise if only fixed probe domains were used. Exploiting this behaviour, dynamic protocols can indeed encode channel patterns into more easily discriminated image spaces.
This is a remarkable property of dynamic block protocols, one that depends strongly on the choice of entangled quantum probes and the quantum channel patterns. Explicit examples of this behaviour and physical/mathematical intuition are elucidated in the ‘Methods’ section.
Designing unassisted block protocols
Given an m-length channel pattern discrimination problem, there are clearly an enormous number of ways in which one can design a (generally non-disjoint) a probe-domain distribution. Let us provide a diagrammatic approach to constructing these protocols.
An m-length channel pattern \({{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}}\) can be represented by an m-pixel grid. Each pixel is used to represent an individual channel \({{{{\mathcal{E}}}}}_{{{{{\boldsymbol{i}}}}}_{j}}\) and the grid can adopt any preferred height, width and shape. In order to create a tidy language that allows one to convey probe domains which contain both local and non-local channels, we provide two ways to portray a probe domain. First, a probe domain can be indicated by means of a coloured box, which covers a number of local channels. The size and position of the coloured-probing domains indicate the regions of a channel pattern that are irradiated by a multipartite input state. This is particularly useful for illustrating fixed block protocols with local probe domains, as shown in Fig. 3a, which can be intuitively interpreted.

a Disjoint and b non-disjoint distributions of multipartite probe domains. The example in b is in fact the nearest-neighbour configuration described in Eq. (21).
It is also useful to possess a convention for probe domains which contain non-local channels, or when are a number of overlapping domains in close proximity. Hence, we can equivalently illustrate a probe domain via connective lines between coloured single-pixel boxes. A probe domain is indicated by means of a continuous (unbroken) connecting line between a number of pixels. Dashed connective lines through channel boxes indicate a lack of entanglement, used to bypass certain channels while illustrating non-local domains. A clear example of this is shown in Fig. 3b. Here we describe a distribution of probe domains where each domain is of size ∣s∣ = 2, i.e., \({{{{\mathcal{S}}}}}_{{{{\rm{nd}}}}}=\{\{1,2\},\{2,3\},\ldots ,\{8,9\},\{9,1\}\}\). A dashed connective line is used to connect the non-local channel labels 1 and 9 so that 5 is not included in the probe-domain.
Bosonic Gaussian channel patterns
We wish to corroborate the construction of these classes of unassisted discrimination protocols and demonstrate their efficacy. To do so, we will focus on the discrimination of bosonic Gaussian Phase Insensitive (GPI) channels. This is a family of very important channels within the CV quantum communications, sensing and computation34 and can be used to model a vast array of physically significant scenarios. Crucially, a GPI channel maintains the Gaussianity of its input state. Hence, the transformation of a Gaussian state (with zero first moments) through under the action of a GPI channel can be fully characterised using its covariance matrix (CM) V, assuming zero first moments (see ‘Methods’ for the explicit transformations). The overall quantum channel can be denoted as \({{{{\mathcal{E}}}}}_{\tau ,\nu }\) and is defined with respect to a transmissivity parameter 0 ≤ τ ≤ 1 describing attenuation/amplification properties and an induced noise parameter ν ≥ 0. When τ = 1 and ν = 0, we regain the identity channel.
Binary GPI channel patterns then consist of a sequence of m GPI channels with unique target/background transmissivities τB, τT and noise properties νB, νT. In general, we may write the channel pattern
Let us identify some essential GPI channels: setting τ = η, such that 0 < η < 1 and ν = (1 − η)/2, then we have the single-parameter bosonic pure-loss channel \({{{{\mathcal{E}}}}}_{\eta }\). This describes the interaction of bosonic mode with a zero-temperature bath. This is an essential channel model for the description of optical fibres and short-range optical target detection known as quantum reading. The multi-hypothesis setting of discrimination pure-loss channel patterns has also been equated to the task of optical imaging, pattern recognition and classical data readout from optical memories25,41. Hence, the discrimination of bosonic loss poses a key problem setting for our work.
Alternatively, we may study thermal-loss channels \({{{{\mathcal{E}}}}}_{\tau ,\nu }\) such that the transmissivity satisfies 0 < τ < 1 or thermal-amplifier channels where τ > 1. In both the cases, the induced thermal noise is connected to the number of thermal photons in the channel environment Nenv, such that \(\nu =({N}_{{{{\rm{env}}}}}+\frac{1}{2})| 1-\tau |\). In the idealised absence of loss, we have a Gaussian additive-noise channel \({{{{\mathcal{E}}}}}_{\nu }\), where the transmissivity satisfies τ = 1 but we have non-zero noise ν > 0. The discrimination of thermal multi-channels is known as environment localisation and has been used to model fascinating scenarios within target detection and thermal pattern recognition42,43. In this work, we focus on the discrimination of additive-noise binary channel patterns, as the performance of this task will always be an upper bound for multi-channels with non-trivial transmissivity.
Unassisted Bosonic quantum pattern recognition
In order to devise fixed/dynamic unassisted block protocols for the discrimination of GPI channel patterns, we must specify a class of multipartite probe state. Here we make use of the Gaussian analogue of the entangled Greenberger-Horne-Zeilinger (GHZ) state known as a the CV-GHZ state, which is designed as the extension of a TMSV state to many modes. Consider a probe domain s, which describes a collection of ∣s∣ channels over which an input probe state is irradiated. A CV-GHZ state defined over this probe domain is a ∣s∣ mode, fully symmetric state denoted by \({{{\Phi }}}_{{{{\boldsymbol{s}}}}}^{\mu }\). It can be completely characterised by its CM with zero first moments58,
Here, μ denotes the energy (squeezing) of the state for shot noise 1/2 and mean photon number (or signal energy) NS, and I denotes the 2 × 2 identity matrix. Therefore, \({V}_{{{{\boldsymbol{s}}}}}^{\mu }\) is a 2∣s∣ × 2∣s∣ real matrix, which is fully symmetric. In order to capture maximal correlations at finite squeezing, we set the correlation parameters
See the ‘Methods’ section for more details on this state. Hence, we may construct unassisted, global quantum probe states from CV-GHZ sub-states. Given an arbitrary N-partite probe-domain distribution \({{{\mathcal{S}}}}\), and assuming that all sub-states are of the same energy μ, the global M-copy input state is given by
As seen in Eq. (19), the magnitude of the correlations held by CV-GHZ states \({c}_{\max }\) has a reciprocal dependence on the number of modes m in the state. This implies that the quantum correlations become ‘thinner’ as the number of modes increase, demanding more energy in order to maintain a high degree of entanglement. It is therefore beneficial to consider probe-domain distributions of shorter range CV-GHZ states in order to make the best use of the enhanced distinguishability that entanglement can provide. Motivated by this, we can design specific probe-domain distributions that exclusively use unassisted TMSV entangled states rather than wider-spread CV-GHZ states with weaker quantum correlations, i.e. the probe domain of each sub-state is simply ∣sj∣ = 2, ∀ j. By employing TMSV states in conjunction with dynamic block protocols, we can combine the enhanced distinguishability of entangled input states with the implicit error-correcting behaviour available through dynamic probing.
To systematically access both of these features, we introduce a nearest-neighbour probe-domain distribution. This defines a non-disjoint probe-domain distribution, which probes neighbouring channels using two-mode probe states (defining neighbouring channels on a closed one-dimensional lattice). The non-disjoint partition set takes the form,
where \({{{\rm{mod}}}}\) denotes the modulo operation. For example, if m = 4, the probe-domain distribution is simply \({{{{\mathcal{S}}}}}_{{{{\rm{nd}}}}}=\{\{1,2\},\{2,3\},\{3,4\},\{4,1\}\}\). In this way, each channel in the global pattern is probed exactly twice per single round of a dynamic block protocol (the average channel use is simply \(\bar{M}=2M\)). Diagrammatically, this distribution is illustrated in Fig. 3b. The nearest-neighbour protocol is conveniently designed, as it allows us to develop non-disjoint probing structures in a consistent way and can be applied to channel patterns of any size (for more detailed arguments and motivations surrounding this protocol, see the ‘Methods’ section).
Numerical results
In this section, we collect numerical results to benchmark the performance of both fixed and dynamic unassisted block protocols for the discrimination of bosonic pure-loss channel patterns (quantum reading) and Gaussian additive-noise channel patterns (environment localisation). We investigate a number of pattern recognition scenarios: CPF, k-CPF and arbitrary binary pattern classification (or barcode decoding). In each setting, we consider the worst-case discrimination scenario such that all patterns within an image space occur with a uniform probability, i.e. we consider the pattern probability distribution
In all cases, we employ unassisted CV-GHZ states in accordance with various disjoint/non-disjoint probe-domain distributions. The average error probability associated with these protocols can be accurately upper and lower bounded using the fidelity bounds in Eqs. (3) and (4) for which a variety of numerical and analytical techniques can be used for arbitrary multipartite distributions (see ‘Methods’ for details on the numerical computations).
These unassisted protocols can be compared to the best known classical and quantum-assisted protocols in order to critically benchmark their efficacy (details can be found in ‘Methods’). A sufficient condition for quantum advantage occurs when the upper bound for the average error probability associated with a quantum-enhanced protocol \({p}_{{{{\rm{err}}}}}^{{{{\rm{q,U}}}}}\) is less than a lower bound on the error probability associated with an optimal classical protocol \({p}_{{{{\rm{err}}}}}^{{{{\rm{cl,L}}}}}\). Hence, we may qualify guaranteed quantum advantage when
We use this quantity Δperr to identify when an unassisted quantum protocol can certifiably obtain quantum advantage over all classical protocols.
Discrimination of Bosonic loss
This can be used to describe a basic imaging setting, in which pixels are described by pure-loss channels of different transmissivity/reflectivity ηj for j ∈ {B, T}. As explored in ref. 41, Banchi et al. showed that the major quantum advantage can be obtained using an idler-assisted approach. This advantage is particularly useful in a low-energy regime, where the number of probe copies required to achieve high precision is dramatically reduced. Here we report that quantum advantage can be similarly guaranteed using a range of unassisted protocols. Moreover, it is possible to achieve unassisted performances comparable with that of full idler assistance via dynamic block protocols.
Figure 4a–c depicts error upper and lower bounds for the multi-channel discrimination of bosonic loss (upper bounds are plotted as dashed lines, lower bounds are solid). We consider m = 9 binary channel patterns such that background channel possess transmissivity ηB = 0.99, whereas target channels possess ηT = 0.97. In each panel a–c, we consider a different image space: CPF, (k = 3)-CPF and barcode pattern recognition respectively. Within each setting, we construct fixed and dynamic unassisted block protocols using CV-GHZ sub-states, each with mean photon energy NS = 20. The precise probe-domain distributions are identified diagrammatically in the legend.

Classification error bounds for CPF/pattern recognition of m = 9 channel patterns of a–c pure-loss channels with parameters ηT, ηB = 0.97, 0.99 and d–f additive-noise channels with parameters νT, νB = 0.01, 0.02, using probe states of mean photon energy NS = 20 and variable structures based on CV-GHZ states (and optimal classical states). All solid lines are lower bounds and all dashed lines are upper bounds, based on Eqs. (3) and (4), respectively. All input state structures are defined diagrammatically in the respective legends.
Figure 4a shows results for CPF. Although one can eventually confirm quantum advantage using a block protocol with a single m = 9 mode CV-GHZ state (as studied in ref. 51), this is only certifiably advantageous using a very large average channel use, \(\bar{M}\approx 3000\), compared to the idler-assisted protocol \(\bar{M}\approx 30\). Furthermore, for the larger image spaces, it quickly becomes too costly to achieve guaranteed quantum advantage, such as for 3-CPF and barcode discrimination. Instead, one may use a dynamic protocol to achieve error rates on par with the idler-assisted performance. Using the nearest-neighbour dynamic protocol as per the probe-domain distribution in Eq. (21), one may readily obtain guaranteed quantum advantage regardless of the image space. This dynamic protocol not only outperforms the optimal classical protocol, but also quickly provides guaranteed advantage over the best fixed, unassisted block protocols also, achieving performance on par with idler assistance.
Figure 5a–c displays the minimum guaranteed quantum advantage Δperr associated with the use of nearest-neighbour dynamic protocols. Here we plot the difference between the quantum upper bound and the optimal classical lower bound for m = 9 channel pattern discrimination. This is carried out for ηT = 1, \(\bar{M}=100\), a variety of signal energies NS, and background transmissivities ηB. The difference in advantage achieved by the idler-assisted protocol and the nearest-neighbour dynamic protocol is too small to be displayed, emphasising that we can not only achieve quantum advantage without idlers but effectively match the performance of idler assistance.

As per Eq. (23), for 9-pixel a, d CPF, b, e 3-CPF and c, f full image space (barcode) discrimination using the nearest-neighbour dynamic protocol compared with full idler assistance. In a–c, the m = 9 pure-loss channels are considered, with target pixel transmissivity ηT = 1 and various background transmissivities ηB, plotted against signal energy NS. Here the difference in advantage with the idler-assisted protocol is too small to be plotted. Panels d–f study additive noise m = 9 channel patterns for target noise νT = 0.01 and various signal energies, plotted against background noise νB.
Environment localisation
We now consider environment localisation. Here, the task is to classify channel patterns in which each channel possesses background or target noise properties, νB/νT. It is noteworthy that we focus on additive-noise channels as an idealised scenario for thermal-loss/amplifier channels, as the inclusion of loss τ ≠ 1 will only degrade the performance of our unassisted protocols. It has recently been proven that the ultimate error bounds for this pattern recognition setting are non-adaptively achieved by idler-assisted TMSV states42,43.
In Fig. 4d–f, we report the performance of a number of different fixed/dynamic unassisted protocols for the task of environment localisation. Again, we consider m = 9 length channel patterns for a trio of image spaces, CPF, (k = 3)-CPF and barcode pattern recognition. Each channel is characterised as an additive-noise channels with νB = 0.02 or νT = 0.01, and our probe states again have mean photon number NS = 20. It is immediately clear that unassisted, fixed block protocols in this setting are ineffective, as shown by the very poor lower bounds in these results. Without idlers, the output distinguishability of disjointly distributed probe states is extremely poor and degrades further with increasing probe domain size.
Yet, performance can be redeemed via dynamic protocols. By overlapping entangled probe domains over channel patterns, we increase the opportunity of interacting with distinguishable channel regions. Indeed, the use of the nearest-neighbour dynamic protocol allows for guaranteed quantum advantage to be obtained in a number of discrimination settings where fixed protocols are unable to even match the classical performance (see ‘Methods’ for more nuanced insight to this result). Interestingly, alternative non-disjoint probe-domain distributions can be seen to achieve quantum advantage also, in some cases outperforming the nearest-neighbour protocol as shown in Fig. 4d. The question of identifying optimal dynamic protocols is thus highly non-trivial and very interesting.
Finally, Fig. 5d–f compare the guaranteed quantum advantage Δperr associated with idler-assisted protocols with that of the nearest-neighbour dynamic protocol in this discrimination setting, for νT = 0.01 and a variety of resource/environmental parameters. The most significant guaranteed advantage is observed for 1-CPF, as shown in both Fig. 4d and Fig. 5d. Although it is clear that unassisted protocols are more sensitive to noisy, thermal environments, quantum advantage is still achievable without the use of idlers. These results emphasise the achievability of quantum-enhanced, idler-free protocols for short-range environment localisation tasks.
Discussion
We have formalised the construction of unassisted, quantum-enhanced discrimination protocols in a multi-channel setting, using multipartite quantum states. We identified two distinct classes of block protocols, fixed and dynamic, which differ in how they distribute multipartite entanglement across channel patterns. The operational interpretations of these protocols were discussed, along with their relationship with one another. Furthermore, we formulated a logical correspondence between dynamic protocols and error correction; variable probe domains throughout discrimination help to correct errors that fixed probe domains cannot.
In order to explicitly study the efficacy of these protocols, we designed unassisted protocols for the discrimination of bosonic Gaussian channel patterns. These protocols were based on the use of entangled, multi-mode CV-GHZ states. Through analytical and numerical investigation, we showed that these unassisted protocols can provide significant advantage over the optimal classical strategies for the discrimination of both bosonic loss and environmental noise. In some cases, idler-free approaches can achieve performance on par with idler assistance.
These results strongly encourage further investigation of dynamic block protocols. Motivated by the problem setting and chosen class of probe states, we were able to engineer high-performance, quantum-enhanced unassisted protocols. However, determining the optimal unassisted protocol for specific multi-channel discrimination tasks is now an open question. It is of interest to explore more sophisticated versions of these protocols based on the optimisation of probing configurations over specific image spaces and adaptive protocols that modify probe-domain distributions on the fly. Such studies could reveal high-performance unassisted discrimination strategies tailored to realistic applications.
As this research was conducted in the CV picture based on Gaussian entangled states, this makes it particularly relevant to near-term quantum-sensing applications. The exploration of alternative entangled probe states is an immediate path of interest, as the employment of popular non-Gaussian entangled states could provide further enhancements to these unassisted protocols. Furthermore, the translation of this research for finite-dimensional channels is also an important topic, in which similar unassisted protocols may display strong quantum advantage.
Investigating the space of unassisted discrimination protocols is of importance for near-term quantum technologies. The insights and results of this work significantly loosen the resource constraints on realisable quantum technologies that rely on pattern recognition, emphasising that idler assistance is not always a necessity.
Methods
Quantum barcode decoding
The most general pattern recognition task for binary channel patterns is quantum barcode decoding41. This is a multi-hypothesis discrimination task of identifying a channel pattern from the entire space of binary channel patterns. For m-length quantum multi-channels, this is characterised by an image space \({{{{\mathcal{U}}}}}_{m}=\{{{{{\boldsymbol{i}}}}}_{1},\ldots ,{{{{\boldsymbol{i}}}}}_{{2}^{m}}\}\) which contains exactly 2m possible patterns. For example, if m = 2, the complete binary image space is explicitly \({{{{\mathcal{U}}}}}_{2}=\{\{B,B\},\{B,T\},\{T,B\},\{T,T\}\}\).
All other image spaces are necessarily a subset of \({{{{\mathcal{U}}}}}_{m}\); hence, quantum barcode decoding embodies the most challenging multi-channel discrimination problem in this setting. It represents a scenario in which we have no a priori information that can narrow the space of potential quantum channel patterns and all \({{{\boldsymbol{i}}}}\in {{{{\mathcal{U}}}}}_{m}\) must be considered within the ensemble.
Channel position finding
The task of CPF describes the multi-hypothesis discrimination task of locating a single target channel \({{{{\mathcal{E}}}}}_{\mathrm{T}}\) hidden among an array of background channels \({{{{\mathcal{E}}}}}_{\mathrm{B}}\). An m-channel CPF problem is associated with the image space \({{{{\mathcal{U}}}}}_{{{{\rm{CPF}}}}}\), which is the set of all m-length multi-channels that contain exactly one target channel.
Let us define a function that constructs an m-length channel pattern with one target channel in the xth position of the set
Here, P1:x is a permutation operator that swaps the position of the first label T with the xth element in the set. Then, we can construct the CPF image space for m-modes,
For a m-channel CPF problem, \(| {{{{\mathcal{U}}}}}_{{{{\rm{CPF}}}}}| =m\). For example, if m = 3, then
More generally, we may investigate k-CPF, where the number of target channels that occur within each channel pattern is precisely k < m, hidden among m − k background channels. We denote this image space \({{{{\mathcal{U}}}}}_{{{{\rm{CPF}}}}}^{k}\). Let us define a more general function that generates an m-length channel pattern with precisely k-target labels in the positions indicated by the unique indices x1, x2, …,xk,
Here, each permutation operator \({P}_{1\ldots k:{x}_{1}\ldots {x}_{k}}\) swaps all of the target channel labels from positions 1, …, k with the channel labels at the positions x1, …, xk. Then, we can construct any k-CPF image space by iterating over all unique permutations of the target channel labels,
For an m-channel k-CPF problem, \({{{{\mathcal{U}}}}}_{{{{\rm{CPF}}}}}^{k}\) contains exact \({C}_{m}^{k}\) channel patterns, where \({C}_{m}^{k}=m!/(k!(m-k)!)\) is the binomial coefficient. For example, if m = 3, k = 2, then the image space is
Clearly, when k = 1, we regather the previous single CPF image space.
Both CPF and k-CPF find a number of fundamental settings within target detection, quantum-enhanced classical data readout and environment localisation. They provide a valuable platform for studying multi-channel discrimination; if we can understand how to attain quantum enhancements in the readily analysable CPF framework, then we can learn to extract and apply these enhancements in more complex settings.
Bosonic Gaussian channel patterns
Under the action of a single-mode GPI quantum channel, an input Gaussian state described completely via its CM Vin with zero first moments undergoes the transformation
where I is a 2 × 2 identity matrix. The overall quantum channel can be denoted as \({{{{\mathcal{E}}}}}_{\tau ,\nu }\) and is defined with respect to a transmissivity parameter 0 ≤ τ ≤ 1 describing attenuation/amplification properties and an induced noise parameter ν ≥ 0.
Binary GPI channel patterns then consist of a sequence of m-GPI channels with unique target/background transmissivities τB, τT and noise properties νB, νT. Consider now an m-mode Gaussian state with CM Vin and zero first moments. Let the following be a matrix function of a general variable x, which depends on a position k in a channel pattern i,
Then, a multi-mode Gaussian state that is transformed according to a GPI binary channel pattern \(\rho \mapsto {{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}}(\rho )\) undergoes the following transformation on its CM in phase space
Therefore, it is easy to study the CMs of multi-mode Gaussian probe states interacting with GPI channel patterns.
Bosonic CV-GHZ states
As discussed in ‘Results’, a CV-GHZ state can be constructed as the extension of a TMSV state to many modes. Indeed, consider a CV-GHZ state defined over an m-length probe domain, \({{{\Phi }}}_{\{1,\ldots ,m\}}^{\mu }\). This m-mode state can be completely characterised by its CM (with zero first moments) as given in Eq. (18). Here we show why maximum correlations are satisfied at \({c}_{1}=-{c}_{2}={c}_{\max }\). The symplectic spectrum of the CV-GHZ state takes the form,
such that ν+ is (m − 1)-degenerate. In order to capture maximal correlations (at finite squeezing), we use the bona fide condition \({\nu }_{\pm }\ \ge \ \frac{1}{2}\) to state that
Hence, this leads to the notion of maximal symmetric correlations when the correlation parameters satisfy \({c}_{1}=-{c}_{2}={c}_{\max }={(m-1)}^{-1}\sqrt{{\mu }^{2}-1/4}\).
CV-GHZ states can then be readily used to construct probe states in conjunction with a probe-domain distribution, where it can be used as a building block for more general multipartite states. This construction can be equivalently represented in phase space, where tensor products over sub-states become direct sums over sub-CMs. More precisely, given an N-partite probe-domain distribution \({{{\mathcal{S}}}}\) (disjoint or non-disjoint) we can equivalently express the global CV-GHZ input state \({{{\Phi }}}_{{{{\mathcal{S}}}}}^{\mu }\) via its CM,
where \({V}_{{{{{\boldsymbol{s}}}}}_{j}}^{\mu }\) is the CM of a ∣sj∣-mode CV-GHZ state irradiated over the modes contained in the probe domain sj.
Numerical computation of error bounds
Consider two unique, m-length Gaussian channel patterns \({{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}}\) and \({{{{\mathcal{E}}}}}_{{{{{\boldsymbol{i}}}}}^{\prime}}\), which are probed by two identical m-mode CV-GHZ states \({{{\Phi }}}_{\{1,\ldots ,m\}}^{\mu }\). We can conveniently write the output states from these interactions,
Now consider the fidelity between these two output states \(F({{{\Phi }}}_{{{{\boldsymbol{i}}}}}^{\mu },{{{\Phi }}}_{{{{{\boldsymbol{i}}}}}^{\prime}}^{\mu })\). Thanks to the Gaussianity of CV-GHZ states and GPI multi-channels, the fidelity between these states can be computed exactly using only their phase space representations using the formulae from59,
where we denote FG as the Gaussian fidelity function.
In summary, we have a way to represent the input probe states of unassisted block protocols, through \({V}_{{{{{\mathcal{S}}}}}}^{\mu }\); the ability to describe output states by transforming input states according to GPI multi-channels \({{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}}\) as in Eq. (32),
and the means to compute the fidelity between any two output states. Given these techniques, and a multi-channel discrimination problem \({\{{\pi }_{{{{\boldsymbol{i}}}}};{{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}}\}}_{{{{\boldsymbol{i}}}}\in {{{\mathcal{U}}}}}\), we can readily compute the fidelity-based error probability lower and upper bounds,
To study the error bounds of dynamic block protocols, we need only invoke the dynamic/fixed protocol transformation discussed in the ‘Results’ section. In this way, we modify the channel patterns according to the probe-domain distribution i → νi. By computing the fidelity between the outputs of CV-GHZ states irradiated over the modified patterns
Error bounds can be readily computed for dynamic block protocols. The numerical methods presented here can always be used for fixed or dynamic block protocols and more generally using any Gaussian input states.
Classical performance
Here we collect expressions for the classical fidelities using optimal coherent states for the multi-channel discrimination settings explicitly studied in this work. These can then be used to derive exact error bounds and benchmark quantum advantage.
The best classical protocol for discriminating a single pure-loss channel is achieved by a block protocol using coherent states. Indeed, the optimal (energy constrained) M-copy, single-mode coherent state given by41,
where NS is the mean photon number of the signal state. If a single pure-loss channel possesses transmissivity ηB or ηT, the fidelity between the two possible single-copy output states is given by
For m-length multi-channels, we simply use m single-mode coherent states to discriminate each channel independently.
For additive-noise channels, τ = 1 and the task is to discriminate between background/target noise νB, νT > 0. The optimal classical input state is just the m-copy vacuum state \({\left|0\right\rangle }^{\otimes m}\), as displacements or phase shifts have no impact on the output states from the channel. The single probe copy fidelity between the potential single-mode output states can be written as43,
Using these fidelity expressions within the error probability bounds from Eqs. (3) and (4), we can provide effective classical benchmarks for both multi-channel discrimination settings.
Idler-assisted performance
We can similarly collect expressions for idler-assisted block protocols in the context of bosonic pure-loss channel patterns and environment localisation.
For the discrimination of bosonic loss, one can employ an idler-assisted protocol in which each channel is probed with one mode from an M-copy TMSV state, Φμ, where μ = NS + 1/2 is the level squeezing. Consider a single pure-loss channel \({{{{\mathcal{E}}}}}_{j}\), which may have transmissivity ηj ∈ {ηB, ηT}. Although one mode interacts with the channel, the other mode is perfectly protected (in a quantum memory for instance) and thus undergoes the action of an identity channel. The output state is then simply the finite-energy Choi state \({{{\Phi }}}_{{{{{\mathcal{E}}}}}_{j}}^{\mu }={{{{\mathcal{E}}}}}_{j}\otimes {{{\mathcal{I}}}}({{{\Phi }}}^{\mu })\). The fidelity between the output states \({{{\Phi }}}_{{{{{\mathcal{E}}}}}_{\mathrm{B}}}^{\mu }\) and \({{{\Phi }}}_{{{{{\mathcal{E}}}}}_{\mathrm{T}}}^{\mu }\) is41
where \({{\Delta }}=1-\sqrt{(1-{\eta }_{\mathrm{B}})(1-{\eta }_{\mathrm{T}})}-\sqrt{{\eta }_{\mathrm{B}}{\eta }_{\mathrm{T}}}\). By extending this to m-channels using M-copy probes, we can easily bound performance of the idler-assisted block protocol.
We can perform an identical analysis for environment localisation by computing the fidelity between possible output states of a pair of additive-noise channels with target noise or background noise νB/νT. In this case, it is convenient to utilise the parameter μ = NS + 1/2, where the output fidelity reads42
Once again extending these fidelities to consider m-channels and using M-copy probes states, we can easily bound the performance of idler-assisted block protocols.
Fidelity degeneracies of CV-GHZ states
Consider an arbitrary N-element image space \({{{\mathcal{U}}}}=\{{{{{\boldsymbol{i}}}}}_{1},{{{{\boldsymbol{i}}}}}_{2},\ldots ,{{{{\boldsymbol{i}}}}}_{N}\}\), which generate m-length quantum channel patterns, and the associated multi-channel ensemble \({\{{\pi }_{{{{\boldsymbol{i}}}}};{{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}}\}}_{{{{\boldsymbol{i}}}}\in {{{\mathcal{U}}}}}\). Now, consider the use of an unassisted block protocol using m-mode CV-GHZ states. As we know from ‘Results’, we can benchmark the performance of this protocol via the fidelity-based error probability bounds in Eqs. (3) and (4).
Although this can be achieved numerically, it can become inefficient. The total number of ways that we can choose unequal pairs of channel patterns is N(N − 1). This means that in general, there exist N(N − 1) potentially unique, non-unit fidelities that one needs to compute in order to calculate the error bounds. For large pattern spaces, this can be enormous, making it difficult to analytically keep track of all possible output fidelities or numerically perform these sums.
However, thanks to their symmetry, when using CV-GHZ states as quantum probes the number of unique fidelities that may occur is dramatically reduced. The CV-GHZ state symmetry causes many of the unique output fidelities within Eqs. (3) and (4) to be highly degenerate. Indeed, fidelity degeneracy tells us that if there are exactly gfid unique output fidelities, typically gfid ≪ N(N − 1).
Let us be more precise: consider a pair of image spaces of m-length, binary channel patterns: one is the k-CPF image space \({{{{\mathcal{U}}}}}_{{{{\rm{CPF}}}}}^{k}\), such that each pattern contains precisely k-target channels, and the other is a l-CPF image space \({{{{\mathcal{U}}}}}_{{{{\rm{CPF}}}}}^{l}\) such that each pattern contains precisely (l ≠ k)-target channels. Take two identical m-mode CV-GHZ states \({{{\Phi }}}_{\{1,\ldots ,m\}}^{\mu }\), which interact with the multi-channels \({{{{\mathcal{E}}}}}_{{{{\boldsymbol{i}}}}}\) and \({{{{\mathcal{E}}}}}_{{{{{\boldsymbol{i}}}}}^{\prime}}\), resulting in two unique output states \({{{\Phi }}}_{{{{\boldsymbol{i}}}}}^{\mu }\) and \({{{\Phi }}}_{{{{{\boldsymbol{i}}}}}^{\prime}}^{\mu }\). Now consider the fidelity,
We find that this fidelity is equivalent for all pairs of channel patterns \({{{\boldsymbol{i}}}},{{{{\boldsymbol{i}}}}}^{\prime}\), which have the same Hamming distance. That is, for all
the fidelity \(F({{{\Phi }}}_{{{{\boldsymbol{i}}}}}^{\mu },{{{\Phi }}}_{{{{{\boldsymbol{i}}}}}^{\prime}}^{\mu })\) is completely degenerate. For a rigorous proof of this, please see ref. 60. Fidelity degeneracies are extremely useful and can help to not only improve numerical efficiency, but reveal analytical insights.
In Fig. 6, we have numerically investigated the fidelity degeneracy properties of a number of different unassisted dynamic/disjoint protocols for the discrimination of pure-loss channel patterns. Here we observe two clear points; CV-GHZ states lose distinguishability when we widen their domain size as expected, due to weakening quantum correlations (discussed in the ‘Results’). This can be seen by comparing the output fidelity spectrum of the m = 10 mode CV-GHZ probe state (green) compared to the other probe-domain distributions.

Histograms of fidelity degeneracies for unequal m = 10 pure-loss channel patterns over the complete image space of binary channel patterns \({{{{\mathcal{U}}}}}_{10}\), for a selection of probe-domain distributions: m-mode CV-GHZ state (green), disjointly distributed TMSV states (orange) and nearest-neighbour distributed TMSV states (blue). The fixed block protocols are using M = 2 probe copies, whereas the dynamic nearest-neighbour protocol is using M = 1 copies. In this way, the average channel use of all the protocols is the same, \(\bar{M}=2\).
Furthermore, non-disjoint probe domain distributions are able to ‘spread out’ the degeneracies involved with disjoint probing protocols. In Fig. 6, we compare a fixed block protocol using a disjoint, exclusively two-mode distribution of probe domains (orange). We then use a dynamic nearest-neighbour protocol with the exact same number of probe modes (blue). Although the output fidelity distributions possess a similar spread in values, the variation in probe domains raises many of the degenerate fidelities. In doing so, it flattens the overall distribution and gives rise to more distinguishable output fidelities.
Fidelity degeneracies of TMSV states
We will now focus on the case of using m = 2 CV-GHZ states, i.e., TMSV states. As discussed in ‘Results’, these states maximise their entanglement content with respect to input energy, as quantum correlations do not need to be spread across many modes. Furthermore, they offer the simplest test case for analytically investigating fidelity degeneracies. This will help to unveil concrete reasons for the discrepancy between fixed and dynamic protocols.
We wish to identify all the possible, unique output fidelities associated with TMSV states irradiated over m = 2 length binary channel patterns. We can summarise this image space easily as it is very small,
Thanks to the fidelity degeneracy properties discussed in the previous section it turns out that there are only four unique sub-fidelities that can occur when one irradiates two-mode binary channel patterns with unassisted TMSV states. Here we define a sub-fidelity as a single output fidelity that occurs between specific pairs of channel patterns. These sub-fidelities are completely determined by the number of the target channels, k and l, contained within the considered channel pair, i and \({{{{\boldsymbol{i}}}}}^{\prime}\), respectively. Hence, we will denote each sub-fidelity in the form Fk:l where k (l) indicates the number of target channels in the channel pattern i (\({{{{\boldsymbol{i}}}}}^{\prime}\)). Doing so, we can write all the unique, two-mode sub-fidelities
The Bures fidelity is a symmetric function; therefore, the order of i and \({{{{\boldsymbol{i}}}}}^{\prime}\) is irrelevant.
These are the only fidelities that can occur when using TMSV states over pairs of m = 2 length channel patterns. Furthermore, the fidelity is multiplicative, meaning that
Hence, when using collections of exclusively two-mode states following some probe-domain distribution (such as in the nearest-neighbour protocol), then all of their unique output fidelities will always be a specific product of these sub-fidelities in Eq. (52). Hence, these sub-fidelities can be used to completely characterise any unassisted discrimination protocol using exclusively TMSV states (see ref. 60 for more details).
Although this may seem like an unnecessary level of detail, the investigation of these sub-fidelities helps to reveal critical features of dynamic block protocols. Each of the sub-fidelities in Eq. (52) is a unique function that can be analytically characterised via the Gaussian fidelity formulae from ref. 59. They each possess a unique behaviour dependent upon the multi-channel discrimination setting that we are considering. If one of the sub-fidelities is typically very large, this means that the specific pair of channel patterns that it refers to are very difficult to discriminate. If a sub-fidelity is very small, then the pair of channels it refers to are very easy to discriminate. For example, if F0:2 ≫ F1:1 in a particular problem setting, then it is much easier to discriminate the patterns {B, T} from {T, B}, rather than {B, B} from {T, T}.
Most importantly, when utilising unassisted discrimination protocols, there is an inconsistency of distinguishability between different collections of quantum channels. This inconsistency leads to the corrective behaviour that dynamic protocols can provide. We will convey this inconsistency by considering the settings studied in the ‘Results’ section.
Analytical insight for dynamic protocols
Let us take the example of environment localisation for m = 2 length binary channel patterns of additive-noise channels with target noise νT and background noise νB. When we look closely at the sub-fidelities concerned with this setting, we notice a glaring inconsistency. Three of these sub-fidelities (F0:1, F0:2 and F1:2) all assume their minimum in the limit of infinite squeezing,
That is, by increasing the energy of our input states, we can expect to improve the discrimination of the appropriate pairs of channel patterns. This sub-fidelity behaviour is displayed in Fig. 7a.

Two-mode sub-fidelity behaviour with respect to increasing signal energy NS for unassisted, single-copy TMSV states interacting with m = 2 length channel patterns for a additive-noise channels νT, νB = 0.01, 0.02 and b pure-loss channels ηT, ηB = 0.97, 0.99.
However, this is not the case for the sub-fidelity F1:1(μ), which is concerned with the discrimination of the pattern {B, T} from {T, B} (and vice versa). This sub-fidelity explicitly takes the form
where we define the quantities
In the limit of infinite squeezing, we find that
meaning that in the limit of infinite probe-state energy, the pair of channel patterns {B, T} and {T, B} become completely indistinguishable. Clearly, this will have a hugely detrimental effect on discrimination performance, which cannot be remedied by increasing the input probe energy.
A similar effect can be observed within pure-loss channel patterns. Let us consider the case of probing m = 2 length binary channel patterns such that each channel is a pure-loss channel with either a target transmissivity ηT or background transmissivity ηB. Now, we find that the two-mode sub-fidelities F0:1, F1:1 and F1:2 tend to zero in the limit of infinite squeezing,
This means that in the limit of infinite energy and maximum entanglement, the channel pairs that characterise each of these sub-fidelities become perfectly distinguishable.
However, we may focus on the quantity F0:2(μ), which defines the distinguishability of the patterns {B, B}, {T, T}. This sub-fidelity takes a relatively compact form given by,
where we use μ = NS + 1/2 as before and we define the quantities
In the limit of infinite squeezing, this sub-fidelity F0:2 instead finds the finite quantity
which is non-zero when either ηj ≠ 1. Therefore, even when using infinitely squeezed input states, the patterns i = {B, B} and \({{{{\boldsymbol{i}}}}}^{\prime}=\{T,T\}\) are not perfectly distinguishable via unassisted input states. The behaviour of these sub-fidelities are displayed in Fig. 7b.
It is now clear why dynamic protocols are so effective at redeeming the performance of these multi-channel discrimination tasks. When using unassisted, multipartite entangled probe states, the distinguishability of the output states can vary considerably, dependent upon the collection of quantum channels that they interact with. By overlapping probe domains, channels can be probed in conjunction with different collections of channels in the pattern. In doing so, we are increasing the likelihood of probing a more a distinguishable collection. These more distinguishable channel regions are then able to correct the errors invoked by probes interacting with poorer regions.
As an example, let us take the discrimination of Gaussian additive-noise channels with TMSV states according to some probe-domain distribution. Consider an m = 4 length channel pattern,
that we wish to discriminate. Here, we first consider a fixed block protocol that follows the probe-domain distribution \({{{{\mathcal{S}}}}}_{{{{\rm{d}}}}}=\{\{1,2\},\{3,4\}\}\). As a result of this distribution, we will possess the following TMSV states which irradiate specific channel sub-patterns,
As discussed earlier in this section, the sub-fidelity F1:1 is very poor, meaning that the sub-patterns {B, T} and {T, B} are very difficult to distinguish from one another. Therefore, if we irradiate a sub-pattern {B, T} or {T, B} directly with a TMSV state, our overall discrimination ability will be very ineffective, as we will struggle to determine which is the true pattern. It is highly desirable to avoid instances of this kind of pattern interaction, but obviously we cannot know prior to interaction where these pairs of channel patterns arise (this would defeat the purpose of discrimination). This embodies a critical weakness of fixed block protocols. If we unwittingly choose a probe-domain distribution which irradiates input states over poorly distinguishable collections of patterns, the ability to discriminate the overall channel pattern will be compromised.
We now see why varying the probe domains is so effective. Consider a non-disjoint probe-domain distribution, \({{{{\mathcal{S}}}}}_{{{{\rm{nd}}}}}=\{\{1,2\},\{2,3\},\{3,4\},\{1,4\}\}\) (this is in fact the nearest-neighbour protocols discussed in ‘Results’). Consider the same m = 4 length channel pattern, i = {B, T, T, B}. As a result of this distribution, we will possess the following TMSV states which irradiate the specific channel sub-patterns,
Although we are still unfortunately irradiating the poorly distinguishable collections of channels {i1, i2} = {B, T} and {i3, i4} = {T, B} with two of our input probes, we now also apply probe states to the sub-patterns {i2, i3} = {T, T} and {i1, i4} = {B, B}. These collections of channels are much more distinguishable, and invoke the stronger sub-fidelities F0:1, F0:2 and F1:2. Hence, by varying our probe domains, we are able to gather different, more distinguishable ‘opinions’ of regions of the channel pattern. The stronger distinguishability of the regions {i2, i3} and {i1, i4} can help to correct the contribution of the poorly distinguishable channel collections.
It is important to note that this improved performance is not connected to an increased number of probe modes. Recall that we can fairly compare dynamic/fixed block protocols with the same average channel use \(\bar{M}\). With equivalent resources, the dynamic protocol will outperform the fixed version thanks to its variable probe domains.
Data availability
The data sets generated and analysed during the current study are available from the corresponding author on reasonable request.
Code availability
The codes used for this study are available from the corresponding author on reasonable request.
References
Nielsen, M. A. & Chuang, I. L. Quantum Computation and Quantum Information: 10th Anniversary Edition, 10th edn (Cambridge Univ. Press, 2011).
Preskill, J. Quantum computing in the NISQ era and beyond. Quantum 2, 79 (2018).
Arute, F. Quantum supremacy using a programmable superconducting processor. Nature 574, 505–510 (2019).
Degen, C. L., Reinhard, F. & Cappellaro, P. Quantum sensing. Rev. Mod. Phys. 89, 035002 (2017).
Helstrom, C. W. Quantum detection and estimation theory. J. Stat. Phys. 1, 231–252 (1969).
Bae, J. & Kwek, L.-C. Quantum state discrimination and its applications. J. Phys. A Math. Theor. 48, 083001 (2015).
Bergou, J. A., Herzog, U. & Hillery, M. In Quantum State Estimation 417–465, https://doi.org/10.1007/978-3-540-44481-7_11 (Springer Berlin Heidelberg, 2004).
Chefles, A. Quantum state discrimination. Contemp. Phys. 41, 401–424 (2000).
Wang, G. & Ying, M. Unambiguous discrimination among quantum operations. Phys. Rev. A 73, 042301 (2006).
Giovannetti, V., Lloyd, S. & Maccone, L. Advances in quantum metrology. Nat. Photonics 5, 222–229 (2011).
Lloyd, S. Enhanced sensitivity of photodetection via quantum illumination. Science 321, 1463–1465 (2008).
Tan, S.-H. et al. Quantum illumination with Gaussian states. Phys. Rev. Lett. 101, 253601 (2008).
Shapiro, J. H. & Lloyd, S. Quantum illumination versus coherent-state target detection. New J. Phys. 11, 063045 (2009).
Zhang, Z., Tengner, M., Zhong, T., Wong, F. N. C. & Shapiro, J. H. Entanglement’s benefit survives an entanglement-breaking channel. Phys. Rev. Lett. 111, 010501 (2013).
Zhang, Z., Mouradian, S., Wong, F. N. C. & Shapiro, J. H. Entanglement-enhanced sensing in a lossy and noisy environment. Phys. Rev. Lett. 114, 110506 (2015).
Barzanjeh, S. et al. Microwave quantum illumination. Phys. Rev. Lett. 114, 080503 (2015).
Dall’Arno, M., Bisio, A. & D’Ariano, G. M. Ideal quantum reading of optical memories. Int. J. Quantum Inf. 10, 1241010 (2012).
Zhuang, Q., Zhang, Z. & Shapiro, J. H. Entanglement-enhanced neyman-pearson target detection using quantum illumination. J. Opt. Soc. Am. B Opt. Phys. 34, 1567 (2017a).
Zhuang, Q., Zhang, Z. & Shapiro, J. H. Quantum illumination for enhanced detection of rayleigh-fading targets. Phys. Rev. A 96, 020302(R) (2017b).
Heras, U. L. et al. Quantum illumination reveals phase-shift inducing cloaking. Sci. Rep. 7, 9333 (2017).
De Palma, G. & Borregaard, J. Minimum error probability of quantum illumination. Phys. Rev. A 98, 012101 (2018).
Nair, R. & Gu, M. Fundamental limits of quantum illumination. Optica 7, 771 (2020).
Lopaeva, E. D. et al. Experimental realization of quantum illumination. Phys. Rev. Lett. 110, 153603 (2013).
Barzanjeh, S., Pirandola, S., Vitali, D. & Fink, J. M. Microwave quantum illumination using a digital receiver. Sci. Adv. 6, eabb0451 (2020).
Pirandola, S. Quantum reading of a classical digital memory. Phys. Rev. Lett. 106, 090504 (2011).
Nair, R. Discriminating quantum-optical beam-splitter channels with number-diagonal signal states: applications to quantum reading and target detection. Phys. Rev. A 84, 032312 (2011).
Tej, J. P., Devi, A. R. U. & Rajagopal, A. K. Quantum reading of digital memory with non-gaussian entangled light. Phys. Rev. A 87, 052308 (2013).
Spedalieri, G., Lupo, C., Mancini, S., Braunstein, S. L. & Pirandola, S. Quantum reading under a local energy constraint. Phys. Rev. A 86, 012315 (2012).
Spedalieri, G. Cryptographic aspects of quantum reading. Entropy 17, 2218–2227 (2015).
Zhuang, Q., Zhang, Z. & Shapiro, J. H. Entanglement-enhanced lidars for simultaneous range and velocity measurements. Phys. Rev. A 96, 040304(R) (2017c).
Hirota, O. Error free quantum reading by quasi bell state of entangled coherent states. Quantum Meas. Quantum Metrol. 4, 70–73 (2017).
Ortolano, G., Losero, E., Pirandola, S., Genovese, M. & Ruo-Berchera, I. Experimental quantum reading with photon counting. Sci. Adv. 7, eabc7796 (2021).
Xia, Y., Li, W., Zhuang, Q. & Zhang, Z. Quantum-enhanced data classification with a variational entangled sensor network. Phys. Rev. X 11, 021047 (2021).
Weedbrook, C. et al. Gaussian quantum information. Rev. Mod. Phys. 84, 621–669 (2012).
Serafini, A. Quantum Continuous Variables: A Primer of Theoretical Methods https://books.google.co.uk/books?id=zHtgvgAACAAJ (CRC, Taylor, Francis Group, 2017).
Adesso, G., Ragy, S. & Lee, A. R. Continuous variable quantum information: Gaussian states and beyond. Open Syst. Inf. Dyn. 21, 1440001 (2014).
Pirandola, S., Laurenza, R., Lupo, C. & Pereira, J. L. Fundamental limits to quantum channel discrimination. npj Quantum Inf. 5, 50 (2019).
Pereira, J. L. & Pirandola, S. Bounds on amplitude-damping-channel discrimination. Phys. Rev. A 103, 022610 (2021).
Zhuang, Q. & Pirandola, S. Entanglement-enhanced testing of multiple quantum hypotheses. Commun. Phys. 3, 103 (2020a).
Zhuang, Q. & Pirandola, S. Ultimate limits for multiple quantum channel discrimination. Phys. Rev. Lett. 125, 080505 (2020b).
Banchi, L., Zhuang, Q. & Pirandola, S. Quantum-enhanced barcode decoding and pattern recognition. Phys. Rev. Appl. 14, 064026 (2020).
Harney, C., Banchi, L. & Pirandola, S. Ultimate limits of thermal pattern recognition. Phys. Rev. A 103, 052406 (2021).
Pereira, J. L., Zhuang, Q. & Pirandola, S. Optimal environment localization. Phys. Rev. Res.2, 043189 (2020).
Pirandola, S., Bardhan, B. R., Gehring, T., Weedbrook, C. & Lloyd, S. Advances in photonic quantum sensing. Nat. Photonics 12, 724–733 (2018).
Lvovsky, A. I., Sanders, B. C. & Tittel, W. Optical quantum memory. Nat. Photonics 3, 706–714 (2009).
Jensen, K. et al. Quantum memory for entangled continuous-variable states. Nat. Phys. 7, 13–16 (2010).
Cho, Y.-W. et al. Highly efficient optical quantum memory with long coherence time in cold atoms. Optica 3, 100 (2016).
Wang, Y. et al. Efficient quantum memory for single-photon polarization qubits. Nat. Photonics 13, 346–351 (2019).
Karsa, A., Spedalieri, G., Zhuang, Q. & Pirandola, S. Quantum illumination with a generic gaussian source. Phys. Rev. Res. 2, 023414 (2020).
Braun, D. et al. Quantum-enhanced measurements without entanglement. Rev. Mod. Phys. 90, https://doi.org/10.1103/revmodphys.90.035006 (2018).
Pereira, J. L., Banchi, L., Zhuang, Q. & Pirandola, S. Idler-free channel position finding. Phys. Rev. A 103, 042614 (2021).
Gutoski, G. & Watrous, J. Toward a general theory of quantum games. In Proc. 39th Annual ACM Symposium on Theory of computing - STOC ’07, https://doi.org/10.1145/1250790.1250873 (2007).
Chiribella, G., D’Ariano, G. M. & Perinotti, P. Quantum circuit architecture. Phys. Rev. Lett. 101, 060401 (2008).
Laurenza, R., Lupo, C., Spedalieri, G., Braunstein, S. L. & Pirandola, S. Channel simulation in quantum metrology. Quantum Meas. Quantum Metrol. 5, 1–12 (2018).
Montanaro, A. A lower bound on the probability of error in quantum state discrimination. In 2008 IEEE Information Theory Workshop pp. 378–380 (2008).
Barnum, H. & Knill, E. Reversing quantum dynamics with near-optimal quantum and classical fidelity. J. Math. Phys. 43, 2097–2106 (2002).
Blizard, W. D. Multiset theory. Notre Dame J. Form. Log. 30, 36 – 66 (1988).
Adesso, G., Serafini, A. & Illuminati, F. Multipartite entanglement in three-mode gaussian states of continuous-variable systems: quantification, sharing structure, and decoherence. Phys. Rev. A 73, 032345 (2006).
Banchi, L., Braunstein, S. L. & Pirandola, S. Quantum fidelity for arbitrary gaussian states. Phys. Rev. Lett. 115, 260501 (2015).
Harney, C. & Pirandola, S. Analytical bounds for dynamic multi-channel discrimination. Phys. Rev. A 104, 032402 (2021).
Acknowledgements
C.H. acknowledges funding from the EPSRC via a Doctoral Training Partnership (EP/R513386/1). S.P. acknowledges funding from the European Union’s Horizon 2020 Research and Innovation Action under grant agreement number 862644 (Quantum readout techniques and technologies, QUARTET).
Author information
Authors and Affiliations
Contributions
S.P. developed the core idea and methodology, and steered the research project. C.H. derived the theoretical results presented and wrote the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Harney, C., Pirandola, S. Idler-free multi-channel discrimination via multipartite probe states. npj Quantum Inf 7, 153 (2021). https://doi.org/10.1038/s41534-021-00488-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41534-021-00488-x
