
Boosting Arithmetic Optimization Algorithm with Genetic Algorithm Operators for Feature Selection: Case Study on Cox Proportional Hazards Model

 ,
,  ,
,  ,
,  ,
, 
Abstract
:1. Introduction
- A modified approach of the classical AOA and GA is proposed that further enhances the exploration and convergence characteristics of this evolutionary-based wrapper feature selection method through the diverse population design.
- Boosted mutation and crossover operators are introduced for search-based exploration and exploitation of the search.
- The GA operator’s inclusion promotes the convergence rate to balance the exploration and exploitation characteristic of the proposed approach.
- Decrease of the feature input set using the proposed search method for high dimensional problems is conducive to develop a high-performing decision method.
- Comparing the proposed method with several state-of-the-art methods on twenty datasets is conducted.
2. Methods
2.1. Problem Formulation of FS
2.2. Arithmetic Optimization Algorithm (AOA)
| Algorithm 1 Steps of AOA |
|
2.3. Genetic Algorithm
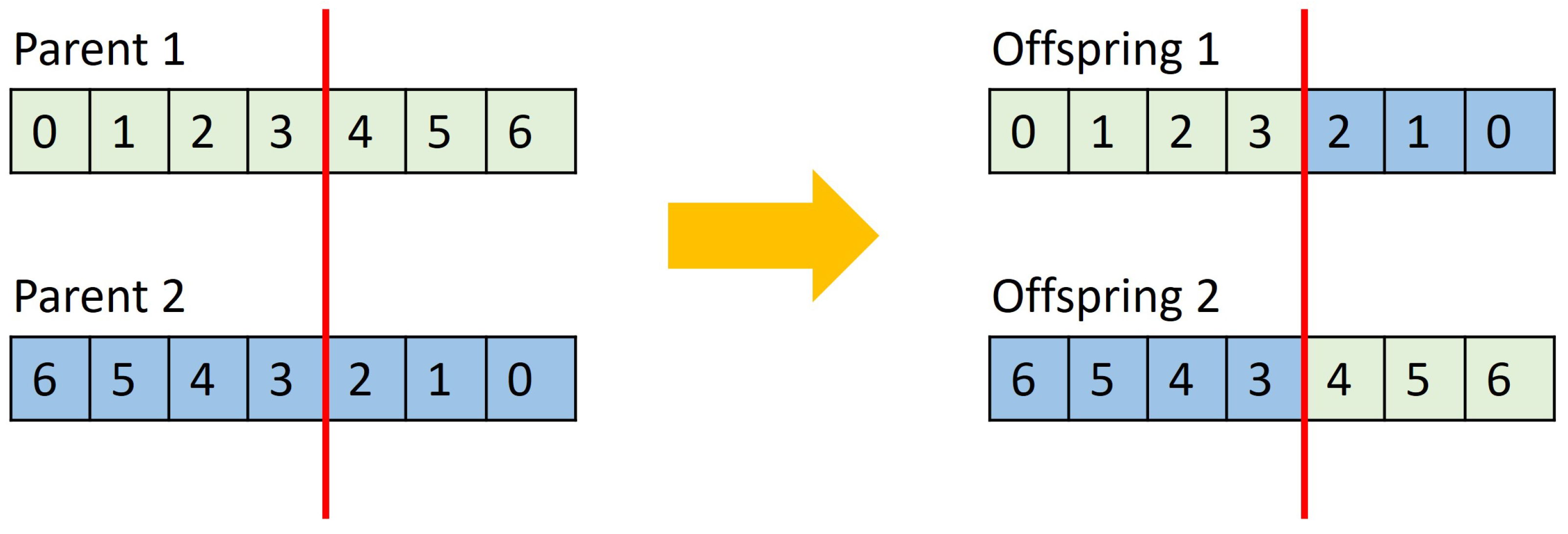
2.3.1. Crossover
2.3.2. Mutation
2.3.3. Selection
3. Proposed AOAGA Feature Selection
4. Experimental Results and Discussion
4.1. Performance Measures
- Average of accuracy is used to compute the ability of an algorithm to predict the correct label of each class over the runs. Higher value is better [65]. It is defined as:
- Standard deviation (STD) is used to check to what extent an algorithm can obtain the same results over different runs. Smaller value is better [65]. It is formulated as:
- Average of selected features is applied to test an algorithm’s ability to choose the smallest subset of relevant features overall runs. Smaller value is better [65]. It is given as:where denotes the cardinality of at k-th run.
4.2. Experimental Series 1: UCI Datasets Results and Discussion
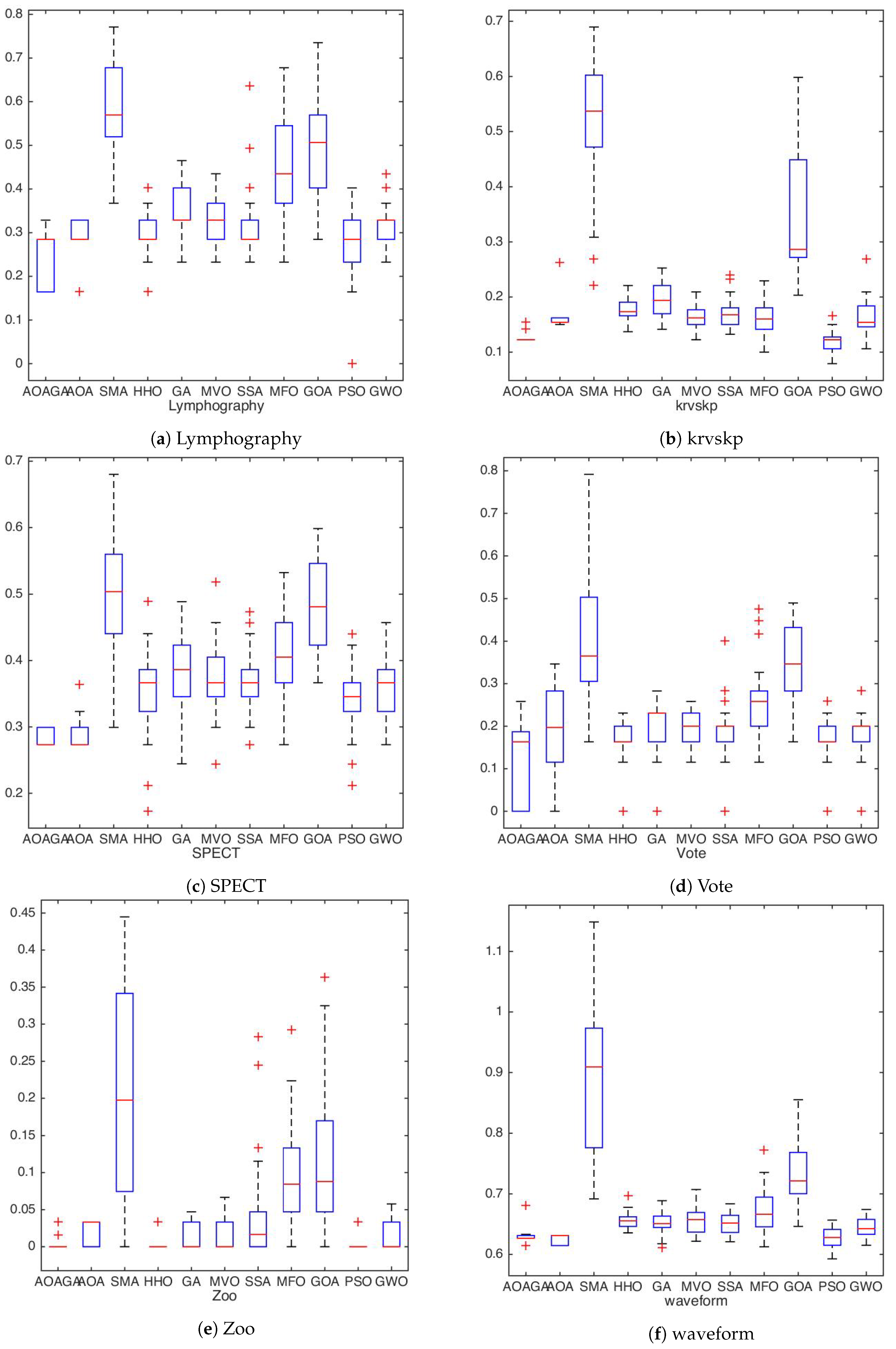
4.2.1. Results and Discussion of UCI Dataset
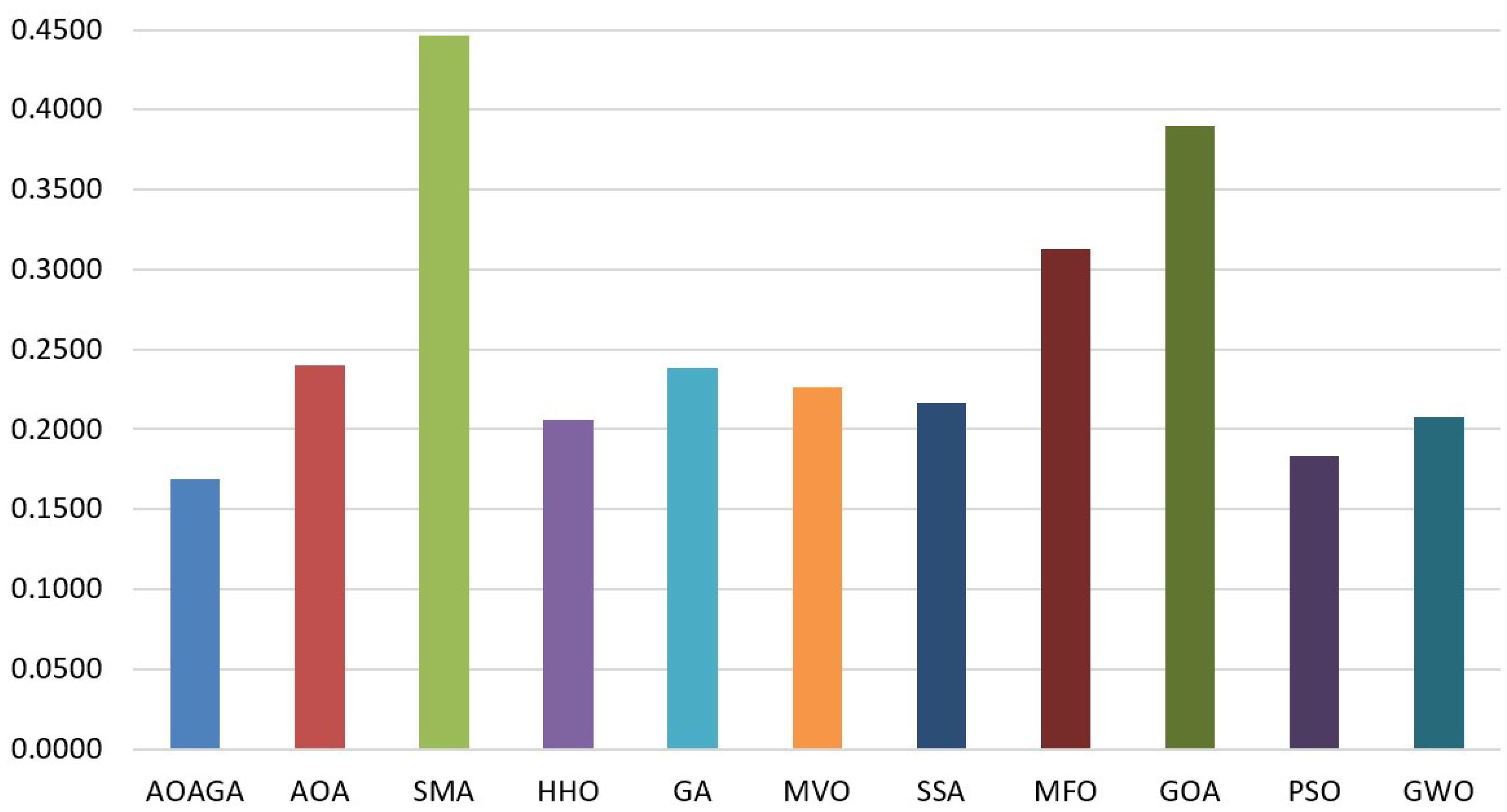
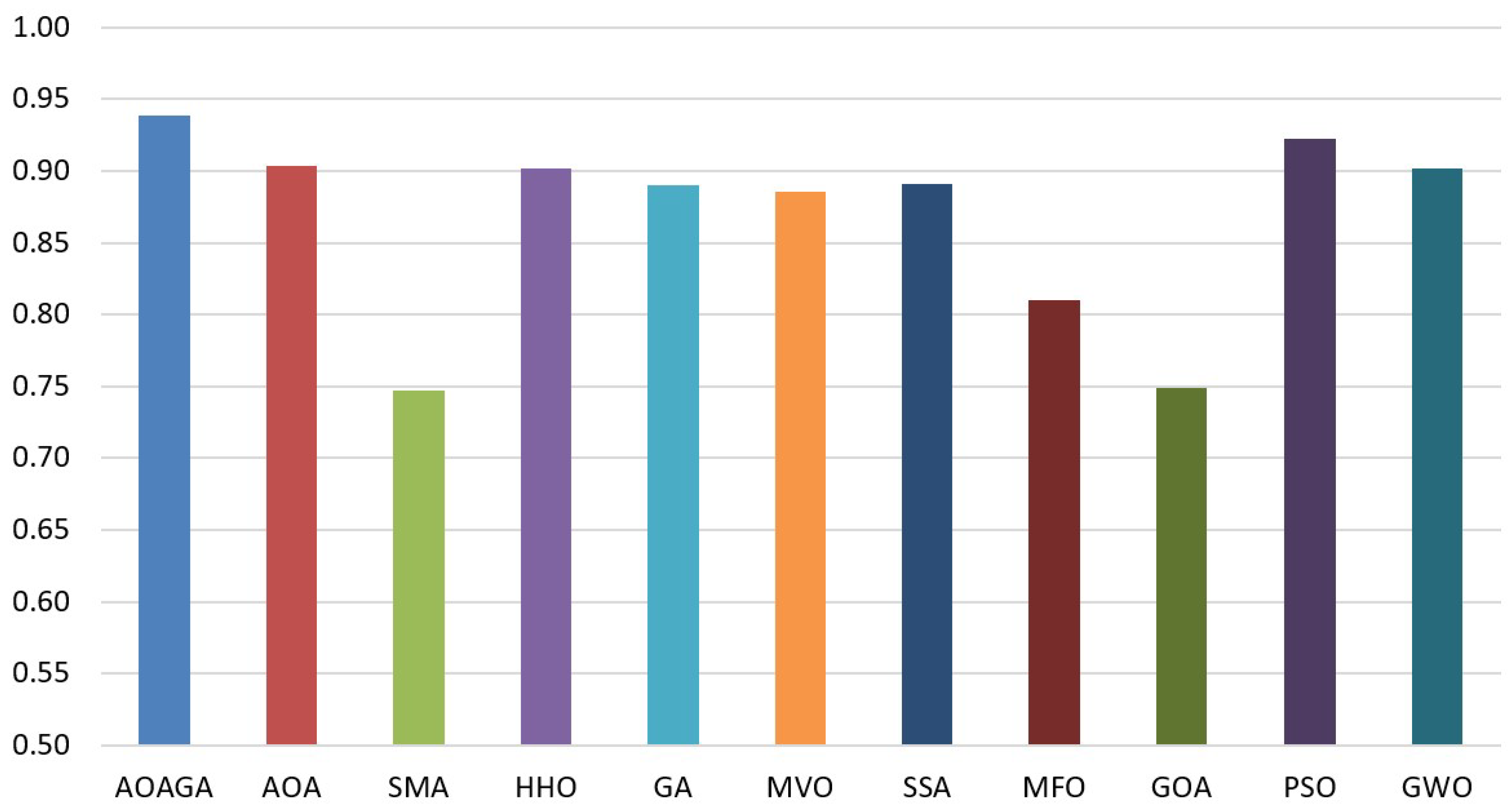
4.2.2. Comparison with State-of-the-Art Methods
4.3. Experimental Series 2: Real Application of AOAGA
Results and Discussion of Real Gene Datasets
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ghamisi, P.; Benediktsson, J.A. Feature selection based on hybridization of genetic algorithm and particle swarm optimization. IEEE Geosci. Remote Sens. Lett. 2014, 12, 309–313. [Google Scholar] [CrossRef] [Green Version]
- Garg, H. A hybrid PSO-GA algorithm for constrained optimization problems. Appl. Math. Comput. 2016, 274, 292–305. [Google Scholar] [CrossRef]
- Shao, Z.; Wu, W.; Li, D. Spatio-temporal-spectral observation model for urban remote sensing. Geo-Spat. Inf. Sci. 2021, 1–15. [Google Scholar] [CrossRef]
- Ibrahim, A.M.; Tawhid, M.A.; Ward, R.K. A binary water wave optimization for feature selection. Int. J. Approx. Reason. 2020, 120, 74–91. [Google Scholar] [CrossRef]
- Şahin, C.B.; Abualigah, L. A novel deep learning-based feature selection model for improving the static analysis of vulnerability detection. Neural Comput. Appl. 2021, 1–19. [Google Scholar] [CrossRef]
- Al-qaness, M.A. Device-free human micro-activity recognition method using WiFi signals. Geo-Spat. Inf. Sci. 2019, 22, 128–137. [Google Scholar] [CrossRef]
- Abd Elaziz, M.; Dahou, A.; Abualigah, L.; Yu, L.; Alshinwan, M.; Khasawneh, A.M.; Lu, S. Advanced metaheuristic optimization techniques in applications of deep neural networks: A review. Neural Comput. Appl. 2021, 1–21. [Google Scholar] [CrossRef]
- Shao, Z.; Sumari, N.S.; Portnov, A.; Ujoh, F.; Musakwa, W.; Mandela, P.J. Urban sprawl and its impact on sustainable urban development: A combination of remote sensing and social media data. Geo-Spat. Inf. Sci. 2021, 24, 241–255. [Google Scholar] [CrossRef]
- Ewees, A.A.; Abualigah, L.; Yousri, D.; Algamal, Z.Y.; Al-qaness, M.A.; Ibrahim, R.A.; Abd Elaziz, M. Improved Slime Mould Algorithm based on Firefly Algorithm for feature selection: A case study on QSAR model. Eng. Comput. 2021, 1–15. [Google Scholar] [CrossRef]
- Ayesha, S.; Hanif, M.K.; Talib, R. Overview and comparative study of dimensionality reduction techniques for high dimensional data. Inf. Fusion 2020, 59, 44–58. [Google Scholar] [CrossRef]
- Molina, L.C.; Belanche, L.; Nebot, À. Feature selection algorithms: A survey and experimental evaluation. In Proceedings of the 2002 IEEE International Conference on Data Mining, Maebashi City, Japan, 9–12 December 2002; pp. 306–313. [Google Scholar]
- Şahin, C.B.; Dinler, Ö.B.; Abualigah, L. Prediction of software vulnerability based deep symbiotic genetic algorithms: Phenotyping of dominant-features. Appl. Intell. 2021, 1–17. [Google Scholar] [CrossRef]
- Al-Tashi, Q.; Kadir, S.J.A.; Rais, H.M.; Mirjalili, S.; Alhussian, H. Binary optimization using hybrid grey wolf optimization for feature selection. IEEE Access 2019, 7, 39496–39508. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, Y.; Yu, C.; Heidari, A.A.; Li, S.; Chen, H.; Li, C. Gaussian mutational chaotic fruit fly-built optimization and feature selection. Expert Syst. Appl. 2020, 141, 112976. [Google Scholar] [CrossRef]
- Abd Elaziz, M.; Ewees, A.A.; Ibrahim, R.A.; Lu, S. Opposition-based moth-flame optimization improved by differential evolution for feature selection. Math. Comput. Simul. 2020, 168, 48–75. [Google Scholar] [CrossRef]
- Alshaer, H.N.; Otair, M.A.; Abualigah, L.; Alshinwan, M.; Khasawneh, A.M. Feature selection method using improved CHI Square on Arabic text classifiers: Analysis and application. Multimed. Tools Appl. 2021, 80, 10373–10390. [Google Scholar] [CrossRef]
- Dela Torre, D.M.G.; Gao, J.; Macinnis-Ng, C. Remote sensing-based estimation of rice yields using various models: A critical review. Geo-Spat. Inf. Sci. 2021, 1–24. [Google Scholar] [CrossRef]
- Yang, J.; Honavar, V. Feature subset selection using a genetic algorithm. In Feature Extraction, Construction and Selection; Springer: Berlin/Heidelberg, Germany, 1998; pp. 117–136. [Google Scholar]
- Wang, X.; Yang, J.; Teng, X.; Xia, W.; Jensen, R. Feature selection based on rough sets and particle swarm optimization. Pattern Recognit. Lett. 2007, 28, 459–471. [Google Scholar] [CrossRef] [Green Version]
- Garg, H. A hybrid GA-GSA algorithm for optimizing the performance of an industrial system by utilizing uncertain data. In Handbook of Research on Artificial Intelligence Techniques and Algorithms; IGI Global: Hershey, PA, USA, 2015; pp. 620–654. [Google Scholar]
- Hu, Y.; Zhang, Y.; Gong, D. Multiobjective particle swarm optimization for feature selection with fuzzy cost. IEEE Trans. Cybern. 2020, 51, 874–888. [Google Scholar] [CrossRef]
- Garg, H. A hybrid GSA-GA algorithm for constrained optimization problems. Inf. Sci. 2019, 478, 499–523. [Google Scholar] [CrossRef]
- Alweshah, M.; Al Khalaileh, S.; Gupta, B.B.; Almomani, A.; Hammouri, A.I.; Al-Betar, M.A. The monarch butterfly optimization algorithm for solving feature selection problems. Neural Comput. Appl. 2020, 1–15. [Google Scholar] [CrossRef]
- Agrawal, P.; Ganesh, T.; Mohamed, A.W. A novel binary gaining–sharing knowledge-based optimization algorithm for feature selection. Neural Comput. Appl. 2021, 33, 5989–6008. [Google Scholar] [CrossRef]
- Sharma, M.; Kaur, P. A Comprehensive Analysis of Nature-Inspired Meta-Heuristic Techniques for Feature Selection Problem. Arch. Comput. Methods Eng. 2021, 28, 1103–1127. [Google Scholar] [CrossRef]
- Ghosh, K.K.; Guha, R.; Bera, S.K.; Kumar, N.; Sarkar, R. S-shaped versus V-shaped transfer functions for binary Manta ray foraging optimization in feature selection problem. Neural Comput. Appl. 2021, 33, 11027–11041. [Google Scholar] [CrossRef]
- Hassan, M.H.; Kamel, S.; Abualigah, L.; Eid, A. Development and application of slime mould algorithm for optimal economic emission dispatch. Expert Syst. Appl. 2021, 182, 115205. [Google Scholar] [CrossRef]
- Wang, S.; Jia, H.; Abualigah, L.; Liu, Q.; Zheng, R. An Improved Hybrid Aquila Optimizer and Harris Hawks Algorithm for Solving Industrial Engineering Optimization Problems. Processes 2021, 9, 1551. [Google Scholar] [CrossRef]
- Altabeeb, A.M.; Mohsen, A.M.; Abualigah, L.; Ghallab, A. Solving capacitated vehicle routing problem using cooperative firefly algorithm. Appl. Soft Comput. 2021, 108, 107403. [Google Scholar] [CrossRef]
- Gul, F.; Mir, I.; Abualigah, L.; Sumari, P. Multi-Robot Space Exploration: An Augmented Arithmetic Approach. IEEE Access 2021, 9, 107738–107750. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; El-Shahat, D.; El-henawy, I.; de Albuquerque, V.H.C.; Mirjalili, S. A new fusion of grey wolf optimizer algorithm with a two-phase mutation for feature selection. Expert Syst. Appl. 2020, 139, 112824. [Google Scholar] [CrossRef]
- Al-qaness, M.A.; Ewees, A.A.; Abd Elaziz, M. Modified whale optimization algorithm for solving unrelated parallel machine scheduling problems. Soft Comput. 2021, 25, 9545–9557. [Google Scholar] [CrossRef]
- de Souza, R.C.T.; de Macedo, C.A.; dos Santos Coelho, L.; Pierezan, J.; Mariani, V.C. Binary coyote optimization algorithm for feature selection. Pattern Recognit. 2020, 107, 107470. [Google Scholar] [CrossRef]
- Abualigah, L.M.; Khader, A.T.; Al-Betar, M.A.; Alomari, O.A. Text feature selection with a robust weight scheme and dynamic dimension reduction to text document clustering. Expert Syst. Appl. 2017, 84, 24–36. [Google Scholar] [CrossRef]
- Abualigah, L.M.Q. Feature Selection and Enhanced Krill Herd Algorithm for Text Document Clustering; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Abualigah, L.M.; Khader, A.T.; Hanandeh, E.S. A new feature selection method to improve the document clustering using particle swarm optimization algorithm. J. Comput. Sci. 2018, 25, 456–466. [Google Scholar] [CrossRef]
- Abualigah, L.; Yousri, D.; Abd Elaziz, M.; Ewees, A.A.; Al-qaness, M.; Gandomi, A.H. Aquila Optimizer: A novel meta-heuristic optimization Algorithm. Comput. Ind. Eng. 2021, 157, 107250. [Google Scholar] [CrossRef]
- Abualigah, L.M.; Khader, A.T. Unsupervised text feature selection technique based on hybrid particle swarm optimization algorithm with genetic operators for the text clustering. J. Supercomput. 2017, 73, 4773–4795. [Google Scholar] [CrossRef]
- Abualigah, L.; Alsalibi, B.; Shehab, M.; Alshinwan, M.; Khasawneh, A.M.; Alabool, H. A parallel hybrid krill herd algorithm for feature selection. Int. J. Mach. Learn. Cybern. 2020, 12, 783–806. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M.; Browne, W.N. Particle swarm optimization for feature selection in classification: A multi-objective approach. IEEE Trans. Cybern. 2012, 43, 1656–1671. [Google Scholar] [CrossRef] [PubMed]
- Aghdam, M.H.; Ghasem-Aghaee, N.; Basiri, M.E. Text feature selection using ant colony optimization. Expert Syst. Appl. 2009, 36, 6843–6853. [Google Scholar] [CrossRef]
- Al-Qaness, M.A.; Fan, H.; Ewees, A.A.; Yousri, D.; Abd Elaziz, M. Improved ANFIS model for forecasting Wuhan City air quality and analysis COVID-19 lockdown impacts on air quality. Environ. Res. 2021, 194, 110607. [Google Scholar] [CrossRef]
- Ibrahim, R.A.; Ewees, A.A.; Oliva, D.; Abd Elaziz, M.; Lu, S. Improved salp swarm algorithm based on particle swarm optimization for feature selection. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 3155–3169. [Google Scholar] [CrossRef]
- Patwal, R.S.; Narang, N.; Garg, H. A novel TVAC-PSO based mutation strategies algorithm for generation scheduling of pumped storage hydrothermal system incorporating solar units. Energy 2018, 142, 822–837. [Google Scholar] [CrossRef]
- El-Kenawy, E.S.; Eid, M. Hybrid gray wolf and particle swarm optimization for feature selection. Int. J. Innov. Comput. Inf. Control 2020, 16, 831–844. [Google Scholar]
- Anter, A.M.; Ali, M. Feature selection strategy based on hybrid crow search optimization algorithm integrated with chaos theory and fuzzy c-means algorithm for medical diagnosis problems. Soft Comput. 2020, 24, 1565–1584. [Google Scholar] [CrossRef]
- Tubishat, M.; Ja’afar, S.; Alswaitti, M.; Mirjalili, S.; Idris, N.; Ismail, M.A.; Omar, M.S. Dynamic salp swarm algorithm for feature selection. Expert Syst. Appl. 2021, 164, 113873. [Google Scholar] [CrossRef]
- Abualigah, L.; Diabat, A.; Mirjalili, S.; Abd Elaziz, M.; Gandomi, A.H. The arithmetic optimization algorithm. Comput. Methods Appl. Mech. Eng. 2021, 376, 113609. [Google Scholar] [CrossRef]
- Goldberg, D.E.; Holland, J.H. Genetic algorithms and machine learning. Mach. Learn. 1988, 3, 95–99. [Google Scholar] [CrossRef]
- Eshelman, L.J.; Schaffer, J.D. Real-coded genetic algorithms and interval-schemata. In Foundations of Genetic Algorithms; Elsevier: Amsterdam, The Netherlands, 1993; Volume 2, pp. 187–202. [Google Scholar]
- Higashi, N.; Iba, H. Particle swarm optimization with Gaussian mutation. In Proceedings of the 2003 IEEE Swarm Intelligence Symposium. SIS’03 (Cat. No.03EX706), Indianapolis, IN, USA, 26 April 2003; pp. 72–79. [Google Scholar]
- Lipowski, A.; Lipowska, D. Roulette-wheel selection via stochastic acceptance. Phys. A Stat. Mech. Its Appl. 2012, 391, 2193–2196. [Google Scholar] [CrossRef] [Green Version]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: https://archive.ics.uci.edu/ml/ (accessed on 22 August 2021).
- Rosenwald, A.; Wright, G.; Chan, W.C.; Connors, J.M.; Campo, E.; Fisher, R.I.; Gascoyne, R.D.; Muller-Hermelink, H.K.; Smeland, E.B.; Giltnane, J.M.; et al. The use of molecular profiling to predict survival after chemotherapy for diffuse large-B-cell lymphoma. N. Engl. J. Med. 2002, 346, 1937–1947. [Google Scholar] [CrossRef]
- Beer, D.G.; Kardia, S.L.; Huang, C.C.; Giordano, T.J.; Levin, A.M.; Misek, D.E.; Lin, L.; Chen, G.; Gharib, T.G.; Thomas, D.G.; et al. Gene-expression profiles predict survival of patients with lung adenocarcinoma. Nat. Med. 2002, 8, 816–824. [Google Scholar] [CrossRef]
- Li, S.; Chen, H.; Wang, M.; Heidari, A.A.; Mirjalili, S. Slime mould algorithm: A new method for stochastic optimization. Future Gener. Comput. Syst. 2020, 111, 300–323. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Forrest, S. Genetic algorithms. ACM Comput. Surv. (CSUR) 1996, 28, 77–80. [Google Scholar] [CrossRef]
- Ewees, A.A.; Abd El Aziz, M.; Hassanien, A.E. Chaotic multi-verse optimizer-based feature selection. Neural Comput. Appl. 2019, 31, 991–1006. [Google Scholar] [CrossRef]
- Mirjalili, S.; Gandomi, A.H.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S.M. Salp Swarm Algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 2017, 114, 163–191. [Google Scholar] [CrossRef]
- Ewees, A.A.; Abd Elaziz, M.; Houssein, E.H. Improved grasshopper optimization algorithm using opposition-based learning. Expert Syst. Appl. 2018, 112, 156–172. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Gu, S.; Cheng, R.; Jin, Y. Feature selection for high-dimensional classification using a competitive swarm optimizer. Soft Comput. 2018, 22, 811–822. [Google Scholar] [CrossRef] [Green Version]
- Hu, P.; Pan, J.S.; Chu, S.C. Improved binary grey wolf optimizer and its application for feature selection. Knowl.-Based Syst. 2020, 195, 105746. [Google Scholar] [CrossRef]
- Neggaz, N.; Ewees, A.A.; Abd Elaziz, M.; Mafarja, M. Boosting salp swarm algorithm by sine cosine algorithm and disrupt operator for feature selection. Expert Syst. Appl. 2020, 145, 113103. [Google Scholar] [CrossRef]
- Dhiman, G.; Oliva, D.; Kaur, A.; Singh, K.K.; Vimal, S.; Sharma, A.; Cengiz, K. BEPO: A novel binary emperor penguin optimizer for automatic feature selection. Knowl.-Based Syst. 2021, 211, 106560. [Google Scholar] [CrossRef]
- Faris, H.; Mafarja, M.M.; Heidari, A.A.; Aljarah, I.; Ala’M, A.Z.; Mirjalili, S.; Fujita, H. An efficient binary salp swarm algorithm with crossover scheme for feature selection problems. Knowl.-Based Syst. 2018, 154, 43–67. [Google Scholar] [CrossRef]
- Emary, E.; Zawbaa, H.M.; Hassanien, A.E. Binary grey wolf optimization approaches for feature selection. Neurocomputing 2016, 172, 371–381. [Google Scholar] [CrossRef]
- Arora, S.; Anand, P. Binary butterfly optimization approaches for feature selection. Expert Syst. Appl. 2019, 116, 147–160. [Google Scholar] [CrossRef]
- Mafarja, M.; Aljarah, I.; Faris, H.; Hammouri, A.I.; Ala’M, A.Z.; Mirjalili, S. Binary grasshopper optimisation algorithm approaches for feature selection problems. Expert Syst. Appl. 2019, 117, 267–286. [Google Scholar] [CrossRef]
- Das, A.; Das, S. Feature weighting and selection with a Pareto-optimal trade-off between relevancy and redundancy. Pattern Recognit. Lett. 2017, 88, 12–19. [Google Scholar] [CrossRef]
- Cockeran, M.; Meintanis, S.G.; Allison, J.S. Goodness-of-fit tests in the Cox proportional hazards model. Commun. Stat.-Simul. Comput. [CrossRef]
- Emura, T.; Chen, Y.H.; Chen, H.Y. Survival prediction based on compound covariate under cox proportional hazard models. PLoS ONE 2012, 7, e47627. [Google Scholar]
- Jiang, H.K.; Liang, Y. The L1/2 regularization network Cox model for analysis of genomic data. Comput. Biol. Med. 2018, 100, 203–208. [Google Scholar] [CrossRef] [PubMed]
- Leng, C.; Helen Zhang, H. Model selection in nonparametric hazard regression. Nonparametr. Stat. 2006, 18, 417–429. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Number of Features | Number of Instances | Number of Classes | Data Category |
|---|---|---|---|---|
| breastWDBC | 30 | 569 | 2 | Biology |
| ionosphere | 34 | 351 | 2 | Physical |
| wine | 13 | 178 | 3 | Chemistry |
| breastcancer | 9 | 699 | 2 | Biology |
| sonar | 60 | 208 | 2 | Biology |
| glass | 9 | 214 | 7 | Physics |
| tic-tac-toe | 9 | 958 | 2 | Game |
| Lymphography | 18 | 148 | 2 | Biology |
| waveform | 40 | 5000 | 3 | Physics |
| clean1data | 166 | 476 | 2 | Artificial |
| Zoo | 16 | 101 | 6 | Artificial |
| SPECT | 22 | 267 | 2 | Biology |
| ecoli | 7 | 336 | 8 | Biology |
| CongressEW | 16 | 435 | 2 | Politics |
| M-of-n | 13 | 1000 | 2 | Biology |
| Exactly | 13 | 1000 | 2 | Biology |
| Exactly2 | 13 | 1000 | 2 | Biology |
| Vote | 16 | 300 | 2 | Politics |
| heart | 13 | 270 | 2 | Biology |
| krvskp | 36 | 3196 | 2 | Game |
| Dataset | AOAGA | AOA | SMA | HHO | GA | MVO | SSA | MFO | GOA | PSO | GWO |
|---|---|---|---|---|---|---|---|---|---|---|---|
| breastWDBC | 0.0968 | 0.1107 | 0.3503 | 0.1207 | 0.1261 | 0.1329 | 0.1122 | 0.1754 | 0.2134 | 0.1058 | 0.1080 |
| ionosphere | 0.1567 | 0.2086 | 0.3920 | 0.2049 | 0.2262 | 0.2167 | 0.2213 | 0.2704 | 0.3201 | 0.1828 | 0.1803 |
| wine | 0.0000 | 0.0480 | 0.1858 | 0.0067 | 0.0151 | 0.0194 | 0.0610 | 0.1252 | 0.1578 | 0.0043 | 0.0117 |
| breastcancer | 0.1620 | 0.2216 | 0.3947 | 0.1898 | 0.2159 | 0.2140 | 0.2082 | 0.2580 | 0.3293 | 0.1682 | 0.1640 |
| glass | 0.1406 | 0.1452 | 0.2183 | 0.1434 | 0.1520 | 0.1492 | 0.1499 | 0.1879 | 0.2203 | 0.1419 | 0.1451 |
| sonar | 0.1387 | 0.2232 | 0.4116 | 0.2065 | 0.2083 | 0.1769 | 0.1885 | 0.2703 | 0.3332 | 0.1204 | 0.1423 |
| Lymphography | 0.2547 | 0.3261 | 0.5342 | 0.3054 | 0.3561 | 0.3245 | 0.3188 | 0.4523 | 0.5144 | 0.2818 | 0.3221 |
| tic-tac-toe | 0.0000 | 0.2079 | 0.5394 | 0.0022 | 0.1560 | 0.1370 | 0.0255 | 0.4405 | 0.5227 | 0.0018 | 0.1513 |
| waveform | 0.6323 | 0.6646 | 0.9059 | 0.6561 | 0.6512 | 0.6551 | 0.6489 | 0.6719 | 0.7307 | 0.6349 | 0.6435 |
| clean1data | 0.2305 | 0.2472 | 0.4384 | 0.2633 | 0.2589 | 0.2465 | 0.2680 | 0.2692 | 0.3470 | 0.2240 | 0.2092 |
| SPECT | 0.2982 | 0.3640 | 0.4780 | 0.3442 | 0.3633 | 0.3572 | 0.3535 | 0.4028 | 0.4728 | 0.3287 | 0.3418 |
| Zoo | 0.0000 | 0.0154 | 0.2063 | 0.0029 | 0.0145 | 0.0137 | 0.0443 | 0.0966 | 0.1260 | 0.0038 | 0.0083 |
| ecoli | 0.1945 | 0.2178 | 0.3464 | 0.2208 | 0.2271 | 0.2259 | 0.2263 | 0.2712 | 0.3355 | 0.2202 | 0.2212 |
| CongressEW | 0.1090 | 0.1478 | 0.4035 | 0.1645 | 0.1842 | 0.1707 | 0.1812 | 0.2308 | 0.3025 | 0.1363 | 0.1565 |
| Exactly | 0.0000 | 0.2092 | 0.5858 | 0.0539 | 0.1897 | 0.1659 | 0.0576 | 0.4333 | 0.5944 | 0.0000 | 0.0869 |
| Exactly2 | 0.4699 | 0.5030 | 0.5699 | 0.4929 | 0.5048 | 0.5060 | 0.5081 | 0.5447 | 0.5816 | 0.4884 | 0.4970 |
| M-of-n | 0.0000 | 0.1867 | 0.4790 | 0.0383 | 0.1419 | 0.0645 | 0.0388 | 0.3096 | 0.4955 | 0.0000 | 0.0381 |
| Vote | 0.0929 | 0.1871 | 0.4115 | 0.1727 | 0.2015 | 0.1906 | 0.1871 | 0.2595 | 0.3431 | 0.1626 | 0.1719 |
| krvskp | 0.1541 | 0.1857 | 0.5281 | 0.1752 | 0.1954 | 0.1639 | 0.1718 | 0.1578 | 0.3534 | 0.1192 | 0.1628 |
| heart | 0.3366 | 0.3884 | 0.5425 | 0.3575 | 0.3794 | 0.3998 | 0.3617 | 0.4255 | 0.4969 | 0.3471 | 0.3941 |
| Dataset | AOAGA | AOA | SMA | HHO | GA | MVO | SSA | MFO | GOA | PSO | GWO |
|---|---|---|---|---|---|---|---|---|---|---|---|
| breastWDBC | 0.0839 | 0.0839 | 0.0839 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.1187 | 0.1187 | 0.0000 | 0.0000 |
| ionosphere | 0.0000 | 0.0000 | 0.2132 | 0.1066 | 0.1066 | 0.1066 | 0.1066 | 0.1508 | 0.1846 | 0.1066 | 0.0000 |
| wine | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| breastcancer | 0.1508 | 0.1066 | 0.1846 | 0.0000 | 0.1066 | 0.1066 | 0.1066 | 0.1066 | 0.2132 | 0.1066 | 0.0000 |
| glass | 0.0869 | 0.0869 | 0.0991 | 0.0869 | 0.0869 | 0.0952 | 0.0869 | 0.1166 | 0.1289 | 0.0869 | 0.0869 |
| sonar | 0.0000 | 0.0000 | 0.2774 | 0.0000 | 0.1387 | 0.0000 | 0.0000 | 0.1387 | 0.1961 | 0.0000 | 0.0000 |
| Lymphography | 0.1644 | 0.1644 | 0.3676 | 0.1644 | 0.2325 | 0.2325 | 0.2325 | 0.2325 | 0.2847 | 0.1644 | 0.2325 |
| tic-tac-toe | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.2587 | 0.0000 | 0.0000 | 0.0000 |
| waveform | 0.6145 | 0.6267 | 0.6917 | 0.6255 | 0.6112 | 0.6119 | 0.6007 | 0.5973 | 0.6306 | 0.6112 | 0.6138 |
| clean1data | 0.2245 | 0.1588 | 0.2750 | 0.1588 | 0.1833 | 0.1296 | 0.1833 | 0.1588 | 0.2593 | 0.1588 | 0.1296 |
| SPECT | 0.2732 | 0.2732 | 0.2732 | 0.1728 | 0.2443 | 0.2443 | 0.2732 | 0.2732 | 0.3665 | 0.2116 | 0.2116 |
| Zoo | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| ecoli | 0.1509 | 0.1519 | 0.2032 | 0.1750 | 0.1750 | 0.1750 | 0.1750 | 0.1903 | 0.2056 | 0.1750 | 0.1750 |
| CongressEW | 0.0000 | 0.0000 | 0.1916 | 0.0958 | 0.0958 | 0.0958 | 0.0958 | 0.0958 | 0.0958 | 0.0000 | 0.0000 |
| Exactly | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| Exactly2 | 0.4427 | 0.4517 | 0.4648 | 0.4427 | 0.4427 | 0.4427 | 0.4427 | 0.4648 | 0.5292 | 0.4427 | 0.4427 |
| M-of-n | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| Vote | 0.0000 | 0.1155 | 0.1633 | 0.1155 | 0.0000 | 0.1155 | 0.0000 | 0.1155 | 0.1633 | 0.0000 | 0.0000 |
| krvskp | 0.1501 | 0.1061 | 0.2209 | 0.1370 | 0.1415 | 0.1226 | 0.1324 | 0.1001 | 0.2032 | 0.0791 | 0.1061 |
| heart | 0.3232 | 0.2993 | 0.3665 | 0.2993 | 0.3232 | 0.3455 | 0.2732 | 0.2993 | 0.3455 | 0.2732 | 0.3232 |
| Dataset | AOAGA | AOA | SMA | HHO | GA | MVO | SSA | MFO | GOA | PSO | GWO |
|---|---|---|---|---|---|---|---|---|---|---|---|
| breastWDBC | 0.1187 | 0.1187 | 0.6766 | 0.1876 | 0.2056 | 0.1876 | 0.2374 | 0.2654 | 0.3140 | 0.1876 | 0.1876 |
| ionosphere | 0.2132 | 0.3198 | 0.5539 | 0.2820 | 0.3015 | 0.3015 | 0.3371 | 0.4129 | 0.4767 | 0.2611 | 0.2611 |
| wine | 0.0000 | 0.0754 | 0.4264 | 0.0754 | 0.0754 | 0.0754 | 0.2820 | 0.2611 | 0.3454 | 0.0754 | 0.1066 |
| breastcancer | 0.1846 | 0.3198 | 0.5741 | 0.2611 | 0.3371 | 0.3015 | 0.3198 | 0.3989 | 0.4523 | 0.2611 | 0.2820 |
| glass | 0.1822 | 0.2146 | 0.2894 | 0.1903 | 0.1903 | 0.1981 | 0.2664 | 0.2855 | 0.3442 | 0.1903 | 0.1903 |
| sonar | 0.1387 | 0.3397 | 0.5371 | 0.3397 | 0.3922 | 0.3669 | 0.3669 | 0.4804 | 0.4599 | 0.3397 | 0.2774 |
| Lymphography | 0.2847 | 0.4932 | 0.6778 | 0.4027 | 0.4650 | 0.4350 | 0.6367 | 0.6778 | 0.7352 | 0.4027 | 0.4350 |
| tic-tac-toe | 0.0000 | 0.3935 | 0.7516 | 0.0647 | 0.4574 | 0.4884 | 0.5786 | 0.6501 | 0.7318 | 0.0647 | 0.4387 |
| waveform | 0.6512 | 0.7172 | 1.1486 | 0.6969 | 0.6888 | 0.7071 | 0.6835 | 0.7720 | 0.8686 | 0.6573 | 0.6741 |
| clean1data | 0.2425 | 0.3430 | 0.7101 | 0.3667 | 0.3305 | 0.3430 | 0.3889 | 0.3430 | 0.4674 | 0.3305 | 0.2899 |
| SPECT | 0.3232 | 0.4732 | 0.6802 | 0.4405 | 0.4571 | 0.4571 | 0.4571 | 0.5325 | 0.5985 | 0.4232 | 0.4405 |
| Zoo | 0.0000 | 0.0333 | 0.4447 | 0.0333 | 0.0471 | 0.0667 | 0.2828 | 0.2925 | 0.3636 | 0.0333 | 0.0577 |
| ecoli | 0.2226 | 0.2861 | 0.5898 | 0.2806 | 0.2819 | 0.2819 | 0.3818 | 0.3721 | 0.7703 | 0.2806 | 0.2844 |
| CongressEW | 0.1355 | 0.2709 | 0.7103 | 0.2534 | 0.2709 | 0.2346 | 0.4064 | 0.4064 | 0.5747 | 0.2346 | 0.2346 |
| Exactly | 0.0000 | 0.5586 | 0.7430 | 0.3688 | 0.5762 | 0.5404 | 0.5514 | 0.6419 | 0.7266 | 0.0000 | 0.5477 |
| Exactly2 | 0.4817 | 0.5621 | 0.7071 | 0.5441 | 0.5441 | 0.5550 | 0.6419 | 0.6000 | 0.7211 | 0.5441 | 0.5441 |
| M-of-n | 0.0000 | 0.4000 | 0.6419 | 0.3225 | 0.4147 | 0.3795 | 0.5762 | 0.6419 | 0.6261 | 0.0000 | 0.4690 |
| Vote | 0.1633 | 0.2828 | 0.7916 | 0.2309 | 0.2828 | 0.2582 | 0.4000 | 0.4761 | 0.4899 | 0.2582 | 0.2828 |
| krvskp | 0.1621 | 0.2896 | 0.6896 | 0.2209 | 0.2526 | 0.2093 | 0.2399 | 0.2293 | 0.5983 | 0.1659 | 0.2694 |
| heart | 0.3455 | 0.5183 | 0.7228 | 0.4405 | 0.4732 | 0.4732 | 0.4405 | 0.5464 | 0.6465 | 0.4232 | 0.4571 |
| Dataset | AOAGA | AOA | SMA | HHO | GA | MVO | SSA | MFO | GOA | PSO | GWO |
|---|---|---|---|---|---|---|---|---|---|---|---|
| breastWDBC | 0.0159 | 0.0146 | 0.1665 | 0.0383 | 0.0456 | 0.0389 | 0.0571 | 0.0413 | 0.0447 | 0.0391 | 0.0511 |
| ionosphere | 0.0626 | 0.0680 | 0.0915 | 0.0432 | 0.0457 | 0.0608 | 0.0514 | 0.0621 | 0.0659 | 0.0478 | 0.0567 |
| wine | 0.0000 | 0.0347 | 0.1106 | 0.0214 | 0.0302 | 0.0329 | 0.0846 | 0.0516 | 0.0658 | 0.0175 | 0.0289 |
| breastcancer | 0.0160 | 0.0521 | 0.1066 | 0.0480 | 0.0456 | 0.0441 | 0.0491 | 0.0674 | 0.0569 | 0.0448 | 0.0483 |
| glass | 0.0335 | 0.0296 | 0.0487 | 0.0221 | 0.0251 | 0.0250 | 0.0319 | 0.0431 | 0.0485 | 0.0244 | 0.0279 |
| sonar | 0.0555 | 0.0758 | 0.0771 | 0.0718 | 0.0666 | 0.0847 | 0.0822 | 0.0877 | 0.0658 | 0.0939 | 0.0941 |
| Lymphography | 0.0521 | 0.0832 | 0.0840 | 0.0570 | 0.0610 | 0.0659 | 0.0804 | 0.1079 | 0.1158 | 0.0641 | 0.0528 |
| tic-tac-toe | 0.0000 | 0.1650 | 0.2297 | 0.0116 | 0.1778 | 0.1726 | 0.1040 | 0.0947 | 0.1954 | 0.0108 | 0.1639 |
| waveform | 0.0150 | 0.0229 | 0.1369 | 0.0132 | 0.0166 | 0.0217 | 0.0191 | 0.0372 | 0.0541 | 0.0127 | 0.0166 |
| clean1data | 0.0085 | 0.0516 | 0.0951 | 0.0417 | 0.0372 | 0.0435 | 0.0459 | 0.0467 | 0.0547 | 0.0382 | 0.0370 |
| SPECT | 0.0250 | 0.0477 | 0.0994 | 0.0551 | 0.0529 | 0.0538 | 0.0503 | 0.0669 | 0.0648 | 0.0443 | 0.0507 |
| Zoo | 0.0000 | 0.0160 | 0.1566 | 0.0093 | 0.0181 | 0.0204 | 0.0700 | 0.0620 | 0.0962 | 0.0106 | 0.0158 |
| ecoli | 0.0305 | 0.0337 | 0.1048 | 0.0221 | 0.0260 | 0.0257 | 0.0345 | 0.0454 | 0.1100 | 0.0231 | 0.0233 |
| CongressEW | 0.0419 | 0.0492 | 0.1553 | 0.0426 | 0.0430 | 0.0381 | 0.0691 | 0.0697 | 0.1088 | 0.0612 | 0.0460 |
| Exactly | 0.0000 | 0.2162 | 0.1336 | 0.0827 | 0.2236 | 0.2005 | 0.1178 | 0.2065 | 0.1163 | 0.0000 | 0.1944 |
| Exactly2 | 0.0162 | 0.0295 | 0.0694 | 0.0246 | 0.0235 | 0.0292 | 0.0412 | 0.0307 | 0.0407 | 0.0259 | 0.0218 |
| M-of-n | 0.0000 | 0.1540 | 0.2008 | 0.0683 | 0.1509 | 0.1171 | 0.1100 | 0.1836 | 0.1269 | 0.0000 | 0.1161 |
| Vote | 0.0685 | 0.0373 | 0.1505 | 0.0381 | 0.0585 | 0.0436 | 0.0675 | 0.0776 | 0.0873 | 0.0650 | 0.0614 |
| krvskp | 0.0043 | 0.0409 | 0.1207 | 0.0205 | 0.0287 | 0.0186 | 0.0268 | 0.0311 | 0.1164 | 0.0176 | 0.0308 |
| heart | 0.0109 | 0.0424 | 0.0932 | 0.0395 | 0.0431 | 0.0363 | 0.0390 | 0.0633 | 0.0794 | 0.0378 | 0.0377 |
| Dataset | AOAGA | AOA | SMA | HHO | GA | MVO | SSA | MFO | GOA | PSO | GWO |
|---|---|---|---|---|---|---|---|---|---|---|---|
| breastWDBC | 0.9905 | 0.9875 | 0.8496 | 0.9840 | 0.9820 | 0.9808 | 0.9842 | 0.9675 | 0.9525 | 0.9880 | 0.9857 |
| ionosphere | 0.9785 | 0.9517 | 0.8380 | 0.9562 | 0.9468 | 0.9494 | 0.9484 | 0.9231 | 0.8932 | 0.9643 | 0.9643 |
| wine | 1.0000 | 0.9855 | 0.8575 | 0.9980 | 0.9955 | 0.9942 | 0.9643 | 0.9286 | 0.8968 | 0.9987 | 0.9961 |
| breastcancer | 0.9735 | 0.9481 | 0.8329 | 0.9617 | 0.9513 | 0.9523 | 0.9542 | 0.9289 | 0.8883 | 0.9697 | 0.9708 |
| glass | 0.8066 | 0.7547 | 0.6593 | 0.6695 | 0.6253 | 0.6156 | 0.6873 | 0.5585 | 0.5100 | 0.6965 | 0.6491 |
| sonar | 0.9846 | 0.9442 | 0.8246 | 0.9522 | 0.9522 | 0.9615 | 0.9577 | 0.9192 | 0.8846 | 0.9767 | 0.9709 |
| Lymphography | 0.9324 | 0.8865 | 0.7076 | 0.5730 | 0.7297 | 0.5707 | 0.7290 | 0.4981 | 0.4000 | 0.8092 | 0.6958 |
| tic-tac-toe | 1.0000 | 0.9283 | 0.6563 | 0.9999 | 0.9441 | 0.9515 | 0.9885 | 0.7790 | 0.6886 | 0.9999 | 0.9503 |
| waveform | 0.7928 | 0.7761 | 0.6005 | 0.7848 | 0.7831 | 0.7826 | 0.7874 | 0.7749 | 0.7411 | 0.7921 | 0.7857 |
| clean1data | 0.9468 | 0.9361 | 0.7988 | 0.9289 | 0.9316 | 0.9373 | 0.9261 | 0.9253 | 0.8766 | 0.9484 | 0.9549 |
| SPECT | 0.9104 | 0.8652 | 0.7593 | 0.8784 | 0.8639 | 0.8695 | 0.8725 | 0.8333 | 0.7723 | 0.8900 | 0.8806 |
| Zoo | 1.0000 | 0.9815 | 0.9138 | 0.9966 | 0.9269 | 0.9029 | 0.7291 | 0.3726 | 0.2389 | 0.9954 | 0.9634 |
| ecoli | 0.8405 | 0.7853 | 0.6032 | 0.8405 | 0.8423 | 0.8452 | 0.8393 | 0.7857 | 0.8185 | 0.8413 | 0.8405 |
| CongressEW | 0.9878 | 0.9756 | 0.8324 | 0.9711 | 0.9642 | 0.9694 | 0.9624 | 0.9419 | 0.8966 | 0.9777 | 0.9734 |
| Exactly | 1.0000 | 0.9072 | 0.6363 | 0.9903 | 0.8917 | 0.9323 | 0.9828 | 0.7696 | 0.6332 | 1.0000 | 0.9313 |
| Exactly2 | 0.7790 | 0.7461 | 0.6358 | 0.7505 | 0.7375 | 0.7349 | 0.7295 | 0.6986 | 0.6601 | 0.7594 | 0.7478 |
| M-of-n | 1.0000 | 0.9393 | 0.7338 | 0.9939 | 0.9571 | 0.9821 | 0.9864 | 0.8704 | 0.7384 | 1.0000 | 0.9851 |
| Vote | 0.9867 | 0.9636 | 0.8080 | 0.9687 | 0.9560 | 0.9618 | 0.9604 | 0.9267 | 0.8747 | 0.9693 | 0.9667 |
| krvskp | 0.9762 | 0.9638 | 0.7065 | 0.9689 | 0.9610 | 0.9728 | 0.9698 | 0.9741 | 0.8615 | 0.9855 | 0.9725 |
| heart | 0.8866 | 0.8473 | 0.6811 | 0.8706 | 0.8542 | 0.8388 | 0.8677 | 0.8149 | 0.7468 | 0.8781 | 0.8433 |
| Dataset | AOAGA | AOA | SMA | HHO | GA | MVO | SSA | MFO | GOA | PSO | GWO |
|---|---|---|---|---|---|---|---|---|---|---|---|
| breastWDBC | 10.50 | 13.23 | 11.13 | 15.03 | 15.97 | 15.83 | 15.78 | 15.53 | 15.47 | 15.09 | 13.97 |
| ionosphere | 11.00 | 12.32 | 11.23 | 11.94 | 15.49 | 15.57 | 14.49 | 16.06 | 17.29 | 14.11 | 12.40 |
| wine | 6.22 | 6.27 | 6.73 | 7.56 | 7.46 | 7.26 | 7.00 | 7.34 | 6.49 | 7.49 | 7.06 |
| breastcancer | 11.00 | 13.27 | 12.13 | 11.09 | 15.74 | 15.86 | 14.51 | 16.09 | 16.31 | 14.70 | 12.31 |
| glass | 4.00 | 4.90 | 4.82 | 4.93 | 5.31 | 5.34 | 5.23 | 5.09 | 4.80 | 4.97 | 4.74 |
| sonar | 24.00 | 24.50 | 24.81 | 27.54 | 29.69 | 30.71 | 29.60 | 30.31 | 29.91 | 29.15 | 24.14 |
| Lymphography | 7.33 | 7.67 | 7.73 | 9.43 | 10.14 | 9.71 | 8.57 | 9.86 | 9.34 | 9.00 | 8.06 |
| tic-tac-toe | 9.00 | 8.05 | 5.41 | 9.00 | 8.31 | 8.37 | 8.86 | 6.29 | 5.00 | 9.00 | 8.29 |
| waveform | 11.33 | 12.33 | 6.11 | 14.54 | 13.20 | 13.17 | 13.60 | 13.97 | 11.51 | 13.50 | 11.69 |
| clean1data | 47.50 | 63.57 | 48.90 | 71.63 | 81.74 | 79.91 | 82.00 | 85.63 | 82.09 | 81.06 | 58.54 |
| SPECT | 8.50 | 8.20 | 9.28 | 9.26 | 10.74 | 11.03 | 10.80 | 11.89 | 11.34 | 10.49 | 9.71 |
| Zoo | 7.56 | 8.62 | 7.80 | 9.91 | 9.40 | 9.31 | 9.14 | 8.63 | 8.40 | 9.51 | 9.63 |
| ecoli | 5.20 | 4.73 | 5.56 | 5.13 | 4.80 | 5.29 | 4.97 | 4.20 | 3.51 | 4.94 | 5.11 |
| CongressEW | 3.83 | 6.66 | 4.21 | 6.63 | 7.57 | 7.70 | 7.43 | 7.53 | 7.63 | 7.00 | 6.13 |
| Exactly | 6.56 | 7.29 | 7.10 | 7.40 | 7.60 | 7.37 | 7.20 | 8.13 | 6.67 | 6.83 | 6.83 |
| Exactly2 | 3.00 | 4.50 | 3.90 | 4.00 | 6.07 | 5.40 | 5.73 | 6.40 | 7.23 | 6.50 | 5.30 |
| M-of-n | 7.25 | 7.82 | 5.78 | 7.53 | 7.70 | 7.87 | 7.37 | 7.87 | 6.87 | 7.17 | 7.13 |
| Vote | 6.17 | 6.70 | 6.80 | 6.10 | 7.97 | 7.50 | 7.33 | 7.77 | 8.07 | 7.67 | 6.13 |
| krvskp | 12.83 | 17.23 | 12.90 | 20.40 | 20.43 | 20.03 | 19.97 | 20.57 | 18.57 | 19.60 | 15.57 |
| heart | 6.25 | 6.53 | 7.37 | 7.17 | 7.60 | 8.40 | 7.37 | 7.17 | 6.93 | 7.37 | 6.70 |
| Dataset | AOAGA | AOA | SMA | HHO | GA | MVO | SSA | MFO | GOA | PSO | GWO |
|---|---|---|---|---|---|---|---|---|---|---|---|
| breastWDBC | 38.226 | 56.868 | 6.608 | 15.705 | 7.075 | 6.337 | 6.352 | 6.294 | 6.959 | 6.301 | 6.334 |
| ionosphere | 35.944 | 51.773 | 6.393 | 15.432 | 6.866 | 6.160 | 6.184 | 6.124 | 6.812 | 6.174 | 6.213 |
| wine | 12.851 | 52.921 | 6.216 | 15.418 | 7.174 | 6.442 | 6.419 | 6.447 | 6.725 | 6.460 | 6.418 |
| breastcancer | 34.480 | 52.491 | 6.253 | 15.040 | 6.745 | 6.052 | 6.021 | 6.043 | 6.685 | 6.036 | 6.076 |
| glass | 35.307 | 51.165 | 5.045 | 11.607 | 7.377 | 6.576 | 6.653 | 6.568 | 6.778 | 6.557 | 6.617 |
| sonar | 34.131 | 47.956 | 6.288 | 14.656 | 6.714 | 6.029 | 6.040 | 6.022 | 7.143 | 6.061 | 5.974 |
| Lymphography | 29.140 | 48.230 | 5.274 | 13.185 | 6.645 | 5.576 | 5.868 | 5.805 | 6.175 | 5.717 | 5.655 |
| tic-tac-toe | 28.221 | 61.421 | 6.958 | 15.562 | 8.152 | 7.341 | 7.361 | 7.357 | 7.319 | 7.259 | 7.153 |
| waveform | 208.100 | 249.785 | 12.398 | 41.034 | 20.358 | 18.163 | 18.189 | 18.704 | 18.460 | 18.126 | 17.410 |
| clean1data | 41.632 | 62.067 | 6.688 | 16.741 | 7.837 | 7.064 | 7.047 | 7.073 | 10.088 | 7.014 | 6.762 |
| SPECT | 33.499 | 50.294 | 5.865 | 14.640 | 6.698 | 6.048 | 6.091 | 6.024 | 6.477 | 6.059 | 6.116 |
| Zoo | 15.742 | 50.040 | 4.934 | 14.817 | 7.337 | 6.317 | 6.385 | 6.428 | 6.503 | 6.187 | 5.824 |
| ecoli | 25.238 | 31.632 | 4.541 | 11.425 | 5.772 | 5.195 | 5.189 | 5.240 | 5.269 | 5.178 | 5.209 |
| CongressEW | 34.109 | 52.574 | 6.453 | 15.527 | 7.252 | 6.474 | 6.468 | 6.448 | 6.830 | 6.486 | 6.474 |
| Exactly | 26.764 | 57.360 | 6.686 | 16.482 | 7.891 | 7.202 | 7.058 | 7.033 | 7.349 | 7.110 | 7.066 |
| Exactly2 | 33.948 | 49.714 | 6.936 | 16.190 | 7.772 | 6.856 | 6.889 | 6.988 | 7.584 | 7.025 | 6.968 |
| M-of-n | 14.282 | 57.857 | 6.887 | 16.764 | 8.054 | 7.205 | 7.231 | 7.227 | 7.554 | 7.200 | 7.232 |
| Vote | 34.804 | 52.274 | 6.439 | 15.561 | 7.247 | 6.527 | 6.466 | 6.544 | 6.733 | 6.557 | 6.508 |
| krvskp | 122.824 | 169.704 | 10.450 | 29.577 | 14.121 | 12.649 | 12.548 | 12.698 | 13.119 | 12.573 | 11.564 |
| heart | 33.902 | 51.467 | 10.302 | 24.904 | 11.529 | 10.486 | 10.318 | 10.322 | 11.038 | 10.278 | 10.636 |
| Dataset | AOAGA | AOA | SMA | HHO | GA | MVO | SSA | MFO | GOA | PSO | GWO |
|---|---|---|---|---|---|---|---|---|---|---|---|
| breastWDBC | 3.100 | 4.050 | 10.033 | 5.667 | 5.917 | 6.367 | 4.533 | 8.667 | 9.900 | 3.217 | 4.550 |
| ionosphere | 2.050 | 2.817 | 10.333 | 5.333 | 6.550 | 6.233 | 6.717 | 8.217 | 10.000 | 3.800 | 3.950 |
| wine | 3.900 | 5.633 | 10.133 | 4.000 | 4.600 | 4.733 | 6.000 | 8.933 | 9.667 | 4.033 | 4.367 |
| breastcancer | 2.267 | 3.150 | 10.117 | 5.417 | 6.767 | 6.517 | 6.467 | 8.083 | 10.200 | 3.383 | 3.633 |
| glass | 2.717 | 3.117 | 9.900 | 4.700 | 6.333 | 5.800 | 5.117 | 9.167 | 10.067 | 4.117 | 4.967 |
| sonar | 3.583 | 3.983 | 10.700 | 5.967 | 6.567 | 5.350 | 5.700 | 7.883 | 9.583 | 3.483 | 4.700 |
| Lymphography | 2.917 | 3.767 | 10.517 | 4.800 | 6.700 | 5.600 | 4.933 | 8.817 | 9.400 | 3.250 | 5.300 |
| tic-tac-toe | 3.817 | 4.567 | 9.917 | 4.417 | 5.750 | 5.633 | 4.000 | 9.300 | 9.467 | 4.350 | 5.783 |
| waveform | 4.133 | 5.600 | 10.800 | 6.683 | 5.800 | 6.250 | 5.517 | 6.933 | 9.867 | 2.050 | 5.367 |
| clean1data | 4.068 | 4.700 | 10.850 | 7.033 | 6.133 | 5.517 | 6.450 | 6.783 | 9.950 | 3.750 | 3.150 |
| SPECT | 3.500 | 6.550 | 10.033 | 5.367 | 6.750 | 6.300 | 5.700 | 8.133 | 9.817 | 3.750 | 5.100 |
| Zoo | 3.717 | 6.067 | 9.600 | 3.717 | 5.300 | 5.200 | 5.967 | 9.017 | 9.200 | 3.717 | 4.500 |
| ecoli | 2.933 | 4.700 | 9.083 | 4.300 | 5.783 | 5.583 | 4.950 | 8.983 | 9.833 | 4.617 | 5.233 |
| CongressEW | 3.683 | 3.833 | 10.283 | 4.417 | 6.350 | 5.450 | 6.000 | 8.867 | 9.317 | 2.783 | 5.567 |
| Exactly | 3.650 | 6.200 | 10.017 | 4.567 | 5.767 | 5.567 | 4.333 | 8.500 | 10.183 | 3.167 | 4.050 |
| Exactly2 | 3.850 | 4.667 | 8.733 | 4.317 | 6.300 | 6.317 | 5.650 | 8.967 | 10.133 | 4.083 | 4.983 |
| M-of-n | 3.917 | 6.150 | 9.933 | 4.750 | 6.333 | 4.833 | 4.283 | 8.483 | 9.833 | 3.433 | 4.050 |
| Vote | 3.867 | 4.100 | 10.250 | 4.283 | 6.867 | 5.767 | 5.350 | 8.333 | 10.117 | 4.367 | 4.700 |
| krvskp | 2.900 | 4.450 | 10.833 | 6.700 | 7.633 | 5.533 | 6.200 | 4.967 | 10.050 | 1.533 | 5.200 |
| heart | 2.400 | 3.817 | 10.317 | 4.917 | 6.267 | 6.283 | 5.033 | 7.917 | 9.700 | 3.817 | 5.533 |
| Datasets | AOAGA | SMAFA [9] | BSSAS3 [67] | bGWO2 [68] | SbBOA [69] | BGOAM [70] | Das [71] | S-bBOA [69] |
|---|---|---|---|---|---|---|---|---|
| breastWDBC | 0.990 | 0.989 | 0.948 | 0.935 | 0.971 | 0.970 | - | 0.971 |
| ionosphere | 0.979 | 0.971 | 0.918 | 0.834 | 0.907 | 0.946 | 0.865 | 0.907 |
| wine | 1.000 | 1.000 | 0.993 | 0.920 | 0.984 | 0.989 | 0.961 | 0.984 |
| breastcancer | 0.973 | 0.976 | 0.976 | 0.975 | 0.969 | 0.974 | 0.971 | 0.969 |
| glass | 0.807 | 0.795 | - | - | - | - | 0.692 | - |
| sonar | 0.985 | 0.989 | 0.937 | 0.729 | 0.936 | 0.915 | 0.793 | 0.936 |
| Lymphography | 0.932 | 0.930 | 0.890 | 0.700 | 0.868 | 0.912 | - | 0.868 |
| tic-tac-toe | 1.000 | 0.857 | 0.821 | - | 0.798 | 0.791 | - | 0.798 |
| waveform | 0.793 | 0.793 | 0.733 | 0.789 | 0.743 | 0.751 | - | 0.743 |
| clean1data | 0.947 | 0.949 | 0.880 | 0.727 | 0.883 | - | - | 0.883 |
| SPECT | 0.910 | 0.906 | 0.836 | 0.822 | 0.846 | 0.826 | - | 0.846 |
| Zoo | 1.000 | 1.000 | 1.000 | 0.879 | 0.978 | 0.958 | 0.960 | 0.978 |
| ecoli | 0.840 | 0.857 | - | - | - | - | 0.789 | - |
| CongressEW | 0.988 | 0.987 | 0.963 | 0.938 | 0.959 | 0.976 | 0.526 | 0.959 |
| Exactly | 1.000 | 0.999 | 0.980 | 0.776 | 0.972 | 1.000 | - | 0.972 |
| Exactly2 | 0.779 | 0.774 | 0.758 | 0.750 | 0.760 | 0.736 | - | 0.760 |
| M-of-n | 1.000 | 1.000 | 0.991 | 0.963 | 0.972 | 1.000 | - | 0.972 |
| Vote | 0.987 | 0.981 | 0.951 | 0.920 | 0.965 | 0.963 | - | 0.965 |
| krvskp | 0.976 | 0.976 | 0.964 | 0.956 | 0.966 | 0.974 | - | 0.966 |
| heart | 0.887 | 0.885 | 0.860 | 0.776 | 0.824 | 0.836 | 0.784 | 0.824 |
| Dataset | AOAGA | AOA | SMA | GA | HHO | PSO | SSA | MFO | GOA |
|---|---|---|---|---|---|---|---|---|---|
| DLBC2002 | −234.3245 | −230.2966 | −233.6701 | −230.0083 | −232.3211 | −230.4959 | −229.1562 | −228.8837 | −227.5548 |
| Lung_cancer | −62.9218 | −59.5755 | −57.7912 | −60.0389 | −62.3429 | −59.6144 | −58.6842 | −57.4670 | −58.4467 |
| MIN | AOAGA | AOA | SMA | GA | HHO | PSO | SSA | MFO | GOA |
|---|---|---|---|---|---|---|---|---|---|
| DLBC2002 | −236.4848 | −234.0571 | −236.4848 | −234.8838 | −235.6193 | −234.8838 | −232.6768 | −231.3313 | −230.0000 |
| Lung_cancer | −63.9350 | −63.9350 | −59.1967 | −63.9350 | −63.9350 | −63.9350 | −63.9350 | −60.8395 | −60.8263 |
| AOAGA | AOA | SMA | GA | HHO | PSO | SSA | MFO | GOA | |
|---|---|---|---|---|---|---|---|---|---|
| breastWDBC | −231.3218 | −227.6297 | −231.2671 | −227.3983 | −231.1883 | −227.8288 | −226.5824 | −226.0087 | −224.0000 |
| Lung_cancer | −59.2110 | −57.5195 | −55.8756 | −57.5195 | −59.1744 | −57.5195 | −56.9506 | −56.1811 | −56.0671 |
| AOAGA | AOA | SMA | GA | HHO | PSO | SSA | MFO | GOA | |
|---|---|---|---|---|---|---|---|---|---|
| DLBC2002 | 1.3164 | 1.9293 | 1.7683 | 2.1215 | 1.4501 | 2.1030 | 1.7937 | 1.6517 | 2.3251 |
| Lung_cancer | 1.1933 | 1.8862 | 1.2576 | 2.2921 | 1.8003 | 1.8522 | 1.9929 | 1.2527 | 2.3796 |
| AOAGA | AOA | SMA | GA | HHO | PSO | SSA | MFO | GOA | |
|---|---|---|---|---|---|---|---|---|---|
| DLBC2002 | 0.2809 | 0.2831 | 0.2762 | 0.4987 | 0.2867 | 0.5010 | 0.5010 | 0.5312 | 0.5008 |
| Lung_cancer | 0.3504 | 0.3589 | 0.3521 | 0.5036 | 0.3987 | 0.4983 | 0.5001 | 0.5227 | 0.4961 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ewees, A.A.; Al-qaness, M.A.A.; Abualigah, L.; Oliva, D.; Algamal, Z.Y.; Anter, A.M.; Ali Ibrahim, R.; Ghoniem, R.M.; Abd Elaziz, M. Boosting Arithmetic Optimization Algorithm with Genetic Algorithm Operators for Feature Selection: Case Study on Cox Proportional Hazards Model. Mathematics 2021, 9, 2321. https://doi.org/10.3390/math9182321
Ewees AA, Al-qaness MAA, Abualigah L, Oliva D, Algamal ZY, Anter AM, Ali Ibrahim R, Ghoniem RM, Abd Elaziz M. Boosting Arithmetic Optimization Algorithm with Genetic Algorithm Operators for Feature Selection: Case Study on Cox Proportional Hazards Model. Mathematics. 2021; 9(18):2321. https://doi.org/10.3390/math9182321
Chicago/Turabian StyleEwees, Ahmed A., Mohammed A. A. Al-qaness, Laith Abualigah, Diego Oliva, Zakariya Yahya Algamal, Ahmed M. Anter, Rehab Ali Ibrahim, Rania M. Ghoniem, and Mohamed Abd Elaziz. 2021. "Boosting Arithmetic Optimization Algorithm with Genetic Algorithm Operators for Feature Selection: Case Study on Cox Proportional Hazards Model" Mathematics 9, no. 18: 2321. https://doi.org/10.3390/math9182321