
A Fuzzy Delphi Consensus Methodology Based on a Fuzzy Ranking
by
 , , , and
, , , and
Antonio Francisco Roldán López de Hierro
1,* ,
,
Miguel Sánchez
2,
Daniel Puente-Fernández
3,
Rafael Montoya-Juárez
3 and
Concepción Roldán
1 1
Department of Statistics and Operations Research, University of Granada, 18010 Granada, Spain
2
Juan XXIII Secondary School, 18010 Granada, Spain
3
Department of Nursing, Mind, Brain and Behavior Research Center (CIMCYC-UGR), University of Granada, 18010 Granada, Spain
*
Author to whom correspondence should be addressed.
Mathematics 2021, 9(18), 2323; https://doi.org/10.3390/math9182323
Submission received: 3 August 2021
/
Revised: 9 September 2021
/
Accepted: 16 September 2021
/
Published: 19 September 2021
(This article belongs to the Special Issue General Metric Spaces: Usage and Applications in Statistics and Fixed Point Theory)
Abstract
:Delphi multi-round survey is a procedure that has been widely and successfully used to aggregate experts’ opinions about some previously established statements or questions. Such opinions are usually expressed as real numbers and some commentaries. The evolution of the consensus can be shown by an increase in the agreement percentages, and a decrease in the number of comments made. A consensus is reached when this percentage exceeds a certain previously set threshold. If this threshold has not been reached, the moderator modifies the questionnaire according to the comments he/she has collected, and the following round begins. In this paper, a new fuzzy Delphi method is introduced. On the one hand, the experts’ subjective judgments are collected as fuzzy numbers, enriching the approach. On the other hand, such opinions are collected through a computerized application that is able to interpret the experts’ opinions as fuzzy numbers. Finally, we employ a recently introduced fuzzy ranking methodology, satisfying many properties according to human intuition, in order to determine whether the expert’s fuzzy opinion is favorable enough (comparing with a fixed fuzzy number that indicates Agree or Strongly Agree). A cross-cultural validation was performed to illustrate the applicability of the proposed method. The proposed approach is simple for two reasons: it does not need a defuzzification step of the experts’ answers, and it can consider a wide range of fuzzy numbers not only triangular or trapezoidal fuzzy numbers.
1. Introduction
The Delphi method was developed during the 1950–1960s to forecast the impact of technology on warfare by Dalkey and Helmer [1] and Rieger [2]. This approach consists of a survey conducted in several rounds that presents some common characteristics:
- The process can be conducted by a moderator.
- An anonymous group of experts is invited to participate through the process of mail or online questionnaires and to give their independent opinions (the questionnaire survey is conducted anonymously and does not require meeting them in person) about the items of the questionnaire.
- Iterative surveys (often more than two, up to three or four rounds) are usually used.
- The experts give their opinions about each item in a numeric way or by using labels and make some commentaries to improve the statement of the item from their respective point of views.
- After each round, a report with the results from the previous round is sent to the experts for the next round, so they can modify their opinions in order to increase the collective agreement, taking into account the report and the comments made by other experts.
- This process is repeated until some consensus conditions are reached (or after a previously set number of rounds).
Although the traditional Delphi methods have been widely accepted as an effective tool and have been used in a wide range of applications, problems of ambiguity and uncertainty in experts’ opinions still remain. The measurement of human judgement is considered as being an emotional, complex, perceptual, subjective, and personal phenomenon, involving many domains of an individual life experience. In general, classic rating scales (e.g., 5- or 7-point Likert scales) inherently consider crisp numbers to measure human thinking. However, due to the complicated nature and uncertainty of a human judgment, it is very difficult to get an accurate numerical number for evaluating it.
The Fuzzy Delphi Method (FDM) was developed to overcome this problem through the combination of fuzzy theory and the classical methodology [3,4,5,6,7,8,9]. In general, FDMs usually use linguistic variables in designing the questionnaires to gather opinions from experts and, after that, they consider a defuzzification step; that is, a step in which linguistic labels (or fuzzy numbers) are reduced to real numbers. As a consequence, the process suffers a great loss of information. The reason for considering defuzzification is not based on the difficulty to operate with fuzzy numbers (which is reasonably easy in some contexts) but on the fact that there is no universally accepted methodology for ranking fuzzy numbers. Although many procedures have been introduced in the last fifty years, almost all of them suffer the same drawback: it is relatively easy to determine two fuzzy numbers that, when ordered through the proposed methodology, one gets the opposite ordering that any expert would propose. In other words, these procedures lead to results that, in many cases, are counter-intuitive, so they cannot be considered in a decision-making process.
To face the above-mentioned problems, the main aim of this paper is to develop a simple theoretical and methodological approach that leads to diverse applications in many fields and can be employed without a defuzzification step, considering a wide range of fuzzy numbers to collect the experts’ judgments. On the one hand, the experts’ opinions are collected as fuzzy numbers, which enrich the different ways of expressing an (maybe, subjective) opinion. On the other hand, such opinions are collected through a computerized application that is able to interpret the experts’ opinions as fuzzy numbers. In addition, in order to overcome the ordering drawback, we propose employing a recently introduced fuzzy ranking methodology (see [10]) in order to determine whether the expert’s fuzzy opinion is favorable enough (comparing with a fixed fuzzy number that indicates Agree or Strongly Agree). The main advantages of the proposed methodology are the following: (1) it satisfies a great set of reasonable properties (see [11,12]); (2) it is according to human intuition in practical cases; (3) it is applicable to the whole set of fuzzy numbers (it is not reduced to triangular or trapezoidal fuzzy numbers); (4) it is very easy to compute and interpret in practice, and it overcomes certain shortcomings that appear when applying other more complex algorithms; and (5) in the case of triangular or trapezoidal fuzzy numbers, the procedure is particularly simple and intuitive (see [13]).
In the traditional case, Delphi studies usually consider a certain level of agreement (e.g., more than 80% on a 5-point Likert scale in the two top measurements, desirable/highly desirable) as a consensus [14]. In this paper, we propose a method that tries to extend this idea to the fuzzy context: the moderator will set a particular fuzzy number for indicating Agree (or Strongly Agree), and he/she will compare each expert’ opinion to this fuzzy threshold by using the proposed fuzzy ranking. After that, the computation of the percentage of experts’ opinions that are greater than or equal to this threshold will determine whether a sufficient level of consensus is attained or not. Furthermore, to reach a consensus, it is often required that no comments are made by the experts (which means that they do not know how to improve the item).
To illustrate the approach, we consider a cross-cultural adaptation of a questionnaire performed using fuzzy answers in a healthcare study. In this context, a visual analogue scale (introduced by Freyd [15]) is often used. For example, the amount of pain that a patient feels ranges indicate a point across a continuum line between two points that is from none to an extreme amount of pain. In this case, this choice appears continuous since the answer does not take discrete jumps, as a categorization of none, mild, moderate, and severe would suggest. It captures this idea of an underlying continuum that this scale was devised on. No training is required to determine a score, and traditional statistical techniques can be used to analyze them. Therefore, it is commonly used to appropriately translate the intensity of symptoms between the patient and the medical and healthcare professionals. Taking into account that a visual analogue scale is often used in epidemiologic and clinical research to measure the intensity or frequency of various symptoms [16], this research also investigates the development of a computational appliance for the rapid collection of fuzzy data.
The organization of the rest of the paper is as follows. First, we give some background on fuzzy numbers and fuzzy ranking. Next, we present the framework of the proposed fuzzy Delphi method, in which the computerized application to collect experts’ opinions as TFNs plays an important role. In the fourth section, we describe the results of an application of this method to the problem of consensus in healthcare, and later, we discuss the obtained results. Finally, some conclusions are given, and prospective work is proposed.
2. Preliminaries
In this section, we include some basic definitions and notations about fuzzy numbers and the fuzzy ranking considered in this paper for a good comprehension of the rest of the manuscript.
2.1. Fuzzy Numbers
Let and stand for the set of all real numbers and the closed real interval [0,1], respectively. A fuzzy set on is an arbitrary function (no additional assumptions are supposed on a fuzzy set). However, although a fuzzy number is a fuzzy set, there is no unique definition associated with the notion of fuzzy numbers because distinct properties can be considered. As a consequence, several notions about the idea of fuzzy numbers can be found in the literature (see, for instance, [17,18,19]). For our purposes, we will employ the following one.
A fuzzy number (for short, a FN) of the real line is a fuzzy set of the real line, , satisfying: (1) normality ( for some ), (2) fuzzy convexity ( for and ), and (3) upper semicontinuity (if and , there is such that whenever ). Some researchers replace the normality condition with the existence of an absolute maximum. Function is usually referred to as the membership function of the FN. Each real number can be interpreted as the uncertain degree that the point x belongs to the FN .
For each , the -level set (or -cut) of the FN is the crisp set , and the kernel (or core) of is . Each level set is a (bounded or unbounded) closed interval of the real line (involving the Euclidean topology). In general, when is an FN, the set can be closed, open, or none of them. To maintain the closedness of the level sets, we define the support of an FN as the set , where denotes the closure of a subset in the Euclidean topology. In such a case, its support is also a closed interval. Notice that for all such that .
Each level set and the support of an FN can be bounded or unbounded in . For our purposes, we will only consider FNs whose supports are bounded in . Coherently, we will denote by the set of all FNs of the real line with bounded support. In such a case, if we use the convention , then each level set is a non-empty, closed, and bounded real interval, so it can be denoted by for each , where and are, respectively, the inferior and superior extremes of the -level set of the FN .
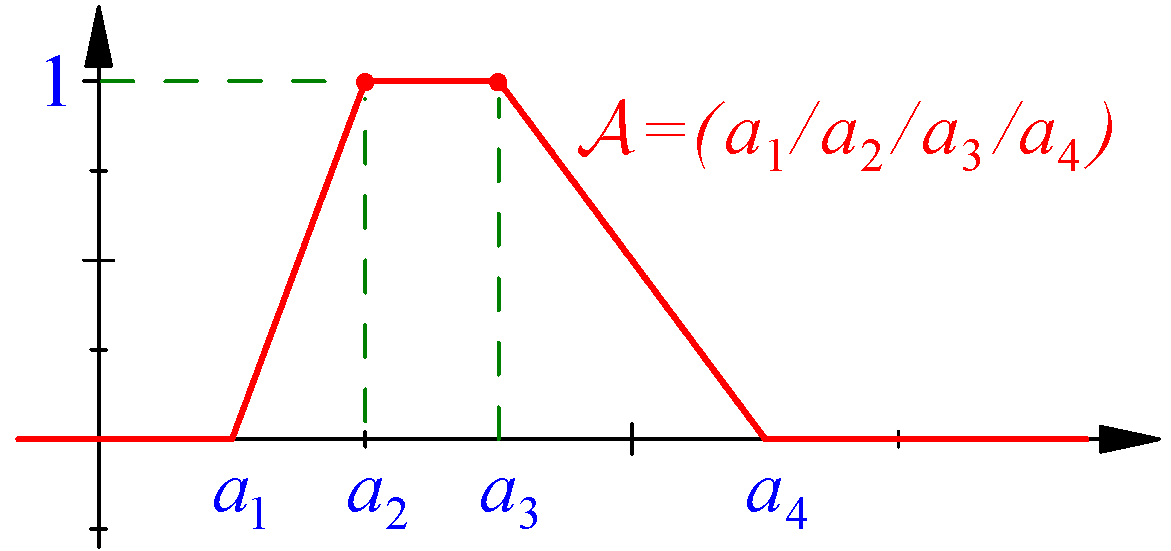
Although FNs can be represented by very general functions, we prefer to restrict our study to FNs (general enough) with simple shapes because, in practice, these are the FNs that are most frequently used in practical applications. For instance, given four real numbers and such that , a trapezoidal fuzzy number (for short, a TFN), denoted by , is the FN defined by (as shown in Figure 1):
The real numbers , , , and are usually called the corners of the FN because, when , they correspond to the vertices of the trapezoid that we obtain when the real function is plotted. Triangular FNs, denoted by , are trapezoidal FNs such that . The previous definition extends the notion of a real number to the fuzzy setting because when , the FN (which takes the value 1 if and the value 0 in any other case) represents the real number r.
TFNs are appropriate tools in order to represent both the imprecision that is necessarily associated with each measuring instrument and the subjective opinions that several experts could express about a finite set of items. For instance, the TFN ... could represent a very good, but imprecise, opinion about the quality of a wine when the range interval is considered.
Basic operations on the real line can also be extended to the family by Zadeh’s Extension Principle [20], that is, by defining
where is a traditional operation (notice that the division can only be considered when the real number 0 does not belong to the support of the divisor, see [18,21,22]). This definition is equivalent to that obtained by the interval arithmetic with the -level sets ([23]): for instance, if , then
2.2. Fuzzy Ranking
As we commented in the Introduction, it is not an easy task to rank FNs. Many approaches have been introduced, but many of them produce counter-intuitive results when the FNs are twisted, that is, when their corresponding graphic representations show several common points, giving place to intricate positions. The pointwise binary relation among functions is not useful when such functions have a concrete meaning in order to generalize the real numbers. In this context, in [10], Roldán López de Hierro et al. introduced a novel methodology for ranking FNs, whose main characteristic is to be according to human reasoning in most cases. To describe it, let denote the Euclidean measure of subsets of (in practice, the measure of a real bounded interval is ). Given two FNs , let us consider the subsets of defined as:
In a way, the set (which is an interval when and are TFNs) represents the family of probabilistic levels in which the FN is less than or equal to with regards to the binary relation ≼ that is going to be defined. Therefore, the respective measures of the sets and must be compared in the following way. We will write
This binary relation ≼ is not based on any ranking index, and, as we have commented, it satisfies a great list of reasonable properties according to human intuition (see [10]). In [13], the authors completely described how this ranking methodology works when it is applied to compare two TFNs. We highlight that we will use the ranking process given by Equation (1) in order to obtain the agreement percentage that we consider in the main sections (necessary code can be found in Appendix A).
3. A Novel Fuzzy Delphi Methodology
In this section, we describe a novel FDM in order to face any problem in which a consensus between many experts is needed regarding one or more items. Our approach assumes that the experts’ opinions are given by FNs, which generalize other methodologies based on real numbers and/or linguistic labels, and also permit the judges to express their opinions using a range of ambiguity that is full of information. Before explaining the main steps to apply the proposed FDM, we highlight the work done to program a computerized tool, developed in cooperation with professionals of the healthcare system, to facilitate a rapid and secure application of the fuzzy method.
3.1. A Computerized Application to Collect Experts’ Opinions as TFNs
Starting from the visual analogic scale, in healthcare studies, we can consider FNs described as follows. Respondents select a representative rating point on a bounded interval and indicate higher or lower rating points, depending on the relative ambiguity of their judgment (see Figure 2).
In this case, the interval is the largest support that can be considered for any FN in the study, i.e., , and it corresponds to a 10-centimeter line in the printed questionnaire. This free-response format gives triangular FNs and lets us collect fuzzy data without training. However, we need to use a ruler to measure the values corresponding to the FN and safe data manually before applying the FDM.
Following this idea, we have generated a computerized application to collect the fuzzy data. In the first stage of the implementation, we considered green/blue/red marks indicated in the bar to gather the opinions in terms of triangular FNs. Respondents select a representative rating point using the blue mark in a bar that represents the bounded interval and indicates higher or lower rating points with the green and red marks, respectively (see Figure 3). When the survey is finished, the fuzzy data are exported to an .xlsx file (which can be easily imported in RStudio [24] for fuzzy computations).
The second stage of the implementation considers TFNs, , for the answers. In this case, responders were instructed to select a representative rating interval using two blue marks within a bounded bar and then move the green and the red marks to indicate lower and upper rating points, respectively (see Figure 4). The green and red marks give two numbers, and , corresponding to the support of the TFN, and the interval defined by the blue marks corresponds to the kernel of the TFN.
With this computer appliance, the ambiguity of the judgement can be easily and automatically translated into a quantitative form based on TFNs and collected for applying the FDM explained in the next subsection.
3.2. The Proposed Fuzzy Delphi Method
In this subsection, we describe the steps we have to follow to carry on the proposed FDM and the framework in which it can be developed. Without loss of generalization and to facilitate its comprehension, we will assume that the experts’ opinions are performed by TFNs (in fact, the computerized application was designed only to capture the four corners of such kind of FNs). Moreover, the methodology implemented in Equation (1) can be applied even if the experts’ opinions are modeled by FNs with more complicated shapes, which means that the following procedure can be applied to a wide range of FNs collected by a fuzzy questionnaire.
Suppose that a committee of experts (or judges), represented by , are asked about m items (or decision criteria). Let be a TFN to represent the fuzzy performance rating assigned to the i-th item (e.g., the agreement of the cultural translation to Spanish of the item of the QOD-LTC questionnaire) by expert (where and ).
In the next lines, we describe the proposed fuzzy Delphi approach:
- Step 1:
- To create an initial version of the questionnaire, describing the items as clearly as possible. At the same time, set the necessary elements to identify the consensus. For instance, in the research we will describe in the next section, having the maximum support to express an opinion in mind, we have chosen the triangular FN to indicate Agree and Strongly Agree (other researchers could use any other threshold). To reach the consensus on the i-th item, it will be necessary that two conditions hold: (1) there is, at least, 80% agreement among experts about the item, that is, at least 80% of experts’ opinions about the i-th item will satisfy (this means that the expert’s opinion is very favorable to the item); (2) there will not be any comments from experts (if there is at least one comment, we understand that the item could be improved).
- Step 2:
- To create a group of people that are experts on the subject that agree accept to participate in the survey.
- Step 3:
- To email the questionnaire and collect the answers, which refer (measure) to the level of agreement with each of the items. In this step, experts were invited to respond using a free-response format fuzzy rating scale-based questionnaire via the web involving TFNs.
- Step 4:
- After receiving the experts’ opinions and the corresponding comments, the next step is to compute the agreement percentage among experts about the i-th item (), as the quotient between the number of experts’ opinions for which (from 1 to n) over the number n of experts, multiplied by 100. Then, compute the number of commentaries made by the set of experts.
- Step 5:
- If the consensus is reached for the i-th item using the criteria previously set in the first step, then such item will not be posed again to the experts in the next round. On the contrary, if the consensus is not attained on some items (maybe because the percentage is not great enough or maybe because there still exist some commentary), the moderator will modify the items in which there is not a consensus by following the experts’ commentaries, and he/she will complete a report in order to let all experts know about the other experts’ opinions. Such a new questionnaire and report will be submitted to the experts, and Step 3 starts again.
- Step 6:
- The procedure will stop after iterative surveys (often more than twice, up to three or four rounds) when the consensus is reached on each item or after a previously set number of rounds.
4. Survey Outcomes (Results)
Many questionnaires and measurements have been developed to assess medical conditions and quality of life or death. Measuring the quality of the dying experience is important for improving care for dying patients. However, few instruments exist that assess the quality of one’s dying process in Spain. This study uses the new FDM proposed to validate the design of a new Spanish version of the “Quality of Dying in Long-Term Care” (QoD-LTC) [25], one of the most widely used scales to assess the quality of dying in long-term care facilities.
For Spain, 11 issues were proposed (). This section summarizes the FDM in terms of how much consensus and stability evolved through rounds 1 to 3 by the agreement percentages and the number of comments (we also include the mean of the answers).
A heterogeneous group of thirteen experts (eight nurses, three psychologists, and two doctors) was considered (). The average age was 43 years, and the average professional experience was 10.8 years (5 are dedicated to care work, 8 to teaching and clinical research, and 1 to both tasks).
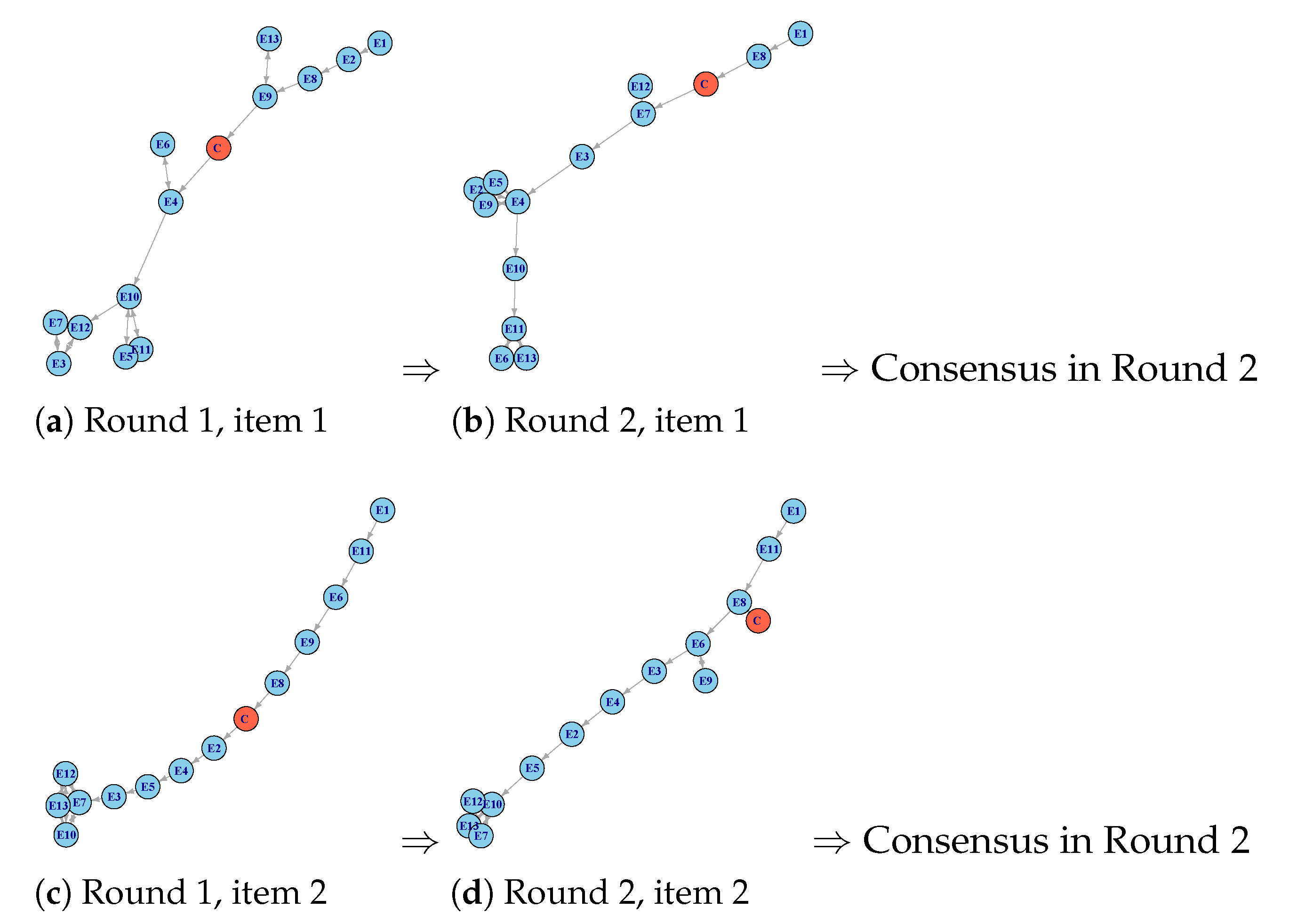
The initial version of the questionnaire was submitted to the 13 experts, and by using the computerized tool, we collected their opinions about the 11 items. For instance, Figure 5 represents the 13 experts’ opinions collected for Item 1 in the blue color, and in the red color, the comparison FN is presented. We can observe that, although it is clear the relative positions between some TFNs and , there are other cases in which even experts on fuzzy ranking could suffer some doubts about what FN is greater or lesser. Hence, it was necessary to apply the binary relation ≼ to decide whether or vice versa. Such comparisons can be observed in Figure 6a. Ana arrows diagram with the 13 experts’ opinions as blue circles (denoted by ) and the comparison FN, , in red color is shown. We have used the following criterion: each arrow points to the largest fuzzy number by the fuzzy binary relation ≼; that is, if , we have plotted the arrow ; if , the represented arrow is ; and if , we have plotted .
As we can see, eight opinions were greater than by the fuzzy binary relation ≼, and five of them were lower than . As a consequence, the percentage of the agreement of the cultural translation to Spanish for Item 1 of the QOD-LTC questionnaire was 8/13 = 61.5%, which was clearly insufficient to reach the consensus. Moreover, four comments were collected from the experts for Item 1 in the first round, which confirms that the consensus was not attained. These data can be found on the third line of Table 1, associated with Item 1, where we can notice that the agreement percentage was 61.5%, and the number N of comments was four.
Taking into account the experts’ suggestions, the moderator modified Item 1 in the questionnaire, and it was submitted to the experts in the second round. The experts had access to other experts’ opinions, and they expressed their opinions about the new version of Item 1. In the second round, as we can see in Figure 6b, 11 opinions were greater than by the fuzzy binary relation ≼, and only 2 of them were lower than . As a result, the percentage of agreement for Item 1 in the second round was 11/13 = 84.6%, which was greater than 80%. As there was no comments, we considered that the consensus was reached for Item 1. Accordingly, Item 1 was not included in the third round of the questionnaire. The corresponding information can also be found in the third line of Table 1 in the columns that are dedicated to the second round.
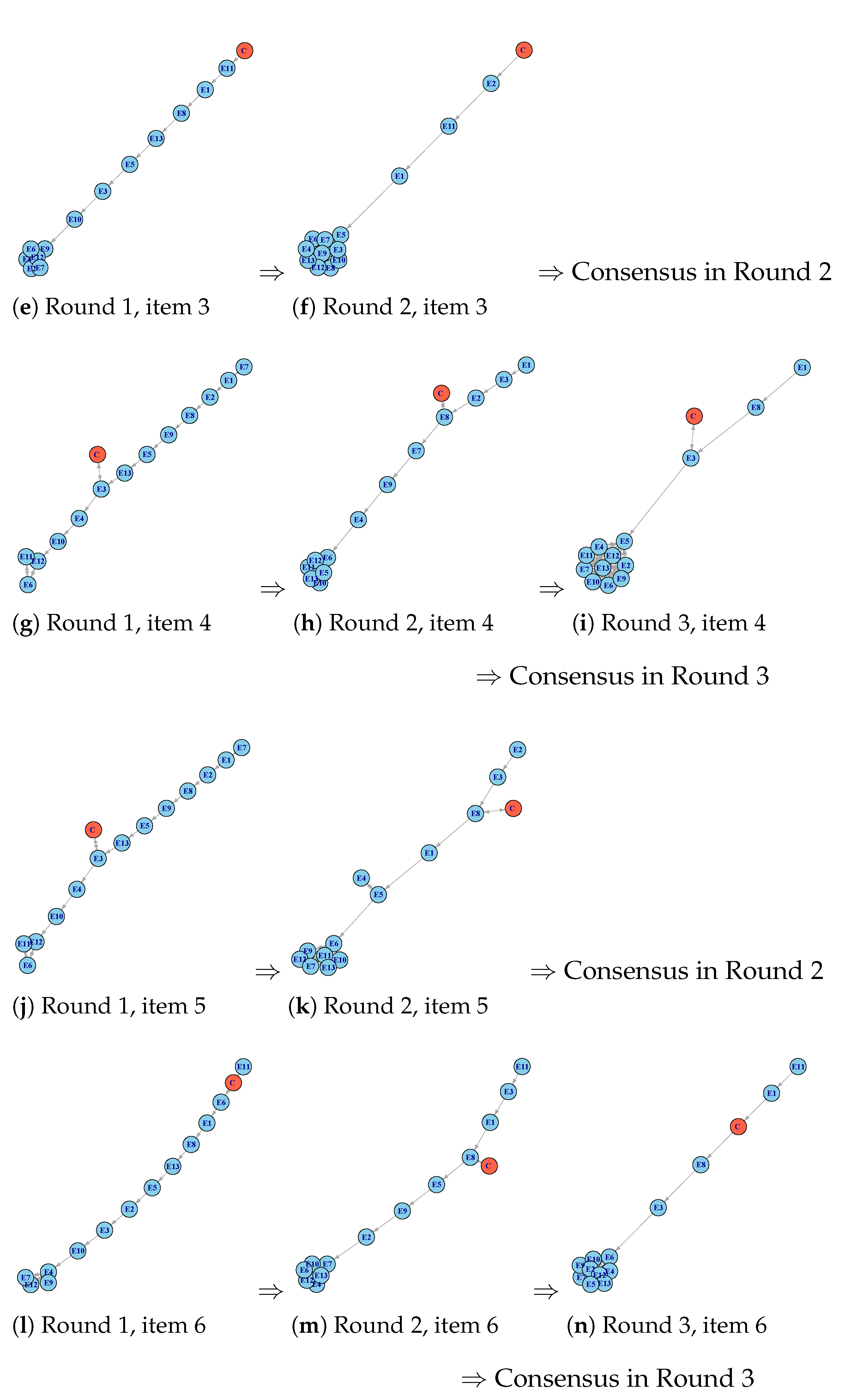
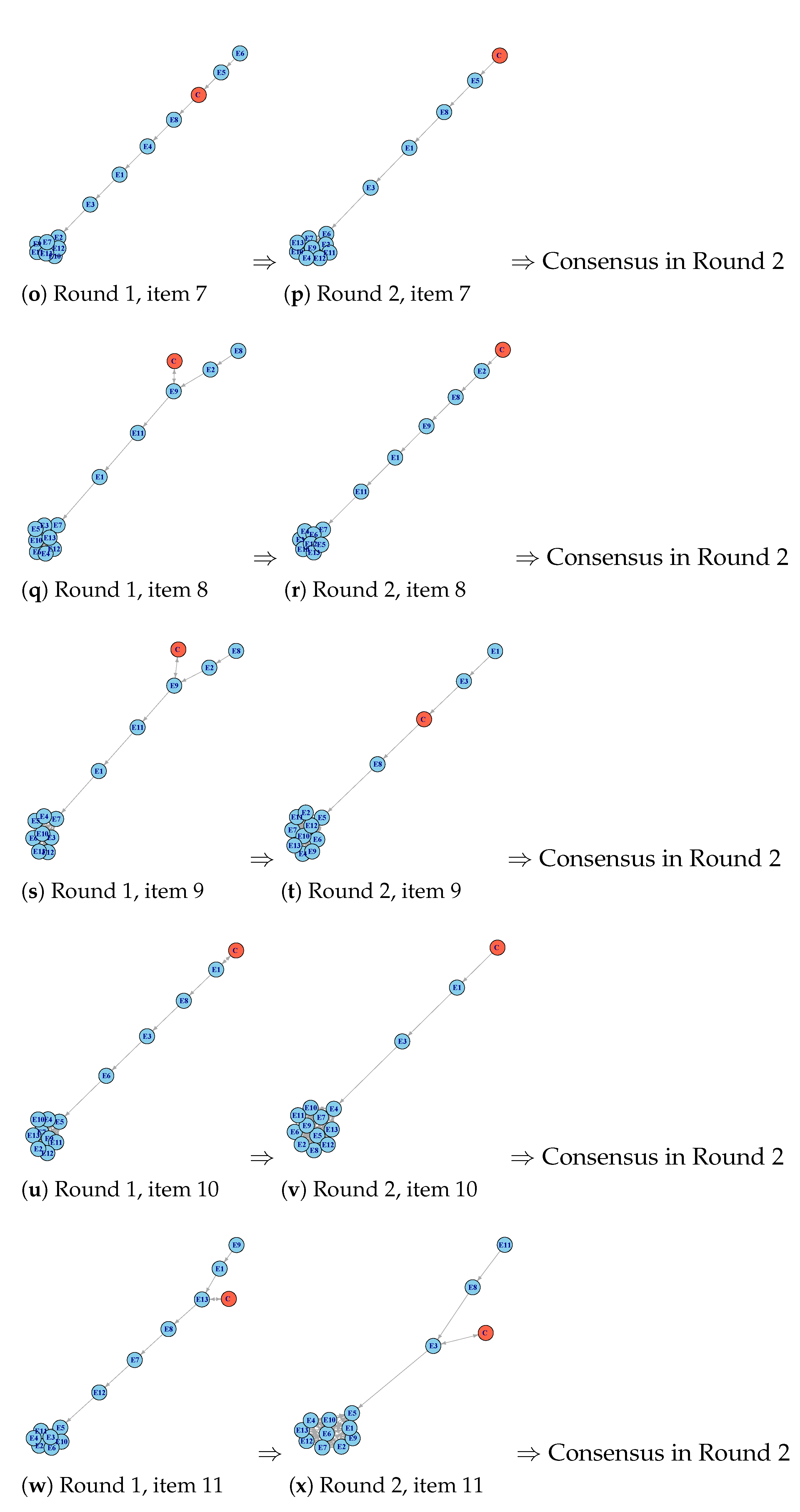
This process was implemented for each one of the 11 items considered in the questionnaire. In order not to be repetitive, we summarize the results obtained for each item as follows. Figure 7a–p represent the fuzzy data corresponding to the 13 expert’s opinions (in blue color), ranked for each round and each item. In this ranking, the comparison FN was plotted in red.
Table 1 summarizes the results of the fuzzy Delphi rounds. For each round, the first four columns give four numbers ) corresponding to the fuzzy mean of the 13 experts’ opinions; the next column gives the computed agreement percentage (%); the last column is the number of comments made corresponding to each item, denoted by N. Figure 7a–p let us easily check the obtained agreement percentage. We can interpret the sixth line of Table 1 (corresponding to Item 4) as follows. In the first round, the agreement percentage among experts was 46.2%, and there were eight comments. As the consensus was not reached, a second round was necessary. In the second round, there was an agreement percentage among experts around 76.9%, and there were three comments. Consequently, a new round was carried out. Finally, in the third round, the mentioned percentage was 84.6% with no comments. The consensus about Item 4 was reached after three rounds. These data have been represented in Figure 7g–i, which correspond to Item 4. It is interesting to notice that, in the case of Item 3, there was 100% agreement on the proposed translation. However, this item was included in the second round because there was still one comment that could improve the statement of the item.
Finally, we highlight that the consensus on all items was reached after three rounds.
5. Discussion
The Delphi results show a change in experts’ views towards consensus and stability. For all the items, an increase in the percentage agreements was observed over the three rounds. The highest disagreement percentage in round 1 corresponds to Item 4, demonstrating that by taking into account the experts’ comments, these views can be considerably altered. The number of comments decreased in each round. This reduction supports the evolution of the consensus.
The proposed method, which follows the original methodology for the case of fuzzy answers, is suggested to be an effective way to measure group consensus. The main characteristics of the proposed FDM are: (1) the computerized tool to collect the experts’ opinions, which avoids any kind of imprecision when measuring the TFNs plotted on a paper, and (2) the fuzzy binary relation ≼, which contains the necessary fuzzy complexity in order to decide whether the expert’s opinion is favorable enough to the item.
This methodology is distinct from other previously introduced FDMs because it does not involve any kind of defuzzification at any stage of the process. For us, it is very important that the experts’ opinions are expressed in terms of FNs because these judgements need to involve a certain level of ambiguity that cannot be modeled by using real numbers and/or linguistic labels. Hence, if we apply any kind of defuzzification on the experts’ opinions at any step of the process, we will suffer a great loss of information that will cause the use of fuzzy elements to seem unjustified throughout the process. Although many researchers have attempted to develop FDMs, few of them have proposed methods without a defuzzification step, and we have not found any method that could be applied to the whole set of FNs in the literature.
6. Conclusions and Prospect Works
The Delphi multi-round survey is a procedure that has been widely and successfully used to aggregate experts’ opinions. The Fuzzy Delphi Method (FDM) is the modified and enhanced version of the classical Delphi technique. In this paper, the proposed method expands a classic Delphi method to incorporate the fuzzy data in experts’ opinions. The evolution of consensus is shown by the increase in agreement percentages and a decrease in the number of comments made.
In this paper, we have presented a novel FDM that overcomes some of the shortcomings that usually appear in this context. On the one hand, we have assumed that the experts’ opinions can be modeled by FNs, which are more appropriate to perform the complex human judgement about each item of the questionnaire. On the other hand, we have developed a computerized tool in order to easily collect the experts’ responses. This information system is, for the moment, reduced to collect TFNs, but, in prospective work, we plan to develop a computer tool that will be capable of collecting any kind of FN. By comparing the experts’ fuzzy responses with a fuzzy agreement level (implemented as a particular FN), the moderator is able to determine whether there is a sufficient percentage of experts that is reasonable according to the statement given on each item of the questionnaire. If such a minimal percentage is not attained, the moderator can start a new round after modifying the questionnaire accordingly to experts’ comments. Some advantages of the proposed FDM are the following:
- It is simple and can be employed without loss of information (that is, without a defuzzification step).
- It can be applied to a wide range of FNs not only TFNs.
- The computer appliance developed for collecting the fuzzy data saves time and costs in handling fuzzy questionnaires.
A cross-cultural adaptation was used to illustrate the new approach. Many processes in healthcare that may need a consensus are susceptible to applying the introduced methodology. Further research is needed in this field of study in order to complete the development of new products, services, and techniques that may also be needed to consider a FDM.
Author Contributions
Conceptualization, A.F.R.L.d.H., M.S., D.P.-F., R.M.-J., and C.R.; methodology, A.F.R.L.d.H., M.S. and C.R.; software, M.S.; validation, A.F.R.L.d.H., M.S., D.P.-F., R.M.-J., and C.R.; formal analysis, A.F.R.L.d.H., M.S., and C.R.; investigation, A.F.R.L.d.H., M.S., D.P.-F., R.M.-J., and C.R.; resources, A.F.R.L.d.H., M.S., D.P.-F., R.M.-J., and C.R.; data curation, D.P.-F. and C.R.; writing—original draft preparation, A.F.R.L.d.H., M.S., D.P.-F., R.M.-J., and C.R.; writing—review and editing, A.F.R.L.d.H., M.S., D.P.-F., R.M.-J., and C.R.; visualization, A.F.R.L.d.H., M.S., D.P.-F., R.M.-J., and C.R.; supervision, A.F.R.L.d.H. and C.R.; project administration, A.F.R.L.d.H.; funding acquisition, A.F.R.L.d.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors thank the University of Granada (Spain). A.F. Roldán López de Hierro is grateful to the Ministerio de Ciencia e Innovación by Project PID2020-119478GB-I00 and to Junta de Andalucía by Project FQM-365 of the Andalusian CICYE.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| FN | Fuzzy number |
| TFN | Trapezoidal fuzzy number |
| FDM | Fuzzy Delphi method |
Appendix A. R Code for Ranking Two TFNs
In Appendix A, we include the necessary code in order to rank two TFNs by using Roldán López de Hierro et al.’s methodology [10] described in Equation (1).
Suppose that we wish to rank two TFNs, and , for which we know their corners. We identify such TFNs in R as the vectors and . Next, we describe all the functions we need.
- (✠)
- The function LeftInterval takes two vectors and as inputs representing the inferior corners of the TFNs and , that is, , , and , and it produces the compact subinterval (closed an bounded) of all values as output such that . Such interval is described as a vector , where and are the extremes of that interval. If such interval is empty, the output is −− (in what follows, we use the number to represent a computing mistake or the empty set).LeftInterval= function(a,b){a1<-a[1]a2<-a[2]b1<-b[1]b2<-b[2]if(a1<= b1 && a2 <= b2){return(c(0,1))} else if(b1<a1 && b2<a2){return(c(-1,-1))} else if(a1<=b1 && b1<=b2 && b2<= a2){y1<-abs(a1-b1)/(abs(a1-b1) + abs(a2-b2))return(c(0,y1))}else if(b1<=a1 && a1 <= a2 && a2<= b2){y1<-abs(a1-b1)/(abs(a1-b1) + abs(a2-b2))return(c(y1,1))} else{# some paremeter is wrongcat(paste(‘‘Something’s wrong:Failure in function -LeftInterval-.’’))}}
- (✠)
- The function RightInterval takes two vectors and as inputs representing the superior corners of the TFNs and , that is, , , and , and it produces the compact subinterval of all values as output such that . Such interval is described as a vector , where and are the extremes of that interval. If such interval is empty, the output is −−.RightInterval= function(a,b){a3<a[1]a4<a[2]b3<b[1]b4<b[2]if(a3<= b3 && a4 <= b4){return(c(0,1))} else if(b3<a3 && b4<a4){return(c(-1,-1))} else if(a3<=b3 && b3<=b4 && b4<= a4){y2<-abs(a4-b4)/(abs(a3-b3) + abs(a4-b4))return(c(y2,1))} else if(b3<=a3 && a3 <= a4 && a4<= b4){y2<-abs(a4-b4)/(abs(a3-b3) + abs(a4-b4))return(c(0,y2))} else{# some paremeter is wrongcat(paste(‘‘Something’s wrong:Failure in function -RightInterval-.’’))}}
- (✠)
- The function Intersection takes two intervals and (described as vectors ) as inputs, and it computes their intersection (also described as a vector ). If such interval is empty, the output is −−.Intersection= function(i1,i2){alfa1<-i1[1]beta1<-i1[2]alfa2<-i2[1]beta2<-i2[2]if(alfa1 == -1 || alfa2 == -1){return(c(-1,-1))}else {if(max(alfa1,alfa2)<= min(beta1,beta2)){return(c(max(alfa1,alfa2),min(beta1,beta2)))} else{return(c(-1,-1))}}}
- (✠)
- The function Interval takes two TFNs (described as the vectors and ) as inputs, and it computes the interval given as a vector . If such interval is empty, the output is −−.Interval= function(FNa,FNb){return(Intersection(LeftInterval(c(FNa[1],FNa[2]),c(FNb[1],FNb[2])),RightInterval(c(FNa[3],FNa[4]),c(FNb[3],FNb[4]))))}
- (✠)
- The function LengthInterval takes a compact interval (described as a vector ) as input, and it computes the length (which is a real number). If such interval is empty, the output is −1.LengthInterval= function(i){if(i[1]==-1 )return(0)elsereturn(i[2]-i[1])}
- (✠)
- The function Decision takes two TFNs (described as the vectors and ) as inputs, and it gives the following logical value: TRUE, if , and FALSE, if the ranking is false.Decision= function(FNa, FNb){lengthAB<- LengthInterval(Interval(FNa, FNb))lengthBA<- LengthInterval(Interval(FNb,FNa))if(lengthAB>0 && lengthAB>=lengthBA)return(TRUE)else if(lengthAB==0 && lengthBA==0 && (sum(FNa)<=sum(FNb)))return(TRUE)elsereturn(FALSE)}
- (✠)
- The function Ranking2TraFN takes two TFNs (described as the vectors as inputs and ) and two character strings (linguistic labels), and , that represent such TFNs, and it produces the following character string as output:Notice that this function asks us for the linguistic labels that we want to use to denote the fuzzy numbers. It is usual to call the first fuzzy number “A” and “B” as the second. In this way, the function will produce one of the following three outputs: “”, “”, or “”. However, when working with more than two fuzzy numbers, it is usual to use other labels. In this case, if we write other linguistic labels, we could get outputs, such as “”, “”, or “”. It will depend on the text that we will introduce into the arguments.Ranking2FN = function(FNa, FNb, texta, textb){AlessB<- Decision(FNa,FNb)BlessA<- Decision(FNb,FNa)if(AlessB == TRUE && BlessA == TRUE)return(paste(texta,‘‘~’’,textb))else if(AlessB == TRUE && BlessA == FALSE)return(paste(texta,‘‘<’’,textb))else if(AlessB == FALSE && BlessA == TRUE)return(paste(texta,‘‘>’’,textb))elsecat(paste(‘‘Something’s wrong:Failure in function -Ranking2FN-.’’))}
- (✠)
- The function menu() will ask the user for the four corners of the TFNs and jointly with their linguistic labels and , and after checking that the inequalities and hold, the output is the correct ranking of the FNs and by employing the labels y (if the inequalities are not fulfilled, it outputs a warning message). This function uses the library “FuzzyNumbers” in order to represent the involved TFNs, so it will be necessary to previously install such library.install.packages(‘‘C:/FuzzyNumbers_0.4-6.tar.gz’’,repos = NULL, type = ‘‘source’’)menu = function(){# We check that library ’FuzzyNumbers’ is installedif (!require(’FuzzyNumbers’))stop(‘‘Please, install library ’FuzzyNumbers’before continuing.’’)library(’FuzzyNumbers’) # startcat(paste(‘‘Insert the quantity of trapezoidal fuzzy numbersto carry out the ranking’’))cantidadNumeros<-scan(n=1)# if a positive number has been loadedif(cantidadNumeros>0){# Initializing the vectors for parameters as nulla=NULLb=NULLc=NULLd=NULLetiqueta = NULLcat(paste(‘‘\nPlease, insert each fuzzy number throughits corners (a,b,c,d) and a label (text)\n’’))cat(paste(‘‘\n(recall b=c if it is triangular)\n’’))cat(paste(‘‘\n(make sure a<=b<=c<=d)\n’’))# caption of the corners of the fuzzy numbersfor(i in 1:cantidadNumeros){cat(paste(‘‘\nCorners of the trapezoidal fuzzynumber’’,i,‘‘are :\n’’))num=scan(nmax =4)# We check that corners are correctly ordered as# real numbersif(num[1]<=num[2]&&num[2]<=num[3]&&num[3]<=num[4]){a=c(a,num[1])b=c(b,num[2])c=c(c,num[3])d=c(d,num[4])# caption of labelscat(paste(‘‘Insert the label of this fuzzynumber\n’’))etiqueta= c(etiqueta,scan(,what = character(),1))}else{cat(paste(‘‘Failure:corners are incorrectly ordered. END.’’))return(0)}}}else{cat(paste(‘‘Failure: incorrect quantity of fuzzynumbers. END.’’))return(0)}# computation of rankingvalorRanking<-Ranking2FN(c(a[1],b[1],c[1],d[1]),c(a[2],b[2],c[2],d[2]), etiqueta[1],etiqueta[2])# definition of the trapezoidal fuzzy number for plottingA<-TrapezoidalFuzzyNumber(a[1],b[1],c[1],d[1])B<-TrapezoidalFuzzyNumber(a[2],b[2],c[2],d[2])A1<-as.PiecewiseLinearFuzzyNumber(A, knot.n=0)B1<-as.PiecewiseLinearFuzzyNumber(B, knot.n=0)# computation of the appropriate interval for plottingFNa<-c(a[1],b[1],c[1],d[1])FNb<-c(a[2],b[2],c[2],d[2])m1<-min(FNa,FNb)m2<-max(FNa,FNb)l<-m2-m1l1<-m1-0.15*ll2<-m2+0.15*l# Plotting fuzzy numbers and rankingplot(A1, xlim=c(l1,l2), main=‘‘Ranking trapezoidalfuzzy numbers’’,lwd=2, col=‘‘red’’)plot(B1, add=TRUE, lwd=2,col=‘‘blue’’)legend(‘‘topright’’, legend=c(etiqueta[1], etiqueta[2]),col=c(‘‘red’’,‘‘blue’’), lty=c(1,1), title = valorRanking,bg=’lightblue’)}
References
- Dalkey, N.; Helmer, O. An experimental application of the Delphi method to the use of experts. Mgmt. Sci. 1963, 9, 458–467. [Google Scholar] [CrossRef]
- Rieger, W.G. Directions in Delphi developments: Dissertations and their quality. Technol. Forecast. Soc. Chang. 1986, 29, 195–204. [Google Scholar] [CrossRef]
- Byrne, M.; Mc Sharry, J.; Meade, O.; Lavoie, K.L.; Bacon, S.L. An international, Delphi consensus study to identify priorities for methodological research in behavioural trials: A study protocol. HRB Open Res. 2020, 21, 1–13. [Google Scholar]
- Banno, M.; Tsujimoto, Y.; Kataoka, Y. Reporting quality of the Delphi technique in reporting guidelines: A protocol for a systematic analysis of the EQUATOR Network Library. BMJ Open. 2019, 9, 1–4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dapari, R.; Ismail, H.; Ismail, R.; Ismail, N.H. Application of fuzzy Delphi in the selection of COPD risk factors among steel industry workers. Tanaffos 2017, 16, 46–52. [Google Scholar] [PubMed]
- Huang, C.Y.; Huang, J.J.; Chang, Y.N.; Lin, Y.C. A fuzzy-mop-based competence set expansion method for technology roadmap definitions. Mathematics 2021, 9, 135. [Google Scholar] [CrossRef]
- Mengistu, A.T.; Panizzolo, R. Indicators and framework for measuring industrial sustainability in italian footwear small and medium enterprises. Sustainability 2021, 13, 5472. [Google Scholar] [CrossRef]
- Tsai, H.C.; Lee, A.S.; Lee, H.N.; Chen, C.N.; Liu, Y.C. An application of the fuzzy Delphi method and fuzzy AHP on the discussion of training indicators for the regional competition, Taiwan national skills competition, in the trade of joinery. Sustainability 2020, 12, 1–19. [Google Scholar]
- Yusoff, A.F.M.; Hashim, A.; Muhamad, N.; Hamat, W.N.W. Application of Fuzzy Delphi Technique to Identify the Elements for Designing and Developing the e-PBM PI-Poli Module. Asian J Univ. Educ. 2021, 17, 292–304. [Google Scholar] [CrossRef]
- Roldán López de Hierro, A.F.; Roldán, C.; Herrera, F. On a new methodology for ranking fuzzy numbers and its application to real economic data. Fuzzy Sets Syst. 2018, 353, 86–110. [Google Scholar] [CrossRef]
- Ban, A.I.; Coroianu, L. Simplifying the search for effective ranking of fuzzy numbers. IEEE Trans. Fuzzy Syst. 2015, 23, 327–339. [Google Scholar] [CrossRef]
- Wang, X.; Kerre, E.E. Reasonable properties for the ordering of fuzzy quantities (I). Fuzzy Sets Syst. 2001, 118, 375–385. [Google Scholar] [CrossRef]
- Roldán López de Hierro, A.F.; Márquez-Montávez, A.; Roldán, C. A novel fuzzy methodology applied for ranking trapezoidal fuzzy numbers and new properties. Int. J. Comput. Math. 2020, 97, 358–386. [Google Scholar] [CrossRef]
- Heiko, A. Consensus measurement in Delphi studies Review and implications for future quality assurance. Technol. Forecast. Soc. Chang. 2012, 79, 1525–1536. [Google Scholar]
- Freyd, M. A graphic rating scale for teachers. J. Educ. Psychol. 1923, 8, 433–439. [Google Scholar] [CrossRef]
- Crichton, N. Visual Analogue Scale (VAS). J. Clin. Nurs. 2001, 10, 697–706. [Google Scholar]
- Dubois, D.; Prade, H. Operations on fuzzy numbers. Int. J. Syst. Sci. 1978, 9, 613–626. [Google Scholar] [CrossRef]
- Roldán, A.; Martínez-Moreno, J.; Roldán, C. Some applications of the study of the image of a fuzzy number: Countable fuzzy numbers, operations, regression and a specificity-type ordering. Fuzzy Sets Syst. 2014, 257, 204–216. [Google Scholar] [CrossRef]
- Roldán López de Hierro, A.F.; Roldán, C.; Martínez-Moreno, J.; Aguilar Peña, C. Estimation of a fuzzy regression model using fuzzy distances. IEEE Trans. Fuzzy Syst. 2016, 24, 344–359. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy set. Inf. Control. 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Goetschel, R.; Voxman, W. Elementary fuzzy calculus. Fuzzy Sets Syst. 1986, 18, 31–43. [Google Scholar] [CrossRef]
- Mizumoto, M.; Tanaka, J. Some properties of fuzzy numbers. In Advances in Fuzzy Set Theory and Applications; Gupta, M.M., Ragade, R.K., Yager, R.R., Eds.; North-Holland: New York, NY, USA, 1979; pp. 153–164. [Google Scholar]
- Dubois, D.; Kerre, E.; Mesiar, R.; Prade, H. Fuzzy interval analysis. In Fundamentals of Fuzzy Sets; Kluwer: Alphen aan den Rijn, The Netherlands, 2000; pp. 483–581. [Google Scholar]
- RStudio Team. RStudio: Integrated Development for R; RStudio, PBC: Boston, MA, USA, 2020; Available online: http://www.rstudio.com/ (accessed on 17 September 2021).
- Puente-Fernández, D.; Jimeno-Uclés, R.; Mota-Romero, E.; Roldán, C.; Froggatt, K.; Montoya-Juárez, R. Cultural Adaptation and Validation of the Quality of Dying in Long-Term Care Scale (QoD-LTC) for Spanish Nursing Homes. Int. J. Environ. Res. Public Health 2021, 18, 5287. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
An example of FNs.

Figure 2.
Example of an answer collected from a writing form using a fuzzy rating scale.

Figure 3.
Example of answers collected from an electronic form via the web using a fuzzy rating scale that generates triangular FNs.
Figure 3.
Example of answers collected from an electronic form via the web using a fuzzy rating scale that generates triangular FNs.

Figure 4.
Example of answers collected from a computerized application using a fuzzy rating scale that generates trapezoidal FNs.
Figure 4.
Example of answers collected from a computerized application using a fuzzy rating scale that generates trapezoidal FNs.

Figure 5.
Fuzzy rating scale-based data from the 13 experts on Item 1 in blue and the comparison FN, , in red.
Figure 5.
Fuzzy rating scale-based data from the 13 experts on Item 1 in blue and the comparison FN, , in red.

Figure 6.
Fuzzy data corresponding to the 13 expert’s opinions (in blue color) ranked for the first round and the first item and the comparison FN (in red color).
Figure 6.
Fuzzy data corresponding to the 13 expert’s opinions (in blue color) ranked for the first round and the first item and the comparison FN (in red color).

Figure 7.
Fuzzy data corresponding to the 13 experts’ opinions ranked for each round and each item in blue and the comparison FN, , in red.
Figure 7.
Fuzzy data corresponding to the 13 experts’ opinions ranked for each round and each item in blue and the comparison FN, , in red.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The results of the fuzzy Delphi rounds, with the reasons why an item must be included in the following round highlighted in gray.
Table 1.
The results of the fuzzy Delphi rounds, with the reasons why an item must be included in the following round highlighted in gray.
| Round 1 | Round 2 | Round 3 | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| % | % | % | ||||||||||||||||
| Item 1 | 7.4 | 8.2 | 8.8 | 9.4 | 61.5 | 4 | 8.0 | 9.1 | 9.5 | 9.5 | 84.6 | 0 | - | - | - | - | - | - |
| Item 2 | 7.2 | 8.0 | 8.8 | 9.8 | 61.5 | 4 | 7.7 | 8.5 | 9.3 | 9.6 | 84.6 | 0 | - | - | - | - | - | - |
| Item 3 | 8.8 | 9.4 | 9.6 | 10.0 | 100.0 | 1 | 9.3 | 9.6 | 9.8 | 10.0 | 100.0 | 0 | - | - | - | - | - | - |
| Item 4 | 7.4 | 8.1 | 8.8 | 9.4 | 46.2 | 8 | 8.2 | 8.7 | 9.1 | 9.6 | 76.9 | 3 | 9.1 | 9.4 | 9.5 | 9.5 | 84.6 | 0 |
| Item 5 | 7.2 | 8.0 | 8.8 | 9.9 | 46.2 | 2 | 8.8 | 9.3 | 9.6 | 9.7 | 84.6 | 0 | - | - | - | - | - | - |
| Item 6 | 8.7 | 9.4 | 9.5 | 10.0 | 92.3 | 3 | 8.4 | 9.0 | 9.2 | 9.4 | 76.9 | 0 | 9.0 | 9.5 | 9.7 | 9.9 | 84.6 | 0 |
| Item 7 | 7.3 | 8.2 | 8.8 | 9.4 | 84.6 | 4 | 9.2 | 9.6 | 9.9 | 10.0 | 100.0 | 0 | - | - | - | - | - | - |
| Item 8 | 7.2 | 8.0 | 8.8 | 9.9 | 84.6 | 4 | 8.9 | 9.3 | 9.6 | 9.9 | 100.0 | 0 | - | - | - | - | - | - |
| Item 9 | 8.7 | 9.4 | 9.5 | 10.0 | 84.6 | 6 | 9.1 | 9.4 | 9.6 | 9.7 | 84.6 | 0 | - | - | - | - | - | - |
| Item 10 | 7.4 | 8.2 | 8.8 | 9.4 | 100.0 | 1 | 9.5 | 9.7 | 9.9 | 9.9 | 100.0 | 0 | - | - | - | - | - | - |
| Item 11 | 7.2 | 8.0 | 8.8 | 9.9 | 84.6 | 3 | 9.1 | 9.4 | 9.6 | 9.7 | 84.6 | 0 | - | - | - | - | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Roldán López de Hierro, A.F.; Sánchez, M.; Puente-Fernández, D.; Montoya-Juárez, R.; Roldán, C. A Fuzzy Delphi Consensus Methodology Based on a Fuzzy Ranking. Mathematics 2021, 9, 2323. https://doi.org/10.3390/math9182323
AMA Style
Roldán López de Hierro AF, Sánchez M, Puente-Fernández D, Montoya-Juárez R, Roldán C. A Fuzzy Delphi Consensus Methodology Based on a Fuzzy Ranking. Mathematics. 2021; 9(18):2323. https://doi.org/10.3390/math9182323
Chicago/Turabian StyleRoldán López de Hierro, Antonio Francisco, Miguel Sánchez, Daniel Puente-Fernández, Rafael Montoya-Juárez, and Concepción Roldán. 2021. "A Fuzzy Delphi Consensus Methodology Based on a Fuzzy Ranking" Mathematics 9, no. 18: 2323. https://doi.org/10.3390/math9182323
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.