
JSCC-Cast: A Joint Source Channel Coding Video Encoding and Transmission System with Limited Digital Metadata



Abstract
:1. Introduction
- Analog encoding and transmission systems are capable of adapting to the channel conditions without any prior knowledge. By contrast, all-digital video systems require either certain channel information provided by a feedback channel or the transmission of a large amount of redundancy in order to ensure successful reception regardless of the channel conditions.
- All-digital video systems guarantee error-free transmissions above a certain channel quality, keeping fixed the received video quality, hence, wasting bandwidth due to redundancy. In case the channel quality is not sufficient to guarantee an error-free transmission, the video quality will be significantly degraded, and even temporal drops in the video sequence will occur due to the loss of complete video frames.
- In a wireless-multicast scenario, an all-digital system has to target the worst of the receivers or broadcast several video layers simultaneously. The required redundancy to combat low-quality channels will penalize those receivers with high-quality channels. Notice that in the case of multiple video layers, the bandwidth will also be reduced. By contrast, analog encoding and transmission video systems send exactly the same information to all the receivers regardless of their channel status. The quality of the image received will depend on the channel quality experienced by each receiver.
- Video visualization on different types of fixed and mobile devices is growing every year [1]. This makes it necessary to develop advanced video coding and transmission systems. In particular, with the growth of the Internet of Things, the use of simple microprocessors with very low power consumption is expanding, thus requiring systems with ultra-low complexity and computational load [2,3].
Contributions of the Paper
- JSCC-Cast, a comprehensive analog video encoding and transmission system, is proposed which requires a minimum amount of metadata to reconstruct the video. Since the corruption of metadata during the transmission makes video decoding impossible, it is crucial to properly protect such metadata, resulting in a reduction in the available bandwidth for video data. JSCC-Cast is also designed to provide a video quality comparable to other similar alternatives with high compression levels and minimum computational cost and delay.
- A detailed analysis and design of the different components of JSCC-Cast is performed. This analysis allows us to evaluate the impact of several design parameters on the system performance and the quality of the resulting decoded video.
2. State of the Art
2.1. All-Digital Video Systems
2.2. Hybrid Video Systems
2.2.1. 2D-DCT Hybrid Systems
- DCAST [9] exploits temporal redundancy through the technique of distributed source coding, making use of coset and syndrome coding. DCAST transmits an amount of metadata larger than Softcast because it has to send temporal redundancy information without errors in order to produce correct video decoding.
- The system proposed in [10] uses high-efficiency video coding (HEVC) as a base layer, and the residual is transmitted as a two-dimensional (2D)-DCT version of Softcast.
- SparseCast [11] uses compressive sensing instead of decimation of the DCT output; it does not consider the time dimension and, hence, is limited to the 2D-DCT.
- CG-Cast [12] is a Softcast-based system that employs a compressive-gradient-based image representation to describe perceptually sensitive image details. It also uses the fast Fourier transform (FFT) to determine the low-frequency data corresponding to the global and local luminance of the image.
2.2.2. 3D-DCT Hybrid Systems
- ParCast [13] is a video system similar to Softcast in which the encoded symbols are simultaneously transmitted over orthogonal subchannels. ParCast is more sophisticated than Softcast because the subchannels are optimized individually and requires a feedback channel. A later version, called ParCast+ [14], utilizes a motion compensated temporal filtering (MCTF) in order to integrate temporal redundancy within a 2D-DCT and, therefore, improves performance.
- The work in [15] is a Softcast-based system optimised for the transmission over fast fading channels. This is achieved by prioritizing and altering the order of the transmitted symbols according to the power of the DCT coefficients.
- SharpCast [16] is a hybrid system that uses HEVC to send the structure of the image and a 3D-DCT to transmit the residual. A similar system is proposed in [17] using Shannon–Kotel’nikov mapping to protect the analog residue. The system proposed in [18] is also similar to SharpCast, with the advantage of not requiring perfect decoding of the digital data in order to recover the video.
- Wireless Cooperative Video Coding (WCVC) [19] is based on the idea that certain nodes repeat the source signal over wireless channels using hybrid technologies. This system is based on the H.264/AVC standard to encode the base layer and an analog system similar to Softcast for the residues of the digital system. Hence, the modulation scheme superimposes the digital and analog information so that the digital part is the basic quality layer and the analog part adds quality to the video. This system is highly complex and computationally expensive since it requires two complete analog and digital schemes.
- The system described in [20] improves the Softcast scheme by protecting the top-left region at the 3D-DCT output matrix with a digital transmission. This system exhibits a better performance at the expense of increasing the amount of digital data.
- The system described in [21] is another version of Softcast that uses Gaussian Markov random field (GMRF) to significantly reduce the amount of metadata, while maintaining high video quality.
- MCast [22] is a version of Softcast optimised to achieve high-quality video transmissions over time-frequency varying channels.
2.2.3. Wavelet-Based Hybrid Systems
- WaveCast [23] employs 3D Wavelets together with a motion time filter in order to efficiently exploit the temporal redundancy. However, this information needs to be transmitted with no errors for the decoder to work properly. Thus, it requires an even larger amount of metadata than previous systems.
- The work in [24] describes a system which encodes the 2D-discrete wavelet transform (DWT) output low-frequency subband using H.264/AVC, while LH, HL, and HH are encoded with a DCT-based approach.
- Adaptive hybrid digital–analog video transmission (A-HDAVT) [25] is a fading channel oriented video transmission scheme. Some frames are selected to be transmitted digitally using H.264/AVC, while others are transmitted using an analog Haar DWT.
3. JSCC-Cast: Encoding and Transmission System
3.1. JSCC-Cast: Analog Encoder and Transmitter
3.2. AWGN Channel
3.3. JSCC-Cast: Analog Decoder and Receiver
3.4. Evaluation Metrics
4. System Design
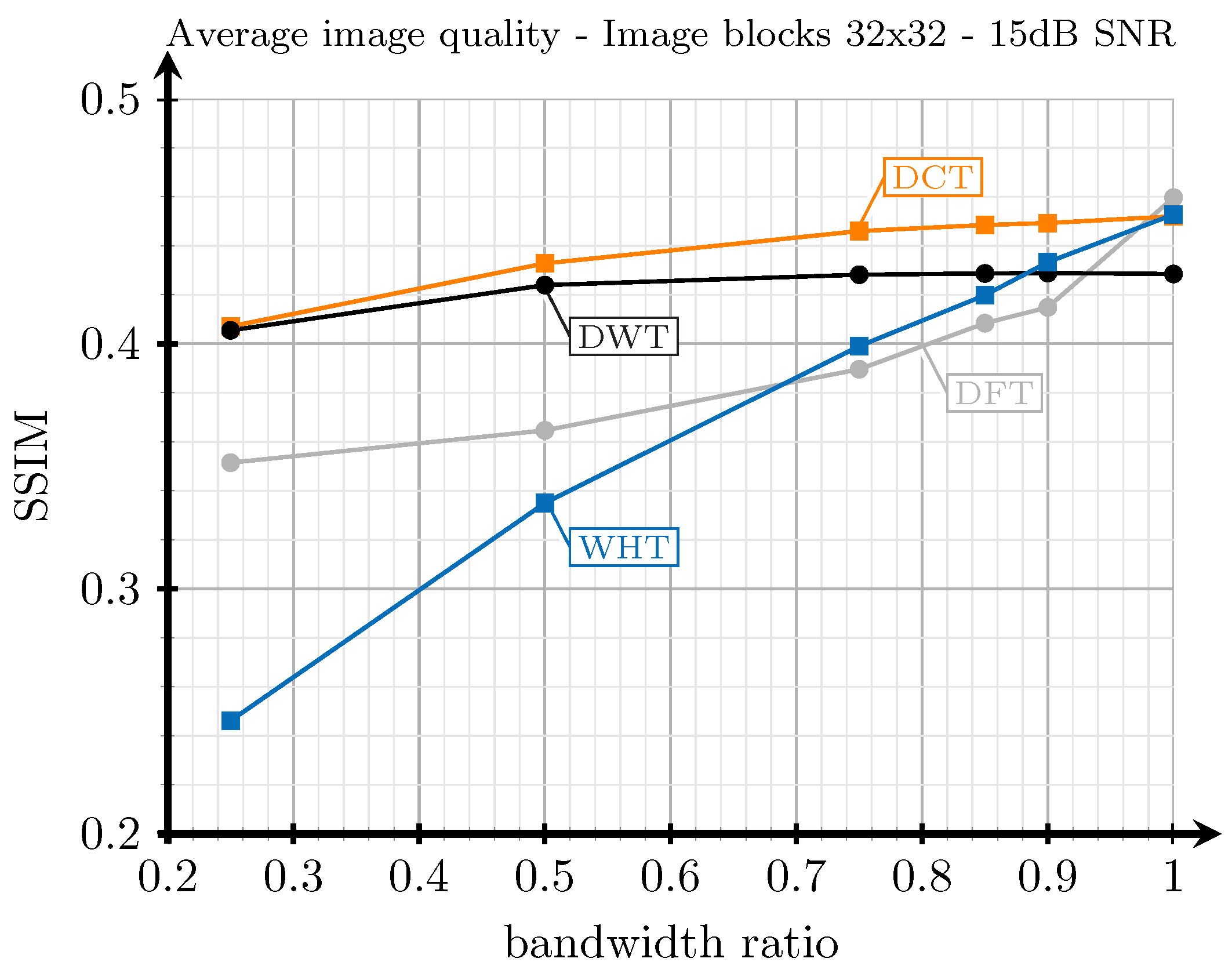
4.1. Domain Transforms for Images and Video
4.2. Block Spatial Division of the Video Frames
4.3. Temporal Redundancy
4.4. Frequency Coefficients Rearrangement Pattern
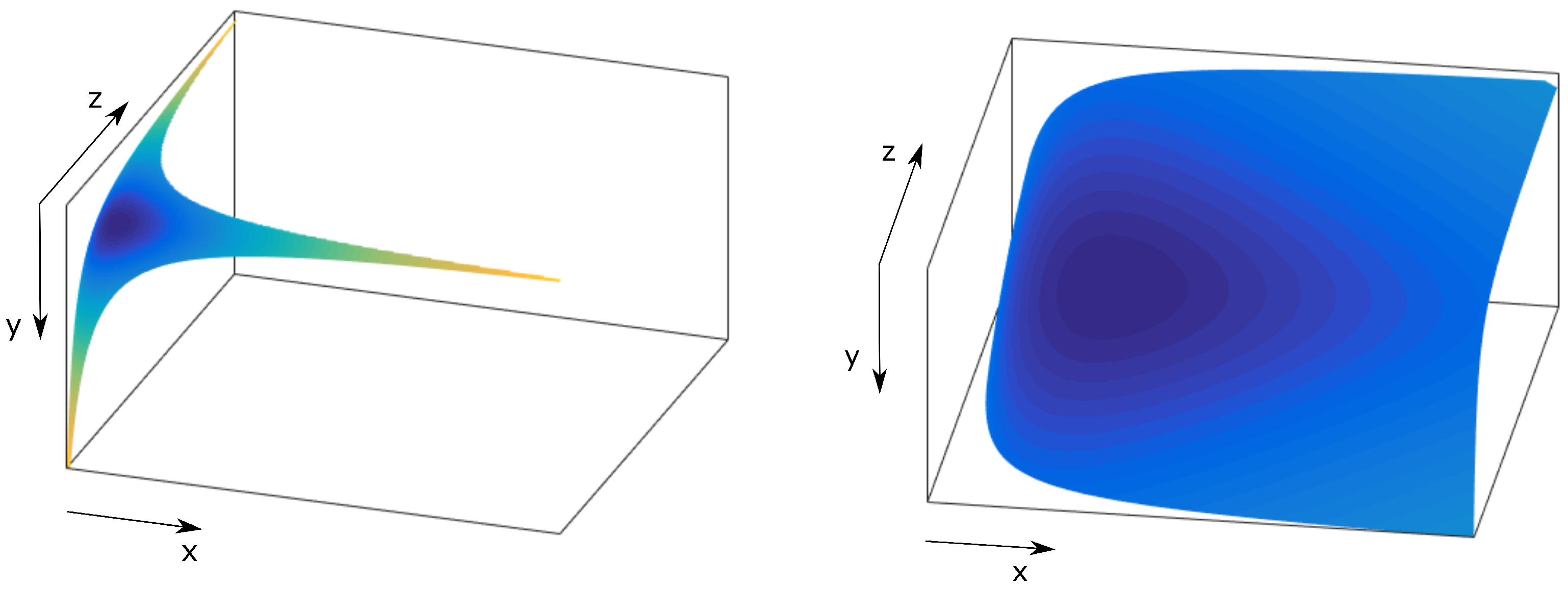
4.4.1. Isoplane
4.4.2. Hyperboloid
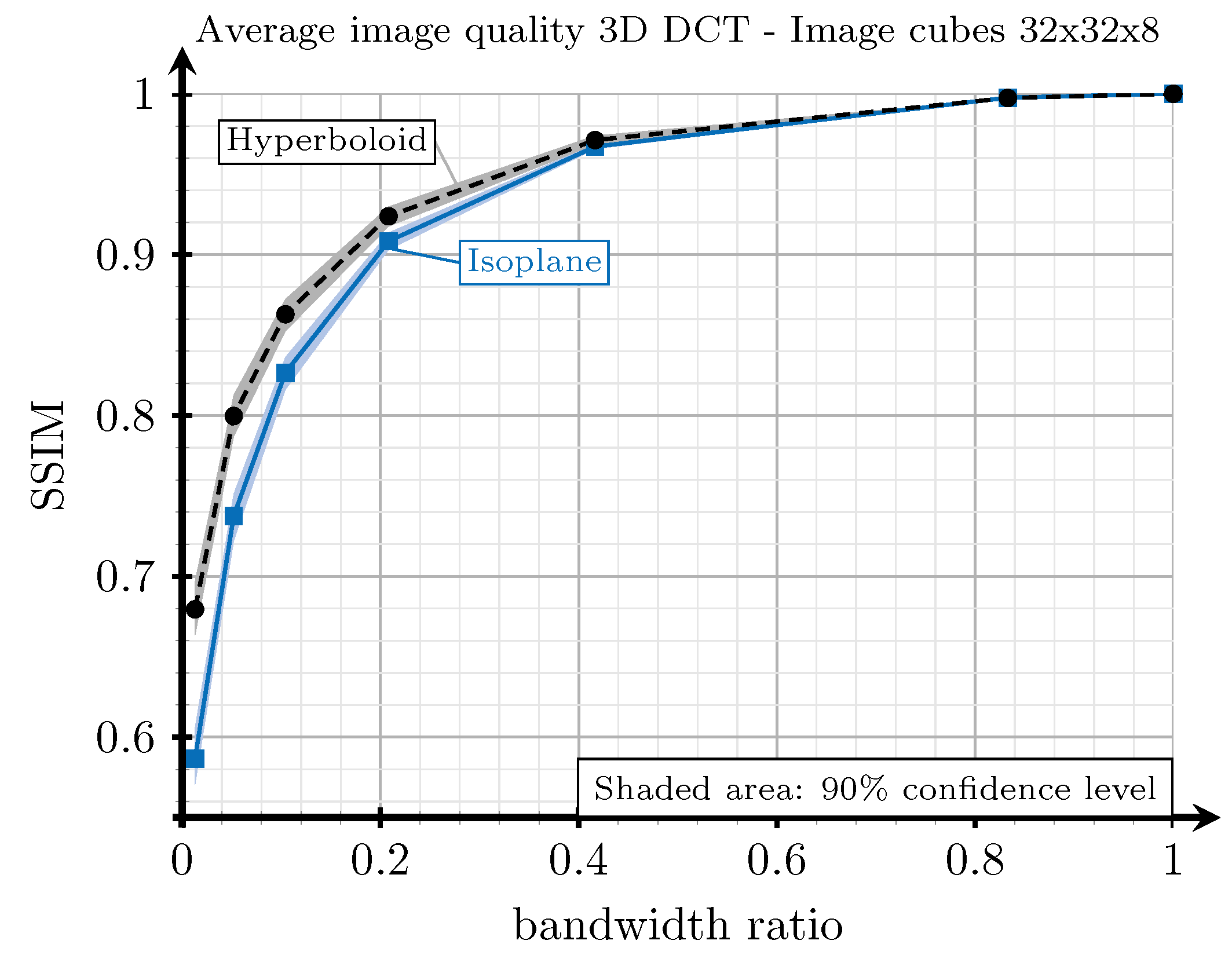
4.4.3. Analysis of the Rearranging Methods
4.5. Redundancy Analysis
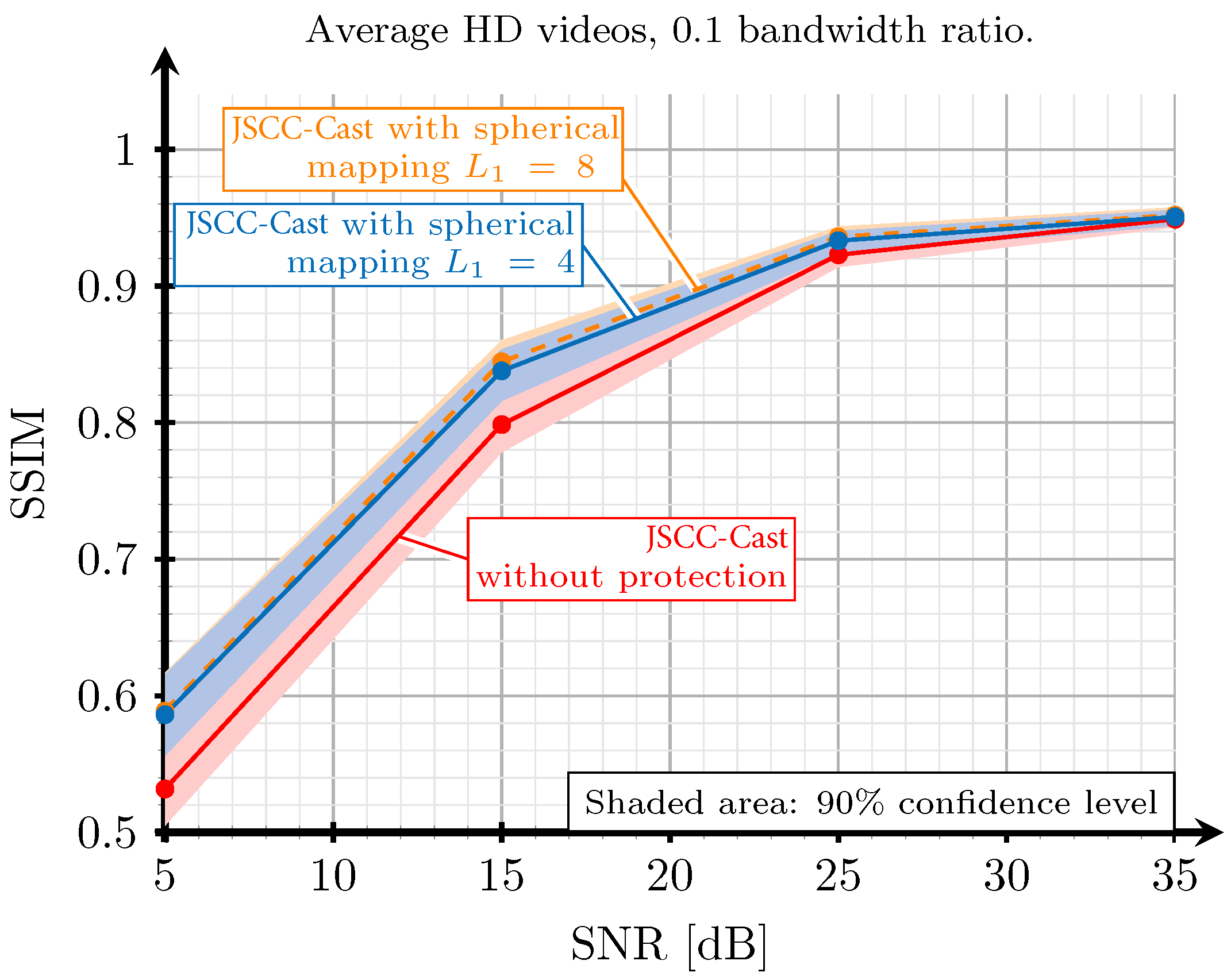
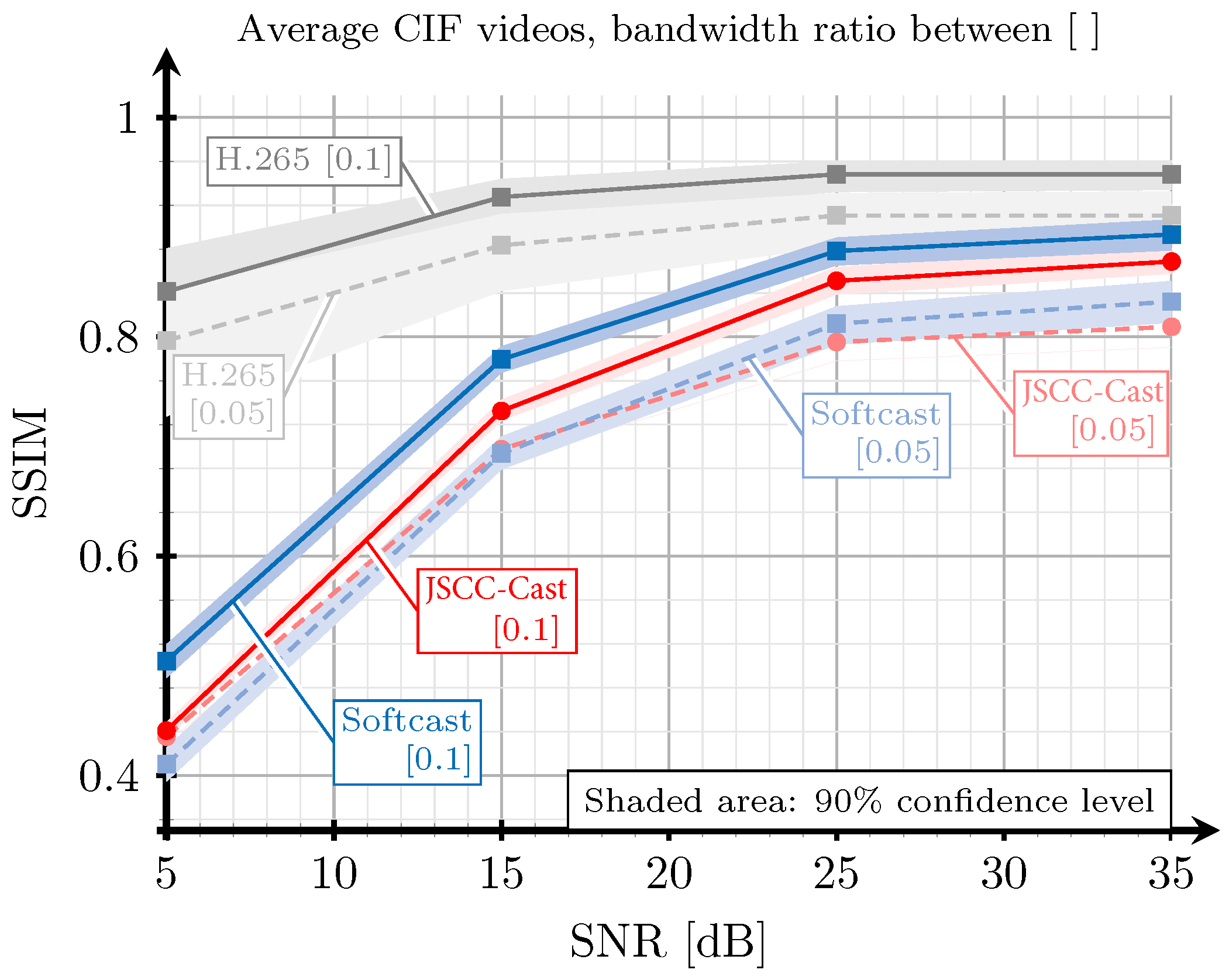
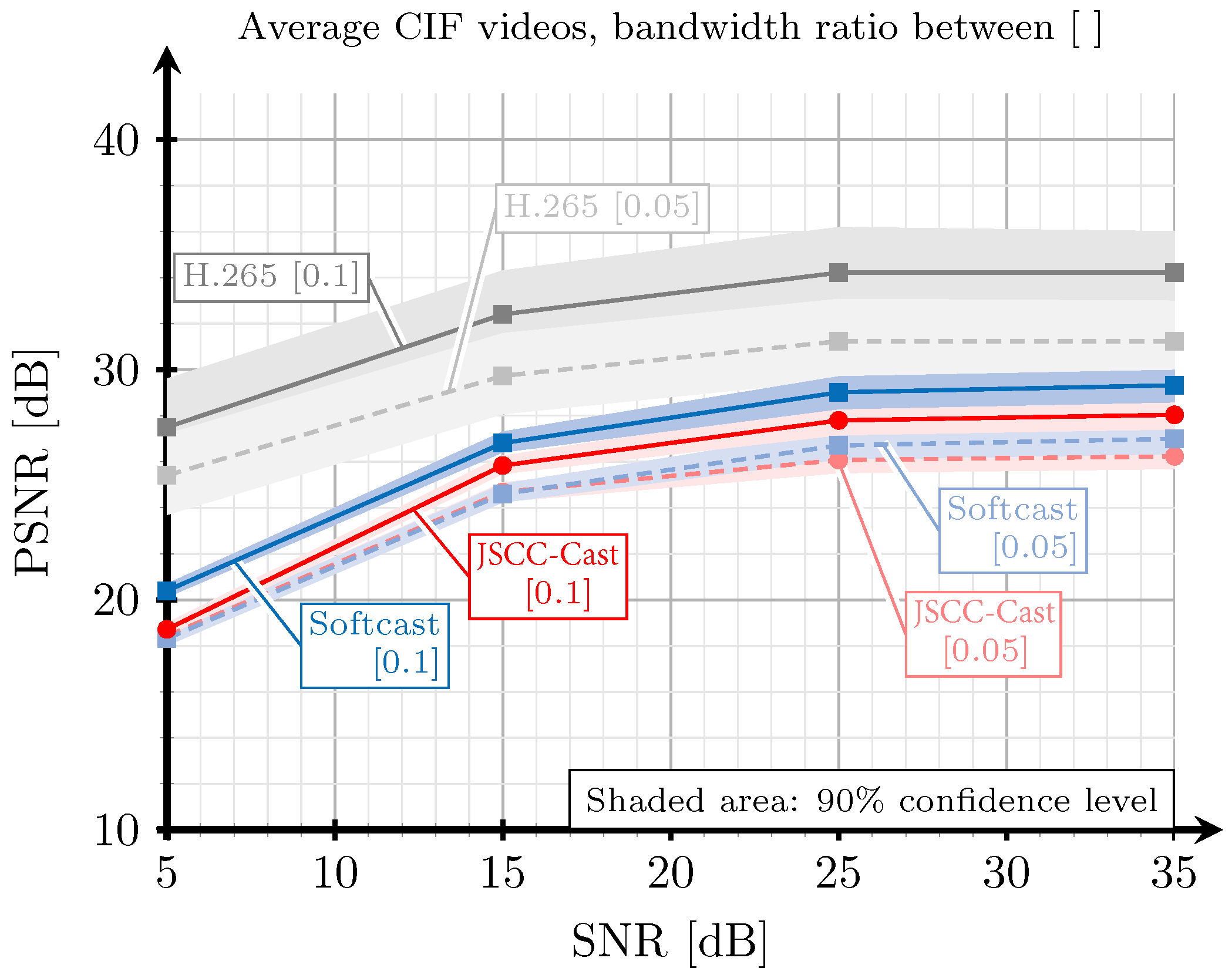
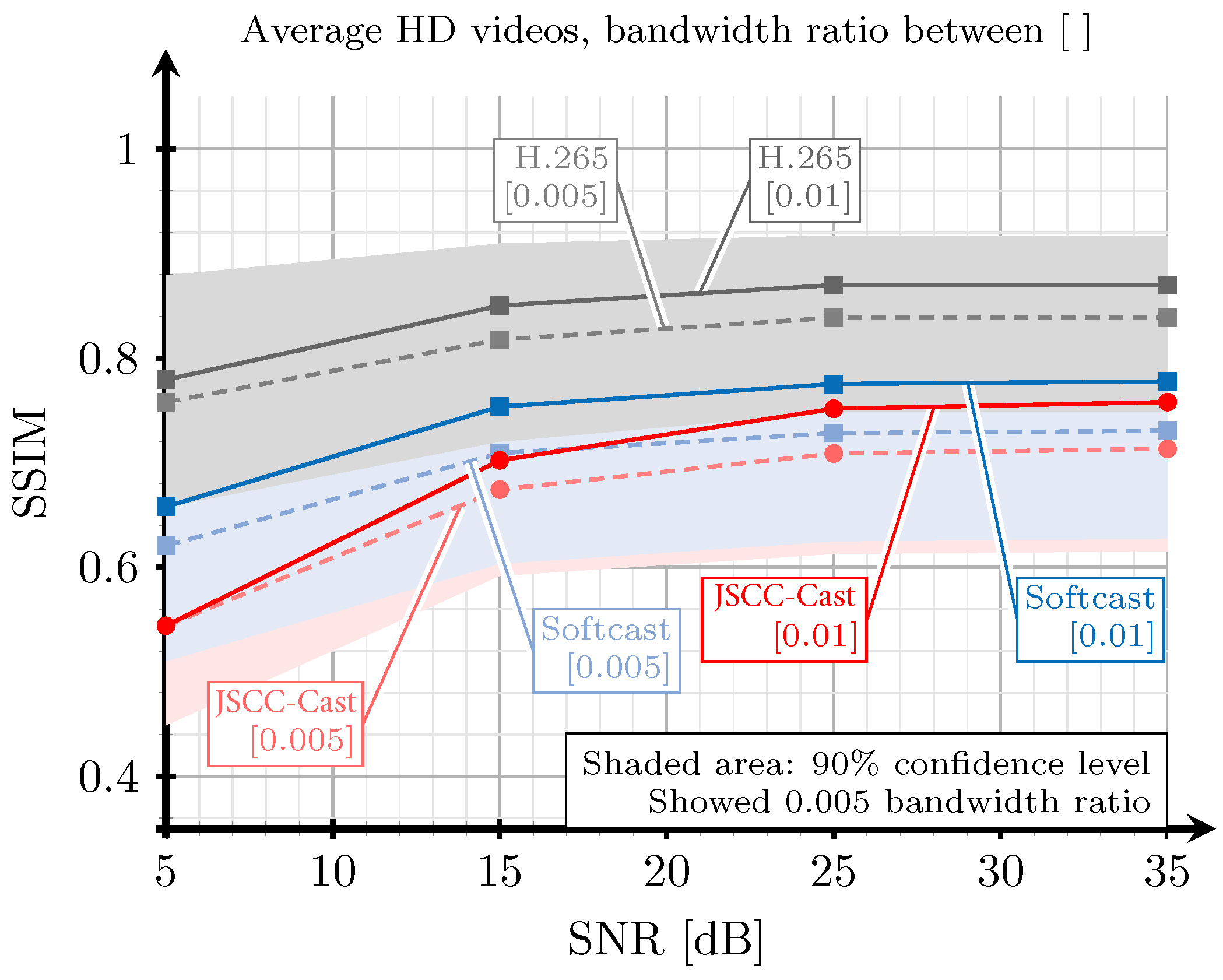
5. Evaluation and Results
5.1. Digital Implementation
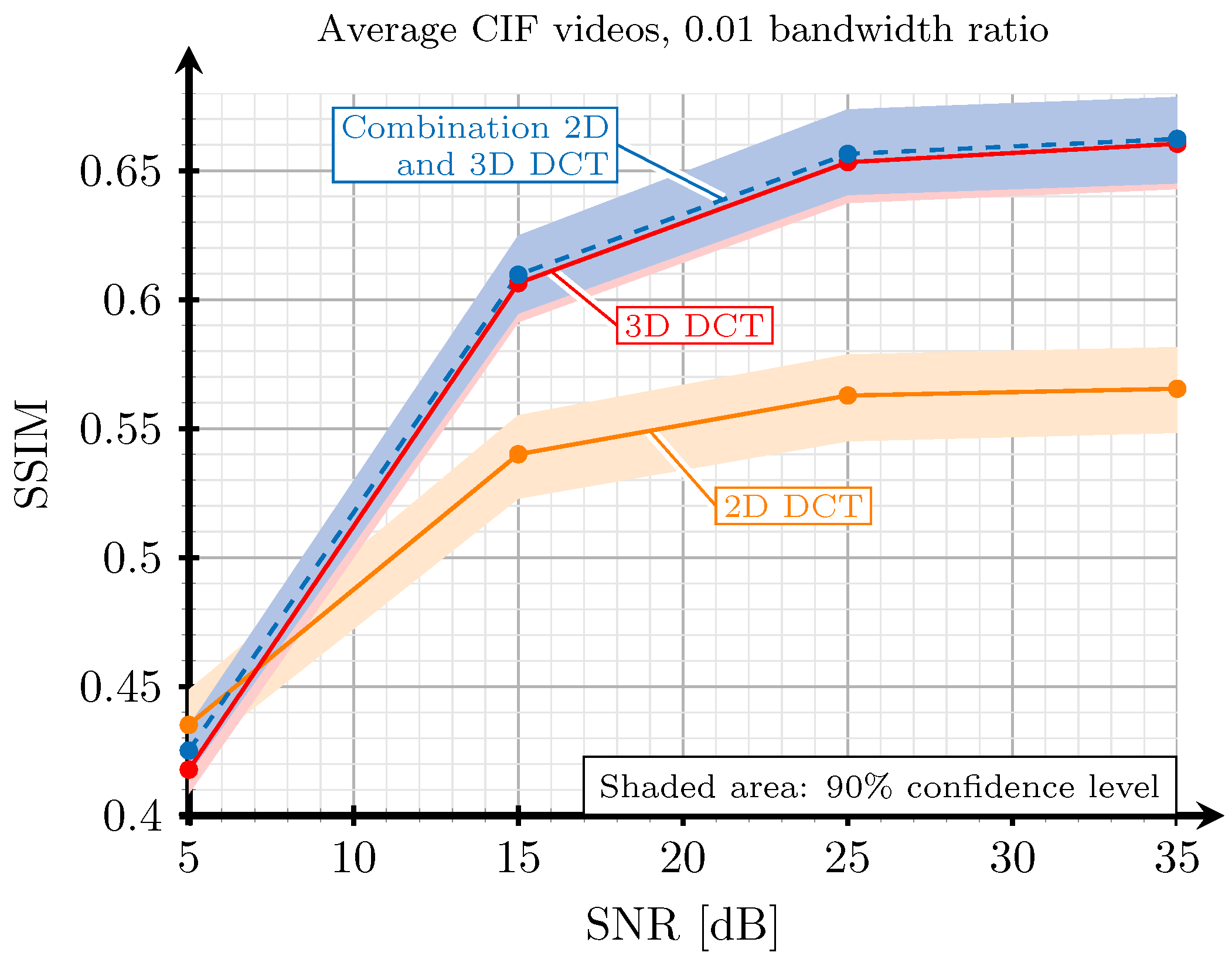
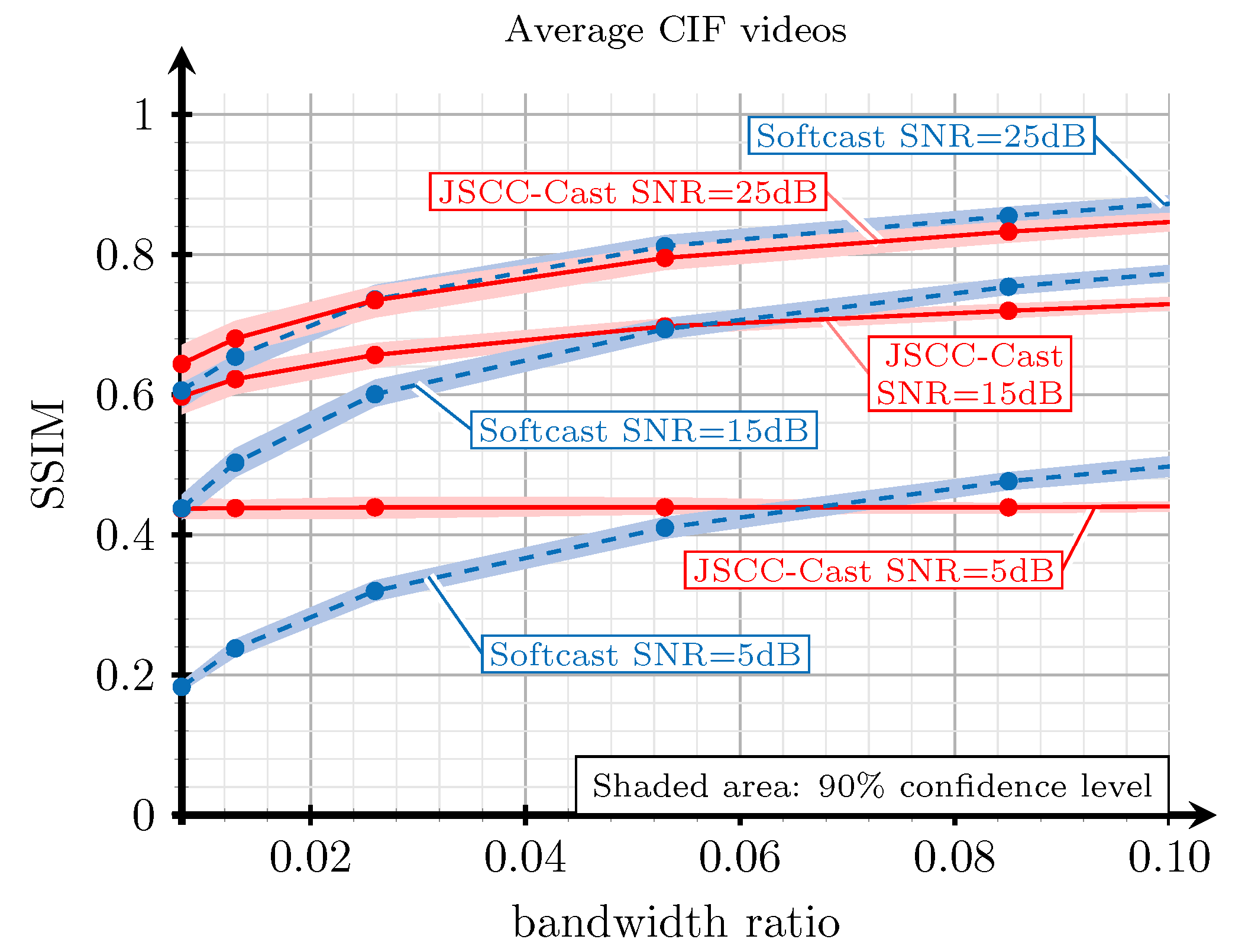
5.2. Evaluation Based on SSIM and PSNR
- A feedback link between the receiver and the transmitter is required to inform the transmitter about the channel quality. According to this information, the transmitter adapts its modulation and coding scheme, resulting in slower transmissions when the channel quality drops, hence reducing the overall system performance.
- In the case of deep channel fading situations, it is very likely that the digital system transmits above the channel capacity, especially if the channel fluctuates fast over time. This results in a situation where the receiver cannot recover the transmitted data, hence requiring additional strategies such as retransmissions, which severely penalize the throughput.
5.3. Perceptual Evaluation Based on Visual Comparison
5.4. Metadata Evaluation
6. Conclusions
Future Work
- Although JSCC-Cast exhibits blocking effects in some situations, they can be mitigated at the decoder by means of smooth filtering, hence increasing the quality of video at reception.
- The performance of JSCC-Cast is relatively far from that of H.265, the state-of-the-art digital system, for a specific SNR in channels with high noise. This problem could be mitigated by applying more complex analog coding techniques in order to protect the transmitted information at the cost of increasing the computational cost of the system, without significantly increasing the amount of transmitted information.
- In analog systems the image quality is directly proportional to the noise level of the channel. In this work, we have evaluated simulated channels with AWGN noise, but it would be very interesting to deal with real channels in order to evaluate how it affects the video quality.
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| 2D | Two-dimensional |
| 3D | Three-dimensional |
| AC | Alternate current |
| AJSCC | Analog joint source channel coding |
| AWGN | Additive white Gaussian noise |
| CBR | Constant bit rate |
| CIF | Common intermediate format |
| DC | Direct current |
| DCT | Discrete cosine transform |
| DFT | Discrete Fourier transform |
| DWT | Discrete wavelet transform |
| FFT | Fast Fourier transform |
| FHT | Fast Hadamard transform |
| GMRF | Gaussian Markov random field |
| HD | High-definition |
| HEVC | High-efficiency video coding |
| IoT | Internet of Things |
| JSCC | Joint source channel coding |
| ML | Maximum likelihood |
| MMSE | Minimum mean square error |
| MOS | Mean opinion scores |
| MSE | Mean square error |
| PSNR | Peak signal-to-noise ratio |
| SNR | Signal-to-noise ratio |
| SSIM | Structural similarity index measure |
| WHT | Walsh–Hadamard transform |
References
- CISCO. Cisco Annual Internet Report (2018–2023) White Paper; Technical Report; CISCO: San Jose, CA, USA, 2020. [Google Scholar]
- Lee, D.; Kim, H.; Rahimi, M.; Estrin, D.; Villasenor, J.D. Energy-Efficient Image Compression for Resource-Constrained Platforms. IEEE Trans. Image Process. 2009, 18, 2100–2113. [Google Scholar] [CrossRef]
- Phamila Y, A.V.; Amutha, R. Low complexity energy efficient very low bit-rate image compression scheme for wireless sensor network. Inf. Process. Lett. 2013, 113, 672–676. [Google Scholar] [CrossRef]
- Balsa, J.; Domínguez-Bolaño, T.; Fresnedo, O.; García-Naya, J.A.; Castedo, L. Transmission of Still Images Using Low-Complexity Analog Joint Source-Channel Coding. Sensors 2019, 19, 2932. [Google Scholar] [CrossRef] [Green Version]
- Domínguez-Bolaño, T.; Rodríguez-Piñeiro, J.; García-Naya, J.A.; Castedo, L. Bit Error Probability and Capacity Bound of OFDM Systems in Deterministic Doubly-Selective Channels. IEEE Trans. Veh. Technol. 2020, 69, 11458–11469. [Google Scholar] [CrossRef]
- Vass, J.; Zhuang, X. Multiresolution-multicast video distribution over the Internet. In Proceedings of the 2000 IEEE Wireless Communications and Networking Conference. Conference Record (Cat. No. 00TH8540), Chicago, IL, USA, 23–28 September 2000; Volume 3, pp. 1457–1461. [Google Scholar]
- Sundaresan, K.; Rangarajan, S. Video Multicasting with Channel Diversity in Wireless OFDMA Networks. IEEE Trans. Mob. Comput. 2014, 13, 2919–2932. [Google Scholar] [CrossRef]
- Jakubczak, S.; Katabi, D. SoftCast: One-Size-Fits-All Wireless Video. SIGCOMM Comput. Commun. Rev. 2010, 40, 449–450. [Google Scholar] [CrossRef] [Green Version]
- Fan, X.; Wu, F.; Zhao, D.; Au, O.C.; Gao, W. Distributed Soft Video Broadcast (DCAST) with Explicit Motion. In Proceedings of the 2012 Data Compression Conference, Snowbird, UT, USA, 10–12 April 2012; pp. 199–208. [Google Scholar]
- Tan, B.; Cui, H.; Wu, J.; Chen, C.W. An optimal resource allocation for superposition coding-based hybrid digital–analog system. IEEE Internet Things J. 2017, 4, 945–956. [Google Scholar] [CrossRef]
- Tung, T.; Gündüz, D. SparseCast: Hybrid Digital-Analog Wireless Image Transmission Exploiting Frequency-Domain Sparsity. IEEE Commun. Lett. 2018, 22, 2451–2454. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Xiong, R.; Fan, X.; Zhao, D.; Zhang, Y.; Gao, W. CG-Cast: Scalable wireless image SoftCast using compressive gradient. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 1832–1843. [Google Scholar] [CrossRef]
- Liu, X.L.; Hu, W.; Pu, Q.; Wu, F.; Zhang, Y. ParCast: Soft Video Delivery in MIMO-OFDM WLANs. In Proceedings of the 18th Annual International Conference on Mobile Computing and Networking; Association for Computing Machinery: New York, NY, USA, 2012; pp. 233–244. [Google Scholar] [CrossRef]
- Liu, X.L.; Hu, W.; Luo, C.; Pu, Q.; Wu, F.; Zhang, Y. ParCast+: Parallel video unicast in MIMO-OFDM WLANs. IEEE Trans. Multimed. 2014, 16, 2038–2051. [Google Scholar] [CrossRef]
- Cui, H.; Luo, C.; Chen, C.W.; Wu, F. Robust uncoded video transmission over wireless fast fading channel. In Proceedings of the IEEE INFOCOM 2014—IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; pp. 73–81. [Google Scholar]
- He, D.; Luo, C.; Lan, C.; Wu, F.; Zeng, W. Structure-preserving hybrid digital-analog video delivery in wireless networks. IEEE Trans. Multimed. 2015, 17, 1658–1670. [Google Scholar] [CrossRef]
- Liang, F.; Luo, C.; Xiong, R.; Zeng, W.; Wu, F. Hybrid Digital—Analog Video Delivery With Shannon—Kotel’nikov Mapping. IEEE Trans. Multimed. 2018, 20, 2138–2152. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, A.; Liang, J.; Wang, H.; Li, S.; Zhang, X. Distortion estimation-based adaptive power allocation for hybrid digital–analog video transmission. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 1806–1818. [Google Scholar] [CrossRef]
- Yu, L.; Li, H.; Li, W. Wireless Cooperative Video Coding Using a Hybrid Digital–Analog Scheme. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 436–450. [Google Scholar] [CrossRef]
- Lin, X.; Liu, Y.; Zhang, L. Scalable video SoftCast using magnitude shift. In Proceedings of the 2015 IEEE Wireless Communications and Networking Conference (WCNC), New Orleans, LA, USA, 9–12 March 2015; pp. 1996–2001. [Google Scholar]
- Fujihashi, T.; Koike-Akino, T.; Watanabe, T.; Orlik, P.V. High-quality soft video delivery with GMRF-based overhead reduction. IEEE Trans. Multimed. 2017, 20, 473–483. [Google Scholar] [CrossRef]
- He, C.; Wang, H.; Hu, Y.; Chen, Y.; Fan, X.; Li, H.; Zeng, B. MCast: High-quality linear video transmission with time and frequency diversities. IEEE Trans. Image Process. 2018, 27, 3599–3610. [Google Scholar] [CrossRef]
- Fan, X.; Xiong, R.; Wu, F.; Zhao, D. WaveCast: Wavelet based wireless video broadcast using lossy transmission. In Proceedings of the 2012 Visual Communications and Image Processing, San Diego, CA, USA, 27–30 November 2012; pp. 1–6. [Google Scholar]
- Yu, L.; Li, H.; Li, W. Wireless scalable video coding using a hybrid digital-analog scheme. IEEE Trans. Circuits Syst. Video Technol. 2013, 24, 331–345. [Google Scholar] [CrossRef]
- Zhao, X.; Lu, H.; Chen, C.W.; Wu, J. Adaptive hybrid digital–analog video transmission in wireless fading channel. IEEE Trans. Circuits Syst. Video Technol. 2015, 26, 1117–1130. [Google Scholar] [CrossRef]
- Vaishampayan, V.A.; Costa, S.I.R. Curves on a sphere, shift-map dynamics, and error control for continuous alphabet sources. IEEE Trans. Inf. Theory 2003, 49, 1658–1672. [Google Scholar] [CrossRef]
- Evangelaras, H.; Koukouvinos, C.; Seberry, J. Applications of Hadamard matrices. J. Telecommun. Inf. Technol. 2003, 2, 3–10. [Google Scholar]
- Beer, T. Walsh transforms. Am. J. Phys. 1981, 49, 466–472. [Google Scholar] [CrossRef]
- Beauchamp, K.G. Applications of Walsh and Related Functions: With an Introduction to Sequency Theory; Academic Press: Cambridge, MA, USA, 1984. [Google Scholar]
- Fresnedo, O.; Vazquez-Araujo, F.J.; Castedo, L.; Garcia-Frias, J. Low-Complexity Near-Optimal Decoding for Analog Joint Source Channel Coding Using Space-Filling Curves. IEEE Commun. Lett. 2013, 17, 745–748. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Winkler, S. Digital Video quality: Vision Models and Metrics; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Vranjes, M.; Rimac-Drlje, S.; Grgic, K. Locally averaged PSNR as a simple objective Video Quality Metric. In Proceedings of the 2008 50th International Symposium ELMAR, Zadar, Croatia, 10–12 September 2008; Volume 1, pp. 17–20. [Google Scholar]
- Huynh-Thu, Q.; Ghanbari, M. The accuracy of PSNR in predicting video quality for different video scenes and frame rates. Telecommun. Syst. 2012, 49, 35–48. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing; Pearson-Prentice Hall: Hoboken, NJ, USA, 2008. [Google Scholar]
- Balsa, J. Comparison of Image Compressions: Analog Transformations. Proceedings 2020, 54, 37. [Google Scholar] [CrossRef]
- The Waterloo Fractal Coding and Analysis Group Image Repository. Available online: http://links.uwaterloo.ca/Repository.html (accessed on 7 September 2020).
- Servais, M.; de Jager, G. Video compression using the three dimensional discrete cosine transform (3D-DCT). In Proceedings of the 1997 South African Symposium on Communications and Signal Processing, COMSIG ’97, Grahamstown, South Africa, 9–10 September 1997; pp. 27–32. [Google Scholar]
- Xiph.org Video Test Media [Derf’s Collection]. Available online: https://media.xiph.org/video/derf/ (accessed on 30 August 2021).
- Lee, M.; Chan, R.K.; Adjeroh, D.A. Quantization of 3D-DCT Coefficients and Scan Order for Video Compression. J. Vis. Commun. Image Represent. 1997, 8, 405–422. [Google Scholar] [CrossRef]
- Mulla, A.; Baviskar, J.; Baviskar, A.; Warty, C. Image compression scheme based on zig-zag 3D-DCT and LDPC coding. In Proceedings of the 2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Delhi, India, 24–27 September 2014; pp. 2380–2384. [Google Scholar]
- Yeo, B.L.; Liu, B. Volume rendering of DCT-based compressed 3D scalar data. IEEE Trans. Vis. Comput. Graph. 1995, 1, 29–43. [Google Scholar]
- He, L.; Lu, W.; Jia, C.; Hao, L. Video quality assessment by compact representation of energy in 3D-DCT domain. Neurocomputing 2017, 269, 108–116. [Google Scholar] [CrossRef]
- Adjeroh, D.A.; Sawant, S.D. Error-Resilient Transmission for 3D DCT Coded Video. IEEE Trans. Broadcast. 2009, 55, 178–189. [Google Scholar] [CrossRef]
- Song, Z.; Xiong, R.; Ma, S.; Fan, X.; Gao, W. Layered image/video softcast with hybrid digital-analog transmission for robust wireless visual communication. In Proceedings of the 2014 IEEE International Conference on Multimedia and Expo (ICME), Chengdu, China, 14–18 July 2014; pp. 1–6. [Google Scholar]
- He, D.; Lan, C.; Luo, C.; Chen, E.; Wu, F.; Zeng, W. Progressive pseudo-analog transmission for mobile video streaming. IEEE Trans. Multimed. 2017, 19, 1894–1907. [Google Scholar] [CrossRef]
- Jiang, X.; Feng, J.; Song, T.; Katayama, T. Low-Complexity and Hardware-Friendly H.265/HEVC Encoder for Vehicular Ad-Hoc Networks. Sensors 2019, 19, 1927. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- x265 Video Encoder. Available online: https://www.videolan.org/developers/x265.html (accessed on 2 September 2021).
- FFmpeg Tool. Available online: http://ffmpeg.org/ (accessed on 30 August 2021).
- Jakubczak, S.; Katabi, D. SoftCast: Clean-slate scalable wireless video. In Proceedings of the 2010 48th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 29 September–1 October 2010; pp. 530–533. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SNR Value | Constellation |
|---|---|
| SNR ≤ 8.5 dB | BPSK |
| 8.5 dB < SNR ≤ 13.5 dB | QPSK |
| 13.5 dB < SNR ≤ 22 dB | 16-QAM |
| 22 dB < SNR | 64-QAM |
| Bandwidth Ratio | Video Resolution | Bits/Frame | |
|---|---|---|---|
| Analog | Softcast | ||
| 0.05 | CIF | 3.9 | 50.8 |
| 0.1 | CIF | 3.8 | 113.6 |
| 0.2 | CIF | 4.0 | 258.6 |
| 0.005 | Full HD | 49.8 | 148 |
| 0.01 | Full HD | 20.4 | 329.7 |
| 0.05 | Full HD | 71.1 | 2106.5 |
| 0.1 | Full HD | 73.2 | 4598.6 |
| 0.2 | Full HD | 76.8 | 9974.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Balsa, J.; Fresnedo, Ó.; García-Naya, J.A.; Domínguez-Bolaño, T.; Castedo, L. JSCC-Cast: A Joint Source Channel Coding Video Encoding and Transmission System with Limited Digital Metadata. Sensors 2021, 21, 6208. https://doi.org/10.3390/s21186208
Balsa J, Fresnedo Ó, García-Naya JA, Domínguez-Bolaño T, Castedo L. JSCC-Cast: A Joint Source Channel Coding Video Encoding and Transmission System with Limited Digital Metadata. Sensors. 2021; 21(18):6208. https://doi.org/10.3390/s21186208
Chicago/Turabian StyleBalsa, Jose, Óscar Fresnedo, José A. García-Naya, Tomás Domínguez-Bolaño, and Luis Castedo. 2021. "JSCC-Cast: A Joint Source Channel Coding Video Encoding and Transmission System with Limited Digital Metadata" Sensors 21, no. 18: 6208. https://doi.org/10.3390/s21186208