
Abstract
We derive symmetric and antisymmetric kernels by symmetrizing and antisymmetrizing conventional kernels and analyze their properties. In particular, we compute the feature space dimensions of the resulting polynomial kernels, prove that the reproducing kernel Hilbert spaces induced by symmetric and antisymmetric Gaussian kernels are dense in the space of symmetric and antisymmetric functions, and propose a Slater determinant representation of the antisymmetric Gaussian kernel, which allows for an efficient evaluation even if the state space is high-dimensional. Furthermore, we show that by exploiting symmetries or antisymmetries the size of the training data set can be significantly reduced. The results are illustrated with guiding examples and simple quantum physics and chemistry applications.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Kernel methods and neural networks are two of the most prevalent and versatile machine learning techniques. While various recent publications focus on invariant or equivariant deep learning algorithms, our goal is to derive kernel-based methods that exploit symmetries. Symmetries play an important role in many research areas such as physics and chemistry [1–3], but also point cloud classification problems [4] or problems defined on sets [5] are naturally permutation-invariant. One of the most prominent applications is in quantum physics. Systems of bosons require symmetric wave functions, whereas systems of fermions are represented by antisymmetric wave functions. Exploiting such symmetries of the underlying system is a popular and powerful approach that has been used to improve the performance of kernel-based methods as well as deep-learning algorithms. The goal is to obtain more accurate representations without increasing the number of training data points—resulting in more efficient learning algorithms—and to ensure that symmetry constraints are satisfied. In [1] and [2], for instance, neural networks and kernel approaches that take into account symmetries of molecules are constructed. These methods are then used for learning potential energy surfaces. An approach for constructing potential energy surfaces based on Gaussian processes combined with permutation-invariant kernels can be found in [6]. Gaussian processes that exploit symmetries by summing over permutations of identical atoms are also utilized in [7] to improve the accuracy of density functional theory descriptions. Moreover, the so-called SOAP (smooth overlap of atomic positions) kernel [8] is a popular framework to design translation-, rotation-, and permutation-invariant descriptors of molecules. In [9], general invariant kernels (capturing discrete and continuous transformations) for pattern analysis are defined and analyzed. Recently, neural network architectures for antisymmetric wavefunctions have been proposed [10–14] that typically operate by applying Slater determinants to the outputs. The neural networks optimize the basis functions entering the Slater determinants through a deep learning variant of a technique called backflow. Backflow is a method to modify the basis functions used in quantum Monte Carlo as trial wavefunctions [15]. Neural network approaches such as FermiNet [11] and PauliNet [12] achieve extremely high accuracy with relatively few Slater determinants compared to standard quantum chemistry methods that build Slater determinants with fixed basis functions. Kernels, on the other hand, accomplish this by mapping the data to potentially infinite-dimensional feature spaces. Any continuous antisymmetric function can be approximated by antisymmetrized universal kernels. The universal approximation of symmetric and anti-symmetric functions is also studied in [16].
In this work, we develop kernels that are intrinsically symmetric or antisymmetric. Although we focus mostly on physics and chemistry applications in what follows, the derived kernels can be used in the same way in other kernel-based supervised or unsupervised learning algorithms such as kernel principal component analysis (kernel PCA) [17], kernel canonical correlation analysis (kernel CCA) [18], or support vector machines (SVMs) [19]. The main contributions are:
- We derive symmetric and antisymmetric kernels based on conventional kernels such as polynomial and Gaussian kernels and show that certain kernels can be expressed as Slater permanents or determinants.
- We analyze the feature spaces and approximation properties of such kernels.
- We demonstrate that these techniques improve the efficiency of kernel-based methods for problems exhibiting symmetries or antisymmetries.
- We apply kernel-based methods for solving the time-independent Schrödinger equation to simple quantum mechanics problems. Furthermore, we predict the boiling points of molecules using kernel ridge regression.
In section 2, we first introduce kernels, reproducing kernel Hilbert spaces, and kernel-based methods for solving the time-independent Schrödinger equation. Antisymmetric kernels will be derived in section 3 and symmetric kernels in section 4. These two sections contain the main theoretical results, in particular the analysis of the properties of the resulting polynomial and Gaussian kernels. Numerical results will be presented in section 5. We conclude the paper with a list of open problems and future research.
2. Kernels and kernel-based methods
We will briefly recapitulate the properties of kernels and introduce the induced reproducing kernel Hilbert spaces. Additionally, we will present a kernel-based method for solving the time-independent Schrödinger equation.
2.1. Reproducing kernel Hilbert spaces
A kernel can be regarded as a similarity measure. We will focus on real-valued kernels, but the definitions can be easily extended to complex domains. Kernel [19]
Definition 2.1
Given a non-empty set
 , a function
, a function
 is called
kernel if there exists a Hilbert space
is called
kernel if there exists a Hilbert space
 and a
feature map
and a
feature map
 such that
such that

For a given kernel k, the so-called Gram matrix
 associated with a data set
associated with a data set  is defined by
is defined by  .
Positive definiteness [19]
.
Positive definiteness [19]
Definition 2.2
A function
 is called positive definite if for all
m, all vectors
is called positive definite if for all
m, all vectors
![$ c = [c_1, \dots, c_m]^\top \in \mathbb{R}^m $](https://content.cld.iop.org/journals/2632-2153/2/4/045016/revision2/mlstac14adieqn9.gif) , and all subsets
, and all subsets
 it holds that
it holds that

Strictly positive definite means that  for mutually distinct data points only if c = 0. It can be shown that a function
for mutually distinct data points only if c = 0. It can be shown that a function  is a kernel if and only if it is symmetric, i.e.
is a kernel if and only if it is symmetric, i.e.  , and positive definite (s.p.d. in what follows to avoid confusion between different notions of symmetry), see [19]. Such kernels induce so-called reproducing kernel Hilbert spaces.
RKHS [19, 20]
, and positive definite (s.p.d. in what follows to avoid confusion between different notions of symmetry), see [19]. Such kernels induce so-called reproducing kernel Hilbert spaces.
RKHS [19, 20]
Definition 2.3
Let
 be a non-empty set. A space
be a non-empty set. A space
 of functions
of functions
 is called reproducing kernel Hilbert space (RKHS) with inner product
is called reproducing kernel Hilbert space (RKHS) with inner product
 if a kernel
k
exists such that
if a kernel
k
exists such that
- (a)
 for all
, and
for all
, and
- (b).



The first requirement is called the reproducing property. For f = k(x, ·), this results in 
 so that we can define the so-called canonical feature map by φ(x) = k(x, ·). Additionally, for a data set
so that we can define the so-called canonical feature map by φ(x) = k(x, ·). Additionally, for a data set  , we define
, we define ![$ \Phi = [\phi(x_1), \dots, \phi(x_m)] $](https://content.cld.iop.org/journals/2632-2153/2/4/045016/revision2/mlstac14adieqn24.gif) so that
so that  . For more details on kernels and reproducing kernel Hilbert spaces, we refer to [19, 20]. It was shown in [21, 22] that not only function evaluations but also derivative evaluations can be represented as inner products in the RKHS
. For more details on kernels and reproducing kernel Hilbert spaces, we refer to [19, 20]. It was shown in [21, 22] that not only function evaluations but also derivative evaluations can be represented as inner products in the RKHS  , provided the kernel is sufficiently smooth. Let now
, provided the kernel is sufficiently smooth. Let now  be a multi-index. We define
be a multi-index. We define  as usual and, for a fixed
as usual and, for a fixed  , the index set
, the index set  . Given a function
. Given a function  , the partial derivative of f with respect to α is defined by
, the partial derivative of f with respect to α is defined by

[21, 22]
Theorem 2.4 Let  be a non-negative number,
be a non-negative number,  a kernel, and
a kernel, and  the induced RKHS. Then:
the induced RKHS. Then:
- (a) for any and α ∈ Ir
.
- (b) for any , , and α ∈ Ir
.





In (i) and (ii), the derivative  is understood as acting on the first argument of the kernel k.
is understood as acting on the first argument of the kernel k.
We will need this property later for the approximation of differential operators. Another question is how rich these Hilbert spaces  induced by a kernel k are.
Universal kernel [23]
induced by a kernel k are.
Universal kernel [23]
Definition 2.5
Let
 be compact and
be compact and
 the space of all continuous functions mapping from
the space of all continuous functions mapping from
 to
to
 equipped with
equipped with
 . A kernel
k
is called
universal
if the induced RKHS
. A kernel
k
is called
universal
if the induced RKHS
 is dense in
is dense in
 .
.
That is, for a function  , we can find a function
, we can find a function  such that
such that  for any
for any  . The Gaussian kernel
. The Gaussian kernel

for instance, is universal, while the polynomial kernel

is not. We will analyze the properties of these kernels and their symmetrized and antisymmetrized counterparts in more detail below. Various other notions of universality and the relationships between universal and characteristic kernels are discussed in [24]. In what follows, we will omit the subscript  if it is clear which inner product or norm we are referring to.
if it is clear which inner product or norm we are referring to.
2.2. Kernel-based solution of the Schrödinger equation
In [25], we proposed a kernel-based method for the solution of the time-independent Schrödinger equation and the approximation of other differential operators such as the generator of the Koopman operator. We will restrict ourselves to the Schrödinger equation. Let V be a potential and  the Hamiltonian, where ћ is the reduced Planck constant and
the Hamiltonian, where ћ is the reduced Planck constant and  the mass, then the time-independent Schrödinger equation is defined by
the mass, then the time-independent Schrödinger equation is defined by

That is, we want to compute eigenfunctions ψ and the associated eigenvalues E, which correspond to energies of the system. We define

where el is the lth unit vector, and operators

Here,  is the standard covariance operator (see [26]) and
is the standard covariance operator (see [26]) and  contains the action of the Schrödinger operator. Since these integrals typically cannot be computed in practice, we estimate them using µ-distributed training data
contains the action of the Schrödinger operator. Since these integrals typically cannot be computed in practice, we estimate them using µ-distributed training data  , resulting in the empirical operators
, resulting in the empirical operators

Assuming that the eigenfunctions can be represented as  , i.e. they are contained in the space spanned by the functions
, i.e. they are contained in the space spanned by the functions  , we obtain a matrix eigenvalue problem
, we obtain a matrix eigenvalue problem

where the entries of the (generalized) Gram matrices  are defined by
are defined by

and

Eigenfunctions are then of the form

A detailed derivation and numerical results for simple quantum mechanics problems—the quantum harmonic oscillator and the hydrogen atom—can be found in [25].
3. Antisymmetric kernels and their properties
In this section, we will introduce the notion of antisymmetric kernels and define antisymmetric counterparts of well-known kernels such as the polynomial kernel and the Gaussian kernel. Furthermore, we analyze the properties of the resulting reproducing kernel Hilbert spaces. Most results can then be carried over to the symmetric case, which will be studied in section 4.
3.1. Antisymmetric kernels
Let  be the state space. Furthermore, let Sd
be the symmetric group and π ∈ Sd
a permutation. With a slight abuse of notation, we define
be the state space. Furthermore, let Sd
be the symmetric group and π ∈ Sd
a permutation. With a slight abuse of notation, we define ![$ \pi(x) = [x_{\pi(1)}, \dots, x_{\pi(d)}]^\top $](https://content.cld.iop.org/journals/2632-2153/2/4/045016/revision2/mlstac14adieqn63.gif) to be the vector
to be the vector  permuted by π. A function
permuted by π. A function  is called antisymmetric if
is called antisymmetric if

where  denotes the sign of the permutation π, which is 1 if the number of transpositions is even and −1 if it is odd. We define the antisymmetrization operator
denotes the sign of the permutation π, which is 1 if the number of transpositions is even and −1 if it is odd. We define the antisymmetrization operator
 by
by

Remark 3.1. In the same way, we can consider state spaces of the form  . Functions would then be antisymmetric with respect to permutations of vectors in
. Functions would then be antisymmetric with respect to permutations of vectors in  . That is, for
. That is, for ![$ x = [x_1, \dots, x_{d_x}]^\top $](https://content.cld.iop.org/journals/2632-2153/2/4/045016/revision2/mlstac14adieqn70.gif) with
with  , the permuted vector is then
, the permuted vector is then ![$ \pi(x) = [x_{\pi(1)}, \dots, x_{\pi(d_x)}]^\top $](https://content.cld.iop.org/journals/2632-2153/2/4/045016/revision2/mlstac14adieqn72.gif) . For typical quantum mechanics applications, for instance, dy
= 3 (every particle has a position in a three-dimensional space) and dx
the number of fermions (or bosons in the symmetric case). The special case dx
= 2 is considered in [27], where the spectral properties of symmetric and antisymmetric pairwise kernels are analyzed. Supervised learning problems with such pairwise kernels are discussed in [28].
. For typical quantum mechanics applications, for instance, dy
= 3 (every particle has a position in a three-dimensional space) and dx
the number of fermions (or bosons in the symmetric case). The special case dx
= 2 is considered in [27], where the spectral properties of symmetric and antisymmetric pairwise kernels are analyzed. Supervised learning problems with such pairwise kernels are discussed in [28].
Our goal is to define antisymmetric kernels for arbitrary d, which can then be used in kernel-based learning algorithms. Antisymmetric kernel function
Definition 3.2
Let
 be a kernel. We define an antisymmetric function
be a kernel. We define an antisymmetric function
 by
by

Clearly, if  , then also
, then also  . Furthermore, for a fixed permutation
. Furthermore, for a fixed permutation  , it holds that
, it holds that

Here, we used the fact that  and
and  . Additionally, we utilized the property that for a function
. Additionally, we utilized the property that for a function  it holds that
it holds that  , which corresponds to a reordering of the summands. Thus,
, which corresponds to a reordering of the summands. Thus,  is antisymmetric in both arguments. From (1) it directly follows that
is antisymmetric in both arguments. From (1) it directly follows that  if at least two entries of x or
if at least two entries of x or  are equal
6
.
are equal
6
.
Lemma 3.3. The function  defines an s.p.d. kernel.
defines an s.p.d. kernel.

where  . That is,
. That is,  is a kernel. Symmetry was shown above. To see that the function is positive definite, let
is a kernel. Symmetry was shown above. To see that the function is positive definite, let ![$ c = [c_1, \dots, c_m]^\top \in \mathbb{R}^m $](https://content.cld.iop.org/journals/2632-2153/2/4/045016/revision2/mlstac14adieqn91.gif) be a coefficient vector and
be a coefficient vector and  . Then
. Then

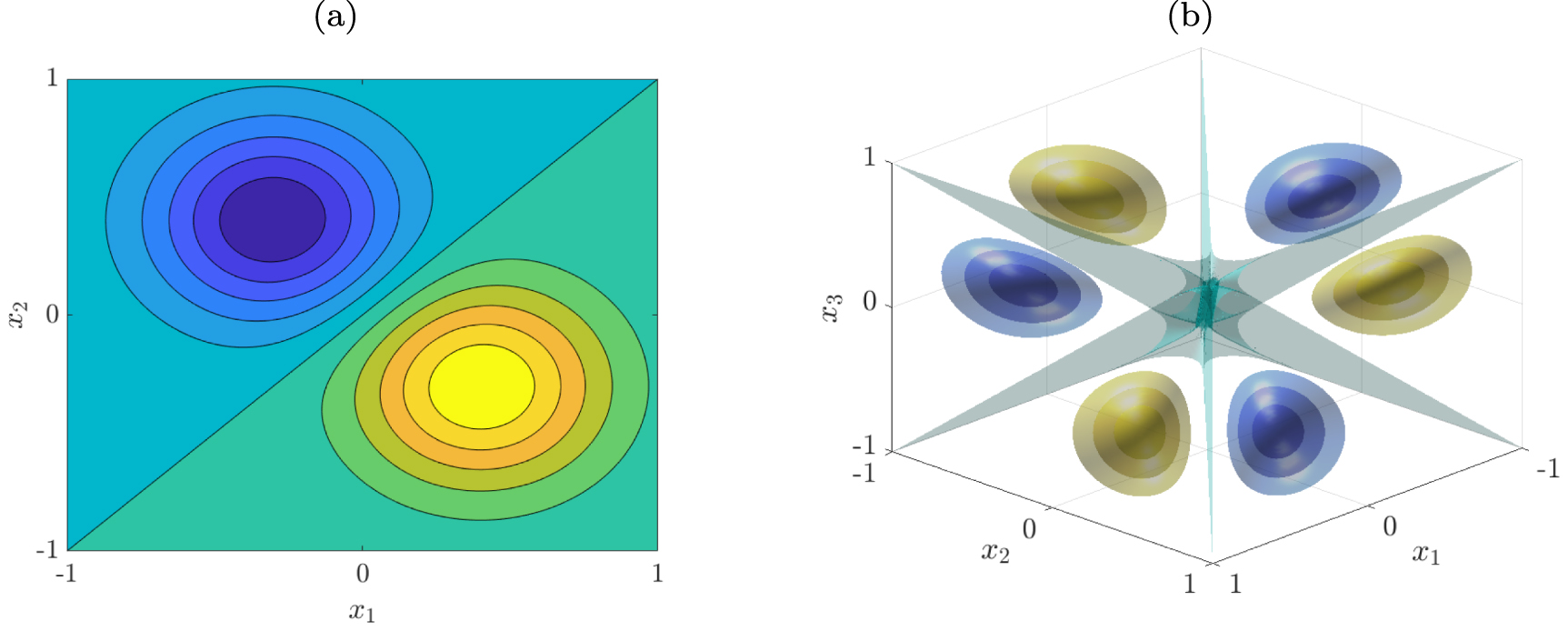
The antisymmetrized two- and three-dimensional Gaussian kernels are visualized in figure 1. The feature space mapping of the antisymmetric kernel  is the antisymmetrization operator
is the antisymmetrization operator  applied to the feature space mapping of the kernel k.
applied to the feature space mapping of the kernel k.
Example 3.4. For  , the feature space of the quadratic kernel
, the feature space of the quadratic kernel  is spanned by
is spanned by  and thus six-dimensional. The feature space of the antisymmetrized kernel
and thus six-dimensional. The feature space of the antisymmetrized kernel  is spanned by the two antisymmetric functions
is spanned by the two antisymmetric functions  . This illustrates that the feature space is significantly reduced.
. This illustrates that the feature space is significantly reduced. 

Figure 1. (a) Two-dimensional antisymmetric Gaussian kernel  , where
, where ![$ x^{\prime} = [0.4, -0.3]^\top $](https://content.cld.iop.org/journals/2632-2153/2/4/045016/revision2/mlstac14adieqn96.gif) and σ = 0.3. Yellow corresponds to positive and blue to negative values. (b) Three-dimensional antisymmetric Gaussian kernel
and σ = 0.3. Yellow corresponds to positive and blue to negative values. (b) Three-dimensional antisymmetric Gaussian kernel  , where
, where ![$ x^{\prime} = [0.3, -0.6, 0.4]^\top $](https://content.cld.iop.org/journals/2632-2153/2/4/045016/revision2/mlstac14adieqn98.gif) and σ = 0.2. The separating isosurface in the middle is defined by
and σ = 0.2. The separating isosurface in the middle is defined by  .
.
Download figure:
Standard image High-resolution imagePolynomial kernels of arbitrary degree p for d-dimensional spaces will be discussed in more detail in section 3.2.
Remark 3.5. The Mercer features of a kernel k are defined by the eigenfunctions of the integral operator

multiplied by the square root of the associated eigenvalues λ, see [19]. The Mercer features of an antisymmetric kernel  are automatically antisymmetric. This can be seen as follows: let ϕ be an eigenfunction of
are automatically antisymmetric. This can be seen as follows: let ϕ be an eigenfunction of  with corresponding eigenvalue λ, then
with corresponding eigenvalue λ, then

Mercer features of the Gaussian kernel and its antisymmetric and symmetric (see section 4) counterparts—computed by a spectral decomposition of the covariance operator, cf [29]—are shown in figure 2.
Permutation invarianceDefinition 3.6 We call a kernel permutation-invariant if

for all permutations π ∈ Sd .
The Gaussian kernel and the polynomial kernel are permutation-invariant since the standard inner product and induced norm are permutation-invariant, i.e.  for a permutation π ∈ Sd
. The antisymmetric kernel
for a permutation π ∈ Sd
. The antisymmetric kernel  is permutation-invariant by construction. While many kernels used in practice are naturally permutation-invariant, an open question is whether this assumption limits the expressivity of the induced function space. We will analyze the properties of the Gaussian kernel in section 3.3. The permutation-invariance allows us to simplify the representation of the antisymmetric kernel.
is permutation-invariant by construction. While many kernels used in practice are naturally permutation-invariant, an open question is whether this assumption limits the expressivity of the induced function space. We will analyze the properties of the Gaussian kernel in section 3.3. The permutation-invariance allows us to simplify the representation of the antisymmetric kernel.
Lemma 3.7. Given a permutation-invariant kernel k, it holds that

Proof.

since all permutations occur d! times. In the third line, we used the same properties of permutations as above. The proof for the second representation is analogous.
For the sake of simplicity, assume now that the kernel k is permutation-invariant. We want to show that for a universal kernel k, the reproducing kernel Hilbert space induced by the corresponding antisymmetric kernel  is dense in the space of antisymmetric functions.
is dense in the space of antisymmetric functions.
Proposition 3.8. Let  be bounded. Given a universal, permutation-invariant, continuous kernel k, the space
be bounded. Given a universal, permutation-invariant, continuous kernel k, the space  induced by
induced by  is dense in the space of continuous antisymmetric functions given by
is dense in the space of continuous antisymmetric functions given by  .
.
proof Let f be antisymmetric. It follows that  for all π ∈ Sd
and thus
for all π ∈ Sd
and thus

Since k is assumed to be universal, we can find coefficients  and vectors
and vectors  such that
such that  . Then
. Then

Continuous antisymmetric functions can be approximated arbitrarily well by universal antisymmetric kernels such as the Gaussian kernel. Although we used the same number of data points for the approximation in the proof (i.e. n points for the expansion in terms of k and also  ), fewer data points are required in practice if we employ the antisymmetric kernel, see example 3.14.
), fewer data points are required in practice if we employ the antisymmetric kernel, see example 3.14.

Figure 2. (a) Numerically computed normalized features of the Gaussian kernel k with bandwidth  . (b) Similar-looking but antisymmetric features of the associated kernel
. (b) Similar-looking but antisymmetric features of the associated kernel  . (c) Symmetric features of the kernel
. (c) Symmetric features of the kernel  derived in section 4.
derived in section 4.
Download figure:
Standard image High-resolution image3.2. Antisymmetric polynomial kernels
We have seen in example 3.4 that the feature space dimension of the polynomial kernel of order two for  is reduced from six to two by the antisymmetrization. Let
is reduced from six to two by the antisymmetrization. Let  be a multi-index and
be a multi-index and  . We define
. We define  . For a d-dimensional state space
. For a d-dimensional state space  , the polynomial kernel of order p is then given by
, the polynomial kernel of order p is then given by

where

and  , cf [30]. The multinomial coefficients are defined by
, cf [30]. The multinomial coefficients are defined by

Thus, the feature space is spanned by the monomials  and the dimension of the feature space is
and the dimension of the feature space is  , see, e.g. [31].
, see, e.g. [31].
We now want to find the feature space of the corresponding antisymmetric kernel ka
. Given a multi-index q, assume that there exist two entries qi
and qj
with  . Since the transposition (i, j) leaves the multi-index (and thus xq
) unchanged, this monomial will be eliminated by the antisymmetrization operator. It follows that the monomials must have distinct indices. In fact, the nonzero images of monomials under antisymmetrization are of the form
. Since the transposition (i, j) leaves the multi-index (and thus xq
) unchanged, this monomial will be eliminated by the antisymmetrization operator. It follows that the monomials must have distinct indices. In fact, the nonzero images of monomials under antisymmetrization are of the form

where  and
and  with
with  is a partition of a positive integer
7
, see [32]. The degrees of the terms of this antisymmetric polynomial are
is a partition of a positive integer
7
, see [32]. The degrees of the terms of this antisymmetric polynomial are  . Since we need all monomials of order
. Since we need all monomials of order  , we have to consider the partitions µ of
, we have to consider the partitions µ of  .
.
This representation uses the fact that multi-indices corresponding to antisymmetric polynomials can be written as q = δ + µ, where δ is defined as above and µ a partition. It follows that an antisymmetric polynomial must be at least of order  . Equation (2) can be regarded as a Slater determinant (introduced below) for a specific set of functions. We also obtain the Vandermonde determinant (up to the sign) as a special case where µ = 0.
Partition function
. Equation (2) can be regarded as a Slater determinant (introduced below) for a specific set of functions. We also obtain the Vandermonde determinant (up to the sign) as a special case where µ = 0.
Partition function
Definition 3.9 Let  be the function that counts the partitions of n into exactly
be the function that counts the partitions of n into exactly  parts.
parts.
A closed-form expressions for  is not known, but it can be expressed in terms of generating functions or computed using the recurrence relation
is not known, but it can be expressed in terms of generating functions or computed using the recurrence relation

where we define  if n = 0 and
if n = 0 and  and
and  if
if  or
or  (but not
(but not  ), see [33] for more details about partitions and partition functions.
), see [33] for more details about partitions and partition functions.
Lemma 3.10. The dimension of the feature space generated by the antisymmetrized polynomial kernel of order p is

Proof.
proof Since  of the
of the  exponents are already spoken for, we can use only the remaining
exponents are already spoken for, we can use only the remaining  to generate partitions µ, with
to generate partitions µ, with  . All these numbers can be decomposed into at most d parts since we have only d variables. If the number of components is smaller than d, we simply add zeros.
. All these numbers can be decomposed into at most d parts since we have only d variables. If the number of components is smaller than d, we simply add zeros.
Example 3.11. For d = 3 and p = 6, the base case is δ = (2, 1, 0), and we can generate partitions for

resulting in seven antisymmetric polynomials. 
The sizes of the feature spaces of the polynomial kernels k and  for different dimensions d and degrees p are summarized in table 1. This shows that antisymmetric polynomial kernels might not be feasible for higher-dimensional problems. For d = 10, for example, the lowest degree of the monomials is already 45.
for different dimensions d and degrees p are summarized in table 1. This shows that antisymmetric polynomial kernels might not be feasible for higher-dimensional problems. For d = 10, for example, the lowest degree of the monomials is already 45.
Table 1. Dimensions of the feature spaces spanned by the polynomial kernel k and its antisymmetric counterpart  . Here, d is the dimension of the state space and p the degree of the polynomial kernel.
. Here, d is the dimension of the state space and p the degree of the polynomial kernel.
| p | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| d |

|

|

|

|

|

|

|

|

|

|

|

|

|

|
| 2 | 6 | 2 | 10 | 4 | 15 | 6 | 21 | 9 | 28 | 12 | 36 | 16 | 45 | 20 |
| 3 | 10 | 0 | 20 | 1 | 35 | 2 | 56 | 4 | 84 | 7 | 120 | 11 | 165 | 16 |
| 4 | 15 | 0 | 35 | 0 | 70 | 0 | 126 | 0 | 210 | 1 | 330 | 2 | 495 | 4 |
3.3. Antisymmetric Gaussian kernels
We will now analyze the properties of the Gaussian kernel. We have shown in Proposition 3.8 that the space spanned by the antisymmetric Gaussian kernel is dense in the space of continuous antisymmetric functions. For the Gaussian kernel, the expression obtained in lemma 3.7 can be simplified even further.
Lemma 3.12. Let k be the Gaussian kernel with bandwidth σ, then

Proof.
proof Applying Leibniz' formula

we have

Lemma 3.7 then yields the desired result.
This decomposition is akin to the well-known Slater determinant (see, e.g. [34]), which defines an antisymmetric wave function by

Notice that here the normalization factor is chosen in such a way that, provided the wave functions ψi
,  , are normalized and orthogonal to each other,
, are normalized and orthogonal to each other,  is normalized as well.
is normalized as well.
Remark 3.13. We can define a more general class of antisymmetric kernels. Let  be a function, then
be a function, then

defines an antisymmetric kernel. We call such a function  a Slater kernel. The Gaussian kernel can be obtained by setting
a Slater kernel. The Gaussian kernel can be obtained by setting  and the Laplacian kernel—using the 1-norm—by setting
and the Laplacian kernel—using the 1-norm—by setting  . Alternatively, kernels based on generalized Slater determinants could be constructed or by concatenating creation and annihilation operators, see also [11–13].
. Alternatively, kernels based on generalized Slater determinants could be constructed or by concatenating creation and annihilation operators, see also [11–13].
The advantage of the Slater determinant formulation is that we can compute it efficiently using matrix decomposition techniques, without having to iterate over all permutations, which would be clearly infeasible for higher-dimensional problems.
Example 3.14. In order to illustrate the difference between a standard Gaussian kernel k and its antisymmetrized counterpart  , we define an antisymmetric function
, we define an antisymmetric function  by
by  and apply kernel ridge regression (see, e.g. [31]) to randomly sampled data points
8
. That is, we generate m data points x(i) in
and apply kernel ridge regression (see, e.g. [31]) to randomly sampled data points
8
. That is, we generate m data points x(i) in ![$ \mathbb{X} = [-1, 1] \times [-1, 1] $](https://content.cld.iop.org/journals/2632-2153/2/4/045016/revision2/mlstac14adieqn181.gif) and compute
and compute  . We then try to recover f from the training data
. We then try to recover f from the training data  . Additionally, we define an augmented data set of size 2 m by adding the antisymmetrized data set, i.e.
. Additionally, we define an augmented data set of size 2 m by adding the antisymmetrized data set, i.e.  , where π = (1, 2) in cycle notation. The bandwidth of the kernel is set to
, where π = (1, 2) in cycle notation. The bandwidth of the kernel is set to  . The results are shown in figure 3. We measure the root-mean-square error (RMSE)—averaged over 5000 runs—in the midpoints of a regular 30 × 30 box discretization of the domain. Kernel ridge regression using
. The results are shown in figure 3. We measure the root-mean-square error (RMSE)—averaged over 5000 runs—in the midpoints of a regular 30 × 30 box discretization of the domain. Kernel ridge regression using  results in more accurate function approximations and is, for small m, numerically equivalent to kernel ridge regression using k applied to the augmented data set of size 2 m. For larger values of m, doubling the size of the data set leads to ill-conditioned matrices and increased numerical errors
9
.
results in more accurate function approximations and is, for small m, numerically equivalent to kernel ridge regression using k applied to the augmented data set of size 2 m. For larger values of m, doubling the size of the data set leads to ill-conditioned matrices and increased numerical errors
9
. 

Figure 3. (a) Antisymmetric function  . (b) Kernel ridge regression approximation error as a function of the number of data points. The antisymmetric Gaussian kernel leads to more accurate function approximations without increasing the size of the training data set.
. (b) Kernel ridge regression approximation error as a function of the number of data points. The antisymmetric Gaussian kernel leads to more accurate function approximations without increasing the size of the training data set.
Download figure:
Standard image High-resolution imageThe example shows that the antisymmetrized kernel is indeed advantageous, it enables a more accurate representation without increasing the size of the data set. For higher-dimensional problems, this effect will be even more pronounced. To obtain the same accuracy for a three-dimensional antisymmetric function, we would already need 6 m data points. The kernel evaluations, on the other hand, become more expensive, but are easily parallelizable. The bottleneck of kernel-based methods is often the size of the training data set, which enters in a cubic way (since a generally dense system of linear equations has to be solved, or, if we are interested in eigenfunctions of operators associated with dynamical systems, a generalized eigenvalue problem).
3.4. Derivatives of antisymmetric kernels
For the approximation of differential operators, we will also need partial derivatives of the kernel  . Since
. Since  just comprises alternating sums of kernel functions k, we can compute derivatives of
just comprises alternating sums of kernel functions k, we can compute derivatives of  by summing over derivatives of k. For polynomial and Gaussian kernels, the derivatives of k can be found in [25]. Alternatively, the partial derivatives of the antisymmetric Gaussian kernel can be computed via Slater determinants.
by summing over derivatives of k. For polynomial and Gaussian kernels, the derivatives of k can be found in [25]. Alternatively, the partial derivatives of the antisymmetric Gaussian kernel can be computed via Slater determinants.
Example 3.15.
For the antisymmetric Gaussian kernel, let
 be the matrix with entries
be the matrix with entries

Then

Similar formulas can be derived for the second-order derivatives.

4. Symmetric kernels and their properties
Although we focused on antisymmetric functions so far, symmetric functions also play an important role in quantum physics. Other typical applications include point clouds, sets, and graphs, where the numbering of points, elements, or vertices should not impair the learning algorithms. Some of the above results can be easily carried over to the symmetric case. The special case dx = 2 is analyzed in [27]. Similar symmetrized kernels are also constructed in [6]. We focus on the analysis of the induced functions spaces.
4.1. Symmetric kernels
We call a function  symmetric if
symmetric if

for all permutations π ∈ Sd and define the symmetrization operator

Symmetric kernel function
Definition 4.1 Let  be a kernel. We then define a symmetric function
be a kernel. We then define a symmetric function  by
by

We simply omitted the signs of the permutations here. As before, if  , then also
, then also  . The function
. The function  is permutation-symmetric in both arguments. Note that the definition of permutation-symmetry is different from permutation-invariance, which was defined by
is permutation-symmetric in both arguments. Note that the definition of permutation-symmetry is different from permutation-invariance, which was defined by  . Permutation-symmetric kernels are, however, automatically permutation-invariant. We briefly restate the above results for symmetric functions, the proofs are analogous to their counterparts for antisymmetric functions.
. Permutation-symmetric kernels are, however, automatically permutation-invariant. We briefly restate the above results for symmetric functions, the proofs are analogous to their counterparts for antisymmetric functions.
Lemma 4.2. The function  defines an s.p.d. kernel.
defines an s.p.d. kernel.
Example 4.3.
For
 , the feature space of the symmetrized polynomial kernel of order 2 is spanned by the symmetric functions
, the feature space of the symmetrized polynomial kernel of order 2 is spanned by the symmetric functions
 .
. 
More general results for polynomial kernels will be derived in section 4.2. Eigenfunctions of the integral operator associated with  are symmetric. Mercer features of the symmetrized Gaussian kernel for d = 2 are shown in figure 2.
are symmetric. Mercer features of the symmetrized Gaussian kernel for d = 2 are shown in figure 2.
Lemma 4.4. Given a permutation-invariant kernel k, it holds that

Analogously, continuous symmetric functions can be approximated arbitrarily well by symmetric universal kernels.
Proposition 4.5. Let  be bounded. Given a universal, permutation-invariant, continuous kernel k, the space
be bounded. Given a universal, permutation-invariant, continuous kernel k, the space  induced by
induced by  is dense in the space of continuous symmetric functions given by
is dense in the space of continuous symmetric functions given by  .
.
4.2. Symmetric polynomial kernels
Let us compute the dimensions of the feature spaces spanned by symmetrized polynomial kernels.
Lemma 4.6. The dimension of the feature space generated by the symmetrized polynomial kernel of order p is

Proof.
proof Let π be a permutation, then the multi-indices q and π(q) generate the same feature space function when we apply the symmetrization operator  to the corresponding monomials xq
and
to the corresponding monomials xq
and  . We thus have to consider only partitions µ of the integers
. We thus have to consider only partitions µ of the integers  since the ordering of the multi-indices does not matter.
since the ordering of the multi-indices does not matter.
This case is similar to the antisymmetric case, with the difference that we require partitions of integers up to p instead of  . Table 2 lists the dimensions of the feature spaces spanned by the polynomial kernel k and its symmetric version
. Table 2 lists the dimensions of the feature spaces spanned by the polynomial kernel k and its symmetric version  for different combinations of d and p. Compared to the standard polynomial kernel, the number of features is significantly lower, but higher than the number of features generated by the antisymmetric polynomial kernel.
for different combinations of d and p. Compared to the standard polynomial kernel, the number of features is significantly lower, but higher than the number of features generated by the antisymmetric polynomial kernel.
Table 2. Dimensions of the feature spaces spanned by the polynomial kernel k and its symmetric counterpart  . Here, d is again the dimension of the state space and p the degree, cf table 1.
. Here, d is again the dimension of the state space and p the degree, cf table 1.
| p | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| d |

|

|

|

|

|

|

|

|

|

|

|

|

|

|
| 2 | 6 | 4 | 10 | 6 | 15 | 9 | 21 | 12 | 28 | 16 | 36 | 20 | 45 | 25 |
| 3 | 10 | 4 | 20 | 7 | 35 | 11 | 56 | 16 | 84 | 23 | 120 | 31 | 165 | 41 |
| 4 | 15 | 4 | 35 | 7 | 70 | 12 | 126 | 18 | 210 | 27 | 330 | 38 | 495 | 53 |
4.3. Symmetric Gaussian kernels
The symmetric kernel cannot be expressed as a Slater determinant anymore, but we can utilize a related concept. The permanent of a matrix  is defined by
is defined by

While for d = 2 the permanent can be written as a determinant (by flipping the sign of a12 or a21), this is not possible anymore for  [35]. No polynomial-time algorithm for the computation of the permanent is known, but there are efficient approximation schemes for matrices with non-negative entries [36].
[35]. No polynomial-time algorithm for the computation of the permanent is known, but there are efficient approximation schemes for matrices with non-negative entries [36].
Lemma 4.7. Let k be the Gaussian kernel with bandwidth σ, then

Proof.
proof The proof is analogous to the one for lemma 3.12. Using the definition of the permanent, we obtain

The result then follows from lemma 4.4.
Example 4.8. Assume we have a set of undirected graphs that we would like to classify or categorize. The results should not depend on the vertex labels and thus be identical for isomorphic graphs. Let  be the adjacency matrices of the graphs G and
be the adjacency matrices of the graphs G and  , respectively. We define a Gaussian kernel for graphs by
, respectively. We define a Gaussian kernel for graphs by

where  denotes the Frobenius norm, and make it symmetric as described above. The only difference here is that we have to define
denotes the Frobenius norm, and make it symmetric as described above. The only difference here is that we have to define  to permute rows and columns simultaneously. The kernel function
to permute rows and columns simultaneously. The kernel function  can then be expressed in terms of so-called hyperpermanents. We have
can then be expressed in terms of so-called hyperpermanents. We have

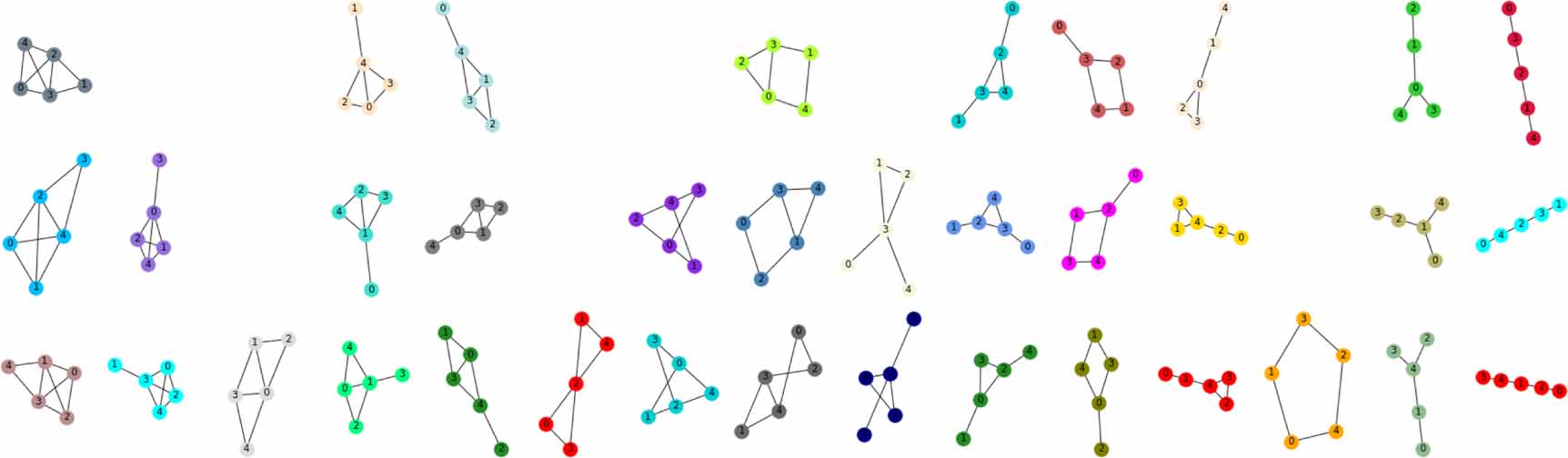
The derivation of a formula for the Laplace expansion of hyperpermanents can be found in appendix A.1. For the considered example, we set σ = 1 and randomly generate a set of 100 undirected connected graphs of size d = 5. We then apply kernel PCA, see [17], using the symmetric kernel  . Sorting the graphs according to the first principal component, we obtain the ordering shown in figure 4 (only a subset of the graphs is displayed). Isomorphic graphs are grouped into the same category.
. Sorting the graphs according to the first principal component, we obtain the ordering shown in figure 4 (only a subset of the graphs is displayed). Isomorphic graphs are grouped into the same category. 

Figure 4. Application of kernel PCA to a set of undirected graphs. The x-direction corresponds to the first principal component. The results show that isomorphic graphs are assigned the same value.
Download figure:
Standard image High-resolution imageOther learning algorithms such as kernel k-means, kernel ridge regression, or support vector machines can be used in the same way, enabling us to cluster, make predictions for, or classify data where the order of elements is irrelevant.
4.4. Product or quotient representations of symmetric kernels
The aim now is to express a symmetric kernel not as a Slater permanent but as a product or quotient of antisymmetric functions. As shown in section 3.1, an antisymmetric kernel is zero for all x for which a (non-trivial) permutation π exists such that π(x) = x. Therefore, products of antisymmetric kernels are zero for such x as well, see also figure 5. We thus mainly restrict ourselves to quotients. Let  and
and  be two permutation-invariant antisymmetric kernels and
be two permutation-invariant antisymmetric kernels and  . We define
. We define

Then

Remark 4.9. If the numerator and denominator can be written as determinants, i.e.  and
and  , we obtain
, we obtain

Example 4.10. Suppose d = 2. Let k(1) and k(2) be two Gaussian kernels with bandwidths σ1 and σ2, respectively, where  . If the bandwidths are sufficiently small, either
. If the bandwidths are sufficiently small, either  and
and  or
or  and
and  will be close to zero (unless π(x) = x), where π = (1, 2) in cycle notation. Assume w.l.o.g. the latter holds, then
will be close to zero (unless π(x) = x), where π = (1, 2) in cycle notation. Assume w.l.o.g. the latter holds, then

which is a Gaussian with bandwidth σ satisfying  . This is illustrated in figure 5. Furthermore, the limit of
. This is illustrated in figure 5. Furthermore, the limit of  as
as  exists and is given by
exists and is given by

with ![$ x = [x_1, x_1]^\top $](https://content.cld.iop.org/journals/2632-2153/2/4/045016/revision2/mlstac14adieqn252.gif) , see appendix
, see appendix 

Figure 5. (a) Symmetric Gaussian kernel. (b) Quotient of antisymmetric Gaussian kernels. (c) Product of antisymmetric Gaussian kernels. The bandwidths of the antisymmetric kernels were chosen in such a way that the resulting functions approximate the symmetric Gaussian kernel. In the top row ![$ x^{\prime} = [0.4, -0.3]^\top $](https://content.cld.iop.org/journals/2632-2153/2/4/045016/revision2/mlstac14adieqn254.gif) and in the bottom row
and in the bottom row ![$ x^{\prime} = [0.4, 0.35]^\top $](https://content.cld.iop.org/journals/2632-2153/2/4/045016/revision2/mlstac14adieqn255.gif) . Product kernels cannot approximate the symmetric Gaussian kernel if
. Product kernels cannot approximate the symmetric Gaussian kernel if  is close to the separating boundary given by
is close to the separating boundary given by  .
.
Download figure:
Standard image High-resolution imageThe symmetric Gaussian kernel can be approximated by a quotient of antisymmetric Gaussian kernels, which can be evaluated in  , thus avoiding the non-polynomial complexity of the permanent. The question whether such kernels are universal is beyond the scope of this work.
, thus avoiding the non-polynomial complexity of the permanent. The question whether such kernels are universal is beyond the scope of this work.
5. Applications
In addition to the guiding examples presented above, we will illustrate the efficacy of the derived kernels with the aid of quantum physics and chemistry problems.
5.1. Particles in a one-dimensional box
Let us first consider a simple one-dimensional two-particle system. We define a potential V by

Furthermore, we assume that the two particles do not interact and obtain the Schrödinger equation

for  . By separating the two variables, we obtain the classical particle in a box problem, with eigenvalues
. By separating the two variables, we obtain the classical particle in a box problem, with eigenvalues  and eigenfunctions
and eigenfunctions  , for
, for  , see, for instance, [37]. For the two-particle system, the eigenvalues are hence of the form
, see, for instance, [37]. For the two-particle system, the eigenvalues are hence of the form

and the eigenfunctions are

However, since the two particles are physically indistinguishable, the wave functions must satisfy  , which implies that the functions are either symmetric (if the particles are bosons) or antisymmetric (if the particles are fermions). Let us assume that the two particles are electrons, i.e. fermions. We thus want to compute antisymmetric solutions of the time-independent Schrödinger equation by applying the approach introduced in section 2.2, see also [25]. In the same way, we could assume that the particles are bosons and compute symmetric solutions by replacing the antisymmetric kernel by a symmetric kernel.
, which implies that the functions are either symmetric (if the particles are bosons) or antisymmetric (if the particles are fermions). Let us assume that the two particles are electrons, i.e. fermions. We thus want to compute antisymmetric solutions of the time-independent Schrödinger equation by applying the approach introduced in section 2.2, see also [25]. In the same way, we could assume that the particles are bosons and compute symmetric solutions by replacing the antisymmetric kernel by a symmetric kernel.
We define ћ = 1,  , and
, and  , choose the antisymmetric Gaussian kernel with bandwidth σ = 0.1, and generate m = 900 uniformly sampled points in [0, L]×[0, L]. Additionally, to ensure that the eigenfunctions are zero outside the box, we place 124 equidistantly distributed test points on the boundary and enforce
, choose the antisymmetric Gaussian kernel with bandwidth σ = 0.1, and generate m = 900 uniformly sampled points in [0, L]×[0, L]. Additionally, to ensure that the eigenfunctions are zero outside the box, we place 124 equidistantly distributed test points on the boundary and enforce  for these boundary points. We thus have to solve a constrained eigenvalue problem and use the algorithm described in [38]. The first three eigenfunctions ψ1,2, ψ1,3, and ψ2,3 are shown in figure 6 and good approximations of the analytically computed eigenfunctions. The probability that the two electrons are in the same location is always zero. Furthermore, the results show that by increasing the number of data points we obtain more accurate and less noisy estimates of the true eigenvalues.
for these boundary points. We thus have to solve a constrained eigenvalue problem and use the algorithm described in [38]. The first three eigenfunctions ψ1,2, ψ1,3, and ψ2,3 are shown in figure 6 and good approximations of the analytically computed eigenfunctions. The probability that the two electrons are in the same location is always zero. Furthermore, the results show that by increasing the number of data points we obtain more accurate and less noisy estimates of the true eigenvalues.
Remark 5.1. We would like to point out that
- This example is just meant as an illustration of the concepts and not as a realistic physical model;
-
Eigenfunctions with
are symmetric and eliminated by the antisymmetrization operation;
-
Approximations of the eigenfunctions can be obtained using far fewer points (), but the eigenvalues will be considerably overestimated (kernels tailored to quantum mechanics applications might lead to better approximations);
- The antisymmetry assumption is encoded only in the kernel, not in the Schrödinger equation itself.



Figure 6. Numerically computed antisymmetric eigenfunctions (a) ψ1,2, (b) ψ1,3, and (c) ψ2,3 with corresponding eigenvalues λ1,2 ≈ 2.75, λ1,3 ≈ 5.40, and λ2,3 ≈ 7.07 for m = 900. The eigenvalues are slightly larger than the analytically computed values λ1,2 = 2.5, λ1,3 = 5, and λ2,3 = 6.5. (d) Eigenvalues as a function of the number of data points. The solid lines represent the numerically computed eigenvalues, the shaded areas the standard deviation, and the dashed lines the analytically computed eigenvalues.
Download figure:
Standard image High-resolution imageThis can be easily extended to the multi-particle case. We now add electron–electron interaction terms resulting in the Hamiltonian

For d = 3, we randomly generate 3000 interior points and 600 boundary points to enforce Dirichlet boundary conditions. We choose a Gaussian kernel with bandwidth σ = 0.1, assemble the Gram matrices, and again solve the resulting constrained eigenvalue problem. The results are shown in figure 7. For the sake of comparison, we also plot the corresponding eigenfunctions of the Schrödinger equation without the electron–electron interaction. It can be seen that the eigenfunctions for the separable case are similar to the eigenfunctions where the interaction terms are included. For this particular system, the interaction terms do not seem to have a drastic effect on the system's low-lying energy states. In general, however, their effect on the electronic wavefunction can be significant. We also remark that energies and wavefunctions of the interacting system could in principle be approximated by perturbation techniques. However, due to the degeneracy of the antisymmetric states, such a perturbation analysis seems beyond the scope of this work.

Figure 7. Antisymmetric eigenfunctions (a) ψ1,2,3, (b) ψ1,2,4, and (c) ψ1,3,4. The top row shows the analytically computed eigenfunctions omitting electron–electron interaction, the bottom row the numerically computed eigenfunctions including repulsive forces.
Download figure:
Standard image High-resolution image5.2. Acyclic molecules
As a second example, we consider a data set of acyclic molecules [39]. The aim is to determine the boiling points of these molecules containing the elements C, H, O, and S. The data set
10
consists of 183 graphs G = (V, E) representing the molecular structures and the corresponding boiling points in degrees Celsius, see figure 8 for a few examples of molecules included in the data set. The number of vertices  varies between 3 and 11, where the hydrogen atoms of the molecules are neglected. Thus, in order to compare the graphs of different sizes, we expand all adjacency matrices to
varies between 3 and 11, where the hydrogen atoms of the molecules are neglected. Thus, in order to compare the graphs of different sizes, we expand all adjacency matrices to  with d = 11 by appending rows and columns of zeros, representing artificial isolated nodes.
with d = 11 by appending rows and columns of zeros, representing artificial isolated nodes.

Figure 8. Skeletal formulas of a selection of samples taken from the data set. The set contains oxygen and sulfur compounds of different complexities. The associated boiling points are between −23.7 ∘C and 250 ∘C.
Download figure:
Standard image High-resolution imageWe define a symmetrized Laplacian kernel on graphs, cf example 4.8. Given the adjacency matrices  of the graphs G = (V, E) and
of the graphs G = (V, E) and  as well as the kernel parameter
as well as the kernel parameter  , we define the tensor
, we define the tensor  by
by

for i ≠ j and k ≠ l and

The latter definition ensures that we avoid unwanted effects of any ordinal labeling of the nodes. Using the hyperpermanent of T, the kernel evaluation  can be written as
can be written as

Note that we do not consider entries ti,j,k,l
with either i = j, k ≠ l or i ≠ j, k = l since  . We refer to appendix
. We refer to appendix
For kernel-based (ridge) regression (see, e.g. [40]), we extract 165 adjacency matrices (≈90%) and their corresponding boiling point temperatures from the data set as training samples, the other data pairs constitute the test set. That is, for any G in the test set, the regression function is given by  , where the vector
, where the vector  is the Gram matrix (or kernel matrix) corresponding to the training samples (rows) and the test sample G (column). The vector
is the Gram matrix (or kernel matrix) corresponding to the training samples (rows) and the test sample G (column). The vector  is the solution of
is the solution of  with b being the vector of boiling points of the molecules in the training set. We then compute the average error as well the root-mean-square error in the boiling points of the test set in order to evaluate the generalizabilty of the learned regression function. We repeat each experiment 10 000 times with randomly chosen training and test sets, the results for different kernel parameters σ are shown in figure 9(a).
with b being the vector of boiling points of the molecules in the training set. We then compute the average error as well the root-mean-square error in the boiling points of the test set in order to evaluate the generalizabilty of the learned regression function. We repeat each experiment 10 000 times with randomly chosen training and test sets, the results for different kernel parameters σ are shown in figure 9(a).

Figure 9. (a) Average errors and root-mean-square errors for the test set for different values of σ. The solid lines depict the median and the semi-transparent areas comprise the 30th to the 70th percentile of the respective errors. (b) Entries of the Gram matrix corresponding to the whole data set for σ = 3 with a logarithmically scaled color map. The samples are sorted by number of atoms, type of compound (oxygen/sulfur), and number of contained heteroatoms.
Download figure:
Standard image High-resolution imageThe best results in terms of the average and the root-mean-square error are obtained for kernel parameters σ between 2.5 and 2.8, see table 3 for details. According to the data set's website, the best results so far for the boiling point prediction on 90% of the set as training data and 10% as test data are achieved by applying so-called treelet kernels which exploit all possible graph/tree patterns up to a given size [39]. In this case, the average error is listed as 4.87 and the root-mean-square error as 6.75. Both values are comparable with our results.
Table 3. Mean and median of the average error and root-mean-square error over all repetitions for values of σ between 2.5 and 2.8.
| σ | Average error | Root-mean-square error | ||
|---|---|---|---|---|
| mean | median | mean | median | |
| 0.25 | 4.90 | 4.76 | 6.85 | 6.57 |
| 0.26 | 4.91 | 4.77 | 6.87 | 6.53 |
| 0.27 | 4.92 | 4.77 | 6.88 | 6.47 |
| 0.28 | 4.94 | 4.80 | 6.91 | 6.44 |
As shown in figure 9(b), the entries of the Gram matrix tend to decrease for larger molecules. This effect can be explained by the expansion of the adjacency matrices and similarities of the molecules with small numbers of atoms. For instance, the first two compounds in the (ordered) data set are dimethyl ether (C2H6O) and dimethyl sulfide (C2H6S). Due to the expansion from  to
to  , the majority of the permutations in (4) do not affect the adjacency matrix of
, the majority of the permutations in (4) do not affect the adjacency matrix of  , cf appendix A.3. The block structure of the matrix arises from the ordering of the data set, i.e. each group of molecules with the same number of atoms is divided into subgroups of compounds containing one oxygen atom, two oxygen atoms, one sulfur atom, and two sulfur atoms.
, cf appendix A.3. The block structure of the matrix arises from the ordering of the data set, i.e. each group of molecules with the same number of atoms is divided into subgroups of compounds containing one oxygen atom, two oxygen atoms, one sulfur atom, and two sulfur atoms.
6. Conclusion
We derived symmetric and antisymmetric kernels that can be used in kernel-based learning algorithms such as kernel PCA, kernel CCA, or support vector machines, but also to approximate symmetric or antisymmetric eigenfunctions of transfer operators or differential operators (e.g. the Koopman generator or Schrödinger operator). Potential applications range from point cloud analysis and graph classification to quantum physics and chemistry. Furthermore, we analyzed the induced reproducing kernel Hilbert spaces and resulting feature space dimensions. The effectiveness of the proposed kernels was demonstrated using guiding examples and simple benchmark problems.
The next step is now to apply kernel-based methods to more complex quantum systems. Such problems might require kernels tailored to the system at hand. By exploiting additional properties (sparsity, low-rank structure, weak coupling between subsystems), it could be possible to improve the performance of kernel-based methods. Furthermore, the kernel flow approach proposed in [41] could be extended to operator estimation problems. This would allow us to also learn the kernel from data.
Another topic for future research would be to consider other types of symmetries and to develop kernels that explicitly take these properties into account. While the antisymmetric kernel can be evaluated efficiently using matrix factorizations, this is not possible for the symmetric kernel, which requires the evaluation of a matrix permanent. Utilizing efficient approximation schemes could speed up the generation of the required Gram matrices significantly. Alternatively, the product or quotient formulation of symmetric kernels could be exploited to facilitate the application of the proposed methods to higher-dimensional problems.
Acknowledgments
We would like to thank Jan Hermann for helpful discussions about quantum chemistry and the reviewers for their helpful comments and suggestions.
Data availability statement
The data and code that support the findings of this study are openly available at https://github.com/sklus/d3s/.
Funding
P Gelß and F Noé have been partially funded by Deutsche Forschungsgemeinschaft (DFG) through grant CRC 1114 'Scaling Cascades in Complex Systems' (Project ID: 23 522 1301, projects A04 and B06). F Noé also acknowledges funding from BMBF through the Berlin Institute for the Foundations of Learning and Data (BIFOLD), the European Commission (ERC CoG 772 230), and the Berlin Mathematics center MATH+ (AA2-8).
Appendix A.: Hyperpermanents
Given a tensor  , the hyperpermanent of T is given by
, the hyperpermanent of T is given by

In example 4.8, we considered tensor entries of the form

for adjacency matrices  in order to construct the symmetrized Gaussian kernel for graphs. Another example for defining the entries of T, as described in section 5.2, is
in order to construct the symmetrized Gaussian kernel for graphs. Another example for defining the entries of T, as described in section 5.2, is

which results in the symmetrized Laplacian kernel for graphs. For both choices, we set  and
and  , respectively, if
, respectively, if  and ti,i,k,k
= exp(0), otherwise. In what follows, we will consider different techniques for computing the hyperpermanent of T.
and ti,i,k,k
= exp(0), otherwise. In what follows, we will consider different techniques for computing the hyperpermanent of T.
A.1. Laplace expansion for the computation of hyperpermanents
Define  by
by

Let  denote the tensor that results from
denote the tensor that results from  by removing all entries
by removing all entries  with i = 1, j = 1, k = µ, or l = µ. The hyperpermanent can then be written as
with i = 1, j = 1, k = µ, or l = µ. The hyperpermanent can then be written as

where δij denotes the Kronecker delta. Note that i = j implies π(i) = π(j).
A.2. Hyperpermanents of pairwise symmetric tensors
Suppose  and
and  for all
for all  . For instance, this is the case for tensors T containing elementwise evaluations of Gaussian and Laplacian kernels as given in (5) and (6), respectively. The hyperpermanent of T can then be written as
. For instance, this is the case for tensors T containing elementwise evaluations of Gaussian and Laplacian kernels as given in (5) and (6), respectively. The hyperpermanent of T can then be written as

The advantage of the above formula is that we can reduce the computational costs for the hyperpermanent. Additionally, we do not have to compute all elements of T, which also reduces the computational costs.
A.3. Hyperpermanents for graphs with isolated nodes
In order to compare graphs of different sizes, we include artificial isolated nodes in section 5.2. That is, the adjacency matrix of a given graph is expanded by adding zero entries. In this case, all permutations among the isolated nodes do not change the result of the product  . Assume that the dimension of the adjacency matrix A used in (5) and (6) is initially
. Assume that the dimension of the adjacency matrix A used in (5) and (6) is initially  before the expansion to
before the expansion to  . Then, it holds that
. Then, it holds that

if  or
or  . Thus, given two permutations π1 and π2 with
. Thus, given two permutations π1 and π2 with

it follows that

This means that for each permutation π ∈ Sd
, any of the  permutations of the set
permutations of the set  does not change the value of the quotient in (7). This fact can be exploited using the formula
does not change the value of the quotient in (7). This fact can be exploited using the formula

which enables us to decrease the number of considered permutations significantly if  is much smaller than d.
is much smaller than d.
Appendix B.: Quotient representation of symmetric Gaussian kernels





Footnotes
- 6
Assume w.l.o.g. that
for some indices i ≠ j. Let be the permutation which only swaps the positions i and j, then it holds that . - 7
A partition of a positive integer n is a decomposition into positive integers so that the sum is n. The order of the summands does not matter, i.e.
and are the same partition. We sort partitions in non-increasing order, e.g. µ = (3, 2, 1) is a partition of 6 into three parts. - 8
We use a bold
for the mathematical constant to avoid confusion with permutations π. - 9
This could be mitigated by decreasing the bandwidth or by regularization techniques.
- 10
The data set can be found at https://brunl01.users.greyc.fr/CHEMISTRY/.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}