1. Introduction
In approximate methods, the guarantee of finding global optimum solutions is sacrificed due to the computational complexity of hard optimization problems. Approximate algorithms can be classified as specific heuristics and MH. Heuristics are techniques specifically designed to solve a particular problem. On the contrary, MH are defined as upper-level general methodologies (templates), which can be used as guiding strategies for the design of underlying heuristics for solving a problem [
1]. Then, MH extends basic heuristic methods by including them in an iterative framework, augmenting their exploration and exploitation capabilities. Notice that exploration is the process of visiting new regions of a search space (solutions), whereas exploitation is the process of visiting those regions within the neighborhood of previously visited solutions. Thus, MH needs to establish a good ratio between exploration and exploitation to be successful. That means that designing and applying good MH is to make a proper trade-off between these two “forces” [
2,
3]. Unfortunately, the proper handling of this trade-off is an open question in the literature [
4,
5,
6,
7,
8,
9]. A comprehensive review about MH can be found in [
1,
10].
Optimization problems can be classified depending on the domain of the decision variables in discrete and continuous problems. In recent years, discrete optimization problems have become more and more frequent in the industry with problems as Set Covering Problem (SCP) [
11,
12], Knapsack Problem [
13], Software Project Scheduling Problem [
14,
15] and Feature Selection [
16]. The No-Free-Lunch Theorem (NFLT) [
17] tells us that there is no universal optimization algorithm for all existing optimization problems. This means that, despite the existence of algorithms designed to solve discrete problems, none of them are good for all combinatorial optimization problems and there will always be a better one for a specific problem. This best algorithm can be one designed for discrete problems as well as an algorithm designed for continuous problems adapted to discrete problems. However, there are many MH (most of them are swarm intelligence) designed to work in the continuous domain, meaning that binarization techniques are required [
18]. Among the most commonly used binarization operators, two-step techniques are the most common [
18] and its performance has been improved by the use of ml-based techniques [
13,
19].
Several variations of MH are proposed in the literature to improve MH algorithms. Among the most relevant trends, hybrid MH represent a class of algorithms that combine MH with other applicable algorithms. The resulting algorithms take advantage of the strengths of algorithms composing the hybridization, finding better results while keeping complexity low. According to the taxonomy defined in [
1] for hybrid MH, MH are usually combined with MH with exact mathematical programming algorithms (resulting in matheuristics [
20]), with simulation (resulting in simheuristics [
21]) and with machine learning (ML) (resulting in learnheuristics [
22,
23,
24]). This work focuses on proposing a learnheuristic.
Focusing on ML, these techniques have become popular in recent years with many applications, from industrial to everyday applications [
25,
26]. Usually, ML techniques are divided in supervised, unsupervised, semi-supervised and Reinforcement Learning. Supervised techniques learn from labeled data to infer future samples in the form of classification or regression [
27]. Unsupervised techniques consider unlabeled data to find clusters or patterns with usual algorithms as k-means [
28], dbscan [
29] or BIRCH [
30]. Semi-supervised techniques share features of supervised and unsupervised learning, resulting in a hybrid approach in which labeled data are managed in a supervised manner while unlabeled data are managed in an unsupervised manner [
31]. Reinforcement Learning techniques are based on the notion of cumulative reward, where the system received a positive or negative reward after each decision, adjusting the behavior of the system according to this feedback. Thus, instead of learning from labeled data, as supervised techniques, the system learns from the experience of making decisions [
32].
Based on the existing difficulties in applying binarization techniques in MH algorithms designed for solving continuous problems, the main contribution in this paper consists in a novel binarization scheme powered by the QL algorithm, which is a Reinforcement-Learning technique. The authors apply this binarization scheme in conjunction with two MH to solve the SCP, resulting in two hybrid MH. As a result, the authors verified that the hybrid approach including the novel binarization scheme outperforms the regular MH with a usual fixed binarization approach from the literature.
The reminder of this paper is organized as follows.
Section 2 presents the related work. In
Section 3, the classical binarizarion techniques are described.
Section 4 describes the QL based binarization scheme proposed in this paper.
Section 5 explains the two implemented MH.
Section 6 presents SCP.
Section 7 details the statistical methodology and the experimental results. Finally,
Section 8 concludes the work with some final remarks.
2. Related Work
This section discusses related work along two lines. First, works in which metaheuristics are improved by applying ML techniques and, second, works in which Q-Learning is applied together with MH, resulting in hybrid MH.
2.1. Metaheuristics Enhanced by Machine Learning
Regarding ML techniques supporting MH, the work of García et al. [
19] reviewed two lines of research. The first one consists in the integration of ML as a replacement for an operator (e.g., population management, solution initialization, local search, disturbance of solutions and parameter tuning, among others). The second one consists in the use of ML as a selection tool for a set of MH, choosing the most appropriate for solving an specific instance of a problem.
Regarding the first line, the authors may cite the work of Veček et al. [
33], where they performed a parameter tuning for the chess rating system problem. In the work of Ries et al. [
34], a similar implementation was performed but using fuzzy logic and Decision Trees. Deng et al. [
35] proposed a clustering-based initial solution generation for the Traveling Salesman Problem. Within this line, the binarization operator was also of considerable interest. Some examples are observed in [
13] by solving the Multidimensional Knapsack Problem by unsupervised learning techniques, in [
36] by using the concept of percentile and in [
37] where they implemented the framework of Apache Spark for large combinatorial problems.
When considering ML as a selection tool to obtain a MH among a set of these, this task is divided into three groups. The first one is the algorithm selection that chooses among a set of techniques and characteristics of each problem in order to obtain better performance for a set of similar instances [
38]. The second one is the hyperheuristic strategies, which aims at automating the design of the MH to address a set of problems [
39]. The third group is composed of cooperative strategies, which combine algorithms in a sequential and parallel manner to improve robustness, sharing a part of the solution or its totality [
40].
Reinforcement Learning is often used for the intelligent selection of operators [
41]. An example of this is the work of Zhang et al. [
42] where they proposed an adaptive evolutionary programming algorithm. For each individual, an optimal mutation operator was selected based on immediate performance.
2.2. Metaheuristics Enhanced by Q-Learning
Reviewing the literature, it is possible to find various implementations of QL supporting MH to solve a wide range of problems. Among the first works are those made by Gambardella and Dorigo, where they incorporate QL replacing pheromone behavior in Ant Colony Optimization [
43] to solve Travelling Salesman Problem [
44] and its asymmetric version. In [
45], QL is used as an heuristic selector inside an hyperheuristic scheme to solve the Cutting Stock Problem. The same strategy is used in [
46,
47] in order to solve the cross-domain heuristic search challenge [
48] and Stochastic mixed-model assembly line sequencing problem. In [
42,
49], a hybridization is proposed where QL is an intelligent selector of mutation operators in Genetic Algorithms. In [
50], QL and SARSA are implemented for League Championship Algorithm to strengthen the search power of each individual in the algorithm to extract better stock trading rules for various types of trading conditions. In [
51,
52], parameters of the Firefly Algorithm [
53] and a version Sine Cosine Algorithm combined with Cuckoo Search are dynamically controlled to improve the search and to avoid falling into local optima. There are also several implementations in the literature where QL supports MH, such as Particle Swarm Optimization [
54,
55], Cuckoo Search [
56], Bat Algorithm [
57] and Meta-RaPS [
58].
Summarizing what has been found in the literature, two models of conceptual interaction between QL and a MH are shown and these two major interest groups are: (1) how QL can support within the MH; and (2) how QL can support from outside the MH (with a hyperheuristic approach).
The interaction model shows that QL can support learning from the behavior of operators associated with the MH for the problem in the search of solutions, i.e., it is an additional element to the layer of the MH.
On the other hand, QL can be a component of a higher-level layer called Hyperheuristics (HH), which is given back to operators at a lower level with each iteration of the MH addressing the problem. The operators from the lower level problem form part of the problem to be solved at the top layer where any MH learning from QL can take place.
The literature review shows the contribution of ML works to improve the performance of metaheuristics as well as the contribution of metaheuristics to improve the performance of ML. However, in an essential topic in the behavior of a MH, such as the exploration-exploitation balance, there is an area of research that is interesting to work on in order to find better solutions that are applicable to the industry.
3. Continuous Metaheuristics Working in Binary Domains
The binary techniques for continuous MH consist of transferring the values of continuous domain of the MH to a binary domain, this is conducted to preserve the quality movements that possess continuous MH and, thus, generate quality binary solutions.
Although there are MH that work in binary domains without the need to incorporate a binary scheme, the continuous MH together with a binary scheme have presented great performance in diverse combinatorial NP-Hard problems for which they have called the interest of the scientific community. Some examples include Particle Swarm Optimization [
59], Binary Salp Sawrm Algorithm [
60], Binary Dragonfly [
61] and Binary Magnetic Optimization Algorithm [
62], among others [
63,
64,
65,
66].
Among the binary schemes, two large groups can be defined: First, the operators that do not alter the operation of the other elements of the MH where the two-step techniques stand out, as they are the most used previously [
18] and the Angle Modulation technique [
67]. The second group consists of the methods that alter the normal functioning of MH, which are Quantum Binary [
68] and Set-Based Approaches in addition to the techniques based on clustering [
13,
19].
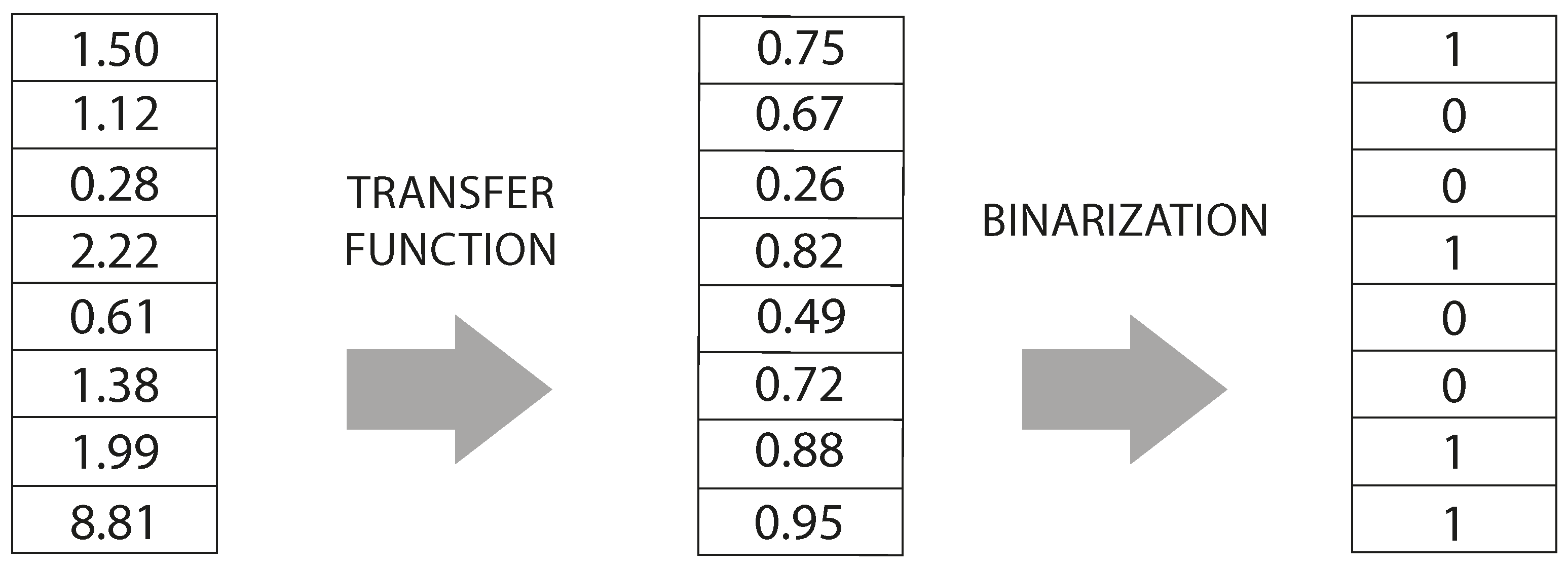
3.1. Two-Step Binarization Scheme
Two-step binary schemes are of great relevance for various types of problems [
69]. This binarization scheme is composed by two steps, the first one is the
transfer function, which transfers the values generated by the continuous MH to a continuous interval between 0 and 1, while the second step is the
binarization, which consists in transferring the real number in a binary value. This is best exemplified in
Figure 1.
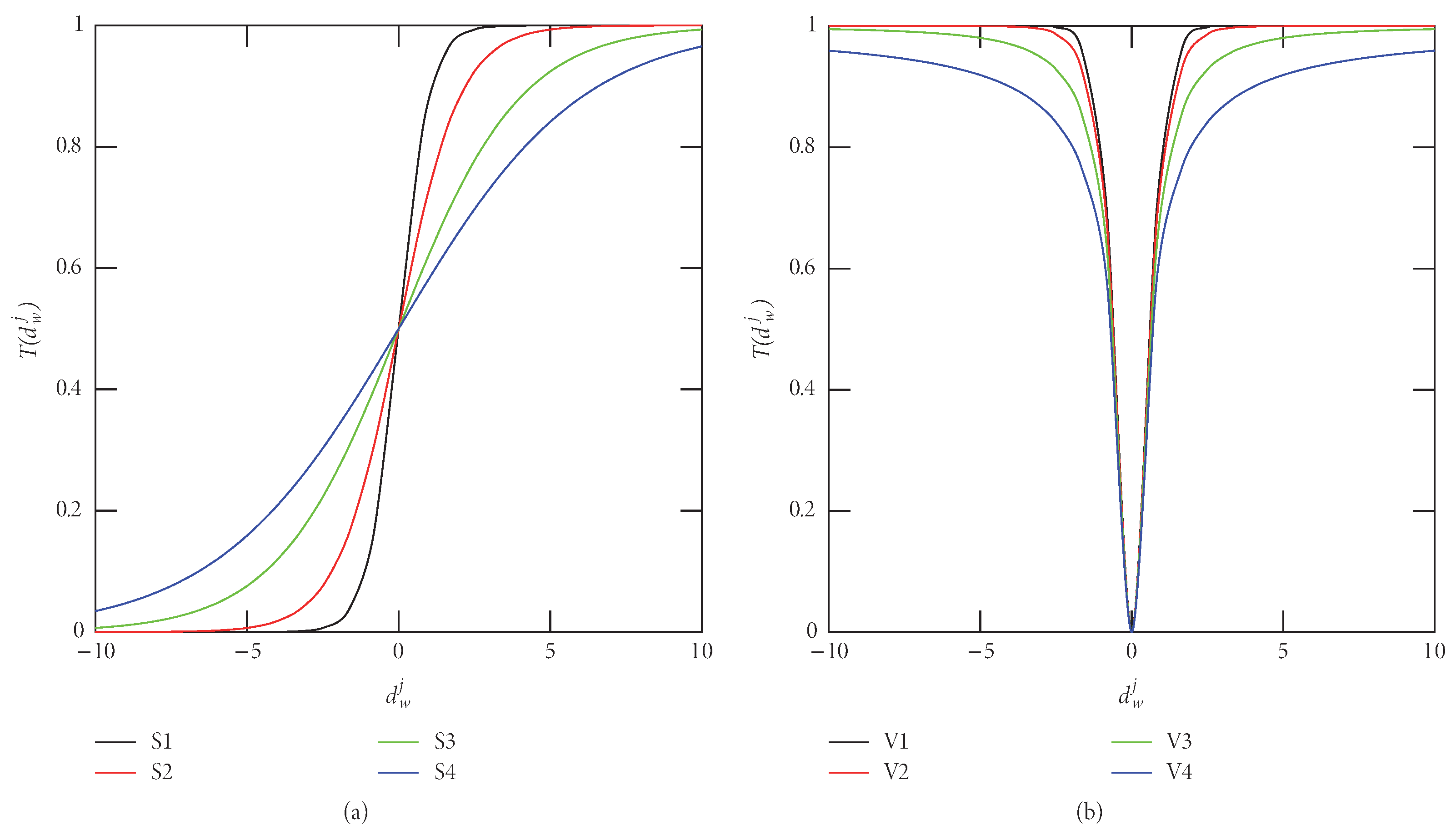
3.1.1. Transfer Functions
Transfer functions were introduced by Kennedy et al. in 1997 [
70]. Having as main advantage the delivery of a probability between 0 and 1 at a low computational cost. There are two types of functions, the S-Shaped [
63] and the V-Shaped [
71] where each has four variations presented for both the S-Shape and for the V-Shape. The variations for the S-Shape functions,
for
are defined as follows:
and
where
denotes the discrete value in the individual
in dimension
and
n and
l are the number of individuals and dimensions, respectively. The variations for the V-Shape functions,
for
, are defined as follows:
and
The results of plotting the tuples
and
for
are shown in
Figure 2.
3.1.2. Binarization
The second step is binarization, which has the function of discretizing the probability obtained from the transfer function
calculated according to
Section 3.1.1 by delivering a binary value.
For this step, there are different techniques in the literature such as Standard, Complement, Static Probability, Elitist and Elitist Roulette. The values for the binarization obtained by using different methods are defined as follows.
Let
be the binarization value obtained by using the
Standard method. Then,
is defined as the following:
where
, for
, is a random value generated following a uniform distribution
,
denotes the discrete value in the individual
in dimension
and
n and
l are the number of individuals and dimensions, respectively.
Let
be the binarization value obtained by using the
Complement method. Then,
is defined as the following:
where
denotes the complementary binary value of
in the individual
w for dimension
j, i.e., if the value of
is 0, the complement corresponds to 1.
Let
be the binarization value obtained by using the
Static Probability method. Then,
is defined as the following:
where
denotes the value of the dimension
in the individual
,
l and
n are the number of dimensions and individuals, respectively, and
corresponds to a parameter determined by the user.
Let
be the binarization value obtained by using the
Elitist method. Then,
is defined as the following:
where
denotes the value of the dimension
j in the individual
, which has obtained the best fitness so far, and
l and
n are the number of dimensions and individuals, respectively.
Let
be the binarization value obtained by using the
Elitist Roulette method [
72]. Then,
is defined as follows.
4. Binarization Scheme Selector Proposal
Nowadays, combinatorial problems in the binary domain are becoming increasingly complex and frequent in the industry. Solving them in reasonable a reasonable time period with high quality solutions is a priority for both academia and the industry.
This work proposes an intelligent selector of binarization schemes where the existing binarization methods in the literature are integrated to control the exploration and exploitation balance, thus, avoiding local optimizations. This is because several authors [
5,
8,
73,
74,
75] propose that for a metaheuristic to work well, it must have a good balance between exploration and exploitation. Exploration or diversification consists of visiting unexplored regions of the search space to ensure that the search is performed in biased regions [
1]. In contrast, exploitation or intensification and promising regions with good solutions are further explored in hopes of finding better solutions [
1].
This new binarization strategy is inspired by the behavior of hyperheuristics and techniques that have performed well for various types of problems [
39,
76,
77,
78]. This method consists in using an intelligent operator to determine which type of binarization is most appropriate at the iteration level, i.e., based on the information of the problem and the results obtained in previous iterations, the binarization scheme that is most likely to obtain the best quality results can be used.
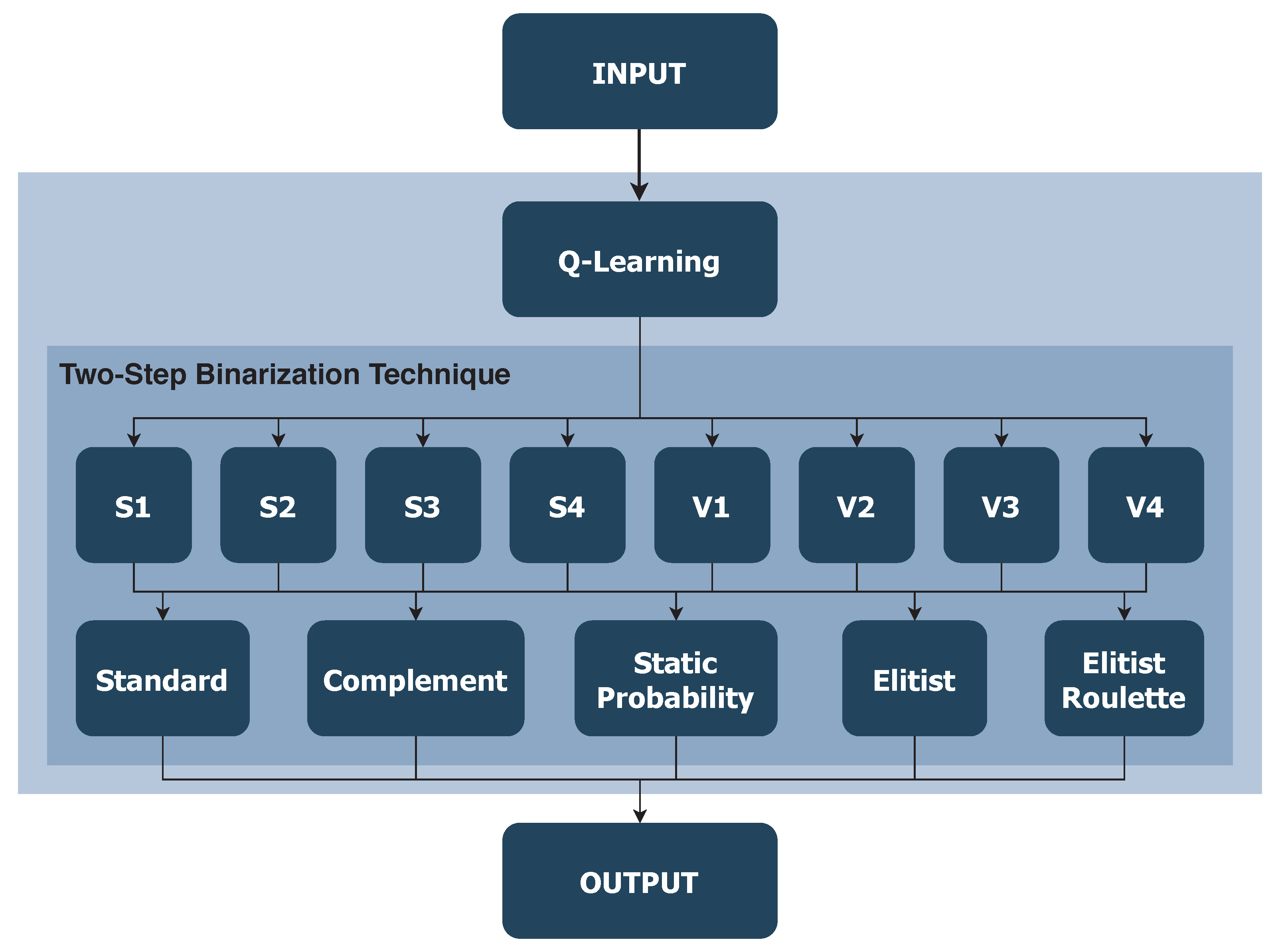
4.1. Q-Learning as a Smart Operator
In the present work, QL is implemented as the intelligent operator of the proposal, which chooses the two-step binarization technique to be used according to a reward system, with which it learns in a deterministic way. The structure of the implemented proposal is exemplified in
Figure 3.
4.2. Q-Learning
Within Reinforcement Learning (RL) techniques there are Time Difference (TD) algorithms, which are characterized by exploring the environment and by using this information to update the current state [
32]. The TD algorithms show the difference between the current estimation of the value of a state, the discounted value of the next state and the reward. It focuses on state-to-state transitions and learned values of states.
Prominent among the TD algorithms is QL [
79], which provides agents with the ability to learn to act in the best way through the consequences of their actions taken. There are different “states” and different possible “actions” where the working “environment” is the current state in which the agent is in and must select and execute an action which affects the “environment” by changing its state. Actions are punished or rewarded by “rewards”, which are judged by the consequence obtained by applying an action in a particular state. Rewards are delayed, allowing the agent to learn from the system. In order to solve the problem, the agent tries to learn the best course of actions that will maximize the accumulated reward. The learning process lies in a set of episodes, where in each episode the agent selects and executes an action in a particular state. For the new episode, the agent’s learning is given by Equation (
14):
where
is called
Q-value and represents the cumulative quality or reward of the action taken
in state
at time
t;
is the reward or punishment received when action
is taken in state
at time
t;
is the
Q-value for the previous iteration for action
in state
;
is the maximum
Q-value of the action for the next state, i.e., the best action the agent can take in the next state;
is the learning factor for which its value must be
; and
is the discount factor for which its value must be
. If
is close to 0, the historical information learned becomes more relevant, whereas if
is close to 1 the information received immediately becomes more relevant. If
equals 0, only the immediate reward is taken into account, while, as it approaches 1, the future reward receives greater emphasis relative to the immediate reward. The procedure of this algorithm is reflected in Algorithm 1.
| Algorithm 1 Q-Learning Algorithm. |
- 1:
Initialize , , - 2:
whilet < Maximum number of iterations do - 3:
Choose base on - 4:
Execute action and get immediate reward or punishment - 5:
Observe the next state - 6:
- 7:
- 8:
end while - 9:
Return
|
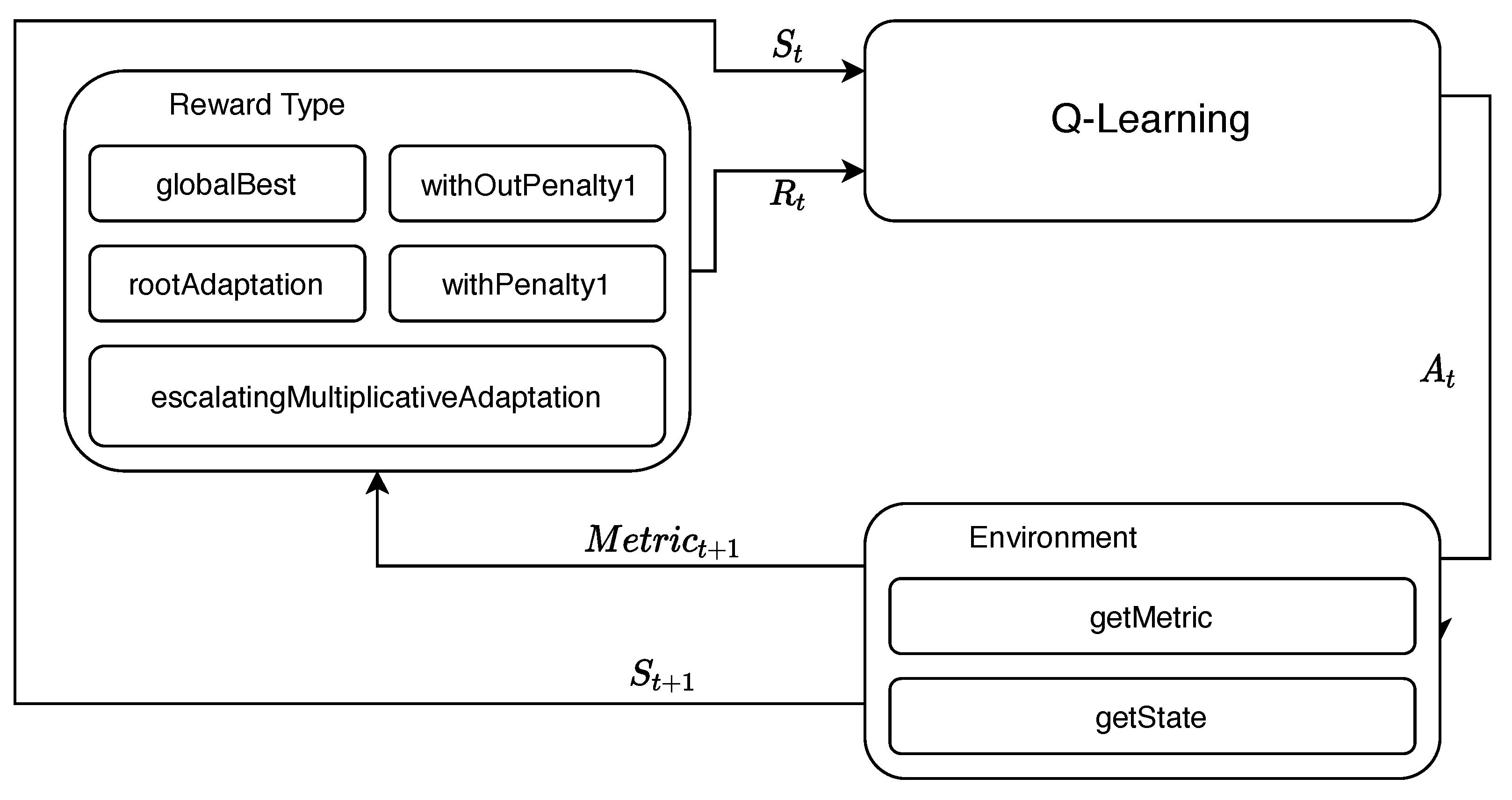
4.3. Rewards
The reward in the RL algorithm is fundamental for a correct performance of these same algorithms; that is why, in the literature, there are several methods to calculate the rewards. The type of reward from the chosen metrics determine the value
for the general QL equation, as detailed in
Figure 4.
For the implementation of this work, five forms of rewards were used where two of them are among the simplest in the literature. The first is the one used in [
46,
54], where it is increased by a fixed value for the action that generated an improvement in the overall fitness of the problem and a decrease in the same fixed value if no improvement was generated. This fixed value is detailed in Equation (
15). The second type of reward is a variation of the previous one used in the Q-table, where there is no penalty on the Q-table values, as presented in Equation (
16). The last three rewards are collected by Nareyek in [
80], which are detailed in Equations (
17)–(
19), respectively:
and
where
W and
are defined as a constant of value 10 and the best fitness found so far, respectively.
4.4. Actions
As mentioned above, the main objective of Q-Learning is to find an optimal policy within a set of actions. Therefore, it is important to define which actions the agent will take during its learning process. In the present work, the actions taken by the agents are the combinations between the transfer functions and the binarization functions extracted from the Two-Step Technique. Thus, we obtain 40 possible actions to be selected in the learning process.
4.5. Obtaining Metrics (getMetric)
The reward or punishment is judged by the consequence obtained by the performance of the action. Therefore, it is important to define what the comparison metrics will be to discriminate the consequence. In the present work, the comparison metric is the fitness obtained in each iteration of the optimization process and it is compared with the best fitness obtained. If fitness improves, action is rewarded, while if fitness worsens, action is punished.
4.6. State Determination (getState)
As QL carries out its learning process through the state transition, it is important to define which states to use and how it will transition between them.
In the present work, two states were defined which refer to the phases of a metaheuristic: exploration and exploitation. These states were not chosen at random since, as mentioned above, the objective of this work is to improve the balance of exploration and exploitation of metaheuristics to obtain better results.
In the literature, different authors [
81,
82,
83,
84,
85] propose metrics that allow us to quantify the diversity of individuals in population algorithms where Hussain’s Dimensional Diversity [
85] stands out.
Let
be the diversity of the population at a particular time where Hussain et al. [
85] stands out. In order to the calculate
, the following equation is used:
where
denotes the mean of the individuals in the dimension
d,
is the the
i-th individual value of the
d-th dimension,
n is the number of individuals in the population and
l is the dimension size of individuals.
One of the methods to estimate exploration and exploitation is the one proposed by Morales-Castañeda et al. in [
4] who, based on the quantification of the diversity of a population, proposed a method to estimate exploration and exploitation in terms of percentages. The percentage of exploration (XPL %) and exploitation (XPT %) are calculated as follows:
and
where
is the determination of the diversity state given by Equation (
20) and
denotes the maximum value of the diversity state found in the entire optimization problem.
Equations (
21) and (
22) are generic, so it is possible to use any other metric that calculates the diversity of a population.
Thus, the transition of states will be determined by the following method.
5. Instantiated Metaheuristics
In this section we describe the MH to be used, which include the Sine-Cosine Algorithm [
86] and the Whale Optimization Algorithm [
87]. Both have different implementations for solving combinatorial problems, basing the choice of these MH over others on the no free lunch theorem [
17,
88], which leaves all MH with the same probability of success until their performance in each specific problem has been demonstrated by experimentation.
5.1. Sine-Cosine Algorithm
To the best of our knowledge, the Sine-Cosine Algorithm (SCA) was first defined by Mirjalili [
89] in 2016. It is based on sine and cosine trigonometric functions. As all iteration-based optimization techniques, this one starts with a random population. Let
,
,
and
be the four parameters of the motion equations. Thus, let
be the parameter that determines the direction of the motion relative to the best solution and it is given by the following:
where
T represents the total number of iterations that will be performed,
t is the current iteration of the optimization process and
a is a constant. In the first iterations, the motion consists in moving away from the best solution (exploration) and, in the last iterations, the motion consists of moving closer to the best solution (exploitation).
Let
be the parameter which defines the magnitude of the motion and it is given by the following:
where
and
represent the domain of the sine and cosine functions
.
Let
be the parameter which integrates the motion randomness and it is given by the following:
where
. If
, the motion will be more stochastic.
Finally, let
be the parameter which determines if the motion will be performed with the sine or cosine function in the same proportion defined as follows:
where
. Then, the motion equation definition depends on the value of
. Let
be the
i-th component of the general solution in the iteration
. The value of
depends on the value of the parameter
; thus, the following is the case:
where
denotes the
i-th component of the general solution in the iteration
t and
denotes the Best
i-th component of the general solution in the iteration
t. The procedure of MH is explained in Algorithm 2.
| Algorithm 2 Sine-Cosine Algorithm. |
- 1:
Initialize a set of search agents (Solutions) (X) - 2:
while Maximum number of iterations do - 3:
Evaluate each of the search agents by objective function - 4:
Update the best solution obtained so far () - 5:
Update , , and - 6:
Update the position of the search agents using the Equation ( 28) - 7:
- 8:
end while - 9:
Return the best solution obtained ()
|
5.2. Whale Optimization Algorithm
The Whale Optimization Algorithm (WOA) is inspired by the hunting behavior of humpback whales, specifically, how they make use of a strategy known as “bubble netting”. This strategy consists of locating the prey and, by means of moving in spiral turns that are similar to a “9”, enclosing in on the prey. This algorithm was invented by Mirjalili and Lewis in 2015 [
90].
The WOA metaheuristic starts with a set of random solutions. At each iteration, the search agents update their positions with respect to a randomly chosen search agent or the best solution obtained so far. There is a parameter
a that is reduced from 2 to 0 to provide changes between exploration and exploitation. When the equation vector (
29) has value:
, a new random search agent is chosen. On the other hand, when
, the best solution is selected; the point of this is to be able to update the position of the search agents.
On the other hand, the value of the parameter p (random number between 0 and 1) allows the algorithm to switch between a spiral or circular motion. In order to assimilate this, there are three movements that are crucial when working with the metaheuristic:
Searching for prey ( and ): The whales search for prey randomly based on the position of each prey. When the algorithm determines that
, then we can say that it is exploring and allows WOA to perform a global search. We represent this first move with the following mathematical model:
where
t denotes the current iteration,
and
are coefficient vectors and
is a random position vector (i.e., a random whale) chosen from the current population. The vectors
and
can be computed according to the following Equation (
30):
where,
decreases linearly from 2 to 0 over iterations (both in the exploration and exploitation phases) and
corresponds to a random vector of values between
.
Encircling the prey ( and ): Once the whales have found and recognized their prey, they begin to encircle them. Since the position of the optimal design in the search space is not known in the first instance, the metaheuristic assumes that the current best solution is the target prey or is close to the optimum. Therefore, once the best search agent is defined, the other agents will attempt to update their positions toward the best search agent. Mathematically, it is modeled in Equation (
31):
where
is the position vector of the best solution obtained so far and
is the position vector. The vector
and
are calculated in Equation (
30). It is worth mentioning that
must be updated at each iteration if a better solution exists.
Bubble net attack (): For this attack, the “shrinking net mechanism” is presented and this behavior is achieved by decreasing the value of
a in the Equation (
30). Thus, as the whale spirals, it shrinks the bubble net until it finally catches the prey. This motion is modeled with the following Equation (
32):
where
is the distance of the i-th whale from the prey (the best solution obtained so far),
b is a constant for defining the shape of the logarithmic spiral and
l is a random number between
.
It is worth mentioning that humpback whales simultaneously swim around the prey within a shrinking circle and along a spiral trajectory. In order to model this simultaneous behavior, there is a 50% probability of choosing between the encircling prey mechanism (2) or the spiral model (3) to update the position of the whales during optimization. The mathematical model is as follows:
We include the pseudo-code (Algorithm 3) of the metaheuristic [
91] for a better understanding of what was previously stated.
| Algorithm 3: Whale Optimization Algorithm. |
- 1:
Initialize the whale population () - 2:
Calculate the fitness of each search agent - 3:
The best search agent - 4:
while Maximum number of iterations do - 5:
for each search agent do - 6:
Update and p - 7:
if () then - 8:
if () then - 9:
Update the position of the current search agent using of Equation ( 31). - 10:
else() - 11:
Select a random search agent ( - 12:
Update the position of the current search agent using Equation ( 29). - 13:
end if - 14:
else() - 15:
update the position of the current search agent using Equation ( 32). - 16:
end if - 17:
end for - 18:
Check if any search agent goes beyond the search space and we modify it. - 19:
Calculate the fitness of each search agent - 20:
Update if there is a better solution - 21:
- 22:
end while - 23:
Return ()
|
6. Set Covering Problem
SCP is defined as a binary matrix (
A), where
is the value of each cell in the matrix
A and
i and
j are the size m-rows and n-columns, respectively:
Defining the column j satisfies a row i if is equal to 1 and this will be the contrary case if this is 0. In addition, it has an associated cost , where together with and are the sets of rows and columns, respectively.
The problem results in the following objective: to minimize the cost of the subset , with the constraint that all rows are covered by at least one column . It is taken into consideration that when the column j is in the subset of solution S, this is equal to 1 and 0 otherwise.
The SCP can be defined as the following.
7. Experimental Results and Performance Evaluation
In order to determine if the integration of QL as a binary scheme selector improves the results of the MH, five versions of QL have been implemented with different fixes, which have been named as indicated in the
Table 1.
The five implementations of QL have been compared in a subset of instances of Set Covering Problem for each metaheuristic against two recommendations of binary schemes presented in the literature, which are presented in
Table 2.
Both the code and the results obtained can be reviewed in the github repository.
7.1. Statistical Test
Given the increasing use of MH applied to different combinatorial problems, there is a natural interest in comparing which one performs better because, sometimes, it is not so obvious as to which one is better. In this sense, statistical techniques provide a real alternative to compare results.
In order to determine the difference between the results obtained by different algorithms, it is necessary to use a statistical technique to establish whether the difference exists [
92,
93]. The most appropriate test to compare our algorithms is the Wilcoxon–Mann–Whitney test. This test is specifically used when two samples are independent and we cannot assume normality of at least one of them. The hypotheses used for this test are as follows:
where
and
denotes the average value provided by Algorithms A and B, respectively. We assume that if a
p-value
is obtained,
will be rejected and
will be accepted.
7.2. Experimental Results
In order to demonstrate the results obtained by WOA and SCA,
Table 3 and
Table 4 are arranged. In the contents of both tables, the best values obtained from each row are highlighted. Experiments solving the SCP with Beasley’s OR-Library instances totaled 45 instances. For both metaheuristics (WOA and SCA), instances were run with a population consisting 40 individuals and 1000 iterations were performed per run. With this, the stopping condition is at 40,000 evaluations of the objective function, as used in [
92]. The implementation was developed in Python 3.8.5 and processed using the free Google Colaboratory service [
94]. The parameter settings for the SARSA and QL algorithms are as follows:
and
. These tables are composed of the following: the first column corresponds to the name of the instance, the second column is the optimum known to date, the next four columns (
Best,
Avg,
Sec and
RPD) present the best value and the averages obtained from the 31 independent runs, the average time of its executions and, finally, the Relative Percentage Deviation defined in Equation (
38). These three columns mentioned above are repeated for all versions (
BCL1,
MIR2,
QL1,
QL2,
QL3,
QL4 and
QL5). Finally, the last row is the sum of each column. We can denote that the adaptations and versions of QL are produce effects on the chosen metaheuristics, obtaining better results than their counterparts without QL.
In
Figure 5,
Figure 6,
Figure 7 and
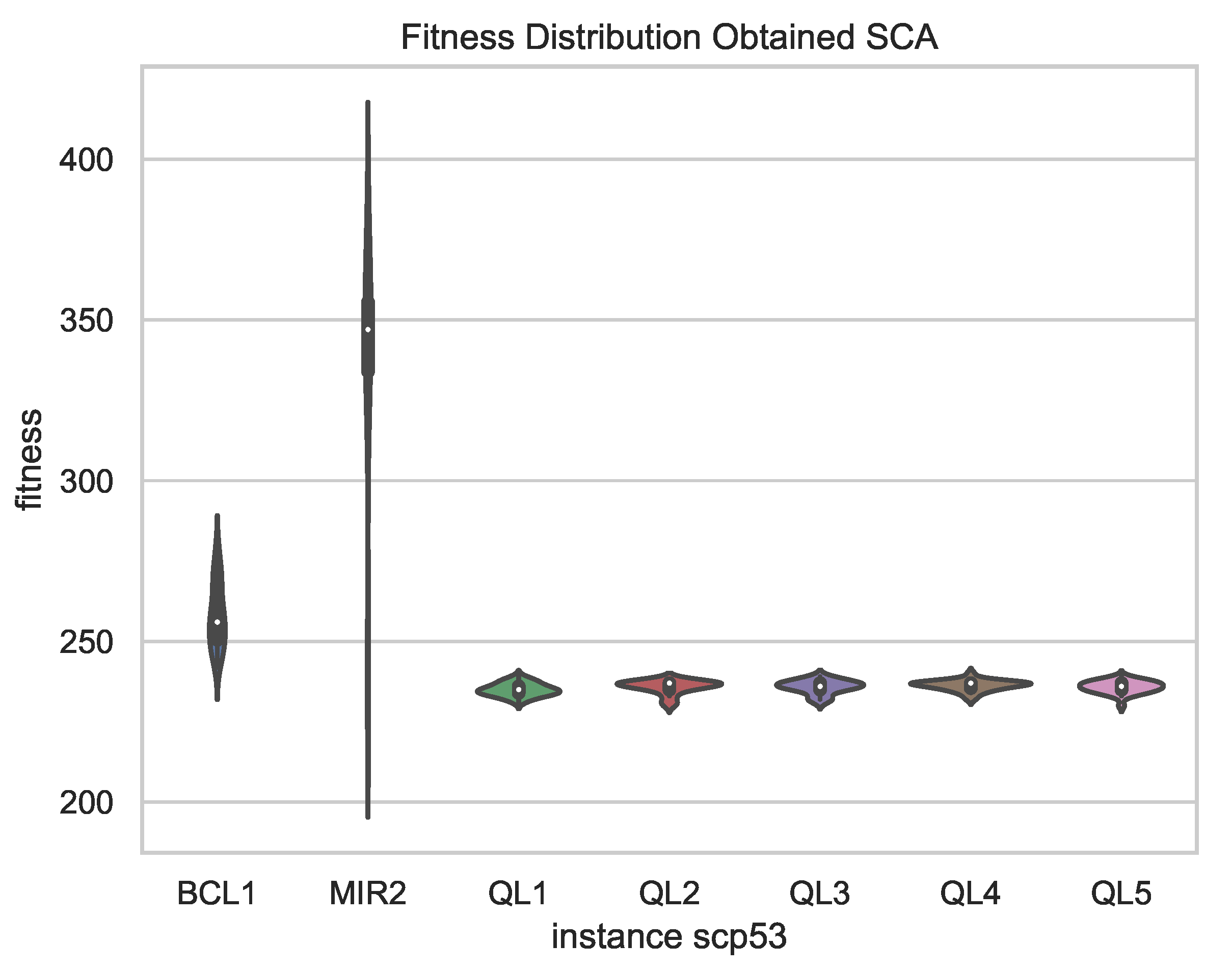
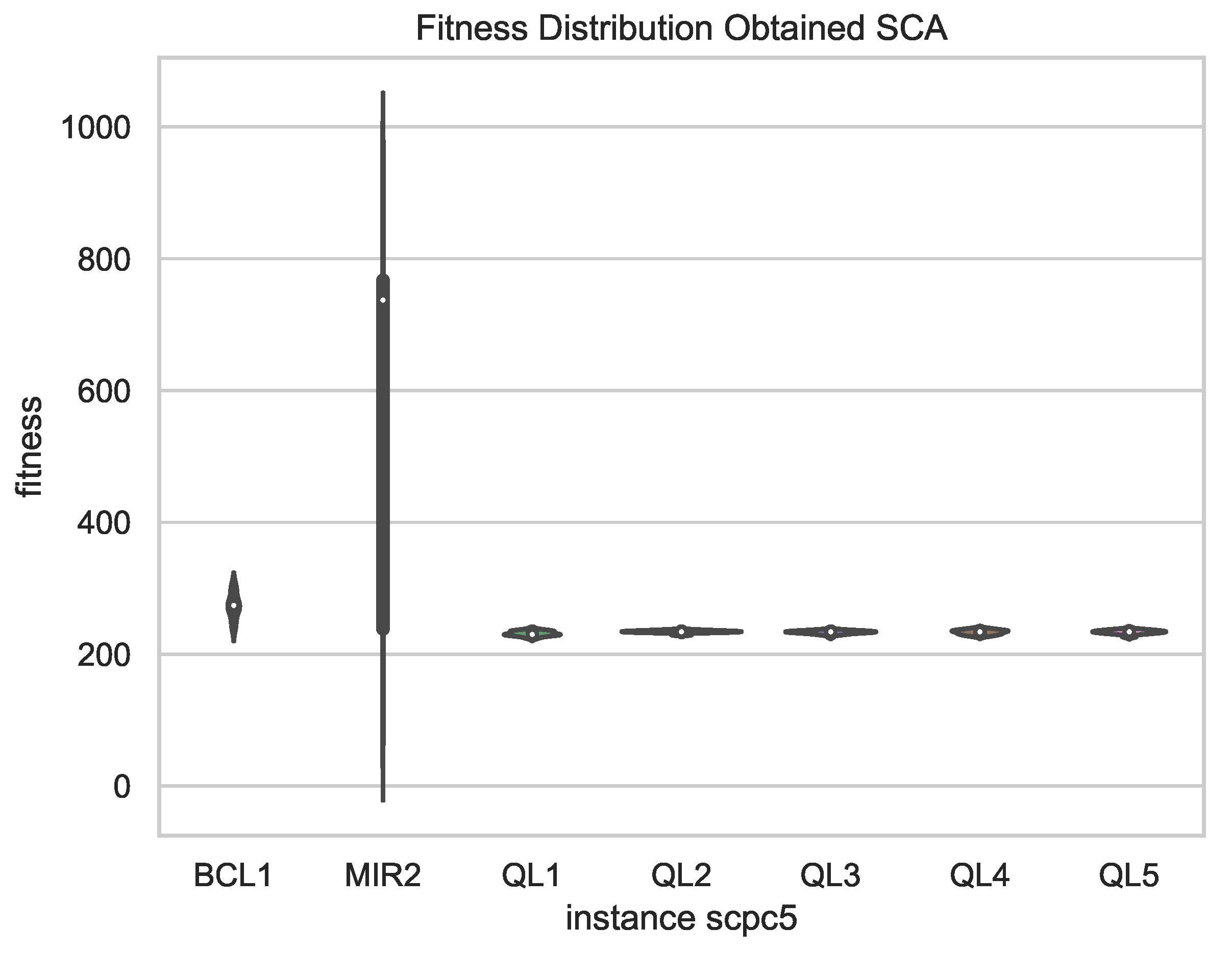
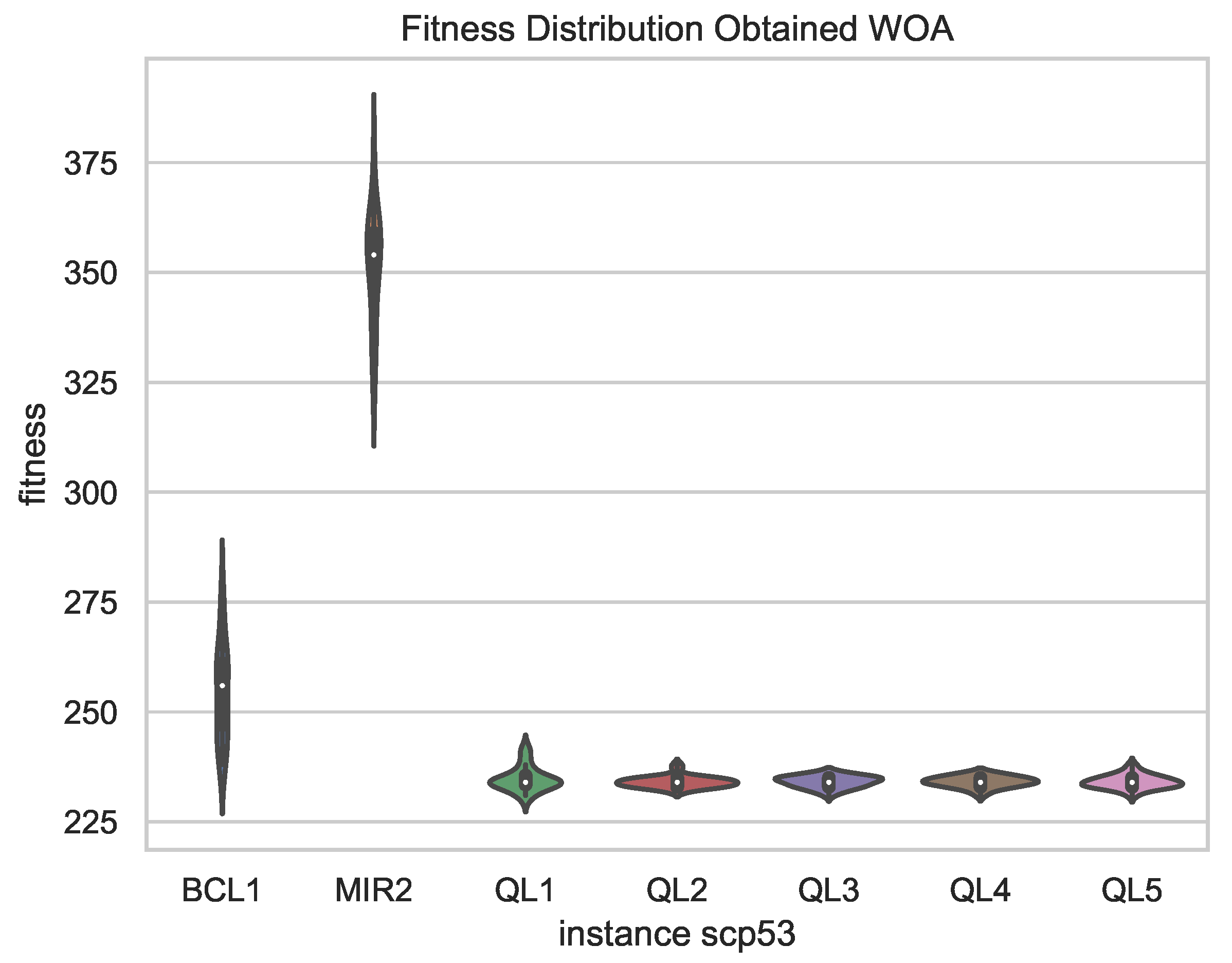
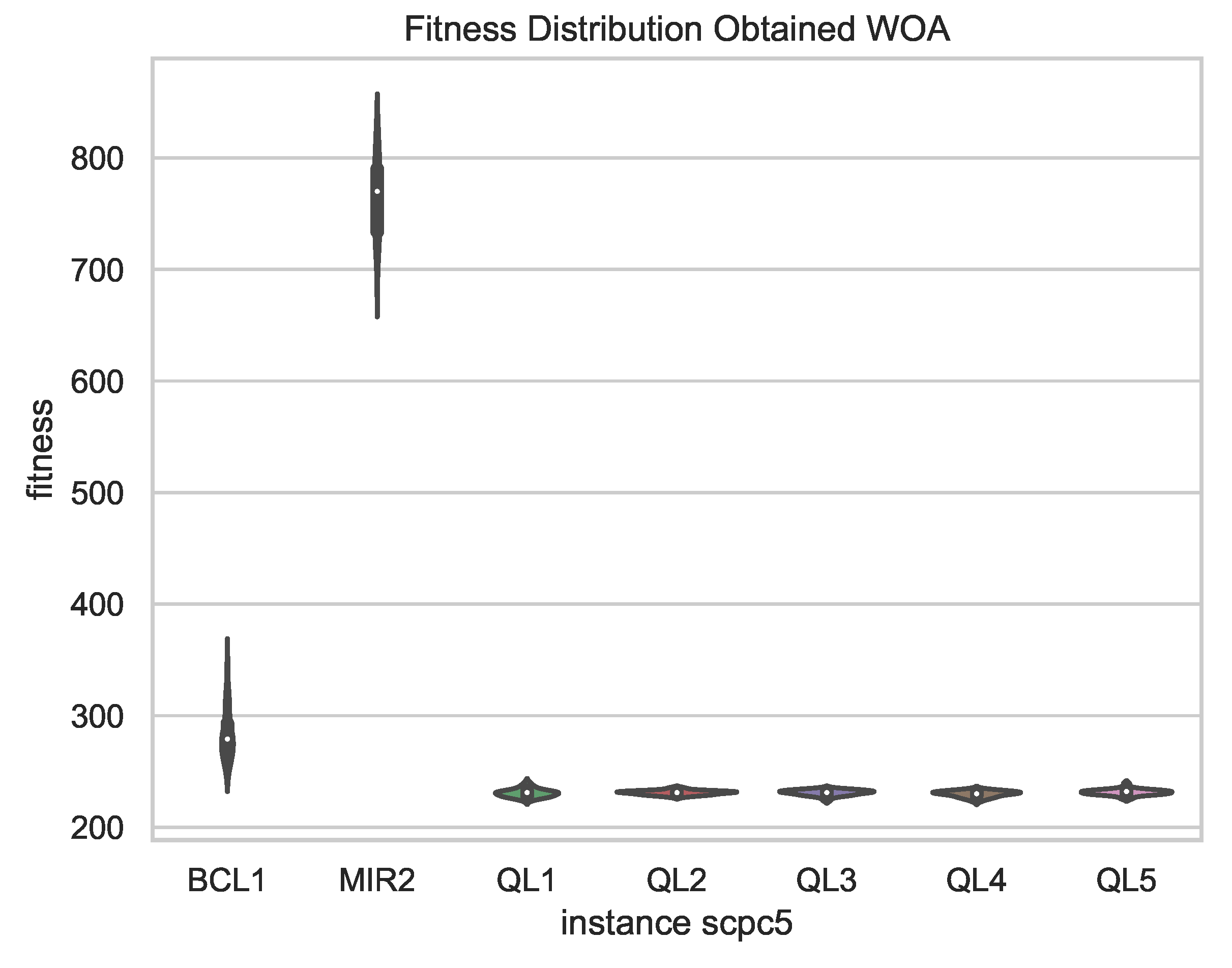
Figure 8, a comparison of the best results obtained in 31 independent runs of the chosen schemes is presented, showing less dispersion in the results for the versions with QL, which supports the robustness of the proposal compared to fixed binarization schemes, since, in addition to obtaining better results, these vary in smaller magnitude in independent runs.
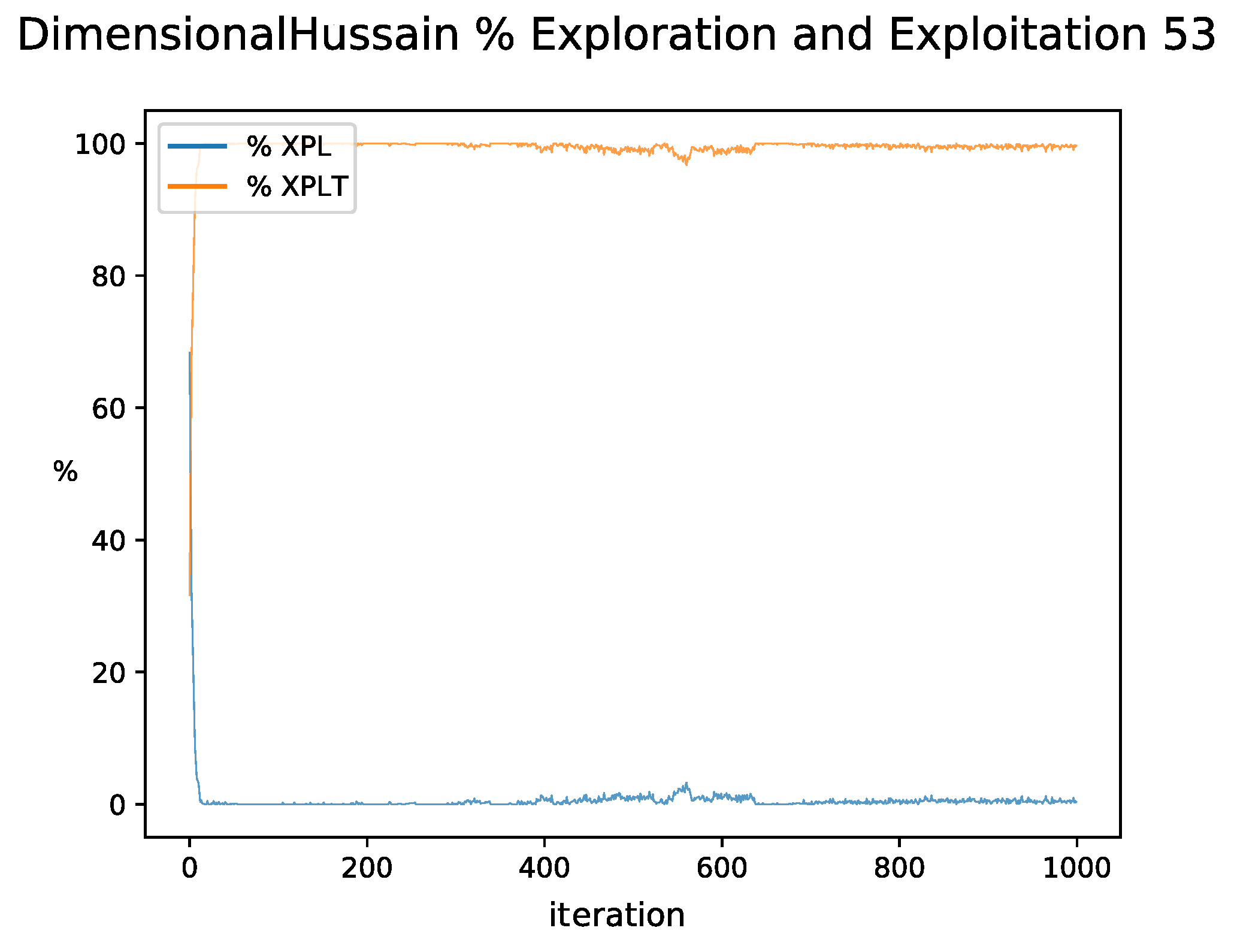
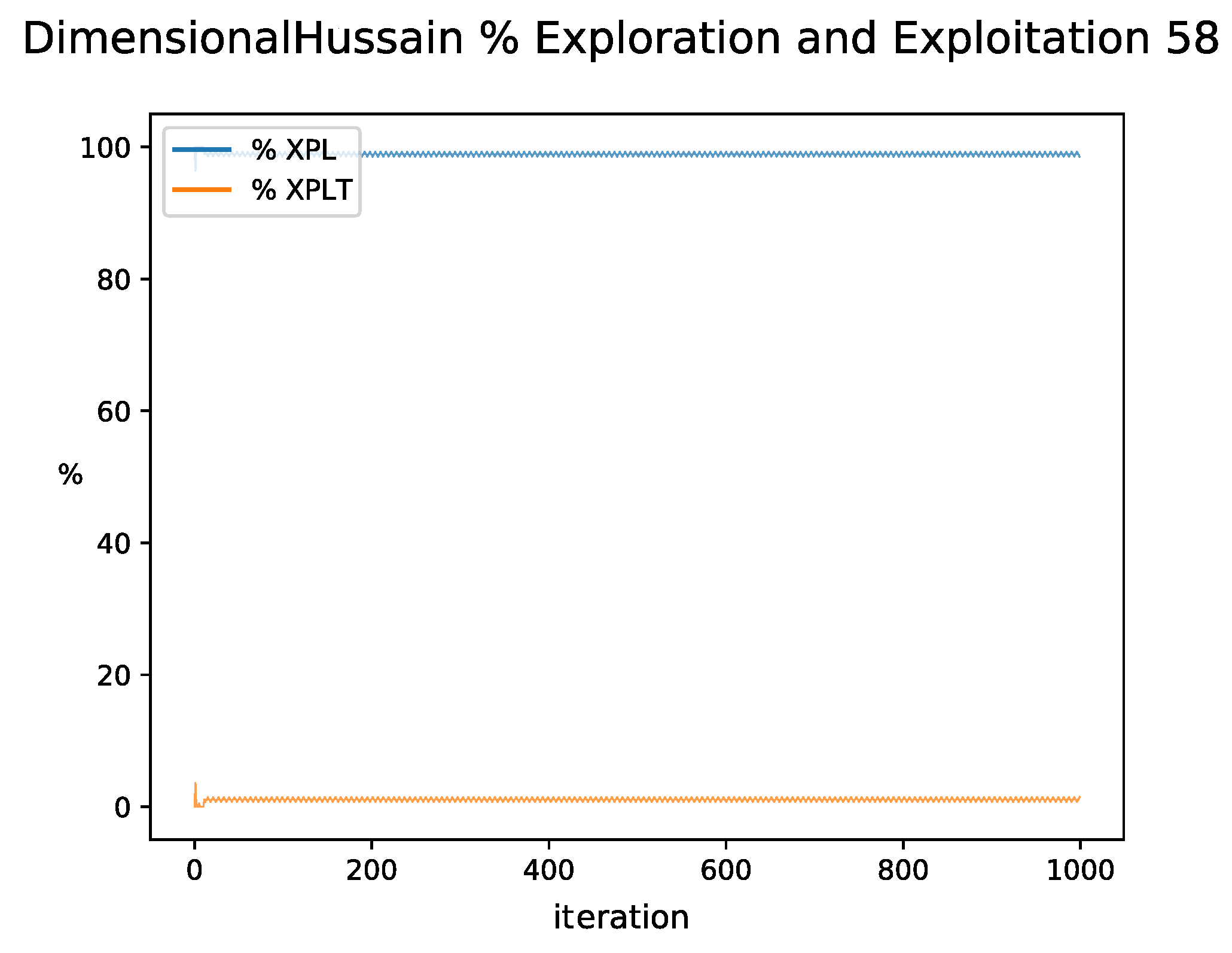
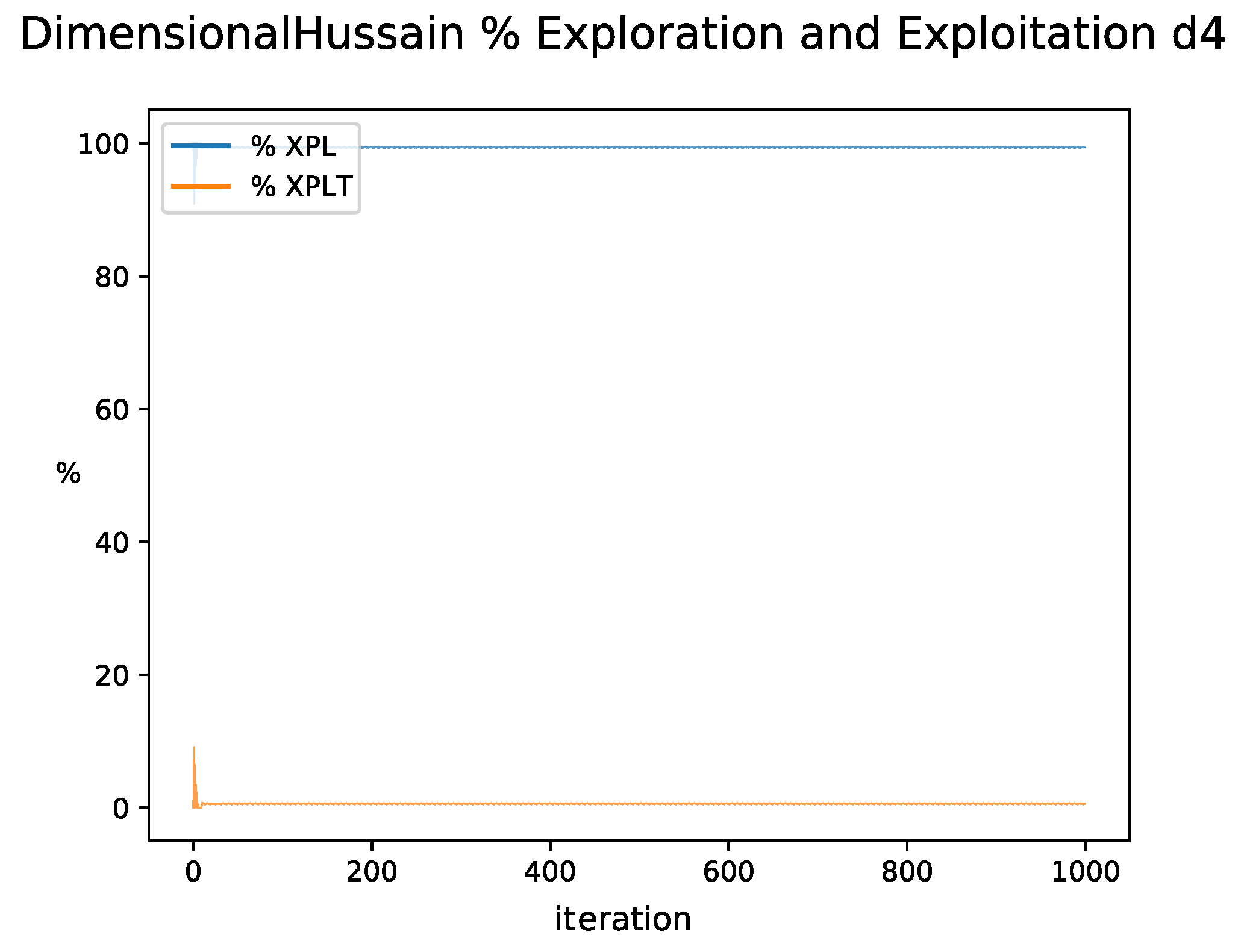
By observing the behavior of the exploration and exploitation percentages in the figures, it can be clearly observed that there are two different behaviors. In the case of
Figure 10 and
Figure 12, there is a clear beginning of exploration in the first iterations, while the exploitation increases until maintaining high values during the rest of the iterations. This behavior is the one recommended by [
4], while for the case of
Figure 14 and
Figure 16, the exploration percentage remains at high values during all iterations and similar behavior is observed when random searches occur. For the versions with QL, the expected exploration and exploitation behavior is observed, where exploration predominates at the beginning and gradually changes to exploitation. However, in this one, variations in the percentages are observed given by the dynamic change of the binarization scheme in each iteration, which in turn has been reflected in better quality results.
These variations in exploration and exploitation percentages open the discussion about the implications of changing real-time binarization schemes, quantifying these percentage variations and the question of how to assess the quality of these changes.
8. Conclusions
Today, Machine Learning techniques are increasingly used in most areas of research, as data capture has been steadily increasing in recent years. MH have not been the exception, where these ML techniques have supported MH from various approaches in order to improve their performance. This is one of the main motivations for this proposal, since MH generate a large amount of data that is not always used for their operation. In the brief review of QL implementations, it is shown how this technique improves the performance of MH, managing to identify two methods of implementation: (1) as a selector of low-level heuristics in the context of hyperheuristics; (2) as a selector of a certain operator among a set of operators, as is the example of the choice of a mutation operator among different mutation operators. On the other hand, it is noted that the size of the Q-Table tends to take small sizes, since the sets of operators to be selected are usually small compared to other techniques of Machine Learning that address large amounts of input variables. The use of enhancements and combinations of QL with other Temporal Difference techniques such as SARSA (State-Action-Reward-State-Action) is also identified.
The algorithms presented in this work have shown that the choice of binarization schemes affects the balance of exploration and exploitation turning them into balanced metaheuristics [
95], used in [
96,
97,
98]. The balance achieved by our method shows an improvement in the quality of solutions, obtaining statistically significant better results.
Under the results obtained, it can be concluded that the versions that have incorporated QL in the selection of binarization schemes obtained variations in the percentages of exploration and exploitation, which are reflected in improvements in the quality of the solutions and in the techniques that do not present these disturbances in their static versions. These perturbations can be associated with better quality movements that will present a greater probability of finding better values when presenting variations in the percentages of exploration and exploitation, meaning that the solutions will have a greater rate of movement in the search space.
On the other hand, when observing the comparison between the average execution times (“Sec” column in
Table 3 and
Table 4), a great increase in time is observed for the versions that incorporate the binarization scheme selector, which are approximately around 447% in WOA and 223% for SCA; this is justifiable since the incorporation of QL to the iterative process of the MH, means a greater demand of calculation, since in each iteration the decision of which binarization scheme to use must be taken. However, this difference in time when comparing against a single binarization scheme, among the 40 combinations that were already explained in
Section 3, produces an unequal comparison. Moreover, by not having a selector of binarization schemes, the 40 combinations of binarization schemes presented in this work should be tested, but since this would involve too much computation time, recommendations presented in the literature are usually used; however, they do not ensure to be the best binarization scheme for the problem and techniques implemented. Consequently, our proposal of a binarization scheme selector is of greater relevance since the high computational costs for the choice of binarization schemes are often not affordable; thus, under this scenario our proposal excels when compared with fixed binarization schemes.
In terms of future work, the option of evaluating other MH with exploration and exploitation behaviors similar to those presented will be contemplated, as well as other more established MH such as Differential Evolution (DE) and Particle Swarm Optimization (PSO) in order to verify that the incorporation of QL generates the same effect on them. We also consider the evaluation of other Temporal Difference techniques to compete with QL, the inclusion of other existing transfer functions in the literature, such as O-Shapes, and the evaluation of other methods of rewarding in addition to the five we have evaluated in the present work.
Author Contributions
B.C.: Conceptualization, funding acquisition, investigation, methodology, project administration, resources, supervision, writing—original draft and writing—review and editing. R.S.: conceptualization, funding acquisition, investigation, methodology, project administration, resources, writing—original draft and Writing—review and editing. J.L.-R.: data curation, investigation, software, visualization, writing—original draft and formal analysis. M.B.-R.: data curation, investigation, software, visualization, writing—original draft, formal analysis. J.M.L.-G.: formal analysis, methodology, validation, writing—review and editing. N.C.: formal analysis, methodology, validation, writing—review and editing. M.C.: data curation, investigation, software, visualization, writing—original draft. D.T.: data curation, investigation, software, visualization, writing—original draft. F.C.-C.: data curation, investigation, software, visualization, writing—original draft. J.G.: formal analysis, funding acquisition, methodology, validation, writing—review and editing. G.A.: formal analysis, methodology, validation, writing—review and editing. C.C.: formal analysis, methodology, validation, writing—review and editing. J.-M.R.: formal analysis, methodology, validation, writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
The APC was funded by Grant ANID/FONDECYT/REGULAR/1210810.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Acknowledgments
Broderick Crawford is supported by Grant ANID/FONDECYT/REGULAR/ 1210810: “DATA-DRIVEN AMBIDEXTROUS METAHEURISTICS: USING MACHINE LEARNING APPROACHES TO MANAGE BALANCE OF EXPLORATION AND EXPLOITATION WHEN SOLVING COMBINATORIAL PROBLEMS WITH CONTINUOUS SWARM INTELLIGENCE ALGORITHMS”. Ricardo Soto is supported by Grant ANID/FONDECYT/REGULAR/1190129: “BUILDING REACTIVE LEARNING-BASED HYBRID METAHEURISTICS”. José Lemus-Romani is supported by National Agency for Research and Development (ANID)/Scholarship Program/ DOCTORADO NACIONAL/2019-21191692. Marcelo Becerra-Rozas is supported by National Agency for Research and Development (ANID)/Scholarship Program/DOCTORADO NACIONAL/ 2021-21210740. José García was supported by the Grant ANID/FONDECYT/INICIACION/ 11180056: “APPLYING MACHINE LEARNING TECHNIQUES TO METAHEURISTIC ALGORITHMS TO SOLVE COMBINATORIAL OPTIMIZATION PROBLEMS”.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Talbi, E. Metaheuristics: From Design to Implementation; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 74. [Google Scholar]
- Xu, J.; Zhang, J. Exploration-exploitation tradeoffs in metaheuristics: Survey and analysis. In Proceedings of the 33rd Chinese Control Conference, Nanjing, China, 28–30 July 2014; pp. 8633–8638. [Google Scholar]
- Yang, X.S.; Deb, S.; Fong, S. Metaheuristic algorithms: Optimal balance of intensification and diversification. Appl. Math. Inf. Sci. 2014, 8, 977. [Google Scholar] [CrossRef]
- Morales-Castañeda, B.; Zaldivar, D.; Cuevas, E.; Fausto, F.; Rodríguez, A. A better balance in metaheuristic algorithms: Does it exist? Swarm Evol. Comput. 2020, 54, 100671. [Google Scholar] [CrossRef]
- Eftimov, T.; Korošec, P. Understanding exploration and exploitation powers of meta-heuristic stochastic optimization algorithms through statistical analysis. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Prague, Czech Republic, 13–17 July 2019; pp. 21–22. [Google Scholar]
- Hussain, A.; Muhammad, Y.S. Trade-off between exploration and exploitation with genetic algorithm using a novel selection operator. Complex Intell. Syst. 2019, 6, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Glover, F.; Samorani, M. Intensification, Diversification and Learning in metaheuristic optimization. J. Heuristics 2019, 25, 517–520. [Google Scholar] [CrossRef] [Green Version]
- Hussain, K.; Salleh, M.N.M.; Cheng, S.; Shi, Y. On the exploration and exploitation in popular swarm-based metaheuristic algorithms. Neural Comput. Appl. 2019, 31, 7665–7683. [Google Scholar] [CrossRef]
- Liu, H.L.; Chen, L.; Deb, K.; Goodman, E.D. Investigating the effect of imbalance between convergence and diversity in evolutionary multiobjective algorithms. IEEE Trans. Evol. Comput. 2016, 21, 408–425. [Google Scholar]
- Gendreau, M.; Potvin, J.Y. Handbook of Metaheuristics; International Series in Operations Research & Management Science; Springer: Cham, Switzerland, 2019; Volume 272. [Google Scholar] [CrossRef]
- Crawford, B.; Soto, R.; Astorga, G.; Lemus-Romani, J.; Misra, S.; Rubio, J.M. An adaptive intelligent water drops algorithm for set covering problem. In Proceedings of the 2019 19th International Conference on Computational Science and Its Applications (ICCSA), St. Petersburg, Russia, 1–4 July 2019; pp. 39–45. [Google Scholar]
- Crawford, B.; Soto, R.; Olivares, R.; Embry, G.; Flores, D.; Palma, W.; Castro, C.; Paredes, F.; Rubio, J.M. A binary monkey search algorithm variation for solving the set covering problem. Nat. Comput. 2019, 19, 825–841. [Google Scholar] [CrossRef]
- García, J.; Crawford, B.; Soto, R.; Castro, C.; Paredes, F. A k-means binarization framework applied to multidimensional knapsack problem. Appl. Intell. 2018, 48, 357–380. [Google Scholar] [CrossRef]
- Crawford, B.; Soto, R.; Astorga, G.; Lemus, J.; Salas-Fernández, A. Self-configuring Intelligent Water Drops Algorithm for Software Project Scheduling Problem. In International Conference on Information Technology & Systems; Springer: Cham, Switzerland, 2019; pp. 274–283. [Google Scholar]
- Crawford, B.; Soto, R.; Astorga, G.; Castro, C.; Paredes, F.; Misra, S.; Rubio, J.M. Solving the software project scheduling problem using intelligent water drops. Teh. Vjesn. 2018, 25, 350–357. [Google Scholar]
- Mafarja, M.M.; Mirjalili, S. Hybrid whale optimization algorithm with simulated annealing for feature selection. Neurocomputing 2017, 260, 302–312. [Google Scholar] [CrossRef]
- Ho, Y.C.; Pepyne, D.L. Simple explanation of the no-free-lunch theorem and its implications. J. Optim. Theory Appl. 2002, 115, 549–570. [Google Scholar] [CrossRef]
- Crawford, B.; Soto, R.; Astorga, G.; García, J.; Castro, C.; Paredes, F. Putting continuous metaheuristics to work in binary search spaces. Complexity 2017, 2017, 8404231. [Google Scholar] [CrossRef] [Green Version]
- García, J.; Moraga, P.; Valenzuela, M.; Crawford, B.; Soto, R.; Pinto, H.; Peña, A.; Altimiras, F.; Astorga, G. A Db-Scan Binarization Algorithm Applied to Matrix Covering Problems. Comput. Intell. Neurosci. 2019, 2019, 3238574. [Google Scholar] [CrossRef] [Green Version]
- Maniezzo, V.; Stützle, T.; Voß, S. (Eds.) Matheuristics—Volume 10 of Annals of Information Systems; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Juan, A.A.; Faulin, J.; Grasman, S.E.; Rabe, M.; Figueira, G. A review of simheuristics: Extending metaheuristics to deal with stochastic combinatorial optimization problems. Oper. Res. Perspect. 2015, 2, 62–72. [Google Scholar] [CrossRef] [Green Version]
- Juan, A.A.; Keenan, P.; Martı, R.; McGarraghy, S.; Panadero, J.; Carroll, P.; Oliva, D. A Review of the Role of Heuristics in Stochastic Optimisation: From Metaheuristics to Learnheuristics. Ann. Oper. Res. 2021. [Google Scholar] [CrossRef]
- Arnau, Q.; Juan, A.A.; Serra, I. On the use of learnheuristics in vehicle routing optimization problems with dynamic inputs. Algorithms 2018, 11, 208. [Google Scholar] [CrossRef] [Green Version]
- Bayliss, C.; Juan, A.A.; Currie, C.S.; Panadero, J. A learnheuristic approach for the team orienteering problem with aerial drone motion constraints. Appl. Soft Comput. 2020, 92, 106280. [Google Scholar] [CrossRef]
- Lavecchia, A. Machine-learning approaches in drug discovery: Methods and applications. Drug Discov. Today 2015, 20, 318–331. [Google Scholar] [CrossRef] [Green Version]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef] [Green Version]
- Kotsiantis, S.B.; Zaharakis, I.; Pintelas, P. Supervised machine learning: A review of classification techniques. Emerg. Artif. Intell. Appl. Comput. Eng. 2007, 160, 3–24. [Google Scholar]
- Celebi, M.E.; Aydin, K. Unsupervised Learning Algorithms; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9. [Google Scholar]
- Valdivia, S.; Soto, R.; Crawford, B.; Caselli, N.; Paredes, F.; Castro, C.; Olivares, R. Clustering-based binarization methods applied to the crow search algorithm for 0/1 combinatorial problems. Mathematics 2020, 8, 1070. [Google Scholar] [CrossRef]
- Lorbeer, B.; Kosareva, A.; Deva, B.; Softić, D.; Ruppel, P.; Küpper, A. Variations on the clustering algorithm BIRCH. Big Data Res. 2018, 11, 44–53. [Google Scholar] [CrossRef]
- Chapelle, O.; Scholkopf, B.; Zien, A. Semi-supervised learning (chapelle, o. et al., eds.; 2006) [book reviews]. IEEE Trans. Neural Netw. 2009, 20, 542. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Veček, N.; Mernik, M.; Filipič, B.; Črepinšek, M. Parameter tuning with Chess Rating System (CRS-Tuning) for meta-heuristic algorithms. Inf. Sci. 2016, 372, 446–469. [Google Scholar] [CrossRef]
- Ries, J.; Beullens, P. A semi-automated design of instance-based fuzzy parameter tuning for metaheuristics based on decision tree induction. J. Oper. Res. Soc. 2015, 66, 782–793. [Google Scholar] [CrossRef] [Green Version]
- Deng, Y.; Liu, Y.; Zhou, D. An improved genetic algorithm with initial population strategy for symmetric TSP. Math. Probl. Eng. 2015, 2015, 212794. [Google Scholar] [CrossRef] [Green Version]
- García, J.; Crawford, B.; Soto, R.; Astorga, G. A percentile transition ranking algorithm applied to binarization of continuous swarm intelligence metaheuristics. In International Conference on Soft Computing and Data Mining; Springer: Cham, Switzerland, 2018; pp. 3–13. [Google Scholar]
- García, J.; Altimiras, F.; Peña, A.; Astorga, G.; Peredo, O. A binary cuckoo search big data algorithm applied to large-scale crew scheduling problems. Complexity 2018, 2018, 8395193. [Google Scholar] [CrossRef]
- de León, A.D.; Lalla-Ruiz, E.; Melián-Batista, B.; Moreno-Vega, J.M. A Machine Learning-based system for berth scheduling at bulk terminals. Expert Syst. Appl. 2017, 87, 170–182. [Google Scholar] [CrossRef]
- Asta, S.; Özcan, E.; Curtois, T. A tensor based hyper-heuristic for nurse rostering. Knowl. Based Syst. 2016, 98, 185–199. [Google Scholar] [CrossRef] [Green Version]
- Martin, S.; Ouelhadj, D.; Beullens, P.; Ozcan, E.; Juan, A.A.; Burke, E.K. A multi-agent based cooperative approach to scheduling and routing. Eur. J. Oper. Res. 2016, 254, 169–178. [Google Scholar] [CrossRef] [Green Version]
- Song, H.; Triguero, I.; Özcan, E. A review on the self and dual interactions between machine learning and optimisation. Prog. Artif. Intell. 2019, 8, 143–165. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Lu, J. Adaptive evolutionary programming based on reinforcement learning. Inf. Sci. 2008, 178, 971–984. [Google Scholar] [CrossRef]
- Dorigo, M.; Birattari, M.; Stutzle, T. Ant colony optimization. IEEE Comput. Intell. Mag. 2006, 1, 28–39. [Google Scholar] [CrossRef] [Green Version]
- Gambardella, L.M.; Dorigo, M. Ant-Q: A reinforcement learning approach to the traveling salesman problem. In Machine Learning Proceedings 1995; Elsevier: Amsterdam, The Netherlands, 1995; pp. 252–260. [Google Scholar]
- Khamassi, I.; Hammami, M.; Ghédira, K. Ant-q hyper-heuristic approach for solving 2-dimensional cutting stock problem. In Proceedings of the 2011 IEEE Symposium on Swarm Intelligence, Paris, France, 11–15 April 2011; pp. 1–7. [Google Scholar]
- Choong, S.S.; Wong, L.P.; Lim, C.P. Automatic design of hyper-heuristic based on reinforcement learning. Inf. Sci. 2018, 436, 89–107. [Google Scholar] [CrossRef]
- Mosadegh, H.; Ghomi, S.F.; Süer, G. Stochastic mixed-model assembly line sequencing problem: Mathematical modeling and Q-learning based simulated annealing hyper-heuristics. Eur. J. Oper. Res. 2020, 282, 530–544. [Google Scholar] [CrossRef]
- Burke, E.K.; Gendreau, M.; Hyde, M.; Kendall, G.; McCollum, B.; Ochoa, G.; Parkes, A.J.; Petrovic, S. The cross-domain heuristic search challenge—An international research competition. In International Conference on Learning and Intelligent Optimization; Springer: Cham, Switzerland, 2011; pp. 631–634. [Google Scholar]
- Li, Z.; Li, S.; Yue, C.; Shang, Z.; Qu, B. Differential evolution based on reinforcement learning with fitness ranking for solving multimodal multiobjective problems. Swarm Evol. Comput. 2019, 49, 234–244. [Google Scholar] [CrossRef]
- Alimoradi, M.R.; Kashan, A.H. A league championship algorithm equipped with network structure and backward Q-learning for extracting stock trading rules. Appl. Soft Comput. 2018, 68, 478–493. [Google Scholar] [CrossRef]
- Sadhu, A.K.; Konar, A.; Bhattacharjee, T.; Das, S. Synergism of firefly algorithm and Q-learning for robot arm path planning. Swarm Evol. Comput. 2018, 43, 50–68. [Google Scholar] [CrossRef]
- Zamli, K.Z.; Din, F.; Ahmed, B.S.; Bures, M. A hybrid Q-learning sine-cosine-based strategy for addressing the combinatorial test suite minimization problem. PLoS ONE 2018, 13, e0195675. [Google Scholar]
- Yang, X.S. Firefly Algorithms. Nature-Inspired Optimization Algorithms; Elsevier: Amsterdam, The Netherlands, 2021; pp. 123–139. [Google Scholar]
- Xu, Y.; Pi, D. A reinforcement learning-based communication topology in particle swarm optimization. Neural Comput. Appl. 2019, 32, 10007–10032. [Google Scholar] [CrossRef]
- Das, P.; Behera, H.; Panigrahi, B. Intelligent-based multi-robot path planning inspired by improved classical Q-learning and improved particle swarm optimization with perturbed velocity. Eng. Sci. Technol. Int. J. 2016, 19, 651–669. [Google Scholar] [CrossRef] [Green Version]
- Abed-alguni, B.H. Action-selection method for reinforcement learning based on cuckoo search algorithm. Arab. J. Sci. Eng. 2018, 43, 6771–6785. [Google Scholar] [CrossRef]
- Abed-alguni, B.H. Bat Q-learning algorithm. Jordanian J. Comput. Inf. Technol. (JJCIT) 2017, 3, 56–77. [Google Scholar]
- Arin, A.; Rabadi, G. Integrating estimation of distribution algorithms versus Q-learning into Meta-RaPS for solving the 0–1 multidimensional knapsack problem. Comput. Ind. Eng. 2017, 112, 706–720. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. S-shaped versus V-shaped transfer functions for binary particle swarm optimization. Swarm Evol. Comput. 2013, 9, 1–14. [Google Scholar] [CrossRef]
- Faris, H.; Mafarja, M.M.; Heidari, A.A.; Aljarah, I.; Ala’M, A.Z.; Mirjalili, S.; Fujita, H. An efficient binary salp swarm algorithm with crossover scheme for feature selection problems. Knowl. Based Syst. 2018, 154, 43–67. [Google Scholar] [CrossRef]
- Mafarja, M.; Aljarah, I.; Heidari, A.A.; Faris, H.; Fournier-Viger, P.; Li, X.; Mirjalili, S. Binary dragonfly optimization for feature selection using time-varying transfer functions. Knowl. Based Syst. 2018, 161, 185–204. [Google Scholar] [CrossRef]
- Mirjalili, S.; Hashim, S.Z.M. BMOA: Binary magnetic optimization algorithm. Int. J. Mach. Learn. Comput. 2012, 2, 204. [Google Scholar] [CrossRef] [Green Version]
- Crawford, B.; Soto, R.; Olivares-Suarez, M.; Palma, W.; Paredes, F.; Olguin, E.; Norero, E. A binary coded firefly algorithm that solves the set covering problem. Rom. J. Inf. Sci. Technol 2014, 17, 252–264. [Google Scholar]
- Crawford, B.; Soto, R.; Berríos, N.; Johnson, F.; Paredes, F.; Castro, C.; Norero, E. A binary cat swarm optimization algorithm for the non-unicost set covering problem. Math. Probl. Eng. 2015, 2015, 578541. [Google Scholar] [CrossRef] [Green Version]
- Soto, R.; Crawford, B.; Olivares, R.; Barraza, J.; Figueroa, I.; Johnson, F.; Paredes, F.; Olguin, E. Solving the non-unicost set covering problem by using cuckoo search and black hole optimization. Nat. Comput. 2017, 16, 213–229. [Google Scholar] [CrossRef]
- Soto, R.; Crawford, B.; Olivares, R.; Taramasco, C.; Figueroa, I.; Gómez, A.; Castro, C.; Paredes, F. Adaptive Black Hole Algorithm for Solving the Set Covering Problem. Math. Probl. Eng. 2018, 2018, 2183214. [Google Scholar] [CrossRef]
- Leonard, B.J.; Engelbrecht, A.P.; Cleghorn, C.W. Critical considerations on angle modulated particle swarm optimisers. Swarm Intell. 2015, 9, 291–314. [Google Scholar] [CrossRef]
- Zhang, G. Quantum-inspired evolutionary algorithms: A survey and empirical study. J. Heuristics 2011, 17, 303–351. [Google Scholar] [CrossRef]
- Saremi, S.; Mirjalili, S.; Lewis, A. How important is a transfer function in discrete heuristic algorithms. Neural Comput. Appl. 2015, 26, 625–640. [Google Scholar] [CrossRef] [Green Version]
- Kennedy, J.; Eberhart, R.C. A discrete binary version of the particle swarm algorithm. In Proceedings of the 1997 IEEE International conference on systems, man, and cybernetics. Computational cybernetics and simulation, Orlando, FL, USA, 12–15 October 1997; Volume 5, pp. 4104–4108. [Google Scholar]
- Rajalakshmi, N.; Subramanian, D.P.; Thamizhavel, K. Performance enhancement of radial distributed system with distributed generators by reconfiguration using binary firefly algorithm. J. Inst. Eng. (India) Ser. B 2015, 96, 91–99. [Google Scholar] [CrossRef]
- Crawford, B.; Soto, R.; Peña, C.; Riquelme-Leiva, M.; Torres-Rojas, C.; Johnson, F.; Paredes, F. Binarization methods for shuffled frog leaping algorithms that solve set covering problems. In Software Engineering in Intelligent Systems; Springer: Cham, Switzerland, 2015; pp. 317–326. [Google Scholar]
- Tamayo-Vera, D.; Chen, S.; Bolufé-Röhler, A.; Montgomery, J.; Hendtlass, T. Improved Exploration and Exploitation in Particle Swarm Optimization. In Recent Trends and Future Technology in Applied Intelligence; Mouhoub, M., Sadaoui, S., Ait Mohamed, O., Ali, M., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 421–433. [Google Scholar]
- Črepinšek, M.; Liu, S.H.; Mernik, M. Exploration and Exploitation in Evolutionary Algorithms: A Survey. ACM Comput. Surv. 2013, 45. [Google Scholar] [CrossRef]
- Olorunda, O.; Engelbrecht, A.P. Measuring exploration/exploitation in particle swarms using swarm diversity. In Proceedings of the 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence, Hong Kong, China, 1–6 June 2008; pp. 1128–1134. [Google Scholar] [CrossRef]
- Burke, E.K.; Hyde, M.R.; Kendall, G.; Ochoa, G.; Özcan, E.; Woodward, J.R. A Classification of Hyper-Heuristic Approaches: Revisited. In Handbook of Metaheuristics; Gendreau, M., Potvin, J.Y., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 453–477. [Google Scholar] [CrossRef]
- Oyebolu, F.B.; Allmendinger, R.; Farid, S.S.; Branke, J. Dynamic scheduling of multi-product continuous biopharmaceutical facilities: A hyper-heuristic framework. Comput. Chem. Eng. 2019, 125, 71–88. [Google Scholar] [CrossRef] [Green Version]
- Leng, L.; Zhao, Y.; Wang, Z.; Zhang, J.; Wang, W.; Zhang, C. A Novel Hyper-Heuristic for the Biobjective Regional Low-Carbon Location-Routing Problem with Multiple Constraints. Sustainability 2019, 11, 1596. [Google Scholar] [CrossRef] [Green Version]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Nareyek, A. Choosing search heuristics by non-stationary reinforcement learning. In Metaheuristics: Computer Decision-Making; Springer: Boston, MA, USA, 2003; pp. 523–544. [Google Scholar]
- Salleh, M.N.M.; Hussain, K.; Cheng, S.; Shi, Y.; Muhammad, A.; Ullah, G.; Naseem, R. Exploration and exploitation measurement in swarm-based metaheuristic algorithms: An empirical analysis. In International Conference on Soft Computing and Data Mining; Springer: Cham, Switzerland, 2018; pp. 24–32. [Google Scholar]
- Cheng, S.; Shi, Y.; Qin, Q.; Zhang, Q.; Bai, R. Population Diversity Maintenance In Brain Storm Optimization Algorithm. J. Artif. Intell. Soft Comput. Res. 2014, 4, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Mattiussi, C.; Waibel, M.; Floreano, D. Measures of diversity for populations and distances between individuals with highly reorganizable genomes. Evol. Comput. 2004, 12, 495–515. [Google Scholar] [CrossRef] [Green Version]
- Lynn, N.; Suganthan, P.N. Heterogeneous comprehensive learning particle swarm optimization with enhanced exploration and exploitation. Swarm Evol. Comput. 2015, 24, 11–24. [Google Scholar] [CrossRef]
- Hussain, K.; Zhu, W.; Salleh, M.N.M. Long-term memory Harris’ hawk optimization for high dimensional and optimal power flow problems. IEEE Access 2019, 7, 147596–147616. [Google Scholar] [CrossRef]
- Abualigah, L.; Diabat, A. Advances in Sine Cosine Algorithm: A comprehensive survey. Artif. Intell. Rev. 2021, 54, 2567–2608. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Saremi, S.; Mirjalili, S. Whale optimization algorithm: Theory, literature review, and application in designing photonic crystal filters. Nat. Inspired Optim. 2020, 219–238. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl. Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Hassan, A.A.; Abdullah, S.; Zamli, K.Z.; Razali, R. Combinatorial Test Suites Generation Strategy Utilizing the Whale Optimization Algorithm. IEEE Access 2020, 9, 192288–192303. [Google Scholar] [CrossRef]
- Lanza-Gutierrez, J.M.; Crawford, B.; Soto, R.; Berrios, N.; Gomez-Pulido, J.A.; Paredes, F. Analyzing the effects of binarization techniques when solving the set covering problem through swarm optimization. Expert Syst. Appl. 2017, 70, 67–82. [Google Scholar] [CrossRef]
- Osaba, E.; Carballedo, R.; Diaz, F.; Onieva, E.; Masegosa, A.D.; Perallos, A. Good practice proposal for the implementation, presentation, and comparison of metaheuristics for solving routing problems. Neurocomputing 2018, 271, 2–8. [Google Scholar] [CrossRef] [Green Version]
- Bisong, E. Google colaboratory. In Building Machine Learning and Deep Learning Models on Google Cloud Platform; Springer: Berlin/Heidelberg, Germany, 2019; pp. 59–64. [Google Scholar]
- Crawford, B.; León de la Barra, C. Los Algoritmos Ambidiestros. 2020. Available online: https://www.mercuriovalpo.cl/impresa/2020/07/13/full/cuerpo-principal/15/ (accessed on 12 February 2021).
- Lemus-Romani, J.; Crawford, B.; Soto, R.; Astorga, G.; Misra, S.; Crawford, K.; Foschino, G.; Salas-Fernández, A.; Paredes, F. Ambidextrous Socio-Cultural Algorithms. In International Conference on Computational Science and Its Applications; Springer: Cham, Switzerland, 2020; pp. 923–938. [Google Scholar]
- Cisternas-Caneo, F.; Crawford, B.; Soto, R.; de la Fuente-Mella, H.; Tapia, D.; Lemus-Romani, J.; Castillo, M.; Becerra-Rozas, M.; Paredes, F.; Misra, S. A Data-Driven Dynamic Discretization Framework to Solve Combinatorial Problems Using Continuous Metaheuristics. In Innovations in Bio-Inspired Computing and Applications; Springer International Publishing: Cham, Switzerland, 2021; pp. 76–85. [Google Scholar]
- Tapia, D.; Crawford, B.; Soto, R.; Cisternas-Caneo, F.; Lemus-Romani, J.; Castillo, M.; García, J.; Palma, W.; Paredes, F.; Misra, S. A Q-Learning Hyperheuristic Binarization Framework to Balance Exploration and Exploitation. In International Conference on Applied Informatics; Springer: Cham, Switzerland, 2020; pp. 14–28. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}