
A Fast Aircraft Detection Method for SAR Images Based on Efficient Bidirectional Path Aggregated Attention Network

 , , , ,
, , , ,
Abstract
:1. Introduction
- (1)
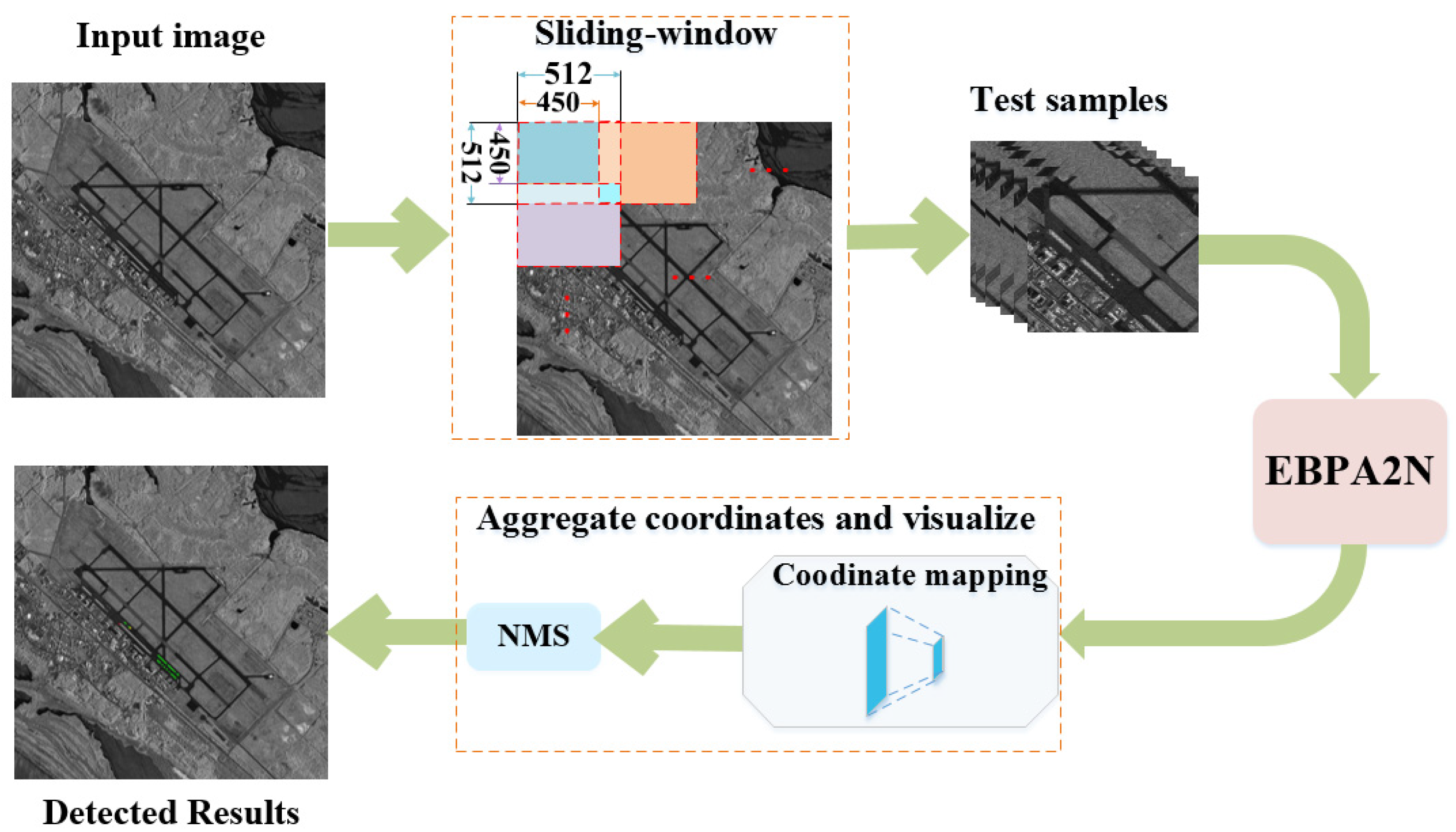
- An effective and efficient aircraft detection network EBPA2N is proposed for SAR image analytics. Combined with the sliding window detection method, an end-to-end aircraft detection framework based on EBPA2N was established, which offers accurate and real-time aircraft detection from large-scale SAR images.
- (2)
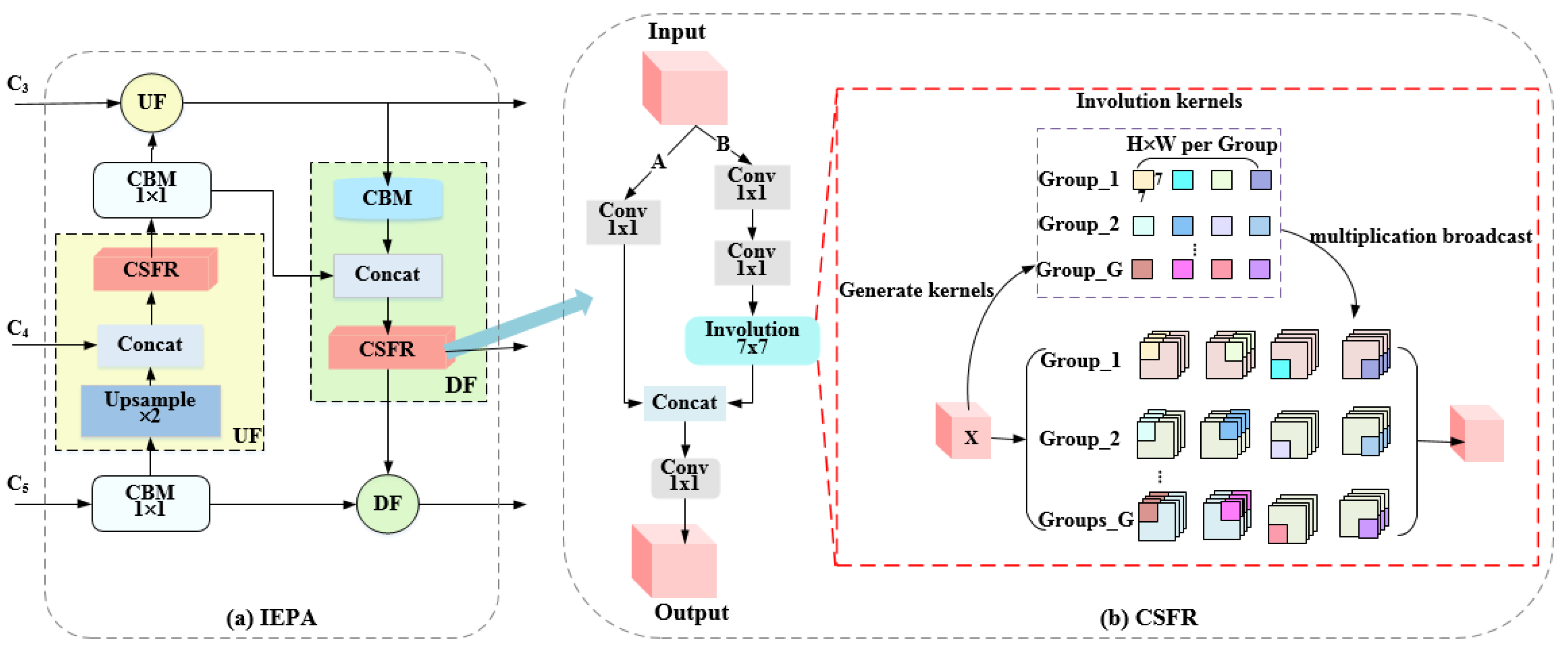
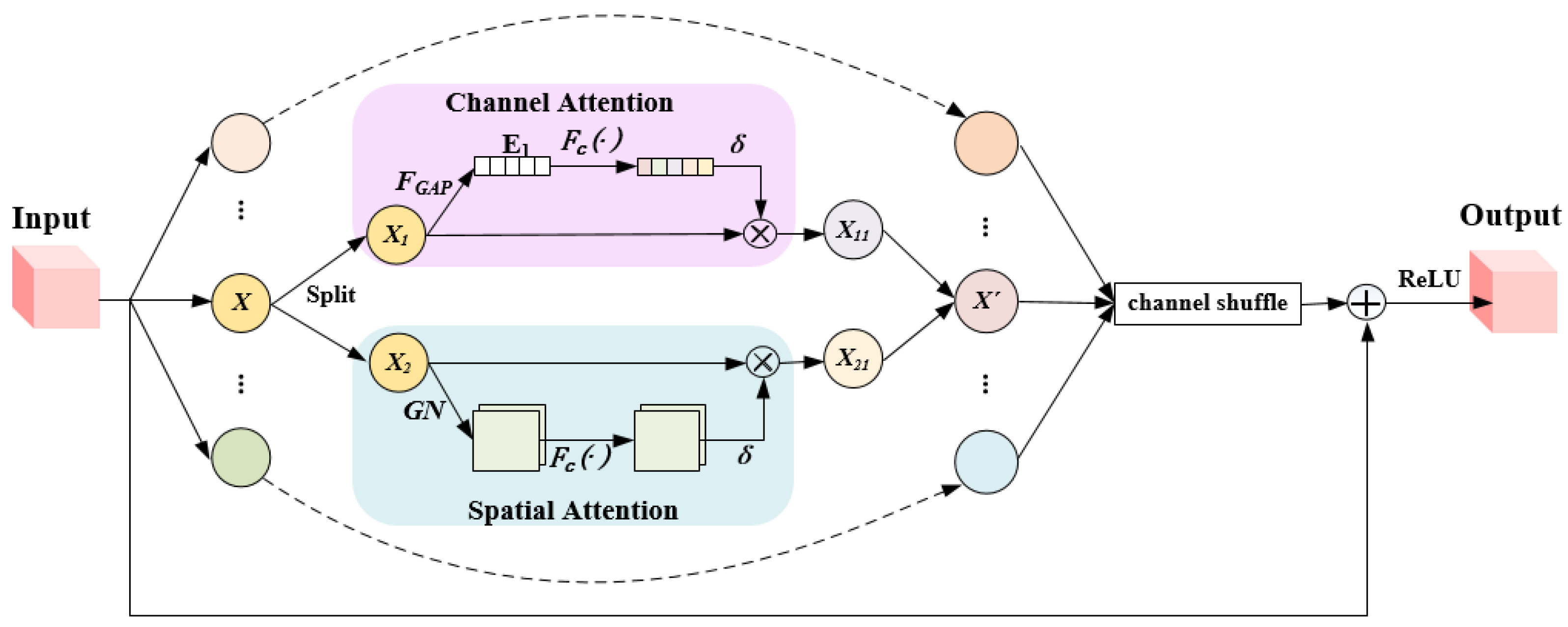
- As far as we know, we are the first to apply involution in SAR image analytics. We invented the Involution Enhanced Path Aggregation (IEPA) and Effective Residual Shuffle Attention (ERSA) module in an independent efficient Bidirectional Path Aggregation Attention Module (BPA2M). The IEPA module is proposed to capture the relationship among aircraft’s backscattering features to better encode multi-scale geospatial information. As the basic module of the IEPA module, involution redefines the design method of feature extraction. By contrast with the traditional standard convolution, it uses different involution kernels in different spatial positions (i.e., spatial specificity) to integrate pixel spatial information, which is more conducive to establishing the correlation between aircraft scattering features in SAR images. On the other hand, the ERSA module mainly focuses on the scattering features information of the target and suppresses the influence of background clutter, then the influence of speckle noise in SAR images can be reduced.
- (3)
- Our experiment has proved the outstanding performance of EBPA2N, which indicates the success of implementing multi-scale SAR image analytics as geospatial attention within deep neural networks. This paper has paved the path for further integration of SAR domain knowledge and advanced deep learning algorithms.
2. Methodology
2.1. Overall Detection Framework
2.2. YOLOv5s Backbone
2.3. Bidirectional Path Aggregation and Attention Module (BPA2M)
2.3.1. Involution Enhanced Path Aggregation (IEPA) Module
2.3.2. Effective Residual Shuffle Attention (ERSA) Module
2.4. Classification and Box Prediction Network
2.5. Detection by Sliding
3. Experimental Results and Analyzer
3.1. Data and Evaluation Metrics
3.2. Implementation Details
3.3. Analysis of the Experimental Results
3.3.1. Analysis of Aircraft Detection for Airport I
3.3.2. Analysis of Aircraft Detection for Airport II
3.3.3. Analysis of Aircraft Detection for Airport Ⅲ
3.4. Performance Evaluation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sportouche, H.; Tupin, F.; Denise, L. Extraction and three-dimensional reconstruction of isolated buildings in urban scenes from high-resolution optical and SAR spaceborne images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3932–3945. [Google Scholar] [CrossRef]
- Pan, B.; Tai, J.; Zheng, Q.; Zhao, S. Cascade convolutional neural network based on transfer-learning for aircraft detection on high-resolution remote sensing images. J. Sens. 2017, 2017, 1796728. [Google Scholar] [CrossRef] [Green Version]
- Guo, Q.; Wang, H. Research progress on aircraft detection and recognition in SAR imagery. J. Radars 2020, 9, 497–513. [Google Scholar]
- Zhang, T.; Zhang, X. High-Speed ship detection in SAR images based on a grid convolutional neural network. Remote Sens. 2019, 11, 1206. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unifified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ren, S.; Kaiming, H.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anl. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767v1. [Google Scholar]
- Wang, C.-Y.; Liao, H.; Yeh, I.-H.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 13–19 June 2020; pp. 1571–1580. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934v1. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H. Scaled-YOLOv4: Scaling cross stage partial network. arXiv 2020, arXiv:2011.08036v2. [Google Scholar]
- Ultralytics. yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 18 May 2020).
- Zhang, L.; Li, C.; Zhao, L.; Xiong, B.; Kuang, G. A cascaded three-look network for aircraft detection in SAR images. Remote Sens. Lett. 2019, 11, 57–65. [Google Scholar] [CrossRef]
- Wang, J.; Xiao, H.; Chen, L.; Xing, J.; Pan, Z.; Luo, R.; Cai, X. Integrating weighted feature fusion and the spatial attention module with convolutional neural networks for automatic aircraft detection from SAR images. Remote Sens. 2021, 13, 910. [Google Scholar] [CrossRef]
- Wang, S.; Gao, X.; Sun, H. An aircraft detection method based on convolutional neural networks in high-resolution SAR images. J. Radars 2017, 6, 195–203. [Google Scholar]
- Li, C.; Zhao, L.; Kuang, G. A two-stage airport detection model for large scale SAR images based on faster R-CNN. In Proceedings of the Eleventh International Conference on Digital Image Processing, Guangzhou, China, 10–13 May 2019; pp. 515–525. [Google Scholar]
- Du, L.; Li, L.; Wei, D.; Mao, J. Saliency-guided single shot multibox detector for target detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3366–3376. [Google Scholar] [CrossRef]
- Chen, L.; Tan, S.; Pan, Z. A New framework for automatic airports extraction from SAR images using multi-level dual attention mechanism. Remote Sens. 2020, 12, 560. [Google Scholar] [CrossRef] [Green Version]
- Zhang, P.; Chen, L.; Li, Z.; Xing, J.; Xing, X.; Yuan, Z. Automatic extraction of water and shadow from SAR images based on a multi-resolution dense encoder and decoder network. Sensors 2019, 19, 3576. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, Y.; Zhao, L.; Li, C.; Kuang, G. Pyramid attention dilated network for aircraft detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 662–666. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, H.; Xu, F. Scattering Enhanced attention pyramid network for aircraft detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2020, 99, 1–18. [Google Scholar] [CrossRef]
- Neubeck, A.; Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 850–855. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. Proc. IEEE Trans. Pattern Anal. Mach. Intelli. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yan, B.; Fan, P.; Lei, X.; Yang, F. A real-time apple targets detection method for picking robot based on improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Liu, Y.; Lu, B.; Peng, J.; Zhang, Z. Research on the use of YOLOv5 object detection algorithm in mask wearing recognition. World Sci. Res. J. 2020, 6, 276–284. [Google Scholar]
- Li, D.; Hu, J.; Wang, C. Involution: Inverting the inherence of convolution for visual recognition. arXiv 2021, arXiv:2103.06255. [Google Scholar]
- Chen, L.; Weng, T.; Xing, J.; Pan, Z.; Yuan, Z.; Xing, X.; Zhang, P. A new deep learning network for automatic bridge detection from SAR images based on balanced and attention mechanism. Remote Sens. 2020, 12, 441. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, Q.-L.; Yang, Y.-B. SA-Net: Shuffle attention for deep convolutional neural networks. arXiv 2021, arXiv:2102.00240v1. [Google Scholar]
- Xing, J.; Sieber, R.; Kalacska, M. The challenges of image segmentation in big remotely sensed imagery data. Ann. GIS 2014, 20, 233–244. [Google Scholar] [CrossRef]
- Li, S.; Gu, X.; Xu, X.; Xu, D.; Zhang, T.; Liu, Z.; Dong, Q. Detection of concealed cracks from ground penetrating radar images based on deep learning algorithm. Constr. Build. Mater. 2021, 273, 121949. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Lu, J.; Vahid, B.; Hao, P.; Zuo, H.; Xue, S.; Zhang, G. Transfer learning using computational intelligence: A survey. Knowl. Based Syst. 2015, 80, 14–23. [Google Scholar] [CrossRef]
- Wei, P. Deep SAR imaging and motion compensation. IEEE Trans. Image Process. 2021, 30, 2232–2247. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Airport | Detection Rate (%) | False Alarm Rate (%) | Testing Time (s) |
|---|---|---|---|---|
| EfficientDet-D0 | Airport Ⅰ | 77.50 | 34.51 | 18.05 |
| Airport Ⅱ | 83.22 | 46.64 | 28.03 | |
| Airport Ⅲ | 96.97 | 23.81 | 5.98 | |
| Mean | 85.90 | 34.99 | 17.03 | |
| YOLOv5s | Airport Ⅰ | 80.83 | 8.49 | 8.24 |
| Airport Ⅱ | 90.21 | 5.15 | 12.11 | |
| Airport Ⅲ | 90.91 | 6.25 | 4.80 | |
| Mean | 87.32 | 6.63 | 8.38 | |
| EBPA2N(Ours) | Airport Ⅰ | 89.17 | 6.14 | 9.68 |
| Airport Ⅱ | 93.01 | 4.32 | 13.50 | |
| Airport Ⅲ | 96.97 | 3.03 | 5.01 | |
| Mean | 93.05 | 4.49 | 9.40 |
| Network | Training Time (h) |
|---|---|
| EfficientDet-D0 | 5.10 |
| YOLOv5s | 0.69 |
| EBPA2N(Ours) | 0.882 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, R.; Chen, L.; Xing, J.; Yuan, Z.; Tan, S.; Cai, X.; Wang, J. A Fast Aircraft Detection Method for SAR Images Based on Efficient Bidirectional Path Aggregated Attention Network. Remote Sens. 2021, 13, 2940. https://doi.org/10.3390/rs13152940
Luo R, Chen L, Xing J, Yuan Z, Tan S, Cai X, Wang J. A Fast Aircraft Detection Method for SAR Images Based on Efficient Bidirectional Path Aggregated Attention Network. Remote Sensing. 2021; 13(15):2940. https://doi.org/10.3390/rs13152940
Chicago/Turabian StyleLuo, Ru, Lifu Chen, Jin Xing, Zhihui Yuan, Siyu Tan, Xingmin Cai, and Jielan Wang. 2021. "A Fast Aircraft Detection Method for SAR Images Based on Efficient Bidirectional Path Aggregated Attention Network" Remote Sensing 13, no. 15: 2940. https://doi.org/10.3390/rs13152940