
ABCDP: Approximate Bayesian Computation with Differential Privacy


1
Computer Science, University of British Columbia, Vancouver, BC V6T 1Z4, Canada
2
Max Planck Institute for Intelligent Systems, 72076 Tübingen, Germany
3
Department of Computer Science, University of Tübingen, 72076 Tübingen, Germany
4
Google Research, 80636 Munich, Germany
*
Author to whom correspondence should be addressed.
Entropy 2021, 23(8), 961; https://doi.org/10.3390/e23080961
Submission received: 19 May 2021
/
Revised: 15 July 2021
/
Accepted: 20 July 2021
/
Published: 27 July 2021
(This article belongs to the Special Issue Approximate Bayesian Inference)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:We developed a novel approximate Bayesian computation (ABC) framework, ABCDP, which produces differentially private (DP) and approximate posterior samples. Our framework takes advantage of the sparse vector technique (SVT), widely studied in the differential privacy literature. SVT incurs the privacy cost only when a condition (whether a quantity of interest is above/below a threshold) is met. If the condition is sparsely met during the repeated queries, SVT can drastically reduce the cumulative privacy loss, unlike the usual case where every query incurs the privacy loss. In ABC, the quantity of interest is the distance between observed and simulated data, and only when the distance is below a threshold can we take the corresponding prior sample as a posterior sample. Hence, applying SVT to ABC is an organic way to transform an ABC algorithm to a privacy-preserving variant with minimal modification, but yields the posterior samples with a high privacy level. We theoretically analyzed the interplay between the noise added for privacy and the accuracy of the posterior samples. We apply ABCDP to several data simulators and show the efficacy of the proposed framework.
1. Introduction
Approximate Bayesian computation (ABC) aims to identify the posterior distribution over simulator parameters. The posterior distribution is of interest as it provides the mechanistic understanding of the stochastic procedure that directly generates data in many areas such as climate and weather, ecology, cosmology, and bioinformatics [1,2,3,4].
Under these complex models, directly evaluating the likelihood of data is often intractable given the parameters. ABC resorts to an approximation of the likelihood function using simulated data that are similar to the actual observations.
In the simplest form of ABC called rejection ABC [5], we proceed by sampling multiple model parameters from a prior distribution : . For each , a pseudo dataset is generated from a simulator (the forward sampler associated with the intractable likelihood ). The parameter for which the generated are similar to the observed , as decided by , is accepted. Here, is a notion of distance, for instance, L2 distance between and in terms of a pre-chosen summary statistic. Whether the distance is small or large is determined by , a similarity threshold. The result is samples from a distribution, , where and . As the likelihood computation is approximate, so is the posterior distribution. Hence, this framework is named by approximate Bayesian computation, as we do not compute the likelihood of data explicitly.
Most ABC algorithms evaluate the data similarity in terms of summary statistics computed by an aggregation of individual datapoints [6,7,8,9,10,11]. However, this seemingly innocuous step of similarity check could impose a privacy threat, as aggregated statistics could still reveal an individual’s participation to the dataset with the help of combining other publicly available datasets (see [12,13]). In addition, in some studies, the actual observations are privacy-sensitive in nature, e.g., Genotype data for estimating tuberculosis transmission parameters [14]. Hence, it is necessary to privatize the step of similarity check in ABC algorithms.
In this light, we introduce an ABC framework that obeys the notion of differential privacy. The differential privacy definition provides a way to quantify the amount of information that the distance computed on the privacy-sensitive data contains, whether or not a single individual’s data are included (or modified) in the data [15]. Differential privacy also provides rigorous privacy guarantees in the presence of arbitrary side information such as similar public data.
A common form of applying DP to an algorithm is by adding noise to outputs of the algorithm, called output perturbation [16]. In the case of ABC, we found that adding noise to the distance computed on the real observations and pseudo-data suffices for the privacy guarantee of the resulting posterior samples. However, if we choose to simply add noise to the distance in every ABC inference step, this DP-ABC inference imposes an additional challenge due to the repeated use of the real observations. The composition property of differential privacy states that the privacy level degrades over the repeated use of data. To overcome this challenge, we adopt the sparse vector technique (SVT) [17], and apply it to the rejection ABC paradigm. The SVT outputs noisy answers of whether or not a stream of queries is above a certain threshold, where privacy cost incurs only when the SVT outputs at most c “above threshold” answers. This is a significant saving in privacy cost, as arbitrarily many “below threshold” answers are privacy cost free.
We name our framework, which combines ABC with SVT, as ABCDP (approximate Bayesian computation with differential privacy). Under ABCDP, we theoretically analyze the effect of noise added to the distance in the resulting posterior samples and the subsequent posterior integrals. Putting together, we summarize our main contributions:
- We provide a novel ABC framework, ABCDP, which combines the sparse vector technique (SVT) [17] with the rejection ABC paradigm. The resulting ABCDP framework can improve the trade-off between the privacy and accuracy of the posterior samples, as the privacy cost under ABCDP is a function of the number of accepted posterior samples only.
- We theoretically analyze ABCDP by focusing on the effect of noisy posterior samples in terms of two quantities. The first quantity provides the probability of an output of ABCDP being different from that of ABC at any given time during inference. The second quantity provides the convergence rate, i.e., how fast the posterior integral using ABCDP’s noisy samples’ approaches that using non-private ABC’s samples. We write both quantities as a function of added noise for privacy to better understand the characteristics of ABCDP.
- We validate our theory in the experiments using several simulators. The results of these experiments are consistent with our theoretical findings on the flip probability and the average error induced by the noise addition for privacy.
Unlike other existing ABC frameworks that typically rely on a pre-specified set of summary statistics, we use a kernel-based distance metric called maximum mean discrepancy following K2-ABC [18] to eliminate the necessity of pre-selecting a summary statistic. Using a kernel for measuring similarity between two empirical distributions was also proposed in K-ABC [19]. K-ABC formulates ABC as a problem of estimating a conditional mean embedding operator mapping (induced by a kernel) from summary statistics to corresponding parameters. However, unlike our algorithm, K-ABC still relies on a particular choice of summary statistics. In addition, K-ABC is a soft-thresholding ABC algorithm, while ours is a rejection-ABC algorithm.
To avoid the necessity of pre-selecting summary statistics, one could resort to methods that automatically or semi-automatically learn the best summary statistics given in a dataset, and use the learned summary statistics in our ABCDP framework. An example is semi-auto ABC [6], where the authors suggest using the posterior mean of the parameters as a summary statistic. Another example is the indirect-score ABC [20], where the authors suggest using an auxiliary model which determines a score vector as a summary statistic. However, the posterior mean of the parameters in semi-auto ABC as well as the parameters of the auxiliary model in indirect-score ABC need to be estimated. The estimation step can incur a further privacy loss if the real data need to be used for estimating them. Our ABCDP framework does not involve such an estimation step and is more economical in terms of privacy budget to be spent than semi-auto ABC and indirect-score ABC.
2. Background
We start by describing relevant background information.
2.1. Approximate Bayesian Computation
Given a set containing observations, rejection ABC [5] yields samples from an approximate posterior distribution by repeating the following three steps:
where the pseudo dataset Y is compared with the observations via:
where is a divergence measure between two datasets. Any distance metric can be used for . For instance, one can use the L2 distance under two datasets in terms of a pre-chosen set of summary statistics, i.e., , with an L2 distance measure D on the statistics computed by S.
A more statistically sound choice for would be maximum mean discrepancy (MMD, [21]) as used in [18]. Unlike a pre-chosen finite dimensional summary statistic typically used in ABC, MMD compares two distributions in terms of all the possible moments of the random variables described by the two distributions. Hence, ABC frameworks using the MMD metric such as [18] can avoid the problem of non-sufficiency of a chosen summary statistic that may occur in many ABC methods. For this reason, in this paper, we demonstrate our algorithm using the MMD metric. However, other metrics can be used as we illustrated in our experiments.
Maximum Mean Discrepancy
Assume that the data and let be a positive definite kernel. MMD between two distributions is defined as
By following the convention in kernel literature, we call simply MMD.
The Moore–Aronszajn theorem states that there is a unique Hilbert space on which k defines an inner product. As a result, there exists a feature map such that , where denotes the inner product on . The MMD in (5) can be written as
where is known as the (kernel) mean embedding of P, and exists if [22]. The MMD can be interpreted as the distance between the mean embeddings of the two distributions. If k is a characteristic kernel [23], then is injective, implying that , if and only if . When are observed through samples and , MMD can be estimated by empirical averages [21] (Equation (3)): When applied in the ABC setting, one input to is the observed dataset and the other input is a pseudo dataset generated by the simulator given .
2.2. Differential Privacy
An output from an algorithm that takes in sensitive data as input will naturally contain some information of the sensitive data . The goal of differential privacy is to augment such an algorithm so that useful information about the population is retained, while sensitive information such as an individual’s participation in the dataset cannot be learned [17]. A common way to achieve these two seemingly paradoxical goals is by deliberately injecting a controlled level of random noise to the to-be-released quantity. The modified procedure, known as a DP mechanism, now gives a stochastic output due to the injected noise. In the DP framework, a higher level of noise provides stronger privacy guarantee at the expense of less accurate population-level information that can be derived from the released quantity. Less noise added to the output thus reveals more about an individual’s presence in the dataset.
More formally, given a mechanism (a mechanism takes a dataset as input and produces stochastic outputs) and neighboring datasets , differing by a single entry (either by replacing one’s datapoint with another, or by adding/removing a datapoint to/from ), the privacy loss of an outcome o is defined by
The mechanism is called -DP if and only if , for all possible outcomes o and for all possible neighboring datasets . The definition states that a single individual’s participation in the data does not change the output probabilities by much; this limits the amount of information that the algorithm reveals about any one individual. A weaker or an approximate version of the above notion is ()-DP: is ()-DP if , with probability , where is often called a failure probability which quantifies how often the DP guarantee of the mechanism fails.
Output perturbation is a commonly used DP mechanism to ensure the outputs of an algorithm to be differentially private. Suppose a deterministic function computed on sensitive data outputs a p-dimensional vector quantity. In order to make h private, we can add noise to the output of h, where the level of noise is calibrated to the global sensitivity [24], , defined by the maximum difference in terms of some norm for neighboring and (i.e., differ by one data sample).
There are two important properties of differential privacy. First, the post-processing invariance property [24] tells us that the composition of any arbitrary data-independent mapping with an -DP algorithm is also -DP. Second, the composability theorem [24] states that the strength of privacy guarantee degrades with the repeated use of DP-algorithms. Formally, given an -DP mechanism and an -DP mechanism , the mechanism is -DP. This composition is often-called linear composition, under which the total privacy loss linearly increases with the number of repeated use of DP-algorithms. The strong composition [17] [Theorem 3.20] improves the linear composition, while the resulting DP guarantee becomes weaker (i.e., approximate -DP). Recently, more refined methods further improve the privacy loss (e.g., [25]).
2.3. AboveThreshold and Sparse Vector Technique
Among the DP mechanisms, we will utilize AboveThreshold and sparse vector technique (SVT) [17] to make the rejection ABC algorithm differentially private. AboveThreshold outputs 1 when a query value exceeds a pre-defined threshold, or 0 otherwise. This resembles rejection ABC where the output is 1 when the distance is less than a chosen threshold. To ensure the output is differentially private, AboveThreshold adds noise to both the threshold and the query value. We take the same route as AboveThreshold to make our ABCDP outputs differentially private. Sparse vector technique (SVT) consists of c calls to AboveThreshold, where c in our case determines how many posterior samples ABCDP releases.
Before presenting our ABCDP framework, we first describe the privacy setup we consider in this paper.
3. Problem Formulation
We assume a data owner who owns sensitive data and is willing to contribute to the posterior inference.
We also assume a modeler who aims to learn the posterior distribution of the parameters of a simulator. Our ABCDP algorithm proceeds with the two steps:
- Non-private step: The modeler draws a parameter sample ; then generates a pseudo-dataset , where for for a large T. We assume these parameter-pseudo-data pairs are publicly available (even to an adversary).
- Private step: the data owner takes the whole sequence of parameter-pseudo-data pairs and runs our ABCDP algorithm in order to output a set of differentially private binary indicators determining whether or not to accept each .
Note that T is the maximum number of parameter-pseudo-data pairs that are publicly available. We will run our algorithm for T steps, while our algorithm can terminate as soon as we output the c number of accepted posterior samples. So, generally, . The details are then introduced.
4. ABCDP
Recall that the only place where the real data appear in the ABC algorithm is when we judge whether the simulated data are similar to the real data, i.e., as in (4). Our method hence adds noise to this step. In order to take advantage of the privacy analysis of SVT, we also add noise to the ABC threshold and to the ABC distance. Consequently, we introduce two perturbation steps.
Before we introduce them, we describe the global sensitivity of the distance, as this quantity tunes the amount of noise we will add in the two perturbation steps. For with a bounded kernel, then the sensitivity of the distance is as shown in Lemma 1.
Lemma 1.
( for MMD). Assume that and each pseudo dataset are of the same cardinality N. Set with a kernel k bounded by , i.e., . Then:
and
A proof is given in Appendix B. For using a Gaussian kernel, where is the bandwidth of the kernel, for any .
Now, we introduce the two perturbation steps used in our algorithm summarized in Algorithm 1.
| Algorithm 1 Proposed c-sample ABCDP |
|
Step 1: Noise for privatizing the ABC threshold.
where , i.e., drawn from the zero-mean Laplace distribution with a scale parameter b.
Step 2: Noise for privatizing the distance.
where .
Due to these perturbations, Algorithm 1 runs with the privatized threshold and distance. We can choose to perturb the threshold only once, or every time we output 1 by setting RESAMPLE to false or true. After outputting c number of 1’s, the algorithm is terminated. How do we calculate the resulting privacy loss under the different options we choose?
We formally state the relationship between the noise scale and the final privacy loss for the Laplace noise in Theorem 1.
Theorem 1.
(Algorithm 1 is-DP) thmmrejdp For any neighboring datasetsof size N and any dataset Y, assume thatis such that. Algorithm 1 is-DP, where:
A proof is given in Appendix A. The proof uses linear composition, i.e., the privacy level linearly degrading with c. However, using the strong composition or more advanced compositions can reduce the resulting privacy loss, while these compositions turn pure-DP into a weaker, approximate-DP. In this paper, we focus on the pure-DP. For the case of RESAMPLE = True, the proof directly follows the proof of the standard SVT algorithm using the linear composition method [17], with an exception that we utilize the quantity representing the minimum noisy value of any query evaluated on , as opposed to the maximum utilized in SVT. For the case of RESAMPLE= False, the proof follows the proof of Algorithm 1 in [26].
Note that the DP analysis in Theorem 1. holds for other types of distance metrics and not limited to only MMD, as long as there is a bounded sensitivity under the chosen metric. When there is no bounded sensitivity, one could impose a clipping bound C to the distance by taking the distance from , such that the resulting distance between any pseudo data and with modifying one datapoint in cannot exceed that clipping bound. In fact, we use this trick in our experiments when there is no bounded sensitivity.
4.1. Effect of Noise Added to ABC
Here, we would like to analyze the effect of noise added to ABC. In particular, we are interested in analyzing the probability that the output of ABCDP differs from that of ABC: at any given time t. To compute this probability, we first compute the probability density function (PDF) of the random variables in the following Lemma.
Lemma 2.
Recall , . The subtraction of these yields another random variable , where the PDF of Z is given by
Furthermore, for , , and the CDF of Z is given by where is the Heaviside step function.
See Appendix C for the proof. Using this PDF, we now provide the following proposition:
Proposition 1.
Denote the output of Algorithm 1 at time t by and the output of ABC by . The flip probability, the probability that the outputs of ABCDP and ABC differ given the output of ABC, is given by , where is defined in Lemma 1, and .
See Appendix D for proof.
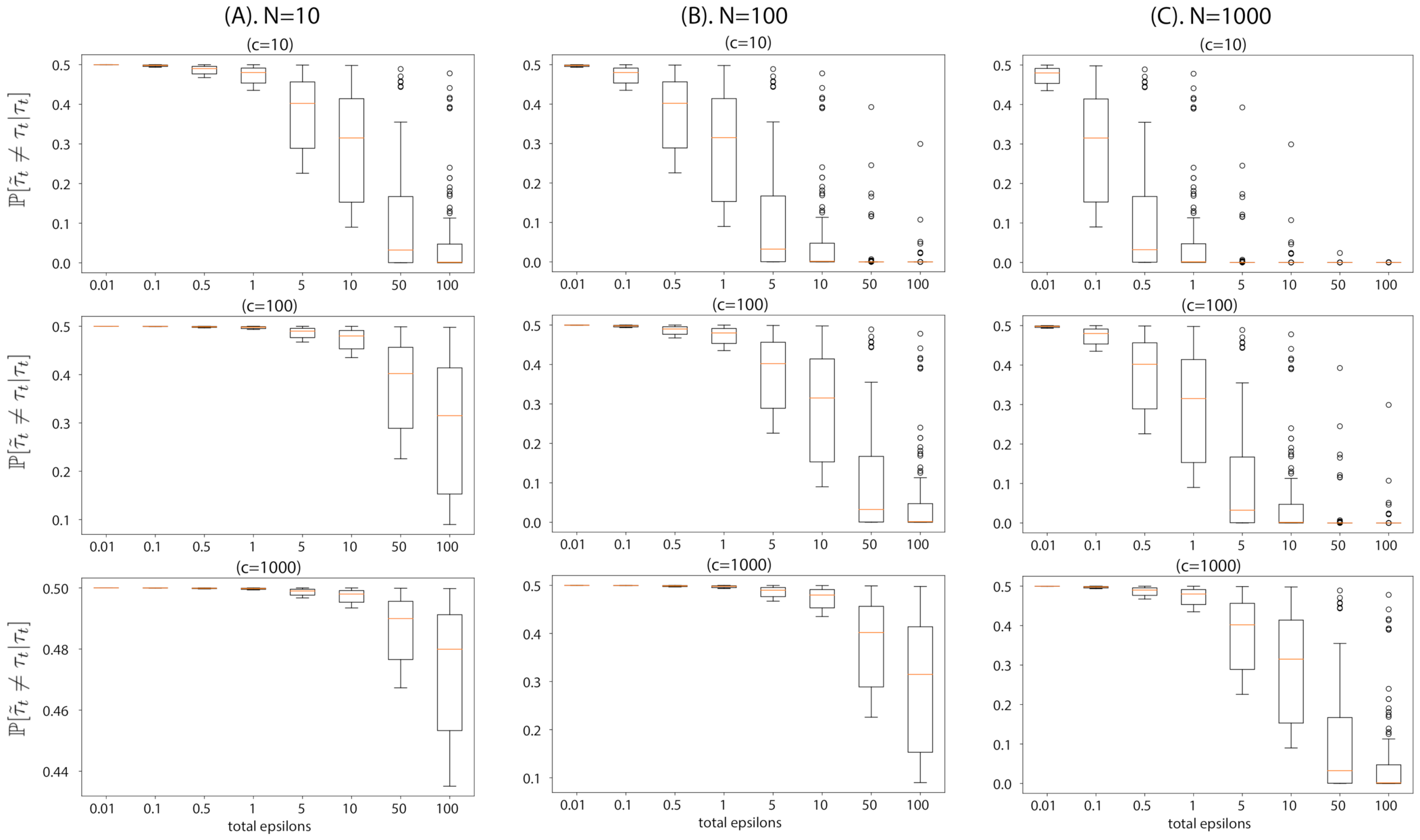
To provide an intuition of Proposition 1, we visualize the flip probability in Figure 1. This flip probability provides a guideline for choosing the accepted sample size c given the datasize N and the desired privacy level . For instance, if a given dataset is extremely small, e.g., containing datapoints on the order of 10, c has to be chosen such that the flip probability of each posterior sample remains low for a given privacy guarantee (). If a higher number of posterior samples are needed, then one has to reduce the desired privacy level for the posterior sample of ABCDP to be similar to that of ABC. Otherwise, with a small with a large c, the accepted posterior samples will be poor. On the other hand, if the dataset is bigger, then a larger c can be taken for a reasonable level of privacy.
4.2. Convergence of Posterior Expectation of Rejection-ABCDP to Rejection-ABC
The flip probability studied in Section 4.1 only accounts for the effect of noise added to a single output of ABCDP. Building further on this result, we analyzed the discrepancy between the posterior expectations derived from ABCDP and from the rejection ABC. This analysis requires quantifying the effect of noise added to the whole sequence of outputs of ABCDP. The result is presented in Theorem 2.
Theorem 2.
Given of size N, and as input, let be the output from Algorithm 1 where indicates that is accepted, for . Similarly, let denote the output from the traditional rejection ABC algorithm, for . Let f be an arbitrary vector-valued function of θ. Assume that the numbers of accepted samples from Algorithm 1, and the traditional rejection ABC algorithm are and , respectively. Let if RESAMPLE=True, and if RESAMPLE=False (see Theorem 1. Define . Then, the following statements hold for both RESAMPLE options:
1. where the decreasing function for any is defined in Lemma 2;
2. as ;
3. For any :
where the probability is taken with respect to .
Theorem 2 contains three statements. The first states that the expected error between the two posterior expectations of an arbitrary function f is bounded by a constant factor of the sum of the flip probability in each rejection/acceptance step. As we have seen in Section 4.1, the flip probability is determined by the scale parameter b of the Laplace distribution. Since (see Theorem 1 and Lemma 1), it follows that the expected error decays as N increases, giving the second statement.
The third statement gives a probabilistic bound on the error. The bound guarantees that the error decays exponentially in N. Our proof relies on establishing an upper bound on the error as a function of the total number of flips which is a random variable. Bounding the error of interest then amounts to characterizing the tail behavior of this quantity. Observe that in Theorem 2, we consider ABCDP and rejection ABC with the same computational budget, i.e., the same total number of iterations T performed. However, the number of accepted samples may be different in each case (c for ABCDP and for reject ABC). The fact that c itself is a random quantity due to injected noise presents its own technical challenge in the proof. Our proof can be found in Appendix E.
5. Related Work
Combining DP with ABC is relatively novel. The only related work is [27], which states that a rejection ABC algorithm produces posterior samples from the exact posterior distribution given perturbed data, when the kernel and bandwidth of rejection ABC are chosen in line with the data perturbation mechanism. The focus of [27] is to identify the condition when the posterior becomes exact in terms of the kernel and bandwidth of the kernel through the lens of data perturbation. On the other hand, we use the sparse vector technique to reduce the total privacy loss. The resulting theoretical studies including the flip probability and the error bound on the posterior expectation are new.
6. Experiments
6.1. Toy Examples
We start by investigating the interplay between and , in a synthetic dataset where the ground truth parameters are known. Following [18], we also consider a symmetric Dirichlet prior and a likelihood given by a mixture of uniform distributions as
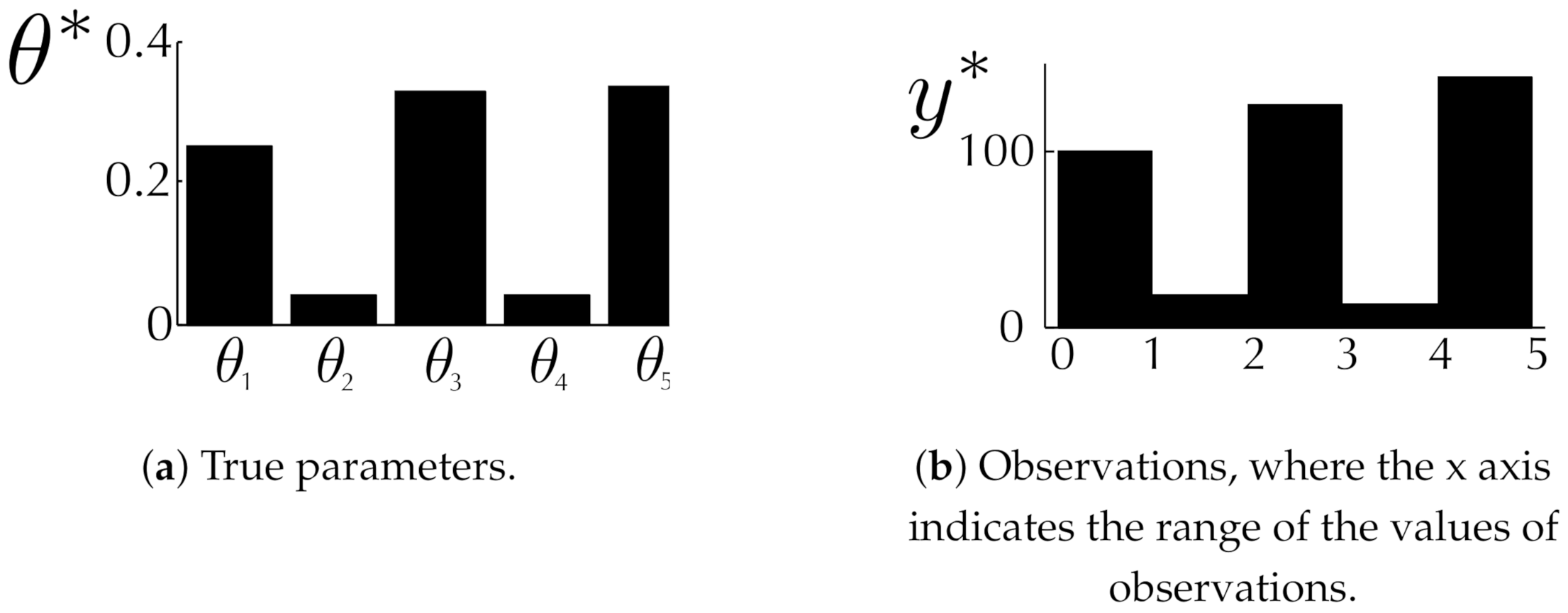
A vector of mixing proportions is our model parameters , where the ground truth is (see Figure 2). The goal is to estimate where is generated with .
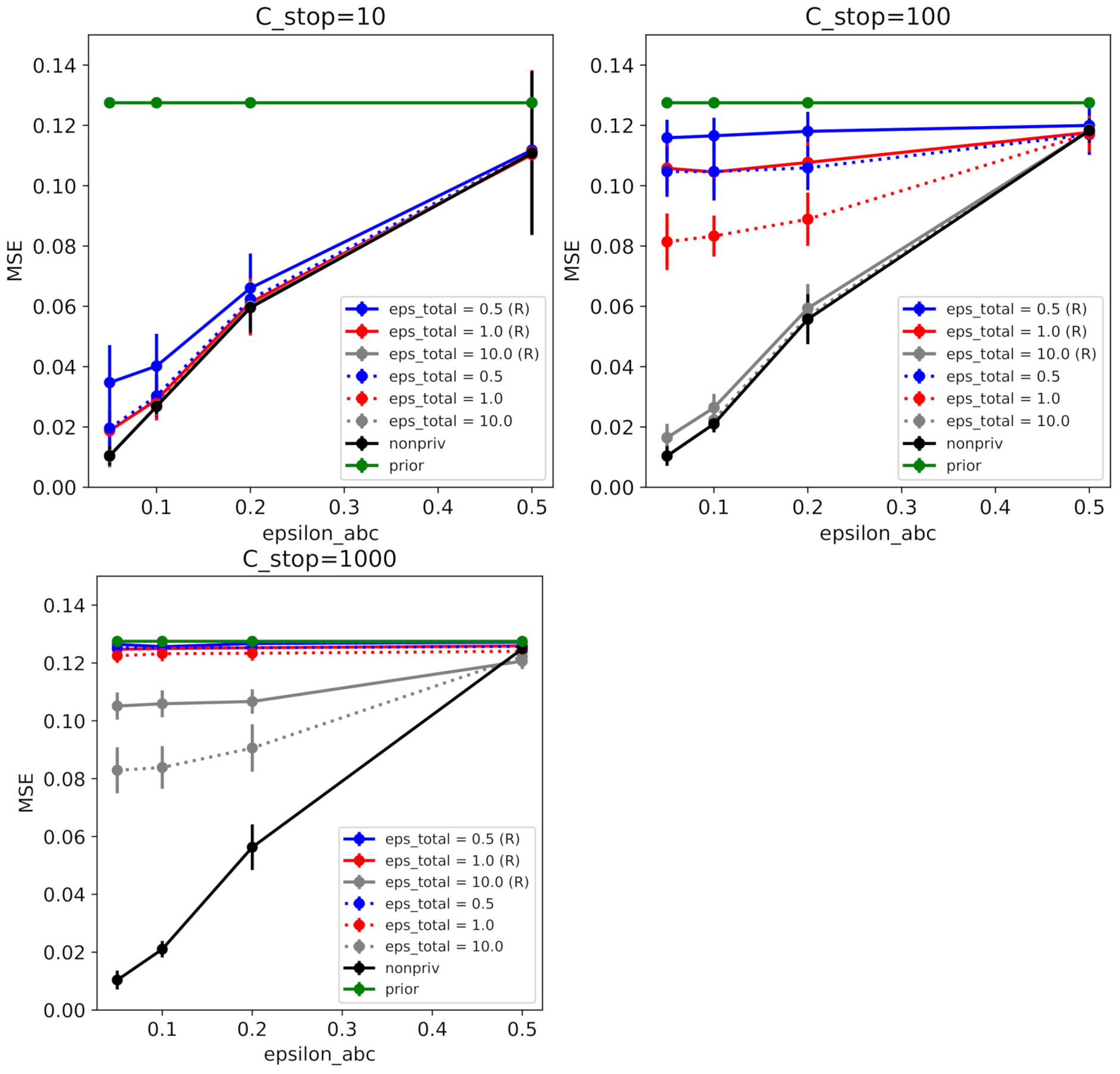
We first generated 5000 samples for drawn from (11) with true parameters . Then, we tested our two ABCDP frameworks with varying and . In these experiments, we set with a Gaussian kernel. We set the bandwidth of the Gaussian kernel using the median heuristic computed on the simulated data (i.e., we did not use the real data for this, hence there is no privacy violation in this regard).
6.2. Coronavirus Outbreak Data
In this experiment, we modelled coronavirus outbreak in the Netherlands using a polynomial model consisting of four parameters , which we aimed to infer, where:
The observed (https://www.ecdc.europa.eu/en/publications-data/download-todays-data-geographic-distribution-COVID-19-cases-worldwide, accessed on 10 October 2020) data are the number of cases of the coronavirus outbreak from 27 February to 17 March 2020, which amounts to 18 datapoints (). The presented experiment imposes privacy concern as each datapoint is a count of the individuals who are COVID positive at each time. The goal is to identify the approximate posterior distribution over these parameters, given a set of observations.
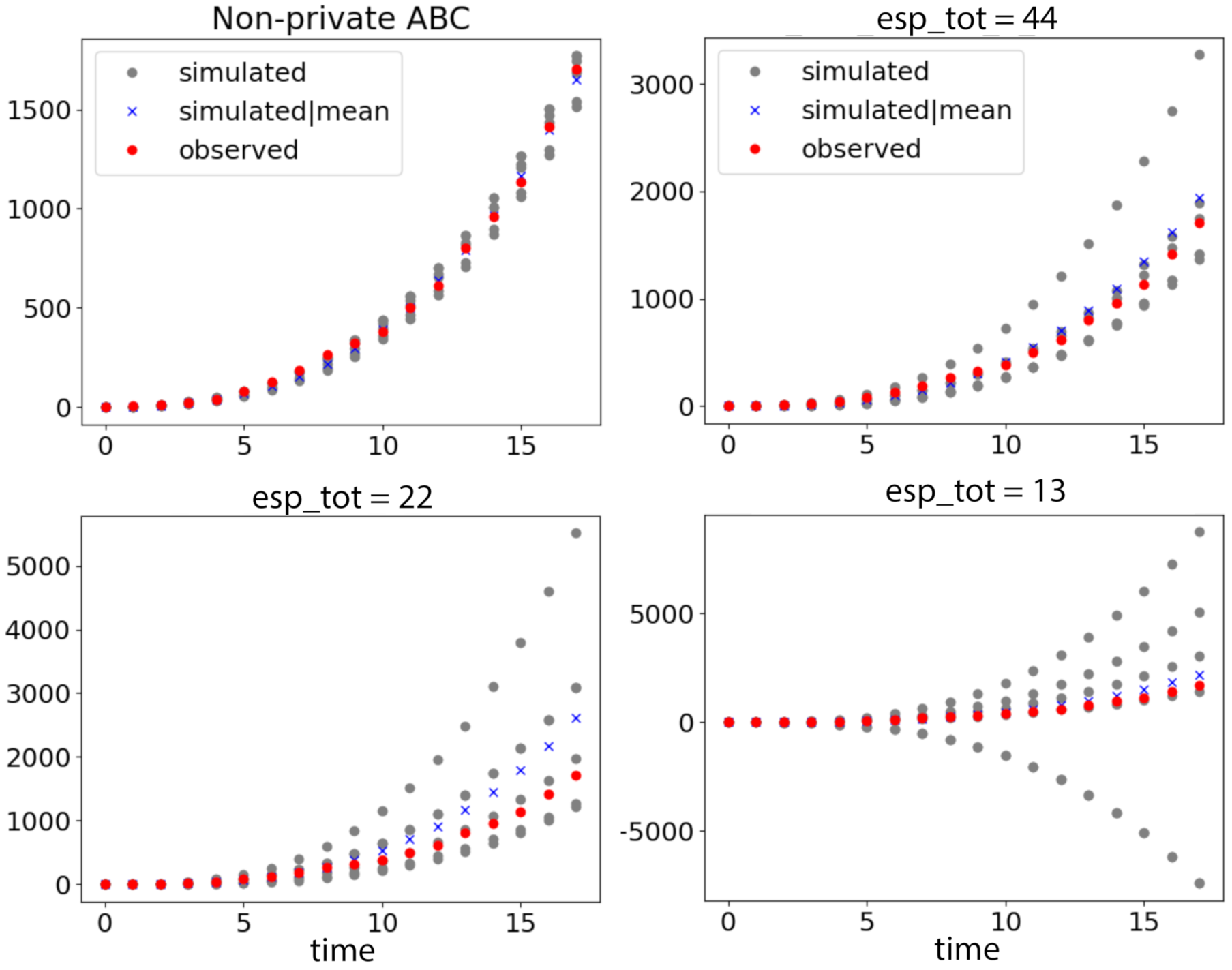
Recalling from Figure 1 that the small size of data worsens the privacy and accuracy trade-off, the inference is restricted to a small number of posterior samples (we chose ) since the number of datapoints is extremely limited in this dataset. We used the same prior distributions for the four parameters as for all . We drew samples from the Gaussian prior, and performed our ABCDP algorithm with and , as shown in Figure 4.
6.3. Modeling Tuberculosis (TB) Outbreak Using Stochastic Birth–Death Models
In this experiment, we used the stochastic birth–death models to model Tuberculosis (TB) outbreak. There are four parameters that we aim to infer, which go into the communicable disease outbreak simulator as inputs: burden rate , transmission rate , reproductive numbers and . The goal is to identify the approximate posterior distribution over these parameters given a set of observations. Please refer to Section 3 in [28] for the description of the birth–death process of the model. We used the same prior distributions for the four parameters as in [28]: , , , .
To illustrate the privacy and accuracy trade-off, we first generated two sets of observations ( and ) by some true model parameters (shown as black bars in Figure 5). We then tested our ABCDP algorithm with a privacy level . We used the summary statistic described in Table 1 in [28] and used a weighted L2 distance as as done in [28], together with . Since there is no bounded sensitivity in this case, we impose an artificial boundedness by clipping the distance by C (we set ) when the distance goes beyond C.
As an error metric, we computed the mean absolute distance between each posterior mean and the true parameter values. The top row in Figure 5 shows that the mean of the prior (red) is far from the true value (black) that we chose. As we increase the data size from (middle) to (bottom), the distance between true values and estimates reduces, as reflected in the error from to for RESAMPLE = True; and from to for RESAMPLE=False.
7. Summary and Discussion
We presented the ABCDP algorithm by combining DP with ABC. Our method outputs differentially private binary indicators, yielding differentially private posterior samples. To analyze the proposed algorithm, we derived the probability of flip from the rejection ABC’s indicator to the ABCDP’s indicator, as well as the average error bound of the posterior expectation.
We showed experimental results that output a relatively small number of posterior samples. This is due to the fact that the cumulative privacy loss increases linearly with the number of posterior samples (i.e., c) that our algorithm outputs. For a large-sized dataset (i.e., N is large), one can still increase the number of posterior samples while providing a reasonable level of privacy guarantee. However, for a small-sized dataset (i.e., N is small), a more refined privacy composition (e.g., [29]) would be necessary to keep the cumulative privacy loss relatively small, at the expense of providing an approximate DP guarantee rather than the pure DP guarantee that ABCDP provides.
When we presented our work to the ABC community, we often received the question of whether we could apply ABCDP to other types of ABC algorithms such as the sequential Monte Carlo algorithm which outputs the significance of each proposal sample, as opposed to its acceptance or rejection as in the rejection ABC algorithm. Directly applying the current form of ABCDP to these algorithms is not possible, while applying the Gaussian mechanism to the significance of each proposal sample can guarantee differential privacy for the output of the sequential Monte Carlo algorithm. However, the cumulative privacy loss will be relatively large, as now it is a function of the number of proposal samples, whether they are taken as good posterior samples or not.
A natural by-product of ABCDP is differentially private synthetic data, as the simulator is a public tool that anybody can run and hence differentially private posterior samples suffice for differentially private synthetic data without any further privacy cost. Applying ABCDP to generate complex datasets is an intriguing future direction.
Author Contributions
M.P. and W.J. contributed to conceptualization and methodology development. M.P. and M.V. contributed to software development. All three authors contributed to writing the paper. All authors have read and agreed to the published version of the manuscript.
Funding
Gips Schüle Foundation and the Institutional Strategy of the University of Tübingen (ZUK63).
Data Availability Statement
A publicly available dataset was analyzed in this study. This data can be found here: https://www.ecdc.europa.eu/en/publications-data/download-todays-data-geographic-distribution-covid-19-cases-worldwide.
Conflicts of Interest
The authors declare no conflict of interest.
Note
Our code is available at https://github.com/ParkLabML/ABCDP.
Appendix A. Proof of Theorem 1
Proof of Theorem 1.
Case I: . We prove the case of first. The case of is a c-composition of the case of , where the privacy loss linearly increases with c.
Given any neighboring datasets and of size N and any dataset Y, assume that is such that and is bounded by .
Let A denote the random variable that represents the outputs Algorithm 1 given (, , , , ) and the random variable that represents the outputs given (, , , , ). The output of the algorithm is some realization of these variables, where and for all , and . For the rest of the proof, we will fix the arbitrary values of and take probabilities over the randomness of and . We define the deterministic quantity ( are fixed):
that represents the minimum noised value of the distance evaluated on any dataset .
Let be the pdf of evaluated on a and the pdf of evaluated on v, and the indicator function of event x. We have:
and:
Now, we define the following variables:
We know that for each , is -sensitive and hence, the quantity is -sensitive as well. In this way, we obtain that and . Applying these changes of variables, we have:
where the inequality comes from the bounds considered throughout the proof (i.e., and ) and the form of the cdf for the Laplace distribution.
Appendix B. Proof of Lemma 1
Proof of Lemma 1.
We will establish when is MMD. Recall that is a pair of neighboring datasets, and Y is an arbitrary dataset. Without loss of generality, assume that , such that for all , and . We start with:
where at , we use the reverse triangle inequality. Furthermore:
□
Appendix C. Proof of Lemma 2
Proof of Lemma 2.
The PDF is computed from the convolution of two PDFs:
where and :
For case :
For case :
With the obtained PDF for , it is straightforward to compute for . In other words, for where denotes the CDF of Z.
To show that the CDF of Z is where is the Heaviside step function, we note that the density is an even function, i.e., for any z. It follows that if , . This means that:
or equivalently:
More concisely:
where at (a), we use . □
Appendix D. Proof of Proposition 1
Proof of Proposition 1.
Using this pdf above, we can compute the following probabilities:
and:
So:
The two cases can be combined with the use of an absolute value to give the result. □
Appendix E. Proof of Theorem 2
Proof of Theorem 2.
Let be the Heaviside step function. Recall from our algorithm that each accepted sample is associated with two independent noise realizations: (i.e., ) and (added to )). With this notation, we have for . Similarly, . For brevity, we define . It follows that where .
Proof of the first claim: we start by establishing an upper bound for:
where . Consider . We can show that it is bounded by by
Combining this bound with (A31), we have:
We will need to characterize the distribution of . Let . By Lemma 2, we have:
where the decreasing function for any is defined in Lemma 2. We observe that where . We can rewrite as
To prove the first claim, we take the expectation on both sides of (A32):
where and we use the fact that . Note that these are T independent, marginal expectations, i.e., they do not depend on the condition that noise is added to the ABC threshold.
Proof of the second claim: observe that as . The claim follows by noting that .
Proof of the third claim: based on (A32), characterizing the tail bound of amounts to establishing a tail bound on . By Markov’s inequality:
Applying this bound to (A32) gives:
With a reparametrization so that we have:
Since , we have:
which gives the result in the third claim. □
References
- Tavaré, S.; Balding, D.J.; Griffiths, R.C.; Donnelly, P. Inferring coalescence times from DNA sequence data. Genetics 1997, 145, 505–518. [Google Scholar] [CrossRef] [PubMed]
- Ratmann, O.; Jørgensen, O.; Hinkley, T.; Stumpf, M.; Richardson, S.; Wiuf, C. Using Likelihood-Free Inference to Compare Evolutionary Dynamics of the Protein Networks of H. pylori and P. falciparum. PLoS Comput. Biol. 2007, 3, e230. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bazin, E.; Dawson, K.J.; Beaumont, M.A. Likelihood-Free Inference of Population Structure and Local Adaptation in a Bayesian Hierarchical Model. Genetics 2010, 185, 587–602. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schafer, C.M.; Freeman, P.E. Likelihood-Free Inference in Cosmology: Potential for the Estimation of Luminosity Functions. In Statistical Challenges in Modern Astronomy V; Springer: Berlin/Heidelberg, Germany, 2012; pp. 3–19. [Google Scholar]
- Pritchard, J.; Seielstad, M.; Perez-Lezaun, A.; Feldman, M. Population growth of human Y chromosomes: A study of Y chromosome microsatellites. Mol. Biol. Evol. 1999, 16, 1791–1798. [Google Scholar] [CrossRef] [Green Version]
- Fearnhead, P.; Prangle, D. Constructing summary statistics for approximate Bayesian computation: Semi-automatic approximate Bayesian computation. J. R. Stat. Soc. Ser. 2012, 74, 419–474. [Google Scholar] [CrossRef] [Green Version]
- Joyce, P.; Marjoram, P. Approximately Sufficient Statistics and Bayesian Computation. Stat. Appl. Genet. Molec. Biol. 2008, 7, 1544–6115. [Google Scholar] [CrossRef] [PubMed]
- Robert, C.P.; Cornuet, J.; Marin, J.; Pillai, N.S. Lack of confidence in approximate Bayesian computation model choice. Proc. Natl. Acad. Sci. USA 2011, 108, 15112–15117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nunes, M.; Balding, D. On Optimal Selection of Summary Statistics for Approximate Bayesian Computation. Stat. Appl. Genet. Molec. Biol. 2010, 9. [Google Scholar] [CrossRef] [PubMed]
- Aeschbacher, S.; Beaumont, M.A.; Futschik, A. A Novel Approach for Choosing Summary Statistics in Approximate Bayesian Computation. Genetics 2012, 192, 1027–1047. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Drovandi, C.; Pettitt, A.; Lee, A. Bayesian Indirect Inference Using a Parametric Auxiliary Model. Statist. Sci. 2015, 30, 72–95. [Google Scholar] [CrossRef] [Green Version]
- Homer, N.; Szelinger, S.; Redman, M.; Duggan, D.; Tembe, W.; Muehling, J.; Pearson, J.V.; Stephan, D.A.; Nelson, S.F.; Craig, D.W. Resolving Individuals Contributing Trace Amounts of DNA to Highly Complex Mixtures Using High-Density SNP Genotyping Microarrays. PLoS Genet. 2008, 4, e1000167. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Johnson, A.; Shmatikov, V. Privacy-preserving Data Exploration in Genome-wide Association Studies. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1079–1087. [Google Scholar]
- Tanaka, M.M.; Francis, A.R.; Luciani, F.; Sisson, S.A. Using approximate Bayesian computation to estimate tuberculosis transmission parameters from genotype data. Genetics 2006, 173, 1511–1520. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the TCC, New York, NY, USA, 4–7 March 2006; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3876, pp. 265–284. [Google Scholar]
- Chaudhuri, K.; Monteleoni, C.; Sarwate, A.D. Differentially Private Empirical Risk Minimization. J. Mach. Learn. Res. 2011, 12, 1069–1109. [Google Scholar] [PubMed]
- Dwork, C.; Roth, A. The Algorithmic Foundations of Differential Privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Park, M.; Jitkrittum, W.; Sejdinovic, D. K2-ABC: Approximate Bayesian Computation with Infinite Dimensional Summary Statistics via Kernel Embeddings. In Proceedings of the AISTATS, Cadiz, Spain, 9–11 May 2016. [Google Scholar]
- Nakagome, S.; Fukumizu, K.; Mano, S. Kernel approximate Bayesian computation in population genetic inferences. Stat. Appl. Genet. Mol. Biol. 2013, 12, 667–678. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gleim, A.; Pigorsch, C. Approximate Bayesian Computation with Indirect Summary Statistics; University of Bonn: Bonn, Germany, 2013. [Google Scholar]
- Gretton, A.; Borgwardt, K.; Rasch, M.; Schölkopf, B.; Smola, A. A Kernel Two-Sample Test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Smola, A.; Gretton, A.; Song, L.; Schölkopf, D. A Hilbert space embedding for distributions. In Algorithmic Learning Theory, Proceedings of the 18th International Conference, Sendai, Japan, 1–4 October 2007; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Sriperumbudur, B.; Fukumizu, K.; Lanckriet, G. Universality, characteristic kernels and RKHS embedding of measures. J. Mach. Learn. Res. 2011, 12, 2389–2410. [Google Scholar]
- Dwork, C.; Kenthapadi, K.; McSherry, F.; Mironov, I.; Naor, M. Our Data, Ourselves: Privacy Via Distributed Noise Generation. In Advances in Cryptology—EUROCRYPT 2006, Proceedings of the 24th Annual International Conference on the Theory and Applications of Cryptographic Techniques, St. Petersburg, Russia, 28 May–1 June 2006; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4004, pp. 486–503. [Google Scholar]
- Mironov, I. Rényi Differential Privacy. In Proceedings of the 30th IEEE Computer Security Foundations Symposium (CSF), Santa Barbara, CA, USA, 21–25 August 2017; pp. 263–275. [Google Scholar]
- Lyu, M.; Su, D.; Li, N. Understanding the Sparse Vector Technique for Differential Privacy. Proc. VLDB Endow. 2017, 10, 637–648. [Google Scholar] [CrossRef] [Green Version]
- Gong, R. Exact Inference with Approximate Computation for Differentially Private Data via Perturbations. arXiv 2019, arXiv:stat.CO/1909.12237. [Google Scholar]
- Lintusaari, J.; Blomstedt, P.; Rose, B.; Sivula, T.; Gutmann, M.; Kaski, S.; Corander, J. Resolving outbreak dynamics using approximate Bayesian computation for stochastic birth?death models [version 2; peer review: 2 approved]. Wellcome Open Res. 2019, 4. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Wang, Y.X. Improving Sparse Vector Technique with Renyi Differential Privacy. In Proceedings of the 2020 Conference on Neural Information Processing Systems, Virtual, 6–12 December 2020; Volume 33. [Google Scholar]
Figure 1.
Visualization of flip probability derived in Proposition 1, the probability that the outputs of ABCDP and ABC differ given an output of ABC, with different dataset size N and accepted posterior sample size c. We simulated (drew 100 values for ) and used : (A) This column shows the flip probability at a regime of extremely small datasets, . Top plot shows the probability at , middle plot at , and bottom plot at . In this regime, even cannot reduce the flip probability to perfectly zero when . The flip probability remains high when we accept more samples, i.e., ; (B) the flip probability at ; (C) the flip probability at . As we increase the dataset size N (moving from the left to right columns), the flip probability approaches zero at a smaller privacy loss .
Figure 1.
Visualization of flip probability derived in Proposition 1, the probability that the outputs of ABCDP and ABC differ given an output of ABC, with different dataset size N and accepted posterior sample size c. We simulated (drew 100 values for ) and used : (A) This column shows the flip probability at a regime of extremely small datasets, . Top plot shows the probability at , middle plot at , and bottom plot at . In this regime, even cannot reduce the flip probability to perfectly zero when . The flip probability remains high when we accept more samples, i.e., ; (B) the flip probability at ; (C) the flip probability at . As we increase the dataset size N (moving from the left to right columns), the flip probability approaches zero at a smaller privacy loss .

Figure 2.
Synthetic data. (a): 5-dimensional true parameters; (b): observations sampled from the mixture of uniform distributions in (11) with the true parameters.
Figure 2.
Synthetic data. (a): 5-dimensional true parameters; (b): observations sampled from the mixture of uniform distributions in (11) with the true parameters.

Figure 3.
ABCDP on synthetic data. Mean-squared error (between true parameters and posterior mean) as a function of similarity threshold given each privacy level. We ran ABCDP with the following options: RESAMPLE = True (denoted by R and solid line); or RESAMPLE = False (without R and dotted line) for 60 independent runs. (Top Left) When at different values of , ABCDP and non-private ABC (black trace) achieved the highest accuracy (lowest MSE) at the smallest (). Notice that ABCDP RESAMPLE = False (dotted) outperformed ABCDP RESAMPLE=True (solid) for the same privacy tolerance () at small values of . (Top Right) MSE for at different values of ; (Bottom Left) MSE for at different values of . We can observe when is large, ABCDP (gray) marginally outperforms non-private ABC (black) due to the excessive noise added in ABCDP.
Figure 3.
ABCDP on synthetic data. Mean-squared error (between true parameters and posterior mean) as a function of similarity threshold given each privacy level. We ran ABCDP with the following options: RESAMPLE = True (denoted by R and solid line); or RESAMPLE = False (without R and dotted line) for 60 independent runs. (Top Left) When at different values of , ABCDP and non-private ABC (black trace) achieved the highest accuracy (lowest MSE) at the smallest (). Notice that ABCDP RESAMPLE = False (dotted) outperformed ABCDP RESAMPLE=True (solid) for the same privacy tolerance () at small values of . (Top Right) MSE for at different values of ; (Bottom Left) MSE for at different values of . We can observe when is large, ABCDP (gray) marginally outperforms non-private ABC (black) due to the excessive noise added in ABCDP.

Figure 4.
COVID-19 outbreak data () and simulated data under different privacy guarantees. Red dots show observed data, and gray dots show simulated data drawn from 5 posterior samples accepted in each case. The blue crosses are simulated data given the posterior mean in each case: (Top left) simulated data by non-private ABC; (Top right) simulated data by ABCDP with are relatively well aligned with regard to the extremely small size of the data. Note that we use a different scale for left and right plots for better visibility. If we use the same y scale in both plots, the simulated and observed points are not distinguishable on the left plot: (Bottom left) the simulated data given 5 posterior samples exhibit a large variance when ; and (Bottom right) when , the simulated data exhibit an excessively large variance.
Figure 4.
COVID-19 outbreak data () and simulated data under different privacy guarantees. Red dots show observed data, and gray dots show simulated data drawn from 5 posterior samples accepted in each case. The blue crosses are simulated data given the posterior mean in each case: (Top left) simulated data by non-private ABC; (Top right) simulated data by ABCDP with are relatively well aligned with regard to the extremely small size of the data. Note that we use a different scale for left and right plots for better visibility. If we use the same y scale in both plots, the simulated and observed points are not distinguishable on the left plot: (Bottom left) the simulated data given 5 posterior samples exhibit a large variance when ; and (Bottom right) when , the simulated data exhibit an excessively large variance.

Figure 5.
Posterior samples for modeling tuberculosis (TB) outbreak. In all ABCDP methods, we set . True values in black. Mean of samples in red: (R) indicates ABCDP with Resampling = True. (1st row): Histogram of 50 samples drawn from the prior (we used the same prior as [28]); (2nd row): 10 posterior samples from ABCDP with (R) given observations; (3rd row): 10 posterior samples from ABCDP without (R) given observations; (4th row): 10 posterior samples from ABCDP with (R) given observations; and (5th row): 10 posterior samples from ABCDP without (R) given observations. The distance between the black bar (true) and red bar (estimate) reduces as the size of data increases from 100 to 1000. ABCDP with Resampling=False performs better regardless of the data size.
Figure 5.
Posterior samples for modeling tuberculosis (TB) outbreak. In all ABCDP methods, we set . True values in black. Mean of samples in red: (R) indicates ABCDP with Resampling = True. (1st row): Histogram of 50 samples drawn from the prior (we used the same prior as [28]); (2nd row): 10 posterior samples from ABCDP with (R) given observations; (3rd row): 10 posterior samples from ABCDP without (R) given observations; (4th row): 10 posterior samples from ABCDP with (R) given observations; and (5th row): 10 posterior samples from ABCDP without (R) given observations. The distance between the black bar (true) and red bar (estimate) reduces as the size of data increases from 100 to 1000. ABCDP with Resampling=False performs better regardless of the data size.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Park, M.; Vinaroz, M.; Jitkrittum, W. ABCDP: Approximate Bayesian Computation with Differential Privacy. Entropy 2021, 23, 961. https://doi.org/10.3390/e23080961
AMA Style
Park M, Vinaroz M, Jitkrittum W. ABCDP: Approximate Bayesian Computation with Differential Privacy. Entropy. 2021; 23(8):961. https://doi.org/10.3390/e23080961
Chicago/Turabian StylePark, Mijung, Margarita Vinaroz, and Wittawat Jitkrittum. 2021. "ABCDP: Approximate Bayesian Computation with Differential Privacy" Entropy 23, no. 8: 961. https://doi.org/10.3390/e23080961
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.