
BeiDou Short-Message Satellite Resource Allocation Algorithm Based on Deep Reinforcement Learning

1
Institute of Meteorology and Oceanography, National University of Defense Technology, Changsha 410005, China
2
Basic Department, Nanjing Tech University Pujiang Institute, Nanjing 211112, China
*
Author to whom correspondence should be addressed.
Entropy 2021, 23(8), 932; https://doi.org/10.3390/e23080932
Submission received: 23 June 2021
/
Revised: 13 July 2021
/
Accepted: 20 July 2021
/
Published: 22 July 2021
(This article belongs to the Special Issue Machine Learning for Communications)
Abstract
:The comprehensively completed BDS-3 short-message communication system, known as the short-message satellite communication system (SMSCS), will be widely used in traditional blind communication areas in the future. However, short-message processing resources for short-message satellites are relatively scarce. To improve the resource utilization of satellite systems and ensure the service quality of the short-message terminal is adequate, it is necessary to allocate and schedule short-message satellite processing resources in a multi-satellite coverage area. In order to solve the above problems, a short-message satellite resource allocation algorithm based on deep reinforcement learning (DRL-SRA) is proposed. First of all, using the characteristics of the SMSCS, a multi-objective joint optimization satellite resource allocation model is established to reduce short-message terminal path transmission loss, and achieve satellite load balancing and an adequate quality of service. Then, the number of input data dimensions is reduced using the region division strategy and a feature extraction network. The continuous spatial state is parameterized with a deep reinforcement learning algorithm based on the deep deterministic policy gradient (DDPG) framework. The simulation results show that the proposed algorithm can reduce the transmission loss of the short-message terminal path, improve the quality of service, and increase the resource utilization efficiency of the short-message satellite system while ensuring an appropriate satellite load balance.
1. Introduction
The global BeiDou Navigation System (BDS-3) is the fourth fully-fledged satellite navigation system to be developed after GPS, GLONASS, and Galileo. The BDS-3 has timing, positioning, and short-messaging services, and its unique short-messaging is widely used in meteorological and marine service, such as meteorological observation data collection [1,2], early warning information dissemination [3,4,5], and high-precision ocean measurements [6,7]. With the comprehensive completion of the BDS-3, the performance and service range of BDS-3 short-message communication (BDS3-SMC) have further improved, which has great practical significance for the more effective development of meteorological and marine service [8].
BDS3-SMC can provide regional short-message communication (RSMC) and global short-message communication (GSMC) [9]. The RSMC is served by three GEO satellites with large communication and service capacities, a low response delay (≤1 s), and high service frequency. GSMC is served by 14 MEO satellites, and its communication capacity and service capacity are significantly lower than those of RSMC. The GSMC processing resources for the satellite are scarce. For GSMC, on one hand, it is necessary to improve the resource utilization of the short-message satellite to ensure adequate system throughput. On the other hand, it is necessary to respond to the service requests of each terminal, provide the required services for the terminal, avoid uplink congestion, and shorten the request delay by up to hundreds of milliseconds. However, to determine how to reasonably allocate the global short-message processing resources of the BDS3-SMC, improve the resource utilization rate, and ensure the service quality of the short-message terminal, further study is required.
The existing satellite resource allocation (SRA) algorithms can be divided into traditional algorithms and artificial intelligence algorithms. Research involving the use of traditional optimization algorithms in satellite resource allocation is quite advanced. Developed algorithms include the genetic algorithm (GA) [10], simulated annealing algorithm (SA) [11], non-dominated sorting genetic algorithm (NSGA) [12], random geometry [13], and game theory [14,15]. Artiga et al. [16] established the satellite system power allocation optimization problem and used Lagrangian duality theory to optimize the total system capacity. Similarly, Choi et al. [17] applied Lagrangian theory to Karush–Kuhn–Tucker (KKT) conditions. Kan et al. [18] achieved multi-objective joint optimization of the energy efficiency (EE) and spectral efficiency (SE) of multi-beam satellites. At the same time, it was proven that the resource allocation problem in a multi-objective constraint scenario is an NP-hard problem. Therefore, heuristic algorithms such as the GA, SA, and NSGA can be widely used in satellite resource allocation scenarios. Aravanis et al. [19] proposed a multi-objective optimization strategy to minimize the power consumption of user terminals and satellites by using a meta-heuristic algorithm to reach a Pareto optimal solution. However, the calculation delay of the algorithm is long, and it is difficult to meet the requirements of real-time processing on the satellite using this method.
Based on the above problems, Efrem et al. [20] designed a continuous convex approximation algorithm to solve the multi-objective optimization problem of power distribution for energy-sensing of multi-beam satellites. This algorithm has a fast convergence speed and can be used for the dynamic allocation of satellite resources. By combining the particle swarm optimization algorithm and the Lyapunov optimization framework, Jiao et al. [21] solved the joint network stability and resource allocation optimization problems of high-throughput satellites (HTSs). Lin et al. [22] achieved joint optimization of wireless information resource allocation and power transmission of multi-beam solar satellites through particle swarm optimization (SPO), the improved harmony search algorithm (IHSA), and the monkey algorithm (MA), and analyzed SPO, ISHA, and MA algorithms. The results showed that the IHSA algorithm can maximize power transmission without affecting information transmission. However, the above work [20,21,22] did not consider the transmission power consumption and the quality of service of the task initiator.
There has been little research on short-message satellite resource allocation. Yang et al. [23] proposed a task-oriented satellite network resource allocation algorithm (SAGA) based on the GA. Xia et al. [24] combined this with the BDS3-SMC to form a short-message transmission mechanism and solved the problem of short-message satellite resource allocation by improving the Hungarian algorithm. However, for scenarios with a large number of terminals, the applicability of the algorithm is poor.
With the development of artificial intelligence technology, deep reinforcement learning (DRL) has made a substantial breakthrough in many tasks that need to interpret high-dimensional raw input data and implement sequential decision-making control [25]. Researchers have proven the effectiveness of DRL in many fields. Preliminary applications of DRL include resource allocation in the Internet of Things [26], heterogeneous cellular networks [27], and 5GHetNet uplink/downlink [28]; dynamic beam-hopping of satellite broadband systems [29]; and edge computing in the Internet of Things [30]. DRL has frequently been used in research work to optimize satellite resources. In fact, the SRA problem can be modeled as an interaction between the satellite system and the user terminal service, where the best solution to the problem is equivalent to the maximal cumulative reward that the agent (satellite system or user terminal) can get from the environment. In terms of multi-agent environments, DRL has been considered a solution for cognitive radio networks [31]. Ferreira et al. [32] proposed a reinforcement learning algorithm based on a deep neural network to solve the multi-objective optimization problem of resource allocation in cognitive satellite communication. Hu et al. [29,33,34] used DRL to make dynamic decisions for hopping beams in multi-beam satellite systems and next-generation broadband satellite systems, which have a lower level of complexity than traditional algorithms. He also proposed a resource allocation framework for multi-beam satellite systems based on DRL. In contrast, Luis et al. [35] proposed a dynamic satellite power allocation method based on DRL to minimize system power consumption. Yu et al. [36] proposed an optimization method to balance energy, power consumption, and efficiency in heterogeneous computing systems through reinforcement learning, and carry out hardware simulation experiments based on FGPA. The results show that reinforcement learning can greatly reduce system energy consumption without affecting hardware performance. Zhang et al. [37] proposed a multi-objective optimization algorithm based on deep reinforcement learning (DRL-MOP), which achieves multi-objective joint optimization of the satellite spectrum efficiency and improvements in energy efficiency and the service satisfaction index. Compared with the traditional GA and SA algorithms, it has been verified that the DRL-MOP algorithm has the characteristics of fast convergence and low complexity. Qiu et al. [38] proposed a software-defined satellite-terrestrial network (STN), which can be used to coordinate a satellite cache and computing resources, and can be combined with the DQN algorithm to optimize the cache and computing resources jointly.
Combined with the previous work in the field of multi-objective optimization, we find that DRL has surprising results in the field of multi-objective optimization. However, there is no relevant literature on the resource allocation of the SMSCS in the current research. Considering the actual scenario, the global short message resources of the SMSCS are very scarce. Due to the uneven distribution of short message terminals in various world regions (similar to IoT communication terminals, mobile phone terminals, etc.) it is reasonable to allocate the short message satellite processing resources as a critical way to improve the use efficiency of satellite resources and meet the needs of terminal services. Because of the above situation, the main work of this paper includes: (1) establishing a resource allocation model for the global short message satellite system of the SMSCS; and (2) proposing a resource allocation strategy to meet the needs of short message satellites and short message terminals.
According to the parameters of the short-message satellite communication system (SMSCS) [39], we first established a resource allocation model for the SMSCS. Furthermore, a resource allocation strategy for the BDS-3 short-message satellite is proposed with the optimization goals of improving the utilization of satellite resources and ensuring the service demands of the terminal are met. The resource allocation problem is described as a Markov decision process (MDP) and is solved by DRL.
The main contributions of the study are as follows.
- (1)
- Based on the characteristics of the BDS3-SMC, an ideal SMSCS model is proposed. We formally describe the path transmission loss of the short-message terminal, satellite load balance, and satellite service quality through the above model and then establish a multi-objective optimization mathematical model for short-message satellite resource allocation.
- (2)
- Considering that the number of short message terminals in the application scenario can reach more than one million, the huge input data makes DRL-SRA challenging to perform in the training process. We improve the ideal model of short-message satellite resource allocation and propose a region division strategy and a resource allocation model based on this strategy to reduce the computational complexity. The state space, action space, and reward mechanism of satellite resource allocation are defined according to the improved model.
- (3)
- We design a feature extraction network to extract features from the state space to reduce the dimensions of the input data. Combined with the DDPG framework, it solves resource allocation in continuous states. Finally, we propose a BeiDou short-message satellite resource allocation algorithm based on DRL (DRL-SRA).
The rest of the paper is presented as follows. In Section 2 we introduce the system model. In Section 3 we optimize the proposed model and propose the DRL-SRA to solve the multi-objective optimization problem of short-message satellite resource allocation. In Section 4 we evaluate the performance of the proposed algorithm and the corresponding strategy through a simulation and compare it with the traditional algorithm and other reference strategies. In Section 5 we provide conclusions and present ideas for future work.
2. System Model
We consider the following scenario. In a snapshot [40] of an SMSCS, there are short-message satellites (SAT) that cover the ground area; these are recorded as a set , where is the total number of short-message satellites in the . At the same time, there are short-message terminals (ST) in the coverage area; these are recorded as a set , where is the total number of short-message terminals in the . The communication link of the system adopts the Gaussian white noise channel, and the task requests of the short-message terminal have a Poisson distribution.
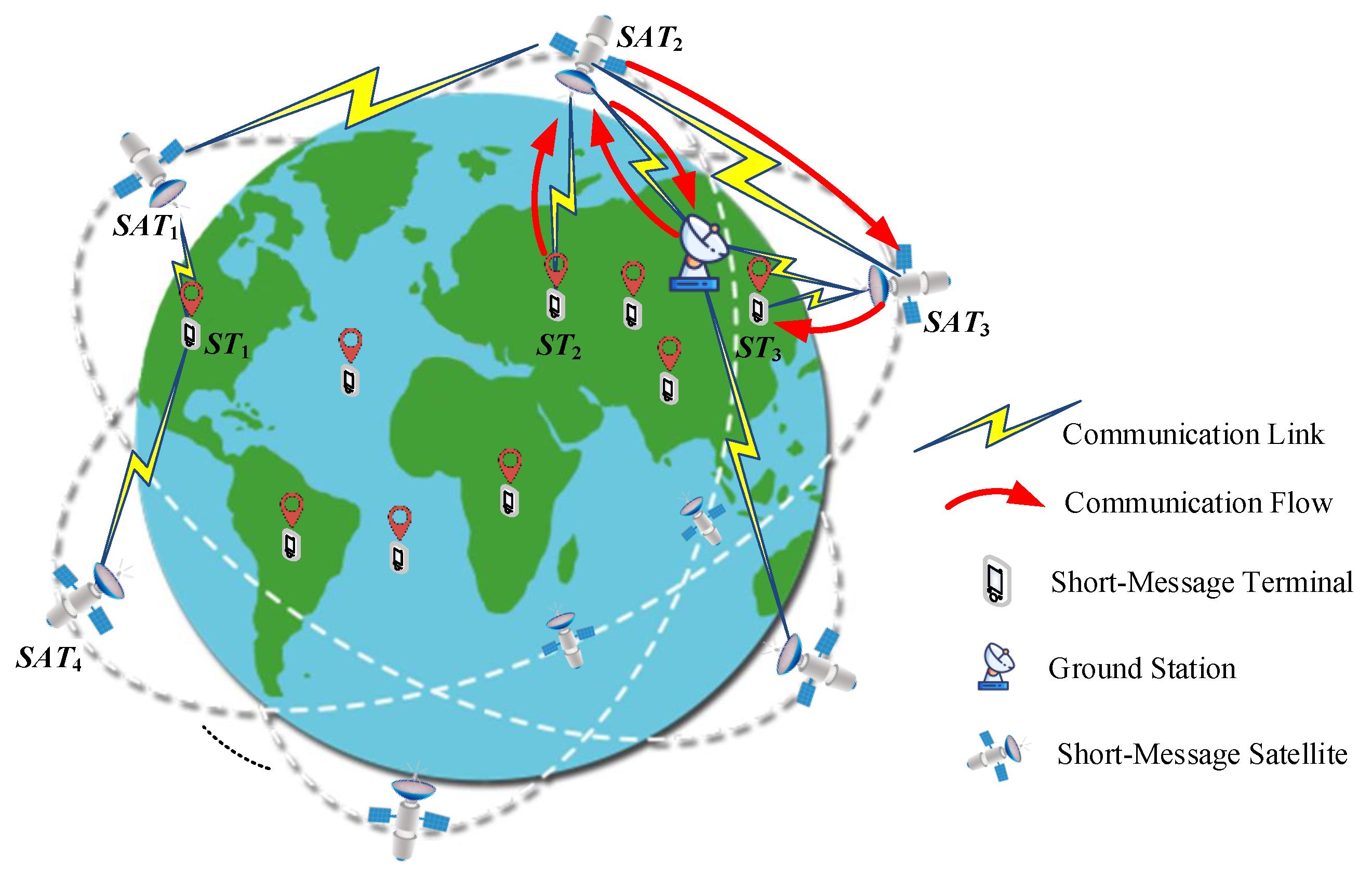
Our system model is shown in Figure 1 and consists of the BDS-3 short-message satellite constellation, ground station, and short-message terminal.
The short-message satellite constellation adopted is the Walker 24/3/1 constellation, which is used to collect short-message transmission requests and return related information such as the working status to the ground station, and then wait for control commands from the ground station. The ground station can collect information on the working status, resource information, and transmission control instructions from the short-message satellite. The short-message terminal initiates task requests and receives short messages from other terminals.
The system workflow is divided into three stages. (1) The short-message terminal and the short-message satellite establish uplink and downlink communication links. (2) The short-message satellite establishes a communication link with the ground station, and the inbound information from the short-message terminal is sent to the ground station. (3) The short-message satellite sends the short message to the target terminal through itself or via the intersatellite link depending on the service instructions provided by the ground station. Short-message satellites can establish intersatellite links to achieve intersatellite information exchange. The red arrow in Figure 1 shows the end-to-end communication flow of a complete short-message terminal. First, sends a short-message task request. Secondly, collects the request and informs the ground station, and the ground station sends the request to so that it can respond. Finally, transmits the short message from to through the intersatellite link established with .
In the system model, the task requests from each short-message terminal can only be answered by a unique short-message satellite. Multiple short-message terminals can be distributed within the coverage area of each short-message satellite in the short-message satellite constellation. There is a one-to-many mapping relationship between a short-message satellite and the short-message terminal. As the short-message satellite has the characteristics of a large ground coverage area, the vast majority of short-message terminals are covered by multiple short-message satellites. Therefore, there is competition among short-message satellites to respond to short-message terminal tasks. For example, the task request of shown in Figure 1 can be responded to by or .
In different snapshots of the above model, due to the characteristics of short-message satellite coverage and the uneven distribution of short-message communication traffic in different regions, the resource utilization of the SMSCS and the energy efficiency of the short-message terminal are low. Consequently, our optimization objectives include the following:
- (1)
- To reduce the transmission energy consumption of short-message terminals;
- (2)
- To improve the resource utilization of short-message satellites;
- (3)
- To produce adequate short-message terminal service quality.
To achieve these three optimization objectives, we formally describe the transmission energy consumption in the short-message terminal, the resource utilization of the satellite system, and the quality of service from the terminal.
Definition 1.
Path transmission loss (L) is used to describe the transmission energy consumption of the short-message terminal, and it represents the transmission loss during the process of task transmission from the short-message terminal to the target satellite in dB.
Definition 2.
The load balancing index (LI) is used to describe the resource utilization rate of the satellite system. It indicates the degree of balance in task processing by short-message satellites, where the larger LI is, the higher the resource utilization rate of the satellite system will be.
Definition 3.
The service satisfaction index (SI) is used to describe the service quality of a short-message satellite transmitting to a short-message terminal. It indicates the efficiency at which a task is sent by the short-message satellite to the short-message terminal: the larger the SI, the higher the service quality.
Additionally, the system model includes a communication model and a resource allocation model.
Communication model: The short-message terminal transmits the task request and content to the short-message satellite via the satellite link. The transmission delay is related to the size of the task data and the transmission rate. According to Shannon’s theorem, the communication model of and can be defined as shown in Equation (1):
where is , is , and is , but . represents the communication rate between and . is the channel bandwidth. is the communication noise power (Gaussian white noise). is the transmission power of , which can be approximated by the path transmission loss between and , i.e., . is the channel gain between and . is the interference to caused by other short-message terminals.
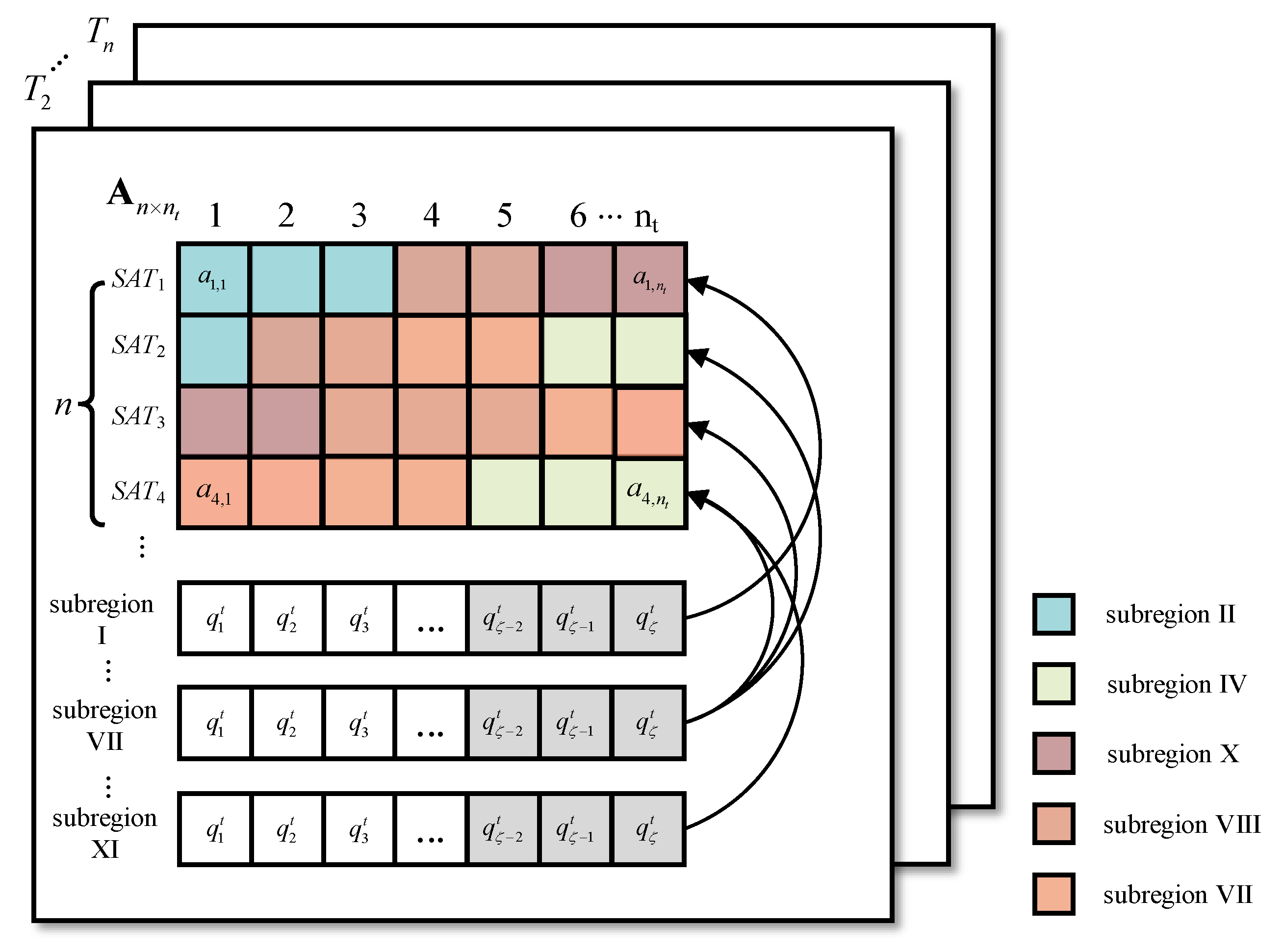
Resource allocation model: This is divided into the satellite resource allocation model and the task queue model, as shown in Figure 2.
For satellite resource allocation, a snapshot is divided into time slices, where is the number of time slices in a snapshot. The duration of a time slice is called a time unit, and the value of the time unit is determined by its actual application. Because the amount of data transmitted by the short-message task is limited, the maximum single transmission length of GSMC is 560 bits. In this article, a certain time unit is required for the short-message satellite to process the task of maximum length (assuming that all satellites have the same task processing ability). Thus, in a snapshot, the short-message satellite resource can be formally described as resource matrix with . Each row in represents the utilization of the short-message request processing resource that a satellite has over time slices, . For element in matrix , , represents the resource utilization on time slice of , where . When , the resource is available. When , the resource has been allocated.
The task queue is shared by all short-message satellites following the first-in-first-out principle. The task queue is recorded as the set , where is the maximum capacity of the task queue , and the element is defined as a quadruple:
where is the short-message task size. is the response matrix, which records the short-message satellites that can respond to the task. For example, when , , which means that and can respond to . records the time when the task enters the queue. records the time that the task is processed.
The task queue is updated after the end of each snapshot, i.e., time slices. The unprocessed tasks in the previous snapshot are copied to the head of the queue, and new tasks continue to be received in the current snapshot, i.e., . indicates that the task has been responded to, and is the new task.
2.1. Path Transmission Loss Model
First of all, we discuss the path transmission loss of the satellite-to-ground link between the short-message satellite and the short-message terminal. satellite-to-Earth links can be established between the elements of set and set , and the satellite-to-Earth link matrix can be expressed as shown in Equation (3):
where is a Boolean variable indicating the link relationship between and . When , and do not establish a link relationship, but when , and establish a link relationship.
Suppose the path transmission loss of the satellite-to-Earth link is , there is:
In Equation (4), is the free-space path loss. is the rain loss. is the atmospheric absorption loss, and its value is related to the antenna elevation angle at the transmitting terminal. denotes other losses. satisfies Equation (5):
In Equation (5), is the free-space transmission distance in . is the frequency in . Generally, in the case of a fixed band, is only related to . , , and can be used to obtain the corresponding value of the band used in the current scene by consulting the related literature [41].
can be obtained from geometric relations. Since the moving speed of the short-message terminal is very slow relative to the satellite speed, it can be assumed that the short-message terminal is motionless relative to the Earth [42]. In Figure 3, O is the geocenter, and T is the short-message terminal. S and N are, respectively, the position of the satellite and the sub-satellite point at time t. is the geocentric angle between T and N. is the elevation angle of the short-message terminal between S and A. R and h are the radius of the Earth and the orbital altitude, respectively.
For , there is:
Furthermore, the free-space transmission distance is:
For satellite-to-ground links, the path transmission loss matrix between the elements of set and set can be expressed as shown in Equation (8):
Then, the total path transmission loss that occurs when completing a message transmission in the current snapshot in the above set can be expressed as:
2.2. Satellite Load Balancing Model
Satellite load balancing is an essential index for the rational utilization of satellite resources and the efficient processing of short-message tasks. We use the load balancing index to characterize the load balancing degree of the SMSCS.
Let respond to the number of short-message tasks , recorded as the set . A task will continuously occupy time slices. Since each satellite has, at most, time slices in a snapshot, the satellite resource utilization of in that snapshot is:
After the short-message satellite responds to the short-message task, the processing of each short-message does not affect the processing of others; they are processed in parallel. Therefore, for :
Intuitively, the smaller is, the more balanced the load of the short-message satellite system is.
2.3. Terminal Satisfaction Model
In the previous section, the short-message tasks requested by short-message terminals were recorded as the set . We define the short-message task as a triple:
where is the content of the short-message to be transmitted by . is the size of the transmission task (in bytes). is the acceptable processing delay for .
The satisfaction of the short-message terminal depends on the processing speed of the short-message satellite in response to the short-message terminal task request. The factors affecting the processing speed include the short-message transmission delay , the processing delay , and the task queuing delay . Assuming that responds to the task request of , Equation (13) shows that the communication rate is , the size of the transmission task is , and the transmission delay is:
The processing delay is:
where is the computing power of the short-message satellite, i.e., the number of bytes processed per unit of time.
The task queuing delay is:
Equations (13)–(15) show that the total execution delay for is:
If does not request a short-message task, .
Thus, the service satisfaction index for the short-message terminal set is:
where is the service satisfaction index of .
The main problem considered in this article is determining how to improve the resource utilization of the SMSCS, meet the quality-of-service requirements of the short-message terminal, and reduce the energy loss of the short-message terminal at the same time. In summary, the objective function of optimization under the snapshot is:
where , , and are weight values, and . represents the minimum value of the overall path transmission loss of the short-message under the snapshot . represents the maximum value of the load balance index. represents the maximum value of the terminal satisfaction index. The optimization objectives can be expressed as follows:
is used to ensure that the short-message task of each short-message terminal in the communication system is answered by, at most, one short-message satellite. is used to ensure that the number of short-message tasks answered by each short-message satellite does not exceed the maximum capacity it can handle. is used to ensure that the energy consumed by the terminal transmission is not greater than the maximal amount of energy contained in the short-message terminal. is used to ensure that the message size transmitted by the terminal does not exceed the maximal length specified by the system.
3. Algorithm Design
Based on the work of predecessors in multi-objective optimization, we propose DRL-SRA to solve the problem of short message satellite resource allocation. The area division strategy and the short message resource allocation algorithm based on the DDRG framework are used to solve two challenges: (1) Data preprocessing of SMSCS; and (2) DRL solves resource allocation in a continuous state.
3.1. Regional Division Strategy
The terminal capacity of the GSMS is about 1 million, and the terminal capacity of the RSMS is about 10 million. If the short-message satellites respond to the task requests of each short-message terminal, the calculation time complexity and space complexity will be high. Therefore, before designing the resource allocation algorithm, the system model needs to be optimized to reduce the overall overheads of the resource allocation algorithm.
Because the BDS-3 MEO satellites use the Walker 24/3/1 constellation, an area is often covered by multiple short-message satellites. The coverage area is divided into subregions according to the type and number of covering satellites, and is recorded as the set , where is the -th subregion, and the maximum number of subregions that can be covered by a single short-message satellite is recorded as . The subregion is represented by a tuple, and for , there is:
where is the number of short-message terminals included in subregion . is the number of short-message satellites covering subregion . As shown in Figure 4b, the coverage area can be divided into 11 subregions (because the Walker 24/3/1 constellation can achieve global coverage, the uncovered area in the schematic diagram is not discussed). The number of short-message satellites covered by subregions I, III, V, and XI is 1; therefore, the mission request of the short-message terminal in this region can only be responded to by the covered satellite. There are at least two short-message satellites in other subregions, so the optimal response scheme needs to be considered to satisfy Equation (19).
By introducing regional division, short-message terminals in a given subregion are regarded as a whole. The short-message satellite only needs to respond to the subregion, and does not need to respond to each short-message terminal separately. Thus, the satellite dynamic allocation problem of computation to the 106–107 power can be transformed into computation to the 102–103 power. However, the model proposed in the previous section needs to be improved further. The details are as follows.
The purpose of regional division is to approximate the number of short-message terminals in the subregion. Therefore, it is necessary to treat the short-message terminals in the subregion as a whole.
Firstly, considering the path transmission loss of a short-message terminal in a subregion, the following definition is given.
Definition 4.
where is the regional distance from to , and is the distance from to in .
The regional distance is the average sum of distances of all the short-message terminals in the subregion from the target short-message satellite, i.e.,
Equation (5) shows that the path transmission loss from the short-message terminal in to is:
where is the number of responding to short-message task requests in and .
The path transmission loss matrix between the elements of set and set can be expressed as shown in Equation (27):
The total path transmission loss is:
where indicates that there is an intersatellite link between and , and indicates that there is no intersatellite link between and .
Secondly, after completing regional division, each short-message satellite usually needs to serve multiple subregions; as shown in Figure 4, serves subregions I, II, IX, and X. Unlike the previous model, task requests in a subregion can be responded to by multiple satellites, and there are significant differences in the number and density of terminals in different subregions. Furthermore, each short-message satellite needs to allocate its own short-message processing resources to the subregions it covers. By using the resource allocation model proposed above, an improved satellite resource allocation model suitable for regional division can be obtained.
As shown in Figure 5, a snapshot is divided into time slices, and each short-message satellite resource is allocated to a certain proportion of its covered subregion (the value of the subregion ratio is explained in detail in the next section). The color of the squares in Figure 5 corresponds to the colors of the subregions in Figure 4b, indicating how the resources are allocated in the current snapshot. Resources from different satellites obtained in the subregion are recorded as the set , , where represents the resources allocated by to subregion , and there is .
Each subregion has a task queue, and its operation mode is similar to the resource allocation model mentioned in the second section. The difference lies in the task allocation in the task queue. In the improved model, based on the proportion of resources allocated by each satellite to the subregion, the tasks are divided among the covering satellites. For example, in subregion VII, the proportion of resources allocated by accounts for 45% of the resources obtained by subregion VII, so then 45% of the tasks in subregion VII are allocated to . The unprocessed tasks in the current snapshot are copied to the next snapshot.
3.2. DRL-SAR Algorithm
When the short-message satellite receives a task request from short-message terminals in all subregions, it forwards the information, such as the short-message satellite status and the short-message terminal task request, to the ground station. The ground station determines the optimal strategy and returns the information to the short-message satellite system by using the satellite resource allocation algorithm to respond to the task request. Because the task request from the short-message terminal occurs randomly in the time dimension, the state transition probability of the system is difficult to calculate, and it is challenging to solve the problem by using the traditional value iteration method. The critical problem is determining the optimal strategy for allocating the short-message satellite response to short-message terminal tasks. As one of the basic methods of DRL, DQN is widely used in many optimization fields and can be used to effectively deal with tasks with a large state space and action space. However, because the output of DQN is discrete and the resource capacity of the short-message satellite and the energy of the short-message terminal are continuous variables, in order to meet the requirements for DQN input, the above continuous variables need to be quantized into discrete variables. This causes the action space to grow exponentially, which makes it challenging to guarantee the performance of DQN.
In order to solve the resource allocation problem of the short-message satellite system in continuous space, we propose a satellite short-message resource allocation algorithm based on deep reinforcement learning (DRL-SAR). The DRL-SAR algorithm takes Equation (18) as the optimization goal, models the short-message satellite as the agent, considers the response to the short-message terminal request as the action of the agent, and models the satellite-to-ground link as an interactive environment. The three elements of the DRL-SAR —status, action, and reward—can be described as follows.
- (1)
- Status
Suppose the state space of the DRL-SAR is , where is defined as the system state under snapshot . For there is:
where . is the total path transmission loss of the terminal in subregion under . is the resource matrix under , which involves the use information of satellite resources, such as resource occupancy and resource allocation. In , is the satisfaction degree of the terminal in area under .
Since satellites and terminals are mobile, their levels of mobility are mapped as the change in distance between the subregion and the covered satellite and then further mapped to show the path transmission loss of the entire region. The mobility mentioned above only affects the state change of the DRL-SAR, but does not affect the overall framework design of the algorithm.
- (2)
- Action
Suppose the action space is , when all possible resource allocation decisions of the satellite under are included:
where is the resource allocation decision of under snapshot . , where is the proportion of resources allocated to subregion by the using its own resources, and there is . The allocation ratio has a continuous quantity, so it is necessary for the DRL-SAR to effectively deal with the continuous action space to solve the action dimension problem.
- (3)
- Reward
Suppose that, under status , the reward obtained by the system is .
Using Equation (18), the gain of the optimization objective can be expressed as:
For , there is:
When , the system revenue is increasing, . When , the system revenue is unchanged or decreasing, , and .
For the short-message satellite resource allocation scenario, the proposed DRL-SAR framework is shown in Figure 6. The basic process is that the short-message satellite and the short-message terminal continuously interact to determine the current state of the environment and transmit environmental information to the ground station. Based on the state of the current system, the ground station sends the action instructions to the short-message satellite to be executed. After executing the instructions, the system environment moves from the current state to the next state and receives rewards through the environmental feedback. At the same time, the ground station stores the quadruple as a sample in the memory pool, which is composed of the current environment state, the next state, executes actions and feeds back rewards. In the DRL-SAR training process, the training speed can be accelerated through experience replay.
The above algorithm framework is divided into two steps:
- STEP 1: DRL-SAR input data reconstruction
The deep learning process carried out in the DRL-SAR involves the use of a feature extraction network to extract state features. The essence of the feature extraction network is the use of convolutional neural networks (CNNs). CNNs usually require input data to conform to the form of a graph tensor. For the state , , , and are split into one-dimensional vectors, and is transformed into graphic tensors of through operations such as zero padding and matrix transformation. The resource allocation of short-message satellites and information about the path transmission loss of the terminal in the subregion and the service satisfaction of the short-message terminal are recorded. The graphic tensor outputs a one-dimensional vector with dimensions of through the feature extraction network. The one-dimensional vector records the characteristics of each short-message satellite for its covered subregion and inputs this information into the action decision mechanism.
- STEP 2: DRL-SAR training and update
In state of the SMSCS, the ground station sends the instruction to execute action . At this time, it receives a reward and is transferred to state . Assuming that the initial state of the SMSCS is , strategy is transferred from the initial state to the state , as follows:
In DRL-SAR, for , the action value function is used to evaluate the benefits of action in the current state of the SMSCS. According to the Bellman equation, the action function is:
The state function is:
where is the attenuation factor. is the probability that the SMSCS transfers to under state and action . is the probability of performing action under state .
Equations (34) and (35) can be used to obtain the optimal action function and the optimal state function :
The optimal strategy is , the corresponding optimal action is , and its expression is:
Each snapshot in the SMSCS corresponds to the state action function , the state function , and the optimal action . The optimal strategy for transferring from the initial state to the state is:
However, it is usually challenging to determine the state transition probability of the SMSCS, the state of the resource allocation problem is continuous, and the scale of the state set is large. We include the DDPG in the action decision mechanism of the DRL-SAR. Through the introduction of actor–critic, the continuous spatial state is parameterized.
First, by introducing and , the state function and the action function are approximated. They are:
Similarly, to approximate the strategy function, we have:
where and are the weight parameters in the network.
DDPG includes four networks, namely, the target critic network, the critic network, the target actor network, and the actor network. The basic idea is that the strategy gradient is approximated by the strategy function and the value function. In this process, the strategy function can evaluate and optimize the strategy based on the value function. The optimized strategy function can also make the value function reflect the value of the state more accurately, and the functions can influence each other to obtain the optimal solution [44]. The actor network has a policy function and is responsible for agent selection and environment interactions. The critic network has a value function and is used to evaluate the behavior of the actor. In the DRL-SAR, the main functions of the four networks are as follows.
- (1)
- The target critic network is responsible for calculating targets and based on the state sampled in the experience replay pool. Parameter in the target critic network is regularly copied from in the critic network, i.e.,where is the updated coefficient, and .
- (2)
- The critic network is responsible for iteratively updating parameter in the value function and calculating the current values of and . The loss function of the critic network can be defined as:where is the number of samples drawn from the experience playback pool and .
- (3)
- The target actor target network is responsible for selecting the optimal action based on the state sampled in the experience replay pool. The parameter in the target actor target network is periodically copied from in the actor network, i.e.,
- (4)
- The actor network is responsible for iteratively updating parameter in the strategy function. According to the state of the SMSCS in the current snapshot , it selects the current action , obtains the reward , and determines the initial state of snapshot . The loss of the actor network can be simply understood as follows: the greater the value of the action obtained, the smaller the network loss. Therefore, the loss function of the actor network can be defined as:
The loss functions and use gradient direction propagation to update the neural network parameters. At the same time, they balance the exploration of new actions and the use of known actions, increase the randomness of the learning process, and improve the generalization ability of the DRL-SAR. We add random noise to action obtained by the actor network in state , which is given by:
In summary, the DRL-SAR is shown as Algorithm 1.
| Algorithm 1 DRL-SAR |
| Input:, , Output: Optimization result Begin
End |
4. Simulation and Performance Analysis
This section describes the evaluation of the performance of the algorithm proposed in this article for different system parameters. To verify the effectiveness and convergence of the DRL-SAR, we used the throughput and load balance index of the SMSCS, the path transmission loss of the short-message terminal, and the terminal service satisfaction index as the algorithm evaluation criteria. At the same time, the DRL-SAR was compared with the DQN, GA, and TS-IHA [24]. An Intel(R) Xeon(R) W-2104 CPU @3.20 Hz, 16 GB RAM computer was used for the simulation experiments conducted in this work. The simulation platform was based on Python 3.6, and the neural network in the DRL-SAR was built through TensorFlow.
4.1. Simulation Parameter Setting
The SMSCS uses MEO satellites with an orbital altitude of 21,528 km and an orbital inclination of 55°. It is distributed in the Walker 24/3/1 constellation, which contains a total of 24 satellites, of which 14 provide GSMC. The scene was built with STK satellite simulation software.
Considering future practical application scenarios, 1000 short-message terminals were randomly placed in the Asia-Pacific region at 55° N–10° S and 75° W–135° E (the red area in Figure 7). In the other region, 100,400 short-message terminals were randomly placed.
The short-message terminals in the two areas can randomly choose whether or not to send short-message requests in each snapshot. The size of short-messages transmitted by the short-message terminals obeys a normal distribution with an expectation of and a variance of 1.
The network design consists of two parts. The feature extraction network includes two convolution layers (Conv) and three FC layers (FC), which were used to extract the features of the graph tensor. The specific parameters are shown in Table 1.
The four DDPG networks have the same network structure, in which there are three hidden layers. The loss function adopts the Relu function, and the number of neurons in each layer were set to 16, 32, 64, and 128, respectively. First of all, the deep neural networks with different structures were run to analyze the training efficiency, as shown in Figure 8. The abscissa represents the number of iterations, and the ordinate represents the average loss of the network after continuous learning. The average loss was obtained by exponential moving average (EMA) smoothing, and the smoothed curve better reveals the changing trends of the data. The results show that deep neural networks with different neurons converge after 35,000 iterations of training. However, the structure of 64 neurons in each layer can ensure the minimum network parameters are met to ensure the best convergence performance is achieved. Therefore, we set the number of neurons in the hidden layers to 64, which can also be used as the training structure for the next part of the network performance evaluation.
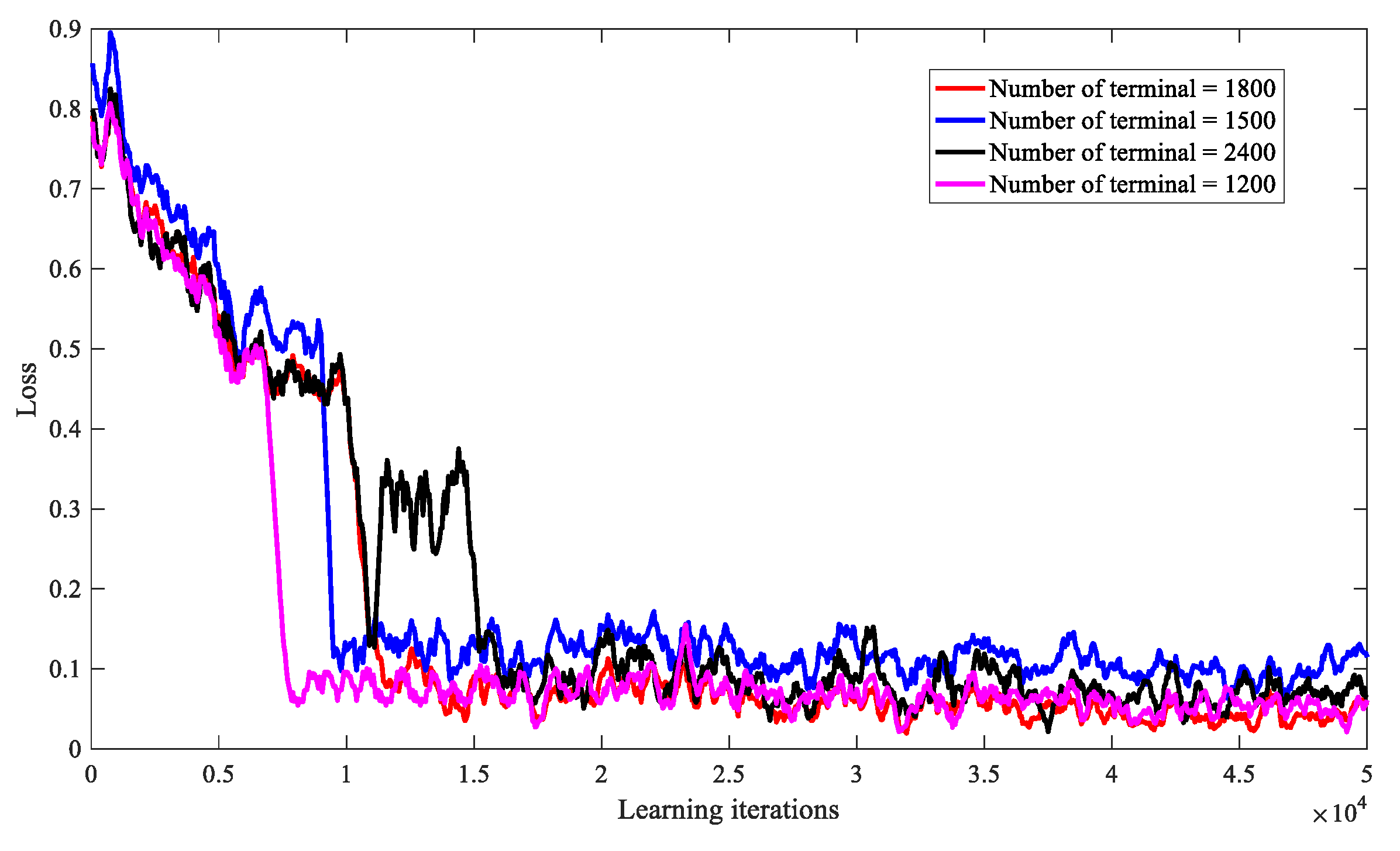
At the same time, we analyze the scalability of DRL-SRA when the number of short message terminals is 1200, 1500, 1800, and 2400, and the impact on the performance of the DRL-SRA algorithm. As shown in Figure 9, it can be found that when the number of short message terminals takes different values, the algorithms can all converge. Moreover, the smaller the number of short message terminals, the faster the convergence speed of the algorithm, but the approximate convergence state can be obtained in the end, indicating that the algorithm has good scalability.
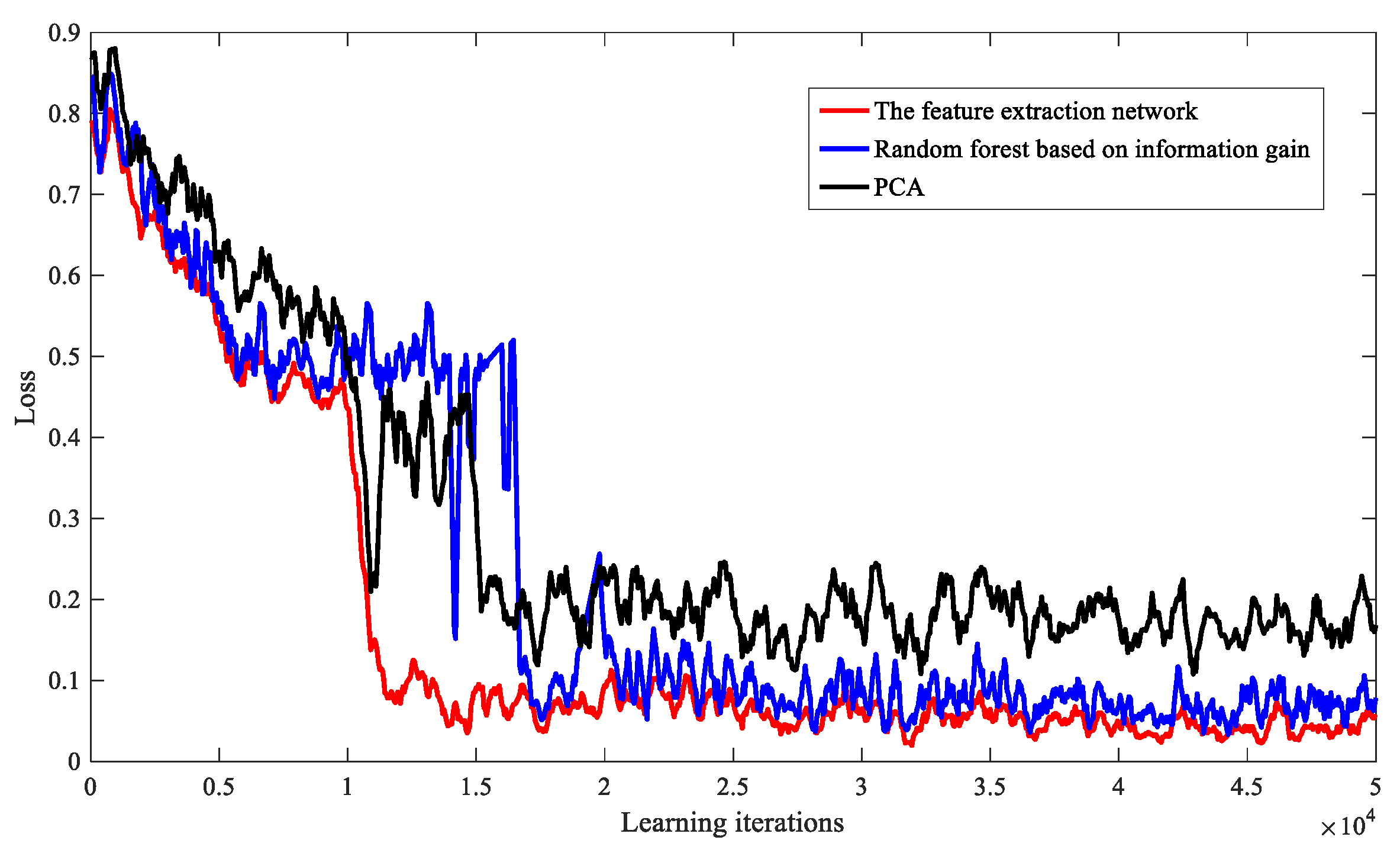
Finally, when the number of terminals is 1500, we compare the performance of the feature extraction network with the PCA dimensionality reduction model and the random forest feature extraction model based on information gain. As shown in Figure 10, the comparison results show that the algorithm using the feature extraction network has a better convergence effect during training.
The specific simulation parameters are shown in Table 2.
4.2. Analysis of Simulation Results
4.2.1. Algorithm Performance Comparison
We compared the DRL-SRA with the DQN, TI-SHA, and GA. Using different numbers of short-message terminals, the optimization effects of the total path transmission loss (), load balancing index (), and service satisfaction index () were analyzed. The comparison algorithm is described as follows:
- (1)
- DQN: The Q network and target Q network with the same network structure are included, the Q network has three hidden layers, and the number of neurons in each layer is 64. The DQN strategy is shown in Equation (38).
- (2)
- TS-IHA: The Hungarian algorithm is satisfied by adding a virtual satellite and terminal.
- (3)
- GA: The population size is 50, the termination evolution number is 400, the crossover probability is 0.9, and the mutation probability is 0.01.
The above four algorithms have the same weights for the three objectives, i.e., .
In addition, after the training has been completed, the network parameters in DRL-SRA are not updated in subsequent experiments.
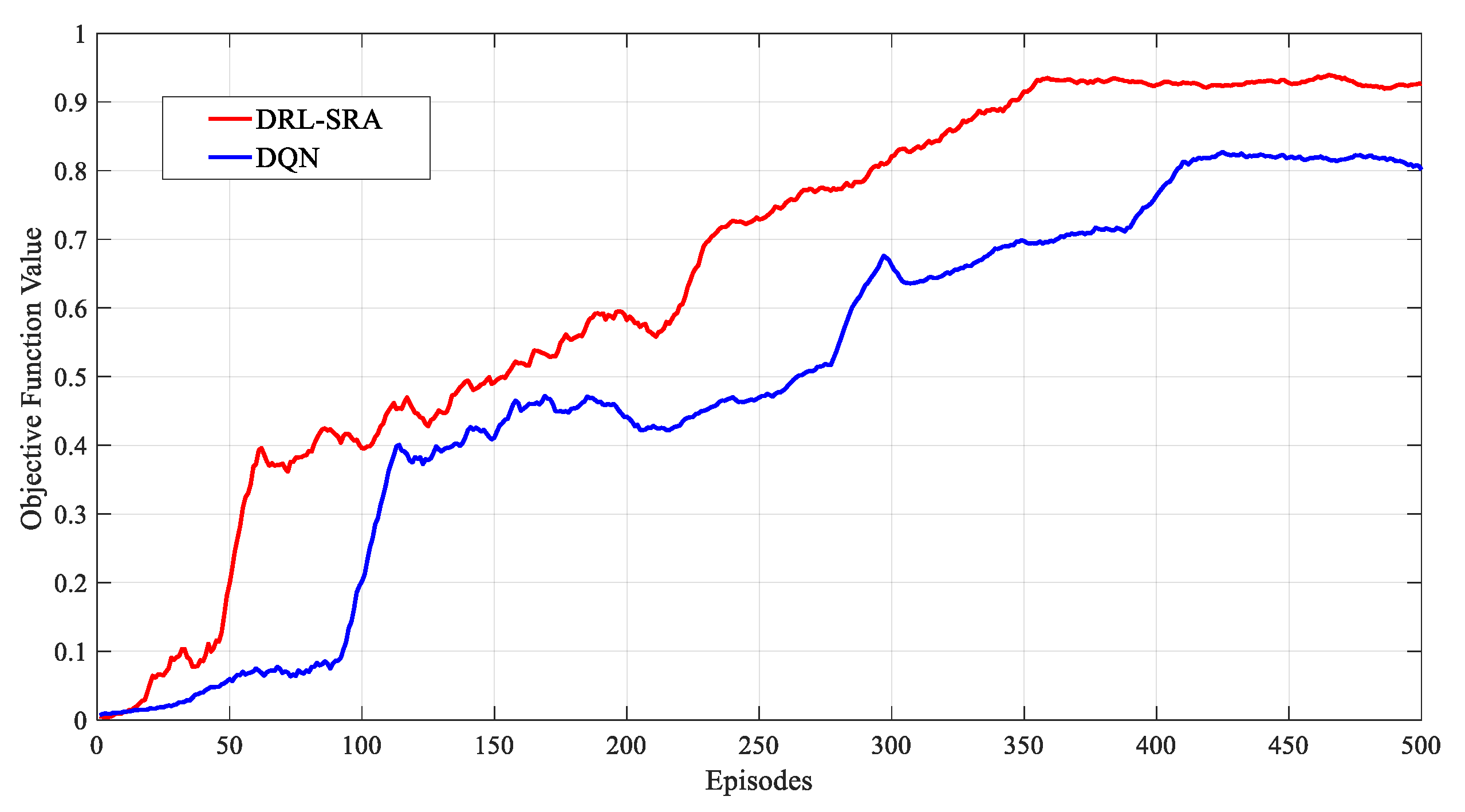
First of all, we evaluated the convergence of the proposed algorithm. Figure 11 shows the convergence effect of the DRL-SRA when the number of short-message terminals was 1500, the number of training steps was 500, and the number of iterations was 500. The abscissa shows the number of iterations, and the ordinate shows the objective function for Equation (18), which is compared with the DQN. In the process of comparison, the EMA was also used to smooth each original data curve for these objective function values. As shown in Figure 11, the objective function value curves of the two algorithms grew at different rates as the training process proceeded. In the first 50 iterations of DRL-SRA, the value of the objective function quickly reached 0.492. After 350 iterative periods, the value of the objective function increased to 0.957, obtaining a state of convergence. The value of the objective function of the DQN reached 0.823 in the first 400 iterations and did not continue to grow. At the end of the training period, the DRL-SRA algorithm had a higher objective function value than the DQN algorithm; that is, a better convergence performance.
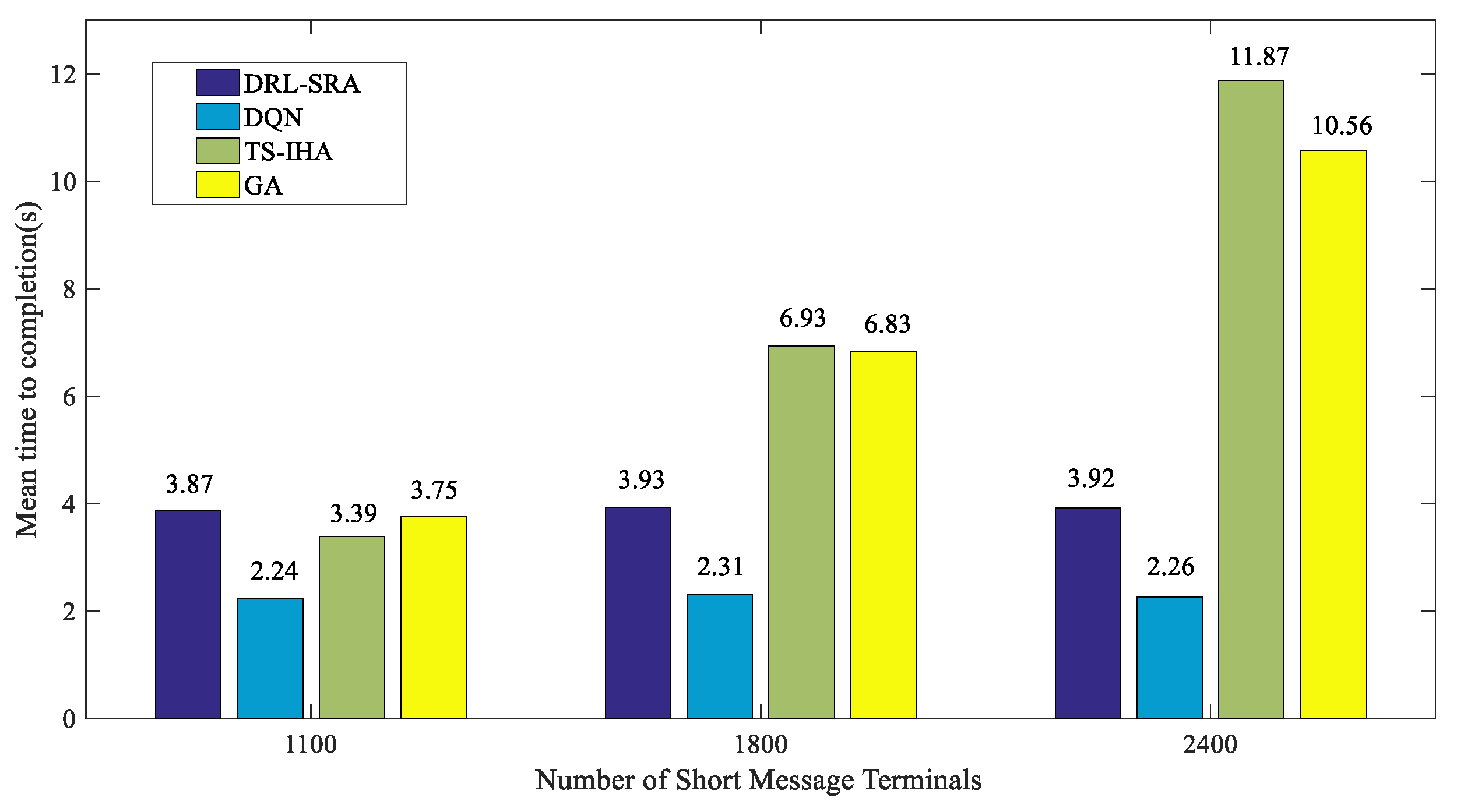
Furthermore, the running times of the four algorithms were compared. As shown in Figure 12, the average time taken by the four algorithms to complete a strategy selection process was calculated when there were 1100, 1800, and 2400 short-message terminals.
When there were 1100, 1800, and 2400 short-message terminals, the average completion time for the DRL-SRA algorithm was 3.87 s, 3.93 s, and 3.92 s, respectively. The average completion time for the DQN is slightly lower than that of the DRL-SRA because there are fewer network parameters in the DQN compared with the DRL-SRA. With an increase in the number of terminals in the TS-IHA and GA, the time required to run the algorithm obviously increased. However, the time consumed by the DRL-SRA and DQN remained unchanged, which shows that the average completion time of decision actions input into the DRL-SRA and DQN is determined by the parameters of the network (such as the number of network layers). In contrast, the network parameters are fixed after the DRL-SRA and DQN complete the training period.
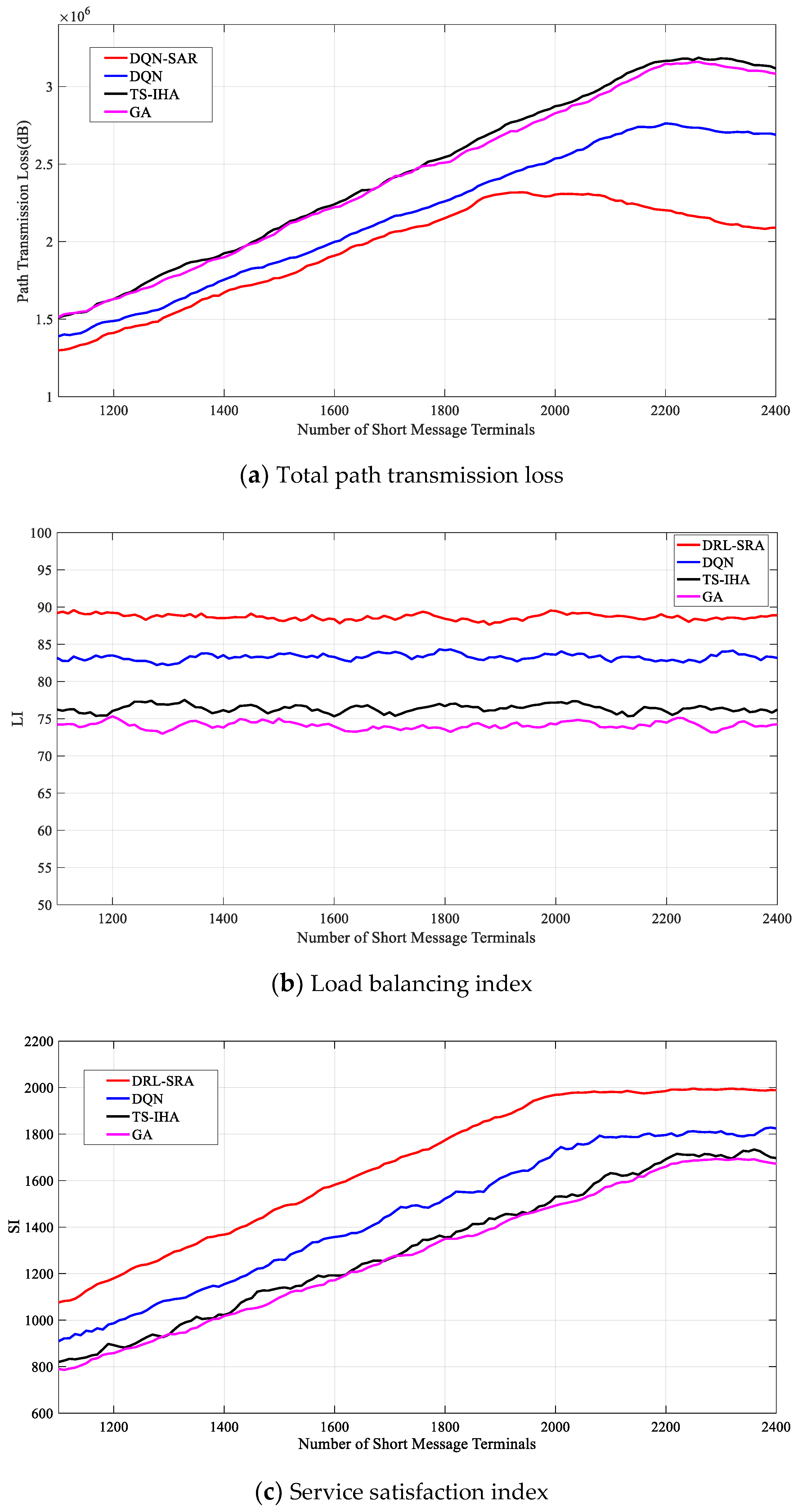
Finally, to illustrate the performance of the DRL-SRA, we set the weight factor to and analyzed the optimization of , , and using the four algorithms.
As shown in Figure 13, according to the deployment requirements of the short-message terminals described above, as the number of short-message terminals increased from 1100 to 2400, the obtained by different algorithms showed a trend of rising at first and then decreasing. basically remained stable, and showed a trend of growing at first and then becoming steady. This is in line with the expected effects. With an increase in the number of short-message terminals, the number of short-message tasks received by the short-message satellite also increased, and L also increased. However, the number of tasks increased to a certain extent because the choice of tasks that the satellite can respond to will also increase when both and remain stable, and will slowly decrease. At the same time, when the short-message satellite resources are fixed and when the number of short-message tasks reaches a certain threshold, the task processing capacity of the short-message satellite reaches saturation, leading to the inability to respond to more short-message tasks in time.
Figure 13a shows that the DRL-SRA performed the best and the TS-IHA performed the worst. The of the DRL-SRA was lower than that of the other three algorithms in the simulation process. Figure 13b shows that DRL-SRA performed the best and GA performed the worst. When the number of terminals was 1100 or 2250, the obtained by the DRL-SRA algorithm was about 89.14%, which is higher than the values obtained by the other algorithms: 83.58% by the DQN algorithm, 76.37% by the DQN, and 73.83% by the GA. Figure 13c shows that the DRL-SRA performed the best and the GA performed the worst. When the number of short-message terminals was 2050, the obtained by the DRL-SRA was about 2000, which is higher than the value of 1800 obtained by the DQN algorithm when the number of short-message terminals was 2100 and the value of 1700 obtained by the TS-IHA algorithm when the number of short-message terminals was 2250.
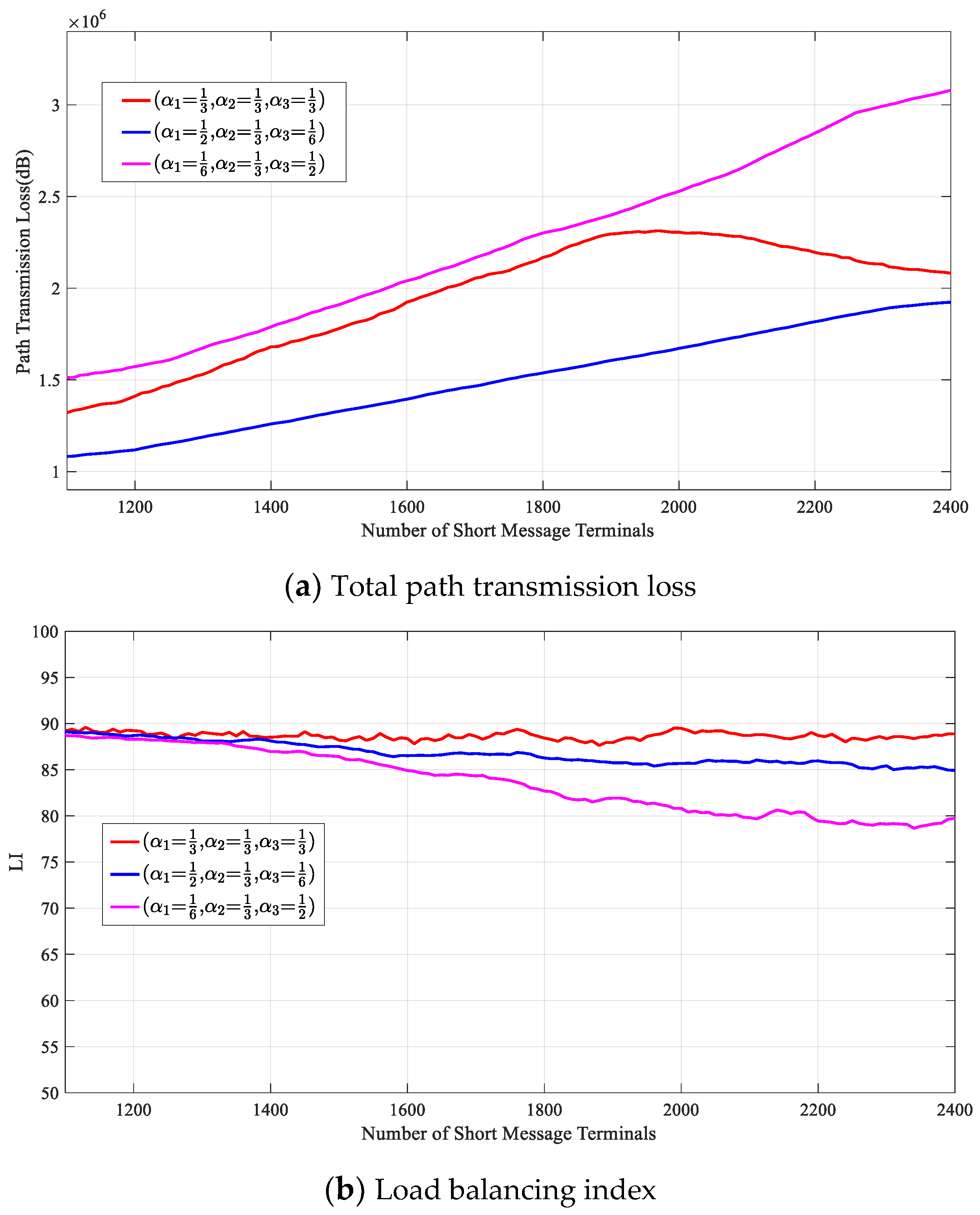
4.2.2. The Influences of Different Weight Values on the Optimization Results
Figure 14 shows the optimization effect of the DRL-SRA on the throughput of the short-message satellite system and , , and when the weight factors of , , and were , , and , respectively.
As shown in Figure 14d, as the number of short-message terminals increased, the total throughput of each algorithm first increased and then stabilized. Because the user service arrival model and service requirements used in the simulation were the same, when the weight parameter was and the number of terminals was 2250, the throughput of the system was 1790, which was the best because the weight of was relatively high. To improve the quality of service of the short-message terminal as much as possible, the DRL-SRA will have a greater requirement for the response time to the short-message request. This can also be proven by looking at the satellite load balance shown in Figure 14b. To improve the quality of service of the short-message terminal, the utilization of satellite resources needs to be maximized, so when the weight of is less than that of , is not significantly reduced relative to other weights.
When the weight parameter is , the system will reduce as much as possible, which will reduce the efficiency of short-message task processing, so the quality of service of the terminal in this set of weight parameters will be reduced relative to other weights. Additionally, the short-message satellite will respond to the task request as accurately as possible, which will make it challenging to achieve a relative balance in the use of satellite resources in the scenario of an uneven distribution of short-message terminals. is significantly lower than other weights.
5. Conclusions
In this paper we focused on the existing conditionally constrained short-message satellite resource allocation model. In order to reduce the path transmission loss of the SMSCS and maximize the satellite load balancing and terminal service quality, a multi-objective optimization mathematical model was proposed. Due to the large number of terminals and problems with the action dimension, we proposed a region division strategy and the DRL-SRA algorithm based on the feature extraction network and DDPG. This method can achieve dynamic multi-objective optimization and resource allocation with a low level of complexity. By simulating a real application scenario, DRL-SRA was shown to be more effective than traditional algorithms for optimizing the path transmission loss of the short-message terminal and maintaining the load balance and quality of service of the short-message satellite. When there are different numbers of terminals, the DRL-SRA can send better results. The simulation results also show that, compared with other algorithms, the DRL-SRA has a better effect on improving the throughput of short-message task requests.
In future work, we will combine the short-message terminal equipment and the low-power computing chip that supports the deep learning algorithm to consider the hardware implementation flow of the DRL-SRA. We conclude that, in real application scenarios, our algorithm improves the efficiency of short-message satellite resource allocation.
Author Contributions
Conceptualization, K.X. and C.Y.; methodology, C.Y.; software, C.D.; validation, K.X., C.Y., and J.F.; formal analysis, C.Y.; investigation, K.X.; resources, J.F.; data curation, K.X.; writing—original draft preparation, K.X.; writing—review and editing, K.X.; visualization, C.Y.; supervision, J.F.; project administration, J.F.; funding acquisition, C.Y. All authors have read and agreed to the published version of the manuscript.
Funding
The National Natural Science Foundation of China under contract No. 61371119 and the Blue project of Jiangsu Province.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare that they have no conflict of interest to report regarding the present study.
Abbreviations
| Summary of Main Notations | |
| Symbol | Description |
| Model | |
| () | The set of short-message satellites |
| () | The set of short-message terminals |
| The number of short-message satellite | |
| The number of short-message terminal | |
| Snapshoot | |
| . | |
| Resource matrix | |
| The set of task queue | |
| The satellite-to-Earth link matrix | |
| The path transmission loss | |
| The path transmission loss matrix | |
| The total path transmission loss | |
| The load balancing index | |
| The set of short-message task | |
| The service satisfaction index | |
| The objective function | |
| Algorithm | |
| The set of subregion | |
| State space | |
| The system state under snapshot | |
| The resource allocation decisions | |
| The action under | |
| The reward function | |
| The size of tensor | |
| The action function | |
| The state function | |
| The optimal action function | |
| The optimal state function | |
| The optimal action | |
| The critic network of loss function | |
| The actor network of loss function | |
| Random noise | |
References
- Wang, M.J.; Chen, X.X.; Wu, T.; Si, D.R.; Zhai, Z.Z. Design of integrated radio meteorological parameter monitoring system based on LoRa. Chin. J. Radio Sci. 2020, 6, 943–948. [Google Scholar]
- Wang, C.M.; Lei, W.Y.; Huang, H.; Huang, F.L. Designation of automatic weather station message transmission project based on Beidou. Meteorol. Sci. Technol. 2019, 6, 900–904. [Google Scholar]
- Chen, S.T.; Lin, T.; Zhang, Y.Y. Weather warning information transmission method based on Beidou. Chin. J. Electron Devices 2018, 5, 1269–1274. [Google Scholar]
- Li, H.S.; Cao, Z.Y.; He, S.S.; Zhou, G.Z. Design and application of meteorological disaster early warning release system based on Beidou Satellite technology. Meteorol. Sci. Technol. 2014, 5, 799–803. [Google Scholar]
- Wang, C.F.; Chen, Y.T.; Li, C.L.; Jiang, K.J. Technology and implementation of warning information distribution based on Beidou satellite. J. Appl. Meteorol. Sci. 2014, 3, 375–384. [Google Scholar]
- Li, B.F.; Zhang, Z.T.; Zhang, N.; Wang, S.Y. High-precision GNSS ocean positioning with BeiDou short-message communication. J. Geod. 2019, 2, 125–139. [Google Scholar] [CrossRef]
- Liu, D.G.; Wu, B.G.; Xie, Y.Y.; Luo, H.H. Present state and development trend of maritime meteorological support service. Navig. China 2014, 37, 131–135. [Google Scholar]
- He, K.F.; Weng, D.J.; Ji, S.Y.; Wang, Z.J.; Chen, W.; Lu, Y.W. Ocean Real-Time Precise Point Positioning with the BeiDou Short-Message Service. Remote Sens. 2020, 12, 4167. [Google Scholar] [CrossRef]
- Li, G.; Guo, S.R.; Lv, J.; Zhao, K.L.; He, Z.H. Introduction to global short message communication service of BeiDou-3 navigation satellite system. Adv. Space Res. 2021, 67, 1701–1708. [Google Scholar] [CrossRef]
- Xiang, Y.W.; Zhang, W.Y.; Tian, M.M. Satellite data transmission integrated scheduling and optimization. Syst. Eng. Electron. 2018, 40, 1288–1293. [Google Scholar]
- Cocco, G.; Cola, T.D.; Angelone, M.; Erl, S. Radio Resource Management Optimization of Flexible Satellite Payloads for DVB-S2 Systems. IEEE Trans. Broadcast. 2018, 64, 266–280. [Google Scholar] [CrossRef] [Green Version]
- Zhang, P.; Wang, X.H.; Ma, Z.G.; Song, J.D. Joint optimization of satisfaction index and spectrum efficiency with cache restricted for resource allocation in multi-beam satellite systems. China Commun. 2019, 16, 189–201. [Google Scholar]
- Dai, J.H.; Liu, J.J.; Shi, Y.P.; Zhang, S.B.; Ma, J.F. Analytical Modeling of Resource Allocation in D2D Overlaying Multihop Multichannel Uplink Cellular Networks. IEEE Trans. Veh. Technol. 2017, 66, 6633–6644. [Google Scholar] [CrossRef]
- Sawyer, N.; Smith, D.B. Flexible Resource Allocation in Device-to-Device Communications Using Stackelberg Game Theory. IEEE Trans. Commun. 2019, 67, 653–667. [Google Scholar] [CrossRef]
- Vakilian, V.; Frigon, J.F.; Roy, S. Distributed Resource Allocation for D2D Communications Underlaying Cellular Networks in Time-Varying Environment. IEEE Commun. Lett. 2018, 22, 388–391. [Google Scholar]
- Artiga, X.; Nunez-Martinez, J.; Perez-Neira, A.; Vela, G.; Garcia, J.; Ziaragkas, G. Terrestrial-satellite integration in dynamic 5G backhaul networks. In Proceedings of the 2016 8th Advanced Satellite Multimedia Systems Conference and the 14th Signal Processing for Space Communications Workshop (ASMS/SPSC), Palma de Mallorca, Spain, 5–7 September 2016; pp. 1–6. [Google Scholar]
- Choi, J.P.; Chan, V.W.S. Optimum power and beam allocation based on traffic demands and channel conditions over satellite downlinks. IEEE Trans. Wirel. Commun. 2005, 4, 2983–2993. [Google Scholar] [CrossRef]
- Kan, X.; Xu, X.D. Power allocation based on energy and spectral efficiency in multi-beam satellite systems. J. Univ. Sci. Technol. China 2016, 46, 138–147. [Google Scholar]
- Aravanis, A.I.; Shankar, M.R.B.; Arapoglou, P.D.; Danoy, G.; Cottis, P.G.; Ottersten, B. Power Allocation in Multibeam Satellite Systems: A Two-Stage Multi-Objective Optimization. IEEE Trans. Wirel. Commun. 2015, 14, 3171–3182. [Google Scholar] [CrossRef]
- Efrem, C.N.; Panagopoulos, A.D. Dynamic Energy-Efficient Power Allocation in Multibeam Satellite Systems. IEEE Wirel. Commun. Lett. 2020, 9, 228–231. [Google Scholar] [CrossRef] [Green Version]
- Jiao, J.; Sun, Y.Y.; Wu, S.H. Network Utility Maximization Resource Allocation for NOMA in Satellite-Based Internet of Things. IEEE Internet Things J. 2020, 7, 3230–3242. [Google Scholar] [CrossRef]
- Lin, C.C.; Su, N.W.; Deng, D.J.; Tsai, I.H. Resource allocation of simultaneous wireless information and power transmission of multi-beam solar power satellites in space–terrestrial integrated networks for 6G wireless systems. Wirel. Netw. 2020, 26, 4095–4107. [Google Scholar] [CrossRef]
- Yang, L.; Yang, H.; Wei, D.B.; Pan, C.S. SAGA: A Task-oriented Resource Allocation Algorithms for Satellite Network. J. Chin. Comput. Syst. 2020, 41, 122–127. [Google Scholar]
- Xia, K.W.; Feng, J.; Wang, Q.R.; Yan, C. Optimal Selection Mechanism of Short Message Terminal for “Beidou-3”. In Proceedings of the 2020 IEEE 5th International Conference on Signal and Image Processing (ICSIP), Nanjing, China, 23–25 October 2020; pp. 1106–1111. [Google Scholar]
- Liu, Q.; Zhai, J.W.; Zhang, Z.C.; Zhong, S.; Zhou, Q.; Zhang, P.; Xu, J. A survey on deep reinforcement learning. Chin. J. Comput. 2018, 41, 1–27. [Google Scholar]
- Gu, B.; Zhang, X.; Lin, Z.; Alazab, M. Deep Multiagent Reinforcement-Learning-Based Resource Allocation for Internet of Controllable Things. IEEE Internet Things J. 2021, 8, 3066–3074. [Google Scholar] [CrossRef]
- Zhao, N.; Liang, Y.; Niyato, D.; Pei, Y.; Wu, M.; Jiang, Y. Deep Reinforcement Learning for User Association and Resource Allocation in Heterogeneous Cellular Networks. IEEE Trans. Wirel. Commun. 2019, 18, 5141–5152. [Google Scholar] [CrossRef]
- Tang, F.; Zhou, Y.; Kato, N. Deep Reinforcement Learning for Dynamic Uplink/Downlink Resource Allocation in High Mobility 5G HetNet. IEEE J. Sel. Areas Commun. 2020, 38, 2773–2782. [Google Scholar] [CrossRef]
- Hu, X.; Zhang, Y.; Liao, X.; Liu, Z.; Wang, W.; Ghannouchi, F.M. Dynamic Beam Hopping Method Based on Multi-Objective Deep Reinforcement Learning for Next Generation Satellite Broadband Systems. IEEE Trans. Broadcast. 2020, 66, 630–646. [Google Scholar] [CrossRef]
- Xiong, X.; Zheng, K.; Lei, L.; Hou, L. Resource Allocation Based on Deep Reinforcement Learning in IoT Edge Computing. IEEE J. Sel. Areas Commun. 2020, 38, 1133–1146. [Google Scholar] [CrossRef]
- Takahashi, M.; Kawamoto, Y.; Kato, N.; Miura, A.; Toyoshima, M. Adaptive Power Resource Allocation with Multi-Beam Directivity Control in High-Throughput Satellite Communication System. IEEE Wirel. Commun. Lett. 2019, 8, 1248–1251. [Google Scholar] [CrossRef]
- Ferreira, P.; Paffenroth, R.; Wyglinski, A.M. Multiobjective Reinforcement Learning for Cognitive Satellite Communications Using Deep Neural Network Ensembles. IEEE J. Sel. Areas Commun. 2018, 36, 1030–1041. [Google Scholar]
- Hu, X.; Liu, S.; Chen, R.; Wang, W.; Wang, C. A Deep Reinforcement Learning-Based Framework for Dynamic Resource Allocation in Multibeam Satellite Systems. IEEE Commun. Lett. 2018, 22, 1612–1615. [Google Scholar] [CrossRef]
- Hu, X.; Liu, S.; Wang, Y.; Xu, L.; Zhang, Y.; Wang, C.; Wang, W. Deep reinforcement learning based beam hopping algorithm in multibeam satellite systems. IET Commun. 2019, 13, 2485–2491. [Google Scholar] [CrossRef]
- Luis, J.J.G.; Guerster, M.; del Portillo, I.; Crawley, E.; Cameron, B. Deep Reinforcement Learning for Continuous Power Allocation in Flexible High Throughput Satellites. In Proceedings of the 2019 IEEE Cognitive Communications for Aerospace Applications Workshop (CCAAW), Cleveland, OH, USA, 25–26 June 2019; pp. 1–4. [Google Scholar]
- Yu, Z.; Machado, P.; Zahid, A.; Abdulghani, A.M.; Dashtipour, K.; Heidari, H.; Imran, M.A.; Abbasi, Q.H. Energy and performance trade-off optimization in heterogeneous computing via reinforcement learning. Electronics 2020, 9, 1812. [Google Scholar] [CrossRef]
- Zhang, P.; Liu, S.J.; Ma, Z.G.; Wang, X.H.; Song, D.J. Improved satellite resource allocation algorithmbased on DRL and MOP. J. Commun. 2020, 41, 51–60. [Google Scholar]
- Qiu, C.; Yao, H.; Yu, F.R.; Xu, F.; Zhao, C. Deep Q-Learning Aided Networking, Caching, and Computing Resources Allocation in Software-Defined Satellite-Terrestrial Networks. IEEE Trans. Veh. Technol. 2019, 68, 5871–5883. [Google Scholar] [CrossRef]
- China Satellite Navigation Office. BeiDou Navigation Satellite System Open Service Performance Standard [EB/OL]. 2018-12-28. Available online: http://www.beidou.gov.cn (accessed on 28 December 2018).
- Gounder, V.V.; Prakash, R.; Abu-Amara, H. Routing in LEO-based satellite networks. In Proceedings of the 1999 IEEE Emerging Technologies Symposium, Wireless Communications and Systems (IEEE Cat. No.99EX297), Richardson, TX, USA, 12–13 April 1999; pp. 22.1–22.6. [Google Scholar]
- Ministry of Industry and Information Technology of the People’s Republic of China. Methods for Calculating Attanuations by Atmospheric Gases and Rain in the Satellite Communication Link (YD/T 984-2020); Standards Press of China: Beijing, China, 2020.
- Chen, L.M.; Guo, Q.; Yang, M.C. Probability-Based Bandwidth Reservation Strategy for LEO Satellite Networks with Multi-Class Traffic. J. South China Univ. Technol. (Nat. Sci. Ed.) 2012, 40, 84–89. [Google Scholar]
- Yang, B.; He, F.; Jin, J.; Xu, G.H. Analysis of Coverage Time and Handoff Number on LEO Satellite Communication Systems. J. Electron. Inf. Technol. 2014, 36, 804–809. [Google Scholar]
- Xu, S.Y.; Xing, Y.F.; Guo, S.G.; Yang, C.; Qiu, X.S.; Meng, L.M. Deep reinforcement learning based task allocation mechanism for intelligent inspection in energy Internet. J. Commun. 2021, 42, 191–204. [Google Scholar]
Figure 1.
Short-message satellite communication system model.

Figure 2.
Short-message satellite communication system resource allocation model.

Figure 3.
Geometric relationship between short-message terminal and satellite [43].
Figure 3.
Geometric relationship between short-message terminal and satellite [43].

Figure 4.
Schematic diagrams of short-message satellite coverage.

Figure 5.
Improved satellite resource allocation model adapted for regional division.

Figure 6.
DRL-SAR algorithm framework.

Figure 7.
Schematic diagram of the short-message terminal distribution.

Figure 8.
Convergence rate under different numbers of hidden layer units.

Figure 9.
Convergence of DRL-SRA algorithm under different numbers of short message terminals.

Figure 10.
Convergence of DRL-SRA algorithm under different feature extraction algorithms.

Figure 11.
Convergence comparison of the DRL-SRA and DQN.

Figure 12.
Comparison of the running times of different algorithms.

Figure 13.
Performance analysis and comparison of different algorithms.

Figure 14.
Performance analysis of the DRL-SRA with different weight values.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The parameters of feature extraction network.
| Layer | Input | Kernel | Activation | Output |
|---|---|---|---|---|
| Conv1 | ,4 | Relu | ||
| Conv2 | ,8 | Relu | ||
| FC1 | NA | Relu | 1024 | |
| FC2 | 1024 | NA | Relu | 256 |
| FC3 | 256 | NA | Relu |
Table 2.
The parameters of the feature extraction network.
| Simulation Parameter | Value |
|---|---|
| Uplink operating frequency/MHz | 1620 |
| Downlink operating frequency/MHz | 1207.14 |
| Orbital altitude/km | 21,528 |
| Total number of short-message terminals | 1100~2400 |
| /bit | 560 |
| /s | 60 |
| Time taken up by each snapshot/s | 60 |
| 1000 | |
| /Mbit/s | 50 |
| 10 | |
| Episodes | 500 |
| Steps T | 500 |
| Batch size | 8 |
| Discount factor | 0.9 |
| Soft update factor | 0.01 |
| Learning rate | 0.01 |
| Activation function | Relu |
| 64 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Xia, K.; Feng, J.; Yan, C.; Duan, C. BeiDou Short-Message Satellite Resource Allocation Algorithm Based on Deep Reinforcement Learning. Entropy 2021, 23, 932. https://doi.org/10.3390/e23080932
AMA Style
Xia K, Feng J, Yan C, Duan C. BeiDou Short-Message Satellite Resource Allocation Algorithm Based on Deep Reinforcement Learning. Entropy. 2021; 23(8):932. https://doi.org/10.3390/e23080932
Chicago/Turabian StyleXia, Kaiwen, Jing Feng, Chao Yan, and Chaofan Duan. 2021. "BeiDou Short-Message Satellite Resource Allocation Algorithm Based on Deep Reinforcement Learning" Entropy 23, no. 8: 932. https://doi.org/10.3390/e23080932
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.