
Design of a 2-Bit Neural Network Quantizer for Laplacian Source


1
Faculty of Electronic Engineering, University of Nis, Aleksandra Medvedeva 14, 18000 Nis, Serbia
2
Faculty of Sciences and Mathematics, University of Pristina in Kosovska Mitrovica, Ive Lole Ribara 29, 38220 Kosovska Mitrovica, Serbia
3
Faculty of Technical Sciences, University of Novi Sad, Trg Dositeja Obradovica 6, 21000 Novi Sad, Serbia
4
Department of Computer Science, Faculty of Science, Technology and Medicine, University of Luxembourg, Avenue de la Fonte 6, L-4364 Esch-sur-Alzette, Luxembourg
*
Author to whom correspondence should be addressed.
Entropy 2021, 23(8), 933; https://doi.org/10.3390/e23080933
Submission received: 19 June 2021
/
Revised: 16 July 2021
/
Accepted: 20 July 2021
/
Published: 22 July 2021
(This article belongs to the Special Issue Methods in Artificial Intelligence and Information Processing)
Abstract
:Achieving real-time inference is one of the major issues in contemporary neural network applications, as complex algorithms are frequently being deployed to mobile devices that have constrained storage and computing power. Moving from a full-precision neural network model to a lower representation by applying quantization techniques is a popular approach to facilitate this issue. Here, we analyze in detail and design a 2-bit uniform quantization model for Laplacian source due to its significance in terms of implementation simplicity, which further leads to a shorter processing time and faster inference. The results show that it is possible to achieve high classification accuracy (more than 96% in the case of MLP and more than 98% in the case of CNN) by implementing the proposed model, which is competitive to the performance of the other quantization solutions with almost optimal precision.
1. Introduction
Distributed neural networks, which process a lot of sensor data locally on edge devices instead of communicating with a cloud server, are becoming popular due to significantly reduced communication cost compared to a standard cloud offloading approach [1]. As utilization of server-grade graphics processing units (GPUs) in many embedded systems is impractical due to their enormous energy dissipation, there is a need to design resource-efficient systems for the deployment of various neural networks that are already trained [2]. The goal is to optimize design and resources in a such way that inference is only slightly degraded while there is significant energy saving. This goal can be commonly achieved by implementing various quantization techniques to simplify the numerical representation of weights, activations, and the intermediate results of convolution and fully connected layers, as well as to reduce their numerical ranges. We can highlight two approximation strategies that can be found in the literature: multilevel quantization and binarization. This way, the 32-bit floating-point representation of numerical values (i.e., full precision) can be reduced to lower representations.
Pioneering research focused on the effects of weight quantization in multilayer neural networks has been presented in [3,4,5]. Their main focus was to understand the performance degradation affected by weight quantization, including the convergence property of the learning algorithm [5]. However, quantization theory was significantly improved in later decades, and the contemporary understanding of an accurate quantizer design differs a lot. Although non-uniform quantization provides a better performance for a wide range of input signal variances [6,7] and advanced dual-mode asymptotic solutions are developed [8,9], simple uniform quantization [6,7,10,11,12] is the first choice when the simplicity of the system is one of the major goals. Thus, uniform quantization has been widely applied for quantizing parameters of neural networks (i.e., for neural network compression) [13,14,15,16,17,18], and different solutions have been considered, e.g., using 8-bits [13], 4-bits [14], or 2-bits [15,16,17,18]; further, non-uniform quantization has also been used [19,20,21]. It has been found that quantizing network parameters using 8-bits [13] or 16-bits [19] enable slightly lower performance when compared to the full precision case, mainly due to the ability of quantizers to achieve high quality reconstructed data. Further, in the case of applying quantizers with smaller resolution, e.g., with 4-bits [14] or 2-bits [15,16,17,18,20,21], performance degradation has been observed; however, the achieved results are still comparable, accompanied with a significantly high level of compression. Eventually, significant attention was paid to the development of binary quantizer models to compress neural networks [22,23,24,25,26], whose attractiveness lies in the amount of compression that can be achieved, with a goal to preserve competitive performance achievements.
In general, 2-bit quantization models require less energy compared to the models with a higher number of representative levels, which makes them appropriate for resource-constrained real-time systems. Consequently, we decided to focus on the designing of the simplest multilevel scalar quantizer model. The main contribution of this paper is the proposal of an accurate 2-bit optimal uniform quantizer design, achieved by optimizing step size or, equivalently, support region threshold (also known as the clipping factor). Optimization is carried out by considering the mean squared error (MSE) distortion, whereas the Laplacian source is assumed at the input. Specifically, the Laplacian source is widely used to model signals, such as speech [6,7,26,27] or images [6,7,26,28]; recent research conducted in [15,16,20,26,29] has shown its appropriateness in modeling the weights of neural networks. Note that the determination of the clipping factor for various quantizer solutions has been the subject of many research papers [14,15,16,26,29], implying the significance of this parameter. In addition to other research papers, e.g., [13,14,15,16,17,18,19,20,21,29], we perform several other analyses from the aspect of signal processing, including an analysis in the wide range of input signal variances and adaptation of the quantization model.
We analyze the effectiveness of the proposed adaptive 2-bit quantizer in a real environment by implementing it in a neural network compression task, and the obtained performance is compared with the performance of the full-precision network, as well as with the performance of other contemporary 2-bit quantization models, either uniform [17,18] or non-uniform ones [20,21]. The first neural network model adopted in this paper is multi-layer perceptron (MLP) [30], which represents a kind of simple feedforward artificial neural network. Although it can be considered as a classical model and it is succeeded by the convolutional neural network (CNN) in advanced computer vision applications, its simplicity can be exploited in edge computing devices for real-time classification tasks [31,32,33,34]. We also employ a simple CNN network [30] for analysis, and both networks are used for image classification.
The rest of the paper is organized as follows: In Section 2, we describe in detail the proposed quantizer, including the design for the reference variance and analysis in a wide dynamic range. In Section 3, we provide the experimental results, obtained by implementing the considered quantizer in a neural network compression task. Finally, the advantages and disadvantages of the proposed model are summed up in the Conclusions Section.
2. A 2-Bit Uniform Scalar Quantizer of Laplacian Source
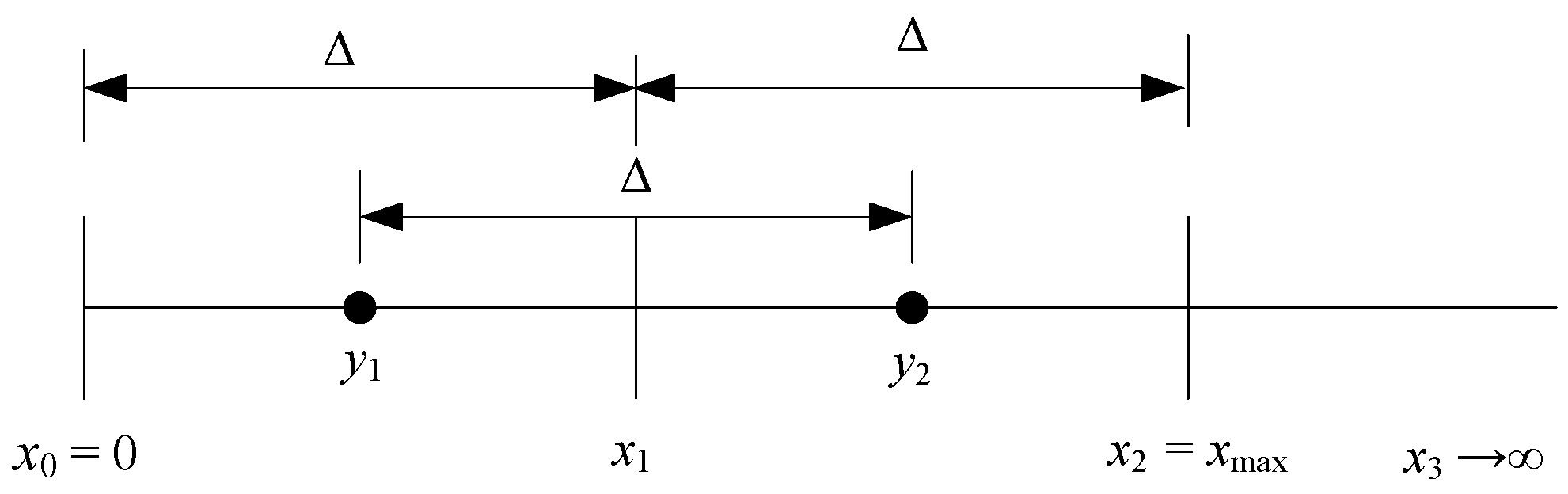
The 2-bit symmetrical uniform scalar quantizer we are interested in is illustrated in Figure 1. To uniquely define the quantizer, it is necessary to specify its parameters, namely the decision thresholds xi and the representative levels yi [6,7]. For such a uniform quantizer, it holds:
where Δ is the parameter known as the step size. In Figure 1, with we denote the support region threshold of the quantizer (or equivalently the clipping factor). As the quantizer is symmetrical, parameters in the negative range are the inversions of the positive ones. Based on Equations (1) and (2), we can see that Δ (or ) is a critical design parameter. The general manner to specify its value assumes the usage of some performance criterion, such as minimal MSE (mean squared error) distortion.
Let us define the designed-for and applied-to sources as the memoryless Laplacian with zero mean, described by probability density functions (PDFs) (3) and (4), respectively:
where and denote the variances.
In the following subsections, we consider the quantizer performance for two scenarios, namely the variance-matched () and variance-mismatched ().
2.1. The Variance-Matched 2-Bit Uniform Quantizer
The variance-matched situation implies that the variance for which the quantizer is designed and the variance of the input data to be quantized are equal, and, accordingly, the equality of PDFs defined by (3) and (4) also holds. Therefore, we use for the purpose of quantizer designing, and, further, we adopt , which is a commonly used approach in scalar quantization [6,7].
To measure the error produced within the data quantization process, MSE distortion is commonly used [7]. Considering Figure 1, we can see that the 2-bit uniform quantizer divides the range of the input data values into two regions, the inner defined in (−xmax, xmax) and the outer defined in (−∞,−xmax) (xmax, ∞). Therefore, the MSE distortion will be the sum of the distortions incurred in the inner (Din) and outer regions (Do), defined using the following lemmas:
Lemma 1.
The inner distortion of a 2-bit uniform quantizer of Laplacian source depends on the quantization step ∆, and it is equal to
Proof of Lemma 1.
The inner distortion of an arbitrary quantizer Q with N representative levels for a processing signal described by an arbitrary source p(x) can be defined as [6,7]:
where are decision boundaries, whereas are representative levels. Let us consider that the source p(x) is the Laplacian of a unit variance and zero mean, i.e., let us p(x) = q(x, σq = 1). For a 2-bit quantizer, we obtain:
Taking into account Equations (1)–(3), we obtain the following expression for the inner distortion:
Finally, by solving integrals from the previous equation, we obtain the expression (5), which concludes the proof. □
Lemma 2.
The overload distortion of a 2-bit uniform quantizer of Laplacian source depends on the quantization step ∆, and it is equal to
Proof of Lemma 2.
The overload distortion of an arbitrary quantizer Q for processing a signal described by an arbitrary source p(x) can be defined as [6,7]:
where xmax is the support region threshold value, whereas ymax is the last representative level in the codebook. We observe the 2-bit uniform quantizer xmax= 2∆, whereas ymax = 3∆/2. Thus, the overload distortion of the 2-bit uniform quantizer of Laplacian source is defined as:
By solving the previous integral, we obtain the expression for overload distortion defined with (9), concluding the proof. □
Based on Lemmas 1 and 2, the total distortion Dt for the 2-bit uniform quantizer of Laplacian source is defined using the following expression:
It can be noticed that distortion also depends on Δ, and its optimal value (denoted with Δopt) is specified using the following lemma:
Lemma 3.
The optimal value of Δ of a 2-bit uniform quantizer of Laplacian source can be determined using the following iterative rule:
Proof of Lemma 3.
Finding the first derivative of the total distortion (expression (12)) with respect to Δ and equaling it to zero, we obtain:
Based on the last equation, we can express Δ as:
indicating that Δ can be determined iteratively, concluding the proof. □
As an appropriate initialization of the iterative process given with (13), one can use (motivated by the formula that was proposed in [35] as an approximate solution for xmax of N-levels uniform quantizer of Laplacian source). Moreover, by substituting this initial value into (13), one can obtain the asymptotic step size value:
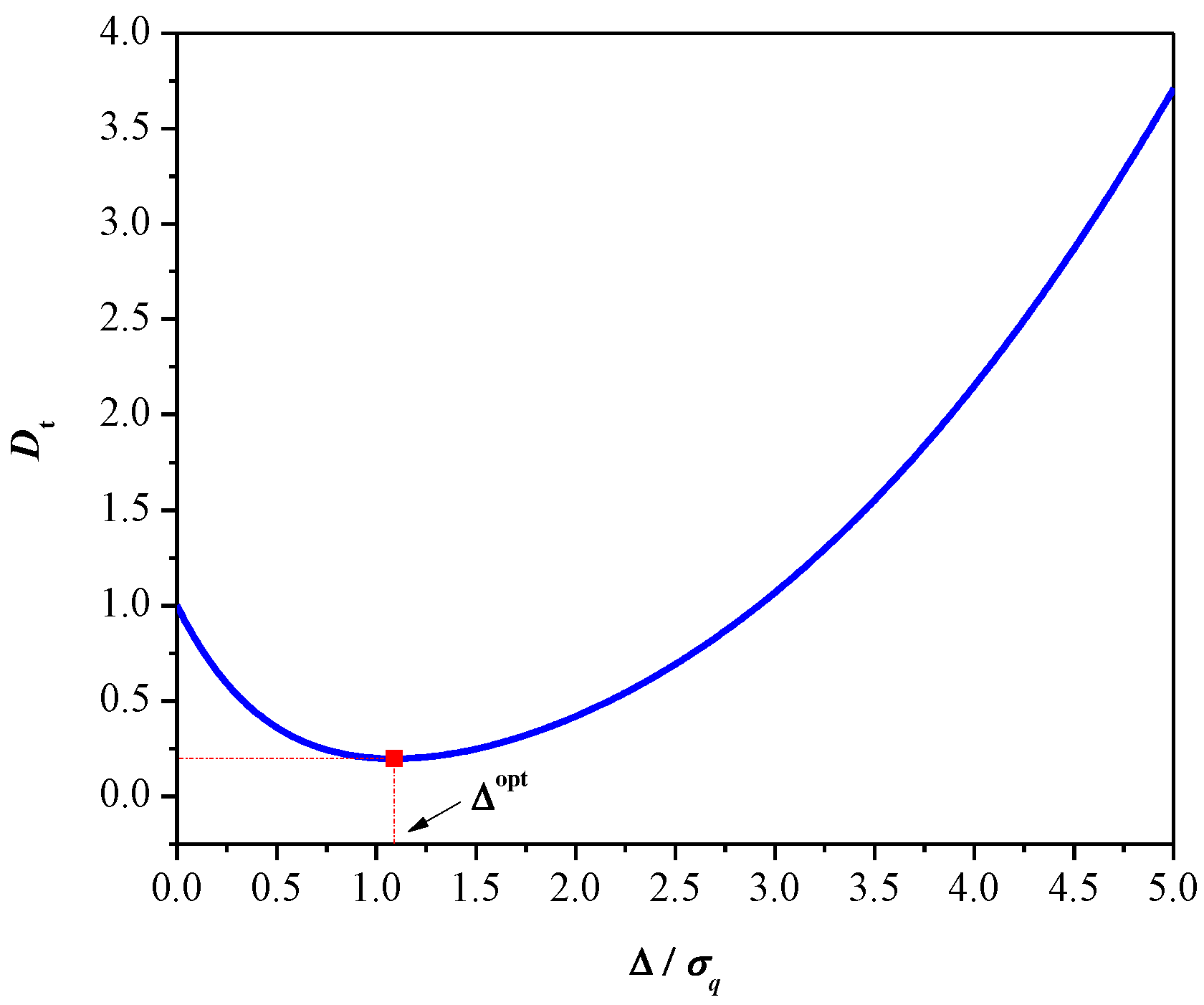
Such a determined asymptotic value can be useful if we want to quickly estimate the performance of the Laplacian 2-bit uniform quantizer (clearly, a more exact and accurate value for step size can be obtained using (13)). Let us define SQNR = 10∙log10(1/D), which is a standardly used objective performance measure of a quantization process [6,7]. Let SQNR(Δa = 1.061) and SQNR(Δopt = 1.087) denote the SQNR obtained using the asymptotic and optimal step size value, respectively. It can be shown that these two SQNRs are very close, as the calculated relative error amounts to 0.08%, meaning that the proposed asymptotic step size is very accurate when compared to the optimal one. Nevertheless, the analysis conducted in this paper is focused only on the optimal 2-bit uniform quantizer of Laplacian source. Next, we will show that the minimum of the total distortion is achieved for Δ = Δopt, as it is defined with the following lemma.
Lemma 4.
Total distortion of a 2-bit uniform quantizer of Laplacian source is a convex function with a minimum at the point Δ = Δopt.
Proof of Lemma 4.
Second derivative of the total distortion is given by:
which also depends on Δ. On the other hand, the optimal value of Δ, i.e., Δopt, is specified as (see Lemma 1):
showing that the step size is upper bounded with , that is, 0 < Δopt < . Using this fact and applying it to (17), it holds that:
which proves that distortion is a convex function, and the minimum is achieved at the point Δ = Δopt. □
Figure 2 shows the total distortion with respect to Δ for the 2-bit uniform quantizer of Laplacian source obtained by numerical simulations, where perfect matching with the outcomes of Lemmas 3 and 4 is provided.
2.2. The Variance-Mismatched 2-Bit Uniform Quantizer
The variance-mismatched scenario considered here implies the application of a 2-bit uniform quantizer, optimally designed in terms of MSE distortion for variance σq2 = 1 (see Section 2.1), for processing the Laplacian data with variance σp2, where it holds σq2 ≠ σp2. In particular, this scenario is worth investigating, as it is often encountered in practice and reveals the robustness level of the quantizer model, which is a very important property when dealing with non-stationary data [6,7]. On the other hand, it is known that the variance-mismatch effect may cause serious degradation in quantizer performance [6,7,36,37]. In this subsection, we derive the closed-form expressions for the performance evaluation of the discussed quantizer.
As in the previous subsection, performance of the variance-mismatched 2-bit uniform quantizer is investigated using MSE distortion or, equivalently, using SQNR. Total distortion can be assessed as follows:
where Δ(σq) = σq Δ denotes the optimal step size value determined for variance σq2 = 1 (see Section 2.1).
SQNR can be calculated according to:
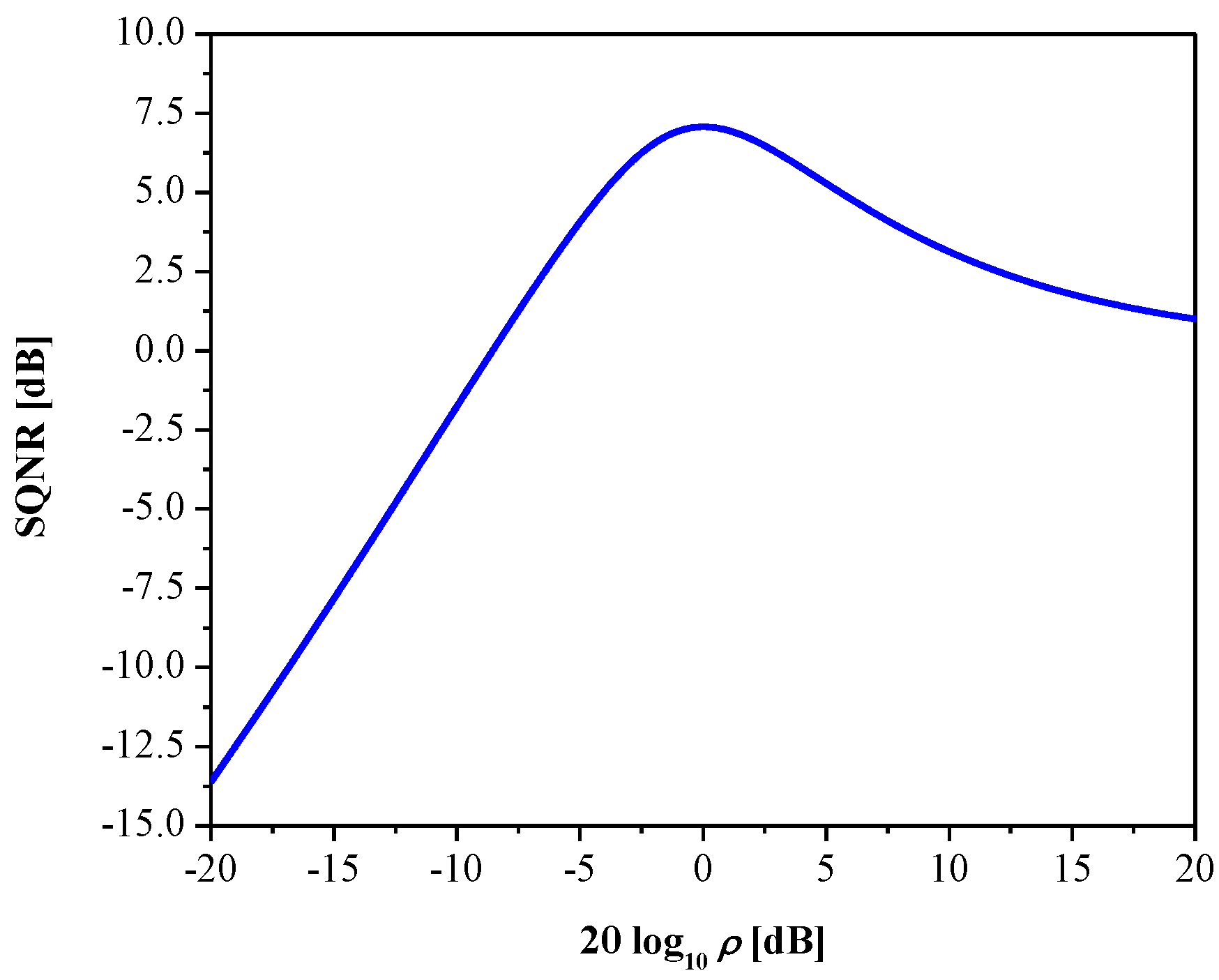
In Figure 3, we show SQNR as the function of ρ for the proposed quantizer. Observe that the SQNR curve attains its maximal value of 7.07 dB for the variance-mismatch case (σp = σq = 1, that is, ρ = 1), but it does not retain that value over the entire range and significantly decreases. Accordingly, the robustness of the quantizer is not at the satisfactory level, as the variance-mismatch effect has a strong influence on its performance; this, in turn, is reflected in limited efficiency of processing various Laplacian data.
In a real situation, such as the quantization of neural network parameters, the convergence of the model depends on several aspects, including the dataset size, network architecture, number of epochs etc.; therefore, differences between designed-for and applied-to sources may exist. In particular, the decreasing of SQNR (note that we deal with low-resolution quantization where SQNR values are rather small) can be a serious issue, as it may have negative effects on classification accuracy, which is undesirable. Furthermore, the mentioned effect is also present even in the case of high-resolution (N is high) quantization, as pointed out in [38], where the post-quantization of neural network weights is performed. Hence, it is of particular interest to avoid variance-mismatch and enhance performance of the quantizer by achieving constant SQNR across a wide variance range of input data. To this end, we describe an efficient method that is based on adaptive quantization, which can also be important for the final deployment.
2.3. Adaptation of the 2-Bit Uniform Quantizer
The goal of this subsection is to make the proposed quantizer able to provide improved performance expressed by a constant SQNR over the variance range of interest. This can be achieved using an adaptation technique [6,7], where some statistical parameters, e.g., variance and mean, are estimated from the input data and further used for adaptation purposes. Let us denote with xi the data of the input source X, where i = 1, …, M, and M is the total number of data samples. A flowchart is depicted in Figure 4 and can be described with the following steps:
Step 1. Estimation of the mean value and quantization. The mean value of the input data can be estimated as [6,7]:
This parameter is quantized using a floating-point quantizer [39] and stored using 32 bits (32-bits floating point format is typically used in neural network applications [13,14,15,16,17,18,19,20,21,22,23,24,25,26,29,30]).
Step 2. Estimation of the standard deviation (rms value) and quantization. The rms of the input data can be evaluated according to [6,7]:
This parameter is also quantized using a 32-bits floating-point quantizer [39].
Step 3. Form the zero mean input data. Each element of the input source X is reduced by the quantized mean, and zero mean data denoted with T are obtained:
where μq is the quantized version of μ. Note that this is carried out in order to properly use the quantizer (as it is designed for a zero mean Laplacian source).
Step 4. Design of adaptive quantizer and quantization of zero mean data. The quantized variance, σq, is used to scale the crucial design parameter Δ as follows:
and the adaptive quantizer is obtained, where ε is a constant used to compensate the imperfections between the theoretical model and the distribution of the experimental data. Input data ti of the source T are passed through the adaptive quantizer, and the quantized data tiq are obtained.
Step 5. Recover the original data. Since the mean value is subtracted from the original data and further quantized (using 32 bits), an inverse process has to be performed to recover the original data:
where xiQ denotes the data recovered after quantization. It should be emphasized that the described process is equivalent to the normalization process widely used in neural network applications [15,18,22], as the same performance in terms of SQNR can be achieved [40]. Particularly, the normalization process assumes the following steps:
- Step 1.
- Estimation of the mean value and quantization.
- Step 2.
- Estimation of the standard deviation (rms value) and quantization.
- Step 3.
- Normalization of the input data. Each element of the input source X is normalized according to:and the source T with transformed (normalized) coefficients is formed.
- Step 4.
- Quantization of the normalized data. To quantize normalized data (modeled as the PDF with zero mean and unit variance), the quantizer designed in Section 2.1 can be used, and quantized data tiq are obtained.
- Step 5.
- Denormalization of the data. Since the input data are appropriately transformed for the purpose of efficient quantization, an inverse process referred to as denormalization has to be performed to recover the original data:
To measure the theoretical performance of the adaptive 2-bit uniform scalar quantizer, we can also use Equation (22) under the constraint that Δ is replaced with Δ(σp) defined with (26), which gives:
since , as we use a high number of bits for its quantization.
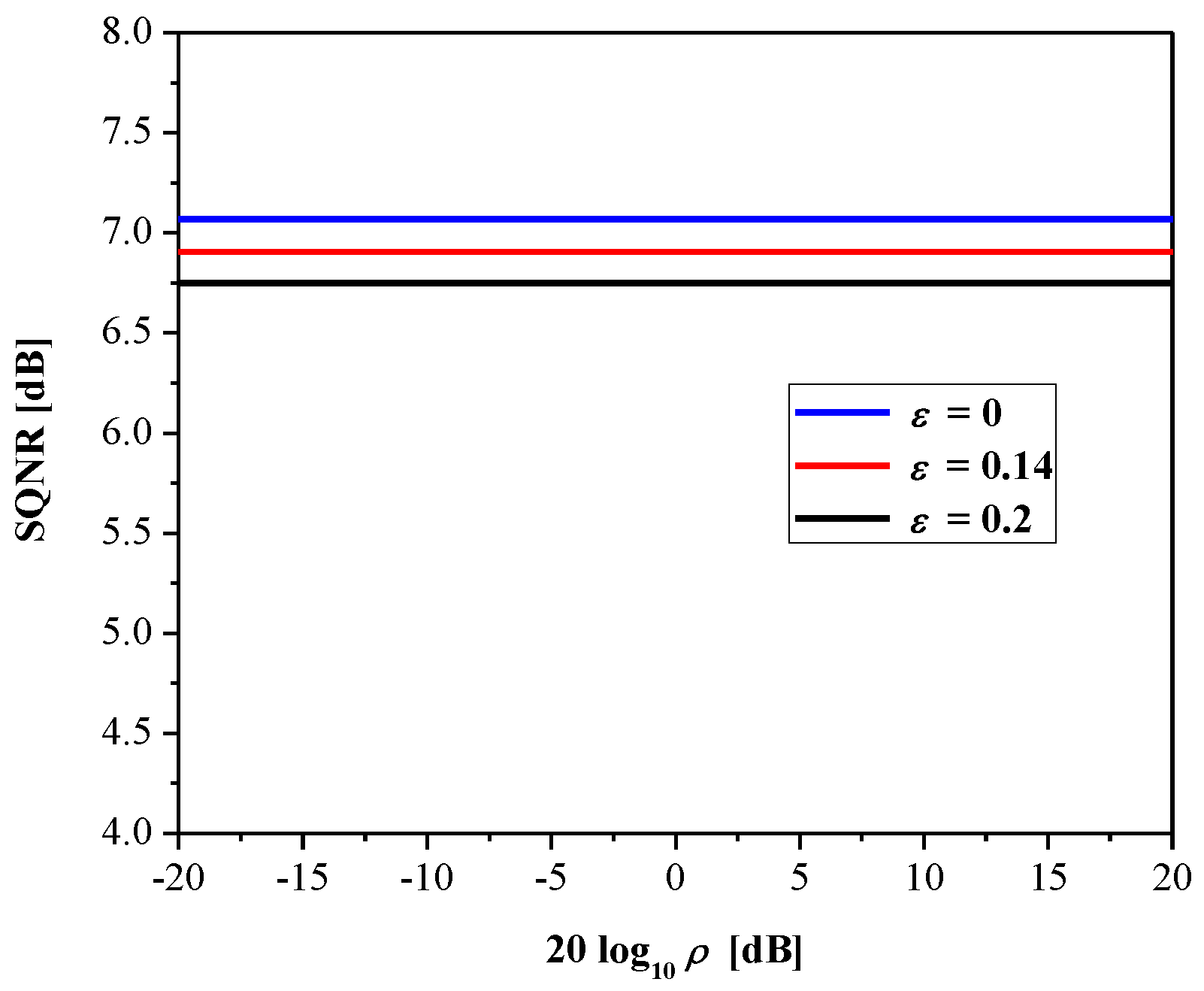
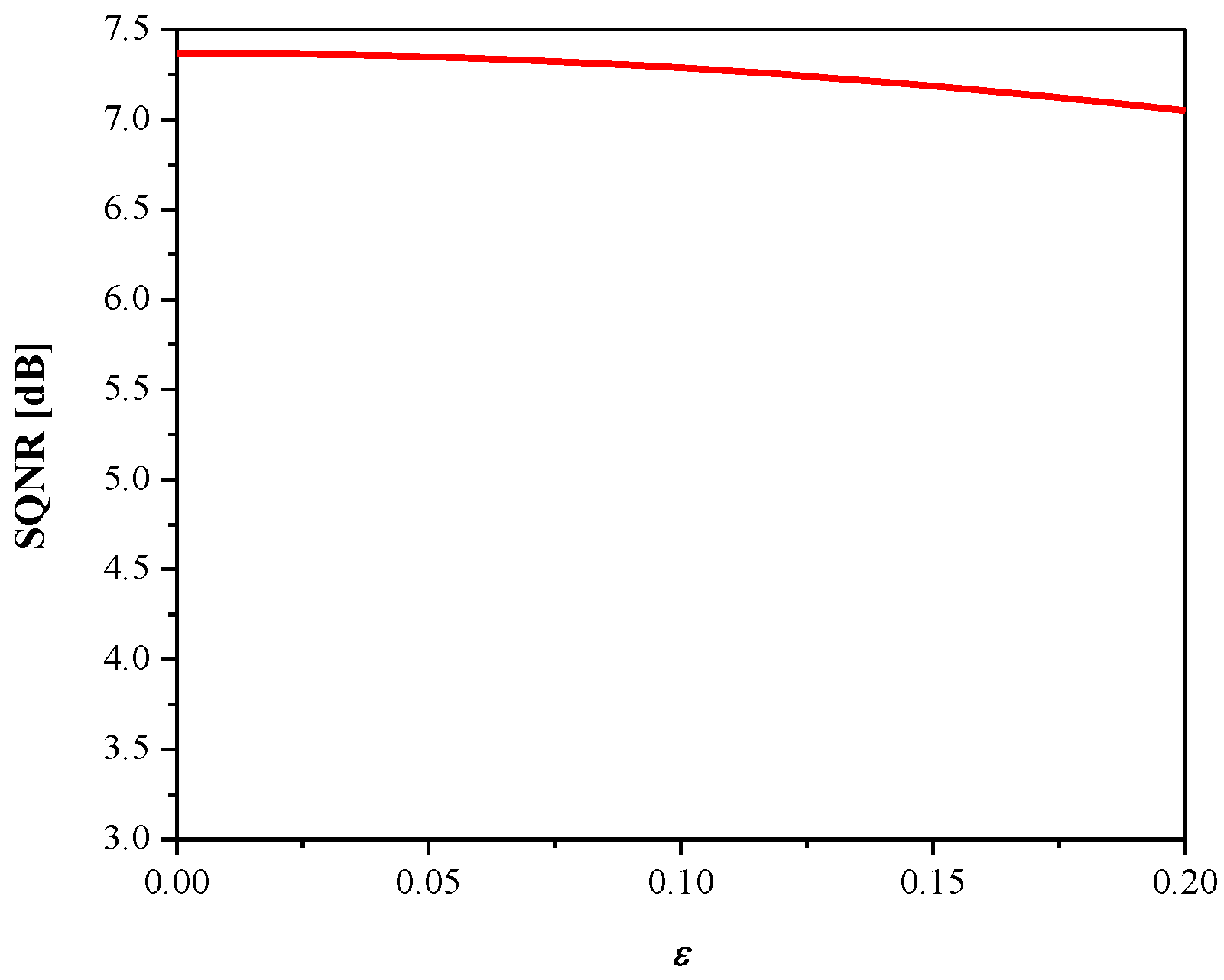
Figure 5 plots the SQNR of the adaptive 2-bit uniform quantizer, where it is obvious that adaptation successfully improves performance when compared to the case observed in Section 2.2 (see Figure 3), since a constant SQNR value is achieved in the considered range (that is, SQNR is independent of the input data variance). Note also the influence of parameter ε on the performance, where the case ε = 0 implies perfect adaptation of the quantizer to the data variance and the achieved SQNR is equal to 7.07 dB (this value corresponds to the optimal 2-bit uniform quantizer). With the increasing of ε, performance becomes slightly lower, as adaptation is not perfect.
3. Experimental Results and Discussion
This section investigates the suitability of 2-bit uniform quantization in the compression of neural networks. Firstly, we consider the MLP network architecture [30] applied to an image classification task and investigate how the quantization of weights affects performance of the network measured by classification accuracy. Specifically, MLP is still attractive and is applied in solving different challenges occurring in different research areas, e.g., [30,31,32,33,34], and, hence, it is worth investigating. Further, the results from the aspect of SQNR will also be analyzed by checking the agreement between the theoretically and experimentally obtained values.
The MLP network used in the experiment is constituted by the input, hidden, and output layer. Training, validation, and test data are taken from the MNIST database [41], which contains 70,000 grayscale images of handwritten single digits with a resolution of 28 × 28 pixels, where 60,000 and 10,000 images are intended for training and testing purposes, respectively. We apply the rectified linear unit (ReLU) activation function in the hidden layer and softmax activation function in the output layer. We also perform the following setup: regularization rate = 0.01, learning rate = 0.0005, and batch size = 128.
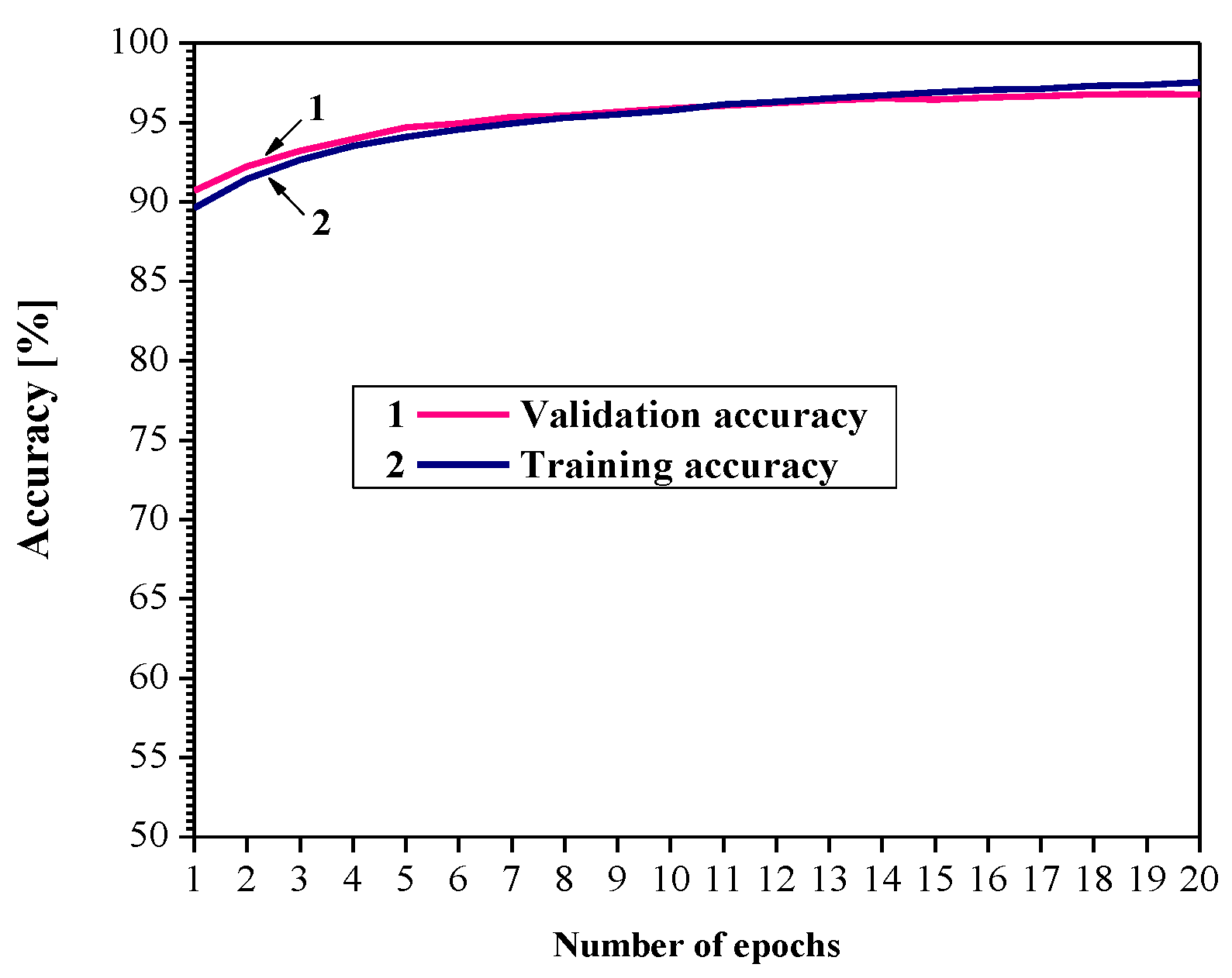
In our consideration, the goal is to apply an adaptive 2-bit uniform quantizer to quantize the weights of a trained MLP network, that is, to perform post-training quantization. Thus, Figure 6 shows the learning curves for the employed network, where after 20 epochs we obtain a training accuracy of 97.37%. As our model is evaluated on the training dataset and on a hold-out validation dataset after each update during the training, we show the measured performance by drawing two learning curves (training and validation learning curves). In this case, training and validation accuracy increase to a point of stability and have a minimal gap between their values, so that overfitting and underfitting do not exist.
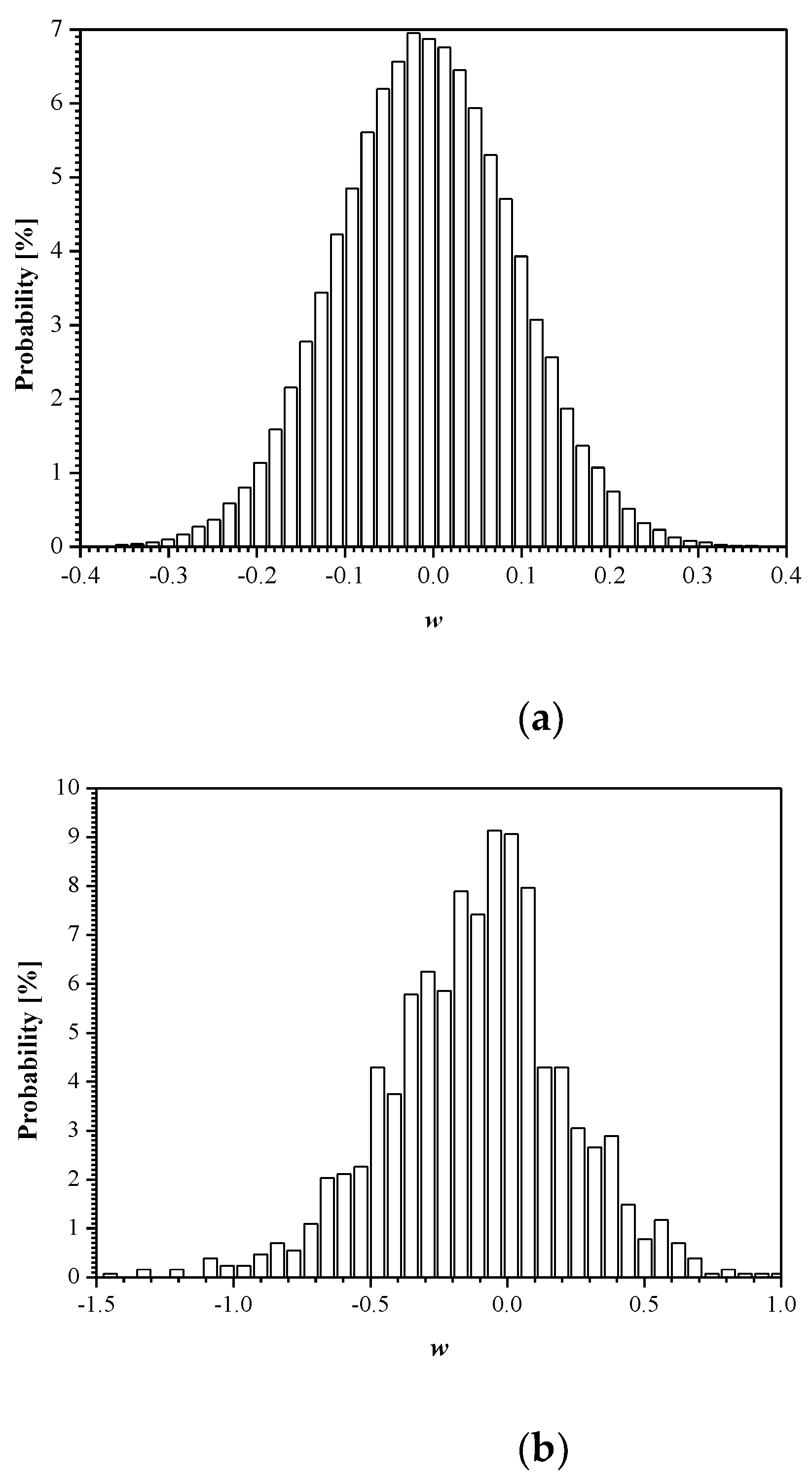
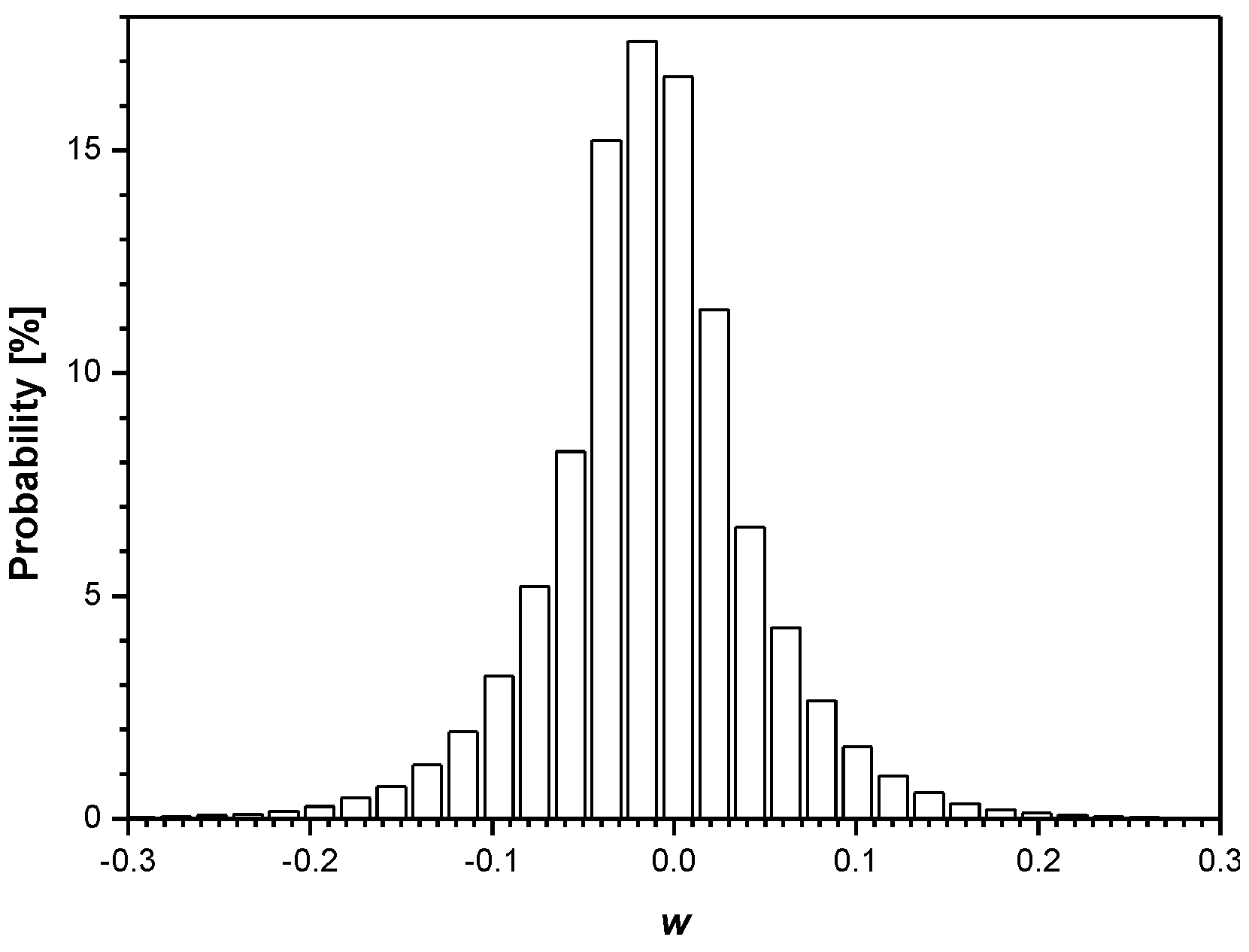
In Figure 7, we present the histograms for the weights both between the input and hidden layer (784 × 128 = 100,352 in total) and between the hidden and output layer (128 × 10 = 1280 in total) of the trained MLP network (training is completed at the 20th epoch). Note also that there is a significantly lower number of weights between the hidden and output layer, and, hence, there is little benefit to compress them. It should be noted that the good approximation of the distribution given in Figure 7a is the Laplacian distribution with some specific value σw2 and mean value μw that is very close to zero. This, in turn, enables proper implementation of the developed adaptive quantizer model (Section 2.3).
Let us further define SQNRex, by which the experimental value of SQNR can be measured:
where Dw is the distortion inserted by the adaptive uniform quantization (using 2-bits) of weights, W is the total number of weights, and wi are original while wiq are quantized values of the weights. Recall that beside classification accuracy, this is an additional objective performance measure used for the analysis of the quantized neural network.
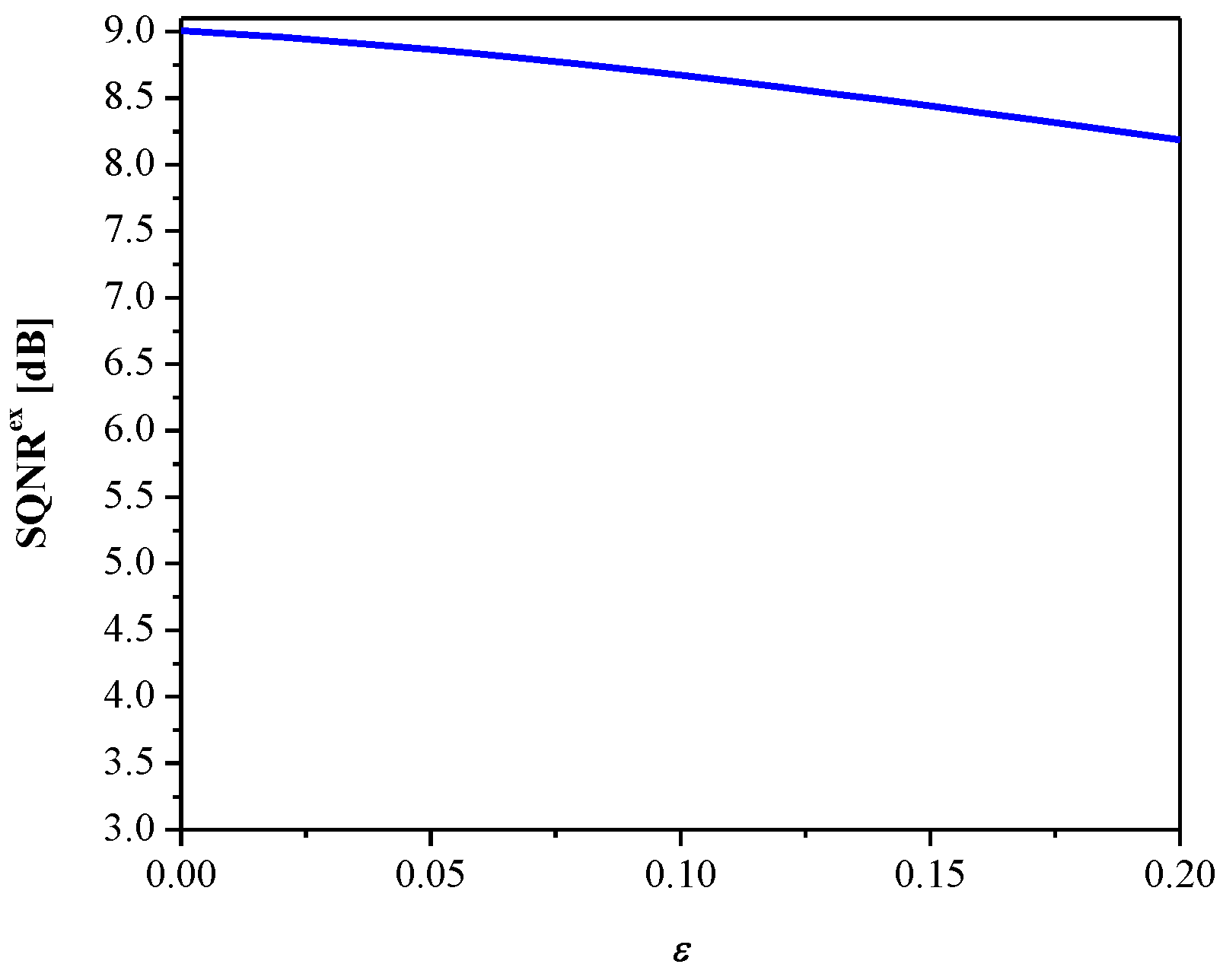
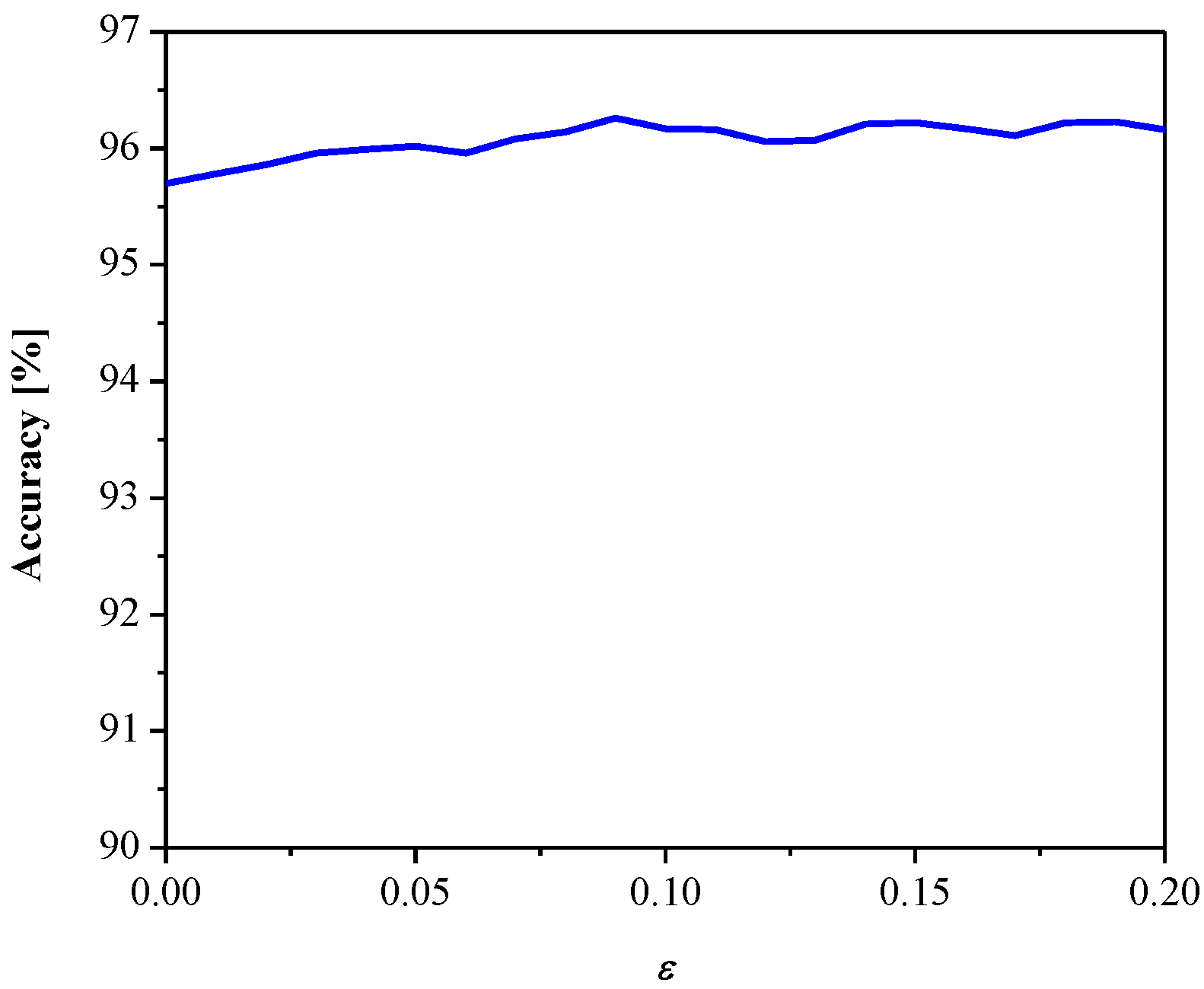
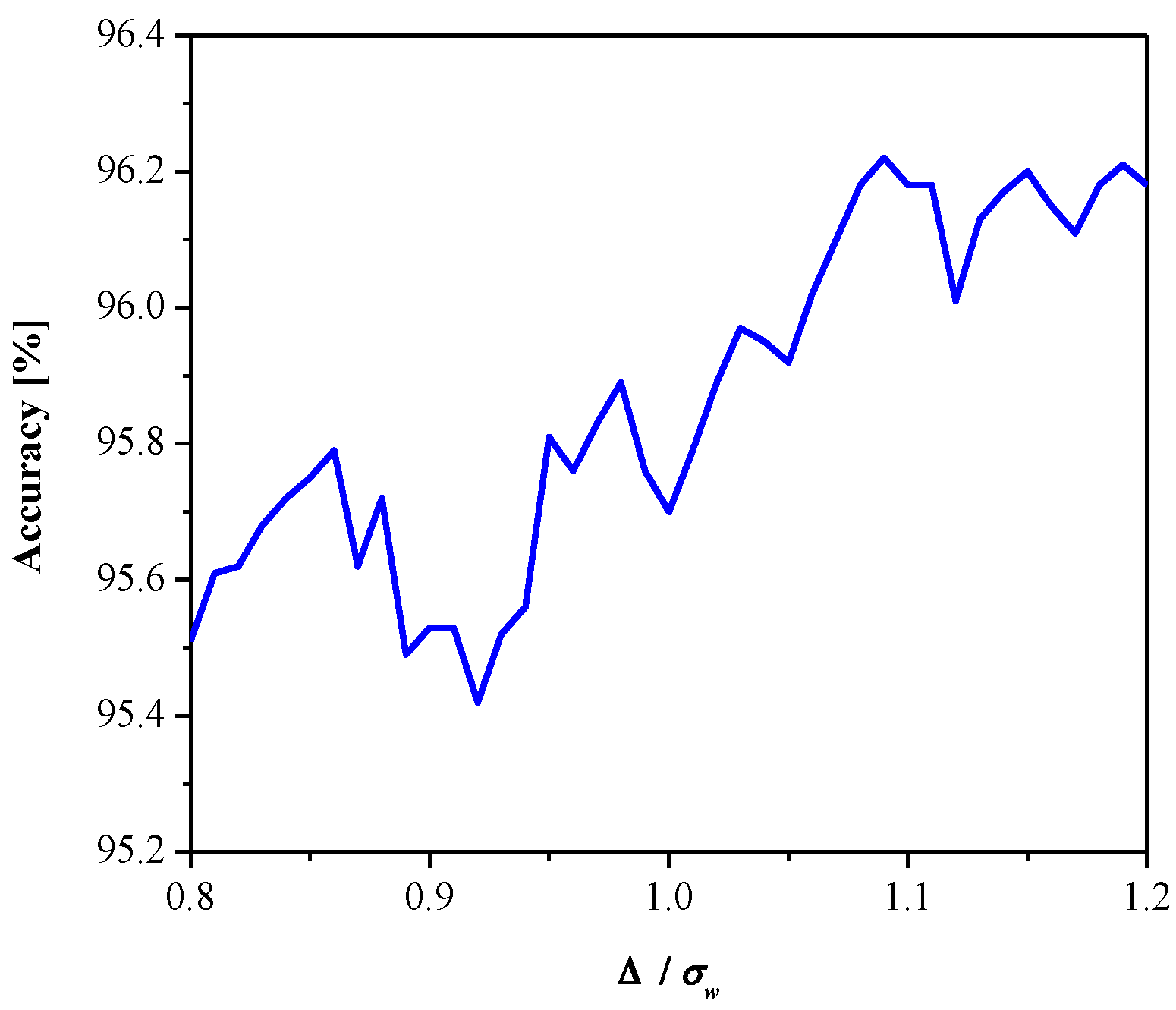
Figure 8 gives SQNRex versus the parameter ε. It can be observed that SQNR decreases as ε increases, which is in accordance with the theoretical results presented in Figure 5 (observing one particular variance value). In addition, both the theoretical and experimental values of SQNR agree well (considering some specific value of ε for a given variance value). Moreover, we examined the influence of the parameter ε (observing the same range as in Figure 8) on the MLP performance obtained in the test data [41], as shown in Figure 9. Note that the increasing of ε slightly increases performance (classification accuracy), while the performance maximum is achieved for ε = 0.09. Thus, we can conclude that ε affects the introduced performance measures differently for the given network configuration and input data. Since classification accuracy is a relevant measure for neural networks, for the purpose of further analysis, we adopt corresponding values of classification accuracy and the SQNR achieved for ε = 0.09, which are listed in Table 1. In addition, we plot in Figure 10 the classification accuracy as the function of step size Δ/σw, when ε = 0.09. It can be seen that the maximum score of classification accuracy is achieved for Δ = 1.09, which corresponds to the theoretically optimal value, confirming the applicability of the optimal quantizer.
Table 1 also summarizes the achieved performance (classification accuracy and SQNR) for adaptive 1-bit (binary) quantization of Laplacian source [26] and existing 2-bit solutions taken from [17,18,20,21], which serve as the baselines for comparison. The classification accuracy score of the non-quantized MLP network (full precision weights) is also included. Regarding the baseline 2-bit uniform quantizer [17], it is described by the following set (in a positive part) of representative levels {y3 = wmax−Δ, y4 = wmax} and by the set of decision thresholds {xo = 0, x1 = Δ, x2 = 2Δ}, where [17], R = 2, and wmax is the maximal value of the weights. For the 2-bit uniform quantizer defined in [18], it holds: {y3 = wmaxa − 3Δ/2, y4 = wmaxa − Δ/2} and {xo = 0, x1 = Δ, x2 = 2Δ}, where [18], R = 2, and wmaxa is the maximal absolute value of the weights. In the case of the 2-bit non-uniform quantizer described in [20], it holds: {y3 = Δ/2, y4 = 2Δ} and {xo = 0, x1 = Δ, x2 = 3Δ = xmaxopt}, where [20] and xmaxopt denotes the value of the optimal support region threshold of the proposed 2-bit uniform quantizer. Finally, a 2-bit non-uniform quantizer [21] is defined as follows: {5/8 = F(y3), 7/8 = F(y4)} and {xo = 0, 3/4 = F(x1)}, where .
Observe in Table 1 that quantized MLP using the proposed adaptive 2-bit quantizer provides a classification accuracy score that is only 0.6% below the full precision case, while the network size is reduced by 16 times, which is significant. Note also that our proposal is able to outperform all introduced 2-bit baselines, as quantized MLP in that case attains higher classification accuracy scores at the same compression level, along with the significantly higher SQNR. This can be interpreted in a manner that the benefit is attained as the result of proper quantizer design, as the baseline quantizer approaches [17,18,20,21] can be considered as suboptimal for the given task. Thus, we report the following gains in SQNR (in dB) and classification accuracy (in %): 7.08 dB and 1.56% with respect to the baseline in [17], 7.52 dB and 1.77% with respect to the baseline in [18], 17.6 dB and 3.88% with respect to the baseline in [20], and 11.12 dB and 3.53% when compared to the baseline in [21]. Moreover, a gain in performance over the 1-bit solution from [26] is also notable (4.5 dB in SQNR and 5.1% for classification accuracy), which is achieved at the expense of a slightly lower compression level.
Additionally, we perform quantization of a simple CNN model [30] using the proposed 2-bit uniform quantizer. The model consists of one convolutional layer, one max-pooling layer, one fully connected layer, and the output layer. The number of output filters in the convolutional layer is set to 32, whereas it’s kernel size is 3 × 3. The size of the pooling window is set to 2 × 2. The fully connected layer with 100 units on top of it, which is activated by the ReLU activation function, is placed further, before the output layer. Dropout of 0.5 is performed on the fully connected layer. The network is trained for 10 epochs in batches of size 128 on the same MNIST dataset as the MLP model. The distribution of the weight coefficients in the fully connected layer after the training process is presented in Figure 11.
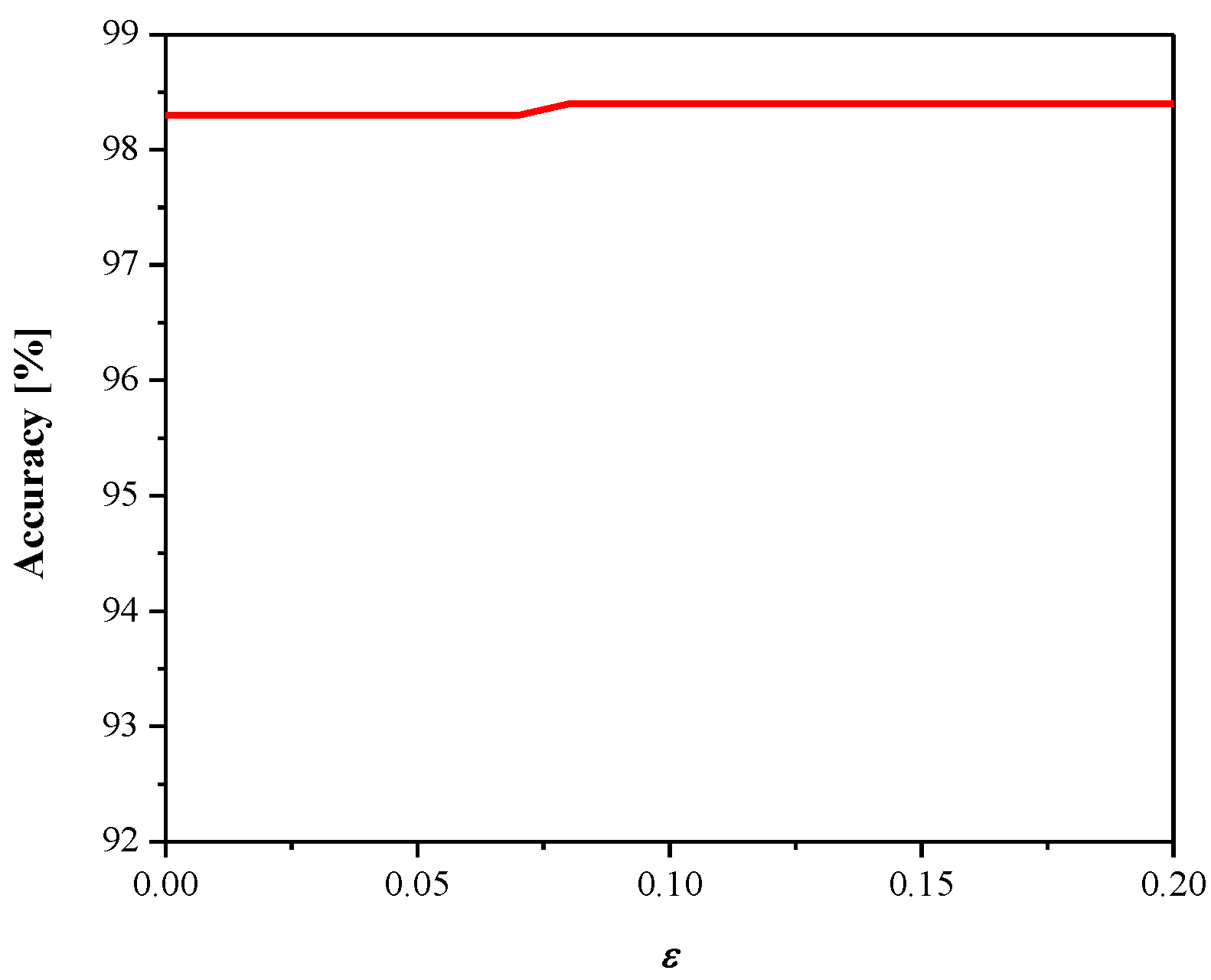
We obtained a classification accuracy of 98.7% in the test dataset, which is a higher accuracy compared to that of the MLP model and could be expected. The quantized CNN model is obtained by applying the proposed 2-bit quantizer (Δ = 1.09) for the task of fully connected layer weight quantization. Figure 12 and Figure 13 give the dependence of SQNR and classification accuracy on the parameter ε, respectively, where similar conclusions can be derived as in the previous case where MLP is considered (see Figure 8 and Figure 9). The achieved maximal classification accuracy of the quantized CNN model is 98.4%, achieved for ε = 0.08, which is only 0.3% less than the full-precision accuracy.
Finally, Table 2 compares the attained performance (classification accuracy and SQNR) of the quantized CNN in cases when the proposed (Δ = 1.09, ε = 0.08) and baseline (the same as in Table 1) quantization approaches are implemented. The superiority of the proposed quantizer is clearly visible from the given table, as significant improvements in SQNR and classification accuracy can be observed: 14.4 dB and 2.1% with respect to the baseline in [17], 11.33 dB and 1.5% with respect to the baseline in [18], 22.17 dB and 2.3% with respect to the baseline in [20], and 16.39 dB and 2.3% with respect to the baseline in [21]. Finally, better performance is also found in comparison to the 1-bit quantizer reported in [26].
Based on the overall analysis and results presented herein, we can point out that our proposal is very effective and is worth implementing for the post-training compression of neural networks.
4. Conclusions
In this paper, a detailed analysis of 2-bit uniform quantization for processing the data described with the Laplacian PDF was conducted from both a theoretical and experimental point of view. During the theoretical design, using MSE distortion as a criterion, it was shown that distortion has a global minimum, specified by using the proposed iterative rule; thus, the optimal 2-bit uniform quantizer model was developed. In addition, the asymptotic value of the crucial designing parameter (step size) was provided, which is very close to the theoretically calculated optimal value. The analysis in a wide range of input data variances was also carried out, where a low robustness level and the need for adaptation (as an efficient method for performance improvement) were indicated. To obtain experimental results, the proposed adaptive model was employed in real-data processing using the parameters of a neural network (weights), where, as proof of concept, both MLP and CNN networks were used. It was demonstrated that the employed MLP and CNN in combination with the proposed approach (i.e., quantized neural networks) are able to achieve near-optimal performance, with significantly lower memory requirements when compared to MLP and CNN with full precision weights, which also lead to faster classification. Moreover, the advantage over different 2-bit quantizer solutions available in the literature, providing the same compression level, as well as the 1-bit quantizer solution, was demonstrated. Based on these promising results, one can expect implementation of the proposed quantizer in the compression of some modern networks, knowing that they are based on MLP, and also to IoT resource-constrained devices. Moreover, our future research will be directed toward the compression of some of the state-of-the-art networks, such as ResNet, AlexNet, or GoogleNet.
Author Contributions
Conceptualization and supervision, Z.P.; software and validation, M.S.; data curation and writing—original draft preparation, N.S.; writing—review and editing, B.D.; resources V.D. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Science Fund of the Republic of Serbia, grant number 6527104, AI-Com-in-AI.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Data analyzed in this paper are available in a publicly accessible repository (MNIST dataset): http://yann.lecun.com/exdb/mnist/ (accessed on 15 May 2021).
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Teerapittayanon, S.; McDanel, B.; Kung, H.T. Distributed Deep Neural Networks Over the Cloud, the Edge and End Devices. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; pp. 328–339. [Google Scholar]
- Gysel, P.; Pimentel, J.; Motamedi, M.; Ghiasi, S. Ristretto: A Framework for Empirical Study of Resource-Efficient Inference in Convolutional Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5784–5789. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Classification and Regression Trees; CRC Press: Belmont, CA, USA, 1984. [Google Scholar]
- Langley, P.; Iba, W.; Thompson, K. An analysis of Bayesian classifiers. In Proceedings of the 10th National Conference on Artificial Intelligence, San Jose, CA, USA, 12–16 July 1992; AAAI and MIT Press: Cambridge, MA, USA, 1992; pp. 223–228. [Google Scholar]
- Fu, L. Quantizability and learning complexity in multilayer neural networks. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 1998, 28, 295–299. [Google Scholar] [CrossRef]
- Sayood, K. Introduction to Data Compression, 5th ed.; Morgan Kaufmann: Burlington, MA, USA, 2017. [Google Scholar]
- Jayant, N.S.; Noll, P. Digital Coding of Waveforms: Principles and Applications to Speech and Video; Prentice Hall: Hoboken, NJ, USA, 1984. [Google Scholar]
- Perić, Z.; Simić, N.; Nikolić, J. Design of single and dual-mode companding scalar quantizers based on piecewise linear approximation of the Gaussian PDF. J. Frankl. Inst. 2020, 357, 5663–5679. [Google Scholar] [CrossRef]
- Nikolic, J.; Peric, Z.; Jovanovic, A. Two forward adaptive dual-mode companding scalar quantizers for Gaussian source. Signal Process. 2016, 120, 129–140. [Google Scholar] [CrossRef]
- Na, S.; Neuhoff, D.L. Asymptotic MSE Distortion of Mismatched Uniform Scalar Quantization. IEEE Trans. Inf. Theory 2012, 58, 3169–3181. [Google Scholar] [CrossRef]
- Na, S.; Neuhoff, D.L. On the Convexity of the MSE Distortion of Symmetric Uniform Scalar Quantization. IEEE Trans. Inf. Theory 2017, 64, 2626–2638. [Google Scholar] [CrossRef]
- Na, S.; Neuhoff, D.L. Monotonicity of Step Sizes of MSE-Optimal Symmetric Uniform Scalar Quantizers. IEEE Trans. Inf. Theory 2018, 65, 1782–1792. [Google Scholar] [CrossRef]
- Banner, R.; Hubara, I.; Hoffer, E.; Soudry, D. Scalable Methods for 8-bit Training of Neural Networks. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montreal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Pham, P.; Abraham, J.; Chung, J. Training Multi-Bit Quantized and Binarized Networks with a Learnable Symmetric Quantizer. IEEE Access 2021, 9, 47194–47203. [Google Scholar] [CrossRef]
- Banner, R.; Nahshan, Y.; Soudry, D. Post Training 4-bit Quantization of Convolutional Networks for Rapid-Deployment. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–10 December 2019. [Google Scholar]
- Choi, J.; Venkataramani, S.; Srinivasan, V.; Gopalakrishnan, K.; Wang, Z.; Chuang, P. Accurate and Efficient 2-Bit Quantized Neural Networks. In Proceedings of the 2nd SysML Conference, Stanford, CA, USA, 31 March–2 April 2019. [Google Scholar]
- Bhalgat, Y.; Lee, J.; Nagel, M.; Blankevoort, T.; Kwak, N. LSQ+: Improving Low-Bit Quantization Through Learnable Offsets and Better Initialization. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations. J. Mach. Learn. Res. 2018, 18, 1–30. [Google Scholar]
- Zamirai, P.; Zhang, J.; Aberger, C.R.; De Sa, C. Revisiting BFloat16 Training. arXiv 2020, arXiv:2010.06192v1. [Google Scholar]
- Li, Y.; Dong, X.; Wang, W. Additive Powers-of-Two Quantization: An Efficient Non-uniform Discretization for Neural Networks. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Conference, Formerly Addis Ababa, Ethiopia, 26 April–1 May 2020. [Google Scholar]
- Baskin, C.; Liss, N.; Schwartz, E.; Zheltonozhskii, E.; Giryes, R.; Bronstein, M.; Mendelso, A. Uniq: Uniform Noise Injection for Non-Uniform Quantization of Neural Networks. ACM Trans. Comput. Syst. 2021, 37, 1–15. [Google Scholar] [CrossRef]
- Simons, T.; Lee, D.-J. A Review of Binarized Neural Networks. Electronics 2019, 8, 661. [Google Scholar] [CrossRef] [Green Version]
- Qin, H.; Gong, R.; Liu, X.; Bai, X.; Song, J.; Sebe, N. Binary Neural Networks: A Survey. Pattern Recognit. 2020, 105, 107281. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Bao, Y.; Chen, W. Fixed-Sign Binary Neural Network: An Efficient Design of Neural Network for Internet-of-Things Devices. IEEE Access 2018, 8, 164858–164863. [Google Scholar] [CrossRef]
- Zhao, W.; Teli, M.; Gong, X.; Zhang, B.; Doermann, D. A Review of Recent Advances of Binary Neural Networks for Edge Computing. IEEE J. Miniat. Air Space Syst. 2021, 2, 25–35. [Google Scholar] [CrossRef]
- Perić, Z.; Denić, B.; Savić, M.; Despotović, V. Design and Analysis of Binary Scalar Quantizer of Laplacian Source with Applications. Information 2020, 11, 501. [Google Scholar] [CrossRef]
- Gazor, S.; Zhang, W. Speech Probability Distribution. IEEE Signal Proc. Lett. 2003, 10, 204–207. [Google Scholar] [CrossRef]
- Simić, N.; Perić, Z.; Savić, M. Coding Algorithm for Grayscale Images—Design of Piecewise Uniform Quantizer with Golomb–Rice Code and Novel Analytical Model for Performance Analysis. Informatica 2017, 28, 703–724. [Google Scholar] [CrossRef]
- Banner, R.; Nahshan, Y.; Hoffer, E.; Soudry, D. ACIQ: Analytical Clipping for Integer Quantization of Neural Networks. arXiv 2018, arXiv:1810.05723. [Google Scholar]
- Zhang, A.; Lipton, Z.C.; Li, M.; Smola, A.J. Dive into Deep Learning. arXiv 2020, arXiv:2106.11342. [Google Scholar]
- Wiedemann, S.; Shivapakash, S.; Wiedemann, P.; Becking, D.; Samek, W.; Gerfers, F.; Wiegand, T. FantastIC4: A Hardware-Software Co-Design Approach for Efficiently Running 4Bit-Compact Multilayer Perceptrons. IEEE Open J. Circuits Syst. 2021, 2, 407–419. [Google Scholar] [CrossRef]
- Kim, D.; Kung, J.; Mukhopadhyay, S. A Power-Aware Digital Multilayer Perceptron Accelerator with On-Chip Training Based on Approximate Computing. IEEE Trans. Emerg. Top. Comput. 2017, 5, 164–178. [Google Scholar] [CrossRef]
- Savich, A.; Moussa, M.; Areibi, S. A Scalable Pipelined Architecture for Real-Time Computation of MLP-BP Neural Networks. Microprocess. Microsyst. 2012, 36, 138–150. [Google Scholar] [CrossRef]
- Wang, X.; Magno, M.; Cavigelli, L.; Benini, L. FANN-on-MCU: An Open-Source Toolkit for Energy-Efficient Neural Network Inference at the Edge of the Internet of Things. IEEE Internet Things J. 2020, 7, 4403–4417. [Google Scholar] [CrossRef]
- Hui, D.; Neuhoff, D.L. Asymptotic Analysis of Optimal Fixed-Rate Uniform Scalar Quantization. IEEE Trans. Inf. Theory 2001, 47, 957–977. [Google Scholar] [CrossRef] [Green Version]
- Na, S. Asymptotic Formulas for Mismatched Fixed-Rate Minimum MSE Laplacian Quantizers. IEEE Signal Process. Lett. 2008, 15, 13–16. [Google Scholar]
- Na, S. Asymptotic Formulas for Variance-Mismatched Fixed-Rate Scalar Quantization of a Gaussian source. IEEE Trans. Signal Process. 2011, 59, 2437–2441. [Google Scholar] [CrossRef]
- Peric, Z.; Denic, B.; Savić, M.; Dincic, M.; Mihajlov, D. Quantization of Weights of Neural Networks with Negligible Decreasing of Prediction Accuracy. Inf. Technol. Control 2012. Accept. [Google Scholar]
- Peric, Z.; Savic, M.; Dincic, M.; Vucic, N.; Djosic, D.; Milosavljevic, S. Floating Point and Fixed Point 32-bits Quantizers for Quantization of Weights of Neural Networks. In Proceedings of the 12th International Symposium on Advanced Topics in Electrical Engineering (ATEE), Bucharest, Romania, 25–27 March 2021. [Google Scholar]
- Peric, Z.; Nikolic, Z. An Adaptive Waveform Coding Algorithm and its Application in Speech Coding. Digit. Signal Process. 2012, 22, 199–209. [Google Scholar] [CrossRef]
- LeCun, Y.; Cortez, C.; Burges, C. The MNIST Handwritten Digit Database. Available online: yann.lecun.com/exdb/mnist/ (accessed on 15 May 2021).
Figure 1.
Illustration of the observed 2-bit uniform quantizer.

Figure 2.
The total distortion depending on the parameter Δ for 2-bit uniform quantizer.

Figure 3.
SQNR of 2-bit uniform quantizer (designed optimally with respect to MSE distortion) in a wide dynamic range of input data variances.
Figure 3.
SQNR of 2-bit uniform quantizer (designed optimally with respect to MSE distortion) in a wide dynamic range of input data variances.

Figure 4.
Adaptation process of 2-bit uniform scalar quantizer.

Figure 5.
SQNR of the adaptive 2-bit uniform quantizer in a wide dynamic range of input data variances.
Figure 5.
SQNR of the adaptive 2-bit uniform quantizer in a wide dynamic range of input data variances.

Figure 6.
Learning curves for MLP neural network.

Figure 7.
Distribution of weights of trained MLP network: (a) between input and hidden layer and (b) between hidden and output layer.
Figure 7.
Distribution of weights of trained MLP network: (a) between input and hidden layer and (b) between hidden and output layer.

Figure 8.
SQNR vs. ε achieved for weights quantization.

Figure 9.
Performance of quantized MLP for different values of ε.

Figure 10.
Classification accuracy of quantized MLP network as a function of quantization step size, ε = 0.09.
Figure 10.
Classification accuracy of quantized MLP network as a function of quantization step size, ε = 0.09.

Figure 11.
Distribution of fully connected layer weights of trained CNN network.

Figure 12.
SQNR vs. ε achieved for weights quantization (CNN).

Figure 13.
Performance of the quantized CNN model for various values of ε.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Performance (classification accuracy and SQNR) of quantized MLP for various applied quantization models.
Table 1.
Performance (classification accuracy and SQNR) of quantized MLP for various applied quantization models.
| Quantizer | Full Precision | ||||||
|---|---|---|---|---|---|---|---|
| 1-Bit [26] | 2-Bit Uniform [17] | 2-Bit Uniform [18] | 2-Bit Non-Uniform [20] | 2-Bit Non-Uniform [21] | 2-Bit Uniform Proposed | ||
| Accuracy (%) | 91.12 | 94.70 | 94.49 | 92.38 | 92.73 | 96.26 | 96.86 |
| SQNR (dB) | 4.25 | 1.63 | 1.19 | −8.89 | −2.41 | 8.71 | - |
Table 2.
Performance (classification accuracy and SQNR) of quantized CNN for various applied quantization models.
Table 2.
Performance (classification accuracy and SQNR) of quantized CNN for various applied quantization models.
| Quantizer | Full Precision | ||||||
|---|---|---|---|---|---|---|---|
| 1-Bit [26] | 2-Bit Uniform [17] | 2-Bit Uniform [18] | 2-Bit Non-Uniform [20] | 2-Bit Non-Uniform [21] | 2-Bit Uniform Proposed | ||
| Accuracy (%) | 96.2 | 96.3 | 96.9 | 96.1 | 96.1 | 98.4 | 98.7 |
| SQNR (dB) | 3.21 | −7.08 | −4.01 | −14.85 | −9.07 | 7.32 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Perić, Z.; Savić, M.; Simić, N.; Denić, B.; Despotović, V. Design of a 2-Bit Neural Network Quantizer for Laplacian Source. Entropy 2021, 23, 933. https://doi.org/10.3390/e23080933
AMA Style
Perić Z, Savić M, Simić N, Denić B, Despotović V. Design of a 2-Bit Neural Network Quantizer for Laplacian Source. Entropy. 2021; 23(8):933. https://doi.org/10.3390/e23080933
Chicago/Turabian StylePerić, Zoran, Milan Savić, Nikola Simić, Bojan Denić, and Vladimir Despotović. 2021. "Design of a 2-Bit Neural Network Quantizer for Laplacian Source" Entropy 23, no. 8: 933. https://doi.org/10.3390/e23080933
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.