
Abstract
Medical imaging is an essential medical diagnosis system subsequently integrated with artificial intelligence for assistance in clinical diagnosis. The actual medical images acquired during the image capturing procedures generate poor quality images as a result of numerous physical restrictions of the imaging equipment and time constraints. Recently, medical image super-resolution (SR) has emerged as an indispensable research subject in the community of image processing to address such limitations. SR is a classical computer vision operation that attempts to restore a visually sharp high-resolution images from the degraded low-resolution images. In this study, an effective medical super-resolution approach based on weighted least squares optimisation via multiscale convolutional neural networks (CNNs) has been proposed for lesion localisation. The weighted least squares optimisation strategy that particularly is well-suited for progressively coarsening the original images and simultaneously extract multiscale information has been executed. Subsequently, a SR model by training CNNs based on wavelet analysis has been designed by carrying out wavelet decomposition of optimized images for multiscale representations. Then multiple CNNs have been trained separately to approximate the wavelet multiscale representations. The trained multiple convolutional neural networks characterize medical images in many directions and multiscale frequency bands, and thus facilitate image restoration subject to increased number of variations depicted in different dimensions and orientations. Finally, the trained CNNs regress wavelet multiscale representations from a LR medical images, followed by wavelet synthesis that forms a reconstructed HR medical image. The experimental performance indicates that the proposed model SR restoration approach achieve superior SR efficiency over existing comparative methods
Similar content being viewed by others


Introduction
In the field of image processing community and human visual analysis, high-resolution images are extremely essential. Several fields pursue high-resolution image, i.e. medical imaging, computer vision, remote sensing and machine vision, etc. We may use hardware processes to upgrade an image sensor constructing technology or use the large sensor dimension to improve a resolution of the images. However Upgrading a hardware is typically costly because of the constraints of the physical system and possess lengthy duration, particularly in some specific sectors namely Computerised Tomography (CT) and Magnetic Resonance Imaging (MRI) in medical imaging. Thus, a particular algorithm to enhance the quality of the images is another good choice. An image processing system, i.e. super resolution has gained more attention over the past 2 decades. Super-resolution is an approach that relates to retrieve the HR images from its LR counterparts. Super-resolution technology and methods have grown rapidly over the years and has widespread application in the field of remote sensing [1], object recognition [2], security monitoring [3] and medical imaging [4]. Using resolution degradation, HR images could smoothly create their respective LR images. However, owing to the general absence of images information and sharp edges, inverse mapping reconstruction from low-resolution to high-resolution is a challenging process. Substantial numbers of SR techniques have recently been introduced and that using machine learning are excellent. In recent years, many developments have been made in super-resolution models since the advent of the pioneering work [5], and numerous techniques have been introduced not only for images, however, but also for videos and range images that is mostly related to CNN. Although the performance of the resent convolutional neural networks related techniques are mostly fuzzy and overly smoothed since whole characteristics from the input images, i.e. from LR images have not been completely exploited and the fine details cannot be retrieved [6,7,8,9]. Therefore, obtaining a superior quality image from the equivalent LR images is still very difficult. The resolution of the medical image is the relatively significant component influencing the diagnostic result. HR diagnostic images may allow doctors to assess the situation of patients further precisely. Enhancing the resolution of medical imaging utilizing super resolution will dramatically increase an accuracy of the diagnosis at the same time saving a material together with funds needed to upgrade equipment. For accurate disease diagnosis, description of minute anatomical regions and pathologies are important. Microscopic changes in the microvasculature around the tumour for instance are a significant biomarker for the diagnosis of cancer [10] and non-apparent soft exudates are relevant pathologies for the diagnosis of retina disease [11]. Although due to imaging equipment and limited specifications, various original medical images undergo from restricted resolution. This low resolution of medical images prevents small anatomical landmarks and pathologies from being correctly identified or segmented and hinders the proper diagnosis of certain sever disease at premature stages. A significant amount of effort have been reported in recent few years to enhance the resolution of real medical images. For improving pioneering resolution techniques, i.e. simple bicubic interpolations and their variants, typically undergo a large loss of sharp edge information and high local contrast [12]. Super-resolution reconstruction methods then became popular for improvement of the resolution of medical images.
The remaining article is structured as follows: Section “Related work” illustrates the related work. Section “Weighted least squares optimisation framework” discusses weighted least squares optimisation framework. Section “The proposed SR method” illustrates the particulars of the proposed weighted least squares optimisation-based CNN approach. Section “Experimental results and analysis” discusses the experimental setup details, procedures, results and visual interpretation and subsequently detailed conclusion is mentioned in Section “Conclusion”.
Related work
Yang et al. suggested a regularised image super-resolution system for medical imaging on the basis of sparse representations [13]. Rueda et al. restored a HR version of a LR brain MRI images [14] and Wei et al. introduced a medical imaging SR algorithm in [15] along with a strong PSNR and visual perception ratio [15]. Dou et al. recently suggested an SR approach to obtain additional details from a LR medical images on the basis of the random forest model selection strategy [16]. Peter and Jebadurai suggested a SR for retinal images on the basis of multi-kernel support vector regression [17] While these approaches are, moreover, successful as compares to conventional interpolation related methods, however, in case of high upscaling factor still do not recover high-quality images. Some new SR methods have also been published, powered by the huge achievement of machine learning in the computer vision. Kim et al. provided a more adequate super-resolution system with VDSR on the basis of VGG-net [18]. Deep residual learning [19] is used by VDSR, which was introduced which by Microsoft research (MR) researchers and are renowned for taking first position in ILSVRC 2015, a large image classification competition. VDSR suggested a way to substantially accelerate the training procedure by utilizing residual learning together with gradient clipping. Dong et al. initially introduced single image CNNs known as SRCNN model [5]. The super-resolution technique for grayscale medical image is introduced in [20], based on the fundamental structures of CNNs. He et al. suggested residual neural network, i.e. ResNet for simplifying SR model training process [19]. To further boost the SR efficiency of ResNet [21], Tei et al introduced a 52-layer recursive network and Lim et al. eliminated redundant component in ResNet thus expending the structure size [22] and achieved a substantial improvement. In the SR model, Zhang et al. [23] endorsed an efficient residual dense block. A deep network having channel attenuation [24] was further explored and the state-of-the-art PSNR output was achieved. GAN based SR has recently emerged and continues to develop because of great result of GANs by generating realistic image. SRGAN [25], Neural Enhance [26] and ESRGAN [27], for instance, are whole GAN-related methods. In particular, Mahapatra et al. suggested an SR algorithm for medical images utilizing P-GANs [11]. Although there are so many methods published, as described above, medical images super resolution is still a challenging task and the performance of reconstruction is still unsatisfactory for higher upscaling factors. The model suggested at a very early stage is SRCNN [28]. Two to four CNN layers are used by Dong et al. to demonstrate that trained convolutional neural network layer design executes well on SR operations. The researchers found that, it is better to use a large convolutional neural network filter size rather than deep convolutional neural network layers. Super-resolution CNNs (SRCNN) are accompanied by the image super-resolution Deeply-Recursive Convolutional Neural (DRCN) [29]. DRCN uses deep CNN layers (20 in total), meaning the method have large parameters. Still, they share the weight of individual convolutional neural network to decrease the number of training parameters, i.e. they are able to train the deeper convolutional neural network and achieve significant efficiency. Very deep RED networks [30] are related to residual learning. RED [30] is reacted to residual learning. RED involves symmetrical convolutional, i.e. encoder and deconvolutional, i.e. decoder layers. It also possesses skip connections and connects each two or three layers instead. They basically train deep, i.e. 30 layers with this symmetric structure to obtain excellent results. Therefore, this study represents the “the deeper the better” theme. Yaniv Romano et al., on the other hand, suggested rapid and accurate image super resolution (RAISR) [31] that focused on shallow and quick learning. Its categorizes source image patches in accordance to the intensity, angle and patch coherence and then forms maps between the clustered patches from LR image to HR image. FSRCNN [32] was also introduced by Dong et al. as the faster variant of their SRCNN [30]. Wang et al. implemented WMCNN [33] by training CNNs based on wavelet analysis, an aerial image super-resolution process. For multiple representations, wavelet decomposition was performed in aerial images. FSRCNN makes use of transposed CNN to directly perform an input image. The processing speed of RAISR and FRSCNN is 10–20 times quicker than other existing approaches focused on machine learning. Their efficiency still is not as good as other deeply convolutional techniques. However, convolutional neural network-based SR techniques have obtained remarkable success in handling bicubic degradation, it is not easy to apply them to deal with other more realistic degradation models. Several methods, i.e. LapSR [34] having progressive upsampling, i.e. MDSR [22] together with scale specific approaches, i.e. meta super-resolution [35] having meta upscale procedure have been proposed for resolving bicubic degradation together with multiple scale factors for a single design. The techniques introduced in [26, 36] take the PCA size decreased and blur kernel as an input to deal with a fuzzy LR image for versatility. These techniques, however, are restricted to the Gaussian blur kernel. The deep plug-and-play techniques [37, 38] are possibly the most convolutional neural network related works that can manage multiple kernels, noise levels and scale factors. Under a MAP framework, the key concept of corresponding approaches is to plug the learned convolutional neural network into an iterative solution. However, these are basically model-related techniques that undergo from a higher computing burden and requires hyper-parameters selected manually. To develop an end–end training model to produce superior performance with fewer iterations remains under investigation. Although the restoration of blind images based on learning has recently received significant attention [39,40,41,42,43], we observe that these works focused on non-blind SR that implies that the low-resolution image, noise level and blur kernel are to be known in advance. Non blind SR is yet in fact, an active research direction. Following [44], Li et al. [45] divide input HSIs into overlapping groups of bands using a grouping technique. The spectral similarity between neighbouring bands can be effectively exploited in this manner without raising the model parameter. Corrales et al. [46] suggested a method that combined denoising and super-resolution. To that end, they investigate two architectural designs: in-network incorporates all tasks at the feature level, and pre-network performs denoising first, then super resolution. Jiang et al. [47] proposed a deep edge map driven super-resolution approach that includes both an edge prediction and a SR subnetwork. The edge prediction subnetwork utilizes a hierarchical representation of color and depth images to generate an appropriate edge maps that the super-resolution subnetwork to perform better. The super-resolution subnetwork is a disentangling cascaded network that up samples super-resolution results incrementally, with . each stage consisting of a weight sharing module and an adaptive module. Recently, Quantum image processing (QIP) [48] is playing a pivotal role by taking the benefit of quantum mechanics features to characterize images in a quantum computer, thereafter implements various image operations based on the image format. It is a branch of quantum information and computing science. Many researchers have shown that quantum computing has significantly enhanced computational performance. With the recent accomplishment in the area of quantum information, the pursuit for a Quantum Neural Network (QNN) model [49] by combining quantum computing with the remarkable features of classical neural networks has already begun. Tenne et al. suggested SR enhancement by quantum image scanning microscopy (QISM) [50], which implemented image microscopy: by integrating image scanning microscopy and the measurement of quantum photo relationship, the resolution of image scanning microscopy can be increased up to twofold, four times beyond diffraction limit. Alves et al. [51] proposed a method that integrates the advantages of RAISR [31], a non-hallucinating and efficient computational approach, and Variational Quantum Eigen-solver (VQE), a hybrid classical-quantum method, to conduct super-resolution with the assistance of a quantum computer while maintaining analytical efficiency. It covers the production of extra hash-based filters learned with the traditional execution of super-resolution methods to further investigate performance refinements, create substantially sharper image, and influence the learning of efficient upscaling filters along with integrated enhancement effects. Israel et al. [52] identified an imaging system with a larger fill factor, higher quantum performance, low noise, and scalable structure based on a fibre bundle coupled to single photon avalanche detectors. Their device enables super-resolution microscopy based on localization in a non-sparse non-stationery scenario using details on the number of active emitters derived from non-classical photon statistics [66, 67].

Weighted least squares optimisation framework
Edge preserving smoothening via weighted least squares optimisation
We initially define an edge-preserving smoothening method related to the Weighted Least Squares Optimisation 55 system and further demonstrate to establish multiscale edge-preserving decomposition which captures information on different scales. An edge-preserving smoothing could be seen as negotiate between two theoretically inconsistent priorities. Considering an original image g, we are seeking for a new image u, which possess similar to g and, at the same time, smooth as far as possible everywhere, except for crucial gradient in g. It can be demonstrated formally for finding a minimum of
where the subscript p indicates a pixel's spatial location. The purpose of data expression (\(u_{p} - g_{p} )^{2}\) is for reducing a gap among g and u, further the second expression (regularisation) seeks to gain smoothness by reducing the partial derivative of u. A smoothness necessity implemented through weights of smoothness \(a_{x}\) and \(a_{y}\), that rely on g, in the spatially varying form. Finally, an equilibrium between the two terms is responsible for λ; raising the value of λ affects in increasingly smoothes image u. We could re-write equation using matrix notation in quadratic form:
Here \(A_{x} \) and \(A_{y}\) are diagonal metrics comprising \(a_{x} \left( g \right)\) and \(a_{y} \left( g \right)\), smoothness weight, respectively, and \(D_{x}\) and \(D_{y}\) represent discrete differentiation operators. A vector u which minimises Eq. (2) is defined specially as a linear system solution.
where \(L_{{\text{g}}} = D_{x}^{T} A_{x} D_{x} + D_{y}^{T} A_{y} D_{y}\). It is precisely a linear system utilized in Lischinki et al. [56], in which the modulo of the differences in notation were mainly utilized for extracting piece-wise smooth adapting maps from a sparse group of constraints.
\(D_{x}\) and \(D_{y}\) are forward difference operators in our implementation, and thus \(D_{x}^{{\text{T}}}\) and \(D_{y}^{{\text{T}}}\) are reverse differences operator, that means \(L_{{\text{g}}}\) is the spatially in-homogenous Laplacian matrix operator of five points.
We describe smoothness weights in similar form as in Lischinki et al. [56],
The exponent α (typically 1.2 and 2.0) defines the sensitivity to the gradient of g, while ℓ represents log luminance channel of the original image g, where ɛ is the minor constant, i.e. typically 0.0001 which prohibits division by 0 in regions in which g is constant. Let us investigate a relationship between a value of λ parameter and degree of smoothening to finalise the exposition of Weighted Least Squares related operator. Doubling a spatial help of kernel prepares the filter in a frequency domain approximately twice narrower by utilizing the linear invariant smoothing filter, i.e. a Gaussian filter. We further want to know in what way the similar effect can be accomplished through adjusting a value of λ. Equation (3) inform us that using a nonlinear operator \(F_{\lambda }\), that rely on g, u is obtained from g as:
While this operator is spatially variant its frequency response is difficult for evaluation. Hence, as in Fattel et al.[57], our evaluation is restricted to the areas of an image which does not have important edges. In particular, the weights of smoothness \(a_{x}\) and \(a_{y}\) are approximately equal in areas while g is approximately constant, i.e. \(a_{x}\) ≈ \(a_{y}\) ≈ a, and, therefore,
While the ordinary (homogeneous) Laplacian matrix L = \(D_{x}^{{\text{T}}} D_{x}\) + \(D_{y}^{{\text{T}}} D_{y}\). Oppenheim and Schafer [58] then give the frequency response of \(F_{\lambda }\),
In frequency domain, therefore, scaling by the factor of c which is similar to multiplying λ by the factor of \(c^{2}\):
While the image areas of approximately constant slope, in which each of \(a_{x}\) and \(a_{y} \) is constant, the same conclusion may be reached (but not necessarily equally to each other). It should be noted that the resultant operator is not rotationally invariant while the smoothness coefficients in Eq. (4) split between gradients in x and y directions, having a small tendency for retaining axis aligned edge, moreover, than diagonal ones. Although, in our experiments, this did not consequence in any observable artefacts; it must also be noted that a discrete representation of image in a regular grid, therefore, is a rotational variant in itself.
Multiscale edge-preserving decompositions
A multiscale edge-preserving decompositions, modelled following the notable Laplacian pyramid in Burt and Adelson [59] is simple to create utilizing an edge-preserving operator mentioned above. A decomposition comprises of a smooth, coarse, piece-wise model, together with a series of different image, capturing information on increasingly fine scale. Further precisely, let g represent an original image in which we want to build a decomposition level of (k + 1). Then \(u^{1} , \ldots\)\(u^{k}\) gradually indicate a coarser category of g. \(u^{k}\) will act as base layer b of a coarsest of these versions, together with a k detail layer is define by
While simple addition of base and detail layer, the original image g is easily recovered from this decomposition,
Note that the smoothed image \(u^{i}\), is not down sampled since it is obtained from edge-preserving smoothing and is not band limited in a usual sense. Therefore, our multiscale decomposition a full detail of original image. We had evaluated the progressive coarsening sequence \(u^{1} , \ldots .,u^{k}\) with two methods of computing. The first is to resolve a linear system in Eq. (3) k times, incrementing the value of a λ component each time. In other expressions, that is
Considering a certain foremost value of λ and a certain value of c. We observed that the resulting decompositions are well-suited (using α = 1.2 –.4) for high dynamic range (HDR) compression and multiscale details enhancement. The second approach is to use an operator iteratively,
Similar to the mean shift filtering in Comaniciu and Meer [60] along with a multiscale bilateral transform in Fattel et al. [57], the images are frequently smoothed in this process, and a resultant coarsened image prefer more firmly towards piecewise constant areas separated by edges. At each iteration, we still increase λ by a c factor, since this results in a further notable increase in smoothness in every iteration. Considering applications which attenuate or discard some of the information, i.e. image abstraction with α = 1.8 or 2.0, we considered the iterative system to be better suited.
The proposed SR method
Multiscale tone manipulation via WLS
A simple iterative tool has been introduced to manipulate the contrast and tone of information at varying scale. Considering an image, we initially create the three level decompositions of the CIELAB lightness channel, i.e. coarse base level b and two detail levels \(d^{1} , d^{2}\). This achieved utilizing the initial, i.e. non-iterative construction provided in Eq. (12). A collection of sliders to control the exposure η of a base is then provided to the user, along with the boosting factors, \(\delta_{0}\) for base and \(\delta_{1} ,\delta_{2}\) for a median and fine detail layer. At each pixel p, the output of the manipulation \(\hat{g}\) is further provided by
While µ is a lightness range mean, and S is the sigmoid curve, S (a, x) = \(1/(1 + \exp \left( { - ax} \right)),\) i.e. shifted and normalised approximately. A purpose of this sigmoid is to avert the difficult clipping which could otherwise appear when a detail layer is increased. The contrast and the exposure of a base layer is managed by a term S (\(\delta_{0 } ,\) η \(b_{p} - \mu\)), where the remaining expressions check the increase in fine and medium details. Consider that Eq. (13) is evaluated in real-time once the decomposition has been computed. We found that this simple tool is already very successful in managing contrast of local quantities at varying scales. The efficient manipulation range is very large: usually, a very severe manipulation is required to make artifacts appear. For the fine scale filtering, the decomposition for whole outcomes is made with the parameters α = 1.2 and λ = 0.1.
Multiscale convolutional neural networks [33]
This section explains how to train multiscale CNNs to characterize different scales of cultural variance and how to restore a medical image through trained multiscale convolutional neural networks.
I. The wavelet representation of HR Medical image as multiscale regression features
Wavelet decomposition is used to multiscale analysis of the medical images. For filter banks, we introduce wavelet decomposition comprising of bio-orthogonal high frequency pass filters and low frequency pass filters. Here, L indicates a LF pass filter matrix where columns represent LF pass filter coefficients, similarly H indicates a HF pass filter matrix where columns depicts HF pass filter coefficients. By referring to [61] for clarifications of matrices L and H for particular wavelet decompositions. As the initial level representation \(C_{{\text{o}}}\), here utilize one original HR image and do a wavelet decomposition as follows:
where j denotes the level of decomposition and s↓ indicates the downsampling operation to \(1/s\) of initial resolution. In relation to multiple spatial ratios, the recursive downsampling decomposition (14) characterises a medical image that favours complete remote observations related to medical image. \(C_{j} , D_{j}^{h} , D_{j}^{v} , D_{j}^{d}\), representing the entire LF, horizontal HF together with LF, vertical HF together with horizontal LF, and entire HF features of the final level representations \(C_{j - 1}\) appropriately. A wavelet decomposition, therefore, leads to multiscale representations with regards to spatial ratio, frequency range and orientation for a medical image. In the next sub section, here we utilize wavelet multiscale presentations as regressing features to train numerous convolutional neural networks for SR.
II. Based on CNNs; regress wavelet multiscale features through LR image
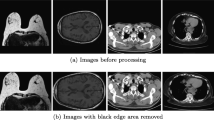
Figure 1 illustrates the different types of medical modalities obtained from open sources. Multiple CNNs are trained to regress wavelet multiscale feature through LR image. Figure 2 illustrates training architecture related to 1-level wavelet decomposition. Four CNNs are trained by the exemplary architecture. The LR images layer-by-layer are processed by each CNN along with last layer pursue to regress one of the multiscale presentations of HR images defined above in 4.2 − I. The layout of the existing SRCNN [5] was adopted for each individual CNN construction. Considering a LR \(I_{{\text{L}}}\) medical images down sampled out of HR images as input, a n-th convolutional layer output is

The proposed SR framework
where \(W_{n}\), \(b_{n}\) represent weights of network and training biases, subsequently. δ represents rectified linear function, i.e. max (0, x) that allows CNNs to converge rapidly (e.g. max (0, x)). Each CNN is penalised by a loss function to calculate the distant in-between the representations created through convolutional neural network through LR image and the representations through wavelet decomposition of corresponding HR images to generate characteristics that mostly regress wavelet multiscale representation. The loss function in Fig. 2 for a top convolutional neural network is represented by
where k is the wavelet multiscale representation's pixel index, and C represents wavelet multiscale presentation which conserves a high-resolution medical image's two-direction smoothing features, \(\hat{C}\) defines a representation created by a convolutional neural network through a LR image \(I_{{\text{L}}}\). In Fig. 2, one convolutional neural network produced representation for regression of C is a top patch. Whereas for remaining three convolutional neural networks, the loss functions could be set through replacing C in Eq. (16) with \(D^{h} , D^{v}\) and \(D^{d}\), separately. Using back propagation, the multiple CNNs are trained separately to reduce a loss function, therefore, each CNN is trained for learning features characterised through a corresponding wavelet representation. A numerous convolutional neural network trained, therefore, captures the multiscale image characteristics in various directions along with different frequency bands.
III. SR via wavelet multiscale CNNs.
We begin SR by separately inserting a LR image into the different convolutional neural networks. Then execute wavelet synthesis from j-th level to (j – 1)-th level on the CNN generated representations as follows:
The tidal symbol denotes that \(\check{C}_{j} , \widehat{D}_{j}^{h} , \widehat{D}_{j}^{v} , \widehat{D}_{j}^{d}\) are representations generated by CNN from the low-resolution image \(I_{L}\), which differ from those representations obtained from wavelet decomposition in Eq. (14). A wavelet synthesis intrinsically ensemble a structural information along with diversity of object through multiscale frequency bands together with directions, since one convolutional neural network produced representation is provided with an image feature characterised in one-frequency band having fixed orientation defined by a wavelet decomposition and achieves efficient super resolution. The last level in Fig. 2 indicates a super-resolution one-level wavelet synthesis sample that four convolutional neural networks produced representation is synthesised, reconstructing a HR medical images.
IV. Observations
Local processing and multiscale analysis are two main factors facilitating the efficacy of convolutional neural networks, which are somewhat resemble to human brain receptive fields. Train the network weights which employ local filtering on one entire image influence a local processing. The sampling down of multiscale analysis as the key manipulation. Existing CNN SR techniques such as SRCNN, however, prefer to provide local processing, however, neglect multiscale analysis due to SR works strive for upscaling image features representation in comparison to features condensation needed for appropriate patter recognition. Therefore, the upscaling purpose of super resolution is explicitly contradicted by simple downsampling operations. We suggest training multiple convolutional neural networks lacking pooling-based in image wavelet representations for the purpose of completely leverage the representation capacity of convolutional neural networks related to both multiscale analyses along with local processing. The weights of the convolutional neural network are retrieved by training along with supervised filtering of medical images representation by convolutional neural networks. A wavelet decompositions and synthesis alternatively use the shelf wavelet filter and execute un-supervised filtering on a multiscale representation. Additionally, to filtering executed by convolutional neural network weights, they thus enrich the results of local processing, therefore, improved local processing prefers to capture additional detailed land covering together with object features. In wavelet decomposition, downsampling operations are an efficient replacement for pooling operations discarded from current super-resolution methods based on CNN. In addition, different frequency bands filtering having multiple orientations is involved in the wavelet analysis, forming the additional general multiscale synthesis. In addition, multiscale representation not only enhance precise visible features, further favour comprehensive medical image details. Lastly, with filtering updates, the wavelet synthesis upscale a multiple representation along with the wavelet decomposition, resulting in super resolution. The four convolutional neural networks trained at one-level could be reutilized recursively to regress wavelet multiscale representations at different stages for multilevel analysis. Therefore, this recursive employment will upscale a medical image to high-resolutions. However, this allows to one drawback where a resolution of one medical image could only be increased through multiples of two. This is due to with reference to filter banks, a wavelet analysis specifically includes down sampled and up sampled should be scaled by two. In addition, a computing complexity of various approaches are analysed. In contrast to SR methods related to deep learning, our method is successful in both training and testing operations. It is clear that the complexity of proposed model is four times as compares to SRCNN, since it follows four convolutional neural networks, each having similar SRCNN structure. Although the complexity of proposed model is greater as compares to super-resolution convolutional neural network, it is appropriate since it is complexness adopts a liner growth in the no. of convolutional neural networks and do not suffer exponentially raised overheads. Alternatively, unlike the deeper SR methods that have 20 weight layers, such as very deep resolution [18], our three-layered models are not very deep. We enhance the SR capability of the convolutional neural network, unlike the very deep structure by avoiding deep network, however, expending wider, i.e. train multiple three layers convolutional neural networks in parallel in decomposed frequency sub-bands.
Experimental results and analysis
A set of experiments are presented in this section to demonstrate the efficiency and robustness of our proposed SR algorithm.
Experimental setup details
We developed an experimental evaluation with other super-resolution algorithms on the medical imaging datasets [53, 54] and performed overall empirical assessment on our proposed framework. Open source medical datasets [53, 54] have been taken for training and validation purposes. We have considered 850 medical images for both training and validation purposes. We utilized 70% of the images, i.e. 595 images, to train the proposed model and the rest 30%, i.e. 255 images, to validate the performance of the trained model. We have conducted numerous experiments for obtaining better results by varying the value of different parameters. In the end, by performing numerous experiments in terms of datasets, parameters and performance metrics, we have considered eight experimental results of eight datasets mentioned in Fig. 1 for demonstration of the experimental results. The quantitative results along with visual performance are demonstrated in the paper to indicate the effectiveness and efficiency of the proposed method. The dataset consists of ultrasound (US) image (Dataset1), four sets of magnetic resonance imaging (MRI) images (Dataset2,4, 6 and 7) and three sets of computed tomography (CT) images (Dataset3, 5 and 8).
We compare our proposed weighted least squares optimisation strategy via wavelet multiscale CNNs based SR algorithm with bicubic interpolation and seven state-of-the-art SR methods: CCR_SISR [64], Dual_Dic_SR [63], HT_SR [65], SR_ALS [62], SRCNN [5], WMCNN [33], QSIM [50]. For verifying the reliability of our method, we performed an experiment through adding different Gaussian noise to the input image to produce LR-HR image pairs. A pixel value is normalised to [0,1] along with Gaussian noise with a mean vale of 0.05, 0.1, 0.15 & 0.2 is applied to normalised image. To validate the quality of SR results with different prevailing methods, we employed peak-signal-to-noise ratio (PSNR, dB) and structural similarity index measure (SSIM) in our experiments. All of these evaluation metrics are carried out between the original HR image and the reconstructed image.
Experimental procedures
At initial, we employed weighted least squares optimization operation, which uses an edge-preserving smoothing operator that is especially suitable for progressive image coarsening and multiscale information extraction which smoothes the image while retaining the edges. Our multiscale convolutional neural networks improve previous method by training multiple convolutional neural networks to characterize wavelet multiscale representations. We compare their speed of convergence for training. The experiments are performed with the same network configuration and computation environment. The previous CNN approaches directly restore single whole medical image. In comparison, our method regresses the wavelet multiscale representations of the whole medical image. A wavelet-based divide (i.e. multiple orientations and frequency bands) and conquer (via training convolutional neural networks) approach renders a powerful representation than the single comprehensive representations. Our method's successful training convergence displays that convolutional neural networks learn medical images intrinsic faster from wavelet multiscale representations from the whole images. A proposed approach exploits wavelet multiscale analysis to capture spackle invariable statistics of medical images compared to traditional spatial domain-based super-resolution techniques. These properties contribute to noise removal and preserve vital information of the images. The efficient performance of our method shows that CNNs more effectively remove the effect of noise by learning the nature of multiscale wavelet representations that from the whole images. As one CNN generated representation is endowed with the image features characterized in one-frequency band with certain orientations specified the wavelet decomposition, the wavelet synthesis intrinsically ensembles the structural information and object diversity from multiscale frequency bands and the directions and achieves effective super-resolution. The right dash box of Fig. (1) describes a one-level wavelet synthesis for super-resolution, in which four CNN generated representations are synthesized, restoring a high-resolution medical image. Experiments are carried out with upscaling factors two and four.
Quantitative and qualitative assessments
Tables 1 and 2 indicate the experimental SR results based on SSIM and PSNR for upscale factor two and four. As in case of all datasets, bicubic interpolation, CCR_SSIR, Dual_Dic_SR, SRCNN loses bone structure information, however, HT_SR, SR_ALS, WMCNN, QISM and proposed method shows better contrast. However, the output generated by SRCNN and WMCNN losses details of soft tissues (see in Figs. 3 and 4). Paying attention to the SR results of dataset1-8, we can observe that the HT_SR, WMCNN conserves an information precisely, however, the low contrast still remains. Furthermore, by focusing on the closeup in datasets 3 and 4, the bone structures are distinctly present in the proposed method. Tables 1 and 2 provide the quantitative measurement of the various SR methods on eight datasets of ultrasound, MRI and CT datasets. Looking after an experimental result, the output obtained by our method demonstrates high efficiency in terms of objective metrics, however, small improvements were seen in the case of other algorithms. In Tables 1 and 2, we could observe that nearly in both performance metrics of our approach gets good result comparing to the state-of-the-art methods. Even though in few metrics are high with small margins than other methods, but the differences in most of the terms are higher than other methods. Further, to have an additional intuitive understanding of quantitative evaluations comparing to different methods, the average results of these objective metrics are demonstrated in Tables 1 and 2. In summarization, the SR result of the proposed algorithm outperforms other seven methods. The effectiveness of SR image is optimal when the above proposed performance metrics possesses high value.The key role of the SR is to improve overall, appropriate and accurate information in resultant image such that the SR result is highly adequate for human interpretation. Similarly, the visual analysis is also highly essential in addition to objective/quantitative performance. To represent performance visually, the respective SR image is demonstrated in Figs. 3 and 4. It has demonstrated better visualization compares to other modalities. It also makes for the easy process of checking the other modalities which is comparatively very low in measured parameters. The wavelet multiscale analysis gains huge improvement over other CNN models, which not only gives a solution for a missing pooling task in previous methods, however, also improves its local filtering operations with wavelet filter. In addition, the proposed approach that is built based on concatenating four versions of the original SRCNN frameworks is compared empirically. The empirical findings in Tables 1 and 2 and visual analysis in Figs. 3 and 4 demonstrate that our model surpasses other models over upscaling factor two and four in terms of performance measurements. The experimental comparison suggests that a wavelet synthesis is, however, the secret for our model success rather than the larger size of the model. It can be note that other models have more weight layers, however, proposed structure comprises of four three-layered convolutional neural networks, leading to a complete compact twelve-layered framework. The examination shows that proposed approach bear far less complex structure as compares to other SR methods, however, still obtains comparable efficiency with them. One explanation for the positive results is that some of the CNN models take whole images as an input to complete model for training and proposed system train the convolutional neural networks to reconstruct various frequency sub-bands by ensuring that each frequency representation is properly reconstructed. The overall output of the upscaling factor four is lower than that of two, since greater upscaling restoration creates greater uncertainty of super resolution. Some comparative methods and our proposed method display comparable performance for certain groups in this scenario. Our proposed method, however, still performs better than other techniques. We have only used SRCNN in our work as fundamental model for multiscale learning. Since multiscale representation generate holistic features subspace, it is expected that wavelet learning related to alternative SR model. As compares to a method proposed by Tenne et al. using quantum image scanning microscopy (QISM) and other methods, our method demonstrates higher efficiency in both objective matrices, i.e. PSNR and SSIM. The proposed method possesses 0.1–0.5 higher PSNR rate and 0.05–0.2 higher SSIM rate for all medical image datasets as compares to other methods as demonstrated in Tables 1 and 2. Also, from the Figs. 3 and 4, it observed that, the visual representation of our method is much better than QSIM and other methods. From Fig. 3, it can be seen that the super-resolved images of HT_SR, Dual_Dic_SR preserve proper information, but the details in the dark regions are not very clear and overall show low global contrast. Comparatively, the results of SR_ALS, WMCNN obtain the good contrast, but the information of soft tissues is disproportional. QSIM can preserve the details of the source images, but the visual appearance is slightly low quality. The super-resolved image generated by the proposed method presents better visual performance and the details are abundant. Tables 1 and 2 show the evaluation metrices of different methods for eight medical images. We can see that the values of PSNR and SSIM of the proposed method are highest in all datasets. In Fig. 4, Bicubic, CCR_SISR have low contrast. The QSIM and WMCNN and the proposed method can maintain the details well, and the contrast of these approaches is better than the other methods. Additionally, the brightness of the proposed method in some regions is higher than the most of the comparative methods (as is shown in the color blocks). In case of all medical images produced by our method present the proper global brightness and texture. We can notice that, our model reconstructs the clear and accurate textures as compares to other comparative methods. The SR outcomes of various quantitative measurement metrices and respective visual performance are demonstrated for validation. The detailed information can be preserved well in the results of our method. So, this indicates that the proposed method can effectively extract the features of source images. It is noticeable that nearly all the performance metric values of the proposed method are higher than the other methods.

Qualitative comparison of proposed method with other SR algorithms (scale factor → 2)

Visual analysis of proposed method with other SR algorithms (scale factor → 2)
Conclusion
In this paper, we have proposed a weighted least squares optimization-based image SR framework using multiscale CNNs. A WLS set-up used in our method performs an edge-preserving operation, that smoothes the image while preserving the edges simultaneously thus strengthen the edges by having the balance between blurring and sharpening in a better manner. It has been extended to several image processing applications, such as multi-resolution system construction and tone mapping. In addition, we built a SR model by training CNNs based on wavelet analysis. We use wavelet filters that increase the local processing power of CNNs. The absence of CNN-based SR pooling operations in previous techniques is compensated by the downsampling in wavelet decomposition. Our model combines the representational capacity of CNNs to learn basic features along with multiscale potential of wavelet synthesis to acquire multiple orientations and frequency representation. The efficiency of our super-resolution method has been validated by both visual interpretation and experimental evaluations. The SR results obtained by the proposed method demonstrated better performance in terms of both quantitative and qualitative analyses for all medical images. Our method helps to retained information of the medical images precisely and also the bone structures are distinctly present in the proposed method. Similarly, our method demonstrates high performance in both objective metrics in terms of PSNR and SSIM. The proposed method demonstrates 0.1–0.5 increment in PSNR value and 0.05–1.0 more SSIM value for all medical datasets as compares to other methods that indicate improvement in image restoration approach for all the medical images. The standardized SR evaluation techniques are on the basis of difference between reconstructed HR image and original HR image, and the actual HR image is unfeasible to obtained in practical. However, we shall explore to establish a visual interpretation and no reference quality indexes as measurement metrics in our future work. To enhance perceptual performance, we will also explore to integrate visual interpretation and more reference quality indexes in the objective features.
Availability of data and material
Open source data has been taken.
Code availability
Matlab TM software has been used.
Change history
13 August 2021
A Correction to this paper has been published: https://doi.org/10.1007/s40747-021-00490-y
References
Wu W, Yang X, Liu K, Liu Y, Yan B (2016) A new framework for remote sensing image super-resolution: sparse representation-based method by processing dictionaries with multi-type features. J Syst Architect 64:63–75
Chen H, He X, Qing L, Teng Q, Ren C (2018) SGCRSR: Sequential gradient constrained regression for single image super-resolution. Signal Process Image Commun 66:1–18
Shamsolmoali P, Zareapoor M, Jain DK, Jain VK, Yang J (2019) Deep convolution network for surveillance records super-resolution. Multimed Tools Appl 78(17):23815–23829
Amin J, Sharif M, Yasmin M, Fernandes SL (2018) Big data analysis for brain tumor detection: deep convolutional neural networks. Futur Gener Comput Syst 87:290–297
Dong C, Loy CC, He K, Tang X (2015) Image super-resolution using deep convolutional networks. IEEE Trans Pattern Anal Mach Intell 38(2):295–307
Fernandes SL, Gurupur VP, Sunder NR, Arunkumar N, Kadry S (2017) A novel nonintrusive decision support approach for heart rate measurement. Pattern Recogn Lett 139:148–156
Lin G, Qingxiang Wu, Chen L, Qiu L, Wang X, Liu T, Chen X (2018) Deep unsupervised learning for image super-resolution with generative adversarial network. Signal Process Image Commun 68:88–100
Zareapoor M, Shamsolmoali P, Jain DK, Wang H, Yang J (2018) Kernelized support vector machine with deep learning: an efficient approach for extreme multiclass dataset. Pattern Recognit Letters 115:4–13
Fernandes SL, Tanik UJ, Rajinikanth V, Arvind Karthik K (2020) A reliable framework for accurate brain image examination and treatment planning based on early diagnosis support for clinicians. Neural Comput Appl 32(20):15897–15908
Raja NSM, Fernandes SL, Dey N, Satapathy SC, Rajinikanth V (2018) Contrast enhanced medical MRI evaluation using Tsallis entropy and region growing segmentation. J Ambient Intell Hum Comput, pp 1–12
Amin J, Sharif M, Yasmin M, Ali H, Fernandes SL (2017) A method for the detection and classification of diabetic retinopathy using structural predictors of bright lesions. J Comput Sci 19:153–164
Lehmann TM, Gonner C, Spitzer K (1999) Survey: Interpolation methods in medical image processing. IEEE Trans Med Imaging 18(11):1049–1075
Yang S, Sun Y, Chen Y, Jiao L (2012) Structural similarity regularized and sparse coding based super-resolution for medical images. Biomed Signal Process Control 7(6):579–590
Rueda A, Malpica N, Romero E (2013) Single-image super-resolution of brain MR images using overcomplete dictionaries. Med Image Anal 17(1):113–132
Wei S, Zhou X, Wei Wu, Qiang Pu, Wang Q, Yang X (2018) Medical image super-resolution by using multi-dictionary and random forest. Sustain Cities Soc 37:358–370
Dou Q, Wei S, Yang X, Wei Wu, Liu K (2018) Medical image super-resolution via minimum error regression model selection using random forest. Sustain Cities Soc 42:1–12
Jebadurai J, Dinesh Peter J (2018) Super-resolution of retinal images using multi-kernel SVR for IoT healthcare applications. Future Gener Comput Syst 8:338–346
Ki, J, Lee JK, Lee KM (2016) Accurate image super-resolution using very deep convolutional networks. In: Proceedings of the IEEE Conference on computer vision and pattern recognition, pp 1646–1654
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on computer vision and pattern recognition, pp. 770–778
Liu H, Jun Xu, Yan Wu, Guo Q, Ibragimov B, Xing L (2018) Learning deconvolutional deep neural network for high resolution medical image reconstruction. Inf Sci 468:142–154
Tai Y, Yang J, Liu X (2017) Image super-resolution via deep recursive residual network. In: Proceedings of the IEEE Conference on computer vision and pattern recognition, pp 3147–3155
Lim B, Son S, Kim H, Nah S, Lee KM (2017) Enhanced deep residual networks for single image super-resolution In: Proceedings of the IEEE Conference on computer vision and pattern recognition workshops, pp 136–144
Zhang Y, Tian Y, Kong Y, Zhong B, Fu Y (2018) Residual dense network for image super-resolution. In: Proceedings of the IEEE Conference on computer vision and pattern recognition, pp 2472–2481
Zhang Y, Li K, Li K, Wang L, Zhong B, Fu Y (2018) Image super-resolution using very deep residual channel attention networks. In: Proceedings of the European Conference on computer vision (ECCV), pp 286–301
Ledig C, Theis L, Huszár F, Caballero J, Cunningham A, Acosta A, Aitken A et a (2017) Photo-realistic single image super-resolution using a generative adversarial network. In: Proceedings of the IEEE Conference on computer vision and pattern recognition, pp 4681–4690
Sajjadi MSM, Scholkopf B, Hirsch M (2017) Enhancenet: single image super-resolution through automated texture synthesis. In: Proceedings of the IEEE International Conference on computer vision, pp 4491–4500
Wang X, Yu K, Wu S, Gu J, Liu Y, Dong C, Qiao Y, Loy CC (2018) Esrgan: Enhanced super-resolution generative adversarial networks. In: Proceedings of the European Conference on Computer Vision (ECCV) Workshops
Dong C, Loy CC, He K, Tang X (2014) Learning a deep convolutional network for image super-resolution." In: European Conference on computer vision, pp 184–199. Springer, Cham
Kim J, Lee JK, Lee KM (2016) Deeply-recursive convolutional network for image super-resolution. In: Proceedings of the IEEE Conference on computer vision and pattern recognition, pp 1637–1645
Mao, X-J, Shen X, Yang Y-B (2016) Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. arXiv preprint arXiv:1603.09056
Romano Y, Isidoro J, Milanfar P (2016) RAISR: rapid and accurate image super resolution. IEEE Trans Comput Imaging 3(1):110–125
Dong C, Loy CC, Tang X (2016). Accelerating the super-resolution convolutional neural network. In: European Conference on computer vision, pp 391–407. Springer, Cham, 2016
Wang T, Sun W, Qi H, Ren P (2018) Aerial image super resolution via wavelet multiscale convolutional neural networks. IEEE Geosci Remote Sens Lett 15(5):769–773
Agustsson E, Timofte R (2017) Ntire 2017 challenge on single image super-resolution: dataset and study. CVPRW 3:126–135
Hu X, Mu H, Zhang X, Wang Z, Tan T, Sun J (2019) Meta-SR: a magnification-arbitrary network for super-resolution. In: CVPR, pp 1575–1584
Roth S, Black MJ (2009) Fields of experts. IJCV 82(2):205–229
Zhang K, Zuo W, Gu S, Zhang L (2017) Learning deep CNN denoiser prior for image restoration. In: CVPR, pp 3929–3938
Zhang K, Zuo W, Zhang L (2018) FFDNet: toward a fast and flexible solution for CNN-based image denoising. IEEE TIP 27(9):4608–4622
Chen Y, Tai Y, Liu X, Shen C, Yang J (2018). Fsrnet: End-to-end learning face super-resolution with facial priors. In: CVPR, pages 2492–2501, 2018
Lugmayr A, Danelljan M, Timofte R (2019) Unsupervised learning for real-world super-resolution. In: IC-CVW, pp 3408–3416
Ren D, Zhang K, Wang Q, Hu Q, Zuo W (2020) Neural blind deconvolution using deep priors. In: CVPR, pp 1628–1636
Shen Z, Lai W-S, Xu T, Kautz J, Yang M-H (2018) Deep semantic face deblurring. In: CVPR, pp 8260–8269
Yasarla R, Perazzi F, Patel VM (2019) Deblurring face images using uncertainty guided multi-stream semantic networks. arXiv preprint arXiv:1907.13106
Jiang J, Sun He, Liu X, Ma J (2020) Learning spatial-spectral prior for super-resolution of hyperspectral imagery. IEEE Trans Comput Imaging 6:1082–1096
Li K, Dai D, Konukoglu E, Gool LV (2021). Hyperspectral image super-resolution with spectral mixup and heterogeneous datasets. arXiv preprint arXiv:2101.07589
Villar-Corrales A, Schirrmacher F, Riess C (2021) Deep learning architectural designs for super-resolution of noisy images. arXiv preprint arXiv:2102.05105
Jiang Z, Yue H, Lai Y-K, Yang J, Hou Y, Hou C (2021) Deep edge map guided depth super resolution. Signal Process Image Commun 90:116040
Ruan Y, Xue X, Shen Y (2021) Quantum image processing: opportunities and challenges. Math Probl Eng
Schuld M, Sinayskiy I, Petruccione F (2014) The quest for a quantum neural network. Quantum Inf Process 13(11):2567–2586
Tenne R, Rossman U, Rephael B, Israel Y, Krupinski-Ptaszek A, Lapkiewicz R, Silberberg Y, Oron D (2019) Super-resolution enhancement by quantum image scanning microscopy. Nat Photon 13(2):116–122
Alves Ystallonne CS (2019) Quantum computing application in super-resolution Master's thesis, Brasil
Israel Y, Tenne R, Oron D, Silberberg Y (2017) Quantum correlation enhanced super-resolution localization microscopy enabled by a fibre bundle camera. Nat Commun 8(1):1–5
http://splab.cz/en/download/databaze/ultrasound. Accessed 27 Aug 2020
https://www.kaggle.com/kmader/siim-medical-images#__sid=js0. Accessed 27 Aug 2020
Farbman Z, Fattal R, Lischinski D, Szeliski R (2008) Edge-preserving decompositions for multi-scale tone and detail manipulation. ACM Trans Graph (TOG) 27(3):1–10
Lischinski D, Farbman Z, Uyttendaele M, Szeliski R (2006) Interactive local adjustment of tonal values. ACM Trans Graph 25(3):646–653
Fattal R, Agrawala M, Rusinkiewicz S (2007) Multiscale shape and detail enhancement from multi-light image collections. ACM Trans Graph. 26(3):51
Oppenheim AV, Schafer RW (1989) Discrete-time signal processing. Prentice Hall
Burt P, Adelson EH (1983) The Laplacian pyramid as a compact image code. IEEE Trans Comm 31:532–540
Comaniciu D, Meer P (2002) Mean shift: A robust approach toward feature space analysis. IEEE Trans Pattern Anal Mach Intell 24(5):603–619
Cohen A, Daubechies I et al (1992) A stability criterion for biorthogonal wavelet bases and their related subband coding scheme. Duke Math J 68(2):313–335
Wang Y, Yang J, Xiao C, An W (2018) Fast convergence strategy for multi-image superresolution via adaptive line search. IEEE Access 6:9129–9139
Zhang J, Zhao C, Xiong R, Ma S, Zhao D (2012) Image super-resolution via dual-dictionary learning and sparse representation. In: 2012 IEEE International Symposium on circuits and systems (ISCAS), pp 1688–1691. IEEE, 2012
Zhang Y, Zhang Y, Zhang J, Dai Q (2015) CCR: Clustering and collaborative representation for fast single image super-resolution. IEEE Trans Multimed 18(3):405–417
Luo J, Sun X, Yiu ML, Jin L, Peng X (2018) Piecewise linear regression-based single image super-resolution via Hadamard transform. Inf Sci 462:315–330
Goyal B, Dogra A, Agrawal S, Sohi BS, Sharma A (2020) Image denoising review: from classical to state-of-the-art approaches. Inf Fusion 55:220–244
Goyal B, Dogra A, Agrawal S, Sohi BS (2017) Dual way residue noise thresholding along with feature preservation. Pattern Recognit Lett 94:194–201
Funding
None.
Author information
Authors and Affiliations
Contributions
BG: conceptualization, writing—original draft preparation, methodology and software. DCL: data curation, writing—draft preparation. AD: visualization, investigation, supervision and validation. S-HW: software, validation, reviewing and editing.
Corresponding author
Ethics declarations
Conflict of interest
There is no conflict of interest.
Ethics approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this article was revised due to incorrect affiliation of Third Author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Goyal, B., Lepcha, D.C., Dogra, A. et al. A weighted least squares optimisation strategy for medical image super resolution via multiscale convolutional neural networks for healthcare applications. Complex Intell. Syst. 8, 3089–3104 (2022). https://doi.org/10.1007/s40747-021-00465-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-021-00465-z