
Abstract
Contact tracing is one of several strategies employed in many countries to curb the spread of SARS-CoV-2. Digital contact tracing (DCT) uses tools such as cell-phone applications to improve tracing speed and reach. We model the impact of DCT on the spread of the virus for a large epidemiological parameter space consistent with current literature on SARS-CoV-2. We also model DCT in combination with random testing (RT) and social distancing (SD).
Modelling is done with two independently developed individual-based (stochastic) models that use the Monte Carlo technique, benchmarked against each other and against two types of deterministic models.
For current best estimates of the number of asymptomatic SARS-CoV-2 carriers (approximately 40%), their contagiousness (similar to that of symptomatic carriers), the reproductive number before interventions (\({R_{0}}\) at least 3) we find that DCT must be combined with other interventions such as SD and/or RT to push the reproductive number below one. At least 60% of the population would have to use the DCT system for its effect to become significant. On its own, DCT cannot bring the reproductive number below 1 unless nearly the entire population uses the DCT system and follows quarantining and testing protocols strictly. For lower uptake of the DCT system, DCT still reduces the number of people that become infected.
When DCT is deployed in a population with an ongoing outbreak where \(\mathcal{O}\) (0.1%) of the population have already been infected, the gains of the DCT intervention come at the cost of requiring up to 15% of the population to be quarantined (in response to being traced) on average each day for the duration of the epidemic, even when there is sufficient testing capability to test every traced person.
Similar content being viewed by others

1 Introduction
Tracing and isolation of people who were in contact with an infectious person (contact tracing) can be used to control the spread of communicable diseases [1, 2]. In the traditional understanding of contact tracing (CT), public health employees interview known carriers (index cases) of the disease and then track down people who had the type of close contact with the index case necessary to transmit the disease. Contacts are then diagnosed and isolated. This implementation is only suited for infections that spread relatively slowly, and where cases can be easily diagnosed [3]. SARS-CoV-2, with its unspecific symptoms, high number of asymptomatic carriers, and incubation times as short as a day, does not fit this mold.Footnote 1 Recent studies indicate that an outbreak of SARS-CoV-2 could be controlled using fast and efficient digital contact tracing (DCT) [4, 5]. DCT systems using cellphone applications based on Bluetooth proximity measurements are currently being developed and/or deployed in many countries [6–15]. Predicting the effect of DCT on an outbreak is challenging, especially since the values of many epidemiological parameters that describe the outbreak dynamics have not been determined accurately yet, with clinical studies yielding conflicting results. Almost no practical experience for DCT is available. Partly automated CT systems were in use during the Ebola outbreak 2014–2016 [16] and it turned out that the technical difficulties that come with that approach must not be underestimated.
Simulation studies focusing on classical CT for COVID-19 consistently indicate that around 70% of the contacts need to be traced, and that the tracing delay has to be as short as 1 day [5, 17]. For these reasons, [17] doubt that COVID-19 can be controlled by traditional CT in practice. Ferretti et al. [4] however point out that DCT could significantly reduce tracing delays, so that the outbreak could be controlled for tracing probabilities much smaller than 70%. Meanwhile, several other simulation studies indicate that a high tracing probability and a combination of fast CT and testing is required to control SARS-CoV-2 [16]. However, it also became clear that not only the reduction of the reproduction number, or the final size of the epidemic, need attention, but also the number of persons that go to quarantine [18]: A naive application of DCT leads to a situation that resembles a lock-down as a large fraction of the population is quarantined. An appropriate choice of the tracing and testing protocol is central.
We developed individual-based models with the Monte Carlo (MC) simulation technique, flanked and cross-checked by deterministic models, to evaluate the dynamics of a COVID-19 outbreak under different intervention protocols, focusing on DCT and DCT combined with random testing (administering a SARS-CoV-2 test to some fraction of the population at random, that is regardless of each person’s symptoms or contact history) and social distancing. We determine not just the immediate effective reproductive number \({R_{e}}\), but also the daily \({R_{e}}\), the number of healthy people in quarantine, and the number of people infected, for up to a year of continuous interventions. The sensitivity of all outcomes to the reported ranges of values of the epidemiological parameters is studied in detail.
The goal of this paper is to study quantitatively under which conditions and to which degree DCT combined with fast testing and social distancing can replace rigorous shelter-in-place policies for keeping the effective reproduction rate \({R_{e}}\leq 1\).
All abbreviations used can be found in Table 2.
2 Model inputs
Table 1 presents an overview of all model input parameters and the values considered for them. They will be discussed in detail in the following subsections.
Many model inputs that are properly described by a distribution rather than just a mean value are modelled using a shifted Gamma distribution, defined as
where \(x\geq \mu \). The gamma distribution can describe the shapes of and interpolate between several other probability distributions and is widely used to model skewed distributions for which the underlying true probability distribution is not known [19, 20]. As this distribution is flexible, we also use a discretized version \((n\in \mathbb {N} _{0})\)
2.1 Social contact structure
Our deterministic models describe contacts between individuals in a population by the usual mass action law. The stochastic models allow for a more detailed investigation. Particularly, two different strategies are considered: For the first, in the following referred to as homogeneous population, we choose the contacts for each person randomly out of the entire population. The probability for a person to have n unique contacts close enough to transmit a respiratory virus on a given day is taken from the empirical distributions reported in [21]. These are well described by
where \({n_{c}}\) is the mean number of contacts per day. We also consider a more realistic contact pattern, in the following referred to as social graph population. The population is described by a social graph, were each individual is represented by a node and contacts are represented by edges. Each individual is given a fixed set of contact persons for the entire simulation. We employ a modified version of the Lancichinetti–Fortunato–Radicchi benchmark graph (LFR) [22] as shown in [23] (therein referred to as LFR-BA). In this model, the population is divided into communities with sizes distributed according to a power-law distribution. Node edges are constructed according to the linear preferential attachment model [24] under the constraint that an average fraction of \((1-\mu )\) of the edges of each node connect nodes within the same community. A graph constructed in this manner results in a power-law probability distribution with index \(a=2\) for the node degree n [24]:
where \(n_{\mathrm{min}}\) is the minimum node degree. Here, the mean number of contacts per day is given by \({n_{c}}= \frac{a\cdot n_{\mathrm{min}}}{a-1}\). We assume that each edge is active once per day, so that the node degree corresponds to the number of contacts per day.
2.2 Epidemiological parameters
Figure 1 schematically shows the probability distributions for symptom onset, transmission, and true positive test results. The parameters are explained in the following paragraphs.

Course of the disease with probability distribution for the incubation period \({T_{\mathrm {Inc}}}\) (top) [25] and the fully correlated probability density function for the contagiousness \({T_{\mathrm {con}}}\) (bottom) [26]. The dotted vertical lines corresponds to the median of \({T_{\mathrm {Inc}}}\). The probability for a true–positive point-of-care (POC) test is displayed on the bottom left (grey line). The diamonds correspond to exposure (contact, black), end of latency/begin of contagious period (magenta) and symptom onset (teal)
Incubation period P(\({T_{\mathrm {Inc}}}\) ). The distribution of incubation periods is taken as
(Fig. 1 upper curve) with shape parameters chosen to match the curve reported in [25], which has median and mean incubation periods of 7 days and 7.44 days, respectively, with a range from 0–23 days. The authors included a relatively large group of patients (\(n= 587\)) with a wide age (0–90 years) and symptom (asymptomatic to severe) range. Other studies, albeit with smaller number of patients and with a bias towards more severe symptoms, have reported lower medians [27, 28]. Therefore, in addition to the parameters matching [25] (printed in black in Table 1) we also model a curve with shorter median and mean incubation periods of 3.6 days and 4 days (printed in gray in Table 1).
Latent period \({T_{\mathrm {lat}}}\). The latent period for SARS-CoV-2 is shorter than the incubation period, meaning pre-symptomatic transmission can occur [1, 29]. The latent period is difficult to determine empirically, as it requires exact information about the time of exposure and contagiousness. As, to our knowledge, no reliable, large-scale studies have been published on the latent period of SARS-CoV-2 so far, we use the measured contagiousness relative to the incubation time as an auxiliary means to infer latency,
where the value of 2.5 days comes from the transmission probability curve discussed in the next paragraph.
The transmission probability curve \(P_{\mathrm{trans}}({\tau })\). The transmission probability is the probability that a contagious person infects someone they have contact with. This probability is often given as an average “infectivity per day”, \({\beta _{i}}\), even though it changes significantly as a function of the time since infection τ. The infectivity was measured as a function of the time since onset of symptoms by He et al. [26]. They find that carriers become contagious approximately 2.5 days before the onset of symptoms, and that approximately 44% of transmissions occur during this pre-symptomatic phase.
We take as the contagious period \({T_{\mathrm {con}}}\) the time from the end of the latent period until 99% of the cumulative transmission probability is reached; a person is considered to be recovered afterwards. Therewith, the transmission probability as a function of time since infection is given by a scaled and truncated Gamma distribution (Fig. 1 lower curve). After infection, an individual has a (random) latent period \({T_{\mathrm {lat}}}\), during which the transmission probability is zero. Afterward, for \({\tau }={T_{\mathrm {lat}}}+t\) (and \(t\geq 0\)), we have
where χ is 1 if the condition in the argument is met, and 0 otherwise.
The shape parameters shown in black in Table 1 are our defaults, taken to match the curve in [26]. Pre-symptomatic infectivity is strongly debated. Therefore, we model a second shape where only 18% of the transmission occurs during the pre-symptomatic phase (shape parameter values printed in gray).
The course of the disease for asymptomatic carriers is the same as that for symptomatic carriers as shown in Fig. 1, and the incubation time is the time when symptoms would have started.
Fraction of asymptomatic cases \(1-\alpha \). The proportion of asymptomatic carriers (\(1-{\alpha }\)) described in the literature ranges from ∼4% [30] to ∼40%[31] of all cases. Initial reports for (\(1-{\alpha }\)) derived from testing of specific cohorts (cruise ship, returning travellers) ranged from 17–31% [29, 32, 33], however larger studies suggest even higher numbers. Analysis of the mass screening of the full population of the municipality of Vo’, Italy [31] report that 41.1% of the confirmed SARS-CoV-2 infections were asymptomatic (as defined by the absence of fever and/or cough). Ferretti et al. [4] analyzed 40 selected transmission pairs and also derived a value of 40% for the proportion of asymptomatic infected individuals. We model several different values for α to cover the reported ranges.
Reduced asymptomatic transmission probability \({\eta _{as}}\). While initial studies assumed that asymptotic cases were less contagious [4, 34], newer reports indicate that the viral load of asymptomatic cases is similar to symptomatic cases, which suggests similar contagiousness [35–40]. We nevertheless introduce the parameter \({\eta _{as}}\in [0,1]\), which scales the transmission probability for pre- and asymptomatic cases, and vary that parameter to explore its effects. We note that when we model with \({\eta _{as}}<1\), we apply the scaling to both pre- and asymptomatic phases; since there most likely is no difference in viral load, if asymptomatic transmission is suppressed, this is likely due to circumstantial factors, like lack of coughing, which apply to the pre-symptomatic phase as well.
The basic reproductive number \({R_{0}}\). If the contagiousness is independent of the symptom status, i.e. \({\eta _{as}}= 1\), the reproductive number is given by the number of contacts during the contagious period, \({n_{c}}{T_{\mathrm {con}}}\), times the average probability to transmit the infection in one contact, \({\beta _{i}}\). However, we need to distinguish between symptomatic, pre-symptomatic, and asymptomatic cases in order to allow for \({\eta _{as}}<1\). We find
Note that—though \(P_{\mathrm{trans}}\) is a random function—the random part of the function is a pure translational offset (the latency period), s.t. the integral is deterministic.
\({R_{0}}\) is expected to be different in different populations because \({n_{c}}\) is different by factors of up to 4 just within the populations of different European countries. Values of \({R_{0}}\) ranging from 1.4 to 6.5 have been reported [45], though it is not always clear whether or not the reported \({R_{0}}\) is for the case where symptomatic individuals are quarantined. Furthermore, \({R_{0}}\) is usually not corrected for the contact rate in the population where it is studied. We consider \({R_{0}}\) the reproductive number without any form of interventions. We take \({R_{0}}\) of 3 (approximately the median reported in [45]) as our default, but also run the models for \({R_{0}}\) of 2 and 4.
Following [46], we introduce the random reproduction number for an individual \(R_{0,i}\). \({R_{0}}\) is the expectation value over the \(R_{0,i}\). For simplicity (and since two of our models are not based on continuous time but on discrete time/days), we state the time-discrete formula for \(P(R_{0,i}=n)\). Assume that an individual did infect n persons. These n persons can be arbitrarily distributed over the contagious period. In a slight abuse of notation, let \(T_{c}\) denote the number of days that a person is contagious for. Furthermore, let \(C_{n} = \{\vec{n}\in \mathbb {N} _{0}^{T_{c}}: \sum_{i=1}^{T_{c}} \vec{n}_{i} = n\}\) be all possible ways to distribute the n infectees to \(T_{c}\) days. Then, for a homogeneous population,
where the convolution ⊛ is over the parameter m. This distribution is shown for some parameter combinations in Fig. 2.

The distribution of the number of people a carrier infects (Eq. (8)) for 3 combinations of \({n_{c}}\) (the mean number of contacts per day) and \({\beta _{i}}\) (the average transmission probability per day) that result in \({R_{0}}=3\) (see Tab. 1) (left) and for a fixed \({n_{c}}\) but different social structures (right). Default values for the infection probability curve are used, \({\eta _{as}}=1\), and no interventions are applied. Compared to a Poisson distribution with mean of 3, the distribution is over-dispersed
2.3 Intervention protocols
The interventions considered here are (1) DCT, (2) quarantining, (3) testing, and (4) social distancing. Reported symptomatic cases are quarantined starting right at the beginning of the epidemic. The remaining interventions are turned on once a fraction \({f_{i}}\) of the population has become exposed.
(1) DCT. We assume that a fraction \({ p_{\mathrm {app}}}\) of the population uses the DCT system and that we can trace all contacts between users of this system with time delay \({T_{\mathrm {delay}}}\). In case that both infector and infectee have a DCT device, the probability for successful tracing is \({\eta _{\mathrm {DCT}}}\), while tracing always fails if either infector or infectee do not use the system. \({\eta _{\mathrm {DCT}}}\) accounts for situations where cell phones run out of battery, are not with the owner at all times, Bluetooth is turned off, or where an alert is ignored. The DCT system (DCTS) identifies contacts within the past \({\Delta T _{\mathrm {trace}}}\) days.
In the literature, the overall tracing probability across the population is often taken as \(p_{\mathrm{trace}} = p_{\mathrm{app}}^{2} {\eta _{\mathrm {DCT}}}\) (e.g. in [4]). We note that this formula is not correct but becomes approximately right if \({ p_{\mathrm {app}}}^{2} {\eta _{\mathrm {DCT}}}\) is small (see the Appendix).
To become an index case for tracing, a person must be reported. We assume that from the group of symptomatic carriers, a fraction \({f_{m}}\) sees a doctor to get tested with a reliable laboratory test and is then reported. A fraction (\(1-{\alpha }\)) of cases will go unreported because they do not exhibit symptoms, unless they get tested due to being traced. A fraction \({\alpha }(1-{f_{m}})\) of symptomatic cases will go unreported due to lack of access to medical tests. In the case where \({\eta _{as}}= 1\), α and \({f_{m}}\) are degenerate.
First order tracing refers to a protocol where contacts of an index case are traced. DCT also allows immediate tracing of contacts-of-contacts. We refer to this as second order tracing. If the \({\Delta T _{\mathrm {trace}}}\) is big enough, DCT will identify the infector. Second order tracing then can trace not just the people infected by an index case, but also the people who were infected by the same infector as the index case.
A DCT system will identify all contacts, regardless of their infection status. Since many models assume perfect accuracy in identifying only contacts that became infected (e.g. [4, 5, 47]), we run all parameters both with (closer to reality) and without (to be comparable to other models) tracing of the uninfected contacts.
All traced people immediately go into quarantine. This is necessary to suppress the pre- and asymptomatic transmission rates.
(2) Quarantining. Quarantining refers to any intervention that reduces the transmission probability significantly; this includes self-quarantine at home as well as being hospitalized. We assume that all reported symptomatic patients are immediately quarantined, regardless of any other interventions. This already reduces the reproductive number to
Figure 3 shows \(R_{e,Q}\) for combinations of α, \({f_{m}}\), and \({\eta _{as}}\). In Fig. 3 (top), \({\eta _{as}}= 1\), so only the product of α and \({f_{m}}\) is relevant, and results are shown for \({R_{0}}= 3\) and for \({R_{0}}= 2\). In Fig. 3 (bottom), \({\eta _{as}}<1\), so both \({R_{0}}\) and \(R_{e,Q}\) depend on α and on \({f_{m}}\). For each combination of α and \({f_{m}}\), the transmission probability \({\beta _{i}}\) was adjusted to obtain \({R_{0}}= 3\).

The effective reproductive number reached just from quarantining reported symptomatic carriers, \(R_{\mathrm{e;Q}}\), is shown for four different values of \({\eta _{as}}\) (asymptomatic infectivity scaling) as calculated from Eq. (9). Top panel: In the case of \({\eta _{as}}= 1\), \(R_{\mathrm{e;Q}}\) depends only on the product of α (symptomatic fraction) and \({f_{m}}\) (fraction reported and tested) and is shown for two values of \({R_{0}}\). Lower three panels: For each combination of \({\eta _{as}}\) and α, the infection probability was adjusted to obtain \({R_{0}}=3\)
In response to being reported or being traced, people are quarantined by default for 14 days. Symptomatic cases may leave quarantine 8 days after the symptoms start. Uninfected contacts can leave quarantine early following a testing protocol.
(3) Testing. We consider two types of tests. A reliable laboratory test for symptomatic carriers seeing a medical professional, and a fast point of care (POC) test that can be performed at home or at mobile testing stations. In either case, carriers only test positive while they have a high enough viral load. We assume the tests have \(p^{\mathrm{true\ positive}} = 0.0\) while the carrier is in the latent period, that is up to approximately 2.5 days before symptom onset. The viral load rises quickly after the end of the latent period. We further assume that the laboratory test then has a true positive rate of 100% until the carrier has recovered. The POC test on the other hand has \(p^{\mathrm{max}}_{\mathrm{true\ positive}} = 0.9\) until approximately 5 days after symptom onset.Footnote 2 After this time, the true positive rate falls at the same rate as the transmission-probability curve; the true positive rate as a function of days since symptom onset is shown in Fig. 1 (bottom gray curve).
All people who are traced must be tested for two reasons: (a) A positive test result is the only way for asymptomatic individuals to become index cases for tracing, and index cases are needed for tracing to be effective, and (b) so uninfected traced people can be released from quarantine. Keeping all traced people in quarantine for the full quarantining duration means that a large fraction of the uninfected population may end up quarantined on any given day of the outbreak. We use the following release protocol: All traced people go into quarantine and get tested with a POC test. Regardless of the test result, everyone stays in quarantine, because the person may still be in the latent period. Those who tested negative on the first day are re-tested \({\delta T_{\mathrm {re\text{-}test}}}\) days later. If both tests were negative, the person may leave quarantine, but is tested again after another \({\delta T_{\mathrm {re\text{-}test}}}\) days in case they were still in the latent period when the second test was done.
In addition to testing in response to being traced, we simulate the option of randomly testing a fraction \({f_{\mathrm {RT}}}\) of the population each day. This is done with a testing protocol assumed to have a negligible number of false positives.
(4) Social Distancing. Social distancing includes both a reduction of the total number of contacts per day \({n_{c}}\) to \({n_{c}}\cdot {f_{\mathrm {SD}}}\), and limiting the maximum number of contacts per day. In the absence of second-order effects, and if the upper limit does not change the distribution mean significantly, this reduces the reproductive number to
where R is the reproductive number without social distancing.
3 Models
Epidemiological modelling is a well established scientific discipline and different approaches, including contact tracing, are described in the rich literature [50–53]. Epidemiological models that account for CT date back to the 1980s [54]. The main challenge to modelling a CT system is the individual-based character of CT, and the handling of the resulting stochastic dependencies between individuals. Individual-based simulation models [55] readily describe this process. For the scope of this paper, we developed two deterministic and two individual-based models. While, for reasons of brevity, most of the results that will be presented here come from the individual-based models, the redundant modelling approach served to cross-validate and understand the results.
3.1 Deterministic models
The early phase of an outbreak can be quantitatively described with compartmental models based on ordinary differential equations (ODE) [56] or with age-since-infection models [57].
The deterministic models used here bridge the different scales utilizing the mathematical analysis of the underlying, microscopic stochastic branching process with contact tracing. The effect of contact tracing on the removal rates is determined. These effective removal rates are then used in the deterministic models. Our first deterministic, compartmental model explicitly predicts the status (exposed/infectious) for a newly infected person, when he/she will eventually be traced. Eventually traced and never-traced individuals go to different compartments. In that, the (exponentially distributed) waiting times can be readily adapted. Particularly, the model is close to standard SEIR-models (see Fig. 4), and is feasible to analytical analysis (Appendix A.1). In contrast, the second model, based on age since infection, does not explicitly formulate an exposed and an infectious period. The basic assumption is that the state of an individual is a function of his/her age of infection, that is the time that has passed since he or she became infected. The structure is less pronounced, but it is possible to use transition rates that are more realistic (supplemental materials A.2). At the present time, the analytical treatment of the interdependence of contact tracing and correlations between infected individuals at the plateau phase of an epidemic is not well understood. Therefore, both models focus on the onset of the epidemics, where the reduction of the number of susceptible people by quarantine or recovery does not play a central role. The main outcomes of these two models are the doubling time \(T_{2}\) and effective reproductive number \(R_{\mathrm{eff}}\) for interventions starting on the first day of the epidemic, though both models are able to predict in a heuristic way the total course of the epidemic.

3.2 Individual-based models
We developed two independent individual-based models (IBMs), which use the Monte Carlo (MC) technique to simulate social interactions, the progression of the viral disease, and interventions, at the level of individual people. The code for the models is available from [59] and [60]. The MC simulations proceed through the outbreak in steps of one day. Each day of the outbreak, every infected person not in quarantine has contact with a number of other people randomly drawn either from \(P_{\mathrm{social}}(n)\) (for a homogeneous population structure) or from the person’s social graph. The probability to infect each contact is given by \(P_{\mathrm{trans}}({\tau })\). When a contact becomes infected, the incubation time is drawn from \(P({T_{\mathrm {Inc}}})\). The intervention protocols are implemented as described in Sect. 2.
Figure 5 shows a chain of infections from one of the simulation runs. Each box represents a person, and arrows between boxes represent infections and tracing.

Spread and containment of SARS-CoV-2 using tracing and quarantine interventions in a Monte Carlo simulation including 1st and 2nd order tracing. The downward arrow indicates the time axis. Shown is a small sub-tree of the full infection tree. This sub-tree starts with simulated person P936, who was exposed on day 147, and includes the infection chains for the first three generations of infectees. The input settings for the simulation were: \({R_{0}}= 2.0\), \({\Delta T _{\mathrm {trace}}}= 7\) days, \({ p_{\mathrm {app}}}= 0.6\), \({\eta _{\mathrm {DCT}}}= 0.9\), \({\alpha }= 0.6\). Each box represents a person. The leftmost column in each box gives the person ID and whether or not they use the DCT app. The middle column indicates the days when the person was exposed, became infectious, and recovered. The rightmost column indicates if and when the person was traced, reported, and quarantined
In this example, P936 is exposed to the virus on day 147 of the simulated epidemic and has a latent period of 5 days, but never develops symptoms (light blue background) or tests positive and is therefore never reported (R–). He or she infects three others—P576 on day 152, P747 on day 154, and P277 on day 155. All three infectees develop symptoms (purple background). P576 sees a doctor on day 155, tests positive, and is reported. This triggers tracing of his infector, P936, and of the person he or she infected, P392. Tracing to P392 fails because this person does not use the app. Since P392 also does not develop symptoms, he or she is never reported or quarantined and infects three others. The backward trace from P576 to P936 puts P936 in quarantine on day 155 and thus prevents him or her from infecting more people after this time. P936 does not test positive (dashed outline of the box indicates the person was traced but never reported), so never becomes an index case him- or herself. However, since second order tracing is active in this simulation, the ‘siblings’ of P576 are identified. P747 is put in quarantine before he or she can infect anyone else, and tests positive the same day. This makes him or her an index case, so that the common infector, P936, is traced again. P277 does not use the app, therefore the trace fails. However, P277 happens to not meet many people on the first two days of infectiousness, then develops symptoms, sees a doctor, and is quarantined.
In this example, the chain of infections was stopped at P747 through second order tracing, the chain was stopped at P277 due to luck, but the chain could not be interrupted at P576 because the person he or she infected did not use the tracing app.
For a given set of input parameters, that is for a specific scenario, each run of the MC simulation represents one possible course of the epidemic. To find the most likely outcome for a scenario, the simulation is run 50 to 1000 times and the outcomes are averaged. As an example, Figs. 6 shows the course of the epidemic for 50 MC runs. The stochastic nature of the processes involved creates a spread in outcomes. Especially near the beginning of the epidemic where only few people are infected, statistical fluctuations cause large differences in the outbreak dynamics.

Stochastic variation in outbreak dynamics. The results are from 50 runs of the MC simulation; each run has the same input parameters (\({ p_{\mathrm {app}}}= 0.9\), \({\alpha }\cdot {f_{m}}= 0.95\), \({\eta _{as}}= 1\), trace uninfected = true). Top: The fraction of infectious (green), quarantined (blue) and cumulative exposed (yellow) people for each day of the simulated outbreak. Curves for only 20 out of the 50 runs are shown to improve legibility. Outcomes from one selected run are drawn as bold lines. Middle: \({R_{e}}\) each day is shown for the MC run drawn in bold in the top plot. The red vertical line indicates the time when 0.4% of the population have been infected, which is when interventions (other than quarantining of reported symptomatic cases, which is enabled from the beginning) are turned on. To measure their effectiveness, \({R_{e}}\) is averaged over 18 days (red area), starting 10 days after interventions commence. Bottom: Outcomes from the 50 MC runs, such as the maximum fraction of the population quarantined, are histogramed to show the statistical variation more clearly
The \({R_{e}}\) shown for each day is given as the average number of people infected by everyone who recovered on that day. After the interventions are turned on, \({R_{e}}\) begins to decrease and in the absence of non-linear effects reaches a plateau after approximately 10 to 14 days. In runs where more than a few percent of the population has been exposed at that time, \({R_{e}}\) declines naturally due to an increasing chance that contact persons are already infected or recovered, and therefore cannot be infected again. When reporting the \({R_{e}}\) for a simulation run, \({R_{e}}(t)\) is averaged in the time span of 10 days to 28 days after interventions start, or from 10 days to the day more than 50% of the population has been exposed, whichever period is shorter. This time window is a compromise between being far enough away from the start of interventions for the effect of the interventions to fully manifest, and not getting to close to the region where \({R_{e}}\) changes naturally. The \({R_{e}}\) reported for a scenario is the average \({R_{e}}\) over all the simulation runs for that scenario.
We consider the following outcomes:
-
The fraction of the population exposed after one year of continuous interventions. The one year is counted from the day interventions start.
-
The fraction of the population sick on the day when most people are sick.
-
The average fraction of the population in quarantine each day over one year of continuous interventions.
-
The fraction of the population in quarantine on the day when most people are in quarantine.
-
The effective reproductive number after interventions.
-
The fraction of simulations that did not generate an outbreak, where an outbreak is defined as at least 0.4% of the population becoming exposed in runs where interventions do not start on day 0, and is defined as at least 50 people becoming exposed in runs where interventions start on day 0. These numbers are chosen since they represent a robust threshold separating simulation runs where exponential rise in the number of people infected (i.e. an outbreak) takes place from those where it does not.
4 Results
We highlight three outcomes for select scenarios and as function of the app coverage. Unless stated otherwise, the values printed in black in Table 1 are used for those parameters not explicitly varied in the figures or stated in the figure captions. The full set of outcomes for all scenarios is shown in the Appendix. Note that the size of the simulated population and the number of MC runs was chosen such that the uncertainties on the outcomes are very small. Hence the error bars on most points are smaller than the marker size.
4.1 The effect of instantaneous contact tracing on an ongoing epidemic
Figure 7 and Fig. 8 show three outcomes each for the four simulated symptom/reporting fractions and for \({R_{0}}= 3\) (Fig. 7) and \({R_{0}}= 2\) (Fig. 8). Results are shown for the realistic case where tracing identifies contacts regardless of their infection status, and for the case where only infected contacts are traced. The latter is included so that results can be compared to other models, and because the difference in the number of quarantined people between the two cases indicates how many healthy people are quarantined when uninfected contacts are also traced. \({R_{0}}=2\) is likely too optimistic, the results, however, are also valid in the situation where R was lowered to \(R= 2\) by other interventions, such as mask wearing, before tracing and quarantining starts.

The effect of \({\alpha }\cdot {f_{m}}\) (tested symptomatic fraction) for different app coverages on the reproductive number after interventions (DCTS and quarantine) (top), the average of daily quarantined people as a percentage of the total population (middle) and the percentage of the population exposed after 1 year of continuous interventions (bottom). The points for 60% app coverage and 60% symptomatic fraction, outlined in red, will be studied further. This is for \({R_{0}}=3\) and \({\eta _{\mathrm {DCT}}}=1\)

The same as Fig. 7 but for starting conditions where \(R= 2\). \(R= 2\) could be achieved by interventions other than DCT
The \({R_{e}}\) shown in the top panels of Fig. 7 and Fig. 8 should be compared to Fig. 3. For example for \({R_{0}}=3\) and \({\alpha }\cdot {f_{m}}=0.6\), just quarantining reported symptomatic cases yields R\(_{e;q}=2.2\), so DCT only lowers \({R_{e}}\) by another 0.5 (if tracing is independent of infection status), or 0.3 (if tracing finds only infected contacts).
Assuming that α is about 60% in European populations and that not everyone who has symptoms sees a doctor or is tested, the region between \({\alpha }\cdot {f_{m}}=0.4\) to 0.6 is likely relevant for Europe. If the reports of higher α in Asian countries are due to true differences in symptom fraction rather than to differences in study methods, the higher \({\alpha }\cdot {f_{m}}\) values simulated should be more relevant to Asian countries.
We will use \({R_{0}}=3\), \({ p_{\mathrm {app}}}=0.6\), \({\alpha }\cdot {f_{m}}=0.6\), and \({\eta _{\mathrm {DCT}}}=1\) (points outlined in red in Fig. 7) as defaults.
In Fig. 9, the lightest-coloured points correspond to these defaults. The other colors indicate what happens when the tracing efficiency is reduced. For the lower app coverages, the results are barely sensitive to \({\eta _{\mathrm {DCT}}}\) because DCT is not very effective to begin with.

The effect of the tracing probability \({\eta _{\mathrm {DCT}}}\) for different app coverages (\({R_{0}}= 3\), \({\alpha }\cdot {f_{m}}= 0.6\))
In the realistic case where traced uninfected contacts are quarantined until two test results are negative (see Sect. 2.3), as many as 15% of the population are in quarantine on each day of the simulated outbreak, most of them healthy. Without a POC test to release healthy contacts, this number rises to 25%. At the peak of the outbreak, approximately 30% of the population is quarantined and half of those quarantined are actually sick.
People are not available to be infected while in quarantine, so the mean number of contacts per day, and with it the effective reproductive number, goes down and fewer people become exposed. The number of people quarantined rises with higher app coverage (because more people are traced in that case) and with a higher number of people exposed (because there are more index cases). A higher app coverage eventually leads to fewer exposed people though. Hence for a given reported symptomatic fraction, the number of people quarantined rises until an app coverage of approximately 75% (for lower reported symptomatic fractions) or 90% (for higher reported symptomatic fractions) and then falls sharply.
Contact tracing cannot reduce R below 1 in any of the simulations presented here except for \({\alpha }\cdot {f_{m}}\geq 0.8\) and \({ p_{\mathrm {app}}}\geq 0.9\) (if \({R_{0}}=3\)) or \({ p_{\mathrm {app}}}\geq 0.7\) (if R when tracing and quarantining is started is (2), and perfect tracing probability.
We note that in some cases, the fraction of the population exposed after 1 year is higher than the herd immunity level. The herd immunity level is defined as the fraction of the population that must be immune for the increase in new infections to not be able to grow exponentially, that is for \({R_{e}}\) to become 1. In an ongoing epidemic, many people are infectious when this point is reached, and the number of exposed people continues to rise until enough people are immune for \({R_{e}}=0\), therefore the curve overshoots herd immunity level.
4.2 Contact tracing in combination with random testing and social distancing
To control the epidemic, R must be reduced by additional measures. We simulated the effect of random testing (RT) and social distancing (SD). Figure 10 shows the outcomes for our standard scenario with the addition of RT of 5% and 20% of the population per day, and social distancing bringing \({n_{c}}\) to 0.8 and 0.6 of its original value. The reduction in contact rate is always connected to an upper limit in the number of contacts as shown in Table 1.

The effect of social distancing (SD) and random testing (RT) for different app coverages in combination with CT (\({R_{0}}= 3\), \({\eta _{\mathrm {DCT}}}= 1\), \({\alpha }\cdot {f_{m}}=0.6\))
Random testing even at 20% of the population per day in combination with contact tracing can only achieve \({R_{e}}\leq 1\) for \({ p_{\mathrm {app}}}\geq 0.75\). It does however bring \({R_{e}}\) close enough to 1 to significantly reduce the fraction of the population that becomes exposed, even for lower app coverages.
Social distancing reliably reduces the reproductive number. Social distancing to just 80% of the contact rate does as well as randomly testing 20% of the population each day. Reducing the contact rate to 60% pushes \({R_{e}}\) below 1 for 60% app coverage.
4.3 The effect of reduced contagiousness of asymptomatic carriers
As we saw in Fig. 3, in a situation where reported symptomatic cases are quarantined, down-scaling the contagiousness of asymptomatic carriers reduces R significantly. Figure 11 shows the outcomes when DCT is then applied.

Outcomes when the contagiousness of a- and pre-symptomatic carriers, \({\eta _{as}}\), is smaller than 1. Settings are \({R_{0}}= 3\), \({ p_{\mathrm {app}}}= 0.6\), \({\eta _{\mathrm {DCT}}}= 1.0\), trace uninfected contacts = false. The values printed for \({R_{e}}\) correspond to: (first number) the mean minus the standard deviation, and (second number) the mean plus the standard deviation, of the distribution of \({R_{e}}\) from 100 simulations (compare Fig. 6 bottom right panel), while the color of the field shows the mean. Where values are exactly 0.0, none of the 100 simulations had an outbreak (compare Sect. 4.5)
In the case where \({\eta _{as}}=0.1\) and all symptomatic carriers are reported when symptoms start, the simulations generate no outbreaks (fewer than 400 people become infected in total). When 75% of symptomatic cases are reported, \({R_{e}}\) has large fluctuations between simulation runs, and outcomes are very sensitive to the fraction of symptomatic cases.
4.4 The effect of timing, delays, and second order tracing
Figure 12 shows the outcomes as a function of tracing delay, that is the time in days between when an index case is identified and when his or her contacts are traced and quarantined. Outcomes are again grouped by whether or not uninfected contacts are identified by tracing. Results are also shown for both 1st order tracing and 2nd order tracing and for the two incubation time curves (the default one with mean incubation time (IT) of 7 days and the alternative one with the shorter IT = 4 days). The yellow marker uses the default incubation time curve with the alternate transmission probability curve (IC) where there is less pre-symptomatic transmission. In addition to the simulation results, the calculated \({R_{e}}\) from the age-of-infection model is shown for the settings with the default incubation time and transmission probability curves, and first order tracing. Approximations had to be made in the calculation, hence the absolute value is not expected to match the simulation results perfectly.

The effect of incubation time (IT) and tracing order (TO) for different tracing delays. IT = 7 refers to the curve with mean incubation period of 7 days, and IT = 4 to the one with mean incubation period of 3.6 days. The yellow point shows results for the alternate transmission probability curve (IC) as shown in Tab. 1 (grey values). Predictions from the “age-of-infection” (AOI) model, where only infected contacts are traced, are shown as the dark green line for parameters IT = 7, TO = 1 - the result shown is not exact (see Suppl. Materials). This is for \({ p_{\mathrm {app}}}=0.75\), \({\eta _{\mathrm {DCT}}}=1\), and \({\alpha }\cdot {f_{m}}=0.6\)
Results are shown for an app coverage of 75%. Some of the dynamics are quite sensitive to the app coverage (see supplemental materials), and at 75% trends are clearer than at 60% app coverage.
The difference between first and second order tracing is small in all three outcomes (this changes in some situations for higher app coverages). For the default incubation time curve with mean of 7 days, tracing delays of up to 6 days have only a small effect, increasing the number of people exposed after 1 year from approximately 72% to 82%. When the mean incubation time is only 4 days, \({R_{e}}\) is more sensitive to tracing delays, with a 7 day delay increasing the number of people exposed from approximately 60% to 81%. The infection probability curve with less pre-symptomatic transmission probability improves the outcomes only very slightly, though the effect becomes bigger with larger tracing delay.
Second order tracing can find the infector and through him or her, the ‘siblings’ of the index case. The chance that the infection took place within \({\Delta T _{\mathrm {trace}}}\) is higher with a longer \({\Delta T _{\mathrm {trace}}}\). However even for \({\Delta T _{\mathrm {trace}}}= 14\) days, the outcomes are not significantly different. The look-back time must be balanced against the number of healthy people quarantined. People typically become index cases before they have recovered, and thus would have had a chance to infect others in the approximately 7 days prior. Looking back longer than that means one has a bigger chance of finding the infector, but it also means tracing many uninfected contacts.
When considering the realistic case where uninfected contacts are traced, second order tracing with a 7 day look-back time sends about 1.3 times as many people into quarantine on average over 1 year as first order tracing.
4.5 Outbreak probability
The results discussed so far consider situations where an outbreak is ongoing and interventions are started at some point into the outbreak. But not all simulation runs result in an outbreak. The stochastic nature of the outbreak means that there are large statistical variations at the beginning of the chain. For example, if patient zero happens to not infect anyone, no outbreak happens.
The chance for an outbreak to occur increases with R. The more people a case typically infects, the less likely it is that cases at the beginning of the infection chain do not infect anyone. Therefore, keeping interventions in place even in populations without an ongoing outbreak can be useful to decrease the probability that an outbreak will occur when a case is introduced into the population, for example through travel.
Figure 13 shows the outbreak probability as a function of the reproductive number when an infected person enters a fully susceptible population.

The probability for an outbreak to start as a function of the reproductive number at the time when patient 0 enters a fully susceptible population. An outbreak here is defined as more than 50 people becoming infected. The error bars shown are statistical
4.6 Sensitivity of results to the social contact structure
The results presented so far assumed a homogeneous population of size \(1\times 10^{5}\) and a distribution of the number of contacts with infection potential per day from Eq. (3). We also ran some sets of parameters for different population sizes and for different contact structures. The results are shown in Fig. 14.

The sensitivity of the outcomes to the size and the structure of the simulated population is shown. The three population structures (described in Sect. 2.1) correspond to the homogeneous population with a gamma distribution (Eq. (3)) describing the number of contacts per day, a homogeneous distribution using the power law (Eq. (4)) for the number of contact per day, and the social graph population. Settings are \({R_{0}}=3\), \({\alpha }\cdot {f_{m}}=0.6\), \({\eta _{\mathrm {DCT}}}=1\), trace uninfected = true. For the 10,000 people population, outcomes have large statistical fluctuations and error bars show the error on the mean. For the other points, the error bars are smaller than the marker size
The introduction of a social graph introduces non-linear effects that change \({R_{e}}\) on timescales much longer than what is captured by our standard analysis. In some cases, this means that fewer people are exposed after one year, even though \({R_{e}}\) is higher (see Fig. 21 in Appendix A.8).
5 Discussion
Contact tracing relies on index cases from which to trace. When there is a large fraction of mildly symptomatic and asymptomatic carriers who never go to the doctor or get tested, many carriers do not become index cases, so DCT does not have a large impact. Outcomes improve strongly the higher the fraction of reported symptomatic carriers. This is partially because DCT is more efficient, and partially because R is additionally reduced just from quarantining the index cases. Therefore it is crucial that every person with even the mildest symptoms has easy access to a COVID-19-test.
The extend to which pre- and asymptomatic carriers drive the outbreak depends on their contagiousness. If for some reason they are less contagious than symptomatic carriers, missing them as index cases does not worsen outcomes much. In the case where \({\eta _{as}}\) is 0.1, as proposed for example in [4], quarantining of index cases, without CT, reduces R from \({R_{0}}=3\) to \({R_{e}}<1\) even when just 40% of cases are symptomatic.
Randomly testing a fraction of the population regularly to find unreported carriers helps to make up for the large fraction of asymptomatic carriers. We find that a very large fraction of the population must be tested daily to significantly improve outcomes. For our default parameters, even when testing 20% of the population daily, at least 90% of the population would have to use the DCTS for \({R_{e}}\) to become smaller than one. Since typical PCR test capacities are much lower than these numbers, POC tests are likely the only realistic option for mass testing.
Reducing the contact rate (social distancing) by as little as 20% is as effective as testing 20% of the population every day while requiring fewer people to be quarantined.
Tracing delays of a few days do not significantly worsen the outcomes. Two studies, Ferretti et al. [4] and [5], indicate that a DCTS could control a SARS-CoV-2 outbreak (that is achieve \({R_{e}}<1\)) because it allows for contact tracing without delays. We find that the asymptomatic infectiousness scaling of \({\eta _{as}}= 0.1\) used by [4] is the main driver of their \({R_{e}}\) and given these starting conditions, DCT only has to lower R by a small amount to achieve outbreak control and is therefore then effective. Kretzschmar et al. [5] are more careful about the reduction in R achievable with DCT, but do confirm the improved outcomes with short tracing delays. However, [5] use a very short latency period. With the longer median latency periods consistent with recent large-scale studies, this effect is small. Therefore, the advantage of a DCT in the case of COVID-19 lies mostly in the possibility to scale tracing to a large number of cases without needing a large increase in the number of manual contact tracers.
Most models consider that contacts that were actually infected are traced with some probability. In reality, it is impossible to tell immediately whether or not a traced contact has been infected. Even if a test performed immediately on tracing is negative, it could just mean that the person is still in the latent period. Therefore, all traced contacts should be quarantined and tested multiple times. In principle, one could devise other schemes, such as testing each traced person every morning (e.g. with a POC tests that can be done at home and gives results within minutes) for a few days without requiring quarantine unless the test comes up positive. Right now, such frequent testing is not realistic in most countries.
We find that including the effect that quarantining of uninfected contacts has on the outbreak dynamics can lead to significantly different, typically more positive, outcomes compared to models where this effect is ignored. The improvement in outcomes is due to the large number of people quarantined even though they are healthy. Our simulations probably underestimate this number, because we use contact rates for the types of contacts that have a high chance of transmitting a respiratory virus. A DCT system will typically pick up many persons who were in spacial proximity to the index case, but not in a manner that was likely to transmit the virus, so the number of contacts traced per index case could be bigger in reality. For any serious large-scale use of a DCT system during an ongoing epidemic, dealing with these uninfected contacts in quarantine is going to be a major challenge, especially as the compliance of the population with quarantining procedures may decrease once someone has been traced and quarantined multiple times.
The statistical nature of virus transmission and contact rates leads to large variations in outbreak dynamics at the start of the outbreak. Sometimes, an infectious person entering a susceptible population does not start an outbreak. This becomes less likely the higher R is. This also means that under identical conditions, one population could have hundreds of cases within a week of the arrival of patient 0, while in another population the case number does not start rising for several weeks, just by luck.
Beside control of the outbreak, that is achieving \({R_{e}}\) below 1, an important outcome is how many people will have been exposed by the time a vaccine might be available. Due to the heavy social and economical burden imposed by virus control, some countries are aiming at \({R_{e}}\) around 1, rather than total control. Our simulations assume that the same interventions are applied throughout the epidemic, so the outcomes over 1 year are guidelines rather than realistic predictions for any real country. They do give a qualitative idea of what achieving a given \({R_{e}}\) means in terms of the number of people exposed (and with that, the number of fatalities).
For reasons of computing power, most simulations were run for a homogeneous population. In reality, society is organized into social units. Introducing such social units into the simulation means that an infectious person tends to meet the same people every day, exposing them again and again. This leads to slight changes in outcome, while the qualitative results remain the same.
5.1 Limitations
We assumed that all people, once they have recovered from the infection, are immune to a secondary infection. Whether and for how long a recovered person is immune remains to be answered. Studies show that neutralizing antibodies are produced during infection and to a higher degree in symptomatic carriers, but decline significantly 2–3 months after recovery [61, 62]. The minimal antibody titer to confer protection is, however, still unclear. Furthermore, memory T cells to SARS-CoV-2 have been found in patients including asymptomatic and mildly symptomatic ones, which likely contribute to protective immunity as well [63].
In our models, everyone adheres to quarantine protocols. That is, every time someone is alerted by the DCT system to having been in proximity of a contagious individual, this person must follow the quarantining and testing procedure. This is crucial to suppress pre- and asymptomatic transmission, but may be difficult to achieve in reality. We also assume that the fraction of symptomatic individuals who see a doctor/get tested do so the day they become symptomatic.
The transmission probability in our models changes with the time since infection, but not between individuals. Current research, however, suggests that COVID-19 is over-dispersed, meaning some individuals spread the virus to many others, in so-called “superspreading events”, while most do not transmit the virus at all or only to very few people [64]. Part of this over-dispersion is due to the random nature of the contact number—some people just meet more others, and is therefore included in our models (see Sect. 2.2 and Fig. 2).
We assume that no manual tracing is performed at all. Typically, the types of close contact persons to whom spreading the disease is most likely, that is friends and family, can be manually traced without much effort, hence the fraction of infected contacts traced could be larger in reality.
6 Summary
Many countries enforced a policy of ‘shelter–in–place’ and/or extreme social distancing, effectively putting most of the population into quarantine. This significantly slowed down the infection rate [65, 66], but came with large economical and social costs to society. World-wide, a lot of effort has been put into the development of CT systems, in the hope that large-scale CT could replace other public health measures at much smaller cost to society.
We modelled the effect of instantaneous DCT in combination with a testing and quarantining protocol, as well as random testing and social distancing, on an ongoing COVID-19 epidemic. Results were validated by running the scenarios with two independently developed individual-based models, which were further cross-checked by two types of deterministic models. We modelled many different parameter values for the still not well-known properties of SARS-CoV-2, COVID-19 and for the interventions, leading to well over 10,000 simulated scenarios. The goal was to find the regions in this parameter space where CT without additional interventions could lower the effective reproductive number enough to halt exponential growth.
Wherever modelling approximations had to be made, we chose defaults that lead to better outcomes, hence these results are likely on the optimistic side. Our results are stable under different simulated social structures and epidemiological parameters, with significantly different outcomes seen only when varying the fraction of asymptomatic individuals or down-scaling the contagiousness of pre- and asymptomatic cases.
We find that for large regions of the parameter space, including the currently most likely parameter values, an outbreak of COVID-19 cannot be fully controlled by DCT even if a large fraction of the population uses the system. Furthermore, if interventions are started once an outbreak is already ongoing, DCT causes a large fraction of the healthy population to be traced and quarantined.
DCT can be combined with other measures, such as face-mouth coverings, social distancing, and/or random testing, to achieve outbreak control.
The availability of fast testing, and coordination of test results with the DCT system, are crucial to allow symptomatic cases to become index cases for tracing, and to release traced healthy contacts from quarantine. Since SARS-CoV-2 symptoms are unspecific, everyone with even a slight cough of fever must be able to get a test (a) quickly, because the infection probability peaks just before symptom onset and then falls quickly and people who are not sure they are infected likely will not effectively quarantine themselves, and (b) easily, so that a large fraction of symptomatic cases do seek out testing. The gains of a DCT system in outbreak control quickly vanish if many symptomatic cases do not seek out testing, or if positively tested individuals do not become index cases.
Availability of data and materials
The equations derived for the deterministic models are presented in detail in the supplementary materials. All data generated or analysed during this study are included in this published article and its supplementary information files, and can be re-generated using computer code made publicly available [59, 60].
References
Rothe C, Schunk M, Sothmann P et al. (2020) Transmission of 2019-NCOV infection from an asymptomatic contact in Germany. N Engl J Med 382(10):970–971. https://doi.org/10.1056/NEJMc2001468
Lee VJ, Chiew CJ, Khong WX (2020) Interrupting transmission of COVID-19: lessons from containment efforts in Singapore. J Travel Med 27(3). https://doi.org/10.1093/jtm/taaa039
Fraser C, Riley S, Anderson RM, Ferguson NM (2004) Factors that make an infectious disease outbreak controllable. Proc Natl Acad Sci 101(16):6146–6151. https://doi.org/10.1073/pnas.0307506101
Ferretti L, Wymant C, Kendall M et al. (2020) Quantifying SARS-CoV-2 transmission suggests epidemic control with digital contact tracing. Science. https://doi.org/10.1126/science.abb6936
Kretzschmar M, Rozhnova G, Bootsma M et al (2020) Time is of the essence: impact of delays on effectiveness of contact tracing for COVID-19. medRxiv. https://doi.org/10.1101/2020.05.09.20096289
Australia. COVIDSafe app. https://github.com/AU-COVIDSafe. Accessed June 09, 2020
Austria. StoppCorona app. https://github.com/austrianredcross. Accessed: June 09, 2020
France. StopCovid app. https://gitlab.inria.fr/stopcovid19. Accessed: June 09, 2020
India. Aarogya Setu app. https://www.mygov.in/aarogya-setu-app. Accessed: June 09, 2020
Iceland. Rakning C19. https://github.com/aranja/rakning-c19-app. Accessed: June 09, 2020
Italy. Immuni App. https://github.com/immuni-app. Accessed: June 09, 2020
Norway. Smittestopp app. https://github.com/djkaty/no.simula.smittestopp. Accessed: June 09, 2020
UK. NHS Covid-19 app. https://github.com/nhsx/. Accessed: June 09, 2020
Singapore. TraceTogether. https://github.com/OpenTrace-community and https://bluetrace.io. Accessed: June 09, 2020
Switzerland. SwissCovid App. https://github.com/DP-3T/dp3t-app-android-ch. Accessed: 2020-06-09
Braithwaite I, Callender T, Bullock M, Aldridge RW (2020) Automated and partly automated contact tracing: a systematic review to inform the control of COVID-19. Lancet Dig Health. https://doi.org/10.1016/s2589-7500(20)30184-9
Hellewell J, Abbott S, Gimma A et al. (2020) Feasibility of controlling COVID-19 outbreaks by isolation of cases and contacts. Lancet Glob Health 8(4):488–496. https://doi.org/10.1016/S2214-109X(20)30074-7
Firth JA, Hellewell J et al. (2020) Using a real-world network to model localized COVID-19 control strategies. Nat Med. https://doi.org/10.1038/s41591-020-1036-8
Kiche J, Ngesa O, Orwa G (2019) On generalized gamma distribution and its application to survival data. Int J Stat Prob 8:65. https://doi.org/10.5539/ijsp.v8n5p65
Mun J (2008) Models and 300 applications from the basel II accord to wall street and beyond. Wiley, New York. ISBN 978-0470179215
Mossong JL, Hens N, Jit M et al (2008) Social contacts and mixing patterns relevant to the spread of infectious diseases. PLoS Med 5. https://doi.org/10.1371/journal.pmed.0050074
Lancichinetti A, Fortunato S, Radicchi F (2008) Benchmark graphs for testing community detection algorithms. Phys Rev E 78:046110. https://doi.org/10.1103/PhysRevE.78.046110
Keziban Orman G, Labatut V, Cherifi H (2013) Towards realistic artificial benchmark for community detection algorithms evaluation. Int J Web Based Commun 9. https://doi.org/10.1504/IJWBC.2013.054908
Réka A, Barabási A-L (2002) Statistical mechanics of complex networks. Rev Mod Phys 74:47–97. https://doi.org/10.1103/RevModPhys.74.47
Ma S, Zhang J, Zeng M et al (2020) Epidemiological parameters of coronavirus disease 2019: a pooled analysis of publicly reported individual data of 1155 cases from seven countries. medRxiv. https://doi.org/10.1101/2020.03.21.20040329
He X, Lau EHY, Wu P et al (2020) Temporal dynamics in viral shedding and transmissibility of COVID-19. Nat Med 26. https://doi.org/10.1038/s41591-020-0869-5
Sanche S, Ting Lin Y, Xu C et al (2020) High Contagiousness and Rapid Spread of Severe Acute Respiratory Syndrome Coronavirus 2. Emerg Infect Dis. https://doi.org/10.3201/eid2607.200282
Lauer SA, Grantz KH, Bi Q et al. (2020) The incubation period of coronavirus disease 2019 (COVID-19) from publicly reported confirmed cases: estimation and application. Ann Intern Med. https://doi.org/10.7326/M20-0504
Mizumoto K, Kagaya K, Zarebski A, Chowell G (2020) Estimating the Asymptomatic Proportion of 2019 Novel Coronavirus onboard the Princess Cruises Ship, 2020. Euro Surveill: Eur Commun Dis Bull 25(10). https://doi.org/10.1101/2020.02.20.20025866
Park SY, Kim Y-M, Yi S et al. (2020) Coronavirus disease outbreak in call center, South Korea. Emerging infectious diseases. https://doi.org/10.3201/eid2608.201274
Lavezzo E, Franchin E, Ciavarella C et al (2020) Suppression of COVID-19 outbreak in the municipality of Vo’, Italy. medRxiv. https://doi.org/10.1101/2020.04.17.20053157
Corman VM, Rabenau HF, Adams O et al (2020) SARS-CoV-2 asymptomatic and symptomatic patients and risk for transfusion transmission. medRxiv. https://doi.org/10.1101/2020.03.29.20039529
Nishiura H, Kobayashi T, Suzuki A et al. (2020) Estimation of the asymptomatic ratio of novel coronavirus infections (COVID-19). Int J Infect Dis. https://doi.org/10.1016/j.ijid.2020.03.020
Li R, Pei S, Chen B et al (2020) Substantial undocumented infection facilitates the rapid dissemination of novel coronavirus (SARS-CoV2). Science 3221. https://doi.org/10.1126/science.abb3221
Zou L, Ruan F, Huang M et al. (2020) SARS-CoV-2 viral load in upper respiratory specimens of infected patients. N Engl J Med 382(12):1177–1179. https://doi.org/10.1056/NEJMc2001737
Kai-Wang To K, Tak-Yin Tsang O, Leung W-S et al Temporal profiles of viral load in posterior oropharyngeal saliva samples and serum antibody responses during infection by SARS-CoV-2: an observational cohort study. Lancet Infect Dis 3099(20). https://doi.org/10.1016/s1473-3099(20)30196-1
Furukawa NW, Brooks JT, Sobel J (2020) Evidence supporting transmission of severe acute respiratory syndrome coronavirus 2 while presymptomatic or asymptomatic. Emerg Infect Dis 26. https://doi.org/10.3201/eid2607.201595
Wölfel R, Corman VM, Guggemos W et al. (2020) Virological assessment of hospitalized patients with COVID-2019. Nature. https://doi.org/10.1038/s41586-020-2196-x
Wei L, Su Y-Y, Zhi S-S et al (2020) Viral shedding dynamics in asymptomatic and mildly symptomatic patients infected with SARS-CoV-2. Clinical microbiology and infection: the official publication of the European Society of Clinical Microbiology and Infectious Diseases. https://doi.org/10.1016/j.cmi.2020.07.008
Lee S, Kim T, Lee E et al. (2020) Clinical course and molecular viral shedding among asymptomatic and symptomatic patients with SARS-CoV-2 infection in a community treatment center in the republic of Korea. JAMA internal medicine. https://doi.org/10.1001/jamainternmed.2020.3862
Liu Y, Yan LM, Wan L et al. (2020) Viral dynamics in mild and severe cases of COVID-19. Lancet Infect Dis 2019(20):2019–2020. https://doi.org/10.1016/S1473-3099(20)30232-2
Backer JA, Klinkenberg D, Wallinga J (2020) Incubation period of 2019 novel coronavirus (2019- ncov) infections among travellers from Wuhan, China, 20 28 January 2020. Euro Surveill 25. https://doi.org/10.2807/1560-7917.ES.2020.25.5.2000062
Streeck H, Schulte B, Kümmerer BM et al (2020) Infection fatality rate of SARS-CoV-2 infection in a German community with a super-spreading event. medRxiv. https://doi.org/10.1101/2020.05.04.20090076
Byambasuren O, Cardona M, Bell KJL et al (2020) Estimating the extent of true asymptomatic covid-19 and its potential for community transmission: systematic review and meta-analysis. medRxiv. https://doi.org/10.1101/2020.05.10.20097543v2
Liu Y, Gayle AA, Wilder-Smith A, Rocklöv J (2020) The reproductive number of COVID-19 is higher compared to SARS coronavirus. J Travel Med 27(2). https://doi.org/10.1093/jtm/taaa021
Lloyd-Smith JO, Schreiber SJ, Kopp PE, Getz WM (2005) Superspreading and the effect of individual variation on disease emergence. Nature 438(7066):355–359. https://doi.org/10.1038/nature04153
Keeling MJ, Déirdre Hollingsworth T, Read JM (2020) The Efficacy of Contact Tracing for the Containment of the 2019 Novel Coronavirus (COVID-19). medRxiv. https://doi.org/10.1101/2020.02.14.20023036
Marc Schwob J, Miauton A, Petrovic D et al (2020) Antigen rapid tests, nasopharyngeal pcr and saliva pcr to detect SARS-CoV-2: a prospective comparative clinical trial. medRxiv. https://doi.org/10.1101/2020.11.23.20237057
Merino-Amador P, Guinea J, Muñoz-Gallego I et al (2020) Multicenter evaluation of the panbio™ covid-19 rapid antigen-detection test for the diagnosis of SARS-CoV-2 infection. medRxiv. https://doi.org/10.1101/2020.11.18.20230375
Diekmann O, Heesterbeek JAP (2000) Mathematical epidemiology of infectious diseases: model building, analysis and interpretation. Wiley, New York. ISBN 9780471492412
Brauer F (2008) Mathematical epidemiology: compartmental models in epidemiology. Lecture notes in mathematics. Springer, Berlin. ISBN 978-3-540-78911-6
Diekmann O, Heesterbeek H, Britton T (2012) Mathematical tools for understanding infectious disease dynamics, Princeton series in theoretical and computational biology. Princeton University Press, Princeton. ISBN 9781400845620
Müller J, Kuttler C (2015) Methods and models in mathematical biology deterministic and stochastic approaches. Springer, Berlin. ISBN 978-3-642-27250-9
Hethcote HW, Yorke JA (1984) Gonorrhea transmission dynamics and control. Springer, Berlin. ISBN 978-3-662-07544-9
Kiss IZ, Green DM, Kao RR (2006) Infectious disease control using contact tracing in random and scale-free networks. J R Soc Interface. https://doi.org/10.1098/rsif.2005.0079
Webb G, Browne C, Huo X et al (2015) A model of the 2014 ebola epidemic in West Africa with contact tracing. PLoS Curr. https://doi.org/10.1371/currents.outbreaks.846b2a31ef37018b7d1126a9c8adf22a
Müller J, Kretzschmar M, Dietz K (2000) Contact tracing in stochastic and deterministic epidemic models. Math Biosci 164. https://doi.org/10.1016/S0025-5564(99)00061-9
Browne C, Gulbudak H, Webb G (2015) Modeling contact tracing in outbreaks with application to Ebola. J Theor Biol 384:33–49. https://doi.org/10.1016/j.jtbi.2015.08.004
Pollmann TR, Wiesinger C. COVID-MC. https://github.com/tinapollmann/CVMC
Hack C, Meighen-Berger S, Turcati A. Contagion. https://github.com/chrhck/contagion
Seow J, Graham C, Merrick B et al (2020) Longitudinal evaluation and decline of antibody responses in SARS-CoV-2 infection. medRxiv. https://doi.org/10.1101/2020.07.09.20148429
Quan, Long X, Jun Tang X, Lin Shi Q et al Clinical and immunological assessment of asymptomatic SARS-CoV-2 infections. Nat Med 26. https://doi.org/10.1038/s41591-020-0965-6
Sekine T, Perez-Potti A, Rivera-Ballesteros O et al (2020) Robust T cell immunity in convalescent individuals with asymptomatic or mild COVID-19. bioRxiv. https://doi.org/10.1101/2020.06.29.174888
Endo A, Abbott S, Kucharski AJ, Funk S (2020) Estimating the overdispersion in COVID-19 transmission using outbreak sizes outside China. Wellcome Open Res 5:67. https://doi.org/10.12688/wellcomeopenres.15842.1
Kucharski AJ, Russell TW, Diamond C et al Early dynamics of transmission and control of COVID-19: a mathematical modelling study. Lancet Infect Dis 20. https://doi.org/10.1016/S1473-3099(20)30144-4
Aylward BW, Liang WP (2020) Report of the WHO-China Joint Mission on Coronavirus Disease 2019 (COVID-19). The WHO-China Joint Mission on Coronavirus Disease 2019, 16–24
Harrison RL (2010) The construction of next-generation matrices for compartmental epidemic models. J R Soc Interface 7:873–885. https://doi.org/10.1098/rsif.2009.0386
Acknowledgements
We acknowledge the support by the DFG Cluster of Excellence “Origin and Structure of the Universe”. The simulations were carried out on the computing facilities of the Computational Center for Particle and Astrophysics (C2PAP) and on the Max Planck Institute for Physics computing cluster. This work was undertaken in the context of the ContacTUM collaboration.
Funding
This work was undertaken pro-bono by the authors without any funding. Computing resources available to the authors were used as listed in the acknowledgements section. Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
TRP and SS coordinated the four different models and the epidemiological inputs. JM coordinated the analytic models. JP prepared the epidemiological input parameters and made sure all model assumptions were based on proper virological inputs. ER proposed the questions to answer and coordinated with the digital contact tracing community. TRP and CW wrote one of the MC simulations. CH, SMB, and AT wrote the other MC simulation. LS and AT ran the simulations and prepared the graphical output. JM, UA, and AO developed the ‘age since infection’ model. BN, GZ, and MN developed the ODE model. TRP, SS, ER, and JM interpreted the results. TRP, SS, JM, JP, and BN wrote the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Appendix
Appendix
1.1 A.1 The ODE model
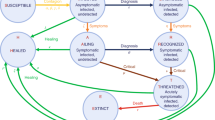
The compartment model is based on the SEIR-type model from Reference [58] and is extended to visualize infectious individuals for their whole infectious period \({T_{\mathrm {con}}}\) even though they might be quarantined or hospitalized (see Fig. 15). To do so, we introduce the convalescing compartment ‘C’ in between the infectious I and recovered R status.

Structure of the compartmental model. The model is based on a SEIR-type model from Ref. [58] and is extended with a convalescing (C) compartment. A person in the convalescing compartment is technically still infectious, but the chance to infect further is drastically reduced, as this person is either isolated or the viral load is too low. The sum of the specific infectious periods is given by \({T_{\mathrm {con}}}\). Untraced compartments are indicated in gray and traced compartments in blue. See Table 3 for the definitions of the variables
I denotes infectious individuals, who are able to infect susceptible individuals S for the mean infectious period T. In contrast, C are convalescing individuals that cannot infect further as they are either isolated or the probability to infect others is very small (because they no longer have enough viral load). A similar second infectious state has been implemented by Ref. [31] to describe individuals that still test positive even though they are no longer contagious. After the residual infectious period \({T_{\mathrm {con}}}-T\), C enter the recovered status R. In Fig. 18, the infectious population is defined as the sum of all I and C subgroups.
The model differentiates between untraced and traced individuals. Contact tracing is triggered by reported infectious individuals that appear with a fraction α of the untraced individuals. The model incorporates forward contact tracing, e.g. one traces the contacts that have been infected by the reported index case and predicts the probability \(p_{e}\) that the traced contact is still in the exposed compartment when traced. This prediction relies on exponential probability distributions for the latent and infectious period. We assume that traced contacts that are still in the exposed phase \({E}_{t}^{e}\) are immediately isolated and can no longer infect others. In contrast, contacts that are traced during their infectious period \({I}_{t}^{i}\) could have already infected other people. The corresponding mean infectious time \(T_{t}\) of \({I}_{t}^{i}\) is calculated within the model and depends on the latent and the infectious period of the reported infectious individuals. Traced infectious contacts \({I}_{t}^{i}\) can also trigger contact tracing and the probability that the traced contact of \({I}_{t}^{i}\) is still in the exposed phase is given by \(p_{e}^{i}\) that depends then on \(T_{t}\). Table 3 summarizes the parameters and definitions of the compartmental model. For a detailed description and the proof of the computation of \(p_{e}\), \(p_{e}^{i}\), and \(T_{t}\), we refer the reader to Reference [58].
In order to compute the doubling time \({T_{2}}\) and the basic reproduction number \({R_{e}}\), we focus on the initial infection-free state, in which the entire population is given by \(S_{0}\) [58, 67]. At this stage, the system of differential equations can be linearised, and the aforementioned parameters can be extracted from the Jacobian of the system J. In particular, the doubling time is computed as \(\ln (2 )/\lambda \), where λ is the largest eigenvalue of J, known as the exponential-growth parameter. The basic reproduction number is obtained using the next-generation analysis, in which the Jacobian is split into two matrices: F, containing the terms relative to the generation of new infections, and V containing the transfer from one infectious compartment to another. The basic reproduction number \({R_{e}}\) is then obtained as the spectral radius of the matrix \(FV^{-1}\).
We derive the mean latent and infectious periods \({T_{\mathrm {lat}}}\), \(T_{r}\), and \(T_{u}\) using the probability functions described in Sect. 2 to 5.0 d, 1.4 d, and 2.5 d, respectively. Further, the total infectious period \({T_{\mathrm {con}}}\) is assumed to be 10.4 d.
The model is given by the following set of ordinary differential equations (ODEs):
1.2 A.2 The age since infection model
We propose here a simple deterministic model for contact tracing, where the class of infecetees is structured by age since infection.
Let \({S}(t)\) denote the density of susceptibles at time t, \({I}(t,a)\) the density of infectees at time t with age of infection a, and \({R}(t)\) the removed individuals at time t (recovered, quarantined, dead—in any case, not infectious any more). Note that the infected individuals may not be infectious while they are in the latent period—exposed and infectious are distinguished based on the age of infection. The total number of infectees at time t is given by \({I}(t)=\int _{0}^{\infty }{I}(t,a) \,da\). \(N(t)={S}(t)+\int _{0}^{\infty }{I}(t,a) \,da+{R}(t)\) denotes the total population size. Since we do not consider population dynamics (i.e. the population size does not change), \(N(t)=N\) is a constant.
We first describe the model without contact tracing and discuss how to incorporate contact tracing afterwards. Infected individuals with age of infection a have infectivity \(\beta (a)\) and recover spontaneously without diagnosis at rate \(\mu (a)\); alternatively, an infected person develops symptoms and gets diagnosed at rate \(\sigma (a)\). In that case, he/she is quarantined immediately and will not infect others anymore. We chose standard incidence, s.t. the model equations become
In order to prepare for the effect of contact tracing, we slightly rewrite the model equations. We note that
is the probability to be in the class I at time of infection a. Below, we will modify \(\kappa (a)\). For now, we note that
(which is also called the hazard rate). Therewith, our model becomes
In order to compute the effect of contact tracing, we only need to adapt \(\kappa (a)\) accordingly. The overall model structure is not touched. The analysis of the probability to be infectious at age of infection a as given below is mathematically precise for the onset of the epidemic.
1.3 A.3 Contact tracing
We now slightly switch the perspective, and consider single individuals. Much of the following was published in [57]; we summarize these considerations for the convenience of the reader. Below, we investigate a forest: An infected individual infects other individuals, in that, we get a random tree with a directed node from infector to infectee. Individuals who recover leave this tree, that is, we are left with a forest.
Contact tracing acts on this forest. At rate \(\sigma (a)\) an individual is (directly) detected/diagnosed and forms an index case. All neighbouring individuals (within the forest of infectees) have probability p to be detected by contact tracing. Either we stop here (one step tracing) or the individuals detected by CT recursively form new index cases (recursive tracing). This process modifies \(\kappa (a)\): contact tracing increases the probability to be removed at age of infection a.
In order to understand \(\kappa (a)\), we consider two simplified scenarios first: (a) we assume that we can only trace contacts from infectee to infector (backward tracing), and (b) we assume that we can only trace contact from infector to infectee (forward tracing). Then, we combine both approaches to understand the full tracing we aim at.
Backward tracing
Proposition 7.1
The probability to be infectious for an individual at age of infection a for recursive contact tracing follows the following system of integro-differential equations,
with \(\kappa ^{-}(0)=1\).
Proof
Clearly, without contact tracing, we have \({\kappa ^{-}}'(a) = -(\mu (a)+\sigma (a)) \kappa ^{-}(a)\). If backward tracing is active, we add an additional component to the removal rate that is caused by a tracing event triggered by an infectee. As only infectees cause tracing (tracing events are only triggered by “children”), the probability to be infectious at a given age of infection a is the same for infector and infectee. Hence the recovery rate of an infectee can be written as the hazard rate
This hazard rate includes the rate of direct observation (that triggers a backward tracing event), the rate at which the infectee is discovered by recursive tracing (which triggers a tracing event), and by spontaneous removal (which does not trigger a tracing event). Since spontaneous removal does not lead to contact tracing, we subtract this rate and find the rate at which direct diagnosis or detection by contact tracing happens,
The focal individual (for which we compute \(\kappa ^{-}(a)\)) produces during his/her infectious period (so far) \([0,a]\) infectees. When he/she had age \(c\in [0,a]\), his/her infection rate was \(\beta (c)\). The probability that the infectee is still infectious when the age of the focal individual/the infector is a is \(\kappa (a-c)\). The rate of direct or indirect observation of the infectee with age of infection \(a-c\) is \(\frac{-{\kappa ^{-}_{\ast }}'(a-c)}{\kappa ^{-}_{\ast }(a-c)}-\mu (a-c)\). A detected individual triggers a successful tracing event with probability \({\eta _{\mathrm {DCT}}}\). Hence, the contribution to the removal rate of our focal individual due to tracing is given by
□
Proposition 7.2
The probability that a case is infectious at age of infection a for one-step contact tracing follows the following system of integro-differential equations,
with \(\kappa ^{-}(0)=1\).
Proof
The proof parallels that of Proposition 7.1; we only need to know that individuals have the rate of direct detection \(\sigma (a-c)\); this rate replaces the expression (detection rate for recursive tracing) \(\frac{-{\kappa ^{-}_{\ast }}'(a-c)}{\kappa ^{-}_{\ast }(a-c)}-\mu (a-c)\). □
Forward tracing. In contrast to backward tracing, in forward tracing the position of a focal individual in the tree/forest of infectees matter. If I’m the primary infected person (generation 0), I have no infector (inside of the population). I cannot be traced by forward tracing. The first generation (infectee of generation 0) can only be traced via the primary infected person. The second generation can be traced by the zeroth and first generation, and so on.
That is, for forward tracing, the “generation” of an individual does influence the probability to be infectious at age of infection a. “Generation” refers to generation of infection; the primary case has generation 0, those infected by the primary case have generation 1 etc. We denote by \(\kappa ^{+}_{i}(a)\) the probability to be infectious at age of infection a for an individual of generation \(i\in \mathbb {N} _{0}\) under forward tracing.
Furthermore, we introduce the probability to be infectious at age of infection a in case that we do not have contact tracing (\(p=0\)) for symptomatic/asymptomatic infectees,
In order to determine \(\kappa ^{+}_{i}(a)\), we first introduce and investigate
which is the probability that an individual in generation i is infectious at age of infection a, if we condition on the fact that the infector has age of infection \(a+b\) (s.t. the infector—at the time of the corresponding infectious contact—has age of infection b).
Proposition 7.3
In case of recursive tracing we have for \(i>0\)
Proof
Our focal individual is infectious if he/she did not recover already without being traced, times the probability that no tracing event removed the individual from the class of infectees,
In order to obtain the probability for a successful tracing event, we first note that we know that the infector has been infectious at (his/her) age of infection b, s.t. the probability for him/her to be infectious at age of infection \(b+c\) reads
As before, for recursive tracing, the detection rate is the hazard rate minus the rate to recover spontaneously/unobserved,
Hence, the desired probability reads
□
Proposition 7.4
In case of one-step-tracing we have
Proof
The argument parallels that of Proposition 7.3. We only need to take into account that in one-step tracing the infectee has to be detected directly, which happens at rate \(\sigma (\cdot)\). This rate replaces the hazard rate minus the spontaneous recovery rate. □
In order to determine the desired probability \(\kappa ^{+}_{i}(a)\) we remove the condition in \(\kappa _{i}^{+}(a|b)\). Thereto we determine the probability density for an infector to have age of infection b. The net infection rate is \({\beta _{i}}(b) \kappa _{i-1}(b)\). Therefore, the distribution of the age of the infector at the time of infection is given by
Corollary 7.5
In one-step tracing as well as in recursive tracing, we have for \(i>0\)
where we have to use for \(\kappa _{i}^{+}(a|b)\) the solution for one-step or recursive tracing, depending on the scenario chosen.
We find an iterative formula. Analysis for p small as well as numerical analysis (for general \({\eta _{\mathrm {DCT}}}\in [0,1]\)) shows that the convergence is rather fast: after 3–5 generations, the \(\kappa _{i}^{+}(a)\) have largely converged.
Full tracing. Full tracing is just a combination of forward- and backward tracing. Let \(\kappa _{i}(a)\) denote the “survival probability” for a target individual of generation i under full tracing.
In order to find \(\kappa _{0}(a)\), we only need to understand that the primary infected individual can only be traced by downstream infectees, that is, is only exposed to backward tracing. Also the next generations have—without forward tracing—just the “survival” probability \(\kappa ^{-}(a)\). We need to multiply this probability with the probability not to be target of a forward tracing event in order to obtain \(\kappa _{i}(a)\).
That is, we use the argument for forward tracing, where we replace \(\hat{\kappa }(a)\) (survival probability without tracing) by \(\kappa ^{-}(a)\) (survival probability under backward tracing only), and get immediately the following result (notation is an obvious extension of the notation above).
Proposition 7.6
In case of recursive tracing we have for \(i>0\)
Proposition 7.7
In case of one-step-tracing we have
With
and for recursive contact tracing (one-step: parallel formula)
we finally get the result for full tracing (we summarize all necessary equations):
Theorem 7.8
(Recursive tracing)
Let
with \(\kappa ^{-}(0)=1\). Then,
Theorem 7.9
(One-step tracing)
Let
with \(\kappa ^{-}(0)=1\). Then,
Note that it is straightforward (but tedious) to simplify these equations, s.t. they become handy for the numerical analysis.
1.4 A.4 Reproduction number and exponential growth
A direct consequence of the dynamic, age-structured model is the possibility to determine the reproduction number and the exponential growth rate right away from the survival probability \(\kappa _{\infty }(a)\). The effective reproduction number is simply given by
The exponent λ of the exponential growth in the onset \(S(t)\approx S_{0} \approx N\) can be determined by the unique real root of the equation
From here, we obtain \({T_{2}}=\ln (2)/\lambda \).
1.5 A.5 Reproduction number in case of DCT
Recall that we consider a homogeneously mixing population, where a fraction \({ p_{\mathrm {app}}}\) of individuals have a DCT device. Only contacts between these individuals can be traced, with probability \({\eta _{\mathrm {DCT}}}\). Let \(R_{\mathrm{eff}}(p)\) denote the reproduction number of a homogeneous model, where each contact is traced with probability p. Then, a straightforward generalization of the considerations above yields that non-app-users have the reproduction number \(R_{\mathrm{eff}}(0)\), while those with app have the reproduction number
Since we assume homogeneous mixing, we obtain the overall reproduction number as
This formula is exact, but due to the nonlinearity in \(R_{\mathrm{eff}}(\cdot)\) it cannot be simplified. However, if \({ p_{\mathrm {app}}},{\eta _{\mathrm {DCT}}}\ll 1\), we can linearize at \({ p_{\mathrm {app}}}=0\), and find
In lowest order, tracing within a subgroup of relative size \({ p_{\mathrm {app}}}\) and a tracing probability \({\eta _{\mathrm {DCT}}}\) is equivalent with tracing the total population with a tracing probability \({ p_{\mathrm {app}}}^{2} {\eta _{\mathrm {DCT}}}\).
1.6 A.6 Results
We identify the parameters of the models as described below. Using numerical analysis, it is possible to estimate the influence of control measures on the spread of the infection. Particularly, we are interested in the effect of contact tracing and social distancing on the effective reproduction number and the doubling time. Moreover, the sensitivity of the results on parameters for which there is little data is explored. Here, our focus is the fraction of asymptomatic cases.
If we inspect Fig. 16, we find first of all that recursive tracing is more efficient than one-step tracing (one must not confuse one-step tracing with level-1 tracing: here, we only follow infectious contacts for one step). In practice, the tracing delay will lead to a situation between one-step tracing and recursive tracing: even if recursive tracing is the aim, as we loose time in tracing each contacts, after a few steps persons might already be recovered when traced. In any case, small tracing probabilities have only a minor impact. If we increase the tracing probability to 0.7–0.8, we find that an eradication of the infection is possible. On the other side, social distancing is most effective for small tracing probabilities. The combination of contact tracing and social distancing is most likely best in the middle range: a reduction of contacts by 30%, and a tracing probability around 0.6–0.7 will be able to reduce the doubling time considerably, and even bring \({R_{e}}\) down to values around 1.

Influence of social distancing (reduction of the contact rate) and contact tracing on \({R_{e}}\) and \({T_{2}}\). (a) and (c): One-step tracing, (b) and (d) recursive tracing. (a) and (b) \({R_{e}}\), (b) and (d) \({T_{2}}\). Note that in (b) and (c), there is a singularity for \({T_{2}}\) at the line \({R_{e}}=1\), where \({T_{2}}\) becomes infinite
The parameter values are not all precisely known. In particular, at the present time, the fraction of undiagnosed cases is rather unclear. In the literature, there are numbers between 1.2% and 95%. The parameter scan in Fig. 17 indicates that the results are rather stable for a wide range of α (from 10–50%). A major change can be observed above 70%. This figure might imply that the results are rather stable against the parameter choice in α.

Influence of the assumed fraction of asymptomatic and unreported cases on (a) \({R_{e}}\) and (b) \({T_{2}}\), where we also take \({\eta _{\mathrm {DCT}}}\) into account (only recursive tracing considered)
1.7 A.7 Choice of parameter functions
The medical investigations yield particularly data on:
-
Incubation period (time to the onset of symptoms/diagnosis)
-
latent period (time until infectivity becomes positive) and viral load (a proxy for infectivity)
-
fraction of asymptomatic cases.
Incubation period
Time to symptoms: We use a Γ distribution, density
with parameters \({\beta _{i}}= 2.44\), \(\gamma _{I} = 3.06\) days. Let \(\hat{\sigma }(a)\) be the conditioned detection rate: It is only valid under the condition that an individual is indeed detected. That rate is just the hazard rate of \(f(a)\),
We later need to compute the rate \(\sigma (a)\) for the model, where we take into account the fraction of asymptomatic cases.
Infectivity
Given that the onset of symptoms of a person at age \(A_{0}\) (a Gamma-distributed random variable, as described above), the infectious period starts \(A_{0}-\Delta _{\mathrm{onset}}\), where \(\Delta _{\mathrm{onset}}\) is a fixed time span (we choose \(\Delta _{\mathrm{onset}} = 3\) days). If \(a_{0}-\Delta <0\), then the infectivity period starts right away at the time of the infection. That is, \(\max \{A_{0}-\Delta _{\mathrm{onset}},0\}\) is the latent period. We furthermore assume that the infectious period is a fixed (deterministic) time span \({T_{\mathrm {con}}}\).
This assumption about the latent period is an input for the age-dependent infection rate as well as for the recovery rate.
(b.1) Recovery rate. If \(A_{0}\sim \operatorname{Gamma}({\beta _{i}},\mu _{I})\) is a random variable that states the onset of symptoms, we aim at the distribution of the recovery age \(A_{r} = \operatorname{max}\{A_{0}-\Delta _{\mathrm{onset}},0\}+{T_{\mathrm {con}}}\). Clearly, \(P(A_{r}< a) = 0\) for \(a\leq {T_{\mathrm {con}}}\). A short computation yields for \(a > {T_{\mathrm {con}}}\)
Hence, in total we have
As the cumulative distribution involves a jump, the hazard rate (recovery rate) incorporates a delta peak. However, for the practical implication, we replace the jump by a steep linear increase during a small age interval. The corresponding hazard rate yields the removal rate \(\hat{\mu }(a)\), conditioned on the fact that a person will not be diagnosed if they recover spontaneously. The parameter \({T_{\mathrm {con}}}\) is computed below.
(b.2) Infectivity. We again denote by \(A_{0}\) the random variable that states the onset of the symptoms, \(A_{0}\sim \operatorname{gamma}({\beta _{i}}, \gamma _{I})\).
The ingredient for the infectivity is an approximation of the viral load, given by a shifted Gamma distribution,
with the understanding that this formula is only valid for \(A_{0}>-\mu _{x}\). Here, \((x)_{+}=0\) for \(x<0\) and \((x)_{+}=x\) if \(x>0\). The parameters are given by:
If \(A_{0}+\mu _{x}<0\), we assume that symptoms start right away. Hence,
Then (as in our case \(\mu _{x}<0\)). \({\beta _{i}}\) is proportional to
where \(f(b)\) is given in (41). The unknown proportionality constant models the number of contacts per day. This constant is calibrated s.t. the basic reproduction number \({R_{0}}\) is 2.5.
We define \({T_{\mathrm {con}}}\) by
Asymptomatic cases
We define the effective detection rate \(\sigma (a)\) and the effective removal rate \(\mu (a)\), based on the conditioned rates \(\hat{\sigma }(a)\) and \(\hat{\mu }(a)\), and the fraction of asymptomatic cases α. The probability to be infectious is a convex combination of the probabilities to be infectious for a symptomatic resp. asymptomatic individual (where we understand that an “asymptomatic individual” is not only asymptomatic at a given time, but will remain asymptomatic until recovery). That is,
In order to find the effective rates, we compute the hazard rate of \(\kappa (a)\),
From here, we immediately find the desired definitions for \(\mu (a)\) and \(\sigma (a)\),
1.8 A.8 Model benchmarking
Monte Carlo models rely on computer code, and therefore must be verified to work as designed. We do this in two ways: (a) by comparing results to deterministic models, and (b) by comparing the results from two implementations written independently by two teams using two different programming languages and toolsets. One example for (a) is shown in Fig. 18. The deterministic models cannot model all effects we consider, therefore POC testing and social distancing was turned off in the Monte Carlo models, and other parameters were chosen as summarized in Table 4. The parameters in the ODE model do not have straight-forward correspondence to the parameters in the table, so they were tuned such that the outcome matches the other models as well as possible.

The cumulative number of exposed people from the four models and for the settings from Tab. 4
The analytic models are, strictly speaking, not valid once a sizable fraction of the population has been exposed, since they do not model non-linear effects such as two exposed people meeting each other. Nevertheless we show the full outbreak curves here.
The ODE model matches quite well with the Python and C++ models, but it has the advantage of having been tuned to achieve as good a match as possible. The age-structure model has a time offset compared to the others, but the time when the outbreak takes off in the IB models is very variable so such offsets are not relevant.
Even though both individual-based models implement the same disease parameters and intervention protocols, there are a number of implementations details that are treated differently and can lead to slightly different outcomes. Examples of this are whether nor not people with a 0 days latency period can infect others on the same day they themselves became infected, or whether we allow someone to still infect others on the day they become symptomatic and are quarantined.
Figures 19 and 20 compare what happens for two implementations of a latency period of zero days. In one implementation, it is possible for the carrier to infect others on the same day he or she became exposed. In the other implementation, a carrier can infect others only on days after he or she became exposed.

Outbreak dynamics when someone with zero days latency period cannot infect others on the same day he or she became infected

Outbreak dynamics when someone with zero days latency period can infect others on the day he or she became infected
One big difference between the IB models is that the Python model accounts for the case where a contact is traced from an index case who did not infect the contact, but in the time between when the contact took place and when the person was traced, the contact was infected by someone else. In the C++ model, this special case is not considered. The effect on the outcomes is small, especially when taking a look-back time of only 7 days as done for most of the main scan.
Figure 21 shows how the population structure affects the course of the epidemic.

The number if infectious people each day for a social graph and a homogeneous population is compared
Social graph populations lead to long-term changes in the outbreak dynamic that are not accurately captured by just the reproductive number reached after interventions.
Figure 22 is similar to Fig. 6 but for different parameters. In this scenario, the reproductive number changes both due to the interventions and naturally because a large enough fraction of the population becomes exposed early on that non-linear effects are important.

Same as Fig. 6 changing the following parameters: \({ p_{\mathrm {app}}}= 0.6\), \({\alpha }\cdot {f_{m}}= 0.6\)
1.9 A.9 Results from all scenarios
The results for the main parameter scan are shown in Figs. 23 through 28. Results for the scan with different timing and delays are shown in Figs. 29 through 34.

The effective reproductive number reached once interventions are turned on is shown for all combinations of parameters in the default parameter scan (black font color in Tab. 1)

The fraction of the population quarantined on average over one year of the outbreak is shown for all combinations of parameters in the default parameter scan (black font color in Tab. 1)

The fraction of the population that is quarantined on the day when most people are quarantined is shown for all combinations of parameters in the default parameter scan (black font color in Tab. 1)

The total fraction of the population that has been exposed one year into the outbreak is shown for all combinations of parameters in the default parameter scan (black font color in Tab. 1)

The fraction of the population that is sick on the day when most people are sick is shown for all combinations of parameters in the default parameter scan (black font color in Tab. 1)

The fraction of MC runs where the outbreak stopped (by chance) before the threshold number of infected people to start interventions was reached

The effective reproductive number reached once interventions are turned on is shown for all combinations of parameters in the timing and delay parameter scan

The fraction of the population quarantined on average over one year of the outbreak is shown for all combinations of parameters in the timing and delay parameter scan

The fraction of the population that is quarantined on the day when most people are quarantined is shown for all combinations of parameters in the timing and delay parameter scan

The total fraction of the population that has been exposed one year into the outbreak is shown for all combinations of parameters in the timing and delay parameter scan

The fraction of the population that is sick on the day when most people are sick is shown for all combinations of parameter in the timing and delay parameter scan

The fraction of MC runs where the outbreak stopped (by chance) before the threshold number of infected people to start interventions was reached (timing and delay parameter scan)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pollmann, T.R., Schönert, S., Müller, J. et al. The impact of digital contact tracing on the SARS-CoV-2 pandemic—a comprehensive modelling study. EPJ Data Sci. 10, 37 (2021). https://doi.org/10.1140/epjds/s13688-021-00290-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjds/s13688-021-00290-x