
Abstract
Quantum memory—the capacity to faithfully preserve quantum coherence and correlations—is essential for quantum-enhanced technology. There is thus a pressing need for operationally meaningful means to benchmark candidate memories across diverse physical platforms. Here we introduce a universal benchmark distinguished by its relevance across multiple key operational settings, exactly quantifying (1) the memory’s robustness to noise, (2) the number of noiseless qubits needed for its synthesis, (3) its potential to speed up statistical sampling tasks, and (4) performance advantage in non-local games beyond classical limits. The measure is analytically computable for low-dimensional systems and can be efficiently bounded in the experiment without tomography. We thus illustrate quantum memory as a meaningful resource, with our benchmark reflecting both its cost of creation and what it can accomplish. We demonstrate the benchmark on the five-qubit IBM Q hardware, and apply it to witness the efficacy of error-suppression techniques and quantify non-Markovian noise. We thus present an experimentally accessible, practically meaningful, and universally relevant quantifier of a memory’s capability to preserve quantum advantage.
Similar content being viewed by others


Introduction
Memories are essential for information processing, from communication to sensing and computation. In the context of quantum technologies, such memories must also faithfully preserve the uniquely quantum properties that enable quantum advantages, including quantum correlations and coherent superpositions1. This has motivated extensive work in experimental realisations across numerous physical platforms2,3, and presents a pressing need to find operationally meaningful means to compare quantum memories across diverse physical and functional settings. In contrast, present approaches towards detecting and benchmarking the quantum properties of memories are often ad hoc, involving experimentally taxing process tomography, or only furnishing binary measures of performance based on tests of entanglement and coherence preservation4,5,6,7,8,9,10,11.
Our work addresses these issues by envisioning memory as a physical resource. We provide a means to quantify this resource by asking: how much noise can a quantum memory sustain before it is unable to preserve uniquely quantum aspects of information? Defining this as the robustness of a quantum memory (RQM), we demonstrate that the quantifier has diverse operational relevance in benchmarking the quantum advantages enabled by a memory—from speed-up in statistical sampling to non-local quantum games (see Fig. 1). We prove that RQM behaves like a physical resource measure, representing the number of copies of a pure idealised qubit memory that are required to synthesise the target memory. We show the measure to be exactly computable for many relevant cases, and introduce efficient general bounds through experimental and numerical methods. The quantifier is, in particular, experimentally accessible without full tomography, enabling immediate applications in benchmarking different memory platforms and error sources, as well as providing a witness for non-Markovianity. We experimentally test our benchmark on the five-qubit IBM Q hardware for different types of error, demonstrating its versatility. In addition, the generality of our methods within the broad physical framework of quantum resource theories12,13,14 ensures that many of our operational interpretations of the RQM can also extend to the study of more general quantum processes15,16,17,18,19,20, including general resource theories of quantum channels, gate-based quantum circuits, and dynamics of many-body physics. Our work thus presents an operationally meaningful, accessible and practical performance-based measure for benchmarking quantum processors that is immediately relevant in today’s laboratories.

This work focuses on the resource theory of quantum memories. We define a entanglement-breaking memories as free resources and propose the RQM as a resource measure of b a quantum channel. We consider three operational interpretations of the measure in c one-shot memory synthesis with resource non-generating (RNG) transformations; d classical simulation of the measurement statistics of quantum memory; and e a family of two-player non-local quantum games generalising state discrimination.
Results
Framework of quantum memories
Any quantum memory can be viewed as a channel in time—mapping an input state we wish to encode into a state we will eventually retrieve in the future. An ideal memory preserves all information, such that proper post-processing operations on the output state can always undo the effects of the channel. Such channels preserve all state overlaps, in the sense that any pair of distinguishable input states remain distinguishable at output. In contrast, this is not possible with classical memories that store only classical data. To distinguish orthogonal states in some basis \(\left|k\right\rangle\), we are forced to measure in this basis and record only the classical measurement outcome k. Such a measure-and-prepare process will never distinguish \(\left|0\right\rangle \,+\,\left|1\right\rangle\) from \(\left|0\right\rangle -\left|1\right\rangle\). In fact, this procedure exactly encompasses the class of all entanglement-breaking (EB) channels21,22: if we store one part of an entangled bipartite state within classical memory, the output is always separable. As such, classical memories are mathematically synonymous with EB channels.
To systematically characterise how well a general memory preserves quantum information, we consider how robust it is against noise. We define the robustness of quantum memories (RQM) as the minimal amount of a classical memory that needs to be mixed with the target memory \({\mathcal{N}}\) such that the resultant probabilistic mixture is also classical:
where the minimisation is over the set of all EB channels EB. We explicitly prove that the robustness measure is a bona fide resource measure of quantum memories, satisfying all necessary operational properties. Crucially, we show that the robustness satisfies monotonicity—a memory’s RQM can never increase under any resource non-generating (RNG) transformation, that is, any physical transformation of quantum channels that maps EB channels only to EB channels. We thus refer to such transformations as free within the resource theory of quantum memories. Commonly encountered free transformations include pre- or post-processing with an arbitrary channel or, more generally, the class of so-called classically correlated transformations10.
Operational interpretations
We illustrate the operational relevance of RQM in three distinct settings. The first is memory synthesis. From the perspective of physical resources, one important task is to synthesise a target resource by expending a number of ideal resources, which can be thought of as the “currency” in this process. Intuitively, a more resourceful object would be harder to synthesise and hence require more ideal resources, allowing us to understand the required number of ideal memories as the resource cost of a given memory. In entanglement theory, an analogous concept involves determining the minimum number of Bell pairs that are required to engineer a particular entangled state using free operations (entanglement cost)23,24. For quantum memories, we consider an ideal qubit memory \({{\mathcal{I}}}_{2}\) as the identity channel that perfectly preserves any qubit state. The task of single-shot memory synthesis is then to convert n copies of ideal qubit memories \({{\mathcal{I}}}_{2}^{\otimes n}\) to the target memory \({\mathcal{N}}\) via a free transformation. We show that the robustness measure lower bounds the number n of the requisite ideal memories, i.e., \(n\,\ge\, \lceil {{\rm{log}}}_{2}(\lceil {\mathcal{R}}({\mathcal{N}})\rceil \,+\,1)\rceil\). Therefore, a larger robustness indicates that the memory requires more ideal resources to synthesise. Furthermore, we show that there always exists an optimal RNG transformation that saturates this lower bound, and thus the robustness tightly captures the optimal resource cost for this task. We summarise our first result as follows.
Theorem 1 The minimal number of ideal qubit memories required to synthesise a memory \({\mathcal{N}}\) is \(n\,=\,\lceil {{\rm{log}}}_{2}(\lceil {\mathcal{R}}({\mathcal{N}})\rceil \,+\,1)\rceil\).
In “Methods” section, we further consider imperfect memory synthesis by allowing an error ε and show that the optimal resource cost is characterised by a smoothed robustness measure with smoothing parameter ε. Theorem 1 thus corresponds to the special case of ε = 0. Complementing our result on memory synthesis, recent works25,26 studied the task of single-shot memory distillation with another resource measure based on the hypothesis testing entropy.
In the second task, we consider the classical simulation of quantum memories. The motivation here is analogous to computational speed-up—the observational statistics of any quantum algorithm can be simulated on a classical computer, albeit at an exponential overhead. Similarly, one strategy for simulating quantum memories is to perform full tomography of the input state and store the resulting classical density matrix. Then, at the output of the memory, the input state ρ is reconstructed and any observational statistics on ρ can be directly obtained. This method clearly requires an exponential amount of input samples for an n-qubit memory—and thus results in an exponential overhead in resources and speed.
Formally, the functional behaviour of any memory is fully described by how its observational statistics vary as a function of input, i.e., the set of expectation values \({\rm{Tr}}(O{\mathcal{N}}(\rho ))\), for each possible observable O and input state ρ. In order to estimate \({\rm{Tr}}[O{\mathcal{N}}(\rho )]\) to an additive error ε with failure probability δ, we need T0 ∝ 1/ε2log(δ−1) samples when having access to \({\mathcal{N}}\) due to Hoeffding’s inequality27. Alternatively, we can linearly expand the target memory as \({\mathcal{N}}\,=\,{\sum }_{i}{c}_{i}{{\mathcal{M}}}_{i},{c}_{i}\in {\mathbb{R}}\) and obtain the target statistics by using \({{\mathcal{M}}}_{i}\) and measuring \({\rm{Tr}}[O{{\mathcal{M}}}_{i}(\rho )]\) as \({\rm{Tr}}[O{\mathcal{N}}(\rho )]\,=\,{\sum }_{i}{c}_{i}{\rm{Tr}}[O{{\mathcal{M}}}_{i}(\rho )]\). When only having access to free resources in a specific decomposition \({\mathcal{N}}\,=\,{\sum }_{i}{c}_{i}{{\mathcal{M}}}_{i}\), we need \(T\propto \| c{\| }_{1}^{2}/{\varepsilon }^{2}{\rm{log}}({\delta }^{-1})\) samples. The simulation overhead is thus given by \(C\,=\,\| c{\|}_{1}^{2}\propto T/{T}_{0}\). We then prove that the optimal overhead that minimizes over all possible expansions is given exactly by the RQM of the quantum channel.
Theorem 2 The minimal overhead—in terms of extra runs or input samples needed—to simulate the observation statistics of a quantum memory \({\mathcal{N}}\) is given by \({{\mathcal{C}}}_{\min }\,=\,{(1\,+\,2{\mathcal{R}}({\mathcal{N}}))}^{2}\).
For EB channels \({\mathcal{M}}\), the robustness \({\mathcal{R}}({\mathcal{M}})\) vanishes and hence \({{\mathcal{C}}}_{\min }({\mathcal{M}})\,=\,1\), aligning with the intuition that classical memories require no extra simulation cost. For n ideal qubit memories, \({\mathcal{R}}({{\mathcal{I}}}_{2}^{\otimes n})\,=\,{2}^{n}\,-\,1\) and hence the classical simulation overhead scales exponentially with n.
In the third setting, we consider the capability of quantum memories to provide advantages in a class of two-player non-local quantum games. Related games of this type have previously been employed in understanding features of Bell nonlocality28 and detecting quantum memories10. Consider then a set of states {σi}, from which one party (Alice) selects one state uniformly at random and encodes it in a memory \({\mathcal{N}}\). Her counterpart Bob is given this memory and tasked with guessing which of the states {σi} was encoded by performing a measurement {Oj}. The probability that Bob guesses σj when the input state is σi is given by \({\rm{Tr}}[{\mathcal{N}}({\sigma }_{i}){O}_{j}]\). Thus, by associating with each such guess a coefficient \({\alpha }_{ij}\in {\mathbb{R}}\), we can define the payoff of the game—this can be used to give different weights to corresponding states, or to penalise certain guesses. The performance of the two players in the game defined by \({\mathcal{G}}\,=\,\{\{{\alpha }_{ij}\},\{{\sigma }_{i}\},\{{O}_{j}\}\}\) is then evaluated using the average payoff function,
Such games can be considered as a generalisation of the task of quantum state discrimination, as can be seen by taking αij = δijpi for some probability distribution \(p_i\). We see that the players’ maximum achievable performance is limited by Bob’s capacity to discern Alice’s inputs, and thus each such game serves as a gauge for the memory quality of \({\mathcal{N}}\). In order to establish a quantitative benchmark for the resourcefulness of a given memory, we can then compute the best advantage it can provide in the same game \({\mathcal{G}}\) over all classical memories. To make such a problem well-defined, we will constrain ourselves to games for which the payoff \({\mathcal{P}}({\mathcal{M}},{\mathcal{G}})\) is non-negative. In the “Methods” section, we then show that the maximal capabilities of a quantum memory in this setting are exactly measured by the robustness.
Theorem 3 The advantage that a quantum memory \({\mathcal{N}}\) can provide over classical memories in all non-local quantum games is given by
We will shortly see that such games, in addition to showcasing another operational aspect of the robustness, allow us to efficiently bound \({\mathcal{R}}({\mathcal{N}})\) in many relevant cases.
Computability and measurability
We can efficiently detect and bound the robustness of a memory through the performance of the memory in game scenarios. Specifically, consider games \({\mathcal{G}}\) such that all classical memories achieve a payoff in the range [0, 1]. By Theorem 3, we know that any such game \({\mathcal{G}}\) provides a lower bound \({\mathcal{P}}({\mathcal{N}},{\mathcal{G}})\,-\,1\) on \({\mathcal{R}}({\mathcal{N}})\), akin to an entanglement witness quantitatively bounding measures of entanglement29. This provides a physically accessible way of bounding the robustness measure by performing measurements on a chosen ensemble of states, and in particular there always exists a choice of a quantum game \({\mathcal{G}}\) such that \({\mathcal{P}}({\mathcal{N}},{\mathcal{G}})\,-\,1\) is exactly equal to \({\mathcal{R}}({\mathcal{N}})\). This approach makes the measure accessible also in experimental settings, avoiding costly full process tomography. We use this method to explicitly compute the robustness of some typical quantum memories in Fig. 2a, with detailed construction of the quantum games deferred to the Supplementary Notes.

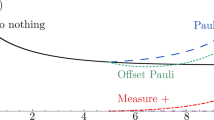
a Robustness of memories with qubit inputs and computational basis \(\{\left|0\right\rangle ,\left|1\right\rangle \}\) for dephasing channels Δp(ρ) = pρ + (1 − p)ZρZ, stochastic damping channels \({{\mathcal{D}}}_{p}(\rho )\,=\,p\rho \,+\,(1\,-\,p)\left|0\right\rangle \left\langle 0\right|\), and erasure channels \({{\mathcal{E}}}_{p}(\rho )\,=\,p\rho \,+\,(1\,-\,p)\left|2\right\rangle \left\langle 2\right|\) with \(\left|2\right\rangle\) orthogonal to \(\{\left|0\right\rangle ,\left|1\right\rangle \}\). b Memory robustness under dynamical decoupling (DD) and its quantification of non-Markovianity. We consider a qubit memory (M) coupled to a qubit bath (B) with an initial state \({\rho }_{B}(0)\,=\,0.4\left|0\right\rangle \left\langle 0\right|\,+\,0.6\left|1\right\rangle \left\langle 1\right|\) and an interaction Hamiltonian H = 0.2(XM ⊗ XB + YM ⊗ YB) + ZM ⊗ ZB. Here X, Y, Z are the Pauli matrices. We consider the evolution with time t from 0 to π. To decouple the interaction, we apply X operations on the memory at a constant rate. We show that the memory robustness can be enhanced via dynamical decoupling (DD). Furthermore, as the memory robustness can increase with time, we calculate the non-Markovianity using the robustness derived measure as defined in Eq. (5).
In addition to the above linear witness method, we also give non-linear witnesses of a memory \({\mathcal{N}}\) based on the moments of its Choi state. Consider channels \({\mathcal{N}}\) with input dimension d and k = 0, 1, …, ∞, in Supplementary Notes, we prove \({\mathcal{R}}({\mathcal{N}})\ge {d}^{\frac{k\,-\,1}{k}}{\left({\rm{Tr}}\left[{\left({{{\Phi }}}_{{\mathcal{N}}}\right)}^{k}\right]\right)}^{\frac{1}{k}}\,-\,1\), where \({{{\Phi }}}_{{\mathcal{N}}}\) is the Choi state of \({\mathcal{N}}\). Higher values of k provide tighter lower bounds, which can be measured in experiment by implementing a generalised swap test on k copies of the channel. In the limit k → ∞, we obtain the strongest bound, which depends only on the maximal eigenvalue of the Choi state. Remarkably, the bound is actually tight for all qubit-to-qubit and qutrit-to-qubit channels.
Theorem 4 The RQM of any quantum channel \({\mathcal{N}}\) with input dimension dA and output dimension dB can be lower bounded by
and equality holds when dA ≤ 3 and dB = 2.
We stress that this provides an exact and easily computable expression for the robustness for low-dimensional channels. This contrasts with related measures of entanglement of quantum states, such as the robustness of entanglement30, for which no general expression exists even in 2 × 2 dimensional systems.
Given a full description of the memory, we can also provide efficiently computable numerical bounds on the robustness via a semi-definite programme, which we show to be tight in many relevant cases. We leave the detailed discussion to Supplementary Notes.
Applications
The RQM, being information theoretical in nature, applies across all physical and operational settings. This enables its immediate applicability to many present studies of quantum memory. For example, non-Markovianity and mitigation of errors resulting from non-Markovianity are widely studied problems in the context of quantum memories. RQM can be used both to identify the former, and measure the efficacy of the latter.
In particular, considering a memory Nt that stores states from time 0 to t ≥ 0, we can quantify its non-Markovianity as
For any Markovian process \({{\mathcal{N}}}_{t}\), the robustness measure \({\mathcal{R}}({{\mathcal{N}}}_{t})\) is a decreasing function of time owing to monotonicity of \({\mathcal{R}}\) (see “Methods” section). Thus \({\mathcal{I}}(T)\,=\,0\) for any Markovian process \({{\mathcal{N}}}_{t}\), and nonzero values of \({\mathcal{I}}(T)\) directly quantify the memory’s non-Markovianity in a similar way to ref. 31. Meanwhile, the goal of any error-mitigation procedure is to preserve encoded qubits. Thus, the characterisation of an increase in the RQM of relevant encoded sub-spaces provides a universal measure of the efficacy for any such behaviour.
In Fig. 2b, we illustrate these ideas using a single-qubit memory subject to unwanted coupling from a qubit bath. The RQM degrades over time (yellow-starred line)—but has a revival around t = 1, indicating non-Markovianity. Indeed, plotting \({\mathcal{I}}(t)\), we see clear signatures of non-Markovian effects arise at this moment (cyan-crossed line). Meanwhile, the green-dotted line quantifies how dynamical decoupling improves this memory through increased RQM. This improvement has a direct operational interpretation. For example, the approximately fourfold increase in robustness around t = 0.8 indicates that a quantum protocol that runs on a dynamically decoupled quantum memory could be much harder to simulate than its counterpart.
Experiment
We experimentally verify our benchmarking method on the ‘ibmq-ourense’ processor on the IBM Q cloud. We first consider a proof-of-principle verification of the scheme by estimating the RQM of three types of single-qubit noise channels—the dephasing channel, stochastic damping channel, and erasure channels. We synthesise the noise channels by entangling the target state with ancillary qubits. For example, the dephasing channel Δp(ρA) = pρA + (1 − p)ZρAZ can be realised by the circuit in the dashed box of Fig. 3a, where we input an ancillary state \({\left|0\right\rangle }_{E}\), rotate it with \({R}_{\theta }^{Y}\,=\,\exp (-i\theta Y/2)\), and apply a controlled-Z. Here \(\theta \,=\,2\arccos (\sqrt{p})\) and Y is Pauli-Y matrix. We exploit the quantum game approach to estimate the RQM of the three types of noise channels. We choose a normalised quantum game \({\mathcal{G}}\) with the maximal payoff for EB channels of \(\mathop{\max}\nolimits_{{\mathcal{M}}\in {\rm{EB}}}{\mathcal{P}}({\mathcal{M}},{\mathcal{G}})\,=\,1\), so that the robustness of memory \({\mathcal{N}}\) can be lower bounded by \({\mathcal{R}}({\mathcal{N}})\,\ge\, {\mathcal{P}}({\mathcal{N}},{\mathcal{G}})\,-\,1\). For each input-output setting (σi, Oj), we measure the probability \(p(j| i)\,=\,{\rm{Tr}}[{O}_{j}{\mathcal{N}}({\sigma }_{i})]\) with 8192 experimental runs. The payoff is obtained as a linear combination of the probabilities \({\mathcal{P}}({\mathcal{N}},{\mathcal{G}})\,=\,{\sum }_{i,j}{\alpha }_{i,j}p(j| i)\) with real coefficients αi,j. As shown in Fig. 3b, the experimental data (circles, upper and lower triangles) align well with the theoretical result (solid lines), with a deviation of less than 0.13. The deviation mostly results from the inherent noise in the hardware, especially the notable two-qubit gate error and the read-out error.

a Circuit diagram for realising the dephasing channel. b The RQM of dephasing channels Δp(ρ) = pρ + (1 − p)ZρZ, stochastic damping channels \({{\mathcal{D}}}_{p}(\rho )\,=\,p\rho \,+\,(1\,-\,p)\left|0\right\rangle \left\langle 0\right|\), and erasure channels \({{\mathcal{E}}}_{p}(\rho )\,=\,p\rho \,+\,(1\,-\,p)\left|2\right\rangle \left\langle 2\right|\) with \(\left|2\right\rangle\) orthogonal to the basis \(\{\left|0\right\rangle ,\left|1\right\rangle \}\). We synthesise the noise channels by interacting the target system with up to two ancillary qubits. We measure the payoff of quantum games \({\mathcal{P}}({\mathcal{N}},{\mathcal{G}})\) which lower bounds the RQM as \({\mathcal{R}}({\mathcal{N}})\,\ge\, {\mathcal{P}}({\mathcal{N}},{\mathcal{G}})\,-\,1\). c Benchmarking IBM Q hardware via the RQM of sequential controlled-X (CX) gates. We interchange the control and target qubit so that two sequential CX gates will not cancel out. For example, denote \(C{X}_{1}^{0}\) to be the CX gate with control qubit 0 and target qubit 1; the three CX gates are the swap gate \(C{X}_{1}^{0}C{X}_{0}^{1}C{X}_{1}^{0}\equiv SWAP\) and the six controlled-X gates become the identity gate \(C{X}_{0}^{1}C{X}_{1}^{0}C{X}_{0}^{1}C{X}_{1}^{0}C{X}_{0}^{1}C{X}_{1}^{0}\equiv {I}_{4}\). The error bar is three times the standard deviation for both plots.
Next, we show that the RQM can be applied to benchmark quantum gates and quantum circuits. Conventional quantum process benchmarking approaches, such as randomised benchmarking32,33, generally focus on characterising the similarity between the noisy circuit and the target circuit. In contrast, our method is concerned with the capability of the noisy quantum processor in preserving quantum information, which can be thus regarded as an alternative operational approach for benchmarking processes. In the experiment, we focus on the two-qubit controlled-X (CX) gate, a standard gate used for entangling qubits. We sequentially apply n (up to six) CX gates with interchanged control and target qubits for two adjacent gates. For example, one, three, and six CX gates correspond to the CX gate, the swap gate, and the identity gate, respectively.
Assuming that the dominant error is due to depolarising or dephasing effects, we estimate the RQM of each circuit via the correspondingly designed quantum game. As shown in Fig. 3c, we can see that although the robustness with one CX is 2.667 ± 0.106, it only slowly decreases to 2.497 ± 0.115 for six CX gates. Our results thus indicate that while the CX gate is imperfect (with an average 0.0340 decrease of robustness for each CX gate), the dominant noise of the two-qubit circuit may instead stem from imperfect state preparation and measurement (roughly leading to a 0.3 decrease in robustness). We also note that the large robustness loss of a single CX gate might also be due to the existence of other errors, which would imply that the choice of the quantum game could be further optimised. However, whenever the quantum game gives a large lower bound for the robustness, this is sufficient to ensure that the quantum process performs well in preserving quantum information. To demonstrate this, we consider the circuit \({CX}_{2}^{0}\cdot {CX}_{1}^{0}\) for preparing the three-qubit GHZ state. We lower bound the robustness as 5.837 ± 0.548, verifying that the three-qubit noisy circuit can preserve more quantum information than all two-qubit circuits, whose robustness is upper bounded by 3. We leave the detailed experimental results and analysis to the Supplementary Notes.
Discussion
In this work, we introduced an operationally meaningful, practically measurable and platform-independent benchmarking method for quantum memories. We defined the RQM and showed it to be an operational measure of the quality of a memory in three different practical settings. The greater the robustness of a memory, the more ideal qubit memories are needed to synthesise the memory; the more classical resources are required to simulate its observational statistics; and the better the memory is at two-player non-local quantum games based on state discrimination. The measure can be evaluated exactly in low-dimensional systems, and efficiently approximated both numerically by semi-definite programming and experimentally through measuring suitable observables. This thus constitutes a promising means to quantify the quantum mechanical aspects of information storage, and provides practical tools for benchmarking quantum memories across different experimental platforms and operational settings. The theory is applicable across different physical platforms exhibiting any known type of error source, as we experimentally confirm on the five-qubit IBM Q hardware. With the development of near-term noisy intermediate-scale quantum technologies34,35, we anticipate that our quantifier can become an industry standard for benchmarking quantum devices.
From a theoretical perspective, our work also constitutes a significant development in the resource theory of quantum memories. The only previously known general measure of this resource involved a performance optimisation over a large class of possible quantum games10, thus making it difficult to evaluate, experimentally inaccessible, and obscuring a direct quantitative connection to tasks of practical relevance—the robustness explicitly addresses all of these issues. Furthermore, the generality of the resource-theoretic framework ensures that the tools developed here for quantum memories can be naturally extended to other settings, including purity, coherence, entanglement of channels18,36,37,38,39,40,41,42,43,44,45,46, and the magic of operations47,48.
There are a number of interesting future considerations. One is to consider how memory robustness relates to another operational task: the storage and retrieval of encoded quantum states, whose performance can thought to represent some sort of memory capacity. This latter quantifier can be thought in the context of resource distillation. It asks how much many imperfect memories in question can be used to synthesize an ideal qubit memory. Thus, memory capacity is essentially the dual to memory robustness, which was shown above to quantify the reverse process of resource dilution (quantifying the amount of ideal qubit memory needed to synthesis a target memory). Indeed, recent follow-up works suggest that memory distillation could also be described within the same resource-theoretic framework, albeit with a resource monotone alternative to robustness25,26,49. Other interesting potentials include consideration of infinite-dimensional quantum systems, where one may be interested in quantum memories that preserve non-classicality or non-Gaussianity—potential sources of quantum advantage in continuous-variable quantum computation50,51,52,53,54. Finally, memories are essentially a question of reversibility, and thus naturally relate to heat dissipation in thermodynamics55,56. Indeed, recent results show connections between free energy and information encoding57, opening interesting possibilities toward understanding the thermodynamic consequences of such memory quantifiers.
Methods
Here we present properties of the robustness measure, formal statements of Theorems 1–4 and sketch their proofs. Full version of the proofs and details on the numerical simulations can be found in Supplementary Notes.
Properties of RQM
Recall the definition of RQM
where our chosen set of free channels are the EB channels. Define free transformation \({\mathcal{O}}\) as the set of physical transformations on quantum channels (super-channels) that map EB channels to EB channels, i.e. \({\mathcal{O}}\,=\,\{{{\Lambda }}:{{\Lambda }}({\mathcal{M}})\in {\rm{EB}},\forall {\mathcal{M}}\in {\rm{EB}}\}\). This class includes, for instance, the family of classically correlated transformations, which were considered in10 as a physically motivated class of free transformations under which quantum memories can be manipulated. In particular, transformations \({{\Lambda }}({\mathcal{N}})\,=\,{{\mathcal{M}}}_{1}\circ {\mathcal{N}}\circ {{\mathcal{M}}}_{2}\) with arbitrary pre- and post-processing channels \({{\mathcal{M}}}_{1},{{\mathcal{M}}}_{2}\) are free. We show that RQM satisfies the following properties.
Non-negativity. \({\mathcal{R}}({\mathcal{N}})\,\ge\, 0\) with equality if and only if \({\mathcal{N}}\in {\rm{EB}}\).
Monotonicity. \({\mathcal{R}}\) does not increase under any free transformation, \({\mathcal{R}}({{\Lambda }}({\mathcal{N}}))\,\le\, {\mathcal{R}}({\mathcal{N}})\) for arbitrary \({\mathcal{N}}\) and \({{\Lambda }}\in {\mathcal{O}}\).
Convexity. \({\mathcal{R}}\) does not increase by mixing channels, \({\mathcal{R}}\left({\sum }_{i}{p}_{i}{{\mathcal{N}}}_{i}\right)\,\le\, {\sum }_{i}{p}_{i}{\mathcal{R}}({{\mathcal{N}}}_{i})\).
Additional properties, such as bounds under the tensor product of channels are presented in Supplementary Notes.
Proof Non-negativity follows directly from the definition. For monotonicity, suppose \(s\,=\,{\mathcal{R}}({\mathcal{N}})\) with the minimisation achieved by \({\mathcal{M}}\) such that
Apply an arbitrary free transformation Λ on both sides and using linearity, we obtain \(\frac{1}{s\,+\,1}{{\Lambda }}({\mathcal{N}})\,+\,\frac{s}{s\,+\,1}{{\Lambda }}({\mathcal{M}})\,=\,{{\Lambda }}\left({\mathcal{M}}^{\prime} \right)\in {\rm{EB}}\). Therefore by definition \({\mathcal{R}}({{\Lambda }}({\mathcal{N}}))\,\le\, s\,=\,{\mathcal{R}}({\mathcal{N}})\). For convexity, suppose \({s}_{i}\,=\,{\mathcal{R}}({{\mathcal{N}}}_{i})\) with the minimisation achieved by \({{\mathcal{M}}}_{i}\) for each i and let \({{\mathcal{M}}^{\prime}_{i}} \,=\,({{\mathcal{N}}}_{i}\,+\,{s}_{i}{{\mathcal{M}}}_{i})/(1\,+\,{s}_{i})\). Let s = \({\mathop{\sum}\nolimits_{i}}{\mathop{p}\nolimits_{i}} {\mathop{s}\nolimits_{i}}\), \({\mathcal{N}}\,=\,{\sum }_{i}{p}_{i}{{\mathcal{N}}}_{i}\) and \({\mathcal{M}}\,=\,\frac{1}{s}{\sum }_{i}{p}_{i}{s}_{i}{{\mathcal{M}}}_{i}\), then by convexity of the set of EB channels
therefore by definition we have \({\mathcal{R}}\left({\sum }_{i}{p}_{i}{{\mathcal{N}}}_{i}\right)\,=\,{\mathcal{R}}({\mathcal{N}})\le s\,=\,{\sum }_{i}{p}_{i}{s}_{i}\,=\,{\sum }_{i}{p}_{i}{\mathcal{R}}({{\mathcal{N}}}_{i})\).
Single-shot memory synthesis
Here we study a more general scenario, imperfect memory synthesis, which allows a small error between the synthesised memory and the target memory. The resource cost for this task is defined as the minimal dimension required for the ideal qudit memory \({{\mathcal{I}}}_{d}\),
where \({\parallel }\,\cdot\,{\parallel }_{\diamond}\) denotes the diamond norm, which describes the distance of two channels. We also include a smooth parameter ε of the cost which tolerates an arbitrary amount of error in the synthesis protocol. The case with ε = 0 corresponds to the case with exact synthesis. When considering the ideal qubit memory \({{\mathcal{I}}}_{2}\) as the unit optimal resource, the minimal number of ideal qubit memories \({{\mathcal{I}}}_{2}^{\otimes n}\) required for memory synthesis is given by \(n=\lceil {{\rm{log}}}_{2}({R}_{{\rm{syn}}}^{\varepsilon }({\mathcal{N}}))\rceil\)
Correspondingly, we define a smoothed version of the robustness measure by minimising over a small neighbourhood of quantum channels,
We prove that the smoothed robustness measure exactly quantifies the resource cost for imperfect single-shot memory synthesis.
Formal statement of Theorem 1. For any quantum channel \({\mathcal{N}}\) and any 0 ≤ ε < 1, the resource cost for single-shot memory synthesis satisfies
Note that by setting ε = 0 we recover the result for perfect memory synthesis stated in the main text.
Proof We start by proving \({R}_{{\rm{syn}}}^{\varepsilon }({\mathcal{N}})\,\ge\, 1\,+\,\lceil {{\mathcal{R}}}^{\varepsilon }({\mathcal{N}})\rceil\). The first step is to show that the robustness of the identity channel is \({\mathcal{R}}({{\mathcal{I}}}_{d})\,=\,d\,-\,1\). The proof of this fact is omitted here. Next we show that the desired inequality can be proven using the monotonicity property. For an arbitrary memory synthesis protocol \({{\Lambda }}({{\mathcal{I}}}_{d})\,=\,{\mathcal{N}}^{\prime}\) where \(\parallel {\mathcal{N}}^{\prime} \,-\,{\mathcal{N}}{\parallel }_{\diamond}\,\le\, \varepsilon\), we have
Here the second line follows by definition and the fourth line follows from monotonicity. As the above inequality holds for all memory synthesis protocols, it also holds for the optimal protocol. Also notice that dimensions are integers. Thus we derive that \({R}_{{\rm{syn}}}^{\varepsilon }({\mathcal{N}})\,\ge\, 1\,+\,\lceil {{\mathcal{R}}}^{\varepsilon }({\mathcal{N}})\rceil\).
To prove the other side \({R}_{{\rm{syn}}}^{\varepsilon }({\mathcal{N}})\,\le\, 1\,+\,\lceil {{\mathcal{R}}}^{\varepsilon }({\mathcal{N}})\rceil\), suppose the channel achieves the mimum of Eq. (10) is \({\mathcal{N}}^{\prime}\), and let \({d}_{c}\,=\,1\,+\,\lceil {\mathcal{R}}({\mathcal{N}}^{\prime} )\rceil\). To prove the desired inequality, it suffices to show that \(\exists {{\Lambda }}\in {\mathcal{O}}\) such that \({{\Lambda }}({{\mathcal{I}}}_{{d}_{c}})\,=\,{\mathcal{N}}^{\prime}\). Indeed such a Λ is a protocol that achieves the required accuracy using resource \(1+\lceil {{\mathcal{R}}}^{\varepsilon }({\mathcal{N}})\rceil\), thus the optimal protocol should only use less resource.
Next we explicitly construct such a free transformation Λ, which transforms a quantum channel to another channel. As there is a one-to-one correspondence between Choi states and quantum channels, we give this construction based on transformation of the Choi state:
where Φ denotes the Choi state of the subscript channel and ϕ+ is the maximally entangled state. In the full proof we show that Λ is a valid physical transformation, i.e. a quantum super-channel.
As it is easy to verify that \({{\Lambda }}({{\mathcal{I}}}_{{d}_{c}})\,=\,{\mathcal{N}}^{\prime}\), it only remains to show that Λ is a free transformation, which maps EB channels to EB channels. To do this, first notice that as \({d}_{c}\,\ge\, 1\,+\,{\mathcal{R}}({\mathcal{N}}^{\prime} )\), there exists \({\mathcal{M}},{\mathcal{M}}^{\prime} \in {\rm{EB}}\) such that
Then we can rewrite Eq. (13) as
with \(q\,=\,{d}_{c}{\rm{Tr}}\left[{\phi }^{+}{{{\Phi }}}_{{\mathcal{C}}}\right]\). When \({\mathcal{C}}\) is an EB channel, \({{{\Phi }}}_{{\mathcal{C}}}\) is a separable state, and we have 0 ≤ q ≤ 1. Thus \({{\Lambda }}({{{\Phi }}}_{{\mathcal{C}}})\) is a separable Choi state that corresponds to an EB channel, which means that Λ is a free transformation and concludes the proof.
Simulating observational statistics
Observe that the general simulation strategy is to find a set of free memories \(\{{{\mathcal{M}}}_{i}\}\subseteq {\rm{EB}}\) such that the target memory can be linearly expanded as \({\mathcal{N}}\,=\,{\sum }_{i}{c}_{i}{{\mathcal{M}}}_{i},{c}_{i}\in {\mathbb{R}}\). By using \({{\mathcal{M}}}_{i}\) and measuring \({\rm{Tr}}[O{{\mathcal{M}}}_{i}(\rho )]\), we can obtain the target statistics as \({\rm{Tr}}[O{\mathcal{N}}(\rho )]\,=\,{\sum }_{i}{c}_{i}{\rm{Tr}}[O{{\mathcal{M}}}_{i}(\rho )]\). Thus, compared with having access to \({\mathcal{N}}\) and directly measuring O, the classical simulation introduces an extra sampling overhead with a multiplicative factor \({\parallel\,{c}\,\parallel }_{1}^{2}\,=\,{\left({\sum }_{i}| {c}_{i}| \right)}^{2}\). In particular, suppose we aim to estimate \({\rm{Tr}}[O{\mathcal{N}}(\rho )]\) to an additive error ε with failure probability δ. Due to Hoeffding’s inequality27, when having access to \({\mathcal{N}}\) we need T0 ∝ 1/ε2log(δ−1) samples to achieve this estimate to desired precision, and when only having access to free resources in a specific decomposition \({\mathcal{N}}\,=\,{\sum }_{i}{c}_{i}{{\mathcal{M}}}_{i}\), we need \({T}\propto {\parallel\,{c}\,\parallel}_{1}^{2}/{\varepsilon }^{2}{\rm{log}}({\delta }^{-1})\) samples. The simulation overhead is thus given by \({\parallel\,{c}\,\parallel }_{1}^{2}\propto T/{T}_{0}\).
By minimising the simulation overhead over all possible expansions, we obtain the optimal simulation cost
Our second result shows that this optimal cost is quantified by the robustness measure.
Formal statement of Theorem 2. For any quantum channel \({\mathcal{N}}\), the optimal cost for the observational simulation of \({\mathcal{N}}\) using EB channels is given by
Proof For any linear expansion \({\mathcal{N}}\,=\,{\sum }_{i}{c}_{i}{{\mathcal{M}}}_{i}\), denote the positive and negative coefficients of ci by \({c}_{i}^{+}\) and \({c}_{i}^{-}\), respectively. Then we have
with \(\parallel c\parallel \,=\,{\sum }_{i:{c}_{i}\,\ge\, 0}| {c}_{i}^{+}| \,+\,{\sum }_{i:{c}_{i}\,{\,<\,}\,0}| {c}_{i}^{-}|\). As the channel is trace preserving, taking trace on both sides we get \({\sum }_{i:{c}_{i}\,\ge\, 0}| {c}_{i}^{+}| \,-\,{\sum }_{i:{c}_{i}\,{\,<\,}\,0}| {c}_{i}^{-}| \,=\,1\). Denote \(s\,=\,{\sum }_{i:{c}_{i}\,{\,<\,}\,0}| {c}_{i}^{-}|\), hence with ∥c∥1 = 2s + 1, \({\mathcal{M}}\,=\,{\sum }_{i:{c}_{i}\,{\,<\,}\,0}| {c}_{i}^{-}| {{\mathcal{M}}}_{i}/s\), and \({\mathcal{M}}^{\prime} \,=\,{\sum }_{i:{c}_{i}\,\ge\, 0}| {c}_{i}^{+}| {{\mathcal{M}}}_{i}/(1\,+\,s)\), we have
where by convexity of EB, we have \({\mathcal{M}},{\mathcal{M}}^{\prime} \in {\rm{EB}}\). Therefore finding the optimal expansion is equivalent to finding the smallest s such that Eq. (19) holds, which by definition equals to the robustness, i.e. \({s}_{\min }\,=\,{\mathcal{R}}({\mathcal{N}})\). Then we conclude that \({{\mathcal{C}}}_{\min }({\mathcal{N}})\,=\,{(1\,+\,2{\mathcal{R}}({\mathcal{N}}))}^{2}\).
Non-local games
Consider a quantum game \({\mathcal{G}}\) defined by the tuple \({\mathcal{G}}=(\{{\alpha }_{ij}\},\{{\sigma }_{i}\},\{{O}_{j}\})\), where σi are input states, {Oj} is a positive observable valued measures at the output, and \({\alpha }_{i}\in {\mathbb{R}}\) are the coefficients which define the particular game. The maximal performance in the game \({\mathcal{G}}\) enabled by a channel \({\mathcal{N}}\) is quantified by the payoff function \({\mathcal{P}}({\mathcal{N}},{\mathcal{G}})={\sum }_{ij}{\alpha }_{ij}{\rm{Tr}}[{O}_{j}{\mathcal{N}}({\sigma }_{i})]\). Theorem 3 establishes the connection between the advantage of a quantum channel in the game scenario over all EB channels and the robustness measure. To ensure that the optimisation problem is well-defined and bounded, we will optimise over games which give a non-negative payoff for classical memories, which include standard state discrimination tasks.
Formal statement of Theorem 3. Let \({\mathcal{G}}^{\prime}\) denote games such that all EB channels achieve a non-negative payoff, that is,
Then the maximal advantage of a quantum channel \({\mathcal{N}}\) over all EB channels, maximised over all such games, is given by the robustness:
Proof The proof is based on duality in conic optimisation (see ref. 17 and references there in). First we write the robustness as an optimisation problem
where \({{{\Phi }}}_{{\mathcal{N}}}\) is the Choi state of \({\mathcal{N}}\), Choi(EB) denotes the Choi states of EB channels, i.e. bipartite separable Choi states, and cone(⋅) represents the unnormalised version. This can be written in the standard form of conic programming, based on which we can write the dual form of this optimisation problem. The dual form can be simplified as
We can verify that these primal and dual forms satisfy the condition for strong duality, therefore \({\rm{OPT}}=1+{\mathcal{R}}({\mathcal{N}})\), and it remains to show that OPT equals the maximal advantage in games.
As the constraints in the dual form (Eq. (23)) are linear, without loss of generality, we can rescale the optimisation so that we only need to consider games \({\mathcal{G}}^{\prime}\) that satisfy
for any \({\mathcal{M}}\in {\rm{EB}}\). We can then write
where d is the input dimension of \({\mathcal{N}}\) and \(W\,=\,d{\sum }_{i,j}{\alpha }_{ij}{\sigma }_{i}^{T}\otimes {O}_{j}\). Using this representation, the maximal advantage can be written as an optimisation problem equivalent to (23). In particular, since any Hermitian matrix can be expressed in the form of W for some real coefficients {αij}, any witness W in (23) can be used to construct a corresponding game \({\mathcal{G}}^{\prime}\), and conversely any game \({\mathcal{G}}^{\prime}\) satisfying the optimisation constraints gives rise to a valid witness W in (23). We thus have
concluding the proof.
Computability and bounds
It is known that the description of the set of separable states is NP-hard in the dimension of the system58, and indeed this property extends to the set of EB channels59, making it intractable to describe in general. Nonetheless, we can solve the problem of quantifying the RQM in relevant cases, as well as establish universally applicable bounds. As described in the main text, suitably constructing non-local games \({\mathcal{G}}\) can provide such lower bounds, which can indeed be tight. More generally, one can employ the positive partial transpose criterion60 to provide an efficiently computable semi-definite programming relaxation of the problem, often providing non-trivial and useful bounds on the value of the RQM. We leave a detailed discussion of these methods to the Supplementary Notes. In the case of low-dimensional channels, which is of particular relevance in many near-term technological applications, we can go further than numerical bounds and establish an analytical description of the RQM.
Formal statement of Theorem 4. For any channel \({\mathcal{N}}\) with input dimension dA and output dimension dB, its RQM satisfies
and equality holds when dA ≤ 3 and dB = 2.
Proof The idea behind the proof is to employ the reduction criterion for separability61,62, which can be used to show that any EB channel \({\mathcal{M}}:A\to B\) satisfies \({{{\Phi }}}_{{\mathcal{M}}}\,\le\, \frac{1}{{d}_{A}}{I}_{AB}\). Therefore, the set of channels satisfying this criterion provides a relaxation of the set of EB channels, and we can define a bound on the RQM by computing the minimal robustness with respect to this set. A suitable decomposition of a channel \({\mathcal{N}}\) can then be used to show that, in fact, this bound is given exactly by the larger of \({d}_{A}\max {\mathrm{eig}}\,({{{\Phi }}}_{{\mathcal{N}}})\,-\,1\) and 0. In the case of dA ≤ 3 and dB = 2, the reduction criterion is also a sufficient condition for separability, which ensures that the robustness \({\mathcal{R}}({\mathcal{N}})\) matches the lower bound.
Experiment details
The processor has five qubits with T1 and T2 ranging from 25 to 110 μs, single-qubit gate error 3.3–6.5 × 10−4, two-qubit gate error 1.0–1.5 × 10−2, and read-out error 1.9–4.5 × 10−2. Our experiments are run on the first three qubits, which have the highest gate fidelities, and the circuits are implemented with Qiskit63.
Data availability
The authors declare that all data supporting this study are contained within the article and its supplementary files.
Code availability
The code that supports the findings of this study are available from the corresponding author upon reasonable request.
References
Duan, L.-M., Lukin, M., Cirac, J. I. & Zoller, P. Long-distance quantum communication with atomic ensembles and linear optics. Nature 414, 413 (2001).
Zhong, M. et al. Optically addressable nuclear spins in a solid with a six-hour coherence time. Nature 517, 177 (2015).
Wang, Y. et al. Single-qubit quantum memory exceeding ten-minute coherence time. Nat. Photonics 11, 646 (2017).
Chuang, I. L. & Nielsen, M. A. Prescription for experimental determination of the dynamics of a quantum black box. J. Mod. Opt. 44, 2455–2467 (1997).
Poyatos, J. F., Cirac, J. I. & Zoller, P. Complete characterization of a quantum process: the two-bit quantum gate. Phys. Rev. Lett. 78, 390–393 (1997).
D’Ariano, G. M. & Lo Presti, P. Quantum tomography for measuring experimentally the matrix elements of an arbitrary quantum operation. Phys. Rev. Lett. 86, 4195–4198 (2001).
Namiki, R. Verification of the quantum-domain process using two nonorthogonal states. Phys. Rev. A 78, 032333 (2008).
Häseler, H. & Lütkenhaus, N. Quantum benchmarks for the storage or transmission of quantum light from minimal resources. Phys. Rev. A 81, 060306 (2010).
Macchiavello, C. & Rossi, M. Quantum channel detection. Phys. Rev. A 88, 042335 (2013).
Rosset, D., Buscemi, F. & Liang, Y.-C. Resource theory of quantum memories and their faithful verification with minimal assumptions. Phys. Rev. X 8, 021033 (2018).
Simnacher, T., Wyderka, N., Spee, C., Yu, X.-D. & Gühne, O. Certifying quantum memories with coherence. Phys. Rev. A 99, 062319 (2019).
Horodecki, M. & Oppenheim, J. (quantumness in the context of) resource theories. Int. J. Mod. Phys. B B 27, 1345019 (2013).
Coecke, B., Fritz, T. & Spekkens, R. W. A mathematical theory of resources. Inf. Comput. 250, 59–86 (2016).
Chitambar, E. & Gour, G. Quantum resource theories. Rev. Mod. Phys. 91, 025001 (2019).
Kuo, C.-C. et al. Quantum process capability. Sci. Rep. 9, (2019).
Gour, G. Comparison of quantum channels by superchannels. IEEE Trans. Inf. Theory 65, 5880–5904 (2019).
Takagi, R. & Regula, B. General resource theories in quantum mechanics and beyond: operational characterization via discrimination tasks. Phys. Rev. X 9, 031053 (2019).
Liu, Y. & Yuan, X. Operational resource theory of quantum channels. Phys. Rev. Res. 2, 012035 (2020).
Liu, Z.-W. & Winter, A. Resource theories of quantum channels and the universal role of resource erasure. Preprint at https://arxiv.org/abs/1904.04201 (2019).
Takagi, R., Wang, K. & Hayashi, M. Application of the resource theory of channels to communication scenarios. Phys. Rev. Lett. 124, 120502 (2020).
Horodecki, M., Shor, P. W. & Ruskai, M. B. Entanglement breaking channels. Rev. Math. Phys. 15, 629–641 (2003).
Holevo, A. S. Entanglement-breaking channels in infinite dimensions. Probl. Inf. Transm. 44, 171–184 (2008).
Buscemi, F. & Datta, N. Entanglement cost in practical scenarios. Phys. Rev. Lett. 106, 130503 (2011).
Brandao, F. G. S. L. & Datta, N. One-shot rates for entanglement manipulation under non-entangling maps. IEEE Trans. Inf. Theory 57, 1754–1760 (2011).
Regula, B. & Takagi, R. One-shot manipulation of dynamical quantum resources.Preprint at https://arxiv.org/abs/2012.02215 (2020).
Yuan, X., Zeng, P., Gao, M. & Zhao, Q. One-shot dynamical resource theory. Preprint at https://arxiv.org/abs/2012.02781 (2020).
Pashayan, H., Wallman, J. J. & Bartlett, S. D. Estimating outcome probabilities of quantum circuits using quasiprobabilities. Phys. Rev. Lett. 115, 070501 (2015).
Buscemi, F. All entangled quantum states are nonlocal. Phys. Rev. Lett. 108, 200401 (2012).
Eisert, J., Brandão, F. G. S. L. & Audenaert, K. M. R. Quantitative entanglement witnesses. New J. Phys. 9, 46 (2007).
Vidal, G. & Tarrach, R. Robustness of entanglement. Phys. Rev. A 59, 141 (1999).
Rivas, A., Huelga, S. F. & Plenio, M. B. Entanglement and non-markovianity of quantum evolutions. Phys. Rev. Lett. 105, 050403 (2010).
Emerson, J., Alicki, R. & Życzkowski, K. Scalable noise estimation with random unitary operators. J. Opt. B: Quantum Semiclass. Opt. 7, S347 (2005).
Knill, E. et al. Randomized benchmarking of quantum gates. Phys. Rev. A 77, 012307 (2008).
Preskill, J. Quantum computing in the nisq era and beyond. Quantum 2, 79 (2018).
Arute, F. et al. Quantum supremacy using a programmable superconducting processor. Nature 574, 505–510 (2019).
Bennett, C. H., Harrow, A. W., Leung, D. W. & Smolin, J. A. On the capacities of bipartite hamiltonians and unitary gates. IEEE Trans. Inf. Theory 49, 1895–1911 (2003).
Pirandola, S., García-Patrón, R., Braunstein, S. L. & Lloyd, S. Direct and reverse secret-key capacities of a quantum channel. Phys. Rev. Lett. 102, 050503 (2009).
García-Patrón, R., Pirandola, S., Lloyd, S. & Shapiro, J. H. Reverse coherent information. Phys. Rev. Lett. 102, 210501 (2009).
Pirandola, S., Laurenza, R., Ottaviani, C. & Banchi, L. Fundamental limits of repeaterless quantum communications. Nat. Commun. 8, 15043 (2017).
Kaur, E. & Wilde, M. M. Amortized entanglement of a quantum channel and approximately teleportation-simulable channels. J. Phys. A Math. Theor. 51, 035303 (2017).
Pirandola, S., Laurenza, R. & Banchi, L. Conditional channel simulation. Ann. Phys. 400, 289–302 (2019).
Theurer, T., Egloff, D., Zhang, L. & Plenio, M. B. Quantifying operations with an application to coherence. Phys. Rev. Lett. 122, 190405 (2019).
Gour, G. & Scandolo, C. M. The entanglement of a bipartite channel. Preprint at https://arxiv.org/abs/1907.02552 (2019).
Bäuml, S., Das, S., Wang, X. & Wilde, M. M. Resource theory of entanglement for bipartite quantum channels. Preprint at https://arxiv.org/abs/1907.04181 (2019).
Yuan, X. Hypothesis testing and entropies of quantum channels. Phys. Rev. A 99, 032317 (2019).
Gour, G. & Wilde, M. M. Entropy of a quantum channel. Phys. Rev. Res. 3, 023096 (2021).
Seddon, J. R. & Campbell, E. T. Quantifying magic for multi-qubit operations. P. Roy. Soc. A-Math. Phy. 475, 20190251 (2019).
Wang, X., Wilde, M. M. & Su, Y. Quantifying the magic of quantum channels. New J. Phys. 21, 103002 (2019).
Kim, H.-J., Lee, S., Lami, L. & Plenio, M. One-shot manipulation of entanglement for quantum channels. Preprint at https://arxiv.org/abs/2012.02631 (2020).
Yadin, B. et al. Operational resource theory of continuous-variable nonclassicality. Phys. Rev. X 8, 041038 (2018).
Takagi, R. & Zhuang, Q. Convex resource theory of non-gaussianity. Phys. Rev. A 97, 062337 (2018).
Albarelli, F., Genoni, M. G., Paris, M. G. A. & Ferraro, A. Resource theory of quantum non-gaussianity and wigner negativity. Phys. Rev. A 98, 052350 (2018).
Kwon, H., Tan, K. C., Volkoff, T. & Jeong, H. Nonclassicality as a quantifiable resource for quantum metrology. Phys. Rev. Lett. 122, 040503 (2019).
Regula, B., Lami, L., Ferrari, G. & Takagi, R. Operational quantification of continuous-variable quantum resources. Phys. Rev. Lett. 126, 110403 (2021).
Goold, J., Huber, M., Riera, A., del Rio, L. & Skrzypczyk, P. The role of quantum information in thermodynamics: a topical review. J. Phys. A Math. Theor. 49, 143001 (2016).
Bérut, A. et al. Experimental verification of landauer’s principle linking information and thermodynamics. Nature 483, 187 (2012).
Narasimhachar, V., Thompson, J., Ma, J., Gour, G. & Gu, M. Quantifying memory capacity as a quantum thermodynamic resource. Phys. Rev. Lett. 122, 060601 (2019).
Gurvits, L. Classical deterministic complexity of edmonds’ problem and quantum entanglement. In Proceedings of the Thirty-Fifth Annual ACM Symposium on Theory of Computing, STOC ’03, 10–19 (ACM, New York, NY, USA, 2003).
Gharibian, S. Strong NP-hardness of the quantum separability problem. Quant. Inf. Comput. 10, 343–360 (2010).
Horodecki, M., Horodecki, P. & Horodecki, R. Separability of mixed states: necessary and sufficient conditions. Phys. Lett. A 223, 1–8 (1996).
Horodecki, M. & Horodecki, P. Reduction criterion of separability and limits for a class of distillation protocols. Phys. Rev. A 59, 4206–4216 (1999).
Cerf, N. J., Adami, C. & Gingrich, R. M. Reduction criterion for separability. Phys. Rev. A 60, 898–909 (1999).
Aleksandrowicz, G. et al. Qiskit: an open-source framework for quantum computing (2019).
Acknowledgements
We are grateful to Ryuji Takagi for making us aware of errors in a preliminary version of this manuscript. We acknowledge Simon Benjamin and Earl Campbell for insightful discussions. This work is supported by the EPSRC National Quantum Technology Hub in Networked Quantum Information Technology (EP/M013243/1), the National Natural Science Foundation of China grants nos. 11875173 and 11674193, and the National Key R&D Programme of China grants nos. 2017YFA0303900 and 2017YFA0304004, the National Research Foundation of Singapore fellowship no. NRF-NRFF2016-02 and the National Research Foundation and L’Agence Nationale de la Recherche joint Project no. NRF2017-NRFANR004 VanQuTe, the MOE Tier 1 grant RG162/19 (S), the Foundational Questions Institute (FQXi) large grant FQXi-RFP-IPW-1903 ‘Are quantum agents more energetically efficient at making predictions?’ the National Research Foundation of Singapore under its NRF-ANR joint programme (NRF2017-NRF-ANR004 VanQuTe), the National Research Foundation Fellowship NRF-NRFF2016-02, the Singapore Ministry of Education Tier 1 grant 2019-T1- 002-015 (RG190/17), FQXi-RFP-1809 from the Foundational Questions Institute and Fetzer Franklin Fund, a donor advised fund of Silicon Valley Community Foundation and the Quantum Engineering Programme QEP-SP3. Finally, we acknowledge use of the IBM Q for this work. The views expressed are those of the authors and do not reflect the official policy or position of IBM, the IBM Q team, the National Foundation of Singapore or the Ministry of Education of Singapore.
Author information
Authors and Affiliations
Contributions
X.Y., Y.L. and B.R. devised the main conceptual and proof ideas. X.Y. and Q.Z. performed the numerical simulation and the experiment on the IBM Q cloud. All authors contributed to the development of the theory and the writing of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yuan, X., Liu, Y., Zhao, Q. et al. Universal and operational benchmarking of quantum memories. npj Quantum Inf 7, 108 (2021). https://doi.org/10.1038/s41534-021-00444-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41534-021-00444-9
