
Abstract
This article deals with testing simultaneous hypotheses about the mean structure and the covariance structure in models with blocked compound symmetric (BCS) covariance structure. Considered models are used for double multivariate data, which means that m-variate vector of observation is measured repeatedly over u levels of some factor on each of n individual. Additionally, the assumption of multivariate normality for this type of data is made. We use framework of ratio of positive and negative parts of best unbiased estimators to obtain simultaneous F test. The test statistic is constructed as a ratio of test statistics for testing single hypotheses about the mean vector and the covariance matrix. In simulation study power of obtained test is compared with powers of three other F tests—two for testing single hypotheses and one for testing simultaneous hypotheses, whose test statistic is convex combination of test statistics of these two single F tests. The problem of simultaneous testing of the mean vector and covariance matrix was also consider in paper (Hyodo and Nishiyama, Commun Stat Theory Methods, https://doi.org/10.1080/03610926.2019.1639751, 2019).
Similar content being viewed by others


1 Introduction
Let us consider the following multivariate model
where \({\mathrm{vec}}\) is a vectorization operator that is a linear transformation which converts the matrix into a column vector obtained by stacking the columns of a matrix on top of one another, \({\varvec{I}}_{n}\) is \(n\times n\) identity matrix, \({\varvec{Y}}=\left( {\varvec{y}}_1,\ldots ,{\varvec{y}}_n\right) \) stands for data matrix, \({\varvec{y}}_j\) is \(um \times 1\)-dimensional vector of all measurements corresponding to the j-th individual, \({\varvec{1}}_{n}\) is n-vector of ones, \(\otimes \) denotes Kronecker product, \(\varvec{\mu }\) is \(um \times 1\)-dimensional unknown mean vector. Here the \((um \times um)\)-dimensional covariance matrix \(\varvec{\Gamma }\) has BCS structure which is defined as
where \({\varvec{J}}_{u}\) denotes the \(u\times u\) matrix of ones, the \(m \times m\) block diagonals \(\varvec{\Gamma }_{0}\) represent the covariance matrix of the m response variables at any given level of factor, while the \(m \times m\) block off diagonals \(\varvec{\Gamma }_{1}\) represent the covariance matrix of the m response variables between any two levels of factor.
The matrix \(\varvec{\Gamma }\) is positive definite if and only if \(\varvec{\Gamma }_{0}+(u-1)\varvec{\Gamma }_{1}\) and \(\varvec{\Gamma }_{0}-\varvec{\Gamma }_{1}\) are positive definite matrices. For the proof see Roy and Leiva (2011) or Zmyślony et al. (2018).
In the second section we deal with problem of testing simultaneous hypotheses both for the expectation vector and the covariance structure in model (1.1). In the next section we present simulation study to compare powers of considered tests. In the fourth section we deal with real data and calculate p-value for each presented test. The last section contains summary of all obtained results in the paper and some remarks.
2 Simultaneous ratio F test
In Zmyślony et al. (2018) test for single hypothesis about the mean vector is considered and in Fonseca et al. (2018) test for single hypothesis about the covariance matrix is constructed. More precisely, the null hypothesis for the mean vector is
what means that mean vectors stay unchanged between all levels of factor. Under the null hypothesis such structure of mean vector is called the structured mean vector. For more details about model with the structured mean structure see Kozioł et al. (2018).
The null hypothesis for the covariance matrix \(\varvec{\Gamma }_1\) is
what means that there is no correlation between any two levels of factor.
Now let us consider the following simultaneous hypothesis
For hypotheses (2.1) and (2.2) test statistics have been constructed in Zmyślony et al. (2018) and Fonseca et al. (2018), as a ratio of positive and negative parts of best unbiased estimators. Details about this framework can be found in Michalski and Zmyślony (1996, 1999). These two test statistics have F distribution under null hypotheses with different numbers of degrees of freedom in numerator and the same number of degrees of freedom in denominator.
Let \(\varvec{{\widetilde{\mu }}}_j^{(c)}\) be best unbiased estimator (BUE) of orthogonal normalized contrast vector of \(\varvec{\mu }_j\) for \(j=2,\ldots ,u\). This estimator can be obtained using Helmert matrices, see Zmyślony et al. (2018). Then \(\sum _{j=2}^{u}\varvec{{\widetilde{\mu }}}_j^{(c)}\varvec{{\widetilde{\mu }}}_j^{(c)'}\) is positive part of estimator of \(\sum _{j=2}^{u}\varvec{\mu }_j^{(c)}\varvec{\mu }_j^{(c)'}\). The best unbiased estimators for \(\varvec{\Gamma }_0\) and \(\varvec{\Gamma }_1\) are
while
where \(\varvec{\overline{y}}_{\bullet s}=\frac{1}{n}\sum _{r=1}^{n}{{\varvec{y}}_{r,s}}\) and \({\varvec{y}}_{r,s}\) is m-variate vector of measurements on the \(r-th\) individual at the sth level of factor, \(r=1,\ldots ,n,\) and \(s=1,\ldots ,u\). For details see Roy et al. (2016). Moreover, let \(\widetilde{\varvec{\Gamma }}_{1+}\) and \(\widetilde{\varvec{\Gamma }}_{1-}\) be positive and negative part of best unbiased estimator \(\widetilde{\varvec{\Gamma }}_{1}\) for \(\varvec{\Gamma }_1\) (see Fonseca et al. 2018), respectively.
Following the above mentioned idea we prove
Theorem 1
The test statistic
with \({\varvec{x}}\ne {\varvec{0}}\), under null hypothesis (2.3) has F distribution with \(n-1\) and \(u-1\) degrees of freedom.
Proof
Let \(\varvec{{\widetilde{\Gamma }}}_{0}\) and \(\varvec{{\widetilde{\Gamma }}}_{1}\) be BUE for \(\varvec{\Gamma }_0\) and \(\varvec{\Gamma }_1\), respectively (see Roy et al. 2016; Seely 1977; Zmyślony 1980). From Fonseca et al. (2018) we get that under null hypothesis (2.2):
and are independent. Throughout the paper \({\mathcal {W}}_m\left( \varvec{\Sigma },n\right) \) stands for Wishart distribution with covariance matrix \(\varvec{\Sigma }\) and number of degrees of freedom equal to n.
Moreover, under null hypothesis (2.1):
and are independent. Additionally, statistics given in (2.7) and (2.9) are independent. For the proof see Zmyślony et al. (2018)
From (2.5) and (2.6) we have that for any \({\varvec{x}}\ne {\varvec{0}}\) test statistics for testing hypothesis (2.2) about the covariance matrix \(\varvec{\Gamma }_1\) is
For details see Fonseca et al. (2018). On the other hand, using (2.7) and (2.8), we get that for any \({\varvec{x}}\ne {\varvec{0}}\) test statistic for testing hypothesis (2.1) about the mean vector \(\varvec{\mu }\) is
The proof is given in Zmyślony et al. (2018). One should note that in denominators of (2.9) and (2.10) there are the same expression \({\varvec{x}}'(\varvec{{\widetilde{\Gamma }}}_{0} -\varvec{{\widetilde{\Gamma }}}_{1}){\varvec{x}}\). Thus taking ratio of \(F^{\varvec{\Gamma }_1}\) and \(F^{\varvec{\mu }}\) we get that under null hypothesis (2.3) for any \({\varvec{x}}\ne {\varvec{0}}\)
\(\square \)
Remark 1
Note that test statistic for ratio F test can be also obtained as a ratio of \(F^{\varvec{\mu }}\) and \(F^{\varvec{\Gamma }_1}\). In this case, under null hypothesis (2.3) for any fixed \({\varvec{x}}\ne {\varvec{0}}\) such test statistic has F distribution with \(u-1\) and \(n-1\) degrees of freedom.
3 Simulation study
In this section we compare powers of simultaneous ratio F test obtained in the previous section with two tests for single hypotheses i.e. (2.1) and (2.2) and also with simultaneous F test for (2.3) constructed in Zmyślony and Kozioł (2019), whose test statistic is convex combination of test statistics of single F tests. For simulation study we assume that vector \({\varvec{x}}={\varvec{1}}\), which means that in (2.4) in nominator and denominator we take a sum of elements of estimators. Regarding parameters, we choose \(n=15\), \(u=2\), \(m=3\) and in case when all elements in vector of contrasts and in \(\varvec{\Gamma }_1\) have the same sign, we take vector of contrast in the following form
and the following matrices \(\varvec{\Gamma }_{0}\) and \(\varvec{\Gamma }_{1}\)
For these matrices \(\varvec{\Gamma }_0\), \(\varvec{\Gamma }_1\) and value of u, we determined interval for positive values of multiplier \(\lambda \), so that the following two conditions are satisfied:
-
1.
\(\varvec{\Gamma }_{0}+(u-1)\lambda \varvec{\Gamma }_{1}\) is positive definite matrix,
-
2.
\(\varvec{\Gamma }_{0}-\lambda \varvec{\Gamma }_{1}\) is positive definite matrix.
These conditions ensure positive definite of matrix \(\varvec{\Gamma }\). Moreover, in each step of simulation in test for expectation vector we add randomly chosen vectors to the vector of contrasts multiplied by the same \(\lambda \) to obtain power function of the test. Note that for \(\lambda =0\) we have null hypotheses. The simulation study is given in the same manner as in Zmyślony and Kozioł (2019).
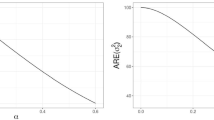
As can be seen from Fig. 1 in case when all elements in covariance matrix \(\varvec{\Gamma }_1\) and vector of contrasts \(\varvec{\mu }^{(c)}_{2}\) have the same sign, simultaneous ratio F test has bigger power than three other tests, both for single hypotheses and simultaneous convex combination F test.

Powers of tests in case when all elements in \(\varvec{\Gamma }_1\) and \(\varvec{\mu }^{(c)}_{2}\) are positive
Now we consider case when elements in \(\varvec{\mu }^{(c)}_{2}\) have different signs. We take the following vector of contrasts
Matrices \(\varvec{\Gamma }_0\) and \(\varvec{\Gamma }_1\) have the same elements as in the previous case.
Figure 2 shows that this time simultaneous convex combination F test has the biggest power. Ratio F test close to null hypothesis has relatively small power but the farther away from the null hypothesis, the bigger increase power of this test, especially compared with power of F test for testing single hypothesis about covariance matrix. Power of test for testing single hypothesis about mean vector is poor which was predictable because in test statistic for this test is taken ratio of sum of elements of positive and sum of elements of negative part of BUE. For elements with different signs sum could be close to zero even if elements are far from 0.

Powers of tests in case when all elements in \(\varvec{\Gamma }_1\) are positive and elements in \(\varvec{\mu }^{(c)}_{2}\) have different signs
In third case we take the same \(\varvec{\mu }^{(c)}_{2}\) as in the first case and matrices \(\varvec{\Gamma }_{0}\) and \(\varvec{\Gamma }_{1}\) of the following forms
Thus now we consider case when elements in \(\varvec{\Gamma }_{1}\) have different signs and all elements in \(\varvec{\mu }^{(c)}_{2}\) have the same sign.
In Fig. 3 one can see different situation from two previous cases. Powers of simultaneous tests, both based on ratio and convex combination, are very low compared with the power of test for testing single hypothesis about \(\varvec{\mu }\). Nevertheless, ratio F test is better than convex combination F test in this comparison. Test for testing single hypothesis about \(\varvec{\Gamma }_{1}\) has the lowest power. The reason for this is the same as the one described in second case for test for \(\varvec{\mu }\). Poor power of simultaneous tests reveals fact that different signs of elements in the covariance matrix has big impact on power of these tests.

Powers of tests in case when elements in \(\varvec{\Gamma }_1\) have different signs and all elements in \(\varvec{\mu }^{(c)}_{2}\) are positive
For the last considered case we take matrices \(\varvec{\Gamma }_0\) and \(\varvec{\Gamma }_1\) as in the previous case and vector of contrasts as in the second case. Thus elements in \(\varvec{\Gamma }_1\) and elements in \(\varvec{\mu }^{(c)}_{2}\) have different signs.
In Fig. 4 one can see that all four considered tests have low powers and this is clear from two previous cases. Thus in case when in the covariance matrix and in vector of contrasts there are both positive and negative elements, none of these tests are recommended for testing hypotheses about the mean vector \(\varvec{\mu }\) and the covariance matrix \(\varvec{\Gamma }_1\).

Powers of tests in case when elements in \(\varvec{\Gamma }_1\) and elements in \(\varvec{\mu }^{(c)}_{2}\) have different signs
4 Data example
We consider clinical study data on mineral contents in bones of the upper arm and the forearm (radius, humerus and ulna) in 25 women. Measurements were taken on the dominant and non-dominant side of each woman. This data is taken from Johnson and Wichern (2007) on page 43 to give example of the use of the proposed test. For this data \(m=3\), \(u=2\) and \(n=25\). According to results given in Roy et al. (2016) the best unbiased estimators of \({\varvec{\Gamma }}_{0}\) and \({\varvec{\Gamma }}_{1}\) for model with unstructured mean vector are
and the unbiased estimator of mean vector \(\varvec{\mu }\) is the following:
We calculated p-values for F tests and LRTs for testing single hypotheses about matrix \(\varvec{\Gamma }_1\) and mean vector \(\varvec{\mu }\) and p-values for simultaneous F tests, both convex combination and ratio F test. Regarding mean structure p-value for F test is equal to 0.0363 and for LRT is equal to 0.1725, so that we make different conclusions on standard 5% level of significance (for details see Zmyślony et al. 2018). P-value for F test for testing hypothesis about covariance matrix is equal to \(1.0607\times 10^{-9}\) and for LRT is equal to \(1.8074\times 10^{-13}\), so in this case for both tests we make the same conclusions on any reasonable significance level. Finally p-values for simultaneous convex combination F test is equal to \(1.2832\times 10^{-9}\), while for ratio F test p-value is equal to 0.4126. The reason of difference between conclusions of those two simultaneous tests is that for single F test about mean structure p-value is relatively big comparing to p-value for F tests about covariance matrix \(\varvec{\Gamma }_1\). Thus ratio of these two single test statistics is relatively small what implies that p-value for ratio F test is quite high.
5 Conclusions
The test presented in this paper, whose statistic has explicit F distribution, provides a valid alternative to tests for single hypotheses about covariance components and mean vector in multivariate models with BCS covariance structure and convex combination F test for testing simultaneous hypotheses. Test statistic of proposed test is ratio of test statistics for single hypotheses mentioned in this paper. Simulation study shows good and bad sides of obtained ratio F test. In case when all elements in contrast vector and covariance matrix have the same sign proposed test is more powerful than all three other compared F tests. In the other cases it is recommended to use simultaneous convex combination F test or single F tests.
References
Fonseca M, Zmyślony R, Kozioł A (2018) Testing hypotheses of covariance structure in multivariate data. Electron. J. Linear Algebra 33:53–62
Hyodo M, Nishiyama T (2019) Simultaneous testing of the mean vector and covariance matrix among k populations for high-dimensional data. Commun Stat Theory Methods. https://doi.org/10.1080/03610926.2019.1639751
Johnson RA, Wichern DW (2007) Applied multivariate statistical analysis, sixth edn. Pearson Prentice Hall, Englewood Cliffs
Kozioł A, Roy A, Zmyślony R, Leiva R, Fonseca M (2018) Free-coordinate estimation for doubly multivariate data. Linear Algebra Appl 547C:217–239
Michalski A, Zmyślony R (1996) Testing hypotheses for variance components in mixed linear models. Statistics 27:297–310
Michalski A, Zmyślony R (1999) Testing hypotheses for linear functions of parameters in mixed linear models. Tatra Mt Mat Publ 17:103–110
Roy A, Leiva R (2011) Estimating and testing a structured covariance matrix for three-level multivariate data. Commun Stat Theory Methods 40:1945–1963
Roy A, Zmyślony R, Fonseca M, Leiva R (2016) Optimal estimation for doubly multivariate data in blocked compound symmetric covariance structure. J Multivar Anal 144:81–90
Seely JF (1977) Minimal sufficient statistics and completeness for multivariate normal families. Sankhya (Statistics). Indian J Stat Ser A 39:170–185
Zmyślony R (1980) Completeness for a family of normal distributions. Math Stat 6:355–357
Zmyślony R, Kozioł A (2019) Simultaneous hypotheses testing in models with blocked compound symmetric covariance structure. Commun Stat Simul Comput. https://doi.org/10.1080/03610918.2019.1634205
Zmyślony R, Žežula I, Kozioł A (2018) Application of Jordan algebra for testing hypotheses about structure of mean vector in model with block compound symmetric covariance structure. Electron J Linear Algebra 33:41–52
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zmyślony, R., Kozioł, A. Ratio F test for testing simultaneous hypotheses in models with blocked compound symmetric covariance structure. Stat Papers 62, 2109–2118 (2021). https://doi.org/10.1007/s00362-020-01182-4
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00362-020-01182-4