
Abstract
This paper studies the saddle point problem of polynomials. We give an algorithm for computing saddle points. It is based on solving Lasserre’s hierarchy of semidefinite relaxations. Under some genericity assumptions on defining polynomials, we show that: (i) if there exists a saddle point, our algorithm can get one by solving a finite hierarchy of Lasserre-type semidefinite relaxations; (ii) if there is no saddle point, our algorithm can detect its nonexistence.
Similar content being viewed by others

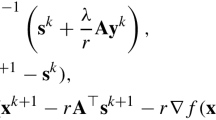
1 Introduction
Let \(X \subseteq {\mathbb {R}}^n, Y \subseteq {\mathbb {R}}^m\) be two sets (for dimensions \(n,m>0\)), and let F(x, y) be a continuous function in \((x,y) \in X \times Y\). A pair \((x^*,y^*) \in X \times Y\) is said to be a saddle point of F(x, y) over \(X \times Y\) if
The above implies that
On the other hand, it always holds that
Therefore, if \((x^*,y^*)\) is a saddle point, then
All saddle points share the same objective value, although there may exist different saddle points. The definition of saddle points in (1.1) requires the inequalities to hold for all points in the feasible sets X, Y. That is, when y is fixed to \(y^*\), \(x^*\) is a global minimizer of \(F(x,y^*)\) over X; when x is fixed to \(x^*\), \(y^*\) is a global maximizer of \(F(x^*,y)\) over Y. Certainly, \(x^*\) must also be a local minimizer of \(F(x,y^*)\) and \(y^*\) must be a local maximizer of \(F(x^*,y)\). So, the local optimality conditions can be applied at \((x^*,y^*)\). However, they are not sufficient to guarantee that \((x^*,y^*)\) is a saddle point, since (1.1) needs to be satisfied for all feasible points.
The saddle point problem of polynomials (SPPP) is for cases that F(x, y) is a polynomial function in (x, y) and X, Y are semialgebraic sets, i.e., they are described by polynomial equalities and/or inequalities. The SPPP concerns the existence of saddle points and the computation of them if they exist. When F is convex–concave in (x, y) and X, Y are nonempty compact convex sets, there exists a saddle point. We refer to [5, §2.6] for the classical theory for convex–concave-type saddle point problems. The SPPPs have broad applications. They are of fundamental importance in duality theory for constrained optimization, min–max optimization and game theory [5, 30, 56]. The following are some applications.
-
Zero-sum games can be formulated as saddle point problems [1, 40, 53]. In a zero-sum game with two players, suppose the first player has the strategy vector \(x :=(x_1, \ldots , x_n)\) and the second player has the strategy vector \(y :=(y_1, \ldots , y_m)\). The strategies x, y usually represent probability measures over finite sets, for instance, \(x \in \Delta _n\), \(y \in \Delta _m\). (The notation \(\Delta _n\) denotes the standard simplex in \({\mathbb {R}}^n\).) A typical profit function of the first player is
$$\begin{aligned} f_1(x,y) \, := \, x^TA_1x + y^TA_2y + x^TBy, \end{aligned}$$for matrices \(A_1,A_2, B\). For the zero-sum game, the profit function \(f_2(x,y)\) of the second player is \(-f_1(x,y)\). Each player wants to maximize the profit, for the given strategy of the other player. A Nash equilibrium is a point \((x^*,y^*)\) such that the function \(f_1(x,y^*)\) in x achieves the maximum value at \(x^*\), while the function \(f_2(x^*,y)\) in y achieves the maximum value at \(y^*\). Since \(f_1(x,y) + f_2(x,y) =0\), the Nash equilibrium \((x^*,y^*)\) is a saddle point of the function \(F := -f_1\) over feasible sets \(X = \Delta _n\), \(Y = \Delta _m\).
-
The image restoration [23] can be formulated as a saddle point problem with the function
$$\begin{aligned} F(x,y) \, := \, x^TAy + \frac{1}{2}\Vert Bx-z\Vert ^2 \end{aligned}$$and some feasible sets X, Y, for two given matrices A, B and a given vector z. Here, the notation \(\Vert \cdot \Vert \) denotes the Euclidean norm. We refer to [12, 19, 23] for related work on this topic.
-
The saddle point problem plays an important role in robust optimization [6, 21, 32, 61]. For instance, a statistical portfolio optimization problem is
$$\begin{aligned} \min _{x\in X} \quad -\mu ^Tx + x^TQx, \end{aligned}$$where Q is a covariance matrix, \(\mu \) is the estimation of some parameters, and X is the feasible set for the decision variable x. In applications, there often exists a perturbation for \((\mu ,Q)\). Suppose the perturbation for \((\mu , Q)\) is \((\delta \mu , \delta Q)\). There are two types of robust optimization problems
$$\begin{aligned} \begin{array}{ccl} \min \limits _{x\in X} &{} \max \limits _{(\delta \mu ,\delta Q)\in Y} &{} -(\mu +\delta \mu )^Tx + x^T(Q+\delta Q)x, \\ \max \limits _{(\delta \mu ,\delta Q)\in Y} &{} \min \limits _{x\in X} &{} -(\mu +\delta \mu )^Tx + x^T(Q+\delta Q)x, \end{array} \end{aligned}$$where Y is the feasible set for the perturbation \((\delta \mu , \delta Q)\). People are interested in \(x^*\) and \((\delta \mu ^*, \delta Q^*)\) such that the above two robust optimization problems are solved simultaneously by them. In view of (1.2), this is equivalent to solving a saddle point problem.
For convex–concave-type saddle point problems, most existing methods are based on gradients, subgradients, variational inequalities, or other related techniques. For these classical methods, we refer to the work by Chen et al. [13], Cox et al. [14], He and Yuan [23], He and Monteiro [24], Korpelevich [29], Maistroskii [38], Monteiro and Svaiter [39], Nemirovski [42], Nedić and Ozdaglar [41], and Zabotin [60]. For more general cases of non convex–concave-type saddle point problems (i.e., F is not convex–concave, and/or one of the sets X, Y is nonconvex), the computational task for solving SPPPs is much harder. A saddle point may, or may not, exist. There is very little work for solving non-convex–concave saddle point problems [16, 51]. Obviously, SPPPs can be formulated as a first-order formula over the real field \({\mathbb {R}}\). By the Tarski–Seidenberg theorem [2, 11], the SPPP is equivalent to a quantifier-free formula. Such quantifier-free formula can be computed symbolically, e.g., by cylindrical algebraic decompositions [2, 11, 28]. Theoretically, the quantifier elimination (QE) method can solve SPPPs exactly, but it typically has high computational complexity [10, 17, 54]. Another straightforward approach for solving (1.1) is to compute all its critical points first and then select saddle points among them. The complexity of computing critical points is given in [55]. This approach typically has high computational cost, because the number of critical points is dramatically high [43] and we need to check the global optimality relation in (1.1) for getting saddle points. In Sect. 6.3, we will compare the performance between these methods and the new one given in this paper.
The basic questions for saddle point problems are: If a saddle point exists, how can we find it? If it does not, how can we detect its nonexistence? This paper discusses how to solve saddle point problems that are given by polynomials and that are non-convex–concave. We give a numerical algorithm to solve SPPPs.
1.1 Optimality Conditions
Throughout the paper, a property is said to hold generically in a space if it is true everywhere except a subset of zero Lebesgue measure. We refer to [22] for the notion of genericity in algebraic geometry. Assume X, Y are basic closed semialgebraic sets that are given as
Here, each \(g_i\) is a polynomial in \(x := (x_1,\ldots ,x_n)\) and each \(h_j\) is a polynomial in \(y := (y_1,\ldots , y_m)\). The \(\mathcal {E}^X_1, \mathcal {E}^X_2, \mathcal {E}^Y_1, \mathcal {E}^Y_2\) are disjoint labeling sets of finite cardinalities. To distinguish equality and inequality constraints, denote the tuples
When \(\mathcal {E}^X_1 = \emptyset \) (resp., \(\mathcal {E}^X_2 = \emptyset \)), there is no equality (resp., inequality) constraint for X. The same holds for Y. For convenience, denote the labeling sets
Suppose \((x^*, y^*)\) is a saddle point. Then, \(x^*\) is a minimizer of
and \(y^*\) is a maximizer of
Under the linear independence constraint qualification (LICQ), or other kinds of constraint qualifications (see [4, §3.3]), there exist Lagrange multipliers \(\lambda _i, \mu _j\) such that
In the above, \(a\perp b\) means the product \(a \cdot b =0\) and \(\nabla _x F\) (resp., \(\nabla _y F\)) denotes the gradient of F(x, y) with respect to x (resp., y). When g, h are nonsingular (see the below for the definition), we can get explicit expressions for \(\lambda _i, \mu _j\) in terms of \(x^*,y^*\) (see [49]). For convenience, write the labeling sets as
Then, the constraining polynomial tuples can be written as
The Lagrange multipliers can be written as vectors
Denote the matrices
The tuple g is said to be nonsingular if \(\text{ rank }\, G(x) = \ell _1\) for all \(x \in {\mathbb {C}}^n\). Similarly, h is nonsingular if \(\text{ rank }\, H(y) = \ell _2\) for all \(y \in {\mathbb {C}}^m\). Note that if g is nonsingular, then LICQ must hold at \(x^*\). Similarly, the LICQ holds at \(y^*\) if h is nonsingular. When g, h have generic coefficients (i.e., g, h are generic), the tuples g, h are nonsingular. The nonsingularity is a property that holds generically. We refer to the work [49] for more details.
1.2 Contributions
This paper discusses how to solve saddle point problems of polynomials. We assume that the sets X, Y are given as in (1.3)–(1.4) and the defining polynomial tuples g, h are nonsingular, i.e., the matrices G(x), H(y) have full column rank everywhere. Then, as shown in [49], there exist matrix polynomials \(G_1(x), H_1(y)\) such that (\(I_\ell \) denotes the \(\ell \times \ell \) identity matrix)
When g, h have generic coefficients, they are nonsingular. Clearly, the above and (1.8)–(1.9) imply that
(For a matrix A, the notation \(A_{i,1:n}\) denotes its ith row with column indices from 1 to n.) Denote the Lagrange polynomial tuples
(The notation \(A_{:,1:n}\) denotes the submatrix of A consisting of its first n columns.) At each saddle point \((x^*, y^*)\), the Lagrange multiplier vectors \(\lambda , \mu \) in (1.8)–(1.9) can be expressed as
Therefore, \((x^*,y^*)\) is a solution to the polynomial system
However, not every solution \((x^*, y^*)\) to (1.15) is a saddle point. This is because \(x^*\) might not be a minimizer of (1.6), and/or \(y^*\) might not be a maximizer of (1.7). How can we use (1.15) to get a saddle point? What further conditions do saddle points satisfy? When a saddle point does not exist, what is an appropriate certificate for the nonexistence? This paper addresses these questions. We give an algorithm for computing saddle points. First, we compute a candidate saddle point \((x^*, y^*)\). If it is verified to be a saddle point, then we are done. If it is not, then either \(x^*\) is not a minimizer of (1.6) or \(y^*\) is not a maximizer of (1.7). For either case, we add a new valid constraint to exclude such \((x^*, y^*)\), while all true saddle points are not excluded. Then, we solve a new optimization problem, together with the newly added constraints. Repeating this process, we get an algorithm (i.e., Algorithm 3.1) for solving SPPPs. When the SPPP is given by generic polynomials, we prove that Algorithm 3.1 is able to compute a saddle point if it exists, and it can detect nonexistence if there does not exist one. The candidate saddle points are optimizers of certain polynomial optimization problems. We also show that these polynomial optimization problems can be solved exactly by Lasserre’s hierarchy of semidefinite relaxations, under some genericity conditions on defining polynomials. Since semidefinite programs are usually solved numerically (e.g., by SeDuMi) in practice, the computed solutions are correct up to numerical errors.
The paper is organized as follows: Sect. 2 reviews some basics for polynomial optimization. Section 3 gives an algorithm for solving SPPPs. We prove its finite convergence when the polynomials are generic. Section 4 discusses how to solve the optimization problems that arise in Sect. 3. Under some genericity conditions, we prove that Lasserre-type semidefinite relaxations can solve those optimization problems exactly. Proofs of some core theorems are given in Sect. 5. Numerical examples are given in Sect. 6. Conclusions and some discussions are given in Sect. 7.
2 Preliminaries
This section reviews some basics in polynomial optimization. We refer to [9, 33, 34, 36, 37, 57] for the books and surveys in this field.
2.1 Notation
The symbol \({\mathbb {N}}\) (resp., \({\mathbb {R}}\), \({\mathbb {C}}\)) denotes the set of nonnegative integral (resp., real, complex) numbers. Denote by \({\mathbb {R}}[x] := {\mathbb {R}}[x_1,\ldots ,x_n]\) the ring of polynomials in \(x:=(x_1,\ldots ,x_n)\) with real coefficients. The notation \({\mathbb {R}}[x]_d\) stands for the set of polynomials in \({\mathbb {R}}[x]\) with degrees \(\le d\). Sometimes, we need to work with polynomials in \(y:=(y_1,\ldots ,y_m)\) or \((x,y):=(x_1,\ldots ,x_n,y_1,\ldots ,y_m)\). The notation \({\mathbb {R}}[y],{\mathbb {R}}[y]_d\), \({\mathbb {R}}[x,y],{\mathbb {R}}[x,y]_d\) is similarly defined. For a polynomial p, \(\deg (p)\) denotes its total degree. For \(t \in {\mathbb {R}}\), \(\lceil t \rceil \) denotes the smallest integer \(\ge t\). For an integer \(k>0\), denote \([k] \, := \, \{1,2,\ldots , k\}.\) For \(\alpha := (\alpha _1, \ldots , \alpha _l) \in {\mathbb {N}}^l\) with an integer \(l >0\), denote \(|\alpha |:=\alpha _1+\cdots +\alpha _l\). For an integer \(d > 0\), denote
For \(z =(z_1,\ldots , z_l)\) and \(\alpha = (\alpha _1, \ldots , \alpha _l)\), denote
In particular, we often use the notation \([x]_d, [y]_d\) or \([(x,y)]_d\). The superscript \(^T\) denotes the transpose of a matrix/vector. The notation \(e_i\) denotes the ith standard unit vector, while e denotes the vector of all ones. The notation \(I_k\) denotes the k-by-k identity matrix. By writing \(X\succeq 0\) (resp., \(X\succ 0\)), we mean that X is a symmetric positive semidefinite (resp., positive definite) matrix. For matrices \(X_1,\ldots , X_r\), \(\text{ diag }(X_1, \ldots , X_r)\) denotes the block diagonal matrix whose diagonal blocks are \(X_1,\ldots , X_r\). For a vector z, \(\Vert z\Vert \) denotes its standard Euclidean norm. For a function f in x, in y, or in (x, y), \(\nabla _x f\) (resp., \(\nabla _y f\)) denotes its gradient vector in x (resp., in y). In particular, \(F_{x_i}\) denotes the partial derivative of F(x, y) with respect to \(x_i\).
2.2 Positive Polynomials
In this subsection, we review some basic results about positive polynomials in the ring \({\mathbb {R}}[x,y]\). The same kind of results hold for positive polynomials in \({\mathbb {R}}[x]\) or \({\mathbb {R}}[y]\). An ideal I of \({\mathbb {R}}[x,y]\) is a subset such that \( I \cdot {\mathbb {R}}[x,y] \subseteq I\) and \(I+I \subseteq I\). For a tuple \(p=(p_1,\ldots ,p_k)\) of polynomials in \({\mathbb {R}}[x,y]\), \(\text{ Ideal }(p)\) denotes the smallest ideal containing all \(p_i\), which is the set
In computation, we often need to work with the truncation:
For an ideal \(I \subseteq {\mathbb {R}}[x,y]\), its complex and real varieties are defined, respectively, as
A polynomial \(\sigma \) is said to be a sum of squares (SOS) if \(\sigma = s_1^2+\cdots + s_k^2\) for some real polynomials \(s_1,\ldots , s_k\). Whether or not a polynomial is SOS can be checked by solving a semidefinite program (SDP) [31, 50]. Clearly, if a polynomial is SOS, then it is nonnegative everywhere. However, the reverse may not be true. Indeed, there are significantly more nonnegative polynomials than SOS ones [8, 9]. The set of all SOS polynomials in (x, y) is denoted as \(\Sigma [x,y]\), and its dth truncation is
For a tuple \(q=(q_1,\ldots ,q_t)\) of polynomials in (x, y), its quadratic module is
We often need to work with the truncation
For two tuples \(p=(p_1,\ldots ,p_k)\) and \(q=(q_1,\ldots ,q_t)\) of polynomials in (x, y), for convenience, we denote
The set \(\text{ IQ }(p,q)\) (resp., \(\text{ IQ }(p,q)_{2k}\)) is a convex cone that is contained in \({\mathbb {R}}[x,y]\) (resp., \({\mathbb {R}}[x,y]_{2k}\)).
The set \(\text{ IQ }(p,q)\) is said to be archimedean if there exists \(\sigma \in \text{ IQ }(p,q)\) such that \(\sigma (x,y) \ge 0\) defines a compact set in \({\mathbb {R}}^n \times {\mathbb {R}}^m\). If \(\text{ IQ }(p,q)\) is archimedean, then the set \(K: = \{p(x,y)=0, \, q(x,y)\ge 0 \}\) must be compact. The reverse is not always true. However, if K is compact, say, \(K \subseteq B(0,R)\) (the ball centered at 0 with radius R), then \(\text{ IQ }(p, {\tilde{q}})\) is always archimedean, with \({\tilde{q}} = (q, R-\Vert x\Vert ^2 - \Vert y\Vert ^2)\), while \(\{p(x,y)=0, \, {\tilde{q}}(x,y) \ge 0 \}\) defines the same set K. Under the assumption that \(\text{ IQ }(p,q)\) is archimedean, every polynomial in (x, y), which is strictly positive on K, must belong to \(\text{ IQ }(p,q)\). This is the so-called Putinar’s Positivstellensatz [52]. Interestingly, under some optimality conditions, if a polynomial is nonnegative (but not strictly positive) over K, then it belongs to \(\text{ IQ }(p,q)\). This is shown in [46].
The above is for polynomials in (x, y). For polynomials in only x or y, the ideals, sum of squares, quadratic modules, and their truncations are defined in the same way. The notations \(\Sigma [x],\Sigma [x]_d, \Sigma [y],\Sigma [y]_d\) are similarly defined.
2.3 Localizing and Moment Matrices
Let \(\xi :=(\xi _1, \ldots , \xi _l)\) be a subvector of \((x,y):=(x_1,\ldots ,x_n, y_1, \ldots , y_m)\). Throughout the paper, the vector \(\xi \) is either x, or y, or (x, y). Denote by \({\mathbb {R}}^{{\mathbb {N}}_d^l}\) the space of real sequences indexed by \(\alpha \in {\mathbb {N}}_d^l\). A vector in \(w :=(w_\alpha )_{ \alpha \in {\mathbb {N}}_d^l} \in {\mathbb {R}}^{{\mathbb {N}}_d^l}\) is called a truncated multi-sequence (tms) of degree d. It gives the Riesz functional \({\mathscr {R}}_w\) acting on \({\mathbb {R}}[\xi ]_d\) as (each \(f_\alpha \in {\mathbb {R}}\))
For \(f \in {\mathbb {R}}[\xi ]_d\) and \(w \in {\mathbb {R}}^{{\mathbb {N}}_d^l}\), we denote
Consider a polynomial \(q \in {\mathbb {R}}[\xi ]_{2k}\) with \(\deg (q) \le 2k\). The kth localizing matrix of q, generated by a tms \(w \in {\mathbb {R}}^{{\mathbb {N}}^l_{2k}}\), is the symmetric matrix \(L_q^{(k)}(w)\) such that
for all \(a_1,a_2 \in {\mathbb {R}}[\xi ]_{k - \lceil \deg (q)/2 \rceil }\). (The \(vec(a_i)\) denotes the coefficient vector of \(a_i\).) For instance, when \(n=2\) and \(k=2\) and \(q = 1 - x_1^2-x_2^2\), we have
When \(q = 1\) (the constant one polynomial), \(L_q^{(k)}(w)\) is called the moment matrix and we denote
The columns and rows of \(L_q^{(k)}(w)\), as well as \(M_k(w)\), are labeled by \(\alpha \in {\mathbb {N}}^l\) with \(2|\alpha | \le 2k - \deg (q) \). When \(q = (q_1, \ldots , q_t)\) is a tuple of polynomials, then we define
which is a block diagonal matrix. Moment and localizing matrices are important tools for constructing semidefinite programming relaxations for solving moment and polynomial optimization problems [20, 25, 31, 47]. Moreover, moment matrices are also useful for computing tensor decompositions [48]. We refer to [59] for a survey on semidefinite programming and applications.
3 An Algorithm for Solving SPPPs
Let F, g, h be the polynomial tuples for the saddle point problem (1.1). Assume g, h are nonsingular. So the Lagrange multiplier vectors \(\lambda (x,y),\mu (x,y)\) can be expressed as in (1.13)–(1.14). We have seen that each saddle point \((x^*,y^*)\) must satisfy (1.15). This leads us to consider the optimization problem
where \(\lambda _i(x,y)\) and \(\mu _j(x,y)\) are Lagrange polynomials given as in (1.13)–(1.14). The saddle point problem (1.1) is not equivalent to (3.1). However, the optimization problem (3.1) can be used to get a candidate saddle point. Suppose \((x^*,y^*)\) is a minimizer of (3.1). If \(x^*\) is a minimizer of \(F(x,y^*)\) over X and \(y^*\) is a maximizer of \(F(x^*,y)\) over Y, then \((x^*,y^*)\) is a saddle point; otherwise, such \((x^*,y^*)\) is not a saddle point, i.e., there exists \(u \in X\) and/or there exists \(v \in Y\) such that
The points u, v can be used to give new constraints
Every saddle point (x, y) must satisfy (3.2), so (3.2) can be added to the optimization problem (3.1) without excluding any true saddle points. For generic polynomials F, g, h, problem (3.1) has only finitely many feasible points (see Theorem 3.3). Therefore, by repeatedly adding new inequalities like (3.2), we can eventually get a saddle point or detect nonexistence of saddle points. This results in the following algorithm.
Algorithm 3.1
(An algorithm for solving saddle point problems.)
- Input::
-
The polynomials F, g, h as in (1.1), (1.3), (1.4) and Lagrange multiplier expressions as in (1.13)–(1.14).
- Step 0::
-
Let \(K_1=K_2 = \mathcal {S}_a := \emptyset \) be empty sets.
- Step 1::
-
If problem (3.1) is infeasible, then (1.1) does not have a saddle point and stop; otherwise, solve (3.1) for a set \(K^0\) of minimizers. Let \(k:=0\).
- Step 2::
-
For each \((x^*, y^*) \in K^k\), do the following:
-
(a):
(Lower-level minimization) Solve the problem
$$\begin{aligned} \left\{ \begin{array}{rl} \vartheta _1(y^*):= \min \limits _{x \in X} &{} F(x,y^*) \\ \text{ subject } \text{ to } &{} \nabla _x F(x,y^*) - \sum _{i \in \mathcal {E}^X} \lambda _i(x,y^*) \nabla _x g_i(x) = 0, \\ &{} 0 \le \lambda _i(x,y^*) \perp g_i(x) \ge 0 \, (i \in \mathcal {E}_2^X ),\\ \end{array} \right. \end{aligned}$$(3.3)and get a set of minimizers \(S_1(y^*)\). If \(F(x^*,y^*) > \vartheta _1(y^*)\), update
$$\begin{aligned} K_1 \, := \, K_1 \cup S_1(y^*). \end{aligned}$$ -
(b):
(Lower-level maximization) Solve the problem
$$\begin{aligned} \left\{ \begin{array}{rl} \vartheta _2(x^*):= \max \limits _{y \in Y} &{} F(x^*,y) \\ \text{ subject } \text{ to } &{} \nabla _y F(x^*,y) - \sum _{j \in \mathcal {E}^Y} \mu _j(x^*,y) \nabla _y h_j(y) = 0, \\ &{} 0 \ge \mu _j(x^*,y) \perp h_j(y) \ge 0 ( j \in \mathcal {E}_2^Y) \\ \end{array} \right. \end{aligned}$$(3.4)and get a set of maximizers \(S_2(x^*)\). If \(F(x^*,y^*) < \vartheta _2(x^*)\), update
$$\begin{aligned} K_2 \, := \, K_2 \cup S_2(x^*). \end{aligned}$$ -
(c):
If \(\vartheta _1(y^*) = F(x^*,y^*) = \vartheta _2(x^*)\), update:
$$\begin{aligned} \mathcal {S}_a := \mathcal {S}_a \cup \{ (x^*, y^*) \}. \end{aligned}$$
- Step 3::
-
If \(\mathcal {S}_a \ne \emptyset \), then each point in \(\mathcal {S}_a\) is a saddle point and stop; otherwise go to Step 4.
- Step 4::
-
(Upper-level minimization) Solve the optimization problem
$$\begin{aligned} \left\{ \begin{array}{cl} \min \limits _{x\in X, y\in Y} &{} F(x,y) \\ \text{ subject } \text{ to } &{} \nabla _x F(x,y) - \sum _{i \in \mathcal {E}^X} \lambda _i(x,y) \nabla _x g_i(x) = 0, \\ &{} \nabla _y F(x,y) - \sum _{j \in \mathcal {E}^Y} \mu _j(x,y) \nabla _y h_j(y) = 0, \\ &{} 0 \le \lambda _i(x,y) \perp g_i(x) \ge 0 \, (i \in \mathcal {E}_2^X ), \\ &{} 0 \ge \mu _j(x,y) \perp h_j(y) \ge 0 ( j \in \mathcal {E}_2^Y), \\ &{} F(u,y) - F(x,y) \ge 0 \, ( u \in K_1), \\ &{} F(x,v) - F(x,y) \le 0 \, ( v \in K_2). \\ \end{array} \right. \end{aligned}$$(3.5)If (3.5) is infeasible, then (1.1) has no saddle points and stop; otherwise, compute a set \(K^{k+1}\) of optimizers for (3.5). Let \(k:=k+1\) and go to Step 2.
- Output::
-
If \(\mathcal {S}_a\) is nonempty, every point in \(\mathcal {S}_a\) is a saddle point; otherwise, output that there is no saddle point.
For generic polynomials, the feasible set \(\mathcal {K}_0\) of (3.1), as well as each \(K^k\) in Algorithm 3.1, is finite. The convergence of Algorithm 3.1 is shown as follows.
Theorem 3.2
Let \(\mathcal {K}_0\) be the feasible set of (3.1) and let \(\mathcal {S}_a\) be the set of saddle points for (1.1). If the complement set of \(\mathcal {S}_a\) in \(\mathcal {K}_0\) (i.e., the set \(\mathcal {K}_0 {\setminus } \mathcal {S}_a\)) is finite, then Algorithm 3.1 must terminate after finitely many iterations. Moreover, if \(\mathcal {S}_a \ne \emptyset \), then each \((x^*, y^*) \in \mathcal {S}_a\) is a saddle point; if \(\mathcal {S}_a = \emptyset \), then there is no saddle point.
Proof
At an iteration, if \(\mathcal {S}_a \ne \emptyset \), then Algorithm 3.1 terminates. For each iteration with \(\mathcal {S}_a = \emptyset \), each point \((x^*, y^*) \in K^k\) is not feasible for (3.5). When the kth iteration goes to the \((k+1)\)th one, the nonempty sets
are disjoint from each other. All the points in \(K^i\) are not saddle points, so
Therefore, when the set \(\mathcal {K}_0 {\setminus } \mathcal {S}_a\) is finite, Algorithm 3.1 must terminate after finitely many iterations.
When \(\mathcal {S}_a \ne \emptyset \), each point \((x^*, y^*) \in \mathcal {S}_a\) is verified as a saddle point in Step 2. When \(\mathcal {S}_a = \emptyset \), Algorithm 3.1 stops in Step 4 at some iteration, with the case that (3.5) is infeasible. Since every saddle point is feasible for both (3.1) and (3.5), there does not exist a saddle point if \(\mathcal {S}_a = \emptyset \). \(\square \)
The number of iterations required by Algorithm 3.1 to terminate is bounded above by the cardinality of the complement set \(\mathcal {K}_0 {\setminus } \mathcal {S}_a\), which is always less than or equal to the cardinality \(|\mathcal {K}_0|\) of the feasible set of (3.1). Generally, it is hard to count \(|\mathcal {K}_0 {\setminus } \mathcal {S}_a|\) or \(|\mathcal {K}_0|\) accurately. When the polynomials F, g, h are generic, we can prove that the number of solutions for equality constraints in (3.1) is finite. For degrees \(a_0, b_0 >0\), denote the set product \({\mathbb {C}}[x,y]_{a_0, b_0} := {\mathbb {C}}[x]_{a_0} \cdot {\mathbb {C}}[y]_{b_0}\).
Theorem 3.3
Let \(a_0\), \(b_0\) and \(a_i\), \(b_j >0\) be positive degrees, for \(i \in \mathcal {E}^X\) and \(j \in \mathcal {E}^Y\). If \(F(x,y) \in {\mathbb {C}}[x,y]_{a_0,b_0}\), \(g_i \in {\mathbb {C}}[x]_{a_i}\), \(h_j\in {\mathbb {C}}[y]_{b_j}\) are generic polynomials, then the polynomial system
has only finitely many complex solutions in \({\mathbb {C}}^n \times {\mathbb {C}}^m\).
The proof for Theorem 3.3 will be given in Sect. 5. One would like to know what is the number of complex solutions to the polynomial system (3.6) for generic polynomials F, g, h. That number is an upper bound for \(|\mathcal {K}_0|\) and so is also an upper bound for the number of iterations required by Algorithm 3.1 to terminate. The following theorem gives an upper bound for \(|\mathcal {K}_0|\).
Theorem 3.4
For the degrees \(a_i, b_j\) as in Theorem 3.3, let
where in the above the number s is given as
If F(x, y), \(g_i\), \(h_j\) are generic, then (3.6) has at most M complex solutions, and hence, Algorithm 3.1 must terminate within M iterations.
The proof for Theorem 3.4 will be given in Sect. 5. We remark that the upper bound M given in (3.7) is not sharp. In our computational practice, Algorithm 3.1 typically terminates after a few iterations. It is an interesting question to obtain accurate upper bounds for the number of iterations required by Algorithm 3.1 to terminate.
4 Solving Optimization Problems
We discuss how to solve the optimization problems that appear in Algorithm 3.1. Under some genericity assumptions on F, g, h, we show that their optimizers can be computed by solving Lasserre-type semidefinite relaxations. Let X, Y be feasible sets given as in (1.3)–(1.4). Assume g, h are nonsingular, so \(\lambda (x,y), \mu (x,y)\) can be expressed as in (1.13)–(1.14).
4.1 The Upper-Level Optimization
The optimization problem (3.1) is a special case of (3.5), with \(K_1=K_2 = \emptyset \). It suffices to discuss how to solve (3.5) with finite sets \(K_1,K_2\). For convenience, we rewrite (3.5) explicitly as
Recall that \(\lambda _i(x,y)\), \(\mu _j(x,y)\) are Lagrange polynomials as in (1.13)–(1.14). Denote by \(\phi \) the tuple of equality constraining polynomials
and denote by \(\psi \) the tuple of inequality constraining ones
They are polynomials in (x, y). Let
Then, the optimization problem (4.1) can be simply written as
We apply Lasserre’s hierarchy of semidefinite relaxations to solve (4.5). For integers \(k=d_0, d_0+1,\cdots \), the kth-order semidefinite relaxation is
The number k is called a relaxation order. We refer to (2.4) for the localizing and moment matrices used in (4.6).
Algorithm 4.1
(An algorithm for solving the optimization (4.1).)
- Input::
- Step 0::
-
Let \(k:=d_0\).
- Step 1::
-
Solve the semidefinite relaxation (4.6).
- Step 2::
-
If the relaxation (4.6) is infeasible, then (1.1) has no saddle points and stop; otherwise, solve it for a minimizer \(w^*\). Let \(t := d_0\).
- Step 3:
-
Check whether or not \(w^*\) satisfies the rank condition
$$\begin{aligned} \text{ rank }\, M_{t} (w^*) \, = \, \text{ rank }\, M_{t-d_0} (w^*). \end{aligned}$$(4.7) - Step 4:
-
If (4.7) holds, extract \(r := \text{ rank }\, M_{t} (w^*)\) minimizers for (4.1) and stop.
- Step 5:
-
If \(t< k\), let \(t:=t+1\) and go to Step 3; otherwise, let \(k:=k+1\) and go to Step 1.
- Output::
-
Minimizers of the optimization problem (4.1) or a certificate for the infeasibility of (4.1).
The conclusions in the Steps 2 and 3 are justified by Proposition 4.2. The rank condition (4.7) is called flat extension or flat truncation [15, 44]. It is a sufficient and also almost necessary criterion for checking convergence of Lasserre-type relaxations [44]. When it is satisfied, the method in [27] can be applied to extract minimizers in Step 4. It was implemented in the software GloptiPoly 3 [26].
Proposition 4.2
Suppose g, h are nonsingular polynomial tuples. For the hierarchy of relaxations (4.6), we have the properties:
-
(i)
If (4.6) is infeasible for some k, then (4.1) is infeasible and (1.1) has no saddle points.
-
(ii)
If (4.6) has a minimizer \(w^*\) satisfying (4.7), then \(F_k = f_{*}\) and there are \(r := \text{ rank }\, M_{t} (w^*)\) minimizers for (4.1).
Proof
Since g, h are nonsingular, every saddle point must be a critical point, and Lagrange multipliers can be expressed as in (1.13)–(1.14).
-
(i)
For each (u, v) that is feasible for (4.1), \([(u,v)]_{2k}\) satisfies all the constraints of (4.6), for all k. Therefore, if (4.6) is infeasible for some k, then (4.1) is infeasible.
-
(ii)
The conclusion follows from the classical results in [15, 27, 35, 44].
\(\square \)
We refer to (2.1) for the notation \(\text{ IQ }\), which is the sum of an ideal and a quadratic module. The polynomial tuples \(\phi ,\psi \) are from (4.2)–(4.3). Algorithm 4.1 is able to solve (4.1) successfully after finitely many iterations, under the following genericity conditions.
Condition 4.3
The polynomial tuples g, h are nonsingular and F, g, h satisfy one (not necessarily all) of the following:
-
(1)
\(\text{ IQ }(g_{eq},g_{in})+\text{ IQ }(h_{eq}, h_{in})\) is archimedean;
-
(2)
the equation \(\phi (x,y)=0\) has finitely many real solutions;
-
(3)
\(\text{ IQ }(\phi ,\psi )\) is archimedean.
In the above, the item (1) is almost the same as that X, Y are compact sets; the item (2) is the same as that (3.6) has only finitely many real solutions. Also note that the item (1) or (2) implies (3). In Theorem 3.3, we have shown that (3.6) has only finitely many complex solutions when F, g, h are generic. Therefore, Condition 4.3 holds generically. Under Condition 4.3, Algorithm 4.1 can be shown to have finite convergence.
Theorem 4.4
Under Condition 4.3, we have that:
-
(i)
If problem (4.1) is infeasible, then the semidefinite relaxation (4.6) must be infeasible for all k big enough.
-
(ii)
Suppose (4.1) is feasible. If (4.1) has only finitely many minimizers and each of them is an isolated critical point (i.e., an isolated real solution of (3.6)), then, for all k big enough, (4.6) has a minimizer and each minimizer must satisfy the rank condition (4.7).
We would like to remark that when F, g, h are generic, every minimizer of (4.1) is an isolated real solution of (3.6). This is because (3.6) has only finitely many complex solutions for generic F, g, h. Therefore, Algorithm 4.1 has finite convergence for generic cases. We would also like to remark that Proposition 4.2 and Theorem 4.4 assume that the semidefinite relaxation (4.6) is solved exactly. However, semidefinite programs are usually solved numerical (e.g., by SeDuMi), for better computational performance. Therefore, in computational practice, the optimizers obtained by Algorithm 4.1 are correct up to numerical errors. This is a common feature of all numerical methods.
4.2 Lower-Level Minimization
For a given pair \((x^*,y^*)\) that is feasible for (3.1) or (3.5), we need to check whether or not \(x^*\) is a minimizer of \(F(x,y^*)\) over X. This requires us to solve the minimization problem
When g is nonsingular, if it has a minimizer, the optimization (4.8) is equivalent to (by adding necessary optimality conditions)
Denote the tuple of equality constraining polynomials
and denote the tuple of inequality ones
They are polynomials in x but not in y, depending on the value of \(y^*\). Let
We can rewrite (4.9) equivalently as
Lasserre’s hierarchy of semidefinite relaxations for solving (4.13) is
for relaxation orders \(k = d_1, d_1+1, \ldots \). Since \((x^*,y^*)\) is a feasible pair for (3.1) or (3.5), problems (4.8) and (4.13) are also feasible; hence, (4.14) is also feasible. A standard algorithm for solving (4.13) is as follows.
Algorithm 4.5
(An algorithm for solving the problem (4.13).)
- Input::
-
The point \(y^*\) and polynomials \(F(x,y^*), \phi _{y^*}, \psi _{y^*} \) as in (4.10)–(4.11).
- Step 0::
-
Let \(k \, := \, d_1\).
- Step 1::
-
Solve the semidefinite relaxation (4.14) for a minimizer \(z^*\). Let \(t := d_1\).
- Step 2::
-
Check whether or not \(z^*\) satisfies the rank condition
$$\begin{aligned} \text{ rank }\, M_{t} (z^*) \, = \, \text{ rank }\, M_{t-d_1} (z^*). \end{aligned}$$(4.15) - Step 3::
-
If (4.15) holds, extract \(r :=\text{ rank }\, M_{t} (z^*)\) minimizers and stop.
- Step 4::
-
If \(t< k\), let \(t:=t+1\) and go to Step 3; otherwise, let \(k:=k+1\) and go to Step 1.
- Output::
-
Minimizers of the optimization problem (4.13).
Similar conclusions as in Proposition 4.2 hold for Algorithm 4.5. For cleanness of the paper, we do not state them again. The method in [27] can be applied to extract minimizers in the Step 3. Moreover, Algorithm 4.5 also terminates within finitely many iterations, under some genericity conditions.
Condition 4.6
The polynomial tuple g is nonsingular and the point \(y^*\) satisfies one (not necessarily all) of the following:
-
(1)
\(\text{ IQ }(g_{eq}, g_{in})\) is archimedean;
-
(2)
the equation \(\phi _{y^*}(x)=0\) has finitely many real solutions;
-
(3)
\(\text{ IQ }(\phi _{y^*},\psi _{y^*})\) is archimedean.
Since \((x^*, y^*)\) is feasible for (3.1) or (3.5), Condition 4.3 implies Condition 4.6, which also holds generically. The finite convergence of Algorithm 4.5 is summarized as follows.
Theorem 4.7
Assume the optimization problem (4.8) has a minimizer and Condition 4.6 holds. If each minimizer of (4.8) is an isolated critical point, then, for all k big enough, (4.14) has a minimizer and each of them must satisfy (4.15).
The proof of Theorem 4.7 will be given in Sect. 5. We would like to remark that every minimizer of (4.13) is an isolated critical point of (4.8), when F, g, h are generic. This is implied by Theorem 3.3.
4.3 Lower-Level Maximization
For a given pair \((x^*, y^*)\) that is feasible for (3.1) or (3.5), we need to check whether or not \(y^*\) is a maximizer of \(F(x^*,y)\) over Y. This requires us to solve the maximization problem
When h is nonsingular, if it has a minimizer, the optimization (4.16) is equivalent to (by adding necessary optimality conditions) the problem
Denote the tuple of equality constraining polynomials
and denote the tuple of inequality ones
They are polynomials in y but not in x, depending on the value of \(x^*\). Let
Hence, (4.17) can be simply expressed as
Lasserre’s hierarchy of semidefinite relaxations for solving (4.21) is
for relaxation orders \(k=d_2, d_2+1, \cdots \). Since \((x^*, y^*)\) is feasible for (3.1) or (3.5), problems (4.16) and (4.21) must also be feasible. Hence, the relaxation (4.22) is always feasible. Similarly, an algorithm for solving (4.21) is as follows.
Algorithm 4.8
(An algorithm for solving the problem (4.21).)
- Input::
-
The point \(x^*\) and polynomials \(F(x^*,y),\phi _{x^*},\psi _{x^*} \) as in (4.18)–(4.19).
- Step 0::
-
Let \(k:=d_2\).
- Step 1::
-
Solve the semidefinite relaxation (4.22) for a maximizer \(z^*\). Let \(t := d_2\).
- Step 2::
-
Check whether or not \(z^*\) satisfies the rank condition
$$\begin{aligned} \text{ rank }\, M_{t} (z^*) \, = \, \text{ rank }\, M_{t-d_2} (z^*). \end{aligned}$$(4.23) - Step 3::
-
If (4.23) holds, extract \(r :=\text{ rank }\, M_{t} (z^*)\) maximizers for (4.21) and stop.
- Step 4::
-
If \(t< k\), let \(t:=t+1\) and go to Step 3; otherwise, let \(k:=k+1\) and go to Step 1.
- Output::
-
Maximizers of the optimization problem (4.21).
The same kind of conclusions like in Proposition 4.2 hold for Algorithm 4.8. The method in [27] can be applied to extract maximizers in Step 3. We can show that it must also terminate within finitely many iterations, under some genericity conditions.
Condition 4.9
The polynomial tuple h is nonsingular and the point \(x^*\) satisfies one (not necessarily all) of the following:
-
(1)
\(\text{ IQ }(h_{eq},h_{in})\) is archimedean;
-
(2)
the equation \(\phi _{x^*}(y)=0\) has finitely many real solutions;
-
(3)
\(\text{ IQ }(\phi _{x^*}, \psi _{x^*})\) is archimedean.
By the same argument as for Condition 4.6, we can also see that Condition 4.9 holds generically. Similarly, Algorithm 4.8 also terminates within finitely many iterations under some genericity conditions.
Theorem 4.10
Assume that (4.16) has a maximizer and Condition 4.9 holds. If each maximizer of (4.16) is an isolated critical point, then, for all k big enough, (4.22) has a maximizer and each of them must satisfy (4.23).
The proof of Theorem 4.10 will be given in Sect. 5. Similarly, when F, g, h are generic, each maximizer of (4.16) is an isolated critical point of (4.16).
5 Some Proofs
This section gives the proofs for some theorems in the previous sections.
Proof of Theorem 3.3
Under the genericity assumption, the polynomial tuples g, h are nonsingular, so the Lagrange multipliers in (1.8)–(1.9) can be expressed as in (1.13)–(1.14). Hence, (3.6) is equivalent to the polynomial system in \((x,y,\lambda ,\mu )\):
Due to the complementarity conditions, \(g_i(x) = 0\) or \(\lambda _i = 0\) for each \(i \in \mathcal {E}^X_2\), and \(h_j(x) = 0\) or \(\mu _j = 0\) for each \(j \in \mathcal {E}^Y_2\). Note that if \(g_i(x) \ne 0\) then \(\lambda _i = 0\) and if \(h_j(x) \ne 0\) then \(\mu _j = 0\). Since \(\mathcal {E}^X_2, \mathcal {E}^Y_2\) are finite labeling sets, there are only finitely many cases of \(g_i(x) = 0\) or \(g_i(x) \ne 0\), \(h_j(x) = 0\) or \(h_j(x) \ne 0\). We prove the conclusion is true for every case. Moreover, if \(g_i(x) = 0\) for \(i \in \mathcal {E}^X_2\), then the inequality \(g_i(x) \ge 0\) can be counted as an equality constraint. The same is true for \(h_j(x) = 0\) with \(j \in \mathcal {E}^Y_2\). Therefore, we only need to prove the conclusion is true for the case that has only equality constraints. Without loss of generality, assume \(\mathcal {E}^X_2 =\mathcal {E}^Y_2 = \emptyset \) and write the labeling sets as
When all \(g_i\) are generic polynomials, the equations \(g_i(x) = 0\) (\(i \in \mathcal {E}^X_1\)) have no solutions if \(\ell _1 > n\). Similarly, the equations \(h_j(x) = 0\) (\(j \in \mathcal {E}^Y_1\)) have no solutions if \(\ell _2 > m\) and all \(h_j\) are generic. Therefore, we only consider the case that \(\ell _1 \le n\) and \(\ell _2 \le m\). When F, g, h are generic, we show that (5.1) cannot have infinitely many solutions. System (5.1) is the same as
Let \({\tilde{x}}= (x_0, x_1, \ldots , x_n)\) and \({\tilde{y}}= (y_0, y_1, \ldots , y_m)\). Denote by \({\tilde{g}}_i({\tilde{x}})\) (resp., \({\tilde{h}}_j({\tilde{y}})\)) the homogenization of \(g_i(x)\) (resp., \(h_j(y)\)). Let \({\mathbb {P}}^n\) denote the n-dimensional complex projective space. Consider the projective variety
It is smooth, by Bertini’s theorem [22], under the genericity assumption on \(g_i, h_j\). Denote the bi-homogenization of F(x, y)
When F(x, y) is generic, the projective variety
is also smooth. One can directly verify that (for homogeneous polynomials)
(They are called Euler’s identities.) Consider the determinantal variety
Its homogenization is
The projectivization of (5.2) is the intersection
If (3.6) has infinitely many complex solutions, so does (5.2). Then, \({\widetilde{W}} \cap \mathcal {U}\) must intersect the hypersurface \(\{ {\tilde{F}}({\tilde{x}},{\tilde{y}}) = 0 \}\). This means that there exists \(({\bar{x}}, {\bar{y}}) \in \mathcal {V}\) such that
for some \(\lambda _i, \mu _j\). Also note \({\tilde{g}}_i({\bar{x}}) = {\tilde{h}}_j({\bar{y}}) = {\tilde{F}}({\bar{x}}, {\bar{y}}) =0\). Write
-
If \({\bar{x}}_0 \ne 0\) and \({\bar{y}}_0 \ne 0\), by Euler’s identities, we can further get
$$\begin{aligned} \partial _{x_0} {\tilde{F}}({\bar{x}},{\bar{y}}) = \sum _{i=1}^{\ell _1} \lambda _i \partial _{x_0} {\tilde{g}}_i({\bar{x}}), \quad \partial _{y_0} {\tilde{F}}({\bar{x}},{\bar{y}}) = \sum _{j=1}^{\ell _2} \mu _j \partial _{y_0} {\tilde{h}}_j({\bar{y}}). \end{aligned}$$This implies that \(\mathcal {V}\) is singular, which is a contradiction.
-
If \(x_0 = 0\) but \(y_0 \ne 0\), by Euler’s identities, we can also get
$$\begin{aligned} \partial _{y_0} {\tilde{F}}({\bar{x}},{\bar{y}}) = \sum _{j=1}^{\ell _2} \mu _j \partial _{y_0} {\tilde{h}}_j({\bar{y}}). \end{aligned}$$This means the linear section \(\mathcal {V} \cap \{x_0 = 0\}\) is singular, which is a contradiction again, by the genericity assumption on F, g, h.
-
If \(x_0 \ne 0\) but \(y_0 = 0\), then we can have
$$\begin{aligned} \partial _{x_0} {\tilde{F}}({\bar{x}},{\bar{y}}) = \sum _{i=1}^{\ell _1} \lambda _i \partial _{x_0} {\tilde{g}}_i({\bar{x}}). \end{aligned}$$So the linear section \(\mathcal {V} \cap \{y_0 = 0\}\) is singular, which is again a contradiction.
-
If \(x_0 = y_0 = 0\), then \(\mathcal {V} \cap \{x_0 = 0, y_0 = 0\}\) is singular. It is also a contradiction, under the genericity assumption on F, g, h.
For every case, we obtain a contradiction. Therefore, the polynomial system (3.6) must have only finitely many complex solutions, when F, g, h are generic. \(\square \)
(Proof of Theorem 3.4)
Each solution of (3.6) is a critical point of F(x, y) over the set \(X \times Y\). We count the number of critical points by enumerating all possibilities of active constraints. For an active labeling set \(\{i_1, \ldots , i_{r_1} \} \subseteq [\ell _1]\) (for X) and an active labeling set \(\{j_1, \ldots , j_{r_2} \} \subseteq [\ell _2]\) (for Y), an upper bound for the number is critical points \( a_{i_1} \cdots a_{ i_{r_1} } b_{j_1} \cdots b_{ j_{r_2} } \cdot s, \) which is given by Theorem 2.2 of [43]. Summing this upper bound for all possible active constraints, we eventually get the bound M. Since \(\mathcal {K}_0\) is a subset of (3.6), Algorithm 3.1 must terminate within M iterations, for generic polynomials. \(\square \)
(Proof of Theorem 4.4)
In Condition 4.3, the item (1) or (2) implies (3). Note that the dual optimization problem of (4.6) is
(i) When (4.1) is infeasible, the set \(\{\phi (x,y)=0, \, \psi (x,y) \ge 0 \}\) is empty. Since \(\text{ IQ }(\phi ,\psi )\) is archimedean, by the classical Positivstellensatz [7] and Putinar’s Positivstellensatz [52], we have \( -1 \in \text{ IQ }(\phi ,\psi ). \) So, \( -1 \in \text{ IQ }(\phi ,\psi )_{2k} \) for all such k big enough. Hence, (5.3) is unbounded from above for all big k. By weak duality, we know (4.6) must be infeasible.
(ii) When (4.1) is feasible, every feasible point is a critical point. By Lemma 3.3 of [18], F(x, y) achieves finitely many values on \(\phi (x,y)=0\), say,
Recall that \(f_{*}\) is the minimum value of (4.5). So, \(f_{*}\) is one of the \(c_i\), say, \(c_\ell = f_{*}\). Since (4.1) has only finitely many minimizers, we can list them as the set
If (x, y) is a feasible point of (4.1), then either \(F(x,y) = c_k\) with \(k>\ell \), or (x, y) is one of \((u_1, v_1), \ldots , (u_B, v_B)\). Define the polynomial
We partition the set \(\{ \phi (x,y) = 0 \}\) into four disjoint ones:
Note that \(U_3\) is the set of minimizers for (4.5).
-
For all \((x,y) \in U_1\) and \(i=\ell +1, \ldots , N\),
$$\begin{aligned} (F(x,y)-c_i)^2 \ge (c_{\ell -1} - c_{\ell +1} )^2. \end{aligned}$$The set \(U_1\) is closed and each \((u_j, v_j) \not \in U_1\). The distance from \((u_j, v_j)\) to \(U_1\) is positive. Hence, there exists \(\epsilon _1 >0\) such that \(P(x,y) > \epsilon _1\) for all \((x,y) \in U_1\).
-
For all \((x,y) \in U_2\), \( (F(x,y)-c_i)^2 = (c_{\ell } - c_i)^2. \) For each \((u_j, v_j) \in O\), its distance to \(U_2\) is positive. This is because each \((u_i, v_i) \in O\) is an isolated real critical point. So, there exists \(\epsilon _2 >0\) such that \(P(x,y) > \epsilon _2\) for all \((x,y) \in U_2\).
Denote the new polynomial
On the set \(\{ \phi (x,y)=0 \}\), the inequality \(q(x,y) \ge 0\) implies \((x,y) \in U_3 \cup U_4\). Therefore, (4.1) is equivalent to the optimization problem
Note that \(q(x,y) > 0\) on the feasible set of (4.1). (This is because if (x, y) is a feasible point of (4.1), then \(F(x,y) \ge f_{*} = c_{\ell }\), so \((x,y) \not \in U_1\). If \(F(x,y)= c_{\ell }\), then \((x,y) \in O\) and \(P(x,y)=0\), so \(q(x,y) = \min (\epsilon _1, \epsilon _2) > 0\). If \(F(x,y) > c_{\ell }\), then \(P(x,y) =0\) and we also have \(q(x,y) = \min (\epsilon _1, \epsilon _2) > 0\).) By Condition 4.3 and Putinar’s Positivstellensatz, it holds that \( q \, \in \, \text{ IQ }(\phi ,\psi ). \) Now, we consider the hierarchy of Lasserre’s relaxations for solving (5.4):
Its dual optimization problem is
\(\square \)
Claim: For all k big enough, it holds that \( f_k = f_k^\prime = f_{*}. \)
Proof
The possible objective values of (5.4) are \(c_\ell , \ldots , c_N\). Let \(p_1, \ldots ,p_N\) be real univariate polynomials such that \(p_i( c_j) = 0\) for \(i \ne j\) and \(p_i( c_j) = 1\) for \(i = j\). Let
Then \(s := s_\ell + \cdots + s_N \in \Sigma [x]_{2k_1}\) for some order \(k_1 > 0\). Let
Note that \({\hat{F}}(x) \equiv 0\) on the set
It has a single inequality. By the Positivstellensatz [7, Corollary 4.1.8], there exist \(0< t \in {\mathbb {N}}\) and \(Q = b_0 + q b_1 \) (\(b_0, b_1 \in \Sigma [x]\)) such that \( {\hat{F}}^{2 t} + Q \in \text{ Ideal }(\phi ). \) Note that \(Q \in \text{ Qmod }(q)\). For all \(\epsilon >0\) and \(\tau >0\), we have \( {\hat{F}} + \epsilon = \phi _\epsilon + \theta _\epsilon \) where
By Lemma 2.1 of [45], when \(\tau \ge \frac{1}{2t}\), there exists \(k_2\) such that, for all \(\epsilon >0\),
Hence, we can get
where \(\sigma _\epsilon = \theta _\epsilon + s \in \text{ Qmod }(q)_{2k_2}\) for all \(\epsilon >0\). For all \(\epsilon >0\), \(\gamma = f_{*}-\epsilon \) is feasible in (5.6) for the order \(k_2\), so \(f_{k_2} \ge f_{*}\). Because \(f_k \le f_{k+1} \le \cdots \le f_{*}\), we have \(f_{k} = f_{k}^\prime = f_{*}\) for all \(k \ge k_2\). \(\square \)
Because \(q \in \text{ Qmod }(\psi )\), each w, which is feasible for (4.6), is also feasible for (5.5). This can be implied by [44, Lemma 2.5]. So, when k is big, each w is also a minimizer of (5.5). The problem (5.4) also has only finitely many minimizers. By Theorem 2.6 of [44], the condition (4.7) must be satisfied for some \(t\in [d_0,k]\), when k is big enough. \(\square \)
(Proof of Theorem 4.7)
The proof is the same as the one for Theorem 4.4. This is because the Lasserre’s relaxations (4.14) are constructed by using optimality conditions of (4.8), which is the same as for Theorem 4.4. In other words, Theorem 4.7 can be thought of a special version of Theorem 4.4 with \(K_1 = K_2 = \emptyset \), without variable y. The assumptions are the same. Therefore, the same proof can be used. \(\square \)
(Proof of Theorem 4.10)
The proof is the same as the one for Theorem 4.7. \(\square \)
6 Numerical Experiments
This section presents numerical examples of applying Algorithm 3.1 to solve saddle point problems. The computation is implemented in MATLAB R2012a, on a Lenovo Laptop with CPU@2.90GHz and RAM 16.0G. The Lasserre-type moment semidefinite relaxations are solved by the software GloptiPoly 3 [26], which calls the semidefinite program solver SeDuMi [58]. For cleanness, only four decimal digits are displayed for computational results.
In prior existing references, there are very few examples of non-convex–concave-type SPPPs. We construct various examples, with different types of functions and constraints. When g, h are nonsingular tuples, the Lagrange multipliers \(\lambda (x,y),\mu (x,y)\) can be expressed by polynomials as in (1.13)–(1.14). Here we give some expressions for \(\lambda (x,y)\) that will be frequently used in the examples. The expressions are similar for \(\mu (x,y)\). Let F(x, y) be the objective.
-
For the simplex \(\Delta _n =\{x \in {\mathbb {R}}^n: e^Tx=1, x \ge 0 \}\), \(g=(e^Tx-1, x_1, \ldots , x_n)\) and we have
$$\begin{aligned} \lambda (x,y) \,= \, (x^T \nabla _x F, F_{x_1}-x^T\nabla _x F, \ldots , F_{x_n}-x^T\nabla _x F). \end{aligned}$$(6.1) -
For the hypercube set \([-1,1]^n\), \(g=(1-x_1^2, \ldots , 1-x_n^2)\) and
$$\begin{aligned} \lambda (x,y) \,= \, -\frac{1}{2} ( x_1 F_{x_1}, \ldots , x_n F_{x_n}). \end{aligned}$$(6.2) -
For the box constraint \([0,1]^n\), \(g=(x_1, \ldots , x_n, 1-x_1, \ldots , 1-x_n)\) and
$$\begin{aligned} \lambda (x,y) \,= \, ((1-x_1) F_{x_1}, \ldots , (1-x_n) F_{x_n}, -x_1 F_{x_1}, \ldots , -x_n F_{x_n} ). \end{aligned}$$(6.3) -
For the ball \(B_n(0,1) = \{ x \in {\mathbb {R}}^n: \, \Vert x\Vert \le 1\}\) or sphere \({\mathbb {S}}^{n-1} = \{ x \in {\mathbb {R}}^n: \, \Vert x\Vert = 1\}\), \(g=1-x^Tx\) and we have
$$\begin{aligned} \lambda (x,y) \,= \, -\frac{1}{2}x^T \nabla _x F. \end{aligned}$$(6.4) -
For the nonnegative orthant \({\mathbb {R}}_+^n\), \(g=(x_1,\ldots ,x_n)\) and we have
$$\begin{aligned} \lambda (x,y) \, = \, (F_{x_1}, \ldots , F_{x_n}). \end{aligned}$$(6.5)
We refer to [49] for more details about Lagrange multiplier expressions.
6.1 Some Explicit Examples
Example 6.1
Consider the simplex feasible sets \(X = \Delta _n\), \(Y = \Delta _m\). The Lagrange multipliers can be expressed as in (6.1).
-
(i)
Let \(n=m=3\) and
$$\begin{aligned} F(x,y) \, = \, x_1x_2+x_2x_3+x_3y_1+x_1y_3+y_1y_2+y_2y_3. \end{aligned}$$This function is neither convex in x nor concave in y. After 1 iteration by Algorithm 3.1, we got the saddle point:
$$\begin{aligned} x^* =(0.0000, \, 1.0000, \, 0.0000), \quad y^*=(0.2500,\, 0.5000,\, 0.2500). \end{aligned}$$It took about 2 s.
-
(ii)
Let \(n=m=3\) and F(x, y) be the function
$$\begin{aligned} x_1^3+x_2^3-x_3^3-y_1^3-y_2^3+y_3^3+x_3y_1y_2(y_1+y_2)+x_2y_1y_3(y_1+y_3)+x_1y_2y_3(y_2+y_3). \end{aligned}$$This function is neither convex in x nor concave in y. After 2 iterations by Algorithm 3.1, we got the saddle point
$$\begin{aligned} x^*=(0.0000,0.0000,1.0000), \quad y^*=(0.0000,0.0000,1.0000). \end{aligned}$$It took about 7.5 s.
-
(iii)
Let \(n=m=4\) and
$$\begin{aligned} F(x,y) \,=\, \sum \limits _{i,j=1}^4 x_i^2y_j^2-\sum \limits _{i\ne j} (x_ix_j+y_iy_j). \end{aligned}$$This function is neither convex in x nor concave in y. After 2 iterations by Algorithm 3.1, we got 4 saddle points:
$$\begin{aligned} x^*=(0.2500,0.2500,0.2500,0.2500), \quad y^*=e_i, \end{aligned}$$with \(i=1,2,3,4\). It took about 99 s.
-
(iv)
Let \(n=m=3\) and
$$\begin{aligned} F(x,y) \, := \, x_1x_2y_1y_2 + x_2x_3y_2y_3 + x_3x_1y_3y_1 -x_1^2y_3^2 -x_2^2y_1^2 -x_3^2y_2^2. \end{aligned}$$This function is neither convex in x nor concave in y. After 4 iterations by Algorithm 3.1, we got that there is no saddle point. It took about 32 s.
Example 6.2
Consider the box constraints \(X =[0,1]^n\) and \(Y =[0, 1]^m\). The Lagrange multipliers can be expressed as in (6.3).
-
(i)
Consider \(n=m=2\) and
$$\begin{aligned} F(x,y) \, := \, (x_1+ x_2 + y_1 + y_2 + 1)^2 -4(x_1x_2 +x_2y_1 + y_1y_2 + y_2 + x_1). \end{aligned}$$This function is convex in x but not concave in y. After 2 iterations by Algorithm 3.1, we got the saddle point
$$\begin{aligned} x^* = ( 0.3249, 0.3249 ), \quad y^* = ( 1.0000, 0.0000 ). \end{aligned}$$It took about 3.7 s.
-
(ii)
Let \(n=m=3\) and
$$\begin{aligned} F(x,y) \, := \, \sum \limits _{i=1}^n (x_i+y_i) + \sum \limits _{i<j} (x_i^2y_j^2-y_i^2x_j^2) . \end{aligned}$$This function is neither convex in x nor concave in y. After 3 iterations by Algorithm 3.1, we got that there is no saddle point. It took about 12.8 s.
Example 6.3
Consider the cube constraints \(X=Y=[-1,1]^3\). The Lagrange multipliers can be expressed as in (6.2).
-
(i)
Consider the function
$$\begin{aligned} F(x,y) \, := \, \sum \limits _{i=1}^3 (x_i+y_i) - \prod \limits _{i=1}^3 (x_i - y_i). \end{aligned}$$This function is neither convex in x nor concave in y. After 1 iteration by Algorithm 3.1, we got 3 saddle points:
$$\begin{aligned} x^*= & {} (-1.0000, -1.0000, 1.0000), \quad y^* = (1.0000, 1.0000, 1.0000), \\ x^*= & {} ( -1.0000, 1.0000, -1.0000 ), \quad y^* = (1.0000, 1.0000, 1.0000), \\ x^*= & {} (1.0000, -1.0000, -1.0000), \quad y^* = (1.0000, 1.0000, 1.0000). \end{aligned}$$It took about 75 s.
-
(ii)
Consider the function
$$\begin{aligned} F(x,y) \, := \, y^Ty-x^Tx+\sum \limits _{1 \le i<j \le 3} (x_iy_j-x_jy_i). \end{aligned}$$This function is neither convex in x nor concave in y. After 4 iterations by Algorithm 3.1, we got the saddle point
$$\begin{aligned} x^* = (-1.0000, 1.0000, -1.0000), \quad y^* = (-1.0000, 1.0000, -1.0000). \end{aligned}$$It took about 6 s.
Example 6.4
Consider the sphere constraints \(X = {\mathbb {S}}^{2}\) and \(Y = {\mathbb {S}}^{2}\). They are not convex. The Lagrange multipliers can be expressed as in (6.4).
-
(i)
Let F(x, y) be the function
$$\begin{aligned} x_1^3 + x_2^3 + x_3^3 + y_1^3 + y_2^3 + y_3^3 +2(x_1x_2y_1y_2 + x_1x_3y_1y_3 + x_2x_3y_2y_3). \end{aligned}$$After 2 iterations by Algorithm 3.1, we got 9 saddle points \((-e_i, e_j)\), with \(i, j =1, 2, 3\). It took about 64 s.
-
(ii)
Let F(x, y) be the function
$$\begin{aligned}&x_1^2y_1^2+x_2^2y_2^2+x_3^2y_3^2 + x_1^2 y_2y_3 + x_2^2 y_1y_3 + x_3^2 y_1y_2 \\&\quad + y_1^2x_2x_3 + y_2^2x_1x_3 + y_3^2x_1x_2. \end{aligned}$$After 4 iterations by Algorithm 3.1, we got that there is no saddle point. It took about 127 s.
Example 6.5
Let \(X=Y=B_3(0,1)\) be the ball constraints and
The Lagrange multipliers can be expressed as in (6.4). The function F is not convex in x but is concave in y. After 1 iteration by Algorithm 3.1, we got the saddle point:
It took about 3.3 s.
Example 6.6
Consider the function
and the sets
They are nonnegative portions of spheres. The feasible sets X, Y are non-convex. The Lagrange multipliers are expressed as
After 3 iterations by Algorithm 3.1, we got that there is no saddle point. It took about 37.3 s.
Example 6.7
Let \(X=Y= {\mathbb {R}}_+^4\) be the nonnegative orthant and F(x, y) be
The Lagrange multipliers can be expressed as in (6.5). The function F is neither convex in x nor concave in y. After 1 iteration by Algorithm 3.1, we got the saddle point
It took about 4.8 s.
Example 6.8
Let \(X = Y = {\mathbb {R}}^3\) be the entire space, i.e., there are no constraints. There are no needs for Lagrange multiplier expressions. Consider the function
It is neither convex in x nor concave in y. After 1 iteration by Algorithm 3.1, we got the saddle point
It took about 113 s.
Example 6.9
Consider the sets and the function
The function F(x, y) is not convex in x but is concave in y. The Lagrange multipliers can be expressed as
The same expressions are for \(\mu _j(x,y)\). After 9 iterations by Algorithm 3.1, we get the saddle point:
It took about 64 s.
6.2 Some Application Problems
Example 6.10
We consider the saddle point problem arising from zero-sum games with two players. Suppose \(x \in {\mathbb {R}}^n\) is the strategy for the first player and \(y \in {\mathbb {R}}^m\) is the strategy for the second one. The usual constraints for strategies are given by simplices, which represent probability measures on finite sets. So we consider feasible sets \(X = \Delta _n\), \(Y = \Delta _m\). Suppose the profit function of the first player is
for matrices \(A_1 \in {\mathbb {R}}^{n\times n}\), \(A_2 \in {\mathbb {R}}^{m\times m}\), \(B \in {\mathbb {R}}^{n\times m}\). For the zero-sum game, the profit function for the second player is \(f_2(x,y) := -f_1(x,y)\). Each player wants to maximize the profit, for the given strategy of the other player. The Nash equilibrium is a point \((x^*,y^*)\) such that the maximum of \(f_1(x,y^*) \) over \(\Delta _n\) is achieved at \(x^*\), while the maximum of \(f_2(x^*,y)\) over \(\Delta _m\) is achieved at \(y^*\). This is equivalent to that \((x^*, y^*)\) is a saddle point of the function \(F := -f_1(x,y)\) over X, Y. For instance, we consider the matrices
The resulting saddle point problem is of the non-convex–concave type. After 2 iterations by Algorithm 3.1, we get two Nash equilibria
It took about 7 s.
Example 6.11
Consider the portfolio optimization problem [21, 61]
where Q is a covariance matrix and \(\mu \) is the estimation of some parameters. There often exists a perturbation \((\delta \mu , \delta Q)\) for \((\mu ,Q)\). This results in two types of robust optimization problems
We look for \(x^*\) and \((\delta \mu ^*, \delta Q^*)\) that can solve the above two robust optimization problems simultaneously. This is equivalent to the saddle point problem with \(F = -(\mu +\delta \mu )^Tx + x^T(Q+\delta Q)x\). For instance, consider the case that
with the feasible sets
In the above, \({\mathcal {S}}{\mathbb {R}}^{3 \times 3}\) denotes the space of real symmetric 3-by-3 matrices. The Lagrange multipliers can be similarly expressed as in (6.3). After 1 iteration by Algorithm 3.1, we got the saddle point
It took about 32 s. The above two min–max and max–min optimization problems are solved simultaneously by them.
6.3 Some Comparisons with Other Methods
Upon the request by referees, we give some comparisons between Algorithm 3.1 and other methods. The saddle point problems can also be solved by the straightforward approach of enumerating all KKT points. When all KKT points are to be computed, the numerical homotopy method such as Bertini [3] can be used. Saddle points can also be computed by quantifier elimination (QE) methods. Note that the definition (1.1) automatically gives a quantifier formula for saddle points. In the following, we give a comparison of the performance of these methods and Algorithm 3.1.
For computing all KKT points, the Maple function Solve is used. After they are obtained, we select saddle points from them by checking the definition. For the QE approach, the Maple function QuantifierElimination is used to solve the quantifier elimination formulae. For the numerical homotopy approach, the software Bertini is used to solve the KKT system for getting all KKT points first and then we select saddle points from them. When there are infinitely many KKT points, the function Solve and the software Bertini experience difficulty to get saddle points by enumerating KKT points. This happens for Examples 6.1(i), 6.2(i), 6.4(ii). The computational time (in seconds or hours) for these methods is reported in Table 1. We would like to remark that the Maple function QuantifierElimination cannot solve any example question (it does not terminate within 6 h for each one). So we also try the Mathematica function Resolve to implement the QE method. It can solve Example 6.1(iii) in about 1 second, but it cannot solve any other example question (it does not terminate within 6 h). The software Bertini can solve Examples 6.1(ii), 6.2(ii), 6.3(i), 6.4(i), 6.5, 6.7, 6.8, 6.9. For other example questions, it cannot finish within 6 hours. For these examples, Algorithm 3.1 took much less computational time, except Example 6.1(iii). We also like to remark that the symbolic methods like QE can obtain saddle points exactly in symbolic operations, while numerical methods can only obtain saddle points correctly up to round off errors.
7 Conclusions and Discussions
This paper discusses how to solve the saddle point problem of polynomials. We propose an algorithm (i.e., Algorithm 3.1) for computing saddle points. The Lasserre-type semidefinite relaxations are used to solve the polynomial optimization problems. Under some genericity assumptions, the proposed algorithm can compute a saddle point if there exists one. If there does not exist a saddle point, the algorithm can detect the nonexistence. However, we would like to remark that Algorithm 3.1 can always be applied, no matter whether the defining polynomials are generic or not. The algorithm needs to solve semidefinite programs for Lasserre-type relaxations. Since semidefinite programs are usually solved numerically (e.g., by SeDuMi), the computed solutions by Algorithm 3.1 are correct up to numerical errors. If the computed solutions are not accurate enough, classical nonlinear optimization methods can be applied to improve the accuracy. The method given in this paper can be used to solve saddle point problems from broad applications, such as zero-sum games, min–max optimization and robust optimization.
If the polynomials are such that the set \(\mathcal {K}_0\) is infinite, then the convergence of Algorithm 3.1 is not theoretically guaranteed. For future work, the following questions are important and interesting.
Question 7.1
When F, g, h are generic, what is an accurate (or sharp) upper bound for the number of iterations required by Algorithm 3.1 to terminate? What is the complexity of Algorithm 3.1 for generic F, g, h?
Theorem 3.4 gives an upper bound for the number of iterations. However, the bound given in (3.7) is certainly not sharp. Beyond the number of iterations, the complexity of solving the polynomial optimization problems (3.3), (3.4) and (3.5) is another concern. For efficient computational performance, Algorithms 4.1, 4.5 and 4.8 are applied to solve them. However, their complexities are mostly open, to the best of the authors’ knowledge. We remark that Algorithms 4.1, 4.5 and 4.8 are based on the tight relaxation method in [49], instead of the classical Lasserre relaxation method in [31]. For the method in [31], there is no complexity result for the worst cases, i.e., there exist instances of polynomial optimization such that the method in [31] does not terminate within finitely many steps. The method in [49] always terminates within finitely many steps, under nonsingularity assumptions on constraints, while its complexity is currently unknown.
The finite convergence of Algorithm 3.1 is guaranteed if the set \(\mathcal {K}_0 {\setminus } \mathcal {S}_a\) is finite. If it is infinite, it may or may not have finite convergence. If it does not, how can we get a saddle point? The following question is mostly open for the authors.
Question 7.2
For polynomials F, g, h such that the set \(\mathcal {K}_0 {\setminus } \mathcal {S}_a\) is not finite, how can we compute a saddle point if it exists? Or how can we detect its nonexistence if it does not exist?
When X, Y are nonempty compact convex sets and the function F is convex–concave, there always exists a saddle point [5, §2.6]. However, if one of X, Y is nonconvex or if F is not convex–concave, a saddle point may, or may not, exist. This is the case even if F is a polynomial and X, Y are semialgebraic sets. The existence and nonexistence of saddle points for SPPPs are shown in various examples in Sect. 6. However, there is a new interesting property for SPPPs. We can write the objective polynomial F(x, y) as
for degrees \(d_1, d_2 > 0\) and a matrix G (see Sect. 2 for the notation \([x]_{d_1}\) and \([y]_{d_2}\)). Consider new variables \(u:=[x]_{d_1}\), \(v:=[y]_{d_2}\) and the new sets
A convex moment relaxation for the SPPP is to find \((u^*,v^*) \in \text{ conv }(\mathcal {X}) \times \text{ conv }(\mathcal {Y})\) such that
for all \(u \in \text{ conv }(\mathcal {X})\), \(v \in \text{ conv }(\mathcal {Y})\). (The notation \(\text{ conv }(T)\) denotes the convex hull of T.) When X, Y are nonempty compact sets, the above \((u^*, v^*)\) always exists, because \(u^TGv\) is bilinear in (u, v) and \(\text{ conv }(\mathcal {X}),\text{ conv }(\mathcal {Y})\) are compact convex sets. In particular, if such \(u^*\) is an extreme point of \(\text{ conv }(\mathcal {X})\) and \(v^*\) is an extreme point of \(\text{ conv }(\mathcal {Y})\), say, \(u^*=[a]_{d_1}\) and \(v^*=[b]_{d_2}\) for \(a \in X, b\in Y\), then (a, b) must be a saddle point of the original SPPP. If there is no saddle point \((u^*,v^*)\) such that \(u^*,v^*\) are both extreme, the original SPPP does not have saddle points. We refer to [30] for related work about this kind of problems.
References
T. Başar and G. Olsder, Dynamic noncooperative game theory, SIAM, 1998
S. Basu, R. Pollack and M.-F. Roy, Algorithms in Real Algebraic Geometry, Algorithms and Computation in Mathematics, 10, Springer-Verlag, 2003.
D. Bates, J. Hauenstein, A. Sommese and C. Wampler, Bertini: Software for Numerical Algebraic Geometry, Available at bertini.nd.edu with permanent https://doi.org/10.7274/R0H41PB5.
D. Bertsekas, Nonlinear programming, second edition, Athena Scientific, 1995.
D. Bertsekas, A. Nedić and A. Ozdaglar, Convex Analysis and Optimization, Athena Scientific, Belmont, 2003.
D. Bertsimas, O. Nohadani and M. Teo, Robust optimization for unconstrained simulation-based problems, Operations Research 58(2010), no. 1, 161–178.
J. Bochnak, M. Coste and M-F. Roy, Real Algebraic Geometry, Springer, 1998.
G. Blekherman, There are significantly more nonnegative polynomials than sums of squares, Isr. J. Math. 153(2006), 355–380.
G. Blekherman, P. Parrilo and R. Thomas (eds.), Semidefinite Optimization and Convex Algebraic Geometry, MOS-SIAM Series on Optimization, SIAM, 2013.
C. Brown and J. Davenport, The complexity of quantifier elimination and cylindrical algebraic decomposition, Proceedings of the 2007 international symposium on Symbolic and algebraic computation, 54–60, 2007.
B. Caviness and J. Johnson, Quantifier elimination and cylindrical algebraic decomposition, Springer Science & Business Media, 2012.
A. Chambolle and T. Pock, A first-order primal-dual algorithm for convex problems with applications to imaging, Journal of Mathematical Imaging And Vision 40(2011), no. 1, 120–145.
Y. Chen, G. Lan, and Y. Ouyang. Optimal primal-dual methods for a class of saddle point problems. SIAM J. Optim. 24(2014), no. 4, 1779–1814.
B. Cox, A. Juditsky, and A. Nemirovski, Decomposition techniques for bilinear saddle point problems and variational inequalities with affine monotone operators, J. Optim. Theory Appl. 172(2017), no. 2, 402–435.
R. Curto and L. Fialkow, Truncated K-moment problems in several variables, J. Operator Theory 54(2005), 189–226.
Y. Dauphin, R. Pascanu, C. Gülehre, K. Cho, S. Ganguli and Y. Bengio, Identifying and attacking the saddle point problem in high-dimensional non-convex optimization, in: Advances in Neural Information Processing Systems 27 (NIPS 2014), 2933–2941, Curran Associates, Inc., 2014.
J. Davenport and J. Herntz, Real quantifier elimination is doubly exponential, J. Symb. Comput. 5(1988), no. 1-2, 29–35.
J. Demmel, J.Nie and V. Powers, Representations of positive polynomials on non-compact semialgebraic sets via KKT ideals, J. Pure Appl. Algebra 209(2007), no. 1, pp. 189–200.
E. Esser, X. Zhang, and T. F. Chan, A general framework for a class of first order primal-dual algorithms for convex optimization in imaging science, J. Imaging Sci. 3(2010), 1015–1046.
L. Fialkow and J. Nie, The truncated moment problem via homogenization and flat extensions, J. Funct. Anal. 263(2012), no. 6, 1682–1700.
B. Halldórsson and R. Tütüncü, An interior-point method for a class of saddle-point problems, J. Optim. Theory Appl. 116(2003), no. 3, 559–590.
J. Harris, Algebraic Geometry, A First Course, Springer Verlag, 1992.
B. He and X. Yuan, Convergence analysis of primal-dual algorithms for a saddle-point problem: from contraction perspective, SIAM J. Imaging Sci. 5(2012), no. 1, 119–149.
Y. He and R. Monteiro, Accelerating block-decomposition first-order methods for solving composite saddle-point and two-player nash equilibrium problems, SIAM J. Optim. 25(2015), no. 4, 2182–2211.
J.W. Helon and J. Nie, A semidefinite approach for truncated K-moment problems, Found. Comput. Math. 12(2012), no. 6, 851–881.
D. Henrion, J. Lasserre and J. Loefberg, GloptiPoly 3: moments, optimization and semidefinite programming, Optim. Methods Softw. 24(2009), no. 4-5, 761–779.
D. Henrion and J. Lasserre, Detecting global optimality and extracting solutions in GloptiPoly, Positive polynomials in control, 293–310, Lecture Notes in Control and Inform. Sci., 312, Springer, Berlin, 2005.
H. Hong and M. S. El Din, Variant quantifier elimination, J. Symb. Comput. 47(2012), 883–901.
G.M. Korpelevič, An extragradient method for finding saddle points and other problems, Èkonom. i Mat. Metody 12(1976), no. 4, 747–756.
R. Laraki and J. Lasserre, Semidefinite programming for min-max problems and games, Math. Program. 131(2012), 305–332.
J. Lasserre, Global optimization with polynomials and the problem of moments, SIAM J. Optim. 11(2011), no. 3, 796–817.
J. Lasserre, Min-max and robust polynomial optimization. Journal of Global Optimization 51(2011), no. 1, 1–10.
J. Lasserre, Introduction to polynomial and semi-algebraic optimization, Cambridge University Press, Cambridge, 2015.
J. Lasserre, The Moment-SOS Hierarchy, In Proceedings of the International Congress of Mathematicians (ICM 2018), vol 4, B. Sirakov, P. Ney de Souza and M. Viana (Eds.), World Scientific, 2019, pp. 3773–3794.
M. Laurent, Revisiting two theorems of Curto and Fialkow on moment matrices, Proceedings of the AMS 133(2005), no. 10, 2965–2976.
M. Laurent, Sums of squares, moment matrices and optimization over polynomials, Emerging Applications of Algebraic Geometry, Vol. 149 of IMA Volumes in Mathematics and its Applications (Eds. M. Putinar and S. Sullivant), Springer, pp. 157–270, 2009.
M. Laurent, Optimization over polynomials: Selected topics, Proceedings of the International Congress of Mathematicians, 2014.
D. Maistroskii, Gradient methods for finding saddle points, Matekon 13 (1977), 3–22.
R. Monteiro and B. Svaiter, Complexity of variants of Tseng’s modified F-B splitting and Korpelevich’s methods for hemivariational inequalities with applications to saddle-point and convex optimization problems, SIAM J. Optim. 21(2011), no. 4, 1688–1720.
J. Nash, Non-cooperative games, Annals of Mathematics (1951): 286-295
A. Nedić and A. Ozdaglar, Subgradient methods for saddle-point problems, J. Optim. Theory Appl. 142(2009), no. 1, 205–228.
A. Nemirovski, Prox-method with rate of convergence \(O(1/t)\) for variational inequalities with Lipschitz continuous monotone operators and smooth convex-concave saddle point problems, SIAM J. Optim. 15 (2004), no. 1, 229–251.
J. Nie and K. Ranestad, Algebraic degree of polynomial optimization, SIAM J. Optim. 20(2009), no. 1, 485–502.
J. Nie, Certifying convergence of Lasserre’s hierarchy via flat truncation, Math. Program. 142(2013), no. 1-2, 485–510.
J. Nie, Polynomial optimization with real varieties, SIAM J. Optim. 23(2013), no. 3, 1634–1646.
J. Nie, Optimality conditions and finite convergence of Lasserre’s hierarchy, Math. Program. 146(2014), no. 1-2, 97–121.
J. Nie, Linear optimization with cones of moments and nonnegative polynomials, Math. Program. 153(2015), no. 1, 247–274.
J. Nie, Generating polynomials and symmetric tensor decompositions, Found. Comput. Math. 17(2017), no. 2, 423–465.
J. Nie, Tight relaxations for polynomial optimization and lagrange multiplier expressions, Math. Program. 178(2019), no. 1-2, 1–37.
P. Parrilo, Semidefinite programming relaxations for semialgebraic problems, Math. Program. 96(2003), no.2, 293–320.
R. Pascanu, Y. Dauphin, S. Ganguli and Y. Bengio, On the saddle point problem for non-convex optimization, Preprint, 2014. arXiv:1405.4604 [cs.LG]
M. Putinar, Positive polynomials on compact semi-algebraic sets, Ind. Univ. Math. J. 42(1993), 969–984.
L. Ratliff, S. Burden and S. Sastry, Characterization and computation of local Nash equilibria in continuous games, 2013 51st Annual Allerton Conference on Communication, Control, and Computing (Allerton), 917–924, 2013.
J. Renegar, On the computational complexity and geometry of the first-order theory of the reals, Parts I, II, III. J. Symbolic Comput. 13(1992), no. 3, 255–352.
P. J. Spaenlehauer, On the complexity of computing critical points with Gröbner bases, SIAM J. Optim. 24(2014), no. 3, 1382–1401.
P. Shah and P. Parrilo, Polynomial stochastic games via sum of squares optimization, Proceedings of the 46th IEEE Conference on Decision and Control, New Orleans, LA, USA, Dec. 12-14, 2007.
C. Scheiderer, Positivity and sums of squares: A guide to recent results, Emerging Applications of Algebraic Geometry (M. Putinar, S. Sullivant, eds.), IMA Volumes Math. Appl. 149, Springer, 2009, pp. 271–324.
J. Sturm, SeDuMi 1.02: A MATLAB toolbox for optimization over symmetric cones, Optim. Methods Softw. 11 & 12 (1999), 625–653.
M. Todd, Semidefinite optimization, Acta Numerica 10(2001), 515–560.
I. Zabotin, A subgradient method for finding a saddle point of a convex-concave function, Issled. Prikl. Mat. 15(1988), 6–12.
L. Zhu, T. Coleman and Y. Li, Min-max robust CVaR robust mean-variance portfolios, Journal of Risk 11(2009), no. 3, 55.
Acknowledgements
Jiawang Nie and Zi Yang were partially supported by the NSF Grants DMS-1417985 and DMS-1619973.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Michael Overton.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nie, J., Yang, Z. & Zhou, G. The Saddle Point Problem of Polynomials. Found Comput Math 22, 1133–1169 (2022). https://doi.org/10.1007/s10208-021-09526-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10208-021-09526-8