
Abstract
State-of-the-art deep neural network plays an increasingly important role in artificial intelligence, while the huge number of parameters in networks brings high memory cost and computational complexity. To solve this problem, filter pruning is widely used for neural network compression and acceleration. However, existing algorithms focus mainly on pruning single model, and few results are available to multi-task pruning that is capable of pruning multi-model and promoting the learning performance. By utilizing the filter sharing technique, this paper aimed to establish a multi-task pruning framework for simultaneously pruning and merging filters in multi-task networks. An optimization problem of selecting the important filters is solved by developing a many-objective optimization algorithm where three criteria are adopted as objectives for the many-objective optimization problem. With the purpose of keeping the network structure, an index matrix is introduced to regulate the information sharing during multi-task training. The proposed multi-task pruning algorithm is quite flexible that can be performed with either adaptive or pre-specified pruning rates. Extensive experiments are performed to verify the applicability and superiority of the proposed method on both single-task and multi-task pruning.
Similar content being viewed by others


Introduction
With the success on applications in ImageNet challenge, the deep neural networks (DNNs) have been extensively utilized in a wide variety of applications [1,2,3] and showed superiorities over other approaches. However, as the structure becomes deeper and larger, the number of network parameters would increase considerably, resulting in a dramatic escalation in computing cost during the utilization of DNNs. Therefore, DNN with relatively low computing cost yet high accuracy is urgently needed nowadays, which gives rise to the development of network pruning technique to simplify the structure and reduce the parameters. Pruning deep CNNs is an important direction for accelerating the network. Recent developments on pruning can be generally divided into two categories, namely weight pruning [4,5,6] and filter pruning [7,8,9,10, 60,61,62].

An illustration of the difference between the traditional single-task pruning method and our multi-task pruning method
It is the objective of model pruning to compress the model size and accelerate the inference of the network. Weight-pruning methods remove connections in the filters or across different layers, thereby reducing the cost of memory cost. However, the main weakness of weight pruning is the unstructural operation manner. The unstructured sparsity of the filters makes weight pruning hard to deploy existing basic linear algebra subprograms (BLASs) libraries. Hence, weight pruning is not effective in reducing computational cost. In contrast, filter pruning allows models to be structured with sparsity, reducing the storage usage on devices and achieving practical acceleration.
It should be noted that most of the existing results regarding the network pruning mainly concentrates on single network structure, and few effort has been devoted to investigating the multi-task pruning due primarily to the difficulty brought by the cross-coupling of different tasks as well as increasing parameters. Moreover, different from traditional multi-task learning algorithms, the methods proposed in this paper of sharing information for different tasks should be designed with a trade-off between network size and performance. In addition, keeping the balance between different tasks is also a challenge for multi-task pruning.
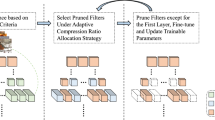
Very recently, it has been declared in [11] that the key of multi-task pruning is to reduce both intra-redundancy in single task and inter-redundancy between multiple tasks. However, the proposed algorithm cannot be applied directly for pruning because of depending on the results of network merging. Motivated by this, we intend to propose a unified Multi-task Filter Index Sharing (MFIS) framework which could systematically deal with both single-task and multi-task pruning. As illustrated in Fig. 1, we first establish a filter candidate box which contains all filters in both tasks. Different from traditional methods for single-task pruning, within our proposed framework, important filters are selected under certain criteria imposed on multi-task, which is converted into a many-objective optimization problem (MOP) [12]. Then, filter sharing (FS) strategy is developed to force each filter choosing one and only one important candidate to support. Filters that support the same candidate might be pruned, merged or remained according to FS strategy. Moreover, an index matrix is introduced by the pruning and merging results of multi-networks to keep the network structure and to regulate the information sharing in subsequent multi-task learning.
The main contributions of this paper can be highlighted as follows:
-
i)
Different from most traditional pruning techniques only applicable for single task, we propose a more general framework MFIS, which is able to deal with both multi-task pruning and single-network pruning.
-
ii)
The proposed FIS in different networks is capable of selecting important filters and determining the most suitable operation (pruning, merging, or remaining) for each filter. Meanwhile, the index matrix in FIS can keep the network structure in multi-task training.
-
iii)
Three criteria for selecting targeted important filters are put forward to further appropriately characterize the performance of MFIS that is subsequently optimized via the MOP method.
-
iv)
The proposed algorithm is quite flexible where two pruning rate strategies, namely adaptive rates for different tasks and fixed rate for individual task, are adopted to balance the learning speed and accuracy.
-
v)
Via extensive experiments, the effectiveness and efficiency of MFIS are demonstrated on different networks and databases. We prove that MFIS performs better compared with both single-task pruning methods and multi-task pruning methods.
The remainder of this paper is organized as follows. In Section 2, we introduce the related work of model pruning, multi-task learning and many-objective optimization problem. In Section 3, we describe our framework in detail. The experimental study and the corresponding analysis are presented in Section 4. Section 5 gives the conclusions of this paper.
Related Work
Model Pruning
Filter pruning removes the entire filters, which could reduce the memory cost, and meanwhile, shows effectiveness of promotion on the inference speed. In recent publications, some works (e.g., [13, 14]) have utilized the training data and filter activations to determine the pruned filters, while other methods (e.g., [15, 16]) have determined the importance of the filters by weights. Commonly, data-independent algorithms are more effective than the former because the utilizing of training data is always computation consuming. Among data-independent algorithms, researchers design criterions to prune unimportant filters. In most existing publications regarding the model compression task, only single model compression has been considered which means that most criterions are designed for single mission. Although there have been some initial results on corresponding multi-task case, the developed algorithms have certain limitations. For instance, in [17], the proposed MTZ framework has only been able to deal with compression without pruning. In [11], an RDNet has been first established by two pre-trained models with a threshold parameter \(\alpha\), but the technique of pruning, i.e., Variational Information Bottleneck (VIB), is borrowed from [18].
Multi-task Learning
As is well known, multi-task Learning aims to improve generalization performance and reduces the risk of overfitting by jointly learning multiple related tasks [19,20,21,22]. ML of DNNs has been applied nowadays in various applications, from scene understanding [23] to face detection [1], to name but a few. ML enables combined model to generalize better for all tasks by sharing representations from related original networks. Recently, many researchers have devoted efforts on issues of ‘what to share’ and ‘how to share’ among tasks, especially those relevant to deep neural networks. Some representative works can be summarized as follows. Yang et al. [24] have proposed an algorithm of learning cross-task sharing structure at each layer in a deep network. Cross-stitching networks developed in [25] have introduced cross-stitch units to learn shared representations. In [26], soft ordering approach of shared layers has been applied in multi-task learning which shows more effective sharing ability. Lu et al. has proposed an automatic approach in [27] for designing multi-task deep learning architectures, which starts with a thin multi-layer network that is dynamically widened during training. All the mentioned multi-task learning methods do not consider the network size and only focus on tasks highly related. The parameters even grow during training process, leading to opposite outcome for pruning. Hence, a new multi-task pruning algorithm should be designed for combining model pruning and multi-task learning.
Many-objective Optimization Problem
On another reach frontier, MOP has been attracting particular attention in machine learning due to the fact that many relevant optimization problems can be converted to MOPs [12]. The description of an MOP problem is illustrated by the following (1) with m objectives:
where \(\varvec{\nu }=(\nu _1,\nu _2,\ldots ,\nu _n)\) is a set of n decision variables; \(\mathcal {F}(\cdot )\) is the objective function.
In our proposed work, by borrowing the idea from many-objective optimization problem, we first convert the issues of selecting the important filters into an MOP and then solve the problem by evolutionary algorithm, which will be discussed later in detail.
Methodology
Criteria for Selection
Taking two tasks as example, filter set \(V_A\) and \(V_B\) contain the original filters in model A and B, respectively. Filter candidate set C is initialize with V. We should first obtain an important filter set \(C^E\) from C. For the purpose of converting the selection of important filters \(C^E\) into an MOP, we introduce a binary-valued hyperparameter \(\alpha _i\in \{0,1\}\) for each filter \(f_i\in C\). When \(\alpha _i=1\), it is said that \(f_i\) belongs to \(C^E\). Then, \(\varvec{\alpha }=(\alpha _1,\alpha _2,\ldots ,\alpha _m)\) is the set of decision variables. The objectives of MOP can be designed according to the following criteria.
Loss of Replacing
This criterion aims to assure that each filter in V has appropriately small \(\delta E\) with a candidate in \(C^E\):
where \(\delta E(i,j)\) denotes the loss of replacing \(f_i\) with \(f_j\). Here, we calculate the loss of replacing \(f_i \in V\) with \(f_j \in C\) on task A by
Similarly, the loss of replacing \(f_i\) with \(f_j\) on task B is defined by
Then, the corresponding objective functions are defined as follows:
\(\mathcal {F}_1(\cdot )\) and \(\mathcal {F}_2(\cdot )\) describe the losses of replacing for network A and B, respectively. With limit on size of \(C^E\), \(\mathcal {F}_1(\cdot )\) and \(\mathcal {F}_2(\cdot )\) will get rid of inappropriate candidates from \(C^E\), thereby reducing the intra-redundancy in tasks and inter-redundancy between tasks at the minimum loss.

Filter sharing in networks
The Diversity of Selected Candidates
This criterion is to keep the diversity of selected candidates in \(C^E\). To this end, we define the diversity of \(C^E\) as the sum of losses by replacing \(f_i\in C^E\) with all the other filters in \(C^E\), which is represented as follows:
Then, the corresponding objective function \(\mathcal {F}_3(\cdot )\) is defined by
The Entropy of Weights
A filter without variation may be failed on capturing the important information from input data [28]. Here, entropy of layer is introduced to evaluate the variation of filters’ weights, which can be calculated as follows:
where n is the number of classes of sampling weights and \(p_k\) is the probability of classes k. High entropy of filters means high variation on weights. Then, the corresponding objective function \(\mathcal {F}_4(\cdot )\) is defined by
Among aforementioned objectives, \(\mathcal {F}_1(\cdot )\) and \(\mathcal {F}_2(\cdot )\) control the intra-redundancy in tasks and inter-redundancy between tasks; \(\mathcal {F}_3(\cdot )\) ensures diversity and searches candidates which are more similar to the clustering centres, close to supporters but irreplaceable with each other; Criterion \(\mathcal {F}_4(\cdot )\) pays more attention to the contributions of candidates for preserving useful information. Each criterion conflicts with others and is chosen for different purpose. It is worth noting that though pruning with small \(L_2\) norm is a mainly used criterion for filter pruning [15, 16], ‘smaller-norm-less-important’ has been reconsidered in some literature [29]. For multi-task pruning, searching filters with similar information that can be shared (in multi-network) or replaced (in single-network) are more important for designing criteria.
Filter Sharing
As illustrated in Fig. 2, all filters in V should choose one and only one candidate in the important filter set \(C^E\). If \(f_{j^*}\in C^E\) satisfies
we call \(f_i\) a supporter of candidate \(f_{j^*}\).
The key point of the proposed filter sharing (FS) strategy is to collect filters which share the same candidate, with the same shape of colours in Fig. 2. On the one hand, pruning filters working on the same task (e.g., filters with green in \(V_A\) or filters with blue in \(V_B\)) can help to reduce the parameters of networks and accelerate the inference. On the other hand, merging filters with different tasks (e.g., filters with cyan in \(V_A\) and \(V_B\)) can share information of two tasks. The orange and purple filters will be maintained in the new layers.
Then, we define \(C^E=\{C^E_A,C^E_B,C^E_S\}\) with
where \(C^E_A\), \(C^E_B\) and \(C^E_S\) consist of filters attributed to, respectively, task A, task B and both tasks; \(S_\eta\) is comprised of supporters with the same candidate \(f_\eta\), which is defined by
Note that \(S_\eta \ne \emptyset\) because \(S_\eta\) contains at least \(f_\eta\), namely, \(f_\eta\) will support itself.

Pruning and Merging
Suppose that layer l has \(N_l\) filters. If a pruning rate \(P_l\) is set for layer in network A and B, we would not get \(P_l\times N_l\) filters pruned with \(N^E=(1-P_l)\times N_l\) for each network. Actually, the real sum of pruned filters is \(2\times P_l\times N_l-length(C^E_S)\) according to Algorithm 1.
Base on the aforementioned discussions, we have two strategies for pruning and merging step. Strategy one is to simply restrict the pruning rate P for the whole models and the real sum of reduced filters will be determined adaptively by FS strategy as well as the pruning rates on different tasks. Strategy two is to restrict the pruning rate for each network, under which we will prune additional \(length(C^E_S)\) with norm-based criterion (pruning filters with small \(L_p\) norm) after filter sharing. Then the real pruning rate can be confirmed for each network. These two strategies can be chosen under different situations. Strategy one does not need to decide the specific rates on tasks. However, the real pruning rates cannot be confirmed. In contrast, although the rate on every task should be manually decided when using strategy two, pruning on networks are strictly executed under the preset rates.
MOP Model for Multi-task Pruning
Consequently, the MOP model is established as
In this paper, we shall use MOEA/D proposed in [30] to optimize the many-objective problem in (14). We provide the modified mutating strategy of MOEA/D as shown in Algorithm 2. Instead of randomly changing \(\varvec{\alpha }\), we impose a probabilistic constraint on the mutation of \(\varvec{\alpha }\) in the following way:
First, we remove the filter \(f_k\) from \(C^E_{cur}\) which is nearest to \(C^E_{cur}\):
Then, we add a filter \(f_k\in {C \setminus C^E_{cur}}\) into \(C^E_{cur}\):
Since the PF \(P=\{\varvec{\alpha }_1,\ldots ,\varvec{\alpha }_p\}\) obtained by MOP algorithm is not a single optimal solution, we should seek an optimal value for \(\varvec{\alpha }\). For instance, \(\varvec{\alpha ^*}\) can be chosen as follows:
where \(N^E\) is the limit size of \(C^E\).

How to Update Weights
Suppose \(\delta E(i,j)\) is the difference between the original output results of \(f_i\) and the corresponding results replaced by \(f_j\). We apply an alternative way introduced in [5, 31] to approximate the error function by Taylor series expansion as follows:
where \(l=1,\ldots ,L\) is the number of layers; \(\delta \theta _l = \theta _{l,j}-\theta _{l,i}\) denotes the perturbation when \(f_i\) with parameter \(\theta _{l,i}\) changes to \(f_j\) with parameter \(\theta _{l,j}\); \(\mathbf {H}_l=\partial ^2 E_l/\partial \theta _l^2\) is the Hessian matrix which contains the whole second-order derivatives. The first term in (18) is vanished during training and higher-order terms \(O(\Vert \delta \theta _l\Vert ^3)\) can be regarded as 0 [5]. Hence, \(\delta E_l^A(i,j)\) for task A can be redefined by
where \(\mathbf {H}^A_l\) is calculated by
with \(x_l^A\) the input of layer l for task A.
Then, in order to merge filters with as less losses as possible, \(f_\eta\) can be updated by optimizing the following error function:
where n is the number of filters in \(S_\eta\). By applying the method of Lagrange multipliers, the optimal result \(\theta (\eta )\) of \(f_\eta\) is obtained via the following formula:
with \(\mathbf {H}(n)\) denoting the Hessian matrix of \(f_n\). Particularly, if all the filters have the same input, then \(\theta (\eta )\) can be computed by
It should be mentioned that computing \(\mathbf {H}\) is still a tough work in some databases. Hence, we can calculate the distance instead (e.g., Euclidean distance) in the experiments:
where \(N_{l-1}\) is the input channels of layer l; \(K\times K\) denotes the kernel size. When using Euclidean distance in (7), the selection under criterion \(\mathcal {F}_3(\cdot )\) is similar to judging filters by geometric median in [7].

Multi-task Filter Index Sharing Framework

The multi-task indexing steps
We are now in a position to propose the MFIS framework. MFIS can be classified into the following two categories according to the number of tasks: single-task pruning FIS (SP-FIS) and multi-task pruning FIS (MP-FIS).
For SP-FIS, we only need to establish one network and prune the redundant filters by setting weights with 0. The MOP of SP-FIS is established according to (14) as follows,
For MP-FIS, distinguishing from [17] and [11], index sharing is proposed for multiple networks to keep network structure where sharing index will be preserved along with an index matrix I, shown in Fig. 3. To be specific, we record the indices of each single filter pointing to pruning, merging or remaining. Then, new networks can be easily recovered and trained according to the index matrix. The importance of keeping network structure has been proved in Section 4.4.1. Finally, the MFIS framework is described in Algorithm 3. It should be noticed that if a filter \(f_i\in C^E_S\) is pruned in step 11 when using strategy two, it will be removed from \(C^E_S\) along with its shared filter in the other model.
In order to show the differences between MFIS framework and other methods more clearly, we compare with model compression methods, shown in Table 1.
Extending MFIS to Many-task Cases
MFIS can be easily extended to an M-task (\(M\ge 3\)) case which is illustrated in Fig. 4. Each network \(M_k\) can accept information from the other networks because FIS can determine each filter to be pruned, merged or remained for networks. In Fig. 4, original networks are presented with different color blocks in the bottom line. In the top block line, the grey blocks describe the unimportant filters selected by our algorithm and the color ones are the remained or merged filters for three tasks. Each filter may work for one to three tasks after pruning and merging.
Experiments
In this section, we shall examine our MFIS framework on single-task pruning and multi-task pruning on various benchmarks with different networks. We will further explore the influence of keeping network structure and the balance on different tasks with MFIS. Finally, the MFIS will be extended to more task case.

The many-task case of MFIS
Experimental Settings
Databases
In our experiments, the following databases are considered: MNIST database [32] is a small digital handwriting data set, which contains 60,000 images. CIFAR-10 and CIFAR-100 [33] contain 60,000 colour images in each database, in which 50,000 training images and 10,000 testing images are included. SVHN [34] is a real-world image dataset, which is obtained from house numbers in Google Street View images, with 73,257 digits for training and 26,032 digits for testing. ILSVRC-2012 [35] (ImageNet) is a large-scale dataset containing 1.28 million training images and 50,000 validation images of 1,000 classes.
Training Settings
Two types of network structure are used in the following experiments: VGG-net [37] and ResNet [38]. VGG used here is a slight modified version in [39] without Dropout [40], which contains only 2 FC layers. Compared with VGG-16 [37], the modified VGG has much fewer parameters in the fully connected layers. Hence, it could be more challenging to do compression work on it. We train the pre-trained networks with optimizer (stochastic gradient descent algorithm, SGD), initial learning rate (0.1) for baseline, momentum (0.9), batch size (128) and weight decay (0.0005). For CIFAR, the learning rate is divided by \(5\times\) at epoch 60, 120 and 160 and the network is trained for 200 epochs in total. For ImageNet, the learning rate is divided by \(10\times\) after every 30 epochs and the total epoch is 100. The training schedule of learning rate is set following the work in [7].
Pruning Settings
For pruning the scratch model, we utilize the regular training schedule without additional fine-tuning. For pruning, the pre-trained model with fine-tuning, the learning rate is reduced to one-tenth of the original learning rate [7]. For MOEA/D, we set the scale of the optimization iteration to be 200 for ResNet-20, 32, 56, 110 and 1000 for VGG-net and ResNet-50. The probabilities of mating and mutating are set to be 0.5 and 0.7.
Performance Metric
To measure the network compression and testing performance, the following measurements are applied:
Acc. The accuracy of testing on database. Acc. \(\downarrow\) (%) is the accuracy drop between pruned and the baseline model. The smaller, the better. For CIFAR-10, top-1 accuracy is provided, while for ILSVRC-2012, both top-1 and top-5 accuracies are reported.
Params. In this paper, Params. \(\downarrow\) (%) indicates the percentage of reduced parameters in networks. Bigger Params. \(\downarrow\) (%) means larger compression ratio.
FLOPs The overall floating point operations (FLOPs) denote the computation cost of networks. We use FLOPs \(\downarrow\) (%) to describe the percentage of reduced FLOPs.
Single-task Pruning
For CIFAR-10 dataset, we test our SP-FIS on ResNet with depth 20, 32, 56, 110 and show the results in Table 2. We compare SP-FIS with existing single-task acceleration algorithms, namely, PFEC [16], CP [13], MIL [36], SFP [15], NISP [10], FPGM [7] and HRank [8]. For CIFAR, we run each setting three times and report the “mean ± std”. In “Fine-tune?” column, “✓” and “✗” denote whether to use the pre-trained model as initialization or not, respectively. The experiment results validate the effectiveness of our method. Specifically, the best result of FPGM (FPGM-mix) on ResNet-110 accelerates the random initialized with an improvement of 0.17% on accuracy, but our SP-FIS achieves the results of 0.33% improvement with the same speedup ratio. Likewise, on ResNet-56, FPGM achieves the best result of 0.66% accuracy drop with FPGM-only, while our SP-FIS gains better result of only 0.32% accuracy drop. In comparison to SFP, our SP-FIS shows 0.49% accuracy drop which is better than 0.55% for SFP on ResNet-32, while the acceleration rate of 53.2% is also much better than 41.5% for SFP. To make the comparison more clearly, we also provide a result of 41.5% acceleration rate for SP-FIS, which gives an accuracy drop of only 0.18%. For pre-trained models, SP-FIS also achieve comparable results compared to other state-of-the-art methods. SP-FIS gives superior results because our method selects proper candidates for both pre-trained and randomly initialized networks by taking into account the three objectives mentioned earlier.
The proposed framework is also tested on ILSVRC-2012 with pre-trained ResNet-50. Following [7], we do not prune the projection shortcuts for simplification. The results are described in Table 3 and compared with six state-of-the-art methods.
Multi-task Pruning
In the experiments of MP-FIS, we first perform MP-FIS on VGG-net with pruning rate P on the whole models. Because few methods prune multi-task networks simultaneously, the following two methods are utilized for the comparison with our MP-FIS, namely, MTZ [17], a multi-task model compression method but without pruning, and PFEC [16], a pruning method for single task. All models use the same pre-trained networks. All models use the same pre-trained networks.
The experiment results are described in Table 4, where “ / ” denotes no result is provided. Considering that PFEC is a single-task method, we perform it on CIFAR-10 and CIFAR-100 separately with two types of compression ratio strategies: 49.90% parameters reduced on CIFAR-10 and 49.74% on CIFAR-100; 71.19% parameters reduced on CIFAR-10 and 27.41% on CIFAR-100. Note that MTZ does not accelerate the networks (no result on “FLOPs \(\downarrow\) (%)” column) because of lack of pruning step. In “Params. \(\downarrow\) (%)” column, the percentage of reduced parameters is given in three conditions: whole networks, network on CIFAR-10 and network on CIFAR-100, due to the existence of shared parameters in MTZ and MP-FIS. For MP-FIS, MP-FIS “with H” and “w/o H” describe computing \(\delta E\) by (19) or computing Euclidean distance instead. Obviously, it can be seen that the proposed MP-FIS performs much better in comparison to other methods.
The advantages of MP-FIS can be attributed to the fact that it allows access to relevant information in different tasks and limits redundant information in the same task, while traditional pruning methods only focus on one single task and do not take into account the facilitation of multi-task for learning. Although MTZ can deal with multiple tasks, it just simply forces one-to-one merging of filters between different tasks without pruning, which may lead to adverse outcome for tasks, especially when tasks are not strongly correlated, such as CIFAR-10 and CIFAR-100.
Then, we test our method with pruning rate P on each network of ResNet with depth 32, 56, and 110. The additional \(length \ (C^E_S)\) filters are pruned with norm-based criterion. As shown in shown in Table 5, we record the best accuracy results for two tasks, respectively, which means that filters in \(C^E_S\) are not forced to be shared for testing in this experiment. Likewise, as a single-task pruning method, FPGM is performed on CIFAR-10 and CIFAR-100 separately for comparison. The result also validates the effectiveness of our method.

The tendency TE of sharing filters from different tasks in the second FC layer with and without keeping layer structure

The pruning rate of networks on different tasks in the last 6 layer
More Explorations
Influence of Keeping Network Structure
For the purpose of proving the necessity of keeping network structure, we define TE to scale the tendency of sharing information from different tasks in the next layer as follows:
where \(\delta E^A(A,B)\) represents the average loss on model A of replacing filters in model A with those in model B. For pre-trained models, Lenet-300-100 network [32], which is a fully connected network with 2 FC hidden layers will be trained on MNIST database. We change the limit size in the first FC layer and then observe the variation of TE in the second FC layer. The results are shown in Fig. 5, from which we can observe that, without keeping network structure, the difference between filters becomes much bigger in two models. Such a phenomenon is mainly due to the fact that the filter similarity between two models has been influenced after breaking layer structure in the pruning step.
Balance on Tasks
With the hope of further showing that MFIS is able to prune the most appropriate filters between networks, we depict, in Fig. 6, the pruning rates of CIFAR-10 and CIFAR-100 in the last 6 layers of VGG-net. It is seen that the average pruning rate in CIFAR-100 is far smaller than that in CIFAR-10, as for VGG-net, network of CIFAR-10 has much more redundant filters compared with CIFAR-100. This has also been proved in Table 4 that PFEC achieves similar accuracies with 71.19% or 49.90% parameters reduced on CIFAR-10, while the performance is much worse with 49.74% or 27.41% parameters reduced on CIFAR-100.
Extending MFIS to Many-task Cases
We extend MFIS to a 3-task (CIFAR-10, CIFAR-100 and SVHN) case and give the results in Table 6. We can see that the results of the MP-FIS (\(M=3\)) are further improved compared to MP-FIS (\(M=2\)).
Conclusion
In this paper, a multi-task pruning algorithm MFIS has been provided by virtue of the filter index sharing approach. A filter sharing strategy has been proposed capable of automatically sharing filters of both inner networks (pruning) and external networks (merging). Through FIS, the proposed algorithm can determine the most suitable operation for filters. Three criteria have been developed to select important filters of multi-task networks. The proposed MFIS can deal with both multi-task pruning and single-network pruning by converting the optimization problem into MOP. In experiment parts, our proposed framework has shown much better performance in comparison to certain state-of-the-art methods via tests based on several benchmarks. It is has also been proved that MFIS works well on many-task case. However, there are still certain limitations of the developed MFIS. For instance, the criteria proposed in this paper for MFIS are only applicable for image classification task. In the future, some other type of tasks (e.g., semantic segmentation) should be considered in applications. One of the potential research topics might be taking more sorts of criteria into consideration and applying the framework into real-world applications [2, 3, 41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59]
References
Ranjan R, Patel VM, Chellappa R. Hyperface: A deep multi-task learning framework for face detection, landmark localization, pose estimation and gender recognition. IEEE Trans Patt Anal Mach Intell. 2017;41(1):121–35.
Ieracitano C, Mammone N, Bramanti A, Hussain A, Morabito FC. A convolutional neural network approach for classification of dementia stages based on 2d-spectral representation of EEG recordings. Neurocomputing. 2019;323:96–107.
Ieracitano C, Paviglianiti A, Campolo M, Hussain A, Pasero E, Morabito FC. A novel automatic classification system based on hybrid unsupervised and supervised machine learning for electrospun nanofibers. IEEE/CAA J Automatica Sinica. 2021;8(1):64–76.
Carreira-Perpinán MA, Idelbayev Y. Learning-compression algorithms for neural net pruning, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018:8532–8541.
Dong X, Chen S, Pan S. Learning to prune deep neural networks via layer-wise optimal brain surgeon, in Advances in Neural Information Processing Systems. 2017:4857–4867.
Zhong G, Liu W, Yao H, Li T, Liu X. Merging similar neurons for deep networks compression. Cogn Comput. 2020;12(6):577–88.
He Y, Liu P, Wang Z, Hu Z, Yang Y. Filter pruning via geometric median for deep convolutional neural networks acceleration, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019:4340–4349.
Lin M, Ji R, Wang Y, Zhang Y, Zhang B, Tian Y, Shao L. Hrank: Filter pruning using high-rank feature map, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020:1529–1538.
Lin M, Ji R, Zhang Y, Zhang B, Wu Y, Tian Y. Channel pruning via automatic structure search, in International Joint Conference on Artificial Intelligence. 2020:673–679.
Yu R, Li A, Chen CF, Lai JH, Morariu VI, Han X, Gao M, Lin CY, Davis LS. Nisp: Pruning networks using neuron importance score propagation, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018:9194–9203.
He X, Gao D, Zhou Z, Tong Y, Thiele L. Disentangling redundancy for multi-task pruning. 2019. arXiv preprint arXiv:1905.09676.
Jin Y, Sendhoff B. Pareto-based multiobjective machine learning: An overview and case studies, IEEE Transactions on Systems, Man and Cybernetics. Part C (Appl Rev). 2008;38(3):397–415.
He Y, Zhang Z, Sun J. Channel pruning for accelerating very deep neural networks, in Proceedings of the IEEE International Conference on Computer Vision. 2017:1389–1397.
Luo JH, Wu J, Lin W. Thinet: A filter level pruning method for deep neural network compression, in Proceedings of the IEEE International Conference on Computer Vision. 2017:5058–5066.
He Y, Kang G, Dong X, Fu Y, Yang Y. Soft filter pruning for accelerating deep convolutional neural networks, in International Joint Conference on Artificial Intelligence. 2018:2234–2240.
Li H, Kadav A, Durdanovic I, Samet H, Graf HP. Pruning filters for efficient convnets. 2016. arXiv preprint arXiv:1608.08710.
He X, Zhou Z, Thiele L. Multi-task zipping via layer-wise neuron sharing, in Advances in Neural Information Processing Systems. 2018:6016–602.
Dai B, Zhu C, Guo B, Wipf D. Compressing neural networks using the variational information bottleneck, in International Conference on Machine Learning. 2018;1135–1144.
Li Z, Hoiem D. Learning without forgetting. IEEE Trans Patt Anal Machi Intell. 2017;40(12):2935–47.
Long M, Cao Z, Wang J, Philip SY. Learning multiple tasks with multilinear relationship networks, in Adv Neural Info Proc Syst. 2017:1594–1603.
Ruder S. An overview of multi-task learning in deep neural networks. 2017. arXiv preprint arXiv:1706.05098.
Zhang Y, Yang Q. A survey on multi-task learning. 2017. arXiv preprint arXiv:1707.08114.
Kendall A, Gal Y, Cipolla R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018:7482–7491.
Yang Y, Hospedales T. Deep multi-task representation learning: A tensor factorisation approach. 2016. arXiv preprint arXiv:1605.06391.
Misra I, Shrivastava A, Gupta A, Hebert M. Cross-stitch networks for multi-task learning, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016:3994–4003.
Meyerson E, Miikkulainen R. Beyond shared hierarchies: Deep multitask learning through soft layer ordering. 2017. arXiv preprint arXiv:1711.00108.
Lu Y, Kumar A, Zhai S, Cheng Y, Javidi T, Feris R. Fully-adaptive feature sharing in multi-task networks with applications in person attribute classification, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017:5334–5343.
Meng F, Cheng H, Li K, Xu Z, Ji R, Sun X, Lu G. Filter grafting for deep neural networks, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020:6599–6607.
Ye J, Lu X, Lin Z, Wang JZ. Rethinking the smaller-norm-less-informative assumption in channel pruning of convolution layers. 2018. arXiv preprint arXiv:1802.00124.
Zhang Q, Li H. Moea/d: A multiobjective evolutionary algorithm based on decomposition. IEEE Trans Evo Comput. 2007;11(6):712–31.
Hassibi B, Stork D. Second order derivatives for network pruning: Optimal brain surgeon. Advances in Neural Information Processing Systems. 1992;5:164–71.
LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE. 1998;86(11):2278–324.
Krizhevsky A, Hinton G. Learning multiple layers of features from tiny images, 2009.
Netzer Y, Wang T, Coates A, Bissacco A, Wu B, Ng AY. Reading digits in natural images with unsupervised feature learning. 2011.
Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z, Karpathy A, Khosla A, Bernstein M, Alexander CB, Li F-F. Imagenet large scale visual recognition challenge. Int J Comp Vis. 2015;115(3):211–52.
Dong X, Huang J, Yang Y, Yan S. More is less: A more complicated network with less inference complexity, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017:5840–5848.
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. 2014. arXiv preprint arXiv:1409.1556.
He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016:770–778.
Zagoruyko S. 92.45% on cifar-10 in torch, [EB/OL]. 2015. Available: http://torch.ch/blog/2015/07/30/cifar.html.
Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R. Dropout: A simple way to prevent neural networks from overfitting. J Mach Learn Res. 2014;15(1):1929–58.
Cao J, Bu Z, Wang Y, Yang H, Jiang J, Li H-J. Detecting prosumer-community group in smart grids from the multiagent perspective. IEEE Trans Syst Man Cybernet: Syst. 2019;49(8):1652–64.
Cao J, Wang B, Brown D. Similarity based leaf image retrieval using multiscale R-angle description. Info Sci. 2016;374:51–64.
Chen Y, Wang Z, Wang L, Sheng W. Mixed \(H_2/H_\infty\) state estimation for discrete-time switched complex networks with random coupling strengths through redundant channels. IEEE Trans Neural Net Learn Sys. 2020;31(10):4130–42.
Cheng H, Wang Z, Wei Z, Ma L, Liu X. On adaptive learning framework for deep weighted sparse autoencoder: A multiobjective evolutionary algorithm, IEEE Transactions on Cybernetics, in press, https://doi.org/10.1109/TCYB.2020.3009582.
Li Q, Wang Z, Li N, Sheng W. A dynamic event-triggered approach to recursive filtering for complex networks with switching topologies subject to random sensor failures. IEEE Trans Neural Net Learn Syst. 2020;31(10):4381–8.
Liu D, Wang Z, Liu Y, Alsaadi FE. Extended Kalman filtering subject to random transmission delays: Dealing with packet disorders. Info Fusion. 2020;60:80–6.
H. Liu, Z. Wang, B. Shen and H. Dong, Delay-distribution-dependent \(H_{\infty }\) state estimation for discrete-time memristive neural networks with mixed time-delays and fading measurements, IEEE Transactions on Cybernetics, vol. 50, no. 2, pp. 440–451, 2020.
Liu W, Wang Z, Zeng N, Yuan Y, Alsaadi FE, Liu X. A novel randomised particle swarm optimizer. Int J Mach Learning Cybernet. 2021;12(2):529–40.
Liu Y, Chen S, Guan B, Xu P. Layout optimization of large-scale oil-gas gathering system based on combined optimization strategy. Neurocomputing. 2019;332:159–83.
Liu Y, Cheng Q, Gan Y, Wang Y, Li Z, Zhao J. Multi-objective optimization of energy consumption in crude oil pipeline transportation system operation based on exergy loss analysis. Neurocomputing. 2019;332:100–10.
Qian W, Li Y, Chen Y, Liu W. Filtering for stochastic delayed systems with randomly occurring nonlinearities and sensor saturation. Int J Syst Sci. 2020;51(13):2360–77.
Qian W, Li Y, Zhao Y, Chen Y. New optimal method for \(L_{2}\)-\(L_{\infty }\) state estimation of delayed neural networks. Neurocomputing. 2020;415:258–65.
Yang H, Wang Z, Shen Y, Alsaadi FE, Alsaadi FE. Event-triggered state estimation for Markovian jumping neural networks: On mode-dependent delays and uncertain transition probabilities. Neurocomputing. 2021;424:226–35.
Yue W, Wang Z, Liu W, Tian B, Lauria S, Liu X. An optimally weighted user- and item-based collaborative filtering approach to predicting baseline data for Friedreich’s Ataxia patients. Neurocomputing. 2021;419:287–94.
Zhao D, Wang Z, Wei G, Han QL. A dynamic event-triggered approach to observer-based PID security control subject to deception attacks, Automatica. 2020;120 (109128).
Zhao Z, Wang Z, Zou L, Guo J. Set-Membership filtering for time-varying complex networks with uniform quantisations over randomly delayed redundant channels. Int J Syst Sci. 2020;51(16):3364–77.
Zou L, Wang Z, Hu J, Liu Y, Liu X. Communication-protocol-based analysis and synthesis of networked systems: Progress, prospects and challenges, Int J Syst Sci. in press, https://doi.org/10.1080/00207721.2021.1917721.
Zou L, Wang Z, Hu J, Zhou DH. Moving horizon estimation with unknown inputs under dynamic quantization effects. IEEE Trans Auto Control. 2020;65(12):5368–75.
Zou L, Wang Z, Zhou DH. Moving horizon estimation with non-uniform sampling under component-based dynamic event-triggered transmission, Automatica. 2020;120(109154).
Han S, Pool J, Tran J, Dally W. Learning both weights and connections for efficient neural network. Adv Neural Info Proc Syst. 2015;28:1135–43.
He Y, Dong X, Kang G, Fu Y, Yan C, Yang Y. Asymptotic soft filter pruning for deep convolutional neural networks. IEEE Trans Cybernet. 2019;50(8):3594–604.
Liu Z, Mu H, Zhang X, Guo Z, Yang X, Cheng KT, Sun J. Metapruning: Meta learning for automatic neural network channel pruning, in Proceedings of the IEEE International Conference on Computer Vision. 2019:3296–3305.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grants 61701238, 11431015, 61773209, 61873148 and 61933007, the Natural Science Foundation of Jiangsu Province of China under Grant BK20190021, the Six Talent Peaks Project in Jiangsu Province of China under Grant XYDXX-033, the Royal Society of the U.K., and the Alexander von Humboldt Foundation of Germany.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no conflicts of interest.
Ethical Approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cheng, H., Wang, Z., Ma, L. et al. Multi-task Pruning via Filter Index Sharing: A Many-Objective Optimization Approach. Cogn Comput 13, 1070–1084 (2021). https://doi.org/10.1007/s12559-021-09894-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12559-021-09894-x