
Abstract
Image dehazing is an increasingly widespread approach to address the degradation of images of the natural environment by low-visibility weather, dust and other phenomena. Advances in autonomous systems and platforms have increased the need for low-complexity, high-performing dehazing techniques. However, while recent learning-based image dehazing approaches have significantly increased the dehazing performance, this has often been at the expense of complexity and hence the use of prior-based approaches persists, despite their lower performance. This paper addresses both these aspects and focuses on single image dehazing, the most practical class of techniques. A new Dark Channel Prior-based single image dehazing algorithm is presented that has an improved atmospheric light estimation method and a low-complexity morphological reconstruction. In addition, a novel, lightweight end-to-end network is proposed, that avoids information loss and significant computational effort by eliminating the pooling and fully connected layers. Qualitative and quantitative evaluations show that our proposed algorithms are competitive with, or outperform, state-of-the-art techniques with significantly lower complexity, demonstrating their suitability for use in resource-constrained platforms.
Similar content being viewed by others

1 Introduction
Haze is a common atmospheric phenomenon caused by small particles (dust, smoke, water drops) in the air, leading to degradation of image clarity. Traditionally, researchers treated image dehazing as an image processing technique to recover image details and this restricted the use of dehazing algorithms to a limited range of applications. However, the rapid development of autonomous systems, artificial intelligence, and the requirements of high-level computer vision tasks has led to renewed research into improved image dehazing techniques. The development of dehazing algorithms has, therefore, become one of the most topical areas of computer vision and an increasingly important application is the use of single image dehazing algorithms to improve the performance of the autonomous systems and platforms under adverse weather conditions.
The optics of a computer vision system are generally designed using the assumption of bright weather conditions, where the colour intensity of each pixel is solely associated with the brightness of the original scene. Hence, studies at an early stage of computer vision tasks selectively ignored the condition of bad weather. However, researchers soon realised the significance of image restoration techniques. Outdoor images are inevitably adversely influenced by the conditions, and refraction, scattering and absorption happen even on relatively clear days, resulting in loss of detailed information and low contrast. These degraded input images inevitably lead to adverse effects on autonomous systems.
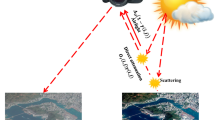
To tackle this problem, a series of studies [1,2,3] proposed the general atmospheric scattering model that is widely accepted in this field, thus providing the theoretical basis for image dehazing. Under this general model, shown in Fig. 1, the reflected light must penetrate the haze before reaching the camera. Therefore, a portion of the reflected light has not been scattered, which is called the direct attenuation, while the scattered portion causes contrast reduction and visibility degradation (see Sect. 2.1 for a mathematical representation). In the field of image dehazing, many investigations have been based on this model [4]. Although the weaknesses of the model have been identified, the improved models proposed by later studies [5, 6] have not received much attention. Consequently, this work adopts the scattering model of Fig. 1, and its variants, and hence benefits from its low complexity and effectiveness.

The atmospheric scattering model
Following the establishment of the theoretical foundations, image dehazing algorithms have been intensively studied. However, dehazing remains a challenging task as the degradation of colour intensity is dependent on the depth information of the original scene, which is usually unavailable, especially for single image dehazing.
Image dehazing algorithms can generally be divided into three categories according to the techniques used [7]. The first of these is dehazing algorithms that require extra information [8,9,10,11,12,13]. As mentioned above, the colour intensity of each pixel is affected by the depth of the corresponding point. Hence, early studies used physical information such as depth [8] or polarisation [9, 12] from the original scene to restore images. This category is limited by the fact that physical information is usually unavailable without special equipment and, for this reason, its techniques are neither practical nor straightforward. The second class is multi-image dehazing [14] in which the dehazing algorithms take several pictures of the same scene to produce a reference to restore the visibility and contrast. To some extent, algorithms in this class are similar to those in the previous one and the difficulty of obtaining multiple images hinders their development.
The final category, single image dehazing [7, 15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30], has received the most attention over the last two decades due to its more realistic assumptions and wide application scenarios. Single image dehazing techniques can be further divided into two subclasses: one group of studies [15,16,17,18,19,20,21] attempt to achieve haze removal using image processing techniques, often employing a prior, while the other applies machine learning methods [22,23,24,25,26,27,28,29,30]. With the rapid development of artificial neural network, over the last five years, more and more convolutional neural network-based single image dehazing algorithms have been proposed. This paper focuses the challenges of performance and complexity that are critical to the successful deployment of image dehazing on resource-constrained platforms such as unmanned aerial vehicles (UAVs) and mobile platforms. To address the challenges, two new, reduced complexity single image dehazing algorithms are proposed, one that is prior based and one learning based.
1.1 Single image dehazing
Most single image dehazing algorithms employ either prior-based image processing-derived or learning-based features to predict the transmission, while inferring the atmospheric light by empirical methods (the exception being end-to-end learning-based algorithms).
A significant development was the discovery by He et al. that there is at least one channel that has a minimal intensity among the three colour channels in non-sky regions, known as the Dark Channel Prior (DCP) [18]. The value of the DCP can be considered to reflect the concentration of haze in this area and infer the transmission. The DCP offers the advantages of simplicity and effectiveness [31] but also has drawbacks in adaptability, speed and edge preservation, motivating many attempts to improve the original method. Xie et al. [32] combined the DCP and Multi-scale Retinex to improve the speed. Later, several papers [33,34,35,36] attributed the long processing time of the original DCP method to the soft matting operation, replacing it with different filters. More recently, morphological reconstruction was incorporated in the DCP process, overcoming the loss of detail caused by the minimum filter [37]. To address real-time processing, Lu and Dong [38] introduced a joint optimization between hardware and algorithm, achieving real-time processing with limited degradation. A recent study [39] employed a novel unsupervised learning method via minimisation of the DCP, feeding the network with real-world hazy images rather than commonly used synthetic data to avoid the possible domain shift. Another problem of the DCP method is the image distortion caused by the over-enhancement, reducing the adaptability of this algorithm.
Tarel et al. [16] proposed the Fast Visibility Restoration (FVR) algorithm, improving the computation speed by applying the median filter. The most significant contribution of the FVR is its linear relationship between computation complexity and image size. Tarel et al. also attempted to apply the FVR algorithm to real-world applications. However, it failed to detect the haze in small gaps between objects and the median filter can blur image edges.
Observing the shortcomings of the DCP, Meng et al. [17] introduced the Boundary Constraint and Contextual Regularisation (BCCR) algorithm which overturned the previous assumption that pixels in the same local patch share the same depth, achieving better adaptability and detail preservation Moreover, Meng et al. identified the problem of the inaccurate prediction of the atmospheric light, which was rarely addressed in previous studies. The actual atmospheric light is slightly darker than the brightest pixel from the object region [17] rather than the commonly used brightest pixel. Hence, the lack of accurate prediction of the atmospheric light is one of the critical reasons for failures in single image dehazing; this is addressed by the new method in Sect. 3.1.1.
Unlike the previous algorithms which aim to improve the overall performance, the Gradient Residual Minimisation (GRM) algorithm [19] addressed the influence of the input image. When the quality of the input image is low, many of the previous methods will enhance the visual artefacts. Chen et al. applied the GRM between the input and output images, refining the coarse transmission generated by priors [19]. This method further extended single image dehazing to a broader range of images, but also inherited the limitations of DCP-based methods.
Zhu et al. [20] introduced the Colour Attenuation Prior (CAP), assuming the brightness and saturation are significantly changed by the haze concentration. Based on this hypothesis, a linear model was established to represent the connection between depth, haze concentration, brightness, and saturation. The CAP algorithm applied a data-driven methodology to acquire the model parameters and recover the haze-free image from the scene depth. As discussed above, the connection between depth and transmission was rarely used because of the unavailability of the depth information. The CAP algorithm restored the depth map by combing the prior with a machine learning method, achieving a unique perspective of haze removal. A recent study introduced a variation function to the original CAP algorithm, which further improved the performance in visibility and efficiency [40].
In [21], Berman et al. proposed a non-local dehazing (NLD) algorithm for single images. According to their observations, the number of colours is much smaller than the number of pixels in an image. Therefore, the colour of a pixel can be replaced by the central value in the same cluster. Berman et al. later extended this theory to hazy images, discovering clusters will become haze lines due to the scattering effect. Finally, the transmission and haze-free image were recovered based on the haze line theory. The NLD algorithm can overcome the deficiency of haze removal at depth discontinuities but its high dependency on colour information leads to a lack of adaptability for this prior.
To summarise, prior-based single image dehazing algorithms seek to develop bespoke solutions based on image processing techniques. Despite the effectiveness of each prior or feature for specific scenarios, their adaptability is inevitably affected by the diversity of the data. Moreover, observation-based features are normally not accurate enough to perform well in objective evaluations, which can be seen in the experimental results later in this paper. Another problem of prior-based methods is the inaccurate estimation of the atmospheric light, an issue which was highlighted in [18] but no significant improvement proposed. According to our knowledge, for these reasons, few prior-based studies have achieved state-of-the-art performances in the last five years. However, these approaches can work well under specific scenarios and, due to their simplicity and practicality, have application in real-time dehazing for resource-limited autonomous systems.
Recognising the recent achievements of the deep neural network in various fields, many researches have proposed data-driven approaches to overcome the bottlenecks in previous dehazing studies and this has been a growing trend in the last five years. Initially, these learning-based approaches also focussed on improving the transmission estimation. One of the most successful of these early attempts, DehazeNet [22], proposed a trainable model to obtain the accurate transmission, demonstrating the superiority of a fully data-driven approach over prior-based approaches. Concurrently, a multi-scale convolutional neural network MSCNN [23] was proposed as a multi-scale architecture to refine the transmission by multi-scale fusion. To avoid learning inaccurate statistical representation from variability and diversity of local regions, a recent study introduced a fully point-wise CNN (FPCNET) architecture [27]. The novelty of FPCNET is the awareness of the importance of shuffling the data, which was mainly overlooked in prior work.
Unfortunately, these studies did not utilise the full potential of deep neural networks as, even though significant performance improvements were achieved, they ignored the previously exposed problems of the atmospheric light and model.
The All-in-One Dehazing Network (AOD-Net) [24] adopted an end-to-end concept that generates the haze-free image directly from the hazy image. To achieve this goal, Li et al. [24] combined the atmospheric light with the transmission. The ingenuity of this design is that the joint learning not only overcomes the cumulative error generated by separate learning but also compensates for the inaccuracy of the existing model to a certain extent through the self-adaptive characteristic of the neural network. This idea can be tracked through to the latest paper [41]. An alternative dehazing approach was suggested by Liu et al. [42], who proposed a generic model-agnostic fully convolutional neural network (GMAN). To enlarge the receptive field without losing information, GCANET [43] applied smoothed dilated convolution instead of downsampling to a gated fusion network. In [28], a Gated Fusion Network (GFN) applied the results of white balance, contrast-enhancing, and gamma correction as inputs, generating the confidence map through training. Finally, the clear image was recovered by fusing the three inputs using weights learnt from the training. As a continuation of previous studies, FAMED-NET [7] integrated the end-to-end structure, multi-scale architecture and fully point-wise network, outperforming all previous state-of-the-art algorithms. Recently, the FFA-Net [44] introduced the attention mechanism into an end-to-end feature fusion network, achieving significantly improved quantitative and qualitative evaluation results but at the expense of increased complexity.
Recent studies [29, 45, 46] have introduced the Generative Adversarial Network (GAN) concept to dehazing. For example, the Densely Connected Pyramid Dehazing Network (DCPDN) [29] proposed a discriminated-based GAN to refine the estimation. Park et al. [45] proposed a heterogeneous GAN and a new loss function, while Zhang et al. [46] proposed a contextualised dilated network. These methods generated the output through a CNN while using a GAN to perform the feature extraction. Despite its high performance, the high storage requirement of this approach severely restricted its practical applications.
Throughout the evolution of learning-based dehazing algorithms, the desire for high performance has driven the development of increasingly sophisticated techniques, such as multi-scale architectures and GAN. This trend has reduced the practical use of single image dehazing algorithms, in particular for resource-constrained applications where real-time operation with limited computational resources is a key driver. Many recent studies [7, 23, 24, 38, 47] recognise the need for real-time processing and the development of techniques to reduce the storage, complexity, processing time and other related aspects without compromising the performance. This is also the main focus of this paper.
1.2 Main contributions
This paper addresses the need for the low-complexity, high-performing single image dehazing algorithms for resource-constrained platforms, such as UAVs, surveillance, and mobile platforms. Both prior-based and learning-based approaches are considered, providing a comprehensive solution to this ill-posed problem. The main contributions are given below.
-
Following the prior-based approach: (1) a new estimation method of the atmospheric light is proposed which significantly enhanced the robustness of the algorithm and (2) a transmission reconstruction technique that addresses the problem of overexposure, with a lower complexity than that proposed in [18].
-
Based on the new deep learning trend in CNN: a new, lightweight end-to-end dehazing network is proposed, that achieves comparable results with the state-of-the-art algorithms using far fewer parameters.
The rest of this paper is organised as follows. The backgrounds of image dehazing and the DCP are explained in Sect. 2, followed by the methodologies of the two new algorithms in Sects. 3 and 4. Section 5 provides a comprehensive performance analysis, including the subjective and objective evaluations, and complexity analysis in comparison with state-of-the-art algorithms. Finally, conclusions are given in Sect. 6, together with potential directions for further work.
2 Background information
2.1 Atmospheric scattering models
As shown in Fig. 1, the degradation of captured images under bad weather conditions is caused by the scattering effect of particles in the air. Following Nayar and Narasimhan [1,2,3], this process can be expressed as:
where \(x\) denotes the position of the pixel, \(I\left( x \right)\) is the colour intensity of the captured image, \(J\left( x \right)\) is the original scene radiance to be recovered, \(A\) is the atmospheric light, and \(t\left( x \right)\) is the transmission. More specifically, \(t\left( x \right)\) is a coefficient used to represent the portion of light in the direct attenuation.
In most image dehazing literature, Eq. (1) is written in a different form:
According to Eq. (2), the problem of restoring the haze-free image \(J\left( x \right)\) can be transformed to predicting the unknown parameters \(A\) and \(t\left( x \right)\). However, it is challenging to achieve accurate predictions of these parameters because \(A\) is not always the pixel with the highest intensity and \(t\left( x \right)\) corresponds to the depth.
Li et al. [24] reformulated the existing model, combining \(A\) and \(t\left( x \right)\) into one variable \(K\), to give:
where \(K\left( x \right) = {{\left[ {\frac{1}{{t\left( x \right)}}\left( {I\left( x \right) - A} \right) + \left( {A - b} \right)} \right]} \mathord{\left/ {\vphantom {{\left[ {\frac{1}{{t\left( x \right)}}\left( {I\left( x \right) - A} \right) + \left( {A - b} \right)} \right]} {\left[ {I\left( x \right) - 1} \right]}}} \right. \kern-\nulldelimiterspace} {\left[ {I\left( x \right) - 1} \right]}}\). Equation (3) established the direct connection between \(I\left( x \right)\) and \(K\left( x \right)\) while adding an unknown constant \(b\). This variant is particularly suitable for learning-based approaches since the network is input adaptive. The ingenuity of this formula is to avoid the potential cumulative error caused by separate learning of \(A\) and \(t\left( x \right)\). In addition, Eq. (3) can be used to reduce the complexity of the network, resulting in lower processing time and storage requirements. Considering the above advantages, this is the model used in our proposed low-complexity learning-based algorithm described in Sect. 4.
2.2 Dark channel prior (DCP)
The DCP is one of the most widely used approaches in prior-based dehazing approaches and is reviewed in almost every paper within this field. As a prior-based method, the DCP was summarised from numerous observations of haze-free images. He et al. [18] discovered that there is a close-to-zero value for at least one colour channel in any non-sky local patch and further expanded this observation to the transmission estimation. The dark channel is defined as [18]:
where \(\Omega \left( x \right)\) is a local patch centred on the pixel \(x\), and \(C\) denotes the \(R,G,B\) colour channels of an image \(I\). Hence, the DCP is represented as:
The DCP of Eq. (5) was extended from clear to hazy conditions such that the hazy condition of a region is indicated by a change in the value of the DCP, establishing the connection between the DCP, haze level and transmission.
Due to the complexity of the mathematical representation, the derivation from [18] is not reproduced here but a flow chart of the DCP algorithm is shown in Fig. 2. This algorithm achieved relatively good results, with the main drawback of low efficiency caused by the soft matting operation, which is applied to refine the transmission. According to one experiment, the processing time was in excess of 20 s for a 400 × 600 image. To reduce this complexity, morphological operations can be used instead of the soft matting to refine the transmission and this is the approach adopted by the improved method proposed in Sect. 3.

The dark channel prior (DCP)-based algorithm [18]
3 The robust atmospheric light estimation with reduced distortion (RALE-RD) prior-based dehazing algorithm
A flow diagram of the proposed algorithm is shown in Fig. 3 and was designed to address the extant problems of the original DCP method. Similar to other prior-based dehazing algorithms, the basis of the proposed approach is atmospheric light estimation and transmission prediction. The improvements to these two components are described in the subsections below.

The system flow diagram of the proposed robust atmospheric light estimation with reduced distortion (RALE-RD) algorithm
3.1 A robust method of atmospheric light estimation
The proposed algorithm is based on the observation that the value of the atmospheric light is slightly darker than the brightest pixel in the sky region. While a lower estimation can result in dim but acceptable results, a higher estimation can lead to overexposure. Thus, a new robust method of estimating the atmospheric light, \(A\), is proposed by introducing a weighting function to two widely used methods, such that:
where \(A_{{brightest}}\) denotes the corresponding value in the original image which the highest value in the dark channel. Similarly, \(A_{{0.1\% }}\) uses the average of the corresponding values for the 0.1% brightest pixels in the dark channel and \(\alpha\) is the weighting function whose default value is 0.66.
Using Eq. (6), the estimation of our method tends to be slightly lower than the ground truth, which can be addressed by image enhancement. However, the robustness of this method has been improved significantly as, while a lower estimation only leads to dim results, an over-estimation produces unacceptable results. Therefore, our approach exploits the best performance while ensuring robustness.
3.2 Transmission reconstruction
In this section, colour distortions in the sky region are prevented by introducing a lower bound of the reconstructed transmission map of the sky region.
The motivation for this approach is the observation that colour distortion in the sky region is caused by low transmission values, resulting in some intensity of the sky region in the recovered image exceeding the maximum value. The proposed approach to mitigate this phenomenon is to set a lower bound for the transmission. It is worth noting that this lower bound is different from the lower bound prosed in [18], which was used to prevent a zero denominator. In the proposed method, the transmission, \(t\), is defined by:
where \(t_{0}\) is the lower bound of the transmission, with a default value of 0.4. Under normal circumstances, the transmission of the object region will not be lower than 0.6, while the transmission of the sky region is close to 0. Therefore, the dehazing process of the object region will not be affected by this lower bound. As the DCP dehazing is applied to the whole image, due to the change of transmission, the colour of the sky region is incorrectly estimated and, as a result, the colour intensity of the sky region is always very high due to the attempt to remove non-existent haze. However, as the colours of the haze and the sky are very similar, this incorrect estimation does not influence the overall quality of the result.
However, this use of Eq. (7) applies the lower bound to the entire transmission map, which is slightly different from our original intention. In the case of dense haze, part of the transmission of the object may be lower than 0.4, resulting in the residual haze in the corresponding area. To address this, a set of morphological operations were introduced to reconstruct the transmission map before applying this lower bound. As shown in Fig. 3, this process first applies the morphological closing operation, \(\emptyset \left( \cdot \right)\), to the coarse transmission generated from the dark channel, followed by an opening, \(\gamma \left( \cdot \right)\), to produce:
and
respectively, where the closing and opening operations are combinations of the fundamental morphological operations of dilation \(\delta _{B}\) and erosion \(\varepsilon _{B}\), with a structuring element \(B\) [48].
The closing is used to fill the holes of the image, enhancing the structure of objects, and the opening removes small image objects while preserving larger objects. These operations maintain the shapes of the main objects in the scene in \(t_{{CO}}\). The size of the structuring element \(B\) for both operations was set equal to the kernel size used in the DCP.
Finally, the sky and objects are separated and the transmission map reconstructed by:
where \(t_{{{\text{reconstructed}}}}\) is the final transmission map which will be used to recover the haze-free image and \(t^{\prime}\left( x \right) = \max \left( {t_{{CO}} ,t_{0} } \right)\). The proposed approach has two benefits. First, the phenomenon of excessive enhancement is prevented by the lower bound and a better estimation of the scene radiance. Second, the morphological reconstruction significantly reduces the processing time and provides smooth edges. In very limited cases, the difference between our atmospheric light estimation and the scene radiance can produce results that appear dim. This can be corrected by employing an optional histogram equalisation step to enhance the luminance for display and, following [18], the Contrast Limited Adaptive Histogram Equalisation (CLAHE) algorithm was used. As this step is not necessary in most cases, it was not included in the performance evaluation in Sect. 5.
To summarise, the proposed algorithm tries to make full use of the potential of the DCP. Despite the excellent results generated from various tests, it cannot avoid inheriting some of the built-in limitations of this prior. For example, the DCP does not hold in exceptional circumstances, such as a scene containing many white buildings, leading to unexpected results. This is further explored and discussed in the results and conclusions sections.
It is worth noting that the problems caused by inaccuracy of the prior and atmospheric light have been mentioned many times in previous sections. Through investigations, the main reason for these inaccuracies is the lack of image recognition capabilities in the algorithm. Conversely, humans can easily predict atmospheric light from the sky region and recognise the haze concentration. This insight inspired the development of a new lightweight learning-based dehazing method, which will be presented in the next section.
4 The lightweight single image dehazing fully convolutional neural network (LSID-FCNN)
A new, lightweight end-to-end CNN (LSID-FCNN) is proposed, with the general architecture shown in Fig. 4. LSID-FCNN consists of two components: the image generator and the K-estimation module. In this way, the haze-free image is recovered from the K-map generated by the estimation network through a variant of the atmospheric scattering model.

The architectures of the proposed network (top) and the K-estimation network (bottom)
4.1 Image generator
As the problem addressed in this paper is the need for real-time dehazing for UAVs and mobile platforms, computation complexity is a critical factor. Therefore, the image generator was adopted in our design.
As discussed in Sect. 1, the existing atmospheric scattering model has been found to be inaccurate in some aspects, which result in errors in the dehazing. Therefore, the design of the image generator was based on the improved variant of this model [24]:
This variant cleverly combined the atmospheric light and transmission into one variable \(K\), which avoided the cumulative error caused by separated learning. Further, the proposed \(K\) used the self-adaptive characteristic of artificial neural networks to overcome the inaccuracy of the model. In other words, the defects of this model can be compensated in part by the adjustment of \(K\) in the learning process. Besides, using the image generator significantly reduces the complexity while still guaranteeing high accuracy.
4.2 K-estimation network
To achieve accurate estimation of the parameter \(K\), a Fully Convolutional Neural Network (FCNN) is proposed, as shown in Fig. 4. Unlike the typical CNN architecture, the proposed network avoids information loss and significant computational effort by abandoning the pooling and fully connected layers. The network consists of ten multi-scale convolutional layers, and the input of each layer is the concatenation of the previous output. All the activation functions are Rectified Linear Unit (ReLU) functions to fit the characteristics of colour intensity.
The main difference between image dehazing and more common CNN applications is the large number of inputs and outputs, which means any kind of information loss is unacceptable. For example, a typical CNN application such as recognition or classification is not sensitive to information loss as the grayscale image, or even partial features, are sufficient to achieve their goal. This allows these networks to use pooling layer and large-scale convolution. However, all the input image information is vital to image dehazing, as predictions of each pixel in three channels are required. Therefore, large-scale convolution and pooling were unsuitable for this task. Although increasing the depth of the network can compensate for the information loss, it also greatly increases the computation complexity and storage requirement.
For the above reasons, the kernel size of most convolution operations in our network is 3 × 3, while a few large-scale convolutions were used to enlarge the receptive field. Concatenation was adopted to compensate the information loss after each convolution. Finally, the K-map was generated through this network, achieving haze removal with the image generator.
In the training stage, all examples were selected from the Realistic Single Image Dehazing (RESIDE) dataset [4]. To demonstrate the low training requirement and effectiveness of the LSID-FCNN for resource-constrained platforms, only one-third of the training examples were used and the specific training configurations are given in Table 1.
5 Experimental results and analysis
The two proposed single image dehazing algorithms were developed from two different approaches: a traditional prior-based method and a learning-based CNN approach. To validate the relative effectiveness of these methods, a series of experimental results are presented consisting of a subjective evaluation, objective evaluation, complexity and processing time analysis. The visual appearance of our proposed algorithms is explored through the subjective evaluation, while a quantitative comparison with a selection of state-of-the-art algorithms forms the objective evaluation. All experiments use images from the RESIDE dataset [4], which was specifically designed to enable the fair evaluation of single image dehazing algorithms. The RESIDE dataset contains training and test sets of synthetic hazy images. The Synthetic Objective Testing Set (SOTS) used here is composed of indoor and outdoor sets, each with 500 synthetic hazy images generated by varying the parameters of the atmospheric scattering model. The testing images from the indoor set have a fixed resolution of 620 × 460 pixels while the resolution of outdoor images varies from 550 × 309 to 550 × 975. The RESIDE dataset has been widely adopted in the field of image dehazing and facilitates a direct comparison with the state-of-the-art.
5.1 Subjective evaluation
The subjective evaluation is divided into three parts, each consisting of subsets from the RESIDE benchmark [4]. Specifically, tests were performed on the SOTS dataset, a synthetic dataset, and a real-world dataset. In both the indoor and outdoor sets of the SOTS dataset the hazy images were generated from real-world scenes, to simulate the real-world environment. To ensure a fair evaluation, all the testing examples are unseen data for our network. Due to the synthetic configuration, testing on the SOTS and synthetic dataset are full-reference evaluations as ground truth images were given. Conversely, the real-world dataset contains only the captured hazy images for which no ground truth is available.
Figure 5 presents results for a representative indoor and outdoor image from the SOTS dataset. These results show the typical characteristics of the techniques and their corresponding peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM) are also provided. For the indoor image, the RALE-RD algorithm outperforms the LSID-FCNN in colour restoration while the LSID-FCNN produces smoother results. For example, the vivid colour of the table indicates the excellent colour restoration ability of RALE-RD. However, the curves of the floor and chairs are slightly thickened, showing the drawback of the smoothing. The outdoor result shows a similar pattern, for example the colour of buildings is still slightly brighter than the ground truth, while the enhancement of edges in outdoor large-scale pictures is unnoticeable.

Representative results using the SOTS dataset for the indoors set (top row) and the outdoor set (bottom row). From left to right: ground truth images, hazy images, results of the RALE-RD algorithm, and results of the LSID-FCNN
These results validate the accuracy of our previous observations, the RALE-RD algorithm tends to generate haze-free images with vivid colours, which is advantageous when dealing with dense haze conditions. For the same reason, the recovered image can be even more colourful than the ground truth, which means it may be considered as a colour restoration image enhancement technique, rather than for recovering the ground truth. On the other hand, the LSID-FCNN algorithm appears to better recover the ground truth, generating more natural results. No severe failure cases were found during this testing stage, underlying the robustness of the proposed algorithms.
Figures 6 and 7 show the results for the synthetic and the real-world sets, respectively. Unlike the SOTS results, the LSID-FCNN algorithm shows superiority over the RALE-RD method in real-world scenes. As shown in Fig. 6, the results produced by LSID-FCNN are close to the ground truth, while the results generated by the RALE-RD are exaggerated. This trend is noticeable in the sky regions. In addition, the edges are enhanced in the results generated by the prior-based method. Although this aspect has been significantly improved from the original algorithm, its smoothness remains a weakness when compared to the learning-based algorithm.

Representative results using the RESIDE synthetic set. From left to right: ground truth image, hazy image, result of the RALE-RD algorithm, result of the LSID-FCNN

Example results using the RESIDE real-world set. From left to right: hazy images, results of the RALE-RD algorithm, results of the LSID-FCNN algorithm
Many of the hazy images in the real-world set were captured under poor airlight conditions which increase the possibility of failure, leading to this dataset being ignored by many previous dehazing studies. Figure 7 presents four of the most challenging images from this real-world dataset, demonstrating that even under insufficient ambient light conditions both the RALE-RD and LSID-FCNN algorithms produce relatively clear and natural results with good details. In addition, the adverse edge enhancement effect of the RALE-RD algorithm is not evident in these large-scale outdoor images.
To facilitate visual comparisons with dehazing test images from outside the RESIDE dataset, Fig. 8 presents results of three images for four significant prior-based methods (DCP, FVR, BCCR and NLR) and one early CNN-based method (DehazeNet). Note that most subsequent learning-based methods have high PSNR and SSIM results and thus similar, high visual quality results. The DCP and FVR results exhibit fuzzy results or have haze residuals, see for example the leaves in the first and third images. Some edge enhancement is evident in all results for the FVR and BCCR methods, while the latter also exhibits some overexposure. NLD produces good results, apart from some sharp curves in the first image, while DehazeNet has smooth and natural result but failed to eliminate the haze, see the haze residuals around the pumpkins (second image) and leaves (third image).

In comparison, the RALE-RD results have vivid colours and good details, the only problem being the enhancement of edges (first image only) and does not occur in the majority of cases. The LSID-FCNN results have natural colours with good details and while slightly dimmer, is possibly closer to the ground truth.
5.2 Objective evaluation
The objective evaluation results provide a quantitative comparison with state-of-the-art algorithms. Both the PSNR and SSIM measures were used in conjunction with the SOTS dataset, as they are both full-reference methods. The results in Table 2 give the average performances of the two proposed methods for the indoor and outdoor sets from SOTS, which each contains 500 images. In addition, results for six significant prior-based and nine learning-based algorithms are also provided. The results were collected from [7] and the original papers for each algorithm.
Our proposed RALE-RD algorithm achieves the highest PSNR and the third highest SSIM among all prior-based algorithms. Further, the RALE-RD results even outperform some of the learning-based algorithms, proving the accuracy of the observations behind its development. The LSID-FCNN algorithm achieves a comparable PSNR to the top 50% of the learning-based algorithms and above all prior-based algorithms. For SSIM, the LSID-FCNN algorithm has the seventh highest performance of the 17 algorithms evaluated. These competitive results can be considered a success considering that the lightweight design of our network is well suited for fast computation and low complexity.
As the motivation for the development of both the RALE-RD and LSID-FCNN algorithms was resource-constrained applications such as UAVs, which typically operate in the more demanding environments, separate quantitative results for the indoor and outdoor SOTS test sets are presented in Table 3. Results for the indoor set are generally not as good as the outdoor set, which is not a major issue as the outdoor environment is the main application area for image dehazing.
5.3 Complexity and time analysis
Recent research in single image dehazing has paid a lot of attention to performance but has often ignored the considerations of resource-constrained platforms. The motivation for the proposed algorithm was to satisfy the requirements of real-time processing while still achieving high performance. To evaluate this aspect, complexity and time analysis results are shown in Table 4 and Table 5, respectively.
Due to the difference in the framework, network complexity may not be directly comparable between the learning-based approaches [49]. Therefore, the model size, which is commonly measured by the number of learnable parameters [49], is used as an estimate of network complexity, see Table 4. Generally, more parameters are indicative of larger model sizes which are more likely to have a higher demand on hardware, leading to a slower runtime. The model size of the proposed LSID-FCNN algorithm is much less than all other learning-based algorithms except the AOD-NET [24]. However, the performance of this algorithm (Table 3) is better than most algorithms of the same order of magnitude.
Although the SSIM of the LSID-FCNN only ranks fifth, the model size of the top four algorithms is several orders of magnitude higher, demonstrating that the LSID-FCNN achieves competitive results with a very limited number of parameters, validating the effectiveness of our design.
The processing time experiment was conducted on a 64-bit Inter Core I7-8750H CPU with 16 GB of RAM. To try to ensure a fair comparison between the prior-based and learning-based algorithms, the GPU acceleration was deactivated. Table 5 shows the average processing time of the algorithms for a 620 × 460 pixels image. Due to their lightweight design, both proposed algorithms have processing speeds among the lowest in each algorithm class, even when recognising that the contributions from the different environments used may influence the processing times to some degree.
In summary, both algorithms achieved excellent results in efficiency, which was precisely the aim of this work. With optimisation, it is believed that both algorithms could satisfy the requirements of real-time processing.
6 Conclusions and future work
Outdoor images are often affected by small atmospheric particles, giving rise to haze that degrades the image clarity. While many single image dehazing algorithms have been proposed, their focus has mainly been on performance at the expense of complexity. This presents particular issues for the deployment of dehazing algorithms in resource-constrained autonomous systems and platforms which require real-time operation, often under adverse weather conditions.
To address this problem, two new low-complexity, high-performance single image dehazing algorithms have been proposed, one prior based and one learning based. As its name suggests, the Robust Atmospheric Light Estimation with Reduced Distortion (RALE-RD) prior-based algorithm offers a robust weighting-based approach to atmospheric light estimation and an improved lower bound to reduce distortion, coupled with an efficient morphological transmission map reconstruction. The lightweight learning-based approach, LSID-FCNN, employs an image generator for atmospheric light estimation with a single parameter, K, that has significantly reduced complexity yet retains high accuracy. A FCNN is employed as a K-estimation network that avoids information loss and has significantly lower complexity than conventional CNN architectures.
Subjective and objectives results show the RALE-RD algorithm to match or outperform many other prior-based techniques and with a complexity amongst the lowest in this class. The LSID-FCNN algorithm’s performance matches that of other learning-based techniques with a significantly lower complexity, offering a major advantage for resource-constrained applications.
For real-time applications, the 0.08-s average processing time of the RALE-RD algorithm for 620 × 460 images would enable a frame rate of 12.5 frames per second (fps) with the hardware used in our experiments. In an example application such as a search and rescue UAV, the on-board imaging may typically range between 25 and 120 fps for 1080p images but due to the limited computational resources, the frame rate and image size are routinely down-sampled for real-time applications such as target detection, where the dehazing is one of a number of image processing tasks employed. Given that our results were achieved with no GPU acceleration, the prior-based RALE-RD approach is useful as it stands for use in real-time application scenarios due to its low computation requirement.
The learning-based LSID-FCNN approach has a higher average runtime of 0.30 s for 620 × 460 images. As GPU acceleration typically reduces the runtime for CNN-based dehazing algorithms by two orders of magnitude, real-time operation is a realistic prospect for systems employing a GPU but remains a challenge for those that do not. However, the LSID-FCNN approach also has the potential to achieve improved results with additional network design and training configurations, as those presented here are for relatively limited training and network depth. While computational complexity still presents a challenge as the network grows larger and deepens with the pursuit of better performance, GPU-based systems have the potential capacity for this.
Future work to improve the performance of the LSID-FCNN algorithm includes the development of an alternative loss function to the simple MSE, which has the potential to improve the SSIM performance instead of focussing on the PSNR. Second, the network still contains redundancy due to the many concatenations used and it may be possible to further reduce this with more experimentation. Finally, the combination of machine learning and handcrafted prior-based features presents an attractive proposition. As few studies to date have successfully adopted useful features into their networks without introducing external interference, this presents an interesting area of future investigation.
References
Nayar, S.K., Narasimhan, S.G.: Vision in bad weather. In: Computer vision, 1999. ICCV 1999. Proceedings of 7th IEEE international conference on IEEE, vol 2, (1999)
Narasimhan, S.G., Nayar S. K.: Removing weather effects from monochrome images. In: Computer vision and pattern recognition, 2001. CVPR 2001. IEEE computer society conference on IEEE, vol 2, pp II–II (2001)
Narasimhan, S.G., Nayar, S.K.: Vision and the atmosphere. Int. J. Comput. Vis. 48, 233–254 (2002)
Li, B., et al.: Benchmarking single-image dehazing and beyond. Image Process. IEEE Trans. 28(1), 492–505 (2019)
Ju, M., Zhang, D., Wang, X.: Single image dehazing via an improved atmospheric scattering model. Vis. Comput. 33, 1613–1625 (2017)
Dai, C., Lin, M., Wu, X., Zhang, D.: Single hazy image restoration using robust atmospheric scattering model. Signal Process. 166, 107257 (2020)
Zhang, J., Tao, D.: FAMED-net: a fast and accurate multi-scale end-to-end dehazing network. Image Process. IEEE Trans. 29, 72–84 (2020)
Tan, K., Oakley, J.P.: Enhancement of color images in poor visibility conditions. In: Image Processing (ICIP), 2000 IEEE International Conference on, IEEE, vol 2, pp 788–791 (2000)
Schechner, Y.Y., Narasimhan, S.G., Nayar, S.K.: Instant dehazing of images using polarization. In: Computer vision and pattern recognition, 2001. CVPR 2001. IEEE computer society conference on IEEE, vol 2, pp I–I (2001)
Yuan, F., Huang, H.: Image haze removal via reference retrieval and scene prior. Image Process. IEEE Trans. 27(9), 4395–4409 (2018)
Narasimhan, S.G., Nayar, S.K.: Contrast restoration of weather degraded images. Pattern Anal. Mach. Intell. IEEE Trans. 25(6), 713–724 (2003)
Treibitz, T., Schechner, Y.Y.:Polarization: beneficial for visibility enhancement? In: Computer vision and pattern recognition, 2009. CVPR 2009. IEEE computer society conference on IEEE, pp 525–532 (2009)
Kopf, J., et al.: Deep photo: model-based photograph enhancement and viewing. ACM Trans. Graph. 27(5), 1–10 (2008)
Joshi, N., Cohen, M.F.: Seeing Mt. Rainier: lucky imaging for multi-image denoising, sharpening, and haze removal. In: International conference on computational photography ICCP 2010, pp 1–8 (2010)
Liu, Q., Gao, X., He, L., Lu, W.: Single image dehazing with depth-aware non-local total variation regularization. Image Process. IEEE Trans. 27(10), 5178–5191 (2018)
Tarel, J., Hautière, N.: Fast visibility restoration from a single color or gray level image. In: Computer vision, 2009. ICCV 2009. Proceedings of 12th IEEE international conference on IEEE, pp 2201–2208 (2009)
Meng, G., Wang, Y., Duan, J., Xiang S., Pan, C.: Efficient image dehazing with boundary constraint and contextual regularization. In: Computer vision, 2013. ICCV 2013. Proceedings of IEEE international conference on IEEE, pp 617–624 (2013)
He, K., Sun, J., Tang, X.: Single image haze removal using dark channel prior. Pattern Anal. Mach. Intell. IEEE Trans. 33(12), 2341–2353 (2011)
Chen C., Do M.N., Wang J.: Robust image and video dehazing with visual artifact suppression via gradient residual minimization. In: Computer vision—ECCV 2016. ECCV 2016. Lecture notes in computer science, vol 9906. Springer (2016)
Zhu, Q., Mai, J., Shao, L.: A fast single image haze removal algorithm using color attenuation prior. Image Process. IEEE Trans. 24(11), 3522–3533 (2015)
Berman, D., Treibitz, T., Avidan, S.: Non-local image dehazing. In: Computer vision and pattern recognition (CVPR), pp 1674–1682 (2016)
Cai, B., Xu, X., Jia, K., Qing, C., Tao, D.: DehazeNet: an end-to-end system for single image haze removal. Image Process. IEEE Trans. 25(1), 5187–5198 (2016)
Ren W., Liu S., Zhang H., Pan J., Cao X., Yang M.H.: Single image dehazing via multi-scale convolutional neural networks. In: Computer vision—ECCV 2016. ECCV 2016. Lecture notes in computer science, vol 9906. Springer (2016)
Li, B., Peng, X., Wang, Z., Xu, J., Feng, D.: AOD-Net: all-in-one dehazing network. In: Computer vision, 2017. ICCV 2017. Proceedings of 12th IEEE international conference on IEEE, pp 4780–4788 (2017)
Tang, K., Yang, J., Wang, J.: Investigating haze-relevant features in a learning framework for image dehazing. In: Computer vision and pattern recognition, 2014. CVPR 2014. IEEE Comp. Soc. Conf. on, IEEE, pp 2995–3002 (2014)
Kratz, L., Nishino, K.: Factorizing scene albedo and depth from a single foggy image. In: Computer vision, 2009. ICCV 2009. Proceedings of 12th IEEE international conference on IEEE, pp 1701–1708 (2009)
Zhang, J., Cao, Y., Wang, Y., Wen, C., Chen, C.W.: Fully point-wise convolutional neural network for modeling statistical regularities in natural images. In: Proceeding of 26th ACM international conference on multimedia (MM ’18), pp 984–992 (2018)
Ren. W., et al.: Gated fusion network for single image dehazing. In: 2018 Conference on computer vision and pattern recognition, IEEE/CVF, pp 3253–3261 (2018)
Zhang, H., Patel, V.M.: Densely connected pyramid dehazing network. In: 2018 Conference on computer vision and pattern recognition, IEEE/CVF, pp 3194–3203 (2018)
Haouassi, S., Wu, D.: Image dehazing based on (CMTnet) cascaded multi-scale convolutional neural networks and efficient light estimation algorithm. Appl. Sci. 10(3), 1190 (2020)
Gibson, K.B., Nguyen, T. Q.: On the effectiveness of the Dark Channel Prior for single image dehazing by approximating with minimum volume ellipsoids. In: IEEE international conference on acoustics, speech and signal processings (ICASSP), pp 1253–1256 (2011)
Xie, B., Guo, F., Cai, Z.: Improved single image dehazing using dark channel prior and multi-scale retinex. In: Proceedings of international conference on intelligent system design and engineering application. IDEA 2010, pp 848–851 (2018)
Park, D., Han, D.K., Ko, H.: Single image haze removal with WLS-based edge-preserving smoothing filter. In: IEEE International conference on acoustics, speech and signal processing (ICASSP), pp 2469–2473 (2013)
Gibson, K.B., Nguyen, T.Q.: Fast single image fog removal using the adaptive Wiener filter. In: IEEE international conference on image processings, ICIP, pp 714–718 (2013)
Xiao, C., Gan, J.: Fast image dehazing using guided joint bilateral filter. Vis. Comput. 28, 713–721 (2012)
Zhang, Q., Li, X.: Fast image dehazing using guided filter. In: IEEE 16th international conference on communication technology (ICCT), pp 182–185 (2015)
Salazar-Colores, S., et al.: A fast image dehazing algorithm using morphological reconstruction. IEEE Trans. Image Proc. 28(5), 2357–2366 (2019)
Lu, J., Dong, C.: DSP-based image real-time dehazing optimization for improved dark-channel prior algorithm. J. Real-Time Image Proc. 17, 1675–1684 (2020)
Golts, A., Freedman, D., Elad, M.: Unsupervised single image dehazing using dark channel prior loss. IEEE Trans. Image Proc. 29, 2692–2701 (2020)
Huang, H., Song, J., Guo, L., Wang, H., Wang, P.: Haze removal method based on a variation function and colour attenuation prior for UAV remote-sensing images. J. Mod. Opt. 66(12), 1282–1295 (2019)
Liu C., Tao L., Kim Y-T., VLW-Net: A very light-weight convolutional neural network (CNN) for single image dehazing. In: International conference on advanced concepts for intelligent vision systems. ACIVS 2020. Lecture notes in computer science, vol 12002. Springer (2020)
Liu, Z., et al.: Single image dehazing with a generic model-agnostic convolutional neural network. IEEE Sig. Proc. Lett. 26(6), 833–837 (2019)
Chen, D., et al.: Gated context aggregation network for image dehazing and deraining. In: IEEE Winter conference on applications of computer vision (WACV). pp. 1375–1383 (2019)
Qin, X., et al.: FFA-net: Feature fusion attention network for single image dehazing. In: Proceeding of AAAI conference on artificial intelligence, pp. 11908–11915 (2020)
Park, J., Han, D.K., Ko, H.: Fusion of heterogeneous adversarial networks for single image dehazing. IEEE Trans. Image Proc. 29, 4721–4732 (2020)
Zhang, S., He, F., Ren, W.: Photo-realistic dehazing via contextual generative adversarial networks. Mach. Vis. Appl. 31, 33 (2020)
Cheng, K., Yu, Y., Zhou, H., Zhou, D., Qian, K.: GPU fast restoration of non-uniform illumination images. J. Real-Time Image Proc. 18, 75–83 (2021)
Soille, P.: Morphological image analysis: principles and applications. Springer Science & Business Media, Berlin (2013)
Zhou H., Alvarez J.M., Porikli F.: Less is more: towards compact CNNs. In: Computer vision—ECCV 2016. ECCV 2016. Lecture notes in computer science, vol 9906. Springer (2016)
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yang, G., Evans, A.N. Improved single image dehazing methods for resource-constrained platforms. J Real-Time Image Proc 18, 2511–2525 (2021). https://doi.org/10.1007/s11554-021-01143-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11554-021-01143-6