
Abstract
We develop a decomposition algorithm for distributionally-robust two-stage stochastic mixed-integer convex conic programs, and its important special case of distributionally-robust two-stage stochastic mixed-integer second order conic programs. This generalizes the algorithm proposed by Sen and Sherali [Mathematical Programming 106(2): 203–223, 2006]. We show that the proposed algorithm is finitely convergent if the second-stage problems are solved to optimality at incumbent first stage solutions, and solution to an optimization problem to identify worst-case probability distribution is available. The second stage problems can be solved using a branch and cut algorithm, or a parametric cuts based algorithm presented in this paper. The decomposition algorithm is illustrated with an example. Computational results on a stochastic programming generalization of a facility location problem show significant solution time improvements from the proposed approach. Solutions for many models that are intractable for an extensive form formulation become possible. Computational results also show that for the same amount of computational effort the optimality gaps for distributionally robust instances and their stochastic programming counterpart are similar.
Similar content being viewed by others


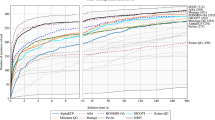
Notes
diff=\(|\text {obj}(d_W)-\text {obj}(d_{TV})|/\text {obj}(d_{TV}).\)
References
Luo, F.Q., Mehrotra, S.: Distributionally robust service center location problem with decision dependent utilities. Tech. report, Northwestern University (2019)
Birge, J., Louveaux, F.: Introduction to stochastic programming. Springer, New York (1997)
Ruszczyński, A., Shapiro, A. (eds.): Stochastic programming, operations research and management science, vol. 10. Elsevier, Amsterdam (2003)
Bertsimas, D., Tsitsiklis, J.N., Tsitsiklis, J.: Introduction to linear optimization. Athena scientific, India (1997)
Blair, C.E., Jeroslow, R.G.: The value function of an integer program. Math Program 23(1), 237–237 (1982)
Schultz, R.: Continuity properties of expectation functions in stochastic integer programming. Math Oper Res 18, 578–589 (1993)
Carøe, C.C., Tind, J.: A cutting-plane approach to mixed 0–1 stochastic integer programs. Eur J Oper Res 101, 306–316 (1997)
Carøe, C.C., Tind, J.: L-shaped decomposition of two-stage stochastic programs with integer recourse. Math Program 83, 451–464 (1998)
Laporte, G., Louveaux, F.V.: The integer L-shaped method for stochastic integer programs with complete recourse. Oper Res Lett 18, 133–142 (1993)
Gade, D., Küçükyavuz, S., Sen, S.: Decomposition algorithms with parametric Gomory cuts for two-stage stochastic integer programs. Math Program 144, 39–64 (2014)
Zhang, M., Küçükyavuz, S.: Finitely convergent decomposition algorithms for two-stage stochastic pure integer programs. SIAM J Opt 24(4), 1933–1951 (2014)
Bansal, M., Huang, K.L., Mehrotra, S.: Tight second stage formulations in two-stage stochastic mixed integer programs. SIAM J Opt 28, 788–819 (2018)
Bansal, M., Zhang, Y.: Two-stage stochastic and distributionally robust \(p\)-order conic mixed integer programs (2018). http://www.optimization-online.org/DB_FILE/2018/05/6630.pdf
Atamtürk, A., Narayanan, V.: Conic mixed-integer rounding cuts. Math Program 122, 1–20 (2008)
Sen, S., Sherali, H.D.: Decomposition with branch-and-cut approaches for two-stage stochastic mixed-integer programming. Math Program 106, 203–223 (2006)
Balas, E.: Disjunctive programming and a hierarchy of relaxations for discrete optimization problems. SIAM. J. on Algebraic Discret Meth 6(3), 466–486 (1985)
Balas, E.: Disjunctive programming: properties of the convex hull of feasible points. Discret Appl Math 89, 3–44 (1998)
Sen, S., Higle, J.L.: The \(C^3\) theorem and a \(D^2\) algorithm for large scale stochastic mixed-integer programming: set convexification. Math Program 104, 1–20 (2005)
Sen, S., Sherali, H.D.: On the convergence of cutting plane algorithms for a class of nonconvex mathematical programs. Math Program 31, 42–56 (1985)
Qi, Y., Sen, S.: The ancestral Benders’ cutting plane algorithm with multi-term disjunctions for mixed-integer recourse decisions in stochastic programming. Math Program 161, 193–235 (2017)
Küçükyavuz, S., Sen, S.: An introduction to two-stage stochastic mixed-integer programming (2017). http://faculty.washington.edu/simge/Preprints/SMIP_Tutorial.pdf
Bansal, M., Huang, K.L., Mehrotra, S.: Decomposition algorithms for two-stage distributionally robust mixed binary programs. SIAM J Opt 28, 2360–2383 (2017)
Bansal, M., Mehrotra, S.: On solving two-stage distributionally robust disjunctive programs with a general ambiguity set. Eur J Oper Res 279(2), 296–307 (2019)
Conforti, M., Cornuéjols, G., Zambelli, G.: Integer programming graduate texts in mathematics. Springer, New York (2014)
Chandrasekaran, V., Shah, P.: Relative entropy optimization and its applications. Math Program Series A 161, 1–32 (2016)
Shapiro, A.: On duality theory of conic linear problems. In: Semi-infinite programming. nonconvex optimization and its applications, vol. 57, pp. 135–165. Springer, US (2001)
Luo, F., Mehrotra, S.: Finitely convergent cutting plane algorithms for mixed-integer convex programs and their stochastic and distributionally robust counterparts. Technical report (in preparation) (2021)
Chen, B., Simge Küçükyavuz, S.S.: Finite disjunctive programming characterizations for general mixed-integer linear programs. Oper Res 59(1), 202–210 (2011)
Lubin, M., Yamangil, E., Bent, R., Vielma, J.P.: Polyhedral approximation in mixed-integer convex optimization. Math Program pp. 139–168 (2018)
Lubin, M.: Mixed-integer convex optimization: outer approximation algorithms and modeling power. Ph.D. thesis, Massachusetts Institute of Technology, One Rogers Street, Cambridge, MA 02142-1209 (2017). https://mlubin.github.io/pdf/thesis.pdf
Luo, F.Q., Mehrotra, S.: Distributionally robust service center location problem with decision dependent utilities. Tech. report, Northwestern University (2019). https://arxiv.org/pdf/1910.09765.pdf
Villani, C.: Optimal transport: old and new. Springer, New York (2008)
Gärtner, B.: Cone programming (2009). https://www.ti.inf.ethz.ch/ew/lehre/ApproxSDP09/notes/conelp.pdf
Balas, E., Ceria, S., Cornuéjols, G.: A lift-and-project cutting plane algorithm for mixed 0–1 programs. Math. Prog. 58, 295–324 (1993)
Rahimian, H., Mehrotra, S.: Distributionally-robust optimization: a review (2019). Available on optimization online
Acknowledgements
This research was supported by the Office of Naval Research grant N00014-18-1-2097-P00001.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Strong duality for conic linear programming
We consider the following conic linear program:
Note that (P) is a general formulation of the node relaxation second-stage problem considered in this paper. The dual of (P) is:
The following theorem (Theorem A.1) on strong duality is based on Theorem 2.5.4 of [33].
Theorem A.1
(Strong Duality) If the conic linear program (P) is feasible and has finite optimal value \(\gamma \), and there exists an interior point \({\tilde{x}}\in int({\mathcal {K}})\) satisfying \(A^1{\tilde{x}}=b^1\), \(A^2{\tilde{x}}>b^2\), then the dual problem of (P) is feasible and has finite optimal value \(\beta \) which is equal to \(\gamma \).
Theorem A.1 implies that the strong duality for the conic linear program (P) holds (P) has a non-empty relative interior.
Proofs
Proof
of Proposition 2.1. Note that the expression on the right side of (9) is the objective in (8) by replacing \(y^k\) with \(y^*\). We denote this expression as \(\psi (y^*)\) in the proof. The SOCP duality implies that
where we have applied the inequalities given by constraints in (7) and (8), the non-negativity of dual variables and the inner product in the second-order cone to derive the above inequality. \(\square \)
Proof
of Proposition 2.2 Let \(x^{\omega }\) be an optimal second-stage solution of \(\text {Sub}(y,\omega )\). There exists a node \(v\in {\mathcal {L}}(y,\omega )\) such that \(x^{\omega }\in {\mathcal {Z}}^{\omega }_{v}\). Then from Proposition 2.1 we have \(\eta ^{\omega }\ge Q(y,\xi ^\omega )\ge R^{k\omega v} y+S^{k\omega v}\), and hence \((\eta ^{\omega },y)\in E^{k\omega }_{v}\). Therefore, we have \((\eta ^{\omega },y)\in {\varPi }^{k\omega }\). \(\square \)
Proof
of Proposition 2.3 It is easy to verify that the solution \(\sigma _v=0\), \(\gamma _v=\varvec{0}\), \(\lambda ={\text {min}}_{v\in {\mathcal {L}}(y^k,\omega )}\;R^{k\omega v}\), \(\zeta ={\text {min}}_{v\in {\mathcal {L}}(y^k,\omega )}\;S^{k\omega v}\) is an extreme point of the polyhedron defined by (13). Therefore, (13) is feasible. Choose an arbitrary leaf node \(v\in {\mathcal {L}}(y^k,\omega )\). Based on the constraints in (12), we have \(\lambda \le R^{k\omega v}-F^{\top }\sigma _v+\gamma _v\) and \(\zeta \le S^{k\omega v}+\sigma ^{\top }_va-\gamma ^{\top }_v\varvec{1}\). The objective of (13) satisfies:
where the last inequality is due to \(\sigma _v\ge 0\), \(Fy^k\ge a\), \(\gamma _v\ge \varvec{0}\), and \(y_k\le \varvec{1}\). Therefore, the optimal value of (12) is finite.
We prove by contradiction to show that (13) has an extreme-point optimal solution. Suppose \(\varvec{v}^*\) is an optimal solution of (13). Let \(\{\varvec{v}^s\}_{s\in S}\) and \(\{\varvec{r}^t\}_{t\in T}\) be the set of extreme points and extreme rays of the polyhedron defined by the feasible set of (13). Then from the polyhedra decomposition theorem \(\varvec{v}^*\) can be represented as
for some coefficients \(\beta _s\ge 0\), \(\sum _{s\in S}\beta _s=1\), and \(c_t\ge 0\). Note that the objective value can not increase along any extreme ray (otherwise, the problem is unbounded). We can take \(c_t=0\). Let \(\varvec{v}_{s_0}\) be the extreme point that has the largest objective value among all \(s\in S\). Then \(\varvec{v}_{s_0}\) is an extreme point optimal solution of (13). \(\square \)
Proof
of Proposition 2.4 Since (11) is valid for \(\text {conv}({\varPi }^{k\omega })\), using Proposition 2.2 we have \(Q(y,\xi ^\omega )\ge \lambda ^{k\omega \top }y+\zeta ^{k\omega }\). Then it follows that
Therefore, (15) is a valid constraint for (5). \(\square \)
Proof
of Proposition 2.5. Denote by Master-k the first-stage problem (6) at the \(k^{\text {th}}\) iteration. Let \(P=\text {conv}({\mathcal {Y}}\cap {\mathcal {B}})\) be the convex hull of the feasible set of the first-stage problem. It is easy to see that P is a polytope, and \(P\subseteq {\mathcal {Y}}^{\prime }\). Note that \(y^k\) is a binary vector. We prove by contradiction that \(y^k\) is an extreme point of \({\mathcal {Y}}^{\prime }\). Suppose \(y^k\) is not an extreme point of \({\mathcal {Y}}^{\prime }\). Then there exist a \(r\in {\mathbb {N}}_+\), a subset of extreme points \(\{u^i\}^r_{i=1}\) of \({\mathcal {Y}}^{\prime }\), and coefficients \(\{\alpha ^i\}^r_{i=1}\) satisfying the following convex-combination equations:
We divide the discussion into two cases. Case 1: There exists an index \(i\in [r]\) and an index \(s\in [n]\) such that \(0<u^i_s<1\). In this case, we must have \(0<y^k<1\), which contradicts with that \(y^k\) is a binary vector. Case 2: All the points \(\{u^i\}^r_{i=1}\) are integral points. For any index \(l\in [n]\), we let  and
and  . There must exist an index \(s\in [n]\), such that both \({\mathcal {I}}^s_0\) and \({\mathcal {I}}^s_1\) are non-empty. Otherwise, all the points in \(\{u^i\}^r_{i=1}\) are equal to each other. Then we have
. There must exist an index \(s\in [n]\), such that both \({\mathcal {I}}^s_0\) and \({\mathcal {I}}^s_1\) are non-empty. Otherwise, all the points in \(\{u^i\}^r_{i=1}\) are equal to each other. Then we have
and hence \(0<y^k_s<1\), which contradicts with the assumption that \(y^k\) is a binary vector. Therefore, \(y^k\) must be an extreme point of \({\mathcal {Y}}^{\prime }\). \(\square \)
Proof
of Lemma 2.1 From Proposition 2.5, \(y^k\) is an extreme point of \({\mathcal {Y}}^{\prime }\). Since the second-stage problem Sub(\(y^k,\omega \)) is solved to optimality, there must exist a node \(v\in {\mathcal {L}}(y^k,\omega )\) such that the optimal solution \(x^{\omega *}\) of Sub(\(y^k,\omega \)) is contained in the feasible set associated with node \(v^*\). Strong duality implies that
Therefore, the point \((Q(y^k,\xi ^\omega ),y^k)\) is in the epigraph

Let \(\{\lambda ^{k\omega *},\zeta ^{k\omega *},\sigma ^{k\omega *}_{v},\gamma ^{k\omega *}_v\;\forall v\in {\mathcal {L}}(y^k,\omega )\}\) be the optimal solution of the linear program (13). Then the inequality \(\eta ^{\omega }\ge \lambda ^{k\omega *\top }y+\zeta ^{k\omega *}\) from (11) must be valid for the point \((Q(y^k,\xi ^\omega ),y^k)\), i.e., we have \(Q(y^k,\xi ^\omega )\ge \lambda ^{k\omega *\top }y^k+\zeta ^{k\omega *}\). We show that \(Q(y^k,\xi ^\omega )=\lambda ^{k\omega *\top }y^k+\zeta ^{k\omega *}\) by contradiction. Assume that \(Q(y^k,\xi ^\omega )>\lambda ^{k\omega *\top }y^k+\zeta ^{k\omega *}\), then there exists an \(\epsilon >0\) such that \(Q(y^k,\xi ^\omega )-\epsilon \ge \lambda ^{k\omega *\top }y^k+\zeta ^{k\omega *}\). It implies that the point \((Q(y^k,\xi ^\omega )-\epsilon ,y^k)\) is a point in the set \(\text {conv}(\cup _{v\in {\mathcal {L}}(y^k,\omega )}E^{k\omega }_v)\). Therefore, there exist a subset \({\mathcal {S}}\) of \({\mathcal {L}}(y^k,\omega )\), a set of points \(\{(\eta ^{\prime }_v,y^{\prime }_v)\}_{v\in {\mathcal {S}}}\), and a set of coefficients \(\{\alpha _v\}_{v\in {\mathcal {S}}}\) satisfying that \((\eta ^{\prime }_v,y^{\prime }_v)\in E^{k\omega }_v\) for all \(v\in {\mathcal {S}}\), and the following convex-combination equations:
Since \(y^{\prime }_v\in {\mathcal {Y}}^{\prime }\) for all \(v\in {\mathcal {S}}\) and \(y^k\) is an extreme point of \({\mathcal {Y}}^{\prime }\), it follows that \(y^{\prime }_{v}=y^k\) for all \(v\in {\mathcal {S}}\) in (59). The equations in (59) further imply that there exists a node \(v_0\in {\mathcal {S}}\) satisfying \(\eta ^{\prime }_{v_0}\le Q(y^k,\xi ^\omega )-\epsilon \) and \(\eta ^{\prime }_{v_0}\ge R^{k\omega v_0\top }y^{\prime }_{v_0}+S^{k\omega v_0} =R^{k\omega v_0\top }y^k+S^{k\omega v_0}\). Let \(x^{v_0}\) be the optimal solution to the node \(v_0\) relaxation of \(\text {Sub}(y^k,\omega )\) in the branch and cut method. Using strong duality, we have
which is a contradiction. Therefore, we must have \(Q(y^k,\xi ^\omega )=\lambda ^{k\omega *\top }y^k+\zeta ^{k\omega *}\). \(\square \)
Proof
of Theorem 2.1 Let the first-stage problem at iteration k be denoted by Master-k. Lemma 2.1 implies that \(Q(y^k,\xi ^\omega )=\lambda ^{k\omega \top }y^k+\zeta ^{k\omega }\). Therefore, we have
Based on the mechanism of the algorithm, it is clear that if the algorithm terminates in finitely many iterations, it returns an optimal solution. We only need to show that the algorithm must terminate in finitely many iterations. Assume that the algorithm does not terminate in finitely many iterations. Then it must generate an infinite sequence of first-stage solutions \(\{y^k\}^{\infty }_{k=1}\). There must have \({k_1}\) and \({k_2}\) so that \(y^{k_1}=y^{k_2}\), with \(k_1<k_2\). At the end of iteration \(k_1\) the upper bound \(U^{k_1}\) satisfies
where (60) is used to obtain the last equation. The optimal value of Master-\(k_2\) gives the lower bound \(L^{k_2}=c^{\top }y^{k_2}+\eta ^{k_2}\). Since \(k_2>k_1\), Master-\(k_2\) has the following constraint:
Therefore, we conclude that
where we use the fact that \(y^{k_1}=y^{k_2}\), and inequalities (61)–(62) to obtain (63). Hence, we have no optimality gap at solution \(y^{k_1}\), and the algorithm should have terminated at iteration \(k_1\). \(\square \)
Proof
of Proposition 3.1. We reorganize terms in the objective and constraints of the primal and dual problems, and then make use of primal, dual feasibility and strong duality. Specifically, we have
where the first and second inequalities make use of the primal, dual feasibility condition. \(\square \)
Proof
of Theorem 4.2. If the algorithm terminates, it will return an optimal solution of (DR-TSS-MICP) since the lower bound equals the upper bound. Suppose the algorithm does not terminate, and let \(\{y^k\}^{\infty }_{k=1}\) be the sequence of solutions generated by the algorithm. Since there are only finitely many first-stage solutions, we have two iteration indices \(k_1,k_2\) (\(k_2>k_1\)) such that \(y^{k_1}=y^{k_2}\). Since \((y^k, p^{k_1}_{\omega })\) is a feasible solution, we have the following upper bound on the optimal value of (DR-TSS-MICP):
Furthermore, the following constraint is added to the master problem of (DR-TSS-MICP) at the end of iteration \(k_1\):
and by Lemma 4.1 we have
The constraint (66) is in the master problem at iteration \(k_2\). Hence, by evaluating the objective value at iteration \(k_2\) and using inequality (66) we have
Here the second equality above is because \(y^{k_2} = y^{k_1}\). Therefore, we have \(L^{k_2}\ge U^{k_1}\ge U^{k_2}\), and hence \(L^{k_2}=U^{k_2}\). Then Algorithm 4 should terminate at the end of iteration \(k_2\). We remark that generating the first-stage valid inequality (49) requires calling Algorithm 3 to solve the second-stage MICP for each scenario at a fixed first-stage solution. When Algorithm 3 terminates, the optimal objective value of the MILP (37) will be equal to the optimal objective value of the conic program (38), but the optimal solutions of the two problems do not have to be the same in general (these problems may have multiple optimal solutions). However, the validness of Theorem 4.2 does not depend on whether the solution of (37) is the same as that of (38). \(\square \)
An oracle for generating parametric inequalities for single scenario two-stage mixed-integer linear programs
We consider a single scenario two-stage mixed-integer linear program, with the coefficients of the first stage objective set to zero:
where we let the set  include constraints \(0 \le y_j \le 1,\ j\in [l_0]\). We assume that the set \(Wx \ge r-T{\hat{y}}\) is feasible and bounded for any \({\hat{y}} \in \{0,1\}^{l_0}\). For a given \({\hat{y}} \in \{0,1\}^{l_0}\), in describe a finite cutting plane algorithm for solving (69). This algorithm generates parametric cuts that are valid for (69) in the (x, y) space. The algorithm is motivated from the finite cutting plane algorithm in [28]. It maintains a cut generation tree \({\mathscr {L}}_{k}\). The cut generation tree maintains nodes that are specified using disjunctions on the integer variables in x identified thus far in the algorithm. The disjunctive set corresponding to node \(\sigma \) of this tree is denoted by \({\mathscr {C}}_{\sigma }\).
include constraints \(0 \le y_j \le 1,\ j\in [l_0]\). We assume that the set \(Wx \ge r-T{\hat{y}}\) is feasible and bounded for any \({\hat{y}} \in \{0,1\}^{l_0}\). For a given \({\hat{y}} \in \{0,1\}^{l_0}\), in describe a finite cutting plane algorithm for solving (69). This algorithm generates parametric cuts that are valid for (69) in the (x, y) space. The algorithm is motivated from the finite cutting plane algorithm in [28]. It maintains a cut generation tree \({\mathscr {L}}_{k}\). The cut generation tree maintains nodes that are specified using disjunctions on the integer variables in x identified thus far in the algorithm. The disjunctive set corresponding to node \(\sigma \) of this tree is denoted by \({\mathscr {C}}_{\sigma }\).
Assume that at the end of iteration k we have added parametric inequalities \(A^{(k)}y+B^{(k)}x \ge b^{(k)}\) to the set in (69). We let

At the beginning of iteration \(k+1\), we have a vertex solution \(x^k\) of the relaxation problem \(\min _{x\in S_k({\hat{y}})}q^{\top }x\), where \(S_k({\hat{y}}) = S_k \cap \{y={\hat{y}}\}\). If \(x^k\) satisfies all integer constraints, it is an optimal solution of
and the cut-generation algorithm terminates. Otherwise, we verify if \(({\hat{y}},x^k)\) belongs to one of the leaf nodes of \({\mathscr {L}}_{k}\). There are two cases: In Case (1) we have a leaf node \(\sigma \in {\mathscr {L}}_{k}\) such that \(({\hat{y}},x^k)\in {\mathscr {C}}_{\sigma }\); and in Case (2) for every leaf node \(\sigma \in {\mathscr {L}}_{k}\), \(({\hat{y}},x^k)\notin {\mathscr {C}}_{\sigma }\). In Case (1), we choose the fractional variable \(x_j\), \(j\in [l_1]\) with the smallest index, and create two new nodes: left (\(l_{\sigma }\)) and right (\(r_{\sigma }\)) children of \(\sigma \). We let \({\mathscr {C}}_{l_{\sigma }}=\left\{ x \in {\mathscr {C}}_{\sigma }\;|\; x_j\le \lfloor x^k_j \rfloor \right\} \), and \({\mathscr {C}}_{r_{\sigma }} = \left\{ x\in {\mathscr {C}}_{\sigma } \;| \; x_j\ge \lceil x^k_j \rceil \right\} \). We now update the collection of leaf nodes from \({\mathscr {L}}_k\) to \({\mathscr {L}}_{k+1}\) by replacing \(\sigma \) with its children nodes if the corresponding polytopes are non-empty. In this case we also update the set, denoted by \(S^{T}\), used for generating parametric cuts in the future. Specifically, we update \(S^{T} := S_k\). In Case (2), the cut generation tree, and the set \(S^{T}\) are unchanged, i.e., we set \({\mathscr {L}}_{k+1}={\mathscr {L}}_k\). In both cases, we generate a valid inequality (in the (y, x) space) for the set \(\text {conv}\{\cup _{t\in {\mathscr {L}}_{k+1}}(S^T\cap {\mathscr {C}}_t)\}\) that cuts off \(({\hat{y}},x^k)\).This valid inequality uses a vertex of the cut generation linear program (CGLP) described for the disjunctive set \(\cup _{t\in {\mathscr {L}}_{k+1}}(S^T\cap {\mathscr {C}}_t)\). The algorithm is outlined in Algorithm 5. We now prove that Algorithm 5 will stop with an optimal solution of (71) after generating a finite number of cuts. We need two intermediate results. The second lemma below shows that a cut generation linear program can be used to generate a parametric cut, even when we obtain solutions from solving second stage linear programs with the first stage variables fixed to a binary solution. Specifically, this lemma shows that even though the vertex solution \(x^k\) is obtained from solving a linear program in the x-space by fixing \({\hat{y}}\), we can still generate a valid parametric inequality in the (x, y)-space that cuts away \(({\hat{y}}, x^k)\).
Lemma C.1
[17, Theorem 4.2 and Corollary 4.2.1] Let \(\{P_i\}^m_{i=1}\) be m polytopes in \({\mathbb {R}}^n\) defined using linear equality and inequality constraints. Then every facet defining inequality of the polytope \(\text {conv}\left( \cup ^m_{i=1}P_i\right) \) can be obtained from using extreme points of a cut generation linear program (CGLP) obtained from the equalty and inequality constriants specifying \(P_i\), \(i\in [m]\).
Lemma C.2
At any iteration \(k+1\) of Algorithm 5, the valid inequality derived from the CGLP for the set \(\text {conv}\{\cup _{t\in {\mathscr {L}}_{k+1}}(S^T\cap {\mathscr {C}}_t)\}\) at Line 25 cuts off \(({\hat{y}},x^k)\).
Proof
of Lemma C.2. Consider iteration \(k+1\) of Algorithm 5. Suppose \(x^k\) is an optimal vertex solution of \(\min _{x\in S_k({\hat{y}})}\;q^{\top }x\). We show that the point \(({\hat{y}},x^k)\) is a vertex of \(S_k\). To see this, we first note that \({\hat{y}}\) is a vertex of the polytope  . If not, there exist two different points \(y^{\prime }\) and \(y^{\prime \prime }\) from this set and \(0<\lambda <1\) such that \({\hat{y}}=\lambda y^{\prime }+(1-\lambda )y^{\prime \prime }\). It follows that there exists an index \(j\in [n]\), such that \(y^{\prime }_j<{\hat{y}}_j<y^{\prime \prime }_j\). Therefore, either \(y^{\prime }_j<0\) or \(y^{\prime \prime }_j>1\), which contradicts to the constraint \(0\le y_j\le 1\). Now we show that \(({\hat{y}},x^k)\) is a vertex of \(S_k\). If not, there exist two different points \((y^{\prime },x^{\prime })\), \((y^{\prime \prime },x^{\prime \prime })\) in \(S_k\) and \(0<\lambda <1\) such that \(({\hat{y}},x^k)=\lambda (y^{\prime },x^{\prime })+(1-\lambda )(y^{\prime \prime },x^{\prime \prime })\). Since \({\hat{y}}\) is a vertex solution of
. If not, there exist two different points \(y^{\prime }\) and \(y^{\prime \prime }\) from this set and \(0<\lambda <1\) such that \({\hat{y}}=\lambda y^{\prime }+(1-\lambda )y^{\prime \prime }\). It follows that there exists an index \(j\in [n]\), such that \(y^{\prime }_j<{\hat{y}}_j<y^{\prime \prime }_j\). Therefore, either \(y^{\prime }_j<0\) or \(y^{\prime \prime }_j>1\), which contradicts to the constraint \(0\le y_j\le 1\). Now we show that \(({\hat{y}},x^k)\) is a vertex of \(S_k\). If not, there exist two different points \((y^{\prime },x^{\prime })\), \((y^{\prime \prime },x^{\prime \prime })\) in \(S_k\) and \(0<\lambda <1\) such that \(({\hat{y}},x^k)=\lambda (y^{\prime },x^{\prime })+(1-\lambda )(y^{\prime \prime },x^{\prime \prime })\). Since \({\hat{y}}\) is a vertex solution of  , we must have \(y^{\prime }=y^{\prime \prime }={\hat{y}}\). Then it follows that \(x^k=\lambda x^{\prime }+(1-\lambda )x^{\prime \prime }\), which contradicts with the assumption that \(x^k\) is an optimal vertex solution of \(S_k({\hat{y}})\). Now we prove by contradiction that the inequality obtained from the CGLP for the set \(\text {conv}\{\cup _{t\in {\mathscr {L}}_{k+1}}(S^T\cap {\mathscr {C}}_t)\}\) cuts \(({\hat{y}},x^k)\). If it is not the case, we must have \(({\hat{y}},x^k)\in \text {conv}\{\cup _{t\in {\mathscr {L}}_{k+1}}(S^T\cap {\mathscr {C}}_t)\}\). Now, if we have a leaf node \(\sigma \in {\mathscr {L}}_{k}\) such that \(({\hat{y}},x^k)\in {\mathscr {C}}_{\sigma }\) (Case 1), \(\sigma \) generates two child nodes using the fractional variable \(v_\sigma \), \(q_{\sigma }<x^k_{v_{\sigma }}<q_{\sigma }+1\), and \(S^T=S_k\). Since \(({\hat{y}},x^k)\) is a vertex of \(S_k\) and \(S_k\) is defined by a subset of facets of \(\text {conv}\{\cup _{t\in {\mathscr {L}}_{k+1}}(S^T\cap {\mathscr {C}}_t)\}\), we have a \(t\in {\mathscr {L}}_{k+1}\) such that \(({\hat{y}},x^k)\in S^T\cap {\mathscr {C}}_t\). It implies that \(x^k_{v_{\sigma }}\le q_{\sigma }\) or \(x^k_{v_{\sigma }}\ge q_{\sigma }+1\), which contradicts to that \(q_{\sigma }<x^k_{v_{\sigma }}<q_{\sigma }+1\). On the other hand if \(({\hat{y}},x^k)\) does not belong to any leaf node in \({\mathscr {L}}_k\) (Case 2), and the leaf nodes are not updated (i.e., \({\mathscr {L}}_{k+1}={\mathscr {L}}_k\)), since \(({\hat{y}},x^k)\) is a vertex of \(S_k\) and if a valid inequality does not cut off \(({\hat{y}},x^k)\), we have a \(t\in {\mathscr {L}}_{k+1}\) such that \(({\hat{y}},x^k)\in S^T\cap {\mathscr {C}}_t\). This contradicts the condition of Case (2). \(\square \)
, we must have \(y^{\prime }=y^{\prime \prime }={\hat{y}}\). Then it follows that \(x^k=\lambda x^{\prime }+(1-\lambda )x^{\prime \prime }\), which contradicts with the assumption that \(x^k\) is an optimal vertex solution of \(S_k({\hat{y}})\). Now we prove by contradiction that the inequality obtained from the CGLP for the set \(\text {conv}\{\cup _{t\in {\mathscr {L}}_{k+1}}(S^T\cap {\mathscr {C}}_t)\}\) cuts \(({\hat{y}},x^k)\). If it is not the case, we must have \(({\hat{y}},x^k)\in \text {conv}\{\cup _{t\in {\mathscr {L}}_{k+1}}(S^T\cap {\mathscr {C}}_t)\}\). Now, if we have a leaf node \(\sigma \in {\mathscr {L}}_{k}\) such that \(({\hat{y}},x^k)\in {\mathscr {C}}_{\sigma }\) (Case 1), \(\sigma \) generates two child nodes using the fractional variable \(v_\sigma \), \(q_{\sigma }<x^k_{v_{\sigma }}<q_{\sigma }+1\), and \(S^T=S_k\). Since \(({\hat{y}},x^k)\) is a vertex of \(S_k\) and \(S_k\) is defined by a subset of facets of \(\text {conv}\{\cup _{t\in {\mathscr {L}}_{k+1}}(S^T\cap {\mathscr {C}}_t)\}\), we have a \(t\in {\mathscr {L}}_{k+1}\) such that \(({\hat{y}},x^k)\in S^T\cap {\mathscr {C}}_t\). It implies that \(x^k_{v_{\sigma }}\le q_{\sigma }\) or \(x^k_{v_{\sigma }}\ge q_{\sigma }+1\), which contradicts to that \(q_{\sigma }<x^k_{v_{\sigma }}<q_{\sigma }+1\). On the other hand if \(({\hat{y}},x^k)\) does not belong to any leaf node in \({\mathscr {L}}_k\) (Case 2), and the leaf nodes are not updated (i.e., \({\mathscr {L}}_{k+1}={\mathscr {L}}_k\)), since \(({\hat{y}},x^k)\) is a vertex of \(S_k\) and if a valid inequality does not cut off \(({\hat{y}},x^k)\), we have a \(t\in {\mathscr {L}}_{k+1}\) such that \(({\hat{y}},x^k)\in S^T\cap {\mathscr {C}}_t\). This contradicts the condition of Case (2). \(\square \)
Theorem C.1
Algorithm 5 terminates after adding finitely many cuts and returns an optimal solution of (71).
Proof
of Theorem C.1. Note that the cut generation tree \({\mathscr {T}}\) has finitely many nodes. This is because, by assumption, the feasible set of (69) is bounded, and after generating a node \(\sigma \) of the form

for some integers \(0\le q_j\le u_j\), \(j\in [l_1]\), the algorithm no longer generates its children nodes. Therefore, we have an iteration index \(k^*\) so that \({\mathscr {L}}_k={\mathscr {L}}_{k^*}\) for any \(k>k^*\); i.e., the cut generation tree \({\mathscr {T}}\) does not change after iteration \(k^*\). Consequently, for \(k>k^*\), the CGLP based on the disjunctive set \(\{S^T\cap {\mathscr {C}}_t\}_{t\in {\mathscr {L}}_{k^*}}\) does not change. By Lemma C.1, the facets of \(\text {conv}\{\cup _{t\in {\mathscr {L}}_{k^*}}S^T\cap {\mathscr {C}}_t\}\) will be generated in finitely many iterations since a previously added cut will not be repeated. \(\square \)
Remark C.1
Algorithm 5 uses a cut generation tree in identifying a finite number of parametric cuts. If the second stage variables are mixed binary, then we can combine arguments in the Proof of Lemma C.2 and Theorem C.1 with those in [34, Section 3.2, Theorem 3.1] to develop an algorithm that generates cuts based on ideas from sequential convexification.

An illustrative numerical example
We now provide a numerical example to illustrate the decomposition branch and cut algorithm developed in this paper. Consider a (DR-TSS-MISOCP) instance with four scenarios \({\varOmega }=\{\omega _1,\omega _2,\omega _3,\omega _4\}\). The optimization problem is as follows:
We let the ambiguity set be defined using the total-variance metric as follows:

where \(p^0=(1/4,1/4,1/4,1/4)\) is the nominal probability distribution, and the total-variance metric \(d_{TV}\) for the problem instance is given by \(d_{TV}(p,p^0)=\sum ^4_{i=1}|p_i-1/4|\). We may use alternative definitions of \({\mathcal {P}}\) such as a set defined using the Wasserstein metric, a moment based set, or a \(\phi \)-divergence based set [35]. The second-stage problems are given as follows.
Scenario \(\omega _1\):
Scenario \(\omega _2\):
Scenario \(\omega _3\):
Scenario \(\omega _4\):
Consider an initial first-stage solution \(y^{0}=(1,1)\). The root relaxation of \(\text {Sub}(y^{0},\xi ^{\omega _1})\) gives a feasible solution \(x^{\omega _1*}=(0,1)\), and \(Q(y^{0},\xi ^{\omega _1})=1\). The branch and cut tree of \(\text {Sub}(y^{0},\omega _1)\) contains only one leaf node (the root node): \({\mathcal {L}}(y^0,\omega _1)=\{v_{11}\}\). The (scenario-node) constraint of scenario \(\omega _1\) at node \(v_{11}\) is given by:
Since there is only one node in \({\mathcal {L}}(y^0,\omega _1)\), taking the union of epigraphs is not needed for \({\mathcal {L}}(y^0,\omega _1)\). Now consider scenario \(\omega _2\). The root relaxation of \(\text {Sub}(y^{0},\omega _2)\) gives a second-stage solution \(x^{\omega _2}=(0.5361,0.4639)\). The branch and cut tree of \(\text {Sub}(y^{0},\omega _2)\) contains two leaf nodes \({\mathcal {L}}(y^0,\omega _2)=\{v_{21},v_{22}\}\), where the feasible subsets of the two nodes are:

By solving the node relaxation SOCP at \(v_{21}\) and \(v_{22}\), we obtain the following constraints for scenario \(\omega _2\) nodes \(v_{21}\) and \(v_{22}\):
The recourse function value at scenario \(\omega _2\) is \(Q(y^0,\xi ^{\omega _2})=1.5\). Solving disjunctive programming formulation (13), we generate a valid scenario constraint:
The parameters in (13) are given by \(y^0=(1,1)\), \(R^{0\omega _21}=(0.75,0.75)^{\top }\), \(R^{0\omega _22}=(1.125,0.4687)^{\top }\), \(S^{0\omega _21}=0\), \(S^{0\omega _22}=0.0938\), \(F=(1,1)\) and \(a=1\). Note that this disjunctive constraint is the same as the constraint for node \(v_{21}\) corresponding to scenario \(\omega _2\). For scenario \(\omega _3\), the root relaxation SOCP gives solution \(x^{\omega _3*}=(1,0)\). The recourse function value at scenario \(\omega _3\) is \(Q(y^0,\xi ^{\omega _3})=1.2\). The corresponding scenario constraint is given by:
For scenario \(\omega _4\), the branch and cut tree of \(\text {Sub}(y^0,\omega _4)\) contains two leaf nodes: \({\mathcal {L}}(y^0,\omega ^4)=\{v_{41},v_{42}\}\). By solving the node relaxation SOCP at \(v_{41}\) and \(v_{42}\), we obtain the following scenario-node constraints:
The recourse function value at scenario \(\omega _4\) is \(Q(y^0,\xi ^{\omega _4})=1\). Solving disjunctive programming formulation (13), we generate a valid scenario constraint
The parameters in (13) are given by \(y^0=(1,1)\), \(R^{0\omega _41}=(0.5,0.5)^{\top }\), \(R^{0\omega _42}=(0.4082,0.155)^{\top }\), \(S^{0\omega _41}=0\), \(S^{0\omega _42}=0.5064\), \(F=(1,1)\) and \(a=1\). Note that this disjunctive constraint is the same as the constraint for \(\omega _4\) from node \(v_{41}\). The worst-case probability distribution is given by the following linear program:
The worst-case probability distribution is \(p^*=(0.25, 0.3, 0.25, 0.2)\). Aggregating constraints (78)-(81) using this worst-case probability distribution \(p^*\), we obtain the following aggregated constraint:
The algorithm adds constraint (83) to the first-stage problem. In the next iteration the lower and upper bounds are \(L=10.535\), \(U=23.2\). The lower bound is attained at \(y^1=(1,0)\).
We repeat the cut generation steps for the current first-stage solution \(y^1=(1,0)\), and obtain the following aggregated constraint:
Adding this constraint to the first-stage problem, we obtain an updated lower bound \(L=10.6375\), which is attained at \(y^2=(1,0)\). The updated upper bound is \(U=10.6375\). Since \(L=U\), the optimal solution is \(y^*=(1,0)\).
Extended formulation of the DR-TSS-MISOCP reformulation of utility robust facility location problem
The extended formulation of (SD-RFL) with \(d_{TV}=0\) is given as follows:
where \(\varvec{p}^0:=\{p^0_{\omega }:\;\omega \in {\varOmega }\}\) is the nominal probability distribution over all scenarios.
Additional numerical results
See Table 6.
Rights and permissions
About this article

Cite this article
Luo, F., Mehrotra, S. A decomposition method for distributionally-robust two-stage stochastic mixed-integer conic programs. Math. Program. 196, 673–717 (2022). https://doi.org/10.1007/s10107-021-01641-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10107-021-01641-2
Keywords
- Distributionally robust optimization
- Two-stage stochastic mixed-integer second-order-cone programming
- Two-stage stochastic mixed-integer conic programming
- Disjunctive programming
- Stochastic facility location