
Abstract
Most existing methods for forecasting the productivity of a factory cannot estimate the range of productivity reliably, especially when future conditions are distinct from those in the past. To address this issue, a fuzzified feedforward neural network (FFNN) approach is proposed in this study. The FFNN approach improves the forecasting precision after generating accurate fuzzy productivity forecasts. In addition, the acceptable range of a fuzzy productivity forecast is specified, based on which the sum of the memberships of actual values is maximized. In this way, the range of productivity can be precisely estimated. After applying the FFNN approach to a real case, the experimental results revealed the superiority of the FFNN approach by improving the forecasting precision, in terms of the hit rate, by 25%. Such an improvement also contributed to a better forecasting accuracy. The superiority of the FFNN approach is in the context that the accuracy of forecasting productivity is optimized only after the range of productivity has been precisely estimated. In contrast, most state-of-the-art methods focus on optimizing the forecasting accuracy, but may be ineffective without information about the range of productivity when future conditions are distinct from the past.
Similar content being viewed by others
Introduction
The productivity of a factory can be evaluated by dividing the output by the input [34]. A high productivity is critical to maintaining a competitive edge in the industry, which contributes to the sustainability of a factory [13, 29]. For this reason, the productivity of a factory needs to be evaluated and enhanced. In addition, it is also necessary to forecast the future productivity of a factory and take actions, such as moving the factory to another region with a lower wage level [4], or switching to a less expensive supplier [30], to elevate productivity.
Forecasting the future productivity of a factory is a challenging task, because productivity is subject to much uncertainty caused by unstable product yield [24, 28], changing workforce [32], etc. Therefore, this study aims to enhance the accuracy and precision of forecasting the productivity of a factory.
Some of the relevant references are reviewed as follows. Mirahadi and Zayed [26] forecasted the productivity of a construction site using a fuzzy inference system (FIS). The antecedents of fuzzy inference rules in the FIS were factors affecting productivity which membership functions were optimized by applying a genetic algorithm (GA). Baumers et al. [6] compared the productivity levels of two manufacturing systems based on three-dimensional (3D) printing—an electron beam melting (EBM) 3D printing system and a direct metal laser sintering (DMLS) 3D printing system. They concluded that the two manufacturing systems based on 3D printing were not productive enough for mass production purposes. To increase the possibility for a fuzzy productivity forecast to contain actual value, Chen and Wang [13] proposed a fuzzy collaborative forecasting (FCF) method, in which the improvement in productivity was modeled as a fuzzy learning process that was applied to forecast the future productivity. Akano and Asaolu [2] constructed an adaptive neuro-fuzzy inference system (ANFIS) to forecast the productivity of a manufacturing system. The ANFIS enumerated all possible fuzzy inference rules and kept only effective rules after training. Mankins [25] distinguished the concepts of productivity and efficiency. In addition, Mankins highlighted the importance of human resource management to productivity enhancement. Lee and Kim [23] applied building information modeling-based four-dimensional (4D) simulation to improve the productivity of a construction project. Recently, predictive maintenance has been recognized as an important strategy to reduce unscheduled downtime and improve productivity. Following this view, Chiu et al. [17] developed a factory-wide intelligent predictive maintenance system based on Industry 4.0. Chen [9] modeled the improvement in productivity as a fuzzy learning process, and constructed an artificial neural network (ANN) to derive the values of parameters in the fuzzy productivity learning model. Zahraee et al. [36] combined factory simulation, response surface methodology (RSM), and design of experiments (DOE) to analyze and improve the productivity of a factory. Instead of forecasting the future productivity, Grabner et al. [19] estimated the impacts of improvement actions, such as lean production, on productivity. Repina et al. [31] applied several statistical analysis techniques, including time series analysis, index method, and factor analysis, to forecast the productivity of a machine-building company. Chen et al. [12] proposed a fuzzy polynomial fitting and mathematical programming approach. Chen et al. [14] considered the uncertainty of productivity with a type-II fuzzy number, and proposed a type-II fuzzy collaborative forecasting approach for productivity forecasting. In the view of Chen and Lin [11], acquiring diversified three-dimensional (3D) printers can increase the productivity of a manufacturer.
Existing methods in this field have the following problems:
-
1.
A productivity forecast is seldom equal to actual value. For this reason, estimating the range of productivity is also important, which, however, has rarely been addressed in the past.
-
2.
A conventional statistical analysis method estimates the range of productivity by constructing a confidence interval [34]. Existing FIS or ANFIS methods generate a fuzzy productivity forecast which range is representative of the range of productivity [2, 29]. However, these methods cannot guarantee that all actual values are included in the corresponding confidence intervals or fuzzy productivity forecasts [8].
To solve the aforementioned problems, a fuzzified feedforward neural network (FFNN) approach is proposed in this study. The novelty of the proposed methodology resides in the following. Existing FCF methods minimizes the sum of the ranges of fuzzy productivity forecasts, while the FFNN approach maximizes the sum of the memberships of actual values in fuzzy productivity forecasts. In this way, the possibility of including actual values in fuzzy productivity forecasts, in terms of the hit rate for test data, can be enhanced. The contribution of this study includes:
-
a new FFNN method for forecasting the productivity of a factory,
-
a new algorithm (i.e., the NLP model) for training the FFNN, and
-
a new method for defuzzifying a fuzzy productivity forecast.
The remainder of this paper is organized as follows. The proposed FFNN approach is detailed in “The FFNN Approach”. To illustrate the applicability of the FFNN approach, and to evaluate its advantages and/or disadvantages over some existing methods, a real case has been investigated, which is described in “Application to a real case”. Finally, the conclusions of this study are made in “Conclusions”. Some directions for future research are also provided.
The FFNN approach
In the proposed FFNN approach, an FFNN [1, 3, 27] is constructed to forecast the productivity of a factory. The training of the FFNN is divided into three steps. First, the FFNN is treated as a crisp one, and then, a feedforward neural network (FNN) is constructed and trained to derive the core of each fuzzy parameter in the FFNN, thereby optimizing the forecasting accuracy for the training data. Subsequently, a nonlinear programming (NLP) model is optimized to determine the upper bound on each fuzzy parameter, thereby optimizing the forecasting precision. After that, another NLP problem is solved to determine the lower bound on each fuzzy parameter. Table 1 summarizes the differences between the FFNN approach and some existing methods.
The FFNN approach comprises the following steps:
Step 1. Construct an FFNN to forecast the productivity of the target factory.
Step 2. Train the FFNN as a crisp one to derive the core of each fuzzy parameter in the FFNN.
Step 3. Optimize an NLP model to determine the upper bound on each fuzzy parameter.
Step 4. Optimize another NLP problem to determine the lower bound on each fuzzy parameter.
Step 5. Apply the trained FFNN to test data.
Step 6. Evaluate the forecasting performance using the FFNN approach.
Construction of an FFNN
First, an FFNN is constructed to forecast the productivity of a factory by fitting the relationship between productivity and relevant factors. Letting the productivity of the target factory at period j be indicated with \(y_{j}\). The configuration of the FFNN is established as follows:
-
Inputs: the values of relevant factors at the jth period, indicated with \(\{ x_{ji} |i = 1\sim m\}\).
-
Single hidden layer: generally, one or two hidden layers are beneficial for the convergence property of the FFNN.
-
Number of neurons in the hidden layer: 2m.
-
Output: the normalized value of the fuzzy productivity forecast, i.e., \(N(\tilde{y}_{j} )\) [15]:
$$ N(\tilde{y}_{j} ) = 0.9 \cdot \frac{{\tilde{y}_{j} - \mathop {\min }\limits_{l} \tilde{y}_{l} }}{{\mathop {\max }\limits_{l} \tilde{y}_{l} - \mathop {\min }\limits_{l} \tilde{y}_{l} }} + 0.1. $$(1)
To convert it back to the un-normalized value
-
Learning rate (η): 0.01 ~ 1.0.
-
Initial conditions: the initial values of network parameters are randomized.
-
Batch learning.
The parameters in the FFNN are defined as follows:
-
◆ \(x_{ji}\): the ith input at period j.
-
◆ \(\tilde{w}_{ik}^{h}\): the connection weight between the ith input node and the kth hidden-layer node.
-
◆ \(\tilde{I}_{jk}^{h}\): the input to the kth hidden-layer node.
-
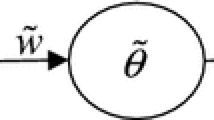
◆ \(\tilde{\theta }_{k}^{h}\): the threshold on the kth hidden-layer node.
-
◆ \(\tilde{h}_{jk}\): the output from the kth hidden-layer node.
-
◆ \(\tilde{w}_{k}^{o}\): the connection weight between the kth hidden-layer node and the output node.
-
◆ \(\tilde{I}_{j}^{o}\): the input to the output node.
-
◆ \(\tilde{\theta }^{o}\): the threshold on the output node.
-
◆ \(\tilde{o}_{j}\): the network output; \(\tilde{o}_{j} = N(\tilde{y}_{j} )\).
Without loss of generality, all fuzzy parameters are given in or approximated with triangular fuzzy numbers (TFNs).
Inputs to the FFNN are propagated from the input layer to the hidden layer as
After receiving this, the output from the hidden-layer node is generated as
where (–) indicates fuzzy subtraction. Outputs from the hidden layer are transmitted to the output layer in the same manner
where (×) denotes fuzzy multiplication. Finally, the output from the FFNN is generated as
which is the normalized fuzzy productivity forecast. The problem is, therefore, how to determine the values of fuzzy parameters (including \(\tilde{w}_{ik}^{h}\), \(\tilde{\theta }_{k}^{h}\), \(\tilde{w}_{k}^{o}\), and \(\tilde{\theta }^{o}\)) to ensure that each fuzzy productivity forecast is close to actual value, which relies on an effective training of the FFNN.
Training of the FFNN
The training process of the FFNN comprises three parts:
-
1.
Applying an existing algorithm to derive the core of each fuzzy network parameter.
-
2.
Optimizing NLP Model I to establish the upper bound on each fuzzy network parameter.
-
3.
Optimizing NLP Model II to establish the lower bound on each fuzzy network parameter.
Deriving the core of each fuzzy parameter
First, to derive the core of each fuzzy parameter, the FFNN is treated as a crisp one and trained using an existing algorithm such as the gradient descent (GD) algorithm, the Levenberg–Marquardt (LM) algorithm, the Fletcher–Powell conjugate gradient (CGF) algorithm, and others. A comparison of these algorithms refers to Eraslan [17]. After training, the optimized cores of fuzzy parameters are indicated with \(w_{ik2}^{h*}\), \(\theta_{k2}^{h*}\), \(w_{k2}^{o*}\), and \(\theta_{2}^{o*}\), respectively. In addition, examples with actual values greater than the cores of fuzzy productivity forecasts are placed in a set \({{\varvec{\Lambda}}}_{{\mathbf{R}}}\), while examples with actual values smaller than cores are placed in another set \({{\varvec{\Lambda}}}_{{\mathbf{L}}}\).
Establishing the upper bound on each fuzzy parameter
Subsequently, the following NLP problem is solved to determine the upper bound on each fuzzy parameter: (NLP MODEL I)
subject to:
The objective function (7) maximizes the sum of the memberships of actual values of fuzzy productivity forecasts on the right side, which are derived according to Eq. (8). In contrast, Chen and Lin’s goal programming (GP) method [10, 22] minimizes the sum of the ranges of fuzzy productivity forecasts. The upper bound of a fuzzy productivity forecast should be greater than the core and the normalized actual value, as required by Constraints (9) and (10). Constraint (11) limits the sum of the half ranges of fuzzy productivity forecasts on the right-hand side to be less than a prespecified threshold \(d_{{\text{R}}}\). Equations (12)–(15) derive the upper (or lower) bounds on fuzzy parameters. Constraints (16)–(20) request each upper (or lower) bound to be greater than (or lower than) the core.
Establishing the lower bound on each fuzzy parameter
In a similar way, another NLP problem is solved to derive the lower bound on each fuzzy parameter: (NLP Model II)
subject to:
The lower bound of a fuzzy productivity forecast should be lower than the core and the normalized actual value, as required by Constraints (23) and (24).
Application to a real case
The FFNN approach has been applied to forecast the productivity of a factory in Nigeria to evaluate its effectiveness. The case contained the productivity data of the factory during twenty periods, as shown in Fig. 1. This case had been investigated by Akano and Asaolu [2]. The productivity data were decomposed into two parts: data of the first 12 periods for building models, and the remaining data for evaluating the forecasting performance. The relationship between productivity and four factors (including preventive maintenance time, off-duty time, machine downtime, and power failure time, as shown in Fig. 2) was to be fitted with an FFNN, so as to forecast the productivity at a future period by considering uncertainty.

The productivity data

The data of relevant factors
At first, the FFNN was treated as a crisp one with the following architecture and trained to derive the cores of fuzzy parameters in it:
-
1.
Four inputs corresponding to the values of the four factors at a period;
-
2.
A single hidden layer with eight nodes;
-
3.
Initial values of network parameters: randomly generated;
-
4.
Training algorithm: the LM algorithm;
-
5.
Learning rate (η): 0.25;
-
6.
Stopping criteria: the network training stopped if the sum of squared error (SSE) fell below 0.001, or 1000 epochs have been run.
The network was constructed and trained on a PC with i7-7700 CPU 3.6 GHz and 8 GB RAM using the neural network toolbox of MATLAB 2017 [5]. The execution time was less than 3 s. Table 2 shows the optimal solution. Preventive maintenance time had the greatest impact on productivity, while power failure time had the most uncertain impact on productivity. Based on Table 2, the core of each fuzzy productivity forecast, i.e., \(y_{j2}^{*}\), was derived, as shown in Fig. 3. As expected, the training data were very precisely fitted; however, there were considerable deviations in forecasting productivity for test data, which might be owing to overfitting. To address this issue, estimating the range of productivity was necessary.

The cores of fuzzy productivity forecasts
To establish the lower and upper bounds on productivity, the two NLP problems were formulated and solved using Lingo [19] on the same PC. The execution time was about 20 s. The thresholds on the sums of half ranges, \(d_{{\text{R}}}\) and \(d_{{\text{L}}}\), were specified as 2.3 and 0.85, respectively. As a result, the range of a fuzzy productivity forecast should be narrower than 2.3/7 + 0.85/5 = 0.5 on average. The optimal solutions to the NLP problems are presented in Tables 3 and 4, respectively, for reproducibility. Obviously, the lower bound of each fuzzy parameter was less than the core, and the core was less than the upper bound. In addition, the lower bound, core, and upper bound of each fuzzy parameter had the same sign, thereby ensuring a consistent impact of the corresponding factor on productivity. The established lower and upper bounds on productivity are illustrated in Fig. 4. The forecasting precision, measured in terms of hit rate, using the proposed methodology was 38% for test data.

The lower and upper bounds on productivity
For making a comparison, four existing methods were also applied to the collected data. The first compared existing method was the fixed allowance method which constructed a confidence interval of productivity. For a fair comparison, a fixed allowance of 0.5/2 = 0.25 was added to and subtracted from the core of each fuzzy productivity forecast. The forecasting results are shown in Fig. 5. In this way, fuzzy productivity forecasts were symmetric. In addition, the ranges of fuzzy productivity forecasts were equally wide. The hit rate achieved using the fixed allowance method was only 13%.

The forecasting results using the fixed allowance method
The second compared method was the fixed parametric adjustment method, in which the modifications made to all network parameters were equal. To meet the requirement for each half range to be narrower than 0.25 on average, each network parameter was reduced by 12.83% to determine the lower bound and increased by 15.68% to determine up the upper bound, respectively. The forecasting results are shown in Fig. 6. However, due to the nonlinear transformation function adopted in the FFNN, fuzzy productivity forecasts were not symmetric. In addition, fuzzy productivity forecasts were not equally wide. The hit rate achieved using the fixed parametric adjustment method for test data was 13%.

The forecasting results using the fixed parametric adjustment method
The third method compared in the experiment was the hybrid statistical analysis and ANN method [7] in which only the threshold on the output node was modified to determine the lower and upper bounds on productivity. The optimization results were:
\(\theta_{1}^{o*} = 0.990;\quad \theta_{3}^{o*} = 2.091.\)
In this way, the average range of fuzzy productivity forecasts was also 0.5. The forecasting results are illustrated in Fig. 7. Fuzzy productivity forecasts generated in this way were asymmetric and unequally wide. In test data, only a single actual value was included in the fuzzy productivity forecast, giving a hit rate of 13%.

The forecasting results using the hybrid statistical analysis and ANN method [7]
The fourth compared existing method was the GP method [10], in which two series of GP problems were solved to determine the lower and upper bounds on productivity, respectively. When the minimal satisfaction level was greater than 0.95, the average range of fuzzy productivity forecasts was minimized as 0.50, making the results comparable to those obtained using the proposed methodology. Fuzzy productivity forecasts made using Chen and Lin’s GP method are shown in Fig. 8. When the core of a fuzzy productivity forecast was closer to actual value, the fuzzy productivity forecast became narrower. As a result, the widths of fuzzy productivity forecasts varied considerably. The hit rate achieved using Chen and Lin’s GP method for test data was only 13%.

The fuzzy productivity forecasts made using Chen and Lin’s GP method
According to the experimental result, the following discussion was made:
-
1.
The FFNN approach surpassed the compared existing methods in elevating the hit rate by 25% for test data.
-
2.
For the training data, a lower bound on productivity was never greater than the core, and the upper bound was never smaller than the core. However, such a property might not hold for test data, since the lower bound of a positive parameter might be negative, which changed the sequence of the two bounds.
-
3.
To evaluate the forecasting accuracy of each method, fuzzy productivity forecasts were defuzzified using the center-of-gravity method. The deviations between fuzzy productivity forecasts and actual values were then measured in terms of mean absolute error (MAE), mean absolute percentage error (MAPE), and root-mean-squared error (RMSE). The results are summarized in Table 5. The FFNN approach achieved the best forecasting accuracy in terms of MAE, MAPE, or RMSE. The most significant advantage of the FFNN approach over existing methods happened when MAE was minimized, which was up to 30% on average.
-
4.
Nevertheless, there was much space for improving the forecasting accuracy, which was owing to the following reasons. First, some data used to calculate productivity may be missing, incorrect, or conflicting, thereby reducing the credibility of the data collected for training the FFNN. In addition, future conditions may be distinct from the past. To overcome these problems, a forecaster may adjust fuzzy productivity forecasts based on his/her subjective judgment [20, 33]. Chiu et al. [16] proposed several strategies to reflect the subjective judgment of a forecaster who adjusts fuzzy productivity forecasts by changing the defuzzification method. In this study, the moderately optimistic strategy was adopted, because the forecaster believed that the productivity of the factory gradually improved through learning, which assigned weights 0.76, 0.1, and 0.14 to the upper bound, core, and lower bound of a fuzzy productivity forecast. After defuzzification, the forecasting accuracy was re-evaluated as
$$ {\text{MAE}} = 0.14 $$$$ {\text{MAPE}} = 11\% $$$$ {\text{RMSE}} = 0.03, $$which was much better than that achieved without considering the subjective judgment of the forecaster.
-
5.
To evaluate whether the advantage of the proposed methodology over existing methods was significant, a paired t test has been conducted with the following hypotheses:
-
6.
If the network had not been fuzzified using the proposed methodology, then the forecasting accuracy would be
$$ {\text{MAE}} = 0.39 $$$$ {\text{MAPE}} = 28\% $$$$ {\text{RMSE}} = 0.17, $$which was much worse than that using the proposed methodology. Therefore, the treatments taken in the proposed methodology did strengthen the confidence of the network.
-
7.
To further elaborate the effectiveness of the FFNN approach, it has been applied to another case that contained the productivity of a dynamic random access memory (DRAM) factory located in Taichung Science Park, Taiwan. This case has been discussed by Chen [8], and was representative, because the DRAM factory belonged to one of the largest DRAM producers in the world. The productivity of the DRAM factory was measured by dividing the monetary output by the monetary input during fourteen months. The productivity during a future period was forecasted based on those during the previous three periods. The forecasting results are shown in Fig. 9, with the following forecasting performance:
$$ {\text{MAE}} = 0.048 $$$$ {\text{MAPE}} = 4.8\% $$$$ {\text{RMSE}} = 0.068 $$$$ {\text{Hit rate}} = 100\% $$$$ {\text{Average range}} = 0.280. $$Obviously, the FFNN approach achieved good forecasting accuracy and precision in this case.
-
8.
By maximizing the hit rate, the FFNN can generate fuzzy productivity forecasts that are very likely to contain actual values. For a new example, if this property holds, there may be no need to learn this new example, which is beneficial to the scalability of the proposed methodology. In contrast, existing methods rarely estimate the range of productivity reliably to support this purpose.
-
9.
In the proposed methodology, the training of the FFNN stopped when the convergence criteria were reached. The forecasting error was not really minimized, and the solution was only suboptimal. Similarly, in solving the two NLP problems, the successive linear programming (SLP) directions algorithm [18] stopped after a number of iterations have been repeated. Only the local optimality of the solutions was guaranteed [35].

The forecasting results in another case
H0
The forecasting accuracy using the proposed methodology in terms of absolute error is the same as that using the existing method;
H1
The forecasting accuracy using the proposed methodology in terms of absolute error is more effective than that using the existing method.
The results are shown in Table 6. The forecasting accuracy using the proposed methodology was significantly improved (α = 0.05) when compared with existing methods.
Conclusions
An FFNN approach is proposed in this study for enhancing the accuracy and precision of forecasting the productivity of a factory. In the FFNN approach, an FFNN is constructed to forecast the productivity of a factory. The FFNN is trained as a crisp one to derive the core of a fuzzy productivity forecast. Then, two NLP models are formulated and optimized to determine the range of the fuzzy productivity forecast. Unlike existing methods in this field that optimize the forecasting accuracy only or prioritize that optimization, the FFNN approach improves the forecasting precision after optimizing the forecasting accuracy. In this way, the range of productivity can be reliably estimated, which is especially helpful when future conditions are distinct from those in the past.
The FFNN approach has been applied to a real case. The experimental results revealed the following:
-
1.
The FFNN approach considerably improved the accuracy and precision of forecasting the productivity of the target factory. In particular, the forecasting precision measured in terms of the hit rate for test data was elevated by 25%.
-
2.
In this case, future conditions seemed to be quite different from those in the past, which made forecasting the future productivity a challenging task.
-
3.
Moreover, the overfitting problem was clearly illustrated by this case.
-
4.
Through specifying the acceptable range and maximizing the sum of memberships, the impact of the overfitting problem was significantly lessened, which accounted for the superiority of the FFNN approach.
The FFNN approach needs to be applied to more cases to further elaborate its effectiveness. In addition, the experimental results revealed that there was still considerable space for improving the forecasting accuracy, which relies on a better mechanism for aggregating the core, lower bound, and upper bound of a fuzzy productivity forecast to arrive at a crisp/representative value. These constitute some directions for future research.
References
Adeli M, Mazinan AH (2020) High efficiency fault-detection and fault-tolerant control approach in Tennessee Eastman process via fuzzy-based neural network representation. Complex Intell Syst 6(1):199–212
Akano TT, Asaolu OS (2017) Productivity forecast of a manufacturing system through intelligent modelling. Futo J Ser 3(1):102–113
Al-Refaie A, Chen T, Al-Athamneh R, Wu HC (2016) Fuzzy neural network approach to optimizing process performance by using multiple responses. J Ambient Intell Humaniz Comput 7(6):801–816
Aubert P, Crépon B (2003) Age, wage and productivity: firm-level evidence. Economie et Statistique 363:95–119
Beale MH, Hagan MT, Demuth HB (2010) Neural network toolbox. User’s Guide MathWorks 2:77–81
Baumers M, Dickens P, Tuck C, Hague R (2016) The cost of additive manufacturing: machine productivity, economies of scale and technology-push. Technol Forecast Soc Change 102:193–201
Chen T (2015) Combining statistical analysis and artificial neural network for classifying jobs and estimating the cycle times in wafer fabrication. Neural Comput Appl 26(1):223–236
Chen T (2017) New fuzzy method for improving the precision of productivity predictions for a factory. Neural Comput Appl 28(11):3507–3520
Chen T (2018) Fitting an uncertain productivity learning process using an artificial neural network approach. Comput Math Organ Theory 24(3):422–439
Chen T, Lin YC (2011) A collaborative fuzzy-neural approach for internal due date assignment in a wafer fabrication plant. Int J Innov Comput Inf Control 7(9):5193–5210
Chen TCT, Lin YC (2021) Diverse three-dimensional printing capacity planning for manufacturers. Robot Comput Integr Manuf 67:102052
Chen T, Ou C, Lin YC (2019) A fuzzy polynomial fitting and mathematical programming approach for enhancing the accuracy and precision of productivity forecasting. Comput Math Organ Theory 25(2):85–107
Chen T, Wang YC (2016) Evaluating sustainable advantages in productivity with a systematic procedure. Int J Adv Manuf Technol 87(5–8):1435–1442
Chen T, Wang YC, Chiu MC (2020) A type-II fuzzy collaborative forecasting approach for productivity forecasting under an uncertainty environment. J Ambient Intell Humaniz Comput 12:1–13
Chen T, Wang YC, Tsai HR (2009) Lot cycle time prediction in a ramping-up semiconductor manufacturing factory with a SOM–FBPN-ensemble approach with multiple buckets and partial normalization. Int J Adv Manuf Technol 42(11–12):1206–1216
Chiu MC, Chen TCT, Hsu KW (2020) Modeling an uncertain productivity learning process using an interval fuzzy methodology. Mathematics 8(6):998
Chiu YC, Cheng FT, Huang HC (2017) Developing a factory-wide intelligent predictive maintenance system based on Industry 4.0. J Chin Inst Eng 40(7):562–571
Cunningham K, Schrage L (2004) The LINGO algebraic modeling language. In: Modeling languages in mathematical optimization, pp 159–171
Eraslan E (2009) The estimation of product standard time by artificial neural networks in the molding industry. Math Probl Eng 2009:527452
Grabner C, Klein P, Lödding H (2019) Success forecast for productivity methods—how companies can predict the impact of methods on labour productivity. ZWF Zeitschrift fuer Wirtschaftlichen Fabrikbetrieb 114(3):105–109
Jansen WJ, de Winter JM (2018) Combining model-based near-term GDP forecasts and judgmental forecasts: a real-time exercise for the G7 countries. Oxf Bull Econ Stat 80(6):1213–1242
Kamal M, Modibbo UM, AlArjani A, Ali I (2021) Neutrosophic fuzzy goal programming approach in selective maintenance allocation of system reliability. Complex Intell Syst 7:1–15
Lee J, Kim J (2017) BIM-based 4D simulation to improve module manufacturing productivity for sustainable building projects. Sustainability 9(3):426
Lin YC, Chen T (2019) An advanced fuzzy collaborative intelligence approach for fitting the uncertain unit cost learning process. Complex Intell Syst 5(3):303–313
Mankins, M. (2017). Great companies obsess over productivity, not efficiency. Harv Bus Rev 3:2–5
Mirahadi F, Zayed T (2016) Simulation-based construction productivity forecast using neural-network-driven fuzzy reasoning. Autom Constr 65:102–115
Moloudi M, Mazinan AH (2019) Controlling disturbances of islanding in a gas power plant via fuzzy-based neural network approach with a focus on load-shedding system. Complex Intell Syst 5(1):79–89
Muthiah KM, Huang SH (2006) A review of literature on manufacturing systems productivity measurement and improvement. Int J Ind Syst Eng 1(4):461–484
Oum TH, Yu C (2012) Winning airlines: productivity and cost competitiveness of the World’s Major Airlines. Springer Science and Business Media, New York
Phusavat K, Jaiwong P, Sujitwanich S, Kanchana R (2009) When to measure productivity: lessons from manufacturing and supplier-selection strategies. Ind Manag Data Syst 109(3):425–442
Repina E, Simonova M, Sukhanova E (2019) The development of a forecast model of labour productivity management at industrial enterprises. In: 2nd international scientific conference on new industrialization: global, national, regional dimension, pp 96–99
Rüßmann M, Lorenz M, Gerbert P, Waldner M, Justus J, Engel P, Harnisch M (2015) Industry 4.0: the future of productivity and growth in manufacturing industries. Boston Consult Group 9(1):54–89
Schwartz Z, Webb T, van der Rest JPI, Koupriouchina L (2019) Enhancing the accuracy of revenue management system forecasts: the impact of machine and human learning on the effectiveness of hotel occupancy forecast combinations across multiple forecasting horizons. Tour Econ. https://doi.org/10.1177/1354816619884800
Stevenson WJ, Sum CC (2014) Operations management. McGraw-Hill/Irwin, New York
Wang YC, Chiu MC, Chen T (2020) A fuzzy nonlinear programming approach for planning energy-efficient wafer fabrication factories. Appl Soft Comput 95:106506
Zahraee SM, Rohani JM, Wong KY (2018) Application of computer simulation experiment and response surface methodology for productivity improvement in a continuous production line: case study. J King Saud Univ Eng Sci 30(3):207–217
Acknowledgements
This study was sponsored by the Ministry of Science and Technology, Taiwan.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chen, T., Lin, YC. Enhancing the accuracy and precision of forecasting the productivity of a factory: a fuzzified feedforward neural network approach. Complex Intell. Syst. 7, 2317–2327 (2021). https://doi.org/10.1007/s40747-021-00416-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-021-00416-8