
Abstract
We derive upper bounds on the complexity of ReLU neural networks approximating the solution maps of parametric partial differential equations. In particular, without any knowledge of its concrete shape, we use the inherent low dimensionality of the solution manifold to obtain approximation rates which are significantly superior to those provided by classical neural network approximation results. Concretely, we use the existence of a small reduced basis to construct, for a large variety of parametric partial differential equations, neural networks that yield approximations of the parametric solution maps in such a way that the sizes of these networks essentially only depend on the size of the reduced basis.
Similar content being viewed by others

1 Introduction
In this work, we analyze the suitability of deep neural networks (DNNs) for the numerical solution of parametric problems. Such problems connect a parameter space with a solution state space via a so-called parametric map [51]. One special case of such a parametric problem arises when the parametric map results from solving a partial differential equation (PDE) and the parameters describe physical or geometrical constraints of the PDE such as, for example, the shape of the physical domain, boundary conditions, or a source term. Applications that lead to these problems include modeling unsteady and steady heat and mass transfer, acoustics, fluid mechanics, or electromagnetics [33].
Solving a parametric PDE for every point in the parameter space of interest individually typically leads to two types of problems. First, if the number of parameters of interest is excessive—a scenario coined many-query application—then the associated computational complexity could be unreasonably high. Second, if the computation time is severely limited, such as in real-time applications, then solving even a single PDE might be too costly.
A core assumption to overcome the two issues outlined above is that the solution manifold, i.e., the set of all admissible solutions associated with the parameter space, is inherently low-dimensional. This assumption forms the foundation for the so-called reduced basis method (RBM). A reduced basis discretization is then a (Galerkin) projection on a low-dimensional approximation space that is built from snapshots of the parametrically induced manifold [60].
Constructing the low-dimensional approximation spaces is typically computationally expensive because it involves solving the PDEs for multiple instances of parameters. These computations take place in a so-called offline phase—a step of pre-computation, where one assumes to have access to sufficiently powerful computational resources. Once a suitable low-dimensional space is found, the cost of solving the associated PDEs for a new parameter value is significantly reduced and can be performed quickly and online, i.e., with limited resources [5, 56]. We will give a more thorough introduction to RBMs in Sect. 2. An extensive survey of works on RBMs, which can be traced back to the seventies and eighties of the last century (see, for instance, [22, 49, 50]), is beyond the scope of this paper. We refer, for example, to [33, Chapter 1.1], [16, 29, 57] and [12, Chapter 1.9] for (historical) studies of this topic.
In this work, we show that the low-dimensionality of the solution manifold also enables an efficient approximation of the parametric map by DNNs. In this context, the RBM will be, first and foremost, a tool to model this low-dimensionality by acting as a blueprint for the construction of the DNNs.
1.1 Statistical Learning Problems
The motivation to study the approximability of parametric maps by DNNs stems from the following similarities between parametric problems and statistical learning problems: Assume that we are given a domain set \(X\subset {\mathbb {R}}^n\), \(n \in {\mathbb {N}}\) and a label set \(Y \subset {\mathbb {R}}^k\), \(k \in {\mathbb {N}}\). Further assume that there exists an unknown probability distribution \(\rho \) on \(X \times Y\).
Given a loss function \({\mathcal {L}} :Y \times Y\rightarrow {\mathbb {R}}^+\), the goal of a statistical learning problem is to find a function f, which we will call prediction rule, from a hypothesis class \(H \subset \{h:X \rightarrow Y\}\) such that the expected loss \({\mathbb {E}}_{({\mathbf {x}},{\mathbf {y}})\sim \rho }{\mathcal {L}}(f({\mathbf {x}}), {\mathbf {y}})\) is minimized [14]. Since the probability measure \(\rho \) is unknown, we have no direct access to the expected loss. Instead, we assume that we are given a set of training data, i.e., pairs \(({\mathbf {x}}_i, {\mathbf {y}}_i)_{i = 1}^N\), \(N \in {\mathbb {N}}\), which were drawn independently with respect to \(\rho \). Then one finds f by minimizing the so-called empirical loss
over H. We will call optimizing the empirical loss the learning procedure.
In view of PDEs, the approach proposed above can be rephrased in the following way. We are aiming to produce a function from a parameter set to a state space based on a few snapshots only. This function should satisfy the involved PDEs as precisely as possible, and the evaluation of this function should be very efficient even though the construction of it can potentially be computationally expensive.
In the above-described sense, a parametric PDE problem almost perfectly matches the definition of a statistical learning problem. Indeed, the PDEs and the metric on the state space correspond to a (deterministic) distribution \(\rho \) and a loss function. Moreover, the snapshots are construed as the training data, and the offline phase mirrors the learning procedure. Finally, the parametric map is the prediction rule.
One of the most efficient learning methods nowadays is deep learning. This method describes a range of learning procedures to solve statistical learning problems where the hypothesis class H is taken to be a set of DNNs [24, 40]. These methods outperform virtually all classical machine learning techniques in sufficiently complicated tasks from speech recognition to image classification. Strikingly, training DNNs is a computationally very demanding task that is usually performed on highly parallelized machines. Once a DNN is fully trained, however, its application to a given input is orders of magnitudes faster than the training process. This observation again reflects the offline–online phase distinction that is common in RBM approaches.
Based on the overwhelming success of these techniques and the apparent similarities of learning problems and parametric problems, it appears natural to apply methods from deep learning to statistical learning problems in the sense of (partly) replacing the parameter-dependent map by a DNN. Very successful advances in this direction have been reported in [17, 34, 39, 42, 58, 68].
1.2 Our Contribution
In the applications [17, 34, 39, 42, 58, 68] mentioned above, the combination of DNNs and parametric problems seems to be remarkably efficient. In this paper, we present a theoretical justification of this approach. We address the question to what extent the hypothesis class of DNNs is sufficiently broad to approximately and efficiently represent the associated parametric maps. Concretely, we aim at understanding the necessary number of parameters of DNNs required to allow a sufficiently accurate approximation. We will demonstrate that depending on the target accuracy the required number of parameters of DNNs essentially only scales with the intrinsic dimension of the solution manifold, in particular, according to its Kolmogorov N-widths. We outline our results in Sect. 1.2.1. Then, we present a simplified exposition of our argument leading to the main results in Sect. 1.2.2.
1.2.1 Approximation Theoretical Results
The main contributions of this work are given by an approximation result with DNNs based on ReLU activation functions. Here, we aim to learn a variation of the parametric map
where \({\mathcal {Y}}\) is the parameter space and \({\mathcal {H}}\) is a Hilbert space. In our case, the parameter space will be a compact subset of \({\mathbb {R}}^p\) for some fixed, but possibly large \(p\in {\mathbb {N}},\) i.e., we consider the case of finitely supported parameter vectors.
We assume that there exists a basis of a high-fidelity discretization of \({\mathcal {H}}\) which may potentially be quite large. Let \({\mathbf {u}}_y\) be the coefficient vector of \(u_y\) with respect to the high-fidelity discretization. Moreover, we assume that there exists a RB approximating \(u_y\) sufficiently accurately for every \(y\in {\mathcal {Y}}\).
Theorem 4.3 then states that, under some technical assumptions, there exists a DNN that approximates the discretized solution map
up to a uniform error of \(\epsilon >0\), while having a size that is polylogarithmical in \(\epsilon \), cubic in the size of the reduced basis, and at most linear in the size of the high-fidelity basis.
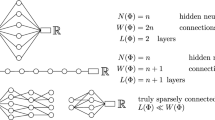
This result highlights the common observation that if a low-dimensional structure is present in a problem, then DNNs are able to identify it and use it advantageously. Concretely, our results show that a DNN is sufficiently flexible to benefit from the existence of a reduced basis in the sense that its size in the complex task of solving a parametric PDE does not or only weakly depend on the high-fidelity discretization and mainly on the size of the reduced basis.
The main result is based on four pillars that are described in detail in Sect. 1.2.2: First, we show that DNNs can efficiently solve linear systems, in the sense that, if supplied with a matrix and a right-hand side, a moderately sized network outputs the solution of the inverse problem. Second, the reduced-basis approach allows reformulating the parametric problem, as a relatively small and parametrized linear system. Third, in many cases, the map that takes the parameters to the stiffness matrices with respect to the reduced basis and right-hand side can be very efficiently represented by DNNs. Finally, the fact that neural networks are naturally compositional allows combining the efficient representation of linear problems with the NN implementing operator inversion.
In practice, the approximating DNNs that we show to exist need to be found using a learning algorithm. In this work, we will not analyze the feasibility of learning these DNNs. The typical approach here is to apply methods based on stochastic gradient descent. Empirical studies of this procedure in the context of learning deep neural networks were carried out in [34, 39, 42, 58, 68]. In particular, we mention the recent study in [23], which analyzes precisely the setup described in this work and finds a strong impact of the approximation-theoretical behavior of DNNs on their practical performance.
1.2.2 Simplified Presentation of the Argument
In this section, we present a simplified outline of the arguments leading to the approximation result described in Sect. 1.2.1. In this simplified setup, we think of a ReLU neural network (ReLU NN) as a function
where \(L \in {\mathbb {N}}\), \(T_1, \dots , T_L\) are affine maps, and \(\varrho : {\mathbb {R}}\rightarrow {\mathbb {R}}\), \(\varrho (x) :=\max \{ 0, x\}\) is the ReLU activation function which is applied coordinate-wise in (1.2). We call L the number of layers of the NN. Since \(T_\ell \) are affine linear maps, we have for all \({\mathbf {x}} \in \mathrm {dom } \, T_\ell \) that \(T_\ell ({\mathbf {x}}) = {\mathbf {A}}_\ell ({\mathbf {x}}) + {\mathbf {b}}_\ell \) for a matrix \({\mathbf {A}}_\ell \) and a vector \({\mathbf {b}}_\ell \). We define the size of the NN as the number of nonzero entries of all \({\mathbf {A}}_\ell \) and \({\mathbf {b}}_\ell \) for \(\ell \in \{1, \dots , L\}\). This definition will later be sharpened and extended in Definition 3.1.
-
1.
As a first step, we recall the construction of a scalar multiplication operator by ReLU NNs due to [69]. This construction is based on two observations. First, defining \(g:[0,1] \rightarrow [0,1]\), \(g(x) :=\min \{2x, 2-2x\}\), we see that g is a hat function. Moreover, multiple compositions of g with itself produce saw-tooth functions. We set, for \(s \in {\mathbb {N}}\), \(g_1 :=g\) and \(g_{s+1} :=g \circ g_s\). It was demonstrated in [69] that
$$\begin{aligned} x^2 = \lim _{n \rightarrow \infty } f_n(x) :=\lim _{n \rightarrow \infty } x - \sum _{s = 1}^n \frac{g_s(x)}{2^{2s}}, \quad \text { for all } x \in [0,1]. \end{aligned}$$(1.3)The second observation for establishing an approximation of a scalar multiplication by NNs is that we can write \(g(x) = 2\varrho (x)-4\varrho (x-1/2) + 2\varrho (x-2)\) and therefore \(g_s\) can be exactly represented by a ReLU NN. Given that \(g_s\) is bounded by 1, it is not hard to see that \(f_n\) converges to the square function exponentially fast for \(n \rightarrow \infty \). Moreover, \(f_n\) can be implemented exactly as a ReLU NN by previous arguments. Finally, the parallelogram identity, \(xz = 1/4((x+z)^2 - (x-z)^2)\) for \(x,z\in {\mathbb {R}}\), demonstrates how an approximate realization of the square function by ReLU NNs yields an approximate realization of scalar multiplication by ReLU NNs.
It is intuitively clear from the exponential convergence in (1.3) and proved in [69, Proposition 3] that the size of a NN approximating the scalar multiplication on \([-1,1]^2\) up to an error of \(\epsilon >0\) is \({\mathcal {O}}(\log _2(1/\epsilon ))\).
-
2.
As a next step, we use the approximate scalar multiplication to approximate a multiplication operator for matrices by ReLU NNs. A matrix multiplication of two matrices of size \(d \times d\) can be performed using \(d^3\) scalar multiplications. Of course, as famously shown in [64], a more efficient matrix multiplication can also be carried out with less than \(d^3\) multiplications. However, for simplicity, we focus here on the most basic implementation of matrix multiplication. Hence, the approximate multiplication of two matrices with entries bounded by 1 can be performed by NN of size \({\mathcal {O}}(d^3 \log _2(1/\epsilon ))\) with accuracy \(\epsilon >0\). We make this precise in Proposition 3.7. Along the same lines, we can demonstrate how to construct a NN emulating matrix-vector multiplications.
-
3.
Concatenating multiple matrix multiplications, we can implement matrix polynomials by ReLU NNs. In particular, for \({\mathbf {A}}\in {\mathbb {R}}^{d\times d}\) such that \(\Vert {\mathbf {A}}\Vert _2 \le 1-\delta \) for some \(\delta \in (0,1)\), the map \({\mathbf {A}} \mapsto \sum _{s = 0}^m {\mathbf {A}}^s\) can be approximately implemented by a ReLU NN with an accuracy of \(\epsilon >0\) and which has a size of \({\mathcal {O}}(m \log _2^2(m)d^3 \cdot ( \log (1/\epsilon )+\log _2(m) )\), where the additional \(\log _2\) term in m inside the brackets appears since each of the approximations of the sum needs to be performed with accuracy \(\epsilon /m\). It is well known that the Neumann series \(\sum _{s = 0}^m {\mathbf {A}}^s\) converges exponentially fast to \((\mathbf {Id}_{{\mathbb {R}}^d}-{\mathbf {A}})^{-1}\) for \(m \rightarrow \infty \). Therefore, under suitable conditions on the matrix \({\mathbf {A}}\), we can construct a NN \(\Phi _{\epsilon }^{\mathrm {inv}}\) that approximates the inversion operator, i.e., the map \({\mathbf {A}} \mapsto {\mathbf {A}}^{-1}\) up to accuracy \(\epsilon >0\). This NN has size \({\mathcal {O}}(d^3\log _2^q(1/\epsilon ))\) for a constant \(q>0\). This is made precise in Theorem 3.8.
-
4.
The existence of \(\Phi _{\epsilon }^{\mathrm {inv}}\) and the emulation of approximate matrix-vector multiplications yield that there exists a NN that for a given matrix and right-hand side approximately solves the associated linear system. Next, we make two assumptions that are satisfied in many applications as we demonstrate in Sect. 4.2:
-
The map from the parameters to the associated stiffness matrices of the Galerkin discretization of the parametric PDE with respect to a reduced basis can be well approximated by NNs.
-
The map from the parameters to the right-hand side of the parametric PDEs discretized according to the reduced basis can be well approximated by NNs.
From these assumptions and the existence of \(\Phi _{\epsilon }^{\mathrm {inv}}\) and a ReLU NN emulating a matrix-vector multiplication, it is not hard to see that there is a NN that approximately implements the map from a parameter to the associated discretized solution with respect to the reduced basis. If the reduced basis has size d and the implementations of the map yielding the stiffness matrix and the right-hand side are sufficiently efficient, then, by the construction of \(\Phi _{\epsilon }^{\mathrm {inv}}\), the resulting NN has size \({\mathcal {O}}(d^3\log _2^q(1/\epsilon ))\). We call this NN \(\Phi _{\epsilon }^{\mathrm {rb}}\).
-
-
5.
Finally, we build on the construction of \(\Phi _{\epsilon }^{\mathrm {rb}}\) to establish the result of Sect. 1.2.1. First of all, let D be the size of the high-fidelity basis. If D is sufficiently large, then every element from the reduced basis can be approximately represented in the high-fidelity basis. Therefore, one can perform an approximation to a change of bases by applying a linear map \({\mathbf {V}} \in {\mathbb {R}}^{D \times d}\) to a vector with respect to the reduced basis. The first statement of Sect. 1.2.1 now follows directly by considering the NN \({\mathbf {V}} \circ \Phi _{\epsilon }^{\mathrm {rb}}\). Through this procedure, the size of the NN is increased to \({\mathcal {O}}(d^3\log _2^q(1/\epsilon )) + d D)\). The full argument is presented in the proof of Theorem 4.3.
1.3 Potential Impact and Extensions
We believe that the results of this article have the potential to significantly impact the research on NNs and parametric problems in the following ways:
-
Theoretical foundation: We offer a theoretical underpinning for the empirical success of NNs for parametric problems which was observed in, e.g., [34, 39, 42, 58, 68]. Indeed, our result, Theorem 4.3, indicates that properly trained NNs are as efficient in solving parametric PDEs as RBMs if the complexity of NNs is measured in terms of free parameters. On a broader level, linking deep learning techniques for parametric PDE problems with approximation theory opens the field up to a new direction of thorough mathematical analysis.
-
Understanding the role of the ambient dimension: It has been repeatedly observed that NNs seem to offer approximation rates of high-dimensional functions that do not deteriorate exponentially with increasing dimension [24, 45].
In this context, it is interesting to identify the key quantity determining the achievable approximation rates of DNNs. Possible explanation for approximation rates that are essentially independent from the ambient dimension have been identified if the functions to be approximated have special structures such as compositionality [48, 55], or invariances [45, 53]. In this article, we identify the highly problem-specific notion of the dimension of the solution manifold as a key quantity determining the achievable approximation rates by NNs for parametric problems. We discuss the connection between the approximation rates that NNs achieve and the ambient dimension in detail in Sect. 5.
-
Identifying suitable architectures: One question in applications is how to choose the right NN architectures for the associated problem. Our results show that NNs of sufficient depth and size are able to produce very efficient approximations. Nonetheless, it needs to be mentioned that our results do not yield a lower bound on the number of layers and thus it is not clear whether deep NNs are indeed necessary.
This work is a step toward establishing a theory of deep learning-based solutions of parametric problems. However, given the complexity of this field, it is clear that many more steps need to follow. We outline a couple of natural further questions of interest below:
-
General parametric problems: Below we restrict ourselves to coercive, symmetric, and linear parametric problems with finitely many parameters. There exist many extensions to, e.g., non-coercive, non-symmetric, or nonlinear problems [10, 11, 25, 38, 67, 70], or to infinite parameter spaces, see, e.g., [2, 4]. It would be interesting to see if the methods proposed in this work can be generalized to these more challenging situations.
-
Bounding the number of snapshots: The interpretation of the parametric problem as a statistical learning problem has the convenient side-effect that various techniques have been established to bound the number of necessary samples N, such that the empirical loss (1.1) is very close to the expected loss. In other words, the generalization error of the minimizer of the learning procedure is small, meaning that the prediction rule performs well on unseen data. (Here, the error is measured in a norm induced by the loss function and the underlying probability distribution.) Using these techniques, it is possible to bound the number of snapshots required for the offline phase to achieve a certain fidelity in the online phase. Estimates of the generalization error in the context of high-dimensional PDEs have been deduced in, e.g., [7, 19, 20, 26, 59].
-
Special NN architectures: This article studies the feasibility of standard feed-forward NNs. In practice, one often uses special architectures that have proved efficient in applications. First and foremost, almost all NNs used in applications are convolutional neural networks (CNNs) [41]. Hence, a relevant question is to what extent the results of this work also hold for such architectures. It was demonstrated in [54] that there is a direct correspondence between the approximation rates of CNNs and that of standard NNs. Thus, we expect that the results of this work translate to CNNs.
Another successful architecture is that of residual neural networks (ResNets) [32]. These neural networks also admit skip-connections, i.e., do not only connect neurons in adjacent layers. This architecture is by design at least as powerful as a standard NN and hence inherits all approximation properties of standard NNs.
-
Necessary properties of neural networks: In this work, we demonstrate the attainability of certain approximation rates by NNs. It is not clear if the presented results are optimal or if there are specific necessary assumptions on the architectures, such as a minimal depth, a minimal number of parameters, or a minimal number of neurons per layer. For approximation results of classical function spaces, such lower bounds on specifications of NNs have been established, for example, in [9, 28, 53, 69]. It is conceivable that the techniques in these works can be transferred to the approximation tasks described in this work.
-
General matrix polynomials: As outlined in Sect. 1.2.2, our results are based on the approximate implementation of matrix polynomials. Naturally, this construction can be used to define and construct a ReLU NN based functional calculus. In other words, for any \(d \in {\mathbb {N}}\) and every continuous function f that can be well approximated by polynomials, we can construct a ReLU NN which approximates the map \({\mathbf {A}} \mapsto f({\mathbf {A}})\) for any appropriately bounded matrix \({\mathbf {A}}\).
A special instance of such a function of interest is given by \(f({\mathbf {A}}):=e^{t{\mathbf {A}}},~t>0,\) which is analytic and plays an important role in the treatment of initial value problems.
-
Numerical studies: In a practical learning problem, the approximation-theoretical aspect only describes one part of the problem. Two further central factors are the data generation and the optimization process. It is conceivable that in comparison with these issues, approximation theoretical considerations only play a negligible role. To understand the extent to which the result of this paper is relevant for applications, comprehensive studies of the theoretical setup of this work should be carried out. A first one was published recently in [23].
1.4 Related Work
In this section, we give an extensive overview of works related to this paper. In particular, for completeness, we start by giving a review of approximation theory of NNs without an explicit connection to PDEs. Afterward, we will see how NNs have been employed for the solution of PDEs.
1.4.1 Review of Approximation Theory of Neural Networks
The first and most fundamental results on the approximation capabilities of NNs were universality results. These results claim that NNs with at least one hidden layer can approximate any continuous function on a bounded domain to arbitrary accuracy if they have sufficiently many neurons [15, 35]. However, these results do not quantify the required sizes of NNs to achieve these rates. One of the first results in this direction was given in [6]. There, a bound on the sufficient size of NNs with sigmoidal activation functions approximating a function with finite Fourier moments is presented. Further results describe approximation rates for various smoothness classes by sigmoidal or even more general activation functions [43, 44, 46, 47].
For the non-differentiable activation function ReLU, first rates of approximation were identified in [69] for classes of smooth functions, in [53] for piecewise smooth functions, and in [27] for oscillatory functions. Moreover, NNs mirror the approximation rates of various dictionaries such as wavelets [62], general affine systems [9], linear finite elements [31], and higher-order finite elements [52].
1.4.2 Neural Networks and PDEs
A well-established line of research is that of solving high-dimensional PDEs by NNs assuming that the NN is the solution of the underlying PDE, e.g., [7, 19, 20, 30, 36, 37, 59, 63]. In this regime, it is often possible to bound the size of the involved NNs in a way that does not scale exponentially with the underlying dimension. In that way, these results are quite related to our approaches. Our results do not seek to represent the solution of a PDE as a NN, but a parametric map. Moreover, we analyze the complexity of the solution manifold in terms of Kolmogorov N-widths. Finally, the underlying spatial dimension of the involved PDEs in our case would usually be moderate. However, the dimension of the parameter space could be immense.
One of the first approaches analyzing NN approximation rates for solutions of parametric PDEs was carried out in [61]. In that work, the analyticity of the solution map \(y\mapsto u_y\) and polynomial chaos expansions with respect to the parametric variable are used to approximate the map \(y\mapsto u_y\) by ReLU NNs of moderate size. Moreover, we mention the works [34, 39, 42, 58, 68] which apply NNs in one way or another to parametric problems. These approaches study the topic of learning a parametric problem but do not offer a theoretical analysis of the required sizes of the involved NNs. These results form our motivation to study the constructions of this paper.
Finally, we mention that the setup of the recent numerical study [23] is closely related to this work.
1.5 Outline
In Sect. 2, we describe the type of parametric PDEs that we consider in this paper, and we recall the theory of RBs. Section 3 introduces a NN calculus which is the basis for all constructions in this work. There we will also construct the NN that maps a matrix to its approximate inverse in Theorem 3.8. In Sect. 4, we construct NNs approximating parametric maps. First, in Theorem 4.1, we approximate the parametric maps after a high-fidelity discretization. Afterward, in Sect. 4.2, we list two broad examples where all assumptions which we imposed are satisfied.
We conclude this paper in Sect. 5 with a discussion of our results in light of the dependence of the underlying NN complexities in terms of the governing quantities.
To not interrupt the flow of reading, we have deferred all auxiliary results and proofs to the appendices.
1.6 Notation
We denote by \({\mathbb {N}}=\{1,2,\ldots \}\) the set of all natural numbers and define \({\mathbb {N}}_0:={\mathbb {N}}\cup \{0\}.\) Moreover, for \(a\in {\mathbb {R}}\) we set \(\lfloor a \rfloor :=\max \{b\in {\mathbb {Z}}:~b\le a\} \) and \(\lceil a\rceil :=\min \{b\in {\mathbb {Z}}:~b\ge a\}. \) Let \(n,l\in {\mathbb {N}}.\) Let \(\mathbf {Id}_{{\mathbb {R}}^n}\) be the identity and \({\mathbf {0}}_{{\mathbb {R}}^n}\) be the zero vector on \({\mathbb {R}}^n.\) Moreover, for \({\mathbf {A}}\in {\mathbb {R}}^{n\times l}\), we denote by \({\mathbf {A}}^T\) its transpose, by \(\sigma ({\mathbf {A}})\) the spectrum of \({\mathbf {A}}\), by \(\Vert {\mathbf {A}}\Vert _2\) its spectral norm and by \(\Vert {\mathbf {A}}\Vert _0:=\# \{(i,j):{\mathbf {A}}_{i,j}\ne 0\},\) where \(\# V\) denotes the cardinality of a set V, the number of nonzero entries of \({\mathbf {A}}\). Moreover, for \({\mathbf {v}}\in {\mathbb {R}}^n\) we denote by \(|{\mathbf {v}}|\) its Euclidean norm. Let V be a vector space. Then we say that \(X\subset ^{\mathrm {s}}V,\) if X is a linear subspace of V. Moreover, if \((V,\Vert \cdot \Vert _V)\) is a normed vector space, X is a subset of V and \(v\in V,\) we denote by \(\mathrm {dist}(v,X):=\inf \{\Vert x-v\Vert _V:~x\in X\}\) the distance between v, X and by \((V^*,\Vert \cdot \Vert _{V^*})\) the topological dual space of V, i.e., the set of all scalar-valued, linear, continuous functions equipped with the operator norm. For a compact set \(\Omega \subset {\mathbb {R}}^n\), we denote by \(C^r(\Omega ),~r\in {\mathbb {N}}_0\cup \{\infty \},\) the spaces of r times continuously differentiable functions, by \(L^p(\Omega ,{\mathbb {R}}^n),p\in [1,\infty ]\) the \({\mathbb {R}}^n\)-valued Lebesgue spaces, where we set \(L^p(\Omega ):=L^p(\Omega ,{\mathbb {R}})\) and by \(H^1(\Omega ):=W^{1,2}(\Omega )\) the first-order Sobolev space.
2 Parametric PDEs and Reduced Basis Methods
In this section, we introduce the type of parametric problems that we study in this paper. A parametric problem in its most general form is based on a map \({\mathcal {P}}:{\mathcal {Y}} \rightarrow {\mathcal {Z}}\), where \({\mathcal {Y}}\) is the parameter space and \({\mathcal {Z}}\) is called solution state space \({\mathcal {Z}}\). In the case of parametric PDEs, \({\mathcal {Y}}\) describes certain parameters of a partial differential equation, \({\mathcal {Z}}\) is a function space or a discretization thereof, and \({\mathcal {P}}(y)\in {\mathcal {Z}}\) is found by solving a PDE with parameter y.
We will place several assumptions on the PDEs underlying \({\mathcal {P}}\) and the parameter spaces \({\mathcal {Y}}\) in Sect. 2.1. Afterward, we give an abstract overview of Galerkin methods in Sect. 2.2 before recapitulating some basic facts about RBs in Sect. 2.3.
2.1 Parametric Partial Differential Equations
In the following, we will consider parameter-dependent equations given in the variational form
where
-
(i)
\({\mathcal {Y}}\) is the parameter set specified in Assumption 2.1,
-
(ii)
\({\mathcal {H}}\) is a Hilbert space,
-
(iii)
\(b_y:{\mathcal {H}}\times {\mathcal {H}}\rightarrow {\mathbb {R}}\) is a continuous bilinear form, which fulfills certain well-posedness conditions specified in Assumption 2.1,
-
(iv)
\(f_{y}\in {\mathcal {H}}^*\) is the parameter-dependent right-hand side of (2.1),
-
(v)
\(u_y\in {\mathcal {H}}\) is the solution of (2.1).
Assumption 2.1
Throughout this paper, we impose the following assumptions on Eq. (2.1).
-
The parameter set \({\mathcal {Y}}\): We assume that \({\mathcal {Y}}\) is a compact subset of \({\mathbb {R}}^p,\) where \(p\in {\mathbb {N}}\) is fixed and potentially large.
Remark
In [12, Section 1.2], it has been demonstrated that if \({\mathcal {Y}}\) is a compact subset of some Banach space V, then one can describe every element in \({\mathcal {Y}}\) by a sequence of real numbers in an affine way. To be more precise, there exist \((v_i)_{i=0}^\infty \subset V\) such that for every \(y\in {\mathcal {Y}}\) and some coefficient sequence \({\mathbf {c}}_y\) whose elements can be bounded in absolute value by 1 there holds \(y=v_0 +\sum _{i=1}^\infty ({\mathbf {c}}_y)_i v_i,\) implying that \({\mathcal {Y}}\) can be completely described by the collection of sequences \({\mathbf {c}}_y\). In this paper, we assume these sequences \({\mathbf {c}}_y\) to be finite with a fixed, but possibly large support size.
-
Symmetry, uniform continuity, and coercivity of the bilinear forms: We assume that for all \(y\in {\mathcal {Y}}\) the bilinear forms \(b_y\) are symmetric, i.e.,
$$\begin{aligned} b_y(u,v)=b_y(v,u), \qquad \text { for all } u,v\in {\mathcal {H}}. \end{aligned}$$Moreover, we assume that the bilinear forms \(b_y\) are uniformly continuous in the sense that there exists a constant \(C_{\mathrm {cont}} > 0\) with
$$\begin{aligned} \left| b_y(u,v) \right| \le C_{\mathrm {cont}}\Vert u\Vert _{{\mathcal {H}}}\Vert v\Vert _{{\mathcal {H}}}, \qquad \text { for all } u\in {\mathcal {H}},v\in {\mathcal {H}},y\in {\mathcal {Y}}. \end{aligned}$$Finally, we assume that the involved bilinear forms are uniformly coercive in the sense that there exists a constant \(C_{\mathrm {coer}}>0\) such that
$$\begin{aligned} \inf _{u\in {\mathcal {H}}\setminus \{0\}} \frac{b_y(u,u)}{\Vert u\Vert _{{\mathcal {H}}}^2} \ge C_{\mathrm {coer}}, \qquad \text { for all } u\in {\mathcal {H}},y\in {\mathcal {Y}}. \end{aligned}$$Hence, by the Lax-Milgram lemma (see [57, Lemma 2.1]), Eq. (2.1) is well-posed, i.e., for every \(y\in {\mathcal {Y}}\) and every \(f_y\in {\mathcal {H}}^*\) there exists exactly one \(u_y\in {\mathcal {H}}\) such that (2.1) is satisfied and \(u_y\) depends continuously on \(f_y\).
-
Uniform boundedness of the right-hand side: We assume that there exists a constant \(C_{\mathrm {rhs}}>0\) such that
$$\begin{aligned} \left\| f_y\right\| _{{\mathcal {H}}^*}\le C_{\mathrm {rhs}}, \qquad \text { for all } y\in {\mathcal {Y}}. \end{aligned}$$ -
Compactness of the solution manifold: We assume that the solution manifold
$$\begin{aligned} S({\mathcal {Y}}):=\left\{ u_y:u_y \text { is the solution of } (2.1),~ y\in {\mathcal {Y}}\right\} \end{aligned}$$is compact in \({\mathcal {H}}.\)
Remark
The assumption that \(S({\mathcal {Y}})\) is compact follows immediately if the solution map \(y\mapsto u_y\) is continuous. This condition is true (see [57, Proposition 5.1, Corollary 5.1]), if for all \(u,v\in {\mathcal {H}}\) the maps \(y\mapsto b_y(u,v)\) as well as \(y\rightarrow f_y(v)\) are Lipschitz continuous. In fact, there exists a multitude of parametric PDEs, for which the maps \(y\mapsto b_y(u,v)\) and \(y\rightarrow f_y(v)\) are even in \(C^{r}\) for some \(r\in {\mathbb {N}}\cup \{\infty \}.\) In this case, \(\left\{ \left( y,u_y\right) :y\in {\mathcal {Y}}\right\} \subset {\mathbb {R}}^p\times {\mathcal {H}}\) is a p-dimensional manifold of class \(C^r\) (see [57, Proposition 5.2, Remark 5.4]). Moreover, we refer to [57, Remark 5.2] and the references therein for a discussion under which circumstances it is possible to turn a discontinuous parameter dependency into a continuous one ensuring the compactness of \(S({\mathcal {Y}})\).
2.2 High-Fidelity Approximations
In practice, one cannot hope to solve (2.1) exactly for every \(y\in {\mathcal {Y}}\). Instead, if we assume for the moment that y is fixed, a common approach toward the calculation of an approximate solution of (2.1) is given by the Galerkin method, which we will describe shortly following [33, Appendix A] and [57, Chapter 2.4]. In this framework, instead of solving (2.1), one solves a discrete scheme of the form
where \(U^{\mathrm {disc}}\subset ^{\mathrm {s}}{\mathcal {H}}\) is a subspace of \({\mathcal {H}}\) with \(\mathrm {dim}\left( U^{\mathrm {disc}} \right) < \infty \) and \(u^{\mathrm {disc}}_y\in U^{\mathrm {disc}}\) is the solution of (2.2). For the solution \(u^{\mathrm {disc}}_y\) of (2.2) we have that
Moreover, up to a constant, we have that \(u^{\mathrm {disc}}_y\) is a best approximation of the solution \(u_y\) of (2.1) by elements in \(U^{\mathrm {disc}}\). To be more precise, by Cea’s Lemma, [57, Lemma 2.2],
Let us now assume that \(U^\mathrm {disc}\) is given. Moreover, if \(N:=\mathrm {dim}\left( U^{\mathrm {disc}}\right) \), let \(\left( \varphi _{i} \right) _{i=1}^N\) be a basis for \(U^{\mathrm {disc}}\). Then, the matrix
is non-singular and positive definite. The solution \(u^{\mathrm {disc}}_y\) of (2.2) satisfies
where
and \({\mathbf {f}}_y:=\left( f_y\left( \varphi _{i}\right) \right) _{i=1}^N\in {\mathbb {R}}^N\). Typically, one starts with a high-fidelity discretization of the space \({\mathcal {H}}\), i.e., one chooses a finite but potentially high-dimensional subspace for which the computed discretized solutions are sufficiently accurate for any \(y\in {\mathcal {Y}}\). To be more precise, we postulate the following:
Assumption 2.2
We assume that there exists a finite dimensional space \(U^\mathrm {h}\subset ^{\mathrm {s}}{\mathcal {H}}\) with dimension \(D<\infty \) and basis \((\varphi _i)_{i=1}^D\). This space is called high-fidelity discretization. For \(y\in {\mathcal {Y}},\) denote by \({\mathbf {B}}_{y}^{\mathrm {h}}:=\left( b_y(\varphi _j,\varphi _i)\right) _{i,j=1}^{D}\in {\mathbb {R}}^{D\times D}\) the stiffness matrix of the high-fidelity discretization, by \({\mathbf {f}}_{y}^{\mathrm {h}}:=\left( f_y(\varphi _i) \right) _{i=1}^{D}\) the discretized right-hand side, and by \({\mathbf {u}}_{y}^{\mathrm {h}}:=\left( {\mathbf {B}}_{y}^{\mathrm {h}} \right) ^{-1}{\mathbf {f}}_{y}^{\mathrm {h}}\in {\mathbb {R}}^{D}\) the coefficient vector of the Galerkin solution with respect to the high-fidelity discretization. Moreover, we denote by \(u^\mathrm {h}_y:=\sum _{i=1}^{D} \left( {\mathbf {u}}_{y}^{\mathrm {h}}\right) _i \varphi _i\) the Galerkin solution.
We assume that, for every \(y\in {\mathcal {Y}}\), \(\sup _{y\in {\mathcal {Y}}} \left\| u_y-u^{\mathrm {h}}_y \right\| _{\mathcal {H}}\le {\hat{\epsilon }}\) for an arbitrarily small, but fixed \({\hat{\epsilon }}>0\). In the following, similarly as in [16], we will not distinguish between \({\mathcal {H}}\) and \(U^{\mathrm {h}}\), unless such a distinction matters.
In practice, following this approach, one often needs to calculate \(u^{\mathrm {h}}_y\approx u_y\) for a variety of parameters \(y\in {\mathcal {Y}}\). This, in general, is a very expensive procedure due to the high-dimensionality of the space \(U^{\mathrm {h}}.\) In particular, given \(\left( \varphi _{i} \right) _{i=1}^{D},\) one needs to solve high-dimensional systems of linear equations to determine the coefficient vector \({\mathbf {u}}^{\mathrm {h}}_y.\) A well-established remedy to overcome these difficulties is given by methods based on the theory of reduced bases, which we will recapitulate in the upcoming subsection.
Before we proceed, let us fix some notation. We denote by \({\mathbf {G}}:=\left( \langle \varphi _i,\varphi _j\rangle _{\mathcal {H}}\right) _{i,j=1}^{D}\in {\mathbb {R}}^{D\times D}\) the symmetric, positive definite Gram matrix of the basis vectors \((\varphi _i)_{i=1}^{D}.\) Then, for any \(v\in U^{\mathrm {h}}\) with coefficient vector \({\mathbf {v}}\) with respect to the basis \((\varphi _i)_{i=1}^{D}\) we have (see [57, Equation 2.41])
2.3 Theory of Reduced Bases
In this subsection and unless stated otherwise, we follow [57, Chapter 5] and the references therein. The main motivation behind the theory of RBs lies in the fact that under Assumption 2.1 the solution manifold \(S({\mathcal {Y}})\) is a compact subset of \({\mathcal {H}}.\) This compactness property allows posing the question whether, for every \({{\tilde{\epsilon }}}\ge {\hat{\epsilon }}\), it is possible to construct a finite-dimensional subspace \(U^{\mathrm {rb}}_{{\tilde{\epsilon }}}\) of \({\mathcal {H}}\) such that \(d({{\tilde{\epsilon }}}):=\mathrm {dim}\left( U^{\mathrm {rb}}_{{\tilde{\epsilon }}}\right) \ll D\) and such that
or, equivalently, if there exist linearly independent vectors \(\left( \psi _{i} \right) _{i=1}^{d({{\tilde{\epsilon }}})}\) with the property that
The starting point of this theory lies in the concept of the Kolmogorov N-width which is defined as follows.
Definition 2.3
[16] For \(N\in {\mathbb {N}},\) the Kolmogorov N-width of a bounded subset X of a normed space V is defined by
This quantity describes the best possible uniform approximation error of X by an at most N-dimensional linear subspace of V. We discuss concrete upper bounds on \(W_N(S({\mathcal {Y}}))\) in more detail in Sect. 5. The aim of RBMs is to construct the spaces \(U_{{{\tilde{\epsilon }}}}^{\mathrm {rb}}\) in such a way that the quantity \( \sup _{y\in {\mathcal {Y}}}\mathrm {dist}\left( u_y,U^{\mathrm {rb}}_{{{\tilde{\epsilon }}}}\right) \) is close to \(W_{d({{\tilde{\epsilon }}})}\left( S({\mathcal {Y}})\right) \).
The identification of the basis vectors \((\psi _i)_{i=1}^{d({{\tilde{\epsilon }}})}\) of \(U_{{{\tilde{\epsilon }}}}^{\mathrm {rb}}\) usually happens in an offline phase in which one has considerable computational resources available and which is usually based on the determination of high-fidelity discretizations of samples of the parameter set \({\mathcal {Y}}.\) The most common methods are based on (weak) greedy procedures (see for instance [57, Chapter 7] and the references therein) or proper orthogonal decompositions (see, for instance, [57, Chapter 6] and the references therein). In the last step, an orthogonalization procedure (such as a Gram–Schmidt process) is performed to obtain an orthonormal set of basis vectors \((\psi _i)_{i=1}^{d({{\tilde{\epsilon }}})}\).
Afterward, in the online phase, one assembles for a given input y the corresponding low-dimensional stiffness matrices and vectors and determines the Galerkin solution by solving a low-dimensional system of linear equations. To ensure an efficient implementation of the online phase, a common assumption which we do not require in this paper is the affine decomposition of (2.1), which means that there exist \(Q_b,Q_f\in {\mathbb {N}},\) parameter-independent bilinear forms \(b^q:{\mathcal {H}}\times {\mathcal {H}}\rightarrow {\mathbb {R}},\) maps \(\theta _q:{\mathcal {Y}}\rightarrow {\mathbb {R}}\) for \(q=1,\ldots ,Q_b,\) parameter-independent \(f^{q'}\in {\mathcal {H}}^*\) as well as maps \(\theta ^{q'}:{\mathcal {Y}}\rightarrow {\mathbb {R}}\) for \(q'=1,\ldots ,Q_f\) such that
As has been pointed out in [57, Chapter 5.7], in principal three types of reduced bases generated by RBMs have been established in the literature—the Lagrange reduced basis, the Hermite reduced basis and the Taylor reduced basis. While the most common type, the Lagrange RB, consists of orthonormalized versions of high-fidelity snapshots \(u^{\mathrm {h}}\left( y^1\right) \approx u\left( y^1\right) ,\ldots ,u^{\mathrm {h}}\left( y^{n}\right) \approx u\left( y^{n}\right) ,\) Hermite RBs consist of snapshots \(u^{\mathrm {h}}\left( y^1\right) \approx u\left( y^1\right) ,\ldots ,u^{\mathrm {h}}\left( y^{n}\right) \approx u\left( y^{n}\right) ,\) as well as their first partial derivatives \(\frac{\partial u^{\mathrm {h}}}{\partial y_i}(y^j)\approx \frac{\partial u}{\partial y_i}(y^j) ,i=1,\ldots ,p,~j=1,\ldots ,n\), whereas Taylor RBs are built of derivatives of the form \(\frac{\partial ^k u^{\mathrm {h}}}{\partial y_i^k}({\overline{y}})\approx \frac{\partial ^k u}{\partial y_i^k}({\overline{y}}),~i=1,\ldots ,p,~k=0,\ldots ,n-1\) around a given expansion point \({\overline{y}}\in {\mathcal {Y}}\). In this paper, we will later assume that there exist small RBs \((\psi _i)_{i=1}^{d({{\tilde{\epsilon }}})}\) generated by arbitrary linear combinations of the high-fidelity elements \((\varphi _i)_{i=1}^{D}\). Note that all types of RBs discussed above satisfy this assumption.
The next statement gives a (generally sharp) upper bound which relates the possibility of constructing small snapshot RBs directly to the Kolmogorov N-width.
Theorem 2.4
[8, Theorem 4.1.] Let \(N\in {\mathbb {N}}.\) For a compact subset X of a normed space V, define the inner N-width of X by
where \({\mathcal {M}}_N:=\left\{ V_N\subset ^{\mathrm {s}}V:~V_N=\mathrm {span}\left( x_i\right) _{i=1}^N,x_1,\ldots ,x_N\in X \right\} .\) Then
Translated into our framework, Theorem 2.4 states that for every \(N\in {\mathbb {N}},\) there exist solutions \(u^{\mathrm {h}}(y^i)\approx u(y^i),\) \(i=1,\ldots ,N\) of (2.1) such that
Remark 2.5
We note that this bound is sharp for general X, V. However, it is not necessarily optimal for special instances of \(S({\mathcal {Y}})\). If, for instance, \(W_N(S({\mathcal {Y}}))\) decays polynomially, then \({\overline{W}}_N(S({\mathcal {Y}}))\) decays with the same rate (see [8, Theorem 3.1.]). Moreover, if \(W_N(S({\mathcal {Y}})) \le C e^{-cN^{\beta }}\) for some \(c,C,\beta >0\) then by [18, Corollary 3.3 (iii)] we have \( {\overline{W}}_N(S({\mathcal {Y}})) \le {\tilde{C}}e^{-{\tilde{c}}N^{\beta }}\) for some \({\tilde{c}},{\tilde{C}}>0.\)
Taking the discussion above as a justification, we assume from now on that for every \({{\tilde{\epsilon }}}\ge {\hat{\epsilon }}\) there exists a RB space \(U_{{\tilde{\epsilon }}}^{\mathrm {rb}}=\mathrm {span} \left( \psi _i \right) _{i=1}^{d({{\tilde{\epsilon }}})},\) which fulfills (2.5), where the linearly independent basis vectors \(\left( \psi _i \right) _{i=1}^{d({{\tilde{\epsilon }}})}\) are linear combinations of the high-fidelity basis vectors \(\left( \varphi _i\right) _{i=1}^{D}\) in the sense that there exists a transformation matrix \({\mathbf {V}}_{{\tilde{\epsilon }}}\in {\mathbb {R}}^{D\times d({{\tilde{\epsilon }}})}\) such that
and where \(d({{\tilde{\epsilon }}})\ll D\) is chosen to be as small as possible, at least fulfilling \(\mathrm {dist}\left( S({\mathcal {Y}}),U_{{\tilde{\epsilon }}}^{\mathrm {rb}}\right) \le {\overline{W}}_{d({{\tilde{\epsilon }}})}(S({\mathcal {Y}})).\) In addition, we assume that the vectors \((\psi _i)_{i=1}^{d({{\tilde{\epsilon }}})}\) form an orthonormal system in \({\mathcal {H}},\) which is equivalent to the fact that the columns of \({\mathbf {G}}^{1/2}{\mathbf {V}}_{{\tilde{\epsilon }}}\) are orthonormal (see [57, Remark 4.1]). This in turn implies
as well as
For the underlying discretization matrix, one can demonstrate (see, for instance, [57, Section 3.4.1]) that
Moreover, due to the symmetry and the coercivity of the underlying bilinear forms combined with the orthonormality of the basis vectors \((\psi _i)_{i=1}^{d({{\tilde{\epsilon }}})}\), one can show (see, for instance, [57, Remark 3.5]) that
implying that the condition number of the stiffness matrix with respect to the RB remains bounded independently of y and the dimension \(d({{\tilde{\epsilon }}}).\) Additionally, the discretized right-hand side with respect to the RB is given by
and, by the Bessel inequality, we have that \(\left| {\mathbf {f}}_{y,{{\tilde{\epsilon }}}}^{\mathrm {rb}} \right| \le \left\| f_{y}\right\| _{{\mathcal {H}}^*} \le C_{\mathrm {rhs}}.\) Moreover, let
be the coefficient vector of the Galerkin solution with respect to the RB space. Then, the Galerkin solution \(u_{y,{{\tilde{\epsilon }}}}^{\mathrm {rb}}\) can be written as
i.e.,
is the coefficient vector of the RB solution if expanded with respect to the high-fidelity basis \(\left( \varphi _i \right) _{i=1}^{D}.\) Finally, as in Eq. 2.3, we obtain
In the following sections, we will emulate RBMs with NNs by showing that we are able to construct NNs which approximate the maps \({\mathbf {u}}_{\cdot ,{{\tilde{\epsilon }}}}^{\mathrm {rb}},\tilde{{\mathbf {u}}}_{\cdot ,{{\tilde{\epsilon }}}}^{\mathrm {h}}\) such that their complexity depends only on the size of the reduced basis and at most linearly on D. The key ingredient will be the construction of small NNs implementing an approximate matrix inversion based on Richardson iterations in Sect. 3. In Sect. 4, we then proceed with building the NNs the realizations of which approximate the maps \({\mathbf {u}}_{\cdot ,{{\tilde{\epsilon }}}}^{\mathrm {rb}},\tilde{{\mathbf {u}}}_{\cdot ,{{\tilde{\epsilon }}}}^{\mathrm {h}}\), respectively.
3 Neural Network Calculus
The goal of this chapter is to emulate the matrix inversion by NNs. In Sect. 3.1, we introduce some basic notions connected to NNs as well as some basic operations one can perform with these. In Sect. 3.2, we state a result which shows the existence of NNs the ReLU-realizations of which take a matrix \({\mathbf {A}}\in {\mathbb {R}}^{d\times d},~\Vert {\mathbf {A}}\Vert _2<1\) as their input and calculate an approximation of \(\left( \mathbf {Id}_{{\mathbb {R}}^d}-{\mathbf {A}}\right) ^{-1}\) based on its Neumann series expansion. The associated proofs can be found in “Appendix A.”
3.1 Basic Definitions and Operations
We start by introducing a formal definition of a NN. Afterward, we introduce several operations, such as parallelization and concatenation that can be used to assemble complex NNs out of simpler ones. Unless stated otherwise, we follow the notion of [53] where most of this formal framework was introduced. First, we introduce a terminology for NNs that allows us to differentiate between a NN as a family of weights and the function implemented by the NN. This implemented function will be called the realization of the NN.
Definition 3.1
Let \(n, L\in {\mathbb {N}}\). A NN \(\Phi \) with input dimension \(\mathrm {dim}_{\mathrm {in}}\left( \Phi \right) :=n\) and L layers is a sequence of matrix-vector tuples
where \(N_0 = n\) and \(N_1, \dots , N_{L} \in {\mathbb {N}}\), and where each \({\mathbf {A}}_\ell \) is an \(N_{\ell } \times N_{\ell -1}\) matrix, and \({\mathbf {b}}_\ell \in {\mathbb {R}}^{N_\ell }\).
If \(\Phi \) is a NN as above, \(K \subset {\mathbb {R}}^n\), and if \(\varrho :{\mathbb {R}}\rightarrow {\mathbb {R}}\) is arbitrary, then we define the associated realization of \(\Phi \) with activation function \(\varrho \) over K (in short, the \(\varrho \)-realization of \(\Phi \) over K) as the map \(\mathrm {R}_{\varrho }^K(\Phi ):K \rightarrow {\mathbb {R}}^{N_L}\) such that
where \({\mathbf {x}}_L\) results from the following scheme:
and where \(\varrho \) acts componentwise, that is, \(\varrho ({\mathbf {v}}) = (\varrho ({\mathbf {v}}_1), \dots , \varrho ({\mathbf {v}}_m))\) for any \({\mathbf {v}} = ({\mathbf {v}}_1, \dots , {\mathbf {v}}_m) \in {\mathbb {R}}^m\).
We call \(N(\Phi ) :=n + \sum _{j = 1}^L N_j\) the number of neurons of the NN \(\Phi \) and \(L = L(\Phi )\) the number of layers. For \(\ell \le L\) we call \(M_\ell (\Phi ) :=\Vert {\mathbf {A}}_\ell \Vert _0 + \Vert {\mathbf {b}}_\ell \Vert _0\) the number of weights in the \(\ell \)-th layer and we define \(M(\Phi ):=\sum _{\ell = 1}^L M_\ell (\Phi )\), which we call the number of weights of \(\Phi .\) Moreover, we refer to \(\mathrm {dim}_{\mathrm {out}}\left( \Phi \right) :=N_L \) as the output dimension of \(\Phi \).
First of all, we note that it is possible to concatenate two NNs in the following way.
Definition 3.2
Let
\(L_1, L_2 \in {\mathbb {N}}\) and let
\({\sum _j} \Phi ^1 = \big ( ({\mathbf {A}}_1^1,{\mathbf {b}}_1^1), \dots , ({\mathbf {A}}_{L_1}^1,{\mathbf {b}}_{L_1}^1) \big ), \Phi ^2 = \big (({\mathbf {A}}_1^2,{\mathbf {b}}_1^2), \dots , ({\mathbf {A}}_{L_2}^2,{\mathbf {b}}_{L_2}^2) \big )\) be two NNs such that the input layer of
\(\Phi ^1\) has the same dimension as the output layer of
\(\Phi ^2\). Then,
 denotes the following
\(L_1+L_2-1\) layer NN:
denotes the following
\(L_1+L_2-1\) layer NN:

We call
 the concatenation of
\(\Phi ^1,\)
\(\Phi ^2\).
the concatenation of
\(\Phi ^1,\)
\(\Phi ^2\).
In general, there is no bound on
 that is linear in
\(M(\Phi ^1)\) and
\(M(\Phi ^2)\). For the remainder of the paper, let
\(\varrho \) be given by the ReLU activation function, i.e.,
\(\varrho (x)=\max \{x,0\}\) for
\(x\in {\mathbb {R}}.\) We will see in the following, that we are able to introduce an alternative concatenation which helps us to control the number of nonzero weights. Toward this goal, we give the following result which shows that we can construct NNs the ReLU-realization of which is the identity function on
\({\mathbb {R}}^n.\)
that is linear in
\(M(\Phi ^1)\) and
\(M(\Phi ^2)\). For the remainder of the paper, let
\(\varrho \) be given by the ReLU activation function, i.e.,
\(\varrho (x)=\max \{x,0\}\) for
\(x\in {\mathbb {R}}.\) We will see in the following, that we are able to introduce an alternative concatenation which helps us to control the number of nonzero weights. Toward this goal, we give the following result which shows that we can construct NNs the ReLU-realization of which is the identity function on
\({\mathbb {R}}^n.\)
Lemma 3.3
For any \(L\in {\mathbb {N}}\), there exists a NN \(\Phi ^{\mathbf {Id}}_{n,L}\) with input dimension n, output dimension n and at most 2nL nonzero, \(\{-1,1\}\)-valued weights such that
We now introduce the sparse concatenation of two NNs.
Definition 3.4
Let \(\Phi ^1,\Phi ^2\) be two NNs such that the output dimension of \(\Phi ^2\) and the input dimension of \(\Phi ^1\) equal \(n\in {\mathbb {N}}\). Then, the sparse concatenation of \(\Phi ^1\) and \(\Phi ^2\) is defined as

We will see later in Lemma 3.6 the properties of the sparse concatenation of NNs. We proceed with the second operation that we can perform with NNs. This operation is called parallelization.
Definition 3.5
[21, 53] Let \(\Phi ^1,\ldots ,\Phi ^k\) be NNs which have equal input dimension such that there holds \(\Phi ^i=\left( ({\mathbf {A}}^i_1,{\mathbf {b}}^i_1),\ldots ,({\mathbf {A}}^i_L,{\mathbf {b}}^i_L) \right) \) for some \(L\in {\mathbb {N}}\). Then, we define the parallelization of \(\Phi ^1,\ldots ,\Phi ^k\) by
Now, let \(\Phi \) be a NN and \(L\in {\mathbb {N}}\) such that \(L(\Phi )\le L.\) Then, define the NN
Finally, let \({\tilde{\Phi }}^1,\ldots ,{\tilde{\Phi }}^k\) be NNs which have the same input dimension and let
Then, we define
We call \(\mathrm {P}\left( {\tilde{\Phi }}^1,\ldots ,{\tilde{\Phi }}^k \right) \) the parallelization of \({\tilde{\Phi }}^1,\ldots ,{\tilde{\Phi }}^k.\)
The following lemma was established in [21, Lemma 5.4] and examines the properties of the sparse concatenation as well as of the parallelization of NNs.
Lemma 3.6
[21] Let \(\Phi ^1,\ldots ,\Phi ^k\) be NNs.
-
(a)
If the input dimension of \(\Phi ^1\), which shall be denoted by \(n_1\), equals the output dimension of \(\Phi ^2,\) and \(n_2\) is the input dimension of \(\Phi ^2,\) then
$$\begin{aligned} \mathrm {R}^{{\mathbb {R}}^{n_1}}_\varrho \left( \Phi ^1\right) \circ \mathrm {R}^{{\mathbb {R}}^{n_2}}_\varrho \left( \Phi ^2\right) = \mathrm {R}^{{\mathbb {R}}^{n_2}}_\varrho \left( \Phi ^1 \odot \Phi ^2\right) \end{aligned}$$and
-
(i)
\(L\left( \Phi ^1 \odot \Phi ^2\right) \le L\left( \Phi ^1\right) +L\left( \Phi ^2\right) ,\)
-
(ii)
\(M\left( \Phi ^1 \odot \Phi ^2\right) \le M\left( \Phi ^1\right) + M\left( \Phi ^2\right) + M_1\left( \Phi ^1\right) +M_{L\left( \Phi ^2\right) }\left( \Phi ^2\right) \le 2M\left( \Phi ^1\right) +2M\left( \Phi ^2\right) ,\)
-
(iii)
\(M_1\left( \Phi ^1\odot \Phi ^2\right) =M_1\left( \Phi ^2\right) ,\)
-
(iv)
\(M_{L\left( \Phi ^1\odot \Phi ^2\right) }\left( \Phi ^1\odot \Phi ^2\right) = M_{L\left( \Phi ^1\right) }\left( \Phi ^1\right) .\)
-
(i)
-
(b)
If the input dimension of \(\Phi ^i\), denoted by n, equals the input dimension of \(\Phi ^j,\) for all i, j, then for the NN \(\mathrm {P}\left( \Phi ^1,\Phi ^2,\ldots ,\Phi ^k\right) \) and all \({\mathbf {x}}_1,\dots {\mathbf {x}}_k\in {\mathbb {R}}^n\) we have
$$\begin{aligned}&\mathrm {R}^{{\mathbb {R}}^n}_\varrho \left( \mathrm {P}\left( \Phi ^1,\Phi ^2,\ldots ,\Phi ^k\right) \right) ({\mathbf {x}}_1,\dots ,{\mathbf {x}}_k) = \left( \mathrm {R}^{{\mathbb {R}}^n}_\varrho \left( \Phi ^1\right) ({\mathbf {x}}_1), \mathrm {R}^{{\mathbb {R}}^n}_\varrho \left( \Phi ^2\right) ({\mathbf {x}}_2) ,\right. \\&\quad \left. \dots , \mathrm {R}^{{\mathbb {R}}^n}_\varrho \left( \Phi ^k\right) ({\mathbf {x}}_k)\right) \end{aligned}$$as well as
-
(i)
\(L\left( \mathrm {P}\left( \Phi _1,\Phi ^2,\ldots ,\Phi ^k\right) \right) = \max _{i=1,\ldots ,k}L\left( \Phi ^i\right) ,\)
-
(ii)
\(M\left( \mathrm {P}\left( \Phi ^1,\Phi ^2,\ldots ,\Phi ^k\right) \right) \le 2\left( \sum _{i=1}^k M\left( \Phi ^i\right) \right) +4\left( \sum _{i=1}^k \mathrm {dim}_{\mathrm {out}}\left( \Phi ^i\right) \right) \max _{i=1,\ldots ,k}L\left( \Phi ^i\right) ,\)
-
(iii)
\(M\left( \mathrm {P}\left( \Phi ^1,\Phi ^2,\ldots ,\Phi ^k\right) \right) = \sum _{i=1}^k M\left( \Phi ^i\right) \), if \(L\left( \Phi ^1\right) = L\left( \Phi ^2\right) = \ldots = L\left( \Phi ^k\right) \),
-
(iv)
\(M_1\left( \mathrm {P}\left( \Phi ^1,\Phi ^2,\ldots ,\Phi ^k\right) \right) =\sum _{i=1}^k M_1\left( \Phi ^i\right) ,\)
-
(v)
\(M_{L\left( \mathrm {P}\left( \Phi ^1,\Phi ^2,\ldots ,\Phi ^k\right) \right) }\left( \mathrm {P}\left( \Phi ^1,\Phi ^2,\ldots ,\Phi ^k\right) \right) \le \sum _{i=1}^k \max \Big \{2\mathrm {dim}_{\mathrm {out}}\left( \Phi ^i\right) ,M_{L\left( \Phi ^i\right) }\left( \Phi ^i\right) \Big \},\)
-
(vi)
\(M_{L\left( \mathrm {P}\left( \Phi ^1,\Phi ^2,\ldots ,\Phi ^k\right) \right) }\left( \mathrm {P}\left( \Phi ^1,\Phi ^2,\ldots ,\Phi ^k\right) \right) =\sum _{i=1}^k M_{L\left( \Phi ^i\right) }\left( \Phi ^i\right) ,\) if \(L\left( \Phi ^1\right) = L\left( \Phi ^2\right) = \ldots = L\left( \Phi ^k\right) \).
-
(i)
3.2 A Neural Network-Based Approach Toward Matrix Inversion
The goal of this subsection is to emulate the inversion of square matrices by realizations of NNs which are comparatively small in size. In particular, Theorem 3.8 shows that, for \(d\in {\mathbb {N}},~\epsilon \in (0,1/4),\) and \(\delta \in (0,1),\) we are able to efficiently construct NNs \(\Phi ^{1-\delta ,d}_{\mathrm {inv};\epsilon }\) the ReLU-realization of which approximates the map
up to an \(\Vert \cdot \Vert _2\)- error of \(\epsilon \).
To stay in the classical NN setting, we employ vectorized matrices in the remainder of this paper. Let \({\mathbf {A}}\in {\mathbb {R}}^{d\times l}.\) We write
Moreover, for a vector \({\mathbf {v}}=({\mathbf {v}}_{1,1},\ldots ,{\mathbf {v}}_{d,1},\ldots ,{\mathbf {v}}_{1,d},\ldots ,{\mathbf {v}}_{d,l})^T\in {\mathbb {R}}^{d l }\) we set
In addition, for \(d,n,l\in {\mathbb {N}}\) and \(Z>0\) we set
as well as
The basic ingredient for the construction of NNs emulating a matrix inversion is the following result about NNs emulating the multiplication of two matrices.
Proposition 3.7
Let \(d,n,l\in {\mathbb {N}},~\epsilon \in (0,1),~Z> 0.\) There exists a NN \(\Phi ^{Z,d,n,l}_{\mathrm {mult};\epsilon }\) with \(n\cdot (d+l) \)- dimensional input, dl-dimensional output such that, for an absolute constant \(C_{\mathrm {mult}}>0,\) the following properties are fulfilled:
-
(i)
\(L\left( \Phi ^{Z,d,n,l}_{\mathrm {mult};{\tilde{\epsilon }}}\right) \le C_{\mathrm {mult}}\cdot \left( \log _2\left( 1/\epsilon \right) +\log _2\left( n\sqrt{dl}\right) +\log _2\left( \max \left\{ 1,Z\right\} \right) \right) \),
-
(ii)
\(M\left( \Phi ^{Z,d,n,l}_{\mathrm {mult};{\tilde{\epsilon }}}\right) \le C_{\mathrm {mult}}\cdot \left( \log _2\left( 1/\epsilon \right) +\log _2\left( n\sqrt{dl}\right) +\log _2\left( \max \left\{ 1,Z\right\} \right) \right) dnl, \)
-
(iii)
\(M_1\left( \Phi ^{Z,d,n,l}_{\mathrm {mult};{\tilde{\epsilon }}}\right) \le C_{\mathrm {mult}} dnl, \qquad \text { as well as } \qquad M_{L\left( \Phi ^{Z,d,n,l}_{\mathrm {mult};{\tilde{\epsilon }}}\right) }\left( \Phi ^{Z,d,n,l}_{\mathrm {mult};{\tilde{\epsilon }}}\right) \le C_{\mathrm {mult}} dnl\),
-
(iv)
\(\sup _{(\mathbf {vec}({\mathbf {A}}),\mathbf {vec}({\mathbf {B}}))\in K^Z_{d,n,l}}\left\| {\mathbf {A}} {\mathbf {B}}- \mathbf {matr}\left( \mathrm {R}_{\varrho }^{K^Z_{d,n,l}}\left( \Phi ^{Z,d,n,l}_{\mathrm {mult};\epsilon }\right) (\mathbf {vec}({\mathbf {A}}),\mathbf {vec}({\mathbf {B}}))\right) \right\| _2 \le \epsilon \),
-
(v)
for any \((\mathbf {vec}({\mathbf {A}}),\mathbf {vec}({\mathbf {B}}))\in K^Z_{d,n,l}\) we have
$$\begin{aligned} \left\| \mathbf {matr}\left( \mathrm {R}_{\varrho }^{K^Z_{d,n,l}}\left( \Phi ^{Z,d,n,l}_{\mathrm {mult};{\tilde{\epsilon }}}\right) (\mathbf {vec}({\mathbf {A}}),\mathbf {vec}({\mathbf {B}}))\right) \right\| _2\le & {} \epsilon +\Vert {\mathbf {A}}\Vert _2 \Vert {\mathbf {B}}\Vert _2\\\le & {} \epsilon +Z^2 \le 1+Z^2. \end{aligned}$$
Based on Proposition 3.7, we construct in “Appendix A.2” NNs emulating the map \({\mathbf {A}}\mapsto {\mathbf {A}}^k\) for square matrices \({\mathbf {A}}\) and \(k\in {\mathbb {N}}.\) This construction is then used to prove the following result.
Theorem 3.8
For \(\epsilon ,\delta \in (0,1)\) define
There exists a universal constant \(C_{\mathrm {inv}} > 0\) such that for every \(d\in {\mathbb {N}},\) \(\epsilon \in (0,1/4)\) and every \(\delta \in (0,1)\) there exists a NN \(\Phi ^{1-\delta , d}_{\mathrm {inv};\epsilon }\) with \(d^2\)-dimensional input, \(d^2\)-dimensional output and the following properties:
-
(i)
\(L\left( \Phi ^{1-\delta , d}_{\mathrm {inv};\epsilon }\right) \le C_{\mathrm {inv}} \log _2\left( m(\epsilon ,\delta ) \right) \cdot \left( \log _2\left( 1/ \epsilon \right) +\log _2\left( m(\epsilon ,\delta ) \right) +\log _2(d)\right) \),
-
(ii)
\(M\left( \Phi ^{1-\delta , d}_{\mathrm {inv};\epsilon }\right) \le C_{\mathrm {inv}} m(\epsilon ,\delta ) \log _2^2(m(\epsilon ,\delta ))d^3\cdot \left( \log _2\left( 1/\epsilon \right) + \log _2\left( m(\epsilon ,\delta )\right) \right. \) \(\left. +\log _2(d) \right) \),
-
(iii)
\(\sup _{\mathbf {vec}({\mathbf {A}})\in K^{1-\delta }_{d}} \left\| \left( \mathbf {Id}_{{\mathbb {R}}^{d}}-{\mathbf {A}} \right) ^{-1} - \mathbf {matr}\left( \mathrm {R}_\varrho ^{K^{1-\delta }_{d}}\left( \Phi ^{1-\delta ,d}_{\mathrm {inv};\epsilon }\right) (\mathbf {vec}({\mathbf {A}}))\right) \right\| _2 \le \epsilon ,\)
-
(iv)
for any \(\mathbf {vec}({\mathbf {A}})\in K^{1-\delta }_d\) we have
$$\begin{aligned}&\left\| \mathbf {matr}\left( \mathrm {R}_\varrho ^{K^{1-\delta }_{d}}\left( \Phi ^{1-\delta ,d}_{\mathrm {inv};\epsilon }\right) (\mathbf {vec}({\mathbf {A}}))\right) \right\| _2\le \epsilon + \left\| \left( \mathbf {Id}_{{\mathbb {R}}^d}-{\mathbf {A}}\right) ^{-1} \right\| _2\\&\quad \le \epsilon + \frac{1}{1-\Vert {\mathbf {A}}\Vert _2} \le \epsilon + \frac{1}{\delta }. \end{aligned}$$
Remark 3.9
In the proof of Theorem 3.8, we approximate the function mapping a matrix to its inverse via the Neumann series and then emulate this construction by NNs. There certainly exist alternative approaches to approximating this inversion function, such as, for example, via Chebyshev matrix polynomials (for an introduction of Chebyshev polynomials, see, for instance, [65, Chapter 8.2]). In fact, approximation by Chebyshev matrix polynomials is more efficient in terms of the degree of the polynomials required to reach a certain approximation accuracy. However, emulation of Chebyshev matrix polynomials by NNs either requires larger networks than that of monomials or, if they are represented in a monomial basis, coefficients that grow exponentially with the polynomial degree. In the end, the advantage of a smaller degree in the approximation through Chebyshev matrix polynomials does not seem to set off the drawbacks described before.
4 Neural Networks and Solutions of PDEs Using Reduced Bases
In this section, we invoke the estimates for the approximate matrix inversion from Sect. 3.2 to approximate the parameter-dependent solution of parametric PDEs by NNs. In other words, for \({{\tilde{\epsilon }}}\ge {\hat{\epsilon }}\), we construct NNs approximating the maps
Here, the sizes of the NNs essentially only depend on the approximation fidelity \({{\tilde{\epsilon }}}\) and the size \(d({{\tilde{\epsilon }}})\) of an appropriate RB, but are independent or at most linear in the dimension of the high-fidelity discretization D.
We start in Sect. 4.1 by constructing, under some general assumptions on the parametric problem, a NN emulating the maps \(\tilde{{\mathbf {u}}}_{\cdot ,{{\tilde{\epsilon }}}}^{\mathrm {h}}\) and \({\mathbf {u}}_{\cdot ,{{\tilde{\epsilon }}}}^{\mathrm {rb}}\). In Sect. 4.2, we verify these assumptions on two examples.
4.1 Determining the Coefficients of the Solution
Next, we present constructions of NNs the ReLU-realizations of which approximate the maps \(\tilde{{\mathbf {u}}}_{\cdot ,{{\tilde{\epsilon }}}}^{\mathrm {h}}\) and \({\mathbf {u}}_{\cdot ,{{\tilde{\epsilon }}}}^{\mathrm {rb}}\), respectively. In our main result of this subsection, the approximation error of the NN approximation \(\tilde{{\mathbf {u}}}_{\cdot ,{{\tilde{\epsilon }}}}^{\mathrm {h}}\) will be measured with respect to the \(|\cdot |_{{\mathbf {G}}}\)-norm since we can relate this norm directly to the norm on \({\mathcal {H}}\) via Eq. (2.4). In contrast, the approximation error of the NN approximating \({\mathbf {u}}^{\mathrm {rb}}_{\cdot ,{{\tilde{\epsilon }}}}\) will be measured with respect to the \(|\cdot |\)-norm due to Eq. 2.8.
As already indicated earlier, the main ingredient of the following arguments is an application of the NN of Theorem 3.8 to the matrix \({\mathbf {B}}_{y,{{\tilde{\epsilon }}}}^{\mathrm {rb}}\). As a preparation, we show in Proposition B.1 in Appendix, that we can rescale the matrix \({\mathbf {B}}_{y,{{\tilde{\epsilon }}}}^{\mathrm {rb}}\) with a constant factor \(\alpha :=(C_{\mathrm {coer}}+C_{\mathrm {cont}})^{-1}\) (in particular, independent of y and \(d({{\tilde{\epsilon }}})\)) so that with \(C_{\mathrm {coer}}\delta :=\alpha C_{\mathrm {coer}}\)
We will fix these values of \(\alpha \) and \(\delta \) for the remainder of the manuscript. Next, we state two abstract assumptions on the approximability of the map \( {\mathbf {B}}_{\cdot ,{{\tilde{\epsilon }}}}^{\mathrm {rb}}\) which we will later on specify when we consider concrete examples in Sect. 4.2.
Assumption 4.1
We assume that, for any \({{\tilde{\epsilon }}}\ge {\hat{\epsilon }},\epsilon >0,\) and for a corresponding RB \((\psi _{i})_{i=1}^{d({{\tilde{\epsilon }}})},\) there exists a NN \(\Phi ^{{\mathbf {B}}}_{{{\tilde{\epsilon }}},\epsilon }\) with p-dimensional input and \(d({{\tilde{\epsilon }}})^2\)-dimensional output such that
We set \(B_{M}\left( {{\tilde{\epsilon }}}, \epsilon \right) :=M\left( \Phi ^{{\mathbf {B}}}_{{{\tilde{\epsilon }}},\epsilon }\right) \in {\mathbb {N}}\) and \(B_{L}\left( {{\tilde{\epsilon }}}, \epsilon \right) :=L\left( \Phi ^{{\mathbf {B}}}_{{{\tilde{\epsilon }}},\epsilon }\right) \in {\mathbb {N}}.\)
In addition to Assumption 4.1, we state the following assumption on the approximability of the map \( {\mathbf {f}}_{\cdot ,{{\tilde{\epsilon }}}}^{\mathrm {rb}}\).
Assumption 4.2
We assume that for every \({{\tilde{\epsilon }}}\ge {\hat{\epsilon }},\epsilon >0,\) and a corresponding RB \((\psi _{i})_{i=1}^{d({{\tilde{\epsilon }}})}\) there exists a NN \(\Phi ^{{\mathbf {f}}}_{{{\tilde{\epsilon }}},\epsilon }\) with p-dimensional input and \(d({{\tilde{\epsilon }}})\)-dimensional output such that
We set \( F_L\left( {{\tilde{\epsilon }}}, \epsilon \right) :=L(\Phi ^{{\mathbf {f}}}_{{{\tilde{\epsilon }}},\epsilon })\) and \(F_M\left( {{\tilde{\epsilon }}}, \epsilon \right) :=M\left( \Phi ^{{\mathbf {f}}}_{{{\tilde{\epsilon }}},\epsilon }\right) \).
Now we are in a position to construct NNs the ReLU-realizations of which approximate the coefficient maps \(\tilde{{\mathbf {u}}}_{\cdot ,{{\tilde{\epsilon }}}}^{\mathrm {h}},{\mathbf {u}}_{\cdot ,{{\tilde{\epsilon }}}}^{\mathrm {rb}}.\)
Theorem 4.3
Let \({{\tilde{\epsilon }}}\ge {\hat{\epsilon }}\) and \(\epsilon \in \left( 0,\alpha /4 \cdot \min \{1,C_{\mathrm {coer}}\} \right) .\) Moreover, define \(\epsilon ':=\epsilon /\max \{6,C_{\mathrm {rhs}}\}\), \(\epsilon '':=\epsilon /3 \cdot C_{\mathrm {coer}}\), \(\epsilon ''':=3/8\cdot \epsilon '\alpha C_{\mathrm {coer}}^2\) and \(\kappa :=2 \max \left\{ 1,C_{\mathrm {rhs}},1/C_{\mathrm {coer}}\right\} \). Additionally, assume that Assumption 4.1 and Assumption 4.2 hold. Then, there exist NNs \(\Phi ^{{\mathbf {u}},\mathrm {rb}}_{{{\tilde{\epsilon }}},\epsilon }\) and \(\Phi ^{{\mathbf {u}},\mathrm {h}}_{{{\tilde{\epsilon }}},\epsilon }\) such that the following properties hold:
-
(i)
\(\sup _{y\in {\mathcal {Y}}}\left| {\mathbf {u}}^{\mathrm {rb}}_{y,{{\tilde{\epsilon }}}} - \mathrm {R}_\varrho ^{\mathcal {Y}}\left( \Phi ^{{\mathbf {u}},\mathrm {rb}}_{{{\tilde{\epsilon }}},\epsilon }\right) (y) \right| \le \epsilon \), and \( \sup _{y\in {\mathcal {Y}}}\left| \tilde{{\mathbf {u}}}^{\mathrm {h}}_{y,{{\tilde{\epsilon }}}} - \mathrm {R}_\varrho ^{\mathcal {Y}}\left( \Phi ^{{\mathbf {u}},\mathrm {h}}_{{{\tilde{\epsilon }}},\epsilon }\right) (y) \right| _{{\mathbf {G}}}\le \epsilon ,\)
-
(ii)
there exists a constant \(C^{{\mathbf {u}}}_L= C^{{\mathbf {u}}}_L(C_{\mathrm {coer}}, C_{\mathrm {cont}}, C_{\mathrm {rhs}})>0\) such that
$$\begin{aligned}&L\left( \Phi ^{{\mathbf {u}}, \mathrm {rb}}_{{{\tilde{\epsilon }}},\epsilon }\right) \le L\left( \Phi ^{{\mathbf {u}},\mathrm {h}}_{{{\tilde{\epsilon }}},\epsilon }\right) \\&\quad \le C^{{\mathbf {u}}}_L \max \left\{ \log _2(\log _2(1/\epsilon ))\left( \log _2(1/\epsilon )+ \log _2(\log _2(1/\epsilon ))+\log _2(d({{\tilde{\epsilon }}}))\right) \right. \\&\quad \quad \left. + B_L({{\tilde{\epsilon }}}, \epsilon '''), F_L\left( {{\tilde{\epsilon }}},\epsilon ''\right) \right\} , \end{aligned}$$ -
(iii)
there exists a constant \(C^{{\mathbf {u}}}_M= C^{{\mathbf {u}}}_M(C_{\mathrm {coer}}, C_{\mathrm {cont}}, C_{\mathrm {rhs}})>0\) such that
$$\begin{aligned}&M\left( \Phi ^{{\mathbf {u}}, \mathrm {rb}}_{{{\tilde{\epsilon }}},\epsilon }\right) \le C^{{\mathbf {u}}}_M d({{\tilde{\epsilon }}})^2 \cdot \bigg (d({{\tilde{\epsilon }}})\log _2(1/\epsilon ) \log _2^2(\log _2(1/\epsilon ))\\&\big (\log _2(1/\epsilon )+\log _2(\log _2(1/\epsilon )) + \log _2(d({{\tilde{\epsilon }}}))\big )\ldots \\&\cdots + B_L({{\tilde{\epsilon }}},\epsilon ''') + F_L\left( {{\tilde{\epsilon }}},\epsilon ''\right) \bigg ) +2B_M({{\tilde{\epsilon }}},\epsilon ''') +F_M\left( {{\tilde{\epsilon }}},\epsilon ''\right) , \end{aligned}$$ -
(iv)
\( M\left( \Phi ^{{\mathbf {u}},\mathrm {h}}_{{{\tilde{\epsilon }}},\epsilon }\right) \le 2 D d({{\tilde{\epsilon }}}) + 2M\left( \Phi ^{{\mathbf {u}}, \mathrm {rb}}_{{{\tilde{\epsilon }}},\epsilon }\right) , \)
-
(v)
\(\sup _{y\in {\mathcal {Y}}}\left| \mathrm {R}_\varrho ^{\mathcal {Y}}\left( \Phi ^{{\mathbf {u}},\mathrm {rb}}_{{{\tilde{\epsilon }}},\epsilon }\right) (y) \right| \le \kappa ^2 + \frac{\epsilon }{3}\), and \( \sup _{y\in {\mathcal {Y}}}\left| \mathrm {R}_\varrho ^{\mathcal {Y}}\left( \Phi ^{{\mathbf {u}},\mathrm {h}}_{{{\tilde{\epsilon }}},\epsilon }\right) (y) \right| _{{\mathbf {G}}}\le \kappa ^2 + \frac{\epsilon }{3}.\)
Remark 4.4
In the proof of Theorem 4.3, we construct a NN \(\Phi ^{{\mathbf {B}}}_{\mathrm {inv};{{\tilde{\epsilon }}},\epsilon }\) the ReLU realization of which \(\epsilon \)-approximates \(\left( {\mathbf {B}}_{y}^{\mathrm {rb}}\right) ^{-1}\) (see Proposition B.3). Then, the NNs of Theorem 4.3 can be explicitly constructed as

Remark 4.5
It can be checked in the proof of Theorem 4.3, specifically (B.4) and (B.5) that the constants \(C^{{\mathbf {u}}}_L, C^{{\mathbf {u}}}_M\) depend on the constants \(C_{\mathrm {coer}},C_{\mathrm {cont}},C_{\mathrm {rhs}}\) in the following way (recall that \( \frac{C_{\mathrm {coer}}}{2C_{\mathrm {cont}}} \le \delta = \frac{C_{\mathrm {coer}}}{C_{\mathrm {coer}}+C_\mathrm {cont}}\le \frac{1}{2}\)):
-
\(C^{{\mathbf {u}}}_L\) depends affine linearly on
$$\begin{aligned} \log ^2_2\left( \frac{\log _2(\delta /2)}{\log _2(1-\delta )}\right) , \quad \log _2\left( \frac{1}{C_{\mathrm {coer}}+C_{\mathrm {cont}}}\right) ,\quad \log _2\left( \max \left\{ 1,C_{\mathrm {rhs}}, 1/C_{\mathrm {coer}}\right\} \right) . \end{aligned}$$ -
\(C^{{\mathbf {u}}}_M\) depends affine linearly on
$$\begin{aligned} \log _2\left( \frac{1}{C_{\mathrm {coer}}+C_{\mathrm {cont}}}\right) , \ \frac{\log _2(\delta /2)}{\log _2(1-\delta )}\cdot \log _2^3\left( \frac{\log _2(\delta /2)}{\log _2(1-\delta )} \right) , \ \log _2\left( \max \left\{ 1,C_{\mathrm {rhs}}, 1/C_{\mathrm {coer}}\right\} \right) . \end{aligned}$$
Remark 4.6
Theorem 4.3 guarantees the existence of two moderately sized NNs the realizations of which approximate the discretized solution maps:
Also of interest is the approximation of the parametrized solution of the PDE, i.e., the map \({\mathcal {Y}}\times \Omega \rightarrow {\mathbb {R}}:\quad (y,x)\mapsto u_y(x)\), where \(\Omega \) is the domain on which the PDE is defined. Note that if either the elements of the reduced basis or the elements of the high-fidelity basis can be very efficiently approximated by realizations of NNs, then the representation
suggests that \((y,x)\mapsto u_y(x)\) can be approximated with essentially the cost of approximating the respective function in (4.1). Many basis elements that are commonly used for the high-fidelity representation can indeed be approximated very efficiently by realizations of NNs, such as, e.g., polynomials, finite elements, or wavelets [31, 52, 62, 69].
4.2 Examples of Neural Network Approximation of Parametric Maps
In this subsection, we apply Theorem 4.3 to a variety of concrete examples in which the approximation of the coefficient maps \({\mathbf {u}}_{\cdot ,{{\tilde{\epsilon }}}}^{\mathrm {rb}},\) \(\tilde{{\mathbf {u}}}_{\cdot ,{{\tilde{\epsilon }}}}^{\mathrm {h}}\) can be approximated by comparatively small NNs. We show that the sizes of these NNs depend only on the size of associated reduced bases by verifying Assumption 4.1 and Assumption 4.2, respectively. We will discuss to what extent our results depend on the respective ambient dimensions D, p in Sect. 5.
We will state the following examples already in their variational formulation and note that they fulfill the requirements of Assumption 2.1. We also remark that the presented examples represent only a small portion of problems to which our theory is applicable.
4.2.1 Example I: Diffusion Equation
We consider a special case of [57, Chapter 2.3.1] which can be interpreted as a generalized version of the heavily used example \(-\mathrm {div}(a\nabla u)=f,\) where a is a scalar field (see for instance [13, 61] and the references therein). Let \(n\in {\mathbb {N}},~\Omega \subset {\mathbb {R}}^n,\) be a Lipschitz domain and \({\mathcal {H}}:=H_0^1(\Omega )=\left\{ u\in H^1(\Omega ):~u|_{\partial \Omega }=0\right\} \). We assume that the parameter set is given by a compact set \({\mathcal {T}}\subset L^{\infty }(\Omega ,{\mathbb {R}}^{n\times n})\) such that for all \({\mathbf {T}}\in {\mathcal {T}}\) and almost all \({\mathbf {x}}\in \Omega \) the matrix \({\mathbf {T}}({\mathbf {x}})\) is symmetric, positive definite with matrix norm that can be bounded from above and below independently of \({\mathbf {T}}\) and \({\mathbf {x}}\). As we have noted in Assumption 2.1, we can assume that there exist some \(({\mathbf {T}}_i)_{i=0}^{\infty }\subset L^{\infty }(\Omega ,{\mathbb {R}}^{n\times n})\) such that for every \({\mathbf {T}}\in {\mathcal {T}}\) there exist \((y_i({\mathbf {T}}))_{i=1}^\infty \subset [-1,1]\) with \({\mathbf {T}}= {\mathbf {T}}_0+\sum _{i=1}^\infty y_i({\mathbf {T}}) {\mathbf {T}}_i.\) We restrict ourselves to the case of finitely supported sequences \((y_i)_{i=1}^\infty .\) To be more precise, let \(p\in {\mathbb {N}}\) be potentially very high but fixed, let \({\mathcal {Y}}:=[-1,1]^{p}\) and consider for \(y\in {\mathcal {Y}}\) and some fixed \(f\in {\mathcal {H}}^*\) the parametric PDE
Then, the parameter dependency of the bilinear forms is linear, hence analytic whereas the parameter dependency of the right-hand side is constant, hence also analytic, implying that \({\overline{W}}(S({\mathcal {Y}}))\) decays exponentially fast. This in turn implies existence of small RBs \((\psi _i)_{i=1}^{d({{\tilde{\epsilon }}})}\) where \(d({{\tilde{\epsilon }}})\) depends at most polylogarithmically on \(1/{{\tilde{\epsilon }}}\). In this case, Assumption 4.1 and Assumption 4.2 are trivially fulfilled: for \({{\tilde{\epsilon }}}>0,\epsilon >0\) we can construct one-layer NNs \(\Phi ^{{\mathbf {B}}}_{{{\tilde{\epsilon }}},\epsilon }\) with p-dimensional input and \(d({{\tilde{\epsilon }}})^2\)-dimensional output as well as \(\Phi ^{{\mathbf {f}}}_{{{\tilde{\epsilon }}},\epsilon }\) with p-dimensional input and \(d({{\tilde{\epsilon }}})\)-dimensional output the ReLU-realizations of which exactly implement the maps \(y\mapsto {\mathbf {B}}^{\mathrm {rb}}_{y,{{\tilde{\epsilon }}}}\) and \(y\mapsto {\mathbf {f}}^{\mathrm {rb}}_{y,{{\tilde{\epsilon }}}},\) respectively.
In conclusion, in this example, we have, for \({{\tilde{\epsilon }}}, \epsilon >0\),
Theorem 4.3 hence implies the existence of a NN approximating \({\mathbf {u}}^{\mathrm {rb}}_{\cdot ,{{\tilde{\epsilon }}}}\) up to error \(\epsilon \) with a size that is linear in p, polylogarithmic in \(1/\epsilon \), and, up to a log factor, cubic in \(d({{\tilde{\epsilon }}})\). Moreover, we have shown the existence of a NN approximating \(\tilde{{\mathbf {u}}}^{\mathrm {h}}_{\cdot ,{{\tilde{\epsilon }}}}\) with a size that is linear in p, polylogarithmic in \(1/\epsilon ,\) linear in D and, up to a log factor, cubic in \(d({{\tilde{\epsilon }}}).\)
4.2.2 Example II: Linear Elasticity Equation
Let \(\Omega \subset {\mathbb {R}}^3\) be a Lipschitz domain, \(\Gamma _D,\Gamma _{N_1},\Gamma _{N_2},\Gamma _{N_3}\subset \partial \Omega ,\) be disjoint such that \(\Gamma _D\cup \Gamma _{N_1}\cup \Gamma _{N_2}\cup \Gamma _{N_3} = \partial \Omega ,\) \({\mathcal {H}}:=[H_{\Gamma _D}^1(\Omega )]^3,\) where \(H_{\Gamma _D}^1(\Omega )= \left\{ u\in H^1(\Omega ):u|_{\Gamma _D}=0 \right\} .\) In variational formulation, this problem can be formulated as an affinely decomposed problem dependent on five parameters, i.e., \(p=5.\) Let \({\mathcal {Y}}:=[{\tilde{y}}^{1,1},{\tilde{y}}^{2,1}]\times \cdots \times [{\tilde{y}}^{1,5},{\tilde{y}}^{2,5}]\subset {\mathbb {R}}^5\) such that \([{\tilde{y}}^{1,2},{\tilde{y}}^{2,2}]\subset (-1, 1/2 )\) and for \(y=(y_1,\ldots ,y_5)\in {\mathcal {Y}}\) we consider the problem
where
-
\(b_y(u_y,v) :=\frac{y_1}{1+y_2} \int _{\Omega } \mathrm {trace}\left( \left( \nabla u_y + (\nabla (u_y)^T \right) \cdot \left( \nabla v + (\nabla v)^T \right) ^T\right) {\text {d}}{\mathbf {x}} + \frac{y_1y_2}{1-2y_2} \int _{\Omega } \mathrm {div}(u_y)\, \mathrm {div}(v)~{\text {d}}{\mathbf {x}}, \)
-
\(f_y(v) :=y_3\int _{\Gamma _1} {\mathbf {n}}\cdot v\, {\text {d}}{\mathbf {x}}+y_4\int _{\Gamma _2} {\mathbf {n}}\cdot v \, {\text {d}}{\mathbf {x}} +y_5\int _{\Gamma _3} {\mathbf {n}}\cdot v \, {\text {d}}{\mathbf {x}},\) and where \({\mathbf {n}}\) denotes the outward unit normal on \(\partial \Omega .\)
The parameter dependency of the right-hand side is linear (hence analytic), whereas the parameter dependency of the bilinear forms is rational, hence (due to the choice of \({\tilde{y}}^{1,2},{\tilde{y}}^{2,2}\)) also analytic and \({\overline{W}}_N(S({\mathcal {Y}}))\) decays exponentially fast implying that we can choose \(d({{\tilde{\epsilon }}})\) to depend polylogarithmically on \({{\tilde{\epsilon }}}\). It is now easy to see that Assumption 4.1 and Assumption 4.2 are fulfilled with NNs the size of which is comparatively small: By [66], for every \({{\tilde{\epsilon }}},\epsilon >0\) we can find a NN with \({\mathcal {O}}(\log ^2_2(1/\epsilon ))\) layers and \({\mathcal {O}}(d({{\tilde{\epsilon }}})^2\log ^3_2(1/\epsilon ))\) nonzero weights the ReLU-realization of which approximates the map \(y\mapsto {\mathbf {B}}_{y,{{\tilde{\epsilon }}}}^{\mathrm {rb}}\) up to an error of \(\epsilon \). Moreover, there exists a one-layer NN \(\Phi ^{{\mathbf {f}}}_{{{\tilde{\epsilon }}},\epsilon }\) with p-dimensional input and \(d({{\tilde{\epsilon }}})\)-dimensional output the ReLU-realization of which exactly implements the map \(y\mapsto {\mathbf {f}}^{\mathrm {rb}}_{y,{{\tilde{\epsilon }}}}\). In other words, in these examples, for \({{\tilde{\epsilon }}}, \epsilon >0\),
Thus, Theorem 4.3 implies the existence of NNs approximating \({\mathbf {u}}^{\mathrm {rb}}_{\cdot ,{{\tilde{\epsilon }}}}\) up to error \(\epsilon \) with a size that is polylogarithmic in \(1/\epsilon \), and, up to a log factor, cubic in \(d({{\tilde{\epsilon }}})\). Moreover, there exist NNs approximating \(\tilde{{\mathbf {u}}}^{\mathrm {h}}_{\cdot ,{{\tilde{\epsilon }}}}\) up to error \(\epsilon \) with a size that is linear in D, polylogarithmic in \(1/\epsilon \), and, up to a log factor, cubic in \(d({{\tilde{\epsilon }}})\).
For a more thorough discussion of this example (a special case of the linear elasticity equation which describes the displacement of some elastic structure under physical stress on its boundaries), we refer to [57, Chapter 2.1.2, Chapter 2.3.2, Chapter 8.6].
5 Discussion: Dependence of Approximation Rates on Involved Dimensions
In this section, we will discuss our results in terms of the dependence on the involved dimensions. We would like to stress that the resulting approximation rates (which can be derived from Theorem 4.3) differ significantly from and are often substantially better than alternative approaches. As described in Sect. 2, there are three central dimensions that describe the hardness of the problem. These are the dimension D of the high-fidelity discretization space \(U^{\mathrm {h}}\), the dimension \(d({{\tilde{\epsilon }}})\) of the reduced basis space, and the dimension p of the parameter space \({\mathcal {Y}}.\)
Dependence on D: Examples I and II above establish approximation rates that depend at most linearly on D; in particular, the dependence on D is not coupled to the dependence on \(\epsilon \). Another approach to solve these problems would be to directly solve the linear systems from the high-fidelity discretization. Without further assumptions on sparsity properties of the matrices, the resulting complexity would be \({\mathcal {O}}(D^3)\) plus the cost of assembling the high-fidelity stiffness matrices. Since \(D \gg d({{\tilde{\epsilon }}})\), this is significantly worse than the approximation rate provided by Theorem 4.3.
Dependence on \(d({{\tilde{\epsilon }}}):\) If one assembles and solves the Galerkin scheme for a previously found reduced basis, one typically needs \({\mathcal {O}}\left( d({{\tilde{\epsilon }}})^3\right) \) operations. By building NNs emulating this method, we achieve essentially the same approximation rate of \({\mathcal {O}}\left( d({{\tilde{\epsilon }}})^3\log _2(d({{\tilde{\epsilon }}}))\cdot C(\epsilon )\right) \) where \(C(\epsilon )\) depends polylogarithmically on the approximation accuracy \(\epsilon .\)
Note that, while having comparable complexity, the NN-based approach is more versatile than using a Galerkin scheme and can be applied even when the underlying PPDE is fully unknown as long as sufficiently many snapshots are available.
Dependence on p:
We start by comparing our result to naive NN approximation results which are simply based on the smoothness properties of the map \(y \mapsto \tilde{{\mathbf {u}}}_{\cdot ,{{\tilde{\epsilon }}}}^{\mathrm {h}}\) without using its specific structure. For example, if these maps are analytic, then classical approximation rates with NNs (such as those provided by [69, Theorem 1], [53, Theorem 3.1] or [28, Corollary 4.2]) promise approximations up to an error of \(\epsilon \) with NNs \(\Phi \) of size \(M(\Phi ) \le c(p,n) D \epsilon ^{-p/n}\) for arbitrary \(n \in {\mathbb {N}}\) and a constant c(p, n). In this case, the dependence on D is again linear, but coupled with the potentially quickly growing term \(\epsilon ^{-p/n}\). Similarly, when approximating the map \(y \mapsto \tilde{{\mathbf {u}}}_{\cdot ,{{\tilde{\epsilon }}}}^{\mathrm {rb}},\) one would obtain an approximation rate of \(\epsilon ^{-p/n}.\) In addition, our approach is more flexible than the naive approach in the sense that Assumptions 4.1 and 4.2 could even be satisfied if the map \(y \mapsto {\mathbf {B}}^{\mathrm {rb}}_{y,{{\tilde{\epsilon }}}}\) is non-smooth.
Now we analyze the dependence of our result to p in more detail. We recall from Theorem 4.3, that in our approach the sizes of approximating networks to achieve an error of \(\epsilon \) depend only polylogarithmically on \(1/\epsilon \), (up to a log factor) cubically on \(d({{\tilde{\epsilon }}})\), are independent from or at worst linear in D, and depend linearly on \(B_{M}({{\tilde{\epsilon }}}, \epsilon ),\) \(B_{M}({{\tilde{\epsilon }}}, \epsilon ),\) \(F_M\left( {{\tilde{\epsilon }}}, \epsilon \right) \), \(F_{L}({{\tilde{\epsilon }}}, \epsilon )\), respectively. First of all, the dependence on p materializes through the quantities \(B_{M}({{\tilde{\epsilon }}}, \epsilon ),\) \(B_{L}({{\tilde{\epsilon }}}, \epsilon ),\) \(F_M\left( {{\tilde{\epsilon }}}, \epsilon \right) \), \(F_{L}({{\tilde{\epsilon }}}, \epsilon )\) from Assumptions 4.1 and 4.2 . We have seen that in both examples above, the associated weight quantities \(B_{M}({{\tilde{\epsilon }}}, \epsilon ),\) \(F_{M}({{\tilde{\epsilon }}}, \epsilon )\) scale like \(pd({{\tilde{\epsilon }}})^2\cdot \mathrm {polylog}(1/\epsilon ),\) whereas the depth quantities \(B_{L}({{\tilde{\epsilon }}}, \epsilon ),\) \(F_{L}({{\tilde{\epsilon }}}, \epsilon )\) scale polylogarithmically in \(1/\epsilon .\) Combining this observation with the statement of Theorem 4.3, we can conclude that the governing quantity in the obtained approximation rates is given by the dimension of the solution manifold \(d({{\tilde{\epsilon }}})\), derived by bounds on the Kolmogorov N-width (and, consequently, the inner N-width).
For problems of the type (2.6), where the involved maps \(\theta _q\) are sufficiently smooth and the right-hand side is parameter-independent, one can show (see, for instance, [1, Equation 3.17] or [51] that \(W_N(S({\mathcal {Y}}))\) (and hence also \({\overline{W}}_N(S({\mathcal {Y}}))\)) scales like \(e^{-cN^{Q_b}}\) for some \(c>0\). This implies for the commonly studied case \(Q_b=p\) (such as in Example I of Sect. 4.2.1) that the dimension \(d({{\tilde{\epsilon }}})\) of the reduced basis space scales like \( {\mathcal {O}}(\log _2(1/{{\tilde{\epsilon }}})^p).\) This bound (which is based on a Taylor expansion of the solution map) has been improved only in very special cases of Example I (see, for instance, [1, 3]) for small parameter dimensions p. Hence, by Theorem 4.3, the number of nonzero weights necessary to approximate the parameter-to-solution map \(\tilde{{\mathbf {u}}}^{\mathrm {h}}_{y,{{\tilde{\epsilon }}}}\), can be upper bounded by \({\mathcal {O}}\left( p \log _2^{3 p}(1/{{\tilde{\epsilon }}})\log _2(\log _2(1/{{\tilde{\epsilon }}}))\log _2^2(1/\epsilon )\log _2^2(\log _2(1/\epsilon )) + D\log _2(1/{{\tilde{\epsilon }}})^p\right) \) and the number of layers by \({\mathcal {O}}\left( p\log ^2_2(1/\epsilon )\log _2(1/{{\tilde{\epsilon }}})\right) .\) This implies that in our results there is a (mild form of a) curse of dimensionality which can only be circumvented if the sensitivity of the Kolmogorov N-width with regard to the parameter dimension p can be reduced further.
References
Bachmayr, M., Cohen, A.: Kolmogorov widths and low-rank approximations of parametric elliptic PDEs. Math. Comput. 86(304), 701–724 (2017)
Bachmayr, M., Cohen, A., Dũng, D., Schwab, C.: Fully discrete approximation of parametric and stochastic elliptic PDEs. SIAM J. Numer. Anal. 55(5), 2151–2186 (2017)
Bachmayr, M., Cohen, A., Dahmen, W.: Parametric PDEs: sparse or low-rank approximations? IMA J. Numer. Anal. 38(4), 1661–1708 (2018)
Bachmayr, M., Cohen, A., Migliorati, G.: Sparse polynomial approximation of parametric elliptic PDEs. Part I: affine coefficients. ESAIM Math. Model. Numer. Anal. 51(1), 321–339 (2017)
Balmès, E.: Parametric families of reduced finite element models, theory and applications. Mech. Syst. Signal Process. 10(4), 381–394 (1996)
Barron, A.: Universal approximation bounds for superpositions of a sigmoidal function. IEEE Trans. Inf. Theory 39(3), 930–945 (1993)
Berner, J., Grohs, P., Jentzen, A.: Analysis of the generalization error: empirical risk minimization over deep artificial neural networks overcomes the curse of dimensionality in the numerical approximation of Black–Scholes partial differential equations. arXiv preprint arXiv:1809.03062 (2018)
Binev, P., Cohen, A., Dahmen, W., DeVore, R., Petrova, G., Wojtaszczyk, P.: Convergence rates for greedy algorithms in reduced basis methods. SIAM J. Math. Anal. 43(3), 1457–1472 (2011)
Bölcskei, H., Grohs, P., Kutyniok, G., Petersen, P.C.: Optimal approximation with sparsely connected deep neural networks. SIAM J. Math. Data Sci. 1, 8–45 (2019)
Canuto, C., Tonn, T., Urban, K.: A posteriori error analysis of the reduced basis method for nonaffine parametrized nonlinear PDEs. SIAM J. Numer. Anal. 47(3), 2001–2022 (2009)
Chkifa, A., Cohen, A., Schwab, C.: Breaking the curse of dimensionality in sparse polynomial approximation of parametric PDEs. J. Math. Pures Appl. (9) 103(2), 400–428 (2015)
Cohen, A., DeVore, R.: Approximation of high-dimensional parametric PDEs. Acta Numer. 24, 1–159 (2015)
Cohen, N., Sharir, O., Shashua, A.: On the expressive power of deep learning: a tensor analysis. In: Conference on Learning Theory, pp. 698–728 (2016)
Cucker, F., Smale, S.: On the mathematical foundations of learning. Bull. Am. Math. Soc. 39, 1–49 (2002)
Cybenko, G.: Approximation by superpositions of a sigmoidal function. Math. Control Signal Syst. 2(4), 303–314 (1989)
Dahmen, W.: How to best sample a solution manifold? In: Sampling Theory, a Renaissance, Appl. Numer. Harmon. Anal., pp. 403–435. Birkhäuser/Springer, Cham (2015)
Dal Santo, N., Deparis, S., Pegolotti, L.: Data driven approximation of parametrized PDEs by reduced basis and neural networks. arXiv preprint arXiv:1904.01514 (2019)
DeVore, R., Petrova, G., Wojtaszczyk, P.: Greedy algorithms for reduced bases in Banach spaces. Constr. Approx. 37(3), 455–466 (2013)
E, W., Han, J., Jentzen, A.: Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations. Commun. Math. Stat. 5(4), 349–380 (2017)
Eigel, M., Schneider, R., Trunschke, P., Wolf, S.: Variational monte carlo-bridging concepts of machine learning and high dimensional partial differential equations. Adv. Comput. Math. 45, 2503–2532 (2019)
Elbrächter, D., Grohs, P., Jentzen, A., Schwab, C.: DNN expression rate analysis of high-dimensional PDEs: application to option pricing. arXiv preprint arXiv:1809.07669 (2018)
Fox, R., Miura, H.: An approximate analysis technique for design calculations. AIAA J. 9(1), 177–179 (1971)
Geist, M., Petersen, P., Raslan, M., Schneider, R., Kutyniok, G.: Numerical solution of the parametric diffusion equation by deep neural networks. arXiv preprint arXiv:2004.12131 (2020)
Goodfellow, I., Bengio, Y., Courville, A.: Deep Learning. MIT Press (2016). http://www.deeplearningbook.org
Grepl, M.A., Maday, Y., Nguyen, N.C., Patera, A.T.: Efficient reduced-basis treatment of nonaffine and nonlinear partial differential equations. Esaim Math. Model. Numer. Anal. 41(3), 575–605 (2007)
Grohs, P., Hornung, F., Jentzen, A., von Wurstemberger, P.: A proof that artificial neural networks overcome the curse of dimensionality in the numerical approximation of Black–Scholes partial differential equations. arXiv preprint arXiv:1809.02362 (2018)
Grohs, P., Perekrestenko, D., Elbrächter, D., Bölcskei, H.: Deep neural network approximation theory. arXiv preprint arXiv:1901.02220 (2019)
Gühring, I., Kutyniok, G., Petersen, P.: Error bounds for approximations with deep relu neural networks in \({W}^{s, p}\) norms. Anal. Appl. (Singap.), pp. 1–57 (2019)
Haasdonk, B.: Reduced basis methods for parametrized PDEs—a tutorial introduction for stationary and instationary problems. In: Model Reduction and Approximation, volume 15 of Comput. Sci. Eng., pp. 65–136. SIAM, Philadelphia, PA (2017)
Han, J., Jentzen, A., W, E.: Solving high-dimensional partial differential equations using deep learning. Proc. Natl. Acad. Sci. USA 115(34), 8505–8510 (2018)
He, J., Li, L., Xu, J., Zheng, C.: ReLU deep neural networks and linear finite elements. arXiv preprint arXiv:1807.03973 (2018)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Hesthaven, J., Rozza, G., Stamm, B.: Certified Reduced Basis Methods for Parametrized Partial Differential Equations. Springer Briefs in Mathematics, 1st edn. Springer, Switzerland (2015)
Hesthaven, J.S., Ubbiali, S.: Non-intrusive reduced order modeling of nonlinear problems using neural networks. J. Comput. Phys. 363, 55–78 (2018)
Hornik, K., Stinchcombe, M., White, H.: Multilayer feedforward networks are universal approximators. Neural Netw. 2(5), 359–366 (1989)
Hutzenthaler, M., Jentzen, A., Kruse, T., Nguyen, T.: A proof that rectified deep neural networks overcome the curse of dimensionality in the numerical approximation of semilinear heat equations. SN Partial Differ. Equ. Appl. 1(10) (2020)
Jentzen, A., Salimova, D., Welti, T.: A proof that deep artificial neural networks overcome the curse of dimensionality in the numerical approximation of Kolmogorov partial differential equations with constant diffusion and nonlinear drift coefficients. arXiv preprint arXiv:1809.07321 (2018)
Jung, N., Haasdonk, B., Kroner, D.: Reduced basis method for quadratically nonlinear transport equations. Int. J. Appl. Math. Comput. Sci. 2(4), 334–353 (2009)
Khoo, Y., Lu, J., Ying, L.: Solving parametric PDE problems with artificial neural networks. arXiv preprint arXiv:1707.03351 (2017)
LeCun, Y., Bengio, Y., Hinton, G.: Deep learning. Nature 521(7553), 436–444 (2015)
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proc. IEEE 86(11), 2278–2324 (1998)
Lee, K., Carlberg, K.: Model reduction of dynamical systems on nonlinear manifolds using deep convolutional autoencoders. J. Comput. Phys. 404 (2020)
Leshno, M., Lin, V.Y., Pinkus, A., Schocken, S.: Multilayer feedforward networks with a nonpolynomial activation function can approximate any function. Neural Netw. 6(6), 861–867 (1993)
Maiorov, V., Pinkus, A.: Lower bounds for approximation by MLP neural networks. Neurocomputing 25(1–3), 81–91 (1999)
Mallat, S.: Understanding deep convolutional networks. Philos. Trans. R. Soc. A 374(2065), 20150203 (2016)
Mhaskar, H.: Approximation properties of a multilayered feedforward artificial neural network. Adv. Comput. Math. 1(1), 61–80 (1993)
Mhaskar, H.: Neural networks for optimal approximation of smooth and analytic functions. Neural Comput. 8(1), 164–177 (1996)
Mhaskar, H., Liao, Q., Poggio, T.: Learning functions: when is deep better than shallow. arXiv preprint arXiv:1603.00988 (2016)
Noor, A.K.: Recent advances in reduction methods for nonlinear problems. Comput. Struct. 13(1–3), 31–44 (1981)
Noor, A.K.: On making large nonlinear problems small. Comput. Methods Appl. Mech. Eng. 34(1-3):955–985 (1982). FENOMECH’81, Part III (Stuttgart, 1981)
Ohlberger, M., Rave, S.: Reduced basis methods: success, limitations and future challenges. In: Proceedings of the Conference Algoritmy, pp. 1–12 (2016)
Opschoor, J.A.A., Petersen, P.C., Schwab, C.: Deep relu networks and high-order finite element methods. Anal. Appl. 1–56, (2020)
Petersen, P.C., Voigtlaender, F.: Optimal approximation of piecewise smooth functions using deep ReLU neural networks. Neural Netw. 180, 296–330 (2018)
Petersen, P.C., Voigtlaender, F.: Equivalence of approximation by convolutional neural networks and fully-connected networks. Proc. Am. Math. Soc. 148, 1567–1581 (2020)
Poggio, T., Mhaskar, H., Rosasco, L., Miranda, B., Liao, Q.: Why and when can deep-but not shallow-networks avoid the curse of dimensionality: a review. Int. J. Autom. Comput. 14(5), 503–519 (2017)
Prud’Homme, C., Rovas, D., Veroy, K., Machiels, L., Maday, Y., Patera, A., Turinici, G.: Reduced–basis output bound methods for parametrized partial differential equations. In: Proceedings SMA Symposium, vol. 1, p. 1 (2002)
Quarteroni, A., Manzoni, A., Negri, F.: Reduced basis methods for partial differential equations, volume 92 of Unitext. An introduction, La Matematica per il 3+2. Springer, Cham (2016)
Raissi, M.: Deep hidden physics models: deep learning of nonlinear partial differential equations. J. Mach. Learn. Res. 19(1), 932–955 (2018)
Reisinger, C., Zhang, Y.: Rectified deep neural networks overcome the curse of dimensionality for nonsmooth value functions in zero-sum games of nonlinear stiff systems. arXiv preprint arXiv:1903.06652 (2019)
Rozza, G., Huynh, D.B.P., Patera, A.T.: Reduced basis approximation and a posteriori error estimation for affinely parametrized elliptic coercive partial differential equations: application to transport and continuum mechanics. Arch. Comput. Methods Eng. 15(3), 229–275 (2008)
Schwab, C., Zech, J.: Deep learning in high dimension: neural network expression rates for generalized polynomial chaos expansions in UQ. Anal. Appl. (Singap.) 17(1), 19–55 (2019)
Shaham, U., Cloninger, A., Coifman, R.R.: Provable approximation properties for deep neural networks. Appl. Comput. Harmon. Anal. 44(3), 537–557 (2018)
Sirignano, J., Spiliopoulos, K.: DGM: a deep learning algorithm for solving partial differential equations. J. Comput. Syst. Sci. 375, 1339–1364 (2018)
Strassen, V.: Gaussian elimination is not optimal. Numer. Math. 13(4), 354–356 (1969)
Sullivan, T.J.: Introduction to Uncertainty Quantification, volume 63 of Texts in Applied Mathematics. Springer (2015)
Telgarsky, M.: Neural networks and rational functions. In: 34th International Conference on Machine Learning, ICML 2017, vol. 7, pp. 5195–5210. International Machine Learning Society (IMLS), 1 (2017)
Veroy, K., Prud’Homme, C., Rovas, D., Patera, A.: A posteriori error bounds for reduced-basis approximation of parametrized noncoercive and nonlinear elliptic partial differential equations. In: 16th AIAA Computational Fluid Dynamics Conference, pp. 3847 (2003)
Yang, Y., Perdikaris, P.: Physics-informed deep generative models. arXiv preprint arXiv:1812.03511 (2018)
Yarotsky, D.: Error bounds for approximations with deep ReLU networks. Neural Netw. 94, 103–114 (2017)
Zech, J., Dũng, D., Schwab, C.: Multilevel approximation of parametric and stochastic pdes. Math. Models Methods Appl. Sci. 29(09), 1753–1817 (2019)
Acknowledgements
M.R. would like to thank Ingo Gühring for fruitful discussions on the topic. G. K. acknowledges partial support by the Bundesministerium für Bildung und Forschung (BMBF) through the Berlin Institute for the Foundations of Learning and Data (BIFOLD), Project AP4, RTG DAEDALUS (RTG 2433), Projects P1, P3, and P8, RTG BIOQIC (RTG 2260), Projects P4 and P9, and by the Berlin Mathematics Research Center MATH+, Projects EF1-1 and EF1-4. P.P. was supported by a DFG Research Fellowship “Shearlet-based energy functionals for anisotropic phase-field methods.” R.S. acknowledges partial support by the DFG through Grant RTG DAEDALUS (RTG 2433), Project P14.
Funding
Open access funding provided by University of Vienna.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Wolfgang Dahmen, Ronald A. DeVore, and Philipp Grohs.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Proofs of the Results from Sect. 3
1.1 Proof of Proposition 3.7
In this subsection, we will prove Proposition 3.7. As a preparation, we first prove the following special instance under which  can be estimated by \(\max \left\{ M(\Phi ^1), M(\Phi ^2)\right\} \).
can be estimated by \(\max \left\{ M(\Phi ^1), M(\Phi ^2)\right\} \).
Lemma A.1
Let \(\Phi \) be a NN with m-dimensional output and d-dimensional input. If \({\mathbf {a}} \in {\mathbb {R}}^{1 \times m}\), then, for all \(\ell = 1, \dots , L(\Phi )\),

In particular, it holds that  Moreover, if \({\mathbf {D}} \in {\mathbb {R}}^{d \times n}\) such that, for every \(k \le d\) there is at most one \(l_k\le n\) such that \({\mathbf {D}}_{k,l_k} \ne 0\), then, for all \(\ell = 1, \dots , L(\Phi )\),
Moreover, if \({\mathbf {D}} \in {\mathbb {R}}^{d \times n}\) such that, for every \(k \le d\) there is at most one \(l_k\le n\) such that \({\mathbf {D}}_{k,l_k} \ne 0\), then, for all \(\ell = 1, \dots , L(\Phi )\),

In particular, it holds that  .
.
Proof
Let \(\Phi = \big ( ({\mathbf {A}}_1,{\mathbf {b}}_1), \dots , ({\mathbf {A}}_{L},{\mathbf {b}}_{L}) \big )\), and \({\mathbf {a}}, {\mathbf {D}}\) as in the statement of the lemma. Then, the result follows if
and
It is clear that \(\Vert {\mathbf {a}} {\mathbf {A}}_L\Vert _0\) is less than the number of nonzero columns of \({\mathbf {A}}_L\) which is certainly bounded by \(\Vert {\mathbf {A}}_L\Vert _0\). The same argument shows that \(\Vert {\mathbf {a}}{\mathbf {b}}_L\Vert _{0} \le \Vert {\mathbf {b}}_L\Vert _{0}\). This yields (A.1).
We have that for two vectors \({\mathbf {p}},{\mathbf {q}} \in {\mathbb {R}}^{k}\), \(k \in {\mathbb {N}}\) and for all \(\mu , \nu \in {\mathbb {R}}\)
where \(I(\gamma ) = 0\) if \(\gamma = 0\) and \(I(\gamma ) = 1\) otherwise. Also,
where, for a matrix \({\mathbf {G}}\), \({\mathbf {G}}_{l, -}\) denotes the l-th row of \({\mathbf {G}}\). Moreover, we have that for all \(l \le n\)
As a consequence, we obtain
\(\square \)
Now we are ready to prove Proposition 3.7.
Proof of Proposition 3.7
Without loss of generality, assume that \(Z\ge 1\). By [21, Lemma 6.2], there exists a NN \(\times ^Z_{\epsilon }\) with input dimension 2, output dimension 1 such that for \(\Phi _{\epsilon } :=\times ^Z_{\epsilon }\)
Since \(\Vert {\mathbf {A}}\Vert _2,\Vert {\mathbf {B}}\Vert _2\le Z\), we know that for every \(i=1,\ldots ,d,~ k=1,\ldots ,n,~j=1,\ldots ,l\) we have that \(|{\mathbf {A}}_{i,k}|,|{\mathbf {B}}_{k,j}|\le Z\). We define, for \(i\in \{1, \dots , d\}, k \in \{1, \dots , n\}, j \in \{1, \dots , l\}\), the matrix \({\mathbf {D}}_{i,k,j}\) such that, for all \({\mathbf {A}} \in {\mathbb {R}}^{d\times n}, {\mathbf {B}} \in {\mathbb {R}}^{n\times l}\)
Moreover, let

We have, for all \(i\in \{1, \dots , d\}, k \in \{1, \dots , n\}, j \in \{1, \dots , l\}\), that \(L\left( \Phi ^Z_{i,k,j;\epsilon }\right) = L\left( \times ^Z_{\epsilon }\right) \) and by Lemma A.1 that \(\Phi ^Z_{i,k,j;\epsilon }\) satisfies (A.2), (A.3), (A.4) with \(\Phi _{\epsilon } :=\Phi ^Z_{i,k,j;\epsilon }\). Moreover, we have by (A.5)
As a next step, we set, for \({\mathbf {1}}_{{\mathbb {R}}^n} \in {\mathbb {R}}^n\) being a vector with each entry equal to 1,

which by Lemma 3.6 is a NN with \(n\cdot (d+l)\)-dimensional input and 1-dimensional output such that (A.2) holds with \(\Phi _{\epsilon } :=\Phi ^Z_{i,j;\epsilon }\). Moreover, by Lemmas A.1 and 3.6 and by (A.3) we have that
Additionally, by Lemmas 3.6 and A.1 and (A.4), we obtain
and
By construction it follows that
and hence we have, by (A.6),
As a final step, we define  . Then, by Lemma 3.6, we have that (A.2) is satisfied for \(\Phi _{\epsilon } :=\Phi ^{Z,d,n,l}_{\mathrm {mult};{\tilde{\epsilon }}}\). This yields (i) of the asserted statement. Moreover, invoking Lemma 3.6, Lemma A.1 and (A.7) yields that
. Then, by Lemma 3.6, we have that (A.2) is satisfied for \(\Phi _{\epsilon } :=\Phi ^{Z,d,n,l}_{\mathrm {mult};{\tilde{\epsilon }}}\). This yields (i) of the asserted statement. Moreover, invoking Lemma 3.6, Lemma A.1 and (A.7) yields that
which yields (ii) of the result. Moreover, by Lemma 3.6 and (A.8) it follows that
completing the proof of (iii). By construction and using the fact that for any \({\mathbf {N}}\in {\mathbb {R}}^{d\times l}\) there holds
we obtain that
Equation (A.9) establishes (iv) of the asserted result. Finally, we have for any \((\mathbf {vec}({\mathbf {A}}),\mathbf {vec}({\mathbf {B}}))\in K^Z_{d,n,l}\) that
This demonstrates that (v) holds and thereby finishes the proof. \(\square \)
1.2 Proof of Theorem 3.8
The objective of this subsection is to prove of Theorem 3.8. Toward this goal, we construct NNs which emulate the map \({\mathbf {A}}\mapsto {\mathbf {A}}^k\) for \(k\in {\mathbb {N}}\) and square matrices \({\mathbf {A}}.\) This is done by heavily using Proposition 3.7. First of all, as a direct consequence of Proposition 3.7 we can estimate the sizes of the emulation of the multiplication of two squared matrices. Indeed, there exists a universal constant \(C_1>0\) such that for all \(d \in {\mathbb {N}}\), \(Z>0\), \(\epsilon \in (0,1)\)
-
(i)
\(L\left( \Phi _{\mathrm {mult}; \epsilon }^{Z, d, d, d}\right) \le C_1\cdot \left( \log _2\left( 1/\epsilon \right) +\log _2\left( d\right) +\log _2\left( \max \left\{ 1,Z\right\} \right) \right) \),
-
(ii)
\(M\left( \Phi _{\mathrm {mult}; \epsilon }^{Z, d, d, d}\right) \le C_1\cdot \left( \log _2\left( 1/\epsilon \right) +\log _2\left( d\right) +\log _2\left( \max \left\{ 1,Z\right\} \right) \right) d^3\),
-
(iii)
\(M_1\left( \Phi _{\mathrm {mult}; \epsilon }^{Z, d, d, d}\right) \le C_1 d^3, \qquad \text {as well as} \qquad M_{L\left( \Phi _{\mathrm {mult}; \epsilon }^{Z, d, d, d}\right) }\left( \Phi _{\mathrm {mult}; \epsilon }^{Z, d, d, d}\right) \le C_1 d^3\),
-
(iv)
\(\sup _{(\mathbf {vec}({\mathbf {A}}),\mathbf {vec}({\mathbf {B}}))\in K^Z_{d,d,d}}\left\| {\mathbf {A}} {\mathbf {B}}- \mathbf {matr}\left( \mathrm {R}_{\varrho }^{K^Z_{d,d,d}}\left( \Phi _{\mathrm {mult}; \epsilon }^{Z, d, d, d}\right) (\mathbf {vec}({\mathbf {A}}),\mathbf {vec}({\mathbf {B}}))\right) \right\| _2 \le \epsilon \),
-
(v)
for every \((\mathbf {vec}({\mathbf {A}}),\mathbf {vec}({\mathbf {B}}))\in K^Z_{d,d,d}\) we have
$$\begin{aligned} \left\| \mathbf {matr}\left( \mathrm {R}_{\varrho }^{K^Z_{d,d,d}}\left( \Phi _{\mathrm {mult}; \epsilon }^{Z, d, d, d}\right) (\mathbf {vec}({\mathbf {A}}),\mathbf {vec}({\mathbf {B}}))\right) \right\| _2\le & {} \epsilon +\Vert {\mathbf {A}}\Vert _2 \Vert {\mathbf {B}}\Vert _2\\\le & {} \epsilon +Z^2 \le 1+Z^2. \end{aligned}$$
One consequence of the ability to emulate the multiplication of matrices is that we can also emulate the squaring of matrices. We make this precise in the following definition.
Definition A.2
For \(d \in {\mathbb {N}}\), \(Z>0\), and \(\epsilon \in (0,1)\) we define the NN

which has \(d^2 \)-dimensional input and \(d^2 \)-dimensional output. By Lemma 3.6 we have that there exists a constant \(C_{\mathrm {sq}}>C_1\) such that for all \(d \in {\mathbb {N}}\), \(Z>0\), \(\epsilon \in (0,1)\)
-
(i)
\(L\left( \Phi ^{Z, d}_{2;\epsilon }\right) \le C_{\mathrm {sq}}\cdot \left( \log _2(1/\epsilon )+\log _2(d)+\log _2\left( \max \left\{ 1,Z\right\} \right) \right) ,\)
-
(ii)
\(M\left( \Phi ^{Z, d}_{2;\epsilon }\right) \le C_{\mathrm {sq}} d^3 \cdot \left( \log _2(1/\epsilon )+\log _2(d)+\log _2\left( \max \left\{ 1,Z\right\} \right) \right) , \)
-
(iii)
\(M_1\left( \Phi ^{Z, d}_{2;\epsilon }\right) \le C_{\mathrm {sq}} d^3,\qquad \text {as well as} \qquad M_{L\left( \Phi ^{Z, d}_{2;\epsilon }\right) }\left( \Phi ^{Z, d}_{2;\epsilon }\right) \le C_{\mathrm {sq}} d^3, \)
-
(iv)
\(\sup _{\mathbf {vec}({\mathbf {A}})\in K^Z_{d}}\left\| {\mathbf {A}}^2- \mathbf {matr}\left( \mathrm {R}_{\varrho }^{K^Z_{d}}\left( \Phi ^{Z, d}_{2;\epsilon }\right) (\mathbf {vec}({\mathbf {A}}))\right) \right\| _2 \le \epsilon , \)
-
(v)
for all \(\mathbf {vec}({\mathbf {A}})\in K^Z_{d}\) we have
$$\begin{aligned} \left\| \mathbf {matr}\left( \mathrm {R}_{\varrho }^{K^Z_{d}}\left( \Phi ^{Z, d}_{2;\epsilon }\right) (\mathbf {vec}({\mathbf {A}}))\right) \right\| _2\le \epsilon + \Vert {\mathbf {A}}\Vert ^2 \le \epsilon +Z^2\le 1+Z^2. \end{aligned}$$
Our next goal is to approximate the map \({\mathbf {A}}\mapsto {\mathbf {A}}^k\) for an arbitrary \(k\in {\mathbb {N}}_0.\) We start with the case that k is a power of 2 and for the moment we only consider the set of all matrices the norm of which is bounded by 1/2.
Proposition A.3
Let \(d\in {\mathbb {N}},~j\in {\mathbb {N}},~\) as well as \(\epsilon \in \left( 0, 1/4\right) \). Then there exists a NN \(\Phi ^{1/2, d}_{2^j;\epsilon }\) with \(d^2\)-dimensional input and \(d^2 \)-dimensional output with the following properties:
-
(i)
\(L\left( \Phi ^{1/2, d}_{2^j;\epsilon }\right) \le C_{\mathrm {sq}} j\cdot \left( \log _2(1/\epsilon )+\log _2(d) \right) +2C_{\mathrm {sq}}\cdot (j-1)\),
-
(ii)
\(M\left( \Phi ^{1/2, d}_{2^j;\epsilon }\right) \le C_{\mathrm {sq}} j d^3\cdot \left( \log _2(1/\epsilon )+\log _2(d) \right) +4C_{\mathrm {sq}}\cdot (j-1)d^3\),
-
(iii)
\(M_1\left( \Phi ^{1/2, d}_{2^j;\epsilon }\right) \le C_{\mathrm {sq}} d^3,\qquad \text {as well as} \qquad M_{L\left( \Phi ^{1/2, d}_{2^j;\epsilon }\right) }\left( \Phi ^{1/2, d}_{2^j;\epsilon }\right) \le C_{\mathrm {sq}} d^3\),
-
(iv)
\(\sup _{\mathbf {vec}({\mathbf {A}})\in K^{1/2}_d}\left\| {\mathbf {A}}^{2^j}- \mathbf {matr}\left( \mathrm {R}_{\varrho }^{K^{1/2}_d}\left( \Phi ^{1/2, d}_{2^j;\epsilon }\right) (\mathbf {vec}({\mathbf {A}}))\right) \right\| _2 \le \epsilon \),
-
(v)
for every \(\mathbf {vec}({\mathbf {A}})\in K^{1/2}_d\) we have
$$\begin{aligned} \left\| \mathbf {matr}\left( \mathrm {R}_{\varrho }^{K^{1/2}_d}\left( \Phi ^{1/2, d}_{2^j;\epsilon }\right) (\mathbf {vec}({\mathbf {A}}))\right) \right\| _2 \le \epsilon +\left\| {\mathbf {A}}^{2^j}\right\| _2\le & {} \epsilon +\left\| {\mathbf {A}}\right\| ^{2^j}_2 \\\le & {} \frac{1}{4}+\left( \frac{1}{2}\right) ^{2^j}\le \frac{1}{2}. \end{aligned}$$
Proof
We show the statement by induction over \(j\in {\mathbb {N}}\). For \(j=1\), the statement follows by choosing \(\Phi ^{1/2, d}_{2;\epsilon }\) as in Definition A.2. Assume now, as induction hypothesis, that the claim holds for an arbitrary, but fixed \(j\in {\mathbb {N}}\), i.e., there exists a NN \(\Phi ^{1/2, d}_{2^j;\epsilon }\) such that
and \(\Phi ^{1/2, d}_{2^j;\epsilon }\) satisfies (i),(ii),(iii). Now we define
By the triangle inequality, we obtain for any \(\mathbf {vec}({\mathbf {A}})\in K_d^{1/2}\)
By construction of \(\Phi ^{1/2, d}_{2^{j+1};\epsilon }\), we know that
Therefore, using the triangle inequality and the fact that \(\Vert \cdot \Vert _2\) is a submultiplicative operator norm, we derive that
where the penultimate estimate follows by the induction hypothesis (A.10) and \(\epsilon <1/4\). Hence, since \(\Vert \cdot \Vert _2\) is a submultiplicative operator norm, we obtain
where we used \(\left\| {\mathbf {A}}^{2^{j}}\right\| _2\le 1/4\) and the induction hypothesis (A.10). Applying (A.13) and (A.12) to (A.11) yields
A direct consequence of (A.14) is that
The estimates (A.14) and (A.15) complete the proof of the assertions (iv) and (v) of the proposition statement. Now we estimate the size of \(\Phi ^{1/2, d}_{2^{j+1};\epsilon }\). By the induction hypothesis and Lemma 3.6(a)(i), we obtain
which implies (i). Moreover, by the induction hypothesis and Lemma 3.6(a)(ii), we conclude that
implying (ii). Finally, it follows from Lemma 3.6(a)(iii) in combination with the induction hypothesis as well Lemma 3.6(a)(iv) that
as well as
which finishes the proof. \(\square \)
We proceed by demonstrating, how to build a NN that emulates the map \({\mathbf {A}}\mapsto {\mathbf {A}}^k\) for an arbitrary \(k \in {\mathbb {N}}_0\). Again, for the moment we only consider the set of all matrices the norms of which are bounded by 1/2. For the case of the set of all matrices the norms of which are bounded by an arbitrary \(Z>0\), we refer to Corollary A.5.
Proposition A.4
Let \(d\in {\mathbb {N}}\), \(k\in {\mathbb {N}}_0\), and \(\epsilon \in \left( 0,1/4\right) \). Then, there exists a NN \(\Phi ^{1/2, d}_{k;\epsilon }\) with \(d^2\)- dimensional input and \(d^2\)-dimensional output satisfying the following properties:
-
(i)
$$\begin{aligned} L\left( \Phi ^{1/2, d}_{k;\epsilon }\right)&\le \left\lfloor \log _2\left( \max \{k,2\}\right) \right\rfloor L\left( \Phi ^{1,d}_{\mathrm {mult};\frac{\epsilon }{4}} \right) + L\left( \Phi ^{1/2, d}_{2^{\left\lfloor \log _2(\max \{k,2\})\right\rfloor };\epsilon }\right) \\&\le 2C_{\mathrm {sq}} \left\lfloor \log _2\left( \max \{k,2\}\right) \right\rfloor \cdot \left( \log _2(1/\epsilon )+\log _2(d)+2 \right) , \end{aligned}$$
-
(ii)
\(M\left( \Phi ^{1/2, d}_{k;\epsilon }\right) \le \frac{3}{2}C_{\mathrm {sq}} d^3\cdot \left\lfloor \log _2\left( \max \{k,2\}\right) \right\rfloor \cdot \left( \left\lfloor \log _2\left( \max \{k,2\}\right) \right\rfloor +1\right) \cdot \left( \log _2(1/\epsilon )+\log _2(d)+4 \right) \),
-
(iii)
\(M_1\left( \Phi ^{1/2, d}_{k;\epsilon } \right) \le C_{\mathrm {sq}}\cdot \left( \left\lfloor \log _2\left( \max \{k,2\}\right) \right\rfloor +1\right) d^3, \ \text {as well as} \ M_{L\left( \Phi ^{1/2, d}_{k;\epsilon }\right) }\left( \Phi ^{1/2, d}_{k;\epsilon }\right) \le C_{\mathrm {sq}} d^3, \)
-
(iv)
\(\sup _{\mathbf {vec}({\mathbf {A}})\in K^{1/2}_d}\left\| {\mathbf {A}}^k- \mathbf {matr}\left( \mathrm {R}_{\varrho }^{K^{1/2}_d}\left( \Phi ^{1/2, d}_{k;\epsilon }\right) (\mathbf {vec}({\mathbf {A}}))\right) \right\| _2 \le \epsilon \),
-
(v)
for any \(\mathbf {vec}({\mathbf {A}})\in K^{1/2}_d\) we have
$$\begin{aligned} \left\| \mathbf {matr}\left( \mathrm {R}_{\varrho }^{K^{1/2}_d}\left( \Phi ^{1/2, d}_{k;\epsilon }\right) (\mathbf {vec}({\mathbf {A}}))\right) \right\| _2 \le \epsilon +\Vert {\mathbf {A}}^k\Vert _2 \le \frac{1}{4}+\Vert {\mathbf {A}}\Vert _2^k \le \frac{1}{4}+\left( \frac{1}{2}\right) ^k. \end{aligned}$$
Proof
We prove the result per induction over \(k\in {\mathbb {N}}_{0}\). The cases \(k=0\) and \(k=1\) hold trivially by defining the NNs
For the induction hypothesis, we claim that the result holds true for all \(k' \le k \in {\mathbb {N}}\). If k is a power of two, then the result holds per Proposition A.3; thus, we can assume without loss of generality, that k is not a power of two. We define \(j :=\lfloor \log _2(k)\rfloor \) such that, for \(t :=k - 2^{j}\), we have that \(0< t < 2^{j}\). This implies that \(A^k= A^{2^j} A^{t}\). Hence, by Proposition A.3 and by the induction hypothesis, respectively, there exist a NN \(\Phi ^{1/2,d}_{2^j;\epsilon }\) satisfying (i)–(v) of Proposition A.3 and a NN \(\Phi ^{1/2,d}_{t;\epsilon }\) satisfying (i)-(v) of the statement of this proposition. We now define the NN

By construction and Lemma 3.6(a)(iv), we first observe that
Moreover, we obtain by the induction hypothesis as well as Lemma 3.6(a)(iii) in combination with Lemma 3.6(b)(iv) that
This shows (iii). To show (iv), we perform a similar estimate as the one following (A.11). By the triangle inequality,
By the construction of \(\Phi ^{1/2, d}_{k;\epsilon }\) and Proposition 3.7, we conclude that
Hence, using (A.16), we can estimate
We now consider two cases: If \(t=1,\) then we know by the construction of \(\Phi ^{1/2, d}_{1;\epsilon }\) that \(\mathrm {II}=0\). Thus,
If \(t\ge 2\), then
where we have used that \(\left( \frac{1}{2}\right) ^{t}\le \frac{1}{4}\) for \(t \ge 2\). This shows (iv). In addition, by an application of the triangle inequality, we have that
This shows (v). Now we analyze the size of \(\Phi ^{1/2,d}_{k;\epsilon }\). We have by Lemma 3.6(a)(i) in combination with Lemma 3.6(b)(i) and by the induction hypothesis that
which implies (i). Finally, we address the number of nonzero weights of the resulting NN. We first observe that, by Lemma 3.6(a)(ii),
Then, by the properties of the NN \(\Phi ^{1,d,d,d}_{\mathrm {mult};\frac{\epsilon }{4}}\), we obtain
Next, we estimate
Without loss of generality we assume that \(L:=L\left( \Phi ^{1/2, d}_{t;\epsilon }\right) - L\left( \Phi ^{1/2, d}_{2^j;\epsilon }\right) > 0.\) The other cases follow similarly. We have that \(L\le 2C_{\mathrm {sq}} j\cdot \left( \log _2(1/\epsilon )+\log _2(d)+2\right) \) and, by the definition of the parallelization of two NNs with a different number of layers that
where we have used the definition of the parallelization for the first two equalities, Lemma 3.6(b)(iii) for the third equality, Lemma 3.6(a)(ii) for the fourth inequality as well as the properties of \(\Phi ^{\mathbf {Id}}_{d^2,L}\) in combination with Proposition A.3(iii) for the last inequality. Moreover, by the definition of the parallelization of two NNs with different numbers of layers, we conclude that

Combining the estimates on \(\mathrm {I'}\), \(\mathrm {II'}(a)\), and \(\mathrm {II'}(b)\), we obtain by using the induction hypothesis that
\(\square \)
Proposition A.4 only provides a construction of a NN the ReLU-realization of which emulates a power of a matrix \({\mathbf {A}}\), under the assumption that \(\Vert {\mathbf {A}}\Vert _2\le 1/2\). We remove this restriction in the following corollary by presenting a construction of a NN \(\Phi ^{Z, d}_{k;\epsilon }\) the ReLU-realization of which approximates the map \({\mathbf {A}}\mapsto {\mathbf {A}}^k,\) on the set of all matrices \({\mathbf {A}}\) the norms of which are bounded by an arbitrary \(Z>0\).
Corollary A.5
There exists a universal constant \(C_{\mathrm {pow}}>C_{\mathrm {sq}}\) such that for all \(Z>0,\) \(d\in {\mathbb {N}}\) and \(k\in {\mathbb {N}}_0,\) there exists some NN \(\Phi ^{Z,d}_{k;\epsilon }\) with the following properties:
-
(i)
\(L\left( \Phi ^{Z, d}_{k;\epsilon }\right) \le C_{\mathrm {pow}} \log _2\left( \max \{k,2\}\right) \cdot \left( \log _2(1/\epsilon )+\log _2(d)+k \log _2\left( \max \left\{ 1,Z\right\} \right) \right) \),
-
(ii)
\(M\left( \Phi ^{Z,d}_{k;\epsilon }\right) \le C_{\mathrm {pow}}\log _2^2\left( \max \{k,2\}\right) d^3 \cdot \left( \log _2(1/\epsilon )+\log _2(d)+k \log _2\left( \max \left\{ 1,Z\right\} \right) \right) \),
-
(iii)
\(M_1\left( \Phi ^{Z,d}_{k;\epsilon } \right) \le C_{\mathrm {pow}} \log _2\left( \max \{k,2\}\right) d^3, \qquad \text {as well as} \qquad M_{L\left( \Phi ^{Z,d}_{k;\epsilon }\right) }\left( \Phi ^{Z}_{k;\epsilon }\right) \le C_{\mathrm {pow}} d^3\),
-
(iv)
\(\sup _{\mathbf {vec}({\mathbf {A}})\in K^{Z}_d}\left\| {\mathbf {A}}^k- \mathbf {matr}\left( \mathrm {R}_{\varrho }^{K^{Z}_d}\left( \Phi ^{Z,d}_{k;\epsilon }\right) (\mathbf {vec}({\mathbf {A}}))\right) \right\| _2 \le \epsilon \),
-
(v)
for any \(\mathbf {vec}({\mathbf {A}})\in K^{Z}_d\) we have
$$\begin{aligned} \left\| \mathbf {matr}\left( \mathrm {R}_{\varrho }^{K^{Z}_d}\left( \Phi ^{Z,d}_{k;\epsilon }\right) (\mathbf {vec}({\mathbf {A}}))\right) \right\| _2 \le \epsilon + \Vert {\mathbf {A}}^k\Vert _2 \le \epsilon +\Vert {\mathbf {A}}\Vert _2^k. \end{aligned}$$
Proof
Let \(\left( ({\mathbf {A}}_1,{\mathbf {b}}_1),\ldots ,({\mathbf {A}}_L,{\mathbf {b}}_L) \right) :=\Phi ^{1/2,d}_{k;\frac{\epsilon }{2\max \left\{ 1,Z^k\right\} }}\) according to Proposition A.4. Then, the NN
fulfills all of the desired properties. \(\square \)
We have seen how to construct a NN that takes a matrix as an input and computes a power of this matrix. With this tool at hand, we are now ready to prove Theorem 3.8.
Proof of Theorem 3.8
By the properties of the partial sums of the Neumann series, for \(m\in {\mathbb {N}}\) and every \(\mathbf {vec}({\mathbf {A}})\in K_d^{1-\delta },\) we have that
Hence, for
we obtain
Let now

where \(\left( \mathbf {Id}_{{\mathbb {R}}^{d^2}}|\cdots |\mathbf {Id}_{{\mathbb {R}}^{d^2}}\right) \in {\mathbb {R}}^{ d^2\times m(\epsilon ,\delta )\cdot d^2}\). Then we set
We have for any \(\mathbf {vec}({\mathbf {A}})\in K^{1-\delta }_{d}\)
where we have used that
This completes the proof of (iii). Moreover, (iv) is a direct consequence of (iii). Now we analyze the size of the resulting NN. First of all, we have by Lemma 3.6(b)(i) and Corollary A.5 that
which implies (i). Moreover, by Lemma 3.6(b)(ii), Corollary A.5 and the monotonicity of the logarithm, we obtain
Since \(\sum _{k=1}^{m(\epsilon ,\delta )}\log _2^2(\max \{k,2\})\le m(\epsilon ,\delta )\log _2^2(m(\epsilon ,\delta )),\) we obtain for some constant \(C_{\mathrm {inv}}>C_{\mathrm {pow}}\) that
This completes the proof. \(\square \)
Proof of Theorem 4.3
We start by establishing a bound on \( \left\| \mathbf {Id}_{{\mathbb {R}}^{d({{\tilde{\epsilon }}})}}-\alpha {\mathbf {B}}_{y,{{\tilde{\epsilon }}}}^{\mathrm {rb}} \right\| _2.\)
Proposition B.1
For any \(\alpha \in \left( 0, {1}/{C_{\mathrm {cont}}}\right) \) and \(\delta :=\alpha C_{\mathrm {coer}}\in (0, 1)\) there holds
Proof
Since \( {\mathbf {B}}_{y,{{\tilde{\epsilon }}}}^{\mathrm {rb}}\) is symmetric, there holds that
for all \(y\in {\mathcal {Y}},~{{\tilde{\epsilon }}}>0.\) \(\square \)
With an approximation to the parameter-dependent stiffness matrices with respect to a RB, due to Assumption 4.1, we can next state a construction of a NN the ReLU-realization of which approximates the map \(y\mapsto \left( {\mathbf {B}}_{y,{{\tilde{\epsilon }}}}^{\mathrm {rb}}\right) ^{-1}\). As a first step, we observe the following remark.
Remark B.2
It is not hard to see that if \( \left( ({\mathbf {A}}^1_{{{\tilde{\epsilon }}},\epsilon },{\mathbf {b}}^1_{{{\tilde{\epsilon }}},\epsilon }),\ldots ,({\mathbf {A}}^L_{{{\tilde{\epsilon }}},\epsilon },{\mathbf {b}}^L_{{{\tilde{\epsilon }}},\epsilon })\right) :=\Phi ^{{\mathbf {B}}}_{{{\tilde{\epsilon }}},\epsilon }\) is the NN of Assumption 4.1, then for
we have that
as well as \(M\left( \Phi ^{{\mathbf {B}},\mathbf {Id}}_{{{\tilde{\epsilon }}},\epsilon }\right) \le B_{M}({{\tilde{\epsilon }}}, \epsilon ) + d({{\tilde{\epsilon }}})^2\) and \(L\left( \Phi ^{{\mathbf {B}},\mathbf {Id}}_{{{\tilde{\epsilon }}},\epsilon }\right) = B_{L}\left( {{\tilde{\epsilon }}}, \epsilon \right) \).
Now we present the construction of the NN emulating \(y\mapsto \left( {\mathbf {B}}_{y,{{\tilde{\epsilon }}}}^{\mathrm {rb}}\right) ^{-1}\).
Proposition B.3
Let \({{\tilde{\epsilon }}}\ge {\hat{\epsilon }},\epsilon \in \left( 0, \alpha /4 \cdot \min \{1,C_{\mathrm {coer}}\} \right) \) and \(\epsilon ':=3/8 \cdot \epsilon \alpha C_{\mathrm {coer}}^2 <\epsilon \). Assume that Assumption 4.1 holds. We define

which has p-dimensional input and \(d({{\tilde{\epsilon }}})^2\)- dimensional output.
Then, there exists a constant \(C_B=C_B(C_{\mathrm {coer}},C_{\mathrm {cont}} ) > 0\) such that
-
(i)
\( L\left( \Phi ^{{\mathbf {B}}}_{\mathrm {inv};{{\tilde{\epsilon }}},\epsilon } \right) \le C_{B} \log _2(\log _2(1/\epsilon ))\big (\log _2(1/\epsilon ) + \log _2(\log _2(1/\epsilon ))+\log _2(d({{\tilde{\epsilon }}}))\big ) + B_L({{\tilde{\epsilon }}}, \epsilon '), \)
-
(ii)
\( M\left( \Phi ^{{\mathbf {B}}}_{\mathrm {inv};{{\tilde{\epsilon }}},\epsilon } \right) \le C_{B} \log _2(1/\epsilon ) \log _2^2(\log _2(1/\epsilon )) d({{\tilde{\epsilon }}})^3\cdot \big (\log _2(1/\epsilon )+\log _2(\log _2(1/\epsilon ))+\log _2(d({{\tilde{\epsilon }}})) \big ) + 2 B_M\left( {{\tilde{\epsilon }}},\epsilon '\right) , \)
-
(iii)
\( \sup _{y\in {\mathcal {Y}}} \left\| \left( {\mathbf {B}}_{y,{{\tilde{\epsilon }}}}^{\mathrm {rb}}\right) ^{-1} -\mathbf {matr}\left( \mathrm {R}_\varrho ^{\mathcal {Y}}\left( \Phi ^{{\mathbf {B}}}_{\mathrm {inv}; {{\tilde{\epsilon }}},\epsilon } \right) (y)\right) \right\| _2 \le \epsilon \),
-
(iv)
\( \sup _{y\in {\mathcal {Y}}} \left\| {\mathbf {G}}^{1/2}{\mathbf {V}}_{{\tilde{\epsilon }}}\cdot \left( \left( {\mathbf {B}}_{y,{{\tilde{\epsilon }}}}^{\mathrm {rb}}\right) ^{-1} -\mathbf {matr}\left( \mathrm {R}_\varrho ^{\mathcal {Y}}\left( \Phi ^{{\mathbf {B}}}_{\mathrm {inv}; {{\tilde{\epsilon }}},\epsilon } \right) (y)\right) \right) \right\| _2 \le \epsilon \),
-
(v)
\(\sup _{y\in {\mathcal {Y}}} \left\| \mathbf {matr}\left( \mathrm {R}_\varrho ^{\mathcal {Y}}\left( \Phi ^{{\mathbf {B}}}_{\mathrm {inv};{{\tilde{\epsilon }}},\epsilon } \right) (y)\right) \right\| _2 \le \epsilon + \frac{1}{C_{\mathrm {coer}}},\)
-
(vi)
\( \sup _{y\in {\mathcal {Y}}} \left\| {\mathbf {G}}^{1/2}{\mathbf {V}}_{{\tilde{\epsilon }}}\mathbf {matr} \left( \mathrm {R}_\varrho ^{\mathcal {Y}}\left( \Phi ^{{\mathbf {B}}}_{\mathrm {inv}; {{\tilde{\epsilon }}},\epsilon } \right) (y)\right) \right\| _2 \le \epsilon + \frac{1}{C_{\mathrm {coer}}}. \)
Proof
First of all, for all \(y\in {\mathcal {Y}}\) the matrix \(\mathbf {matr}\left( \mathrm {R}^{{\mathcal {Y}}}_{\varrho }\left( \Phi ^{{\mathbf {B}}}_{{{\tilde{\epsilon }}},\epsilon '}\right) (y) \right) \) is invertible. This can be deduced from the fact that
Indeed, we estimate
Thus, it follows that
Then,
Due to the fact that for two invertible matrices \({\mathbf {M}},{\mathbf {N}},\)
we obtain
where we have used Assumption 4.1, Eq. (2.9) and Eq. (B.2). Now we turn our attention to estimating II. First, observe that for every \(y\in {\mathcal {Y}}\) by the triangle inequality and Remark B.2, that
Moreover, have that \(\epsilon /(2\alpha ) \le \alpha /(8\alpha )< 1/4.\) Hence, by Theorem 3.8, we obtain that \( \mathrm {II} \le {\epsilon }/{2\alpha }.\) Putting everything together yields
Finally, by construction we can conclude that
This implies (iii) of the assertion. Now, by Equation (2.7) we obtain
completing the proof of (iv). Finally, for all \(y\in {\mathcal {Y}}\) we estimate
This yields (vi). A minor modification of the calculation above yields (v). At last, we show (i) and (ii). First of all, it is clear that \(L\left( \Phi ^{{\mathbf {B}}}_{\mathrm {inv};{{\tilde{\epsilon }}},\epsilon }\right) = L\left( \Phi ^{1-\delta /2,d({{\tilde{\epsilon }}})}_{\mathrm {inv};\frac{\epsilon }{2\alpha }} \odot \Phi ^{{\mathbf {B}},\mathbf {Id}}_{{{\tilde{\epsilon }}},\epsilon '} \right) \) and \(M\left( \Phi ^{{\mathbf {B}}}_{\mathrm {inv};{{\tilde{\epsilon }}},\epsilon }\right) = M\left( \Phi ^{1-\delta /2,d({{\tilde{\epsilon }}})}_{\mathrm {inv};\frac{\epsilon }{2\alpha }} \odot \Phi ^{{\mathbf {B}},\mathbf {Id}}_{{{\tilde{\epsilon }}},\epsilon '} \right) .\) Moreover, by Lemma 3.6(a)(i) in combination with Theorem 3.8 (i) we have
and, by Lemma 3.6(a)(ii) in combination with Theorem 3.8(ii), we obtain
In addition, by definition of \(m(\epsilon ,\delta )\) in the statement of Theorem 3.8, for some constant \({\tilde{C}}>0\) there holds \(m\left( \epsilon /(2\alpha ),\delta /2\right) \le {\tilde{C}}\log _2(1/\epsilon ).\) Hence, the claim follows for a suitably chosen constant \(C_B = C_B(C_{\mathrm {coer}},C_{\mathrm {cont}}) > 0\). \(\square \)
1.1 Proof of Theorem 4.3
We start with proving (i) by deducing the estimate for \(\Phi ^{{\mathbf {u}},\mathrm {h}}_{{{\tilde{\epsilon }}},\epsilon }\). The estimate for \(\Phi ^{{\mathbf {u}},\mathrm {rb}}_{{{\tilde{\epsilon }}},\epsilon }\) follows in a similar, but simpler way. For \(y\in {\mathcal {Y}}\), we have that
We now estimate \(\mathrm {I},\mathrm {II},\mathrm {III}\) separately. By Equation (2.7), Equation (2.9), Assumption 4.2, and the definition of \(\epsilon ''\) there holds for \(y\in {\mathcal {Y}}\) that
We proceed with estimating II. It is not hard to see from Assumption 4.2 that
By definition, \(\epsilon ' = \epsilon /\max \{6,C_{\mathrm {rhs}}\} \le \epsilon .\) Hence, by Assumption 4.1 and (B.3) in combination with Proposition B.3 (i), we obtain
where we have used that \(C_{\mathrm {coer}} \epsilon<C_{\mathrm {coer}} {\alpha }/{4}<1.\) Finally, we estimate III. Per construction, we have that
Moreover, we have by Proposition B.3(v)
and by (B.3) that
Hence, by the choice of \(\kappa \) and Proposition 3.7 we conclude that \(\mathrm {III} \le {\epsilon }/{3}\). Combining the estimates on \(\mathrm {I}, \mathrm {II}\), and \(\mathrm {III}\) yields (i) and using (i) implies (v). Now we estimate the size of the NNs. We start with proving (ii). First of all, we have by the definition of \(\Phi ^{{\mathbf {u}}, \mathrm {rb}}_{{{\tilde{\epsilon }}},\epsilon }\) and \(\Phi ^{{\mathbf {u}}, \mathrm {h}}_{{{\tilde{\epsilon }}},\epsilon }\) as well as Lemma 3.6(a)(i) in combination with Proposition 3.7 that
where we applied Proposition B.3(i) and chose a suitable constant
We now note that if we establish (iii), then (iv) follows immediately by Lemma 3.6(a)(ii). Thus, we proceed with proving (iii). First of all, by Lemma 3.6(a)(ii) in combination with Proposition 3.7 we have
Next, by Lemma 3.6(b)(ii) in combination with Proposition B.3 as well as Assumption 4.1 and Assumption 4.2 we have that
for a suitably chosen constant \(C^{{\mathbf {u}}}_M = C^{{\mathbf {u}}}_M(\epsilon ', C_B, C^{{\mathbf {u}}}_L) = C^{{\mathbf {u}}}_L(C_{\mathrm {rhs}}, C_{\mathrm {coer}},C_{\mathrm {cont}})> 0\). This shows the claim.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kutyniok, G., Petersen, P., Raslan, M. et al. A Theoretical Analysis of Deep Neural Networks and Parametric PDEs. Constr Approx 55, 73–125 (2022). https://doi.org/10.1007/s00365-021-09551-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00365-021-09551-4