
Abstract
Recent studies have examined the role of attention in retaining bound representations in working memory (WM) and found that object-based attention plays a pivotal role. However, no study has investigated whether maintaining bound representations with more features in WM requires extra object-based attention. We investigated this by examining whether a secondary task consuming object-based attention was more disruptive to the maintenance of bindings in WM when more features were stored per object. We instructed participants to memorize three bound representations in a WM task while manipulating the number of features (two vs. three features) contained in each representation. Moreover, we manipulated whether a secondary task consuming object-based attention was interpolated into the maintenance phase of WM. If extra object-based attention was required after the addition of an extra feature in the bound representation, the secondary task would result in a greater disruption of the three- rather than two-featured binding. In two experiments, we found that the added secondary task significantly impaired the binding performance, but the performance of the two- and three-featured bindings was disrupted to the same extent. These results suggest that the presence of more features in a bound representation in WM does not require extra object-based attention.
Similar content being viewed by others


Introduction
Working memory (WM) stores and manipulates a limited set of information (e.g., single features and bound representations) for ongoing cognitive tasks (Baddeley & Hitch, 1974). Recently, researchers have debated whether the retention of bound representations (e.g., colored shapes) in WM requires more attentional resources than constituent single features (e.g., colors and shapes) (for reviews, see Allen, 2015; Gao et al., 2017; Hitch et al., 2020; Schneegans & Bays, 2019), as the answer to this question has a significant impact on the theories and models of WM (e.g., Baddeley, 2000; Baddeley et al., 2011). This question has been predominantly explored using a dual-task paradigm. Participants were presented with a set of stimuli and required to memorize single features or the bindings between these single features in different blocks (for reviews, see Allen, 2015; Schneegans & Bays, 2018). A secondary task consuming a specific type of attention resource was then inserted to compete with the WM task (for reviews, see Allen, 2015; Schneegans & Bays, 2018). If the tested attention is crucial to the retention of binding, the inserted task will lead to a greater disruption in the performance of the bindings relative to that of the constituent features. Using this paradigm, researchers have explored the attentional mechanism of binding in WM from two different perspectives: the roles of visual spatial attention (e.g., Johnson et al., 2008; Wheeler & Treisman, 2002) and domain-general central executive attention (short for central attention) (e.g., Allen et al., 2006, 2014; Allen et al., 2009; Allen et al., 2012; Baddeley et al., 2011; Karlsen et al., 2010; Langerock et al., 2014; Peterson et al., 2019; Peterson & Naveh-Benjamin, 2017; Vergauwe et al., 2014). Currently, the two lines of exploration seem to have reached a consensus that the retention of bindings in WM does not require additional attention than constituent single features (see Allen, 2015, for a review; but see Peterson et al., 2019; Peterson & Naveh-Benjamin, 2017). This conclusion sharply contrasts with perceptual studies stating that feature binding in perception requires the involvement of more attention or resources (e.g., Humphreys, 2001; Treisman & Gelade, 1980; Treisman & Schmidt, 1982).
Nevertheless, bound representations, by nature, are coherent and integrated units (Treisman, 1996, 1998; Treisman & Gelade, 1980). It has been suggested that object-based attention plays a critical role in creating and maintaining such integrated units in perception (e.g., Chen, 2012; Cohen & Tong, 2013; Emmanouil & Magen, 2014; Huang, 2010; Kahneman et al., 1992; Schoenfeld et al., 2003; Schoenfeld et al., 2014) and object WM (Barnes et al., 2001; Matsukura & Vecera, 2009, 2011; Woodman & Vecera, 2011). Therefore, we hypothesized that object-based attention serves as the underlying resource required to retain bound representations in WM. Following previous studies (e.g., Allen et al., 2006; Johnson et al., 2008), we tested the object-based attention hypothesis using a dual-task paradigm, wherein participants maintained a set of single features or the bindings and a secondary task consuming object-based attention was added to the maintenance phase of WM. Supporting the object-based attention hypothesis, the added secondary task led to a greater disruption in the binding conditions relative to the single feature conditions (i.e., selective binding disruption) for separable features (e.g., color and shape; Fougnie & Marois, 2009; Gao et al., 2017; He et al., 2020; Lu et al., 2019; Shen et al., 2015; Wan et al., 2020). This finding is robust, having been consistently observed across different binding types (e.g., visual unitized, cross-WM-module, cross-input-modality, cross-time, dynamic-static feature, and cross-space bindings) and different secondary tasks consuming object-based attention (Duncan’s object feature-report, mental rotation, transparent motion, and multiple object-tracking tasksFootnote 1).
It is worth noting that all existing studies tapping the attentional mechanisms of binding in WM only focused on objects with two features; however, bound representations in daily life usually contain more than two features. It remains unclear whether the presence of extra features in a bound representation in WM requires extra object-based attention. Here, we investigated this by examining whether a secondary task consuming object-based attention was more disruptive to bindings in WM when more features were stored per object. The answer to this question will shed important light on both the characteristics and the processing mechanisms of object-based attention in WM. Two distinct views exist on the relationship between the number of constituent features in a bound representation and the disruption driven by the object-based attention task.
First, the disruption may be independent of the number of constituent features in a bound representation (i.e., feature-independence hypothesis). When object-based attention was initially proposed in perception, an implicit assumption is that the operation of object-based attention is not affected by the number of constituent features. Duncan (1984) found that the performance of processing one feature is the same as that of processing two features from the same object. Duncan proposed that when attention is directed to one feature dimension of an object, the other feature dimensions of this object will also be processed automatically. This process has been supported by several behavioral and neuroimaging studies (e.g., Awh et al., 2001; Duncan, 1984; Schoenfeld et al., 2014; Vecera & Farah, 1994; see Chen, 2012, for a review). Meanwhile, cumulative evidence implies that WM and perception share similar processing mechanisms. For instance, spatial WM recruits spatial attention to rehearse the location information (e.g., Awh & Jonides, 2001; Woodman & Luck, 2004); WM and perception involve similar mechanisms for encoding and manipulating visual information (e.g., Gao & Bentin, 2011; Gao et al., 2010; T. Gao et al., 2011; Kiyonaga & Egner, 2013, 2014; Lu et al., 2016; Mayer et al., 2007). The same primary visual cortices are involved in processing visual features (e.g., color) in both perception and WM (e.g., Harrison & Tong, 2009; but see Xu, 2017, and Yao et al., 2020, for a different view). Therefore, object-based attention in WM may share the same hallmark as that in perception, such that the number of constituent features in the bound representation in WM does not modulate the required object-based attention. Indeed, supporting the feature-independence hypothesis, Luck and Vogel (1997) found that WM performance was not affected by the number of features contained in an object by showing similar performance of retaining objects with one and four features when the same number of objects were maintained in WM.
Conversely, the disruption of the object-based attention task may increase as the number of features per object increases because extra object-based attention is required (i.e., feature-dependence hypothesis). Two lines of evidence support this hypothesis. First, the object-based processing assumption may not work in WM because the schemes of perceptual and post-perceptual objects may differ (e.g., Xie & Zhang, 2016; Xu, 2017; Zhang & Luck, 2011). One potential explanation for the selective disruption of retaining bindings with two features in WM is that each bound representation has an extra feature than the representation of single features. Therefore, as the number of features in a bound representation increases, the amount of object-based attention needed to create a coherent representation may increase accordingly. Second, after Luck and Vogel (1997), several studies found that the number of features in an object affects WM performance (e.g., Balaban & Luria, 2016; Delvenne & Bruyer, 2004; Oberauer & Eichenberger, 2013; Olson & Jiang, 2002; Wheeler & Treisman, 2002; Xu, 2002). For instance, Oberauer and Eichenberger (2013) directly manipulated the number of features (one, three, and six) in each object that had to be maintained in WM and found that WM performance deteriorated as the number of features increased. However, although these findings challenged the feature-independence hypothesis, they did not directly require participants to memorize bound representations in WM, and the test procedure did not assess whether participants retained bound representations. Therefore, these findings indirectly imply the feasibility of the feature-dependence hypothesis. Additional direct empirical evidence is needed to examine the feature-dependence hypothesis strictly.
To examine these two hypotheses, the current study manipulated the number of constituent features in each bound representation by instructing the participants to memorize a set of bindings with two or three features. We further interpolated a secondary task that consumed object-based attention into the WM maintenance phase and manipulated the load of the secondary task. The feature-independence hypothesis predicts that the added secondary task would equally disrupt the performance of bindings with two and three features, whereas the feature-dependence hypothesis predicts that the added secondary task would result in a greater disruption in the performance of bindings with three rather than two features.
Experiment 1: Color-shape-texture binding and mental rotation task
Experiment 1 compared the performance of maintaining color-shape-texture with three corresponding two-featured bindings: color-shape, color-texture, and shape-texture bindings. Following our previous studies (Gao et al., 2017; He et al., 2020; Shen et al., 2015; Wan et al., 2020), we introduced a mental rotation task in the maintenance phase of WM to consume object-based attention. Previous studies have revealed that participants perform object-based mental transformation when mentally rotating an object (Dalecki, Hoffmann, & Bock, 2012; Zacks & Michelon, 2005). That is, the object representation operates by attention when participants mentally rotate an object relative to axes defined respective to the object (object-based frame) without any movement in the 2-D space. Moreover, although the conduction of a mental rotation requires the central executive (e.g., Hegarty et al., 2000), it has been found that object rather than spatial WM is a substrate for mentally rotating a letter (Hyun & Luck, 2007; Prime & Jolicoeur, 2010). Considering that object- rather than spatial-based attention plays a critical role in retaining objects in visual WM (Barnes et al., 2001; Matsukura & Vecera, 2009, 2011; Woodman & Vecera, 2011) and that visual WM is conceived as visual attention sustained internally over time (Chun, 2011; Chun, Golomb, & Turk-Browne, 2011; Kiyonaga & Egner, 2013), we argue that mentally rotating a letter consumes object-based attention (see also Jansen & Lehmann, 2013, for a similar claim) in WM. Corroborating this, we employed a mental rotation task to consume object-based attention to explore the attentional mechanism of binding in WM (see Experiments 1–3 in Shen et al., 2015; and He et al., 2020; Wan et al., 2020). Akin to the Duncan task, which is a standard task showing the existence of object-based attention (Duncan, 1984), we consistently found that the mental rotation task impaired the performance of bindings to a larger degree compared to that of the constituent features. Meanwhile, for integral-feature bindings that do not require extra resources in WM, the mental rotation task does not selectively impair the binding performance (cf. Wan et al., 2020).
Methods
Participants
Following previous studies on the role of object-based attention in retaining bindings (Gao et al., 2017; Lu et al., 2019; Shen et al., 2015; Wan et al., 2020), 24 participants (nine males; aged 23.13 ± 0.57 years) took part in the experiment. All participants were undergraduate students from Zhejiang University, who signed consent forms, had normal color vision, and had normal or corrected-to-normal visual acuity. The study conformed to Standard 8 of the American Psychological Association’s Ethical Principles of Psychologists and Code of Conduct and was approved by the Research Ethics Board of Zhejiang University.
Apparatus and stimuli
Stimuli
Stimuli were presented against a gray (128, 128, 128; RGB) background on a 19-in. CRT monitor with a resolution of 1,024 × 768 pixels at a 100-Hz refresh rate. The participants were seated in a dark room approximately 60 cm from the screen.
WM task
The memory array consisted of three items with three different features: color, shape, and texture. Each feature was randomly selected from a pool of six samples (Fig. 1). The probes were different in the three two-featured blocks to encourage participants to memorize the target bindings without the irrelevant dimension (see Fig. 2, Probe). In the color-shape, color-texture, and shape-texture binding blocks, the probes were a colored shape without any texture, a colored texture blob that did not indicate any shape, and a textured shape without any color, respectively. To ensure the participants memorized all three-featured bindings without resorting to any potential strategies,Footnote 2 in the color-shape-texture binding block, the three probe types were randomly presented with equal probabilities. Following earlier studies (e.g., Allen et al., 2006; Shen et al., 2015), all the probed stimuli were placed 3.38° below the center of the screen.

The features used in Experiments 1 and 2. a Colors used in Experiments 1 and 2. The colors are red (255, 0, 0; RGB), green (0, 255, 0), blue (0, 0, 255), yellow (255, 255, 0), magenta (255, 0, 255), and white (255, 255, 255), from left to right. The colored blobs were also used to mark colors and locations in the probe. b Shapes used in Experiments 1 and 2. The shapes (at an average visual angle of 2.4° × 2.4°) were a circle, diamond, star, triangle, chevron, and an inverted “T.” The hollow shapes were also used to mark the shapes and locations in the probe. c Textures used in Experiment 1

A schematic illustration of a trial in Experiment 1 (the stimuli were not drawn to this scale in the real experiment). The top and bottom frames of mental rotation illustrate the with-rotation and no-rotation conditions, respectively. The English phrases in the figures were not presented in the experiment and are only here for illustration purposes. A colored shape, a colored texture blob, and a textured shape were used as the probe in the color-shape, color-texture, and shape-texture binding blocks, respectively. The three probe types were randomly presented with equal probabilities in the three-featured binding block. When probing a new binding, two features randomly selected from two objects in the memory array were recombined to form a new binding
The mental rotation task
A 0.5° × 1.0° black letter “R” was presented at the center of the screen in its canonical or mirror-reversed form. In the with-rotation condition, the “R” was randomly rotated 72–144° clockwise or counterclockwise. In the no-rotation condition, the “R” remained upright.
Design and procedure
The experiment adopted a 2 (task load: with rotation vs. no rotation) × 4 (memory condition: color-shape, color-texture, shape-texture, and color-shape-texture bindings) within-subjects design. According to the two task-load conditions, the whole experiment was divided into two sessions, the order of which was counterbalanced between participants using an ABBA format. Each session contained four blocks – color-shape, color-texture, shape-texture, and color-shape-texture binding blocks; the orders were fully counterbalanced using the Latin square principle. Each block had 30 trials, resulting in a total of 240 trials for the entire experiment. The participants completed at least ten practice trials before each block. The entire experiment lasted approximately 70 min.
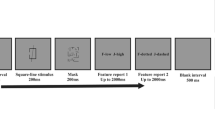
The procedure for each trial is shown in Fig. 2. Each trial began with a 500-ms fixation (a 0.5° × 0.5° black cross at the center of the screen) to indicate the commencement of the trial. Participants were required to fixate on the center of the screen during the entire trial. Then, the memory array was presented for 3,000 ms. The three objects were presented in a horizontal row at the center of the screen with a 3° center-to-center visual distance (e.g., Allen et al., 2006; Gao et al., 2017). After a 500-ms blank interval, the secondary task appeared, wherein the participants were required to form a judgment about the characteristics (i.e., canonical or mirror-reversed) of the letter “R” within 2,000 ms. Finally, after a 500-ms fixation interval, a probe was presented, and participants had to judge whether the probed binding was presented in the memory array or not within 3,000 ms. The inter-trial blank interval was randomly selected from 1,000 to 1,500 ms. In both the WM and secondary tasks, once a participant made a response by pressing the corresponding key, the next step would start immediately.
For the WM task, before the commencement of each block, participants were explicitly instructed on the specific memory condition. Consequently, participants had to memorize color-shape, color-texture, shape-texture, or color-shape-texture bindings in different blocks. When the probe appeared, participants had to determine whether the probed information was presented in the memory array by pressing “J” for presence and “F” for absence. The response accuracy was emphasized. In 50% of the trials, a new binding that recombined two distinct features from two randomly selected objects in the memory array was presented; in the remaining 50% of trials, an old binding in the memory array was displayed. For the secondary task, participants had to press a button to indicate whether the letter “R” was in the canonical (50% trials; F on the keyboard) or mirror-reversed (50% trials; J on the keyboard) form. Participants were instructed to prioritize the secondary task, and the accuracies of the WM and secondary tasks were emphasized.
Analysis
For the secondary task, the ceiling effect was observed in the current study. The analysis also did not reveal any findings of interest, thus we did not report the related analysis here.Footnote 3 For the WM task, only trials with a correct response on the mental rotation task were subjected to further analysis. A two-way repeated-measures ANOVA was conducted on the accuracy (considering both hit rate and correct rejection) of the WM task,Footnote 4 with task load (no-rotation vs. with-rotation) and memory condition (color-shape, color-texture, shape-texture, and color-shape-texture bindings) as within-subjects factors. The data in the color-shape-texture binding condition were also broken according to the probe type; the impairment of the secondary task on the three binding types between the two- and three-feature blocks was then compared. A two-way repeated-measures ANOVA was conducted on the accuracy for each probe type, with the task load (with-rotation vs. no-rotation) and number of features in the block (two vs. three features) as within-subjects factors.
Additionally, we calculated the Bayes factor (BF; Rouder et al., 2012; Rouder et al., 2009) to compare the posterior probability of the null and with alternative models using JASP (version 0.9.1). We divided the posterior probability of the null model with that of a linear model (including the effect of subject and one main effect) to get the BF01s for the main effects, and compared the reduced model (numerator; including the effect of subjects and two main effects) with a full model (denominator; including the effect of subject, the two main effects, and the effect of the interaction between the two factors), to compute the BF01s for the interaction. A BF01 larger than 3 indicates substantial evidence for the null hypothesis, and a BF01 larger than 10 is considered to provide strong evidence for the null hypothesis (cf. Jeffreys, 1961). The p-value of the frequentist analyses can indicate a significant effect (p < .05), but the BF01 is larger than .333, indicating that the evidence for the effect is not reliable. We indicated these situations as \( {BF}_{01}^{\ast } \) in the Results section.
Results
The mean accuracy of the secondary task was 99.27% (95% CI: 98.5–99.79%) and 95.90% (95% CI: 94.43–97.43%) for the no- and with-rotation conditions, respectively. The performance of the with-rotation condition was significantly worse than the no-rotation condition (t[23] = 3.844, p < .001, Cohen’s d = .785, BF01= .024). The accuracy of the WM task under different conditions is presented in Fig. 3a. The ANOVA revealed a significant main effect of task load (F[1,23] = 17.914, p < .001, ηp2 = .438, BF01= .059) suggesting that the performance in the no-rotation condition (mean = .84; 95% CI: .81–.86) was significantly better than that in the with-rotation condition (mean = .79; 95% CI: .75–.82). The main effect of memory condition was also significant (F[3,69] = 17.488, p < .001, ηp2 = .432, BF01= 1.315e-9). The post hoc contrasts (Bonferroni-corrected) revealed that the performance of the color-shape binding was significantly better than the shape-texture binding (t[23] = 2.842, p = .035, Cohen’s d = .580) and the color-shape-texture binding(t[23] = 7.026, p < .001, Cohen’s d = 1.434), but was not significantly different from that of the color-texture binding (t[23] = 1.678, p = .587, Cohen’s d = .343); the performance of the color-texture binding was significantly better than that of the color-shape-texture binding (t[23] = 5.348, p < .001, Cohen’s d = 1.092), but was not significantly different from that of the shape-texture binding (t[23] = 1.164, p = 1.000, Cohen’s d = .238). The performance of shape-texture binding was significantly better than the color-shape-texture binding (t[23] = 4.184, p < .001, Cohen’s d = .854). Importantly, the task load × memory condition interaction was not significant (F[3,69] = .505, p = .680, ηp2 = .022, BF01= 11.478), suggesting that the mental rotation task equally disrupted the performance of the four types of bindings.

Results for Experiment 1. a The accuracy of the working memory (WM) for the four bindings in the no-rotation and with-rotation conditions. b The accuracy of the WM for the two- and three-featured bindings with the same probe type. Error bars represent the bootstrap 95% CIs
Comparisons between the performance of the bindings with two and three features in the same probe condition are presented in Fig. 3b. The two-way ANOVA revealed that the main effect of task load was significant in all three probe types: the color-shape (F[1,23] = 6.476, p = .018, ηp2 = .220, \( {BF}_{01}^{\ast } \)= .513), color-texture (F[1,23] = 5.694, p = .026, ηp2 = .198, \( {BF}_{01}^{\ast } \)= .772), and shape-texture (F[1,23] = 5.354, p = .030, ηp2 = .189, \( {BF}_{01}^{\ast } \) = .982) binding probes. These results indicated that the secondary task significantly impaired the WM performance of the bindings under all probe conditions. The main effect of the number of features was significant in the color-shape (F[1,23] =22.766, p < .001, ηp2 = .497, BF01 = 1.641e-4), color-texture (F[1,23] =19.819, p < .001, ηp2 = .463, BF01 = 3.360e-4), and shape-texture (F[1,23] = 11.842, p = .002, ηp2 = .340, BF01 = .013) probe conditions. These results suggest that the WM performance of bindings was significantly impaired in trials with three rather than two features. Furthermore, the task load × number of feature interaction was not significant in any of the three probe conditions: the color-shape (F[1,23] = .222, p = .642, ηp2 = .010, BF01 = 3.364), color-texture (F[1,23] = 1.287, p = .268, ηp2 = .053, BF01 = 2.287), and shape-texture (F[1,23] = .159, p = .694, ηp2 = .007, BF01 = 3.394) probe conditions.
Discussion
Although the added mental rotation task significantly impaired the WM performance of bindings, the disruptions of the bindings with two and three features were comparable, implying that the number of features per object did not modulate the required object-based attention for maintaining bindings in WM. This supports the feature-independence hypothesis. It should be noted that the key finding of Experiment 1 was a null effect (i.e., the non-significant interaction between memory condition and task load) and that deriving meaning from a null effect requires additional confidence that the other aspects of the experimental method did not fail (e.g., the secondary task setting, the binding stimuli). This was considered in the second experiment.
Experiment 2: Color-shape-location binding and Duncan task
Experiment 2 examined the generality of Experiment 1 using a new set of features for binding and a new secondary task. Specifically, we focused on the binding between the color, shape, and location. Although it has been suggested that the location information serves as an anchor when forming feature bindings according to the feature integration theory (Treisman & Gelade, 1980), our studies found that the performance of retaining location-related, two-featured bindings (e.g., color-location binding, shape-location binding) in WM was similar to that of retaining other conjunctive bindings (e.g., color-shape binding). Both require more object-based attention than maintaining the constituent single features (e.g., He et al., 2020; Lu et al., 2019; Shen et al., 2015).
For the secondary task, we used the Duncan feature-report task (the Duncan task for short) to consume object-based attention. In the Duncan task, we presented participants with two superimposed objects, a box and a line, each containing two task-relevant features. The performance when reporting two features from the same object (e.g., a box; the same-object condition) is significantly better than when reporting two features from two different objects (e.g., a box and a line; the different-objects condition), which is interpreted as processing two objects requiring more object-based attention than processing one object (Duncan, 1984). Through this task, we previously found that the WM performance of bindings was selectively disrupted, compared to the feature conditions, in both the same- and different-object conditions relative to the no-Duncan-task condition (Gao et al., 2017; Shen et al., 2015). Given that the same-object feature-report task also consumes object-based attention, Experiment 2 only required the participants to complete the same-object Duncan task to simplify the experiment and make it less time-consuming. If the feature-independence hypothesis is true, we would obtain results similar to those in Experiment 1.
In Experiment 2, we also intended to re-establish our previous finding that object-based attention plays a pivotal role in retaining bindings containing two features relative to retaining single features (Gao et al., 2017; He et al., 2020; Lu et al., 2019; Shen et al., 2015; Wan et al., 2020) by adding a session involving retaining single features in WM.Footnote 5 The single feature session was contributed by a different group of participants, wherein they were required to maintain the single features (color, shape, and location) with or without a Duncan task during the maintenance phase. We predicted that the disruption caused by the Duncan task would be larger in the binding condition than in the two corresponding feature conditions.
Additionally, because the bindings examined in Experiment 2 were simpler than those in Experiment 1, we reduced the encoding time of the memory array from 3,000 to 500 ms. Our pilot experiment showed that a 500-ms duration was sufficient to encode the memory array since the accuracy was above 80% without any secondary task in all four binding conditions. Moreover, this setting also helped reduce the potential verbal coding of the memory array under a prolonged exposure time.
Methods
Participants
Following previous studies, 24 participants (eight males; age 23.00 ± 0.52 years) participated in the binding session, and a new group of 24 participants (eight males; age 21.33 ± 0.53 years) participated in the single feature session. Five participants in the binding condition were replaced because of the chance-level performance of the WM task; one participant was replaced because of the chance-level performance of the secondary task. The other aspects were the same as those used in Experiment 1.
Apparatus and stimuli
The WM task
The memory array consisted of three items with varied colors, shapes, and locations. Each color and shape were randomly selected from a pool of six different samples (see Fig. 1a and b). Each location was randomly selected from six positions evenly distributed around an invisible circle (radius = 4.7° of visual degree). Two location distributions were used in our experiment equally. The distributions started from either 45° or 15° (12 o’clock as the starting point), and both had a 60° clockwise increment in each step. The probes differed between blocks. In the single feature session, the probe was a colored blob, hollow shape, or a black “#” indicating the tested location (see Fig. 4a–c) in the different feature blocks. In the binding session, the probe was a colored shape at the screen center, a colored blob at a specific location, or a hollow shape at a specific location, indicating the color-shape, color-location, or shape-location bindings (see Fig. 4d–f) in the different binding blocks. In the color-shape-location binding block, the probe was randomly selected from the three aforementioned binding probes with equal probability.

The probe used in Experiment 2 in different memory conditions. Dashed circles were not visible in the experiment
The Duncan task
The stimuli consisted of two superimposed black objects: a box and a line (see Fig. 5, box-line stimuli). Each object had two task-relevant features. The box (1.02° width) was either short (1.02°) or tall (1.43°) and had a gap (0.31° width) on either the left or the right side. The line (3.19° long) was either dashed or dotted and tilted 8° to either the left or right side. The backward mask was 2.11° in width and 2.86° in height.

Design and procedure
The binding session adopted a 2 (task load: no Duncan vs. with Duncan tasks) × 4 (memory condition: color-shape, color-location, shape-location, and color-shape-location bindings) within-subjects design. According to whether the Duncan task was involved, the whole experiment was divided into two sessions, the order of which was counterbalanced between participants using an ABBA format. Each session had four blocks: color-shape, color-location, shape-location, and color-shape-location bindings, the order of which was fully counterbalanced using the Latin square principle. Each block consisted of 30 trials, with 240 trials in total. The participants completed at least ten practice trials before each block. The entire binding session lasted approximately 70 min.
The single feature session adopted a 2 (task load: no Duncan vs. with Duncan tasks) × 3 (memory condition: color, shape, and location) within-subjects design. The entire experiment was also divided into two sessions according to the task load using an ABBA order. Each session had three blocks: color, shape, and location, the order of which was fully counterbalanced using the Latin square principle. Each block consisted of 30 trials, with 180 trials in total. The participants completed at least ten practice trials before each block. The entire feature session lasted approximately 50 min.
The procedure of each trial was the same in the single feature and binding sessions (see Fig. 5), except for the probe. Each trial began with a 500-ms black cross fixation at the center of the screen (0.5° × 0.5°). The memory array was then presented for 500 ms. After a 500-ms blank interval, the Duncan task started, and the participants were required to make two successive responses to report the cued features. Finally, a probe was presented after a 500-ms fixation, and participants had to respond within 3,000 ms. The inter-trial blank interval was randomly selected from 1,000 to 1,500 ms. In both the WM and secondary tasks, once a participant responded by pressing a corresponding key, the next step would start immediately.
For the WM task, before the commencement of each block, participants were explicitly instructed on the specific memory condition in the coming block. The participants maintained color-shape, color-location, shape-location, and color-shape-location bindings in different blocks in the binding session, and colors, shapes, and locations in different blocks in the single feature session. When the probe appeared, participants had to determine whether the probed information was presented in the memory array by pressing “J” for presence and “F” for absence. The response accuracy was emphasized. In 50% of the trials, the probed information was absent from the memory array; a new binding that recombined two distinct features from two randomly selected objects in the memory array was present in the binding blocks, while a new feature that did not appear in the memory array was present in the single feature blocks.
For the secondary task, the participants were informed beforehand whether the Duncan task was going to be conducted and informed of the to-be-reported features when the task was conducted (e.g., the gap direction and height of the box in Chinese characters). When the Duncan task started, a superimposed box-line stimulus was presented for 200 ms and was backward masked for 200 ms. The two question screens were then presented sequentially, informing participants to report the two cued features. Each question window lasted no longer than 2,000 ms. In the no-Duncan-task condition, participants were instructed to ignore the question screens by pressing the spacebar on the keyboard. If they did not respond within the time window or pressed any wrong keys, the secondary task of this trial would be considered incorrect. Participants were asked to prioritize the Duncan task, and the accuracy for both the WM and Duncan task were emphasized.
Analysis
For the WM task, only trials with correct responses in the Duncan task were subjected to further analysis. To examine the feature-independence hypothesis, a two-way repeated-measures ANOVA was conducted on the accuracy of the binding session with task load (no-Duncan vs. with-Duncan tasks) and memory condition (color-shape, color-location, shape-location, and color-shape-location bindings) as within-subjects factors. Similar to Experiment 1, we dissected the data in the three-featured binding condition according to the probe type. A two-way repeated-measures ANOVA was conducted on the accuracy under the three probe types separately, with the task load (no-Duncan vs. with-Duncan tasks) and number of features in the block (two vs. three features) as within-subjects factors. Additionally, a two-way repeated-measures ANOVA was conducted on the accuracy in the single feature session with task load (no-Duncan vs. with-Duncan tasks) and memory condition (color, shape, and location) as within-subjects factors.
To examine the object-based attention hypothesis (Gao et al., 2017; He et al., 2020; Lu et al., 2019; Shen et al., 2015), we compared the disruption of the Duncan task to bindings and the constituent single features. Specifically, we calculated the cost of the secondary task by subtracting the WM performance under the Duncan task condition from that under the no-Duncan task condition. Following previous studies (e.g., Allen et al., 2006; Gao et al., 2017; Shen et al., 2015), we conducted planned contrasts (independent sample one-tail t-tests) to compare the disruptions of the Duncan task in the binding and the corresponding feature conditions. We used the same method as in Experiment 1 to calculate and explain BF01 for each effect.
Results
In the binding session, the overall accuracy of the secondary task (two responses were correct in a trial) was 98.96% (95% CI: 98.5–99.45) and 91.22% (95% CI: 89.2–93.02) in the no- and with-Duncan-task conditions, respectively. The performance in the with-Duncan-task condition was significantly worse than in the no-Duncan-task condition (t[23] = 7.313, p < .001, Cohen’s d = 1.493, BF01 = 1.223e-5). In the single feature session, the overall accuracy of the secondary task was 99.46% (95% CI: 98.5–99.45) and 92.71% (95% CI: 89.2–93.02) in the no- and with-Duncan-task conditions, respectively. The performance in the with-Duncan-task condition was again significantly worse than that in the no-Duncan-task condition (t[23] = 8.520, p < .001, Cohen’s d = 1.739, BF01 = 1.089e-6).
Performance in the binding session
The accuracy of the WM task in different blocks in the binding session is shown in Fig. 6a. The two-way ANOVA revealed a significant main effect of task load (F[1, 23] = 85.085, p < .001, ηp2 = .787, BF01 = 3.630e-16); this suggests that the performance in the no-Duncan-task condition (mean = .88; 95% CI: .85–.91) was significantly better than in the Duncan-task condition (mean = .74; 95% CI: .70–.77). The main effect of memory condition also reached significance (F[3,69] = 22.369, p < .001, ηp2 = .493, BF01 = 1.807e-5). The post hoc contrasts (Bonferroni-corrected) revealed that the performance of the color-location binding was significantly better than that of the shape-location (t[23] = 3.935, p = .001, Cohen’s d = .803), color-shape (t[23] = 7.597, p < .001, Cohen’s d = 1.551), and color-shape-location (t[23] = 6.988, p < .001, Cohen’s d = 1.427) bindings. The performance of the shape-location binding was significantly better than that of the color-shape (t[23] = 3.661, p = .003, Cohen’s d = .747) and color-shape-location (t[23] = 3.053, p = .019, Cohen’s d = .623) bindings, yet the performance of the color-shape binding was not significantly different from that of the color-shape-location binding (t[23] = .608, p = 1.000, Cohen’s d = .124). Of note, similar to Experiment 1, the task load × memory condition interaction was not significant (F[3,69] = 1.626, p = .191, ηp2 = .066, BF01 = 3.606), supporting the feature-independence hypothesis.

Results for Experiment 2. (a) The accuracy of the working memory (WM) of the four bindings in the no-Duncan-task and with-Duncan-task conditions. (b) The accuracy of the WM of the two- and three-featured bindings with the same probe type. (c) The accuracy of the WM of the three single features in the no-Duncan-task and the with-Duncan-task conditions. Error bars represent the bootstrap 95% CIs
The comparisons between the performance of the bindings with two and three features in the same probe-type condition are presented in Fig. 6b. The two-way ANOVA found that the main effect of task load was significant in all the three probe-type conditions: the color-location (F[1,23] = 34.451, p < .001, ηp2 = .600, BF01 = 3.12e-6), shape-location (F[1,23] = 42.964, p < .001, ηp2 = .651, BF01 = 7.72e-8), and color-shape (F[1,23] = 29.812, p < .001, ηp2 = .564, BF01 = 5.106e-6) binding probes. These results suggest that the secondary task significantly disrupted the WM performance in all probe conditions. The main effect of the number of features was significant in both the color-location (F[1,23] =8.321, p = .008, ηp2 = .266, \( {BF}_{01}^{\ast } \)= .528) and shape-location (F[1,23] =7.223, p = .013, ηp2 = .239, \( {BF}_{01}^{\ast } \)= .553) probe conditions, but was not significant in the color-shape probe condition (F[1,23] =2.872, p = .104, ηp2 = .111, BF01= 3.049); this suggests that the performance of the color-location and shape-location bindings was significantly impaired when the number of features increased, but that the performance of the color-shape binding was not. Notably, the task load × number of features interaction was not significant in any probe condition: color-location (F[1,23] = 1.978, p = .173, ηp2 = .079, BF01= 1.592), shape-location (F[1,23] = .134, p = .717, ηp2 = .006, BF01= 3.399), and color-shape (F[1,23] = .035, p = .853, ηp2 = .002, BF01 = 3.37) probe conditions.
Performance in the single feature session
The accuracy of the WM task in different blocks in a single feature session is presented in Fig. 6c. The two-way ANOVA revealed a significant main effect of task load (F[1,23] = 42.178, p < .001, ηp2 = .647, BF01 = 3.604e-7), suggesting that the performance in the no-Duncan-task condition (mean = .90; 95% CI: .88–.92) was significantly better than in the Duncan-task condition (mean = .85; 95% CI: .82–.87). The main effect of memory condition was also significant (F[2,46] = 49.641, p < .001, ηp2 = .683, BF01 = 1.616e-49). The post hoc contrasts (Bonferroni-corrected) revealed that the performance of location was significantly better than color (t[23] = 3.659, p = .002, Cohen’s d = .747) and shape (t[23] = 9.856, p < .001, Cohen’s d = 2.012), and the performance of color was significantly better than shape (t[23] = 6.197, p < .001, Cohen’s d = 1.265). The task load × memory condition interaction was not significant (F[2,46] = .599, p = .553, ηp2 = .004, BF01 = 4.656), suggesting that the Duncan task equally disrupted the WM performance of the three features.
Cost comparison between bindings and single features
The costs of the Duncan task in the binding and single feature conditions are presented in Fig. 7. The planned contrasts revealed that the costs in the binding conditions were all significantly higher than those in the constituent feature conditions (ps < .05). For the color-location binding, the cost in the binding condition was significantly larger than in the color (t[46] = 2.476, p = .009, Cohen’s d = .715, BF01 = .157) and location (t[46] = 2.492, p = .008, Cohen’s d = .719, BF01 = .153) conditions. For shape-location binding, the cost in the binding condition was significantly larger than in the shape (t[46] = 3.381, p < .001, Cohen’s d = .976, BF01 = .022) and location (t[46] = 4.836, p < .001, Cohen’s d = 1.396, BF01 = 4.404e-4) conditions. For the color-shape binding, the cost in the binding condition was significantly larger than in the color (t[46] = 3.603, p < .001, Cohen’s d = 1.040, BF01 = .013) and shape (t[46] = 2.525, p = .008, Cohen’s d = .729, BF01 = .143) conditions. For the color-shape-location binding condition, the cost in the binding condition was significantly larger than in the color (t[46] = 3.581, p < .001, Cohen’s d = 1.034, BF01 = .014), shape (t[46] = 2.557, p = .007, Cohen’s d = .738, BF01 = .134), and location conditions (t[46] = 3.693, p < .001, Cohen’s d = 1.066, BF01 = .010).

The costs of the Duncan task in the binding (left) and single feature (right) conditions. Error bars represent the bootstrap 95% CIs
Discussion
Using a new set of binding stimuli and a new secondary task, we re-established the previous key findings of the object-based attention hypothesis (Gao et al., 2017; He et al., 2020; Lu et al., 2019; Shen et al., 2015). More importantly, Experiment 2 found a similar result pattern to that in Experiment 1. The Duncan task equally disrupted the WM performance of bindings with two and three features, suggesting that the feature-independence hypothesis is not limited to a specific binding type or secondary task setting.
General discussion
The current study investigated whether the presence of more features in a bound representation in WM requires extra object-based attention. We achieved this by examining whether a secondary task consuming object-based attention was more disruptive to the WM maintenance of three- than two-featured bindings. Consistent with previous studies (e.g.,Gao et al., 2017 ; He et al., 2020 ; Lu et al., 2019 ; Shen et al., 2015 ; Wan et al., 2020), we demonstrated that the added object-based attention task selectively disrupted the performance of bindings more than of the constituent single features, suggesting that object-based attention plays a critical role in the retention of bound representations in WM. However, the disruption driven by the secondary task was independent of the number of constituent features in an object by exhibiting a similar degree of disruptions in the two -and three-featured binding conditions. Although some of our results were not of optimal reliability as they were supported only by frequentist but not Bayesian analyses, the central results of the current study that are summarized and discussed here were supported by both statistical frameworks. These results imply that the presence of more features in a bound representation does not require extra object-based attention in WM, supporting the feature-independence hypothesis.
Does the setting of memory array contaminate the current finding?
Before discussing the implications of the current findings, we must first consider whether the current findings were due to the specific setting of the memory array. In particular, we presented participants with the same stimuli under different binding conditions. The underlying logic, which has been adopted in previous WM binding explorations (e.g., Allen et al., 2006; Ding et al., 2015; Fougnie & Marois, 2009; Gao et al., 2017; He et al., 2020), was that participants were able to effectively extract different information from the same stimuli according to different instructions. However, this setting could lead to two alternative explanations for the similar disruptions of the secondary task in the two -and three-featured binding conditions.
The first alternative is that participants may also maintain three-featured bindings in WM in the two-featured binding conditions. Indeed, there is evidence suggesting that other task-irrelevant features are also encoded when participants are only required to memorize two-featured bound representations (Bocincova et al., 2017; Logie et al., 2011). However, for several reasons, we believe that this alternative could not explain our findings. First, Bocincova et al. (2017) suggested that irrelevant features are stored in a high-resolution sensory memory system (e.g., fragile WM, which lies between iconic memory and WM; see Sligte et al., 2008; Sligte et al., 2010; Vandenbroucke et al., 2011) by showing that a visual pattern mask erased representations of irrelevant features. Therefore, irrelevant features may have been encoded, but these are stored in a different buffer from the targets (i.e., two-featured bound representations). Moreover, the added secondary task was partially a visual pattern mask erasing irrelevant features from memory. Second, if this logic was correct, participants would also retain the bound representations in the single feature conditions in Experiment 2; hence, comparable disruptions should be observed in the single feature and binding conditions. However, both Experiment 2 and our previous studies (Gao et al., 2017; He et al., 2020; Lu et al., 2019; Shen et al., 2015; Wan et al., 2020) consistently found that the added secondary task consuming object-based attention led to greater disruptions in bindings than single features. Moreover, because location has been suggested as a primary anchor to which other features are bound (e.g., Allen et al., 2015; Jiang et al., 2000; Logie et al., 2011; Treisman & Zhang, 2006; Woodman et al., 2012), participants were most likely to bind the irrelevant feature – location – to the target feature representations (e.g., color). As such, the same amount of attention should be employed in the binding and feature conditions when location is a constituent feature (e.g., color-location binding and only color conditions). Conversely, both Experiment 2 and Shen et al. (2015) demonstrated that more object-based attention was required to retain color-location bindings than only color or location (see also Gao et al., 2017; Lu et al., 2019). Finally, this alternative could not explain the different results between Experiments 1 and 2. The performance of the three-featured binding was comparable to that of the color-shape binding in Experiment 2; the performance of the three-featured binding was significantly lower than that of the two-featured bindings in Experiment 1.
The second alternative is that participants may retain three two-featured bindings to fulfill the three-feature binding task. However, this alternative is unlikely. As mentioned in Footnote 2, in the post hoc interview after the experiment in both the pilot experiment and the current Experiment 1, all participants reported that they memorized three- rather than two-featured bindings in the three-feature binding condition. A typical answer was that it was difficult for them to split a three-feature binding into three two-featured bindings during the memory array window. Moreover, if participants indeed maintained three two-featured bindings for each three-feature binding, the WM load in the three-featured binding condition would be excessive because they had to retain nine two-feature bindings; this was in sharp contrast to the three two-featured binding conditions. However, as shown in Figs. 2a and 6a, the performance of the three-featured bindings was fairly close to that of some two-featured bindings (the shape-texture and shape-color-texture bindings in Experiment 1 and the color-shape and color-shape-location bindings in Experiment 2).
Overall, we argue that the key finding of the current study was not contaminated by the current setting of the memory array. However, future studies exploring this issue may consider using different memory settings (e.g., keeping the irrelevant feature dimension constant when testing two-featured bindings) to overcome these caveats.Footnote 6 Moreover, attention should be paid to the paradigm used to examine bindings containing more than two features. To ensure that the participants maintained the conjunction among the three features, we modified the probe manner by randomly displaying one of the three types of probes. Although this was effective, using a more direct examination to further verify the current finding may be of value (e.g., presenting participants a feature as a cue and then requiring them to recall the two remaining features).
Role of object-based attention in retaining multi-featured bindings in WM
The current study adds new evidence supporting the notion that retaining bindings in WM requires extra object-based attention compared with retaining the constituent single features. First, we re-established the selective disruptions to the color-location and color-shape bindings observed in Experiment 2 of Shen et al. (2015). We also examined for the first time whether retaining three-feature bindings in WM requires extra object-based attention compared with retaining three constituent features. Consistent with the object-based attention hypothesis, we found that the added Duncan task resulted in a selective binding disruption relative to the three constituent feature conditions, suggesting that retaining three-featured bindings requires extra object-based attention compared to retaining the constituent single features.
Critically, the current study extended the object-based attention hypothesis to retain bound representations in WM by focusing on whether the presence of more features in a bound representation requires extra object-based attention in WM. It is notable that several studies have explored the influence of the number of features in a visual object on WM performance and found that more features usually lead to worse performance (e.g., Delvenne & Bruyer, 2004; Oberauer & Eichenberger, 2013; Olson & Jiang, 2002; Wheeler & Treisman, 2002; Xu, 2002). However, these studies did not explicitly manipulate the bindings between the features, thus participants could finish their tasks without forming any bindings (e.g., Wheeler & Treisman, 2002). Therefore, we cannot directly form conclusions regarding our question from these studies. Our findings are in contrast to the implication of the aforementioned studies; although adding an extra feature to the bound representation significantly impaired the WM performance (except for the color-shape vs. color-shape-location bindings in Experiment 2), a three-featured binding did not cost more object-based attention than a two-featured binding. Hence, the current study fills an important gap in the WM literature on binding. Moreover, it suggests that the phenomenon of retaining two-featured bindings requires more object-based attention than retaining the constituent single features (Gao et al., 2017; He et al., 2020; Lu et al., 2019; Shen et al., 2015; Wan et al., 2020) is not because the bound representation contains an extra feature.
This finding has critical implications for the mechanisms of the episodic buffer (Baddeley, 2000). The episodic buffer is a storage buffer in the multiple-component model of WM by Baddeley (2000) that binds information from the phonological and visuospatial subsystems and long-term memory into a coherent representation. The initial key assumption of the episodic buffer is that it actively builds and maintains bound representations using central attention from the central executive. However, ample studies using a dual-task paradigm did not support this assumption by showing that the disruptions caused by the added secondary task did not differ significantly between the binding and constituent feature conditions (for reviews, see Allen, 2015; Schneegans & Bays, 2018). More recently, Baddeley and his colleagues considered that the episodic buffer passively receives the bound representation that has been formed elsewhere before entering into the episodic buffer (Baddeley et al., 2010, 2011). Given that the secondary tasks consuming object-based attention resulted in selective binding disruptions (Fougnie & Marois, 2009; Gao et al., 2017; He et al., 2020; Lu et al., 2019; Shen et al., 2015; Wan et al., 2020), we therefore suggest that the episodic buffer is not a slave buffer under the control of the central executive; instead, it is an independent storage buffer that is fueled by object-based attention (Gao et al., 2017). The current finding is consistent with this hypothesis, showing that maintaining both two- and three-featured bindings requires extra object-based attention relative to maintaining the constituent single features. Moreover, consistent with the characteristics of the object-based attention shown in perception (see Chen, 2012, for a review), we found that maintaining a three-featured binding does not require extra object-based attention relative to maintaining the corresponding two-featured bindings. The initial assumption of the episodic buffer (Baddeley, 2000) did not predict the relationship between the required attention resource and the number of features in a bound representation. Our findings imply that the operation of the episodic buffer is not affected by the number of features per bound representation but is affected by the nature of the retained representations (e.g., binding or feature; see also Wan et al., 2020). It is necessary to take this point into consideration in the theoretical development of the episodic buffer.
However, we must note that all the existing evidence (including the current study) revealing the role of object-based attention in retaining bound representations only analyzed the maintenance phase of WM. According to Baddeley (2000), the episodic buffer is in charge of both encoding and retaining bound representations in WM. All of Baddeley and colleagues’ studies on the episodic buffer explored the role of central attention in both the encoding and maintenance phases. The encoding and maintenance of bound representations may differ in the request of attentional resources (i.e., the encoding of bindings might be automatic, whereas the maintenance might be resource-demanding). Therefore, it is crucial to determine the role of object-based attention in encoding binding in WM in future studies.
Object representations in WM
The current study contributes new evidence regarding the influence of the number of features contained in an object on WM performance. In most cases, the WM performance of three-featured bindings significantly decreased relative to that of two-featured bindings (see Figs. 2b and 6b). This is consistent with previous findings (e.g., Balaban & Luria, 2016; Delvenne & Bruyer, 2004; Oberauer & Eichenberger, 2013; Olson & Jiang, 2002; Wheeler & Treisman, 2002; Xu, 2002) supporting the weak object hypothesis (Olson & Jiang, 2002). In contrast with previous studies, the current study required the participants to voluntarily bind the retained features, which is a hallmark of defining an integrated object. In this sense, the current study offers a more stringent examination of the weak object hypothesis.
We also added new evidence suggesting that location may play a distinct role in retaining object representations in WM (e.g., Logie et al., 2011; Gu et al., 2020; Pertzov & Husain, 2014; Schneegans & Bays, 2018; Treisman & Zhang, 2006). In particular, unlike in Experiment 1 where the performance of the color-shape-texture binding was significantly lower than those of all the two-featured bindings (i.e., color-shape, color-texture, and shape-texture bindings), the performance of the color-shape-location binding was similar to that of the color-shape binding in Experiment 2. This implies that the maintenance mechanism of location-related bindings in WM is different from other features. This idea has been supported by many studies. For instance, researchers have found that location has several processing advantages in both perception and WM (e.g., Logie et al., 2011; Pertzov & Husain, 2014; Treisman & Zhang, 2006). Schneegans and Bays (2017) even suggested that non-spatial features, such as color and orientation, are bound exclusively via their shared location, implying that location plays a key role in feature bindings in WM.
Implications for the processing mechanism in WM
The current finding is in line with the underlying assumption of object-based attention in perception; the operation of object-based attention is independent of the number of constituent features per object. Moreover, to the best of our knowledge, the current study is the first to directly test the characteristics of object-based attention using objects containing more than two features. The current study offers crucial evidence suggesting that this key assumption may be applicable for objects containing no more than three features in WM. We tentatively suggest that WM and perception share a core characteristic of object-based attention: the feature-independence characteristic. As such, the current study provides new evidence supporting the similarities between WM and perception.
Our study also sheds light on the processing mechanism of object-based attention in WM. Models of object-based attention must consider the current feature-independence view. The integrated competition model (e.g., Duncan, 1996; Duncan et al., 1997; O'Craven et al., 1999; Schoenfeld et al., 2003, 2014) offers a reasonable explanation for the current findings. In particular, this model suggests that when people direct attention to the dimension of an object with multiple features, the cortical activities processing that dimension will first be enhanced. Such activities will then spread to the modules that handle other dimensions of the object. The competition between objects in the human brain is integrated across distinct cortical modules which process their constituent features. Furthermore, once a feature of an object is attended, all features in that object will become dominant in their corresponding cortical modules, resulting in a unified representation of that object in the brain. This object-based processing mechanism has been elucidated in some visual perception studies (e.g., Schoenfeld et al., 2003, 2014), but has not been tested in WM. Based on the findings of the current study, we argue that this processing mechanism also applies to WM. Recent neural imaging research has begun to uncover the object-based selection mechanism in WM. For instance, Sahan et al. (2020) found a same-object benefit in the occipitotemporal regions. Further studies exploring the mechanism of object-based processing in WM (e.g., its characteristics, functional consequences, and neural correlates) are required.
Conclusion
To conclude, through two experiments, we demonstrated that a secondary task consuming object-based attention significantly impaired the binding performance in WM, yet the performance of the two- and three-featured bindings was disrupted to a similar degree. These results suggest that maintaining three-featured bindings in WM does not require extra object-based attention relative to maintaining two-featured bindings.
Notes
Note Fougnie and Marois (2009) inserted a multiple object-tracking (MOT) task during the WM maintenance phase and found a significant selective binding impairment relative to single features. Although it was initially interpreted as the MOT task consuming space-based attention, later studies consistently revealed that the same amount of space-based attention was needed to retain both bindings and constituent features in WM (e.g., Johnson et al., 2008; Langerock et al., 2014; Shen et al., 2015). Subsequently, Hollingworth and Maxcey-Richard (2013) suggested that the findings of Fougnie and Marois (2009) can be explained in terms of additional storage of object-location bindings in WM in the MOT task (cf. footnote 3 of Hollingworth & Maxcey-Richard, 2013).
Twenty-four participants took part in an experiment using the current design with a different set of stimuli (see Zhao, Y., 2017, master thesis, Zhejiang University). All participants reported that for each bound representation, they memorized the binding between the three features instead of memorizing three features or three separated two-featured bindings. We also interviewed the participants in the current study after the completion of the experiment; all participants gave the same answer.
In line with previous studies (e.g., Allen et al., 2006; Shen et al., 2015), the same analysis was also conducted on the corrected recognition (hits minus false alarms; Snodgrass & Corwin, 1988) for Experiments 1 and 2 and revealed similar results to the original accuracy (please see Appendix 1 in the Online Supplemental Materials for details). For the comparison between two- and three-featured bindings with the same probe type, we did not analyze the data in terms of corrected recognition since inadequate data supported this analysis.
We thank Dr. Timothy Brady and Dr. Daryl Fougnie for the suggestion.
We thank Dr. Daryl Fougnie for pointing out this issue.
References
Allen, R. J. (2015). Memory binding. In D.W. James (Ed.), International encyclopedia of the social & behavioral sciences (2nd ed., Vol. 15, pp. 140–146). Elsevier.
Allen, R. J., Baddeley, A. D., & Hitch, G. J. (2006). Is the binding of visual features in working memory resource-demanding? Journal of Experimental Psychology: General, 135(2), 298-313.
Allen, R. J., Baddeley, A. D., & Hitch, G. J. (2014). Evidence for two attentional components in visual working memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40(6), 1499-1509.
Allen, R. J., Castellà, J., Ueno, T., Hitch, G. J., & Baddeley, A. D. (2015). What does visual suffix interference tell us about spatial location in working memory? Memory & Cognition, 43(1), 133-142.
Allen, R. J., Hitch, G. J., & Baddeley, A. D. (2009). Cross-modal binding and working memory. Visual Cognition, 17(1-2), 83-102.
Allen, R. J., Hitch, G. J., Mate, J., & Baddeley, A. D. (2012). Feature binding and attention in working memory: a resolution of previous contradictory findings. Quarterly Journal of Experimental Psychology, 65(12), 2369-2383.
Awh, E., Dhaliwal, H., Christensen, S., & Matsukura, M. (2001). Evidence for two components of object-based selection. Psychological Science, 12(4), 329-334.
Awh, E., & Jonides, J. (2001). Overlapping mechanisms of attention and spatial working memory. Trends in Cognitive Sciences, 5(3), 119-126.
Baddeley, A. D. (2000). The episodic buffer: a new component of working memory?. Trends in Cognitive Sciences, 4(11), 417-423.
Baddeley, A., Allen, R. J., & Hitch, G. (2010). Investigating the episodic buffer. Psychologica Belgica, 50(3), 223–243.
Baddeley, A. D., Allen, R. J., & Hitch, G. J. (2011). Binding in visual working memory: the role of the episodic buffer. Neuropsychologia, 49(6), 1393-400.
Baddeley, A. D., & Hitch, G. J. (1974). Working memory. In G. A. Bower (Ed.), The psychology of learning and motivation: Advances in research and theory (Vol. 8, pp. 47–89). Academic Press.
Balaban, H., & Luria, R. (2016). Integration of distinct objects in visual working memory depends on strong objecthood cues even for different-dimension conjunctions. Cerebral Cortex, 26(5), 2093-2104.
Barnes, L. L., Nelson, J. K., & Reuter-Lorenz, P. A. (2001). Object-based attention and object working memory: overlapping processes revealed by selective interference effects in humans. Progress in Brain Research, 134, 471-481.
Bocincova, A., van Lamsweerde, A. E., & Johnson, J. S. (2017). The role of top-down suppression in mitigating the disruptive effects of task-irrelevant feature changes in visual working memory. Memory & Cognition, 45(8), 1411-1422.
Chen, Z. (2012). Object-based attention: A tutorial review. Attention Perception & Psychophysics, 74(5), 784-802.
Chun, M. M. (2011). Visual working memory as visual attention sustained internally over time. Neuropsychologia, 49(6), 1407-1409.
Chun, M. M., Golomb, J. D., & Turk-Browne, N. B. (2011). A taxonomy of external and internal attention. Annual Review of Psychology, 62, 73–101.
Cohen, E. H., & Tong, F. (2013). Neural mechanisms of object-based attention. Cerebral Cortex, 25(4), 1080-1092.
Dalecki, M., Hoffmann, U., & Bock, O. (2012). Mental rotation of letters, body parts and complex scenes: Separate or common mechanisms?. Human Movement Science, 31(5), 1151–1160.
Delvenne, J. F., & Bruyer, R. (2004). Does visual short-term memory store bound features? Visual Cognition, 11(1), 1-27.
Ding, X. W., Zhao, Y. F., Wu, F., Lu, X. Q., Gao, Z. F., & Shen, M. W. (2015). Binding biological motion and visual features in working memory. Journal of Experimental Psychology: Human Perception and Performance, 41(3), 850-865.
Duncan, J. (1984). Selective attention and the organization of visual information. Journal of Experimental Psychology: General, 113(4), 501-517.
Duncan, J. (1996). Cooperating brain systems in selective perception and action. Attention & Performance, 16, 549-578.
Duncan, J., Humphreys, G., & Ward, R. (1997). Competitive brain activity in visual attention. Current Opinion in Neurobiology, 7(2), 255-261.
Emmanouil, T. A., & Magen, H. (2014). Neural evidence for sequential selection of object features. Trends in Cognitive Sciences, 18(8), 390-391.
Fougnie, D., & Marois, R. (2009). Attentive Tracking Disrupts Feature Binding in Visual Working Memory. Visual Cognition, 17(1-2), 48-66.
Gao, T., Gao, Z., Li, J., Sun, Z., & Shen, M. (2011). The perceptual root of object-based storage: an interactive model of perception and visual working memory. Journal of Experimental Psychology: Human Perception & Performance, 37(6), 1803-1823.
Gao, Z., & Bentin, S. (2011). Coarse-to-fine encoding of spatial frequency information into visual short-term memory for faces but impartial decay. Journal of Experimental Psychology: Human Perception and Performance, 37(4), 1051-1064.
Gao, Z., Li, J., Yin, J., & Shen, M. (2010). Dissociated Mechanisms of Extracting Perceptual Information into Visual Working Memory. Plos One, 5(12), e14273.
Gao, Z., Wu, F., Qiu, F., He, K., Yang, Y., & Shen, M. (2017). Bindings in working memory: The role of object-based attention. Attention Perception & Psychophysics, 79(2), 533-552.
Gu, Q., Wan, X., Ma, H., Lu, X., Guo, Y., Shen, M., & Gao, Z. (2020). Event-based encoding of biological motion and location in visual working memory. Quarterly Journal of Experimental Psychology, 73(8),1261–1277
Harrison, S. A., & Tong, F. (2009). Decoding reveals the contents of visual working memory in early visual areas. Nature, 458(7238), 632-635.
He, K., Li J., Wu F., Wan X., Gao Z., Shen M. (2020). Object-based Attention in Retaining Binding in Working Memory: Influence of Activation States of Working Memory. Memory & Cognition, 48(6), 957-971.
Hegarty, M., Shah, P., & Miyake, A. (2000). Constraints on using the dual-task methodology to specify the degree of central executive involvement in cognitive tasks. Memory & Cognition, 28(3), 376-385.
Hitch G. J., Allen R. J., & Baddeley A. D. (2020). Attention and binding in visual working memory: Two forms of attention and two kinds of buffer storage. Attention, Perception & Psychophysics, 82(1), 280-293.
Hollingworth, A., & Maxcey-Richard, A. M. (2013). Selective maintenance in visual working memory does not require sustained visual attention. Journal of Experimental Psychology: Human Perception & Performance, 39(4), 1047-1058.
Huang, L. (2010). What is the unit of visual attention? object for selection, but boolean map for access. Journal of Experimental Psychology: General, 139(1), 162-179.
Humphreys, G. W. (2001). A multi-stage account of binding in vision: neuropsychological evidence. Visual Cognition, 8(3-5), 381-410.
Hyun, J. S., & Luck, S. J. (2007). Visual working memory as the substrate for mental rotation. Psychonomic Bulletin & Review, 14(1), 154-158.
Jansen, P., & Lehmann, J. (2013). Mental rotation performance in soccer players and gymnasts in an object-based mental rotation task. Advances in cognitive Psychology, 9(2), 92.
Jeffreys, H. (1961). Theory of probability. OUP Oxford.
Jiang, Y., Olson, I. R., & Chun, M. M. (2000). Organization of visual short-term memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26(3), 683.
Johnson, J. S., Hollingworth, A., & Luck, S. J. (2008). The Role of Attention in the Maintenance of Feature Bindings in Visual Short-Term Memory. Journal of Experimental Psychology: Human Perception & Performance, 34(1), 41-55.
Kahneman, D., Treisman, A., & Gibbs, B. J. (1992). The reviewing of object files: object-specific integration of information. Cognitive Psychology, 24(2), 175-219.
Karlsen, P. J., Allen, R. J., Baddeley, A. D., & Hitch, G. J. (2010). Binding across space and time in visual working memory. Memory & Cognition, 38(3), 292-303.
Kiyonaga, A., & Egner, T. (2013). Working memory as internal attention: toward an integrative account of internal and external selection processes. Psychonomic Bulletin & Review, 20(2), 228-242.
Kiyonaga, A., & Egner, T. (2014). The working memory stroop effect: when internal representations clash with external stimuli. Psychological Science, 25(8), 1619-1629.
Langerock, N., Vergauwe, E., & Barrouillet, P. (2014). The maintenance of cross-domain associations in the episodic buffer. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40(4), 1096–1109.
Logie, R. H., Brockmole, J. R., & Jaswal, S. (2011). Feature binding in visual short-term memory is unaffected by task-irrelevant changes of location, shape, and color. Memory & Cognition, 39(1), 24-36.
Lu, X., Huang, J., Yi, Y., Shen, M., Weng, X., & Gao, Z. (2016). Holding biological motion in working memory: An fMRI Study. Frontiers in Human Neuroscience, 10:251.
Lu, X., Ma, X., Zhao, Y., Gao, Z. & Shen, M. (2019). Retaining event files in working memory requires extra object-based attention than the constituent elements. Quarterly Journal of Experimental Psychology, 72(9), 2225–2239.
Luck, S. J., & Vogel, E. K. (1997). The capacity of visual working memory for features and conjunctions. Nature, 390(6657), 279-281.
Matsukura, M., & Vecera, S. P. (2009). Interference between object-based attention and object-based memory. Psychonomic Bulletin & Review, 16(3), 529-536.
Matsukura, M., & Vecera, S. P. (2011). Object-based selection from spatially-invariant representations: evidence from a feature-report task. Attention Perception & Psychophysics, 73(2), 447-457.
Mayer, J. S., Bittner, R. A., Nikolić, D., Bledowski, C., Goebel, R., & Linden, D. E. (2007). Common neural substrates for visual working memory and attention. Neuroimage, 36(2), 441-453.
Oberauer, K., & Eichenberger, S. (2013). Visual working memory declines when more features must be remembered for each object. Memory & Cognition, 41(8), 1212-1227.
O'Craven, K. M., Downing, P. E., & Kanwisher, N. (1999). fMRI evidence for objects as the units of attentional selection. Nature, 401(6753), 584-587.
Olson, I. R., & Jiang, Y. (2002). Is visual short-term memory object based? Rejection of the "strong-object" hypothesis. Perception & Psychophysics, 64(7), 1055-1067.
Pertzov, Y., & Husain, M. (2014). The privileged role of location in visual working memory. Attention, Perception & Psychophysics, 76(7), 1914-1924.
Peterson, D. J., Decker, R., & Naveh-Benjamin, M. (2019). Further studies on the role of attention and stimulus repetition in item–item binding processes in visual working memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 45(1), 56.
Peterson, D. J., & Naveh-Benjamin, M. (2017). The role of attention in item-item binding in visual working memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 43(9), 1403-1414.
Prime, D. J., & Jolicoeur, P. (2010). Mental rotation requires visual short-term memory: evidence from human electric cortical activity. Journal of Cognitive Neuroscience, 22(11), 2437-2446.
Rouder, J. N., Morey, R. D., Speckman, P. L., & Province, J. M. (2012). Default Bayes factors for ANOVA designs. Journal of Mathematical Psychology, 56(5), 356-374.
Rouder, J. N., Speckman, P. L., Sun, D., Morey, R. D., & Iverson, G. (2009). Bayesian t tests for accepting and rejecting the null hypothesis. Psychonomic Bulletin & Review, 16(2), 225-237.
Sahan, M. I., Sheldon, A. D., & Postle, B. R. (2020). The neural consequences of attentional prioritization of internal representations in visual working memory. Journal of Cognitive Neuroscience, 32(5), 917–944.
Schneegans, S., & Bays, P. M. (2017). Neural architecture for feature binding in visual working memory. Journal of Neuroscience, 37(14), 3913-3925.
Schneegans, S., & Bays, P. M. (2018). Drift in neural population activity causes working memory to deteriorate over time. Journal of Neuroscience, 38(21), 4859–4869.
Schneegans, S., & Bays, P. M. (2019). New perspectives on binding in visual working memory. British Journal of Psychology, 110(2), 207-244.
Schoenfeld, M. A., Hopf, J. M., Merkel, C., Heinze, H. J., & Hillyard, S. A. (2014). Object-based attention involves the sequential activation of feature-specific cortical modules. Nature Neuroscience, 17(4), 619-624.
Schoenfeld, M. A., Tempelmann, C., Martinez, A., Hopf, J. M., Sattler, C., Heinze, H. J., & Hillyard, S. A. (2003). Dynamics of feature binding during object-selective attention. Proceedings of the National Academy of Sciences, 100(20), 11806-11811.
Shen, M., Huang, X., & Gao, Z. (2015). Object-based attention underlies the rehearsal of feature binding in visual working memory. Journal of Experimental Psychology: Human Perception & Performance, 41(2), 479-493.
Sligte, I. G., Scholte, H. S., & Lamme, V. A. (2008). Are there multiple visual short-term memory stores? PLOS one, 3(2), e1699.
Sligte, I. G., Vandenbroucke, A. R., Scholte, H. S., & Lamme, V. (2010). Detailed sensory memory, sloppy working memory. Frontiers in psychology, 1, 175.
Snodgrass, J. G., & Corwin, J. (1988). Pragmatics of measuring recognition memory: applications to dementia and amnesia. Journal of Experimental Psychology: General, 117(1), 34-50.
Treisman, A. M. (1996). The binding problem. Current Opinion in Neurobiology, 6(2), 171-178.
Treisman, A. M. (1998). Feature binding, attention and object perception. Philosophical Transactions Biological Sciences, 353(1373), 1295-1306.
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12(1), 97-136.
Treisman, A. M., & Schmidt, H. (1982). Illusory conjunctions in the perception of objects. Cognitive Psychology, 14(1), 107-141.
Treisman, A. M., & Zhang, W. (2006). Location and binding in visual working memory. Memory & Cognition, 34(8), 1704-1719.
Vandenbroucke, A. R., Sligte, I. G., & Lamme, V. A. (2011). Manipulations of attention dissociate fragile visual short-term memory from visual working memory. Neuropsychologia, 49(6), 1559-1568.
Vecera, S. P., & Farah, M. J. (1994). Does visual attention select objects or locations? Journal of Experimental Psychology: General, 123(2), 146-160.
Vergauwe, E., Langerock, N., & Barrouillet, P. (2014). Maintaining bindings between features in visual working memory requires no more attention than maintaining the features themselves. Canadian Journal of Experimental Psychology, 68,158-162.
Wan, X., Zhou, Y., Wu, F., He, K., Shen, M., Gao, Z. (2020). The role of attention in retaining the binding of integral features in working memory. Journal of Vision, 20(7):16, 1–22.
Wheeler, M. E., & Treisman, A. M. (2002). Binding in short-term visual memory. Journal of Experimental Psychology: General, 131(1), 48-64.
Woodman, G. F., & Luck, S. J. (2004). Visual search is slowed when visuospatial working memory is occupied. Psychonomic Bulletin & Review, 11(2), 269-274.
Woodman, G. F., & Vecera, S. P. (2011). The cost of accessing an object's feature stored in visual working memory. Visual Cognition, 19(1), 1-12.
Woodman, G. F., Vogel, E. K., & Luck, S. J. (2012). Flexibility in visual working memory: Accurate change detection in the face of irrelevant variations in position. Visual cognition, 20(1), 1-28.
Xie, W., & Zhang, W. (2016). Negative emotion boosts quality of visual working memory representation. Emotion, 16(5), 760-774.
Xu, Y. (2002). Limitations of object-based feature encoding in visual short-term memory. Journal of Experimental Psychology: Human Perception & Performance, 28(2), 458-468.
Xu, Y. (2017). Reevaluating the sensory account of visual working memory storage. Trends in Cognitive Sciences, 21(10), 794-815.
Yao, N., Guo, Y., Liu, Y., Shen, M., & Gao, Z. (2020). Visual working memory capacity load does not modulate distractor processing. Attention, Perception & Psychophysics, 82, 3291–3313
Zacks, J. M., & Michelon, P. (2005). Transformations of visuospatial images. Behavioral and Cognitive Neuroscience Reviews, 4(2), 96–118.
Zhao, Y. (2017). The Attentional Mechanism Underlying the Maintenance of Biological Motion Event File in Working Memory. Unpublished master's thesis. Zhejiang University, China.
Zhang, W., & Luck, S. J. (2011). The Number and Quality of Representations in Working Memory. Psychological Science, 22(11), 1434-1441.
Acknowledgements
This research was supported by the National Key R&D Program of China (No. 2019YFB1600504), the Science and Technology Innovation 2030 program (2018AAA0101605), and Project of Ministry of Science and Technology of the People's Republic of China (2016YFE0130400). We thank the three anonymous reviewers for their helpful comments.
Author information
Authors and Affiliations
Corresponding authors
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
ESM 1
(DOCX 1647 kb)
Rights and permissions
About this article

Cite this article
Zhou, Y., Wu, F., Wan, X. et al. Does the presence of more features in a bound representation in working memory require extra object-based attention?. Mem Cogn 49, 1583–1599 (2021). https://doi.org/10.3758/s13421-021-01183-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-021-01183-0