
Abstract
In the twenty-first century, clusters can be observed in most developed economies. However, the scientific results regarding the effect of clusters on firm performance are highly contradictive. The inconsistencies in the empirical results make it difficult to infer general conclusions about the firm-specific cluster effect, or in other words, the effect from being located in a cluster on firm performance (e.g. derived through the externalities within clusters). Therefore, this paper aims to reconcile the contradictory empirical findings. It investigates whether the prevalent assumption that clusters are a beneficial location for firms is unconditionally true or whether doubts about the alleged positive effect of clusters on firm performance are justified. By conducting a descriptive meta-analysis of the empirical literature, based on four different performance variables from four separate publication databases, the study investigates the direction of the effect as well as possible moderating influences. We find evidence for a rather positive firm-specific cluster effect. However, we identify several variables from the micro-, meso- and macro-level that directly or interactively moderate the relationship between clusters and firm success. For example, the results demonstrate that a negative firm-specific cluster effect occurs more frequently in low-tech industries than in high-tech industries. “To be or not to be” located in a cluster is therefore not the question, but it rather depends on the specific conditions.
Similar content being viewed by others
1 Introduction
The co-location in regional clustersFootnote 1 is an economic reality that characterizes most developed economies in the twenty-first century. According to the European Cluster Observatory, just within the European Union (EU) there are 2.000 statistically relevant clusters that employ nearly 40% of the European workforce (Brown et al. 2007; Festing et al. 2012; Nathan et al. 2013). In view of conspicuous examples, such as Silicon Valley, the concept has become popular among politicians who are motivated to foster cluster initiatives in order to write a similar success story for their region. Therefore, many cluster initiatives receive financial support from national governments, the EU and other public institutions. For example, since 2005 the German government has launched several programmes with a total volume of 1.391 billion € to foster clusters in Germany (EFI 2015; Festing et al. 2012).
Given the already substantial financial support of cluster activities, it is reasonable to assume that scientists have identified a consistent positive cluster effect on the success of companies within a cluster. However, the scientific results about the firm-specific cluster effect are indeed highly contradictive (Malmberg et al. 2002; Martin et al. 2003). While authors such as Borowiecki (2013) as well as Basant et al. (2011) find evidence that companies located in clusters have a higher productivity than companies outside clusters, other researchers come to different results, ranging from negative performance effects (Pouder et al. 1996) to rather mixed effects (Knoben et al. 2015).
This inconsistency in the empirical results prevents general conclusions about the firm-specific cluster effect,Footnote 2 particularly with regard to the actual effect direction (Fang 2015). According to Frenken et al. (2015), one of the main challenges for future research lies in reconciling the contradictory empirical findings and thereby working towards closing the research gap on the alleged effect of clusters on firm performance. We respond to this call by integrating previous empirical results, thereby answering the following research question: Does being located in a cluster influence firm success? More specifically, we investigate whether the still prevalent assumption in the scientific literature and among policy-makers that clusters are a beneficial location for firms is unconditionally true or whether doubts about the alleged positive effect of clusters on firm performance are reasonable.
In order to answer this research question adequately, we conduct a descriptive meta-analysis of the empirical literature on the firm-specific cluster effect. A descriptive meta-analysis is an appropriate methodical approach in this context, because it is a meaningful way of combining empirical studies with contradicting results (Fang 2015). Yet, up to now, studies have employed a meta-analysis procedure only on the regional level (e.g. De Groot et al. 2007; Melo et al. 2009) and not in the context of firm-specific cluster effects. One important exception is the recent work by Fang (2015). However, this article differs from Fang (2015) in several important ways, for example, its explicit focus on the firm level, its scope of considered performance variables, its extensive literature collection based on four publication databases, as well as a more precise selection process that controls for, among others, a similar cluster understanding across the considered studies. As such, this article follows a clearer and more comprehensive approach to investigate the effect of being located in a cluster on firm success. In general, our results indicate a tendency towards a rather significant positive cluster effect on firm success. But at the same time, we also find evidence for heterogeneity across the individual studies considered in our descriptive meta-analysis, suggesting an influence of moderating variables. By identifying several variables from different levels of analysis (micro-, meso- and macro-level) that directly or interactively moderate the relationship between clusters and firm success, we conclude that, contrary to conventional thinking, being located in a cluster does not automatically lead to positive performance effects, but instead it rather depends on the specific conditions.
By providing an answer to the underlying research question through reconciling the contradictory empirical results, the paper not only provides a comprehensive overview that enriches the understanding about the alleged effect of clusters and serves as a crucial stepping stone to closing a still ubiquitous research gap, but also fulfils a practical demand by informing companies as well as policy-makers so they can gauge the concrete firm-specific effects of cluster initiatives.
The remainder of this paper is structured as follows: The second section introduces the theoretical background, highlighting the theoretical debate about cluster (dis-)advantages and establishing an adequate working definition of a cluster by reviewing the corresponding literature. The third section describes the applied methodical approach and data. Thereafter, the fourth section presents the empirical results. The paper will end with some concluding remarks, including limitations to this study as well as promising future research directions.
2 Theoretical background
In order to develop a useful working definition for the term cluster to analyse the contradictory empirical results regarding the firm-specific cluster effect, a literature overview about the various cluster definitions is undertaken to identify possible similarities. Furthermore, the ongoing theoretical discussion about cluster advantages and disadvantages is described.
2.1 Defining clusters
Although the term cluster is a very widespread and prevalent theme in economics at least since the two scientific papers of Porter (1990 and 1998), there are still fundamental differences in its definition as well as understanding (Brown et al. 2007; Malmberg et al. 2002; Martin et al. 2003). Even Michael Porter applies different kinds of definitions in his numerous articles about the cluster topic. As a consequence of the unclear definitional delimitation, the term has experienced a large proliferation and thereby has lost some of its explanatory power (Brown et al. 2007; Martin et al. 2003; Šarić 2012; Sedita et al. 2012). For a correct implementation of a meta-analysis, this definitional inconsistency implies a serious problem, as it is required that the considered empirical studies have the same underlying understanding of what is meant by cluster when they analyse the firm-specific cluster effects. It is therefore essential to establish an adequate working definition of a cluster which serves as the baseline for the definitions of the empirical studies derived from the literature review.
Given the absence of a more or less mandatory definition, in line with Fornahl et al. (2015) a comparative empirical approach is applied that is explicitly inductive. Thus, this study does not intend to open “pandora´s box” of a theoretical discussion about a new (conceptual) cluster definition, instead a rather pragmatic approach is chosen. By conducting a profound literature overview about the various cluster definitions used in empirical as well as theoretical studies, several similarities could be identified. In general, these similarities can be summarized in the following four central elements:
-
(1) The spatial connection constitutes one of the most important elements of a cluster definition. It includes the sub-dimensions of (spatial) proximity as well as concentration. The latter one refers to a critical mass of actors which is a fundamental condition for the functioning of clusters (e.g. Brenner 2004). However, in most cases, this critical mass is not determined in detail (Fornahl et al. 2015). Additionally, it is also still unclear and highly debated which spatial scale is most appropriated to cover the proximity dimension (Asheim et al. 2006; Martin et al. 2003). In this context, empirical studies make use of different kind of levels of analysis, ranging from Nuts I, II or III to whole labour market regions (Fornahl et al. 2015). Besides these predefined areal units, some empirical studies also consider directly the geographical distance to the cluster in order to increase the geographic precision of their analysis (e.g. Bagley 2019a; Duranton et al. 2005; Maine et al. 2010; Rosenthal et al. 2008). Among others, Maine et al. (2010) indicate in this context that a firm´s geographical distance to a cluster is negatively related with its corresponding growth performance. In general, it can therefore be resumed that spatial proximity is widely acknowledged as a crucial dimension of clusters (Fornahl et al. 2015; Martin et al. 2003).
-
(2) The thematic connection covers the following three sub-dimensions: similar/complementary industries, value chain and specialization. These three sub-dimensions encompass similar value-chain activities of the firms within a cluster and their possible specialization. In accordance with the Marshall-Arrow-Romer (MAR) framework, arguing that the co-location of firms in a single industry fosters firm performance due to externalities,Footnote 3 clusters are often associated with the specialization around on specific industry (Marshall 1920; Maine et al. 2010). However, based on Jacobs (1969) it has been indicated that a single metropolitan area may contain several specialized clusters which may benefit from inter-industry related knowledge flows (Maine et al. 2010). Recently, contributions from the evolutionary economic geography (EEG) thinking school have moved beyond the localization versus urbanization debate and suggested in this context that related economic activities should also be considered as part of the regional specialization (Grillitsch et al. 2018; Kemeny et al. 2015; Neffke et al. 2011; Potter et al. 2014). Likewise in the case of spatial proximity it is therefore indeed rather complex for empirical studies to define potential thematically boundaries, especially in changing (e.g. new or diversifying) clusters (Boschma et al. 2011a; Fornahl et al. 2015).
-
(3) The element of interdependencies deals with the interconnectedness of various actors within a cluster and the resulting externalities, which are defined as the “net benefits to being in a location together with other firms increase with the number of firms in the location” (Arthur 1990, p. 237). The corresponding sub-dimension of co-location advantages thereby depicts the general existence of a firm-specific advantage, while knowledge/technology spillovers, cooperation and competition deal more with the mechanisms of clustering. Whether externalities arise from specialization, diversification or related variety has, however, not been put into concrete terms (Fornahl et al. 2015). At the same time, there exist several cluster mechanisms, such as spinoff formation (e.g. Klepper 2007a, 2007b) or labour mobility (e.g. Angel 1991), that cause the emergence of a cluster and the corresponding co-location advantages (Benner 2009).
-
(4) Complementary institutions and trust consist of formal/institutional relationships and establishments as well as informal exchange/trust. The first sub-dimension summarizes the role of institutions, such as universities or regional development agencies. The second sub-dimension is contrarily concerned with the informal exchange and its significance for cognitive proximity as well as trust.
The results of the literature overview, building on 25 identified cluster definitions, are illustrated in Fig. 1. It can be shown that especially the spatial connection, the thematic connection and the interdependencies are seen as central elements of a cluster definition. In contrast, complementary institutions and trust are only mentioned in a relatively small number of definitions. One explanation may be that not all clusters are built on informal relationships, social capital and trust, but just some specific forms of a cluster such as industrial districts in Italy (Fornahl et al. 2015). Complementary institutions and trust are therefore not further considered as key characteristics of a cluster.

Consequently, based on the results of the literature overview the following working definition for a cluster can be derived: “Clusters are defined as a geographical concentration of closely interconnected horizontal, vertical and lateral actors, such as universities, from the same industryFootnote 4 that are related to each other in terms of a common resource and knowledge base, technologies and/or product-market”.
The here derived working definition for a cluster is therefore very close to Marshall´s understanding and more in line with economic perspectives focussing particularly on the externalities highlighted by Marshall (1920), such as Porter´s competitiveness school, than with socio-economic perspectives, e.g. Innovative Milieu literature stream (Šarić 2012). In light of our focus on firm performance, it is argued that such a theoretical classification is particularly appropriate (e.g. McCann et al. 2008). It therefore differs, on the one hand, from the conceptualization of pure agglomerations where firms are not necessary linked nor related to each other (Šarić 2012). On the other hand, it is also conceptually distinct from Jacob´s externalities (Jacobs 1969) and the further distinction in related and unrelated variety (Frenken et al. 2007), stressing the economic blessings of diversified regional industrial structures promoting the creation of new (rather radical) ideas and protecting against industry-specific shocks (Boschma et al. 2009; Frenken et al. 2007; Jacobs 1969). Even though this theoretical stream should be mentioned when dealing with clusters, in line with the results of Lazzeretti et al. (2014) it is argued that it does not constitute the core of the cluster understanding. Nevertheless, it is crucial to bear in mind that the here derived working definition is generalized in the way that it appropriately captures the definitional core elements of a good functioning cluster in the sustaining phase of the cluster life cycle. As such, across the cluster life cycle (e.g. Menzel et al. 2010) other elements (e.g. the spatial concentration in the emerging phase) may, however, become more important.
2.2 Cluster advantages and disadvantages
Similar to the definitional confusion, the theoretical discussion about cluster advantages and disadvantages is also characterized by a certain inconsistency. In this section, the most prominent arguments will therefore be presented.
Marshall (1920) was among the first to consider the benefits that firms can gain from being located in close proximity to similar firms. He presented four crucial types of localization externalities: access to specialized labour, access to specialized inputs, access to knowledge spillovers and access to greater demand by reducing the consumer search costs (Marshall 1920; McCann et al. 2008).Footnote 5
Specialized labour refers to individuals that make industry-specific investments in their human capital (McCann et al. 2008). Krugman (1991) highlighted, in this context, that clusters create a common market pool for workers with specialized skills, benefiting both the workers as well as the hiring firms. On the one hand, a spatial concentration of similar types of firms reduces the risk for specialized workers able to attain work from multiple employers. On the other hand, this reduced risk also benefits employers by minimizing the risk premium as well as search cost components of workers` wages (David et al. 1990; Krugman 1991). Furthermore, it is also argued that specialized workers may be more willing to invest in industry-specific human capital when they believe that they have a greater ability to appropriate the benefits (Rotemberg et al. 2000). This is, however, a condition more likely to occur when there exist multiple companies pursuing the services of similar workers (McCann et al. 2011). In general, it has been indicated that the pooling of specialized employers and employees in close geographical distance also improves the overall matching process between both sides (Amend et al. 2008; Otto et al. 2010). This results in a pronounced labour mobility within clusters, being crucial for the inter-firm knowledge diffusion, fostering firm performance, due to the person-embedded knowledge (Erikson et al. 2009; Otto et al. 2010). A somehow special case refers in this context to spinoffs, which have been shown to exploit their knowledge of local employees, resulting in a higher probability of hiring employees from the entrepreneur´s prior employer as well as from other nearby firms from the same industry (Carias et al. 2010). While this entails a knowledge transfer from the incumbent firm to the spinoff (Bagley 2019b), it has also been demonstrated that the previous employer gains from this process, due to enduring social relationships with their former employees, contributing to sustained flows of knowledge (Agrawal et al. 2006).
Related to this is the access to knowledge spillovers. It is argued that geographic proximity can facilitate the transfer of knowledge in general (Jaffe et al. 1993) and specifically the transfer of tacit knowledge because it increases the likelihood of face-to-face contacts which is an efficient medium for the transfer of such knowledge (Daft et al. 1986). As such, the eased knowledge diffusion within clusters, particularly the tacit one, can in turn promote collective learning processes and innovation activities of the corresponding firms (Audretsch et al. 2004; Rigby et al. 2015; Terstriep et al. 2018).Footnote 6
Many of the same reasons that firms in clusters have improved access to specialized labour hold also true for the improved access to specialized inputs in general. Due to its demand for specialized inputs, a cluster attracts input suppliers in larger numbers, which in turn provides access to services that firms could otherwise not afford individually (Feldman 1994; Marshall 1920; McCann 2008).
Apart from the previous mentioned supply-side advantages, companies in clusters can also gain from an access to greater demand. The underlying idea is that geographical concentration facilitates the search and evaluation of the variety of options available from multiple firms. By reducing the corresponding consumer costs, the probability that consumers will purchase in specialized agglomerations in comparison with more isolated locations is increased (McCann 2008).
Another argument put forward for the benefits of clusters refers to the competition created by collocating with rivalries. The competition exposes firms to great pressure and in the end motivates them to innovate in order to stay competitive (Harrison et al. 1996; Porter 1998).
Furthermore, it has been highlighted that companies located within clusters can additionally profit from a common reputation (Molina-Morales et al. 2004; Wu et al. 2010), an information and communication ecology (Bathelt et al. 2004; Beaudry et al. 2003) as well as infrastructure benefits (Kuah 2002).
Although much of the discussion so far has focused almost exclusively on the advantages of clusters, there are also some authors highlighting potential disadvantages as a cluster grows larger and ages (Boschma et al. 2011b; McCann et al. 2008). The previously positive aspect of competition can become a negative one with a size increase of the cluster. The higher density of similar actors can lead to increased competition for input factors, which may result in scarcity of these factors as well as significantly price increases (Fang 2015; McCann et al. 2008).Footnote 7 In the case of human resources, such a fierce competition can lead to labour poaching, entailing costs for the corresponding firm. On the one hand, competitors can gain access to the firm´s own knowledge embodied in its employees, thereby increasing their relative competitive advantage over other firms. On the other hand, firms can prevent this and retain their human capital by raising their personnel expenses (e.g. paying higher wages or gratifications). Consequently, in both cases firms are negatively affected (Combes et al. 2006; Otto et al. 2010). Additionally, an increasing density can also lead to what some authors called congestion costs. These costs are typically expressed in outcomes such as increased traffic and transportation costs within a certain region (McCann et al. 2008). Another possible disadvantage refers to negative knowledge spillovers or in other words knowledge leakages that may discourage a firm to further innovate within a cluster, as other firms can actually free-ride on their knowledge (Fang 2015; Shaver et al. 2000). Furthermore, over time companies in clusters may face a certain inertia regarding market and technology changes. In this context, Pouder et al. (1996) argued that the performance decline over time can be explained with the convergent mental models of managers within the corresponding region. This kind of uniform thinking, a sort of group thinking behaviour, reinforces old behaviours and old ways of thinking. As a consequence, it prevents the recognition and adoption of new technological trends and new ideas in general (Martin et al. 2003; McCann et al. 2008; Porter 2000; Pouder et al. (1996)). Additionally, there are some authors suggesting that a simple reliance on local face-to-face contacts and tacit knowledge makes local networks of industry especially vulnerable to lock-in situations which in turn enforce again the inertia of companies within clusters (Boschma 2005; Martin et al. 2003).
Summing up the theoretical discussion, it can be stated that clusters are supposed to comprise several advantages as well as disadvantages to the firms depending on the specific context, such as the firm's absorptive capacity and cluster size (Frenken et al. 2015; McCann et al. 2008).
3 Data and methodology
This rather mixed picture is also reflected in the empirical results. In order to reconcile the conflicting empirical results of the firm-specific cluster effect, a descriptive meta-analysis will be conducted. In general, a meta-analysis statistically integrates empirical results from different studies investigating a common research question (Florax et al. 2002; Quintana 2015; Wagner et al. 2014). It can therefore be defined as the “(…) analysis of analyses.” (Glass 1976, p. 3). There exist indeed many reasons for applying meta-analysis as an appropriate alternative methodical approach to the traditional narrative review. One of the most important reasons refers to the proceeding of narrative reviews which is often insufficient standardized and therefore difficult, if at all, verifiable. It is quite common that the reviewer subjectively chooses which studies to include in his review and what weights to attach to the results of these studies. Contrarily, by its statistical nature meta-analysis can minimize subject bias and offer a great transparency as well as reproducibility (Fang 2015; Melo et al. 2009; Stanley et al. 1989; Wagner et al. 2014). Thus, it is supposed that a meta-analysis is an appropriate methodical approach to answer the underlying research question, whether being located in a cluster does influence firm success. In general, the meta-analysis method can be divided into two broad categories: descriptive meta-analysis and meta-regression (addressing sampling error or addressing both sampling error as well as other artefacts). In light of the available information and the relatively broad research question of this paper it is acceptable to apply a descriptive meta-analysis. This method offers the possibility of not only analysing the cluster effect on firm success, but also the corresponding moderating variables (Hunter et al. 1980; Wagner et al. 2014).
For the measurement of firm success, four different performance variables are taken into consideration: innovativeness, productivity, survival and employment growth. By considering four different performance variables, the effect of being located in a cluster on firm success can be analysed from a broader perspective. It is argued that the selected four performance variables capture most frequently and adequately firm success (Globerman et al. 2005; Sleutjes et al. 2012).Footnote 8
The first step of the publication-based meta-analysis refers to collecting relevant data through a literature review. The empirical studies used in the meta-analysis are first of all collected from three different publication databases, namely Web of Science, Google Scholar as well as Ebsco. The application of various publication databases is crucial in order to avoid a possible database bias, meaning that one database may favour a specific kind of literature and hence in the end contributes to a more meaningful literature collection. The search strategy is based on keyword combinations of “cluster” or “agglomeration”Footnote 9 (which is quite often used as a synonymFootnote 10) and one of the four performance variables and “firm” or “company”. The last two keywords are necessary to exclude empirical studies focusing only on the regional performance level. For the literature collection, only the 200 most relevant articles for each search query are considered.Footnote 11 Moreover, the search is conducted for all years and for all document types, as at the beginning a preferably comprehensive literature collection should be achieved. Since the above procedure returns mainly published articles, which may lead to a publication bias, it is explicitly necessary to include further working papers to mitigate this bias. The four combinations of keywords are therefore additionally used for a search query in the Social Science Research Network (SSRN). This publication database is especially convenient, as it implies an internal review process, even though it mainly deals with working papers (Elsevier Inc 2017). Hence, by choosing SSRN the quality of the data is ensured. Because the main purpose of this publication database is to include recent but not already published articles, only the results for the years 2014 until 2016 are considered.Footnote 12 Furthermore, in some instances relevant empirical studies from different search queries were also taken into consideration. For example, this would be the case if some results from the search query of innovation are also relevant for the performance variable productivity.
After this very broad collection of literature, specific results are sorted out by applying inclusion criteria. The inclusion criteria are as follows: first, the studies need to be empirical. Even though the findings of theoretical papers are briefly summarized in the theoretical discussion, they are not included in the overall meta-analysis. Second, to ensure that all selected studies have the same cluster understanding, the three identified key characteristics (spatial connection, thematic connection and interdependencies) have to be considered. As a consequence, studies focusing only on networks, industrial parks or urbanization are not included in the final sample. Third, relative cluster measures,Footnote 13 such as relative specialization indicators, have to be at least based on the national average in the corresponding industry and not on the regional average. In absence of this condition, one can hardly speak about a cluster, because on a county or city level a high specialization in a specific industry can be achieved quite easily. Fourth, the worker wages as well as the earnings at the establishment level are not seen as adequate measures for firm productivity. In contrast to traditional economic thinking, it is argued that a rise in productivity does not automatically imply a wage increase.Footnote 14 Empirical studies making use of these or similar measures are therefore not incorporated in the final sample. Last, the analytical focus of the empirical studies needs to be on the firm level and not on the regional level. Although already integrated in the search queries, in some cases this condition is not fulfilled. By knowing the essential meaning of the selection process for the overall meta-analysis, in case of doubt a second opinion is recognized.
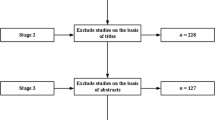
Figure 2 depicts the concrete selection and exclusion process of the considered studies. In total, 2201 studies are collected that match the already mentioned search queries. After excluding duplicate studies and studies without author, only 1944 results are considered in the first review process. In this first review process the title and the abstract are read in order to analyse whether the studies fulfil the inclusion criteria. Consequently, 1465 studies are sorted out, mainly due to their content which often deals with a cluster analysis or with the regional level. Subsequently, two more detailed reviews are implemented. In these more detailed reviews especially the statistical part is analysed. At the end, the final meta-analysis considers a population of 168 empirical studies.Footnote 15 This corresponds to 8.6% of the adapted population (studies without author and duplications excluded).

Selection and exclusion process of the considered empirical studies (own illustration). Note: a: employment growth; b: innovativeness; c: productivity; d: survival
In general, it can be stated that up to now relatively few papers have applied such a meta-analysis in the context of a firm-specific cluster effect. One important exception refers to the recent work of Li Fang (2015) which provides a meta-analysis for relevant empirical studies on the relationship of clusters and the innovativeness of firms and regions. Yet, this scientific work differs from Li Fang (2015) in four mayor aspects. First, instead of mixing firm-level- and regional-level-oriented studies, this article explicitly focuses on the firm level. Consequently, the derived results are not biased by the regional effect of clusters and therefore provide more specific insights into the cluster effect on firms. Second, the meta-analysis here considers not only one performance variable, like innovativeness, but four different performance variables. By taking four different performance variables into account, the influence of the settlement in a cluster on firm success can be detected from a broader and more differentiated perspective. Furthermore, the literature collection of this meta-analysis is more extensive because the search is based on four different publication databases in total. Additionally, during the selection and exclusion process it is controlled whether the underlying cluster definitions of the empirical studies match with the three main elements of a cluster definition, shown in the previous section. Even though the strict definitional compliance is one of the principal reasons for the relatively large exclusion of articles, it is essential for a meaningful meta-analysis, as the firm-specific cluster effect does not get distorted by other network like effects. In other words, the true firm-specific cluster effect can be detected.
4 Empirical results
Before investigating this potential effect, it is, however, first of all interesting to have a closer look at the empirical studies of the final sample. Figure 3 illustrates the years of publication of the sample. At first glance, it becomes obvious that most of the studies in the final sample are relatively new. The oldest empirical record dates back to the year 1998. So, from the introduction of the term cluster by Michael Porter (1990) it took eight more years for an empirical study to test the relationship between clusters and firm performance. One explanation for this delay refers to the theoretical discussion and deepening of the concept. It is quite conventional that a new concept is first of all theoretical discussed within the research community. In this concrete case, it is additionally reasonable to suggest that the first empirical articles mainly focused on the regional level. Indeed, while widely been ignored for quite a long time, only in recent years researchers have shifted their focus of analysis on the firm-specific perspective (Brown et al. 2007; Šarić 2012; Steffen 2012). Apart from employment growth, more or less half of the empirical studies of the analysed performance indicators were published in the last five years (2012–2016). In more concrete terms, 46% of the empirical studies dealing with the cluster effect on firm innovativeness and even 65% of studies concerning the effect on firm survival were published in this period of time. Regarding the firm-specific cluster effect on employment growth at least 28% of the empirical studies were published in the last five years.

Years of publication of the empirical studies (own illustration)
Having a closer look at the specific journals, one can state that the most frequent used journals come from the regional science. However, journals from the field of economics and management are also prevalent. Thus, it can be stated that the relationship between clusters and firm performance has received the attention from a multidisciplinary audience.Footnote 16
Moreover, even though the considered studies in the final sample have analysed the firm-specific cluster effect in the context of various countries worldwide (in total 29 different countries), it can be observed that in most cases, except for productivity, the USA has been the most highly investigated country setting. Partially this can be explained by the fact that due to Michael Porters contributions (1990 and 1998) the roots of the cluster concept lay in the USA. Nevertheless, on a more aggregated level it can be stated that on average half of all considered studies base their empirical analysis in a European country, whereas countries from North America (USA, Canada, Mexico) account on average only for a quarter of all studies in the final sample. Despite some core countries of investigation (e.g. USA, Netherlands, Italy), it can therefore be argued that the final sample of this study appears to be quite diverse in this context.Footnote 17
In order to detect the estimated direction of cluster effects on the four considered performance variables, a vote counting method is applied (De Groot et al. 2007; Fang 2015). Since one study may use several regression models to measure, for example, different kinds of characteristics of the cluster, it can also identify several effects. To treat studies equally, a study-level vote counting is conducted, meaning that all findings regarding the effect direction of clusters on firms performance are for each study summarized. This is necessary in order to avoid a possible overvaluation of studies containing several regressions (Fang 2015). All the available estimates of each study are therefore grouped into seven classes:
-
Sig. positive: Referring to significant positive cluster effects on firm performance.
-
Insignificant: Referring to insignificant cluster effects on firm performance.
-
Sig. negative: Referring to significant negative cluster effects on firm performance.
-
Sig. positive and insignificant: Referring to significant positive and insignificant cluster effects on firm performance.Footnote 18
-
Sig. negative and insignificant: Referring to significant negative and insignificant cluster effects on firm performance.
-
Sig. negative and sig. positive: Referring to significant negative and significant positive cluster effects on firm performance.
-
Sig. negative, sig. positive and insignificant: Referring to significant negative, significant positive and insignificant cluster effects on firm performance.
However, at this point it is essential to highlight that the vote counting method has also been criticized, because the corresponding results are rather imprecise in comparison with the fixed effects model for example. The imprecision refers to the fact that the sample size of each study as well as the actual effect size are not considered at all (Hedges et al. 1980; Stanley 2001). Nevertheless, as already mentioned at the beginning of the previous chapter, in light of the relatively broad research question as well as the available information the vote counting method offers a suitable way of approaching the firm-specific cluster effect. As a consequence, it is suggested that vote counting serves the purpose to get first insights into this effect (Wagner et al. 2014).Footnote 19
The results of the study-level vote counting for all four performance variables are presented in Fig. 4. What is striking the most are indeed the mixed empirical results for all four variables, indicating that there exist possible moderators, such as the industry context, shaping the relationship between cluster and firm performance. Interestingly, this holds also true for the results within the same underlying study. As such, 25.6% of the considered empirical studies determine at the same time sig. negative and sig. positive as well as insignificant firm-specific cluster effects. However, what can be further observed is that the majority of studies report either a sig. positive or a sig. positive and insignificant cluster effect. In total, 45.8% of the considered empirical studies note either one of these two directions. Contrary, only 22 studies (13.1%) find empirical support for a pure sig. negative or a sig. negative and insignificant effect. Thus, a tendency towards a rather sig. positive cluster effect on firm success can be asserted. Nevertheless, having a closer look at the four different performance variables some variation between the results can be found. While the empirical studies dealing with the innovativeness and the productivity of a firm find nearly no evidence for a rather sig. negative cluster effect, the results for the variables of employment growth and survival more frequently indicate to a sig. negative effect. Even though that there also exist evidence for a sig. positive firm-specific cluster effect in these both cases, the results appear to be more negative than for innovativeness as well as productivity. In more concrete terms, 22.2% of the empirical studies dealing with employment growth and even 25% of the studies dealing with survival report a pure sig. negative or a sig. negative and insignificant effect. In comparison, in the case of innovativeness and productivity only 5.7% of the considered empirical studies, respectively, 3.5% assert similar effects.

Study-level vote counting (own illustration)
This can, on the one hand, be explained with differences in the consideration and importance of moderating variables, which are also highlighted later in Table 1. In general, it seems to be plausible that the realization of employment growth and survival depends on different and supposedly more on the specific context than innovativeness and productivity. On the other hand, the results may also indicate towards the two-sided effect of the high competition within clusters. While the high competition between similar firms fosters their innovativeness and productivity, it hampers their employment growth and survival through e.g. labour poaching (Audia et al. 2010; McCann et al. 2008; Porter 1998; Sorenson et al. 2000).
These tendencies can be solidified by re-grouping the vote counting into positive, insignificant and negative estimation results.Footnote 20 As a consequence, a study that previously reported sig. positive and insignificant effects will now appear twice, meaning that in the end it is counted one time for a sig. positive and a second time for an insignificant effect. The results of this re-organization of the data are outlined in Fig. 5.

Re-grouped vote counting (own illustration)
By analysing the re-grouped data for the four different performance variables, it becomes obvious that nearly 40% of the considered empirical studies report at least once a positive cluster effect on firm performance. In contrast to this, only 23% of the studies find evidence for a negative effect. Thus, it can be stated that in general most studies indeed identify a rather positive firm-specific cluster effect.
Although, as already described before, there exists some variation between the four performance variables. In the cases of employment growth and survival the most dominant estimation results refer to an insignificant effect, whereas empirical studies dealing with innovativeness as well as productivity most frequently report a positive effect. One plausible explanation for these differences refers to the unequal consideration of different moderating variables. Even though there are moderating variables, such as the industry, that are considered across all four performance variables, some variables, such as a firm´s internal knowledge base, are only recognized in relatively few cases. Table 1 depicts the results for these and additional moderating variables.Footnote 21 Although all moderating variables have been collected, for a better visualization Table 1 presents only a selection of them. Since the focus lies on moderating variables, the actual level of analysis is thereby on the model level and not on the study level anymore. Consequently, the number of observations exceeds the number of considered empirical studies, because one study may potentially include several empirical models. In total, out of the 168 empirical studies 2.201 statistical models have been considered.
By analysing the moderating effects, shown within the considered empirical studies, it is interesting to note that there exists relatively few evidence for a pure firm-specific cluster effect, meaning a direct and generic cluster effect on firm performance in absence of potential moderating variables. Thus, being located in a cluster does not, at least in most cases, automatically lead to a positive or a negative firm-specific cluster effect. Instead, several variables from the micro-, meso- and macro-level directly or interactively moderate the relationship between clusters and firm performance. In other words, it is a rather complicated relationship which is influenced by a mix of different moderating variables. However, the specific industry is one of the most important moderating effects. Nearly across all four performance variables around 50% of the positive, insignificant and negative firm-specific cluster effects can be explained by the corresponding industry.
By grouping the different industries according to the classification of Eurostat (Eurostat 2014, 2017) and the OECD (OECD, 2011) into low-technologies, medium–low technologies, medium–high technologies and high technologies further interesting results can be derived in this context, which are presented in Table 2.
Across all four performance variables, it can be shown that a negative firm-specific cluster effect can be especially asserted in low-tech industries and not so much in high-tech industries. Indeed, 56.9% of the negative firm-specific cluster effects can be traced back towards low-tech industries, whereas for high-tech industries this share decreases to only 20%. Additionally, the results also point out that there exists a relatively high inter-industry variation (within the aggregated industry groups), indicating that the specific industry characteristics, such as pace of market and technology evolution, are highly important and therefore should be considered in more detail in future empirical studies.
Moreover, as can be seen in Table 1, in comparison with the macro-level, mainly consisting of the industry variable, are the variables of the micro- and meso-level only investigated in a relatively small number of empirical studies. Instead, interaction effects appear to be more important in this context, as 23.3% of the positive, 30.9% of the insignificant and 27.9% of the negative firm-specific cluster effects can be traced back towards different interaction effects.Footnote 22 Especially to highlight is the moderating effect of the geographical distance together with the industry context. This interaction effect is of particular importance for employment growth as well as survival. Having a closer look at the concrete categories of this interaction effect, some interesting patterns can be observed, which are illustrated in Table 3.
For high-tech industries, it appears that a medium geographical distance between the corresponding actors contributes most frequently towards a positive firm-specific cluster effect. In more concrete terms, 33% of the asserted significant positive effects of the interaction between geographical distance and industry can be traced back to a medium distance and a high-tech industry. Although, in this context, it has to be stated that evidence is also found for an insignificant effect for this interaction term (33.6%), indicating towards an inter-industry variation likewise in the case of the sole moderating effect of the industry variable. Despite the inter-industry variation, it can be, however, seen that in high-tech as well as low-tech industries high geographical distance more frequently leads to an insignificant or even negative performance effect. Thus, it can be argued that high geographical distance is in general rather inhibitory for a positive firm-specific cluster effect in the context of both high-tech and low-tech industries. Regarding low geographical distance, the results become more mixed, especially for low-tech industries. Whereas the results for high-tech industries indicate towards a rather positive moderating effect (28%), in the case of low-tech industries there exists nearly equally evidence for a positive (10%) as well as negative (11.1%) effect. Consequently, it can be asserted that low geographical distance and medium geographical distance are more frequently beneficial for companies in high-tech industries, while high geographical distance is rather detrimental for both industry groups.
In light of the results derived from the vote counting and the analysis of the moderating effects, in total it can be resumed that on the one hand there indeed exist evidence for a rather positive firm-specific cluster effect. But, on the other hand, the results remarkably differ in this context between the four considered performance variables. While the results are quite clear in the case of innovativeness and productivity, they are highly equivocal with regard to employment growth and survival. Additionally, strong moderating variables from different levels of analysis, shaping the relationship between clusters and firm performance, can also be asserted, thereby indicating that there exist firm performance differentials within clusters.
5 Conclusion
Even though cluster initiatives have received substantial financial support from national governments, the EU and other public institutions, it is still unclear whether being in a cluster really influences firm success (EFI 2015; Frenken et al. 2015; Martin et al. 2003). By conducting a meta-analysis of the empirical literature that investigates the firm-specific cluster effect, our paper reconciles the so far rather contradictory empirical results, thereby enriching the understanding about the alleged effect of clusters on firm performance. The descriptive analysis of the selected sample indicates that most empirical studies find evidence for the existence of a positive cluster effect on firm success. But at the same time, we also show that the empirical results are rather mixed, also between the four considered performance variables. This pattern can be explained by moderating influences of a mix of different variables from different levels of analysis. The industry context provides a particularly crucial moderating effect. The corresponding results point out that a negative firm-specific cluster effect occurs more frequently in low-tech industries than in high-tech industries. Besides the direct influence of moderating variables, we additionally identify variables from different levels of analysis that interactively moderate the relationship between clusters and firm success. For example, we determine that high geographical distance is in high-tech and low-tech industries rather inhibitory for a positive firm-specific cluster effect, while low distance and medium distance are more frequently beneficial for companies in high-tech industries. In sum, this paper therefore moves beyond the limited focus on single levels of analysis and performance indicators, characterizing the current research on regional clusters (e.g. McCann et al. 2011; Hervas-Oliver et al. 2018). By systematically integrating previous empirical results, the limited perspective of individual studies can be overcome and a comprehensive overview about the effect of clusters on firm performance, particularly with regard to potential moderating variables, can be provided. With this synthesis of the rather inconclusive literature, our study thus contributes to a more sophisticated understanding about the firm-specific cluster effect, which can serve as a valuable starting point for future research in this field.
The derived results, especially the moderating effects, emphasize that future empirical studies about the firm-specific cluster effect have to account for different moderating variables in order to investigate the relationship between clusters and firm success in more detail. It is argued that multilevel analysis methods are for this context especially suitable (Burger et al. 2012). In view of the variation between the four considered performance variables, it is additionally promising for future studies to make use of several outcome measures in order to get a more detailed picture about the effects of regional clusters. This also includes rather alternative socio-economic indicators, focusing, for example, more on environmental pollution or social cohesion, which remain to be properly investigated in the cluster context.
However, there is also one current limitation to this paper. The presented results are only descriptive in nature. The descriptive meta-analysis can only be the first step for a more detailed meta-regression, as the actual magnitude of the effect still needs to be investigated (Koricheva et al. 2013). In this context, it is essential to take the diversity of applied methods into consideration. Furthermore, it would be interesting to analyse whether there exist national differences between the estimation results of the considered empirical studies.
Nevertheless, all in all it can be resumed that this paper makes a first step towards reconciling the contradictory empirical findings and thereby serving as a valuable stepping stone to closing the research gap concerning the alleged effect of clusters on firm performance. Or to say it with Shakespeare “to be or not to be” located in a cluster is not the question, it rather depends on the specific conditions.
Notes
The corresponding working definition for a cluster is presented in Sect. 2.1.
Referring to the effect from being located in a cluster on firm performance (e.g. derived through the existing localization externalities within clusters such as knowledge spillovers).
The same industry can thereby encompass narrowly defined industries (e.g. based on single industry codes) and/or broader industry classifications, such as the automotive industry, consisting of closely related sub-industry groups.
Besides these externalities he also noted that the unique physical conditions of particular areas, such as limited natural resources, are the chief cause for the localization of industries.
Recently, evidence has been found that due to the pronounced knowledge diffusion within clusters, especially regarding tacit knowledge, clusters promote the creation of radical innovations (Grashof et al. 2019), which can open up completely new markets and industries (Castaldi et al. 2015; Verhoeven et al. 2016).
The concrete geographical distance has also be found to matter in this context (e.g. De Silva et al. 2012).
However, as highlighted later in the inclusion criteria, the three identified key characteristics of clusters (spatial connection, thematic connection and interdependencies) have to be fulfilled by the collected studies in order to be included in the final sample. This guarantees a similar conceptual cluster understanding, while ignoring the definitional inconsistency characterizing this particular research field.
The sorting by relevance is provided by the corresponding publication database and is based on the frequency of the search terms that appear in each record (in the title, abstract and keywords). As such, it is argued that only the most suitable (with respect to the research focus of this paper) articles are considered.
The authors acknowledge that it is of course possible that older working papers may not, as assumed, convert itself in a journal article. Nevertheless, it is not illusory to assume that “good” working papers are likely to be published in journals.
For a detailed overview about different cluster measures see for example Brenner (2017).
For a comprehensive overview about this issue, please see Van Biesebroeck (2015).
A detailed overview about the considered empirical studies is illustrated in Table 5.
For a detailed list of the journal distribution of the sample please see Fig. 6.
For a detailed illustration of the countries of investigation, please see Fig. 7.
In other words, studies belong to this class if they find significant positive and insignificant results regarding the influence of clusters on firm performance.
In the context of the localization and urbanization debate such an approach has for instance been applied by Beaudry et al. (2009).
Positive and negative estimation results refer in both cases to significant results.
Moderating variables encompass in this context interaction effects between the applied cluster measure and a contextual variable (e.g. firm size) as well as investigations of the cluster effect in subsamples (e.g. different industry settings), also implying a potential moderating effect.
In this context, an interaction effect between e.g. firm age and industry means that the interaction term between firm age and the corresponding cluster measure in one particular industry setting has a certain influence on one of the four considered performance variables.
References
Agrawal A, Cockburn I, McHale J (2006) Gone but Not Forgotten: Knowledge Flows, Mobility and Enduring Social Relationships. Journal of Economic Geography 6(5):571–591
Amend, E., Herbst, P. (2008). Labor market pooling and human capital investment decisions. IAB Discussion Paper 4/2008.
Andersson M, Klaesson J, Larsson JP (2016) How Local are Spatial Density Externalities? Neighbourhood Effects in Agglomeration Economies. Reg Stud 50(6):1082–1095
Angel DP (1991) High-Technology Agglomeration and the Labor Market: The Case of Silicon Valley. Environ Plan A 23(10):1501–1516
Arthur WB (1990) ‘Silicon Valley’ locational clusters: when do increasing returns imply monopoly? Math Soc Sci 19(3):235–251
Asheim B, Cooke P, Martin R (2006) The rise of the cluster concept in regional analysis and policy: a critical assessment. In: Asheim B, Cooke P, Martin R (eds) Clusters and Regional Development: Critical Reflections and Explorations. Routledge, London, pp 1–19
Audia PG, Rider CI (2010) Close, but not the same: Locally headquartered organizations and agglomeration economies in a declining industry. Res Policy 39(3):360–374
Audretsch DB, Feldman M (2004) Knowledge spillovers and the geography of innovation. In: Henderson JV, Thisse JF (eds) Handbook of Urban and Regional Economics, vol 4. Elsevier, Amsterdam, pp 2713–2739
Bagley MJO (2019a) Networks, geography and the survival of the firm. J Evol Econ 29:1173–1209
Bagley, M. J. O., (2019b). Small worlds, inheritance networks and industrial
clusters. Industry and Innovation 26 (7), 741–768.
Basant, R., Chandra, P., Upadhyayula, R., (2011). Knowledge Flows and Capability Building in the Indian IT Sector: A Comparative Analysis of Cluster and Non-Cluster Locations. IIMA working paper, Indian Institute of Management Bangalore.
Bathelt H, Malmberg A, Maskell P (2004) Clusters and knowledge: local buzz, global pipelines and the process of knowledge creation. Prog Hum Geogr 28(1):31–56
Beaudry C, Breschi S (2003) Are firms in clusters really more innovative? Econ Innov New Technol 12(4):325–342
Beaudry C, Schiffauerova A (2009) Who’s right, Marshall or Jacobs? The localization versus urbanization debate. Res Policy 38(2):318–337
Benner, M., (2009). What do we know about clusters? In search of effective cluster policies. SPACES online. 7(2009–04). Toronto and Heidelberg: www.spaces-online.com.
Borowiecki KJ (2013) Geographic clustering and productivity: An instrumental variable approach for classical composers. J Urban Econ 73(1):94–110
Boschma R (2005) Proximity and Innovation: A Critical Assessment. Reg Stud 39(1):61–74
Boschma R, Iammarino S (2009) Related Variety, Trade Linkages and Regional Growth in Italy. Econ Geogr 85(3):289–311
Boschma R, Frenken K (2011) The emerging empirics of evolutionary economic geography. Journal of Economic Geography 11(2):295–307
Boschma, R., Frenken, K., (2011b). Technological relatedness and regional branching. In: Bathelt, H., Feldman, M. P., Kogler, D. F. (Eds.), Dynamic Geographies of Knowledge Creation and Innovation, Taylor & Francis/Routledge, London, pp. 64–81.
Boschma R (2015) Do spinoff dynamics or agglomeration externalities drive industry clustering? A reappraisal of Steven Klepper’s work. Ind Corp Chang 24(4):859–873
Brenner T (2004) Local Industrial Clusters: Existence, Emergence and Evolution. Routledge, London/New York
Brenner, T., (2017). Identification of Clusters - An Actor-based Approach. Working Papers on Innovation and Space, Philipps-Universität Marburg.
Brown, K., Burgees, J., Festing, M., Royer, S., Steffen, C., (2007). The Value Adding Web – A Conceptual Framework of Competitive Advantage Realisation in Clusters. Working Paper No. 27, ESCP-EAP Europäische Wirtschaftshochschule Berlin.
Burger MJ, Knoben J, Raspe O, Van Oort FG (2012) Multilevel Approaches and the Firm-Agglomeration Ambiguity in Economic Growth Studies. Journal of Economic Surveys 26(3):468–491
Carias, C., Klepper, S., (2010). Entrepreneurship, the Initial Labor Force and the Location of New Firms. Paper presented at the International Schumpeter Society Conference, Aalborg. 21–24.
Castaldi C, Frenken K, Los B (2015) Related variety, unrelated variety and technological breakthroughs: An analysis of US state-level patenting. Reg Stud 49(5):767–781
Combes P-P, Duranton G (2006) Labour pooling, labour poaching and spatial clustering. Reg Sci Urban Econ 36(1):1–28
Daft RL, Lengel RH (1986) Organizational information requirements, media richness and structural design. Manage Sci 32(5):554–571
David PA, Rosenbloom JL (1990) Marshallian factor market externalities and the dynamics of industrial localization. J Urban Econ 28(3):349–370
De Groot, H. L., Poot, J., Smit, M., (2007). Agglomeration, Innovation and Regional Development: Theoretical Perspectives and Meta-Analysis. Discussion Paper No. 07–079/3, Tinbergen Institute.
Delgado M, Porter ME, Stern S (2010) Clusters and entrepreneurship. Journal of Economic Geography 10(4):495–518
De Silva DG, McComb RP (2012) Geographic concentration and high tech firm survival. Reg Sci Urban Econ 42(4):691–701
Duranton G, Overman HG (2005) Testing for Localization Using Micro-Geographic Data. Rev Econ Stud 72(4):1077–1106
EFI (2015) Gutachten zu Forschung. Innovation und Technologischer Leistungsfähigkeit Deutschlands, Expertenkommission Forschung und Innovation
Elsevier Inc, (2017). SSRN — Frequently Asked Questions. Accessed May 24 2017. https://www.ssrn.com/en/index.cfm/ssrn-faq/.
Erikson R, Lindgren U (2009) Localized mobility clusters: impacts of labour market externalities on firm performance. Journal of Economic Geography 9(1):33–53
Eurostat, 2014. Aggregations of manufacturing based on NACE Rev. 2. Accessed May 24 2017. http://statistica.regione.emilia-romagna.it/allegati/factbook_2014/eurostat-high-tech-aggregation-of-manufacturing-and-services-nace-rev-2.
Eurostat, (2017). Glossary: High-tech classification of manufacturing industries. Accessed May 23 2017. http://ec.europa.eu/eurostat/statistics-explained/index.php/Glossary:High-tech_classification_of_manufacturing_industries.
Fang L (2015) Do Clusters Encourage Innovation? A Meta-analysis Journal of Planning Literature 30(3):239–260
Feldman MP (1994) The Geography of Innovation. Kluwer Academic Publishers, Dordrecht
Festing, M., Royer, S., Steffen, C., (2012). Unternehmenscluster schaffen Wettbewerbsvorteile - Eine Analyse des Uhrenclusters in Glashütte. Zeitschrift Führung + Organisation. 81 (4); 264–272.
Florax, R. J., de Groot, H. L., De Mooij, R. A., (2002). Meta-Analysis. Tinbergen Institute Discussion Paper. 2002–041/3.
Fornahl, D., Heimer, T., Campen, A., Talmon-Gros, L., (2015). Cluster als Paradigma der Innovationspolitik — Eine erfolgreiche Anwendung von Theorie in der politischen Praxis?. Studien zum deutschen Innovationssystem Nr. 13–2015.
Frenken K, Van Oort F, Verburg T (2007) Related variety, unrelated variety and regional economic growth. Reg Stud 41(5):685–697
Frenken K, Cefis E, Stam E (2015) Industrial Dynamics and Clusters: A Survey. Reg Stud 49(1):10–27
Glass GV (1976) Primary, Secondary and Meta-Analysis of Research. Educ Res 5(10):3–8
Globerman S, Shapiro D, Vining A (2005) Clusters and intercluster spillovers: their influence on the growth and survival of Canadian information technology firms. Ind Corp Chang 14(1):27–60
Grashof N, Hesse K, Fornahl D (2019) Radical or not? The role of clusters in the emergence of radical innovations. Eur Plan Stud 27(10):1904–1923
Grillitsch M, Asheim B, Trippl M (2018) Unrelated knowledge combinations: the unexplored potential for regional industrial path development. Camb J Reg Econ Soc 11(2):257–274
Harrison B, Kelley MR, Gant J (1996) Innovative Firm Behavior and Local Milieu: Exploring the Intersection of Agglomeration, Firm Effects and Technological Change. Econ Geogr 72(3):233–258
Hedges LV, Olkin I (1980) Vote-counting methods in research synthesis. Psychol Bull 88(2):359–369
Hervas-Oliver J-L, Sempere-Ripoll F, Alvarado RR, Estelles-Miguel S (2018) Agglomerations and firm performance: who benefits and how much? Reg Stud 52(3):338–349
Hunter, J. E., Schmidt, F. L., (1980). Methods of Meta-Analysis — Correcting Error and Bias in Research Findings. Second Edition: Sage Publications.
Jacobs J (1969) The economy of cities. Vintage, New York
Jaffe AB, Trajtenberg M, Henderson R (1993) Geographic localization of knowledge spillovers as evidenced by patent citations. Quart J Econ 108(3):577–598
Kemeny T, Storper M (2015) Is Specialization Good for Regional Economic Development? Reg Stud 49(6):1003–1018
Klepper, S., (2007a). Disagreements, Spinoffs and the Evolution of Detroit as the Capital of the U.S. Automobile Industry. Management Science. 53 (4); 616–631.
Klepper S (2007) The evolution of geographic structures in new industries. In: Frenken K (ed) Applied Evolutionary Economics and Economic Geography. Edward Elgar, Cheltenham, pp 69–92
Klepper S (2010) The origin and growth of industry clusters: the making of Silicon Valley and Detroit. J Urban Econ 67(1):15–32
Knoben J, Arikan AT, Van Oort F, Raspe O (2015) Agglomeration and firm performance: One firm’s medicine is another firm’s poison. Environ Plan A 48(1):1–22
Koricheva J, Gurevitch J (2013) Place of Meta-analysis among Other Methods of Research Synthesis. In: Koricheva J, Gurevitch J, Mengersen K (eds) Handbook of Meta-analysis in Ecology and Evolution. Princeton University Press, Princeton, pp 3–13
Krugman P (1991) Geography and trade. MIT Press, Cambridge, MA
Kuah AT (2002) Cluster Theory and Practice: Advantages for the Small Business Locating in a Vibrant Cluster. J Res Mark Entrep 4(3):206–228
Lazzeretti L, Sedita SR, Caloffi A (2014) Founders and disseminators of cluster research. Journal of Economic Geography 14(1):21–43
Maine EM, Shapiro DM, Vining AR (2010) The role of clustering in the growth of new technology-based firms. Small Bus Econ 34:127–146
Malmberg A, Maskell P (2002) The elusive concept of localization economies: towards a knowledge-based theory of spatial clustering. Environ Plan A 34(3):429–449
Marshall, A,. 1920. Principles of economics. London: Macmillan, 8th ed.
Martin P, Mayer T, Mayneris F (2011) Public support to clusters: A firm level study of French “Local Productive Systems.” Reg Sci Urban Econ 41(2):108–123
Martin R, Sunley P (2003) Deconstructing clusters: chaotic concept or policy panacea? Journal of Economic Geography 3(1):5–35
McCann BT, Folta TB (2008) Location Matters: Where We Have Been and Where We Might Go in Agglomeration Research. J Manag 34(3):532–565
McCann BT, Folta TB (2011) Performance differentials within geographic clusters. J Bus Ventur 26(1):104–123
Melo PC, Graham DJ, Noland RB (2009) A meta-analysis of estimates of urban agglomeration economies. Reg Sci Urban Econ 39(3):332–342
Menzel M-P, Fornahl D (2010) Cluster life cycles—dimensions and rationales of cluster evolution. Ind Corp Chang 19(1):205–238
Molina-Morales FX, Martínez-Fernández MT (2004) How much difference is there between industrial district firms? A net value creation approach. Res Policy 33(3):473–486
Nathan M, Overman H (2013) Agglomeration, clusters and industrial policy. Oxf Rev Econ Policy 29(2):383–404
Neffke F, Henning M, Boschma R, Lundquist KJ, Olander LO (2011) The dynamics of agglomeration externalities along the life cycle of industries. Reg Stud 45(1):49–65
OECD, (2011). ISIC REV. 3 TECHNOLOGY INTENSITY DEFINITION - Classification of manufacturing industries into categories based on R&D intensities. OECD Directorate for Science, Technology and Industry.
Otto A, Fornahl D (2010) Origins of human capital in clusters: Regional, industrial and academic transitions in media clusters in Germany. In: Fornahl D, Henn S, Menzel M-P (eds) Emerging Clusters: Theoretical. Edward Elgar, Empirical and Political Perspectives on the Initial Stage of Cluster Evolution, pp 99–139
Porter ME (1990) The competitive advantage of nations. Macmillan, London
Porter ME (1998) Clusters and the New Economics of Competitiveness. Harv Bus Rev 76(6):77–90
Porter ME (2000) Location, Competition and Economic Development: Local Clusters in a Global Economy. Econ Dev Q 14(1):15–34
Potter A, Watts HD (2014) Revisiting Marshall’s Agglomeration Economies: Technological Relatedness and the Evolution of the Sheffield Metals Cluster. Reg Stud 48(4):603–623
Pouder R, St. John, C. H. (1996) Hot Spots and Blind Spots: Geographical Clusters of Firms and Innovation. Acad Manag Rev 21(4):1192–1225
Quintana, D., (2015). From pre-registration to publication: a non-technical primer for conducting a meta-analysis to synthesize correlational data. Frontiers in Psychology 6 (1549).
Rigby DL, Brown MW (2015) Who Benefits from Agglomeration? Reg Stud 49(1):28–43
Rosenthal SS, Strange WC (2008) The attenuation of human capital spillovers. J Urban Econ 64(2):373–389
Rotemberg JJ, Saloner G (2000) Competition and human capital accumulation: a theory of interregional specialization and trade. Reg Sci Urban Econ 30(4):373–404
Šarić, S., 2012. Competitive Advantages through Clusters - An Empirical Study with Evidence from China. Wiesbaden 2012: Springer Fachmedien.
Sedita, S. R., Lazzeretti, L., Caloffi, A., (2012). The birth and the rise of the cluster concept. Paper presented at the DRUID 2012, CBS, Copenhagen.
Shaver JM, Flyer F (2000) Agglomeration economies, firm heterogeneity and foreign direct investment in the United States. Strateg Manag J 21(12):1175–1193
Sleutjes B, Van Oort F, Schutjens V (2012) A PLACE FOR AREA-BASED POLICY? THE SURVIVAL AND GROWTH OF LOCAL FIRMS IN DUTCH RESIDENTIAL NEIGHBORHOODS. J Urban Aff 34(5):533–558
Sorenson O, Audia PG (2000) The Social Structure of Entrepreneurial Activity: Geographic Concentration of Footwear Production in the United States, 1940–1989. Am J Sociol 106(2):424–462
Stanley TD (2001) Wheat From Chaff: Meta-Analysis As Quantitative Literature Review. J Econ Perspect 15(3):131–150
Stanley TD, Jarrell SB (1989) META-REGRESSION ANALYSIS: A QUANTITATIVE METHOD OF LITERATURE SURVEYS. Journal of Economic Surveys 3(2):161–170
Steffen, C., (2012). How Firms Profit from Acting in Networked Environments: Realising Competitive Advantages in Business Clusters. A Resource-oriented Case Study Analysis of the German and Swiss Watch Industry. Schriftenreihe: Internationale Personal- und Strategieforschung. München: Rainer Hampp Verlag.
Terstriep J, Lüthje C (2018) Innovation, knowledge and relations – on the role of clusters for firms’ innovativeness. Eur Plan Stud 26(11):2167–2199
Van Biesebroeck, J., (2015). How tight is the link between wages and productivity? A survey of the literature. Conditions of Work and Employment Series No. 54, International Labor Organization, Geneva.
Verhoeven D, Bakker J, Veugelers R (2016) Measuring technological novelty with patent-based indicators. Res Policy 45(3):707–723
Wagner M, Weiß B (2014) Meta-Analyse. In: Baur N, Blasius J (eds) Handbuch Methoden der empirischen Sozialforschung. Springer Fachmedien, Wiesbaden, pp 1117–1126
Wennberg K, Lindqvist G (2010) The effect of clusters on the survival and performance of new firms. Small Bus Econ 34(3):221–241
Wu X, Geng S, Li J, Zhang W (2010) Shared Resources and Competitive Advantage in Clustered Firms: The Missing Link. Eur Plan Stud 18(9):1391–1410
Acknowledgements
The author [NG] would like to thank Stephan Bruns and two anonymous referees for useful comments on earlier versions of this manuscript. Furthermore, the author [NG] gratefully acknowledges financial support from the Federal Ministry of Education and Research [grantnumber 03INTBF05A].
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
No potential conflict of interest was reported by the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
See Tables 4 and 5, Figs. 6 and 7.

Journal distribution of the final sample (own illustration created with Datawrapper)

Countries of investigation of the final sample (own illustration)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Grashof, N., Fornahl, D. “To be or not to be” located in a cluster?—A descriptive meta-analysis of the firm-specific cluster effect. Ann Reg Sci 67, 541–591 (2021). https://doi.org/10.1007/s00168-021-01057-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00168-021-01057-y