
An analysis of the locality of binary representations in genetic and evolutionary algorithms
- Published
- Accepted
- Received
- Academic Editor
- Wolfgang Banzhaf
- Subject Areas
- Adaptive and Self-Organizing Systems, Algorithms and Analysis of Algorithms, Artificial Intelligence
- Keywords
- Genetic and evolutionary algorithms, Locality, Binary-integer representations, Gray encoding, Binary encoding
- Copyright
- © 2021 Shastri and Frachtenberg
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2021. An analysis of the locality of binary representations in genetic and evolutionary algorithms. PeerJ Computer Science 7:e561 https://doi.org/10.7717/peerj-cs.561
Abstract
Mutation and recombination operators play a key role in determining the performance of Genetic and Evolutionary Algorithms (GEAs). Prior work has analyzed the effects of these operators on genotypic variation, often using locality metrics that measure the sensitivity and stability of genotype-phenotype representations to these operators. In this paper, we focus on an important subset of representations, namely nonredundant bitstring-to-integer representations, and analyze them through the lens of Rothlauf’s widely used locality metrics. Our main research question is, does strong locality predict good GEA performance for these representations? Our main findings, both theoretical and empirical, show the answer to be negative. To this end, we define locality metrics equivalent to Rothlauf’s that are tailored to our domain: the point locality for single-bit mutation and general locality for recombination. With these definitions, we derive tight bounds and a closed-form expected value for point locality. For general locality we show that it is asymptotically equivalent across all representations and operators. We also reproduce three established GEA empirical results to understand the predictive power of point locality on GEA performance, focusing on two popular and often juxtaposed representations: standard binary and binary-reflected Gray.
Introduction
Genetic and Evolutionary Algorithms (GEAs) solve optimization and search problems by codifying a population of possible solutions, evaluating their fitness in solving the problem, and iteratively modifying them in an attempt to improve their fitness. The digital manifestation of the solutions are called genotypes, and their interpretations into the specific problem domain are called phenotypes. The function that maps from genotypes to phenotypes is simply called the representation, and it can have a significant impact on the success and speed of the GEA to approximate optimal solutions (Doerr, Klein & Storch, 2007; Jansen, Oliveto & Zarges, 2013). Consequently, many empirical and theoretical studies investigated the effects of representation on GEA performance under different operators that modify genotypes. The No Free Lunch Theorems can be interpreted to show that no single representation has a performance advantage for all optimization problems (Wolpert & Macready, 1997).
A key component of evolution, both biological (Mitchell-Olds, Willis & Goldstein, 2007) and computational (Goldberg, Deb & Clark, 1992), is the variation of genotypes. Perhaps the most common operator for variation in GEAs is mutation, which may be combined with another operator, recombination (Bäck, Fogel & Michalewicz, 2018). There are various implementations of the mutation operator, but typically they embody a localized change to an individual genotype. Contrast this with recombination, which requires two or more individuals and often involves nonlocal changes to the genotypes.
One of the most commonly used variation operators is point mutation, a simple mutation operator which randomly changes one allele at a time. There exist various forms and parameters for point mutation that control the magnitude of the genotypic change. By controlling this magnitude, mutation can be used in a search GEA both for exploration—sampling many disparate parts of the search space—and for exploitation—thoroughly searching in a localized subspace (Črepinšek, Liu & Mernik, 2013).
An important property of mutation that can increase the predictability and interpretability of the GEA is to have “strong locality,” which we informally define here as the property that small variations in the genotype lead to small variations in the phenotype (Pereira et al., 2006). Strong locality implies better control of the GEA, because tuning mutation for a certain magnitude of changes in the genotype—the inputs to the search—leads to an expectation of the magnitude of changes in the phenotype—the outcome of the search. Note that the mutation operator is intricately tied to the representation. It is the combination of the mutation operator and representation that determines the magnitude of phenotypic change. Often, the discussion of locality assumes a fixed mutation operator—such as uniform bit flips or Gaussian differences—and focuses on the representations, such as standard binary or Gray.
In his seminal book, Rothlauf (2006) presented a theoretical framework for comparing representations based on three properties: redundancy, scaling, and locality. He proposed two metrics to quantify the locality of representations, one specifically for point mutation (simply called “locality” in the book) and one for any variation operator (called “distance distortion”).
This paper focuses on these metrics when applied to a widely used subclass of representations, namely nonredundant translations from bitstring genotypes to nonnegative integer phenotypes, such as Gray encoding (Whitley, 1999). More precisely, we focus on representations that are one-to-one mappings from bitstrings to integers in the range [0:2ℓ). These representations are very common in practice to represent integers and fixed-point values in GEAs, as well as vectors of such values. One example of such a representation is standard binary encoding (SB), where the ith bit b adds a value of exactly 2b to the phenotype. Another example is binary-reflected Gray encoding (BRG), where the genotypes of successive phenotypes vary only by one bit (Bitner, Ehrlich & Reingold, 1976).
The main purpose of this paper is to study the relationship between locality and GEA performance for these representations. We explore this relationship both theoretically and empirically, and show that despite some contrary claims in the literature, strong locality does not imply good GEA performance in this domain. For example, the poor performance of SB in some simple GEA benchmarks has been attributed to its weak locality (Rothlauf, 2006). In contrast, we claim that Gray encodings do not exhibit general and point locality advantages over SB under the considered domain and assumptions. In fact, we prove that both SB and BRG exhibit optimal point locality under the same benchmark conditions.1
Summary of contributions and paper outline
After surveying related work in ‘Related Work’, we examine the theoretical properties of both locality metrics. We build on Rothlauf’s definitions for locality and distance distortion and redefine them specifically for the domain of binary-integer representations, which we call point locality and general locality, respectively. This lets us contribute proofs and precise computations for the following properties:
-
A tight lower bound of for any such representation on bitstrings of length ℓ.
-
A tight upper bound of 2ℓ−1 for any such representation on bitstrings of length ℓ.
-
A proof that the point localities of SB and BRG encodings are both identical and optimal.
-
An existence proof and construction algorithm for suboptimal Gray encodings.
-
A closed form for the expected value of point locality across random representations.
-
A lower bound and asymptotic limit for general locality.
‘Theoretical Results on Point Locality’ presents these results in higher detail than in previous work (Shastri & Frachtenberg, 2020). To put these theoretical results in context, we also attempt in ‘Experimental Results’ to faithfully reproduce three distinct past experiments from three different types of GEAs that empirically compared SB’s performance to BRG’s. These studies found BRG to generally outperform SB, and in some cases hypothesized that this better performance is the result of stronger locality (Hinterding, Gielewski & Peachey, 1995; Rothlauf, 2006). Here, we recreate these established findings of superior BRG performance and then examine them in the newly proven perspective of the equivalent locality of the two representations. Our experiments are therefore by design not new, but rather a framework to delve deeper into the reasons for performance differences between representations.
Then, in ‘Discussion’, we discuss these results and produce additional experimental data and alternative explanations to BRG’s superior performance. A separate contribution of this section is a discussion of the role of the GEA’s simulation time on dynamically varying the representation, showing that different phases of the simulation can benefit from different locality properties of the representation. Finally, we conclude with suggestions for future work in ‘Conclusion and Future Work’.
Related Work
The representation in a GEA is tightly linked to its performance, which led to numerous studies working to formalize and measure the effects of representation locality (Galván-López et al., 2011; Gottlieb et al., 2001; Gottlieb & Raidl, 1999; Jones & Forrest, 1995; Manderick, 1991; Ronald, 1997). Many of these studies quantify locality in different ways and apply it to different phenotype classes, such as floating-point numbers (Pereira et al., 2006), computer programs (Galván-López et al., 2011; Rothlauf & Oetzel, 2006), permutations (Galván-López & O’Neill, 2009), and trees (Hoai, McKay & Essam, 2006; Rothlauf & Goldberg, 1999). The focus of these approaches is often to measure the effect of genotypic changes on fitness distances (Gottlieb & Raidl, 1999). A more general approach is to instead measure the effect on phenotypic distances, because it provides a way to measure the locality of a representation that is independent of the fitness function (Rothlauf, 2003).
The foundational locality definitions for our study and several others (Chiam, Goh & Tan, 2006; Galván-López et al., 2010) come from Rothlauf’s treatise on the theory of GEA representations (Rothlauf, 2006). Rothlauf defines the locality dm as: (1) where for every two distinct genotypes x, y, is the genotypic distance between x and y, and is the phenotypic distance between their respective phenotypes, based on our choices of genotypic and phenotypic spaces. Similarly, and represent the minimum possible distance between genotypes or phenotypes, respectively.2 For example, for nonredundant representations of integers as bitstrings (the focus of this paper), genotypic distances are measured in Hamming distance and phenotypic distances use the usual Euclidean metric in ℕ.
This definition “describes how well neighboring genotypes correspond to neighboring phenotypes” (ibid. p. 77), which is valuable for measuring small genotypic changes that typically result from mutation. Extending this notion to include large genotypic changes (e.g., from a recombination operator), Rothlauf defines the distance distortion dc as: (2) where np is the size of the search space, and are the phenotypic and genotypic distance, respectively, between two distinct individuals xi, xj. The term is equal to , the proportion of each distinct pair of individuals. This definition “describes how well the phenotypic distance structure is preserved when mapping Φp on Φg”, where Φp is the phenotypic search space and Φg is the genotypic search space (ibid. p. 84).
As observed by Galván-López et al. (2011), high values of dm and dc actually denote low locality while low values denote high locality. To avoid confusion, we will refer to low metric values as strong locality and high metric values as weak locality.
Similar in spirit, Gottlieb & Raidl (1999) also defined a pair of locality metrics for mutation and crossover operators called mutation innovation and crossover innovation. They additionally defined crossover loss, which measures the number of phenotypic properties that are lost by crossover. These metrics are probabilistic and empirical in nature, so they are harder to reason about analytically. But they have been demonstrated in practice to predict GEA performance on the multidimensional knapsack problem (Pereira et al., 2006; Raidl & Gottlieb, 2005).
In a different study, Chiam, Goh & Tan (2006) defined the concept of preservation, which “measure[s] the similarities between the genotype and phenotype search space.” Their study uses Hamming distance between genotypes and L2 norms between phenotypes to define analogous metrics to Rothlauf’s (called proximity preservation and remoteness preservation). Unlike Rothlauf’s metrics, their metrics look in both directions of the genotype-phenotype mapping. The authors demonstrated with examples (as we prove formally in the next section) that SB and BRG have the same genotype-to-phenotype locality, but not phenotype-to-genotype locality. They also predicted, based on this similarity, that crossover-based GEAs would perform about the same with both SB and BRG encodings, which appears to contradict some past experimental results, as we discuss in ‘Genetic algorithms’.
A different approach to approximating locality was given by Mathias & Whitley (1994b), and independently, by Weicker (2010) using the various norms of the phenotype-genotype distance matrix for different representations. These studies did not draw performance predictions from these metrics.
Another interesting aspect of locality of representation is its effect over time. Some studies explored the effects of problems that are themselves dynamic in nature, therefore changing their representation over time (Mueller-Bady et al., 2017; Neumann & Witt, 2015). One such study benchmarked delta coding on the same five De Jong functions as we have. Their algorithm monitors the population diversity, and once the population becomes more homogeneous, it changes the representation to search different subpartitions of the phenotypic hyperspace. This approach performed well compared to contemporaneous state-of-the-art GEA implementations such as CHC and GENITOR (Mathias & Whitley, 1994a). Another example applied a hybrid GEA to the maximum clique problem that changes mutation rates based on the phase of the simulation (Ouch, Reese & Yampolskiy, 2007).
For any search function, there are multiple representations that make the optimization problem trivial (Liepins & Vose, 1990), so it makes sense to try different representations dynamically. Whitley, Rana, and Heckendorn even computed the expected number of local optima for a random representation (Whitley, Rana & Heckendorn, 1997). The first two authors also introduced the concept of shifting to dynamically switch from one Gray representation to another to escape local optima (Rana & Whitley, 1997). Barbulescu, Watson & Whitley (2000) expanded this work by proving a bound on the number of Gray representations available via shifting. They showed that to improve performance, the GEA needs to shift to a dissimilar representation to the current one.
Shifting between representations occurs sequentially in these works, but can also be evaluated in parallel using a modified island model (Skolicki & De Jong, 2004). In all these cases, however, the different representations are either standard binary or Gray. These studies have not explored the possibility of changing to a random representation with different locality to evaluate its effect on GEA performance.
Whitley (2000) did compute summary statistics for any random permutation function, but these did not include average locality. To offer a framework of understanding the effect of arbitrary representations on locality, we also compute in ‘Expected point locality’ the expected point locality of any random representation.
Theoretical Results on Point Locality
Defining point locality
Recall Rothlauf’s definition for locality (Eq. (1)). Since we are for the moment specifically concerned with single-bit mutations, both and are equal to 1. And since we limit ourselves to binary-integer representations, all phenotypic distances fall in the range [0, 2ℓ − 1] and all genotypic distances fall in the range [0, ℓ]. We can use these assumptions to precisely define our own derived metric, point locality, using units that we find more intuitive.
We first define a representation r:{0, 1}ℓ → [0, 2ℓ) as a bijection between the set of ℓ-bit bitstrings {0, 1}ℓ and the discrete integer interval [0, 2ℓ). This ensures that the representation is not redundant –i.e., every integer in the interval [0, 2ℓ) is represented by exactly one ℓ-bit bitstring, and the number of search-space points np is exactly 2ℓ. A representation r can therefore be equivalently described as a permutation π:[0, 2ℓ) → [0, 2ℓ), where π(i) = j if and only if the SB representation of i maps to j under r. Consequently, we can write π as a 2ℓ-tuple where the ith coordinate (starting at 0) is π (ith). We also use the notation to denote the binary string produced from flipping the ith coordinate of the binary string s ∈ {0, 1}ℓ. Formally, , where ⊕ denotes bitwise exclusive-or.
It is worth noting two important assumptions about this definition that limit the generalization of our results. First, we only consider nonredundant representations, because they are the most efficient from an information-theoretic point of view. In other words, they represent the most phenotypic values for a given bitstring length ℓ. Second, we map all phenotypic values to the range [0:2ℓ). This is primarily a choice of convenience. Nonredundant phenotypes could could come in any integer range of size 2ℓ, continuous or not. If a representation is nonredundant or noncontinuous, our theoretical results no longer necessarily hold. However, we believe that many practical applications of GEAs do in fact represent integers as we have, perhaps because the SB encoding is supported in hardware by all extant computer systems and is therefore extremely fast to translate in practice.
We can now define the point locality pr for a nonredundant bitstring-to-integer representation r as the average change in phenotypic value for a uniformly random single-bit flip in the genotype. More formally:
The point locality pr for a representation r is . Explicitly, (3)
Note that for any given ℓ, our definition of pr is a simple linear transformation of Rothlauf’s dm. In our domain, dm simply sums the phenotypic distances minus one between all distinct genotypic neighbors, while pr computes the average phenotypic distance between all ordered pairs of genotypic neighbors. Also note that in Rothlauf’s dm, occurs in the summation ℓ2ℓ times. Coupled with the fact that in our domain, we have the relationship:
Computing tight bounds for point locality
Our first analysis proves lower and upper bounds on pr, computes pr for SB and Gray representations, and verifies the existence of representations with both minimum and maximum pr.
Lower bound
Theorem 1: Lower bound
for nonredundant binary-integer representations,
We reduce the problem of minimizing locality to another problem, that of enumerating nodes on a hypercube while minimizing neighbor distances, for which lower and upper bounds have been established by Harper (1964). We use the term to denote the absolute difference between the numbers assigned to two adjacent vertices i and j on the unit ℓ-cube. The unit ℓ-cube consists of all elements in {0, 1}ℓ. Two vertices in the ℓ-cube are adjacent if they differ by only one bit (i.e., they have Hamming distance 1). Note that assigning a number n to a vertex i can be thought of as a representation r mapping i to n, or r(i) = n. Therefore, we have for adjacent vertices and s, since a 1-bit difference is equivalent to a single bit-flip mutation. Following Harper (1964), we define the sum to be the sum of the absolute difference between two adjacent vertices and s that runs over all possible pairs of neighboring vertices in the ℓ-cube. Note that since the RHS computes twice for every ordered pair.
Harper proved that . Therefore, proving that .
Standard binary encoding is optimal, meaning that it has the strongest (lowest) point locality, equal to .
We prove optimal locality by direct computation of the sum of distances for this encoding. SB encoding is also a representation—call it SB. We consider pSB: The inner sum computes the sum of all differences obtained from flipping the ith bit of a given SB string s. Flipping the ith bit elicits an absolute phenotypic difference of 2i for any s and i, reducing the inner sum to: Now since there are 2ℓ elements in {0, 1}ℓ, the outer sum reduces to ∑s(2ℓ − 1) = (2ℓ)(2ℓ − 1). Combining these lets us compute pSB: which is the lower bound given by Theorem 1. Thus, SB has optimal point locality. □
Upper bound
Theorem 3: Upper bound
pr ≤ 2ℓ−1 for nonredundant binary-integer representations,
We rely on another result from Harper (1964) in which he proved that . We have Thus pr ≤ 2ℓ−1. □
There exists a nonredundant binary-integer representation r with upper bound point locality pr = 2ℓ−1.
Here, we reduce the problem of constructing a representation r with upper bound locality pr = 2ℓ−1 to that of assigning integers in [0, 2ℓ) to vertices in the ℓ-cube, such that is maximized. Harper (1964) constructed an algorithm assigning numbers to vertices to maximize , shown in Algorithm 1. Maximizing is equivalent to maximizing pr, so such a representation exists.
Computing point locality for Gray encodings
Gray encodings are encodings where two phenotypic neighbors are also genotypic neighbors. In our domain, this means that any two phenotypes that are separated by one unit are represented by two genotypes that are separated by one bit flip. For a given length ℓ, there are multiple Gray encodings, but the most common is BRG. Here, we show that BRG has equivalent point locality to SB, and that not all Gray encodings share the same locality value.
Point locality of BRG
Binary Reflected Gray (BRG) encoding is also optimal.
This claim can be derived from Harper’s construction algorithm for optimal representations, which can be shown to also construct BRG. Instead, we show an original proof by induction.
Let BRG notate the representation for Binary Reflected Gray , so
We prove this claim by breaking it up into two lemmas and proving them separately. The first lemma computes the sum of differences from mutating the leftmost (most-significant) bit in BRG. We use this result in the second lemma to compute the sum of differences from mutating all bits in BRG.
.
In other words, the sum of the differences obtained by flipping the leftmost bit over all ℓ-bit bitstrings in BRG encoding is 22ℓ−1.
Consider the recursive nature of BRG codes (Rowe et al., 2004). Let Lℓ be the ordered list of ℓ-bit BRG codes where Lℓ[i] is the bitstring that maps to i. Note that 2ℓ is the length of Lℓ and [] denotes list indexing. The left half of Lℓ contains Lℓ−1 prefixed with 0 and the right half of Lℓ contains Lℓ−1 in reverse order prefixed with 1. Flipping the leftmost bit of Lℓ[i] will yield Lℓ[2ℓ − 1 − i]. Thus we have Note that for a given i ∈ [0, 2ℓ − 1], which lets us split the sum to Splitting the left sum and using the facts that the sum of the first n odd numbers is n2, Thus .
.
We proceed with induction on ℓ. For the base case (ℓ = 1), the set {0, 1} contains two BRG codes, which correspond to the integers 0 and 1, respectively. Thus .
For the inductive hypothesis (I.H.), assume for some ℓ ∈ ℕ. We must now show that . Note that in the inductive step, we are working with strings of length ℓ + 1. By I.H. and the fact that there are two copies of the ℓ-bit BRG code in the (ℓ + 1)-bit BRG code, By Lemma 6, □
Now we can prove Corollary 5 Considering pBRG: which is the lower bound given by Theorem 1. Therefore, BRG has optimal point locality. □
Note that this equivalence in point locality between SB and BRG has already been demonstrated empirically for small values of ℓ (Chiam, Goh & Tan, 2006), but our proof holds for all values of ℓ.
Suboptimal Gray encodings
We now shift to generating a Gray encoding with suboptimal point locality, which requires the following lemma:
For ℓ ≥ 3, the ℓ-cube Qℓ always contains a Hamiltonian path starting with the sequence of nodes 0ℓ−3000, 0ℓ−3001, 0ℓ−3011, 0ℓ−3111, where the notation 0x denotes a length- x bitstring of all 0s.
Recall that the ℓ-cube contains 2ℓ vertices labeled as binary strings in {0, 1}ℓ, where vertex i is connected to vertex j if and only if i and j have Hamming distance 1. We proceed by induction on ℓ.
For the base case (ℓ = 3), the path 000, 001, 011, 111, 101, 100, 110, 010 is Hamiltonian. For the inductive step, assume that Qℓ has a Hamiltonian path starting with 0ℓ−3000, 0ℓ−3001, 0ℓ−3011, 0ℓ−3111. Consider Qℓ+1. By the inductive step, we can trace a path starting with the sequence 0ℓ+1, 0ℓ−2001, 0ℓ−2011, 0ℓ−2111 to some node 0v (v ∈ {0, 1}ℓ) such that the first bit never flips to 1. From there, we hop to 1v, then trace out the remainder of the path until all nodes have been visited, as nodes of the form 1x for all x ∈ {0, 1}ℓ constitute another copy of Qℓ. The resulting path is Hamiltonian, since every node has been visited exactly once.
There exists a Gray encoding g with suboptimal point locality for any ℓ ≥ 3.
A bitstring b ∈ {0, 1}ℓ has ℓ neighbors that are all Hamming distance one away. We can thus reduce the problem of constructing a Gray code to that of constructing a Hamiltonian path on the ℓ-cube. Recall that in Theorem 1 we mapped the problem of minimizing locality to that of minimizing . In the same paper, Harper (1964) formulates an algorithm that provably generates all representations that minimize , which we describe in Algorithm 2:
Our goal is to construct a Hamiltonian path that violates this algorithm. This path in turn will determine a Gray code that has suboptimal point locality, because Harper’s algorithm generates all representations with optimal point locality.
Our modified algorithm starts by assigning 0 to vertex 0ℓ−3000. We then assign 1 to 0ℓ−3001 and assign 2 to 0ℓ−3011. Algorithm 2 would force us to assign 3 to 0ℓ−3010 if we wanted to produce an optimal Gray code. Instead, we assign 3 to 0ℓ−3111, which violates the algorithm. The remainder of the path can be traversed arbitrarily such that it is Hamiltonian, due to Lemma 8. This construction generates a Gray code g with for ℓ ≥ 3. □
Consider a 3-bit Gray code representation g, given by the permutation π = [0, 1, 3, 7, 5, 4, 6, 2]: Then g is a Gray code generated by9, and pg ≈ 3.667 which is greater than the lower bound fromTheorem 1. A visualization of how our modified algorithm from9 generates g appears inFig. 1. Note that in step D, we assign 3 to 111, which has fewer neighbors than 010 that are already labeled.
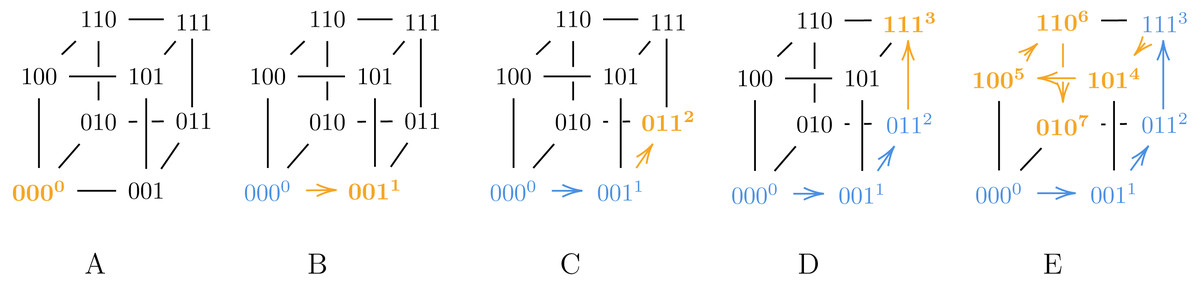
Figure 1: A visualization of our modified algorithm from Claim 9 used to generate g.
In step D, we assign 3 to 111 instead of 010, violating Algorithm ?? and thus ensuring g is a suboptimal Gray code.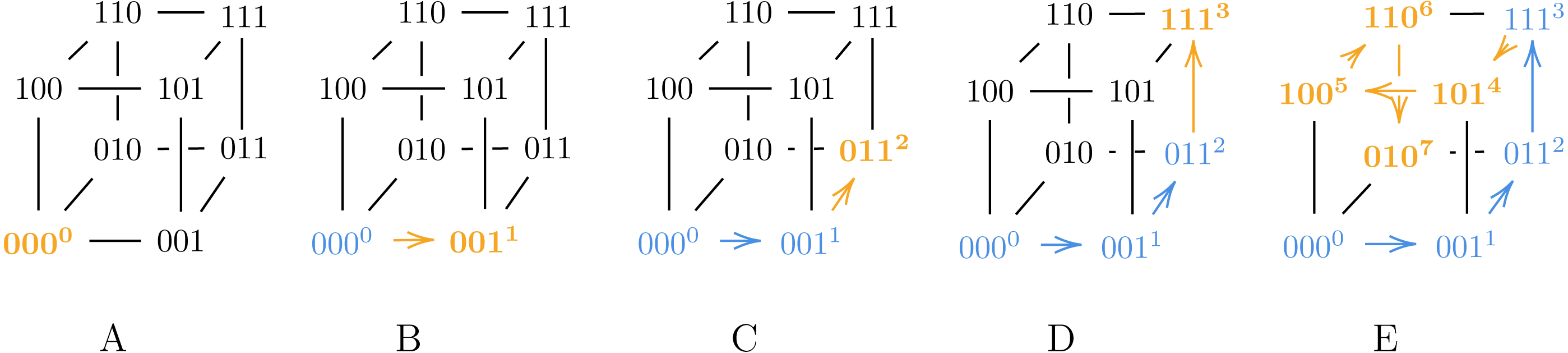{kind=link}
Also note that Algorithm 2 can generate both SB and BRG codes, as illustrated in Figs. 2 and 3.
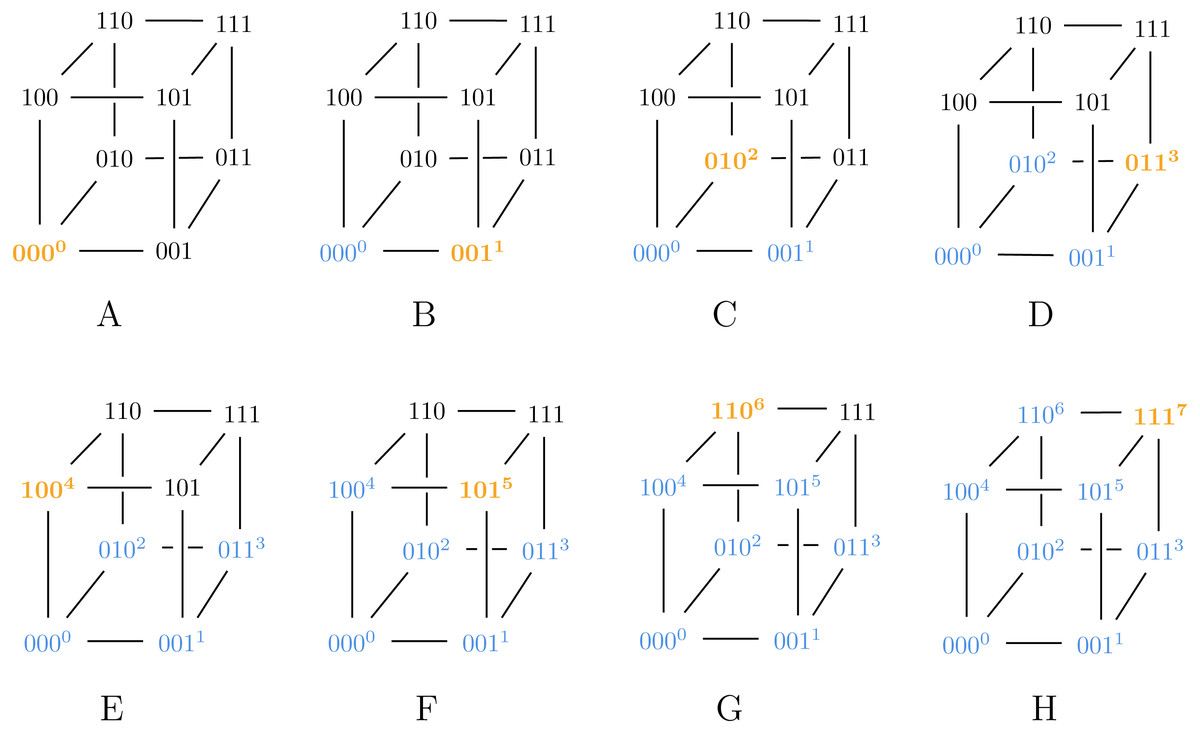
Figure 2: Algorithm 2 generating SB for ℓ = 3.
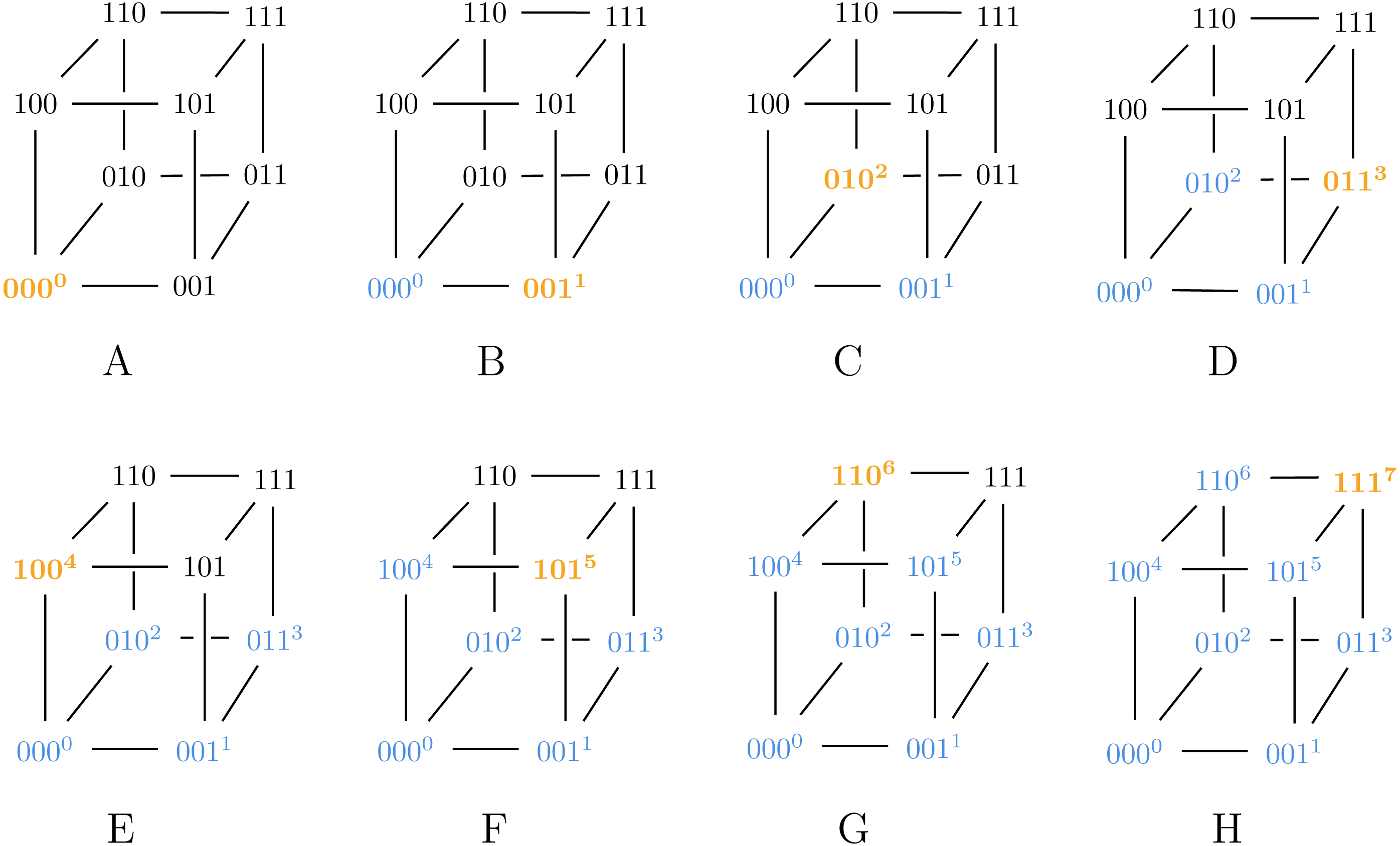{kind=link}
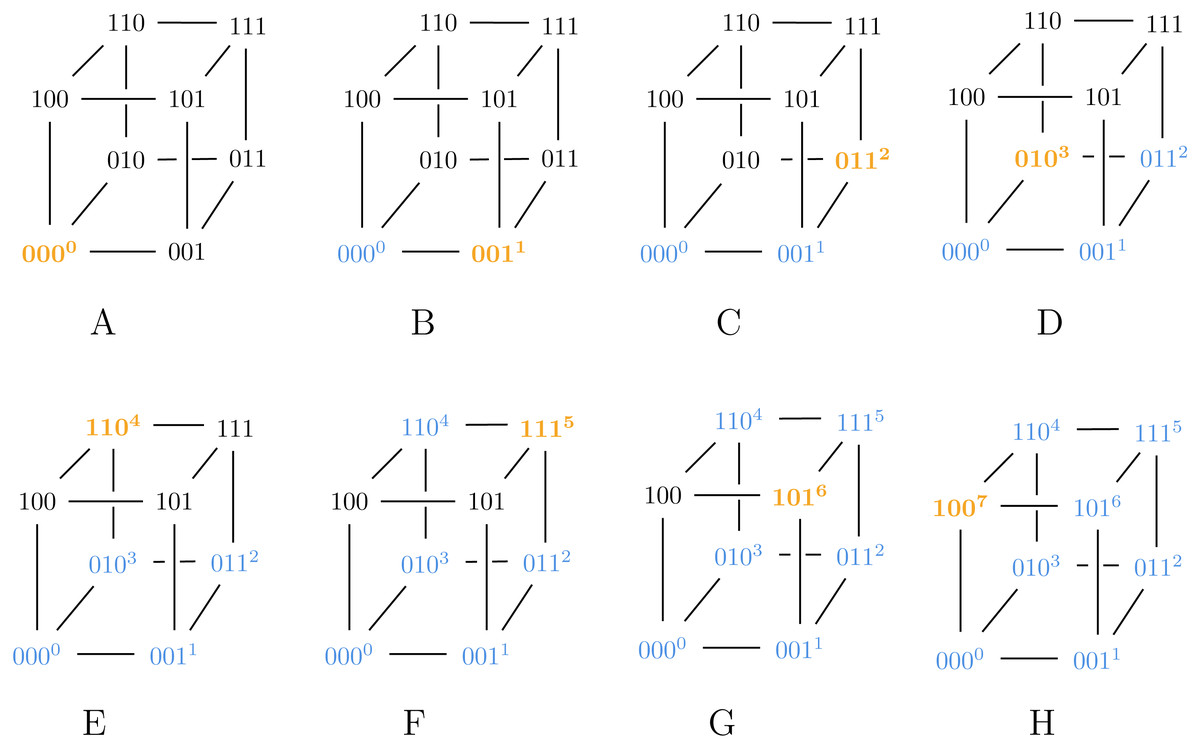
Figure 3: Algorithm 3 generating BRG for ℓ = 3.
{kind=link}
Expected point locality
Our final proof on point locality answers the question: “what is the expected point locality of an arbitrary representation?”
Theorem 10: Expected Point Locality
for nonredundant binary-integer representations.
We prove this by direct computation, using a few identities, starting with the definition of pr: (4) Let L = {0, …, 2ℓ − 1}. Computing the expectation in Eq. (4) is equivalent to assigning numbers in L to vertices of the ℓ-cube uniformly at random, and then summing the absolute differences between every adjacent pair. Let k denote the value assigned to vertex s, and let πk denote a size ℓ random subset of L∖{k}.
Due to linearity of expectation, the sum of absolute differences for each vertex s can be examined independently even though they are dependent variables. Then, s has ℓ neighbors where the ith neighbor is assigned the ith element in πk, which we denote πk(i). This gives us the following relation (letting n = 2ℓ for simplicity): (5) Since every number in L∖{k} has equal probability of appearing as the ith element of πk, 𝔼[πk(i)] does not depend on i at all. Therefore, once we apply linearity of expectation on the right side of Eq. (5), we can replace πk(i) with a discrete uniform random variable sampled from L∖{k}. Denote this random variable as Xk. We then have: where we let . Continuing with the fact that : Let . Then Using the fact that and simplifying: Substituting back into Eq. (4) yields:
We have verified this value experimentally for 1 ≤ ℓ ≤ 8. It is interesting to note that the expected asymptotic value differs from the worst-case (maximum) locality by only a constant factor, and grows further apart with ℓ from the optimal locality.
Having explored the properties of point locality for single-bit mutations, we now turn our attention to general locality and distance distortion for any variation operator.
Theoretical Results on General Locality
General locality is a measurement of the average perturbation of a phenotype for any arbitrary change in genotype, such as the one created by a crossover operator. Again, we refine Rothlauf’s definition for our representation domain. As it turns out, this metric proves to carry no useful information about representations in this domain, because the phenotypic range grows much faster with ℓ than the genotypic range.
Defining general locality
Again we start with Rothlauf’s definition, called distance distortion (Eq. (2)), and develop an equivalent definition, called general locality, that is tailored to our domain. We define the general locality gr for a representation r as the mean difference between phenotypic and genotypic distances between each unique pair of individuals. More formally:
The general locality for a representation r is (6) where Sℓ is the set of all unordered pairs from {0, 1}ℓ (so ), dp(s1, s2) is the phenotypic distance |r(s1) − r(s2)|, and dg(s1, s2) is the genotypic (Hamming) distance between s1 and s2. Note that our definition of general locality mirrors Chiam’s remoteness preservation and is also equivalent to Rothlauf’s dc metric, since is identical to ∑(s1,s2)∈Sℓ.
We begin our analysis of general locality by proving a lower bound on its value, and continue by proving the asymptotic equivalence of all nonredundant binary integer representations under this metric.
Lower bound for general locality
We compute the tight lower bound on general locality for our domain since it gives an order-of-magnitude estimate for its value, as well as a framework to compute its actual asymptotic value.
(Lower bound) for nonredundant binary-integer representations.
By definition, . By the triangle inequality, we have where we let P = ∑(s1,s2)∈Sℓdp(s1, s2) and G = ∑(s1,s2)∈Sℓdg(s1, s2). Since P only deals with phenotypes in ℕ, it is equivalent to Let the outer sum fix i. The inner sum computes the sum of numbers from 1 to 2ℓ − 1 − i. This reduces P to where we let n = 2ℓ − 1 for simplicity. Using the facts that the sum of the first m natural numbers is and the sum of the first m squares is , we have Substituting n = 2ℓ − 1 back into the equation yields:
Now, since G is the sum of the Hamming distances between all unique pairs of bitstrings, it is equivalent to
because for each of the 2ℓ bitstrings, a bitstring has other bitstrings with Hamming distance i (choose i of the ℓ bits to be flipped). We divide by two because we count each pair twice. Simplifying G gives us Substituting P and G back into gr yields
Asymptotic value of general locality
Here, we prove that the asymptotic value of general locality in our domain is invariant of the actual representation.
for any nonredundant binary-integer representation r on ℓ bits. That is, as ℓ grows, the value of gr is independent of the actual representation.
The key intuition behind this proof is that for nonredundant binary-integer representations, as ℓ grows, the phenotypic distances grow at an asymptotically greater rate than the genotypic distances. We can separate the phenotypic distances from the genotypic distances by partitioning Sℓ into two sets , where ⊔ denotes disjoint union: In other words, contains all the pairs in Sℓ where the two bitstrings have greater phenotypic (Euclidean) distance than genotypic (Hamming) distance, and contains all pairs where the two bitstrings have greater or equal genotypic distance than phenotypic distance. We can rewrite gr as (letting ) where we let (7) (8) Note that since each of the 2ℓ bitstrings can have at most 2ℓ − 1 bitstrings for which their genotypic distance is greater or equal to their phenotypic distance. This is because for an integer i ≥ ℓ, the integers between i − ℓ and i + ℓ can be represented by bitstrings with genotypic distances greater than phenotypic distances j ≤ ℓ, where we subtract 1 due to the fact that each bitstring only has one other bitstring with Hamming distance ℓ. We then divide by two since we count each pair twice. Thus . We can now say , so . Consider since grows faster than . Thus dominates , and .
We can now perform a similar analysis for P(ℓ) and P(ℓ) + G(ℓ). Note that since any pair in can have a maximum dg − dp of ℓ − 1. Thus . Also note that since any pair in can have a minimum dp − dg of 1. Thus P(ℓ) = Ω(22ℓ). Consider since P(ℓ) = Ω(22ℓ) grows faster than , and so P(ℓ) + G(ℓ) ∼ P(ℓ). Now we can make a statement about gr. We have Thus . Since and CP(ℓ) ∼ gr, we replace with Sℓ in Eq. (7) to obtain (recall ) which was found in the proof of Theorem 11. Thus gr and are asymptotically equal for any representation r.
Theorem 12 states that all representations have asymptotically equal general locality. Since SB and BRG are well-defined for any number of bits, it follows that their general localities are asymptotically equal as well. In fact, on just their 11-bit representations (with only np = 2, 048 possible genotypes, where a brute-force search likely outperforms many GEAs), we calculate gSB = 677.497 and gBRG = 677.502, only a 0.0007% difference. The implication is therefore that general locality, and by extension, the original definition of distance distortion, are not useful as a description or prediction of any representation in this domain. In a domain where phenotypic and genotypic distances grow with ℓ at similar rates, such as with unary representation, these definitions may have more power.
Experimental Results
As the previous section proved, Gray encoding exhibits no general or point locality advantage over standard binary. On the other hand, several studies found a performance advantage for Gray under various GEAs (Whitley, Rana & Heckendorn, 1997; Whitley & Rana, 1997; Whitley, 1999; Mathias & Whitley, 1994b). As a first step towards understanding why stronger locality does not always lead to a GEA performance advantage, this section expands on past experimental results and analyzes the factors that lead to better performance. Our experiments progress from the simple to the complex, to allow a tractable analysis of the effect of point locality, as well as an evaluation of both localities in richer and more realistic scenarios. All of our source code, representations, choices of parameters, and Markov models can be found in the supplementary material and at https://github.com/shastrihm/GAMO-R.
Simulated annealing
One very simple GEA is single-organism simulated annealing (SA), which we apply to the gen-one-max problem from Sec. 5.4 of Rothlauf’s book (Rothlauf, 2006).3 We start with SA, rather than the somewhat simpler (1+1) EA algorithm that we explore in the next section, because we can replicate Rothlauf’s results exactly, and then expand upon them, giving us a solid basis for comparison.
To recap Rothlauf’s experiment, it defines an ℓ-bit genotype x that is translated to an integer phenotype xp ∈ [0:2ℓ − 1] by a given representation. The fitness of the phenotype includes a deceptive trap, and is evaluated against a target a with the function where xmax is defined as the maximum phenotypic value, 2ℓ − 1, and is attained only at the global maximum a. The genotype is iteratively mutated with a random single-bit flip, and the offspring replaces the parent if it improves its fitness, or at a probability determined by a Boltzmann process. This probability decreases both with the fitness difference between the parent and offspring, and with a global temperature parameter that decreases every iteration.
As in the original study, we set ℓ = 5, the initial temperature to 50, and the cooling factor to 0.995, and experiment with different representations and a values. Each experiment is run for a few thousand generations (mutations) until it converges on a solution. Finally, we repeat each experiment concurrently and independently for thousands of different random starting genotypes and record for each generation the percentage of experiments (genotypes) that are at the global optimum.4
Rothlauf compared the GEA’s performance across two representations, SB and BRG, using either a = 31 (where both representations perform equally) and a = 15, where SB often gets trapped on the local maximum phenotype 16 and thus significantly underperforms BRG. Our code produced the same results, as shown in Fig. 4.
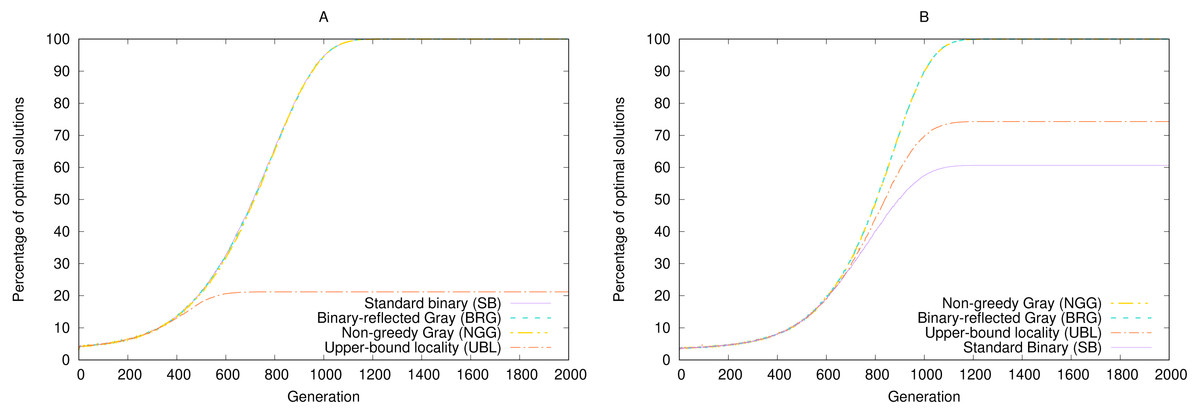
Figure 4: Performance of four representations under simulated annealing for a 5-bit gen-one-max problem averaged over 100,000 random seeds with (A) a = 31 and (B) a = 15.
Higher results are better.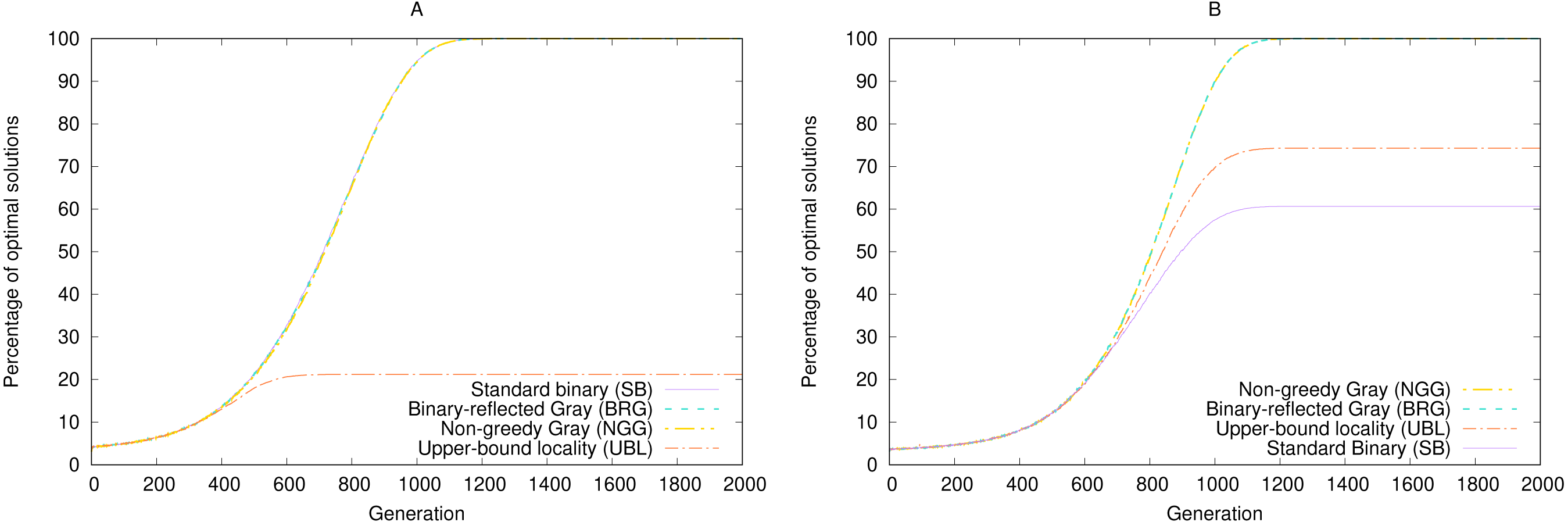{kind=link}
In the original study, Rothlauf summarizes the worse performance of SB as follows: “The binary encoding has problems associated with the Hamming cliff and has low locality. Due its low locality, small changes of the genotype do not always result in small changes of the corresponding phenotype” (p. 136). However, as the previous section showed, BRG has no locality advantage over SB by either metric. In particular, the locality metric that captures the mean degree of variation across single-bit mutations, namely point locality, is equal for both: . Weak locality cannot therefore be an explanation for performance differences in this case.
The other explanation about the Hamming cliff requires some unpacking. A Hamming cliff, which we loosely define as a genotype whose immediate genotypic neighbors are not also phenotypic neighbors, can represent a local phenotype maximum (Rowe & Hidović, 2004). That is because any genotype other than the global maximum, whose immediate genotypic neighbors (i.e., one bit-flip away) are not phenotypic neighbors, will have nonlocal jumps in values of the fitness function. These jumps could therefore all be farther away from the global maximum’s fitness. Such genotypes are disfavored by the selection process to mutate, because any mutation lowers the fitness value. With a certain combination of temperature, cooling factor, and fitness parameters, the Boltzmann selection operator can develop a nonzero probability of getting stuck in the suboptimal genotype, leading to underperformance of the GEA. This is exactly what happens in the example of a = 15, where BRG has only one maximum at 15, but SB also has a suboptimal local maximum at 16, where no single-bit mutation improves fitness. Over time, SB has ≈0.4 probability of getting stuck in this local optimum, leading to ≈60% optimal solutions over all random seeds.
Gray encoding, on the other hand, is guaranteed not to have more than one optimum, because every non-optimal phenotype has at least one genotypic neighbor—one bit flip away—that is also a phenotypic neighbor—one integer away—in the right direction. Whenever such a mutation happens, it is selected by the Boltzmann process, converging eventually to the single optimum. This property is invariant of the point locality value. To demonstrate this, we synthesized a Gray representation based on Claim 9 and termed it non-greedy Gray (NGG).5 By construction, for ℓ = 5, pNGG = 8.35 > pSB. Nevertheless, NGG performs perfectly for both target values, as Fig. 4 shows.
To take this point to the extreme, we synthesized a worst-case representation using the construction in Claim 4 and termed it upper-bound locality (UBL).6 By construction, pUBL = 25−1 = 16 > pSB. And although UBL performs poorly for a = 31 and suboptimally for a = 15, it still outperforms SB in the latter case.
The two point-locality extremes, SB and UBL, outperform each other for different target values. Even among representations with the same locality, performance is uneven. We must therefore conclude again that locality does not determine performance for this particular problem. The second explanation, the existence of Hamming cliffs, is also insufficient to predict performance (Chakraborty & Janikow, 2003).
Gray coding is sometimes described as higher-performing than SB because it can produce fewer local maxima for many useful problems (Whitley, Rana & Heckendorn, 1997). But the local maxima count on its own is not a strong predictor of GEA performance for this problem, because the probability of getting stuck in any specific maximum depends on its fitness distance from its genotypic neighbors. For example, UBL has four Hamming cliffs (local maxima) with a = 15, compared to SB’s two, and yet UBL still outperforms SB. In another example with a = 29, SB has three local maxima, and yet it still converges to the global optimum every single time.
In summary, neither locality nor local maxima count can predict performance for the gen-one-max problem under Boltzmann selection. This holds true for many other functions as well (Chakraborty & Janikow, 2003). A more nuanced explanation of the GEA performance arises from two observations: that the linear fitness function penalizes local maxima that are farther from the global maximum (in phenotypic distance), and that the Boltzmann selection process gives preference to mutations that minimize phenotypic distance.
The interaction between these two factors can be modeled with a simple Markov chain, which fully predicts the probability of converging to the local maximum in the absence of a cooling factor. Adding the cooling factor complicates the model, but it can still be computed with a dynamic probability function. The main constraint this GEA imposes on some representations is the inability to break free from some local maxima. In the next section we turn to a different GEA, so that we may evaluate the effect of point locality with different mutation and selection operators that can always jump out of a local maximum.
Evolutionary algorithms
Our next experiment introduces two changes to the previous GEA. First, we use simple elitist selection instead of Boltzmann selection. An offspring only replaces a parent if it improves its fitness. This change would make local maxima impassable for single-bit mutation, so we change the mutation operator as well. Mutations can now flip any bit independently with probability m, so that any genotype can be mutated to any other genotype at some positive probability that depends on m and the Hamming distance between them. Therefore any genotype could in principle be mutated to the global maximum in a single step. From a locality point of view, invoking multiple bit flips per generation has the same effect as invoking a single random bit flip for multiple generations, so a representation with strong point locality under a single bit flip should also exhibit a smaller mean change in phenotype value in this experiment.
This modified GEA is denoted as (1+1) EA (Droste, Jansen & Wegener, 2002), has been studied extensively, and may be considered as a degenerate kind of simulated annealing. Mühlenbein (1992) investigated this GEA in the context of the simpler ONEMAX problem by developing an analytical model for the expected number of generations to reach the optimum solution. Using a simpler fitness function that merely counts the number of ‘1’ bits in the genotype, his model predicts the mean number of generations to converge on the optimum when the mutation rate is . His prediction holds for any representation since the fitness function ignores the phenotype. Indeed, when we ran the same simulation on various ℓ values larger than 5, we get similar empirical convergence times as Mühlenheim’s experimental results, irrespective of the representation.
Reintroducing Rothlauf’s gen-one-max fitness function adds back a dependency on the representation, as Table 1 shows. Modeling this performance with a Markov chain confirms the empirical results and the differences between the representations. This is an example where SB actually outperforms both Gray encodings, at least for a = 31. In this case, note that a mutation improves fitness if and only if it flips a bit to ‘1’. Improving mutations, which are the only ones that can change the genotype, are independent of each other and of any sequence, so the order of ‘0’ to ‘1’ bit flips does not matter. This leads to swift convergence to the optimum. Conversely, in all other representations, some sequences of fitness improvement require first flipping a specific bit one way, then later the other way. It imposes an ordering or interdependency of mutations that prolongs convergence. It is especially bad for UBL, because many fitness improvements require more than one bit flip at the same time, which occurs less frequently.
| Optimum (a) | SB | BRG | NGG | UBL |
|---|---|---|---|---|
| 31 | 17.5 | 23.8 | 28.3 | 184.8 |
| 15 | 103.6 | 21.3 | 23.3 | 124.8 |
When we switch to a = 15, we introduce the same handicap to SB, because now it has to flip every single bit at once when trying to escape the phenotype 16, at a low probability of mℓ. Despite the dismal performance, it is worth noting that SB still performs better under (1+1) EA than under simulated annealing (SA): in 2,000 generations, it reaches the optimal solution in 65.9% of the runs, compared to SA’s 60.6%, and if allowed to evolve for more generations, all runs will eventually find the optimum.
It is also worth noting that NGG slightly underperforms BRG for both target values, which could be a related to its weaker locality. But overall, locality is a poor explanation for (1+1) EA performance in this experiment, because SB outperforms BRG with a = 31 and underperforms it with a = 15, despite both representations having the exact same point locality.
Genetic algorithms
For our last experiment, we add three more layers of complexity. First, we add a population element with fitness-proportionate selection (roulette-wheel).7 Second, we add a recombination operator, specifically single-point crossover. And finally, we expand our evaluation functions to De Jong’s test suite, which can be more challenging to solve with a GEA than gen-one-max (De Jong, 1975). These five functions take real numbers as inputs, but De Jong and subsequent studies used fixed-point numbers as inputs, which lie in the same binary-to-integer scope as the rest of this paper.
To compare different representations under a genetic algorithm (GA), we attempted to replicate the experiments of Caruana & Schaffer (1988), which in turn derive their GA parameters from Grefenstette (1986). We measured the online performance under SB, BRG, NGG, and UBL representations, where online performance is defined as the average fitness of all function evaluations to the current point. Their results and ours are shown in Table 2.
| Function | Description | Dimensions | Total bits | Optimum | SB | BRG | NGG | UBL |
|---|---|---|---|---|---|---|---|---|
| f1 | Parabola | 3 | 30 | 0 | 2.49 (1.66) | 2.03 (1.43) | 2.03 | 6.70 |
| f2 | Rosenbrock’s Saddle | 2 | 24 | 0 | 32.56 (25.16) | 22.31 (13.18) | 22.35 | 199.48 |
| f3 | Step function | 5 | 50 | −30 | −26.48 (−27.78) | −25.10 (−27.16) | −25.06 | −17.86 |
| f4 | Quadratic with noise | 30 | 240 | 0 | 41.46 (24.28) | 32.32 (21.77) | 32.28 | 65.83 |
| f5 | Shekel’s foxholes | 2 | 34 | ≈1 | 56.71 (30.78) | 35.86 (20.68) | 35.84 | 149.92 |
Unfortunately, we could not uncover the full details or source code of their implementation, and had to construct our own experiment from scratch, likely with different parameter or implementation choices. These differences could help explain why our results are not identical to the original study’s. Another explanation could be that the original study averaged each experiment over only five trials, which we found too noisy. Instead, we averaged performance over 3,000 trials (90,000 fitness evaluations) for each experiment to increase statistical robustness.
While our results differ in quantity, they agree in quality. Caruana and Schaffer found BRG to perform similar to or better than SB on the minimization of all five test functions, as have we and others (Hinterding, Gielewski & Peachey, 1995). While Caruana and Schaffer recognize that an encoding is as likely to outperform another encoding on an arbitrary search, they believe that “many common functions which have ordered domains have local correlations between domain and range. A GA using Gray coding will often perform better on this class of functions than one using binary coding because the Gray coding preserves this structure better than binary code.” The authors suggest that it is the introduction of Hamming cliffs that biases SB away from preserving the domain structure. The fact that the weaker-locality NGG performs so closely to BRG supports this explanation.
Their paper does not clarify whether and how the crossover mechanism interacts with the representation. For example, there is evidence that Gray encoding interferes with standard crossover operators because it disrupts common schemata (Weicker, 2010), and that if crossover is the only variation operator, SB can actually outperform BRG on gen-one-max (Rothlauf, 2002).
What is clear from our experiment is that these behaviors are not captured by the locality metrics. BRG outperforms SB despite having the same point locality, and is equal in performance to NGG, with the weaker locality. Additionally, all four representations share the same values for the distance distortion, general locality, or remoteness preservation metrics.
To summarize all three experiments, none of our results shows that strong locality leads necessarily to better GEA performance. The next section suggests some reasons for this counterintuitive result.
Discussion
Locality and GEA performance
Why should strong locality improve GEA performance? We can list two reasons. First, strong locality helps preserve building blocks (schemata) across variation operators, because it supports the linkage between genotypic and phenotypic building blocks (Vose, 1991). Second, specifically for mutation operators, strong locality enables localized, hill-climbing, or gradient search, by effecting small changes to the genotype, such as single-bit mutation. With strong locality, small genotypic changes lead to small phenotypic changes, and because many practical fitness functions are locally continuous, they also lead to small fitness changes. In Rothlauf’s words (Rothlauf, 2003):
...low-locality representations randomize the search process and make problems that are easy for mutation-based search more difficult and difficult problems more easy. Although low-locality representations increase the performance of local search on difficult, deceptive problems this is not relevant for real-world problems as we assume that most problems in the real-world are easy for mutation-based search.
Despite these reasons, we found no strong association between various locality measures and GEA performance in our work and others’. One possible explanation is that the common test functions we evaluated are better-suited for Gray encoding, perhaps because of their sensitivity to Hamming cliffs (Caruana & Schaffer, 1988; Whitley, 1999). Another explanation is that in the domain we study here, nonredundant binary-integer mappings, our locality and distance metrics are skewed: phenotypic distances grow exponentially with ℓ, while genotypic (Hamming) distances grow linearly. For example, if we instead use the redundant unary bitstring-to-integer representation, for example, then phenotypic distances also grow linearly with genotypic distances, but the GEA would typically underperform nonredundant representations (Rothlauf, 2006). As another example, in the separate domain of program trees, some definitions of locality have been found to correlate well with GEA performance (Galván-López et al., 2011).
Regardless, even if in our domain locality does not affect eventual performance, we think it has a role in predicting GEA performance over time, especially in regards to the mutation operator. The role of the mutation operator in GEAs is to introduce genotypic and phenotypic variation (Hinterding, Gielewski & Peachey, 1995). In other words, mutations serve to diversify the population so that more potential solutions are evaluated. Locality, as defined here, quantifies the average impact of single mutations, with strong locality leading to smaller overall phenotypical variation. Whether or not strong locality improves GEA performance depends on the effect of diversity on performance, which itself varies over time.
Phenotypic diversity over time
In the process of converging towards an optimal solution, GEAs combine and balance two different search strategies, exploration and exploitation (Črepinšek, Liu & Mernik, 2013; Weicker, 2010). In the former, high variance or diversity is desired so that many subspaces of the fitness landscape are explored. When the GEA identifies a promising subspace, large variations in phenotype are more likely to be disruptive rather than helpful to fitness, so small perturbations are usually preferred (Rowe et al., 2004; Mathias & Whitley, 1994b). If the only variance-introducing operator in a GEA is single-bit mutation, then we should expect strong-locality representations to underperform weak-locality representations in the early phase of the search, and outperform in the latter phase. Because of this changing relationship over time, several studies explored dynamically changing the mutation rate and other GEA parameters (Doerr & Doerr, 2019).
This difference matters most if our GEA is meaningfully constrained by computational resources (Jansen, 2020). The GEA’s task then is to quickly explore the solution space for a “good enough” solution, rather than an eventual convergence towards an optimum. If a GEA is configured such that the expected fitness is relatively high after a few generations, and before convergence, then it has a higher probability of finding a decent solution with fewer resources, even if it is slower to converge later. This distinction is similar to the one between online performance and offline performance of the GEA (Grefenstette, 1986).
As an example, consider a comparison of performance over time between a strongest-possible locality representation and a weakest-possible locality representation in the the simulated annealing experiment (‘Simulated annealing’). We picked two arbitrary target a values for SB and UBL such that both representations have the same number of local maxima, four. Because we are interested in the likelihood of getting a “good enough” solution in limited time, rather than an optimal solution, we measure the expected (mean) fitness per generation across 100,000 runs, instead of the percentage of perfect solutions.
Figure 5 shows that for long-enough runs (starting from about 400 generations), both representations perform about the same, with a small eventual advantage to SB. But in the earlier generations, during the exploration phase, SB significantly underperforms UBL. In other words, this example shows that if we must stop our simulation at an early point before convergence, the representation with the weaker locality is more likely to produce a solution of higher fitness. But after that threshold has been passed, the stronger-locality representation may be more suitable for fine-grained exploitation to locate a higher-fitness solution. On the other hand, sometimes we are specifically interested in local or hill-climbing search (Mitchell, Holland & Forrest, 1994), in which case Gray encoding may be preferable to SB, even with the same locality, because it always offers a genotypic neighbor that can move the phenotype towards the maximum (Rowe et al., 2004).
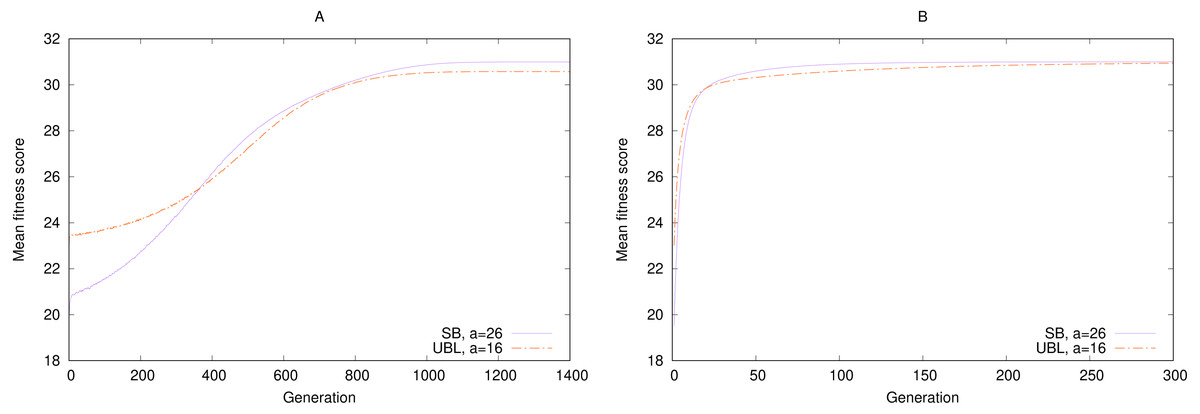
Figure 5: Convergence speed for 5-bit gen-one-max problems with four local maxima each and either (A) Simulated Annealing or (B) (1 + 1) EA.
Fitness is averaged over 100,000 trials.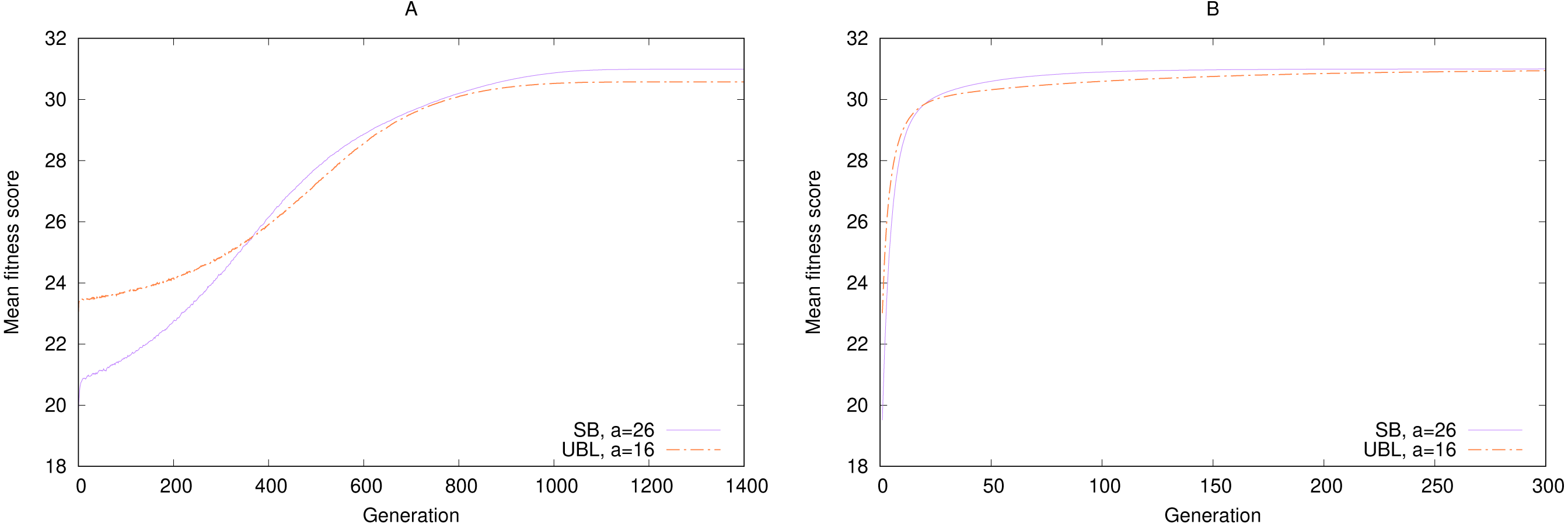{kind=link}
When we repeat the experiment with (1+1) EA, we see the same effect, where UBL starts out stronger but is then quickly surpassed by SB. In this case, both representations end up with the same eventual performance. Even the GA experiments show the same locality effect (Fig. 6), where UBL always starts out stronger than the other representations, even if only for a very short time.

Figure 6: Performance of four representations for the first 20 generations of a genetic algorithm.
Each data point averages fitness values from the best solution in that generation across 3,000 trials. Functions shown are (A) f1; (B) f2; (C) f3; (D) f4; and (D) f5.{kind=link}
This change in the role of mutations over time is also why some GEAs vary the mutation rate or operator over the course of the search (Eiben & Schippers, 1998; Gómez, Dasgupta & González, 2003; Hansen & Ostermeier, 2001; Zhao, Gao & Hu, 2007). An alternative approach would start the search with a weak-locality representation, and switch to a strong-locality representation as we move from the exploration phase to the exploitation phase.
Some consider the recombination operator as the main exploration tool, with mutation as the main exploitation tool (Caruana & Schaffer, 1988), while others disagree (Hinterding, Gielewski & Peachey, 1995). A recent result showed that crossover and mutation outperform any mutation-only algorithm for exploitation, at least for the hill-climbing function OneMax (Corus & Oliveto, 2020). Steady-state GEAs, unlike the generational GEAs considered here, allow for extremely low selective pressure independent from the mutation rate, which lowers the sensitivity to mutation operators and enables more effective exploration (Corus & Oliveto, 2017; Corus et al., 2021).
We think a more nuanced discussion needs to include the locality of the representation under the chosen mutation operator. Our results suggest that strong-locality representations are more suitable for an exploitation-oriented mutation operator, since they limit the perturbation of the phenotype, and vice-versa.
Changing representation randomly during the GEA execution may not be a practical tool to improve performance, because the expected number of local optima is too high (Whitley, Rana & Heckendorn, 1997). As we have shown in ‘Expected point locality’, the expected locality is also too high, closer to the pessimal locality than to the optimal locality, on average. But if our goal for the exploration phase of the GEA is to generate significant genotypic diversity and coverage of the search subspaces, then shifting to and between random representations may help this goal. To the best of our knowledge, no one has tried this approach, and it remains as promising future work for analysis.
Conclusion and Future Work
Various properties of GEA representations have been studied to help explain GEA performance, such as the number of induced local optima or the existence of Hamming cliffs. Among these properties, locality is particularly interesting to analyze, because it is independent of the fitness landscape and can be computed precisely, which is not always the case for other properties.
But if strong locality is also a strong factor in good GEA performance, as has been expressed in the literature, then we do not always have the right metrics to measure it. Our own point and global locality metrics, based on the works of Rothlauf and others, show no clear relationship to offline GEA performance in the domain of nonredundant binary-integer representations. It is quite likely that the result that locality does not predict GEA performance extends to more domains. Conversely, in some other domains, such as redundant representations or those with linear scaling of the phenotype, this negative finding may not hold. We plan to explore locality metrics specific to redundant, nonbinary, or noninteger representations as well. This result also does not always hold for resource-constrained GEAs, since for short-enough executions, weak-locality representations do appear to outperform strong-locality representations in our experiments, as they emphasize exploration over exploitation.
Both the dm and dc locality metrics (and consequently, pr and gr) estimate the locality of a representation by using the sum of phenotypic distances, which grows exponentially in our domain. Another path for future research might be to use other statistics as estimators of locality that grow more slowly with the bitstring length, such as the minimum phenotypic distance, maximum, or standard deviation. In addition, both Rothlauf’s locality metric and our own equivalent point locality focus on the single-bit mutation operator. Other locality metrics could look at different operators, and perhaps combine them with a crossover operator to expand on distance distortion.
Of the two most common binary-integer encodings, Gray has often been shown to outperform standard binary on many GEAs and test functions. There are various context-dependent explanations for this advantage, such as the Hamming cliff, differing numbers of local optima, and the properties of the typical test functions. What our study has shown, both analytically and empirically, is that the locality of the representations cannot reliably be one of these explanations. A complete characterization and understanding of the performance difference between binary and Gray remains an interesting research question, and a different locality metric may be able to shed more light.