
Machine and Deep Learning Applied to Predict Metabolic Syndrome without a Blood Screening

 , , , and
, , , and
Abstract
:1. Introduction
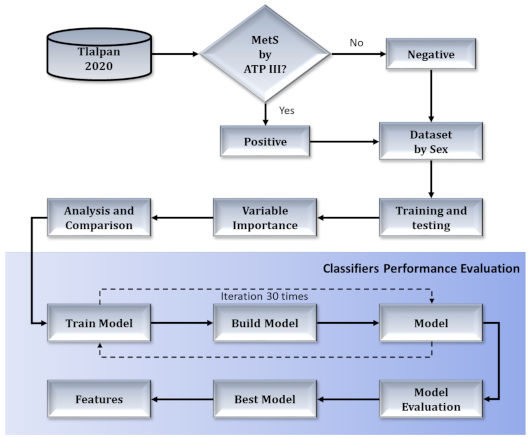
2. Materials and Methods
2.1. Data
2.1.1. Clinical and Anthropometric Parameters
2.1.2. Biochemical Evaluation
2.1.3. Dietary Information
2.1.4. Habits
2.2. Methods
2.2.1. Random Forest
2.2.2. C4.5
2.2.3. Chi-Squared
2.2.4. Pearson Correlation
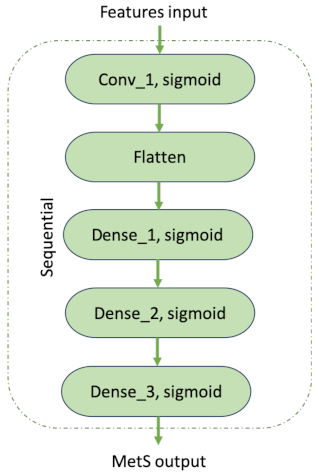
2.2.5. Deep Neural Networks
2.3. Metrics
3. Results
3.1. Variable Importance by Category
- clinical and anthropometric parameters,
- dietary information,
- quality of sleep, and
- habits (smoking, alcohol consumption, physical activity).
3.2. Variable Importance of the Complete Dataset
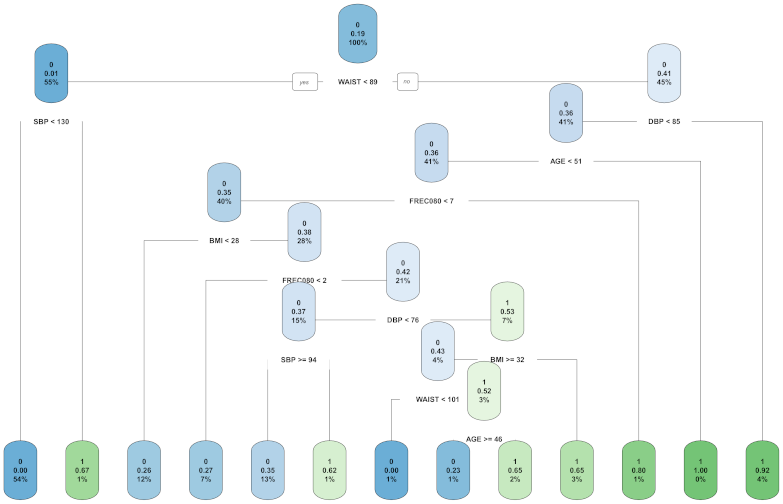
3.3. Most Important Variables in Women
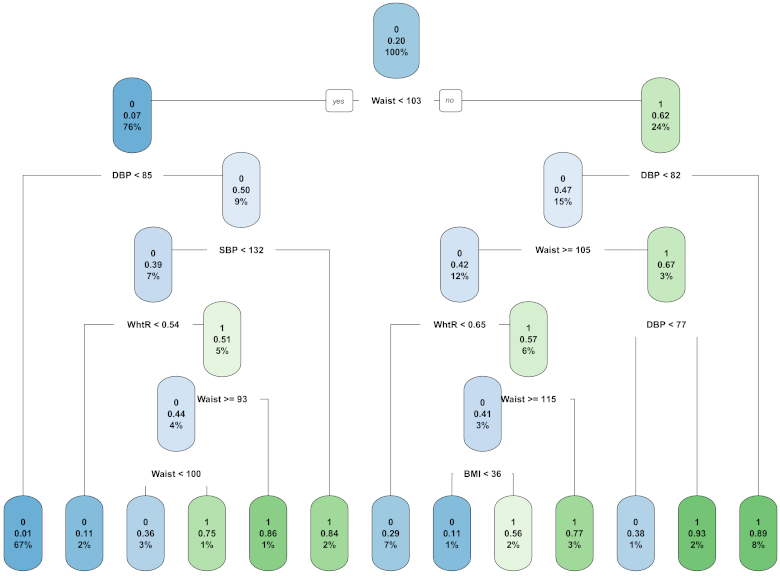
3.4. Most Important Variables in Men
3.5. Analysis and Comparison
3.6. Performance Evaluation of Classifiers
3.7. The Best Model
4. Discussion
4.1. Best Model for the Risk Calculator
4.2. Most Relevant Features
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Eckel, R.H.; Grundy, S.M.; Zimmet, P.Z. The metabolic syndrome. Lancet 2005, 365, 1415–1428. [Google Scholar] [CrossRef]
- Gutiérrez-Solis, A.L.; Datta Banik, S.; Méndez-González, R.M. Prevalence of metabolic syndrome in mexico: A systematic review and meta-analysis. Metab. Syndr. Relat. Disord. 2018, 16, 395–405. [Google Scholar] [CrossRef] [PubMed]
- Moore, J.X.; Chaudhary, N.; Akinyemiju, T. Peer reviewed: Metabolic syndrome prevalence by race/ethnicity and sex in the United States, National Health and Nutrition Examination Survey, 1988–2012. Prev. Chronic Dis. 2017, 14, E24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grundy, S.M.; Brewer, H.B., Jr.; Cleeman, J.I.; Smith, S.C., Jr.; Lenfant, C. Definition of metabolic syndrome: Report of the National Heart, Lung, and Blood Institute/American Heart Association conference on scientific issues related to definition. Circulation 2004, 109, 433–438. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alberti, K.G.M.; Zimmet, P.; Shaw, J. The metabolic syndrome—A new worldwide definition. Lancet 2005, 366, 1059–1062. [Google Scholar] [CrossRef]
- Alberti, K.G.M.M.; Zimmet, P.; Shaw, J. Metabolic syndrome—A new world-wide definition. A consensus statement from the international diabetes federation. Diabet. Med. 2006, 23, 469–480. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization (WHO). Definition, Diagnosis and Classification of Diabetes Mellitus and Its Complications: Report of a WHO Consultation. Part 1, Diagnosis and Classification of Diabetes Mellitus; Technical Report; World Health Organization: Geneva, Switzerland, 1999. [Google Scholar]
- Choe, E.K.; Rhee, H.; Lee, S.; Shin, E.; Oh, S.W.; Lee, J.E.; Choi, S.H. Metabolic Syndrome Prediction Using Machine Learning Models with Genetic and Clinical Information from a Nonobese Healthy Population. Genom. Inform. 2018, 16, e31. [Google Scholar] [CrossRef] [Green Version]
- Salazar, N.A.S.; Oviedo, L.M.V.; Samamé, L.T.; Tell, N.M. Conocimientos sobre síndrome metabólico en pacientes con sobrepeso u obesidad de un hospital de alta complejidad de lambayeque, 2016. Rev. Exp. Med. Hosp. Reg. Lambayeque REM 2018, 4, 56–60. [Google Scholar]
- Oh, E.G.; Bang, S.Y.; Hyun, S.S.; Chu, S.H.; Jeon, J.Y.; Kang, M.S. Knowledge, perception and health behavior about metabolic syndrome for an at risk group in a rural community area. J. Korean Acad. Nurs. 2007, 37, 790–800. [Google Scholar] [CrossRef]
- Yahia, N.; Brown, C.; Rapley, M.; Chung, M. Assessment of college students’ awareness and knowledge about conditions relevant to metabolic syndrome. Diabetol. Metab. Syndr. 2014, 6, 111. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Faes, L.; Kale, A.U.; Wagner, S.K.; Fu, D.J.; Bruynseels, A.; Mahendiran, T.; Moraes, G.; Shamdas, M.; Kern, C.; et al. A comparison of deep learning performance against health-care professionals in detecting diseases from medical imaging: A systematic review and meta-analysis. Lancet Digit. Health 2019, 1, e271–e297. [Google Scholar] [CrossRef]
- Maity, N.G.; Das, S. Machine learning for improved diagnosis and prognosis in healthcare. In Proceedings of the 2017 IEEE Aerospace Conference, Big Sky, MT, USA, 4–1 March 2017; pp. 1–9. [Google Scholar]
- Sethi, P.; Jain, M. A comparative feature selection approach for the prediction of healthcare coverage. In International Conference on Information Systems, Technology and Management; Springer: Berlin/Heidelberg, Germany, 2010; pp. 392–403. [Google Scholar]
- Jain, D.; Singh, V. Feature selection and classification systems for chronic disease prediction: A review. Egypt. Inform. J. 2018, 19, 179–189. [Google Scholar] [CrossRef]
- Foster, K.R.; Koprowski, R.; Skufca, J.D. Machine learning, medical diagnosis, and biomedical engineering research-commentary. Biomed. Eng. Online 2014, 13, 94. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Worachartcheewan, A.; Shoombuatong, W.; Pidetcha, P.; Nopnithipat, W.; Prachayasittikul, V.; Nantasenamat, C. Predicting metabolic syndrome using the random forest method. Sci. World J. 2015, 2015. [Google Scholar] [CrossRef] [Green Version]
- Vrbaški, D.; Vrbaški, M.; Kupusinac, A.; Ivanović, D.; Stokić, E.; Ivetić, D.; Doroslovački, K. Methods for algorithmic diagnosis of metabolic syndrome. Artif. Intell. Med. 2019, 101, 101708. [Google Scholar] [CrossRef]
- Barrios, M.; Jimeno, M.; Villalba, P.; Navarro, E. Novel Data Mining Methodology for Healthcare Applied to a New Model to Diagnose Metabolic Syndrome without a Blood Test. Diagnostics 2019, 9, 192. [Google Scholar] [CrossRef] [Green Version]
- Murguía-Romero, M.; Jiménez-Flores, R.; Méndez-Cruz, A.R.; Villalobos-Molina, R. Predicting metabolic syndrome with neural networks. In Mexican International Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2013; pp. 464–472. [Google Scholar]
- Ivanović, D.; Kupusinac, A.; Stokić, E.; Doroslovački, R.; Ivetić, D. ANN prediction of metabolic syndrome: A complex puzzle that will be completed. J. Med. Syst. 2016, 40, 264. [Google Scholar] [CrossRef]
- Wirfält, E.; Hedblad, B.; Gullberg, B.; Mattisson, I.; Andrén, C.; Rosander, U.; Janzon, L.; Berglund, G. Food patterns and components of the metabolic syndrome in men and women: A cross-sectional study within the Malmö Diet and Cancer cohort. Am. J. Epidemiol. 2001, 154, 1150–1159. [Google Scholar] [CrossRef] [Green Version]
- Panagiotakos, D.B.; Pitsavos, C.; Skoumas, Y.; Stefanadis, C. The association between food patterns and the metabolic syndrome using principal components analysis: The ATTICA Study. J. Am. Diet. Assoc. 2007, 107, 979–987. [Google Scholar] [CrossRef]
- Sarebanhassanabadi, M.; Mirhosseini, S.J.; Mirzaei, M.; Namayandeh, S.M.; Soltani, M.H.; Pakseresht, M.; Pedarzadeh, A.; Baramesipour, Z.; Faraji, R.; Salehi-Abargouei, A. Effect of dietary habits on the risk of metabolic syndrome: Yazd Healthy Heart Project. Public Health Nutr. 2018, 21, 1139–1146. [Google Scholar] [CrossRef] [Green Version]
- Elmadhun, N.Y.; Sellke, F.W. Is there a link between alcohol consumption and metabolic syndrome? Clin. Lipidol. 2013, 8, 5–8. [Google Scholar] [CrossRef]
- Jia, W.P. The impact of cigarette smoking on metabolic syndrome. Biomed. Environ. Sci. 2013, 26, 947–952. [Google Scholar]
- Nambiar, L.; Bhimjiyani, A.; Khandelwal, S. A systematic review to assess the impact of physical activity intervention on people with metabolic syndrome. J. Sci. Med. Sport 2014, 18, e117. [Google Scholar] [CrossRef]
- Fernandez-Mendoza, J.; He, F.; LaGrotte, C.; Vgontzas, A.N.; Liao, D.; Bixler, E.O. Impact of the metabolic syndrome on mortality is modified by objective short sleep duration. J. Am. Heart Assoc. 2017, 6, e005479. [Google Scholar] [CrossRef] [Green Version]
- Colín-Ramírez, E.; Rivera-Mancía, S.; Infante-Vázquez, O.; Cartas-Rosado, R.; Vargas-Barrón, J.; Madero, M.; Vallejo, M. Protocol for a prospective longitudinal study of risk factors for hypertension incidence in a Mexico City population: The Tlalpan 2020 cohort. BMJ Open 2017, 7, e016773. [Google Scholar] [CrossRef]
- Chobanian, A.V.; Bakris, G.L.; Black, H.R.; Cushman, W.C.; Green, L.A.; Izzo, J.L., Jr.; Jones, D.W.; Materson, B.J.; Oparil, S.; Wright, J.T., Jr.; et al. Seventh report of the joint national committee on prevention, detection, evaluation, and treatment of high blood pressure. Hypertension 2003, 42, 1206–1252. [Google Scholar] [CrossRef] [Green Version]
- Marfell-Jones, M.J.; Stewart, A.; De Ridder, J. International Standards for Anthropometric Assessment; International Society for the Advancement of Kinanthropometry: Wellington, New Zealand, 2012. [Google Scholar]
- Hernández-Avila, J.; González-Avilés, L.; Rosales-Mendoza, E. Manual de Usuario. SNUT Sistema de Evaluación de Hábitos Nutricionales y Consumo de Nutrimentos; Instituto Nacional de Salud Pública: Cuernavaca, Mexico, 2003. [Google Scholar]
- Craig, C.L.; Marshall, A.L.; Sjöström, M.; Bauman, A.E.; Booth, M.L.; Ainsworth, B.E.; Pratt, M.; Ekelund, U.; Yngve, A.; Sallis, J.F.; et al. International physical activity questionnaire: 12-country reliability and validity. Med. Sci. Sport. Exerc. 2003, 35, 1381–1395. [Google Scholar] [CrossRef] [Green Version]
- Stewart, A.L.; Ware, J.E. Measuring Functioning and Well-Being: The Medical Outcomes Study Approach; Duke University Press: Durham, NC, USA, 1992. [Google Scholar]
- Spritzer, K.; Hays, R. MOS Sleep Scale: A Manual for Use and Scoring, Version 1.0; RAND: Los Angeles, CA, USA, 2003; pp. 1–8. [Google Scholar]
- Chen, Z.; He, N.; Huang, Y.; Qin, W.T.; Liu, X.; Li, L. Integration of a deep learning classifier with a random forest approach for predicting malonylation sites. Genom. Proteom. Bioinform. 2018, 16, 451–459. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013. [Google Scholar]
- Wayne, D. Bioestadística: Base Para el Análisis de las Ciencias de la Salud; Technical Report; Limusa: Ciudad de Mexico, Mexico, 1983. [Google Scholar]
- GECCO. Genetic and Evolutionary Computation-GECCO 2003. In Proceedings of the Genetic and Evolutionary Computation Conference, Chicago, IL, USA, 12–16 July 2003; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Strobl, C.; Boulesteix, A.L.; Kneib, T.; Augustin, T.; Zeileis, A. Conditional variable importance for random forests. BMC Bioinform. 2008, 9, 307. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1993. [Google Scholar]
- Karegowda, A.; Manjunath, A.; Jayaram, M.A. Comparative study of attribute selection using gain ratio and correlation based feature selection. Int. J. Inf. Technol. Knowl. Manag. 2010, 2, 271–277. [Google Scholar]
- Zheng, Z.; Wu, X.; Srihari, R.K. Feature selection for text categorization on imbalanced data. SIGKDD Explor. 2004, 6, 80–89. [Google Scholar] [CrossRef]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–4. [Google Scholar]
- Bobadilla, J.; Ortega, F.; Hernando, A. A collaborative filtering similarity measure based on singularities. Inf. Process. Manag. 2012, 48, 204–217. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 20 September 2020).
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A Practical Guide to Support Vector Classification; National Taiwan University: Taipei, Taiwan, 2003. [Google Scholar]
- Sun, K.; Ren, M.; Liu, D.; Wang, C.; Yang, C.; Yan, L. Alcohol consumption and risk of metabolic syndrome: A meta-analysis of prospective studies. Clin. Nutr. 2014, 33, 596–602. [Google Scholar] [CrossRef]
- Høstmark, A.T. The Oslo health study: Soft drink intake is associated with the metabolic syndrome. Appl. Physiol. Nutr. Metab. 2010, 35, 635–642. [Google Scholar] [CrossRef]
- Milei, J.; Losada, M.O.; Llambí, H.G.; Grana, D.R.; Suárez, D.; Azzato, F.; Ambrosio, G. Chronic cola drinking induces metabolic and cardiac alterations in rats. World J. Cardiol. 2011, 3, 111. [Google Scholar] [CrossRef]
- Troxel, W.M.; Buysse, D.J.; Matthews, K.A.; Kip, K.E.; Strollo, P.J.; Hall, M.; Drumheller, O.; Reis, S.E. Sleep symptoms predict the development of the metabolic syndrome. Sleep 2010, 33, 1633–1640. [Google Scholar] [CrossRef] [Green Version]
- Alley, D.E.; Chang, V.W. Metabolic syndrome and weight gain in adulthood. J. Gerontol. Ser. Biomed. Sci. Med Sci. 2010, 65, 111–117. [Google Scholar] [CrossRef] [Green Version]
- Tsai, S.S.; Chu, Y.Y.; Chen, S.T.; Chu, P.H. A comparison of different definitions of metabolic syndrome for the risks of atherosclerosis and diabetes. Diabetol. Metab. Syndr. 2018, 10, 56. [Google Scholar] [CrossRef] [Green Version]
- Porchia, L.M.; Lara-Solis, B.; Torres-Rasgado, E.; Gonzalez-Mejia, M.; Ruiz-Vivanco, G.; Pérez-Fuentes, R. Validation of a non-laboratorial questionnaire to identify Metabolic Syndrome among a population in central Mexico. Rev. Panam. Salud Pública 2019, 43, e9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ho, J.S.; Cannaday, J.J.; Barlow, C.E.; Mitchell, T.L.; Cooper, K.H.; FitzGerald, S.J. Relation of the number of metabolic syndrome risk factors with all-cause and cardiovascular mortality. Am. J. Cardiol. 2008, 102, 689–692. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.T.; Tsai, S.S.; Shih, T.S.; Lin, M.H.; Chou, T.C.; Ting, H.; Wu, T.N.; Liou, S.H. The association between obstructive sleep apnea and metabolic markers and lipid profiles. PLoS ONE 2015, 10, e0130279. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zou, J.; Song, F.; Xu, H.; Fu, Y.; Xia, Y.; Qian, Y.; Zou, J.; Liu, S.; Fang, F.; Meng, L.; et al. The relationship between simple snoring and metabolic syndrome: A cross-sectional study. J. Diabetes Res. 2019, 2019, 9578391. [Google Scholar] [CrossRef] [Green Version]
- Basu, S.; McKee, M.; Galea, G.; Stuckler, D. Relationship of soft drink consumption to global overweight, obesity, and diabetes: A cross-national analysis of 75 countries. Am. J. Public Health 2013, 103, 2071–2077. [Google Scholar] [CrossRef]
- Gertner, D.; Rifkin, L. Coca-Cola and the Fight against the Global Obesity Epidemic. Thunderbird Int. Bus. Rev. 2018, 60, 161–173. [Google Scholar] [CrossRef]
- Hu, F.B.; Malik, V.S. Sugar-sweetened beverages and risk of obesity and type 2 diabetes: Epidemiologic evidence. Physiol. Behav. 2010, 100, 47–54. [Google Scholar] [CrossRef] [Green Version]
- Baspinar, B.; Eskici, G.; Ozcelik, A. How coffee affects metabolic syndrome and its components. Food Funct. 2017, 8, 2089–2101. [Google Scholar] [CrossRef]
- Nordestgaard, A.T.; Thomsen, M.; Nordestgaard, B.G. Coffee intake and risk of obesity, metabolic syndrome and type 2 diabetes: A Mendelian randomization study. Int. J. Epidemiol. 2015, 44, 551–565. [Google Scholar] [CrossRef]
- Salas, R.; del Mar Bibiloni, M.; Ramos, E.; Villarreal, J.Z.; Pons, A.; Tur, J.A.; Sureda, A. Metabolic syndrome prevalence among Northern Mexican adult population. PLoS ONE 2014, 9, e105581. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Method | Resulting Variables |
|---|---|---|
| (A) | ||
| Feeding habits | VIM of RF | cola_soda, flav_soda, oax_cheese, c_coffe and flav_water |
| Quality of sleep | VIM of RF | snore, restless, lit_sleep, restless and drowsy |
| Anthropometry | VIM of RF | Waist, WHtR, BMI, SBP, DBP, and Age |
| Habits | VIM of RF | EtOH_AVG, smk.smke and exrcs |
| (B) | ||
| Whole Dataset | VIM of RF | Age, Waist, BMI, WHtR, Weight, Height, SBP, DBP, cola_soda, snore, oax_cheese and c_coffe |
| PCC | Age, Weight, BMI, Waist, WHtR, SBP, DBP, snore, cola_soda and pork_r | |
| Chi.square | Age, BMI, Waist, WHtR, Weight, SBP, DBP, snore and cola_soda |
| Cathegory | Method | Resulting Variables |
|---|---|---|
| (A) | ||
| Feeding habits | VIM of RF | cola_soda, flav_water, hot_chili, c_coffe and tortilla |
| Quality of sleep | VIM of RF | snore, nt_sleep, SLP SMN, restless and tired |
| Anthropometry | VIM of RF | DBP, Waist, SBP, WHtR, BMI and Age |
| Habits | VIM of RF | smk.smke, EtOH_AVG and exrcs |
| (B) | ||
| Whole Dataset | VIM of RF | DBP, Waist, BMI, WHtR, SBP, Weight, Age, snore, cola_soda, flav_water, c_coffe and tortilla |
| PCC | Age, Weight, BMI, Waist, WHtR, SBP, DBP, snore and cola_soda | |
| Chi.square | BMI, Waist, DBP, SBP, Weight, WHtR, Age, snore and cola_soda |
| Category | Method | Gender | Resulting Variables |
|---|---|---|---|
| (A) | |||
| Feeding habits | VIM of RF | women | c_coffe, cola_soda, flav_water, flav_soda, and oax_cheese |
| Feeding habits | VIM of RF | men | c_coffe, cola_soda, flav_water, hot_chili, and tortilla |
| Quality of sleep | VIM of RF | women | drowsy, nt_sleep, restless, snore, and lit_sleep |
| Quality of sleep | VIM of RF | men | drowsy, nt_sleep, restless, snore, and tired |
| Anthropometry | VIM of RF | women | Age, BMI, DBP, SBP, Waist, and WHtR |
| Anthropometry | VIM of RF | men | Age, BMI, DBP, SBP, Waist, and WHtR |
| Habits | VIM of RF | women | EtOH_AVG, exrcs, and smk.smke |
| Habits | VIM of RF | men | EtOH_AVG, exrcs, and smk.smke |
| (B) | |||
| Whole Dataset | VIM of RF | women | Age, Waist, BMI, WHtR, Weight, Height, SBP, DBP, cola_soda, snore, oax_cheese and c_coffe |
| VIM of RF | men | DBP, Waist, BMI, VHtR, SBP, Weight, Age, snore, cola_soda, flav_water, c_coffe, and tortilla | |
| PCC | women | Age, Weight, BMI, Waist, WHtR, SBP, DBP, snore, cola_soda, and pork_r | |
| PCC | men | Age, Weight, BMI, Waist, WHtR, SBP, DBP, snore, and cola_soda | |
| Chi.square | women | Age, BMI, Waist, WHtR, Weight, SBP, DBP, snore and cola_soda | |
| Chi.square | men | BMI, Waist, DBP, SBP, Weight, WHtR, Age, snore and cola_soda |
| Case | Classifier | Features | ACC (%) | B.ACC (%) | PPV (%) | NPV (%) |
|---|---|---|---|---|---|---|
| Whole dataset with RF | Random forest Mtry = 1 Ntree = 300 | Waist, WHtR, DBP, BMI, SBP, Weight, Age, Height, cola_soda, milk, snore, c_coffe, FREC009, oax_cheese | 84.12 ± 0.38 | 62.93 ± 0.81 | 84.78 ± 0.28 | 75.92± 2.81 |
| Deep neural network | Waist, WHtR, DBP, BMI, SBP, Weight, Age, Height, cola_soda, milk, snore, c_coffe, FREC009, oax_cheese | 80.03 ± 1.04 | 63.26 ± 2.42 | 50.78 ± 3.38 | 85.76± 1.11 | |
| Whole dataset with PCC | Deep neural network | Age, Weight, BMI, Waist, WhtR, SBP, DBP, snore, cola_soda, FREQ032 | 81.06 ± 0.75 | 62.4 ± 3.22 | 56.88 ± 5.61 | 84.43± 1.38 |
| Random forest Mtry = 1 Ntree = 500 | Age, Weight, BMI, Waist, WhtR, SBP, DBP, snore, cola_soda, FREQ032 | 83.88 ± 0.30 | 62.63 ± 0.54 | 84.99 ± 0.19 | 70.62± 2.22 | |
| Whole dataset with chi.square | C4.5 | Waist, WhtR, BMI, DBP, SBP, Age, snore, cola_soda | 83.35 ± 0.11 | 61.91 ± 0.33 | 84.82 ± 0.13 | 72.19± 1.24 |
| Resulting variables by category | Random forest Mtry = 3 Ntree = 100 | Waist, WHtR, BMI, SBP, DBP, Age, cola_soda, flav_water, c_coffe, snore, nt_sleep, restless, flav_soda, drowsy | 84.04 ± 0.55 | 64.58 ± 0.92 | 85.73 ± 0.32 | 67.80± 3.33 |
| Deep neural network | Waist, WhtR, BMI, SBP, DBP, Age, cola_soda, flav_water, c_coffe, snore, nt_sleep, restless, flav_soda, drowsy, oax_cheese | 78.32 ± 1.45 | 63.12 ± 1.97 | 45.69 ± 4.08 | 84.96± 0.85 |
| Case | Classifier | Features | ACC (%) | B.ACC (%) | PPV (%) | NPV (%) |
|---|---|---|---|---|---|---|
| Whole datase with RF | Random forest Mtry = 10 Ntree = 800 | Waist, DBP, SBP, BMI, WHtR, Weight, Height, Age, cola_soda, c_coffe, flav_water, tortilla, snore | 88.17 ± 0.49 | 80.73 ± 0.84 | 92.29 ± 0.36 | 70.72± 2.81 |
| Deep neural network | Waist, DBP, SBP, BMI, WHtR, Weight, Height, Age, cola_soda, c_coffe, flav_water, tortilla, snore | 85.30 ± 0.88 | 73.01 ± 4.86 | 59.06 ± 6.00 | 90.77± 2.09 | |
| Complete dataset with PCC | Deep neural network | Age, Weight, BMI, Waist, WHtR, SBP, DBP, snore, cola_soda | 86.38 ± 0.60 | 74.63 ± 4.28 | 61.75 ± 3.54 | 91.26 ± 1.79 |
| Random forest Mtry = 2 Ntree = 800 | Age, Weight, BMI, Waist, WHtR, SBP, DBP, snore, cola_soda | 83.73 ± 0.56 | 65.29 ± 0.95 | 86.05 ± 0.34 | 64.2 ± 2.95 | |
| Complete dataset with chi.square | C4.5 | Waist, WHtR, BMI, DBP, SBP, Age, snore, cola_soda | 86.38 ± 0.12 | 74.12 ± 0.38 | 89.42 ± 0.18 | 71.61 ± 0.78 |
| Resulting variables by category | Random forest Mtry = 9 Ntree = 800 | Waist, DBP, BMI, SBP, WHtR, Age, c_coffe, flav_water, hot_chili, tortilla, drowsy, cola_soda, restless, snore, nt_sleep | 87.47 ± 0.27 | 78.94 ± 0.40 | 91.49 ± 0.18 | 69.65± 1.04 |
| Deep neural network | Waist, DBP, BMI, SBP, WHtR, Age, c_coffe, flav_water, hot_chili, tortilla, drowsy, cola_soda, restless, snore, nt_sleep | 84.96 ± 1.34 | 72.52 ± 2.89 | 57.75 ± 5.58 | 90.13± 1.19 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gutiérrez-Esparza, G.O.; Ramírez-delReal, T.A.; Martínez-García, M.; Infante Vázquez, O.; Vallejo, M.; Hernández-Torruco, J. Machine and Deep Learning Applied to Predict Metabolic Syndrome without a Blood Screening. Appl. Sci. 2021, 11, 4334. https://doi.org/10.3390/app11104334
Gutiérrez-Esparza GO, Ramírez-delReal TA, Martínez-García M, Infante Vázquez O, Vallejo M, Hernández-Torruco J. Machine and Deep Learning Applied to Predict Metabolic Syndrome without a Blood Screening. Applied Sciences. 2021; 11(10):4334. https://doi.org/10.3390/app11104334
Chicago/Turabian StyleGutiérrez-Esparza, Guadalupe O., Tania A. Ramírez-delReal, Mireya Martínez-García, Oscar Infante Vázquez, Maite Vallejo, and José Hernández-Torruco. 2021. "Machine and Deep Learning Applied to Predict Metabolic Syndrome without a Blood Screening" Applied Sciences 11, no. 10: 4334. https://doi.org/10.3390/app11104334