
Minimax Estimation in Regression under Sample Conformity Constraints


1
Federal Research Center “Computer Science and Control” of the Russian Academy of Sciences, 44/2 Vavilova Str., 119333 Moscow, Russia
2
Moscow Aviation Institute, 4, Volokolamskoe Shosse, 125993 Moscow, Russia
3
Faculty of Computational Mathematics and Cybernetics, Lomonosov Moscow State University, GSP-1, 1-52 Leninskiye Gory, 119991 Moscow, Russia
4
Moscow Center for Fundamental and Applied Mathematics, Lomonosov Moscow State University, GSP-1, Leninskie Gory, 119991 Moscow, Russia
Mathematics 2021, 9(10), 1080; https://doi.org/10.3390/math9101080
Submission received: 6 April 2021
/
Revised: 30 April 2021
/
Accepted: 6 May 2021
/
Published: 11 May 2021
(This article belongs to the Special Issue Control, Optimization, and Mathematical Modeling of Complex Systems)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:The paper is devoted to the guaranteeing estimation of parameters in the uncertain stochastic nonlinear regression. The loss function is the conditional mean square of the estimation error given the available observations. The distribution of regression parameters is partially unknown, and the uncertainty is described by a subset of probability distributions with a known compact domain. The essential feature is the usage of some additional constraints describing the conformity of the uncertain distribution to the realized observation sample. The paper contains various examples of the conformity indices. The estimation task is formulated as the minimax optimization problem, which, in turn, is solved in terms of saddle points. The paper presents the characterization of both the optimal estimator and the set of least favorable distributions. The saddle points are found via the solution to a dual finite-dimensional optimization problem, which is simpler than the initial minimax problem. The paper proposes a numerical mesh procedure of the solution to the dual optimization problem. The interconnection between the least favorable distributions under the conformity constraint, and their Pareto efficiency in the sense of a vector criterion is also indicated. The influence of various conformity constraints on the estimation performance is demonstrated by the illustrative numerical examples.
1. Introduction
The problems of the heterogeneous parameter estimation in the regression under the model uncertainty are considered intensively from the various points of view. The guaranteeing (or minimax) approach gives one of the most prospective tools to solve these problems. For the proper formulation of an estimation problem in minimax terms one usually needs:
- A description of the uncertainty set in the observation model;
- A class of the admissible estimators;
- An optimality criterion (a loss function) as a function of the argument pair “estimator–uncertain parameter value”.
The problem is to find the estimator that minimizes the maximal losses over the whole uncertainty set.
In the related literature, the parametric uncertainty set is specified either by geometric [1,2,3,4,5,6,7], or by statistical [8,9,10,11,12,13,14,15] constraints. In the former case, the uncertain parameters are treated as nonrandom but unknown ones lying within the fixed uncertainty set. In the latter case, the parameters are supposed to be random with unknown distribution, and the uncertainty set is formed by all the admissible distributions. In both cases, the guaranteeing estimation presumes a solution to a two-person game problem: the first player is “a statistician”, and the performer of the second, “external” player role is dictated by the problem statement—it might be nature, another human or device. Nevertheless, the guaranteeing approach suggests the unified prescription: finding the best estimator under the worst behavior of the uncertainty. In practice, such a universality leads to a loss of some prior information.
Let us explain this point by an example: the statistician knows that the source of the uncertainty is nature. This means he/she “should bear in mind that nature, as a player, is not aiming for a maximal win (that is, does not want us to suffer a maximal loss), and in this sense, it is ‘impartial’ in the choice of strategies” [12]. Hence, in this case, the minimax approach is too pessimistic and leads to cautious and coarse estimates. Even if we know the second player is a human, this does not imply his/her “bad will” towards the statistician. Hopefully, the second player has goal other than maximizing the loss of the statistician. If the goal of the second player is known, one can change the estimation criterion and transform the initial problem into a non-antagonistic game [16]. Otherwise, the statistician can identify the goal indirectly, relying on the available observations. Hence, in the latter case, it seems natural to introduce additional constraints to the uncertainty set, depending on the realized observations.
The paper aims to present a solution to the minimax estimation problem under additional constraints, which are determined by a conformity index of the uncertain parameters to the available observations.
The paper is organized as follows. Section 2 contains the formal problem statement with the conformity index based on the likelihood function. The section presents the assumptions concerning the observation model, which guarantee the correctness of the stated estimation problem and the existence of its solution. It also contains the comparison of the problem with the recent investigations.
Section 3 provides the main result: the initial estimation problem is reformulated as a game problem, which has a saddle point, defining the minimax estimator completely. Moreover, the point is a solution to a dual finite-dimensional constrained optimization problem, which is simpler than the initial minimax problem. The form of the minimax estimator and properties of the least favorable distributions (LFD) is also included in the section.
Section 4 is devoted to the analysis of the obtained results. First, a numerical algorithm for the dual optimization problem solution is presented along with its accuracy characterization. Second, some other conformity indices based on the empirical distribution function (EDF) and sample mean are also introduced. Third, a new concept of the uncertain distribution choice under a vector criterion is considered. The first criterion component, being the loss function introduced in Section 2, describes the influence of the uncertainty on the estimation quality. The second component is the conformity index, which characterizes the accordance of the unknown distribution of and the realized observations . We present an assertion that the LFD in the minimax estimation problem is Pareto-efficient in the sense of the introduced vector criterion.
Section 5 presents the numerical examples, which illustrate the influence of various conformity constraints on the estimation performance. Section 6 contains concluding remarks.
The following notations are used in this manuscript:
- is the Borel -algebra of the topological space S (is S is the whole space) or its contraction to the set S (if S is a set of the topological space);
- is a column vector formed by the ordinary or block components ;
- is a row vector formed by the ordinary or block components ;
- is a scalar product of two finite-dimensional vectors;
- is a set of all continuous real-valued functions with the domain ;
- is the Euclidean norm of the vector x;
- is the probability of the event A corresponding to the distribution F;
- is a mathematical expectation of the random vector X with the distribution F;
- is a convex hull of the set .
2. Statement of Problem
2.1. Formulation
Let us consider the following observation model:
Here:
- is an unobservable random vector, having an unknown cumulative distribution function (cdf) F;
- is a random unobservable vector with a known cdf dependent on the value of ;
- is a vector of observations;
- is a random vector of observation errors with the known probability density function (pdf) ;
- is a nonrandom function characterizing the observation plant;
- is a nonrandom function characterizing the observation error intensity.
The observation model is defined on the family of the probability triplets , where:
- The outcome space contains all admissible values of the compound vector ;
- -algebra is determined as ;
- The probability measures are determined as:
Using the generalized Bayes rule [17], it is easy to verify that the function:
is the conditional pdf of the observation Y given : . Furthermore, the function:
defines the pdf of the observation Y under the assumption that the distribution law of equals F:
Below in the paper we refer to the function as the sample conformity index based on the likelihood function.
Our aim is to estimate the function of , and the admissible estimators are the functions of the available observations.
The loss function is a conditional mean square of estimate error given the available observations:
and the corresponding estimation criterion:
characterizes the maximal loss for a fixed estimator within the class of the uncertain distributions of , for which .
The minimax estimation problem for the vector h is to find an estimator , such that:
where is a class of admissible estimators.
2.2. Necessary Assumptions Concerning Observation Model
To state the minimax estimation problem (8) properly and guarantee the existence of its solution we have to make additional assumptions concerning the uncertainty of , the observation model (1) and the estimated vector h:
- (i)
- The set is compact.
- (ii)
- Let be a family of all probability distributions with a support lying within the set . The set is itself a convex *–weakly compact [18] subset of .
- (iii)
- The constraintholds for all . The inequality (9) is called the conformity constraint of the level L based on the likelihood function (or, shortly, likelihood constraint).
- (iv)
- The set is nonempty.
- (v)
- .
- (vi)
- pdf for ; ; the function is a regular version of the conditional distribution for .
- (vii)
- The observation noise is uniformly non-degenerate, i.e.,
- (viii)
- The inequalitiesare true.
- (ix)
- The set of admissible estimators contains only the functions , for which:
2.3. Argumentation
First, we discuss the sense of the assumptions in the subsection above.
Conditions (i)–(iv), describing the set , have the following interpretation.
The requirement for to be compact (i.e., fulfillment of condition (i)) is standard for the minimax estimation problems (see, e.g., [2,3]). In the case the prior information about the vector limited by the knowledge of its domain only, it is rather natural to treat as a random vector with an unknown distribution . In practice we often have some additional prior information concerning the moment characteristics of , hence the entire uncertainty set can be significantly reduced. If, for example, is a vector of convex moment functions, and we know the vector of their upper bounds, then the set of admissible distributions takes the form . The *-weak compactness and convexity can be easily verified for this subset. Further in the presentation, we do not stress the explicit form of the “total” constraints other than (9) forming the subset : they should just guarantee the closure and convexity for . That is the sense of condition (ii).
The conditional pdf (3) can also be treated as the likelihood function of the parameter , calculated at the point q given the observed sample . This likelihood value reflects the relevance of the parameter value q to the realized observation y. By analogy, the function can be considered as some generalization of the likelihood function that evaluates the correspondence between the uncertain distribution F and the realized observation y. The following lower and upper bounds for this value are obvious:
Below in the paper we suppose that the likelihood level L lies in . The subset formed by constraint is called a distribution subset satisfying the likelihood conformity constraint of the level L. It is nonempty because it contains at least all distributions with the support lying within the set .
Adjusting the level L, we can vary the uncertainty set , choosing the distributions F, which are more or less relevant to the realized observations . That is an essence of condition (iii). Condition (iv) is obvious: all the constraints, defining the set , should be feasible.
Condition (v) is technical: it provides correctness of a subsequent change of measure. The condition is non-restricting because the broad class of the functions A, B and h can be approximated by the continuous functions. Conditions (vi) and (vii) guarantee correct utilization of the Fubini theorem and an abstract variant of the Bayes formula [19]. In practice these conditions are usually valid. Condition (viii) guarantees finite variance for both the observations and estimated vector independently of the distribution F.
Condition (ix) guarantees a finite variance of the estimate independently of .
The solution to (8) is obvious in the case of the one-point set . This means the distribution F of the parameter is known, and the initial problem is reduced to the traditional optimal in the mean square sense (MS-optimal) estimation problem. The case of the one-point set is quite similar. In both cases the optimal estimator is completely defined by the conditional expectation (CE): in the case of a known distribution F, and in the “one point” case.
In the general case of this result is inapplicable, because the CE is a functional of the unknown distribution F.
The stated estimation problem has a transparent interpretation. First, under prior uncertainty of the distribution F the replacement of the loss function (6) by guaranteeing analog looks natural. Second, utilization of the CE in the criterion means that the desired estimate should be calculated optimally for each observed sample. The criteria in the form of the CE appear often in estimation and control problems [11,17,20,21,22]. Mostly, the estimation is the preliminary stage in the solution to the optimization and/or control problem under incomplete information. The random disturbances/noises in such observation systems represent:
- A result of natural (non-human) impacts;
- A result of some uncontrollable (parasitic) input signals of “the external players”.
The impact of the two latter types is not necessarily the nonrandom functions of available observations, but some “extra generated” random processes with distributions dependent on the observations. This type of control is used in the areas of telecommunications [25,26], cellular networks [27], technical systems [28], etc. The proposed minimax criterion allows inhibiting the negative effect of the “additional randomness” in the external signals (the third type of disturbances mentioned above) to the estimation quality.
The additional comprehension of the natural gaps, which are inherent to the minimax estimation paradigm, and the ways of their partial coverage can be revealed by the following interpretation. It is well-known that in the case a minimax estimation problem can be reduced to a two-person game with a saddle point, the minimax estimator is the best one calculated for the LFD. The form of the LFD can be very strange and artificial. Moreover, the conformity degree of the LFD to the realized observations can be too low. Thus, the utilization of various sample conformity indices (particularly the ones based on the likelihood function) admits all to describe this degree, restrict it from below, implicitly reduce the distribution uncertainty set and exclude “exotic’’ variants of the LFDs.
Minimax estimation of the regression parameters is an investigation object in the various settings. Mostly, the observation model is a linear function of the estimated parameters corrupted by an additive Gaussian noise. The optimality criterion is a mathematical expectation of some loss function. In [29], the problem is solved by engaging the framework of the fuzzy sets. The authors of [30,31] used the criterion other than the traditional mean square one, and the estimated vector was random with the uncertain discrete distribution. In [32], the Gaussian noises have an uncertain but bounded covariance matrix. The papers [33,34,35] are also devoted to the minimax Bayesian estimation in the regression under various geometric and moment constraints of the estimated parameters. The criterion functions are norms of the estimation errors.
The optimality criterion in the form of CE and the admissibility of nonlinear estimates distinguish the proposed estimation problem from the recently considered ones [2,3,5,6,7,9]. A closely related problem considered in [11] has an essential difference. The uncertain parameter in [11] was treated as unknown and nonrandom, and hence the initial minimax problem could not be solved in terms of the saddle points. Moreover, the statistic uncertainty in [11] gave no possibility to take into account any additional prior and posterior information about the moment characteristics, conformity indices, etc. The paper [14] was devoted to the particular case of the likelihood constraints only. An idea to use confidence sets, calculated by the available statistical data, as the uncertainty sets of the distribution moments was used in [36] for the conditionally-minimax prediction.
3. The Main Result
As is known, the CE is determined in a non-unique way, hence we should specify a version of the CE so as to use it in further inferences. If the distribution F of the vector is known, then the CE of an integrable random value can be calculated by the abstract variant of the Bayes formula:
i.e., (11) − a.s. Below in the presentation we use the CE version, defined by (11). It should also be noted that if is the desired minimax estimator, then the inclusion (8) must be satisfied point-wise for any sample .
Further in the paper the function:
is called the dual criterion for (7). All CEs in (12) are calculated by (11).
Using (3) for the calculation of , the notation:
and the CE version (11), the loss function (6) can be rewritten in the form:
As can be seen from (14), the function is neither convex nor concave in F, which complicates the solution to the estimation problem (8). Moreover, the argument F lies in the abstract infinite-dimensional space of the probability measures. Nevertheless, the problem can be reduced to a standard finite-dimensional minimax problem with a convex–concave criterion.
First, we introduce a new reference measure and verify that the loss function (14) represents a functional, which is linear in .
Let:
Lemma 1.
If conditions (i)–(ix) are satisfied, then the following assertions are true.
The proof of Lemma 1 is given in Appendix A.
Applying the Fubini theorem and keeping in mind (11) and (15), we can rewrite the loss function (14) in the form:
To reduce the initial problem to some finite-dimensional equivalent, we also introduce the vectors:
and their collections generated by the subsets and :
Here and below the notation also stands for the whole set of the estimate values calculated for the fixed argument y.
The set is compact; moreover (see [37]), the inclusion holds.
On the set we prepare the new loss function:
The corresponding guaranteeing criterion takes the form:
and its dual can be determined as:
The finite-dimensional minimax problem is to find:
From the definitions of , and criterion (23) it follows that the problem (25) is equivalent to the initial minimax estimation problem (8):
for .
The following theorem characterizes the solution to the finite-dimensional minimax problem in terms of a saddle point of the loss function .
Theorem 1.
For , the loss function (22) has the unique saddle point on the set . The second block subvector of the saddle point is the unique solution to the finite-dimensional dual problem:
and is the second sub-vector of this optimum .
The proof of Theorem 1 is given in Appendix B.
By the definition of , for any vector there exists at least one distribution such that:
is an LFD, and the whole set of the distributions satisfying (29) is denoted by .
Theorem 1 allows to obtain a solution to the initial minimax estimation problem. The result is formulated as:
Corollary 1.
The following assertion characterizes the key property of the LFD set .
Corollary 2.
There exists a variant of the LFD concentrated at most at points of the set .
The proof of Corollary 2 is given in Appendix C.
The presence of the discrete version of LFD is a remarkable fact. Let us remind the reader that initially, we suppose that the uncertain vector lies in the set . The deterministic hypothesis concerning hopelessly obstructed the solution to the minimax estimation problem. To overcome this obstacle we provide the randomness of : the vector keeps constant during the individual observation experiment, and the stochastic nature of appears from experiment to experiment only. The existence of a discrete LFD returns us partially to the primordial situation. The point is that there exists a set of values that are the most difficult for estimation. Tuning to these parameters we can obtain estimates of with the guaranteed quality.
4. Analysis and Extensions
4.1. Dual Problem: A Numerical Solution
To simplify presentation of the numerical algorithm of problem (28)’s solution, we suppose that the uncertainty set takes the form i.e., it is restricted by the conformity constraint only.
Let us consider the case , which corresponds to the practical problem of Bayesian classification [10,38]. Here the dual problem (28) has the form Its solution can be represented as where is a solution to the standard quadratic programming problem (QP problem):
Consequently, in the case of finite the minimax estimation problem can be reduced to the standard QP problem with well-investigated properties and advanced numerical procedures.
Utilization of the finite subsets instead of the original domain allows to calculate the “mesh” approximations for the solution to (8).
Let:
- be a decreasing nonrandom sequence characterizing the approximation accuracy;
- : be a sequence of embedded subdivisions;
- be modulus of continuity for and .
The assertion below characterizes the divergence rate of the approximating solutions to the initial minimax estimate.
Lemma 2.
If are corresponding solutions to the problems:
then the following sequences are convergent as :
with some constant .
The proof of Lemma 2 is given in Appendix D.
4.2. The Least Favorable Distribution in the Light of the Pareto Efficiency
The minimax estimation problem under the conformity constraints is tightly interconnected with the choice of the distribution that is optimal in the sense of a vector-valued criterion. On the one hand, the solution to the considered estimation problem is grounded on the evaluation of the distribution , maximizing the dual criterion (12): . On the other hand, the distribution F should conform to the realized sample , and the maximization of the conformity index leads to the following optimization problem: .
Obviously, the criteria and are conflicting; hence the proper choice of F requires the application of the vector optimization techniques.
Let:
- be a set of the LFDs in the estimation problem (8) without conformity constrains (i.e., as );
- ;
- be an arbitrary fixed conformity level;
- be a solution to the finite-dimensional dual problem;
- be the set of corresponding LFDs.
Lemma 3.
Any least favorable distribution is Pareto-efficient with respect to the vector-valued criterion .
The proof of Lemma 3 follows directly from the Germeyer theorem [16].
Consideration of the constrained minimax estimation problem in light of the optimization by the vector criterion is somehow close to the one investigated in [31], where the estimation quality is characterized by the norm of the error, and the Shannon entropy is characterized as a measure of the statistical uncertainty of the estimated vector.
4.3. Other Conformity Indices
First, we consider the conformity constraint (9) thoroughly. It admits the following treatment. Let be some reference distribution. The constraint is a specific case of (9); the feasible distributions F should be relevant to the available observations no less than the reference distribution is. One more treatment is also acceptable. Let be some “guess” value of the uncertain parameter , and be a fixed value. The constraint:
is a specific case of (9): it means that the likelihood ratio of any feasible distribution F to the one-point distribution at should be no less that the level . Obviously, the guess value could be chosen from the maxima of the function , i.e., , but calculation of these maxima is itself a nontrivial problem of likelihood function maximization. In Section 5 we use some modification of (33):
where is a known subset, and is a fixed parameter. This form is important, because in the case of it guarantees for the constraint (34) to be active in the considered minimax optimization problem for each .
Furthermore, the proposed conformity index (9) is a non-unique numerical characteristic that describes the interconnection between F and Y. For example, an alternative conformity index can be defined as , where is some continuous nondecreasing function. Another way to introduce this index is to set it as , i.e., as a probability that the observation Y lies in the confidence set .
For a particular case of the observation model (1) we can propose one more conformity index that is based on the EDF. Let us consider the observation model with the “pure uncertain” estimated parameter :
Here:
- are available observations;
- is a random vector with unknown distribution F;
- are the observation errors that are i.i.d. centered normalized random values with the pdf .
If the value is known, the observations can be considered as i.i.d. random values, whose pdf is equal to after some shifting and scaling. The EDF of the sample has the form:
On the other hand, the cdf of any observation for a fixed distribution F can be calculated as:
The sample conformity index based on the EDF is the following value:
The new uncertainty set describing all admissible distributions F satisfies conditions (i), (ii) and (iv) above, but condition (iii) is replaced by the following one:
- (x)
- the constraintThis holds for all and some fixed level . It is called the constraint based on the EDF.
The proposed conformity index represents the well known Kolmogorov distance used in the goodness-of-fit test. One also knows the asymptotic characterization of :
Furthermore, the value can be easily calculated, because the function is piece-wise constant while is continuous:
and the cdf is calculated by (37).
The distribution set determined by (39) takes the form:
Using the variational series of the sample , and recalling , , (40) can be rewritten in the form:
It can be seen that this set is a convex closed polyhedron, lying in , with at most facets. All assertions formulated in Section 3 are valid after replacing the uncertainty set , generated by the likelihood function, by the set , generated by the EDF. Moreover, the mesh algorithm for the dual optimization problem solution, presented above in Section 4.1, can also be applied to this case.
Let us consider the observation model (35) again. We can use the sample mean as one more conformity index. Let us remind the reader that due to the model property, the random parameter is constant for each sample . For rather large T values, the central limit theorem allows to treat the normalized value as a standard Gaussian random one. We then fix a standard Gaussian quantile of the confidence level and exscind the subset:
If is compact then the set of all probability distributions with the domain lying in is called the set of admissible distributions satisfying the sample mean conformity constraint of the level α.
The comparison of the minimax estimates, calculated under various types of the conformity constraints, is presented in the next section.
5. Numerical Examples
5.1. Parameter Estimation in the Kalman Observation System
Let us consider the linear Gaussian discrete-time (Kalman) observation system:
where:
- is an unobservable state trajectory (the autoregression is supposed to be stable);
- are available observations;
- and are vectorizations of independent standard Gaussian discrete-time white noises;
- , c and f are known parameters;
- is an uncertain vector lying in the fixed rectangle .
Our goal is to calculate the proposed minimax estimates of the uncertain vector and analyze their performance depending on the specific form of the loss function (6). To vary the loss function we can either specify the estimated test signal or determine different Euclidean weighted norms. We choose the second approach and define the following norm for the compound vector: :
and the corresponding loss function takes the form:
In the case and we obtain “the traditional” case of the mean-square loss conditional function , and the estimation quality of is determined directly through the loss function. Using and we transform the loss function into , and the estimation of appears indirectly via the estimation of the state trajectory .
The minimax estimation is calculated by the numerical procedure introduced in Section 4.1 with the uniform mesh of the uncertainty set ; and are corresponding mesh steps along each coordinate.
We calculate the minimax estimate with the likelihood conformity constraint of the form:
where is a confidence ratio.
We compare the proposed minimax estimate with some known alternatives.
The calculations have been executed with the following parameter values: , , , , , , , , . The choice of the parameters can be explained by the following facts. First, the point of actual parameter values belongs to the domain of the LFD for both loss functions and . This means the appearance of just the LFD for both cases. Second, in spite of sufficient observation length, the signal-to-noise ratio is rather small, which prevents high performance of the asymptotic estimation methods.
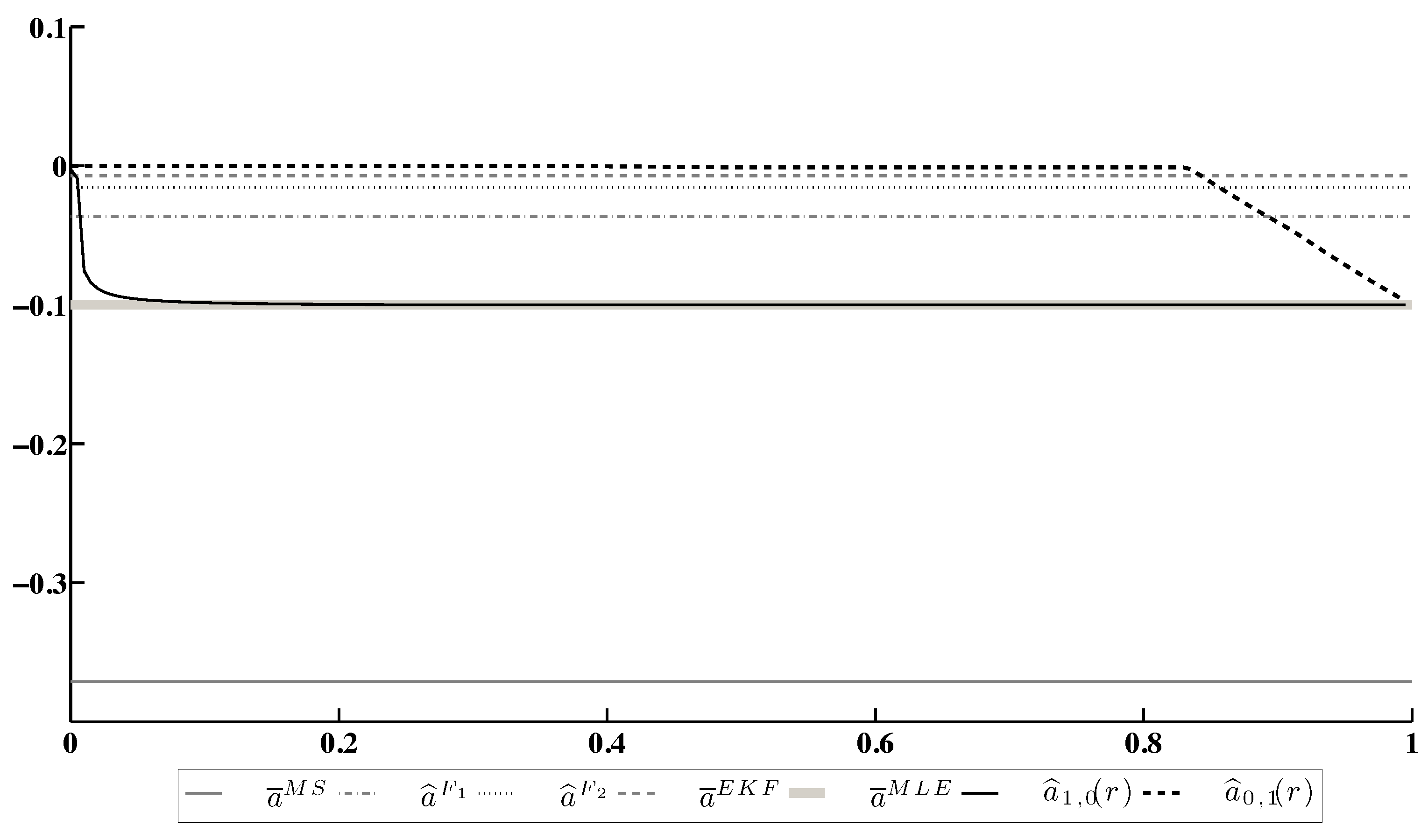
Figure 1 presents the evolution of the minimax estimates and of a drift coefficient depending on the confidence ratio . The minimax estimates are compared with;
- The estimate calculated by the moment/substitution method [12]:
- The Bayesian estimate (11) calculated under the assumption that prior distribution of is uniform over the whole uncertainty set ;
- The Bayesian estimate (11) calculated under the assumption that the prior distribution of is uniform over the vertices of ;
- The estimate calculated by the extended Kalman filter (EKF) algorithm [39] and subsequent residual processing;
- The maximum likelihood estimate (MLE) calculated by the expectation/maximization algorithm (EM algorithm) [17].
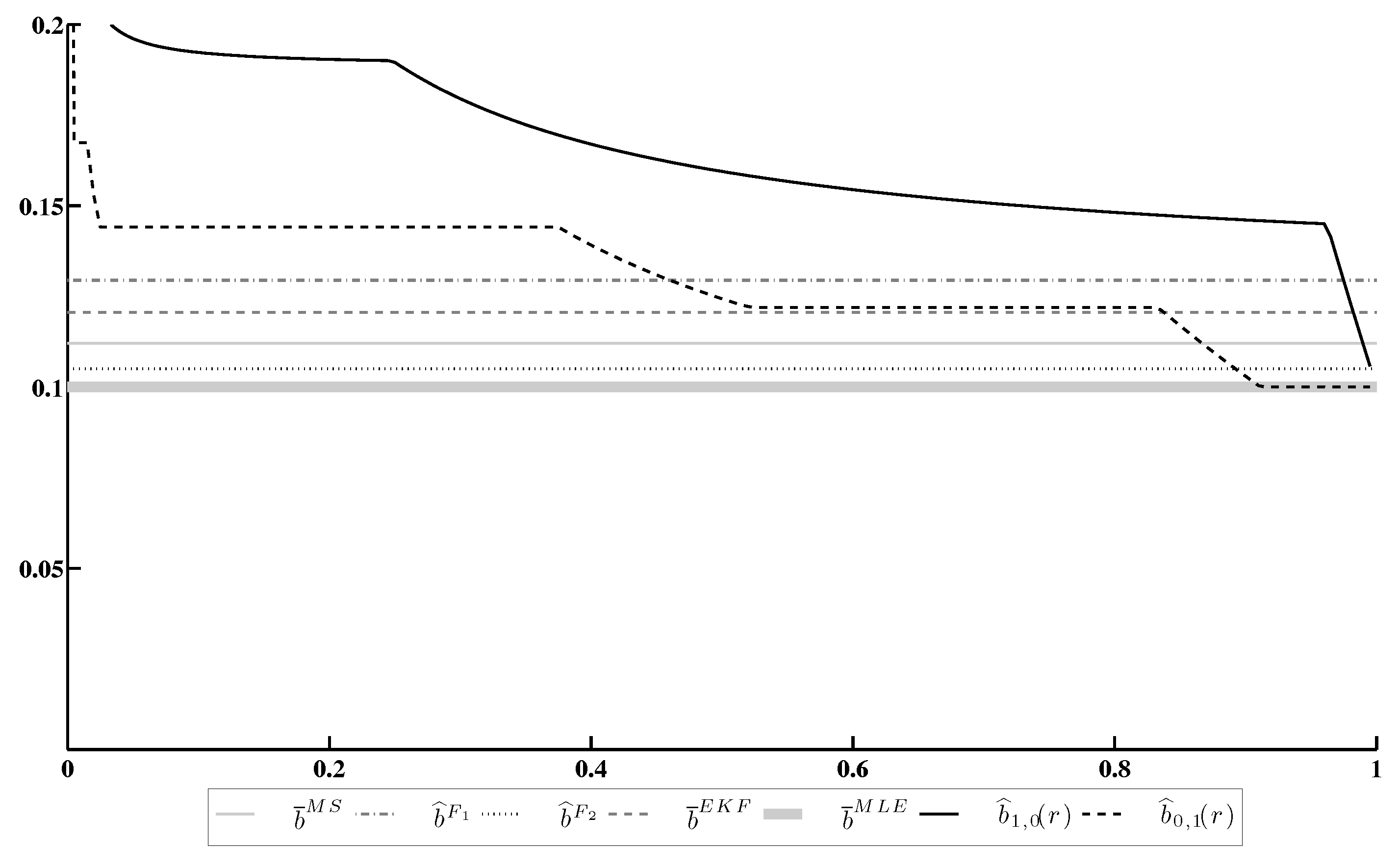
Figure 2 contains a similar comparison of the diffusion coefficient estimates and .
The results of this experiment allow us to make the following conclusions.
- Both minimax estimates and converge to the MLE as . Nevertheless, the rate of convergence depends on the specific choice of the loss function ( or in the considered case).
- Both minimax estimates are more conservative than the MLE, because they take into account a chance for other points of the LFD domain to be realized.
- Under an appropriate choice of the confidence ratio r, both minimax estimates become more accurate than other candidates, except for the MLE.
5.2. Parameter Estimation under Additive and Multiplicative Observation Noises
We consider the observations :
Here:
- a is an estimated value;
- is a vector of the i.i.d. unobservable random values (multiplicative noise): ;
- is a vector of the i.i.d. unobservable random values (additive noise): .
We assume that the parameter a is random with unknown distribution, whose support set lies within the known set . The loss function has the form:
In this example our goal is to compare the minimax estimates of the parameter a under conformity constraint based either on the likelihood function or on the EDF.
The minimax estimations are calculated for the following parameter values: , , , . We use the proposed numerical procedure under a uniform mesh of the set with the step . The example has some features. First, the observation model contains both the additive () and multiplicative () heterogeneous noises. Second, the available observed sample is not too long to provide the high quality for the consistent estimates. Third, the exact value of a is equal 2; meanwhile under the constraint absence there exists a discrete variant of the LFD with the finite support set . This means that the LFD is realized only in the considered observation model.
The likelihood conformity constraint looks similar to the one from the previous subsection:
where is a confidence ratio.
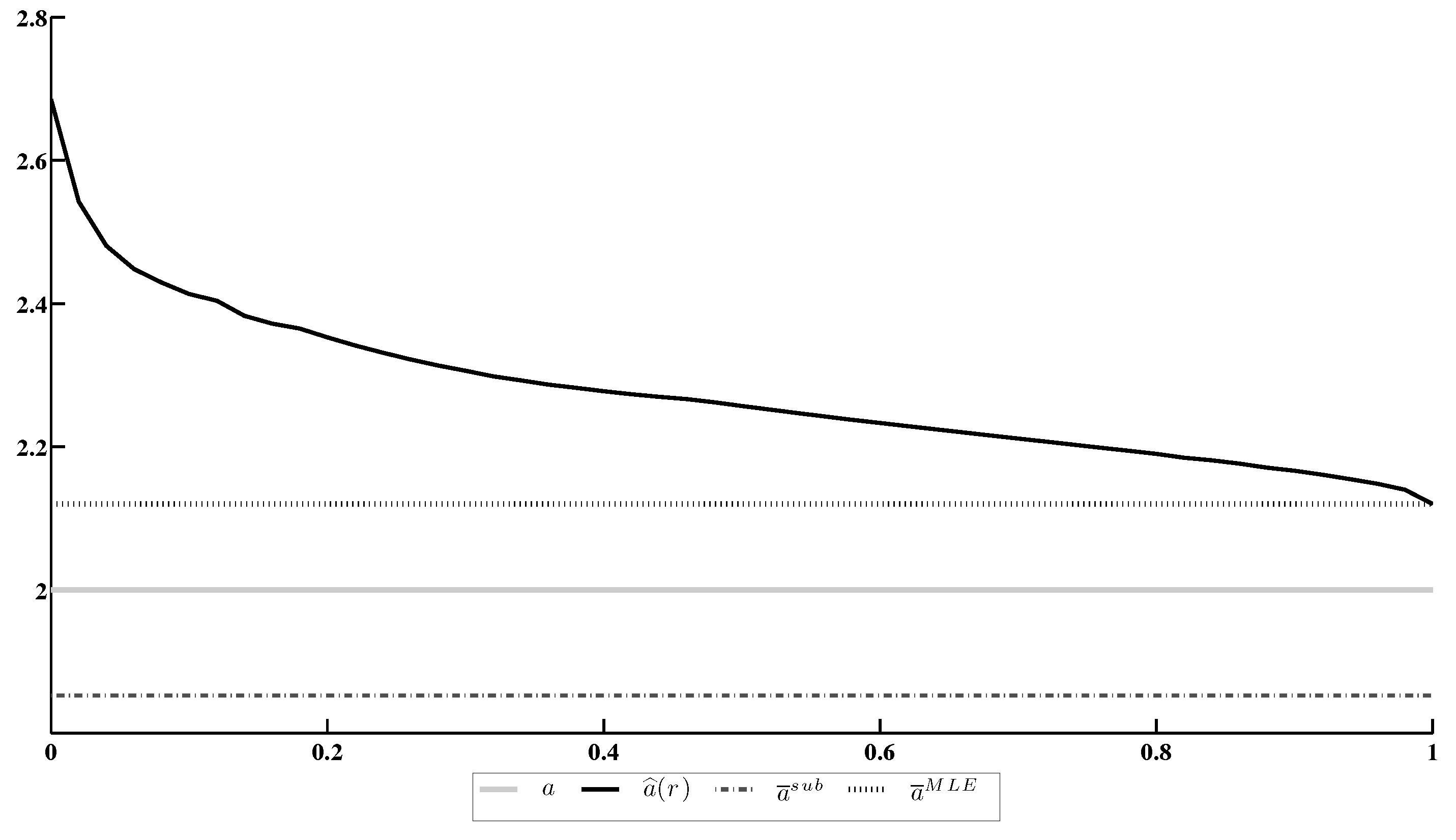
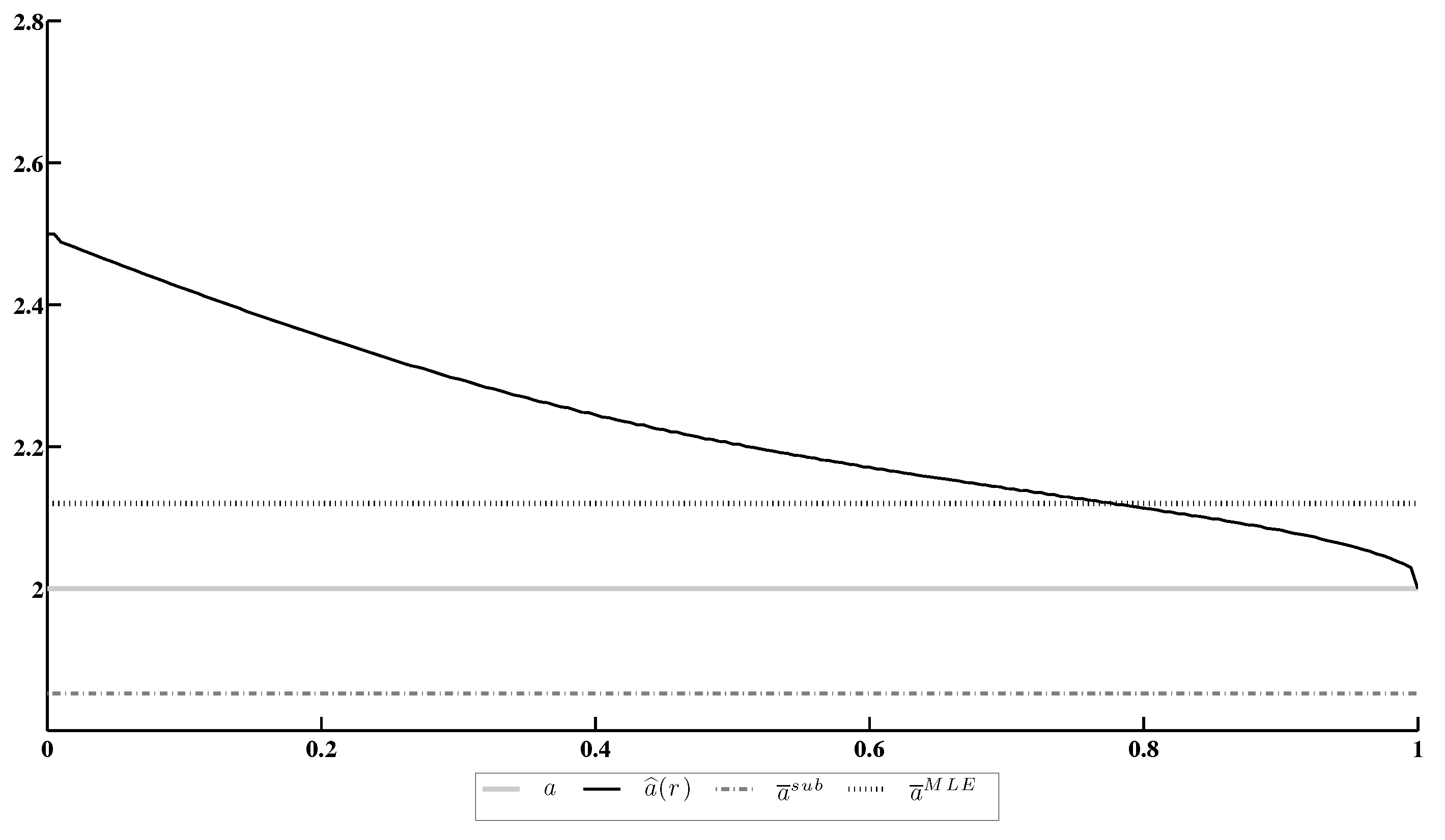
Figure 3 contains comparison of the minimax estimate with its actual value a, the (consistent asymptotically Gaussian) M-estimate , obtained by the moment/substitution method [12] and the MLE .
Next, we investigate minimax posterior estimates under the conformity constraint based on the EDF. The constraint is of the form:
where is some fixed confidence ratio, and is a “mesh” approximation of the set corresponding to the uniform “mesh” . The form (46) of the conformity constraint provides that it is active in the minimax optimization problem for any .
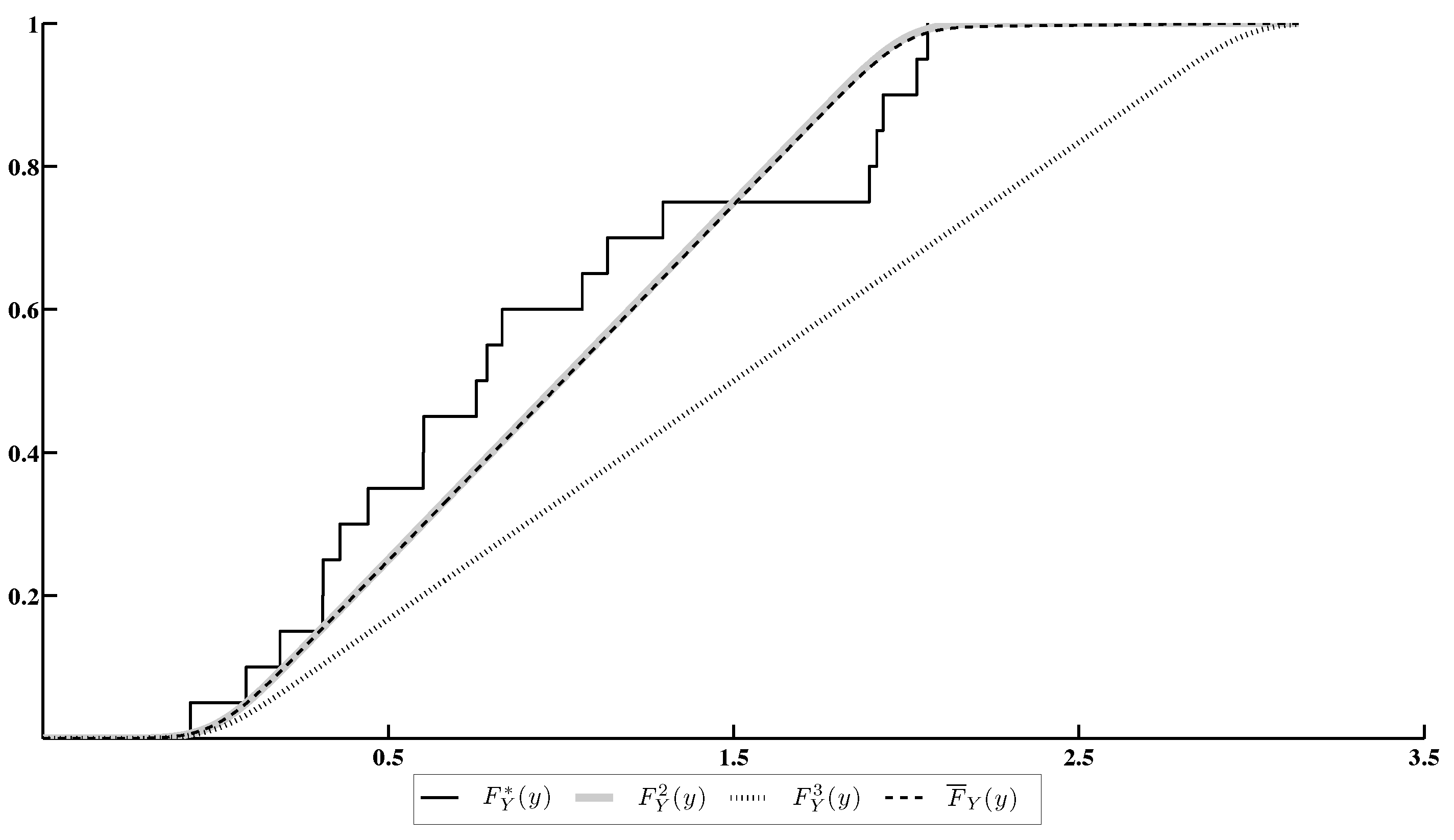
Figure 4 contains:
- The EDF calculated by the sample ;
- The cdf’s of Y, corresponding to the one-point distribution concentrated at the point q ();
- The cdf , closest to the EDF within the set .
Note that is a cdf of Y corresponding to the actual value of a.
Figure 5 contains a comparison of the minimax estimate under the conformity constraint, based on the EDF, with its actual value a, the moment/substitution estimate and the MLE .
The results of this experiment allow us to make the following conclusions.
- The minimax estimate under the conformity constraint, based on the EDF, does not converge to the MLE as .
- Under an appropriate choice of the confidence ratio r, the minimax estimate under the EDF constraint becomes more accurate than other candidates, including the MLE.
6. Conclusions
The paper contains the statement and solution to a new minimax estimation problem for the uncertain stochastic regression parameters. The optimality criterion is the conditional mean square of the estimation error given the realized observations. The class of admissible estimators contains all (linear and nonlinear) statistics with finite variance. The a priori information concerning the estimated vector is incomplete: the vector is random and the part of its components lies in the known compact. The key feature of the considered problem is the presence of the additional constraints for the statistical uncertainty, restricting from below the correspondence degree between the uncertainty and realized observations. The paper presents various indices, characterizing this conformity via the likelihood function, the EDF and the sample mean.
We propose a reduction of the initial optimization problem in the abstract infinite-dimensional spaces to the standard finite-dimensional QP problem with convex constraints along with an algorithm of its numerical realization and precision analysis.
The minimax estimation problem is solved in terms of the saddle points, i.e., besides the estimators with the guaranteed quality, we have a description of the LFDs. First, the investigation of the LFDs’ domains allowed us the detection of the uncertain parameter values, which are the worst for the estimation. Second, the consideration of the performance index pair “conformity index–guaranteed estimation quality” uncovered rather a new conception of the parameter estimation under a vector optimality criterion. The paper contains an assertion, which states that the LFDs are Pareto-optimal for the vector-valued criterion above.
The paper focuses mostly on the conformity indices related to the likelihood function; thus, it is obvious that the performance of the minimax estimate is compared with the one of the MLE. In general, the MLE has several remarkable properties, in particular the asymptotic minimaxity under some additional restrictions [12]. However, the estimate is non-robust to the prior statistical uncertainty. The proposed minimax estimate can be considered as a robustified version of the MLE, which is ready for application in the cases of the short non-asymptotic samples or the violation of the conditions for the MLE asymptotic minimaxity.
The conformity constraints are not exhausted by the likelihood function. In the paper, we present other conformity indices based on the EDF and sample mean. We demonstrate that the minimax estimates with the EDF conformity constraint are better than the MLE. One of the points of the paper is that the flexible choice of the conformity indices and design of the additional conformity constraints for each individual applied estimation problem allows obtaining a tradeoff between the prior uncertainty and available observations.
The reason to choose one or another conformity index depends not only on the conditions of the specific practical estimation problem solved under the minimax settings. One of the essential conditions is the possibility of its quick computation for the subsequent verification of the conformity constraint. For example, calculation of the likelihood conformity constraint (33) with the guess value tends to necessarily solve the auxiliary maximization problem for the likelihood function, which is nontrivial itself. Thus, the conformity indices based on the EDF or sample moments look more prospective from the computational point of view.
The applicability of the proposed minimax estimate also depends on the presence of the analytical formula of the estimates , or the fast numerical algorithms of its calculation. In turn, this possibility is a base for the subsequent effective solution to the QP problem and specification of the LFD.
Finally, the key indicator affecting the estimate calculation process and its precision is the number of the mesh nodes in the approximation of the uncertainty set . It is a function of “the size of / the mesh step ′ ratio and dimensionality m of .
All of the factors above characterize the limits of possible applicability of the proposed minimax estimation method for the solution to one or another practical problem.
Funding
The research was supported by the Ministry of Science and Higher Education of the Russian Federation, project No. 075-15-2020-799.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data sharing is not applicable to this article.
Conflicts of Interest
The author declares no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| cdf | cumulative distribution function |
| CE | conditional expectation |
| EDF | empirical distribution function |
| EKF | extended Kalman filter |
| EM algorithm | expectation/maximization algorithm |
| LFD | least favorable distribution |
| MLE | maximum likelihood estimate |
| MS-optimal | optimal in the mean square sense |
| probability density function | |
| QP problem | quadratic programming problem |
Appendix A
Proof of Lemma 1.
Conditions (v)—(viii) imply fulfillment of the inequalities:
Furthermore, for () there exists a compact set , such that , and by the Weierstrass theorem . Each measure can be associated with the measure . Obviously, , and is finite, i.e., . Hence, and . The measure (15) is probabilistic; moreover . The measure (16) is also a probabilistic one defined on , , and the denominator in (16) has the following lower and upper bounds:
From (15) and (16) it follows that , and the corresponding measure transformations are mutually inverse, i.e., the identity holds, and, moreover, . Assertion (1) of Lemma 1 is proven.
The set is *-weakly closed, because the set is, and the function is nonnegative, continuous and bounded in .
Let be two arbitrary distributions from , and be its convex linear combination with a fixed parameter . We should prove that . By the definition of there exist distributions such that and . Furthermore, for the convex combination with
we can verify easily that , i.e., . Assertion (2) of Lemma 1 is proven. □
Appendix B
Proof of Theorem 1.
The set by condition (ix); thus it is convex and closed. The set is convex and *-weakly closed due to Lemma 1. From this fact and (20) it follows that is also a convex closed set. Moreover, it is bounded due to condition (viii). The function (22) is strictly convex in and concave (affine) in w. These conditions are sufficient for the existence of a saddle point [40]. It should be noted that both the set and the saddle point depend on the observed sample y. For the saddle point the following equalities are true:
i.e., .
Now we prove the uniqueness of the saddle point . Let and be two different saddle points, and and be arbitrary convex combinations of the chosen points (). After elementary algebraic transformations we have:
which contradicts our assumption that and are two different solutions to the finite-dimensional dual problem. Theorem 1 is proven. □
Appendix C
Proof of Corollary 2.
The set is compact, and . By the Krein–Milman theorem [37], each point of the set can be represented as a convex combination at most of extreme points of the set .
Obviously, all extreme points of belong to the set . Hence, for the point which is a solution to the finite-dimensional dual problem (28), there exists a finite set , of parameters, and weights () such that:
The parameters and weights define the reference measure (15) on the space :
We can establish the initial measure by (16):
It is easy to verify that and , i.e., is the required LFD. Corollary 2 is proven. □
Appendix D
Proof of Lemma 2.
Without loss of generality we suppose each -mesh contains at least points. By Corollary 2 the solution to problem (28) can be represented in form (A1). By the condition of Lemma 2 there exists a set , such that . For the vector the inequalities
hold. Furthermore, the sequence of inequalities
proves the convergence as .
Let as . Then there exists a subsequence , such that . This means that , which contradicts the uniqueness of the solution to the finite-dimensional dual problem (28). Lemma 2 is proven. □
References
- Calafiore, G.; El Ghaoui, L. Robust maximum likelihood estimation in the linear model. Automatica 2001, 37, 573–580. [Google Scholar] [CrossRef]
- Kurzhanski, A.B.; Varaiya, P. Dynamics and Control of Trajectory Tubes; Birkhäuser: Basel, Switzerland, 2014. [Google Scholar]
- Matasov, A. Estimators for Uncertain Dynamic Systems; Kluwer: Dortrecht, The Netherlands, 1998. [Google Scholar]
- Borisov, A.V.; Pankov, A.R. Optimal filtering in stochastic discrete-time systems with unknown inputs. IEEE Trans. Autom. Control 1994, 39, 2461–2464. [Google Scholar] [CrossRef]
- Pankov, A.R.; Semenikhin, K.V. Minimax identification of a generalized uncertain stochastic linear model. Autom. Remote Control 1998, 59, 1632–1643. [Google Scholar]
- Poor, V.; Looze, D. Minimax state estimation for linear stochastic systems with noise uncertainty. IEEE Trans. Autom. Control 1981, 26, 902–906. [Google Scholar] [CrossRef]
- Soloviev, V. Towards the Theory of Minimax-Bayesian Estimation. Theory Probab. Its Appl. 2000, 44, 739–754. [Google Scholar] [CrossRef]
- Blackwell, D.; Girshick, M. Theory of Games and Statistical Decisions; Wiley: New York, NY, USA, 1954. [Google Scholar]
- Martin, C.; Mintz, M. Robust filtering and prediction for linear systems with uncertain dynamics: A game-theoretic approach. IEEE Trans. Autom. Control 1983, 28, 888–896. [Google Scholar] [CrossRef]
- Berger, J.O. Statistical Decision Theory and Bayesian Analysis; Springer: Berlin/Heidelberg, Germany, 1985. [Google Scholar]
- Anan’ev, B. Minimax Estimation of Statistically Uncertain Systems Under the Choice of a Feedback Parameter. J. Math. Syst. Estim. Control 1995, 5, 1–17. [Google Scholar]
- Borovkov, A. Mathematical Statistics; Australia Gordon & Breach: Blackburn, Australia, 1998. [Google Scholar]
- Epstein, L.; Ji, S. Ambiguous volatility, possibility and utility in continuous time. J. Math. Econ. 2014, 50, 269–282. [Google Scholar] [CrossRef] [Green Version]
- Borisov, A.V. A posteriori minimax estimation with likelihood constraints. Autom. Remote Control 2012, 73, 1481–1497. [Google Scholar] [CrossRef]
- Arkhipov, A.; Semenikhin, K. Minimax Linear Estimation with the Probability Criterion under Unimodal Noise and Bounded Parameters. Autom. Remote Control 2020, 81, 1176–1191. [Google Scholar] [CrossRef]
- Germeier, Y. Non-Antagonistic Games; Springer: New York, NY, USA, 1986. [Google Scholar]
- Elliott, R.J.; Moore, J.B.; Aggoun, L. Hidden Markov Models: Estimation and Control; Springer: New York, NY, USA, 1995. [Google Scholar]
- Yosida, K. Functional Analysis; Grundlehren der Mathematischen Wissenschaften; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Liptser, R.; Shiryaev, A. Statistics of Random Processes: I. General Theory; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Kats, I.; Kurzhanskii, A. Estimation in Multistep Systems. Proc. USSR Acad. Sci. 1975, 221, 535–538. [Google Scholar]
- Petersen, I.R.; James, M.R.; Dupuis, P. Minimax optimal control of stochastic uncertain systems with relative entropy constraints. IEEE Trans. Autom. Control 2000, 45, 398–412. [Google Scholar] [CrossRef] [Green Version]
- Xie, L.; Ugrinovskii, V.A.; Petersen, I.R. Finite horizon robust state estimation for uncertain finite-alphabet hidden Markov models with conditional relative entropy constraints. In Proceedings of the 2004 43rd IEEE Conference on Decision and Control (CDC) (IEEE Cat. No.04CH37601), Nassau, Bahamas, 14–17 December 2004; Volume 4, pp. 4497–4502. [Google Scholar] [CrossRef]
- El Karoui, N.; Jeanblanc Picque, M. Contrôle de processus de Markov. Séminaire Probab. Strasbg. 1988, 22, 508–541. [Google Scholar]
- Lee, E.; Markus, L. Foundations of Optimal Control Theory; SIAM Series in Applied Mathematics; Wiley: Hoboken, NJ, USA, 1967. [Google Scholar]
- Floyd, S.; Jacobson, V. Random early detection gateways for congestion avoidance. IEEE/ACM Trans. Netw. 1993, 1, 397–413. [Google Scholar] [CrossRef]
- Low, S.H.; Paganini, F.; Doyle, J.C. Internet congestion control. IEEE Control Syst. Mag. 2002, 22, 28–43. [Google Scholar] [CrossRef] [Green Version]
- Altman, E.; Avrachenkov, K.; Menache, I.; Miller, G.; Prabhu, B.J.; Shwartz, A. Dynamic Discrete Power Control in Cellular Networks. IEEE Trans. Autom. Control 2009, 54, 2328–2340. [Google Scholar] [CrossRef]
- Perruquetti, W.; Barbot, J.P. Sliding Mode Control in Engineering; Marcel Dekker, Inc.: New York, NY, USA, 2002. [Google Scholar]
- Arnold, B.F.; Stahlecker, P. Fuzzy prior information and minimax estimation in the linear regression model. Stat. Pap. 1997, 38, 377–391. [Google Scholar] [CrossRef]
- Donoho, D.; Johnstone, I.; Stern, A.; Hoch, J. Does the maximum entropy method improve sensitivity? Proc. Natl. Acad. Sci. USA 1990, 87, 5066–5068. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Donoho, D.L.; Johnstone, I.M.; Hoch, J.C.; Stern, A.S. Maximum Entropy and the Nearly Black Object. J. R. Stat. Society. Ser. B 1992, 54, 41–81. [Google Scholar] [CrossRef]
- Pham, D.S.; Bui, H.H.; Venkatesh, S. Bayesian Minimax Estimation of the Normal Model with Incomplete Prior Covariance Matrix Specification. IEEE Trans. Inf. Theory 2010, 56, 6433–6449. [Google Scholar] [CrossRef] [Green Version]
- Donoho, D.L.; Johnstone, I.M. Minimax risk over lp-balls for lq-error. Probab. Theory Relat. Fields 1994, 99, 277–303. [Google Scholar] [CrossRef]
- Donoho, D.L.; Johnstone, I.M. Minimax estimation via wavelet shrinkage. Ann. Stat. 1998, 26, 879–921. [Google Scholar] [CrossRef]
- Donoho, D.L.; Johnstone, I.; Montanari, A. Accurate Prediction of Phase Transitions in Compressed Sensing via a Connection to Minimax Denoising. IEEE Trans. Inf. Theory 2013, 59, 3396–3433. [Google Scholar] [CrossRef] [Green Version]
- Bosov, A.; Borisov, A.; Semenikhin, K. Conditionally Minimax Prediction in Nonlinear Stochastic Systems. IFAC-PapersOnLine 2015, 48, 802–807. [Google Scholar] [CrossRef]
- Kadets, V. A Course in Functional Analysis and Measure Theory; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis, 2nd ed.; Chapman and Hall/CRC: London, UK, 2004. [Google Scholar]
- Anderson, B.; Moore, J. Optimal Filtering; Prentice-Hall: Upper Saddle River, NJ, USA, 1979. [Google Scholar]
- Grabiner, J.; Balakrishnan, A. Applications of Mathematics: Applied Functional Analysis; Applications of Mathematics; Springer: New York, NY, USA, 1981. [Google Scholar]
Figure 1.
Estimation of the drift coefficient a.

Figure 2.
Estimation of the diffusion coefficient b.

Figure 3.
Estimation of the coefficient a under conformity constraint based on the likelihood function.
Figure 3.
Estimation of the coefficient a under conformity constraint based on the likelihood function.

Figure 4.
The EDF of Y and different cdf’s of Y under various choices of a.

Figure 5.
Estimation of the coefficient a under conformity constraint based on the EDF.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Borisov, A. Minimax Estimation in Regression under Sample Conformity Constraints. Mathematics 2021, 9, 1080. https://doi.org/10.3390/math9101080
AMA Style
Borisov A. Minimax Estimation in Regression under Sample Conformity Constraints. Mathematics. 2021; 9(10):1080. https://doi.org/10.3390/math9101080
Chicago/Turabian StyleBorisov, Andrey. 2021. "Minimax Estimation in Regression under Sample Conformity Constraints" Mathematics 9, no. 10: 1080. https://doi.org/10.3390/math9101080
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.