
Deflated Restarting of Exponential Integrator Method with an Implicit Regularization for Efficient Transient Circuit Simulation

1
School of Microelectronics, Southern University of Science and Technology, Shenzhen 518055, China
2
Engineering Research Center of Integrated Circuits for Next-Generation Communications, Ministry of Education, Southern University of Science and Technology, Shenzhen 518055, China
3
School of Information Science and Technology, Zhongkai University of Agriculture and Engineering, Guangzhou 510550, China
*
Author to whom correspondence should be addressed.
Electronics 2021, 10(9), 1124; https://doi.org/10.3390/electronics10091124
Submission received: 21 March 2021
/
Revised: 15 April 2021
/
Accepted: 7 May 2021
/
Published: 10 May 2021
(This article belongs to the Special Issue Circuit Analysis and Simulation of Modern Electric Systems)
Abstract
:Exponential integrator (EI) method based on Krylov subspace approximation is a promising method for large-scale transient circuit simulation. However, it suffers from the singularity problem and consumes large subspace dimensions for stiff circuits when using the ordinary Krylov subspace. Restarting schemes are commonly applied to reduce the subspace dimension, but they also slow down the convergence and degrade the overall computational efficiency. In this paper, we first devise an implicit and sparsity-preserving regularization technique to tackle the singularity problem facing EI in the ordinary Krylov subspace framework. Next, we analyze the root cause of the slow convergence of the ordinary Krylov subspace methods when applied to stiff circuits. Based on the analysis, we propose a deflated restarting scheme, compatible with the above regularization technique, to accelerate the convergence of restarted Krylov subspace approximation for EI methods. Numerical experiments demonstrate the effectiveness of the proposed regularization technique, and up to convergence improvements for Krylov subspace approximation compared to the non-deflated version.
1. Introduction
High performance and full-accuracy transient circuit simulation has always been one of the major demands in modern IC design industry. And its importance is increasing due to the fast-growing design complexities with advanced technology nodes. Besides IC design, SPICE-type simulators have also been widely used in some other scientific domains, such as electric/thermal analysis [1], electric/magnetic analysis [2], and advection-diffusion analysis [3], where the systems of interest can be described by differential algebraic equations (DAEs).
The essence of transient circuit simulation is to numerically solve a system of DAEs, normally derived from Modified Nodal Analysis (MNA), by an explicit or implicit integration method. Being a category of implicit methods, Backward differentiation formula (BDF) is widely adopted by existing SPICE simulators as it offers larger time steps and better stability than explicit methods. It is also more suitable for handling stiff DAEs with time constants differing by several orders of magnitude.
However, BDF is seeing elevated challenges in scalability, parallelizability and adaptivity as problem sizes grow into million-scale, or even billion-scale. The accuracy order of BDF is typically no higher than 2, which limits the step sizes and demands a large number of time steps. Often, it requires in each time step a sparse LU decomposition, which is known to be less scalable and parallelizable. Although considerable efforts have been dedicated to accelerating BDF-based transient simulation, new integration methods different from BDF might be needed to address the simulation capacity demands from the scientific and industrial communities.
Exponential integrator (EI) method is one of the emerging simulation methodologies to solve ordinary differential equations (ODEs) in a semi-analytical way, where the time span is discretized but the equation is solved analytically in each time step by expressing the solution in a matrix exponential form. For linear circuits, EI is in principle immune to the local truncation error (LTE) of polynomial expansion approximation in BDF [1,2,4,5,6,7]. The error only exists in the Krylov subspace approximation of the matrix exponential vector product; therefore, the accuracy order can be much higher than 2 without compromising stability [7]. Besides, only sparse matrix-vector multiplications are needed in EI method if the ordinary Krylov subspace is applied, which are highly scalable and parallelizable [8,9,10,11]. These advantages make EI a promising alternative to BDF for large-scale transient circuit simulation.
However, Krylov-subspace-based EI also has its own difficulties. One important issue is the singularity problem caused by the singular dynamic matrix of the DAE, which prohibits a straightforward conversion of the circuit DAE to an ODE required by EI. The singularity is mainly due to the algebraic constraints that do not involve time derivatives in the circuit, which leaves empty rows in the dynamic matrix. To solve the singularity problem, Chen has proposed a two-step DAE-ODE transformation for circuit simulation [5]. First, a topology-based approach is applied to reduce the DAE index of the circuit from 2 to 1, which can be skipped if the circuit is already index-1. Second, row echelon reduction is used to swap particular rows between the dynamic matrix and static matrix to eliminate the singularity. The problem lies in that the row echelon reduction is computationally expensive and tends to degrade the sparsity of the resulting matrices. Reference [4] proposed an implicit and sparsity-preserving regularization technique for EI, which is for the rational Krylov subspace only.
Another bottleneck lies in the large Krylov subspace that is needed for EI to handle stiff circuits, if the ordinary Krylov subspace is adopted. To maintain sufficient accuracy, the Krylov subspace dimension easily reaches several hundreds for intermediate stiffness. Storing a number of dense basis vectors in memory and performing full orthogonalization w.r.t. these vectors constitute substantial computational and memory challenges. One solution to this challenge is to use other types of Krylov subspace, such as the rational [8] or the extended Krylov subspace [12], which typically demands a much smaller subspace dimension. The cost, however, is extra LU factorizations that to some extent reduces the benefits of using EI. Another route, as motivated by the Krylov-subspace iterative solvers for linear systems, is to resort to restarting. Weng proposed a restarted scheme for EI [6], in which the Krylov subspace basis generation is restarted every m steps; thus, the memory footprint and orthogonalization cost is limited to a m-dimensional subspace. The drawback of such a simple restarting is that the convergence is slowed down. The total number of subspace dimension of restarted EI is higher than that of the non-restarted version, resulting in degraded performance.
In this paper, we aim to address the above two issues limiting the performance of EI for large stiff circuit simulation. We restrict our focus to linear circuit simulation in this work, though extension to nonlinear circuits is possible. Specifically, our main contributions are two-fold:
- We devise an implicit and algebraic regularization for EI based on the ordinary Krylov subspace, as it works directly on the original sparse matrices in an implicit manner without the row echelon reduction. This way the sparsity of the system matrices is preserved and the computational efficiency is improved.
- We propose a deflated restarting scheme for EI with the ordinary Krylov subspace. The scheme extracts some useful information from the previous round of Arnoldi process and incorporates such information into the new round of process, so as to accelerate the convergence of the Krylov subspace approximation. In other words, the proposed method “deflates” a subspace from the search space, so that the new search space is narrowed down and the convergence becomes faster compared to the non-deflated version. Some preliminary results have been reported in Reference [13], but an in-depth analysis of the root cause of the slow convergence and the optimal selection of the eigenvalues to be deflated are still missing.
With the two techniques, we aim to make EI comparable in robustness and superior in performance compared to BDF, rendering EI a practical alternative for future large-scale transient circuit simulation.
The paper is organized as follows. Section 2 introduces the EI formulation for transient circuit simulation. Section 3 presents the proposed regularization to tackle the singularity problem. Section 4 reveals the causes of the convergence problem of EI methods and proposes a deflated restarting scheme which is compatible with the above regularization to accelerate the convergence. Section 5 shows the numerical results, and Section 6 concludes the paper.
2. Background
In transient circuit simulation, a linear circuit is described by the following DAE:
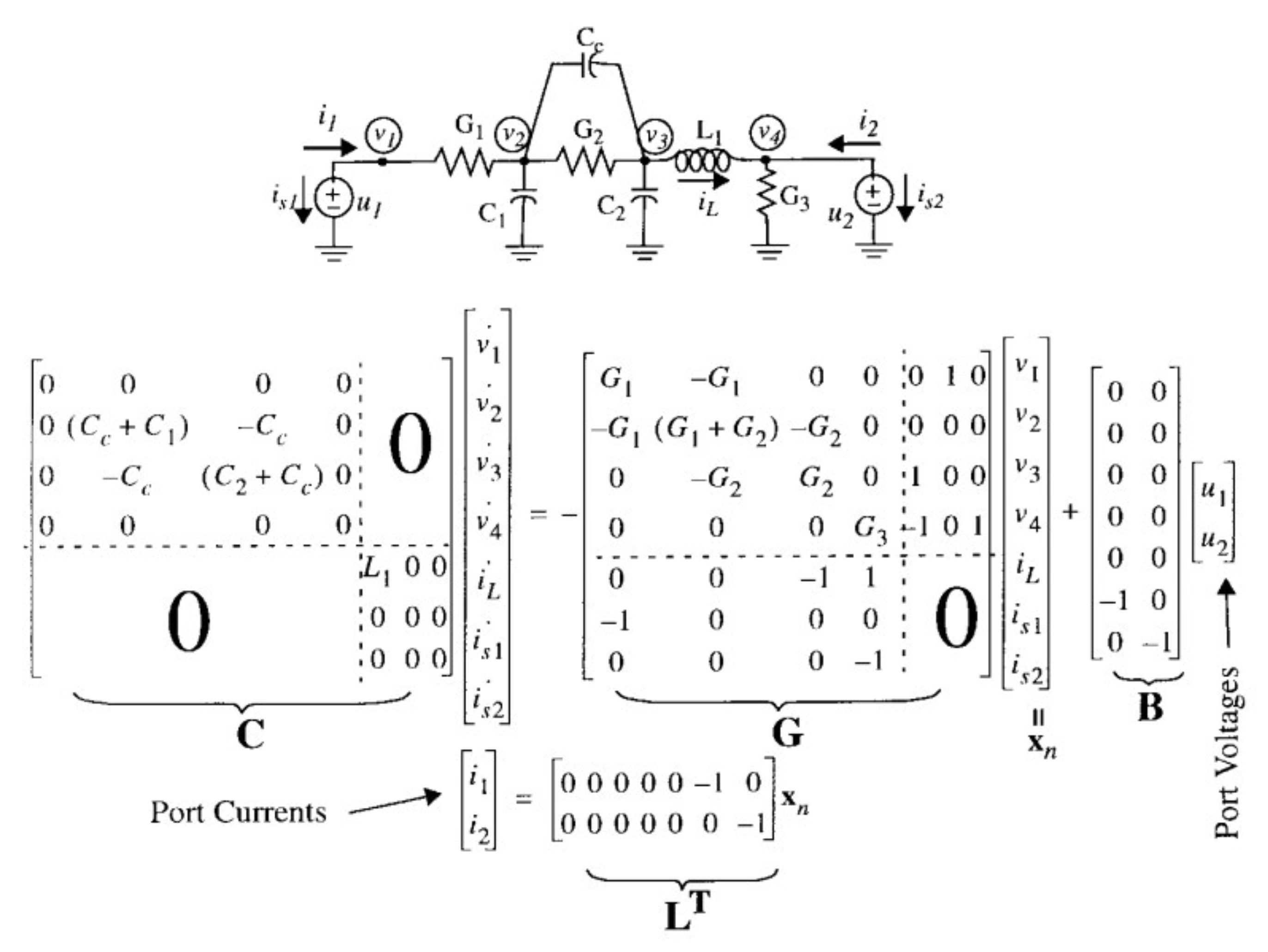
where C and G represent the capacitance/inductance matrix and resistance/conductance matrix, respectively, and the matrix B indicates the locations of independent sources. denotes the input source term. is comprised of the unknown voltages and branch currents at time t. Figure 1 shows an example of (1).
We assume C is non-singular, the above DAE (1) can be directly transformed into an ODE:
where , .
Then, the analytical solution for of the above ODE (2) can be solved with matrix exponential:
where h is the time step size.
The integral term in (3) can be computed analytically by applying the second-order piece-wise-linear (PWL) approximation [14], which turns the solution into the sum of three matrix exponential functions.
where , . And approximates the slope of input waveform.
The analytical solution (4) has three matrix exponential functions, which are generally referred as functions of the zero, first and second order.
Almohy [15] has shown that a series of functions can be calculated by computing the exponential of a matrix, where n and p describe the dimension of A and the order of functions, respectively, which prevents from explicitly calculating each function. Therefore, we can merge the sum of the three terms of functions (4) into the exponential of an augmented matrix.
where
Due to the large matrix size (on the order of millions), direct computation of matrix exponential is prohibitive. However, the Krylov subspace approximation can be applied to reduce the problem to the evaluation of a much smaller matrix exponential by projecting the matrix exponential vector product (MEVP) in (5) onto a smaller Krylov subspace with [16].
It computes an orthogonal basis of from the Arnoldi process; see Algorithm 1:
where is the upper Hessenberg matrix, and is the mth column of identity matrix .
Then, we project A onto the Krylov subspace and use (6) to derive an approximation of :
where can be conveniently evaluated by a dense matrix approach, and Saad [16] proposed a posteriori residue estimate applied to evaluate the approximation (7) quality.
| Algorithm 1: Arnoldi Process |
 |
3. Implicit Regularization
Note that, in (2), we assume C is non-singular and transform the DAE (1) into the ODE (2) directly. However, C is generally singular, since the algebraic constraints without time derivatives result in empty rows or columns in C, which prevents the straightforward multiplication of on both sides of the DAE (1). Higher-order singularity is also possible due to irregular circuit topologies [17].
To eliminate the singularity, Reference [5] has proposed a two-step topology-based regularization. The first step is to reduce the circuit to index-1 by breaking all C-V loops and L-I cutsets [18] in the circuit. The second step is to apply the row echelon reduction to eliminate the variables corresponding to the singular part of the system. However, such row echelon reduction is computationally expensive and does not preserve the sparsity of C and G (1). To enhance the efficiency of regularization for large-scale systems, in this section, we devise a new regularization technique, which is implicit, algebraic, and sparsity preserving. The regularization is applied to EI based on the ordinary Krylov subspace.
3.1. Partition
We firstly define semi-explicit DAEs as follows.
Definition 1.
- 1.
- a singular sparse matrix C,
- 2.
- a non-singular sub-matrix ,
- 3.
- non-singular sub-matrices .
The above partition can be obtained by re-arranging the nonzero part of C in (1) to the upper left corner. If the above conditions do not hold, the DAE (9) is typically index-2 or index-1 with floating capacitors. In such case, the topology-based method in Reference [5] can be applied to break the C-V loops and/L-I cutsets and eliminate the floating capacitors, rendering a system in the form of (9).
3.2. Regularization
From (9), we have the following formula.
Next, we can eliminate from (10) using (11), which yields
With (12), can be solved normally with the EI method, while is obtained by solving the algebraic Equation (13) after is solved. For simplicity, we denote
and we obtain the ODE we need to solve (12) as:
Then, we multiply on both sides of (16) and transform the above DAE to an ODE. And the ODE can be solved analytically by EI assuming PWL inputs:
where , ,
Merging the three functions in (17) yields:
where
Each Arnoldi step requires the computation:
The parameter in (18) is a scaling factor introduced to balance the quantities in and . Besides, the augmented matrix is transformed into a nonsingular matrix as derived in (18).
Then, the computation in each Arnoldi step requires solving:
where is a scalar quantity, and . Specifically, the core computation in Equation (21) is:
where
The main challenge in computing (22) lies in that the regularized matrices and in (22) are rather expensive to compute and tend to have much worse sparsity compared to the original matrices G and W, especially when is large. Hence, it is not recommended to explicitly form the matrices and for computing (22). Instead, we propose to compute in the following implicit and sparsity-preserving manner.
Firstly, we partition the original W matrix following the partition in (9).
And we have .
Substituting the expressions of (14) and into (22) then yields:
i.e., . can be directly computed by matrix-vector multiplications with the corresponding blocks. can be solved by three steps:
- Compute ,
- Solve from ,
- Compute .
The starting vector is obtained as follows:
where has the same index as . And to merge the three functions, we augment in (25) with .
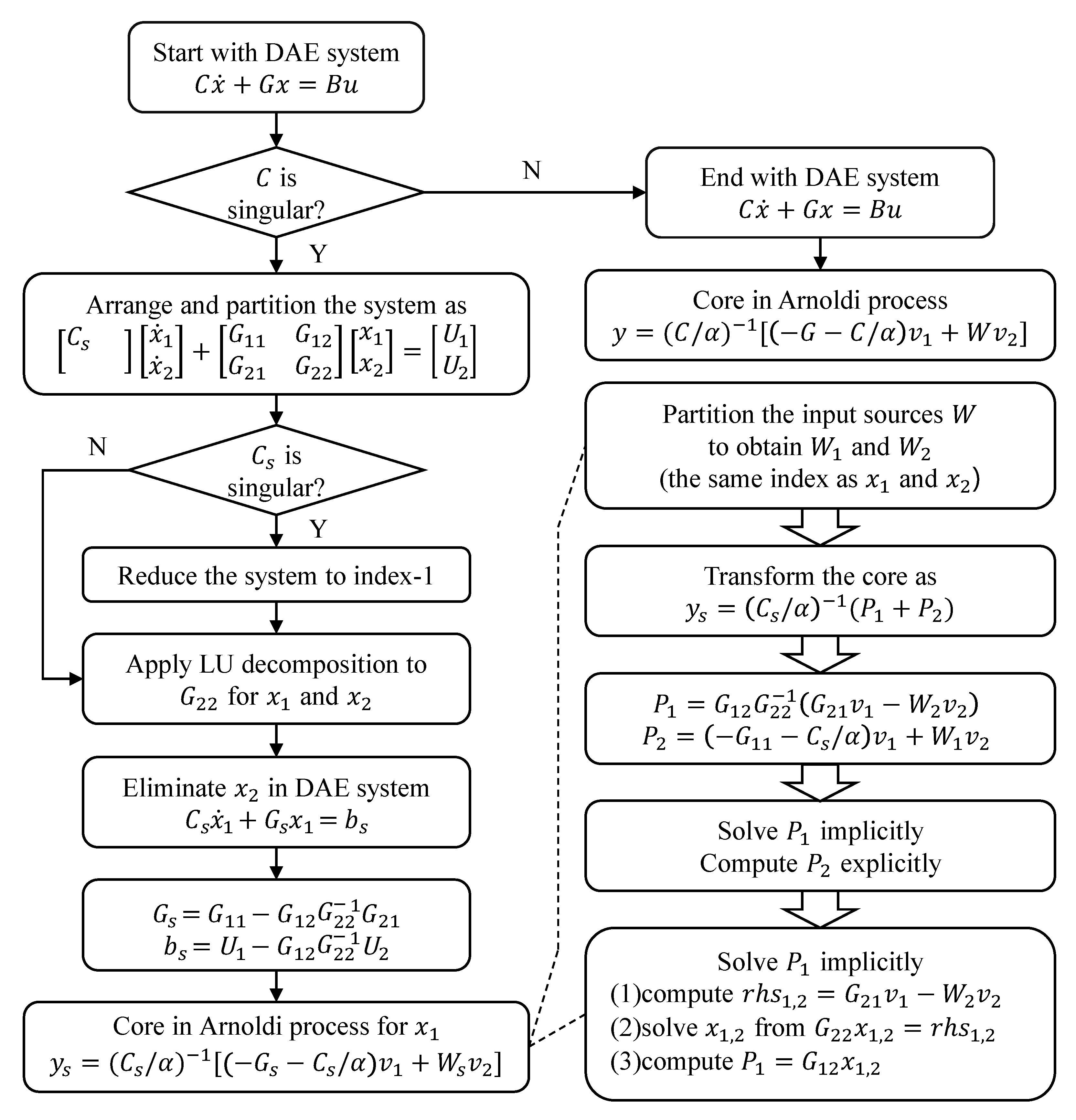
Given a solution v, we start the Arnoldi process with regularization. See Algorithm 2. Once we obtain one part of the solution in (12), the other part is solved algebraically in (13). The whole flow of our regularization is illustrated in Figure 2.
Two remarks are in order:
- The proposed regularization technique is “algebraic” in the sense that it works directly on the matrix level instead of the circuit topology level. It is “implicit” and “sparsity-preserving” since we do not explicitly form and , but instead use the original sparse matrices C, G, W and their blocks in the computation.
- In Algorithm 2, each Arnoldi step involves two linear system solutions, one with and another with . The former is needed for any variation of EI using the ordinary Krylov subspace approximation, while the latter is specifically associated to the proposed regularization technique. Since both the two sub-matrices are constant throughout the simulation, we only need to perform 1 sparse LU factorization for each matrix at the beginning, then re-use the LU factors in all subsequent computations. Thus, the overhead due to the proposed regularization is mild. In contrast, the rational Krylov subspace approach requires to factorize , which is generally much more costly due to the enlarged size and a higher number of nonzeros.
| Algorithm 2: Arnoldi Process with Regularization |
 |
4. Deflated Restarting of Exponential Integrator
Another challenge facing EI with ordinary Krylov subspace is the large subspace dimension required for stiff circuits. The stiffness appears when the time constants of the circuits differ by several orders of magnitudes. To guarantee the simulation accuracy of stiff circuits, one needs to either use small step sizes or a large Krylov subspace dimension m, with commonly . For large problems, storing and performing orthogonalization with all the basis vectors can be highly memory and computation demanding. Moving big chunks of data back and forth between memory and CPU also induces large overheads and hampers parallelizability.
Therefore, there has been a strong desire to limit the subspace dimension for EI when handling stiff circuits. Motivated by the restarting scheme for Krylov subspace iterative solvers (such as GMRES), Reference [6] proposed a restarted Krylov subspace EI method in which the generation of Krylov subspace is restarted after a moderate number of Arnoldi steps, which reduces the memory and orthogonalization cost. However, simple restarting typically results in slower convergence compared to the no-restarted version, consuming more Arnoldi iterations and offsetting the benefit of restarting. In the next parts, we will first analyze the cause of the slow convergence of the ordinary Krylov subspace for stiff circuits, and then propose a deflated restarting scheme to accelerate the convergence by “deflating” certain subspace in the new search space. The deflated restarting scheme is also compatible with the implicit regularization technique described above.
4.1. Slow Convergence in Krylov Subspace Approximation for Stiff Circuits
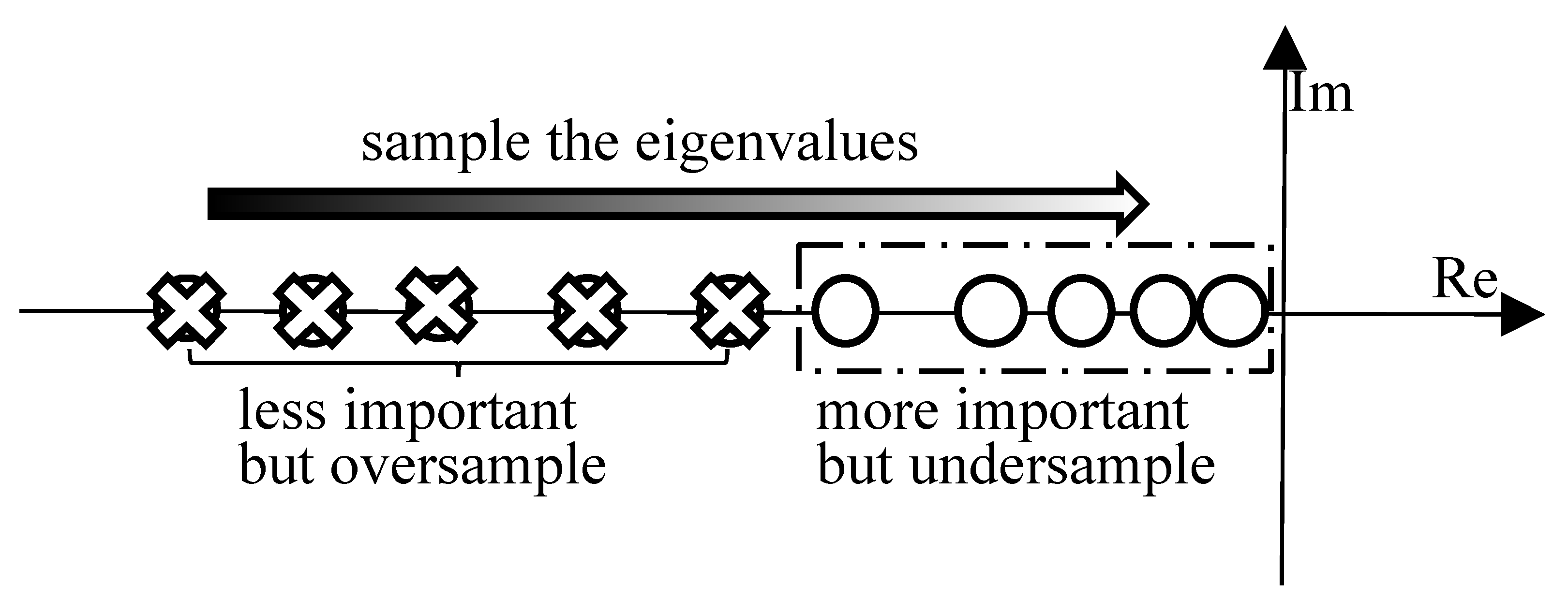
The dimension m required to accurately approximate depends mainly on the eigenvalue distribution of the original projected matrix . The underlying idea is that the eigenvalues of in (6), or the Ritz values, gradually approximate the eigenvalues of A, and the basis gradually forms an orthogonal basis of the subspace spanned by the approximate eigenvectors of A. Being a variant of power iteration, the Arnoldi process is known to approximate large-magnitude (negative) eigenvalues with a higher priority [20]. More specifically, the Arnoldi process spends most of its “dimension resources” building a Krylov subspace spanned by the eigenvectors corresponding to those large-magnitude eigenvalues in A, while leaving fewer “resources” to the subspace corresponding to the small-magnitude eigenvalues. However, for transient circuit simulation, the approximation quality of small (magnitude) eigenvalues is more important than that of the larger ones in deciding the final accuracy. This can be explained by the fact that when , which means an accurate capture of large-magnitude eigenvalues is not necessary since their contributions to the solution are almost zero. On the other hand, small eigenvalues have more tangible impacts on the approximation accuracy.
Consequently, the key problem with the ordinary Krylov subspace EI (6) is that it oversamples the less important region but undersamples the more important region, in the matrix spectrum, as illustrated in Figure 3. For stiff circuits, the gap between small and large eigenvalues becomes more significant, thus demanding a larger subspace to ensure adequate sampling in the critical part of the spectrum.
4.2. Ordinary Restarted Krylov Subspace Method
To mitigate the large subspace dimension m required for stiff circuits, Reference [6] proposed a restarted Krylov subspace method specific for EI [21]. The Arnoldi process is restarted every m iterations, with the last basis vector in (6) in the current run being the initial vector of the next m-step Arnoldi process.
where
and k denotes the total number of restarts.
The restarting scheme effectively generates a sequence of k Krylov subspaces, each of m dimensional. Concatenating the k sets of basis vectors, one could have the following relation
where is defined as
and as
Note that the columns of form a basis of the -dimensional Krylov subspace , albeit not an orthogonal one. Similarly as (7), projecting onto yields the approximation
It is shown in Reference [6] that the restarted Krylov subspace approximation (32) can be obtained efficiently by k iterations, i.e.,
Only a m-dimensional basis local to the current Krylov subspace is involved in each iteration, instead of global basis , leading to substantial saving in memory and orthogonalization.
However, this restarting scheme results in slower convergence than the version without restarting. In other words, is larger than , the subspace dimension in the non-restarted version. This can be attributed partially to the fact that the global subspace basis is not orthogonal; thus, with the same number of basis vectors, the subspace coverage is smaller with that with orthogonal basis. A larger Krylov subspace is thereby needed to ensure the important region of the spectrum is properly sampled.
4.3. Deflated Restarting Krylov Subspace Method
The analysis above reveals an important point that the ordinary Krylov subspace falls short for stiff circuits because it does not capture, with priority, the subspace spanned by the approximate eigenvectors associated to the small-magnitude eigenvalues (called the rightmost eigenvectors as the eigenvalues are all negative) of A. The simple restarting proposed in Reference [6], while mitigating the memory bottleneck, inherits and magnifies this weakness by producing a non-orthogonal basis.
To address this challenge, we propose a new deflated restarting EI scheme, dubbed EI-DR, for transient simulation of linear stiff circuits. Our rationale is that, if some “useful” information from the current run of Arnoldi process can be extracted and added to the new round of Arnoldi process, the convergence will be improved. In other words, certain important-yet-hard-to-reach subspace from the previous computation can be maintained and “deflated” from the search space of the new Arnoldi process. Consequently, the new search space is shrunk and fewer basis vectors are needed to approximately span the reduced search space.
Based on the above analysis, it would be most effective to deflate the subspace spanned by the rightmost eigenvectors of [22]. To avoid confusion, we would like to stress again that we actually want to maintain the information of this subspace in the next round of Arnoldi process. And the term “deflation” means that, since this subspace has been used as the initial subspace, the new Arnoldi process would not search this part again because any newly generated basis vector is orthogonal to the previous subspace. In effect, the subspace becomes “invisible” to the Arnoldi process and deflated from the entire vector space.
To facilitate the discussion of the deflated restarting, we first introduce the Krylov-like decomposition.
Definition 2.
Krylov-like decomposition [23]
- 1.
- ,
- 2.
- ,
- 3.
- are linearly dependent if and only if .
In particular, the Krylov-like decomposition turns into a Krylov decomposition as (6) if .
There are five steps in our proposed deflated restarting scheme. See Algorithm 3.
| Algorithm 3: Krylov-like Approximation of EI with Deflated Restarting |
 |
Step 1: perform the 1st round of Arnoldi process (6) and obtain the relation below:
Step 2: extract l eigenvectors from (more precisely a partial Schur decomposition):
where , . And the columns of form an orthogonal basis of the subspace containing the l eigenvectors we extract from .
Step 3: multiply on both sides of (35) to generate a basis of the deflated subspace :
where , . And forms the deflated subspace spanned by the l approximate eigenvectors (Ritz vectors).
Step 4: apply another m-step Arnoldi process with respect to the new Krylov subspace to obtain:
Note that columns of are orthogonal. And , .
Step 5: glue the basis of the deflated subspace and the basis of the new Krylov subspace.
where
and
After cycles, we have:
where
Similarly, has orthogonal columns. And , .
At the beginning of the kth cycle, we also extract l eigenvectors from by a partial Schur decomposition.
where , . And is an orthogonal basis of the partial eigenspace of . Similarly, we multiply by to obtain an orthogonal basis of the deflated subspace.
where
As (38) and (39), m further Arnoldi steps lead to
where . And we use to represent the partitioned matrix with four blocks in (45).
Ultimately, we glue all the and together to obtain:
where
Now, we obtain a Krylov-like decomposition (46) of A with regard to the Krylov subspace . Then, the approximation of based on the Krylov-like decomposition (46) is:
Taking into account the special structure of , the approximation (47) can be retrieved by compensation [23].
Note that, with the above iterative updating scheme, it only requires to store basis vectors in each round of restart. The extra computational cost induced by the deflation is mainly the eigenvalue decomposition of a matrix. The computation of in (41), while appearing to be expensive, can be performed with nearly zero additional cost in a way outlined in Appendix A. Hence, the overhead arising from the deflation is insignificant for reasonable m and l.
5. Numerical Results
All the numerical experiments are conducted on a computer with Intel Xeon(R) Golden 6140 processor 2.30 GHz × 72 and 128 GB memory under a Linux system. We implement both the regularization technique and the deflated restarting scheme (EI-DR) in an open-source Python circuit simulator Ahkab [24]. The LU factorizations for and are performed by the SuperLU package of SciPY. For all EI-related simulation, we set the scaling parameter and the tolerance and .
We test four cases of IBM P/G networks with the specifications shown in Table 1. Len(x1) and Len(x2) denote the length of and in (9) due to the matrix partitioning, respectively.
5.1. Performance of Regularization
We first confirm the effectiveness of our regularization technique proposed in Section 3. In Table 2, we test a simple RC circuit with 10 nodes in the first time point. The leftmost column shows the generalized eigenvalues of the matrix pencil . The system matrix has three infinite eigenvalues due to the fact that there are three empty rows in C. The remaining columns show the eigenvalues of the Hessenberg matrix in (6) obtained using the proposed regularization algorithm. The data from the seven consecutive Arnoldi steps demonstrate that the Ritz values gradually approximate the finite eigenvalues of the original system in a stable manner. When , the Ritz values reproduces exactly the original eigenvalues as expected, with no infinite eigenvalues included. This proves that our regularization technique does not alter or miss any useful information contained in the original system, except removing those infinite modes to ensure numerical stability.
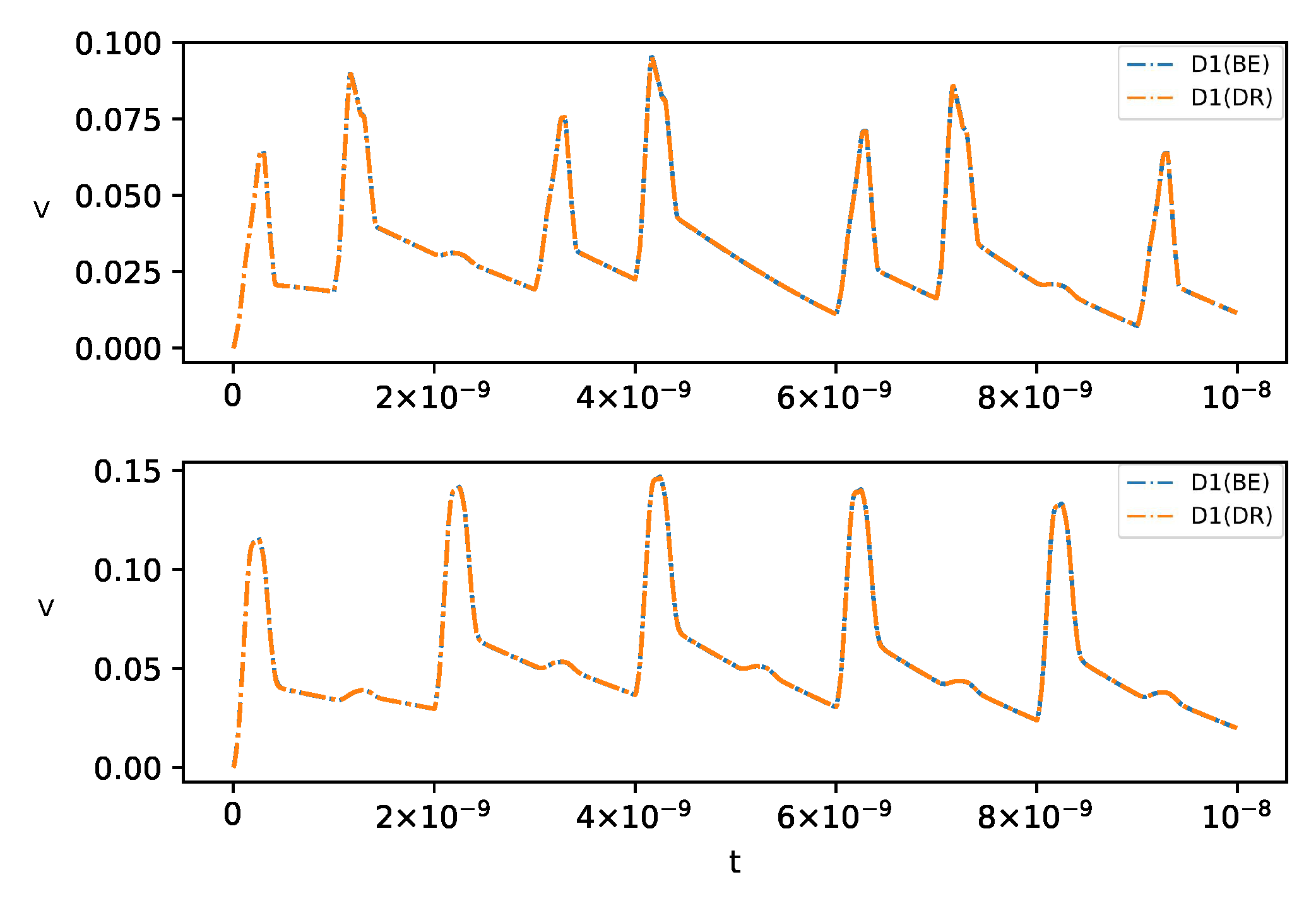
In Figure 4, we compare the transient voltage waveforms simulated by the built-in BE (Backward Euler) method and the EI-DR method combined with the regularization technique. The D1 and D2 cases are used with a fixed time step size s. The overlapping agreements confirm that no accuracy loss is caused by the proposed regularization.
5.2. Deflated Restarting Scheme
In this section, we investigate the performance of the EI-DR method. As mentioned in Section 4.1, the ordinary Arnoldi process (6) tends to oversample the large-magnitude eigenvalues but undersample the small-magnitude ones that are more pertinent to the final accuracy. Hence, the first question of EI-DR is how to choose the proper eigenvalues (or eigenvectors) of the block Hessenberg matrix in (41) be to deflated. Below we compare two different choices of the l eigenvalues for deflation. The D1 case in Table 1 is used with a uniform time step size of 0.2 ns for convenience.
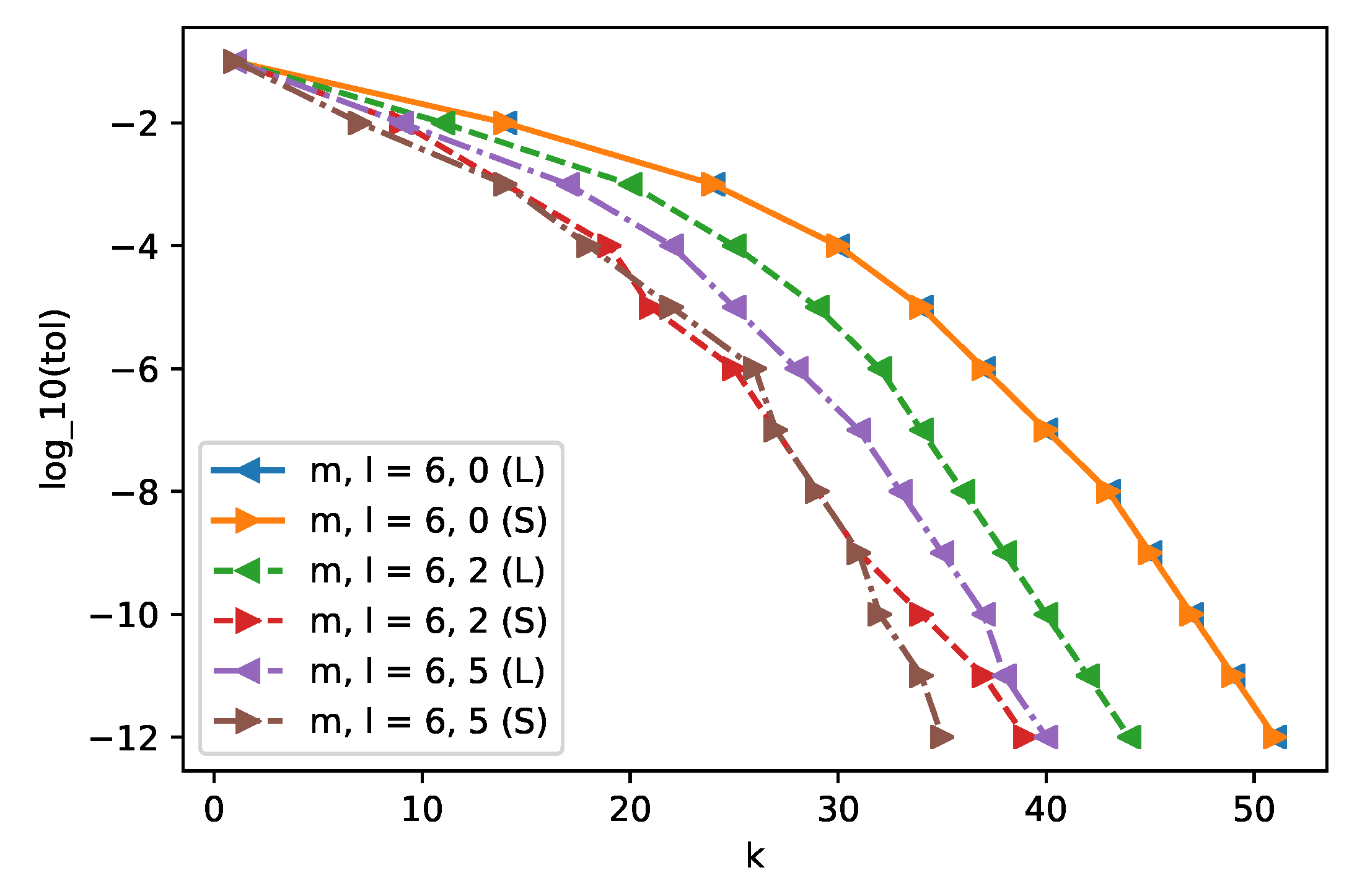
Figure 5 shows the convergence history for different settings, where m and l denote the restarting length of the ordinary Krylov subspace and the number of eigenvectors we extract from for deflation, respectively. The symbol and indicate whether we deflate the eigenvectors corresponding to the l largest eigenvalues or the l smallest eigenvalues. The figure plots how the error decreases with the number of restarts k. Note that, when k differs by 1, the corresponding subspace dimension differs by m.
When , our deflated restarting scheme coincides with the non-deflated version (EI-R) proposed in Reference [6] and the two curves for and overlap in Figure 5 as expected. For nonzero l, however, deflation of the small-magnitude eigenvalues consistently yields faster convergence than that of the large-magnitude eigenvalues, which confirms the analysis in Section 4.1 that slow convergence is due to inadequate sampling of the small eigenvalues. Comparing the curves of and , one can see that the convergence rates are similar, demonstrating a saturated improvement one could obtain by increasing l. This again suggests that the accuracy is controlled by a fraction of small eigenvalues, and further improvements would be limited if these set of eigenvalues have already been deflated from the new search space. Only for a high accuracy requirement below , deflating more small eigenvalues is beneficial as shown by the discrepancy at the bottom part of the leftmost two lines.
Table 3 and Table 4 tabulate the performance data of EI-DR for all the four testcases with different combinations of m and l. denotes the number of triangular solves involved in the Arnoldi process (=km), a main indicator of convergence speed and total runtime. dim() is the effective total subspace dimension for EI-DR taking into account the deflated vectors. The l smallest eigenvalues are chosen for deflation. Several observations can be made:
- A higher restarting length m in general leads to faster convergence and reduced runtime, at the cost of a higher memory consumption. Comparing to EI without restarting, EI-R and EI-DR both consume more , indicating a slower convergence.
- For the same m, a higher l typically improves the convergence and reduces . The improvements, however, tend to saturate after a certain value of l. For instance, for the case D2 with , using or results in the same number of restarting k, suggesting a higher l is not always optimal for a particular m.
- Comparing to EI-R (), EI-DR reduces number of by ratios between to across different cases and various m, confirming that the proposed EI-DR is an effective acceleration scheme. The improvement is more significant for small m than for large m.
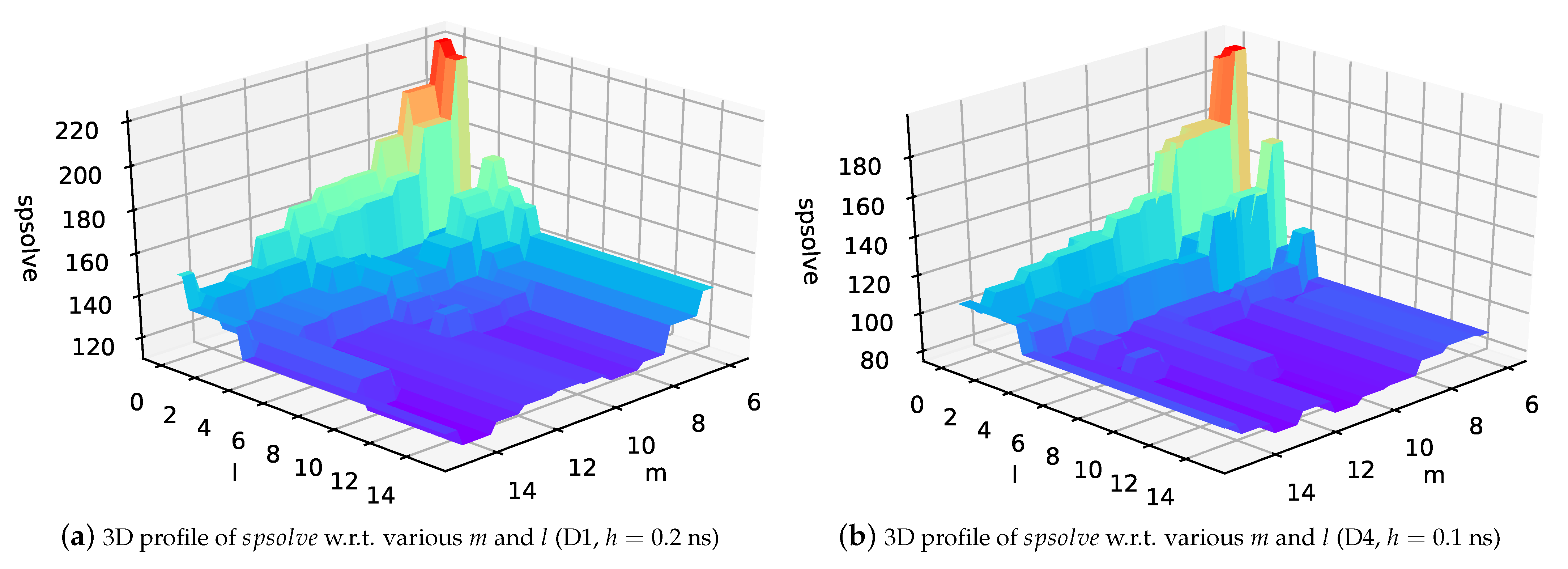
Finally, we plot the 3D profiles of the number of with respect to different pairs for D1 and D4 in Figure 6a,b, respectively. m varies from 6 to 14, and l varies from 0 to m. In the two figures, the peaks are both at , and the valleys are near , which is consistent with our analysis above. The optimal selection of m and l in practice is generally a trade-off between runtime and memory.
- extract l eigenvectors corresponding to the largest-magnitude eigenvalues of .
- extract l eigenvectors corresponding to the smallest-magnitude eigenvalues of .
6. Conclusions
In this paper, we proposed two techniques to improve EI based on the ordinary Krylov subspace for linear circuits. We firstly propose an implicit regularization technique for the ordinary Krylov subspace EI to solve the singular C problem. This regularization is computationally efficient and sparsity preserving. Next, we analyze the convergence problems with the ordinary Krylov subspace and the simple restarting scheme for stiff circuits. Based on the analysis, we then develop a deflated restarting scheme that deflates a carefully chosen region of the matrix spectrum to accelerate the convergence. Numerical results demonstrate the effectiveness of our regularization technique, and the substantial convergence improvement arising from the proposed deflated restarting scheme for stiff circuits. The optimal, even adaptive, selection of m and l in our deflated restarting scheme will be a topic for future investigation.
Author Contributions
Investigation, M.Z.; methodology, Q.C.; validation, M.Z.; visualization, M.Z.; writing—original draft, M.Z.; writing—review and editing, M.Z., J.L., C.Y., Q.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (NSFC) grant number 62034007.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
To compute m further Arnoldi steps (45), the and can be generated by Arnoldi process with a new projector as:
Evidently, it is prohibitive to compute the variable explicitly as it involves m full matrix-vector multiplications. Instead, we obtain from the above equation implicitly following Algorithm A1. Thus, our deflated restarting scheme induces negligible overhead in comparison with the non-deflated restarting.
| Algorithm A1: Compute m further Arnoldi steps |
 |
References
- Chen, Q.; Schoenmaker, W. A new tightly-coupled transient electro-thermal simulation method for power electronics. In Proceedings of the IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Austin, TX, USA, 7–10 November 2016; pp. 1–7. [Google Scholar]
- Chen, Q.; Schoenmaker, W.; Weng, S.H.; Cheng, C.K.; Chen, G.H.; Jiang, L.J.; Wong, N. A fast time-domain EM-TCAD coupled simulation framework via matrix exponential. In Proceedings of the IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Diego, CA, USA, 5–8 November 2012; pp. 422–428. [Google Scholar]
- Caliari, M.; Vianello, M.; Bergamaschi, L. Interpolating discrete advection–diffusion propagators at Leja sequences. J. Comput. Appl. Math. 2004, 172, 79–99. [Google Scholar] [CrossRef] [Green Version]
- Chen, P.; Cheng, C.; Park, D.; Wang, X. Transient circuit simulation for differential algebraic systems using matrix exponential. In Proceedings of the IEEE/ACM International Conference on Computer-Aided Design ICCAD, San Diego, CA, USA, 5–8 November 2018; p. 99. [Google Scholar]
- Chen, Q.; Weng, S.; Cheng, C. A Practical Regularization Technique for Modified Nodal Analysis in Large-Scale Time-Domain Circuit Simulation. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2012, 31, 1031–1040. [Google Scholar] [CrossRef] [Green Version]
- Weng, S.H.; Chen, Q.; Wong, N.; Cheng, C.K. Circuit simulation via matrix exponential method for stiffness handling and parallel processing. In Proceedings of the IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Jose, CA, USA, 5–8 November 2012; pp. 407–414. [Google Scholar]
- Weng, S.H.; Chen, Q.; Cheng, C.K. Time-Domain Analysis of Large-Scale Circuits by Matrix Exponential Method With Adaptive Control. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2012, 31, 1180–1193. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, H.; Weng, S.H.; Cheng, C.K. Power Grid Simulation using Matrix Exponential Method with Rational Krylov Subspaces. In Proceedings of the IEEE 9th International Conference on ASIC (ASICON), Shenzhen, China, 28–31 October 2013; pp. 369–372. [Google Scholar]
- Zhuang, H.; Weng, S.H.; Lin, J.H.; Cheng, C.K. MATEX: A Distributed Framework for Transient Simulation of Power Distribution Networks. In Proceedings of the IEEE/ACM Design Automation Conference (DAC), San Francisco, CA, USA, 1–5 June 2014; pp. 81:1–81:6. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, H.; Yu, W.; Kang, I.; Wang, X.; Cheng, C.K. An Algorithmic Framework for Efficient Large-scale Circuit Simulation Using Exponential Integrators. In Proceedings of the IEEE/ACM Design Automation Conference (DAC), San Francisco, CA, USA, 7–11 June 2015; pp. 163:1–163:6. [Google Scholar]
- Zhuang, H.; Yu, W.; Weng, S.; Kang, I.; Lin, J.; Zhang, X.; Coutts, R.; Cheng, C. Simulation Algorithms With Exponential Integration for Time-Domain Analysis of Large-Scale Power Delivery Networks. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2016, 35, 1681–1694. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Zhao, W.; Wong, N. Efficient matrix exponential method based on extended Krylov subspace for transient simulation of large-scale linear circuits. In Proceedings of the 2014 19th Asia and South Pacific Design Automation Conference (ASP-DAC), Singapore, 20–23 January 2014; pp. 262–266. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Li, J.; Chen, O. Deflated Restarting of Exponential Integrator Method for Efficient Transient Circuit Simulation. In Proceedings of the 2020 IEEE 15th International Conference on Solid-State & Integrated Circuit Technology (ICSICT), Kungming, China, 3–6 November 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Cameron, S.H. Piecewise Linear Approximations. In IIT Research Institute Technical Report No. CSTN-106; IIT Research Institute Press: Chicago, IL, USA, 1966. [Google Scholar]
- Al-Mohy, A.H.; Higham, N.J. Computing the Action of the Matrix Exponential with an Application to Exponential Integrators. SIAM J. Sci. Comput. 2011, 33, 488–511. [Google Scholar] [CrossRef]
- Saad, Y. Analysis of some Krylov subspace approximations to the matrix exponential operator. SIAM J. Numer. Anal. 1992, 29, 209–228. [Google Scholar] [CrossRef]
- Chua, L.O.; Lin, P.M. Computer-Aided Analysis of Electronic Circuits; Prentice-Hall: Hoboken, NJ, USA, 1975. [Google Scholar]
- Schwarz, D.; Tischendorf, C. Structural analysis of electric circuits and consequences for MNA. Int. J. Circuit Theory Appl. 2000, 28, 131–162. [Google Scholar] [CrossRef]
- Ilchmann, A.; Reis, T. Surveys in Differential-Algebraic Equations; Springer International Publishing: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Il’in, V. Projection Methods in Krylov Subspaces. J. Math. Sci. 2019, 240, 772–782. [Google Scholar] [CrossRef]
- Eiermann, M.; Ernst, O. A Restarted Krylov Subspace Method for the Evaluation of Matrix Functions. SIAM J. Numer. Anal. 2006, 44, 2481–2504. [Google Scholar] [CrossRef] [Green Version]
- Gaul, A. Recycling Krylov Subspace Methods for Sequences of Linear Systems. Ph.D. Thesis, Analysis and Applications University of Erlangen, Berlin, Germany, 2014. [Google Scholar] [CrossRef]
- Eiermann, M.; Ernst, O.; Güttel, S. Deflated Restarting for Matrix Functions. SIAM J. Matrix Anal. Appl. 2011, 32, 621–641. [Google Scholar] [CrossRef] [Green Version]
- Venturini, G. Ahkab: An Open-Source SPICE-Like Interactive Circuit Simulator. 2015. Available online: https://ahkab.readthedocs.io/en/latest/ (accessed on 21 March 2021).
Figure 1.
Typical RLC circuit and its MNA equations.

Figure 2.
Flow of the proposed regularization.

Figure 3.
Sampling regions of spectrum in ordinary Krylov subspace methods.

Figure 4.
Voltage waveform comparisons between BE and EI-DR for D1 and D2.

Figure 5.
Convergence comparison between two different selections of eigenvalues to be deflated in EI-DR. (L) refers largest-magnitude eigenvalues, (S) refers to smallest-magnitude eigenvalues. The D1 case is used with a fixed time step 0.2 ns.
Figure 5.
Convergence comparison between two different selections of eigenvalues to be deflated in EI-DR. (L) refers largest-magnitude eigenvalues, (S) refers to smallest-magnitude eigenvalues. The D1 case is used with a fixed time step 0.2 ns.

Figure 6.
3D profile.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Specifications of benchmark circuits.
| Design | Category | Nodes | Len(x1) | Len(x2) |
|---|---|---|---|---|
| D1 | Power Grid | 54.2 K | 12.4 K | 41.8 K |
| D2 | Power Grid | 164.9 K | 55.3 K | 109.6 K |
| D3 | Power Grid | 1.21 M | 0.38 M | 0.83 M |
| D4 | Power Grid | 2.09 M | 0.71 M | 1.38 M |
Table 2.
Eigenvalues of the original and the regularized systems.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|
| −2.050795 | −0.912349 | −1.988669 | −2.007050 | −2.040173 | −2.053679 | −2.051105 | −2.051100 |
| −1.787729 | −0.067203 | −1.226993 | −1.581068 | −1.701136 | −1.780247 | −1.788008 | |
| −1.491372 | −0.058861 | −0.431774 | −1.314589 | −1.471928 | −1.491621 | ||
| −0.865400 | −0.034110 | −0.388962 | −0.447983 | −0.865586 | |||
| −0.404115 | −0.033235 | −0.215691 | −0.404255 | ||||
| −0.189688 | −0.034014 | −0.189807 | |||||
| −0.042095 | −0.042200 | ||||||
| inf | |||||||
| inf | |||||||
| inf | |||||||
Table 3.
Performance data of D1 and D2.
| Tstep = s | D1 ( for No-Restarting) | D2 ( for No-Restarting) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| m | l | k | Spsolve | dim() | Time/s | k | Spsolve | dim() | Time/s |
| 6 | 0 | 37 | 222 | 222 | 4.317771 | 35 | 210 | 210 | 18.117152 |
| 2 | 25 | 150 | 198 | 2.561108 | 26 | 156 | 206 | 13.040628 | |
| 6 | 24 | 144 | 282 | 2.513732 | 22 | 132 | 258 | 10.957821 | |
| 10 | 0 | 17 | 170 | 170 | 2.856241 | 17 | 170 | 170 | 14.299571 |
| 5 | 13 | 130 | 190 | 2.194715 | 12 | 120 | 175 | 10.334383 | |
| 10 | 12 | 120 | 230 | 2.129521 | 12 | 120 | 230 | 10.400039 | |
| 14 | 0 | 10 | 140 | 140 | 2.624997 | 11 | 154 | 154 | 12.873702 |
| 8 | 9 | 126 | 190 | 2.286199 | 9 | 126 | 190 | 10.665583 | |
| 14 | 8 | 112 | 210 | 2.070850 | 8 | 112 | 210 | 9.731642 | |
Table 4.
Performance data of D3 and D4.
| Tstep = s | D3 ( for No-Restarting) | D4 ( for No-Restarting) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| m | l | k | Spsolve | dim() | Time/s | k | Spsolve | dim() | Time/s |
| 6 | 0 | 27 | 162 | 162 | 111.346346 | 32 | 192 | 192 | 127.529831 |
| 2 | 20 | 120 | 158 | 84.746398 | 21 | 126 | 166 | 88.770843 | |
| 6 | 13 | 78 | 150 | 52.377661 | 15 | 90 | 174 | 59.138819 | |
| 10 | 0 | 12 | 120 | 120 | 80.759488 | 12 | 120 | 120 | 78.327367 |
| 5 | 8 | 80 | 115 | 58.257768 | 9 | 90 | 130 | 62.386851 | |
| 10 | 7 | 70 | 130 | 49.326665 | 8 | 80 | 150 | 55.504061 | |
| 14 | 0 | 6 | 84 | 84 | 59.579572 | 7 | 98 | 98 | 66.059572 |
| 8 | 5 | 70 | 102 | 49.267151 | 6 | 84 | 124 | 60.321333 | |
| 14 | 5 | 70 | 126 | 49.801739 | 6 | 84 | 154 | 60.574075 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhang, M.; Li, J.; Yang, C.; Chen, Q. Deflated Restarting of Exponential Integrator Method with an Implicit Regularization for Efficient Transient Circuit Simulation. Electronics 2021, 10, 1124. https://doi.org/10.3390/electronics10091124
AMA Style
Zhang M, Li J, Yang C, Chen Q. Deflated Restarting of Exponential Integrator Method with an Implicit Regularization for Efficient Transient Circuit Simulation. Electronics. 2021; 10(9):1124. https://doi.org/10.3390/electronics10091124
Chicago/Turabian StyleZhang, Meng, Jiaxin Li, Chengcheng Yang, and Quan Chen. 2021. "Deflated Restarting of Exponential Integrator Method with an Implicit Regularization for Efficient Transient Circuit Simulation" Electronics 10, no. 9: 1124. https://doi.org/10.3390/electronics10091124
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.