
Abstract
In view of the problem that the traditional learning service recommendation does not fully consider the distinct differences between individuals, it is easy to lead to the contradiction between unchanging learning resources and learners’ personalized learning needs that are constantly improving, so an adaptive learning service recommendation improvement algorithm based on big data is proposed. Idea is based on adaptive learning platform and function modules. We consider the individual differences between students, to students as the center, collect students’ personalized learning demand data, and according to the data information to build student demand model. On the basis of using data mining methods for clustering recommendation service resources in learning, the adaptive recommend according to students’ individual need is proposed. The experimental results show that the adaptive learning service recommendation algorithm based on big data has high recommendation accuracy, coverage rate and recall rate, which is of great significance in the actual learning service recommendation.
Similar content being viewed by others


1 Introduction
Service recommendation is an important information filtering mechanism, which can effectively solve the problem of information overload [1]. Through obtaining, integrating the student users in the study, social networking, communication, query and so on all have a track record. In the analysis of the student user’s needs and follow up the change of user requirements, recommend algorithm can automatically adjust the way and content of information service, and timely and actively recommend meet the needs of the user study differentiation. At the same time, the efficient resource positioning ability of the recommendation algorithm can accelerate the process of knowledge discovery and dissemination, and promote the construction and development of social informatization. In order to truly realize student-centered education, it is necessary to realize personalization in learning content and content presentation, and provide personalized services corresponding to their own abilities for students with different knowledge bases and cognitive styles [2, 3]. How to deeply integrate information technology with education is of great significance for promoting future educational reform. Through the construction of adaptive learning service recommendation model, we can give the answer of how effective learners’ online learning is. For example, whether digital learning resources can shorten students’ learning time, solve the contradiction between “cognitive overload” and “insufficient learning resources”, and increase learners’ interest in learning so as to improve their academic performance [4, 5]. As an important part of intelligent teaching, adaptive learning recommendation research has become the focus of many researchers and many excellent results have appeared.
Li et al. [6] proposed a personalized learning resource recommendation method (TPLRM) based on collaborative control of three-dimensional features. Firstly, by improving the matching relationship between learners and online learning resources, a personalized learning resources recommendation model based on collaborative control of three-dimensional characteristics was established and described parametrically. Secondly, a binary particle swarm optimization (FCBPSO) algorithm based on fuzzy control of Gaussian membership function was designed to solve the objective function of the recommendation model. Based on the user’s historical resource click rate information, Jiang et al. [7] constructed the directed graph model of user’s resource click data, and transformed the directed graph model into matrix model storage. By solving the matrix model similarity, the user similarity could be obtained, which greatly reduced the complexity of solving the resource click frequency and resource click path user similarity, and improved efficiency and accuracy of solving user similarity. Combined with Leader Clustering algorithm and rough set theory, user clustering and user personalized resource recommendation were carried out. Mu et al. [8] proposed estimating individualized optimal combination therapies through outcome weighted deep learning algorithms, with the advancement in drug development, multiple treatments are available for a single disease. Patients can often benefit from taking multiple treatments simultaneously. For example, patients in Clinical Practice Research Datalink (CPRD) with chronic diseases such as type 2 diabetes can receive multiple treatments simultaneously. Therefore, it is important to estimate what combination therapy from which patients can benefit the most. However, to recommend the best treatment combination is not a single-label but a multi-label classification problem. In this paper, we propose a novel outcome weighted deep learning algorithm to estimate individualized optimal combination therapy. The fisher consistency of the proposed loss function under certain conditions is also provided. In addition, we extend our method to a family of loss functions, which allows adaptive changes based on treatment interactions. The article demonstrate the performance of our methods through simulations and real data analysis. Based on Android platform, Yan Lei et al. [9] studied big data mining technology of mobile learning system. Through the expectation maximization EM algorithm for user clustering, the personalized resource recommendation model of mobile learning system was used for selection and scoring prediction of near neighbor users. According to the time series data of resources downloaded by learners, the CRISP-DM model was used to establish the ARTXP algorithm mining model. Through the English courseware, legal courseware, computer courseware download prediction in 7 days, it showed that the demand for mobile learning resources in English class had declined, and the demand for legal and computer courseware had increased. Similarly, the demand for other types of learning resources in mobile learning system could be predicted, and corresponding mobile learning resources could be made and uploaded according to the change of demand. Intayoad et al. [10] propose a social context-software recommendation for personalized online learning. By considering the learners’ personal characteristics, learning style, knowledge background and other relevant information, the article can provide personalized learning for learners. From the perspective of context-aware computing, a context-aware recommendation system is proposed to promote each learner’s effective personalized online learning. The collected social contexts are classified by K-nearest neighbors and decision trees, and the appropriate learner types are classified. Taking the learners with scientific and non-scientific backgrounds as the research objects, the empirical research is carried out in two different content modules of computer basic skills curriculum. The results show that the proposed personalized context-aware recommendation system can provide acceptable classification accuracy to both classifiers. In addition, the system can also recommend suitable learning paths for different groups of learners. Simko et al. [11] proposed lightweight domain modeling recommendations for adaptive web-based education systems, Support for adaptive learning with respect to increased interaction and collaboration over the educational content in state-of-the-art models of web-based educational systems is limited. Explicit formalization of such models is necessary to facilitate extendibility, reusability and interoperability. Domain models are the most fundamental parts of adaptive web-based educational systems providing a basis for majority of other functional components such as content recommenders or collaboration widgets and tools. The article introduce a collaboration-aware lightweight domain modeling for adaptive web-based learning, which provides a suitable representation for learning resources and metadata involved in educational processes beyond individual learning. It introduces the concept of user annotations to the domain model, which enrich educational materials and facilitate collaboration. Lightweight domain modeling is beneficial from the perspective of automated course semantics creation, while providing support towards automated semantic description of learner-generated content. The article shows that the proposed model can be effectively utilized for intelligent processing of learning resources such as recommendation and can form a basis for interaction and collaboration supporting components of adaptive systems. The article provide the experimental evidence on successful utilization of lightweight domain model in adaptive educational platform ALEF over the period of five years involving more than 1000 real-world students. Liu et al. [12] proposed research on mixed recommendation method of learning resources based on bipartite network. Information recommendation technology has been introduced into online learning, so as to provide learners with personalized learning services. In recent years, the collaborative filtering recommendation method has received wide attention and achieved satisfactory results in practical application. However, by using this method, the range of recommendations is limited and niche resources are ignored, which cannot meet learners’ individual needs. Therefore, this paper introduces the theory of heat conduction and material diffusion in physics into recommendation system, and establishes a mixed recommendation model of learning resources based on bipartite network. The model will use recommendation methods based on both heat conduction and material diffusion, and the two methods can play different roles in different application scenarios according to an adjustable parameter. This model provides an important reference for further research on resource recommendation of personalized learning. Lv et al. [13] proposed next-generation big data analytics: state of the art, challenges, and future research topics, review recent research in data types, storage models, privacy, data security, analysis methods, and applications related to network big data. Finally, we summarize the challenges and development of big data to predict current and future trends. Yang et al. [14] proposed multimedia recommendation and transmission system based on cloud platform, which is a novel application of big data analytics in multimedia recommendation. The benefits of mobile cloud computing are fully explored. The security and privacy of multimedia are integrated into the recommendation system. Sun et al. [15] proposed internet of things and big data analytics for smart and connected communities. This paper promotes the concept of smart and connected communities SCC, which is evolving from the concept of smart cities. SCC are envisioned to address synergistically the needs of remembering the past (preservation and revitalization), the needs of living in the present (livability), and the needs of planning for the future (attainability).
In order to further enhance the adaptive learning services recommendation accuracy and reliability of adaptive learning algorithm based on big data, service recommendation algorithm based on adaptive learning platform and its each function module, take the student as the center, take into account the individual differences between students, for timely and accurate recommend personalized learning resource for students, for students’ personalized learning requirements for data collection, statistics, and based on the data information of students student model is set up. On the basis of the student model, the main task of defining personalized learning path recommendation module is to calculate the learning path and form an adaptive recommendation list. The results show that the algorithm has higher recommendation accuracy, recall rate and coverage rate, and higher satisfaction with the learning effect.
2 Adaptive learning service recommendation based on big data
2.1 Adaptive learning platform
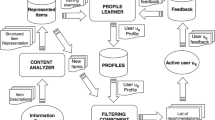
In order to adapt to the characteristics and needs of adaptive learning service recommendation, user roles should include learners and course teachers (and administrators). Based on this, the recommendation algorithm constructed in this paper is mainly divided into two modules: course learning and course management. Among them, course learning is the core module of the system. After a series of work, such as user modeling, personalized content recommendation and content preprocessing, learners need to carry out personalized learning on the basis of learning tools and system related service components; while course teachers or administrators can carry out user model, learning records, course content, teaching strategies, learning resources, etc. Through various course management function components provided by the system unified setting management is proposed. The overall architecture of adaptive learning service recommendation is shown in Fig. 1.

Overall architecture of adaptive learning service recommendation.
The operation mechanism of adaptive learning service recommendation includes five steps.
In the first step, when learners enter the system for the first time, they need to fill in the basic personal information to complete the registration. Then, under the guidance of the system guide, learners can set their own learning style, or alternatively complete a questionnaire to test learners’ learning style, namely, learning style scale. Then, the information is processed and stored in the user model database through the learner modeling component.
Secondly, in the learning process, the system recorder captures the sequence, content, access time and other information of the user’s access page in real time, and updates the user’s learning record database at any time.
In the third step, according to the learning objectives and curriculum structure, the curriculum teachers define the knowledge meta object structure, teaching strategies, learning resources and so on through management components, and establish the domain knowledge model, and store these information in the database to provide data support for the subsequent system recommendation service.
In the fourth step, according to the current learning state of learners, the knowledge meta objects and fragmented learning resources are dynamically matched by extracting model features and their association rules to form learning content fragment sequences. Then these fragment sequences are reorganized by content preprocessing components, and then personalized learning is provided for learners with the support of learning tools and system related service components.
In the fifth step, learners need to complete the test questions are presented to the system dynamically after learning each knowledge unit. Then, the system will analyze and process the learner evaluation score through the learner modeling component, and update the user model database in time, so as to provide reference for further personalized recommendation service.
The adaptive learning platform mainly consists of four modules: learner’s feature information (student model), learning data and analysis results, learning resource recommendation (visual presentation), learning content resources. Different modules have different functions and interrelations. The general process is shown in Fig. 2.

Structure of adaptive learning platform
As shown in Fig. 2, the main function of the platform is to provide personalized learning resource recommendation for students. The platform can improve the learning efficiency of students to a greater extent by obtaining the data information of students’ learning behavior, including personal information and the learning level of relevant knowledge. Based on the analysis of students’ personal information and learning level, personalized learning resources are pushed to improve students’ learning efficiency to a greater extent. The function module of the platform is shown in Fig. 3.

Function module of adaptive learning platform
2.2 The construction of student demand model
The core of the algorithm is “student-centered”, and there are individual differences among different students. In order to provide individualized learning resources in time and accurately, the data of individualized learning needs of students are collected and the model of student needs is constructed according to the data information of students, as shown in Table 1.
-
(1)
Explicit data collection:
The student model mainly includes three categories: basic information, cognitive level and learning data. There are two ways to acquire information of students’ data in adaptive learning system: display acquisition and implicit acquisition. Display acquisition is data information that students directly provide to the system. For example, students can directly enter basic personal information into the system through registration, including name, gender, birth date, grade, etc. The student information obtained in this way is more accurate and can be directly stored in the user model [16].
-
(2)
Implicit data collection:
The implicit data collection of the adaptive learning is obtained through statistical analysis of the system in a certain way. Cognitive level is to analyze and get the knowledge cognitive level of students’ users through evaluation. The evaluation is mainly to judge the degree of knowledge mastery of students. The diagnosis of students is carried out through the way of test. Through the analysis of test results, the overall evaluation of students’ learning status is obtained. The adaptive learning has two parts: pre-test and post-test. The pre-test is the test of students’ cognitive level of knowledge content before they fail to pass the system learning. The result of pre-test is an important basis for the adaptive learning system to provide learning resources for students. Post-test is to judge the knowledge level of students after the learning process of learning system, in order to test whether the learning level has a certain improvement.
Study data is the statistics of the students’ knowledge system related to learning resources and learning the information such as history, study history record store the history learners learning process and related resources, students to learn the history of learning resources such as data, using big data to construct user sets, more efficient personalized learning resources recommended for students planning to provide large data statistical analysis [17, 18].
-
(3)
Personalized model construction:
The premise of students’ personalized learning resources recommendation is to build a perfect personalized model, to understand students’ learning level in detail, and to clearly judge the range of knowledge points that students master or do not master. Therefore, first of all, we need to objectively evaluate the cognitive level of students’ different knowledge points. The evaluation method of the adaptive learning system adopts the form of l + n, that is to say, a test question contains multiple modules of knowledge points, and it analyzes the whole evaluation as well as each module of knowledge points.
In order to adapt to the cognitive level of different learners, the pre-test questions are set as three types of easy, medium and difficult. Students need to pass three different tests to improve the statistics of cognitive level of individual knowledge points. Each time, the system randomly selects the corresponding proportion of test questions according to the difficulty of selecting test questions, and automatically scores the answers. The test results will be recorded in personal information through the system, and stored in the personal data model in the form of vectors according to the scores, to generate the evaluation vectors of knowledge points as the basis for personalized recommendation [19, 20].
By establishing a matrix to represent relations between the test exercises and the knowledge points, the students’ answers are true reflection of the students’ knowledge points [21, 22]. In the previous test paper, for example, the set of knowledge points K = {K1, ⋯, Kn} and the set of test questions T = {T1, ⋯, Tn} form a matrix of test questions-knowledge points. The row represents the order of test questions in the test, and the column represents the different knowledge points investigated. If Ut, k is 1, it means the knowledge point Kn is investigated, and 0 means no investigation. The pre-test questions-knowledge point matrix (U1) of a pretest is established in Table 2.
In Table 2, K1, K2, K3, K4 and K5 respectively represent the number of knowledge point in the matrix, and T1, T2, T3, T4 and T5 respectively represent the number of test sets. The above parameters jointly constitute an examination-knowledge point matrix. The data of students’ evaluation of the project are collected, and the evaluation matrix Rm × n based on the student-test project is established. Supposing that the student set is S = {S1, ⋯, Sn}, for the recommendation system with m students and n test items, the test results of students are taken as the evaluation criteria. The data score of students is expressed by m × n matrix, and the score matrix R = [rm, n]M × N can be obtained. In which rm, n represents the score given by the m student to the n-th item. When rm, n is 1, it means the student answers the question correctly, and when rm, n is 0, it means the answer is wrong. The scoring matrix of students’ test questions is shown in Table 3.
In Table 3, S1, S2 and S3 respectively represent the number of students respectively, and the number of test sets constitute the student question marking matrix. It can be seen from Table 3 that if question 1, question 2 and question 3 of S1 are 1, then the answer is correct, it can be understood that the student S1 has mastered the knowledge content investigated by question 1, question 2 and question 3. It is helpful for the adaptive learning recommendation algorithm to be more accurate to collect students’ scoring data on projects and establish a scoring matrix based on student-test items. In order to obtain students’ different cognitive level of knowledge points, the paper combines the test question-knowledge point matrix and the score matrix of students’ test questions for modeling analysis. For each student’s mastery of knowledge points, student characteristic V is established and V(m, n) represents the score value of knowledge point n in the m-th student of test question A, as shown in Table 4.
The formula of the matrix of students’ characteristic ability is:
where, W represents capability matrix of knowledge points, V(m, n) represents the inspection value of each knowledge point, and Iv represents the total amount of knowledge points to be inspected. The greater the total numbers of knowledge points mastered by students, the stronger the ability, while the smaller the number, the weaker the ability of some knowledge points. Table 5 shows the establishment of the score matrix of students’ knowledge points.
In order to better approach the students’ learning situation, three pre-test papers with different difficulty are set up. Through these three levels of papers, students’ mastery of knowledge points corresponding to each level of learning ability is obtained. Test paper A, test paper B and test paper C are divided into simple degree, medium degree and more difficult degree. The purpose of dividing the test paper into different difficulty levels is to make a more detailed judgment on students’ learning level. After the test and the above series of data statistics, the scores of each knowledge point of the student’s Pre-Test A can be obtained. After the students pass the test of question B and question C with different difficulty levels, the complete knowledge comment diversity of the student can be obtained [23, 24]. Supposing that pretest paper A contains X knowledge points, and the knowledge point set of test paper A is X = {x1, x2, ⋯}; pretest paper B contains Y knowledge points, and the knowledge point set of test paper B is Y = {y1, y2, ⋯}. Pretest paper C contains Z knowledge points, and the set of knowledge points is Z = {z1, z2, ⋯}. Then, the set of knowledge reviews in the pretest paper of this group is WJ = X + Y + Z, so the student’s knowledge reviews will be stored in i = (test _ id, Knowledge point i, Scoring rate i) with the vector of (X + Y + Z) dimensions, providing the data base for the analysis of personalized recommendation in the later stage.
It can be seen from Fig. 4 that the test-knowledge point matrix table, student test score matrix, student feature matrix and student knowledge point ability score matrix are equally important in the adaptive learning service recommendation. On the basis of building the student demand model, this paper analyzes the recommendation model of learning service resources based on big data.

The proportion of each matrix in the adaptive learning service recommendation list
2.3 Big data-based recommendation model for learning services
In personalized learning, the system needs to have a deep understanding of the personality needs of different students, which is very important for the evaluation of students’ knowledge level, and will directly affect the recommendation of final resources [25]. This paper proposes an adaptive learning service recommendation model based on big data mining. On the basis of building the student demand model above, personalized recommendation of learning services can be automatically realized according to the access process of learners, and learners are provided with interested learning services without intervention. Firstly, a fuzzy clustering algorithm based on transitive closure is used to cluster the learning service resources, and weighted association rules are used to mine the trusted association rules among learning service resources.
The recommendation model of adaptive learning service resources based on big data mining is shown in Fig. 5.

Learning Service Recommendation Model Based on Big Data Mining
2.3.1 Recommended values in clustering methods
First, we need to compute the weights of resource clustering for the current user session. The learning service resources accessed by the current user session may not belong to the same resource category, so it is necessary to count the proportion of learning service resources belonging to different resource categories in the current user session as weights. The percentage of the current user session S accessing the Learning Resource i belongs to the resource cluster:
where, Ai is the number of learning resources in the cluster to which i belongs, and Zi is the total number of accessed learning resources. Then the recommendation value of learning resources in clustering algorithm is calculated.
In the formula, SM represents the similarity matrix obtained from the fuzzy clustering of transitive closure.
2.3.2 Similarity measure of current user session and weighted association rule
In order to facilitate representation, each weighted association rule is set as the representation of resource weight pair in this paper, which is recorded as: r = ⟨(p1, p2, …, pk), (qk + 1, qk + 2, qk + t), (w1, w2, …wk + t), δ, α⟩ ∈ R, so active sessions and association rules are regarded as m-dimensional vectors. Therefore, given a weighted association rule, the preceding item rL of the association rule can be expressed as a vector: rL = {w1, w2, …wi}, where,
The current user session is represented as vector S = {s1, s2, …si}. If the current user session has visited learning resource pi, si takes the relevant weight, otherwise, si = 0.
The matching score of the association rule with the current user session is then calculated. The degree of fit is defined as:
In formula (5) and formula (6),Diss(S, sL) represents the matching degree of association rule and recommendation algorithm, Mat(S, sL) represents the matching degree of current session and recommendation algorithm,S represents the currently active user session and SL represents the precursor of the weighted association rule,w(si) represents the adaptive value of association rules, and w(rLi) represents matching value of association rules. Understanding of the formula: Diss(S, sL) is the difference assessment and has been proved in different experiments, in order for Mat(S, sL) value to be between 0 and 1. It must be normalized (divided by the maximum difference value, with 1 to subtract). If the value of Match Score is 1, then it is a perfect match between the active user and the rule. The similarity measure depends on the size of the precursor of the association rule, and the association rule may have several items in the following part of the precursor, but because the prediction problem is independent in nature, and the user will only choose one from the recommended learning resources, we only use the association rule with a single item in the latter.
2.3.3 Calculation of recommended values
An online learning resources personalized recommendation system is designed to recommend users to visit the resources, each learning resource pi has a corresponding recommendation value. There are three factors that determine the recommended value: the proportion of learning resources in each resource category in the current active user session, and the matching degree of the current active user session and weighted association rule and the weighted confidence of this rule. Given a weighted association rule and active session S, the recommended value of the active echo is:
Finally, the top n learning resources with the highest recommendation values are recommended to users. Compared with the traditional methods, which require the exact matching of the active user session and the association rules’ precursors and the single confidence degree as the recommendation standard, our improved method uses similarity of the current session and association rules and the weighted confidence degree of association rules as the parameters to determine the recommendation value, which avoids the problem that the active user session and association rules can not match exactly and leads to no recommended results, and enhances the reliability and applicability of results.
3 Experiment and discussion
In order to improve the use of distance learning platform and the utilization of learning resources, combined with the characteristics of the platform and the user model proposed above, the suitability and efficiency of each recommendation method were comprehensively considered. Finally, the adaptive learning service recommendation algorithm based on big data is adopted to meet the personalized learning needs of distance learners. In order to test the effectiveness and feasibility of the proposed algorithm, experiments are designed.
Training dataset
The input part of learning resource recommendation algorithm is used to get learning resource clustering and weighted association rules. Test data set in the input part of WRTC algorithm, resource clustering and association rules formed by training dataset are used to generate corresponding recommendation resources, and the coverage and accuracy are calculated.
The evaluation experiment is divided into two parts, the first part is the training of resource clustering and association rules, the second part is the evaluation test of recommended results.
The pros and cons of the recommended algorithms are usually measured by precision and coverage. Recommendation accuracy refers to the proportion of correct recommendations in the total recommendation. Correct recommendations are the learning resources that are later accessed by learners in user sessions. By comparing this method with literature [6,7,8,9,10], the experiment was carried out under the MATLAB environment. The running system is Windows 8. The software and hardware environment during the experiment is shown in Table 6.
This experiment uses WS-DREAM data set collected and published by Zheng et al. [26], which is collected by 150 computer nodes in more than 20 countries, and constitutes about 1.5 million call records.
Training dataset
The input part of learning resource recommendation algorithm is used to get learning resource clustering and weighted association rules.
Table 7 shows some of service instance information for this dataset. IP address is the unique address of some data set information on each computer and other devices. It is the number that computer nodes use to collect information.
The advantages and disadvantages of recommendation algorithms are usually measured by accuracy, recall and coverage. Accuracy refers to the proportion of correct recommendation in the total recommendation. The so-called correct recommendation refers to the learning resources accessed by learners in the user session. Recall rate is the ratio of the number of recommended documents to results of retrieval of documents in the document library. Coverage is not only an important indicator to test completion of recommendation algorithm, but also a measure of test usability. Based on user testing, it determines coverage according to the number of users covered in recommendation evaluation process compared with remaining users, calculates the algorithm coverage, and distinguishes whether the algorithm is effective. If there are no errors or unexpected test results, the coverage is perfect.
3.1 Accuracy
R(p) refers to the resource set recommended by the system to the user when accessing resource p, and T(p) refers to all resource sets accessed by the user after resource p in this session. The calculation formula of recommended accuracy Pre is as follows:
The recommendation accuracy of different adaptive learning services is shown in Fig. 6.

Comparison results of accuracy of different methods
As can be seen from Fig. 6, accuracy of the method in this paper is higher than that of the method in literature [6,7,8,9,10]. On the basis of network learning behavior analysis, the adaptive learning service recommendation algorithm based on big data fully respects learning style and learning level of learning users, and makes use of multiple algorithms such as artificial neural network and ant colony probability recommendation to carry out personalized learning path recommendation for users.
3.2 Recall rate
Recall rate, is the ratio of the number of recommended documents to the total number of recommended documents in the document library. The recall rate is evaluated from the perspective of recall rate. The specific formula is as follows:
In the formula, A(α) represents the recall quantity of student α in the recommendation list, B(α) represents the recall quantity of the object set finally selected by student α in test results. Using the above formula, the recall rates of different methods are calculated. The results of the data comparison between different methods and recall files are shown in Table 8.
Table 8 shows that in this example experiment, suppose that there are to join the database of 1000 documents, including the method with 388 documents conform to the definition, system recommendations to the 238 documents, there are 226 meets the requirements, the recall rate was 94.9%, and the method of literature [6,7,8,9,10] the recall rate is respectively 91.7%, 89.5%, 91.6%, 89.8% and 90.5%, illustrate that the method recall rate is high and the retrieval system is effective.
3.3 Coverage
Recommendation coverage refers to the proportion of the number of resources recommended by the system to users in the total number of resources accessed after the current user session. Coverage is an important indicator of the completion of the test algorithm, but also a measure of the usability of the test. Based on the user’s test, it determines the coverage size according to the number of users covered in the evaluation process compared with the remaining users, and calculates whether the algorithm coverage resolution algorithm is effective. If there is no error or unexpected test results, it indicates that the coverage is good. The calculation formula is as follows:
where, R(p) is the recommendation list of adaptive learning services, and T(p) is the recommendation collection of adaptive learning services. Using the above formula to calculate the coverage of different methods, and the comparison results are as shown in Fig. 7.

Comparison of coverage of Learning Service Resource Recommendation
As can be seen from Fig. 7, the coverage rate of the method in this paper is better than that in literature [6,7,8,9,10]. In the absence of errors and exceptions, the coverage rate of the recommended algorithm in this paper is the closest to the ideal state after comparison, indicating smooth and complete coverage. This is because the method in this paper constructs the recommendation model of service resources in the process of adaptive learning service recommendation, and automatically realizes the personalized recommendation of learning service according to the access process of learners, without the need for learners’ intervention, which helps to improve the recommendation coverage rate of learning service to some extent.
In the process of ant colony recommendation, the evaluation information of learning path, the sign-in information of learning users and the representation information of learning materials are fully used to evaluate the students’ knowledge construction and learning ability, which makes the generation of learning path more accurate and personalized, makes up for individual differences, thus improves the learning efficiency and learning quality, and meets the needs of recommendation accuracy and recall of adaptive learning services.
4 Conclusions
Due to the continuous increase of massive learning service data, it is more and more difficult for students to extract the information they need from the huge amount of information. Therefore, an adaptive learning service recommendation algorithm based on big data is proposed, and the proposed algorithm is verified through experiments. The results show that:
-
(1)
The algorithm has higher accuracy, coverage rate and recall rate than the literature method, and has strong reliability.
-
(2)
Through the construction of adaptive learning service recommendation model, the paper gives the answer of how effective learners’ online learning is. The deep integration of information technology and education is of great significance to promote the future educational reform.
-
(3)
Above in personalized recommendation algorithm is adopted in the process of collaborative filtering recommendation, in future studies, to consider in the algorithm to join the students’ interest, hobby and other additional factors such as parameters, accurately and efficiently extract the keywords from the adaptive learning services recommendation algorithm, according to the keywords can be found suitable for student’s study way.
References
Nadal S, Romero O, Abelló A (2019) An integration-oriented ontology to govern evolution in Big Data ecosystems. Inf Syst 79(7):3–19
Shuai L, Xinyu L, Shuai W, Khan M (2020) Fuzzy-aided solution for out-of-view challenge in visual tracking under IoT assisted complex environment, Neural Computing & Applications, online first, https://doi.org/10.1007/s00521-020-05021-3
Peralta M, Alarcon R, Pichara KE (2018) Understanding Learning Resources Metadata for Primary and Secondary Education. IEEE Trans Learn Technol 11(4):456–467
Verma P, Sood SK, Kalra S (2017) Student career path recommendation in engineering stream based on three-dimensional model. Comput appl eng educ 25(4):578–593
Aloysius JA, Hoehle H, Goodarzi S (2018) Big data initiatives in retail environments: linking service process perceptions to shopping outcomes. Annals operations res 270(2):125–131
Li HJ, Zhang Z, Zhang PW (2019) Personalized Learning Resource Recommendation Method Based on Three-dimensional Feature Cooperative Domination [J]. Comput Sci 46(1):461–467
Jiang Y, Zhang DF, Diao ZL (2018) Similarity Personalized Recommendation of User Matrix Model Based on Click Stream. Comput Eng 44(1):219–225
Muxuan L, Ting Y, Haoda F (2018) Estimating individualized optimal combination therapies through outcome weighted deep learning algorithms. Stat Med 12(5):56–62
Yan L, Qi B (2017) Research on big data mining technology of mobile learning system based on android platform. Modern Electron Tech 40(19):142–144,149
Intayoad W, Becker T, Temdee P (2017) Social context-aware recommendation for personalized online learning. Wirel Pers Commun 97(1):1–17
Simko M, Bielikova M (2019) Lightweight domain modeling for adaptive web-based educational system. J Intell Inf Syst 52(1):165–190
Liu Z, Li H, Song W, Kong X, Li H, Zhang J (2018) Research on mixed recommendation method of learning resources based on bipartite network. E-Education Res 8(8):25–31
Lv Z, Song H, Basanta-Val P (2017) Next-generation big data analytics: state of the art, challenges, and future research topics. IEEE Trans Ind Inf 13(4):1891–1899
Yang J, Wang H, Lv Z, Wei W, Song H, Erol-Kantarci M, Kantarci B, He S (2016) Multimedia recommendation and transmission system based on cloud platform. Futur Gener Comput Syst 70(1):94–103
Sun Y, Song H, Jara AJ, Bie R (2017) Internet of Things and Big Data Analytics for Smart and Connected Communities. IEEE Access 4:766–773
Axtell MJ (2018) Revisiting criteria for plant MicroRNA annotation in the era of big data. Plant Cell 25(12):21–30
Ko J, Connor S, Jonkman L, Olufunmilola A (2019) Student Pharmacists' perspectives on service-learning experiences in free clinics. Am J Pharm Educ 83(9):121–131
Liu S, Wang S, Liu X, et al. (2020) Fuzzy Detection aided Real-time and Robust Visual Tracking under Complex Environments. IEEE Transactions on Fuzzy Systems, online published, https://doi.org/10.1109/TFUZZ.2020.3006520
Lemoine F, Domelevo Entfellner JB, Wilkinson E, Correia D, Dávila Felipe M, De Oliveira T, Gascuel O (2018) Renewing Felsenstein's phylogenetic bootstrap in the era of big data. Nature 12(12):151–159
Dameris L, Frerker H, Iler HD (2020) The Southern Illinois Well Water Quality Project: A Service-Learning Project in Environmental Chemistry. J Chem Educ 97(3):668–674
Claudia D, Matthias S (2018) NOMAD: the FAIR concept for big data-driven materials science. MRS Bull 43(09):676–682
Mcelravy L J, Matkin G, Hastings L. How Can Service-Learning Prepare Students for the Workforce? Exploring the Potential of Positive Psychological Capital[J]. J Leadership Educ, 17(1), 35–55 (2018)
Mcgowin AE, Teed R (2019) Increasing expression of civic-engagement values by students in a service-learning chemistry course. Journal of Chem Educ 96(10):2158–2166
Hardin-Ramanan S, Soupramanien L D B , Delapeyre D . Project #NuKapav: A Mauritian service-learning case study. Equality Divers Inclusion Intl J, 37(5), 23–29 (2018)
Liu S, Guo C, Fadi A, Khan M, Albuquerque VHC (2020) Reliability of response region: a novel mechanism in visual tracking by edge computing for IIoT environments. Mech Syst Signal Process 138:106537
Zheng ZB, Zhang YL, Lyu MR (2010) Distributed QoS evaluation for real-world Web services. 8th Intl Conf Web Serv 290(23):83–90
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yang, Yz., Zhong, Y. & Woźniak, M. Improvement of Adaptive Learning Service Recommendation Algorithm Based on Big Data. Mobile Netw Appl 26, 2176–2187 (2021). https://doi.org/10.1007/s11036-021-01772-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11036-021-01772-y