
Validation of Dairy Cow Bodyweight Prediction Using Traits Easily Recorded by Dairy Herd Improvement Organizations and Its Potential Improvement Using Feature Selection Algorithms

 , , , , , , ,
, , , , , , ,
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Training Data
2.2. Features Selection
2.2.1. Filter Selection
2.2.2. Wrapper Selection
2.3. Herd Independent Internal Validation
2.4. External Validation
2.5. Bodyweight Prediction from DHI Dataset
3. Results and Discussion
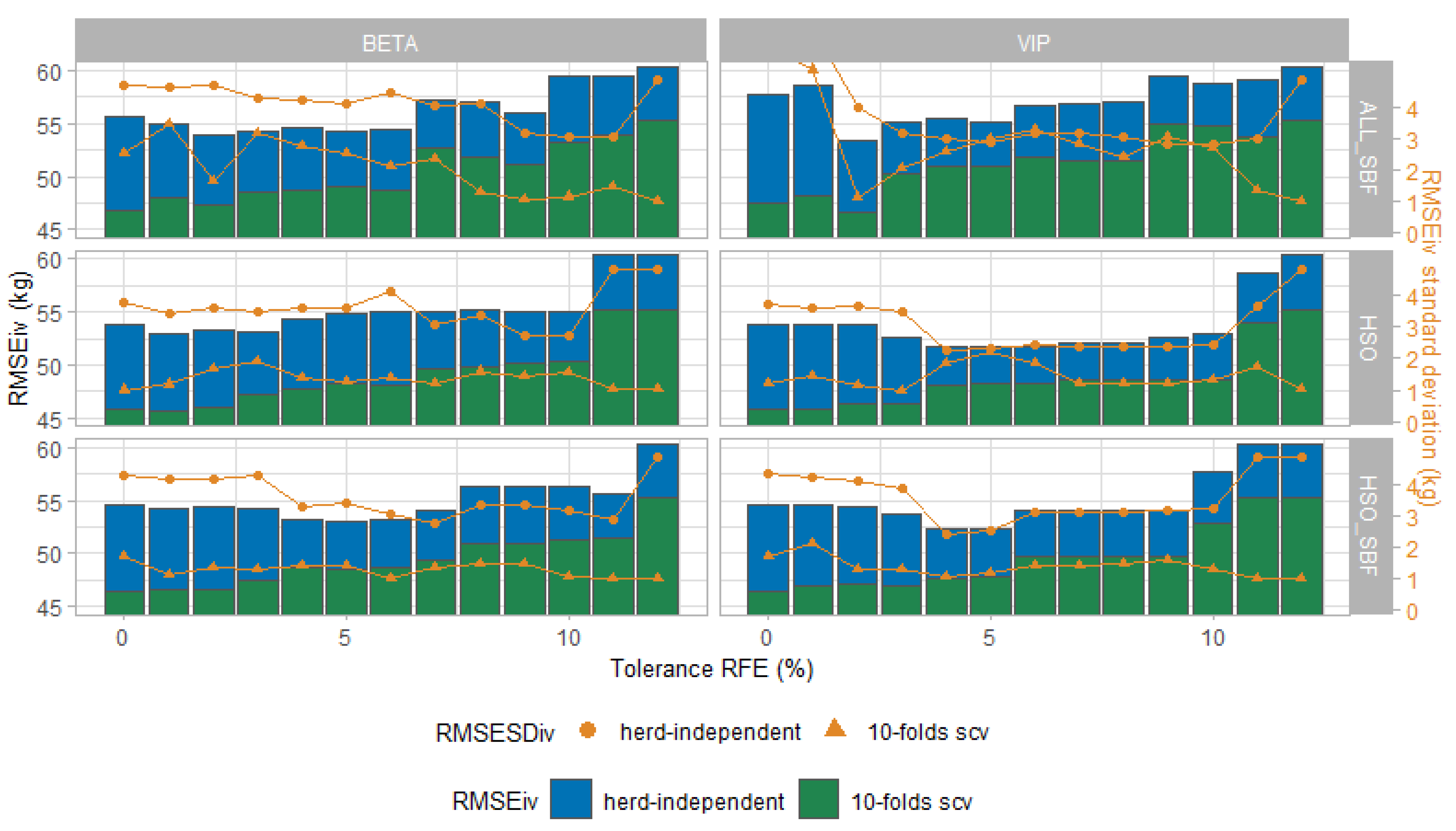
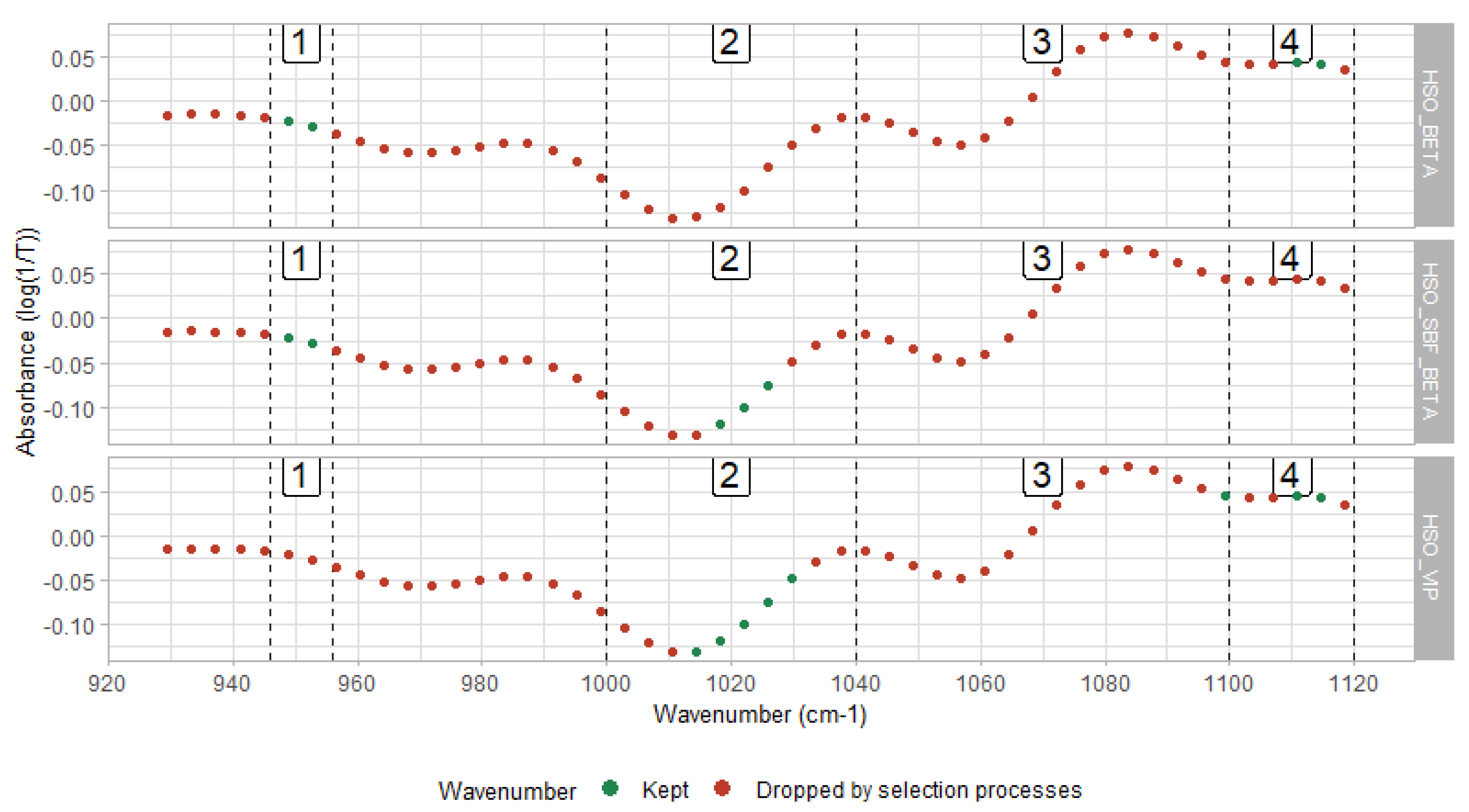
3.1. Features Selection
3.2. Herd-Independent Internal Validation
3.3. External Validation
3.4. Model Interpretation
3.5. Implementation of BW Predictive Models on DHI Database
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Thorup, V.M.; Edwards, D.; Friggens, N.C. On-farm estimation of energy balance in dairy cows using only frequent body weight measurements and body condition score. J. Dairy Sci. 2012, 95, 1784–1793. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Berry, D.P.; Lee, J.M.; Macdonald, K.A.; Stafford, K.; Matthews, L.; Roche, J.R. Associations Among Body Condition Score, Body Weight, Somatic Cell Count, and Clinical Mastitis in Seasonally Calving Dairy Cattle. J. Dairy Sci. 2007, 90, 637–648. [Google Scholar] [CrossRef]
- National Research Council. Nutrient Requirements of Dairy Cattle, 7th ed.; Natl. Acad. Press: Washington, DC, USA, 2001; p. 9825. [Google Scholar]
- Blaxter, K.L.; Clapperton, J.L. Prediction of the amount of methane produced by ruminants. Br. J. Nutr. 1965, 19, 511–522. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Herd, R.M.; Arthur, P.F.; Donoghue, K.A.; Bird, S.H.; Bird-Gardiner, T.; Hegarty, R.S. Measures of methane production and their phenotypic relationships with dry matter intake, growth, and body composition traits in beef cattle. J. Anim. Sci. 2014, 92, 5267–5274. [Google Scholar] [CrossRef] [PubMed]
- van Straten, M.; Shpigel, N.Y.; Friger, M. Associations among patterns in daily body weight, body condition scoring, and reproductive performance in high-producing dairy cows. J. Dairy Sci. 2009, 92, 4375–4385. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alawneh, J.I.; Stevenson, M.A.; Williamson, N.B.; Lopez-Villalobos, N.; Otley, T. Automatic recording of daily walkover liveweight of dairy cattle at pasture in the first 100 days in milk. J. Dairy Sci. 2011, 94, 4431–4440. [Google Scholar] [CrossRef]
- Soyeurt, H.; Froidmont, E.; Dufrasne, I.; Hailemariam, D.; Wang, Z.; Bertozzi, C.; Colinet, F.G.; Dehareng, F.; Gengler, N. Contribution of milk mid-infrared spectrum to improve the accuracy of test-day body weight predicted from stage, lactation number, month of test and milk yield. Livest. Sci. 2019, 227, 82–89. [Google Scholar] [CrossRef]
- Heinrichs, A.J.; Rogers, G.W.; Cooper, J.B. Predicting Body Weight and Wither Height in Holstein Heifers Using Body Measurements. J. Dairy Sci. 1992, 75, 3576–3581. [Google Scholar] [CrossRef]
- Heinrichs, A.J.; Heinrichs, B.S.; Jones, C.M.; Erickson, P.S.; Kalscheur, K.F.; Nennich, T.D.; Heins, B.J.; Cardoso, F.C. Short communication: Verifying Holstein heifer heart girth to body weight prediction equations. J. Dairy Sci. 2017, 100, 8451–8454. [Google Scholar] [CrossRef] [Green Version]
- Enevoldsen, C.; Kristensen, T. Estimation of Body Weight from Body Size Measurements and Body Condition Scores in Dairy Cows. J. Dairy Sci. 1997, 80, 1988–1995. [Google Scholar] [CrossRef]
- Banos, G.; Coffey, M.P. Technical note: Prediction of liveweight from linear conformation traits in dairy cattle. J. Dairy Sci. 2012, 95, 2170–2175. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haile-Mariam, M.; Gonzalez-Recio, O.; Pryce, J.E. Prediction of liveweight of cows from type traits and its relationship with production and fitness traits. J. Dairy Sci. 2014, 97, 3173–3189. [Google Scholar] [CrossRef] [PubMed]
- Vanrobays, M.-L.; Vandenplas, J.; Hammami, H.; Froidmont, E.; Gengler, N. Short communication: Novel method to predict body weight of primiparous dairy cows throughout the lactation. J. Dairy Sci. 2015, 98, 692–697. [Google Scholar] [CrossRef] [PubMed]
- Stajnko, D.; Brus, M.; Hočevar, M. Estimation of bull live weight through thermographically measured body dimensions. Comput. Electron. Agric. 2008, 61, 233–240. [Google Scholar] [CrossRef]
- Tasdemir, S.; Urkmez, A.; Inal, S. Determination of body measurements on the Holstein cows using digital image analysis and estimation of live weight with regression analysis. Comput. Electron. Agric. 2011, 76, 189–197. [Google Scholar] [CrossRef]
- Salau, J.; Haas, J.H.; Junge, W.; Thaller, G. Extrinsic calibration of a multi-Kinect camera scanning passage for measuring functional traits in dairy cows. Biosyst. Eng. 2016, 151, 409–424. [Google Scholar] [CrossRef]
- Song, X.; Bokkers, E.A.M.; van der Tol, P.P.J.; Koerkamp, P.W.G.G.; van Mourik, S. Automated body weight prediction of dairy cows using 3-dimensional vision. J. Dairy Sci. 2018, 101, 4448–4459. [Google Scholar] [CrossRef] [Green Version]
- Nadler, B.; Coifman, R.R. The prediction error in CLS and PLS: The importance of feature selection prior to multivariate calibration. J. Chemom. 2005, 19, 107–118. [Google Scholar] [CrossRef] [Green Version]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef] [Green Version]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Bjørn-Helge, M.; Wehrens, R.; Liland, K.H. Pls: Partial Least Squares and Principal Component Regression; R Package Version 2.7-2; 2019; Available online: https://CRAN.R-project.org/package=pls (accessed on 29 April 2021).
- Kuhn, M. Caret: Classification and Regression Training; R Package Version 6.0-86; 2020; Available online: https://CRAN.R-project.org/package=caret (accessed on 29 April 2021).
- Ragsdale, A.C. Growth standards for dairy cattle. Missouri Agric. Exp. Sin. Bull. 1934, 336. Available online: https://agris.fao.org/agris-search/search.do?recordID=US201300687537 (accessed on 13 July 2020).
- Matthews, C.A.; Fohrman, M.H. Beltsville Growth Standards for Holstein Cattle; U.S. Department of Agriculture: New York, NY, USA, 1954.
- Grelet, C.; Froidmont, E.; Foldager, L.; Salavati, M.; Hostens, M.; Ferris, C.P.; Ingvartsen, K.L.; Crowe, M.A.; Sorensen, M.T.; Pierna, J.F.; et al. Potential of milk mid-infrared spectra to predict nitrogen use efficiency of individual dairy cows in early lactation. J. Dairy Sci. 2020, 103. [Google Scholar] [CrossRef]
- Grelet, C.; Pierna, J.A.F.; Dardenne, P.; Baeten, V.; Dehareng, F. Standardization of milk mid-infrared spectra from a European dairy network. J. Dairy Sci. 2015, 98, 2150–2160. [Google Scholar] [CrossRef] [PubMed]
- Garrido-Varo, A.; Garcia-Olmo, J.; Fearn, T. A note on Mahalanobis and related distance measures in WinISI and The Unscrambler. J. Near. Infrared Spectrosc. 2019, 27, 253–258. [Google Scholar] [CrossRef] [Green Version]
- Delhez, P.; Ho, P.N.; Gengler, N.; Soyeurt, H.; Pryce, J.E. Diagnosing the pregnancy status of dairy cows: How useful is milk mid-infrared spectroscopy? J. Dairy Sci. 2020, 103, 3264–3274. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kuhn, M.; Johnson, K. An Introduction to Feature Selection. In Applied Predictive Modeling; Kuhn, M., Johnson, K., Eds.; Springer: New York, NY, USA, 2013; pp. 487–519. [Google Scholar]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene Selection for Cancer Classification using Support Vector Machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R. Generalized Additive Models. Stat. Sci. 1986, 1, 297–310. [Google Scholar] [CrossRef]
- Vislocky, R.L.; Fritsch, J.M. Generalized Additive Models versus Linear Regression in Generating Probabilistic MOS Forecasts of Aviation Weather Parameters. Weather Forecast. 1995, 10, 669–680. [Google Scholar] [CrossRef] [Green Version]
- John, G.H.; Kohavi, R.; Pfleger, K. Irrelevant Features and the Subset Selection Problem. In Proceedings of the Eleventh International Conference, Rutgers University, New Brunswick, NJ, USA, 10–13 July 1994; pp. 121–129. [Google Scholar] [CrossRef]
- Chong, I.-G.; Jun, C.-H. Performance of some variable selection methods when multicollinearity is present. Chemometr. Intell. Lab. Syst. 2005, 78, 103–112. [Google Scholar] [CrossRef]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence-Volume 2, Montreal, QC, Canada, 20–25 August 1995; pp. 1137–1143. [Google Scholar]
- Ho, P.N.; Marett, L.C.; Wales, W.J.; Axford, M.; Oakes, E.M.; Pryce, J.E. Predicting milk fatty acids and energy balance of dairy cows in Australia using milk mid-infrared spectroscopy. Anim. Prod. Sci. 2020, 60, 164–168. [Google Scholar] [CrossRef]
- Bastin, C.; Gengler, N.; Soyeurt, H. Phenotypic and genetic variability of production traits and milk fatty acid contents across days in milk for Walloon Holstein first-parity cows. J. Dairy Sci. 2011, 94, 4152–4163. [Google Scholar] [CrossRef] [Green Version]
- Karoui, R.; Mouazen, A.M.; Dufour, E.; Pillonel, L.; Schaller, E.; Picque, D.; De Baerdemaeker, J.; Bosset, J.O. A comparison and joint use of NIR and MIR spectroscopic methods for the determination of some parameters in European Emmental cheese. Eur. Food Res. Technol. 2006, 223, 44–50. [Google Scholar] [CrossRef]
- Soyeurt, H.; Misztal, I.; Gengler, N. Genetic variability of milk components based on mid-infrared spectral data. J. Dairy Sci. 2010, 93, 1722–1728. [Google Scholar] [CrossRef]
- Martín-del-Campo, S.T.; Picque, D.; Cosío-Ramírez, R.; Corrieu, G. Evaluation of Chemical Parameters in Soft Mold-Ripened Cheese During Ripening by Mid-Infrared Spectroscopy. J. Dairy Sci. 2007, 90, 3018–3027. [Google Scholar] [CrossRef]
- Zaalberg, R.M.; Shetty, N.; Janss, L.; Buitenhuis, A.J. Genetic analysis of Fourier transform infrared milk spectra in Danish Holstein and Danish Jersey. J. Dairy Sci. 2019, 102, 503–510. [Google Scholar] [CrossRef] [Green Version]
- Picque, D.; Lefier, D.; Grappin, R.; Corrieu, G. Monitoring of fermentation by infrared spectrometry: Alcoholic and lactic fermentations. Anal. Chim. Acta 1993, 279, 67–72. [Google Scholar] [CrossRef]
- Walsh, S.W.; Williams, E.J.; Evans, A.C.O. A review of the causes of poor fertility in high milk producing dairy cows. Anim. Reprod. Sci. 2011, 123, 127–138. [Google Scholar] [CrossRef] [PubMed]
- Dettmann, F.; Warner, D.; Buitenhuis, B.; Kargo, M.; Kjeldsen, A.M.H.; Nielsen, N.H.; Lefebvre, D.M.; Santschi, D.E. Fatty Acid Profiles from Routine Milk Recording as a Decision Tool for Body Weight Change of Dairy Cows after Calving. Animals 2020, 10, 1958. [Google Scholar] [CrossRef] [PubMed]
- Gross, J.; van Dorland, H.A.; Bruckmaier, R.M.; Schwarz, F.J. Milk fatty acid profile related to energy balance in dairy cows. J. Dairy Res. 2011, 78, 479–488. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saussez, G. Contribution à L’étude de L’efficience Énergétique des Vaches Laitières en Wallonie; Université de Liège: Liège, Belgique, 2017. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Herd | Origin | Country | Std 1 | Period Coverage | N (n) 2 | |
|---|---|---|---|---|---|---|
| Min | Max | |||||
| h01 | Walloon Breeding Association | Belgium | No | Oct-08 | Dec-08 | 32 (21) |
| h02 | Walloon Breeding Association | Belgium | No | May-07 | May-07 | 41 (41) |
| h03 | Walloon Agricultural Research Center | Belgium | No | Feb-11 | Sept-12 | 130 (29) |
| h03 | Walloon Agricultural Research Center | Belgium | Yes | Jan-15 | Oct-15 | 23 (14) |
| h04 | University of Alberta | Canada | No | Jul-14 | Dec-14 | 396 (132) |
| h05 | University of Liège | Belgium | No | May-14 | Dec-14 | 155 (47) |
| h06 | The Agri-Food and Biosciences Institute | Ireland | Yes | Sept-14 | Dec-14 | 188 (31) |
| h07 | Aarhus University | Denmark | Yes | Oct-14 | Jan-15 | 635 (18) |
| h08 | Leibniz Institute for Farm Animal Biology | Germany | Yes | May-15 | Jun-16 | 180 (12) |
| h09 | University College Dublin | Ireland | Yes | Feb-15 | May-15 | 135 (18) |
| Total | 1915 (360) 3 | |||||
| h10 | Agriculture Victoria Research | Australia | No | Oct-15 | Dec-17 | 4067 (231) |
| Variables 1 | Measure 2 | Training 3 | Validation 4 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| h01 | h02 | h03 | h04 | h05 | h06 | h07 | h08 | h09 | h10 | ||
| Total number of records | 31 | 39 | 146 | 377 | 153 | 174 | 630 | 174 | 125 | 4066 | |
| Parity | Primiparous | 4 | 14 | 32 | 127 | 46 | 45 | 213 | 12 | 0 | 963 |
| Multiparous | 27 | 25 | 114 | 250 | 107 | 129 | 417 | 162 | 125 | 3103 | |
| Bodyweight | Mean | 677 | 675 | 624 | 628 | 622 | 614 | 599 | 607 | 656 | 550 |
| s.d. | 70 | 73 | 63 | 65 | 75 | 80 | 86 | 60 | 54 | 65 | |
| Milk yield | Mean | 22 | 29 | 23 | 20 | 20 | 31 | 38 | 41 | 35 | 26 |
| s.d. | 8 | 10 | 8 | 5 | 7 | 11 | 10 | 7 | 7 | 5 | |
| DIM | Min | 53 | 15 | 5 | 3 | 1 | 5 | 4 | 5 | 6 | 37 |
| Q1 | 101 | 76 | 58 | 59 | 87 | 16 | 18 | 18.3 | 22 | 95 | |
| Median | 166 | 144 | 134 | 116 | 170 | 28 | 28 | 29.5 | 31 | 105 | |
| Q3 | 210 | 212 | 210 | 181 | 265 | 39 | 40 | 39 | 40 | 116 | |
| Max | 280 | 475 | 424 | 312 | 512 | 50 | 50 | 50 | 50 | 161 | |
| Subset 1 | Nfeat. 2 | SBF Selection | RFE Selection | ||||
|---|---|---|---|---|---|---|---|
| Subset 3 | Nfeat. 2 | Subset 4 | Nsubsets 5 | max. Nfeat. 6 | RMSESCV 7 | ||
| ALL | 800 | ALL_SBF | 379 | ALL_SBF_VIP | 251 | 282 | 47 ± 1.29 |
| ALL_SBF_BETA | 251 | 204 | 47 ± 1.37 | ||||
| HSO | 280 | HSO_SBF | 159 | HSO_SBF_VIP | 158 | 141 | 47 ± 1.40 |
| HSO_SBF_BETA | 158 | 143 | 47 ± 1.45 | ||||
| / | / | HSO_VIP | 231 | 244 | 46 ± 1.30 | ||
| HSO_BETA | 231 | 280 | 46 ± 1.40 | ||||
| Subset 1 | Nfeatures 2 | Herd Independent Internal Validation | Calibration from Entire Dataset | RMSEv 7 | |||
|---|---|---|---|---|---|---|---|
| RMSEiv 3 | RMSESCV 4 | Ncomp 5 | RMSESCV 4 | R²scv 6 | |||
| (kg) | (kg) | (kg) | (kg) | ||||
| ALL_SBF_BETA | 5 | 56 ± 3.16 | 51 ± 1.07 | 2 | 52 ± 1.64 | 0.54 | 101 |
| ALL_SBF_VIP | 62 | 53 ± 3.98 | 47 ± 1.13 | 5 | 48 ± 1.54 | 0.61 | 130 |
| HSO_BETA | 7 | 55 ± 2.71 | 50 ± 1.46 | 3 | 51 ± 1.79 | 0.56 | 56 |
| HSO_VIP | 11 | 52 ± 2.34 | 49 ± 1.22 | 3 | 50 ± 1.63 | 0.58 | 52 |
| HSO_SBF_BETA | 8 | 53 ± 3.06 | 49 ± 1.00 | 7 | 50 ± 1.51 | 0.58 | 52 |
| HSO_SBF_VIP | 20 | 52 ± 2.38 | 48 ± 1.06 | 7 | 48 ± 1.56 | 0.6 | 116 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tedde, A.; Grelet, C.; Ho, P.N.; Pryce, J.E.; Hailemariam, D.; Wang, Z.; Plastow, G.; Gengler, N.; Brostaux, Y.; Froidmont, E.; et al. Validation of Dairy Cow Bodyweight Prediction Using Traits Easily Recorded by Dairy Herd Improvement Organizations and Its Potential Improvement Using Feature Selection Algorithms. Animals 2021, 11, 1288. https://doi.org/10.3390/ani11051288
Tedde A, Grelet C, Ho PN, Pryce JE, Hailemariam D, Wang Z, Plastow G, Gengler N, Brostaux Y, Froidmont E, et al. Validation of Dairy Cow Bodyweight Prediction Using Traits Easily Recorded by Dairy Herd Improvement Organizations and Its Potential Improvement Using Feature Selection Algorithms. Animals. 2021; 11(5):1288. https://doi.org/10.3390/ani11051288
Chicago/Turabian StyleTedde, Anthony, Clément Grelet, Phuong N. Ho, Jennie E. Pryce, Dagnachew Hailemariam, Zhiquan Wang, Graham Plastow, Nicolas Gengler, Yves Brostaux, Eric Froidmont, and et al. 2021. "Validation of Dairy Cow Bodyweight Prediction Using Traits Easily Recorded by Dairy Herd Improvement Organizations and Its Potential Improvement Using Feature Selection Algorithms" Animals 11, no. 5: 1288. https://doi.org/10.3390/ani11051288