The Iterative Learning Gain That Optimizes Real-Time Torque Tracking for Ankle Exoskeletons in Human Walking Under Gait Variations
 Juanjuan Zhang1,2
Juanjuan Zhang1,2  Steven H. Collins1,3*
Steven H. Collins1,3*- 1Department of Mechanical Engineering, Carneigie Mellon University, Pittsburgh, PA, United States
- 2College of Artificial Intelligence, Nankai University, Tianjin, China
- 3Department of Mechanical Engineering, Stanford University, Stanford, CA, United States
Lower-limb exoskeletons often use torque control to manipulate energy flow and ensure human safety. The accuracy of the applied torque greatly affects how well the motion is assisted and therefore improving it is always of interest. Feed-forward iterative learning, which is similar to predictive stride-wise integral control, has proven an effective compensation to feedback control for torque tracking in exoskeletons with complicated dynamics during human walking. Although the intention of iterative learning was initially to benefit average tracking performance over multiple strides, we found that, after proper gain tuning, it can also help improve real-time torque tracking. We used theoretical analysis to predict an optimal iterative-learning gain as the inverse of the passive actuator stiffness. Walking experiments resulted in an optimum gain equal to 0.99 ± 0.38 times the predicted value, confirming our hypothesis. The results of this study provide guidance for the design of torque controllers in robotic legged locomotion systems and will help improve the performance of robots that assist gait.
1. Introduction
Being able to reduce interface impedance, increase the reactiveness of robotic systems and thus improve human safety and comfort (Haddadin et al., 2008; Lasota et al., 2014), torque control has been widely used in physical human-robot interactive systems. This is especially true in lower-limb systems, which help human bodies to locomote and were involved in high density of energy exchange. Torque control enables easy manipulation of energy flow from the robot to the human, which is one major research interest in the field of biomechanics (Veneman et al., 2007; Sawicki and Ferris, 2009; Stienen et al., 2010; Malcolm et al., 2013; Jackson and Collins, 2015). It has also been used to exploit passive system dynamics or render virtual systems with different dynamics in humanoid robots (Pratt et al., 1997), robot prostheses (Sup et al., 2009; Caputo and Collins, 2013), and exoskeletons (Kawamoto et al., 2010; Witte et al., 2015). In torque controlled human-robot interactive systems, torque tracking accuracy equals precision of the applied intervention or assistance and thus directly affects how well the assisted motion is. Therefore, improving torque control performance has always been an active interest in the field of lower-limb human-robot interactive systems.
Due to the presence of complicated, time-varying, and highly non-linear human dynamics, interaction dynamics and transmission dynamics, a fixed accurate system model was neither easy to get nor very meaningful due to the fast changes of system mechanical properties when human walk. Thus, high accuracy torque tracking of lower-limb exoskeletons was not easy to achieve. Different control methods have been introduced to improve torque tracking performances of lower-limb wearable robotic devices (van Dijk et al., 2013; Zanotto et al., 2013; Zhang et al., 2015, 2017a,b; Zhang and Collins, 2017). Among them, the combination of model-free, integration-free feedback control and iterative learning showed high accuracy and has been applied in multiple robotic legged locomotion systems (van Dijk et al., 2013; Zhang et al., 2015, 2017a,b; Zhang and Collins, 2017). This control architecture ignored the complicated and changing system dynamics caused by human-robot interactions and transmission frictions. It focused on the power transmission subsystem which was modeled as a linear spring. A P-type learning term (Arimoto et al., 1984) serves as a stride-wise integral control entity and reduces steady-state errors by exploiting the cyclic behavior of walking. Therefore, the structure is analogous to a traditional PID controller, in which tracking capability, stability and steady-state error manipulation are all managed. In this structure, iterative learning term is added due to the cyclic behavior of walking and is used in a feed-forward way, it thus has lagged response to real-time torque tracking errors. Therefore, the addition of this term in the control structure was expected to eliminate errors nominal to a stabilized gait pattern. However, walking experiments showed interactions of iterative learning gain with real-time tracking performance after stabilization of the learning process. This suggested a possibility to further improve real-time torque tracking performance in lower-limb exoskeletons.
Since the proposal of the basic iterative learning control concept in the 1980s (Arimoto et al., 1984), various techniques have been developed to optimize the learning gain. One approach was to enforce system convergence to follow some gradient of an objective function defined by the quadratic cost of tracking errors (Togai and Yamano, 1985; Moore, 1993; Fukuda and Shin, 1998), or a weighted combination of tracking errors and change in control inputs (Amann et al., 1996). Other works defined learning gains by maximizing convergence speed of control inputs (Atkeson and Mclntyre, 1986; Hać, 1990; Heinzinger et al., 1992; Saab et al., 1997). These early algorithms dealt with invariant and deterministic system dynamics. More recent work has discussed algorithms to compute optimal and sub-optimal iterative learning gains under measurement noises for time-varying linear (Saab, 2003) and non-linear systems (Saab, 2005).
These existing works mainly optimized learning gains by expediting the convergence process of learning. In addition, fairly good knowledge of the system dynamics and noise level were available. However, in the problem of exoskeleton assisted walking, there exist stride-to-stride gait variations and gait adaptation, which make walking not exactly periodical. This results in tracking errors even after stabilization of the iterative learning process. The control architecture combining feedback and iterative learning depends mainly on the feedback part to contain these errors, which might be further reduced by tuning the gain of the iterative learning part.
This paper explores the possibility of optimizing the post-stabilization real-time control performance of Arimoto's P-type learning control on lower-limb legged robots driven by series elastic actuators. Given complicated, varying and uncertain human-robot interaction, transmission friction dynamics, stride-to-stride variations of human gait, and limited knowledge of gait variation distribution, this study investigated whether and how one could maximize the real-time torque control performance. Previous studies have shown that the torque tracking performance can be achieved by a proper feedback + iterative learning structure (Zhang et al., 2015, 2017a), and optimized passive stiffness values of series elastic actuators (Zhang and Collins, 2017). On top of those, this study aims to further improve torque tracking performance of control architecture in Zhang et al. (2015, 2017a,b), and Zhang and Collins (2017) in lower-limb exoskeletons and other robotic locomotion systems. In particular, we look into the possibility of relating the optimal learning gain based on real-time tracking errors with actuator passive stiffness and desired quasi-stiffness. Results of this study are expected to follow previous work (Zhang et al., 2015, 2017a; Zhang and Collins, 2017) to further improve assisted torque assertion accuracy for lower-limb exoskeletons and prosthesis, and thus the locomotion performance of the resulting coupled human-robot systems.
2. Methods
We investigated the effects of iterative learning gain on the torque tracking performance of lower-limb exoskeletons using an ankle exoskeleton driven by a uni-directional Bowden cable.
We hypothesized an optimal value of iterative learning gain based on theoretical analysis and tested it during exoskeleton assisted walking experiments.
In testing the hypothesis, multiple desired quasi-stiffness values, i.e., torque vs. ankle angle relationships, were implemented, each tested with multiple actuator passive stiffness values. For each of the desired stiffness and passive stiffness combination, multiple iterative learning gains were tested. Every experiment session identified by a unique set of {Learning Gain, Desired Stiffness, Passive Stiffness} values required the participant to walk on the treadmill with a fixed speed for at least one hundred strides after stabilization of the iterative learning process. The existence and value of the learning gain were then investigated by comparing the torque tracking errors of different experiment sessions.
2.1. Exoskeleton System and Simplified Model
The system we investigated was a tethered ankle exoskeleton made of an off-board real-time controller and geared motor, a uni-directional Bowden cable transmission with a series spring, and an exoskeleton frame that interfaced with the human body (Figure 1).
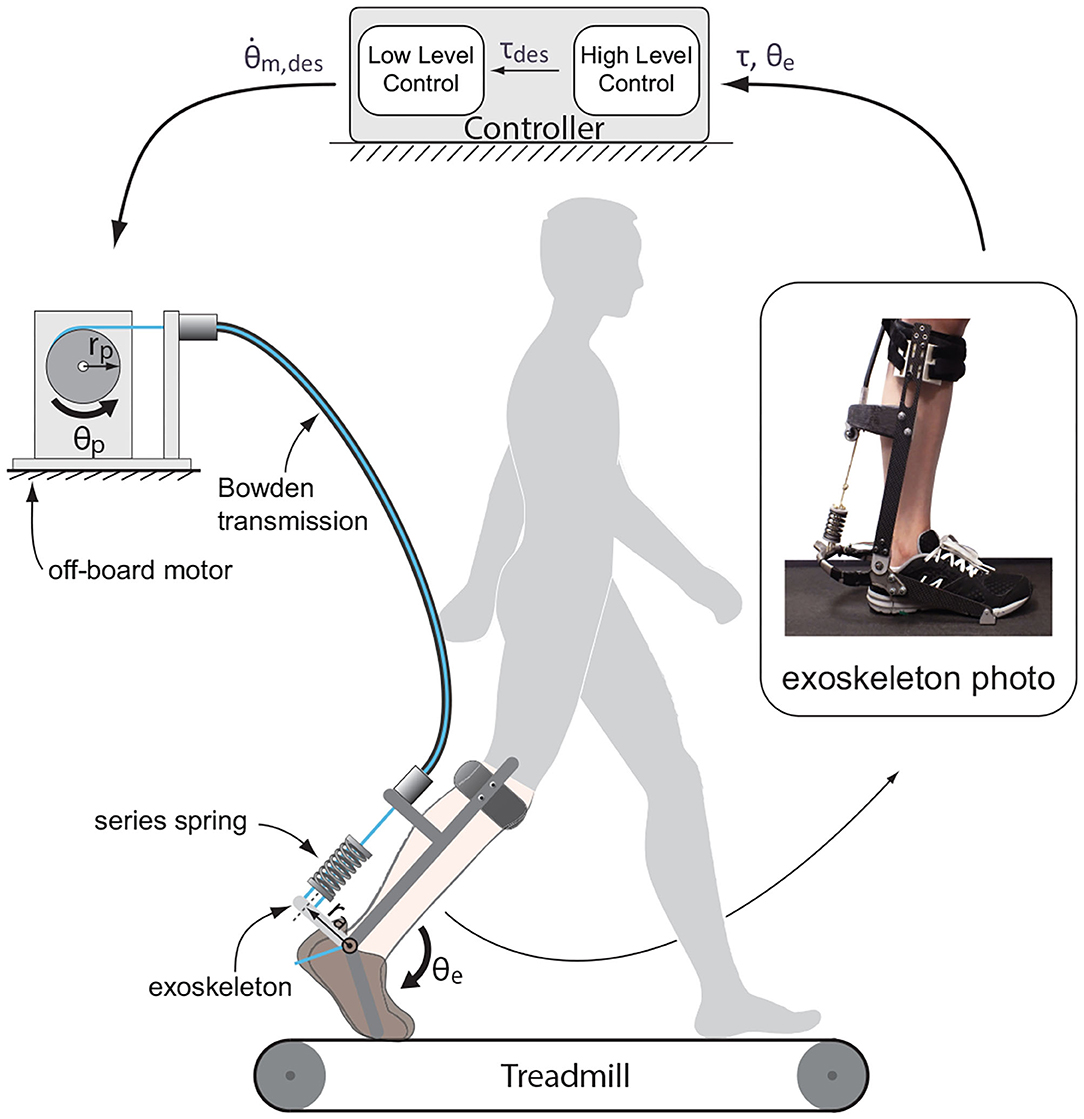
Figure 1. Tethered ankle exoskeleton system. Besides sensor data acquisition and outputting control signal to the motor, the dedicated controller has two main computational modules: a high-level controller that generates the desired torque according to ankle angle in real-time, and a low-level controller that generates control signal as desired motor velocity according to desired torque, applied torque and current motor status. Changes in motor motion status tunes the torque applied through Bowden cable transmission to the end effector, an ankle exoskeleton with series spring.
A real-time control unit (ACE1103, dSPACE Inc.) was used to sample sensory data at 5 kHz, filter them at 200 Hz, and then compute control outputs in terms of desired motor velocity. The actuation unit included a low-inertia 1.6 kW AC servo motor, a 5:1 gear, and a motor driver configured to velocity control mode (BSM90N-175AD, GBSM90-MRP120-5, and MFE460A010B, Baldor Electric Co.). A digital encoder (E4, US Digital Corp.) was used to measure motor position.
A uni-directional Bowden cable was used to transmit forces from the motor side to the exoskeleton side. The cable was made of a coiled-steel conduit (415310-00, Lexco Cable Mfg.) and a 0.003 m diameter synthetic rope. A spring (DWC-148M-12, Diamond Wire Spring Co.) of a 190 N·m·rad−1 effective stiffness (in terms of ankle position) was attached at the end of the rope to realize series elastic actuation.
The exoskeleton frame applied an plantarflflexion torque to human ankle. Torque was measured using strain gauges (MMF003129, Micro-Measurements), and amplified using a 1 kHz signal conditioner (CSG110, Futek Inc.). Ankle angle was measured using a digital encoder (E5, US Digital Corp.).
We made the following assumptions in generating a simplified model of the system for the purpose of theoretical analysis:
1. Both static and dynamic frictions in Bowden cable transmission were zero. Thus, cable tension at the motor output pulley side was always the same as the exoskeletons side. This tension was denoted as F.
2. The Bowden cable transmission and the series spring together behaved as a linear spring, i.e.,
where Kc was the combined effective stiffness of the Bowden cable and series spring; θp and θe were the pulley and exoskeleton joint positions relative to where the Bowden cable first started to go slack; rp and ra were the pulley radius and the lever arm at the ankle joint.
3. Exoskeleton joint rotated in a small range. Thus, the cable tension lever arm at exoskeleton joint side was almost constant, i.e., ra was fixed. Therefore, torque applied to human body by the exoskeleton was always
Denoting the aspect ratio of transmission as
and combining it with Equations (1) and (2), the torque applied by the exoskeleton to the human ankle was
Where Kt was the transmission stiffness which related applied torque to exoskeleton joint. It was defined as
2.2. Controllers
2.2.1. Low Level Control
Prior work in the field found that in real-time torque tracking of lower-lime exoskeletons during walking, the combination of model-free, integral-action-free feedback control and iterative learning were most effective controller with complicated and time-varying dynamics of human-robot interactive systems (Zhang et al., 2015, 2017a,b; Zhang and Collins, 2017). The overall torque tracking performance of Equation (6) is a combined effect of feedback control and iterative learning. To simplify theoretical analysis and experimental tests of the existence of the optimal learning gains, only iterative learning was used as the lower level controller in this study. The controller was expressed as:
Here i is the time index or number of control cycles elapsed within the current stride. n denotes this stride and n + 1 is the next. τ, τdes and eτ = τ − τdes are the measured exoskeleton torque, the desired torque and the torque error, respectively. Kl is the iterative learning gain. The motor run in velocity mode. The desire motor output pulley velocity was always converted to desired motor velocity before commanded. T is a constant simulating the rise time of motor position tracking and N is the gear ratio. As shown by the equation, torque error in the current stride will not affect the control input until the next stride. Therefore, iterative learning was used in a feed-forward way.
2.2.2. High Level Control: Linear Desired Quasi-Stiffness
The main high-level controller used in this study was a linear torque vs. ankle angle curve, i.e., a equilibrium-controlled stiffness as shown in Figure 2 and expressed in Equation (7).
where θe,0 denotes the maximum ankle position to apply external force and Kdes is a quasi-stiffness to be realized.
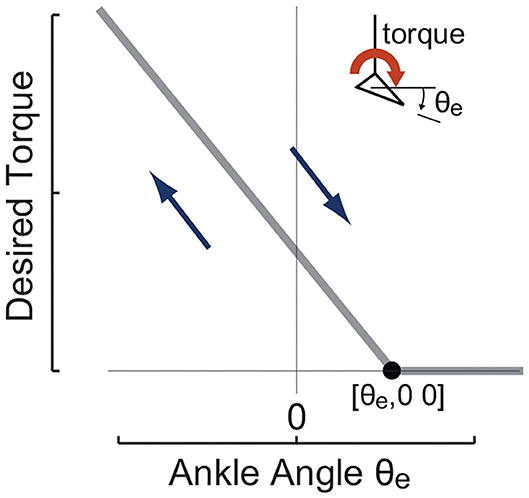
Figure 2. The ankle angle based high-level desired torque curve imposed in experiments to realize different desired quasi-stiffness profiles. It commands desired torque that is linearly proportional to exoskeleton joint angle θe defined by anchor point [θe,0 0] and desired quasi-stiffness Kdes.
2.3. Theoretical Analysis on Optimal Iterative Learning Gain
In this analysis, we assumed perfect motor position tracking, i.e.,
for any index i. θp is the measured motor pulley position and θp,des is the desired one. n denotes the nth stride and i denotes the current index counted from the latest stride start time. The iterative learning of desired motor position was conducted as (Zhang et al., 2015, 2017a,b; Zhang and Collins, 2017),
Torque transmission was modeled in Equation (4) and the desired torque was set as Equation (7).
In this study, we were interested in the real-time torque tracking performance under gait variations after the stabilization of iterative learning, i.e., disturbance rejection performance of the controller. Therefore, we assumed that at stride n − 1 and time index i the learning controller has reached stabilization with perfect torque tracking, i.e.,
The dynamic changes of the desired and generated torque in the next strides due to human gait variations are then investigated hereinafter.
Assuming an ankle kinematics change from stride n − 1 to n at index i of
then the desired torque changes by
Based on the iterative learning rule in Equation (9) and the assumption of perfect motor position tracking in Equation (8), current desired and actual motor position are
Therefore, combining Equation (12) with Equation (4), the measured torque at stride n and index i is
and the desired torque is
Combining Equations (20) and (21), for stride n and index i, the torque error is
This means with perfect torque tracking in stride n − 1, the torque error of stride n is minimized when the desired and passive stiffness match. This agrees with a previous study on the optimization of passive stiffness for torque tracking (Zhang and Collins, 2017). Next, at index i of stride n + 1, the desired/actual motor position (equal per perfect motor tracking assumption 8) is
In case there is no change in ankle kinematics from stride n to n + 1 at time index i, i.e., θe(i, n + 1) = θe(i, n), the desired torque values have τdes(i, n + 1) = τdes(i, n). The actual torque at current stride and index is
Therefore, the latest torque error, i.e., that of stride n + 1 and index i, is
if Kt·Kl·R = 1, i.e., , we have
and balance is restored.
On the other hand, if there exists ankle kinematics change from stride n to n + 1 at index i, i.e.,
we have
and the actual torque at (i, n + 1) is
Combining Equations (20) and (21), the torque error at (i, n + 1) is
Assuming that the ankle kinematics change is bounded, i.e.,
Then, the error at (i, n),
The error at (i, n + 1) then has
It is still in our best interest to assert
Therefore, we make the following hypothesis.
Hypothesis 1. There is an optimal iterative learning gain that benefits real-time torque tracking performance of iterative learning in exoskeleton assisted walking under a linear spring-like desired torque profile:
2.4. Experimental Methods
The experiments of this study was conducted not to quantify human reactions but the performance of various torque control conditions. Therefore, only one healthy subject (N = 1, female, 32 years, 1.65 m, 56 kg) was involved. In all experiment sessions, the subject walked with a self-paced frequency on a treadmill running at 1.25 m/s while wearing the ankle exoskeleton on the right foot. All experimental protocols were approved by Carnegie Mellon University IRB.
In presentation of all experimental methods and results, this paper uses meter, Newton-meter and degree as the units for distance, torque and angle. The testbed system had an aspect ratio R = 2.5 and a gear ratio of N = 5. In all experiments, low level control parameters T in Equation (6) was set as 50 ms.
2.4.1. Generation of Desired Torque Curves
Three different desired quasi-stiffnesses in the form of Equation (7) were implemented to test the hypothesis. In all cases, θe,0 = −2(deg), in which θe = 0 was defined by the neutral standing position. The tested desired stiffness Kdes spans (Table 1) with a maximum value that is 4.25 times the minimum. The resulting desired torque-ankle-angle relationships are demonstrated in Figure 3.

Table 1. List of desired stiffness tested in experiments with assigned ID.
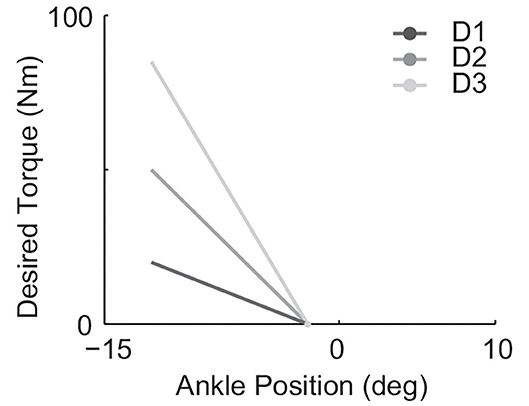
Figure 3. All three tested linear desired torque vs. ankle angle curves used in the form of Equation (7) with θe,0 = −2(deg) and Kdes values listed in Table 1.
2.4.2. Realization of Different Passive Stiffness and Evaluation of Their Values
With every desired stiffness value defined by a torque-angle curve, we tested it in combination with three different passive transmission stiffness values by changing the series spring in the ankle exoskeleton (Figure 1). Two were realized by attaching different compression springs (Diamond Wire Spring, Glenshaw, PA) and the last one was by eliminating the spring from the structure. In that case, the system passive stiffness equalled the stiffness of the rope in Bowden cable.
The values of effective passive stiffness, Kt, with different spring configurations were experimentally evaluated using passive walking where motor position was locked. The process went like this: under each set-up, motor position was fixed where forces began to be generated when the participant stood in a neutral position. Then the participant walked while wearing the exoskeleton on the treadmill for more than one hundred steady strides. Such sessions were done multiple times for each stiffness configurations. For one hundred steady strides of each walking session, the instantaneous passive stiffness value was calculated and plotted against the torque values. Figure 4 shows examples of such plots of passive walking sessions, one session for each spring configuration. Each session produced a stabilized passive stiffness which was defined as the median of the instantaneous stiffness values within a stabilized region. For any passive stiffness set-up, the stabilized region was chosen as a 5.65 Nm torque range, within which the change of the instantaneous stiffness trend averaged over all sessions was minimum. Then, the effective passive stiffness value of a specific spring configuration was defined as the mean of the stabilized passive stiffness values across multiple experimental sessions with this configuration.
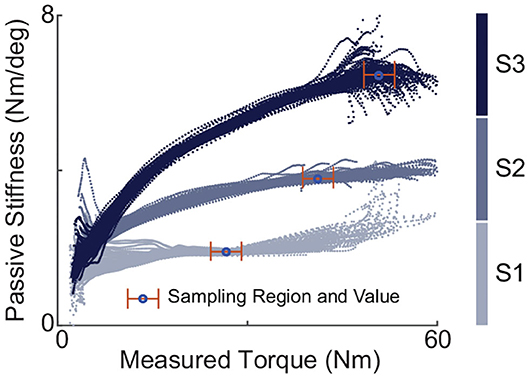
Figure 4. Instantaneous passive stiffness values under passive walking plotted against the measured torques for different spring configurations, one session for each. Each session consisted of one-hundred strides with motor position locked. The stabilized passive stiffness value of one session was defined as the median of the values over a stabilized region. The effective stiffness of the one configuration was defined as the mean of stabilized values of multiple sessions.
The list of springs used and their corresponding properties and their actual values of passive stiffness as calculated with methods discussed above are listed in Table 2. This passive stiffness set spanned a range with a 3.5 times difference between the maximum and minimum values.
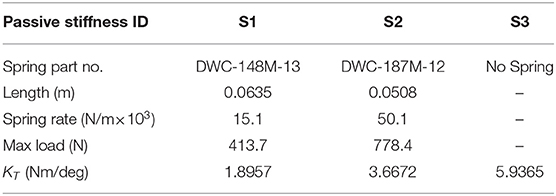
Table 2. List of passive stiffness values.
2.4.3. Experimental Procedures
For each desired stiffness and passive stiffness combination, ten iterative learning gains that span a range with a 20-times difference between the maximum and minimum around the predicted optimal value per Equation (24) (Table 3). Therefore, 3 × 3 × 10 experiment sessions were conducted in total. During each experiment session defined by a unique combination of learning gain, desired stiffness and passive stiffness, the subject walked for at least one hundred strides after stabilization of the learning processes.
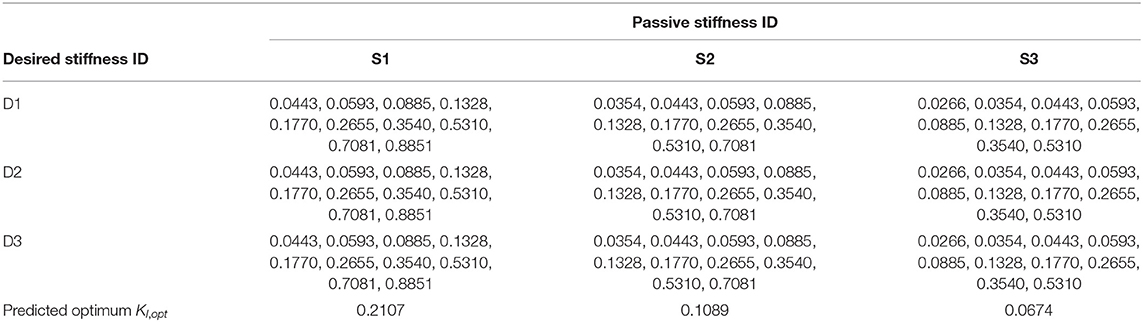
Table 3. List of iterative learning gain values tested in experiments (deg/Nm).
The theory-predicted optimal iterative learning gain values according to Hypothesis 1 were also listed in the table as a comparison.
Four different indicators of torque tracking performance were calculated for each combination. The first as we call an “absolute error” was defined as the mean of stride-wise root-mean-squared torque errors over the one hundred stable strides. The second one was a “relative error” defined by the absolute error divided by the mean of peak desired torque of the one hundred stable strides. Besides, the normalized instantaneous torque error value of a specific time index within the stride was defined by dividing the original torque error by the standard deviation of a centered 1 × 100 ankle position array of the same time index over all one hundred strides. A centered ankle position array of one particular time index of the stride was defined as the difference between the original array and filtered array as demonstrated in Figure 5. The resulting values were then used to calculate the “normalized absolute error” and the “normalized relative error” in a similar fashion as those of the “absolute error” and “relative error.”
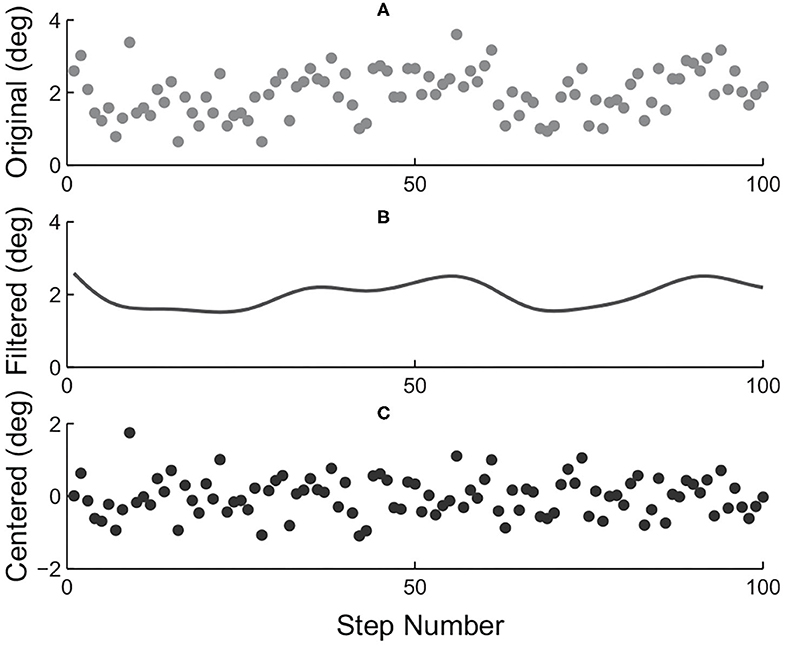
Figure 5. Centering process of index-wise ankle positions. (A) Ankle position array of the one hundred strides investigated for an example time index within strides. (B) Ankle position array as shown in (A) zero-phase filtered with a 1/20 cut-off frequency butter-worth filter. (C) Centered ankle position array achieved by subtracting array in (B) from that in (A).
For each unique combination of desired and passive stiffness values, we investigated the relationship between the defined error indices and the corresponding learning gains to test the hypothesis.
3. Results
The mean of root-mean-squared torque errors of various learning gains were presented against the ratio of actual learning gains to the theory predicted one in logarithmic scale, i.e., (Figure 6). For each combination of passive stiffness values and a desired torque curves, the values tracking errors of and were fitted into a second order polynomial, i.e.,
We defined the Kl value at which the value of the polynomial was minimized as the experimental optimum of iterative learning gain and label it as Kl,opt,exp. The values of all combinations are listed in Table 4.
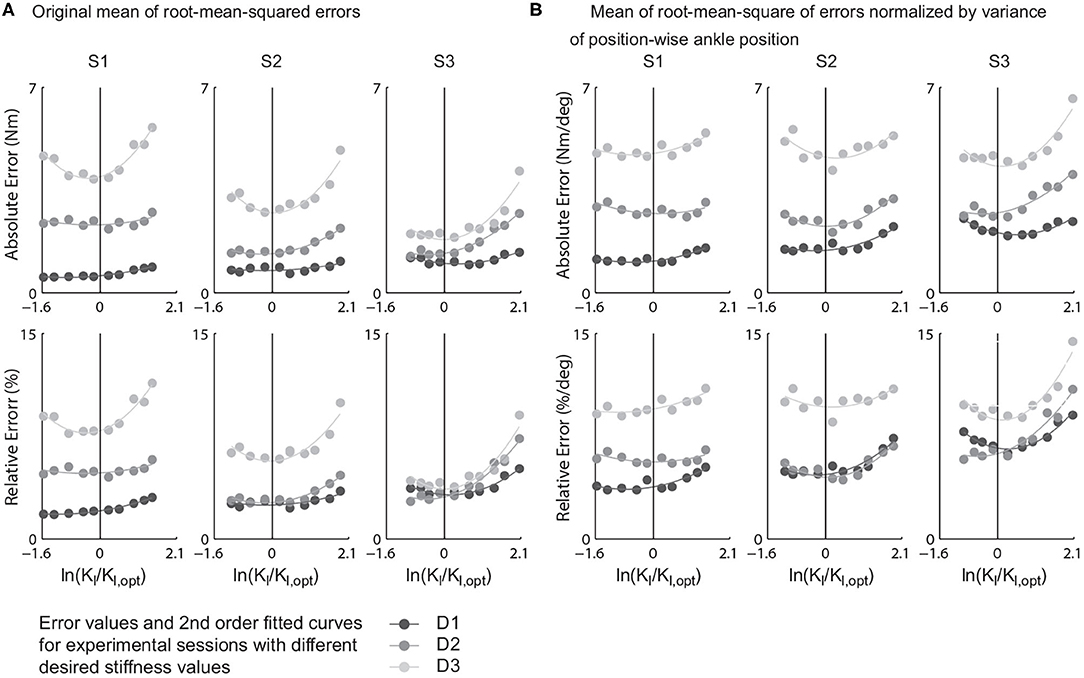
Figure 6. Mean of stride-wise root-mean-squared torque tracking errors of all {gain, desired stiffness, passive stiffness} combinations and the relative errors to their peak desired torques. (A) Values computed with raw torque errors. (B) Values computed by normalizing raw torque errors by position-wise ankle position variance.
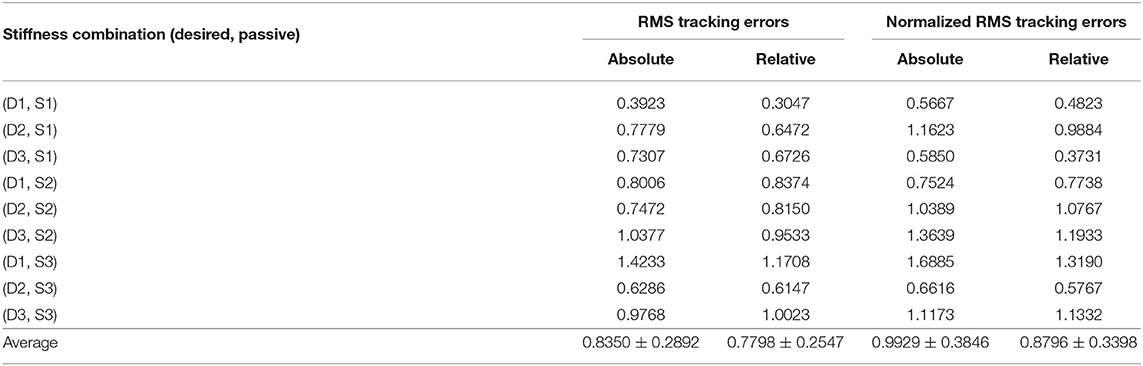
Table 4. Calculated relative optimal iterative learning gain values Kl,opt,exp/Kl,opt through curve-fitting experimental data.
From the results, for all tracking error definitions and all combinations of desired and passive stiffness values, the minimum tracking errors happen in a rather closed neighborhood of Kl = Kl,opt, which agreed with Hypothesis 1. Furthermore, among all four torque error indices, the absolute error normalized to the standard deviation of centered ankle position trajectories showed experimental optimum closest to theory prediction. The average of experimental optimal gains under nine different combinations of passive and desired stiffness values was 0.9929 ± 0.3846 times the predicted optimum (Table 4).
Besides, the slope between the error and learning gain is rather shallow in the area around the expected optimal gain for all combinations of desired and passive stiffness values. A 100% increase in learning gain only results in a 4.54% increase in normalized torque error on average.
4. Discussion
We examined the possibility of optimizing the real-time torque tracking performance of iterative learning control after the stabilization of learning process in series elastic actuator driven walking robots. We made predictions based on theoretical analysis and tested the theory using exoskeleton assisted human walking experiments.
Theoretic analysis suggested that to attenuate the effects of gait variations to minimum using iterative learning feed-forward torque control, the gain should be set as the inverse of the actuator passive stiffness with respect to the motor side. Among the various torque error indices investigated for walking experiments, torque errors normalized by the standard deviation of the centered ankle position array demonstrated strongest agreement with this hypothesis. The experimental optimal iterative learning gain identified was 0.9929 ± 0.3846 times the predicted one, i.e.,
These results showed that this optimal learning gain mostly suppressed the torque errors due to the step-to-step variation of human gait after stabilization, but not those due to slow adaptation of human gaits, which agreed with the theoretical analysis and the purpose of this study. In ankle exoskeleton assisted walking experiments and sessions with less stable gait patterns due to participant conditions or environment, this result is expected to be highly useful.
The results also suggested a shallow slope of tracking error increase when the learning gain deviated from the hypothesized optimum. A 100% increase in learning gain only results in a 4.54% increase in normalized torque error on average. This means a rather robust performance of the theory in this study, which is especially meaningful in exoskeletons. The high non-linearity of the series spring and time-varying property of the transmission and interaction subsystems all mean a difficult system identification process and constantly present model-system mismatch. Besides, the fairly flat bottom of the error-vs.-gain curve also partially explained the relatively big standard deviation of the experimental optimum (0.3846 as in Equation 25).
Due to the presence of the non-linear, complex, and time-varying system dynamics and the employment of a highly simplified model, many features were not reflected in the theoretical hypothesis, which led to imperfection in the alignment between theory and experiment results. One issue that contributed was the non-linearity of the passive stiffness coming from the slow stretching of the synthetic rope as demonstrated by Figure 4. Besides, there existed unstructured changes of passive stiffness between loads and trials, but only one single stabilized value was used for one passive stiffness setup. Another complication of the system dynamics not accounted for in theoretical analysis was the highly non-linear, complex, and time-varying static and dynamic frictions in Bowden cable. We also assumed perfect motor position tracking, which was not true in practical cases due to the limitation of motor velocity.
Regardless of the imperfection of system modeling, the torque tracking errors did arrive at a minimum at the neighborhood of the hypothesized optimal iterative learning gain. The shallow slope of changes around the optimum value also suggested a rather relaxed learning gain tuning process. When the iterative learning gain spans a range of [50% 200%] relative to the theoretical optimum, the average increase in torque error is expected to be <5% of that at the optimal gain. Considering a relative torque error of only 2–8% of desired torque at the optimum, a 5% increase on top is rather insignificant and will not harm exoskeleton performance or accuracy of experiments.
This study is the last part of a series of three studies focusing on improved torque tracking for lower-limb exoskeletons during walking. The first one compared a group of prominent controllers used in this type of devices, and identified model-free, integral-control-free feedback combined with feedforward iterative learning as the most effective controller structure, with the potential to reduce torque tracking error to around 1% of peak desired torque (Zhang et al., 2015, 2017a). The second optimized the passive stiffness value of the series elastic actuator of the exoskeleton (Zhang and Collins, 2017). This last study aimed to further improve the torque tracking performance by tuning iterative learning gain in presence of stride-to-stride human gait variations after stabilization of learning. When the combination of feedback control and iterative learning stabilizes during human walking, the real-time control output mainly comes from the learning part (Zhang et al., 2015, 2017a). Just like a traditional PID control, at the end of which the control output was mainly contributed by the integral control part. Therefore, in analysis and experiments of this study, only the iterative learning part was discussed.
A lot of complications, such as frictions and other non-linearities, uncertainties, time-varying dynamics were not discussed or featured in the analysis of this study. The reason was that previous studies (Zhang et al., 2015, 2017a) have shown that in presence of all these complications, a combination of model-free, integration-free control with iterative learning was most effective. The reason was that it is analogous to a traditional PID control, in which tracking, stability and steady-state errors were all dealt with.
Besides, stability of iterative learning was also solved in previous studies (Zhang et al., 2015, 2017a). Errors accumulated and propagating along the way can be suppressed by adding a forgetting factor, error filtering factor and an optional resetting process during human walking.
5. Conclusions
This study is the last part of a trilogy of studies on accurate torque tracking for lower-limb exoskeletons during human walking, followed by the identification of an effective control structure (Zhang et al., 2015, 2017a) and the optimization of device series elastic actuator passive stiffness (Zhang and Collins, 2017). It hypothesized the existence and value of an optimal iterative learning gain for real-time torque tracking in ankle exoskeleton during walking with gait variations and validated it with walking experiments. The optimal gain was identified as the inverse of transmission stiffness relative to the motor side. This result further improved exoskeleton torque tracking performance considering limited knowledge of the human and interaction dynamics we can achieve with current technologies. It provided clear guide to iterative learning gain tuning process in exoskeleton systems. Besides, a shallow slope of changes in tracking errors around the neighborhood of the optimal gain suggested a rather robust performance, which is especially meaningful for exoskeleton systems that are complicated, time-varying, and difficult to do system identification. Based on the results of this study, we recommend a iterative learning gain range that is [50% 200%] of the hypothesized optimum .
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics Statement
The studies involving human participants were reviewed and approved by Carnegie Mellon University IRB. The patients/participants provided their written informed consent to participate in this study.
Author Contributions
All authors listed have made a substantial, direct and intellectual contribution to the work, and approved it for publication.
Funding
This work was supported by the National Science Foundation under Grant No. IIS-1355716.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Amann, N., Owens, D. H., and Rogers, E. (1996). “Robustness of norm-optimal iterative learning control,” in UKACC International Conference on Control'96 (Conf. Publ. No. 427), Vol. 2 (Exeter: IET), 1119–1124. doi: 10.1049/cp:19960710
Arimoto, S., Kawamura, S., and Miyazaki, F. (1984). Bettering operation of robots by learning. J. Robot. Syst. 1, 123–140. doi: 10.1002/rob.4620010203
Atkeson, C. G., and Mclntyre, J. (1986). “Robot trajecgtory learning through practice,” in Proceedings. 1986 IEEE International Conference on Robotics and Automation (San Francisco, CA: IEEE).
Caputo, J. M., and Collins, S. H. (2013). “An experimental robotic testbed for accelerated development of ankle prostheses,” in 2013 IEEE International Conference on Robotics and Automation (Karlsruhe: IEEE). doi: 10.1109/ICRA.2013.6630940
Fukuda, M., and Shin, S. (1998). “Model reference learning control with a wavelet network,” in Iterative Learning Control (Boston, MA: Springer), 211–226. doi: 10.1007/978-1-4615-5629-9_11
Hać, A. (1990). “Learning control in the presence of measurement noise,” in American Control Conference 1990 (San Diego, CA: IEEE), 2846–2851. doi: 10.23919/ACC.1990.4791239
Haddadin, S., Albu-Schaffer, A., De Luca, A., and Hirzinger, G. (2008). “Collision detection and reaction: a contribution to safe physical human-robot interaction,” in 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems (Nice: IEEE), 3356–3363. doi: 10.1109/IROS.2008.4650764
Heinzinger, G., Fenwick, D., Paden, B., and Miyazaki, F. (1992). Stability of learning control with disturbances and uncertain initial conditions. IEEE Trans. Autom. Control 37, 110–114. doi: 10.1109/9.109644
Jackson, R. J., and Collins, S. H. (2015). An experimental comparison of the relative benefits of work and torque assistance in ankle exoskeletons. J. Appl. Physiol. (1985) 119, 541–557. doi: 10.1152/japplphysiol.01133.2014
Kawamoto, H., Taal, S., Niniss, H., Hayashi, T., Kamibayashi, K., Eguchi, K., et al. (2010). Voluntary motion support control of robot suit HAL triggered by bioelectrical signal for hemiplegia. Annu. Int. Conf. IEEE Eng. Med. Biol. Soc. 2010, 462–466. doi: 10.1109/IEMBS.2010.5626191
Lasota, P. A., Rossano, G. F., and Shah, J. A. (2014). “Toward safe close-proximity human-robot interaction with standard industrial robots,” in 2014 IEEE International Conference on Automation Science and Engineering (CASE) (Taipei: IEEE), 339–344. doi: 10.1109/CoASE.2014.6899348
Malcolm, P., Derave, W., Galle, S., and De Clercq, D. (2013). A simple exoskeleton that assists plantarflexion can reduce the metabolic cost of human walking. PLoS ONE 8:e56137. doi: 10.1371/journal.pone.0056137
Moore, K. L. (1993). Iterative Learning Control for Deterministic Systems. London: Springer Science & Business Media.
Pratt, J., Dilworth, P., and Pratt, G. (1997). “Virtual model control of a bipedal walking robot,” in Proceedings. 1997 IEEE International Conference on Robotics and Automation 1997, Vol. 1 (Albuquerque, NM: IEEE), 193–198. doi: 10.1109/ROBOT.1997.620037
Saab, S. S. (2003). Stochastic p-type/d-type iterative learning control algorithms. Int. J. Control 76, 139–148. doi: 10.1080/0020717031000077717
Saab, S. S. (2005). Selection of the learning gain matrix of an iterative learning control algorithm in presence of measurement noise. IEEE Trans. Autom. Control 50, 1761–1774. doi: 10.1109/TAC.2005.858681
Saab, S. S., Vogt, W. G., and Mickle, M. H. (1997). Learning control algorithms for tracking “slowly” varying trajectories. IEEE Trans. Syst. Man Cybernet B Cybernet. 27, 657–670. doi: 10.1109/3477.604109
Sawicki, G. S., and Ferris, D. P. (2009). Powered ankle exoskeletons reveal the metabolic cost of plantar flexor mechanical work during walking with longer steps at constant step frequency. J. Exp. Biol. 212, 21–31. doi: 10.1242/jeb.017269
Stienen, A. H., Hekman, E. E., ter Braak, H., Aalsma, A. M., van der Helm, F. C., and van der Kooij, H. (2010). Design of a rotational hydroelastic actuator for a powered exoskeleton for upper limb rehabilitation. IEEE Trans. Biomed. Eng. 57, 728–735. doi: 10.1109/TBME.2009.2018628
Sup, F., Varol, H. A., Mitchell, J., Withrow, T. J., and Goldfarb, M. (2009). Preliminary evaluations of a self-contained anthropomorphic transfemoral prosthesis. IEEE ASME Trans. Mechatron. 14, 667–676. doi: 10.1109/TMECH.2009.2032688
Togai, M., and Yamano, O. (1985). “Analysis and design of an optimal learning control scheme for industrial robots: a discrete system approach,” in 24th IEEE Conference on Decision and Control 1985 (Fort Lauderdale, FL: IEEE), 1399–1404. doi: 10.1109/CDC.1985.268741
van Dijk, W., Van Der Kooij, H., Koopman, B., and van Asseldonk, E. (2013). Improving the transparency of a rehabilitation robot by exploiting the cyclic behaviour of walking. IEEE Int. Conf. Rehabil. Robot. 2013:6650393. doi: 10.1109/ICORR.2013.6650393
Veneman, J. F., Kruidhof, R., Hekman, E. E., Ekkelenkamp, R., Van Asseldonk, E. H., and Van Der Kooij, H. (2007). Design and evaluation of the lopes exoskeleton robot for interactive gait rehabilitation. IEEE Trans. Neural Syst. Rehabil. Eng. 15, 379–386. doi: 10.1109/TNSRE.2007.903919
Witte, K. A., Zhang, J., Jackson, R. W., and Collins, S. H. (2015). “Design of two lightweight, high-bandwidth torque-controlled ankle exoskeletons,” in 2015 IEEE International Conference on Robotics and Automation (ICRA) (Seattle, WA). doi: 10.1109/ICRA.2015.7139347
Zanotto, D., Lenzi, T., Stegall, P., and Agrawal, S. K. (2013). Improving transparency of powered exoskeletons using force/torque sensors on the supporting cuffs. IEEE Int. Conf. Rehabil. Robot. 2013:6650404. doi: 10.1109/ICORR.2013.6650404
Zhang, J., Cheah, C. C., and Collins, S. H. (2015). “Experimental comparison of torque control methods on an ankle exoskeleton during human walking,” in 2015 IEEE International Conference on Robotics and Automation (ICRA) (Seattle, WA: IEEE), 5584–5589. doi: 10.1109/ICRA.2015.7139980
Zhang, J., Cheah, C. C., and Collins, S. H. (2017a). “Torque control in legged locomotion,” in Bioinspired Legged Locomotion: Models, Concepts, Control and Applications, eds M. A. Sharbafi and A. Seyfarth (Oxford: Elsevier), 347–400. doi: 10.1016/B978-0-12-803766-9.00007-5
Zhang, J., and Collins, S. H. (2017). The passive series stiffness that optimizes torque tracking for a lower-limb exoskeleton in human walking. Front. Neurorobot. 11:68. doi: 10.3389/fnbot.2017.00068
Keywords: exoskeleton, iterative learning, control, rehabilitation, gait assistance
Citation: Zhang J and Collins SH (2021) The Iterative Learning Gain That Optimizes Real-Time Torque Tracking for Ankle Exoskeletons in Human Walking Under Gait Variations. Front. Neurorobot. 15:653409. doi: 10.3389/fnbot.2021.653409
Received: 14 January 2021; Accepted: 30 April 2021;
Published: 28 May 2021.
Edited by:
Hao Su, City College of New York (CUNY), United StatesReviewed by:
Mingming Zhang, Southern University of Science and Technology, ChinaTadej Petric, Institut Jožef Stefan (IJS), Slovenia
Copyright © 2021 Zhang and Collins. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Steven H. Collins, stevecollins@stanford.edu