
Abstract
Since the emergence of COVID-19, the number of infections has significantly increased. As of April 7, 8:00 am, the total number of global infections has already reached 1,338,415, with the number of deaths being 74,556. Medical experts from various countries have conducted relevant researches in their own fields and countries, and the development of an effective vaccine has been expected soon. Although some progress has been made in the development of therapeutic drugs and vaccines, interdisciplinary and cooperative studies are scarce. However, it is easy to form information islands and conduct repeated scientific research. To date, no therapeutic drug or vaccine for COVID-19 has been officially approved yet for marketing. In this article, the features of experts in cooperation networks, such as graph structure, context attribute, sequential co-occurrence probability, weight features and auxiliary features, are comprehensively analyzed. Based on this, a novel graph neural network + long short-term memory + generative adversarial network (GNN + LSTM + GAN) expert recommendation model based on link prediction is constructed to encourage cooperation among relevant experts in research social networks. Finding experts in related fields, establishing cooperative relations with them and achieving multinational and cross-field expert cooperation are significant to promote the development of therapeutic drugs and vaccines.
Similar content being viewed by others


Introduction
The outbreak of the COVID-19 pandemic had a significant impact on humans worldwide. As of April 7, 8:00 am, the number of infections in china has already reached 83,093, with the number of deaths being 3340. The cumulative number of confirmed cases abroad is 1,260,450, with 71,216 deaths, and more than 8,000 medical personnel have been infected. This deadly virus has infected more than 1.3 million people worldwide, causing at least 74,556 deaths in 206 countries and tens of millions of people being quarantined. Are there currently targeted effective drugs and vaccines? How can medical staff be better protected? How can we win this war? How can we develop relevant vaccines and therapeutic drugs as soon as possible? These are the questions that scientific research institutions and medical experts worldwide need to answer.
Currently, although some progress has been made in the development of therapeutic drugs and vaccines, for this global crisis, experts from various countries have mostly conducted research in their own fields and countries. Moreover, interdisciplinary and cooperative researches are scarce, and repeated scientific research is time-consuming and labor-intensive. Zhong Nanshan stated that, as of the moment, no treatment for COVID-19 has been officially approved yet for marketing. The existing treatment plan is to help COVID-19-infected people control their symptoms, to help their bodies fight the virus, and to develop specific, safe, and effective drugs. Experts from different countries in various fields are urgently encouraged to eliminate bias, share research data, engage in international and interdisciplinary cooperation, and work together to develop vaccines against COVID-19. This will help expedite the research and development of therapeutic drugs and vaccines, shorten the research process, and help us win this war together.
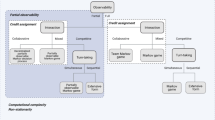
This article takes the research social network as the research object and considers the relationship between experts in the network as a complex network relationship, in which nodes indicate the experts and the edges indicate the cooperation between experts (in the case of academician Zhong Nanshan, as presented in Fig. 1). During the outbreak of the COVID-19 pandemic, the research sought experts with similar research directions or research interests from various countries or collaborators with relevant research experience on COVID-19 to help them establish connection with potential collaborators. This project adopts the theories and methods commonly used in many disciplines, such as computer science and physics. Based on complex networks, recommendation systems, and data-mining related theories, the graph neural network (GNN) + long short-term memory (LSTM) + generative adversarial network (GAN) expert recommendation model based on link prediction was constructed using the deep learning technology. The expert recommendation model learns the features of the experts to form the author’s low-dimensional, dense, and semantic vector representation. Thus, the probability of establishing connection between experts can be calculated to establish an efficient cooperative relationship. The main contributions of this article are as follows:
-
For dynamic weighted research social networks, we propose a novel GNN + LSTM + GAN expert recommendation model based on link prediction. This model is mainly composed of three parts: the GNN, LSTM, and GAN. We use the GNN to explore the features of each snapshot graph of the local topology. Then, the information described by the GNN is input in the LSTM network to capture the dynamic evolution of the graph. In addition, we use the GAN to generate a high-quality recommendation.
-
We propose a new LSTM variant that implements time gates on the LSTM to capture the relation between time and co-authorship. One time gate is designed to control the recent cooperation, whereas the other time gate is designed to control the long-term cooperation. Both the short-term cooperation behavior and long-term cooperation behavior have a certain degree of influence on expert recommendation.
-
We use the graph structure features, including eight popular heuristics and node centrality scores (degrees, closeness, page rank, etc.), which are located inside the observed nodes and edge structures of the network that can be directly observed and computed. The GNN can automatically learn such features, without reliance on predefined ones.
-
To describe the expert information, we introduce the expert’s multidimensional features, including the graph structure features, sequential co-occurrence probability features, context attribute features, weight features and Auxiliary features (GSCWA).
-
This article combines a variety of link prediction methods for expert recommendation, maximizes the strengths and avoids weaknesses, and takes advantage of various link prediction methods.
-
We conduct numerous experiments to confirm the effectiveness of the GNN + LSTM + GAN expert recommendation model in the research social networks in comparison with four baseline approaches. The experimental results indicate that our model is significantly superior to the most advanced methods on various metrics.

Relationship diagram of the GNN + LSTM + GAN expert recommendation model based on link prediction
The remainder of this paper is as follows. In Sect. 2, we introduce the related works of the recommendation system based on link prediction. In Sect. 3, we describe the multidimensional features of experts (GSCWA) and propose the GNN + LSTM + GAN expert recommendation model based on link prediction. Moreover, we compare this model with four baseline approaches, and it is found that the area under the curve (AUC) value and accuracy of the proposed GNN + LSTM + GAN expert recommendation model are higher than those of the four baseline approaches. The experimental results and discussion on the research social network data set are presented in Sect. 4. Finally, Sect. 5 concludes the paper.
Related works
Aiming at the problem of academic information overload, more and more researchers have conducted research on the recommendation problem of the research social networks to enable the users to communicate or share research data with others with similar interests, help them to efficiently and accurately filter out interesting and valuable contents, and improve the quality of recommendations. In recent years, some scholars at home and abroad have used recommendation systems based on link prediction to the research social networks.
Wang et al. (2015) analyzed the expert information and network topology information in the research social networks to construct a link prediction model, made relevant expert recommendations for the users in the research social networks, and confirmed the effectiveness of the algorithm in the research social network ScholarMate. Liu et al. (2014) recommended scholars with potential cooperative relationships using a random walk model based on co-authorship. They yielded good results in terms of the accuracy rate, coverage rate, and recall rate. Victor et al. (2012) employed the link prediction method to analyze the relationships between scholars within the research institution as well as their relationships with external scholars. Moreover, they constructed a multi-academic social model which they applied in the online research community in Brazil. They were able to achieve a good group recommendation effect. Xia et al. (2014) proposed a random walk with restart academic friend recommendation algorithm MVCWlaker. This method first conducts a weighted analysis of the edges in the academic cooperation network. Considering the cooperation order, latest cooperation time, and number of cooperation, they reasonably weight the edges in the social cooperation network and obtain a weighted academic cooperation network, which runs a random walk algorithm to achieve node similarity. Kong et al. (2016) suggested that scholars’ research interests should be considered in the recommendation of academic collaborators. They also revealed that the relevance of scholars’ research interests has a significant impact on academic cooperation. Based on this, they proposed an academic collaborator recommendation algorithm, combining the research content and academic networks. Through the list of scholars’ papers and using the topic model, scholars’ research topics can be obtained, which can improve the random walk algorithm, and accurate author recommendation results can be achieved. Vasuki et al. (2010) extended community recommended to contact recommended, considering the user’s friend relationship and contact network. They also used the algorithm based on the graph proximity model (GPM) and that based on the latent factor model to generate community recommendation for the users. The experimental results revealed that the algorithm based on the GPM was more effective’.
Through the above analysis of the recommendation systems based on link prediction, it can be found that most of them use random walks to make recommendations. With the development of deep learning technology, the use of the deep learning technology to automatically extract topology features and attribute features, so as to carry out expert recommendation is the future of development trend of the recommendation system based on link prediction.
Simulations
To develop effective therapeutic drugs and vaccines as soon as possible, it is necessary to predict and recommend cross-border and cross-domain expert cooperation. This project takes the research social network as the research object, aiming at the problems of dynamic evolution, multidimensional features, high-dimensional sparseness, and artificial design features faced by the current social networks. We proposed a novel GNN + LSTM + GAN expert recommendation model based on link prediction and introduced the GNN technology into the information recommendation. This improves the accuracy of the recommendation, helps avoid the artificial selection of features, and renders the recommendation system autonomous and intelligent. The relationship diagram of the recommendation model based on link prediction investigated in this article is presented in Fig. 1. The subsequent content revolves around the relationship diagram.
Expert recommendation modeling in the research social networks
Different from the traditional static network expert recommendation, to learn the time features of the dynamic network, the key problem that expert recommendation must solve first is the need to establish the time series of the network. If variable Y is measured and evaluated in discrete time, then a series of discrete values \(Y_{1} ,Y_{2} , \, \ldots Y_{t}\) of variable Y with time will be obtained. These discrete values are referred to as a time series. In this article, G(V, E) is defined as the total network, where V denotes the set of experts, and E denotes the set of relations; the total network is divided into T subnetworks. Then, the dynamic research social networks can be formalized as a series of sequence snapshots, in which \(G_{t} = \left\langle {V,E_{t} ,W_{t} } \right\rangle\) is the snapshot at a certain time slice \(t(t \in \{ 1,2, \ldots ,T\} )\) with a node (expert) set V, an edge (relationships between expert) set Et, and a weight (number of cooperation) set Wt.
The Dynamic weighted research social network expert recommendation needs to learn the dynamic features of the network from the evolution of the previous time slice, which is to achieve the expert recommendation. That is, given the adjacency matrix of the previous time slices T and the current time slice \(\left\{ {A_{t - T} ,A_{t - T + 1} , \ldots ,A_{t - 1} } \right\}\), the time series expert recommendation is to predict the topological structure of the next time slice t and make expert recommendations based on the predicted results. Its formula is given as follows:
f(•) denotes the model constructed in this article, and \(\widehat{{A_{t} }}\) denotes the prediction and recommendation result. To simplify the discussion, we use the simplified formula \(A_{t - T}^{t - 1}\) to represent the sequence \(\{ A_{t - T} , \ldots ,A_{t - 1} \}\). Figure 2 demonstrates how the dynamic weighted research social network evolves.

An example of dynamic network evolution
Figure 2 presents the evolution of the dynamic weighted research social network and its adjacency matrix. If a cooperative relationship exists between the experts, then its value is the number of their cooperation; otherwise, its value is 0. From time t−1 to time t, E(2;4;1) and E(1;4;1) appear, E(2;5;2) disappears, and the adjacency matrix also changes from time t−1 to time t. According to the prediction results, we recommend expert 2 and expert 4 as well as expert 1 and expert 4 to conduct collaborative research.
Multidimensional features of experts (GSCWA)
If only a single feature is used, capturing all the valuable information is difficult. Figure 3 presents the personal homepage of academician Zhong Nanshan in the Web of Science. From this website, we can find that the use of only one feature cannot fully reflect the expert information of academician Zhong Nanshan. Thus, we combine five basic features (sequential co-occurrence probability features, graph structure features, context attribute features, weight features, and Auxiliary features) to describe the multidimensional features of experts (see Fig. 4) so that collaborative relationships between authors can be accurately recommended. We analyze and discuss these features below.
-
1.
Deriving the graph structure features (G)

Homepage of academician Zhong Nanshan

Multidimensional features of experts (GSCWA)
The research social network demonstrates the cooperation between experts in the network. We can abstract it into a graph form, where the nodes indicate the experts, and the edges indicate the experts’ cooperation. In the figure below, the color indicates the degree of vertices, showing that the red vertices have high degree (Fig. 5).

Research cooperation diagram
The graph structure features refer to the structural features of the nodes and edges in the network that can be directly observed and calculated (Klaus and Kumar 2015; Zhang 2017; Zhu et al. 2012; Wu et al. 2013; Wang et al. 2007; Barabási et al. 2002). They include eight common heuristic algorithms and node centrality scores (degree, betweeness, etc.), which are presented in Table 1. The heuristic algorithms are simple and effective; they measure the possibility of link connection by calculating the node similarity score. The existing heuristic algorithms can be classified according to the number of hops that need to pass through the neighbors to calculate the score. For example, common neighbors (CN) and preferential attachment (PA) are first-order heuristics, as two target nodes only involve one-hop neighbors. The Adamic/Adar index and resource allocation are second-order heuristics as they involve neighbors up to two hops. There are also other high-order heuristic algorithms that need to fully understand the information of the entire network, such as Katz, PageRank, and SimRank. These predefined graph structure features can be effectively used in the research social networks. We use the GNN to automatically learn these features, to make generalizations, to avoid the artificial selection of features, and to render link prediction more autonomous and intelligent.
In Table 1, M denotes the number of edges in the network; N, the number of nodes; Γ(x), the set of neighbors of node X; β < 1, the weight attenuation factor; Kx, the degree value of the node; and \(\left|{walks}^{<l>}(x,y)\right|\), the number of paths with length \(l\) in the path-connecting nodes X and Y. In addition, [\({\pi }_{x}\)]y denotes the probability that a particle starting from node X will eventually reach node Y; gst, the number of the shortest paths from node s to node t; and \({n}_{st}^{i}\), the number of points i in the shortest path from node s to node t. If a node does not have the shortest path, the value of betweeness is 0.
-
2.
Deriving sequential co-occurrence probability (S)
We represent the dynamic research social network as a graph. In 2009, Wang et al. used the co-occurrence probability as an input feature to predict the missing links between the authors. The co-occurrence probability does not involve the impact of time on link prediction; it often ignores some potentially useful information. For example, long-term partnerships sometimes have a greater impact on expert recommendation than short-term partnerships. Although the short-term interaction behavior of the users has an impact on their next interaction, such an impact is uncertain. The users may cooperate once in the near future and may cooperate or not later. Therefore, we should rely on the long-term cooperative relationship between experts to make predictions and recommendations. This is the reason why we set up two time gates in the LSTM to focus respectively on the short-term and long-term cooperative relationships of the users. One time gate is used to capture the “recent” cooperation, whereas the other time gate is used to capture the “long-term” cooperation.
-
3.
Deriving context attribute features (C)
The author’s context attribute features mainly include subjective and objective information. Subjective information refers to the attribute features declared by the author himself/herself, {\({\mathrm{keyword}}_{1}^{\mathrm{s}},{\mathrm{keyword}}_{2}^{\mathrm{s}},\cdots {\mathrm{keyword}}_{\mathrm{m}}^{\mathrm{s}}\)}, such as research fields and employer. Objective information (content features) refers to the hidden features that we extracted from articles, keywords, undertaken projects, and thesis topics, such as {\({\mathrm{keyword}}_{1}^{0},{\mathrm{keyword}}_{2}^{0},\cdots {\mathrm{keyword}}_{\mathrm{m}}^{0}\)}.
-
4.
Deriving weight features (W)
The weight features in the research social networks include vertex weight and edge weight. Vertex weight refers to the intensity value of the nodes, which is generally used to indicate the importance of experts in the network. Conversely, edge weight is used to indicate the closeness of the relationships between experts and sometimes the similarity between experts. It is composed of two parts: difference weight and similarity weight. The difference weight usually corresponds to the distance. If the weight is large, the distance between the two nodes is also large, and the relationship is more distant. The similarity weight is the opposite of the difference weight. If the weight is large, the two nodes are similar, and their relationship is close.
In this section, we use the similarity weight to indicate the strength of the relationship between research social network experts, which largely depends on several factors, such as the frequency of contact between experts, number of interactions, contact duration, and relationship duration. For example, in a research social network, there is a pair of experts who cooperate for a long time and frequently communicate; thus, the link between them is very strong. Moreover, if the two experts frequently cooperate, the greater the weight of the edge, the stronger the link between the two experts.
-
5.
Deriving Auxiliary features (A)
In recent years, more and more studies have adopted classical social theories, such as community theory and homogeneity theory, as auxiliary features for social network analysis, mining, and recommendation. By using auxiliary features as the input metadata for expert recommendation based on link prediction, potentially useful information can be obtained, and the recommendation performance can be improved.
-
(1)
Community
By using the community structure information of the network as the input metadata, some hidden rules in the network can be easily discovered, and the behavior of the network can be predicted. The division of the community enables us to classify the experts in the research social network, so that the contacts between experts in the same set are relatively dense, whereas the contacts between experts in different sets are relatively sparse. According to the community theory, if Expert A and Expert B are in the same community, they are more likely to cooperate.
-
(2)
Homogeneity
Birds of a feather flock together. The frequency of cooperation between similar experts is much higher compared with that between different people. This phenomenon is called “homogeneity.” Experts are more “willing” to establish cooperative relationships with other experts who have similar research interests. This article adopts the homogeneity theory as an input feature to enable experts to quickly understand people with the same attributes and experience as themselves, thereby establishing a cooperative relationship.
GNN + LSTM + GAN expert recommendation model based on link prediction
This project proposed the GNN + LSTM + GAN expert recommendation model based on link prediction (see Fig. 6), which is divided into three layers. The input layer includes the sequence co-occurrence probability features, graph structure features, text attribute features, weight features, and auxiliary features as input metadata for link prediction. The proceeding layer contains a network-embedded GAN, which consists of a generative network G and a discriminative network D. G tries to fool D and generates high-quality samples. Then, G obtains a snapshot of the structure features of each local map by GNN and gains probability features of the time sequence by LSTM to learn the node low-dimensional vector and extract the adjacency matrix A of the graph and the feature matrix Z of the node. The output layer outputs a high-quality recommendation list via the full connection layer.

GNN + LSTM + GAN expert recommendation model based on link prediction
Input layer
For the dynamic weighted research social network graphs, the GNN is utilized to automatically learn the topological structure information of the graph in the network. Suppose that there are N nodes in the social network and M-dimensional features. The multidimensional features of the dynamic weighted research social network can be represented by the adjacency matrix A (N * N) and the feature matrix Z (N * M).
Proceeding layer
The processing layer of this model is mainly composed of three parts: GNN, LSTM, and GAN. The topological structure matrix At and feature matrix Z learned from the GNN are transformed into Xt. Xt is then input in the LSTM network to capture the dynamic evolution of the graph. At the same time, the GAN is applied to generate a high-quality recommendation list. Among this model, we use the GNN, LSTM, and deep neural network (DNN) to create the generative network G (the left image in Fig. 6) and introduce another DNN to build the discriminative network D (the right image in Fig. 6). In the confrontation process, the generative network G predicts the link and weight value of the next time slice based on the historical topology information of the dynamic graph, and the discriminative network D is used to discriminate the generated predicted value and the actual recorded value by applying the minimax game. The confrontation process will eventually adjust G to generate reasonable and high-quality recommendation results. The following describes in detail the functions of the three parts of the processing layer:
-
1.
GNN part
The GNN is an effective neural network variant. It can directly operate on the graph. Assuming that there are N nodes and M features in a dynamic weighted research social network, the topological structure and node features can be expressed as adjacency matrices At(N × N) and Z(N × M), respectively. The GNN of the node can be expressed as follows:
where \(\widehat{D}^{ - 1/2} \widehat{A}\widehat{D}^{ - 1/2}\) denotes an approximate graph filter; W, a weight matrix; and f (•), an activation function. In addition, X denotes the output given by the GNN unit.
-
2.
LSTM part
The LSTM is a special recurrent neural network (RNN) that can learn short-term and long-term dependencies mainly to solve the problem of gradient disappearance and gradient explosion in the training process of long sequences. In general, the LSTM can perform better in a longer sequence data compared with the ordinary RNN. Moreover, it has become an effective and a scalable model to solve the problem of timing link prediction.
In the link prediction model we designed based on GNN + LSTM + GAN, the Xt learned from the GNN layer and the last state vector ht−1 are sent to the LSTM layer to capture the evolution mode of the weighted dynamic network. Figure 7 presents the design of the LSTM layer module. It, ft, and Qt denote the input, forget, and output gates at time t. Among them, the forget gate ft determines what information we will discard from the cell state. It is mainly used to selectively forget the input passed in from the previous node. The input gate it mainly selects and memorizes the input information and determines which new information is added to the cell state; conversely, the output gate Qt determines which will be the output of the current state. Xt and ht denote the input feature vector and the implicit output vector, respectively, and the value of σ is between 0 and 1, with 1 meaning to keep and 0 meaning to delete. \({W}_{X}^{i}\),\({W}_{X}^{f}\), \({W}_{x}^{o}\), and \({W}_{X}^{c}\) denote the weights of the gate; bi, bf, bo, bc, bt1, and bt2 denote the corresponding bias values; and △tt denote the time interval. We use two time gates to simultaneously simulate the time interval between the short-term cooperative relationship and the long-term cooperative relationship of experts. Among them, T1t is used to control the short-term interaction of experts, whereas T2t controls the long-term interaction. In addition to the input gate it, T1t can be regarded as information filter considering the time features. We have added a new unit state \(\widehat{{c}_{t}}\) to store the result and then transferred it to the hidden state ht. The update formula of the LSTM is as follows:

LSTM variants of the two time gates
The cell state Ct is used to store the expert’s long-term interaction relationship. We designed a time gate to control the update of the cell state Ct. T2t first memorizes \(\Delta t_{t}\) and then transfers to Ct and then to Ct+1, Ct+2, …, Therefore, T2t memory \(\Delta t_{t}\) helps establish long-term interactions between experts, whereas the modeling time intervals help capture the experts’ periodic cooperative behavior.
Generally, the recent cooperation behavior of the experts has a certain impact on the next cooperation between experts. To integrate this common sense into the design gate, we have added the constraint Wxt1 < 0. Therefore, according to (6), if \(\Delta t_{t}\) is small, T1t will be large, and Xt indicates the expert’s short-term interaction relationship; thus, its influence should be increased. Although the short-term cooperation behavior of experts has an impact on their next cooperation, such an impact is uncertain. This is the reason why we set up two time gates to respectively focus on the short-term and long-term partnerships of experts.
-
3.
GAN part
To solve the problem of data sparsity in the dynamic weighted research social network, our model uses the GAN framework.
The idea of the GAN algorithm is inspired by the two-person zero-sum game theory. The network structure of the GAN is composed of the generative network G and the discriminative network D. The function of G is to deceive D to generate a high-quality predicted value. D tries to distinguish between the true value and the predicted value. Then, by applying the minimax game, the confrontation process will eventually adjust G to generate reasonable and high-quality recommendation results.
where Pdata denotes the distribution of real data; Pz, the distribution of original noise; and E, the expected value. Usually, we first fix the generative network G to maximize V(D, G) to obtain the discriminative network D. Subsequently, we fix the discriminative network D and minimize V(D, G) to obtain the generative network G and then go through a series of iterative processes until the best recommendation result is achieved. The following is a detailed introduction to the graph generative network G and the graph discrimination network D:
-
(1)
Graph generative network (G)
The graph generative network G designed in this chapter is composed of the GNN, LSTM, and DNN. The GNN part uses the time series topology matrix = \({A}_{t-T}^{t-1}\){\({A}_{t-T}\),…,\({A}_{t-1}\)} and the feature matrix Z as input, and obtains the output results Xt, Xt, and ht−1 are entered in the LSTM part to get ht, and ht passes through the DNN part to produces the prediction result \(\stackrel{-}{{A}_{t}}\), we use the following formula to represent the graph generative network:
-
(2)
Graph discriminative network (D)
The right image in Fig. 7 presents the graph discriminative network D, which consists of a DNN. The graph discriminative network D takes the predicted value \(\stackrel{-}{{A}_{t}}\) and the true value At as inputs. By applying the minimax game, the confrontation process will eventually generate a reasonable predicted result D (\(\widehat{{A}_{t}}\)).
Output layer
The main function of the output layer is to generate a list of recommendations based on the predicted results.
Loss function
We usually expect that the predicted and recommendation results should be as close to the true value At as possible. In machine learning, we employ a loss function to measure the difference between the predicted value and the true value.
where \({\uptheta }_{G}\) and λ are both parameters, with \({\uptheta }_{G}\) representing the parameters of the generative network G. λ is used to control the effect of the L2 regular term, whereas G reconstructs the current snapshot graph At−1 through the topological snapshot graph \({A}_{t-T-1}^{t-1-1}\) and the feature matrix Z. This process can help generate the network G to fully capture the latest time series information of the dynamic network. The information is considered to be similar to the features of the real At.
where \({\uptheta }_{D}\) and λ are both parameters, with \({\uptheta }_{D}\) representing the parameters of the discriminative network D. λ is used to control the effect of the L2 regular term, whereas D discriminates the predicted value and real At generated by the topological snapshot \({A}_{t-T}^{t-1}\) and the feature matrix Z, so that more accurate results can be obtained.
Simulation model setup
Web of Science is the world’s largest comprehensive academic information resource covering the most disciplines. It contains more than 8700 core academic journals in the most influential fields of natural science, engineering technology, biomedicine, etc. By using Web of Science’s rich and powerful search functions, namely, basic search, author search, cited reference search, and advanced search, one can quickly and easily find valuable scientific research information and fully explore relevant subjects and topics on research experts. We use the “author retrieval” channel as an empirical research object, collecting real data sets from the website to describe and verify the model construction and application.
Firstly, data collection, let’s take academician Li Lanjuan as an example, his personal academic homepage is presented in Fig. 8. The data to be collected include academic background information of scholars, such as the unit, region, and research field; academic achievements of scholars, including all collaborators, publications, time, citation frequency, and citations of the results; and paper data in various levels of publications. We used Python 3.8 + Selenium + Scrapy to construct a crawler. Generally, selenium is used to simulate the process of a real user operating a browser, whereas Scrapy is used to extract web content. We input the data excavated by the crawler in a research social network Gt = <V, Et, Wt> and then divide Et into two parts: training set EtT and testing set EtP. EtT is made up of known information, whereas EtP is used for testing. Et = EtP ∪ EtT, EtP ∩ EtT = Φ, which use 90% as the training set and 10% as the test set. The average of all results in more than 50 separate implementations. According to the two indicators of accuracy and receiver operating characteristic (ROC) curve, the GNN + LSTM + GAN expert recommendation model proposed in this paper is compared with the mainstream classifiers CNN, GNN, PropFlow, and RBM to confirm its effectiveness in expert recommendation based on link prediction.

Academician Li Lanjuan’s personal expert homepage
Metric
We employ two common mathematical model detection methods, AUC and accuracy, to evaluate the effectiveness of the recommended model.
-
(1)
AUC
The area under the ROC curve is the AUC value, which measures the accuracy of the algorithm as a whole. It can be understood as the probability that the score value of the edge in the test set is higher than that of a randomly selected nonexistent edge, If the edge value in the test set is greater than the score value of the side that does not exist, one point is added. If the two scores are equal, we add 0.5. It independently compares the n times. If there are \({n}^{^{\prime}}\) times, the score of the edge in the test set is greater than the score of the nonexistent edge, there are n′' times when two points are equal, the AUC value is defined as follows:
Obviously, if all the scores are randomly generated, then AUC = 0.5; thus, the degree to which AUC is greater than 0.5 measures how much more accurate the algorithm is than the randomly selected method.
-
(2)
Precision
Precision is evaluated based on the ratio of the number of correct recommendation to the total number of recommendation in the test set. Assuming that the value of m of the L recommendation results are in the test set, the accuracy of the model can be calculated using the following formula (Victor et al. 2012):
The size of the precision is related to the number of prediction edges taken. The value of precision ranges from [0, 1]. For a fixed L value, the larger the precision value, the higher the accuracy of the model used.
Baseline approaches
For comparison, the four baseline approaches, CNN, GNN, PropFlow, and RBM, are also presented.
-
CNN Yann Le Cun from New York University proposed the CNN in 1998. CNN can automatically extract features and mine local features of data. Niepert et al. (2017) pointed out that recommended approach based on the link prediction, can be summarized as the learning process from the graph data. They studied a general learning framework based on the CNN, which is used to learn the representation of arbitrary graphs.
-
GNN GNN (Zhang and Chen 2018) is the most primitive semi-supervised deep learning method for graph data. To encode the structural information of the graph, each node can be represented by a low-dimensional state vector. Moreover, it can be applied not only in the field of link prediction but also in knowledge graph completion and recommendation systems.
-
PropFlow PropFlow (Thi et al. 2014) calculates the information between nodes through a local path to evaluate the relationship between two nodes. The higher the PropFlow value, the greater the probability of future connections. Thi et al. (2014) proved that PropFlow is superior to CN, Adamic/Adar index, Jaccard’s coefficient, and PA.
-
RBM RBM consists of a visible layer and a hidden layer (Luo et al. 2014). In general, the visible layer unit is used to describe the acquisition data feature, whereas the hidden layer unit is usually considered as a feature extraction layer. RBMs are generally trained using the contrastive divergence to learn programs.
Results and discussions
The GNN + LSTM + GAN method is adopted to select one of the following features to generate research social network recommendation: time co-occurrence probability features, graph structure features, content features, weight features, and auxiliary features. The effect of the recommended model is presented in Fig. 9. We analyze the results of using these five features and a combination these features. Table 2 presents the AUC value and accuracy of the research social network. At the same time, we draw the ROC curve by combining five different features and compare the proposed GNN + LSTM + GAN model with the current mainstream recommended approach based on link prediction. The result is presented in Fig. 10.

Single-feature ROC curve

Multiple-feature ROC curve comparison for research social network
To evaluate the performance of the recommended model based GNN + LSTM + GAN, the ROC curve is used. The ROC curve visualizes the performance of a classifier, as presented in Fig. 10.
We analyze and evaluate the recommended model based on GNN + LSTM + GAN based on three aspects:
-
(1)
Table 2 demonstrates that, in the AUC value, the graph structure feature is always superior to all other features and has a better recommendation precision. When we combined the five features for recommendation based on link prediction, multiple-feature AUC value and accuracy significantly improved compared with the use of a single feature. Subsequently, we specifically analyzed the implementation results.
In the research social network, when the five features were used in isolation, the graph structure features had the highest AUC value (72.1%), followed by the sequential co-occurrence probability features (71.9%), the content attribute features (70.6%), the auxiliary features (70.0%), and then the weight features (69.9%). Next, we combine the sequential co-occurrence probability features, graph structure features, auxiliary features, weighted features and content attribute features together and use the GNN + LSTM + GAN method to generate recommendation based on link prediction. The AUC value of 93.7% and accuracy rate of 89.89% were obtained by comprehensively using the five features. The experimental results indicate that the multiple-feature link prediction based on GNN + LSTM + GAN is superior to the single-feature recommendation based on link prediction in the research social network.
-
(2)
Fig. 10 presents the experimental results of GNN + LSTM + GAN, CNN, GNN, PropFlow, and RBM in the research social network. From the figure, it can be seen that the AUC value of GNN + LSTM + GAN is 93.7%, whereas that of the CNN is only 82.3%; GNN, 87.3%; PropFlow, 76.2%; and RBM, 78.6%. This indicates that the GNN + LSTM + GAN method has the highest AUC value in the research social network. This shows that the combination of the time co-occurrence probability features, graph structure features, content attribute features, weight features, and auxiliary features under the GNN + LSTM + GAN framework can really improve the performance of recommendation based on link prediction.
Conclusions
With the outbreak of the COVID-19 pandemic, international experts urgently need to work together to develop therapeutic drugs and vaccines as soon as possible. In this article, we proposed a new GNN + LSTM + GAN expert recommendation model based on link prediction to recommend expert cooperation in research social networks. In the proposed model, the graph structure, content attribute, sequential co-occurrence probability, weight, and auxiliary features are initially used as the input features of the recommendation model. We used the GNN to explore the features of each snapshot graph of the local topology. Then, we input the information described by the GNN in the LSTM network to capture the dynamic evolution of the graph. Finally, we applied the GAN to generate a high-quality recommendation list. According to the list of recommendations, experts in related fields from various countries can establish cooperative relations, hoping to help accelerate the development of therapeutic drugs.
References
Barabási, A. L., Jeong, H., Néda, Z., et al. (2002). Evolution of the social network of scientific collaborations. Physica A: Statistical Mechanics and its Applications, 311(3–4), 590–614.
Klaus, G., & Kumar, S. R. (2015). LSTM: A search space odyssey. IEEE Transactions on Neural Networks & Learning, 28(10), 1–12.
Kong, X., Jiang, H., Yang, Z., et al. (2016). Exploiting publication contents and collaboration networks for collaborator recommendation. PLoS ONE, 11(2), e0148492.
Liu, J., Feng, X., Wei, W, et al. (2014). ACRec: A co-authorship based random walk model for academic collaboration recommendation. In Proceedings of the 23rd international conference on world wide web (pp. 1209–1214). ACM.
Luo, D. S., Wang, Y., & Han, X. Q. (2014). A cyclic contrastive divergence learning algorithm for high-order RBMS. IEEE, 18(10), 3–6.
Niepert, M., Ahmed, M., & Kutzkov, K. (2017). Learning convolutional neural networks for graphs. In Proceedings of the 33th international conference on machine learning (pp. 2014–2023).
Thi, D. B., Ichise, R., & Le, B. (2014). Link prediction in social networks based on local weighted paths. Future Data and Security Engineering., 21(19), 151–163.
Vasuki, V., Natarajan, N., Lu, Z., et al. (2010) Affiliation recommendation using auxiliary networks. In ACM conference on recommender systems (pp. 103–110). Academic Medicine.
Victor, S., Zimbrao, G., & Souza, J. M. (2012). Modeling, mining and analysis of multi-relational scientific social network. Journal of Universal Computer Science, 18(8), 1048–1068.
Wang, J., Yue, F., & Wang, G. (2015). Research on expert recommendation based on link prediction in scientific social networks. Information Magazine, 06, 151–157.
Wang, C., Satuluri, V., Parthasarathy, S. (2007) Local probabilistic models for link prediction. In Proceedings of the 7th IEEE international conference on data mining, ICDM’07 (pp. 322–331). IEEE Computer Society.
Wu, S., Sun, J., & Tang, J. (2013). Patent partner recommendation in enterprise social networks. In Proceedings of the 6th ACM international conference on web search and data mining. (pp. 43–52). Rome: WSDM.
Xia, F., Chen, Z., Wang, W., et al. (2014). Mvcwalker: Random walk-based most valuable collaborators recommendation exploiting academic factors. IEEE Transactions on Emerging Topics in Computing, 2(3), 364–375.
Zhang, J. (2017). Uncovering mechanisms of co-authorship evolution by multirelation-based link prediction. Information Processing & Management, 53(1), 42–51.
Zhang, M. H., & Chen, Y. X. (2018). Link prediction based on graph neural networks 1–17. arXiv: 1802.09691v3.
Zhu, Y. X., Lü, L. Y., Zhang, Q. M., & Zhou, T. (2012). Uncovering missing links with cold ends. Physica A: Statistical Mechanics and its Applications, 391(22), 5769–5778.
Acknowledgements
This research is supported in part by Special Funding of "the Belt and Road" International Cooperation of Zhejiang Province (2015C04005) and the Natural National Science Foundation of China (61571399).
Author information
Authors and Affiliations
Contributions
H.W. was mainly responsible for the idea of the paper, the writing of the manuscript. L.Z.C was responsible for the design of the overall structure of the thesis and the analysis of related research progress.
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare no competing interests.
Rights and permissions
About this article

Cite this article
Wang, H., Le, Z. Expert recommendations based on link prediction during the COVID-19 outbreak. Scientometrics 126, 4639–4658 (2021). https://doi.org/10.1007/s11192-021-03893-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-021-03893-3