


Abstract
Single-shot structured light profilometry (SLP) aims at reconstructing the 3D height map of an object from a single deformed fringe pattern and has long been the ultimate goal in fringe projection profilometry. Recently, deep learning was introduced into SLP setups to replace the task-specific algorithm of fringe demodulation with a dedicated neural network. Research on deep learning-based profilometry has made considerable progress in a short amount of time due to the rapid development of general neural network strategies and to the transferrable nature of deep learning techniques to a wide array of application fields. The selection of the employed loss function has received very little to no attention in the recently reported deep learning-based SLP setups. In this paper, we demonstrate the significant impact of loss function selection on height map prediction accuracy, we evaluate the performance of a range of commonly used loss functions and we propose a new mixed gradient loss function that yields a higher 3D surface reconstruction accuracy than any previously used loss functions.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Structured light profilometry (SLP) is the technique of reconstructing the 3D surface map of an object by projecting predefined fringe patterns onto its surface and by observing it under an angle [1, 2]. From the recorded deformed fringe pattern, the full-field height map of the object can be extracted using various triangulation techniques that can be subdivided into different classes depending on the specific demodulation strategy that is employed. Since the recorded intensity map  of the deformed fringe pattern is a linear equation of background illumination
of the deformed fringe pattern is a linear equation of background illumination  , intensity profile modulation
, intensity profile modulation  and phase map
and phase map  (equation (1)), a set of at least three different intensity maps
(equation (1)), a set of at least three different intensity maps  is needed per 3D measurement to extract the phase map
is needed per 3D measurement to extract the phase map  analytically:
analytically:

To solve equation (1), phase shifting profilometry (PSP) techniques permute the modulation of  by integer multiples of
by integer multiples of  (with
(with  ⩾ 3) between successive recordings of
⩾ 3) between successive recordings of  . A larger number of phase shifts
. A larger number of phase shifts  per 3D measurement improves the measurement resolution, but also increases the measurement of 3D recordings, limiting the overall 3D recording speed. This results in the typical trade-off between speed and measurement accuracy.
per 3D measurement improves the measurement resolution, but also increases the measurement of 3D recordings, limiting the overall 3D recording speed. This results in the typical trade-off between speed and measurement accuracy.
Even though modern PSP systems have been reported to acquire high-resolution 3D measurements at real-time speeds [3, 4], several drawbacks to phase-shifting systems remain. For example, the 3D frame rate of PSP techniques is ultimately limited to  th of the camera frame rate which leads to an inevitable degree of motion artifacts to be present in the 3D measurements. Furthermore, PSP setups require custom synchronization between the digital light projector and the camera. Therefore, additional triggering hardware and onboard (flash) projector memory is needed to display a constant loop of fringe patterns. In contrast, single-shot profilometry techniques are designed to extract height information from a single deformed fringe pattern. Generally speaking, all single-shot strategies are either adapted versions of Takeda's Fourier transform profilometry (FTP) [5] or employ additional color channels to superimpose differently modulated intensity patterns onto a single color map [6, 7]. While both approaches have been highly successful and are implemented into a variety of application fields, they each have specific drawbacks. For instance, FTP techniques depend on the correct selection of the originally projected carrier frequency, which is stretched in Fourier space through modulation of the object's surface shape. When the carrier frequency band overlaps with the other frequency components in Fourier space, it cannot be retrieved unambiguously, leading to loss of information especially near sharp edges. Color-sensitive approaches, on the other hand, assume that the object surface reflects different colors uniformly and that there is no crosstalk between adjacent color channels. When this is not the case, the quality of the resulting depth map deteriorates significantly.
th of the camera frame rate which leads to an inevitable degree of motion artifacts to be present in the 3D measurements. Furthermore, PSP setups require custom synchronization between the digital light projector and the camera. Therefore, additional triggering hardware and onboard (flash) projector memory is needed to display a constant loop of fringe patterns. In contrast, single-shot profilometry techniques are designed to extract height information from a single deformed fringe pattern. Generally speaking, all single-shot strategies are either adapted versions of Takeda's Fourier transform profilometry (FTP) [5] or employ additional color channels to superimpose differently modulated intensity patterns onto a single color map [6, 7]. While both approaches have been highly successful and are implemented into a variety of application fields, they each have specific drawbacks. For instance, FTP techniques depend on the correct selection of the originally projected carrier frequency, which is stretched in Fourier space through modulation of the object's surface shape. When the carrier frequency band overlaps with the other frequency components in Fourier space, it cannot be retrieved unambiguously, leading to loss of information especially near sharp edges. Color-sensitive approaches, on the other hand, assume that the object surface reflects different colors uniformly and that there is no crosstalk between adjacent color channels. When this is not the case, the quality of the resulting depth map deteriorates significantly.
Recently, we reported a new technique to obtain object height information directly from only a single deformed fringe pattern [8]. The proposed technique is based entirely on deep learning and uses a neural network to extract full-field height information from deformed fringe patterns with high accuracy. In addition, intermediate data processing steps (such as background masking, noise reduction, and phase unwrapping) that otherwise must be implemented explicitly in classic demodulation algorithms were learned directly as part of the network's mapping function. Since the publication of this proof-of-principle paper, several implementations of deep learning-based SLP systems have been reported, exploring adaptations to the network architecture, training dataset and model hyperparameters. None of them, however, addresses the choice of loss function that is used to train the model. In fact, nearly all models employ the  or mean squared error (MSE)-loss [9–15], one uses smooth
or mean squared error (MSE)-loss [9–15], one uses smooth  -loss [16] and some do not mention the employed loss function in the training of their model at all [17–19]. According to Wang et al [20], the popularity of the
-loss [16] and some do not mention the employed loss function in the training of their model at all [17–19]. According to Wang et al [20], the popularity of the  -norm in the training of neural networks can be explained by several arguments: first, it is easy and computationally inexpensive to calculate. Second, it has a clear physical meaning—it is the natural way to define the energy of the error signal. Third, it is convex, symmetric and differentiable, making it an excellent metric in the context of optimization problems. Finally, and perhaps most importantly, it is readily implemented in nearly every existing deep learning framework as the default loss function. As we will see, the
-norm in the training of neural networks can be explained by several arguments: first, it is easy and computationally inexpensive to calculate. Second, it has a clear physical meaning—it is the natural way to define the energy of the error signal. Third, it is convex, symmetric and differentiable, making it an excellent metric in the context of optimization problems. Finally, and perhaps most importantly, it is readily implemented in nearly every existing deep learning framework as the default loss function. As we will see, the  -norm also possesses some properties that make it a questionable candidate to be implemented as loss function of choice in some contexts. For example, several pre-assumptions are made when the
-norm also possesses some properties that make it a questionable candidate to be implemented as loss function of choice in some contexts. For example, several pre-assumptions are made when the  -norm is used: signal fidelity is assumed to be independent of spatial or temporal relationships between samples, independent of the signs of the error signal and all signal samples are to be equally important to signal fidelity. In any case, the loss function is one of the key components of any neural network: it is the metric that defines the prediction error and its gradient is used to update the network weights with each pass over the training dataset. In this work, we demonstrate that the choice of loss function in a deep learning-based SLP setup has a significant impact on prediction accuracy, we evaluate the performance of several common loss functions and we propose a custom mixed gradient loss function that yields a higher prediction accuracy than any of the other investigated loss functions.
-norm is used: signal fidelity is assumed to be independent of spatial or temporal relationships between samples, independent of the signs of the error signal and all signal samples are to be equally important to signal fidelity. In any case, the loss function is one of the key components of any neural network: it is the metric that defines the prediction error and its gradient is used to update the network weights with each pass over the training dataset. In this work, we demonstrate that the choice of loss function in a deep learning-based SLP setup has a significant impact on prediction accuracy, we evaluate the performance of several common loss functions and we propose a custom mixed gradient loss function that yields a higher prediction accuracy than any of the other investigated loss functions.
2. Methods
2.1. Data set
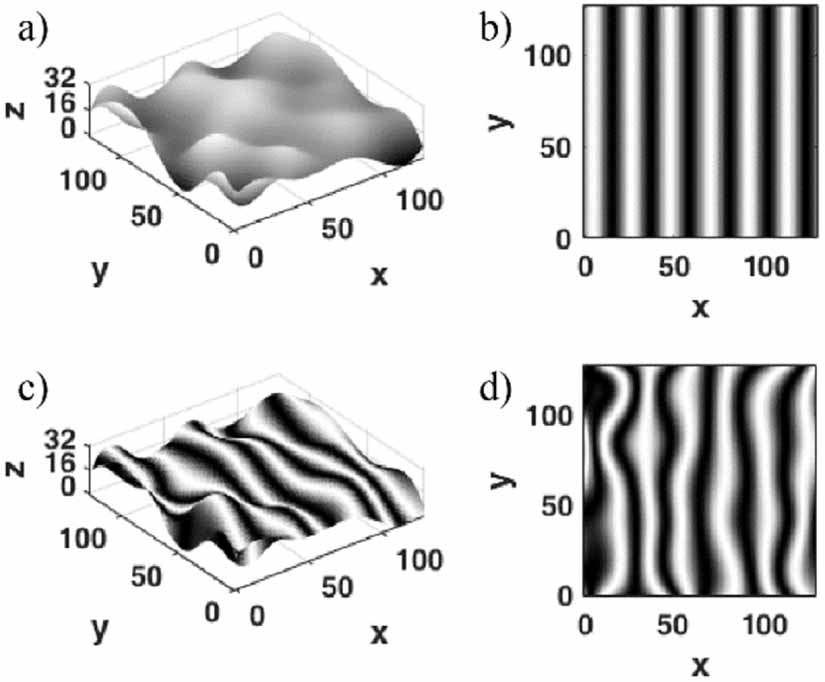
We use a dataset of simulated height maps with corresponding deformed fringe patterns as data couples to train the neural network. To automate the process of constructing a large training dataset, a random surface map generator is designed. Input parameters such as boundary limits, number of peaks, and sharpness or smoothness of the edges can all be set and are randomly varied within predefined limits to produce a set number of randomly varying 3D height maps. Reflectivity is assumed to be uniform and no additional noise is added to the simulated fringe maps. After the creation of a set of randomly fluctuating height maps, a predefined fringe pattern is projected virtually onto each height map and the resulting surface modulation is observed under a fixed angle α. Using straightforward triangulation, the modulated fringe pattern is sampled on a Cartesian grid. The complete process of data-couple generation is illustrated in figure 1.

Figure 1. Fringe modulation process. First, a randomly generated height map is generated (a). Next, a predefined sinusoidally modulated fringe pattern (b) is projected onto it, after which the resulting surface image (c) is observed under an angle α (here α = 30°). Finally, the deformed fringe pattern (d) is sampled onto a Cartesian grid and stored.
Download figure:
Standard image High-resolution imageThe simulated dataset used in this work aims to mimic images obtained with real SLP setups. Consequently, realistic values for fringe pattern frequency (six periods per image width), the angle between projection and observation axes (α = 30°), and maximum width to height ratio (4:1) are chosen in the generation of our dataset.  -values were confined to
-values were confined to ![$z \in {\mathbb{R}^3}\left[ {0,32} \right]$](https://content.cld.iop.org/journals/2515-7647/3/2/024014/revision3/jpphotonabf030ieqn19.gif) . Note that the maximum
. Note that the maximum  -value of 32 does not necessarily need to be attained for every surface map; it is simply the upper limit. The 4:1 ratio between image width and maximum surface height reduces the amount of shadows that may arise during the fringe modulation process. Deformed fringe patterns and height maps are each sampled on a grid of 128 × 128 pixels. After fringe modulation, volumetric boundary limits of the surface maps in our dataset are normalized to
-value of 32 does not necessarily need to be attained for every surface map; it is simply the upper limit. The 4:1 ratio between image width and maximum surface height reduces the amount of shadows that may arise during the fringe modulation process. Deformed fringe patterns and height maps are each sampled on a grid of 128 × 128 pixels. After fringe modulation, volumetric boundary limits of the surface maps in our dataset are normalized to ![$x,y,z \in {\mathbb{R}^3}\left[ {0,1} \right]$](https://content.cld.iop.org/journals/2515-7647/3/2/024014/revision3/jpphotonabf030ieqn21.gif) . For a more detailed description of the training data set generation, we refer the reader to [8].
. For a more detailed description of the training data set generation, we refer the reader to [8].
2.2. Network architecture
The neural network employed in this work is a modified version of the U-net proposed by Ronneberger et al [21]. A schematic representation of its architecture is shown in figure 2. The modified U-net can be divided symmetrically into a contracting path (encoder) and an expansive path (decoder). The contracting path consists of a succession of convolutional layers with 5 × 5 filters, each followed by a rectified linear unit (ReLu) activation function. After every two successive convolutional layers, a 2 × 2 max-pooling operation is applied. Together, two convolutional layers and one max-pooling layer form a downsampling block. Each downsampling block halves the spatial size of the input representation but doubles the number of feature maps, starting with four feature maps for the first block, eight for the second, and so on. The purpose of the contracting path is to capture the context of the input image by increasing the receptive field of the feature maps. By doubling the number of feature maps with each downscaling block, the architecture can detect the complex structures that are present in the input image more efficiently [22]. The expansive path is symmetrically identical to the contracting path, except that the max-pooling operations are replaced by a 2 × 2 deconvolutional layer that precedes the convolutional layers in each upsampling block. The deconvolutional (or transposed convolutional) layers upsample the input feature map by a factor of 2. With each deconvolutional operation, the number of feature maps is halved until finally a single convolutional layer with a 1 × 1 filter is applied to the output of the last upsampling block. By using a symmetric network architecture, the modified U-net produces an output image of identical size as the input image.

Figure 2. Network architecture of the modified U-net. Three downsampling and three upsampling blocks are placed symmetrically between input and output images. Downsampling blocks consist of two convolutional layers followed by a 2 × 2 max-pooling layer, upsampling blocks consist of two convolutional layers preceded by a deconvolutional layer. ReLu activation functions are used after each convolutional layer, except for the final single-channel convolutional layer.
Download figure:
Standard image High-resolution imageNote that each upsampling block has access to the output feature map of its corresponding downsampling counterpart through concatenated skip connections between them. This allows the expansive path to reuse the previously learned local features, allowing information to be retained directly from previous layers of the network. In total, our model contains 78 997 free parameters.
2.3. Loss functions
2.3.1.
 and
and


Single-shot deep learning-based profilometry aims to learn a mapping function  that transforms a 2D modulated fringe map (
that transforms a 2D modulated fringe map ( ) to a continuous 3D height distribution (
) to a continuous 3D height distribution ( ) without any additional intermediary processing steps. The loss function is the metric that defines how close the predicted height map
) without any additional intermediary processing steps. The loss function is the metric that defines how close the predicted height map  is to the ground truth
is to the ground truth  . Common metrics that are used as loss function in the training of neural networks are
. Common metrics that are used as loss function in the training of neural networks are  or mean absolute error (MAE) and
or mean absolute error (MAE) and  or MSE:
or MSE:


with  the number of data points. From their definitions, some properties of
the number of data points. From their definitions, some properties of  - and
- and  -norms can be deducted when they are used as loss function in deep learning models. First, it can be seen that
-norms can be deducted when they are used as loss function in deep learning models. First, it can be seen that  is more sensitive to outliers in the dataset compared to
is more sensitive to outliers in the dataset compared to  since the differences between prediction and ground truth are squared. As a result,
since the differences between prediction and ground truth are squared. As a result,  will adjust the model to minimize the error caused by these single outlier cases at the expense of many other data points if they contribute only little to the general error. On the other hand,
will adjust the model to minimize the error caused by these single outlier cases at the expense of many other data points if they contribute only little to the general error. On the other hand,  -norms produce less stable solutions, meaning that for a small horizontal adjustment of a single data point the slope of the regression line between data samples may jump a large amount. Selection between
-norms produce less stable solutions, meaning that for a small horizontal adjustment of a single data point the slope of the regression line between data samples may jump a large amount. Selection between  and
and  -norms as loss function of choice in a deep learning model is made primarily based on this trade-off between robustness and stability and which of these properties is more desirable for the given minimization problem.
-norms as loss function of choice in a deep learning model is made primarily based on this trade-off between robustness and stability and which of these properties is more desirable for the given minimization problem.
2.3.2. SSIM and MS-SSIM
The structural similarity index (SSIM) is a metric that is frequently used as loss function in single-image super-resolution models [23] and other tasks that involve human perceptual judgment. The SSIM and its multi-scale variant MS-SSIM are loss functions that, unlike  and
and  , are based on the human visual system as they aim to match the luminance
, are based on the human visual system as they aim to match the luminance  , contrast
, contrast  and structural information
and structural information  between images. The SSIM is defined as:
between images. The SSIM is defined as:

with



The variables  ,
,  ,
,  and
and  denote mean pixel intensity and standard deviations of pixel intensity in a local image patch at either
denote mean pixel intensity and standard deviations of pixel intensity in a local image patch at either  or
or  , respectively. In the following, we choose a square region of 3 pixels on either side of
, respectively. In the following, we choose a square region of 3 pixels on either side of  or
or  , which results in patches of 7 × 7 pixels. The variable
, which results in patches of 7 × 7 pixels. The variable  denotes the sample correlation coefficient between corresponding pixels in the patches centered at
denotes the sample correlation coefficient between corresponding pixels in the patches centered at  and
and . The constants
. The constants  ,
, and
and  are small constant values that are added for numerical stability and
are small constant values that are added for numerical stability and  ,
,  and
and  define the weights given to each component of the SSIM.
define the weights given to each component of the SSIM.
The SSIM metric assumes a fixed image sampling density and is a single-scale index. An extension to this metric is the multi-scale variant MS-SSIM, which can operate at multiple scales simultaneously. The ground truth image  and its candidate approximation image
and its candidate approximation image  are both iteratively downsampled by a factor of 2. The contrast
are both iteratively downsampled by a factor of 2. The contrast  and structural
and structural  components are applied at all scales. The luminance component
components are applied at all scales. The luminance component  , however, is only applied at the coarsest scale, denoted
, however, is only applied at the coarsest scale, denoted  . Again, the weighting of the different components is allowed at each scale, leading to the following definition of the MS-SSIM:
. Again, the weighting of the different components is allowed at each scale, leading to the following definition of the MS-SSIM:

Note that both SSIM and MS-SSIM are normalized to ![$\left[ {0,1} \right]$](https://content.cld.iop.org/journals/2515-7647/3/2/024014/revision3/jpphotonabf030ieqn68.gif) where 1 indicates a full correspondence between
where 1 indicates a full correspondence between  and
and  . Since the loss function employed in a neural network is to be minimized, we use 1–SSIM and 1–MS-SSIM instead.
. Since the loss function employed in a neural network is to be minimized, we use 1–SSIM and 1–MS-SSIM instead.
2.3.3. Mean gradient error (MGE) and mixed gradient error (MixGE)
In SLP, we are mainly concerned about relative phase differences. Two surface shapes can be assumed to be identical if their pixel-wise phase difference is a constant value: subtracting the minimum, mean or maximum value of the surface map from each pixel value suffices to unwrap the phase map of dynamically moving surface shapes temporally. It, therefore, makes sense to incorporate the local gradient of the prediction ( ) and the ground truth (
) and the ground truth ( ) surface maps directly into the loss function. Inspired by [24], we introduce classic gradients to the loss function using Sobel operators:
) surface maps directly into the loss function. Inspired by [24], we introduce classic gradients to the loss function using Sobel operators:


where  denotes the convolution operator. Together, the gradients
denotes the convolution operator. Together, the gradients  and
and  are combined into the general pixel-wise gradient map
are combined into the general pixel-wise gradient map  . Likewise, the gradient map
. Likewise, the gradient map  of the predicted surface map
of the predicted surface map  can be calculated. The MGE can then be defined as:
can be calculated. The MGE can then be defined as:

Using the MGE directly as a stand-alone loss function of the neural network would result in divergence of the model since the DC component is completely removed from the solution. The MGE can, however, be used as an auxiliary component by adding it to the standard  -norm in the creation of a MixGE:
-norm in the creation of a MixGE:

where ![$\lambda \in \left[ {0,1} \right]$](https://content.cld.iop.org/journals/2515-7647/3/2/024014/revision3/jpphotonabf030ieqn80.gif) is the gradient error weight factor that needs to be optimized in function of the employed model architecture and dataset.
is the gradient error weight factor that needs to be optimized in function of the employed model architecture and dataset.
2.4. Training the network
To train our network, a dataset of Ntotal = 12 500 simulated data couples is created using the automated surface generator. The number of local surface maxima and minima that are present in the simulated height maps varies randomly between 0 (flat planes of random height) and 15 (highly fluctuating landscapes). Either linear or spline interpolation is used randomly to sample the simulated surfaces on a 128 × 128 grid between the minima and maxima, resulting in a mix of surface maps containing both sharp and smooth edges, respectively. A training dataset of Ntrain = 10 000 simulated input-output pairs is used to train the network and a validation dataset of Nval = 2500 simulated input-output pairs is used to test the performance of the model on previously unseen data.
The Tensorflow framework [25] is used to train the modified U-net. The batch size is set at 4 and roughly 100 full passes (or epochs) through the training dataset are completed, depending on the individual convergence of the network trained with each employed loss function. We use Adam optimization with an initial learning rate of 10−4. Before training, the initial values of the filter weights are set using Xavier initialization to ensure equal variance between successive layers. To regularize training and to reduce overfitting, L2 weight decay is used with an initial setting of 10−3. After every 50 000 iterations, the learning rate is divided by 5, and L2 penalties are divided by 10. During the final set of iterations, L2 penalties are set to 0. The number of training iterations was chosen so that for each loss function investigated in this paper ( ,
,  , SSIM, MS-SSIM, and MixGE), the validation error reached convergence. Convergence is defined here at the point where the validation error does not improve for five consecutive epochs. In addition, validation curves are monitored to confirm the general converging behavior of the network and to ensure that no faulty divergence is occurring. Our implementation uses cuDNN and is optimized for parallel execution. The training time of a single model varies depending on the employed loss function. In total, the training time for a single model ranges between 34 min (MAE), 35 min (MSE), 36 min (MixGE), 42 min (SSIM), and 62 min (MS-SSIM) when deployed on a Titan X Pascal GPU. These convergence times correspond to a total number of training epochs of 98, 102, 92, 106, and 119 for networks trained using
, SSIM, MS-SSIM, and MixGE), the validation error reached convergence. Convergence is defined here at the point where the validation error does not improve for five consecutive epochs. In addition, validation curves are monitored to confirm the general converging behavior of the network and to ensure that no faulty divergence is occurring. Our implementation uses cuDNN and is optimized for parallel execution. The training time of a single model varies depending on the employed loss function. In total, the training time for a single model ranges between 34 min (MAE), 35 min (MSE), 36 min (MixGE), 42 min (SSIM), and 62 min (MS-SSIM) when deployed on a Titan X Pascal GPU. These convergence times correspond to a total number of training epochs of 98, 102, 92, 106, and 119 for networks trained using  ,
,  , MixGE, SSIM, and MS-SSIM, respectively.
, MixGE, SSIM, and MS-SSIM, respectively.
3. Results
3.1. Optimization of gradient weight

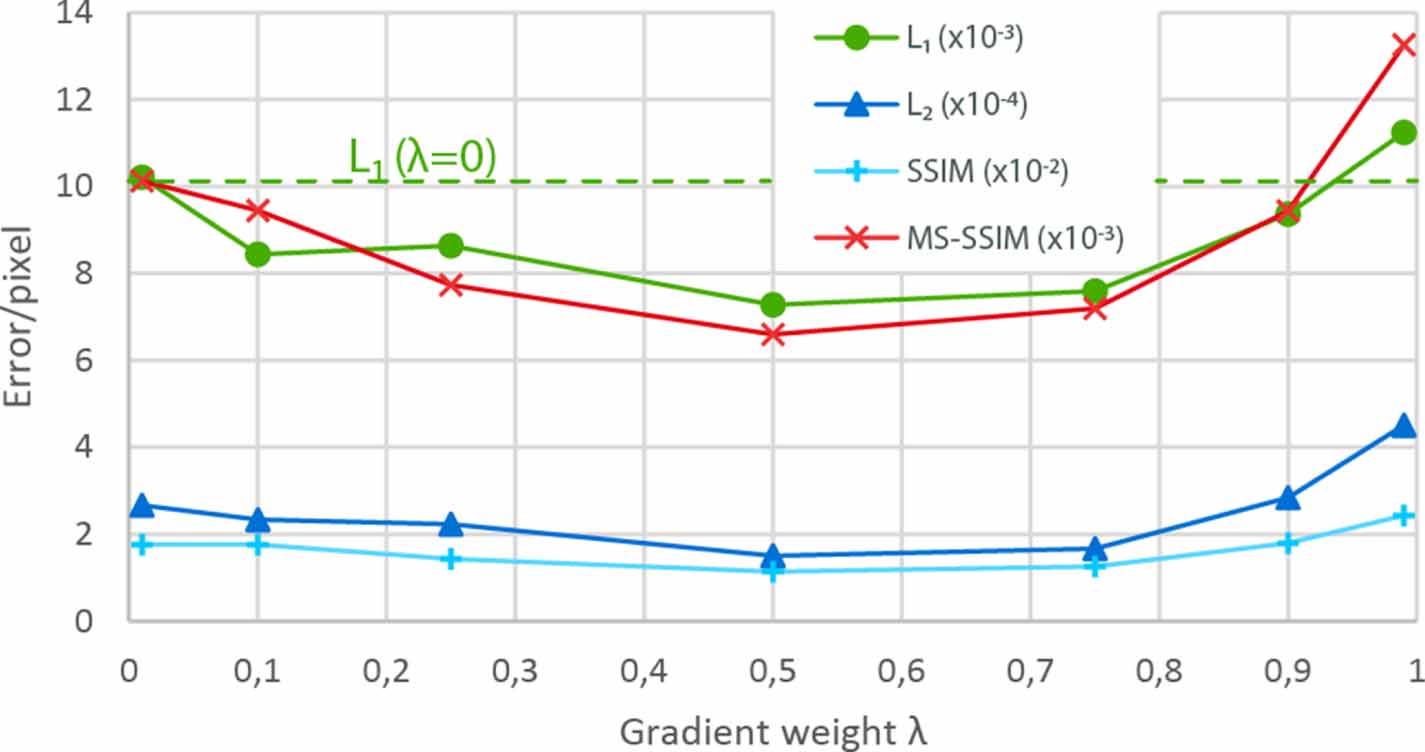
First, the modified U-net model was trained using various ratios of MGE/ to find the optimal contribution of the MGE component to the total MixGE. Several values of
to find the optimal contribution of the MGE component to the total MixGE. Several values of  ranging from 0 to 0.99 were used in equation (6) to modify the impact of the MGE component. Each resulting MixGE loss function was used to train the model to convergence on a fixed dataset. Upon convergence, the model performance was evaluated on the validation data set using the
ranging from 0 to 0.99 were used in equation (6) to modify the impact of the MGE component. Each resulting MixGE loss function was used to train the model to convergence on a fixed dataset. Upon convergence, the model performance was evaluated on the validation data set using the  ,
, , SSIM, and MS-SSIM metrics. The result is shown in figure 3. The models trained with the MixGE outperform those trained with standard
, SSIM, and MS-SSIM metrics. The result is shown in figure 3. The models trained with the MixGE outperform those trained with standard  loss up to a value of
loss up to a value of  ≈ 0.95. Beyond this point, the MGE component becomes too dominant over the DC component provided by
≈ 0.95. Beyond this point, the MGE component becomes too dominant over the DC component provided by  , resulting in divergence of the model and a steep increase in prediction error. Although the various metrics provide different evaluations of the models trained using the differently weighted MixGE loss functions, they all reach a minimum error per pixel when
, resulting in divergence of the model and a steep increase in prediction error. Although the various metrics provide different evaluations of the models trained using the differently weighted MixGE loss functions, they all reach a minimum error per pixel when  is chosen between
is chosen between  = 0.40 and
= 0.40 and  = 0.60. In the following, we will use a gradient weight of
= 0.60. In the following, we will use a gradient weight of  = 0.50 in the MixGE loss function.
= 0.50 in the MixGE loss function.

Figure 3. Optimization of the gradient weight  shows an optimal region between
shows an optimal region between  = 0.4 and
= 0.4 and  = 0.6 for which the error per pixel of the model trained with the mixed gradient error reaches the minimum for various metrics.
= 0.6 for which the error per pixel of the model trained with the mixed gradient error reaches the minimum for various metrics.
Download figure:
Standard image High-resolution image3.2. Performance of various loss functions
The modified U-net was trained to convergence using each of the  ,
,  , SSIM, MS-SSIM, and MixGE loss functions. The performance of each trained model was evaluated by comparing the height map predictions (
, SSIM, MS-SSIM, and MixGE loss functions. The performance of each trained model was evaluated by comparing the height map predictions ( ) of the samples in the validation set to their respective ground truth (
) of the samples in the validation set to their respective ground truth ( ) height maps using each of the corresponding metrics of
) height maps using each of the corresponding metrics of  ,
,  , SSIM, MS-SSIM, and MixGE. The resulting error values were averaged over the entire validation set and are included in table 1.
, SSIM, MS-SSIM, and MixGE. The resulting error values were averaged over the entire validation set and are included in table 1.
Table 1. Evaluation of the modified U-net trained using different loss functions. Top: the general average of the model performance on the entire validation dataset. Middle: model performance on a validation subset composed of entirely spline-interpolated surface maps. Bottom: model performance on a validation subset composed of entirely linearly interpolated surface maps.
| Loss function | |||||
|---|---|---|---|---|---|
| Metric | L1 | L2 | SSIM | MS-SSIM | MixGE |
| General | |||||
| L1 (×10−3) | 10.01 | 10.52 | 13.40 | 11.21 | 7.27 |
| L2 (×10−4) | 2.45 | 1.62 | 1.81 | 1.74 | 1.49 |
| SSIM (×10−2) | 1.83 | 1.85 | 1.25 | 1.27 | 1.13 |
| MS-SSIM (×10−3) | 10.03 | 8.52 | 6.84 | 6.49 | 6.59 |
| MixGE (×10−3) | 2.41 | 2.56 | 2.45 | 2.28 | 2.09 |
| Spline | |||||
| L1 (×10−3) | 10.04 | 10.21 | 12.93 | 11.44 | 7.35 |
| L2 (×10−4) | 2.50 | 1.56 | 1.77 | 1.76 | 1.46 |
| SSIM (×10−2) | 1.81 | 1.72 | 1.24 | 1.26 | 1.17 |
| MS-SSIM (×10−3) | 10.44 | 8.14 | 6.87 | 6.29 | 6.65 |
| MixGE (×10−3) | 2.40 | 2.46 | 2.40 | 2.31 | 2.11 |
| Linear | |||||
| L1 (×10−3) | 10.01 | 11.46 | 13.52 | 11.11 | 7.15 |
| L2 (×10−4) | 2.41 | 1.69 | 1.78 | 1.73 | 1.57 |
| SSIM (×10−2) | 1.87 | 2.02 | 1.25 | 1.27 | 1.08 |
| MS-SSIM (×10−3) | 9.89 | 8.98 | 6.89 | 6.60 | 6.52 |
| MixGE (×10−3) | 2.48 | 2.88 | 2.46 | 2.23 | 2.08 |
The top part of table 1 (General) represents the performance matrix over the entire validation dataset, containing 2500 simulated height map samples with a random mix of both smooth (spline-interpolated) and sharp (linearly interpolated) edges. The MixGE loss function outperforms the other loss functions on this general population of height maps by a significant margin, even when the evaluation metric is the same as the one that was used as loss function in the training of the model. Only when the MS-SSIM metric is used, the model trained with the MixGE loss function is scored second best after the MS-SSIM loss function itself. Top performing metric is underlined.
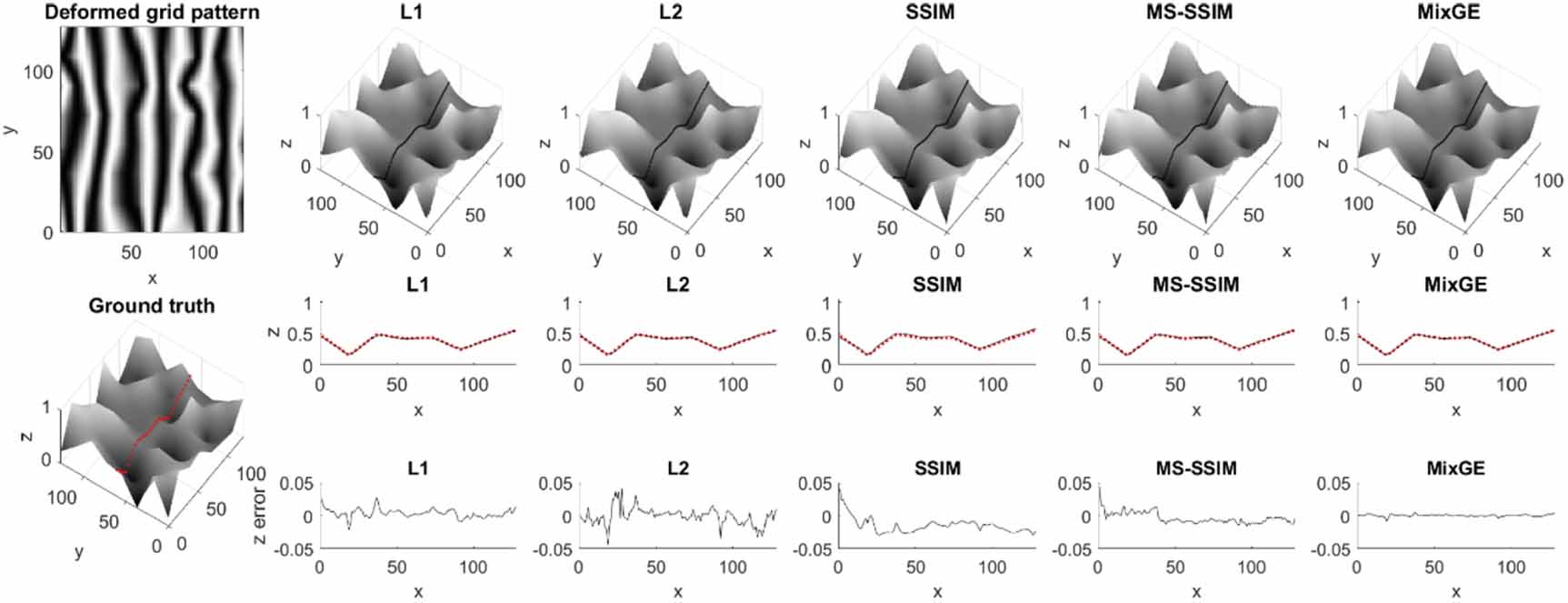
To further investigate the effect of surface shape variation on loss function performance, two additional validation datasets of each N = 1000 data couples were created using the random surface map generator: one in which only spline interpolation was used to connect the peaks and troughs present in the height map, and one in which only linear interpolation was used. From the middle and bottom parts of table 1, a large discrepancy can be observed between  -performance on samples with smooth edges (Spline) and those with sharp edges (Linear). For all metrics,
-performance on samples with smooth edges (Spline) and those with sharp edges (Linear). For all metrics,  performs significantly worse on surfaces with sharp edges than it does on surfaces with smooth edges. This behavior is reflected in the samples illustrated in figures 5 and 6. Whereas models trained with
performs significantly worse on surfaces with sharp edges than it does on surfaces with smooth edges. This behavior is reflected in the samples illustrated in figures 5 and 6. Whereas models trained with  , SSIM, MS-SSIM, and MixGE loss functions perform similarly on spline-interpolated height maps (figure 4) as on linearly interpolated height maps (figure 5), the model trained with
, SSIM, MS-SSIM, and MixGE loss functions perform similarly on spline-interpolated height maps (figure 4) as on linearly interpolated height maps (figure 5), the model trained with  -loss produces a larger error when applied to predict height maps with sharp edges than when applied to predict height maps with smooth, curved edges.
-loss produces a larger error when applied to predict height maps with sharp edges than when applied to predict height maps with smooth, curved edges.

Figure 4. Sample from the validation set composed of spline-interpolated height maps.  - and
- and  -coordinates are displayed as pixel numbers on a 128 × 128 grid;
-coordinates are displayed as pixel numbers on a 128 × 128 grid;  -values are normalized to [0, 1].
-values are normalized to [0, 1].
Download figure:
Standard image High-resolution image
Figure 5. Sample from the validation set composed of linearly interpolated height maps.  -loss struggles to resolve the sharp edges present in the height map and produces a higher error.
-loss struggles to resolve the sharp edges present in the height map and produces a higher error.  - and
- and  -coordinates are displayed as pixel numbers on a 128 × 128 grid;
-coordinates are displayed as pixel numbers on a 128 × 128 grid;  -values are normalized to [0, 1].
-values are normalized to [0, 1].
Download figure:
Standard image High-resolution image
Figure 6. Mannequin doll head sample obtained with standard 4-step phase-shifting profilometry demonstrates superior prediction performance of the model trained with MixGE loss function.  - and
- and  -coordinates are displayed as pixel numbers on a 128 × 128 grid;
-coordinates are displayed as pixel numbers on a 128 × 128 grid;  -values are normalized to [0, 1].
-values are normalized to [0, 1].
Download figure:
Standard image High-resolution imageTo highlight the superior performance of MixGE over the other loss functions, we include the measurement of the surface shape of a mannequin doll head in figure 6. The ground truth 3D surface measurement was obtained using four-step phase-shifting profilometry. Parts of the surface map where shadows, saturated reflections or any other regions of invalid data corrupted the 3D measurement were interpolated in post-processing. It can be seen that the model trained with MixGE does a significantly better job of predicting the mannequin doll surface shape than the models trained with the other loss functions. It should be noted that a clear linear error is present across all prediction maps, including the one reconstructed with the MixGE loss. This may be due to the strong localized height variations near and above the eye region of the mannequin head model. In the training dataset, no samples with such relatively large jumps in Z-value have been included and none of the loss functions seem to handle these properly.
Finally, to assess how the different loss functions are influenced by the presence of noise in the fringe patterns, an additional validation set of N = 1000 data couples was generated in which each input fringe map contained Poisson noise with the pixel value as the mean (before normalization). The corresponding error matrix is included in table 2 and a random sample from the validation set is shown in figure 7. First of all, it can be seen that the models trained with the  ,
,  and MixGE loss functions are able to extract the general form of the 3D map sufficiently well. As the neural network was trained to produce smooth, noise-free surface maps only, the predicted height maps are largely noise-free even when the input maps themselves are not. This way, noise filtering is implicitly learned by the network. The models trained with the SSIM-based losses, however, are more affected by the increased noise level. It should be noted that we assess 'pure' SSIM loss-prediction accuracy here: a mixed loss function containing an additional contribution of
and MixGE loss functions are able to extract the general form of the 3D map sufficiently well. As the neural network was trained to produce smooth, noise-free surface maps only, the predicted height maps are largely noise-free even when the input maps themselves are not. This way, noise filtering is implicitly learned by the network. The models trained with the SSIM-based losses, however, are more affected by the increased noise level. It should be noted that we assess 'pure' SSIM loss-prediction accuracy here: a mixed loss function containing an additional contribution of  - or
- or  -loss might alleviate this oversensitivity to the added shot noise of the SSIM-family of loss functions. It can be seen from table 2 that MixGE outperforms all other loss functions by a significant margin.
-loss might alleviate this oversensitivity to the added shot noise of the SSIM-family of loss functions. It can be seen from table 2 that MixGE outperforms all other loss functions by a significant margin.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 7. Sample from the validation set composed of input fringe maps that were corrupted with Poisson noise. The models trained with  -and MixGE-loss functions are relatively unaffected by the added noise, but the models trained with SSIM-based loss functions experience larger structural errors.
-and MixGE-loss functions are relatively unaffected by the added noise, but the models trained with SSIM-based loss functions experience larger structural errors.  - and
- and  -coordinates are displayed as pixel numbers on a 128 × 128 grid;
-coordinates are displayed as pixel numbers on a 128 × 128 grid;  -values are normalized to [0, 1].
-values are normalized to [0, 1].
Download figure:
Standard image High-resolution image{kind=link}
Table 2. Evaluation of the modified U-net trained using different loss functions when Poisson noise is added to the deformed fringe patterns.
| Loss function | |||||
|---|---|---|---|---|---|
| Metric | L1 | L2 | SSIM | MS-SSIM | MixGE |
| Poisson noise | |||||
| L1 (×10−3) | 10.66 | 10.92 | 18.23 | 19.48 | 9.13 |
| L2 (×10−4) | 3.08 | 1.92 | 4.72 | 4.26 | 1.78 |
| SSIM (×10−2) | 2.14 | 2.15 | 1.41 | 1.55 | 1.33 |
| MS-SSIM (×10−3) | 10.98 | 9.01 | 7.90 | 7.14 | 7.07 |
| MixGE (×10−3) | 2.74 | 2.93 | 2.93 | 5.77 | 2.28 |
4. Conclusion
We demonstrated that careful selection of the loss function can considerably improve the prediction accuracy of a neural network that is trained to reconstruct height maps from single deformed fringe patterns. Our results show clearly that the performance of the commonly used  -loss is highly dependent on the nature of the surface shape: it performs significantly better when applied to height maps with curved, smooth surface variations than it does on surfaces with sharp edges. We introduced the MixGE loss function, which takes into account the local gradient variations of the height maps, and showed that it outperforms any previously used loss functions in deep learning profilometry.
-loss is highly dependent on the nature of the surface shape: it performs significantly better when applied to height maps with curved, smooth surface variations than it does on surfaces with sharp edges. We introduced the MixGE loss function, which takes into account the local gradient variations of the height maps, and showed that it outperforms any previously used loss functions in deep learning profilometry.
Acknowledgments
S Van der Jeught and P Muyshondt thank the Research Foundation—Flanders (FWO) for their financial support. The Titan X GPU used for this research was donated by the NVIDIA Corporation.
Data availability statement
The data that support the findings of this study are available upon reasonable request from the authors.