
Optimizing Expected Shortfall under an ℓ1 Constraint—An Analytic Approach


1
Institute for Physics, Eötvös Loránd University, 1117 Budapest, Hungary
2
Parmenides Foundation, 82049 Pullach, Germany
3
London Mathematical Laboratory, London W6 8RH, UK
4
Complexity Science Hub, Vienna 1080, Austria
5
Department of Computer Science, University College London, London WC1E 6BT, UK
6
Systemic Risk Centre, London School of Economics and Political Sciences, London WC2A 2AE, UK
*
Author to whom correspondence should be addressed.
Entropy 2021, 23(5), 523; https://doi.org/10.3390/e23050523
Submission received: 9 March 2021
/
Revised: 9 April 2021
/
Accepted: 22 April 2021
/
Published: 24 April 2021
(This article belongs to the Special Issue Three Risky Decades: A Time for Econophysics?)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Expected Shortfall (ES), the average loss above a high quantile, is the current financial regulatory market risk measure. Its estimation and optimization are highly unstable against sample fluctuations and become impossible above a critical ratio , where N is the number of different assets in the portfolio, and T is the length of the available time series. The critical ratio depends on the confidence level , which means we have a line of critical points on the plane. The large fluctuations in the estimation of ES can be attenuated by the application of regularizers. In this paper, we calculate ES analytically under an regularizer by the method of replicas borrowed from the statistical physics of random systems. The ban on short selling, i.e., a constraint rendering all the portfolio weights non-negative, is a special case of an asymmetric regularizer. Results are presented for the out-of-sample and the in-sample estimator of the regularized ES, the estimation error, the distribution of the optimal portfolio weights, and the density of the assets eliminated from the portfolio by the regularizer. It is shown that the no-short constraint acts as a high volatility cutoff, in the sense that it sets the weights of the high volatility elements to zero with higher probability than those of the low volatility items. This cutoff renormalizes the aspect ratio , thereby extending the range of the feasibility of optimization. We find that there is a nontrivial mapping between the regularized and unregularized problems, corresponding to a renormalization of the order parameters.
1. Introduction
A risk measure is a functional on the probability distribution of the fluctuating returns of a security or a portfolio. Since it is impossible to condense all the information in a probability distribution into a single number, there is no unique way to choose the “best” risk measure. In Markowitz’s ground breaking portfolio selection theory [1], with the assumption of Gaussian distributed returns, variance offered itself as the natural risk measure. The crises of the late eighties and early nineties led both the industry and regulators to realize that the most dangerous risk lurked in the asymptotically far tail of the return distribution. To grasp this risk, a high quantile of the profit and loss distribution called Value at Risk (VaR) was introduced by J.P. Morgan [2]. For a certain period, VaR became a kind of industry standard, and it was embraced by international financial regulation as the official risk measure in 1996 [3]. Value at Risk is a threshold which losses only exceed with a small probability (such as, e.g., 0.05 or 0.01), corresponding to a confidence level of , resp. . (In this context, it is customary to regard losses as positive and profits as negative). As a quantile, VaR is not sensitive to the distribution of losses above the confidence level and is not subadditive when two portfolios are combined. This triggered a search for alternatives and led Artzner et al. [4] to formulate a set of axioms that any coherent risk measure should satisfy. The simplest and most intuitive of these coherent measures is the Expected Shortfall (ES) [5,6]. ES is essentially the expected loss above a high quantile that can be chosen to be the VaR itself. After a long debate about the relative merits and drawbacks of ES, whose details are not pertinent to our present study, regulators adopted ES as the current official market risk measure to be used to assess the financial health of banks and determine the capital charge they are required to hold against their risks. The regulators and the industry settled on a confidence level of [7].
ES is mainly designed to be a diagnostic tool. At the same time, it is also a constraint that banks have to respect when considering the composition of their portfolios. It is then in their best interest to optimize ES, in order to keep their capital charge as low as possible. However, the optimization of ES is fraught with problems of estimation error, which is quite natural if one considers that the number of different items N in a bank’s portfolio can be very large, whereas the number of observations (the length of the available time series T) is always limited. In addition, at the regulatory confidence level, one has to throw away 97.5% of the data. Moreover, the estimation error increases with the ratio and at a critical value of r, it actually diverges, growing beyond any limit. As shown in [8], the instability of the optimization of ES (as well as all the coherent risk measures) follows directly from the coherence axioms [4].
The divergence of ES is the signature of a phase transition. The critical r for ES is smaller or equal to , its value depending on the confidence level . For ES, there is then a line of critical points, a phase diagram, on the plane. A part of this phase diagram has been traced out by numerical simulations in [9], while the full phase diagram has been determined by analytical calculations by Ciliberti et al. [10]. Going beyond merely determining the phase diagram, a detailed study of the estimation error and other relevant quantities has been performed inside the whole feasibility region in [11,12], and it was shown that, due to the nontrivial behavior of the contour lines of constant estimation error, especially in the vicinity of , the number of data necessary to have a reasonably low estimation error was way above any T available in practice.
Because of the large sample fluctuations of ES, its optimization constitutes a problem in high dimensional statistics [13]. A standard tool to tame these large fluctuations is to introduce regularizers, which penalize large excursions. Although the introduction of these penalties may seem an arbitrary statistical trick coming from outside of finance, it was shown in [14] that these regularizers express liquidity considerations, and take into account, already at the construction of the portfolio, the expected market impact of a future liquidation. The regularizers are usually chosen to be some constraints on the norm of the portfolio weights. In [15], we studied the effect of an regularizer on ES and found that obviously suppresses the instability and, for sufficiently small r and with a strong enough regularizer, it extends the range where the estimation error is reasonably small by a factor of about 4.
It is interesting to see how an regularizer works with ES. (The importance of studying the effect of various regularizers in combination with the different risk measures was emphasized by [16]). The regularizer is known to produce sparse solutions, which means that in order to rein in large fluctuations, it eliminates some of the securities from the portfolio. This obviously contradicts the principle of diversification, but considerations of transaction costs or the technical difficulties of managing large portfolios may make it desirable to remove the most volatile items from the portfolio, and this is precisely what a no-short constraint tends to do.
It has been known for 20 years now that the optimization of ES can be translated into a linear programming problem [17]. Accordingly, as it has been realized in [18], the piece-wise linear with an infinite slope corresponding to an infinite penalty on short selling can prevent the instability of ES. The purpose of this paper is to determine the effect of -regularization on the phase diagram and also on the behavior of the various quantities of interest inside the region where the optimization of ES is feasible and meaningful. (We will see that as a result of regularization new characteristic lines appear on the plane, beyond which the optimization of ES is still mathematically feasible, but the results become meaningless, as they correspond to negative risk.) In [12], a detailed analytical investigation of the behavior of the estimation error, the in-sample cost, the sensitivity to small changes in the composition of the portfolio, and the distribution of optimal weights were carried out in the non-regularized case. Here, we derive the same quantities for an -regularized ES, including the special case where short selling is banned, that is when the portfolio weights are constrained to be non-negative. The density of the items eliminated from the portfolio, to be referred to as the “condensate” in the following, is also determined. The most striking result of the present study is that the regularized solution can be mapped back onto the unregularized one. We are not aware of a similarly tight relationship between a regularized and an unregularized problem, not only in a finance context, but neither in the general context of machine learning.
2. Method and Preliminaries
If the true probability distribution of returns were known, it would be easy to calculate the true value of Expected Shortfall and the optimal portfolio weights. However, the true distribution of returns is unknown, therefore one has to rely on finite samples of empirical data. This means one observes N time series of length T and estimates the optimal weights and ES on the basis of this information. It is clear that the weights and ES so obtained will deviate from their “true” values. (The latter would be obtained in an infinitely long stationary sample.) The deviation of the estimated values will be the stronger the shorter the length T and the larger the dimension N. Performing this measurement on different samples one would obtain different estimates: there is a distribution of ES and of the optimal weights over the samples. In a real market, one cannot repeat such an experiment multiple times. Instead, one has to squeeze out as much information as possible from a single sample of limited size. There are well-known numerical methods for this, like cross-validation or bootstrap [19]. In contrast, in the present work we aim to obtain analytic results. In order to mimic empirical sampling, we choose a simple data generating process, such as a multivariate Gaussian. The true value of ES is easy to obtain for this case, which provides a standard to measure finite sample deviations from. Then we determine ES for a large number of random samples of length T drawn from this underlying distribution, average it over the random samples and finally compare this average to its true value. This procedure will give us an idea about how large the estimation error is for a given dimension N, sample size T, and confidence level , under the idealized conditions of stationarity and Gaussian fluctuations, and how much it will be reduced when we apply an regularizer of a given strength. It is reasonable to assume that the estimation error obtained under these idealized circumstances will be a lower bound to the estimation error for real-life processes.
Now we wish to implement this program via analytic calculations. The averaging over the random samples just described is analogous to the averaging over the random realization of disorder in the statistical physics of random systems, which enables us to borrow methods from that field, in particular the replica method [20]. It assumes that both N and T are large, with their ratio kept finite (thermodynamic or Kolmogorov limit). A small value of r corresponds to the classical setup in statistics where one has a large number of observations relative to the dimension. Estimates in this case are sharp and close to their true values. In contrast, when r is of order unity, or larger, we are in the high dimensional limit where fluctuations are large. It is here that the regularizer becomes important.
In the usual application of in finite dimensional numerical studies, the regularizer eliminates the dimensions one by one, in a stepwise manner, as the strength of the regularizer is increasing. In our present work, the large limit and the averaging over infinitely many samples result in a continuous dependence of the “condensate” density (the relative number of the dimensions eliminated by ) on the aspect ratio r, the confidence level , and the strength of . In a study of -regularized variance [21], we found that the stepwise increase of the density of eliminated weights in a numerical experiment nicely follows the continuous curve obtained analytically. It is obvious that the situation is similar in the case of ES, but we have also confirmed this by numerical simulations.
For the sake of simplicity, we will also assume that the returns are independent, that is the true covariance matrix is diagonal. This is not an innocent assumption: it will be seen, for example, that the maximum degree of sparsity that can achieve in this scheme is one half of the total number of dimensions, whereas for correlated returns the maximum sparsity can be either larger or smaller than , according to whether correlations are predominantly positive or negative. Combining with a non-diagonal covariance matrix poses additional technical difficulties that we wish to avoid in the present account. However, we do allow the diagonal elements of the covariance matrix to be different from each other.
As a further simplification, we do not impose any other constraint on the optimization of ES beside the budget constraint and the regularizer. In particular, we do not set a constraint on the expected return, and seek the global minimum of the regularized ES. This is in line with a number of studies, [22,23,24] among others, which focus on the global minimum in the problem of variance optimization, because of the extremely noisy estimates of the expected return. Furthermore, the global minimum is precisely what one needs in minimizing tracking-errors, that is, when trying to follow, say, a market index as closely as possible [23].
The replica method used below have already been applied with minor variations to various portfolio optimization problems in a number of papers [10,11,12,14,18,21,25,26,27,28], where the replica derivation of the main formulae were repeatedly explained, so we do not need to go through that exercise again here. Then the natural starting point for our present work is the detailed study of the behavior of ES without regularization in [12]. The argument there leads to a relationship between ES and an effective cost or free energy per asset f as follows:
The free energy f itself is given by the minimum of a functional depending on six order parameters
where
and the double average means
Finally, the function g in the integral in (2) is defined as
The differences with respect to the setup in [12] are the following: a trivial change of notation ( there is here); the variable has been introduced in (3), which together with the recipe (4) allows us to consider assets with different volatilities ; and the regularizer has been built into the effective potential (3). Note that the in (3) is asymmetric in order to allow us to penalize long and short positions separately. The usual corresponds to , the ban on short selling to . We will also use the arrangement where there is a finite penalty on short positions and none on long ones .
A note on signs: for consistency, the order parameters , , , and must be positive, negative, and can be of either sign. Furthermore, must be larger or equal to the right slope of the regularizer: .
Before setting out to derive the stationarity conditions that determine the optimal value of the free energy and thence of ES, we spell out the meaning of the order parameters. The first of these is the Lagrange multiplier that enforces the budget constraint:
Note that the sum of portfolio weights is set to N here, instead of the usual 1. This is to keep the weights of order unity in the large N limit.
Because of the relationship between and the budget constraint, can be thought of as a kind of chemical potential. It is an important quantity, because, as we shall see later, its value at the stationary point is equal to the free energy, hence directly related to the optimal value of ES. In [12], we argued that this optimal value of ES is, in fact, the in-sample estimate of Expected Shortfall. According to (1), ES is proportional to the product , which means f, and hence too, must be inversely proportional to r when , because ES is certainly finite in this limit: a finite N and corresponds to the case of having complete information. This spurious divergence of f and is an artifact, due to our having absorbed a factor in their definition. This is explained purely by convenience: we wish to keep as close to the convention in [12] as possible. The opposite limit, when vanishes, is another important point: it signals the instability of the portfolio, and the onset of the phase transition.
The next order parameter, , was suggested by [17] as a proxy for Value at Risk. Indeed, in the limit where we know the true distribution of returns, will be seen to be equal to the known value of VaR for a Gaussian.
The third order parameter, , is of central importance: According to [12], the ratio of the out-of-sample estimate and its true value is given by the square root of . For the case of different s considered here, has to be amended by a factor depending on the structure of the portfolio [21] as
Then the ratio of the estimated and true ES will be
that is the relative estimation error is .
The fourth order parameter, , measures the sensitivity to a small shift in the returns.
The remaining two order parameters, and , are auxiliary variables that do not have an obvious meaning, they enter the picture through the replica formalism, and can be eliminated once the stationarity conditions have been established. The stationarity or saddle point conditions are derived by taking the derivative of the free energy with respect to the order parameters and setting them to zero. They will be written up in the next Section.
3. Results
First, we are going to spell out the saddle point conditions in full detail and reduce them to special cases later.
Let us bring the integral in (2) to a more convenient form by integrating by parts:
With this identity, the free energy becomes
The function W in the above formulae, together with two related functions and , will frequently appear in the following; they are integrals of the Gaussian :
Now we evaluate the minimum of V in (3) and denote the “representative weight” where this minimum is located by . It works out to be
or
With this and (4), one can calculate , the value of V at the minimum, and perform the double averaging to obtain
Then, the fully explicit form of the free energy becomes
It is now straightforward to take the derivatives of f with respect to the order parameters and derive the stationary conditions.
From , it follows that
The derivative with respect to yields
From the derivative with respect to , we get
As mentioned before, determines the out-of-sample estimate for ES and the estimation error.
The derivative with respect to leads to
where use has been made of the identity
The condition for the derivative with respect to to vanish is
The derivation of the last equation takes a little more effort. Let us go back to the free energy in (2) and take the derivative with respect to . Noticing that does not depend on , and using the integral given in (9), we have
valid at the stationary point. From here we find
where (9) was used again and we denoted by the integral I evaluated at the stationary point. Now we apply the identity (22) and the stationary conditions (23), (21) to arrive at
which, combined with (9), finally leads to
The Equations (18)–(23) and (27) constitute the system of equations for the six order parameters. These equations are valid both for the regularized and (setting ) for the unregularized cases.
Let us now work out the relationship between the free energy and the chemical potential. Comparing (16) and (20), we see that , which with (10) and (27), results in the simple formula
at the stationary point, as we anticipated before. In [12], we argued that the stationary value of f determines the in-sample estimate of ES through (1).
The last object to determine is the distribution of weights:
With (14), we find
where is the Dirac delta,
is the (estimated) variance of the ith return,
is the center of the Gaussian distribution of the (estimated) positive weight i,
is the same for negative weight i, and finally,
is the density of the assets whose weights are set to zero by the regularizer.
We wish to make an important remark here: the right hand side of (19) is just . This will prove to be the key to the mapping between the regularized and unregularized cases.
Let us record the condensate density also for the special case when short positions are excluded (), but long positions are not penalized ():
From (36), we can see that, since is monotonic increasing and, for , concave, the contribution to from assets with larger s is larger than that from smaller s. This means that in the no-short limit, the regularizer eliminates more volatile assets with larger probability than the less volatile ones. Thus, we can think of the no-short constraint as a smooth upper cutoff in volatility. This is not true in the generic case (35), where the contributions of the small and large volatility items depend on the order parameters and the regularizer’s slopes and in a complicated manner: the probability of an asset with volatility to be removed is given by the difference of the two term in (35) under the sum. We do not wish to analyze this situation in detail, apart from the remark that a sufficiently large generally favors the elimination of large volatility items.
The integral of is, of course, 1. Its first moment, , works out to be the same as (18):
The second moment of the weight distribution is readily obtained as
The variance of the weight distribution is then
which is equal to , when the variances of the assets are all equal to 1. For a portfolio with different ’s, however, the relevant quantity that determines the out-of-sample estimate of ES is not the second moment of the weight distribution, but the true variance of the ith asset multiplied by the estimated portfolio weights squared and summed over the different assets, that is
which is precisely as given in (20), and this is the quantity (multiplied by the correction as in (7)) that enters the formula for the out-of-sample estimate of ES in (8). For a not too inhomogeneous portfolio, the difference between the second moment of the weight distribution and is not significant, so we can think of as a measure of the variance of the portfolio.
Now we are ready to consider various special cases.
3.1. The Limit of Complete Information
When we have many observations (very long time series, ) relative to the dimension N of the portfolio, we are in the limit. As we have already mentioned, this also corresponds to the “chemical potential” going to infinity. Obviously, in this limit, the regularizer plays no role.
We need the asymptotic behavior of the functions appearing in our stationary conditions: for , , , and , while for , all three vanish exponentially.
Then from (18) we have
From (19)
Combining the two:
We know from (1) and (28) that must be inversely proportional to r when . It follows that for small r.
Then, from (20) we find
Combined with the previous equation, this gives
The “true” () value of the order parameter is thus determined by the structural constant , which is given by the variances of the returns . This is in accord with the corresponding result found in the case of the -regularized variance risk measure [21,29]. The above result for also means that the quantity introduced in (7) is equal to 1, and according to (8) the out-of-sample estimate of ES is equal to its true value , the estimation error is zero—an obvious result for the case of complete information.
From (23) with we obtain , or
Now from (21) we get , or
However, then we have found
Since and , we have the limit (the true value) of ES:
We record the limits of the two auxiliary variables, and , for completeness:
and
with a coefficient that will not be needed in the following.
Let us turn to the distribution of weights now.
In the limit, the widths of the Gaussians in (30) all vanish, so the Gaussians become delta functions:
In the limit, the weights are all positive, so the second sum disappears.
For the weights, we find
They sum to N, as stipulated.
The variance of a linear combination of independent random variables with averages and variances is
Now we recognize the meaning of the (true value of the) order parameter : it is the normalized (to ) variance of the portfolio. This also explains the correction factor appearing in (7). We also see that (46) and (49) are the standard expressions for Value at Risk and Expected Shortfall indeed.
We emphasize again that all the results presented in this subsection are only valid in the limit when we are dealing with a finite dimension N and infinitely long time series T.
For finite r, the sample fluctuations start to broaden the delta spikes in the distribution of weights, the condensation of zero weights begins, decreases, and all the formulae above become considerably more complicated. We turn to this situation in the next subsections.
By now, we have learned everything that was to be learned from keeping the variances different, in particular the tendency of the elimination of the most volatile assets by the regularizer in the case of restriction of short selling. In order to simplify the presentation and avoid the appearance of very large and hardly transparent formulae, henceforth we set all the ’s equal to 1. We stress, however, that the main message of this paper, namely the existence of a mapping between the regularized and unregularized cases, depends only on the structure of the equations, and works also with different ’s.
3.2. Without Regularization
In this subsection, we set , that is we consider our problem without regularization, and according to what has just been said, put . We will make use of the identities
The free energy (17) becomes
For the saddle point equations, we find:
These equations are rather similar to their counterparts in the previous subsection, but of course is not assumed here. As for their solutions, they were discussed and illustrated in several figures in [12], therefore we will not dwell upon them here. (Some results will be given in Section 3.6.) Instead, we write up the corresponding equations in the case where no short positions are allowed and make a term-by-term comparison between the two sets of equations.
3.3. No Short Selling
Short positions will be excluded by imposing infinite penalty on them by letting go to infinity. The functions , , and all vanish when . Long positions will not be penalized, so we set .
The free energy becomes
The stationary conditions now read as:
the last equation being the same as (64), just multiplied by r.
In the distribution of weights in (30), the second sum of Gaussians will disappear, because for , all the weights (34) go to infinity. The weights (33) become
while the density of zero weights is now
which with (68) leads to
From (74), we see that for and increases as decreases, until it reaches its maximal value when vanishes. Mathematically, there is nothing to prevent us from continuing to increase r and driving to negative values, which would allow to grow beyond , up to , but a negative would cause the free energy and thus also ES to change sign—an extreme case of “in-sample optimism”, entirely due to the lack of sufficient information. We consider such a situation “unphysical”, and never go beyond the point where (or if ) vanishes anywhere in this paper.
3.4. No-Short Mapping
We are now ready to spell out the mapping between the no-short case and the unregularized one.
The first point to notice is that the only difference between Equation (62) valid in the unregularized case and its counterpart (70) in the no-short case (combined with (75)) appears on their left hand side: the terms r and , respectively. This suggests to introduce an effective r:
Now , and is the density of the assets removed by the regularizer, thus is the number of surviving assets divided by the length of the time series. As increases from zero to , r will increase between zero and 1.
Inspired by the connection between r and , we compare the two sets of equations and recognize that, in fact, the whole system of saddle point equations can be mapped from the regularized case to the unregularized one. A variable that appears in all the subsequent equations is
where the variables and are those that appear in the no-short equations.
Then the connection between the order parameters belonging to the two cases is the following:
A direct substitution shows that if the order parameters on the left hand sides of the above equations satisfy the no-short equations, then the effective variables satisfy the unregularized ones, provided we also replace r with . In particular, the contour maps of the unregularized order parameters presented in [12] can be taken over and simply blown up by a factor to obtain the contour maps of the no-short variables. Given the relation between and the estimation error, we see that the mapping also means that a given error belongs to a larger r in the no-short case than in the unregularized one, in other words, the no-short constrained problem demands times less data (shorter time series) than the unregularized one.
One may wonder whether this mapping expresses some symmetry of the problem, that is whether the free energy functional is invariant under this mapping. The answer is no: the mapping works only in the saddle point equations, it is a property of the stationary point.
It is important to learn the range of this transformation. In the limit , the transformation is the identity, but this is trivial: when we have complete information, the regularizer does not play any role. It is more interesting to consider the vicinity of the phase transition in the unregularized case, where and diverge. These divergences are removed by the mapping, no singularity is found in the no-short case. This is in accord with [18]: the infinite penalty on short positions precludes the phase transition and no singularity shows up in , , or . Mathematically, we can continue the unregularized solutions into the non-feasible region beyond the phase boundary, but they make no sense there (for example, changes sign, and become imaginary, etc.), while their mapped counterparts continue to behave reasonably. According to (76), when reaches the critical point , the corresponding value of r in the no-short problem will be twice as large, so the whole phase diagram is multiplied by a factor 2. Beyond the mapped phase boundary the regularized solutions still survive, but their meaning becomes questionable, because the free energy, hence also ES change sign. As noted in the previous Subsection, we refrain from the discussion of this unphysical region.
3.5. Mapping for Generic Constraint
The mapping between the generic -constrained ES optimization and the unregularized one is a straightforward generalization of the results in the previous Subsection. The mapping is made more complicated because of the sums and differences of the , , and W functions appearing on the right hand side of Equations (18)–(20). We introduce the following notation for these combinations:
and
where we have set all the .
In terms of these quantities the generic map reads as
For the condensate density , we have
and for the effective aspect ratio
As before, if the order parameters satisfy the regularized stationarity conditions (18)–(27) (with ), then the effective parameters will satisfy the unregularized Equations (59)–(64), and vice versa.
Note that the above equations remain invariant if we redefine as and as . So we can set and without loss of generality. We will use this setup in the following, in order to reduce the number of parameters when solving the stationarity equations.
3.6. Solutions for the Order Parameters
Except for a few exceptional points, it is impossible to obtain the solutions of the stationarity equations in closed, analytical form, but it is perfectly possible to get them numerically, by a computer. (The case of is exceptional in several respects and will not be considered here.) In the following, the solutions will be presented in graphical form.
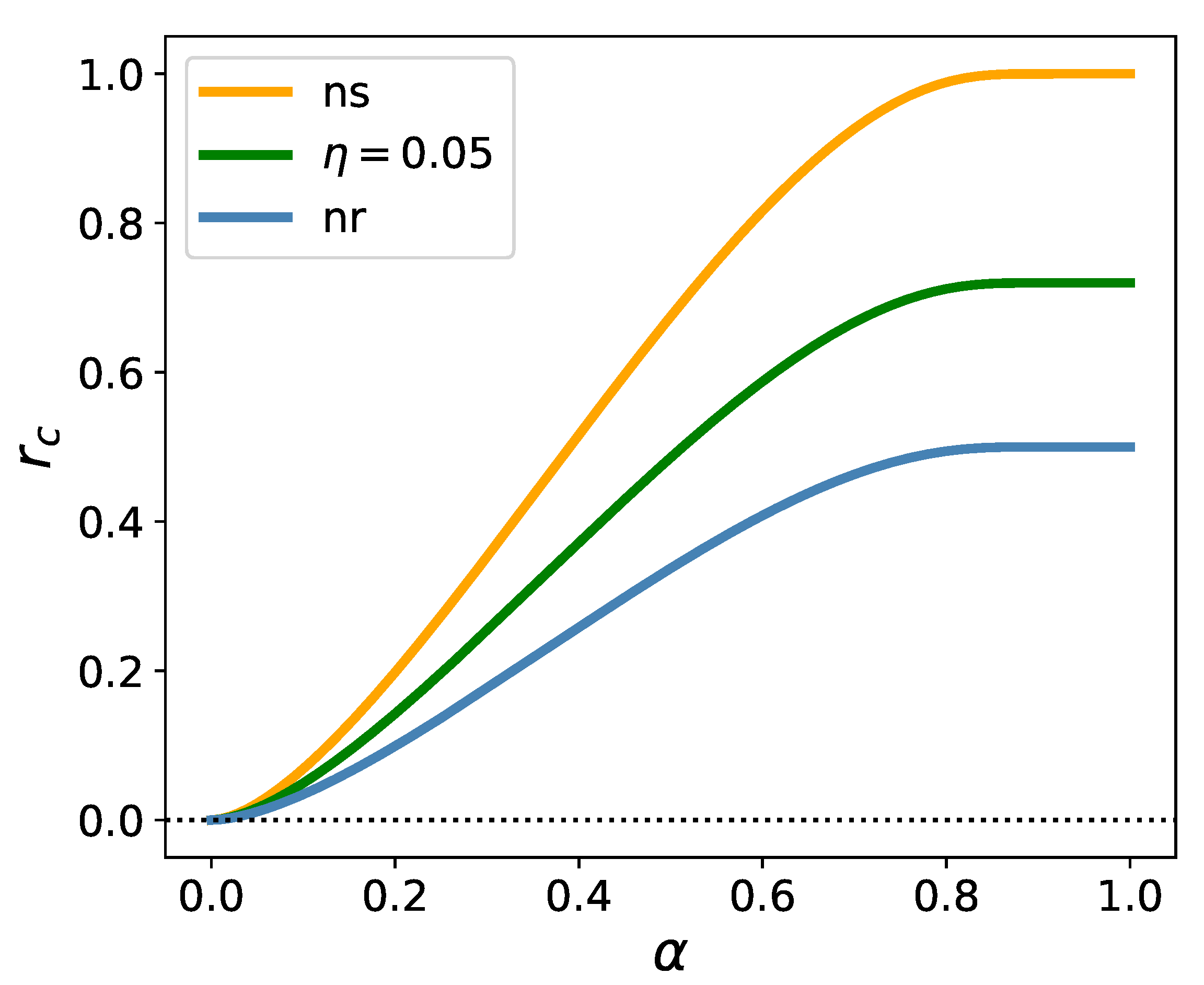
Figure 1 exhibits three special lines, belonging to three different cases: the unregularized case, the one with a finite regularizer, and the one with a no-short constraint.
The blue line is the upper boundary of the region where the optimization of unregularized ES is feasible. This line was first determined in [10]. It is a phase boundary, along which a phase transition takes place: , , and diverge here, while becomes zero. The unregularized equations can be solved also above this line, up to the horizontal line at (not shown in the Figure), but the solutions are meaningless: is negative, while , , and become imaginary. The unregularized equations do not have any solution above .
The green line is the image of the unregularized phase boundary under the mapping described in the previous Subsection, and corresponds to a one-sided regularizer with , . There is no phase transition when we cross this line, the order parameters remain smooth, finite quantities, but (along with the free energy and the in-sample estimate of ES) changes sign, rendering the solution in the region above the green line “unphysical”. Nevertheless, if we keep following the solutions beyond the green line we can go up to the image of the line (mapped into ), where and will ultimately diverge. The region between the green line and the image of the line has an intricate structure, but because it corresponds to negative risk, it is of no interest for us in the present context.
In the no-short case, there is always a solution with the order parameters remaining finite all the way up to infinity, which is the image of the line under the no-short map. However, as we cross the orange line, changes sign, and the region beyond it is meaningless again. The orange line is the unregularized phase boundary (blue line) blown up by a factor . All this is in accord with the picture described in [18] in that the no-short constraint eliminates the critical line. The solutions becoming unphysical beyond a certain r-range could not be foreseen on the basis of the analysis in [18].
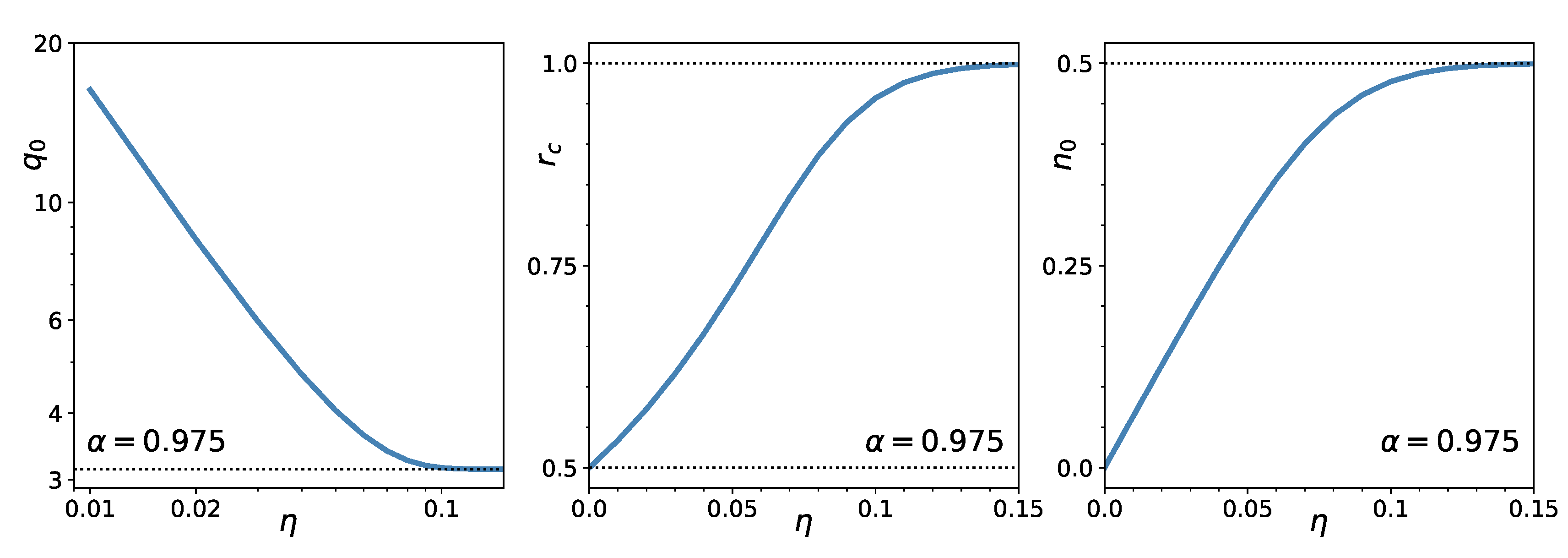
Figure 2 shows the -dependence of and the density of the zero weights at criticality, and that of the value of the critical r. In the unregularized case (), , while in the no-short case () . At , the value of the critical increases from in the unregularized case to for the no-short case. The proportion of the assets eliminated from the portfolio (the condensate density) goes from zero for to for large .
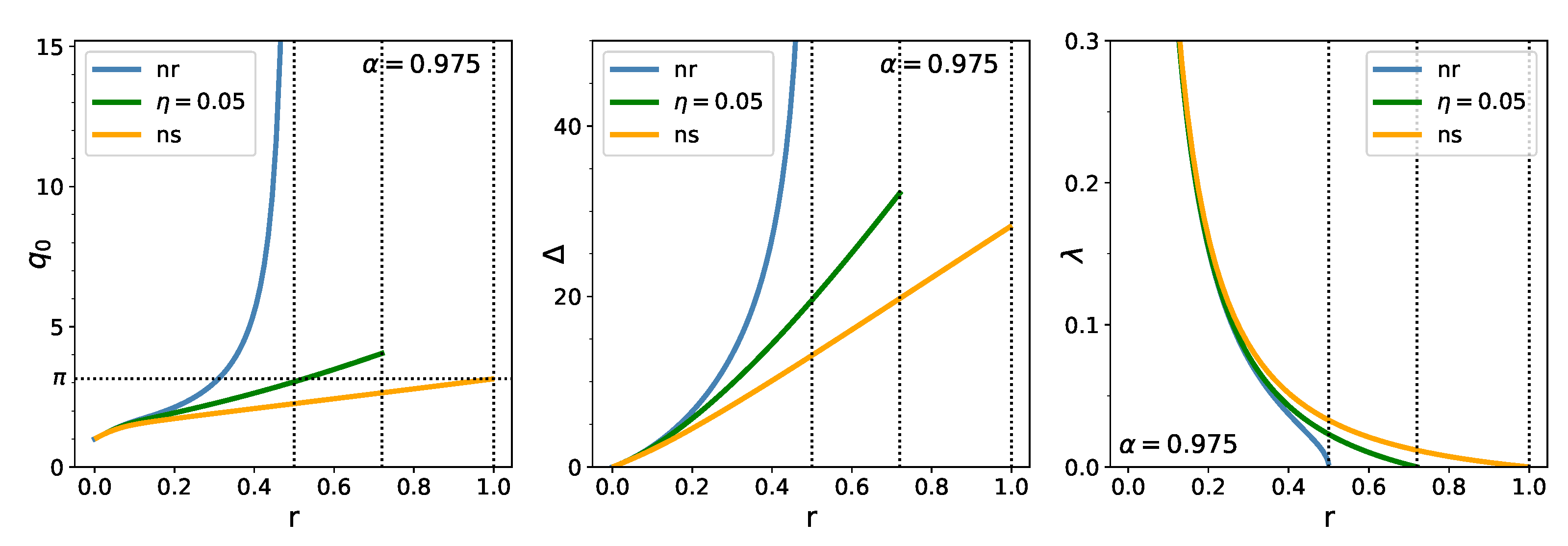
In Figure 3, we display the r-dependence of , , and for the three cases: unregularized, regularized, and no-short. Without regularization, and increase with r and diverge at an slightly less than ; while decreases from infinity at to zero at . (The confidence limit is set at its regulatory value 0.975 in these figures.) Under the regularizer , , , and increases up to the r where vanishes. The situation is similar for an infinitely strong (no-short) regularizer, with the limiting value of and at .
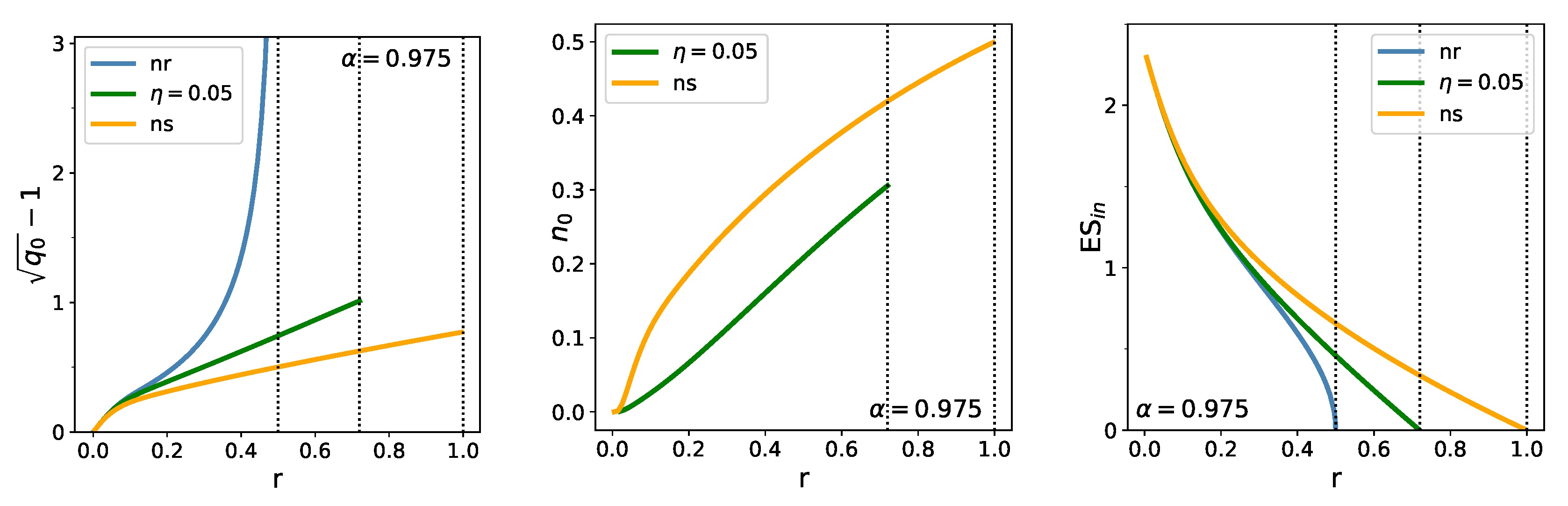
The left panel in Figure 4 shows the relative out-of-sample estimation error, which is related to the out-of-sample estimate of ES by (8) ( now, as we have set all the =1). These curves are similar to the curves of in the previous Figure. It can be seen that the curves of the relative estimation error run very close to each other for small values of r: there is no substantial reduction of the error in this range. Where they fan out and the effect of regularization starts to be felt (say around ), the relative error is already about 20%.
The middle panel in Figure 4 shows the behavior of the density of zero weights as function of r for the finite -regularized and the no-short cases. In the no-short case, reaches its maximal value at (for ) where vanishes. For a regularizer of finite strength, it always remains below .
4. Discussion
In the preceding Section we compared the behavior of the order parameters in the three instances considered in this paper: the case of the unregularized, the -regularized, and the no-short constrained Expected Shortfall optimization. We have seen that without regularization, there is a phase transition as we cross the phase boundary shown in Figure 1 with , , and diverging here, as known since the paper [10]. In contrast, the infinite penalty on short positions suppresses this phase transition, while an regularizer with finite slopes only shifts the phase boundary. These facts were also known from earlier work [14,18]. However, the picture has turned out to be more complicated than envisaged in [18]. The numerical solution for the order parameters performed in this paper has revealed that new characteristic lines emerge both in the case of finite regularization and the no-short constraint, along which the order parameter and, consequently, the free energy and the in-sample estimate of Expected Shortfall change sign. We have determined the position of these new characteristic lines: in the no-short case the new line is the curve , for a finite regularizer it is , where . We have omitted the detailed analysis of the regions above these lines, where the estimated risk becomes negative. Instead, we confined ourselves to merely pointing out that the critical line for the no-short constraint is projected out to infinity, so the phase transition is removed indeed, while for a finite slope regularizer the critical line is shifted into the unphysical, negative risk region, where for some values of the regularizer’s strength , it even develops two branches.
We have also found the behavior of the various order parameters, most notably that of that determines the out-of-sample estimation error of ES, the free energy that gives the in-sample estimator, and the susceptibility-like quantity , and displayed their behavior for the three cases studied here. It is satisfactory to see that and remain finite up to the new characteristic lines, that is, the regularizer acts as expected: it suppresses the divergent sample fluctuations in the optimization of ES. Unfortunately, this suppression is not strong enough to bring down the estimation error to acceptable values, except for the range of small ratios where it demands far too long time series for any realistic N, and where r is small already without any regularization.
What is the meaning of this phase transition? As analyzed in [8,26] it follows from the coherence axioms that coherent risk measures, including ES, are unstable in the sense that whenever an asset or a combination of assets in the portfolio stochastically dominates the others in a given sample, the investor can take an extremely large long position in the dominant asset and compensate this with an appropriately large short position, without violating the budget constraint. This means that the weight of the dominant asset runs away practically to infinity, resulting in an arbitrarily large negative value of the risk measure. This is a mirage of an arbitrage, which can disappear in the next sample, or change into another arbitrage with a different weight running away to infinity. In practice, there are always constraints that prevent such a divergence from taking place. The ban on short selling is just this sort of constraint. The runaway solutions try to escape, but get arrested at the walls constituted by the constraint, in the case of a no-short ban, at the coordinate planes. This is how the condensate of zero weights builds up. This mechanism is the stronger the larger the ratio .
There is nothing surprising about solutions sitting on the constraint-walls or at corners in a linearly programmable problem, such as the optimization of ES. In the usual applications of linear programming, the constraints typically express some physical limitation like a finite amount of resources, material or labor, etc. In the present finance problem, such a finite resource would be the limited budget, but if short selling is not constrained, the budget in itself cannot prevent runaway solutions. The ban on short positions corresponds to an infinitely strong regularizer, which, combined with the budget constraint, is already sufficient to take care of the runaway solutions. So, with a no-short ban on, we can increase r (that is the dimension, or decrease the amount of data) without any mathematical contradiction showing up; neither nor will diverge. It is clear, however, that the solution based on less and less information becomes increasingly meaningless. In these circumstances, the optimization will not tell us anything useful about the structure of the market, it will be determined more and more by the constraint.
What we regard as the most intriguing result of this paper is the existence of a mapping between the regularized and the unregularized problems.
Author Contributions
Conceptualization, G.P., I.K. and F.C.; formal analysis, G.P. and I.K.; funding acquisition, F.C.; investigation, G.P., I.K. and F.C.; writing—original draft preparation, I.K.; writing—review and editing, G.P. and F.C.; visualization, G.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Acknowledgments
We are indebted to Susanne Still and Matteo Marsili for collaboration and useful discussions years ago on joint works preceding the present one. Although they did not participate in this work, their ideas have remained a source of inspiration for us. I.K. is obliged to Risi Kondor for several enlightening discussions.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Markowitz, H. Portfolio selection. J. Financ. 1952, 7, 77–91. [Google Scholar]
- Morgan, J. Riskmetrics Technical Manual; JP Morgan: New York, NY, USA, 1995. [Google Scholar]
- Basel Committee on Banking Supervision. Overview of the Amendment to the Capital Accord to Incorporate Market Risks; Bank for International Settlements: Basel, Switzerland, 1996. [Google Scholar]
- Artzner, P.; Delbaen, F.; Eber, J.M.; Heath, D. Coherent Measures of Risk. Math. Financ. 1999, 9, 203–228. [Google Scholar] [CrossRef]
- Acerbi, C.; Tasche, D. Expected Shortfall: A Natural Coherent Alternative to Value at Risk. Econ. Notes 2002, 31, 379–388. [Google Scholar] [CrossRef] [Green Version]
- Pflug, G.C. Some remarks on the value-at-risk and the conditional value-at-risk. In Probabilistic Constrained Optimization; Uryasev, S., Ed.; Springer: Boston, MA, USA, 2000; pp. 272–281. [Google Scholar]
- Basel Committee on Banking Supervision. Minimum Capital Requirements for Market Risk. 2016. Available online: https://www.bis.org/bcbs/publ/d352.htm (accessed on 23 April 2021).
- Kondor, I.; Varga-Haszonits, I. Instability of portfolio optimization under coherent risk measures. Adv. Complex Syst. 2010, 13, 425–437. [Google Scholar] [CrossRef]
- Kondor, I.; Pafka, S.; Nagy, G. Noise sensitivity of portfolio selection under various risk measures. J. Bank. Financ. 2007, 31, 1545–1573. [Google Scholar] [CrossRef] [Green Version]
- Ciliberti, S.; Kondor, I.; Mézard, M. On the Feasibility of Portfolio Optimization under Expected Shortfall. Quant. Financ. 2007, 7, 389–396. [Google Scholar] [CrossRef]
- Kondor, I.; Caccioli, F.; Papp, G.; Marsili, M. Contour Map of Estimation Error for Expected Shortfall. 2015. Available online: http://ssrn.com/abstract=2567876 and http://arxiv.org/abs/1502.0621 (accessed on 23 April 2021).
- Caccioli, F.; Kondor, I.; Papp, G. Portfolio optimization under expected shortfall: Contour maps of estimation error. Quant. Financ. 2018, 18, 1295–1313. [Google Scholar] [CrossRef] [Green Version]
- Bühlmann, P.; Van De Geer, S. Statistics for High-Dimensional Data: Methods, Theory and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Caccioli, F.; Still, S.; Marsili, M.; Kondor, I. Optimal liquidation strategies regularize portfolio selection. Eur. J. Financ. 2013, 19, 554–571. [Google Scholar] [CrossRef] [Green Version]
- Papp, G.; Caccioli, F.; Kondor, I. Variance-bias trade-off in portfolio optimization under Expected Shortfall with ℓ2 regularization. J. Stat. Mech. Theory Exp. 2019, 2019, 013402. [Google Scholar] [CrossRef] [Green Version]
- Still, S.; Kondor, I. Regularizing portfolio optimization. New J. Phys. 2010, 12, 075034. [Google Scholar] [CrossRef]
- Rockafellar, R.T.; Uryasev, S. Optimization of Conditional Value-at-Risk. J. Risk 2000, 2, 21–41. [Google Scholar] [CrossRef] [Green Version]
- Caccioli, F.; Kondor, I.; Marsili, M.; Still, S. Liquidity Risk and Instabilities In Portfolio Optimization. Int. J. Theor. Appl. Financ. 2016, 19, 1650035. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning, Data Mining, Inference, and Prediction, 2nd ed.; Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Mézard, M.; Parisi, G.; Virasoro, M.A. Spin Glass Theory and Beyond; World Scientific Lecture Notes in Physics Volume 9; World Scientific: Singapore, 1987. [Google Scholar]
- Kondor, I.; Papp, G.; Caccioli, F. Analytic approach to variance optimization under an ℓ1 constraint. Eur. Phys. J. 2019, 92, 8. [Google Scholar] [CrossRef]
- Kempf, A.; Memmel, C. Estimating the global minimum variance portfolio. Schmalenbach Bus. Rev. 2006, 58, 332–348. [Google Scholar] [CrossRef]
- Basak, G.K.; Jagannathan, R.; Ma, T. A jackknife estimator for tracking error variance of optimal portfolios constructed using estimated inputs. Manag. Sci. 2009, 55, 990–1002. [Google Scholar] [CrossRef]
- Frahm, G.; Memmel, C. Dominating estimators for minimum-variance portfolios. J. Econom. 2010, 159, 289–302. [Google Scholar] [CrossRef] [Green Version]
- Ciliberti, S.; Mézard, M. Risk minimization through portfolio replication. Eur. Phys. J. 2007, B 57, 175–180. [Google Scholar] [CrossRef] [Green Version]
- Varga-Haszonits, I.; Kondor, I. The instability of downside risk measures. J. Stat. Mech. Theory Exp. 2008, 2008, P12007. [Google Scholar] [CrossRef] [Green Version]
- Shinzato, T. Minimal investment risk of portfolio optimization problem with budget and investment concentration constraints. J. Stat. Mech. Theory Exp. 2017, 2017, 023301. [Google Scholar] [CrossRef] [Green Version]
- Kondor, I.; Papp, G.; Caccioli, F. Analytic solution to variance optimization with no short positions. J. Stat. Mech. Theory Exp. 2017, 2017, 123402. Available online: https://iopscience.iop.org/article/10.1088/1742-5468/aa9684 (accessed on 23 April 2021). [CrossRef] [Green Version]
- Varga-Haszonits, I.; Caccioli, F.; Kondor, I. Replica approach to mean-variance portfolio optimization. J. Stat. Mech. Theory Exp. 2016, 2016, 123404. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
The boundary of the region where the optimization of ES is feasible in the unregularized case (nr); its image under the map for a finite , regularizer; and the same under the no-short map (ns).
Figure 1.
The boundary of the region where the optimization of ES is feasible in the unregularized case (nr); its image under the map for a finite , regularizer; and the same under the no-short map (ns).

Figure 2.
Dependence of at (left), critical point (middle), and proportion of zero weights at (right) as a function of the regularization strength, (). Note the logarithmic scale in the left panel.
Figure 2.
Dependence of at (left), critical point (middle), and proportion of zero weights at (right) as a function of the regularization strength, (). Note the logarithmic scale in the left panel.

Figure 3.
Dependence of (left), (middle) and “chemical potential” (right) on , for the unregularized (blue), regularized (green), and no-short (yellow) cases.
Figure 3.
Dependence of (left), (middle) and “chemical potential” (right) on , for the unregularized (blue), regularized (green), and no-short (yellow) cases.

Figure 4.
Dependence of the out-of-sample estimation error (left), proportion of zero weights (center), and in-sample ES (right) on , for the non-regularized (blue), () regularized (green), and no-short (orange) cases.
Figure 4.
Dependence of the out-of-sample estimation error (left), proportion of zero weights (center), and in-sample ES (right) on , for the non-regularized (blue), () regularized (green), and no-short (orange) cases.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Papp, G.; Kondor, I.; Caccioli, F. Optimizing Expected Shortfall under an ℓ1 Constraint—An Analytic Approach. Entropy 2021, 23, 523. https://doi.org/10.3390/e23050523
AMA Style
Papp G, Kondor I, Caccioli F. Optimizing Expected Shortfall under an ℓ1 Constraint—An Analytic Approach. Entropy. 2021; 23(5):523. https://doi.org/10.3390/e23050523
Chicago/Turabian StylePapp, Gábor, Imre Kondor, and Fabio Caccioli. 2021. "Optimizing Expected Shortfall under an ℓ1 Constraint—An Analytic Approach" Entropy 23, no. 5: 523. https://doi.org/10.3390/e23050523
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.