
Almost-Minimal-Round BBB-Secure Tweakable Key-Alternating Feistel Block Cipher


Department of Computer Science and Engineering, Shanghai Jiao Tong University, Shanghai 200240, China
*
Author to whom correspondence should be addressed.
Symmetry 2021, 13(4), 649; https://doi.org/10.3390/sym13040649
Submission received: 26 February 2021
/
Revised: 28 March 2021
/
Accepted: 7 April 2021
/
Published: 11 April 2021
(This article belongs to the Section Computer)
Abstract
:This paper focuses on designing a tweakable block cipher via by tweaking the Key-Alternating Feistel ( for short) construction. Very recently Yan et al. published a tweakable construction. It provides a birthday-bound security with 4 rounds and Beyond-Birthday-Bound (BBB for short) security with 10 rounds. Following their work, we further reduce the number of rounds in order to improve the efficiency while preserving the same level of security bound. More specifically, we rigorously prove that 6-round tweakable cipher is BBB- secure. The main technical contribution is presenting a more refined security proof framework, which makes significant efforts to deal with several subtle and complicated sub-events. Note that Yan et al. showed that 4-round provides exactly Birthday-Bound security by a concrete attack. Thus, 6 rounds are (almost) minimal rounds to achieve BBB security for tweakable construction.
1. Introduction
A block cipher, also known as a pseudorandom permutation, which is a pair of algorithms . A block cipher has two important parameters: block length and key length. If the block length is n bits and the key length is k bits, for a mathematical point of view, the block cipher can be seen as a mapping
E represents a mapping that from the key space and the message space to the message space, and D is the opposite direction of the mapping in E. In addition, we call E is encryption, and D is decryption. The schemes of block cipher are roughly separated into two main classes, which are named Feistel networks and substitution—permutation networks (SPNs).
The tweakable block cipher is formalized by Liskov et al. [1]. It introduces to the block cipher an extra public input parameter tweak. The tweak provides inherent variability for building higher higher-level cryptographic schemes, namely modes of operation. So far, the tweakable block cipher has got received wide applications. Examples include Message Encryption, Message Authentication Code [1,2], and Authenticated Encryption Mode [3,4,5], etc. Now designing secure tweakable block ciphers has become a very important research topic. Cryptographers build tweakable block ciphers either from the scratch [6,7,8], or based on existing cryptographic primitives such as block ciphers or permutations [2,9,10,11]. Among these approaches, one is introducing the tweak to general structures of classical block ciphers, namely the Feistel construction [12] and the Even—Mansour construction [13]. We refer the interested readers to [9,14,15,16,17,18] for tweaking the Even—Mansour construction.
This paper mainly focuses on tweaking the Feistel construction. Since invented by Horst Feistel in 1973 [12], the Feistel construction has been a mainstream class of block ciphers. More specifically, there are several Feistel construction variants, such as Luby—Rackoff [19], Generalized Feistel [20], Key-Alternating Feistel [21], etc. They have been adopted in dedicated block ciphers including international and national standards. In 2007, Goldenberg et al. published the first paper of incorporating tweak to the Feistel constructions [22]. In particular, they paid attention to the Luby—Rackoff ciphers, and XOR tweaks to the dataflow branches. We write such tweak injection as linear tweak injection in this paper. Goldenberg et al. found that 6 rounds and more are secure (against polynomial adversaries). Moreover, they showed that 10 rounds are secure against adversarial queries, that is i.e., fully secure with n as the branch bit size of Luby—Rackoff structure. After that, Mitsuda and Iwata analyzed tweaking Generalized Feistel Structures with similar linear tweak injection [20]. They proved that rounds are birthday-bound secure with d as the number of branches of Generalized Feistel Structure. Very recently, Yan et al. published a result of tweaking the Key-Alternating Feistel () Cipher [23]. They introduced the tweak by mixing round keys, and proved that 4 rounds have a birthday-bound security and 10 rounds enable a beyond-birthday-bound security of roughly adversarial queries with n as the branch bit size. We will carry on the research of tweaking the . (It is referred to as Feistel-2 in IACR Tikz Library).
The Feistel network [12] is a popular structure of block ciphers. In the i-th round of the Feistel cipher, the intermediate state of input is updated by the round function , i.e., . After tweaking the generalized Feistel ciphers by Mitsuda and Iwata [20], there is are only a few works about tweaking the Feistel cipher. The most mainstream research is tweaking ciphers as Yan et al did recently [23]. They introduced the tweak with several round keys by using a universal hash function , that is, , where is the secret key, t is the tweak. By tweaking with the i-th round function, the input is updated through
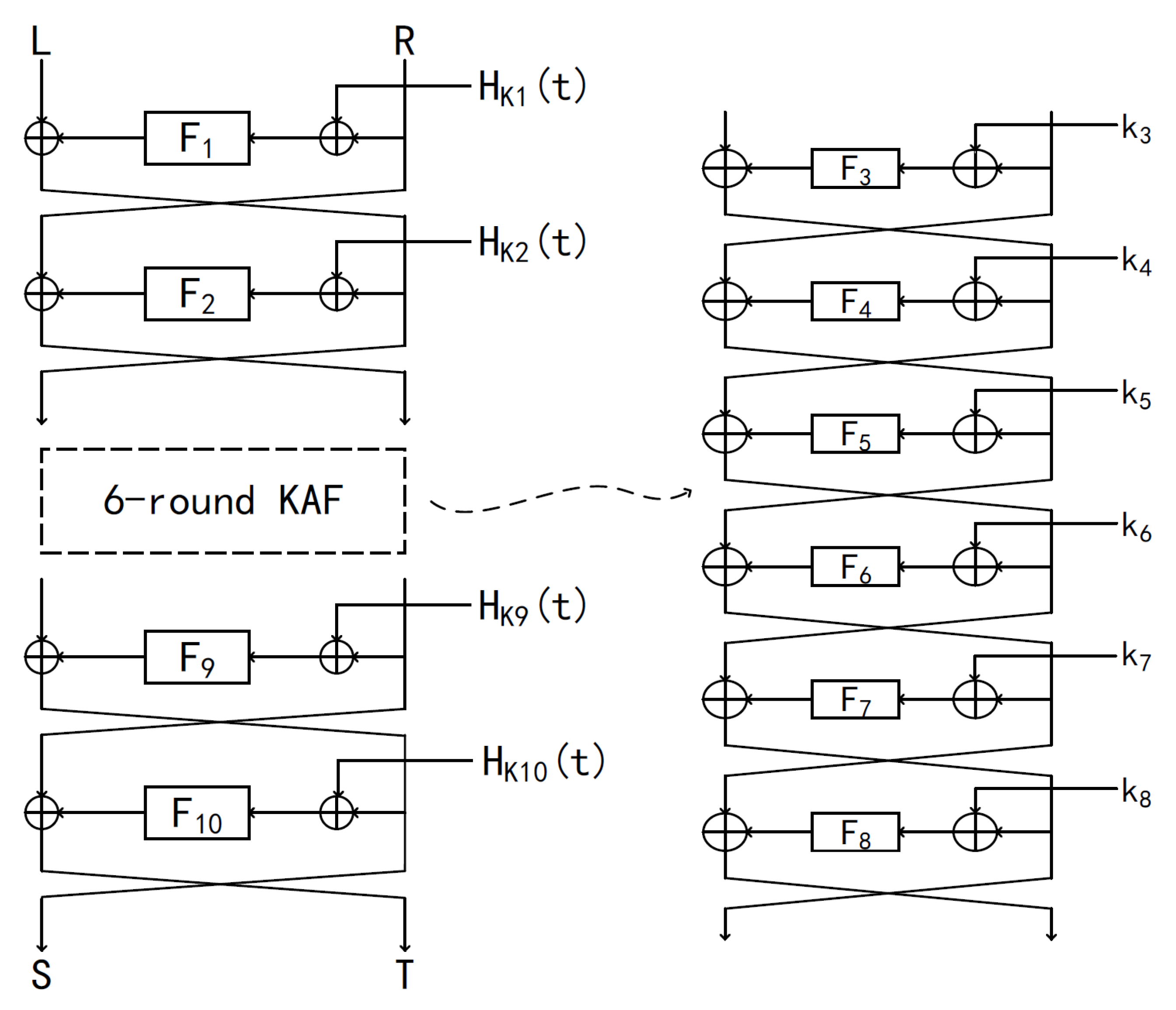
where is the ith-round function. Yan et al. presented a 4-round minimized structure with two round keys and a single random function, proved that it achieves Birthday-Bound security. Meanwhile, they presented a 10-round tweakable ( for short) construction (depict in Figure 1) that can achieve BBB security. In this work, we aim to optimize Yan et al’s 10-round structure, and adopt other distinct construction of tweakable block ciphers. Then we give the proof that the new construction still meets the BBB security. We compared with Yan et al’s work [23] which lists in Table 1.
1.1. Our Contributions
In this paper, we present a 6-round cipher which meets the BBB security, with tweaking the additional outer four rounds based on based on Guo et al.’s 6-round [24]. Unlike Yan et al.’s research, we adopt the approach of introducing tweak into the 6-round directly. By utilizing Guo et al’s proof methodology, we introduce the tweak via using a universal hash function. We prove when the adversary makes distinct queries with different tweaks, due to the uniformity of the mentioned hash function, it still meets BBB security.
1.2. Structure of This Paper
2. Preliminaries
2.1. Notations and General Definitions
Let n denote a positive integer. Then and . denotes the set of all functions mapping from to . denotes the set of all permutations in the range of . Let be a random variable relying on one another random variable s. Then we denote by the expectation of taken over all . For , denote or simply as their concatenation.
2.1.1. Block Cipher
A block cipher is a family of permutations indexed by the secret key. It is denoted as , where is the key space, is the message space, and is the ciphertext space. Hence for each , or simply is a permutation from to . In this paper, .
2.1.2. Tweakable Block Cipher
A tweakable block cipher is a family of permutations indexed by the secret key and the public tweak. It is denoted as , where is the key space, is the tweak space, is the message space, and is the ciphertext space. Hence for each and each , or simply is a permutation from to . Similarly, . We denote as the set of all tweakable permutations with .
2.1.3. Key-Alternating Feistel () Cipher
A is a block cipher with . It has an iterative structure. The i-th round function has the form , where L and R are the left half and the right half of the inputs respectively, is the i-th secret round key, and is the i-th public round function. We denote the r-round with r public round functions in and a round-key vector by
2.1.4. Uniform AXU Hash Functions
A set of hash functions is denoted as . For each key , a keyed hash function or simply maps the tweak space to . is said to be uniform hash function if for any and ,
Moreover, it is said to be -almost XOR-universal (-AXU) if for any with and any ,
2.2. Security Definitions
A distinguisher can be thought as a fundamental attacker, and it can make queries to one (or more) “oracle” which can be the block ciphers or the random permutations. The advantage of a distinguisher in distinguishing two oracles and can be defined as:
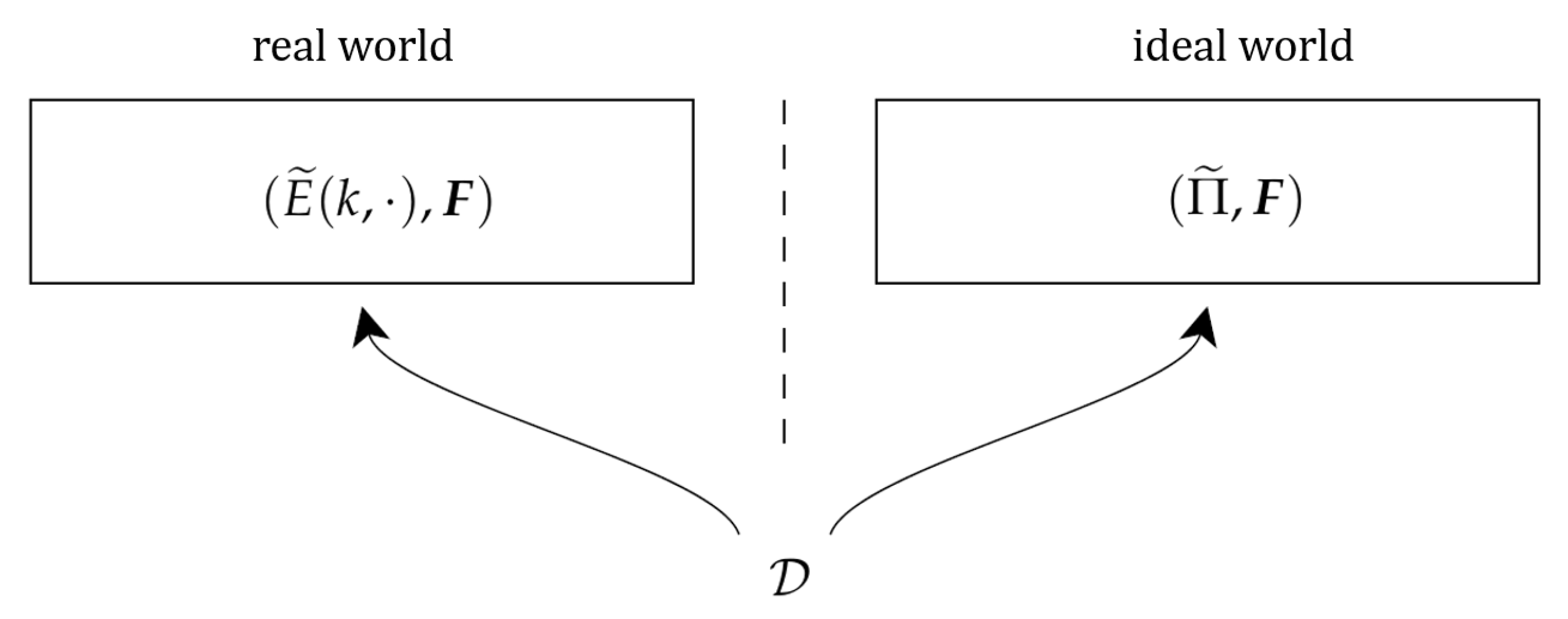
We discuss this under the Random Permutation model. Firstly, we define two worlds–“the real world” and “the ideal world”. When the distinguisher interacts with the oracle , the real world means is a tweakable block cipher , is a public random function or permutation of , where k is uniformly taken from . In addition, in the ideal world, is a tweakable permutation and is a public random function or permutation of . We call construction oracle and inner component oracles. The security of a tweakable block cipher is measured by the advantage of the distinguisher that distinguishes the two worlds: and (depict in Figure 2). We write
Theoretically, we only consider the information-theoretic distinguisher whose computation power is unlimited, i.e., it is determined, and only with limited information, that which means the number of access to the oracle is limited. We assume that the distinguishers do not make redundant queries. We also consider the distinguishers are under the chosen-ciphertext-attack (CCA) model, meanwhile they can choose tweaks, where they have the ability to query all the oracles either forward or backward.
We denote as the quantity of queries to the construction oracle and as the number of queries to each inner component oracle, then the definition of insecurity of the tweakable block cipher is
H-Coefficient Technique
We utilizuse the H-coefficient technique [25,26] to evaluate the upper bound of the advantage of the adversary mentioned above.
Definition 1
(Transcript). A transcript is the response-tuple when the distinguisher interacts with its oracle, where contains the tuples of the form which interacts with the construction oracle and contains the tuples which interacts with the inner component oracle.
By definition, we can see that either makes the direct query to the construction oracle with x to the inner component oracle, receiving answer and y, or makes the inverse query to the construction oracle with y to the inner component oracle, receiving answer and x. Suppose that , and there are m distinct tweaks in the . We assume there exist distinct queries for the i-th tweak, hence . That means , where are the corresponding queries of the i-th tweak. Similarly, we have and .
We note that all the transcripts of queries are directionless and disordered form, but according to our hypothesis that the distinguisher is deterministic. Thus, there is a one-to-one mapping between this statement and the primitive transcript of the interaction of with its oracles. Meanwhile, the output of is a deterministic function of .
In addition, for the function and its set of queries , if for each , , we say that extends, denoted by . Similarly, for the permutation and its transcript sets , if for each , , we say that extends , denoted by . With the above definition of “extend”, we can define . Finally, for and , if , then we have .
We further define the probability that the interactions of the distinguisher with the real world and the ideal world. In addition, we respectively denote them by and , where is a transcript of these interactions.
With these definitions, we give the core lemma of the H-coefficient technique, and the distinguishing advantage could be inferred by the ratio of and .
Lemma 1
(From [27]). Assume that there is a function such that for every possible transcript τ with and queries of the two types it holds
then it holds
According to [27], the upper bound of is named “-point-wise proximity” of , which was raised by Hoang and Tessaro (HT) [27]. We let , where and are mutual exclusive subsets. Denote as the probability that interacts with the real world, where , and is that interacts with the ideal world, where k is a “virtual” key uniformly selected from the key space . With the above definition, HT provided a lemma to establish point-wise proximity.
Lemma 2
(Lemma 1 of [27]). Fix a transcript τ with . Assume that: (i) , and (ii) there is a function such that for all , it holds . Then we have
3. Overview
3.1. Beyond Birthday-Bound Security for Six Rounds
In the beginning, we need to guarantee that tweaking the ciphers does not break its construction, and the influence on efficiency of the scheme execution can not cannot be enormous. For study of the execution efficiency and security, Liskov et al. [1] thought the cost of changing tweaks should be less than that of changing keys. However, the study by Jean et al. [14] showed that the adversary can hardly obtain the key, but has the ability to completely control the tweak.
In this paper, we use a nonlinear compound mode for tweaking the Feistel structure, instead of tweaking dependent or independent keys. As we known, the four rounds of cipher do not meet BBB security [24], Yan’s [23] work showed that tweaking 10 rounds cipher can meet BBB security. Our work shows a method for tweaking the cipher by the nonlinear pattern, and reduces the rounds of the scheme. For requirement of security, we consider to introduce the tweak with the round-key vectors by using a universal hash function.
Firstly, we use the suitable round-key vector which was defined by Guo [24]:
Definition 2
(Suitable Round-Key Vector for 6 Rounds [24]). A round-key vector is suitable if it satisfies the following conditions:
- (i)
- are uniformly distributed in ;
- (ii)
- for , and are independent.
Yan’s [23] work used the minimized 6-round as a “core”, with additional four more rounds on the first and last sides of the “core”, meanwhile introducing the tweak into these four rounds. They gave a 10-round construction with BBB security. In our work, we aim to“tweak” the first and last two rounds of the “core”, and use a universal hash function to merge the tweak into round-key vectors.
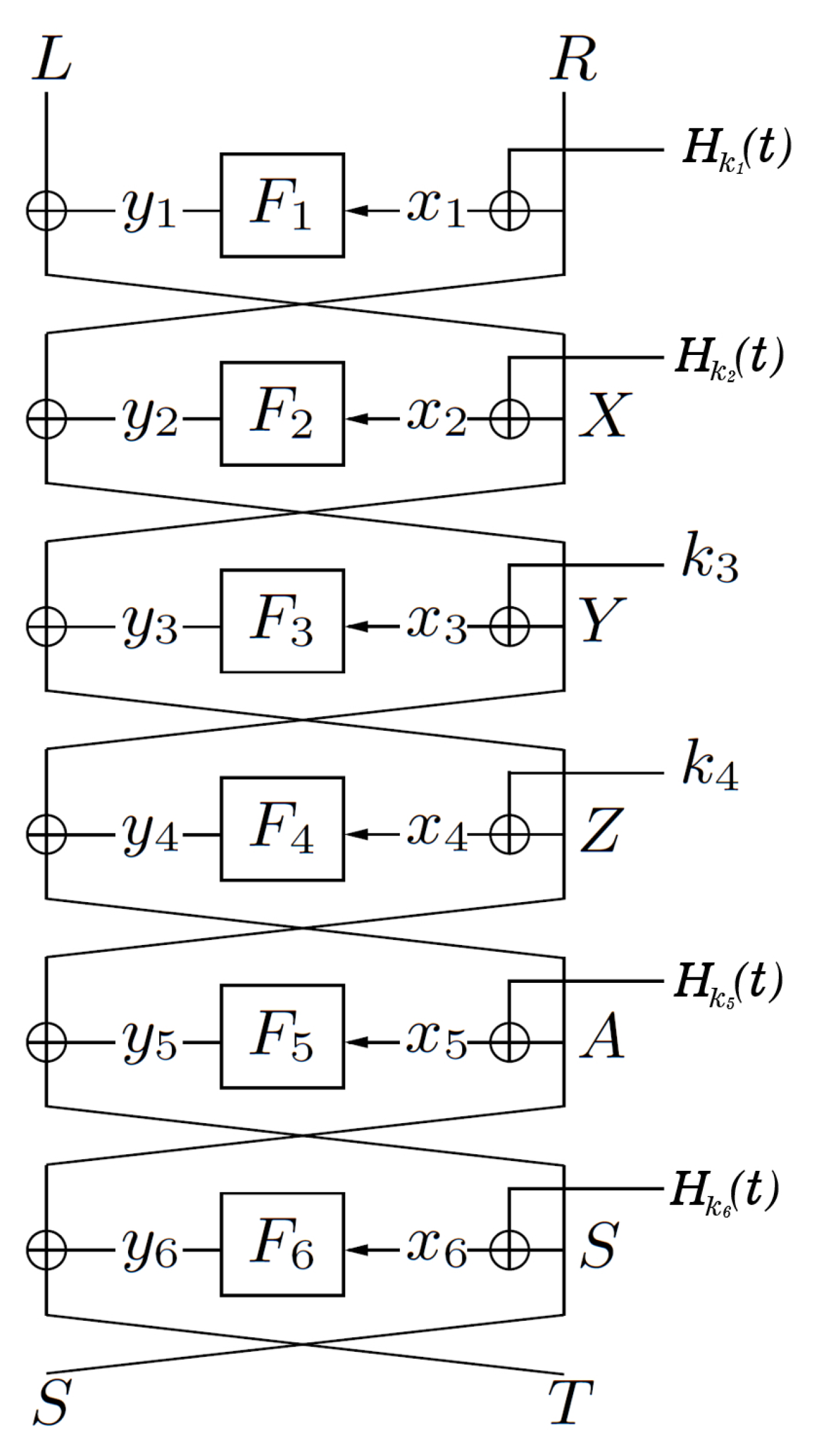
Next, we denote this 6-round construction by
where are random functions, are the corresponding round keys, is a tweak and is a message (depict in Figure 3).
Finally, we upper- bound the advantage of an adversary to attack this scheme. By utilizing the H-coefficient technique which is in Lemma 2, we firstly upper upper-bound the bad key event , then upper- bound the expectation of the function , which holds . By Lemma 1, we could obtain the advantage. Thus, we have this theorem:
Theorem 1.
For the 6-round tweakable cipher with a suitable round-key vector as specified in Definition 2, it holds
3.2. Core Contribution
In our work, we analyze the influence of tweaking ciphers on security. We tweak the outer four rounds of Guo et al’s 6-round and the proof of BBB security is the major research work we have done.
4. Security Proof of Theorem 1
In the following subsections, we present the methodology to prove Theorem 1. We fix a transcript with , where and . We divide the analysis of this claim into two parts: define bad key vectors, then lower bound the probability . We analyze these two parts respectively.
4.1. Bad Key Vectors and Probability
Definition 3
(Bad Key Vectors for 6 rounds). A suitable key vector is bad, for a transcript , if one of the follow conditions is met:
- (A-1)there exists , , , such that , ;
- (A-2)there exists , , , such that , ;
- (A-3)there exists , , , such that , .
otherwise, k is good. We denote for the set of bad key vectors, and for the good key vectors.
In the beginning, we upper- bound the probability of the bad key vectors. Firstly, we analyze the above three conditions respectively, consider (A-1) first. Since we have the key and picked from the key space uniformly and randomly, for the properties of suitable, and are independent of each other (Definition 2). By the uniformity of H, and are also independent. Thus Thus, there are possible choices. For , and , we have at most choices, as , , where is a set of x that there exists such that , i.e., . Therefore, the probability of condition (A-1) is at most .
Similarly, by definition of suitable key vector (Definition 2), it also holds that , are independent, and for the uniformity of H, we have
To sum up, we can upper- bound the probability of the bad key vectors with
4.2. Analysis for Good Keys
In the following, we fix the round- key vectors , and aim to lower bound the probability . By the analytical method of Cogliati et al. [9,15], we divide this proof process into two steps: upper bounding the probability that a pair of functions satisfies “bad” conditions. By these means, the “good” conditions of the function -pair can transfer the transcripts of the distinguisher on 6 rounds to a special transcripts on 4 rounds, it can be said that we “peel off” the outer two rounds [24]; then assuming that is good, by bounding the inner 4 rounds, we will prove the claim of Theorem 1.
Peeling Off the Outer Two Rounds
We pick a pair of round functions such that and . For each transcript , denote and . From this, we obtain transcripts with the form of . For convenience, we denote a new set including all these introduced transcript tuples by . Furthermore, we define two subsets of , the transcripts that collide at the positions of X and A, respectively. Denote them by and :
In order to characterize , we define four key-dependent quantities:
Now we define the “bad event” on the pair . If the corresponding set of the pair fulfills one of the following “collision” conditions, we say that the predicate is bad, denoted by :
- (B-1) there exists , , , such that , ;
- (B-2) there exists , , , such that , ;
- (B-3) there exists , , , such that , ;
- (B-4) there exist two distinct , , such that and ; or symmetrically two distinct , , such that and ;
- (B-5) there exist two distinct , , such that and ; or symmetrically two distinct , , such that and ;
If the predicate does not hold, then we can deem that is good. Now we bound the probability of .
Lemma 3.
It holds
Proof.
We prove the above 5 cases of on the condition of :
(B-1) For arbitrary , if there exists and , such that and . Then for the corresponding , we have and . On account of the uniformity of H, it must hold (if and , then the condition (A-2) is fulfilled). Similarly, it must be . Thus, on the condition of , and keep uniform. SoSo, the probability of both and holding is at most . AndIn addition, the choices of all 3-tuples , , do not exceed . Therefore, we have Pr[(B-1)] .
(B-2) and (B-3) We consider (B-2) firstly.
There exists a 3-tuple , such that the number of is , where is a joint notation of and its corresponding induced X and A. Moreover, means . When , then it can not cannot hold , otherwise (A-2) is fulfilled. Furthermore Furthermore, when , on the condition of , then keeps uniform. Meanwhile H also keeps uniform, thus we have the probability of is at most . Therefore, Pr[(B-2)]. The condition (B-3) is symmetric with (B-2), so with the similar analysis, we have Pr[(B-3)].
(B-4) For the given pair of distinct merged transcripts and together with , we discuss the cases in three conditions:
- Case 1: when , if it holds , i.e., for the - property of H function, the probability of is at most . If , we note that , , otherwise (A-2) is fulfilled. Thus, on the condition of , and are independent with each other, also keep uniformly random. Then it holds . Therefore, the probability of the collision at the position and is at most .
- Case 2: if and , for , the probability of is at most . AndIn addition, for , the probability of is at most . For the property of H, we have the probability of the collision at the position X is at most .
- Case 3: if and but , it can not cannot be held that and .
To sum up, the probability of “former” part of (B-4) can not cannot exceed , and the analysis of “latter” part is similar to the former part. We consider all possible pairs of transcripts, the quantity of these pairs can not cannot exceed . Therefore, Pr[(B-4)].
(B-5) For the given transcripts and , due to the conditions on good key vector, it holds . The same as (B-4), we consider the front part of this condition. According to the state of S, we respectively discuss in three cases:
- Case 1: it holds , then for the distinct and , they all have choices.
- -
- If , if it holds , then the probability of is at most ;
- -
- If , if it holds , then and are independent and uniformly random. Thus, on the condition of , we haveOn the condition of , is also uniform. Hence, similar with (B-4), we have
- -
- If but , if , then it holdsand for , the probability of is at most ;
- -
- If and but , it could not be held that or .
Under the above cases, we have the probability of the collision at the position and is at most . In addition, for , the probability of (B-5)’s front part is at most . - Case 2: For , the choices of are . Similar with Case 1, we have . Therefore, the probability of holding at least one such transcript is at most .
To sum up the above two cases, the probability that the former part of (B-5) holding is at most . Similarly, the latter part of (B-5) is symmetric with the former part. Therefore, we have
We sum up all the five conditions, it holds
Now we prove the Lemma 3. □
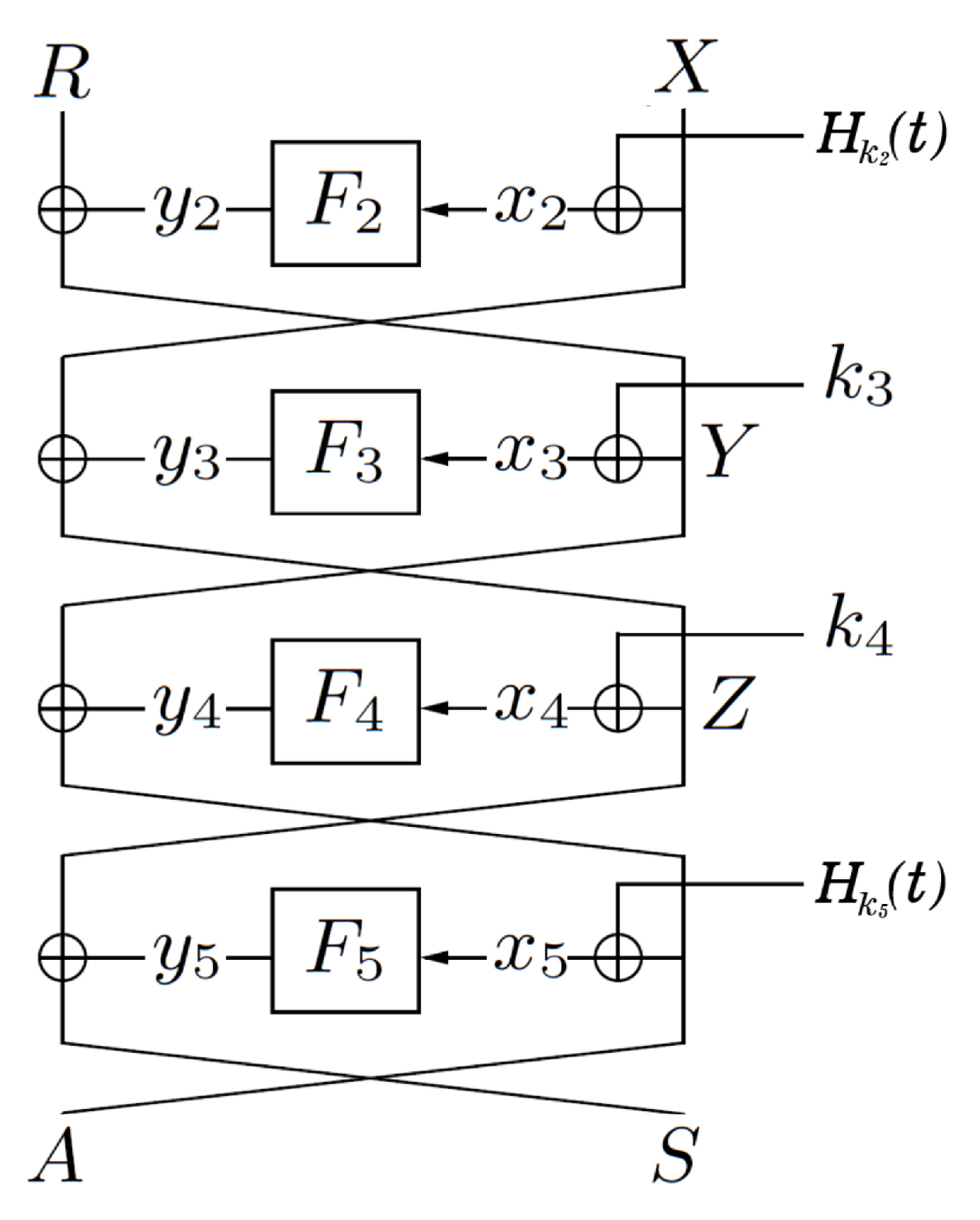
4.3. Analysis of the Inner Four Rounds
In the following section, we analyze the inner four rounds of which depicts in Figure 4. We denote the set of tuples in the form , which is induced by peeling off outer two rounds. Similar with [24], we also write , further denote
Lemma 4
Lemma 5.
For any fixed good tuple , there exists a function of the function pair and the round- key vector k such that the inequality (3) mentioned in Lemma 4. Then,
Proof.
Due to the space constraints, the full proof must be deferred to Appendix A. In the following, we only present a proof sketch and the core conclusions. At the beginning of the proof, we define some notations and values in order to present the proof process.
We divide the transcripts in into four sets:
- ;
- ;
- ;
- .
Then we denote , , and by the events that and respectively, and let , , . We list with some arbitrary orders. Denote the event that extends the i-th tuple . We define four sets of “collision position”:
For convenience, we denote two values , and , which are the quantities of choices in the sets. Finally, the function is the number of pre-images , which belongs to the set . That is .
Since we have these definitions mentioned above, we can lower bound
Analyzing these four sets in turn. First, we consider There are three cases for each transcript :
- (i)
- The two intermediate values Y and Z derived from and will not collide with the values that have been queried in the past time. So, the probability of this case is at least
- (ii)
- The intermediate value Y collides with some values of the past queries, but Z is still “free”. So, the probability of this case is at least
- (iii)
- This case is symmetrical to the second one, where Z collides with some past values, but Y is “free”. The probability is at least
Summing over the above five cases, we have
Then, we analyze , , and . The events and can be considered simultaneously. For the rest events, we need to upper- bound the corresponding “bad” events, then consider the efficiency of introducing tweak. Through this method, we can lower bound these three events. See Appendix A for more details about the proof.
For the proof, we have the results of the following three events:
Finally, we sum up all four events, i.e.,
where , , are (A1), (A2) and (A3) respectively, furthermore . We note that
then for (3), we have
We know that , , and depend on . We consider them respectively, focusing on firstly. For each , if , then it must be because of ¬(A-2). Thus, on the condition of , keeps uniform, then we have
Therefore, The analysis method of is symmetric with , by the uniformity of , we have
To this end, we consider . For the fixed transcript such that , give a distinct . If but , for the uniformity of H, we have
if and , then it must be , thus is impossible; if and but , on account of , then keeps uniformly random conditioned on , therefore . In addition, the choices of distinct pairs and are at most . Thus Thus, we have
For , the number of the transcripts which meet the above conditions is . We have
Symmetrically,
Thus, we have
Finally, and are uniform in possible choices,
Gathering all the above yields, we have
as claimed in (4). □
Now we have Lemma 2, Lemma 4, and (2), we obtain
For the expectation , we note that and are uniformly picked from possibilities, then
It has been shown that . Then Lemma 3 yields
From all above, by Lemmas 1 and 2, we have proved the conclusion of Theorem 1.
5. Conclusions and Future Work
This paper presents a result of constructing a tweakable block cipher from the construction. Our work is based on based on the study by Guo et al. [24], we introduce the tweak into their optimized 6-round scheme in order to achieve the Beyond Birthday-Bound security. We utilize a universal hash function which is called -almost XOR-universal hash function, with tweak and round-key vector, we rebuild a new tweakable scheme which meets the security of beyond birthday-bound. Finally Finally, by using the H-coefficient technique [25], we prove the security requirement and obtain a better conclusion with fewer rounds. Our approach is to introduce the tweak into the first and last two rounds of Guo’s 6-round structure, and utilize the universal hash function as the operation method. Can we introduce the tweak directly into the round function without using the universal hash function, and still meeting the beyond birthday-bound security? Or can we use another linear method to introduce a tweak? We leave these as future work.
Author Contributions
Conceptualization, M.J. and L.W.; methodology, M.J.; validation, M.J. and L.W.; formal analysis, M.J.; investigation, M.J.; writing—original draft preparation, M.J.; writing—review and editing, M.J. and L.W.; supervision, L.W.; project administration, L.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Key Research and Development Program of China No. 2018YFB0803400.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors wish to thank Yaobin Shen for some valuable guidance and advice. At the same time, thanks to other students in our laboratory for their great help in writing the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Lemma 5
Appendix A.1.
Firstly, we consider the event , i.e., lower bounding By the definition, there must be . So, Therefore, we consider to lowering bound the probability of on the condition of .
We note that on the condition of , for arbitrary and , and will be considered to be “fixed”. For convenience, we denote and , furthermore denote and . Depending on the states of two intermediate values and , we consider the event in three cases:
- Case 1-no collision: and satisfyIt holds and ;
- Case 2-left collision: satisfies , but satisfies . It holds and ;
- Case 3-right collision: satisfies , but satisfies . It holds and .
By these, accumulating all probabilities of above three cases, we have
Now we consider these three cases respectively.
Appendix A.1.1. Case 1
For , by definition, we have . With tuples in , does not collide with other corresponding positions since . Thus Thus, remains uniformly random on the condition of . Moreover, . Symmetrically, we have . Then, the probability that these two equations and are simultaneously fulfilled is .
From above,
Appendix A.1.2. Case 2
We consider the opposite case of Case 2, and upper- bound the probability on this condition. Let be the probability of the contrary case. We have
where stands for the collision event
Then, we consider five subcases of the opposite Case 2 respectively, and upper- bound for each in turn.
- Subcase 2.1:For each , by definition, we have the number of which satisfies the collision is . In addition, similar with Case 1, we can still deem as uniformly random. Thus, it holds . Therefore, the upper bound of Subcase 2.1 is
- Subcase 2.2: Define a key-dependent value:Then we have the quantity of which satisfies the collision condition is . Same as Subcase 2.1,Thus, we haveIt can be seen, is uniform in N values. So, the expectation of is at most . Thus Thus, the upper bound of the probability on the condition of Subcase 2.2 is at most .
- Subcase 2.3: By definition, we writewhere , and for i-th tuple , we have . In addition, if and only if i is the smallest index that satisfies , since .First, we focus on . Considering the probability on the condition that fits into Case 1,2 and 3. It can be seen that if fits into Case 3, then we have , it contradicts the Subcase 2.3. Let , write .
- (i)
- fits into Case 1We derive from , and keeps uniform. Then we haveFurthermore, we have . Thus
- (ii)
- fits into Case 2Let . We have . By definition, the number of choices for such is . Furthermore, for these choices of , the probability of the following two collisions is at most , i.e.,Thus
From the above, - Subcase 2.4: By definition, we writewhere , and for i-th tuple , we have . In addition, if and only if i is the smallest index that satisfies , since .First, we focus on . Let , write . That is . Thus, the collision can be seen as . Same as Subcase 2.3, we only need to consider two cases on .
- (i)
- fits into Case 1We know that and keep uniform. Then it holdsThen, we have . Thus
- (ii)
- fits into Case 3Let . We have because of . We note that if , and are “fixed”, then the possibility of choices of is at most 1. Therefore, if collides with , the following two collisions have to happen:Thus
According to Subcase 2.3, we have - Subcase 2.5: By definition, we writewhere , and for i-th tuple , we have . In addition, if and only if i is the smallest index that satisfies , since . In addition, , and for j-th tuple , we have . In addition, if and only if j is the smallest index that satisfies , since .
- (i)
- When , due to , according to Subcase 2.3, the number of choices for such is . Furthermore, for each , the upper bound of the probability is .
- (ii)
- When , due to , according to Subcase 2.4, the upper bound of the probability for each is .
To sum up, - Summing over all five subcases: We haveThe five cases above are opposite conditions to Case 2. Moreover, if it holds , then we have , , that implies the position of can be deemed as “new”.For these arguments above, we have
Appendix A.1.3. Case 3
In this case, if it holds and , then we have
With the similar analysis of Case 2, we denote
Also, we consider five subcases in turn.
- Subcase 3.1: On this condition, as the constraint , we havewhere
- Subcase 3.2: Define a key-dependent value:On account of the uniformity of in N choices, we have
- Subcase 3.3: By definition, we writewhere , and for i-th tuple , we have . In addition, if and only if i is the smallest index that satisfies , since . Similar with Subcase 2.3,
- (i)
- fits into Case 1We have
- (ii)
- fits into Case 3We have . Therefore,
From above with the similar calculation, we have - Subcase 3.4: By definition, we writeIt also holds . When fits into Case 2, due to , we have.Therefore,
- Subcase 3.5: Similar to Subcase 2.5, we have
- Summing over all five subcases: We have
Appendix A.1.4. Conclusions of
Summing over all the three cases:
We denote
, , and . Then it holds
Secondly, we consider . By definition, we have
Thus
Similarly,
Finally, we have the upper bound
Appendix A.2.
Next, we analyze the event , we firstly focus on . Define the “bad” event on this condition, we denote by : there exists , one of the following conditions is fulfilled:
- (i)
- , where ;
- (ii)
- there exists , such that , where ;
- (iii)
- there exists , such that .
We note that for each , let , we have (for the condition of ) and (for the analysis of ). Then, on the condition of , the values of function keep uniform. Thus, for :
- (i)
- the probability of condition (i) fulfilled is at most ;
- (ii)
- for each , if the corresponding , we haveIf the two tuples are distinct, i.e., : (a) , , and , then ; (b) if , , and , then it must be .
- (iii)
- for each , we have
Summing up the above, we have the probability of :
We can see that if does not happen, there are values in which are distinct (otherwise (ii) is fulfilled). In addition, are all undetermined (otherwise (i) and (iii) are fulfilled).
Moreover, at the “right” part, there are also values , such that are also undetermined.
Therefore, the event is equivalent to and satisfying new equations, so the probability does not exceed .
Similar to the analysis of , we consider the event . Likewise, we define the bad event that there exists , one of the following conditions is fulfilled:
- (i)
- , where , the probability is at most ;
- (ii)
- there exists , such that , where , and the probability is at most ;
- (iii)
- there exists , such that , and the probability is at most .
Thus, we have the probability of :
Same as , the event is equivalent to and satisfying new equations.
Therefore, on the condition of , we have
Appendix A.3.
Thirdly, we analyze the event . By definition, for arbitrary , we denote and such that and . Furthermore, on the condition of , and the conditions of bad event , the two values of functions and must be uniform and undetermined.
We also define the bad event that there exists , such that and fulfill one of following conditions:
- left part: consider :
- (i)
- , on account of the randomness of , for each , the probability of which is at most ;
- (ii)
- there exists , such that . For distinct two tuples in , (a) it might be , such that Y collides with some “previously-ly determined” , the probability of which is ; (b) if but (it can not cannot be ), by the randomness of , for each , the upper bound of the probability is .
- right part: consider , similar to the above:
- (i)
- , for each , the probability of which is at most ;
- (ii)
- there exists another distinct , such that . For each , the upper bound of the probability is .
Thus, denote , we have
References
- Liskov, M.; Rivest, R.L.; Wagner, D. Tweakable block ciphers. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 31–46. [Google Scholar]
- Landecker, W.; Shrimpton, T.; Terashima, R.S. Tweakable blockciphers with beyond birthday-bound security. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 19–23 August 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 14–30. [Google Scholar]
- Andreeva, E.; Bogdanov, A.; Luykx, A.; Mennink, B.; Tischhauser, E.; Yasuda, K. Parallelizable and authenticated online ciphers. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Bangalore, India, 1–5 December 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 424–443. [Google Scholar]
- Rogaway, P. Efficient instantiations of tweakable blockciphers and refinements to modes OCB and PMAC. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Jeju Island, Korea, 5–9 December 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 16–31. [Google Scholar]
- Rogaway, P.; Bellare, M.; Black, J. OCB: A block-cipher mode of operation for efficient authenticated encryption. ACM Trans. Inf. Syst. Secur. (TISSEC) 2003, 6, 365–403. [Google Scholar] [CrossRef]
- Crowley, P. Mercy: A fast large block cipher for disk sector encryption. In Proceedings of the International Workshop on Fast Software Encryption, New York, NY, USA, 10–12 April 2000; Springer: Berlin/Heidelberg, Germany, 2000; pp. 49–63. [Google Scholar]
- Ferguson, N.; Lucks, S.; Schneier, B.; Whiting, D.; Bellare, M.; Kohno, T.; Callas, J.; Walker, J. The Skein hash function family. NIST (Round 3) 2010, 7, 3, submitted. [Google Scholar]
- Schroeppel, R. Hasty pudding cipher specification. In Proceedings of the First AES Candidate Workshop, Ventura, CA, USA, 20–22 August 1998. [Google Scholar]
- Cogliati, B.; Seurin, Y. Beyond-birthday-bound security for tweakable Even-Mansour ciphers with linear tweak and key mixing. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Auckland, New Zealand, 29 November–3 December 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 134–158. [Google Scholar]
- Mennink, B. XPX: Generalized tweakable even-mansour with improved security guarantees. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 64–94. [Google Scholar]
- Naito, Y. Tweakable blockciphers for efficient authenticated encryptions with beyond the birthday-bound security. IACR Trans. Symmetric Cryptol. 2017, 1–26. [Google Scholar] [CrossRef]
- Feistel, H. Cryptography and computer privacy. Sci. Am. 1973, 228, 15–23. [Google Scholar] [CrossRef]
- Even, S.; Mansour, Y. A construction of a cipher from a single pseudorandom permutation. J. Cryptol. 1997, 10, 151–161. [Google Scholar] [CrossRef]
- Jean, J.; Nikolić, I.; Peyrin, T. Tweaks and keys for block ciphers: The TWEAKEY framework. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Kaoshiung, Taiwan, 7–11 December 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 274–288. [Google Scholar]
- Cogliati, B.; Lampe, R.; Seurin, Y. Tweaking even-mansour ciphers. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 16–20 August 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 189–208. [Google Scholar]
- Cogliati, B.; Seurin, Y. On the provable security of the iterated Even-Mansour cipher against related-key and chosen-key attacks. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Sofia, Bulgaria, 26–30 April 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 584–613. [Google Scholar]
- Farshim, P.; Procter, G. The related-key security of iterated Even—Mansour ciphers. In Proceedings of the International Workshop on Fast Software Encryption, Istanbul, Turkey, 8–11 March 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 342–363. [Google Scholar]
- Granger, R.; Jovanovic, P.; Mennink, B.; Neves, S. Improved masking for tweakable blockciphers with applications to authenticated encryption. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Vienna, Austria, 8–12 May 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 263–293. [Google Scholar]
- Luby, M.; Rackoff, C. How to construct pseudorandom permutations from pseudorandom functions. SIAM J. Comput. 1988, 17, 373–386. [Google Scholar] [CrossRef]
- Mitsuda, A.; Iwata, T. Tweakable pseudorandom permutation from generalized feistel structure. In Proceedings of the International Conference on Provable Security, Shanghai, China, 30 October–1 November 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 22–37. [Google Scholar]
- Lampe, R.; Seurin, Y. Security analysis of key-alternating Feistel ciphers. In Proceedings of the International Workshop on Fast Software Encryption, London, UK, 3–5 March 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 243–264. [Google Scholar]
- Goldenberg, D.; Hohenberger, S.; Liskov, M.; Schwartz, E.C.; Seyalioglu, H. On tweaking luby-rackoff blockciphers. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Kuching, Malaysia, 2–6 December 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 342–356. [Google Scholar]
- Yan, H.; Wang, L.; Shen, Y.; Lai, X. Tweaking Key-Alternating Feistel Block Ciphers. In Proceedings of the International Conference on Applied Cryptography and Network Security, Rome, Italy, 9–22 October 2020; Springer: Cham, Switzerland, 2020; pp. 69–88. [Google Scholar]
- Guo, C.; Wang, L. Revisiting key-alternating Feistel ciphers for shorter keys and multi-user security. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Brisbane, QLD, Australia, 2–6 December 2018; Springer: Cham, Switzerland, 2018; pp. 213–243. [Google Scholar]
- Patarin, J. The “coefficients H” technique. In Proceedings of the International Workshop on Selected Areas in Cryptography, Sackville, NB, Canada, 14–15 August 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 328–345. [Google Scholar]
- Chen, S.; Steinberger, J. Tight security bounds for key-alternating ciphers. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Copenhagen, Denmark, 11–15 May 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 327–350. [Google Scholar]
- Hoang, V.T.; Tessaro, S. Key-alternating ciphers and key-length extension: Exact bounds and multi-user security. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 3–32. [Google Scholar]
Figure 1.
10-round tweakable Key-Alternating Feistel cipher presented by Yan et al.

Figure 2.
A distinguisher distinguish the real world and the ideal world.

Figure 3.
A tweakable Key-Alternating Feistel cipher with 6 rounds.

Figure 4.
Inner 4 rounds of the tweakable Key-Alternating Feistel cipher.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Jiang, M.; Wang, L. Almost-Minimal-Round BBB-Secure Tweakable Key-Alternating Feistel Block Cipher. Symmetry 2021, 13, 649. https://doi.org/10.3390/sym13040649
AMA Style
Jiang M, Wang L. Almost-Minimal-Round BBB-Secure Tweakable Key-Alternating Feistel Block Cipher. Symmetry. 2021; 13(4):649. https://doi.org/10.3390/sym13040649
Chicago/Turabian StyleJiang, Ming, and Lei Wang. 2021. "Almost-Minimal-Round BBB-Secure Tweakable Key-Alternating Feistel Block Cipher" Symmetry 13, no. 4: 649. https://doi.org/10.3390/sym13040649
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.