
Abstract
Social species rely on the ability to modulate feedback-monitoring in social contexts to adjust one’s actions and obtain desired outcomes. When being awarded positive outcomes during a gambling task, feedback-monitoring is attenuated when strangers are rewarded, as less value is assigned to the awarded outcome. This difference in feedback-monitoring can be indexed by an event-related potential (ERP) component known as the Reward Positivity (RewP), whose amplitude is enhanced when receiving positive feedback. While the degree of familiarity influences the RewP, little is known about how the RewP and reinforcement learning are affected when gambling on behalf of familiar versus nonfamiliar agents, such as robots. This question becomes increasingly important given that robots may be used as teachers and/or social companions in the near future, with whom children and adults will interact with for short or long periods of time. In the present study, we examined whether feedback-monitoring when gambling on behalf of oneself compared with a robot is impacted by whether participants have familiarized themselves with the robot before the task. We expected enhanced RewP amplitude for self versus other for those who did not familiarize with the robot and that self–other differences in the RewP would be attenuated for those who familiarized with the robot. Instead, we observed that the RewP was larger when familiarization with the robot occurred, which corresponded to overall worse learning outcomes. We additionally observed an enhanced P3 effect for the high-familiarity condition, which suggests an increased motivation to reward. These findings suggest that familiarization with robots may cause a positive motivational effect, which positively affects RewP amplitudes, but interferes with learning.
Similar content being viewed by others

Introduction
As social creatures, a considerable part of our lives revolves around interactions with other humans. However, due to the increased availability of artificially intelligent agents in modern societies, our future social interactions will likely expand to nonhuman agents, such as virtual avatars or robots (Wiese et al., 2017). In fact, robots have already been implemented as social assistants for elderly care to increase emotional comfort (Birks et al., 2016; Tapus et al., 2007), in therapeutic settings with children with autism spectrum disorder to practice social-cognitive skills (Bekele et al., 2014; Warren et al., 2015), as well as in rehabilitation settings to improve sensorimotor skills (Basteris et al., 2014). Nonetheless, despite considerable progress in equipping artificial agents with social capabilities, they are still limited in their ability to interact with humans in a natural way (Wiese et al., 2017), and the public remains skeptical concerning the introduction of robot assistants to everyday life (Bartneck & Reichenbach, 2005). Specifically, the use of robots as teachers or companions for children has been discussed controversially due to concerns about privacy, reduced interest in human-human interaction due to attachment to robot companions, and negative impacts on learning and social development (Sharkey, 2016). While these concerns should be taken seriously, there is a lack of empirical studies systematically examining the impact of robots on social-cognitive processing, development and/or wellbeing. Because robots will employ social roles in society and share our environments with us in the future, it is essential to understand how to design them so that they can engage in social interactions by activating relevant social schemes, behaviors, and emotional reactions without negatively impacting human-human interactions and social-cognitive development.
A fundamental part of human interactions revolves around monitoring the behavior of others, and adjusting our behaviors accordingly to ensure a successful exchange of knowledge, affiliation, and support (Insel & Fernald, 2004). In order to be able to adapt our behavior to ever-changing environments and learn from previous experiences, we heavily rely on feedback from others to be able to tell the difference between behavior that is appropriate and behavior that is not. Receiving positive feedback (e.g., smile) positively reinforces a given behavior and increases the likelihood that it will be shown again in the future; negative feedback (e.g., frown) negatively reinforces a given behavior and decreases the likelihood that it will be shown again in future interactions (Krigolson et al., 2009). This suggests that how we learn in social contexts is a consequence of how we process (i.e., feedback monitoring) and are reinforced by (i.e., reinforcement learning) feedback in the presence of others (Hobson & Inzlicht, 2016). While the effect of human presence on feedback processing is relatively well understood, feedback processing in the presence of robot agents has not been examined. This question is of particular importance given that robots are already used (and will be even more so in the future; Rahwan et al., 2019) in educational and therapeutic settings where a reduced response to feedback could have measurable negative effects on learning outcomes. To address this issue, we examined how feedback is processed in the presence of robot agents and, in particular, whether the degree of experience with a robot, based on prior interactions, modulates reward-related processes.
Given the importance of reward processing for engaging in satisfying social interactions (Chevallier et al., 2012), as well as learning through social reinforcement in the presence of others (Krigolson et al., 2009), it is surprising that the impact of familiarity on reward-related processes has not yet been examined with social robots. As a social species, we monitor positive and negative outcomes and/or feedback from others to calibrate our behaviors so that the likelihood for desired outcomes is optimized (Holroyd & Coles, 2002). Feedback-based adaptation can be examined electrophysiologically via an event-related potential (ERP) components, such as the Reward Positivity (RewP; Holroyd et al., 2008), a component that is sensitive to rewards and appears to provide a reinforcement learning signal (Holroyd & Coles, 2002). The RewPFootnote 1 peaks between 200 and 300 ms after the presentation of feedback and is believed to originate from the dorsal anterior cortex (dACC; Holroyd & Coles, 2002; Botvonick et al., 2004). One paradigm that has traditionally been used and adapted to examine feedback-monitoring is the gambling task (Gehring & Willouby, 2002). In one variation, participants are shown two differently colored squares (of which one is associated with a higher chance of winning) and are asked over a consecutive sequence of trials to pick the square that is associated with a higher chance of winning, followed by positive (“Win”) or negative (“Lose”) feedback. Previous studies using the gambling task have shown that greater RewP amplitudes are observed on “Win” versus “Lose” trials, as well as when gambling for oneself (“Self”) versus another person (“Other”; e.g., Hassall et al., 2016; Krigolson et al., 2013). Specifically, when strangers are the recipients of winning outcomes, individuals experience attenuation of reward processing compared with when gambling for themselves, because they assign less value to the winning outcome (Hassall et al., 2016; Krigolson et al., 2013).
Interestingly, the brain’s ability to monitor feedback in the presence of others is altered by the social context in which a task is performed, as well as the social identity of the other entity. For instance, feedback monitoring has been modulated when a person’s performance has a direct impact on their partner’s performance (de Bruijn et al., 2011; Koban et al., 2012), when the interaction is cooperative versus competitive (de Bruijn et al., 2011; Radke et al., 2011; Van Meel & Van Heijningen, 2010) or when the outcome of one partner’s performance causes negative circumstances for the other partner, such as experiencing pain (Koban et al., 2013). Critically, previous studies have demonstrated that the mere presence of others during the delivery of rewarding feedback can modulate feedback-monitoring (Simon et al., 2014). The presence of a social in-group member compared with an out-group member can attenuate the self-other difference in reward processing (the motivation to win is higher when a similar other is present; Hobson & Inzlicht, 2016), and reward processing is enhanced when observing a friend versus a stranger perform a gambling task (Leng & Zhou, 2010). These findings indicate that the extent to which feedback is rewarding in social situations strongly depends on contextual factors related to the situation and/or the interaction partner.
Goal of study
Given the important role of feedback processing for learning during social interactions, as well as the need for robotic agents to be perceived as social interaction partners in the future, it is essential to understand to what extent humans employ feedback-monitoring processes during human-robot interaction. While reward processing in response to gambling outcomes seems to be influenced by the degree of familiarity between the player and the recipient of a reward in human-human interaction (Leng & Zhou, 2010), little is known about how the RewP is influenced in social contexts where humans familiarize themselves with social robots. In the present study, we used the gambling task to examine how participants process reward in the presence of a social robot and to what degree the magnitude of familiarity with the robot plays in reward processing. We used the socially evocative robot Cozmo, which allows participants to engage in social interaction games via a mobile app. During the interaction, Cozmo reacts by displaying positive/negative emotions when winning/losing against the participant. Cozmo was chosen for this experiment, because it was designed to be engaging and promote positive social interactions; it also is a commonly used robot platform when examining social cognition (e.g., empathy, emotion recognition, joint action, social learning, trust) in interactions with mechanistic agents (Chaudhury et al., 2020; Cross et al., 2019; Hinz et al., 2021; Lefkeli et al., 2020; Pelikan et al., 2020, 2020; Zhou & Tian, 2020) For a tutorial on how to use Cozmo as a research platform in everyday interactions, see Chaudhury et al. (2020).
Because familiarity with social agents has been associated with enhanced reward valuation, we hypothesized that participants who familiarized with Cozmo before the task would value rewards for themselves similarly to Cozmo (i.e., no self-other difference in RewP for the high familiarity group), whereas participants who did not familiarize with Cozmo would value rewards that affect Cozmo to a lesser extent compared to rewards that affect themselves (i.e., a self-other difference in RewP for the low familiarity group).
Methods and Materials
Participants
Forty participants were recruited from George Mason University’s undergraduate population (mean age = 21.88, range = 18-55, 27 females)Footnote 2 in exchange for course credit. Five participants were removed from data analysis due to not following the task protocol (n = 3) or technical difficulties with the robot (n = 2). Two participants had corrupted behavioral data files and were excluded from the behavioral analysis, but not the ERP analysis.Footnote 3 All subjects were right-handed, had normal or corrected-to-normal vision, and reported no known neurological deficits, drug intake, or color blindness. Subjects were pseudo-randomized into either the high-familiarity condition (n = 17) or the low-familiarity condition (n = 18). All data handling and collection was in accordance with George Mason University’s ethics board. Based on prior work in ERP methods and feedback monitoring (Hobson & Inzlicht, 2016), we ran a power analysis using G*Power for a Repeated measures mixed-ANOVA using medium effect size (f = 0.25), an alpha of 0.05, power set to 0.8. The power analysis suggested a total sample of 34 participants. All data and power analysis results were uploaded to OSF (EEG data were excluded due to file size restraints): osf.io/m685p/.
Apparatus
Participants interacted with a small tank Social Robot Cozmo (Anki, CA). The Cozmo robot comes with three interaction cubes that a participant can use to interact with Cozmo (e.g., tapping or moving the cubes). All interactions with Cozmo were preprogrammed using the Cozmo mobile app. A picture of the robot can be found on the OSF page. The gambling task was programmed and presented using the MATLAB programming environment (The Mathworks, Natick, MA), functions from Psychtoolbox (Brainard, 1997), as well as other custom scripts and functions. Behavioral analyses were examined using R (version 3.6) with the lme4 package (Bates et al., 2014).
Procedure
After providing consent, the researcher administered the Snellen and Rosenbaum visual acuity tests, as well as the Ishihara color blindness test. Participants were then fitted with an EEG cap while they completed the questionnaires. Participants were given a cover story and informed that the experiment is a collaboration effort between the Psychology department and the Engineering department. They were told that the Engineering department is trying to decide which of their robots to upgrade and that this experiment will help inform that decision. The level of familiarity with the robot was manipulated through prior interaction, such that one group of participants was provided the opportunity to interact with Cozmo for 20 minutes before engaging in the gambling task, whereas the other group of participants plays another interactive game (the Simon game), for 20 minutes before engaging in the gambling task. After this playtime, Cozmo was placed underneath the computer screen for both groups (after being briefly introduced for the participants in the Simon group), where it sat still but made occasional eye blinks while participants completed the gambling task.
Participants were instructed that they would be gambling for themselves for a chance to win a gift card on half the blocks, while gambling for new upgrades for Cozmo (e.g., batteries, new tank, etc.) during the other half of the blocks. They also were instructed that the likelihoods for each block were completely independent. Participants engaged in the gambling task with an equal number of trials being “Self” (i.e., gamble for oneself) versus “Other” (i.e., gamble for Cozmo). At the mid-point of the experiment (i.e., after 16 blocks), participants completed the same interaction task again based on the condition that they were assigned (i.e., if they were in the high-familiarity condition, they interacted with Cozmo, whereas if they were in the low-familiarity condition, they played the Simon game) and then engaged in another 16 blocks of the gambling task. The RewP amplitudes were compared as an index of reward valuation.
Interaction Task
Participants were pseudo-randomized into either the high-familiarity condition or the low-familiarity condition. In the high-familiarity condition, participants interacted with Cozmo, a tank robot and its cubes. The interaction task consisted of two pre-programmed games: Keep Away and Quick Tap. The objective of Keep Away was to hold one of Cozmo’s cubes and push it towards Cozmo while it tries to tap the top of the cube. If participants pulled the cube away from Cozmo before it tapped the cube, the participant earned a point. If Cozmo tapped the cube first, it gained a point. The objective of Quick Tap was to play a color matching game with Cozmo where one cube is placed in front of the participant and one cube was placed in front of Cozmo. Next, both cubes would light up with a color. If the two cubes’ colors matched, participants were to tap the cube before Cozmo did (i.e., similar to a go-trial in a go/nogo task). However, if the colors matched and the colors were red, then neither the participant nor Cozmo were to tap the cube (i.e., no go trial).Footnote 4 After each trial, a point was given to whoever tapped their cube first (with the exception of the no-go trial where the other player won the point if the cube was tapped on red). The order of the two tasks were counterbalanced between participants. Regardless of the outcome of the two tasks, participants were always told that their and Cozmo’s scores were close, but that they won. In the low-familiarity condition, participants played the traditional Simon Says game using an electronic device placed in front of them. The device would then play a random series of tones and lights, and the participant had to imitate and same sequence by tapping the lights in the correct order. The Simon Says game was chosen due to its high similarity with the Quick Tap game with Cozmo.
Gambling task
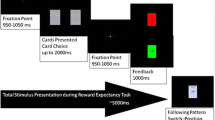
Participants completed a gambling task on behalf of themselves and Cozmo. During the gambling task, participants were instructed to, based on trial and error, determine which of two-colored squares produced a “winning” outcome more often. Each trial started with a central fixation cross, which was presented for 500 ms. Two differently colored squares that were randomly generated by the experiment (i.e., to maximize the likelihood of presenting different color combinations for each block) would then appear on either side of the fixation cross. One color had a winning probability of 60% (i.e., high winning probability), and the other color had a 10% winning probability (i.e., low winning probability). Although the color scheme would be randomly selected for each block, the color of the squares would always appear as complementary colors (e.g., orange and blue). These colors would be presented according to the same color scheme over the course of the entire block. After the colored boxes had been presented for 500 ms, the fixation-cross would change colors from black to grey to indicate to participants that they should choose the color that they think is associated with the higher winning probability. The purpose of the change in color is to encourage the participant to contemplate the odds of the reward prior to responding. If the participant selected a square before the change of color for the fixation cross, that trial was removed from all analyses. The squares remained on the screen until the participants responded with either the “2” key (with their left index finger) to select the color on the left or the “8” key (with their right index finger) to select the color on the right. The probability of each colored square being presented on the left or right side of the screen was equiprobable. After participants responded, feedback would be presented for 1,000 ms to inform them about the gambling outcome (i.e., “win” or “lose”). The inter-trial interval was jittered between 400-600 ms (Fig. 1).

Gambling task trial sequence. Participants were to complete a gambling task on behalf of themselves or Cozmo. The gambling task presented two colors in each block with one color having a higher probability of winning (i.e., 60% chance of winning). After making a choice, feedback was presented regarding whether they won or lost. The ERPs were locked to the feedback.
Participants completed 32 blocks of the gambling task that consist of 20 trials per block. Before the start of each block, a screen would be presented to the participant to indicate whether they were gambling on behalf of themselves “Self” or if they were gambling on behalf of Cozmo “Cozmo.” In essence, subjects completed 16 blocks where they gambled for themselves or Cozmo, which equates to 640 trials overall. The order of “Self” or “Cozmo” blocks were counterbalanced across participants.
Electroencephalogram data recording and processing
The electroencephalogram (EEG) was recorded using a Neuroscan NuAmps amplifier and SCAN 4.01 software (Compumedics, North Carolina, USA). EEG data were collected from 32 scalp sites (extended 10-20 system) using Ag/AgCl electrodes mounted in an elastic cap. Ag/AgCl electrodes also were placed at the left supraorbital and suborbital sites, as well as the left and right outer canthal sites to monitor vertical and horizontal electro-oculographic (EOG) activity, respectively. All scalp electrodes were referenced to the left mastoid (A1) online and re-referenced to the average of the left and right (A2) mastoid offline. The in-cap ground electrode was positioned just anterior to electrode Fz. EEG data were collected at a sampling rate of 500 Hz and were filtered online using a 0.1-Hz high-pass filter and a 70-Hz low-pass filter. Impedance for all electrodes was maintained below 5 kilo-Ohms throughout the duration of the recording session.
EEG data were filtered offline using a 30-Hz low-pass filter and then subjected to independent components analysis (ICA) using Brain Vision Analyzer to identify and reject components corresponding to blinks and saccades. Data were then exported to EEGLAB (Delorme & Makeig, 2004), an EEG processing toolbox for MATLAB, for all remaining processing steps. Data were epoched from 200 ms before feedback presentation to 800 ms following feedback, then subjected to an automated amplitude rejection threshold of ±100 microvolts and a spectral rejection threshold of 50 dB (20-40 Hz bandwidth) using the pop_rejspec function to remove EMG-like activity. If more than 20% of trials were rejected for a given channel, then that channel was removed from the dataset. Channels that were removed were interpolated using spherical spline interpolation. Epochs were baseline corrected using a window spanning −200 ms to 0 ms relative to feedback presentation.
Questionnaires
Previous research has shown that motivational control is related to reward processes, which also is related to reward-associated ERPs (Santesso et al., 2011). Specifically, trait-based factors can influence if participants perceived outcomes as rewarding or punishing (Santesso et al., 2011). Therefore, we used the Gray’s Sensitivity to Reward Questionnaire (SPSRQ: Torrubia et al., 2001) to ensure that any differences observed in reward processing were not related to trait-related differences. The SPSRQ also was used to ensure that the two familiarization conditions were similar in reward sensitivity. In addition, a handedness questionnaire was administered to determine subjects’ preferences in handedness when completing different activities and to ensure that subjects were right-handed (e.g., which hand do you use when you write, use a spoon, etc.).
Analyses
Electrophysiological data
The RewP was characterized as a difference wave of feedback-locked EEG in which losses were subtracted from wins, which were computed separately for each experimental condition. Statistical comparisons were based on data derived from electrode FCz, where the RewP was found to be of maximal amplitude. Mean amplitudes were computed using a 60-ms window (270-330 ms) centered on the peak latency of the grand average difference wave. RewP amplitudes were statistically compared using a 2 x 2 repeated measures mixed ANOVA with Ownership (Self vs. Cozmo) as a within factor and Familiarity (High vs. Low) as a between factor. Post-hoc t-tests were used to follow up any significant interactions. We restricted our analysis to the difference wave between positive and negative feedback because prior studies suggest that the modulation in feedback-related negativity for positive and negative feedback is mainly driven by reward-related mental processes (Holroyd et al., 2008, 2011; Miltner et al., 1997).
We additionally examined the influence of familiarity and ownership on the P3 amplitude, which we derived from the Pz electrode, the site where the amplitude of the P3 was maximal in the grand average parent waveform. Although we chose to use the parent waveform for window selection, because a distinct P3 was not evident in the difference wave, mean amplitude values were collected for statistical comparison from the difference wave in a similar manner to the RewP. Statistical comparisons were based on a 180-ms window (300-480 ms). The larger P3 window is consistent with prior work that uses larger time windows for analyzing P3 amplitudes (Gajewski et al., 2008; Hilgard et al., 2014; Threadgill & Gable, 2020). Analysis of the P3 amplitudes were using a 2 x 2 repeated measures mixed ANOVA with Ownership (Self vs. Cozmo) as a within factor and Familiarity (High vs. Low) as a between factor.
Behavioral data
To examine participant’s performance in the gambling task, we were interested in how quickly participants learned the outcome of the gambling task (i.e., picking the correct color; correct vs. incorrect). This metric, as opposed to actual performance, allowed us to identify how quickly participants were learning while removing any influence of chance that is due to the probabilistic nature of the gambling task. To do this, we constructed conditional growth curves, which tracked each individual’s choice (i.e., a dichotomous variable) for each of the different conditions using log-log mixed linear models on each given trial. In a growth curve analysis, the first step was to examine how the most basic model (i.e., the unconditional model) would track participant’s individual performances. This model contains whether a participant chose the correct color (i.e., the high probability color) on each trial, regressed onto a single predictor, which is the log-log function. This model ignores any variance that is due to the experimental procedure (i.e., not accounting for the Ownership and Familiarity dummy variables). Next, we created a conditional growth curve model by including the factors of interest into the model as well as their interaction with the log-log function predicting whether participants chose the high probability color. Once the conditional growth model was constructed, we compared the conditional growth model to the unconditional growth model using a nested model comparison to test whether a more complex model accounts for more variance compared to the unconditional model (i.e., a more parsimonious model). Because nested model comparisons can favor complex models if they account for more variance in the data, we examined fit indices of the models, which allowed us to have a ratio of variance explained to parsimony. We used the Bayesian Information Criterion (BIC), because it generally favors parsimony over variance explained (Konishi & Kitagawa, 2008). Once a model of best fit was determined, we examined the individual predictors in that model to see if any of the predictors predicted participants learning performance. Specifically, we were interested in examining the interaction terms between the dummy variables (i.e., Ownership and Familiarity) and the log-log function as it allows us to determine whether change overtime was different depending on the factor. In essence, the growth curve model contained Ownership, Familiarity, the growth term, the 2-way interaction between the growth term and each dummy variable, and their 3-way interaction as regressors.
Results
Questionnaire results
Results of the Welch two-sample t-tests did not indicate any differences between our two samples (i.e., high-familiarity vs. low familiarity) in handedness (t(30.24) = −0.63, p = 0.53). There also were no differences in the BIS (t(33.9) = −1.11, p = 0.23), BAS reward (t(27.92) = −0.84, p = 0.4), BAS drive (t(29.64) = −0.85, p = 0.4), and BAS fun (t(31.91) = −0.89, p = 0.37), which indicates that the two samples were identical on reward sensitivity. Cronbach’s alpha showed acceptable reliability scores across all the reward sensitivity items (α = 0.89, 95% confidence interval (CI) [0.79, 0.93]) All degrees of freedom were adjusted for unequal variances in the two groups. Demographic data as well as a breakdown of the results of BIS-BAS by gender can be found in Table 1.
Electrophysiological results
Results of the 2 x 2 repeated measures mixed ANOVA examining RewP amplitudes revealed a nonsignificant main effect of Ownership (F(1, 33) = 0.27, p = 0.6, ηG2 = 0.001), but a significant main effect of Familiarity (F(1, 33) = 4.60, p = 0.03, ηG2 = 0.1). The main effect was such that subjects in the high-familiarity condition had higher RewP amplitudes compared with the low-familiarity condition (MHigh-Fam = 4.13, SD = 2.4 vs. MLow-Fam = 2.44, SD = 2.57). The Ownership x Familiarity interaction revealed a nonsignificant effect (F(1, 33) = 0.33, p = 0.56, ηG2 = 0.001). See Fig. 2.

Mean amplitudes of the RewP (at electrode FCz). The RewP is a difference wave between ERPs that are time-locked to the onset of Win / Loss feedback. The statistical analyses of RewP amplitudes were based on a time window of 270-330 ms, which was centered on the peak of the grand average waveform. The time-window is illustrated by the shaded region. The topographic plots (collapsing across Cozmo and Self gambling conditions) illustrate that the RewP is indeed maximal at electrode FCz. A graph of the parent waveforms can be found in the supplementary materials; see Figure S3. The raincloud plot illustrates the mean amplitudes, the individual data points as well as the distribution of the data. Error bars represent the standard error of the mean. Asterisks represent significance at the 0.05 level.
Results of the ANOVA examining P3 amplitudes also revealed a nonsignificant main effect of Ownership (F(1, 33) < 0.01, p = 0.95, ηG2 < 0.001). The main effect of Familiarity was significant (F(1, 33) = 4.74, p = 0.03, ηG2 = 0.11), with higher P3 amplitudes for participants in the high-familiarity condition compared with those in the low-familiarity condition (MHigh-Fam = 2.76, SD = 2.98 vs. MLow-Fam = 0.72, SD = 2.74). The Ownership x Familiarity interaction was not significant (F(1, 33) = 0.1, p = 0.74, ηG2 < 0.001). See Fig. 3.

Mean amplitudes of the P3 (at electrode Pz). Similar to the RewP, the P3 shown is a difference wave between ERPs that are time-locked to the onset of Win/Loss feedback. The statistical analyses were based on time-window of 300-480 ms and is illustrated by the shaded region. The topographic plots (collapsing across Cozmo and Self gambling conditions) illustrate that the P3 is indeed maximal at electrode Pz. A graph of the parent waveforms can be found in the supplementary materials; see Figure S4. Error bars represent the standard error of the mean. Asterisks represent significance at the 0.05 level.
Behavioral results
The model of best fit revealed that the log-log function was a significant predictor (b = 0.37, SE = 0.03, z(21760) = 10.38, p < 0.001). The dummy variable for Familiarity was not significant (b = 0.04, SE = 0.25, z(21760) = 0.16, p = 0.87), the dummy variable for Ownership was not significant (b = 0.13, SE = 0.11, z(21760) = 1.21, p = 0.22), and the interaction of the two dummy variables also was not significant (b = −17, SE = 0.16, z(21760) = −1.02, p = 0.3). More importantly for our analysis are the effects of the interactions with the growth function. The interaction between the log-log function and the dummy variable of ownership (i.e., Growth X Ownership) revealed a nonsignificant interaction (b = −0.01, SE = 0.05, z(21760) = −0.23, p = 0.81); however, the interaction between the log-log function and the dummy variable for Familiarity (i.e., Growth x Familiarity) was significant (b = 0.29, SE = 0.05, z(21760) = 5.22, p < 0.001), such that participants in the low-familiarity condition learned at a faster rate compared with subjects in the high-familiarity condition. The three way interaction between the growth term, familiarity, and ownership was not significant (b = −0.02, SE = 0.07, z(21760) = −0.32, p = 0.74). See Fig. 4.

Full results of the conditional growth curve model. The conditional growth model revealed a significant difference in learning rates between the high-familiarity (i.e., left panel) and low-familiarity conditions (right panel). However, no differences in learning rates were detected when subjects gambled on behalf of themselves (i.e., gray) or Cozmo (i.e., yellow), regardless of the condition.
Discussion
The goal of the present study was to examine the role of electrophysiological indices related to feedback processing associated with learning during social interactions with robots. We asked participants to either interact with Cozmo or perform a nonsocial task, then complete a learnable gambling paradigm in which they could gamble on behalf of themselves (i.e., Wins go to the participant) or Cozmo (i.e., Wins go to Cozmo). Because previous studies have proposed that social contexts have the ability to change feedback monitoring (e.g., feedback monitoring is altered when a social in-group member is present; Hobson & Inzlicht, 2016), thus influencing learning, we hypothesized that feedback-monitoring would be altered when subjects familiarize themselves with an animate robot, Cozmo, by interacting with it. Specifically, we hypothesized that participants who interacted with Cozmo would exhibit enhanced RewP amplitudes, an electrophysiological index associated with reward and reinforcement learning, when the outcome of the gambling task affected Cozmo compared with the group that did not interact with Cozmo. Additionally, we expected that participants who did not interact with Cozmo would show reduced RewP amplitudes when the outcome affected Cozmo in comparison to when the outcome affected themselves, as previous work has shown that outcomes affecting strangers were associated with inhibited feedback processing (Hassall et al., 2016). Prior work has suggested that motivational control is related to reward processes and that these processes can influence reward related ERPs (Santesso et al., 2011). Specifically, trait-based factors can influence how rewarding and punishing outcomes are perceived (Santesso et al., 2011). Therefore, we used the SPSRQ sensitivity to reward questionnaire to ensure that the differences that we find in RewP were due to our manipulation and not due to SPSRQ differences between familiarization conditions.
The findings revealed that RewP amplitudes were enhanced for participants who interacted with the robot compared with subjects who did not. Additionally, contrary to our expectation, no differences were detected in RewP amplitudes when the outcome of the gambling task affected one’s self or Cozmo for subjects who did not interact with Cozmo. Results of the behavioral data suggest that when participants familiarized themselves with Cozmo, they learned to discriminate which of the two response options (colored squares) would produce the “win” feedback at a slower rate compared with when they did not interact with Cozmo. Taken together, it is not surprising that slow learners (i.e., subjects who interacted with Cozmo) had larger RewP amplitudes, because they relied on the positive feedback signal to inform their following behavior due to the fact that the difference between the outcome of their behavior and the outcome of their desired behavior was large (Holroyd & Coles, 2002; Schultz, 2017), while fast learners (i.e., participants who did not interact with Cozmo) did not have to rely on the feedback as it contained information of little utility. This fast learning process diminished their physiological responses to the feedback stimulus as it carried less weight to inform future behavior. This interpretation is in line with Holroyd and Coles’ (2002) theory of Reinforcement Learning (RL-ERN). The RL-ERN theory suggests that two types of prediction errors exist: a positive prediction error (i.e., outcomes that are better than our expected outcome) and a negative prediction error (i.e., outcomes that are worse than our expected outcome). It is believed that the RewP tracks this difference between our expectation and the actual outcome. While both prediction errors elicit a feedback response, fast learners have a diminished difference between their expectations and the actual outcome, thus resulting in smaller RewP amplitudes. Moreover, the reinforcement learning theory suggests that once fast learners learn a task, they place more weight on their own responses to inform their following behaviors as opposed to the feedback that they are provided (Holroyd & Coles, 2002; Krigolson et al., 2009).
We also observed that the P3 component was affected by our experimental manipulation in a manner that mimics the RewP. This raises the possibility that the observed effect for the latter could be attributed to component overlap. Although there is a parietal local maximum evident in the nonfamiliarity condition, it is distinct from the frontocentral maximum observed for the RewP. The P3 was quantified using an analysis window based on the parent waveforms, which suggests that P3 peak latency (354 ms) was ~50 ms later than that of the RewP (300 ms). Moreover, the topography of the P3 is distinctly parietal (in fact, for the low-familiarity condition, it was maximal at parietal and occipital sites). These findings suggest that the P3 is not the primary factor contributing to the differences observed for the RewP, although we cannot completely rule out this possibility. Nevertheless, the finding of a significant effect for the P3 has theoretical implications for the study (see below).
One possibility as to why participants in the Cozmo group had enhanced RewP amplitudes could be because social interactions can enhance intrinsic motivations (Tauer & Harackiewicz, 2004), which influences reward processing (Mace et al., 2017; Wilhelm et al., 2019). This claim is supported by the Optimizing Performance Through Intrinsic Motivation and Attentional Learning (OPTIMAL) theory of motor learning that posits that motivational factors and attentional factors, which can be enhanced via social interactions and external factors, have the capability of improving learning performance (Wilhelm et al., 2019; Wulf & Lewthwaite, 2016). In other words, participants who interacted with Cozmo were more intrinsically motivated to perform well on the task. Our finding of increased P3 amplitude in the high-familiarity condition is consistent with the suggestion that this condition was associated with increased motivation, given that a number of studies have linked the P3 to motivation for reward (Franken et al., 2011; Hughes et al., 2013; Yeung et al., 2004). However, this account does not explain why reward processing was associated with lower learning rates and future work should investigate this question. Here we note that other work has suggested that an immersive and enriched environment can hinder performance. This hindrance also is associated with descriptive increases in RewP (Lohse et al., 2020). This is a similar pattern to what we observed and could be explained by participants who interacted with Cozmo having experienced social enrichment. Such enrichment could have increased arousal and positive affect—possibly partially explaining the increase in RewP—while simultaneously reducing performance, as a result the social component of the environment creating a distraction from the task. The finding that, in the high-familiarity condition, an increase in amplitude of the P3 occurred in conjunction with an increase in the RewP suggests that generalized arousal (Luck, 2014; Rozenkrants & Polich, 2008) could explain the dissociation between RewP amplitude and behavioral performance. However, because the ERP waveforms did not diverge until relatively late in time, it remains possible that a more selective impact on reward processing associated with differing learning rates, as described above, is capable of explaining the relation between physiology and behavior. Similar research that has examined the use of social agents, avatars, and robots in learning environments has consistently found that these social agents can serve as distractors, which can hinder people’s ability to learn (Kennedy et al., 2015; Momen et al., 2016; Yadollahi et al., 2018).
One remaining question is why participants did not value rewards more highly for themselves in comparison to Cozmo in the low familiarity condition (i.e., no RewP or learning rate difference when gambling for Self vs. Cozmo in the no interaction condition). One possible explanation is that the mere presence of an entity with somewhat social features might have been sufficient to increase participants’ motivation to do well when gambling for the robot. This interpretation would be in line with previous studies on social facilitation showing that the mere presence of other human (Zajonc, 1965) or nonhuman (e.g., robots; Riether et al., 2012) entities positively impacts performance on easy tasks, but negatively impacts performance on difficult tasks, including gambling tasks (Lemoine & Roland-Lévy, 2017). In line with this interpretation, it was suggested that the presence of a social agent could positively affect attentional processes to a similar extent as monetary rewards (Anderson, 2016), which could have been sufficiently motivating to equalize any differences in reward processing between Self and Cozmo conditions.
We acknowledge some limitations in the current study. While we discuss the findings in our study of how interactions with a social agent can influence performance and learning, colleagues suggest that a distinction should be made between the two processes (Cahill et al., 2001). In other words, while we make inferences about learning outcomes from participant’s performance, we acknowledge that learning is a complex process that is affected by a wide array of factors. For example, temporal dynamics of our manipulation could have an influence on performance (i.e., does performance hold up after a long period of interaction with an artificial agent?). This point needs to be made to ensure proper scientific rigor in experimental design (i.e., the need to control for other variables is important). This also suggests that future studies should design experiments that are able to make claims about learning that occurs over long periods. Lastly, it is important to acknowledge that, as the interaction with Cozmo involved a competitive task, participants in the high-familiarity condition may have been predisposed to experience greater reward processing as a result of being motivated by the competitive nature of the engagement task. In line with this idea is work showing that the RewP is enhanced when tasks are performed in a social context (Wilhelm et al., 2019), even when the social context involves insults that promote anger in the participant (Threadgill & Gable, 2020). Threadgill and Gable (2020) posit this could be due to the pleasurable feeling associated with revenge. In future work, it would be informative to include a noncompetitive or cooperative engagement task to determine whether tasks that induce emotions of differing valence impact reward processing.
These findings have several implications for both social cognition and the field of human-robot interaction. First, the findings of the present study add to the body of literature investigating the influence of social context on feedback monitoring. While research has shown that the RewP is modulated based on non-social factors (e.g., magnitude of reward), social factors can also affect feedback monitoring. The findings also provide additional data, which align with the reinforcement learning theory. This study also has several implications for the field of human-robot interaction (HRI). Our data suggest that we are able to perform certain tasks on behalf of robots when we familiarize with them (i.e., no difference in feedback monitoring when others gambling). The data also suggest that the use of social robots in learning settings may have a detrimental effect on learning. While using social robots may provide benefits in some settings (e.g., clinical settings), roboticists and technology adaptors should be wary about including animate and social agents in learning environments as they could hinder learning and performance.
Change history
03 May 2021
A Correction to this paper has been published: https://doi.org/10.3758/s13415-021-00902-z
Notes
Note that an emerging view is that the feedback-locked signal of interest is a positivity modulated by rewards, not a negativity modulated by losses (Holroyd et al., 2008; Proudfit, 2015). Consequently, we operationalized our feedback signal as the RewP, as opposed to the feedback-related negativity (FRN) originally described by Miltner et al. (1997).
Because an outlier in age was evident in our sample, we ran our ERP analysis twice: once including the outlier, and once excluding them. Because the results were the same (i.e., both analyses showed a significant main effect of familiarity), we opted to include the participant.
To account for this discrepancy between the EEG data and the behavioral data, we ran additional analyses that excluded those participants. We also ran a nonparametric Bayesian analysis that mirrors the main analysis of RewP amplitudes to examine the probabilities of the observed and null effects. See supplementary materials for details.
While participants familiarized with Cozmo by playing against it, which can be viewed as a competitive interaction, studies have shown that the cooperation-competition dynamic is complex and that competition can lead cooperation and pro-social behavior in certain instances (Cone & Rand, 2014; Rabois & Haaga, 2002; Sage & Kavussanu, 2007; West, 2002), especially when the interactions are framed in a cooperative sense (Bengtsson & Kock, 2000) and does not adversely influence the participant, which is the case in our study.
References
Anderson, B. A. (2016). The attention habit: How reward learning shapes attentional selection: The attention habit. Annals of the New York Academy of Sciences, 1369(1), 24–39. https://doi.org/10.1111/nyas.12957
Bartneck, C., & Reichenbach, J. (2005). Subtle emotional expressions of synthetic characters. International Journal of Human-Computer Studies, 62(2), 179–192. https://doi.org/10.1016/j.ijhcs.2004.11.006
Basteris, A., Nijenhuis, S. M., Stienen, A. H., Buurke, J. H., Prange, G. B., & Amirabdollahian, F. (2014). Training modalities in robot-mediated upper limb rehabilitation in stroke: A framework for classification based on a systematic review. Journal of NeuroEngineering and Rehabilitation, 11(1), 111. https://doi.org/10.1186/1743-0003-11-111
Bates, D., Mächler, M., Bolker, B., & Walker, S. (2014). Fitting Linear Mixed-Effects Models using lme4. Journal of Statistical Software, 67(1). 10.18637/jss.v067.i01
Bekele, E., Crittendon, J. A., Swanson, A., Sarkar, N., & Warren, Z. E. (2014). Pilot clinical application of an adaptive robotic system for young children with autism. Autism, 18(5), 598–608. https://doi.org/10.1177/1362361313479454
Bengtsson, M., & Kock, S. (2000)."Coopetition" in Business Networks—To Cooperate and Compete Simultaneously. Industrial Marketing Management, 29(5), 411–426. https://doi.org/10.1016/S0019-8501(99)00067-X
Birks, M., Bodak, M., Barlas, J., Harwood, J., & Pether, M. (2016). Robotic Seals as Therapeutic Tools in an Aged Care Facility: A Qualitative Study. Journal of Aging Research, 2016, 1–7. https://doi.org/10.1155/2016/8569602
Botvinick, M. M., Cohen, J. D., & Carter, C. S. (2004). Conflict monitoring and anterior cingulate cortex: An update. Trends in Cognitive Sciences, 8(12), 539–546. https://doi.org/10.1016/j.tics.2004.10.003
Brainard, D. H. (1997). The Psychophysics Toolbox. Spatial Vision, 10(4), 433–436. https://doi.org/10.1163/156856897X00357
Cahill, L., McGaugh, J. L., & Weinberger, N. M. (2001). The neurobiology of learning and memory: Some reminders to remember. Trends in Neurosciences, 24(10), 578–581. https://doi.org/10.1016/S0166-2236(00)01885-3
Chaudhury, B., Hortensius, R., Hoffmann, M., & Cross, E. S. (2020). Tracking Human Interactions with a Commercially-available Robot over Multiple Days: A Tutorial. PsyArXiv. 10.31234/osf.io/fd3h2
Chevallier, C., Kohls, G., Troiani, V., Brodkin, E. S., & Schultz, R. T. (2012). The social motivation theory of autism. Trends in Cognitive Sciences, 16(4), 231–239. https://doi.org/10.1016/j.tics.2012.02.007
Cone, J., & Rand, D. G. (2014). Time Pressure Increases Cooperation in Competitively Framed Social Dilemmas. PLoS ONE, 9(12). https://doi.org/10.1371/journal.pone.0115756
Cross, E. S., Riddoch, K. A., Pratts, J., Titone, S., Chaudhury, B., & Hortensius, R. (2019). A neurocognitive investigation of the impact of socializing with a robot on empathy for pain. Philosophical Transactions of the Royal Society B: Biological Sciences, 374(1771), 20180034. https://doi.org/10.1098/rstb.2018.0034
de Bruijn, E. R. A., Miedl, S. F., & Bekkering, H. (2011). How a co-actor’s task affects monitoring of own errors: Evidence from a social event-related potential study. Experimental Brain Research, 211(3), 397. https://doi.org/10.1007/s00221-011-2615-1
Delorme, A., & Makeig, S. (2004). EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. Journal of Neuroscience Methods, 134(1), 9–21. https://doi.org/10.1016/j.jneumeth.2003.10.009
Franken, I. H. A., Van Strien, J. W., Bocanegra, B. R., & Huijding, J. (2011). The P3 Event-Related Potential as an Index of Motivational Relevance. Journal of Psychophysiology, 25(1), 32–39. https://doi.org/10.1027/0269-8803/a000030
Gajewski, P. D., Stoerig, P., & Falkenstein, M. (2008). ERP—Correlates of response selection in a response conflict paradigm. Brain Research, 1189, 127–134. https://doi.org/10.1016/j.brainres.2007.10.076
Gehring, W. J., & Willoughby, A. R. (2002). The medial frontal cortex and the rapid processing of monetary gains and losses. Science, 295(5563), 2279–2282. https://doi.org/10.1126/science.1066893.
Hassall, C. D., Silver, A., Turk, D. J., & Krigolson, O. E. (2016). We are more selfish than we think: The endowment effect and reward processing within the human medial-frontal cortex. Quarterly Journal of Experimental Psychology, 69(9), 1676–1686. https://doi.org/10.1080/17470218.2015.1091849
Hilgard, J., Weinberg, A., Proudfit, G. H., & Bartholow, B. D. (2014). The Negativity Bias in Affective Picture Processing Depends on Top-Down and Bottom-Up Motivational Significance. Emotion (Washington, D.C.), 14(5), 940–949. https://doi.org/10.1037/a0036791
Hinz, N.-A., Ciardo, F., & Wykowska, A. (2021). ERP markers of action planning and outcome monitoring in human – robot interaction. Acta Psychologica, 212, 103216. https://doi.org/10.1016/j.actpsy.2020.103216
Hobson, N. M., & Inzlicht, M. (2016). The mere presence of an outgroup member disrupts the brain’s feedback-monitoring system. Social Cognitive and Affective Neuroscience, 11(11), 1698–1706. https://doi.org/10.1093/scan/nsw082
Holroyd, C. B., & Coles, M. G. H. (2002). The neural basis of human error processing: Reinforcement learning, dopamine, and the error-related negativity. Psychological Review, 109(4), 679–709. https://doi.org/10.1037/0033-295X.109.4.679
Holroyd, C. B., Krigolson, O. E., & Lee, S. (2011). Reward positivity elicited by predictive cues. NeuroReport, 22(5), 249–252. https://doi.org/10.1097/WNR.0b013e328345441d
Holroyd, C. B., Pakzad-Vaezi, K. L., & Krigolson, O. E. (2008). The feedback correct-related positivity: Sensitivity of the event-related brain potential to unexpected positive feedback. Psychophysiology, 45(5), 688–697. https://doi.org/10.1111/j.1469-8986.2008.00668.x
Hughes, G., Mathan, S., & Yeung, N. (2013). EEG indices of reward motivation and target detectability in a rapid visual detection task. NeuroImage, 64, 590–600. https://doi.org/10.1016/j.neuroimage.2012.09.003
Insel, T. R., & Fernald, R. D. (2004). How the brain processes social information: searching for the social brain. Annu Rev Neurosci, 27, 697–722. https://doi.org/10.1146/annurev.neuro.27.070203.144148.
Kennedy, J., Baxter, P., & Belpaeme, T. (2015). The Robot Who Tried Too Hard: Social Behaviour of a Robot Tutor Can Negatively Affect Child Learning. 2015 10th ACM/IEEE International Conference on Human-Robot Interaction (HRI), 67–74.
Koban, L., Corradi-Dell’Acqua, C., & Vuilleumier, P. (2013). Integration of Error Agency and Representation of Others’ Pain in the Anterior Insula. Journal of Cognitive Neuroscience, 25(2), 258–272. https://doi.org/10.1162/jocn_a_00324
Koban, L., Pourtois, G., Bediou, B., & Vuilleumier, P. (2012). Effects of social context and predictive relevance on action outcome monitoring. Cognitive, Affective, & Behavioral Neuroscience, 12(3), 460–478. https://doi.org/10.3758/s13415-012-0091-0
Konishi, S., & Kitagawa, G. (2008). Information criteria and statistical modeling. Springer.
Krigolson, Olav E., Pierce, L. J., Holroyd, C. B., & Tanaka, J. W. (2009). Learning to Become an Expert: Reinforcement Learning and the Acquisition of Perceptual Expertise. Journal of Cognitive Neuroscience, 21(9), 1833–1840. https://doi.org/10.1162/jocn.2009.21128
Krigolson, Olave E., Hassall, C. D., Balcom, L., & Turk, D. (2013). Perceived ownership impacts reward evaluation within medial-frontal cortex. Cognitive, Affective, & Behavioral Neuroscience, 13(2), 262–269. https://doi.org/10.3758/s13415-012-0144-4
Lefkeli, D., Ozbay, Y., Gürhan-Canli, Z., & Eskenazi, T. (2020). Competing with or Against Cozmo, the Robot: Influence of Interaction Context and Outcome on Mind Perception. International Journal of Social Robotics. https://doi.org/10.1007/s12369-020-00668-3
Lemoine, J. E., & Roland-Lévy, C. (2017). The effect of the presence of an audience on risk-taking while gambling: The social shield. Social Influence, 12(2–3), 101–114. https://doi.org/10.1080/15534510.2017.1373697
Leng, Y., & Zhou, X. (2010). Modulation of the brain activity in outcome evaluation by interpersonal relationship: An ERP study. Neuropsychologia, 48(2), 448–455. https://doi.org/10.1016/j.neuropsychologia.2009.10.002
Lohse, K. R., Miller, M. W., Daou, M., Valerius, W., & Jones, M. (2020). Dissociating the contributions of reward-prediction errors to trial-level adaptation and long-term learning | Elsevier Enhanced Reader. Biological Psychology, 149(107775). https://doi.org/10.1016/j.biopsycho.2019.107775
Luck, S. J. (2014). An Introduction to the Event-Related Potential Technique, second edition. MIT Press.
Mace, M., Kinany, N., Rinne, P., Rayner, A., Bentley, P., & Burdet, E. (2017). Balancing the playing field: Collaborative gaming for physical training. Journal of NeuroEngineering and Rehabilitation, 14(1), 116. https://doi.org/10.1186/s12984-017-0319-x
Miltner, W. H. R., Braun, C. H., & Coles, M. G. H. (1997). Event-Related Brain Potentials Following Incorrect Feedback in a Time-Estimation Task: Evidence for a “Generic” Neural System for Error Detection. Journal of Cognitive Neuroscience, 9(6), 788–798. https://doi.org/10.1162/jocn.1997.9.6.788
Momen, A., Sebrechts, M. M., & Allaham, M. M. (2016). Virtual Agents as a Support for Feedback-Based Learning. Proceedings of the Human Factors and Ergonomics Society Annual Meeting, 60(1), 1780–1784. https://doi.org/10.1177/1541931213601407
Pelikan, H. R. M., Broth, M., & Keevallik, L. (2020). “Are You Sad, Cozmo?”: How Humans Make Sense of a Home Robot’s Emotion Displays. Proceedings of the 2020 ACM/IEEE International Conference on Human-Robot Interaction, 461–470. https://doi.org/10.1145/3319502.3374814
Proudfit, G. H. (2015). The reward positivity: From basic research on reward to a biomarker for depression: The reward positivity. Psychophysiology, 52(4), 449–459. https://doi.org/10.1111/psyp.12370
Rabois, D., & Haaga, D. A. F. (2002). Facilitating police–minority youth attitude change: The effects of cooperation within a competitive context and exposure to typical exemplars. Journal of Community Psychology, 30(2), 189–195. https://doi.org/10.1002/jcop.10003
Radke, S., de Lange, F. P., Ullsperger, M., & de Bruijn, E. R. A. (2011). Mistakes that affect others: An fMRI study on processing of own errors in a social context. Experimental Brain Research, 211(3), 405–413. https://doi.org/10.1007/s00221-011-2677-0
Rahwan, I., Cebrian, M., Obradovich, N., Bongard, J., Bonnefon, J.-F., Breazeal, C., Crandall, J. W., Christakis, N. A., Couzin, I. D., Jackson, M. O., Jennings, N. R., Kamar, E., Kloumann, I. M., Larochelle, H., Lazer, D., McElreath, R., Mislove, A., Parkes, D. C., Pentland, A. ‘Sandy,’ … Wellman, M. (2019). Machine behaviour. Nature, 568(7753), 477–486. https://doi.org/10.1038/s41586-019-1138-y
Riether, N., Hegel, F., Wrede, B., & Horstmann, G. (2012). Social facilitation with social robots? Proceedings of the Seventh Annual ACM/IEEE International Conference on Human-Robot Interaction - HRI ’12, 41. https://doi.org/10.1145/2157689.2157697
Rozenkrants, B., & Polich, J. (2008). Affective ERP processing in a visual oddball task: Arousal, valence, and gender. Clinical Neurophysiology, 119(10), 2260–2265. https://doi.org/10.1016/j.clinph.2008.07.213
Sage, L., & Kavussanu, M. (2007). The Effects of Goal Involvement on Moral Behavior in an Experimentally Manipulated Competitive Setting. Journal of Sport and Exercise Psychology, 29(2), 190–207. https://doi.org/10.1123/jsep.29.2.190
Santesso, D. L., Dzyundzyak, A., & Segalowitz, S. J. (2011). Age, sex and individual differences in punishment sensitivity: Factors influencing the feedback-related negativity. Psychophysiology, 48(11), 1481–1489. https://doi.org/10.1111/j.1469-8986.2011.01229.x
Schultz, W. (2017). Reward prediction error. Current Biology, 27(10), R369–R371. https://doi.org/10.1016/j.cub.2017.02.064
Sharkey, A. J. C. (2016). Should we welcome robot teachers? Ethics and Information Technology, 18(4), 283–297. https://doi.org/10.1007/s10676-016-9387-z
Simon, D., Becker, M. P. I., Mothes-Lasch, M., Miltner, W. H. R., & Straube, T. (2014). Effects of social context on feedback-related activity in the human ventral striatum. NeuroImage, 99, 1–6. https://doi.org/10.1016/j.neuroimage.2014.05.071
Tapus, A., Mataric, M. J., & Scassellati, B. (2007). Socially assistive robotics [Grand Challenges of Robotics]. IEEE Robotics Automation Magazine, 14(1), 35–42. https://doi.org/10.1109/MRA.2007.339605
Tauer, J. M., & Harackiewicz, J. M. (2004). The Effects of Cooperation and Competition on Intrinsic Motivation and Performance. Journal of Personality and Social Psychology, 86(6), 849–861. https://doi.org/10.1037/0022-3514.86.6.849
Threadgill, A. H., & Gable, P. A. (2020). Revenge is sweet: Investigation of the effects of Approach-Motivated anger on the RewP in the motivated anger delay (MAD) paradigm. Human Brain Mapping, 41(17), 5032–5056. https://doi.org/10.1002/hbm.25177
Torrubia, R., Ávila, C., Moltó, J., & Caseras, X. (2001). The Sensitivity to Punishment and Sensitivity to Reward Questionnaire (SPSRQ) as a measure of Gray’s anxiety and impulsivity dimensions. Personality and Individual Differences, 31(6), 837–862. https://doi.org/10.1016/S0191-8869(00)00183-5
Van Meel, C. S., & Van Heijningen, C. A. A. (2010). The effect of interpersonal competition on monitoring internal and external error feedback. Psychophysiology, 47(2), 213–222. https://doi.org/10.1111/j.1469-8986.2009.00944.x
Warren, Z. E., Zheng, Z., Swanson, A. R., Bekele, E., Zhang, L., Crittendon, J. A., Weitlauf, A. F., & Sarkar, N. (2015). Can Robotic Interaction Improve Joint Attention Skills? Journal of Autism and Developmental Disorders, 45(11), 3726–3734. https://doi.org/10.1007/s10803-013-1918-4
West, S. A. (2002). Cooperation and Competition Between Relatives. Science, 296(5565), 72–75. https://doi.org/10.1126/science.1065507
Wiese, E., Metta, G., & Wykowska, A. (2017). Robots as intentional agents: Using neuroscientific methods to make robots appear more social. Frontiers in Psychology, 8. https://doi.org/10.3389/fpsyg.2017.01663
Wilhelm, R. A., Miller, M. W., & Gable, P. A. (2019). Neural and Attentional Correlates of Intrinsic Motivation Resulting from Social Performance Expectancy. Neuroscience, 416, 137–146. https://doi.org/10.1016/j.neuroscience.2019.07.039
Wulf, G., & Lewthwaite, R. (2016). Optimizing performance through intrinsic motivation and attention for learning: The OPTIMAL theory of motor learning. Psychonomic Bulletin & Review, 23(5), 1382–1414. https://doi.org/10.3758/s13423-015-0999-9
Yadollahi, E., Johal, W., Paiva, A., & Dillenbourg, P. (2018). When deictic gestures in a robot can harm child-robot collaboration. Proceedings of the 17th ACM Conference on Interaction Design and Children, 195–206. https://doi.org/10.1145/3202185.3202743
Yeung, N., Botvinick, M. M., & Cohen, J. D. (2004). The Neural Basis of Error Detection: Conflict Monitoring and the Error-Related Negativity. Psychological Review, 111(4), 931–959. https://doi.org/10.1037/0033-295X.111.4.931
Zajonc, R. B. (1965). Social Facilitation. Science, 149(3681), 269–274.
Zhou, S., & Tian, L. (2020). Would you help a sad robot? Influence of robots’ emotional expressions on human-multi-robot collaboration. 2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), 1243–1250. https://doi.org/10.1109/RO-MAN47096.2020.9223524
Author information
Authors and Affiliations
Corresponding author
Additional information
Open Practice Statement
Behavioral data are available on osf.io/m685p/.
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this article was revised due to a retrospective Open Access cancellation.
Impact statement
With an increase in the use of robots in our lives, it is important to understand how robots impact our cognition and behavior. The present study compares the dynamics of outcome monitoring when people gamble on behalf of themselves or on behalf of robots. We demonstrate that interacting with social robots can influence how individuals process rewards during a gambling task.
Supplementary Information
ESM 1
(DOCX 653 kb)
Rights and permissions
About this article

Cite this article
Abubshait, A., Beatty, P.J., McDonald, C.G. et al. A win-win situation: Does familiarity with a social robot modulate feedback monitoring and learning?. Cogn Affect Behav Neurosci 21, 763–775 (2021). https://doi.org/10.3758/s13415-021-00895-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13415-021-00895-9