
Abstract
Ensemble approaches introduced in the Extreme Learning Machine literature mainly come from methods that rely on data sampling procedures, under the assumption that the training data are heterogeneously enough to set up diverse base learners. To overcome this assumption, it was proposed an ELM ensemble method based on the Negative Correlation Learning framework, called Negative Correlation Extreme Learning Machine (NCELM). This model works in two stages: (i) different ELMs are generated as base learners with random weights in the hidden layer, and (ii) a NCL penalty term with the information of the ensemble prediction is introduced in each ELM minimization problem, updating the base learners, (iii) second step is iterated until the ensemble converges. Although this NCL ensemble method was validated by an experimental study with multiple benchmark datasets, no information was given on the conditions about this convergence. This paper mathematically presents sufficient conditions to guarantee the global convergence of NCELM. The update of the ensemble in each iteration is defined as a contraction mapping function, and through Banach theorem, global convergence of the ensemble is proved.

Similar content being viewed by others
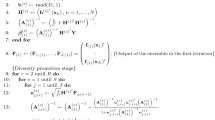


Notes
using NCELM implementation from pyridge, https://github.com/cperales/pyridge
The code for this graphic is published online in a Jupyter notebook, https://github.com/cperales/pyridge/NCELM_convergence.ipynb
References
Arendt W, Nittka R (2009) Equivalent complete norms and positivity. Archiv der Mathematik 92(5):414–427
Banach S (1922) Sur les opérations dans les ensembles abstraits et leur application aux équations intégrales. Fundamenta Mathematicae 3:133–181
Breiman L (1996) Bagging predictors. Mach Learn
Chang P, Zhang J, Hu J, Song Z (2018) A deep neural network based on elm for semi-supervised learning of image classification. Neural Process Lett 48(1):375–388
Chaturvedi I, Ragusa E, Gastaldo P, Zunino R, Cambria E (2018) Bayesian network based extreme learning machine for subjectivity detection. J Franklin Inst 355(4):1780–1797
Chen H, Jiang B, Yao X (2018) Semisupervised negative correlation learning. IEEE Trans Neural Netw Learn Syst 29(11):5366–5379
Ciesielski K (2007) On stefan banach and some of his results. Banach J Math Anal 1(1):1–10
Domingos, P.: Why does bagging work? a bayesian account and its implications. In: 3rd International Conference on Knowledge Discovery and Data Mining, pp 155–158. KDD (1997)
Freund Y (1995) Boosting a weak learning algorithm by majority. Inf Comput. https://doi.org/10.1006/inco.1995.1136
Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (2014)
Huang GBB, Zhou H, Ding X, Zhang R (2012) Extreme learning machine for regression and multiclass classification. IEEE Trans Systems Man Cybern Part B 42(2):513–529
Huanhuan C, Xin Y (2009) Regularized Negative Correlation Learning for Neural Network Ensembles. IEEE Trans Neural Netw 20(12):1962–1979
Kuncheva LI, Whitaker CJ (2003) Measures of diversity in classifier ensembles and their relationship with the ensemble accuracy. Mach Learn
Li, L., Zhao, K., Li, S., Sun, R., Cai, S.: Extreme learning machine for supervised classification with self-paced learning. Neural Process Lett, pp 1–22 (2020)
Lin L, Wang F, Xie X, Zhong S (2017) Random forests-based extreme learning machine ensemble for multi-regime time series prediction. Expert Syst Appl 83:164–176. https://doi.org/10.1016/j.eswa.2017.04.013
Masoudnia S, Ebrahimpour R, Arani SAAA (2012) Incorporation of a regularization term to control negative correlation in mixture of experts. Neural Process Lett 36(1):31–47
Mukherjee I, Rudin C, Schapire RE (2013) The rate of convergence of AdaBoost. J Mach Learn Res 14:2315–2347
Parlett B (1998) The symmetric eigenvalue problem. Society for Industrial and Applied Mathematics, Philadelphia
Perales-González, C., Carbonero-Ruz, M., Pérez-Rodríguez, J., Becerra-Alonso, D., Fernández-Navarro, F.: Negative correlation learning in the extreme learning machine framework. Neural Comput Appl, pp. 1–19 (2020)
Rudin C, Daubechies I, Schapire RE (2004) The dynamics of AdaBoost: Cyclic behavior and convergence of margins. J Mach Learn Res
Shi, Z., Zhang, L., Liu, Y., Cao, X., Ye, Y., Cheng, M.M., Zheng, G.: Crowd counting with deep negative correlation learning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 5382–5390 (2018)
Wang, J., Liu, Z., Wu, Y., Yuan, J.: Mining actionlet ensemble for action recognition with depth cameras. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (2012)
Wang, S., Chen, H., Yao, X.: Negative correlation learning for classification ensembles. In: International Joint Conference on Neural Networks, pp. 1–8. IEEE (2010)
Woodbury, M.: Inverting modified matrices. Tech. rep. (1950)
Wyner AJ, Olson M, Bleich J, Mease D (2017) Explaining the success of adaboost and random forests as interpolating classifiers. J Mach Learn Res 18(1):1558–1590
Xu X, Deng J, Coutinho E, Wu C, Zhao L, Schuller BW (2019) Connecting subspace learning and extreme learning machine in speech emotion recognition. IEEE Trans Multimedia 21(3):795–808
Ykhlef H, Bouchaffra D (2017) An efficient ensemble pruning approach based on simple coalitional games. Inf Fusion
Zhou, X., Xie, L., Zhang, P., Zhang, Y.: An ensemble of deep neural networks for object tracking. In: 2014 IEEE International Conference on Image Processing (ICIP), pp. 843–847. IEEE (2014)
Zhou, Z.H.: Ensemble methods: Foundations and algorithms (2012)
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Perales-González, C. Global convergence of Negative Correlation Extreme Learning Machine. Neural Process Lett 53, 2067–2080 (2021). https://doi.org/10.1007/s11063-021-10492-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11063-021-10492-z