
Abstract
Stephenson (2018) established annealed local convergence of Boltzmann planar maps conditioned to be large. The present work uses results on rerooted multi-type branching trees to prove a quenched version of this limit.
Similar content being viewed by others
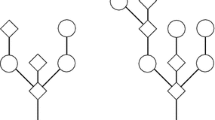


1 Introduction
A planar map M is a connected planar graph, possibly with loops and multiple edges, together with an embedding into the plane. Usually, one edge is directed and distinguished as the root edge. Various analytic, combinatorial, and probabilistic techniques for studying models of random planar maps have been developed, see [3, 6]. The bijection by [5] encodes planar maps as mobiles, which are vertex-labelled 4-type planar trees. This allows for a generating procedure for certain models of random planar maps using 4-type Galton–Watson trees, see [16]. For bipartite Boltzmann planar maps, a bijection constructed by [12] simplifies the generating procedure to use only monotype Galton–Watson trees. However, it is an open problem whether a full reduction to monotype trees is possible in the non-bipartite case; hence, the need to study multi-type Galton–Watson trees for this purpose persists.Footnote 1
Recent work by Stephenson [17] establishes local convergence of conditioned regular critical multi-type Galton–Watson trees, and applies this convergence to a conditioned Boltzmann planar map \(\mathsf {M}_n\). The main application is a limit theorem that shows how an infinite Boltzmann planar map \(\hat{\mathsf {M}}\) describes the asymptotic behaviour of the vicinity of the root edge of \(\mathsf {M}_n\) as \(n \rightarrow \infty \). This generalizes local convergence results for bipartite maps by [4] and special cases like triangulations and quadrangulations by [2, 14].
The present work establishes a corresponding quenched version of the limit theorem. Roughly speaking, the difference is that instead of studying the probability for the vicinity of the root edge of \(\mathsf {M}_n\) to have a certain shape, we establish laws of large numbers for the number of corners, faces, and vertices whose vicinity has this shape; see Theorem 1. Our main tools are quenched limits of rerooted multi-type trees established recently in [21].Footnote 2
As an application, we deduce quenched local convergence of the random planar map \(\mathsf {M}_n^t\) with n edges and a positive weight \(t>0\) at vertices. That is, \(\mathsf {M}_n^t\) assumes a map M with n edges with probability proportional to \(t^{\mathrm {v}(M)}\), with \(\mathrm {v}(M)\) denoting the number of vertices of M; see Theorem 2. The vertex weighted random planar map \(\mathsf {M}_n^t\) is related to the study of uniform random planar graphs, see [7, 11]. We apply the quenched local convergence of \(\mathsf {M}_n^t\) in the subsequent paper [19] to deduce local convergence of the uniform random planar graph.
2 Notation
We let \(\mathbb {N}_0 = \{0,1,2,\ldots \}\) denote the collection of non-negative integers, and \(\mathbb {N}\) the collection of positive integers. The law of a random variable \(X: \Omega \rightarrow S\) with values in some measurable space S is denoted by \(\mathfrak {L}(X)\). If \(Y: \Omega \rightarrow S'\) is a random variable with values in some measurable space \(S'\), we let \(\mathfrak {L}(X \mid Y)\) denote the conditional law of X given Y. All unspecified limits are taken as \(n \rightarrow \infty \). Convergence in probability and distribution are denoted by \(\,{\buildrel p \over \longrightarrow }\,\) and \(\,{\buildrel d \over \longrightarrow }\,\). We say an event holds with high probability if its probability tends to 1 as n becomes large. For any sequence \((a_n)_{n \ge 1}\) of positive real numbers, we let \(O_p(a_n)\) denote a random variable \(Z_n\) such that \((Z_n / a_n)_{n \ge 1}\) is stochastically bounded.
3 Index of Terminology
The following list summarizes frequently used terminology.
- \(\varvec{\xi }\):
-
An unordered D-offspring distribution \(\varvec{\xi } = (\varvec{\xi }_i)_{i \in \mathfrak {G}}\), page 5.
- \(\#_i(\cdot )\):
-
Number of vertices of type \(i \in \mathfrak {G}\), page 4.
- \(|\cdot |_{\varvec{\gamma }}\):
-
Sum of vertices weighted depending on their type, page 4
- \(\varvec{T}(\eta )\):
-
A \(\varvec{\xi }\)-Galton–Watson tree with (possibly random) root type \(\eta \), page 6.
- \(\varvec{T}^\kappa \):
-
Like \(\varvec{T}(\kappa )\), but non-root vertices of type \(\kappa \) receive no offspring, page 6.
- \(\hat{\varvec{T}}^\kappa \):
-
A random tree with a marked leaf of type \(\kappa \). Distributed like \(\varvec{T}^\kappa \) biased by the number of vertices with type \(\kappa \), page 6.
- \(\hat{\varvec{T}}(\kappa )\):
-
A random infinite tree with a marked vertex of type \(\kappa \) and a spine that grows backwards, page 6.
- \(\hat{\varvec{T}}^{\kappa ,\iota }\):
-
A random tree with root type \(\kappa \) and a marked vertex of type \(\iota \). Obtained by biasing \(\varvec{T}^{\kappa }\) by the number of vertices of type \(\iota \), page 6.
- \(\hat{\varvec{T}}(\kappa , \iota )\):
-
A random infinite tree with a marked vertex of type \(\iota \) and a spine that grows backwards, page 6.
4 Preliminaries
4.1 Local Topologies for Planar Maps
The local topology describes how similar two planar maps are in the vicinity of specified root vertices or root edges. We briefly recall relevant notions and refer the reader to the elegant presentations by [8] for details.
Let \(\mathfrak {M}^{\mathrm {e}}\) denote the collection of finite planar maps with an oriented root edge. The origin of this root edge is called the root vertex. The face to the left of the oriented root edge is called the root face. Likewise, we let \(\mathfrak {M}^{\mathrm {v}}\) denote the collection of finite planar maps that only have a specified root vertex instead of an oriented root edge. We also let \(\mathfrak {M}^{\mathrm {f}}\) denote the collection of finite planar maps that only carry a marked root face instead. In the following, \(\mathfrak {M}\) refers to \(\mathfrak {M}^{\mathrm {e}}\), \(\mathfrak {M}^{\mathrm {v}}\), or \(\mathfrak {M}^{\mathrm {f}}\), as all related concepts are analogous for these three cases. Note that \(\mathfrak {M}\) is countably infinite.
For any integer \(k \ge 0\), we may consider the subset \(\mathfrak {M}_k \subset \mathfrak {M}\) of planar maps where each vertex has “distance” at most k from the root. Here, “distance from the root” refers to the graph distance from the root vertex in case of vertex-rooted maps, or the graph distances to the ends of the root edge for edge-rooted maps. For face-rooted maps, we define the distance as the length of some shortest path from the vertex to the boundary of the marked face. We equip \(\mathfrak {M}_k\) with the discrete topology.
The projection
maps a planar map M to the k-neighbourhood \(U_k(M)\) of its root. Depending on whether \(\mathfrak {M}\) refers to \(\mathfrak {M}^{\mathrm {e}}\), \(\mathfrak {M}^{\mathrm {v}}\), or \(\mathfrak {M}^{\mathrm {f}}\) we view \(U_k(M)\) as equipped with an oriented root edge, a root vertex, or a root face.
The local topology on the collection \(\mathfrak {M}\) is the coarsest topology that makes these projections continuous. This projective limit topology is metrizable by
The space \((\mathfrak {M}, d_{\mathrm {loc}})\) is not complete. One way to complete it, is to form the space \(\overline{\mathfrak {M}}\) of coherent sequences
We may interpret \(\mathfrak {M}\) as a subset of \(\overline{\mathfrak {M}}\), and extend \(d_{\mathrm {loc}}\) and \(U_k(\cdot )\) in a canonical way. This makes \(\overline{\mathfrak {M}}\) a Polish space, see [8, Prop. 1] for details.
Let \((\mathsf {M}_n)_{n \ge 1}\) be a sequence of random finite planar maps, and let \(u_n\) be either a uniformly selected vertex, oriented edge, or face. This makes the pair \((\mathsf {M}_n, u_n)\) a random element of \(\overline{\mathfrak {M}}\). Here, we forget about any possibly present root of \(\mathsf {M}_n\), and only consider \(u_n\) as the new root. Distributional convergence of \((\mathsf {M}_n, u_n)_{n \ge 1}\) is equivalent to distributional convergence of each neighbourhood \(U_k(\mathsf {M}_n, u_n)\), \(k \ge 0\), as n tends to infinity. If \(\hat{\mathsf {M}}\) is a random element of \(\overline{\mathfrak {M}}\), then
is equivalent to
for each fixed integer \(k \ge 0\) and each finite planar map \(M \in \mathfrak {M}\) as \(n \rightarrow \infty \). Using language from statistical physics, this form of convergence is also called annealed convergence.
The collection \(\mathbb {M}_1(\overline{\mathfrak {M}})\) of probability measures on the Borel sigma algebra of \(\overline{\mathfrak {M}}\) is a Polish space with respect to the weak convergence topology. The conditional distribution \(\mathfrak {L}( (\mathsf {M}_n, u_n) \mid \mathsf {M}_n)\) is a random element of \(\mathbb {M}_1(\overline{\mathfrak {M}})\). We say \((\mathsf {M}_n, u_n)\) converges in the quenched sense, if the random probability measure \(\mathfrak {L}( (\mathsf {M}_n, u_n) \mid \mathsf {M}_n)\) converges in distribution to a random element of \(\mathbb {M}_1(\overline{\mathfrak {M}})\). For the special case where the limit is almost surely constant and given by the law \(\mathfrak {L}(\hat{\mathsf {M}})\) of some random element \(\hat{\mathsf {M}}\) of \(\overline{\mathfrak {M}}\), we say \((\mathsf {M}_n, u_n)\) converges in the quenched sense towards \(\hat{\mathsf {M}}\).
4.2 Limits of Rerooted Multi-type Trees
Given an integer \(D \ge 1\), a D-type plane tree T is a plane tree where we assign to each vertex a type from \(\{1, \ldots , D\}\). In particular, T has a root vertex, and for each vertex we have a linear order on its collection of children. For \(1 \le j \le D\), we let \(\#_j T\) denote the total number of vertices with type j. Furthermore, for any vector \(\varvec{\gamma } = (\gamma _1, \ldots , \gamma _D) \in \mathbb {R}^D\) we set
If we distinguish a vertex v of T, we form a marked tree (T, v). The subtree consisting of v and all its descendants is called the fringe subtree of T at v. For any integer \(k \ge 0\), we may form the extended fringe subtree \(f^{[k]}(T,v)\) consisting of the fringe subtree of T at the kth ancestor of v, marked at the vertex corresponding to v. Of course, this only makes sense if v has height at least k in T. Otherwise, we set \(f^{[k]}(T,v)\) to some placeholder value.
The path from v to the root of T is called the spine of the marked tree (T, v). We may also consider marked trees where this spine has a countably infinite length, such that v has a countably infinite number of ancestors. We let \(\mathfrak {X}\) denote the collection of all finite marked D-type trees and all marked D-type trees with an infinite spine such that all extended fringe subtrees are finite.
The collection \(\mathfrak {X}\) may be endowed with a metric \(d_{\mathfrak {X}}\) such that for all \(T^\bullet _1, T_2^\bullet \in \mathfrak {X}\)
This makes \((\mathfrak {X}, d_{\mathfrak {X}})\) a Polish space, see [21, Prop. 1].
Let \((\varvec{T}_n)_{n \ge 1}\) be a sequence of random finite D-type trees. Let
denote a non-empty subset, such that the probability for \(\varvec{T}_n\) to have vertices with type in \(\mathfrak {G}_0\) tends to 1 as n becomes large. Let \(v_n\) be uniformly selected among all vertices of \(\varvec{T}_n\) with type in \(\mathfrak {G}_0\). Then, \((\varvec{T}_n, v_n)\) is a random element of \(\mathfrak {X}\). We say \((\varvec{T}_n, v_n)\) convergences in the annealed sense towards a random element \(\varvec{T}^\bullet \) of \(\mathfrak {X}\), if
in the usual sense of distributional convergence of random elements of the Polish space \(\mathfrak {X}\). The conditional distribution \(\mathfrak {L}( (\varvec{T}_n, v_n) \mid \varvec{T}_n)\) is a random element of the collection \(\mathbb {M}_1(\mathfrak {X})\) of Borel probability measures on \(\mathfrak {X}\). That is we take the tree \(\varvec{T}_n\) (this is where the randomness comes from) and consider the uniform distribution on all marked versions of \(\varvec{T}_n\) where the marked vertex has type in \(\mathfrak {G}_0\). We say \(\varvec{T}^\bullet \) is the quenched limit of \((\varvec{T}_n, v_n)\), if
in the sense of distributional convergence of random elements of the Polish space \(\mathbb {M}_1(\mathfrak {X})\).
4.3 Galton–Watson Trees
Let \(D \ge 1\) be an integer. A D-type Galton–Watson tree is a random locally finite D-type plane tree defined as follows. Let \(\varvec{\xi } = (\varvec{\xi }_i)_{1 \le i \le D}\) be a family of random elements \( \varvec{\xi }_i \in \mathbb {N}_0^D\). For any integer \(1 \le \kappa \le D\), the \(\varvec{\xi }\)-Galton–Watson \(\varvec{T}(\kappa )\) starts with a single root vertex with type \(\kappa \). For all \(1 \le i \le D\), any vertex of type i receives offspring vertices according to an independent copy of \(\varvec{\xi }_i\), with the jth coordinate (for \(1 \le j \le D\)) corresponding to the number of children with type j. For our purposes, we will always assume that the collection of all children is ordered uniformly at random. If \(\eta \) is a random element of \(\{1, \ldots , D\}\), independent from all previously considered random variables, we let \(\varvec{T}(\eta )\) denote the mixture of \((\varvec{T}(\kappa ))_{1 \le \kappa \le D}\) that assumes \(\varvec{T}(\kappa )\) with probability \(\Pr {\eta = \kappa }\) for each \( 1\le \kappa \le D\). That is, here the type of the root vertex is random and distributed like \(\eta \).
We define \(\varvec{T}^\kappa \) similar to \(\varvec{T}(\kappa )\), only that non-root vertices with type \(\kappa \) receive no offspring. Let us assume that
This allows us to define the \(\kappa \)-biased version \(\hat{\varvec{T}}^\kappa \) with distribution
for any pair \((T^\kappa , u)\) of a finite \(\mathfrak {G}\)-type tree \(T^\kappa \) (with the root having type \(\kappa \) and all non-root vertices of type \(\kappa \) having no offspring) and a non-root leaf u of \(T^\kappa \) with type \(\kappa \).
We construct a random tree \(\hat{\varvec{T}}(\kappa )\) that has an infinite “backwards” growing spine \(u_0, u_1, \ldots \) of type \(\kappa \) vertices, such that \(u_{\ell + 1}\) is an ancestor (not necessarily parent) of \(u_{\ell }\) for all \(\ell \ge 0\). The construction is as follows. We start with the vertex \(u_0\) that becomes the root of an independent copy of \(\varvec{T}(\kappa )\). The vertex \(u_1\) becomes the root of an independent copy of \(\hat{\varvec{T}}^\kappa \), which has a marked leaf. All non-marked leaves of type \(\kappa \) become roots of independent copies of \(\varvec{T}(\kappa )\), and we identify the marked leaf with \(u_0\) (“glueing” the two vertices together). We proceed in this way with an ancestor \(u_2\) of \(u_1\) and so on, yielding an infinite backwards growing spine \(u_0, u_1, \ldots \) of type \(\kappa \) vertices.
The tree \(\hat{\varvec{T}}(\kappa )\) constitutes the multi-type analogue of Aldous’ invariant sin-tree constructed in [1] for critical monotype Galton–Watson trees. The abbreviation sin stands for single infinite path.
Suppose that \(\iota \in \{1, \ldots , D\}\) is a type. If the number of non-root type \(\iota \)-vertices in \(\varvec{T}^\kappa \) has a finite nonzero expectation E, we may form the \(\iota \)-biased version \(\varvec{T}^{\kappa , \iota }\) of \(\varvec{T}^\kappa \) with distribution
for any pair \((T^\kappa , u)\) of a finite \(\mathfrak {G}\)-type tree \(T^\kappa \) (with the root having type \(\kappa \) and all non-root vertices of type \(\kappa \) having no offspring) and a non-root leaf u of \(T^\kappa \) with type \(\iota \). This allows us to construct the tree \(\hat{\varvec{T}}(\kappa , \iota )\) analogous to \(\hat{\varvec{T}}(\kappa )\) with the only difference being that in the construction we start with a type \(\iota \) vertex \(u_0\) that becomes the root of an independent copy of \(\varvec{T}(\iota )\), and for \(u_1\) we use \(\varvec{T}^{\kappa , \iota }\) instead of a copy of \(\varvec{T}^{\kappa }\). Hence, \(u_1, u_2, \ldots \) have type \(\kappa \), but \(u_0\) has type \(\iota \).
5 Boltzmann Planar Maps
We recall important background on Boltzmann planar maps [16] and the Bouttier–Di Francesco–Guitter transformation [5]. Our presentation follows closely that of [17, Sec. 5], with some additional emphasis in Sect. 3.2 on how the labels of a Boltzmann mobile may be constructed from conditionally independent choices for each vertex of the underlying Galton–Watson tree.
5.1 The Boltzmann Distribution on Planar Maps
The collection of all finite planar maps with an oriented root edge and an additional marked vertex will be denoted by \(\mathcal {M}\). Throughout, we let \(\varvec{q} = (q_n)_{n \ge 1}\) denote a family of non-negative numbers such that \(q_n >0\) for at least one \(n \ge 3\). To any element \(M \in \mathcal {M}\), we assign a weight
Here, the index f ranges over the faces of the planar map M, and \(\mathrm {deg}(f)\) denotes the degree of the face f. That is, \(\mathrm {deg}(f)\) is the number of half-edges on the boundary of the face f. (The reason why we count half-edges instead of edges is that an edge on the boundary has to be counted twice if both of its sides are incident to the face.) A weight sequence \(\varvec{q}\) is said to be admissible, if
In this case, we may form the Boltzmann distributed (vertex marked) planar map \(\mathsf {M}\) with distribution given by
Likewise, we may form analogously the Boltzmann planar map \(\tilde{\mathsf {M}}\) (and conditioned versions thereof) by using the class of maps without a marked vertex instead of \(\mathcal {M}\). Note that \(\tilde{\mathsf {M}}\) and \(\mathsf {M}\) follow different distributions, as \(\mathsf {M}\) is biased by the number of vertices.
5.2 Mobiles Obtained from Branching Processes
A pointed map from \(\mathcal {M}\) is said to be positive, neutral, or negative, if the origin of the directed root edge is closer, equally far away, or farther away from the marked vertex than the destination of the root edge. We let \(\mathcal {M}^+\), \(\mathcal {M}^0\), and \(\mathcal {M}^-\) denote the corresponding subclasses of \(\mathcal {M}\), and form the sums \(Z_{\varvec{q}}^+\), \(Z_{\varvec{q}}^0\), and \(Z_{\varvec{q}}^-\) as in (9), but with the sum index constrained to the corresponding subclass. For all \(x,y\ge 0\), we define the bivariate series
If the weight sequence \(\varvec{q}\) is admissible, we may define an irreducible 4-type offspring distribution \(\varvec{\xi } = (\varvec{\xi })_{1 \le i \le 4}\) as follows. Vertices of the first type produce a geometric number of vertices of the third type:
Vertices of the second type always produce a single offspring vertex of the fourth type, that is
Vertices of the third and fourth type only produce offspring of the first or second type. Their coordinates \({\xi }_{3,1}, {\xi }_{3,2}\) and \({\xi }_{4,1}, {\xi }_{4,2}\) are determined by
Here, we have used that the denominators in (15) and (16) are finite. This follows from [16, Prop. 1], see Sect. 3.4 for details.
For a type \(\kappa =1\) or \(\kappa =2\), we consider the following sampling procedure. The result is a random 4-type tree where the offspring is ordered and each vertex v receives a label \(\ell (v)\) with \(\ell (v) \in \mathbb {Z}\) if v has type 1 or 3, and \(\ell (v) \in \frac{1}{2} + \mathbb {Z}\) otherwise.
-
1.
Consider the \(\varvec{\xi }\)-Galton–Watson tree \(\varvec{T}(\kappa )\) that starts with a single vertex of type \(\kappa \). We consider the offspring vertices as ordered in a uniformly selected manner.
-
2.
For each vertex v of type 3 or 4 in \(\varvec{T}(\kappa )\) with outdegree \(d \ge 1\), let \(v_0\) denote its parent and let \(v_1, \ldots , v_d\) denote its ordered offspring. For ease of notation, we set \(v_{d+1} := v_0\). Note that \(v_0, \ldots , v_d\) all have types in \(\{1,2\}\). Uniformly select a \((d+1)\)-dimensional vector
$$\begin{aligned} \varvec{\beta }_{\varvec{T}(\kappa )}(v_0) = (a_0, \ldots , a_{d}) \end{aligned}$$satisfying the following two conditions:
-
(a)
\(\sum _{i=0}^d a_i = 0\).
-
(b)
For all \(0 \le i \le d\):
-
If \(v_i\) and \(v_{i+1}\) both have type 1, then \(a_i \in \{-1, 0, 1, \ldots \}\).
-
If \(v_i\) and \(v_{i+1}\) both have type 2, then \(a_i \in \{0, 1, 2, \ldots \}\).
-
If \(v_i\) and \(v_{i+1}\) have different types, then \(a_i \in \{-1/2, 1/2, 3/2, \ldots \}\).
-
-
3.
Assign to each vertex \(v \in \varvec{T}(\kappa )\) a label \(\ell (v)\) in a unique way satisfying the following conditions.
-
(a)
The root of \(\varvec{T}(\kappa )\) receives label 0 if it has type 1 and label 1/2 if it has type 2.
-
(b)
Vertices of type 3 or 4 receive the same label as their parent.
-
(c)
If a vertex v of type 3 or 4 has offspring \(v_1, \ldots , v_d\) with \(d \ge 1\), then set \((a_0, \ldots , a_d) := \varvec{\beta }_{\varvec{T}(\kappa )}(v_i)\) and set \(\ell (v_i) := \ell (v) + \sum _{j=0}^{i-1} a_j\) for all \(1 \le i \le d\).
This construction produces a so-called mobile. We emphasize that in the second step we choose for any vertex v of type 3 or 4 the vector \(\varvec{\beta }_{\varvec{T}(\kappa )}(v)\) at random in a way that depends only on the ordered list of offspring vertices of v, their types, and the type of v (since it determines the type of its parent). In combinatorial language, \((\varvec{T}(\kappa ), \varvec{\beta }_{\varvec{T}(\kappa )})\) is a special case of a multi-type enriched plane tree. We refer to it as the canonical decoration of \(\varvec{T}(\kappa )\).
5.3 The Bouttier–Di Francesco–Guitter Transformation
We let \(\varvec{T}^+\) denote an independent copy of \((\varvec{T}(1), \varvec{\beta }_{\varvec{T}(1)})\). We let \(\varvec{T}^0\) denote the result of taking two independent copies of \((\varvec{T}(2), \varvec{\beta }_{\varvec{T}(2)})\) and identifying their roots. Let \((T, \beta )\) be a possible finite outcome of \(\varvec{T}^+\) or \(\varvec{T}^0\), and let \((\ell (v))_{v \in T}\) denote the corresponding labels. The Bouttier–Di Francesco–Guitter transformation [5] associates a planar map \(\Psi (T, \beta )\) to the decorated tree \((T, \beta )\) in such a way that
-
the number of vertices of the map equals \(1 + \#_1T\),
-
the number of edges of the map equals \(\#_1 T + \#_3 T + \#_4 T -1\),
-
and the number of faces of the map equals \(\#_3 T + \#_4 T\).
The transformation \(\Psi \) is as follows. We draw T in the plane and order the corners according to the standard contour process that starts at the root vertex. Let \(v_1, \ldots , v_p\) denote the ordered list of vertices of type 1 or 2 that we visit in the contour process. That is, a vertex gets visited multiple types according to the number of angular sectors around it. We let \(\ell _1, \ldots , \ell _p\) denote their labels. We extend these lists cyclically, so that \(v_{ip+k} = v_{k}\) for \(i \ge 1\) and \(1 \le k \le p\). We add an extra vertex r with type 1 outside of T and let its label \(\ell (r)\) be one less than the minimum of labels of all type 1 vertices. For each \(1 \le i \le p\), we draw an arc between the vertex \(v_i\) and its successor. If \(v_i\) has type 1, then the successor is the next corner in the cyclic list of type 1 with label \(\ell _i - 1\). If there is no such corner, then we let r be the successor of \(v_i\). Likewise, if \(v_i\) has type 2 then the successor of \(v_i\) is the next corner of type 1 with label \(\ell _i - 1/2\), or r if there is no such corner. It is possible to draw all arcs so that they only may intersect at end points. We now delete the original edges of the tree T, as well as all vertices of type 3 and 4. Vertices of type 2 get erased as well, merging the corresponding pairs of arcs. We are left with a planar map having a marked vertex r. If the root of T has type 1, we let the root edge be the first arc that was drawn and have it point to the root of T. If the root of T has type 2 (and hence has precisely two children, both of type 4), we let the root edge be the result of the merger of the two arcs incident to the root of T and let it point towards the successor of the first corner encountered in the contour process. Figure 1 illustrates the transformation \(\psi \) for an example.

The correspondence between mobiles and vertex-marked rooted planar maps
The Boltzmann distributed map \(\mathsf {M}\) is a mixture of the random maps \(\mathsf {M}^+\), \(\mathsf {M}^0\), and \(\mathsf {M}^-\) obtained by conditioning \(\mathsf {M}\) on belonging to \(\mathcal {M}^+\), \(\mathcal {M}^0\), and \(\mathcal {M}^-\). As observed by [16], it holds that \(\Psi (\varvec{T}^+) \,{\buildrel d \over =}\,\mathsf {M}^+\) and \(\Psi (\varvec{T}^0) \,{\buildrel d \over =}\,\mathsf {M}^0\). Moreover, \(\mathsf {M}^{-}\) may be obtained from \(\mathsf {M}^+\) by reversing the direction of the root edge.
5.4 Regimes of Weight Sequences
[16, Prop. 1] showed that the weight sequence \(\varvec{q}\) is admissible if and only if the system of equations
has a solution (x, y) with \(x>1\) such that the matrix
has spectral radius smaller or equal to one. Any such solution (x, y) necessarily satisfies
[16, Def. 1] termed an admissible weight sequence \(\varvec{q}\) critical, if the spectral radius of this matrix is equal to 1. This amounts to the condition
with \(J_f\) denoting the (signed) Jacobian of the function \((f^\bullet , f^\diamond ): \mathbb {R}_+^2 \rightarrow (\mathbb {R}_+ \cup \{\infty \})^2\). It is termed regular critical, if additionally
for some \(\epsilon >0\). As was made explicit by [17], this applies to various useful cases such as unrestricted maps or p-angulations for arbitrary \(p \ge 3\). The irreducible offspring distribution \(\varvec{\xi }\) is critical (or regular critical) if and only if the weight sequence \(\varvec{q}\) is critical (or regular critical).
6 Quenched Local Convergence
Theorem 1
Suppose that the weight sequence \(\varvec{q}\) is regular critical. Let \(\mathsf {M}_n\) denote the \(\varvec{q}\)-Boltzmann planar map, conditioned on either having n vertices, or edges, or faces. Let \(u_n\) denote either a uniformly selected vertex, half-edge, or face. There are integers \(a \ge 0\) and \(d \ge 1\) and a random infinite locally finite limit map \(\hat{\mathsf {M}}\) with finite face degrees such that, in the local topology for vertex-rooted or half-edge-rooted or face-rooted planar maps, the conditional law \(\mathfrak {L}( (\mathsf {M}_n, u_n) \mid \mathsf {M}_n)\) satisfies
as \(n \in a + d \mathbb {Z}\) tends to infinity.
Of course, the limit object differs depending on which conditioning we choose and which type of marking we select. The quenched limit (22) implies the annealed convergence
by dominated convergence. If \(u_n\) denotes a uniformly selected half-edge, then (23) is the annealed convergence established by [17, Thm. 6.1] (see also [2, 4, 9, 14, 15]), who only required criticality in the case where \(\mathsf {M}_n\) is the Boltzmann map with n vertices. Drmota and Stufler [10] described a general method for deducing limits for the vicinity of random vertices if a limit for the vicinity of random corners is known. The method applies to regular critical Boltzmann planar maps and other settings. Obtaining an explicit description of the limit was left as an open question in [10], and the construction of the limit from an infinite mobile with a backwards growing spine the proof of Theorem 1 resolves this question in the present setting.
Note that, as was shown by [17, Sec. 6.3.5], in the present setting the total variational distance between \(\mathsf {M}_n\) (a corner-rooted map with an additional marked vertex, not to be confused with \(u_n\)) and a \(\varvec{q}\)-Boltzmann map \(\tilde{\mathsf {M}}_n\) without a marked vertex tends to zero as n becomes large:
Hence, Theorem 1 also holds for \(\tilde{\mathsf {M}}_n\).
6.1 Proof Strategy
The existence of \(a \ge 0\) and \(d \ge 1\) (which depend on the form of conditioning we use), so that \(\mathsf {M}_n\) is well defined for \(n \in a + d\mathbb {Z}\) large enough, was shown by [17, Lem. 6.1]. Let \(\varvec{\gamma }\in \mathbb {N}_0^4\) be either (1, 0, 0, 0) or (1, 0, 1, 1) or (0, 0, 1, 1), depending on whether we condition on the number of vertices, edges, or faces. We also set \(\mathfrak {G}_0 = \{1\}\) or \(\mathfrak {G}_0 = \{1,3,4\}\) or \(\mathfrak {G}_0 = \{3,4\}\) accordingly.
Recall that \(\varvec{T}^+\) denotes an independent copy of \((\varvec{T}(1), \varvec{\beta }_{\varvec{T}(1)})\), and \(\varvec{T}^0\) is the result of taking two independent copies of \((\varvec{T}(2), \varvec{\beta }_{\varvec{T}(2)})\) and identifying their roots. Recall also that the Boltzmann distributed map \(\mathsf {M}\) is a mixture of the random maps \(\Psi (\varvec{T}^+) \,{\buildrel d \over =}\,\mathsf {M}^+\), \(\Psi (\varvec{T}^0) \,{\buildrel d \over =}\,\mathsf {M}^0\), and the result \(\mathsf {M}^{-}\) of reversing the direction of the root edge \(\mathsf {M}^+\).
Throughout the entire proof, a subscript n of a random tree denotes that we condition the tree on the event \(|\cdot |_{\varvec{\gamma }} = n\) if \(\varvec{\gamma } = (0,0,1,1)\), \(|\cdot |_{\varvec{\gamma }} = n-1\) if \(\varvec{\gamma } = (1,0,0,0)\), and \(|\cdot |_{\varvec{\gamma }} = n+1\) if \(\varvec{\gamma } = (1,0,1,1)\). A subscript n of a random map will denote that we condition the map accordingly on having n faces or vertices or edges.
Let \(\kappa \in \{1, \ldots , 4\}\) be a type. If we select a vertex \(v_n\) from \(\varvec{T}_n(\kappa )\) with type in \(\mathfrak {G}_0\) uniformly at random, then by [21, Thm. 6]
for a random type \(\eta \) that only depends on \(\varvec{\xi }\) and \(\varvec{\gamma }\) (and not on \(\kappa \)). Adding canonical decorations, this implies
(See also [20] for a general theory of limits and fringe distributions of random decorated or enriched trees.)
We are going to show that:
-
(a)
The decorated tree \((\hat{\varvec{T}}(\eta ),\varvec{\beta }_{\hat{\varvec{T}}(\eta )})\) corresponds to an infinite vertex-, corner-, or face-rooted map \(\hat{\mathsf {M}}\) via an extension of the Bouttier–Di Francesco–Guitter transformation.
-
(b)
The convergence (26) implies
$$\begin{aligned} \mathfrak {L}( (\mathsf {M}_n^+, u_n) \mid \mathsf {M}_n^+) \,{\buildrel p \over \longrightarrow }\,\mathfrak {L}(\hat{\mathsf {M}}). \end{aligned}$$(27) -
(c)
Convergence of \(\mathsf {M}_n^-\) follows from (27) and \(\mathsf {M}_n^0\) may be treated analogously as \(\mathsf {M}_n^+\).
Having these intermediate results at hand, Theorem 1 immediately follows. In the following subsection, we verify the three claims individually.
6.2 Claim (a)
In the third step of the procedure given in Sect. 3.2, we described a process for transforming the decorations into labels. We cannot apply this process directly to \((\hat{\varvec{T}}(\eta ),\varvec{\beta }_{\hat{\varvec{T}}(\eta )})\) since the tree has an infinite backwards growing spine of ancestors instead of a root. However, if we assign any valid label to a single vertex v (with value in \(\mathbb {Z}\) if v has type 1 or 3 and value in \(\frac{1}{2} + \mathbb {Z}\) if v has type 2 or 4), then the decorations determine the labels of all other vertices. Moreover, the differences in the labels between any pair of vertices do not depend on the label we started with. Hence, let us assign a valid label 0 or 1/2 to the marked vertex of \((\hat{\varvec{T}}(\eta ),\varvec{\beta }_{\hat{\varvec{T}}(\eta )})\) (depending on whether its type \(\eta \) lies in \(\{1,3\}\) or \(\{2,4\}\)), and extend this in a unique way according to the decorations to labels \((\ell (v))_{v \in \hat{\varvec{T}}(\eta )}\).
Lemma 1
The labels of the type 1 ancestors of the marked vertex in \(\hat{\varvec{T}}(\eta )\) have almost surely no lower bound.
Proof
First, let us observe that
This could be verified directly, or as follows: The limit in Eq. (25) is a special case of [21, Thm. 6], which was obtained as an application of the more general theorem [21, Thm. 1]. We could just as well have applied [21, Thm. 2, Rem. 2] instead, yielding that (25) holds with \(\hat{\varvec{T}}(1,\eta )\) instead of \(\hat{\varvec{T}}(\eta )\). This verifies (28).
Let \(u_1, u_2, \ldots \) denote the list of type 1 ancestors of the marked vertex in \(\hat{\varvec{T}}(\eta )\) (excluding the marked vertex itself, if it has type 1), so that \(u_{i+1}\) is an ancestor of \(u_i\) for all \(i \ge 1\). Then, the family of differences of labels \(\ell (u_{i+1}) - \ell (u_i)\), \(i \ge 1\) are independent and identically distributed. The distribution is given by forming the canonical decoration of \(\hat{\varvec{T}}^1\), assigning labels accordingly with an arbitrary starting value for the root of \(\hat{\varvec{T}}^1\), and forming the difference of the labels between the root and the marked leaf of \(\hat{\varvec{T}}^1\). Thus, the labels \((\ell (u_i))_{i \ge 1}\) form a random walk with i.i.d. steps and a random starting value \(\ell (u_1)\).
It is known that this random walk is centred: Indeed, consider the local weak limit \(\tilde{\varvec{T}}\) of \(\varvec{T}_n(1)\) established by [17], that describes the asymptotic vicinity of the root (and not a random location) of \(\varvec{T}_n(1)\). The construction of \(\tilde{\varvec{T}}\) is as follows. We start with a type 1 vertex that gets identified with an independent copy of \(\hat{\varvec{T}}^1\). All non-marked type 1 leaves become roots of independent copies of \(\varvec{T}(1)\). For the marked leaf, we proceed recursively in the same way as for the root (identifying it with the root of a fresh independent copy of \(\hat{\varvec{T}}^1\), and so on). Hence, \(\varvec{T}(1)\) has an infinite spine, obtained by concatenating independent copies of \(\varvec{T}(1)\). In particular, if we form the canonical decoration of \(\tilde{\varvec{T}}\) and assign labels accordingly (with, say, a starting value 0 for the root vertex), then the labels of the type 1 vertices of the spine form a random walk with i.i.d. steps and the same step distribution as for the random walk \((\ell (u_i))_{i \ge 1}\). Stephenson [17, Proof of Lem. 6.5] showed that this step distribution has average value 0. Hence, analogously as for [17, Lem. 6.5], it follows from [13, Thm. 9.2] that almost surely
This completes the proof. \(\square \)
We may order the corners \((c_i)_{i \in \mathbb {Z}}\) incident to vertices of type 1 or 2 of \(\hat{\varvec{T}}(\eta )\) such that for all \(i \in \mathbb {Z}\) the corner \(c_{i+1}\) is the successor of \(c_i\) in the clock-wise contour exploration. This allows us to canonically extend the Bouttier–Di Francesco–Guitter transformation from Sect. 3.3 to assign an infinite locally finite planar map \(\hat{\mathsf {M}}\) to the infinite labelled tree \((\hat{\varvec{T}}(\eta ), (\ell (v))_{v \in \hat{\varvec{T}}(\eta )})\). Here, we do not have to add an additional marked vertex, because the labels of type 1 vertices along the backwards growing spine of \(\hat{\varvec{T}}(\eta )\) have no lower bound. By construction, all faces of \(\hat{\mathsf {M}}\) have finite degree.
Depending on whether \(u_n\) is a random vertex, half-edge, or face of \(\mathsf {M}_n\), we mark \(\hat{\mathsf {M}}\) as follows. Let w denote the marked vertex of \(\hat{\varvec{T}}(\eta )\), which has an infinite number of ancestors. In the vertex case, w has type 1 and corresponds canonically to a vertex of \(\hat{\mathsf {M}}\). We consider \(\hat{\mathsf {M}}\) as rooted at this vertex. In the face case, w has type 3 or 4 and corresponds canonically to a face. In this case, we consider \(\hat{\mathsf {M}}\) as rooted at this face. In the half-edge case, w has type 1, 3, or 4 and corresponds canonically to an edge, which we orient according to an independent fair coin flip. In detail: If w has type 4, then it is the only child of a non-root type 2 vertex that corresponds to the edge obtained by joining the arcs drawn at its two corners. Hence, w corresponds canonically to this edge. If w has type 1, then each of its corners corresponds to the edge we drew when visiting this corner in the contour exploration. The number of these corners equals 1 plus the number of offspring vertices, all of which have type 3. Hence, w and its children correspond bijectively to the arcs we drew starting at a corner of w. In particular, w corresponds canonically to an arc. Likewise, if w has type 3 it also corresponds canonically to an edge that we drew starting at a corner of its type 1 parent.
This verifies Claim (a).
6.3 Claim (b)
Suppose that \(\kappa =1\). The vertex \(v_n\) of \((\varvec{T}_n(\kappa ), \beta _{\varvec{T}_n(\kappa )})\) corresponds similarly to a marked vertex or face or half-edge \(u_n'\) of \(\mathsf {M}_n^+\). Modifications in the correspondence may be required when \(v_n\) or its parent is the root of \(\varvec{T}_n(\kappa )\), but the probability for this event tends to zero and hence we may safely ignore this. Furthermore, \((\mathsf {M}_n^+, u_n)\) and \((\mathsf {M}_n^+, u_n')\) may not follow the same distribution (for example, when \(u_n\) is a uniform vertex, then \(u_n'\) is a uniform non-marked vertex, as \(u_n'\) is never equal to the additional vertex we added in the BDFG bijection). However, it is clear that there is an event (that depends on n) whose probability tends to 1 as n becomes large, such that \((\mathsf {M}_n^+, u_n)\) and \((\mathsf {M}_n^+, u_n')\) are identically distributed when conditioned on this event. Hence, we may also safely ignore the difference between \(u_n\) and \(u_n'\). Using the continuous mapping theorem, it hence follows from (26) that
This verifies Claim (b).
6.4 Claim (c)
The same convergence as in (29) follows immediately for \(\mathsf {M}_n^-\), since the vicinity of a random point is not affected by the orientation of the root edge. As for \(\mathsf {M}_n^0\), it follows from [17, Prop 2.2] that \(|\varvec{T}(2)|_{\varvec{\gamma }}\) takes only values from a shifted lattice, and has a density that varies regularly with index \(-3/2\) along that shifted lattice. It follows that if we condition independent copies \(\varvec{S}^{(1)}\) and \(\varvec{S}^{(2)}\) of \(\varvec{T}(2)\) on the event \(|\varvec{S}^{(1)}|_{\varvec{\gamma }} + |\varvec{S}^{(2)}|_{\varvec{\gamma }} = n\) then
This may easily be verified elementarily or be viewed as a special case for results on general models of random partitions, see [18, Thm. 3.4, Prop 2.5]. Consequently, all but a negligible number of vertices whose extended fringe subtree has a certain shape will lie in a giant component with size (“size” referring to \(|\cdot |_{\varvec{\gamma }}\)) \(m - O_p(1)\). If we let \(\varvec{S}\) denote the result of identifying the roots of \(\varvec{S}^{(1)}\) and \(\varvec{S}^{(2)}\) and let \(w_n\) denote a uniformly selected vertex of the conditioned tree \(\varvec{S}_n\) with type in \(\mathfrak {G}_0\), then it follows by (25) that
(Recall that above we assigned a clear meaning to all occurrences of n as a subscript of a random tree, making \(\varvec{S}_n\) a conditioned version of \(\varvec{S}\) that depends on \(\varvec{\gamma }\).) Hence, adding canonical decorations,
Thus, quenched convergence of \(\mathsf {M}_n^0\) towards \(\hat{\mathsf {M}}\) may be deduced in exactly the same way using the mapping theorem as for \(\mathsf {M}_n^+\), only instead of using Eq. (26) we use Equation (32). This verifies Claim (c).
7 Random Planar Maps with Vertex Weights
Let \(t>0\) be a constant. We let \(\mathsf {M}_n^t\) denote a random planar map with n edges that assumes a map M (with n edges) with probability proportional to \(t^{\mathrm {v}(M)}\).
Theorem 2
The random map \(\mathsf {M}_n^t\) admits a distributional limit \(\hat{\mathsf {M}}^t\) in the local topology. Letting \(c_n\) denote a uniformly selected corner of \(\mathsf {M}_n^t\), it holds that
Proof
For any \(\lambda >0\), we may consider the weights
This way, any map with n edges and m faces receives weight \(\lambda ^{2n} t^m\). We are going to argue below that for any \(t>0\) we may choose \(\lambda \) so that \(\varvec{q}=(q_n)_{n \ge 1}\) is regular critical. By elementary identities of power series (compare with [17, Proof of Prop. 6.3]), the expressions in Eqs. (11) and (12) simplify to
with
Conditions (17) and (18) may be rephrased by
and
Note that this implies \(x>1\). Combining the last two equalities, we obtain
Plugging this expression into Eqs. (17) and (18) and noting that (38) implies \(x>1\) yields
Moreover, for any triple \((x,y,\lambda )\) of real numbers satisfying (41), we may easily verify that Eqs. (17) and (18) hold (and that \(y>0\) and \(\lambda >0\)). Plugging (41) into the criticality condition (20) yields the complicated expression
This solution is strictly bigger than 1 for any \(t>0\) and defining y and \(\lambda \) according to (41) we obtain a solution to Eqs. (17), (18), and (20). Hence, for this choice of \(\lambda \) (depending on t) the weight sequence \(\varvec{q}\) is critical. It is clear from the expressions (35), (36), (37) that \(\varvec{q}\) is even regular critical in this case.
Let \(\mathsf {M}_n\) denote the corresponding regular critical \(\varvec{q}\)-Boltzmann planar map with n edges. Let \(u_n\) denote a uniformly selected corner of \(\mathsf {M}_n\). As \(\varvec{q}\) is regular critical, it follows by Theorem 1 that there is an infinite random planar map \(\hat{\mathsf {M}}\) with finite face degrees such that
By (24), the \(\varvec{q}\)-Boltzmann map \(\tilde{\mathsf {M}}_n\) without a marked vertex consequently satisfies as well
The random planar map \(\tilde{\mathsf {M}}_n\) assumes any planar map M with n edges, m faces and k vertices with probability proportional to \(t^{m}\). That is,
for some constant \(c_{n,t}>0\) that only depends on n and t. Euler’s formula entails that \(m = 2 + n - k\). Hence,
with \(c_{n,t}' = c_{n,t} t^{2+n}\) again only depending on n and t. Thus,
Replacing t by \(t^{-1}\), Eq. (33) now follows from Eq. (44). \(\square \)
Notes
The author thanks Sigurdur Örn Stefánsson for related comments.
The results of the present work were initially part of [21]. The paper was split during the review process following a referee’s recommendation.
References
Aldous, D.: Asymptotic fringe distributions for general families of random trees. Ann. Appl. Probab. 1(2), 228–266 (1991)
Angel, O., Schramm, O.: Uniform infinite planar triangulations. Comm. Math. Phys. 241(2–3), 191–213 (2003)
Banderier, C., Flajolet, P., Schaeffer, G., Soria, M.: Random maps, coalescing saddles, singularity analysis, and Airy phenomena. Random Struct. Algorithms 19(3–4), 194–246 (2001). Analysis of algorithms (Krynica Morska 2000)
Björnberg, J.E., Stefánsson, S.Ö.: Recurrence of bipartite planar maps. Electron. J. Probab. 19(31), 40 (2014)
Bouttier, J., Di Francesco, P., Guitter, E.: Planar maps as labeled mobiles. Electron. J. Combin., 11(1):Research Paper 69, 27, (2004)
Budd, T.: The peeling process of infinite Boltzmann planar maps. Electron. J. Comb., 23(1): Research paper p. 28, 37, (2016)
Chapuy, G., Fusy, E., Giménez, O., Noy, M.: On the diameter of random planar graphs. In 21st International Meeting on Probabilistic, Combinatorial, and Asymptotic Methods in the Analysis of Algorithms (AofA’10), Discrete Mathematics and Theoretical Computer Science. Proceedings of AM, pp. 65–78. Association of Discrete Mathematics Theoretical Computer Science, Nancy, (2010)
Curien, N.: Peeling random planar maps. Saint-Flour course https://www.dropbox.com/s/bfjbuxiv4ms1gdl/StFlour.pdf, 2016
Curien, N., Ménard, L., Miermont, G.: A view from infinity of the uniform infinite planar quadrangulation. ALEA Lat. Am. J. Probab. Math. Stat. 10(1), 45–88 (2013)
Drmota, M., Stufler, B.: Pattern occurrences in random planar maps. Stat. Probab. Lett. 158, 10866 (2020)
Giménez, O., Noy, M., Rué, J.: Graph classes with given 3-connected components: asymptotic enumeration and random graphs. Random Struct. Algorithms 42(4), 438–479 (2013)
Janson, S., Stefánsson, S.Ö.: Scaling limits of random planar maps with a unique large face. Ann. Probab. 43(3), 1045–1081 (2015)
Kallenberg, O.: Foundations of Modern Probability, 2nd edn. Springer, New York (2002)
Krikun, M.: Local structure of random quadrangulations. arXiv:math/0512304, Dec. 2005
Ménard, L., Nolin, P.: Percolation on uniform infinite planar maps. Electron. J. Probab. 19(79), 27 (2014)
Miermont, G.: An invariance principle for random planar maps. In Fourth Colloquium on Mathematics and Computer Science Algorithms, Trees, Combinatorics and Probabilities, Discrete Mathematical and Theoretical Computer Science. Proceedings of AG, pp. 39–57. Association of Discrete Mathematical and Theoretical Computer Science, Nancy (2006)
Stephenson, R.: Local convergence of large critical multi-type Galton-Watson trees and applications to random maps. J. Theoret. Probab. 31(1), 159–205 (2018)
Stufler, B.: Gibbs partitions: the convergent case. Random Struct. Algorithms 53(3), 537–558 (2018)
Stufler, B.: Local convergence of random planar graphs. arXiv:1908.04850, 2019
Stufler, B.: Limits of random tree-like discrete structures. Probab. Surv. 17, 318–477 (2020)
Stufler, B.: Rerooting multi-type branching trees: the infinite spine case. J. Theoret. Probab., to appear
Acknowledgements
I warmly thank the associate editor and the referee for the thorough reading and helpful comments, in particular, for pointing out a simplification of the proof of Theorem 2.
Funding
Open access funding provided by TU Wien (TUW).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Stufler, B. Quenched Local Convergence of Boltzmann Planar Maps. J Theor Probab 35, 1324–1342 (2022). https://doi.org/10.1007/s10959-021-01089-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10959-021-01089-2