
Abstract
•Key message
We developed a dataset of the potential distribution of seven ecologically and economically important tree species of Europe in terms of their climatic suitability with an ensemble approach while accounting for uncertainty due to model algorithms. The dataset was documented following the ODMAP protocol to ensure reproducibility. Our maps are input data in a decision support tool “SusSelect” which predicts the vulnerability of forest trees in climate change and recommends adapted planting material. Dataset access is at https://doi.org/10.5281/zenodo.3686918 . Associated metadata are available at https://metadata-afs.nancy.inra.fr/geonetwork/srv/fre/catalog.search#/metadata/fe79a36d-6db8-4a87-8a9f-c72a572b87e8 .
Similar content being viewed by others


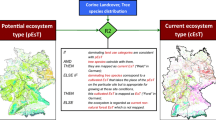
1 Background
Climate change is likely to cause widespread shifts in the composition and range of plant communities worldwide (Scheffers et al. 2016). For long-living communities such as forests, such change may lead to a drastic decline in their ability to support multiple ecosystem services (Maroschek et al. 2009; Härtl et al. 2016; Mina et al. 2017). In Europe, the effects of climate change on forests may include changes in forest productivity (Reyer et al. 2014), changes in the distribution of tree species (Dyderski et al. 2018; Thurm et al. 2018), the economic value of forests (Hanewinkel et al. 2013), effects of intensifying disturbance regimes (Seidl et al. 2011, 2014), and droughts (Allen et al. 2010).
As such, there has been considerable interest in estimating the potential distribution of tree species under scenarios of climate change. Species distribution models (SDMs), often referred to as ecological niche models (ENMs), are the most widely used tools for this purpose (Sykes et al. 1996; Zimmermann et al. 2010; Guisan et al. 2013; Dyderski et al. 2018), because they predict the potential distribution of species by exploiting the correlation between the known occurrence of a species and corresponding environmental conditions.
In the recent decades, SDMs have evolved and were applied for a wide range of questions such as to predict species range in the future (Sykes et al. 1996; Thuiller et al. 2008; Dyderski et al. 2018), to test hypotheses about species distribution limits (Kreyling et al. 2015), to develop conservation and management strategies in climate change (Guisan et al. 2013; Hamann and Aitken 2013; Mcshea 2014; Schueler et al. 2014), and understand the role of genetic variation in tree species distributions (O’Neill et al. 2008; Benito Garzón et al. 2011; Valladares et al. 2014; Chakraborty et al. 2019; Garate-Escamilla et al. 2019).
Despite the recent improvements and widespread use, the free and unrestricted utilization of SDMs in the applied forest and conservation science is often limited due to inadequate documentation and reporting of the predictions and uncertainties. Therefore, Zurell et al. (2020) proposed a reporting protocol known as ODMAP (Overview, Data, Model, Assessment, and Prediction), which offers a standardized way of communicating the results/outputs from SDMs by describing the objectives, model assumptions, scaling issues, data sources, model workflow, model predictions, and uncertainty.
Here we present a dataset on the potential distribution of seven widely occurring tree species of Europe for current and projected future climate scenarios. To ensure transparent reporting and reproducibility, we described the dataset according to the ODMAP protocol suggested by Zurell et al. (2020). The following sections describe the basic elements of the dataset, while the detailed metadata according to ODMAP (Zurell et al. 2020) is presented in Table 2 in Appendix.
2 Methods
2.1 Species occurrence data
Current occurrence (presence and absence) of seven major stand forming tree species in Europe (Table 1) was obtained from the EU-Forest dataset (Mauri et al. 2017). These species are known to form stands in a wide range of forest types across Europe (European Environmental Agency 2006) and are also economically important (Hanewinkel et al. 2013). The Mauri et al. (2017) dataset is one of the most exhaustive, harmonized European tree species occurrence (presence) data available till date, which combines three existing datasets: the Forest Focus (Hiederer et al. 2011), Biosoil (Houston Durrant et al. 2011), and national forest inventories. In our case, the geographic locations of the target species in the EU-Forest dataset were assumed to be true presences, while the presence locations of other target species were assumed to be the absence locations. To ensure that the absence locations are not only climatically dissimilar but also geographically distant from the observed presence locations, we developed the so-called pseudoabsences according to Senay et al. (2013). This is a three-step approach: (i) specifying a geographical extent outside the observed presences, (ii) environmental profiling of the absences outside this geographic extent, and (iii) k-means clustering of the environmental profiles and selecting random samples within each cluster. In our case, a 2-degree buffer was found to be optimum following Senay et al. (2013). The absence locations outside this geographic extent were classified into 10–15 environmentally dissimilar clusters according to the k-means clustering algorithm. The numbers of absence clusters for each species were determined from the elbow of the plot of total within-cluster sum of square (WSS) and number of clusters. The number of pseudoabsence locations was further reduced by randomly selecting a sample of locations defined by the 95% confidence interval from each of the absence clusters. This approach was used to generate pseudo-absence for all seven species. The resultant dataset was used to calibrate the SDMs with the biomod2 platform (Thuiller et al. 2016).
2.2 Climate data
Biologically relevant climate variables were obtained from the ECLIPS 2.0 dataset (Chakraborty et al. 2020a, b). This dataset was developed from dynamically downscaled, and bias-corrected regional climate model results from the EURO-CORDEX with a resolution of 30 arcsec. The EURO-CORDEX (www.eurocordex.net) is an initiative of the World Climate Research Program (Giorgi et al. 2009) for coordinating dynamic regional downscaling of the global climate projections from the CMIP5 (Coupled Model Intercomparison Project Phase 5) (Jacob et al. 2014). All projections were corrected for bias using a distribution scaling method (Yang et al. 2010) to produce 0.11 × 0.11° resolution gridded data for daily mean, minimum, and maximum near-surface air temperature and precipitation. We further refined this 0.11 × 0.11° resolution bias-corrected data to 30 arcsec using the delta algorithm for spatial downscaling (Ramirez-Villegas and Jarvis 2010; Moreno and Hasenauer 2016). With this approach, we developed a gridded dataset for 80 climate variables (Table 3 in Appendix) for historic climate (1961–1990) and three future time frames which include averages of (2041–2060, 2061–2080, and 2081–2100) for two Representative Concentration Pathway (van Vuuren et al. 2011), RCP 4.5 and RCP 8.5. The RCP 4.5 or the moderate scenario assumes a 650-ppm atmospheric CO2 concentration and a 1.0–2.6-°C increase in annual temperature by 2100, whereas in RCP 8.5, a pessimistic scenario assumes a 1350-ppm CO2 and 2.6–4.8-°C increase in annual temperature by 2100 (van Vuuren et al. 2011). The ECLIPS 2.0 dataset is available at https://doi.org/10.5281/zenodo.3952159.
2.3 Variable selection
From the list of potential predictor variables (Table 3 in Appendix), the ones which explain most of the variation in the observed presence and absences of each species were selected with a recursive feature elimination approach (RFE) implemented within the Random forest algorithm (Breiman 2001). Within the RFE approach, the variables were eliminated iteratively, starting from the full set of potential predictors and retaining only those variables that reduce the mean square error over random permutations of the same variable. The variables which were linearly correlated with other variables and had a variance inflation factors VIF > 5, a commonly used threshold in detecting mulicollinearity (Craney and Surles 2002; Thompson et al. 2017), were identified. The identified collinear variables with the lower value according to the Akaike Information Criteria (AIC) (Akaike 1974) were retained for further model development. This subset of uncorrelated climate variables (Table 4 in Appendix) was used as predictor variables for developing the ensemble species distribution models.
2.4 Ensemble species distribution models
To model the potential distribution of the seven European tree species, an ensemble distribution modeling approach, implemented through the R package, biomod2 (Thuiller et al. 2016), was used. biomod2 offers a computational platform for multi-method modeling that generates models of species’ potential distribution for each species. The model algorithms include GLM (Generalized Linear Models), GAM (Generalized Additive Models), GBM (Generalized Boosted regression Models), CTA (Classification Tree Analysis), ANN (Artificial Neural Networks), SRE (Surface Range Envelop or BIOCLIM), FDA (Flexible Discriminant Analysis), MARS (Multivariate Adaptive Regression Spline), RF (Random Forest for classification and regression), and MAXENT. Tsuruoka. Hence, biomod2 combines the strengths of multiple modeling algorithms while accounting for their uncertainties. We used biomod2 default settings for all the modeling algorithms (Thuiller et al. 2016). Each model algorithm predicted the probability of the potential distribution for each species. Such probabilities predicted from the individual models were ensembled into a consensus model by combining the median probability over the selected models with true skill statistics threshold (TSS > 0.7) (Allouche et al. 2006; Coetzee et al. 2009). The median was chosen because it is known to be less sensitive to outliers than the mean. The estimated ensemble model predictions were presented as GeoTIFF rasters. These raster files are available at https://doi.org/10.5281/zenodo.3686918.
2.5 Model evaluation and uncertainty analysis
Model evaluation was carried by splitting the occurrence dataset into 75% for model training and 25% for model testing. Besides, biomod2 allows specifying the number of runs for each combination of training and testing data. Therefore, 10 independent runs, each with a randomly selected set of training and test data, were implemented.
For each such model run as well as the final ensemble models, the model evaluation statistics were recorded. These statistics were true skill statistics (TSS) and area under the relative operating characteristic (ROC), model sensitivity (the ability of the model to predict true presences), and model specificity (the ability of the model to predict the true absences). TSS takes into account both omission and commission errors and ranges also from − 1 to + 1, not being affected by prevalence as KAPPA (Allouche et al. 2006). TSS values ranging from 0.2 to 0.5 were considered poor, from 0.6 to 0.8 useful, and values larger than 0.8 were good to excellent (e.g., Coetzee et al. 2009). Prediction accuracy is considered to be similar to random for ROC values lower than 0.5; poor, for values in the range 0.5–0.7; fair in the range 0.7–0.9; and excellent for values greater than 0.9 (Pontius and Parmentier 2014).
Model uncertainty was also estimated in terms of coefficient of variation (CV) among the predictions of the individual models. The estimated CVs are also presented as GeoTIFF rasters where each cell corresponds to a CV value, whereby higher and lower CV values indicate higher and lower uncertainties, respectively, in the ensemble model. These raster files are available at https://doi.org/10.5281/zenodo.3686918.
In addition to internal evaluation, the model predictions were also tested against independent data on European Forest Genetic Conservation Units (GCU) (Lefèvre et al. 2013). The geographic locations of the 3354 genetic conservation units (Fig. 3 in Appendix) were used to extract the predicted probability of occurrence from the models for the seven target species for the period 1961–1990. The ensemble models were used to predict the distribution of the seven target species at each GCU location. Predicted probability < 60 were assumed to be, “incorrectly predicted,” whereas those > 60% were treated as “correctly predicted” following Dyderski et al. (2018). For most species, the incorrectly classified GCUs are those located in the southeastern part of their potential distribution (Fig. 3 in Appendix).

Potential distribution of seven European tree species under the historical period (1961–1990) and predicted future scenario of 2080–2100 under RCP 4.5 and RCP 8.5
3 Access to the data and metadata description
The dataset is accessible through https://doi.org/10.5281/zenodo.3686918. Associated metadata are available at https://metadata-afs.nancy.inra.fr/geonetwork/srv/fre/catalog.search#/metadata/fe79a36d-6db8-4a87-8a9f-c72a572b87e8
4 Technical validation
In general, for all species, a high correlation was observed between the predictive performance of the models calibrated with both training and evaluation data with mean TSS ranging from 0.79 to 0.92 and mean ROC ranging from 0.92 to 0.98 (Table 1). Average sensitivity or the ability of the models to predict true presences across all species and models range from 95 to 98% and average specificity or the ability of the models to predict true absences range 86–96% (Table 1). Detailed performance of individual models can be found in Table 5 in Appendix.
Model evaluation against independent data reveals that out of the total 3354, 80–96% of the species occurrence in the European genetic conservation unit (GCU) dataset was correctly predicted by our ensemble SDMs (Table 6 in Appendix).
The ensemble SDMs predicts a substantial change in the potential distribution of the seven target species (Fig. 1). A general trend of a northward shift in potential climate suitability (probability > 60%) was predicted, as also observed by recent studies such as Dyderski et al. (2018). Median uncertainty represented by the coefficient of variation between individual models varies between 6 and 15% and with Larix decidua and Abies alba having higher prediction uncertainty compared to other species (Fig. 2).

Uncertainly of predictions for the seven target tree species under a current climate (1961–90) and b RCP 8.5 (1981–2100) expressed as the coefficient of variation
5 Reuse potential and limits
The dataset is currently being used to develop a decision support tool, SusSelect Smartphone app https://play.google.com/store/apps/details?id=com.topolynx.susselect&hl=en, which calculates the vulnerability of tree species under climate change. The dataset is also being used to develop an Integrated Toolbox that combines tools from Interreg CE, Horizon 2020, and EU Life projects. This integrated toolbox (TEACHER-CE) is under development and focuses on climate-proof management of water-related issues such as floods, heavy rain, and drought risk prevention, small water retention measures, and protection of water resources through sustainable land-use management. For details see: https://www.interreg-central.eu/Content.Node/TEACHER-CE.html. Ecological niche models or SDMs assume that the relation between climatic drivers and the species distribution remains constant also in climate change. This assumption needs to be taken into account while interpreting the results of the paper.
6 Dataset citation
Chakraborty D, Móricz N, Rasztovits E, Dobor L, Schueler S (2020). Provisioning forest and conservation science with European tree species distribution models under climate change (Version v1) [data set]. Zenodo. http://doi.org/10.5281/zenodo.3686918
References
Akaike H (1974) A new look at the statistical model identification. IEEE Trans Automat Control. https://doi.org/10.1109/TAC.1974.1100705
Allen CD, Macalady AK, Chenchouni H et al (2010) A global overview of drought and heat-induced tree mortality reveals emerging climate change risks for forests. For Ecol Manage 259:660–684. https://doi.org/10.1016/j.foreco.2009.09.001
Allouche O, Tsoar A, Kadmon R (2006) Assessing the accuracy of species distribution models: prevalence, kappa and the true skill statistic (TSS). J Appl Ecol 43:1223–1232. https://doi.org/10.1111/j.1365-2664.2006.01214.x
Benito Garzón M, Alía R, Robson TM, Zavala MA (2011) Intra-specific variability and plasticity influence potential tree species distributions under climate change. Glob Ecol Biogeogr 20:766–778. https://doi.org/10.1111/j.1466-8238.2010.00646.x
Booth GD, Niccolucci MJ, Schuster EG (1994) Identifying proxy sets in multiple linear-regression - an aid to better coefficient interpretation. USDA For Serv Intermt Res Stn Res Pap
Breiman L (2001) Random forests. Mach Learn 45:5–32. https://doi.org/10.1023/A:1010933404324
Chakraborty D, Schueler S, Lexer MJ, Wang T (2019) Genetic trials improve the transfer of Douglas-fir distribution models across continents. Ecography 42:88–101. https://doi.org/10.1111/ecog.03888
Chakraborty D, Dobor L, Hlásny T, Schueler S (2020) High-resolution gridded climate data for Europe based on bias-corrected EURO-CORDEX: the ECLIPS-2.0 dataset [Zenodo: https://doi.org/10.5281/zenodo.3952159]
Chakraborty D, Móricz N, Rasztovits E, Dobor L, Schueler S (2020) Provisioning forest and conservation science with European tree species distribution models under climate change. V1. Zenodo. https://doi.org/10.5281/zenodo.3686918
Coetzee BWT, Robertson MP, Erasmus BFN et al (2009) Ensemble models predict important bird areas in southern Africa will become less effective for conserving endemic birds under climate change. Glob Ecol Biogeogr 18:701–710. https://doi.org/10.1111/j.1466-8238.2009.00485.x
Craney TA, Surles JG (2002) Model-dependent variance inflation factor cutoff values. Qual Eng 14(3):391–403. https://doi.org/10.1081/QEN-120001878
Dyderski MK, Paź S, Frelich LE, Jagodziński AM (2018) How much does climate change threaten European forest tree species distributions? Glob Chang Biol 24:1150–1163. https://doi.org/10.1111/gcb.13925
European Environmental Agency (2006) European forest types—the European forest types—categories and types for sustainable forest management reporting and policy. EEA technical report No 9/2006. ISBN: 2–9167–886–4
Garate-Escamilla H, Hampe A, Vizcaino-Palomar N et al (2019) Range-wide variation in local adaptation and phenotypic plasticity of fitness-related traits in Fagus sylvatica and their implications under climate change. bioRxiv 513515. https://doi.org/10.1101/513515
Giorgi F, Jones C, Asrar GR (2009) Addressing climate information needs at the regional level: the CORDEX framework. World Meteorol Organ Bull 58:175–183. https://doi.org/10.1109/ICASSP.2009.4960141
Guisan A, Tingley R, Baumgartner JB et al (2013) Predicting species distributions for conservation decisions. Ecol Lett 16:1424–1435. https://doi.org/10.1111/ele.12189
Hamann A, Aitken SN (2013) Conservation planning under climate change: accounting for adaptive potential and migration capacity in species distribution models. Divers Distrib 19:268–280. https://doi.org/10.1111/j.1472-4642.2012.00945.x
Hanewinkel M, Cullmann DA, Schelhaas M-JJ et al (2013) Climate change may cause severe loss in the economic value of European forest land. Nat Clim Chang 3:203–207. https://doi.org/10.1038/nclimate1687
Härtl FH, Barka I, Hahn WA et al (2016) Multifunctionality in European mountain forests — an optimization under changing climatic conditions. Can J For Res 46:163–171. https://doi.org/10.1139/cjfr-2015-0264
Hiederer R , Houston Durrant T, Micheli E (2011) Evaluation of BioSoil demonstration project—soil data analysis.—Vol. 24729 of EUR—Scientific and Technical Research, Publications Office of the European Union.
Houston Durrant T, San-Miguel-Ayanz J, Schulte E, Suarez Meyer A (2011) Evaluation of BioSoil demonstration project: forest biodiversity—analysis of biodiversity module, vol. 24777 of EUR—Scientific and Technical Research (Publications Office of the European Union, 2011).
Jacob D, Petersen J, Eggert B et al (2014) EURO-CORDEX: New high-resolution climate change projections for European impact research. Reg Environ Chang. https://doi.org/10.1007/s10113-013-0499-2
Kreyling J, Schmid S, Aas G (2015) Cold tolerance of tree species is related to the climate of their native ranges. J Biogeogr 42:156–166. https://doi.org/10.1111/jbi.12411
Lefèvre F, Koskela J, Hubert J et al (2013) Dynamic Conservation of Forest Genetic Resources in 33 European Countries. Conserv Biol. https://doi.org/10.1111/j.1523-1739.2012.01961.x
Maroschek M, Seidl R, Netherer S, Lexer MJ (2009) Climate change impacts on goods and services of European mountain forests. Unasylva 60(231):76–80
Mauri A, Strona G, San-Miguel-Ayanz J (2017) EU-Forest, a high-resolution tree occurrence dataset for Europe. Sci Data 4:1–8. https://doi.org/10.1038/sdata.2016.123
Mcshea WJ (2014) What are the roles of species distribution models in conservation planning? Environ Conserv 41:93–96
Mina M, Bugmann H, Cordonnier T et al (2017) Future ecosystem services from European mountain forests under climate change. J Appl Ecol 54:389–401. https://doi.org/10.1111/1365-2664.12772
Moreno A, Hasenauer H (2016) Spatial downscaling of European climate data. Int J Climatol 36:1444–1458. https://doi.org/10.1002/joc.4436
O’Neill GA, Hamann A, Wang T (2008) Accounting for population variation improves estimates of the impact of climate change on species’ growth and distribution. J Appl Ecol. https://doi.org/10.1111/j.1365-2664.2008.01472.x
Pontius RG, Parmentier B (2014) Recommendations for using the relative operating characteristic (ROC). Landsc Ecol 29:367–382. https://doi.org/10.1007/s10980-013-9984-8
R Core Team (2016) R Core Team R. R A Lang Environ Stat Comput R Found Stat Comput, Vienna, Austria. https://www.R-project.org
Ramirez-Villegas J, Jarvis A (2010) Downscaling global circulation model outputs: the Delta method. Policy Analalysis working paper 1. International centre for Tropical Agriculture available at http://ccafs-climate.org/downloads/docs/Downscaling-WP-01.pdf
Reyer C, Lasch-Born P, Suckow F et al (2014) Projections of regional changes in forest net primary productivity for different tree species in Europe driven by climate change and carbon dioxide. Ann For Sci 71:211–225. https://doi.org/10.1007/s13595-013-0306-8
Scheffers BR, De Meester L, Bridge TCL et al (2016) The broad footprint of climate change from genes to biomes to people. Science 354/6313, aaf7671 https://doi.org/10.1126/science.aaf7671
Schueler S, Falk W, Koskela J et al (2014) Vulnerability of dynamic genetic conservation units of forest trees in Europe to climate change. Glob Chang Biol 20:1498–1511. https://doi.org/10.1111/gcb.12476
Seidl R, Schelhaas MJ, Lexer MJ (2011) Unraveling the drivers of intensifying forest disturbance regimes in Europe. Glob Chang Biol 17:2842–2852. https://doi.org/10.1111/j.1365-2486.2011.02452.x
Seidl R, Schelhaas MJ, Rammer W, Verkerk PJ (2014) Increasing forest disturbances in Europe and their impact on carbon storage. Nat Clim Chang 4:806–810. https://doi.org/10.1038/nclimate2318
Senay SD, Worner SP, Ikeda T (2013) Novel three-step pseudo-absence selection technique for improved species distribution modelling. PLoS One 8:e71218. https://doi.org/10.1371/journal.pone.0071218
Sykes MT, Prentice IC, Cramer W (1996) A bioclimatic model for the potential distributions of north European tree species under present and future climates. J Biogeogr 23:203–233
Thompson CG, Kim RS, Aloe AM, Becker BJ (2017) Extracting the variance in flation factor and other multicollinearity diagnostics from typical regression results. Basic Appl Soc Psych. https://doi.org/10.1080/01973533.2016.1277529
Thuiller W, Albert C, Araújo MB et al (2008) Predicting global change impacts on plant species’ distributions: future challenges. Perspect Plant Ecol Evol Syst 9:137–152. https://doi.org/10.1016/j.ppees.2007.09.004
Thuiller W, Georges D, Engler R (2016) biomod2: Ensemble platform for species distribution modeling. R Packag version 2:r560
Thurm EA, Hernandez L, Baltensweiler A et al (2018) Alternative tree species under climate warming in managed European forests. For Ecol Manage 430:485–497. https://doi.org/10.1016/j.foreco.2018.08.028
Valladares F, Matesanz S, Guilhaumon F et al (2014) The effects of phenotypic plasticity and local adaptation on forecasts of species range shifts under climate change. Ecol Lett 17:1351–1364. https://doi.org/10.1111/ele.12348
van Vuuren DP, Edmonds J, Kainuma M et al (2011) The representative concentration pathways: an overview. Clim Change 109:5–31. https://doi.org/10.1007/s10584-011-0148-z
Yang W, Andreasson J, Graham P, Olsson J (2010) Distribution based scaling to improve usability of RCM regional climate model projections for hydrological climate change impact studies. Hydrol Res 41:211–229. https://doi.org/10.2166/nh.2010.004
Zimmermann NE, Edwards TC, Graham CH et al (2010) New trends in species distribution modelling. Ecography (Cop) 33:985–989. https://doi.org/10.1111/j.1600-0587.2010.06953.x
Zurell D, Franklin J, König C et al (2020) A standard protocol for reporting species distribution models. Ecography 01 June 2020 https://doi.org/10.1111/ecog.04960
Acknowledgement
We acknowledge the cooperation of all participating institutes of the Interreg CE-SUSTREE project in compiling the dataset. We also acknowledge Dr. Laura Dobor and Dr. Tomáš Hlásny supported by the grant “EVA4.000, No. CZ.02.1.01/ 0.0/0.0/16_019/0000803” financed by OP RDE for their contribution to acquiring the EURO-CORDEX climate data.
Funding
The research was funded by INTERREG-Central Europe program (Project SUSTREE: Conservation and sustainable utilization of forest tree diversity in climate change).
Author information
Authors and Affiliations
Corresponding author
Additional information
Handling Editor: Marianne Peiffer
Contribution of the co-authors DC: running the data analysis, writing the paper, SS: Research conception, coordination, and supervision writing the paper, NM: Initial model runs, ER: Initial model runs, LD: climate data provision
Appendix
Appendix
Provisioning forest and conservation science with high-resolution maps of potential distribution of major European tree species under climate change.

Locations of the genetic conservation units (Lefèvre et al. 2013) plotted against the predictions of the ensemble SDMs for the period 1961–1990 for the seven target species of Europe. The prediction range 0–1000 refers to 0–100%
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chakraborty, D., Móricz, N., Rasztovits, E. et al. Provisioning forest and conservation science with high-resolution maps of potential distribution of major European tree species under climate change. Annals of Forest Science 78, 26 (2021). https://doi.org/10.1007/s13595-021-01029-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13595-021-01029-4