
Abstract
The attentional blink (AB) is often considered a top-down phenomenon because it is triggered by matching an initial target (T1) in a rapid serial visual presentation (RSVP) stream to a search template. However, the AB is modulated when targets are emotional, and is evoked when a task-irrelevant, emotional critical distractor (CDI) replaces T1. Neither manipulation fully captures the interplay between bottom-up and top-down attention in the AB: Valenced targets intrinsically conflate top-down and bottom-up attention. The CDI approach cannot manipulate second target (T2) valence, which is critical because valenced T2s can “break through” the AB (in the target-manipulation approach). The present research resolves this methodological challenge by indirectly measuring whether a purely bottom-up CDI can modulate report of a subsequent T2. This novel approach adds a valenced CDI to the “classic,” two-target AB. Participants viewed RSVP streams containing a T1–CDI pair preceding a variable lag to T2. If the CDI’s valence is sufficient to survive the AB, it should modulate T2 performance, indirectly signaling bottom-up capture by an emotional stimulus. Contrary to this prediction, CDI valence only affected the AB when CDIs were also extremely visually conspicuous. Thus, emotional valence alone is insufficient to modulate the AB.
Similar content being viewed by others
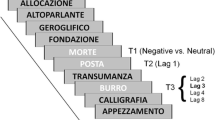

Humans are becoming increasingly reliant on dynamic displays of information stemming from multiple sources—such as time-sensitive navigation instructions interrupted by emotionally laden text messages or images on a cellular phone. Thus, it is imperative to understand the dynamics of attention to serial events of varying task relevance. In the lab, these dynamic processes may be studied by manipulating factors that could alter a momentary lapse in temporal attention, termed the attentional blink (AB). AB studies typically use rapid serial visual presentation (RSVP) displays at a speed of approximately 10 items per second. In the classic AB paradigm, two targets are embedded among a stream of distractors and the lag (ordinal position difference between the two targets) is manipulated (Raymond et al., 1992). Participants report both targets following each trial, a goal-oriented task that can examine aspects of top-down attention. The AB occurs when reporting a second target (T2) is impaired at short lags from the first target (T1). The AB is greatest at Lag 2 and diminishes at longer lags, lasting approximately 200–500 ms (Raymond et al., 1992). Regardless of the (much-debated) exact cause of the AB, most models agree that it can be characterized as a temporal limit on the ability to select and/or encode a goal-relevant stimulus (T2).
Though the AB has classically been studied as an effect of top-down attention (because it entails selection of a target that matches a top-down attentional template), other research has asked whether stimulus-driven (bottom-up) attentional demands can also affect temporal attention. A common approach has been to investigate whether or how the AB is modulated or evoked by the emotional content of stimuli in the RSVP stream. It is generally accepted that emotional stimuli are given higher priority for attentional resources and are able to capture attention, even away from a goal-driven task (e.g., Keil et al., 2005). Past AB research using emotional stimuli has used two main approaches (McHugo et al., 2013), detailed below.
The first such approach uses the classic, two-target AB RSVP paradigm, but presents an emotional stimulus as either T1 or T2. When emotional stimuli are presented as T1, participants’ ability to recall T1 improves, suggesting that emotional stimuli are generally able to capture attention (Ihssen & Keil, 2009; MacLeod et al., 2017; Mathewson et al., 2008; Milders et al., 2006). More importantly, emotional T1s significantly affect T2 performance: by increasing attention to T1, they result in poorer report of T2, increasing the magnitude of the AB effect (MacLeod et al., 2017; Mathewson et al., 2008). In a complementary effect, emotional T2s “break through” the AB (i.e., they are correctly reported more often than neutral T2s presented with the same timing; Anderson, 2005; Keil & Ihssen, 2004; Most et al., 2005). A pitfall of this approach is that it mixes bottom-up and top-down influences on attention by testing how emotional valence can modulate attention to targets that also accord with top-down attentional templates.
The second approach that examines the effects of emotional stimuli on temporal attention is sometimes called the emotional attentional blink (EAB). EAB studies demonstrate that emotional stimuli can elicit a bottom-up attentional capture that results in an AB-like effect on a subsequent (single) target’s identification (for review, see McHugo et al., 2013). As in the classic two-target AB, EAB paradigms use an RSVP task, but with an emotional stimulus acting as a task-irrelevant, critical distractor item (CDI). A target follows the CDI at varying lags. Because the CDI is irrelevant to the task and does not require any behavioral response of the participant, it represents a more pure manipulation of bottom-up attention, whereas the addition of emotional content to targets in the classic, two-target AB paradigm mixes bottom-up attention (due to the affective status of a target) and top-down attention (due to the target’s goal relevance). Both pleasant (Arnell et al., 2007; Ciesielski et al., 2010; MacLeod et al., 2017; Mathewson et al., 2008) and unpleasant (Ciesielski et al., 2010; Kennedy & Most, 2015a, 2015b; Most et al., 2005) CDIs yield an adverse effect on target identification. These results suggest that task-irrelevant emotional stimuli can elicit a bottom-up attentional capture strong enough to compete with top-down attentional goals (target search) and trigger an AB-like effect, almost as if they were T1s in the conventional two-target AB paradigm (Arnell et al., 2007; Ciesielski et al., 2010; Kennedy & Most, 2015a, 2015b; MacLeod et al., 2017; Mathewson et al., 2008; Most et al., 2005).
Neither of the two existing approaches to using emotional stimuli in the AB fully captures the interplay between bottom-up and top-down attention in rapidly changing displays. In particular, the two-target paradigm always considers stimuli that both match top-down attentional templates and evoke bottom-up attentional capture, and the CDI/single-target EAB only considers the ability of a task-irrelevant item to override goal-driven attention settings and evoke an AB-like phenomenon. To our knowledge, no existing study has examined whether an emotional but task-irrelevant item can elicit a bottom-up attentional capture strong enough to survive the T1-evoked AB, which would in turn be expected to affect either the magnitude or duration of the AB. Framed differently, while it is known that an emotional item can break through a top-down attentional set to search for something else, it is unknown whether an emotional item can further evoke a blink when it occurs during the already limited processing resources available during an ongoing AB. In order to bridge this gap, the current study introduces a novel paradigm in which emotional stimuli are decoupled from target stimuli in a two-target AB paradigm. This paradigm allows the evaluation of whether emotional content is sufficiently potent to survive the AB and thus modulate report of a subsequent T2. Such an effect would be expected given that prior research demonstrated that an emotional T2 was reportable even when presented during the blink, but this prediction is tempered by the fact that the prior research confounded bottom-up and top-down attention to T2. To elaborate on this confound: the most direct way to evaluate if a stimulus survives the AB is to monitor performance in reporting that stimulus; however, that approach is not possible here because requiring any report of the CDI would attach task relevance, and thus, direct top-down attention to it. Thus, the present approach instead relies on indirect effects of the CDI that indicate that it has survived the AB. This approach depends on the reasoning that an emotional CDI that survived the AB and has been fully processed would itself affect processing of a subsequent T2 (either by affecting the magnitude or duration of the blink measured on such trials, compared with when the CDI lacked emotional content). On the other hand, a CDI whose content was not fully processed would not be expected to affect processing of a subsequent T2. A similar framework has been used to examine the effects of priming T2 with a semantically similar intertarget distractor item (Maki et al., 1997).
Each trial of each of the six experiments in the present study used three items with special status: two neutral-valence targets and a pleasant-valence, neutral-valence, or unpleasant-valence CDI. If the CDI modulates the AB (i.e., CDI valence interacts with T1–T2 lag), it would constitute evidence for a bottom-up attentional capture strong enough to survive the T1-evoked AB and evoke a further blink that would sum with or sequentially follow the original T1-evoked blink. Alternatively, an emotional CDI could act as a T1–T2 bridge, decreasing the AB effect as if it were a T2 in the three-target AB paradigm; such an alternative would instead predict a reduced AB for trials with emotional CDIs compared with trials with neutral CDIs. Because prior research shows that emotional targets can modulate the AB, and emotional CDIs can evoke an AB-like effect, the present research hypothesized that similarly potent emotional stimuli would modulate the effect of lag on T2 report.
Experiment 1
Experiment 1 was the initial decoupling of emotional stimuli from targets in the two-target AB paradigm. The design used was similar to that of Keil and Ihssen (2004), in which participants identified two green target words in an RSVP stream of white distractor words. This study adopted the design of Keil and Ihssen (2004) to ensure that reporting T1 and T2 could be accomplished without a task switch (Kawahara et al., 2003). However, while Keil and Ihssen (2004) manipulated the emotional valence of T2, the current study is different in that both of the targets were neutral words, but with an added CDI of positive, neutral, or unpleasant valence.
A previous study used a similar paradigm to determine whether (neutral) CDIs in the AB were sufficiently processed to semantically prime T2 (Maki et al., 1997). While Maki et al. (1997) did observe such priming, suggesting that a task-irrelevant distractor can survive the AB, they observed a short-lived effect that was independent of the T1–T2 lag. Critically for the present investigation, their approach demonstrated that placing a CDI immediately after T1 allowed the design to be sensitive to whether that item modulates the AB (interacts with T1–T2 lag) or has an independent effect. Thus, in Experiments 1–5, the current study echoed Maki et al.’ (1997) Experiment 4 by placing valenced CDIs at Lag 1 from T1 in all T1–T2 conditions. This ensured that the CDI was within the known duration of the AB, allowing for the examination of T2 performance at several lags from the CDI without multiplying the number of conditions that are not central to the main question of this research. To summarize, the current study manipulated the valence of the distractor following T1 to determine if emotional bottom-up capture by a task irrelevant CDI was strong enough to magnify the AB, indicated by a CDI Valence × T1–T2 lag interaction.
In this first experiment, the CDI did not visually differ from the distractor items; thus, the neutral CDI condition was effectively a replication of the classic two-target AB paradigm without any CDI at all. This provides a manipulation check that the AB can be obtained with the present word stimuli and timing parameters, and based on its success, subsequent experiments do not include similar checks.
Method
Participants
Data for Experiment 1 were collected at both the University of Florida (N = 18) and the University of Houston (N = 21).Footnote 1 Data from the 18 participants collected at the University of Florida were also used as part of a separate study that examined brain activity during the attentional blink, but did not consider the effects of the CDI’s valence in their final analyses (Petro & Keil, 2015; see Footnote 1). Both subsets of the participant pool consisted of undergraduate students receiving course credit for participating. Overall, Experiment 1 had 39 participants (27 females; Mage = 21.64 years, SD = 5.28). Data from two additional participants were collected, but were excluded from analyses due to their failure to comply with task instructions. In Experiment 1 and all following experiments, participants were at least 18 years of age, able to perform the basic requirements of the task, did not self-report a history of neurological disorder or injury or major psychological disorder known to affect cognitive capacity limits, did not self-report a history of vision problems (other than wearing corrective lenses), and did not self-report using psychoactive medications or drugs. Informed consent was collected from all participants in all experiments.
Sample size justification
In Experiment 1, data collection began with a partial existing data set (published in Petro & Keil, 2015, but without full report of the interaction of interest to the present research; see Footnote 1), as stated above. The present study sought to collect new data in order to ensure sufficient power to find any effect of meaningful size, should one exist. In order to ensure that additional data could reasonably be pooled with the existing data, an approximately matched sample (N = 21) was collected to allow for efficient comparisons of the effect of interest across the two subsets (see Footnote 1). Thus, a total sample size of 39 participants was obtained. Similarly, to anticipate Experiment 2, an existing unpublished data set (22 participants) was pooled with 23 new participants for a total sample size of 45. To remain consistent with Experiments 1 and 2, the remaining experiments sought to achieve a sample size of approximately 40 participants, ultimately ranging from 32 to 45 participants per experiment due to varying rates of participant availability and screening failure.
In order to assess the sufficiency of a sample as small as 32 participants, the sensitivity (i.e., the smallest effect that can be reliably detected) of a 3 x 3 within-subjects factorial analysis of variance (ANOVA) design with 32 participants was sought. Because standard tools do not allow straightforward computation of sensitivity for an interaction between two within-subjects factors, an estimate of sensitivity was achieved by treating one of the within-subjects factors as a between-subjects factor. This approach both assumes no correlated variance among measures for the nominally between-subjects factor, and results in reduced denominator degrees of freedom, making it an extremely conservative estimate. Using this approach in G*Power software (Faul et al., 2007) yields the result that for a total sample size of 32 participants, with three levels of a within-subjects factor and three levels of a between-subjects factor, and with an alpha of .05, the design should have 80% power to detect an effect as small as Cohen’s f = 0.26, which is equivalent to ηp2 = 0.063. A less conservative estimate may be calculated by tripling the nominal sample size (to compensate for the three levels of the nominally between-subjects factor); this approach still assumes no correlated variance for the nominally between-subjects factor, but instead inflates the denominator degrees of freedom. This less conservative approach suggests that the current design should be sensitive to an effect as small as Cohen’s f = 0.13, equivalent to ηp2 = 0.017. For context, prior studies of emotional modulation of the AB reported effect sizes of ηp2 = 0.12 (Mathewson et al., 2008), 0.37 (Keil & Ihssen, 2004), and 0.33 (MacLeod et al., 2017), suggesting that the present sample size was adequate. Moreover, in addition to traditional null-hypothesis testing (for which this power/sensitivity analysis is important), analyses of each experiment throughout this manuscript are complementarily supported by Bayes factor approaches (for which there is no corresponding notion of statistical power; for further discussion see Rouder, 2014; Wagenmakers, Marsman, et al., 2018a).
Procedure
The current study used a variation of the classic two-target AB RSVP paradigm, similar to that used by Keil and Ihssen (2004). Participants were given both verbal and on-screen instructions to attend to two green target words presented among a stream of white words. Participants began each trial by pressing the space bar. Each trial began with an initial blank screen for a random interval between 3 and 5 s, followed by the RSVP stream in which each frame lasted approximately 117 ms. and there were no temporal gaps between frames. The stream (see Fig. 1) began with 5–10 (randomized, uniform distribution) pretarget distractor words, followed by T1; an intertarget interval consisting of either 1 (Lag 2 condition), 3 (Lag 4 condition), or 5 (Lag 6 condition) distractor items; T2; and finally, 8–18 posttarget distractor words; for a total of 26 items (approximately 3 s) per stream. The first intertarget distractor immediately following T1 in the stream was the CDI, which was a white word with a pleasant (one-third of trials), neutral (one-third of trials), or unpleasant (one-third of trials) valence; neutral CDIs were effectively standard distractor items. Following each stream, participants were prompted to recall the target words by entering the first two letters of each word in order, while also saying the words out loud. To ensure that the participants understood the instructions and pace of the experimental trials, one practice trial was completed with the experimenter. Each experiment included 20 trials in each of the nine (3 lags × 3 CDI valence categories) experimental conditions for a total of 180 trials.

An example of the RSVP task used in Experiment 1. Left: Task schematic. Right: Enlarged section of the RSVP stream consisting of an example sequence of a neutral distractor, T1, and CDI, as seen on the computer screen. (Illustration not to scale.)
Following the completion of the RSVP task, participants completed the Form Y version of the State/Trait Anxiety Inventory (STAI; Spielberger et al., 1983); results of this measure are not reported here. Additionally, at the University of Florida, data collection included electroencephalogram (EEG) data that were analyzed as part of a previous study (Petro & Keil, 2015) and were not analyzed for the current study. Those participants were fitted with an EEG before beginning the experiment. An EEG was not used at the University of Houston. All procedures were approved by either the Institutional Review Board of the University of Florida or the Institutional Review Board of the University of Houston for the respective subsets of the participants.
Stimuli and materials
The experiment was run using the Psychophysics Toolbox suite for MATLAB (Brainard, 1997; Kleiner et al., 2007; Pelli, 1997). At the University of Florida, participants were seated at a small desk with a computer keyboard in a sound-attenuated, dimly lit chamber approximately 1 m from a 23-inch LED (Samsung LS23A950) monitor with a refresh rate of 120 Hz. At the University of Houston, participants were seated at a desk with a computer keyboard in a dark room approximately 70 cm from a 19-inch Hitachi CM751 cathode-ray tube (CRT) monitor with a refresh rate of 85 Hz.
All neutral words in the RSVP stream were selected from the Affective Norms of English Words (ANEW) list (Bradley et al., 1999) based on normative valence and arousal ratings using the Self-Assessment Manikin (Bradley & Lang, 1994) 9-point scale. Words from the ANEW list have been used in a multitude of studies on the effects of emotional stimuli on temporal attention (e.g., Huang et al., 2008; Keil & Ihssen, 2004; Petrucci & Pecchinenda, 2018; Todd et al., 2014), as well as in a multitude of studies on the effects of emotional stimuli on other forms of attention (e.g., Chan & Singhal, 2013; Greenberg et al., 2012; Vinson et al., 2014). The target words were drawn from a list of 182 neutral words (arousal: mean = 3.97, SD = 2.11; valence: mean = 5.25, SD = 1.43, all on a 9-point scale, with a mean of 5.0), which were divided in two 90-word groups to serve as either the first (T1) or second (T2) target. Each target word was presented once randomly during the first 90 trials and then again, randomly, during the last 90 trials. Thirty additional neutral words were chosen to serve as neutral distractors preceding T1 and following T2. All words were presented in a 42-point Helvetica font on a dark-gray background, distractor words were presented in a white font, and target words were presented in a green font.
The words used as the CDIs in Experiment 1 were composed of 52 pleasant words (arousal: mean = 6.59, SD = 2.40; valence: mean = 7.90, SD = 1.38), 52 additional neutral words (arousal: mean = 3.95, SD = 2.17; valence: mean = 5.32, SD = 1.33), and 52 unpleasant words (arousal: mean = 6.54, SD = 2.45; valence: mean = 2.17, SD = 1.52), also selected from the ANEW list (see Fig. 2a). All words shown once randomly for the first 156 trials, and a random 24 words (eight from each valence level) were repeated for the remaining trials.

Examples of words (a) and images (b) used as CDIs for each valence category in Experiments 1 and later experiments, respectively. Consistent with the use agreement for the IAPS image set, example images shown here were not drawn from the IAPS database, but from publicly available sources
Results
All statistical analyses were performed using JASP (JASP Team, 2018). T2 accuracy was defined as correctly reporting T2 in trials where T1 was also correctly reported, as is standard in studies of the AB. Within-subject performance data were subjected to a 3 (lag: 2, 4, 6) × 3 (emotional valence: pleasant, neutral, unpleasant) repeated-measures analysis of variance (ANOVA). The goal of the current study was to test whether CDIs’ emotional valence modulate the classic, two-target AB, which would yield a significant Emotional Valence × Lag interaction. Therefore, this interaction was the primary result of interest. Additionally, the current study utilized Bayesian mixed ANOVAs (van Doorn et al., 2019; Wagenmakers, Love, et al., 2018b; Wagenmakers, Marsman, et al., 2018a) to adjudicate between two models: one that included the conventional AB (i.e., a main effect of lag) and a potential effect of CDI emotional content (i.e., a main effect of valence), but no emotional modulation of the AB, and a second model that included all terms from the first model plus emotional modulation of the AB (i.e., a Lag × Emotional Valence interaction).
When the data from Experiment 1 (see Fig. 3) were subjected to the ANOVA, they revealed a significant main effect of lag, F(2, 76) = 116.26, p < .001, ηp2 = .754, representing the expected AB. The ANOVA also showed a significant (though much smaller) main effect of valence, F(2, 76) = 3.36, p = .04, ηp2 = .081. Most important to the current study, the analyses showed no significant Valence × Lag interaction, F(4, 152) = .485, p = .75, ηp2 = .013, suggesting no AB modulation by emotional CDIs. Additionally, Bayesian analyses comparing models with versus without modulation of the AB by CDI emotional valence yielded a Bayes factor (BF) of 43.92, suggesting that the observed data provide about 44 times more support for the no-modulation model than the emotional-modulation model. These analyses show that when intertarget CDIs are words, their valence does not modulate the attentional blink.

Results from Experiment 1. Performance calculated as T2 accuracy in trials where T1 was also accurately reported (T2 | T1). Error bars depict standard error of the mean
Discussion
This experiment tested whether nontarget emotional stimuli (CDIs) could survive the AB and be processed sufficiently to modulate the effect of lag in a two-target AB paradigm with word stimuli (Keil & Ihssen, 2004). The results provide strong evidence against modulation of the AB by these stimuli. The substantial BF against this modulatory effect suggests that this conclusion is not merely the result of Type II error, but instead reflects a true invariance between emotional and nonemotional CDIs. These results suggest that participants were able to suppress the task-irrelevant CDI similarly to other nontarget stimuli and therefore did not process its valence, meaning emotional stimuli were unable to create a bottom-up attentional capture strong enough to survive the AB and evoke a magnified blink of T2.
It is worth mentioning that the significant main effect of valence in this experiment could be interpreted as the participants processing the CDI’s valence (i.e., emotional stimuli surviving the AB). However, the main effect of valence was relatively small (ηp2 = .081, p = .04), and, to preview additional experiments, generally did not replicate. Even if this main effect were to be interpreted as reflecting AB survival of emotional CDIs, the emotional CDIs were unable to affect the Lag 2 performance and the rapid recovery that are the hallmark of the AB, which would be indicated by a Lag × Valence interaction. Thus, even were the main effect to be credited, it would not indicate modulation of the AB time course by CDI valence (as one might expect from the EAB).
The absence of a Lag × Valence interaction was surprising, given that a task-irrelevant emotional CDI preceding a single target in an RSVP stream creates a strong enough bottom-up attentional capture to override top-down search for a target and elicit an AB-like effect (Ciesielski et al., 2010; Most et al., 2005). However, most studies that show this effect use CDIs that are not just emotionally distinct from RSVP filler items, but also visually distinct and therefore conspicuous. For example, Mathewson et al. (2008) used a single-target RSVP stream of uppercase filler words, with red color target words and lowercase emotional word CDIs. Similarly, Ciesielski et al. (2010) used RSVP streams with image stimuli, with upright landscape/architecture images as distractors, rotated landscape/architecture images as targets, and images containing either humans or animals as the emotional CDIs. In both of these examples (and many other studies), although they were categorically different from each other, both the target and the CDI also differed conspicuously from the other distractors, potentially making them easier to notice and process (or, alternatively, difficult to ignore). Thus, it is possible that the emotional valence of the CDIs in the current study did not survive the AB and modulate T2 performance because the CDIs blended in with the other task-irrelevant distractors (all white words), while the targets (green words) stood out. Therefore, a second experiment was conducted to increase the visual distinctiveness of the CDIs, with the aim of making the conspicuity of the CDIs at least as great as past studies (e.g., Ciesielski et al., 2010; Mathewson et al., 2008; Milders et al., 2006; Most et al., 2005).
Experiment 2
The surprising results from Experiment 1 revealed no AB modulation by emotional stimuli. However, this could be because, unlike previous EAB studies (Ciesielski et al., 2010; Mathewson et al., 2008; Milders et al., 2006; Most et al., 2005), the CDIs were not visually distinct from surrounding RSVP stimuli. Thus, Experiment 2 aimed to test this possibility by making the CDIs more visually distinct. Separate research has shown that participants are slower in evaluating the affective content of a stimulus when it is a word, compared with when it is an image (Houwer & Hermans, 1994). It has also been shown that emotional valence effects on amygdala and prefrontal cortex activity are less apparent when participants process words compared with images, suggesting that emotion is more effectively conveyed by images than words (Kensinger & Schacter, 2006). Thus, using words as the CDIs could provide an additional explanation as to why the emotional CDIs could not create a strong enough bottom-up attentional capture to unambiguously modulate the AB in Experiment 1—that their content was not processed at any level, and thus, no attentional capture by their emotional content could occur. Therefore, Experiment 2 was conducted to determine whether the emotional valence of a to-be-ignored CDI could magnify the AB if the CDI were more distinct from the surrounding RSVP stimuli, similar to CDIs in previous research. In order to ensure that the visual distinctiveness of the CDI was the only additional manipulation and to maximize the conspicuity of the CDI, Experiment 2 used the same task design as in Experiment 1, but with a more conspicuous CDI—an image among words.
Method
Participants
Data for Experiment 2 were collected at the University of Florida (N = 22) and the University of Houston (N = 23),Footnote 2 with both sets of participants consisting of undergraduate students receiving course credit for participating. Overall, Experiment 2 had 45 participants (30 females; Mage = 20.16 years, SD = 2.49).
Procedure
The same RSVP paradigm from Experiment 1 was implemented in Experiment 2, except the CDIs were replaced with comparably sized images (see Fig. 4). As with Experiment 1, data collection included EEG (University of Florida only) and STAI (all participants), but these measures were not analyzed for the current study. All procedures were approved by either the Institutional Review Board of the University of Florida or the Institutional Review Board of the University of Houston for the respective subsets of the participants.

An example of the RSVP task used in Experiment 2. Left: Task schematic. Right: Enlarged section of the RSVP stream consisting of an example sequence of a neutral distractor, T1, and CDI, as seen on the computer screen. (Illustration not to scale.)
Stimuli and materials
The same apparatus from Experiment 1 was used. The words used as the neutral distractors and targets were also the same as those in Experiment 1. However, the CDIs were images (see Fig. 2b) selected from the International Affective Picture System (IAPS; Lang et al., 2008) based on normative valence and arousal ratings using the Self-Assessment Manikin (Bradley & Lang, 1994) 9-point scale. IAPS images have been used in a multitude of studies on the effects of emotional stimuli on temporal attention (e.g., Ciesielski et al., 2010; Kanske et al., 2013; Kennedy & Most, 2015a, 2015b; Kennedy et al., 2018; Kennedy et al., 2014; Most & Jungé, 2008; Schimmack & Derryberry, 2005), as well as in a multitude of studies on the effects of emotional stimuli on other forms of attention (e.g., Hajcak et al., 2013; Keil et al., 2003; Keil et al., 2005; Lichtenstein-Vidne et al., 2012; Verbruggen & Houwer, 2007; Zinchenko et al., 2019). An additional nine unpleasant images were selected from the public domain. The IAPS CDIs were composed of 30 pleasant images (arousal: mean = 6.10, SD = .69; valence: mean = 6.84, SD = .52), 30 neutral images (arousal: mean = 3.68, SD = .57; valence: mean = 5.46, SD = .70), and 21 unpleasant images (arousal: mean = 6.58, SD = .51; valence: mean = 2.42, SD = .82). Each image was presented twice during the 180 trials, once randomly during the first 90 trials and again randomly during the second 90 trials. Images were presented in grayscale, sized approximately 5.43 cm by 4.07 cm, at the center of the screen.
Results
When the data from Experiment 2 (see Fig. 5) were subjected to a 3 (lag: Lag 2, Lag 4, Lag 6) × 3 (emotional valence: pleasant, neutral, unpleasant) within-subjects ANOVA, they revealed a significant main effect of lag, F(2, 88) = 50.67, p < .001, ηp2 = .535, representing the expected AB, but no main effect of valence, F(2, 88) = 2.60, p = .08, ηp2 = .056. The ANOVA did not reveal a significant Emotional Valence × Lag interaction, F(4, 176) = 1.28, p = .28, ηp2 = .028, suggesting no AB modulation by emotional CDIs. Additionally, Bayesian analyses (comparing models that included or excluded the Lag × CDI Valence interaction term) yielded a BF of 28.43, suggesting that the no-modulation model was about 28 times as likely as the emotional-modulation model given the data. These analyses show that even when intertarget CDIs are comparably sized images among word distractors/targets, their valence does not modulate the attentional blink.

Results from Experiment 2. Performance calculated as T2 accuracy in trials where T1 was also accurately reported (T2 | T1). Error bars depict standard error of the mean
Discussion
After failing to find the predicted interaction in Experiment 1 using word CDIs, Experiment 2 tested whether nontarget emotional stimuli created a strong enough bottom-up attentional capture to be processed sufficiently to magnify the AB when they were presented as more conspicuous and visually distinct images among words. The results showed that emotional stimuli still did not modulate T2 reports during the AB RSVP task. This suggests that participants were able to suppress stimuli that were task-irrelevant and therefore did not encode the valence of the CDI, even with increased salience. Lending further support to this account, there was evidence against even a main effect of valence in this experiment, suggesting that, if anything, CDI emotional content was perceived to a lesser extent in Experiment 2 than in Experiment 1. This finding was, again, surprising. Emotional stimuli are known to create a bottom-up attentional capture (e.g., Keil et al., 2005; Lang et al., 1997) and, given the increased salience of the CDIs in Experiment 2, were expected to magnify the AB. It is possible, however, that the onset of a rare (occurring once in 26 stimuli), visually dissimilar distractor could have led to inattentional blindness, in which even a conspicuous item fails to capture attention when participants have deployed top-down attention elsewhere (for review, see Simons, 2000). However, one would expect that the status of the image as a rare oddball among words would lead to the opposite result, because oddball stimuli naturally capture attention, even without emotional valence (Folk & Remington, 2015; Han & Marois, 2014; Theeuwes et al., 1998)–and thus the affective valence of the CDI would be processed. Given that these two well-known effects may have been effectively pitted against one another in Experiment 2, it is possible that they simply canceled one another. In other words, it is possible that the CDIs were still not conspicuous enough to create a bottom-up attentional capture strong enough to survive the AB or to evoke a further blink, especially given the participants’ top-down attentional set for green words. Therefore, Experiment 3 was conducted in order to further increase the visual distinctiveness of the CDIs in an effort to overcome any potential inattentional blindness.
Experiment 3
While previous research has shown that emotional stimuli modulate the AB when they replace one of the two targets in the classic AB paradigm (Anderson, 2005; Keil & Ihssen, 2004; MacLeod et al., 2017; Mathewson et al., 2008; Milders et al., 2006; Most et al., 2005) and that they can create an AB-like effect when they act as a CDI preceding a single target in the EAB paradigm (Arnell et al., 2007; Ciesielski et al., 2010; Kennedy & Most, 2015a, 2015b; MacLeod et al., 2017; Mathewson et al., 2008; Most et al., 2005), the results from Experiments 1 and 2 failed to show that a CDI presented between two RSVP targets can modulate the AB. The results thus far suggest that emotional stimuli do not create a strong enough bottom-up attentional capture to be processed sufficiently to magnify the AB and modulate the effect of T1–T2 lag. This pattern held even in Experiment 2, when the CDI was visually dissimilar to the surrounding RSVP stimuli. However, Experiment 2 used CDI images that were comparably sized to the surrounding words, possibly making them less visually distinct than desirable and more easily suppressed by the top-down attentional set for green words. Therefore, Experiment 3 aimed to further increase the salience of the CDIs to make them difficult to suppress, increasing the likelihood that emotional content could be processed sufficiently to potentially modulate the AB. To accomplish this, the CDIs were enlarged to nearly the size of the entire screen, while leaving the task otherwise unchanged.
Method
Participants
Data for Experiment 3 were collected at the University of Houston. The participants included 41 undergraduate students (28 females; Mage = 21.29 years, SD = 4.72) who received course credit for participating and met the study requirements, as outlined in Experiment 1. Informed consent was collected from all participants.
Procedure
The same RSVP paradigm from Experiment 2 was implemented in Experiment 3, except the CDIs were replaced with a nearly full-screen image (see Fig. 6). STAI scores were also collected in Experiment 3. All procedures were approved by the Institutional Review Board of the University of Houston.

An example of the RSVP task used in Experiment 3. Left: Task schematic. Right: Enlarged section of the RSVP stream consisting of an example sequence of a neutral distractor, T1, and CDI, as seen on the computer screen. (Illustration not to scale.)
Stimuli and materials
The materials in Experiment 3 reflected those used at the University of Houston from Experiments 1 and 2. The words used as the neutral distractors and targets were the same as in Experiments 1 and 2. The image CDIs were identical to those used in Experiment 2, but they were sized approximately 27.09 cm × 20.32 cm and covered the entire central portion of the 36.8 cm × 27.6 cm screen.
Results
When the data from Experiment 3 were subjected to a 3 (lag: Lag 2, Lag 4, Lag 6) × 3 (emotional valence: pleasant, neutral, unpleasant) within-subjects ANOVA, they revealed a significant main effect of lag, F(2, 80) = 42.87, p < .001, ηp2 = .517, representing an overall AB. The ANOVA also showed a significant main effect of valence, F(2, 80) = 11.12, p < .001, ηp2 = .218. Most important to the current study, the analysis showed a significant CDI Valence × Lag interaction, F(4, 160) = 3.86, p = .005, ηp2 = .088 (see Fig. 7), suggesting AB modulation by emotional CDIs. Bayesian analyses (comparing models that included or excluded the Lag × CDI Valence interaction term) yielded a BF of 1.12, suggesting a weak preference for the AB modulation model over the no-AB-modulation model given the data. Given that BFs between 1 and 3 are generally viewed as lending merely “anecdotal” support to an effect (Wagenmakers, Marsman, et al., 2018a) and thus should not be taken to either support or reject the tested hypothesis, it is reasonable to default to accepting the results of the null hypothesis testing approach, which support the Valence × Lag interaction (p = .005). Moreover, there was a clear main effect of valence, indicating that these images were sufficiently conspicuous to break through the AB, likely enabling the modulation of the SOA effect represented by the Lag × Valence interaction. Thus, these analyses show that when intertarget CDIs are large images among small word distractors/targets, their valence modulates the AB. Post hoc t tests revealed that participants performed significantly better when the CDIs were neutral stimuli, compared with both pleasant, t(40) = 4.24, p < .001, d = .66 (BF = 190.11 in favor of the effect) and unpleasant, t(40) = 4.47, p < .001, d = .70 (BF =369.64 in favor of the effect) stimuli at Lag 2. Participants also performed significantly worse at Lag 6 when the CDIs were pleasant stimuli, compared with neutral stimuli, t(40) = 3.22, p = .003, d = .50 (BF = 13.25 in favor of the effect).

Results from Experiment 3. Performance calculated as T2 accuracy in trials where T1 was also accurately reported (T2 | T1). Error bars depict standard error of the mean
Though Experiment 3 revealed a significant CDI Valence × T1–T2 lag interaction, inspection of the results revealed an apparently shallower AB in Experiment 3 than in Experiments 1 and 2. Critically, AB magnitudes can be directly compared between Experiments 1–3 as they were measured using the identical word report task; these AB magnitudes cannot be as straightforwardly compared with Experiments 4–5 which, to anticipate, use a distinct report task, or to Experiment 6 because they were presented under different circumstances (online rather than in-lab). The relatively shallow AB in Experiment 3 begs the question of whether the stimulus changes in Experiment 3 abolished the AB—with valenced CDIs restoring it—or whether valenced CDIs actually modulated the size of an existing AB. Thus, post hoc one-way ANOVAs were conducted to examine the simple main effect of lag (indicating an AB) within each valence condition. The reported p values are uncorrected, but may be compared with a Bonferroni-corrected alpha of 0.05 ÷ 3 = .017. The results yielded a significant main effect of lag in the neutral condition, F(2, 80) = 17.07, p < .001, ηp2 = .299 (BF = 20,780 in favor of the effect), the pleasant condition, F(2, 80) = 17.67, p < .001, ηp2 = .306 (BF = 33,668 in favor of the effect), and the unpleasant condition, F(2, 80) = 40.91, p < .001, ηp2 = .506 (BF = 1.35 × 1010 in favor of the effect), indicating a statistically significant AB within each valence condition.
Discussion
The large emotional images used as task-irrelevant CDIs in Experiment 3 led to AB modulation, suggesting that increasing the conspicuity of the images allowed their emotional valence to be processed sufficiently to lead to bottom-up attentional capture that survived the AB. Specifically, the emotional images in Experiment 3 modulated the effect of lag such that pleasant and unpleasant CDIs led to a larger AB compared with neutral CDIs. The same results were not observed with word CDIs (Experiment 1) or smaller image CDIs (Experiment 2), suggesting that emotional valence alone is not sufficient to capture attention and evoke a magnified or additional AB, but once highly conspicuous emotional stimuli (i.e., large image CDIs in an RSVP stream of words; Experiment 3) succeeded in bottom-up attentional capture, processing of the image’s valence resulted in a modulatory effect on T2. It is possible that the highly conspicuous image CDIs lessened the AB effect overall, but less so with the emotional CDIs. A speculative account of such a reduced AB could be that the large differences between T1 and the CDI reduced the efficacy of the CDI as a mask on T1; it is known that an unmasked T1 still leads to an AB, but that AB is reduced from the AB observed with a masked T1 (Nieuwenstein et al., 2009). However, even were there an effectively unmasked T1, there remained a significant AB in the neutral CDI condition. Moreover, regardless of whether including the large image CDI lessened the AB, results from Experiment 3 revealed a Valence × Lag interaction as well as a main effect of lag (representing the AB), both collapsing across valence conditions and within each valence condition. These results show that task-irrelevant, emotional stimuli can modulate the classic, two-target AB, but that those stimuli must be exceedingly conspicuous. This was expected in Experiment 3, but Experiment 2 was also expected to yield such results. As previously mentioned, it is possible that the reason Experiment 2 did not yield a Lag × Valence interaction was that the images in Experiment 2 were too visually distinct, subjecting the CDIs to inattentional blindness (Simons, 2000) and making them easy to suppress, yet were not visually distinct enough to capture attention and magnify the AB, as with the large images in Experiment 3. Importantly, in Experiment 3, neutral images were equally visually conspicuous to emotional images, so the observed effects cannot be explained in a fashion that is dependent only upon the size of the images (visual conspicuity alone) without also considering the valence of the images.
Though Experiment 3 demonstrated that an emotional CDI in a two-target AB paradigm can modulate the main effect of lag, it is important to rule out alternative accounts of the result. Experiments 4 and 5 focus on this goal. In particular, it is plausible that the shift in presentation modality in Experiments 2 and 3 from word fillers and distractors to an image CDI could have obscured (Experiment 2) or reduced (Experiment 3) a Lag × Valence effect that would otherwise be larger. Specifically, if the modality shift made it easier for the visual system to down-weight the CDI (perhaps akin to inattentional blindness; cf. Simons, 2000), a greater effect of CDI valence on lag when the CDI and the remainder of the RSVP stream share a modality should be expected. This was the approach of Experiment 1, but word CDIs may not be optimal for finding emotional valence effects (Houwer & Hermans, 1994; Kensinger & Schacter, 2006). Thus, Experiments 4 and 5 use RSVP streams consisting entirely of images.
Experiment 4
It is possible that the modality shift between an image CDI and words (all other RSVP items) in Experiment 2 caused participants to suppress the CDIs, and therefore they could not create a strong enough bottom-up attentional capture to survive the AB as measured by T2 accuracy decrements. To test whether this was responsible for the otherwise conspicuous emotional image CDIs failing to modulate the AB, Experiment 4 made the same CDIs used in Experiment 2 more similar to the targets and other distractors. Therefore, Experiment 4 used a stream of all images.
Method
Participants
Data for Experiment 4 were collected at the University of Houston. The participants included 37 undergraduate students (26 females; Mage = 20.14 years, SD = 2.13) who received course credit for participating and met the study requirements, as outlined in Experiment 1. Data from three additional participants were collected, but were excluded from analyses due to an overall score that was below chance (with four answer choice options, chance was 25%). Informed consent was collected from all participants.
Procedure
An RSVP stream with identical timing characteristics to those used in Experiments 1–3 was used in Experiment 4, but the stream consisted of all images, rather than words (see Fig. 8). Participants were given verbal and on-screen instructions to attend to two images outlined in green (T1 and T2) presented during a stream of images. All images, including T1 and T2, were grayscale. The two outlined target images were rotated clockwise either 90°, 180°, 270°, or were upright. The targets’ orientations were randomized (uniform distribution) throughout the 180 trials. Following each stream, participants were prompted to indicate each target image’s rotation by entering one of the four arrow keys (↑ = upright, → = 90°, ↓ = 180°, ← = 270°), while also saying the direction they saw out loud. Critically, this change in report task means that accuracies and AB magnitudes cannot be directly compared between Experiments 1–3 and Experiments 4–5). STAI scores were also collected in Experiment 4.

An example of the RSVP task used in Experiment 4. Left: Task schematic. Right: Enlarged section of the RSVP stream consisting of an example sequence of a neutral distractor, T1, and CDI, as seen on the computer screen. (Illustration not to scale.)
Stimuli and materials
The same apparatus from Experiment 3 was used. All images were selected from the IAPS list (Lang et al., 2008). Comparable to the neutrally valenced CDIs in the previous two experiments, 30 images were selected as neutral distractor items for use in RSVP stream positions not occupied by targets or CDIs (arousal: mean = 4.12, SD = 1.05; valence: mean = 5.42, SD = .79). The identity and order of these distractor images were randomized for each trial. The target images were 120 hand-selected neutral images with a clear top and bottom to ensure that rotations could be detected (e.g., buildings or people). The target images were divided into two 60-image groups to serve as either T1 (arousal: mean = 4.12, SD = 1.05; valence: mean = 5.42, SD = .79) or T2 (arousal: mean = 4.12, SD = .87; valence: mean = 6.13, SD = 1.02). Each target image was presented once randomly every 60 trials (i.e., each image served as a target three times). Image rotations were randomized per trial, thus the orientation of a target image on one trial was not predictive of its orientation on subsequent presentation. All filler, target, and CDI images were cropped into squares (for rotation purposes) spanning 4.07 cm by 4.07 cm and the target images had a green border (same shade as the target words in Experiments 1–3) that was .53 cm thick. The CDIs were identical to those used in Experiment 2, except that they were cropped to the size of the filler items. No image was used as both a CDI and a filler item.
Results
When the data from Experiment 4 were subjected to a 3 (lag: Lag 2, Lag 4, Lag 6) × 3 (emotional valence: pleasant, neutral, unpleasant) within-subjects ANOVA, they revealed a significant main effect of lag, F(2, 72) = 32.15, p < .001, ηp2 = .472, representing an overall AB, but no main effect of valence, F(2, 72) = 1.65, p = .20, ηp2 = .044. The ANOVA did not reveal a significant Emotional Valence × Lag interaction, F(4, 144) = .51, p = .73, ηp2 = .014 (see Fig. 9), suggesting no AB modulation by emotional CDIs. Additionally, Bayesian analyses (comparing models that included or excluded the Lag × CDI valence interaction term) yielded a BF of 26.11, suggesting that the no-modulation model was about 26 times as likely as the emotional-modulation model given the data. These analyses show that even when intertarget CDIs are images and thus are more similar to the targets and fillers, their valence does not modulate the AB.

Results from Experiment 4. Performance calculated as T2 accuracy in trials where T1 was also accurately reported (T2 | T1). Error bars depict standard error of the mean. Note. The y-axis range was adjusted due to numerically lower performance in the new all-image task used for Experiment 4 (which required four-alternative forced-choice responses from participants) and thus does not reflect the range shown in Experiments 1–3’s data graphs
Discussion
Experiment 4 revealed that even with the same presentation modality (images) used throughout the RSVP stream, the emotional CDI did not modulate the effect of lag, and thus did not create a strong enough bottom-up attentional capture to magnify the AB. This suggests that the valences of the CDIs were not processed and that the modality switch in Experiment 2 was not the sole reason for the failure to observe a Valence × Lag interaction. However, since Experiment 3 did show AB modulation by CDI valence when the images were larger, it is possible that the content, and therefore the valence, of the images in both Experiments 2 and 4 was not able to be processed simply because the images were too small for their content to be perceived in the short-duration, masked setting of the RSVP stream (i.e., the absence of AB modulation by valence could relate to data limitations; cf. Norman & Bobrow, 1975). In other words, it may have been the size of the full-screen images that both allowed for processing of each image’s valence and allowed emotional images to capture attention in Experiment 3. Thus, Experiment 5 was conducted to test this possibility using an RSVP stream consisting of all large images.
Experiment 5
Experiment 2 showed that task-irrelevant emotional stimuli do not modulate the AB, even when they are visually dissimilar from the other RSVP items. On the other hand, Experiment 3 showed the opposite when the images were significantly larger than the fillers and targets. Additionally, Experiment 4 showed that the images that were sized similarly to the words used in Experiments 1–3 did not lead to AB modulation, even when they were displayed among other images, potentially making them more difficult to filter from the target items. This constellation of results could be explained by one of two possibilities: (1) appearances of image CDIs among words are unable to be processed, possibly due to inattentional blindness, and are only able to capture attention when they are extremely distinct from the other items in the RSVP stream (e.g., when they are much larger images among words). (2) The comparably-sized images were simply too small to be semantically processed, so the absence of AB modulation by the valence of image CDIs in Experiments 2 and 4 can be explained merely by the small size of the images. The goal of Experiment 5 was to distinguish between these two possible accounts of the results of the prior experiments by using an RSVP stream composed entirely of the larger-sized images. In the case of Possibility 1, no AB modulation is expected because the CDIs are visually similar to target and filler items, even when the images are as big as the CDIs that modulated the AB in Experiment 3. On the other hand, in the case of Possibility 2, the full-screen CDIs are expected to modulate the AB, simply because they are large enough for their emotional content to be rapidly processed.
Method
Participants
Data for Experiment 5 were collected at the University of Houston. The participants included 38 undergraduate students (23 females; Mage = 20.97 years, SD = 2.93) who received course credit for participating and met the study requirements, as outlined in Experiment 1. Data from two additional participants were collected, but were excluded from analyses due to an overall score that was less than chance (with four answer choice options, chance was 25%). Informed consent was collected from all participants.
Procedure
The procedure was identical to Experiment 4, except that all images in the stream were sized similarly to the Experiment 3 CDIs (see Fig. 10).

An example of the RSVP task used in Experiment 5. Left: Task schematic. Right: Enlarged section of the RSVP stream consisting of an example sequence of a neutral distractor, T1, and CDI, as seen on the computer screen. (Illustration not to scale.)
Stimuli and materials
The same apparatus from Experiment 3 and 4 was used. The exact same images from Experiment 4 were used in Experiment 5, with the exception that they were enlarged to be 20.32 cm × 20.32 cm.
Results
When the data from Experiment 5 were subjected to a 3 (lag: Lag 2, Lag 4, Lag 6) × 3 (emotional valence: pleasant, neutral, unpleasant) within-subjects ANOVA, they revealed a significant main effect of lag, F(2, 74) = 28.92, p < .001, ηp2 = .439, representing an overall AB, but no main effect of valence, F(2, 74) = .94, p = .394, ηp2 = .025. The ANOVA did not reveal a significant Emotional Valence × Lag interaction, F(4, 148) = 1.73, p = .15, ηp2 = .045 (see Fig. 11), suggesting no AB modulation by emotional CDIs. Additionally, Bayesian analyses (comparing the no-AB modulation model including main effects of lag, emotional valence, or no effects vs. the AB modulation model that also includes a Lag × Emotional Valence interaction) yielded a Bayes factor that suggested the data were in favor of the no AB modulation model by a factor of 6.146:1. These analyses show that even when intertarget CDIs are large images that are identical in size and modality to the targets and other neutral distractors, their valence does not modulate the AB.

Results from Experiment 5. Performance calculated as T2 accuracy in trials where T1 was also accurately reported (T2 | T1). Error bars depict standard error of the mean. Note. The y-axis range was adjusted due to numerically lower performance in the new all-image task used for Experiment 5 (which required four-alternative forced-choice responses from participants) and thus does not reflect the range shown in Experiments 1–3’s data graphs. The range does, however, reflect that in Experiment 4, which used the same all-image task as in Experiment 5
Discussion
The goal of Experiment 5 was to rule out the possibility that the small size of the image CDIs was the sole reason for the lack of AB modulation found in Experiment 4. Experiment 2 showed that emotional image CDIs sized comparably to the surrounding word targets and filler items were not able to create a strong enough bottom-up attentional capture to drive sufficient CDI processing to modulate the AB, while the exact same images blown up to a larger size in Experiment 3 did modulate the AB. Experiment 4 showed that the modality shift in Experiment 2 was not the reason the valences of the image CDIs were not processed. By making an RSVP stream of all large images and still showing no AB modulation by emotional CDIs, Experiment 5 was able to successfully rule out the possibility that prior failure of emotional images to magnify the AB was because the previous images were simply too small to be able to process their semantic and emotional content in the short display interval. Thus, Experiment 5 provided additional support for the results of the previous experiments suggesting that a nontarget emotional stimulus must be severely dissimilar from the surrounding RSVP stimuli in order for its valence to create a strong enough emotional capture to survive the classic two-target AB. Put differently, the only experiment in which CDI valence interacted with lag was Experiment 3; this is consistent with the proposal that a CDI must be perceptually conspicuous to affect an ongoing AB (e.g., by evoking an additional AB).
Experiment 6
Experiments 1–5 showed that, unless highly conspicuous (large images in an RSVP stream of words; Experiment 3), emotional stimuli fail to modulate the AB. However, all experiments thus far have examined AB magnitude as the primary measure and it is possible that this is less sensitive than AB duration. While a reduction in T2 performance for emotional compared with neutral CDI trials at later lags would suggest a prolonged AB, because all emotional stimuli were presented at Lag 1—and thus, at a short and consistent lag from T1—the design might not be as sensitive to changes in duration. To instead look for changes in AB duration with emotional stimuli, which would be expected if AB and EAB effects were to serially chain in this paradigm, Experiment 6 varied the lag at which the CDIs were presented. Varying CDI lags is subject to two constraints: First, the CDI must be presented within the highest-magnitude portion of the AB so as to ensure that processing of an emotional CDI actually happens during, rather than after, the blink. Second, the CDI must still be presented before T2 because T2 performance is the dependent measure. Together, these constraints limit the range of possible CDI lags—but not so severely that CDI lag cannot be manipulated. Thus, Experiment 6 compared the effects of a CDI at lag T1+1 (as in Experiments 1–5) to those of a CDI at lag T1+2. If an emotional CDI prolongs the AB, then a greater AB (i.e., worse T2 report performance) would be observed for emotional compared with neutral CDIs and for CDI lag T1+2 than CDI lag T1+1, statistically characterized by a three-way interaction of CDI valence, CDI lag, and T1–T2 lag. It was hypothesized that no such interaction would be observed, which would be consistent with Experiment 1’s failure to observe an effect of CDI valence on AB magnitude. However, if such an interaction were observed, it would then mean that emotional stimuli that have no goal-driven incentive to be attended cannot change the magnitude of the AB, but can change its duration. A possible reason for this result would be that the CDI might evoke a new instance of an EAB that serially chained with the AB, but could not sum with (magnify) it.
Method
Participants
Experiment 6 was affected by the discontinuation of in-person human research as a result of the COVID-19 pandemic. Therefore, Experiment 6 was conducted online. However, the experiment was made available only to University of Houston students in order to match the population of earlier experiments as closely as feasible. The participants included 32 undergraduate students (23 females; Mage = 22.88 years, SD = 6.38) who received course credit for participating and met the study requirements, as outlined in Experiment 1. Informed consent was collected from all participants.
Procedure
The task in Experiment 6 was identical to that in Experiment 1 with the exception of two key factors: CDI lag and T2 lag, detailed below. Participants were presented with an RSVP stream of 21 words: 18 white filler distractors, two green targets, and one white intertarget CDI that was either a pleasant, neutral, or unpleasant word. Following each trial, participants indicated the two green target words by typing in the first two letters of each word in order while also saying the full word out loud. In order to test whether the AB duration (rather than magnitude) is modulated by emotional stimuli, the critical manipulation in Experiment 6 was the temporal lag of the CDI relative to T1. The CDI was presented at either lag T1+1 (as with Experiments 1–5) or T1+2. This particular T1–CDI temporal position (T1+2) was chosen because it could test whether the duration of the AB was modulated by emotional stimuli, while still keeping the CDI within the typical duration of the AB—in keeping with the study’s main question of whether emotional stimuli can survive the AB. In order to allow varied CDI lags along with varied T2 lags, Experiment 6 also differed from Experiment 1 in that T2 was presented at either Lag 3 or Lag 5 from T1. The manipulations in Experiment 6 lead to a 2 (T1–T2 lag: 3, 5) × 3 (CDI valence: pleasant, unpleasant, neutral) × 2 (T1–CDI lag: 1, 2) design. Trials were presented in a random order. As with Experiments 1–5, Experiment 6 had 20 trials for each condition and with a total of 12 conditions; the experiment was comprised of a total of 240 trials.
Because Experiment 6 was implemented online and therefore participants were unable to receive verbal instructions for the task, they also completed a number of practice trials prior to beginning the experiment. Participants were given feedback after each practice trial and had to accurately recall both target words five times in a row before continuing to the experiment. The first practice trial presented the stimuli at a presentation rate of 497 ms/word, and the word duration decreased by 95 ms after each correct trial, until the presentation speed reached the experiment rate of 117 ms/word. If a participant got a practice trial incorrect, they started back at a presentation rate of 497 ms/word. All practice trials were T1–T2 Lag 5, had a stream of 15 stimuli (to avoid a long target-response delay for the slower trials), and did not contain any emotional CDIs.
Stimuli and materials
While the task in Experiment 6 shared the design of Experiments 1–5 (with the exception of the key manipulations), the setting and materials of the experiment differed because it was conducted online as a result of the COVID-19 pandemic. Experiment 6 was implemented using the PsychoPy experiment builder (Peirce et al., 2019) and translated to JavaScript and HTML code to be hosted on Pavlovia.org. Participants were directed to a Qualtrics.com survey via a link on the University of Houston’s Sona system, where they provided consent, reported demographic information, and read the task instructions (including instructions to ensure quality data collection). Specifically, participants were told to sit up straight at a table in a secluded room, minimize distractions as much as possible (put away cell phone, do not listen to music, do not have the TV on, etc.), complete the experiment on a computer or laptop (no phones or tablets), close all other programs and Internet browser tabs, use the Google Chrome browser, plug in laptops and turn off battery saver, and complete the experiment in one sitting (although they could take short breaks between trials).
The distractor, target, and CDI word stimuli used in Experiment 6 were identical to those used in Experiment 1 (all taken from the ANEW database). As with the previous experiments, the words were presented in either green or white Helvetica font in the center of the screen. The words were presented with a set height of 70 pixels. Because rapidly presenting stimuli based on time can be unreliable for online studies, the stimuli were instead presented at the frame rate closest to the desired presentation time of 117 ms (individually set by taking the refresh rate of the participant’s monitor in cycles per second, multiplying it by .117, and then rounding that number to the nearest whole frame).
Results
The data from Experiment 6 were subjected to a 2 (T1–T2 lag: Lag 3, Lag 5) × 3 (emotional valence: pleasant, neutral, unpleasant) × 2 (T1–CDI lag: T1+1, T1+2) within-subjects ANOVA, presented in Table 1. Of note, the results revealed a significant main effect of lag, F(1, 31) = 54.06, p < .001, ηp2 = .636, representing an overall AB. Surprisingly, the results did yield a weak main effect of CDI lag, F(1, 31) = 4.56, p = .041, ηp2 = .029. However, the direction of the effect shows overall better performance at CDI lag T1+2, compared with CDI lag T1+1, t(31) = −2.14, p = .041, d = −.38, which is the opposite direction from what would be expected if the CDI lag extended the AB. Additionally, the results yielded a Bayes factor of 0.63, suggesting the data are weakly against including this effect in the model—and in fact, the Bayesian analysis suggested that the only factor that modulated performance was T1–T2 lag (see Table 1). Most importantly, the ANOVA did not reveal a significant emotional Valence × Lag × CDI Lag interaction, F(2, 62) = 2.03, p = .140, ηp2 = .061 (see Fig. 12), suggesting that the CDI’s position from T1 did not play a role in AB modulation by emotional stimuli. These results suggest that emotional stimuli do not modulate the AB, either by magnifying it or extending it, unless there are goal-driven reasons to attend the emotional stimuli (see prior work reviewed in Introduction) or the emotional stimuli are highly perceptually conspicuous (Experiment 3).

Results from Experiment 6. Performance calculated as T2 accuracy in trials where T1 was also accurately reported (T2 | T1). Error bars depict standard error of the mean. Note. The y-axis range reflects the range shown in Experiments 1–3’s data graphs, which differ from the ranges in Experiments 4 and 5.
Discussion
Experiments 1–5 showed that unless highly conspicuous (large images among words; Experiment 3), emotional stimuli are not strong enough to survive the AB and further affect the AB magnitude. Experiment 6 was conducted to see if these results extended to the AB’s duration by repeating Experiment 1, but with varying T1–CDI lags (T1+1 or T1+2). We note that, while Experiments 1–5 also should have been sensitive AB duration (if an emotional CDI prolonged the AB, it should have been observed as a reduction in T2 performance for emotional compared with neutral CDI trials restricted to late lags), the T1–CDI lag manipulation more clearly allows the evaluation of AB duration compared with the previous experiments. The results of Experiment 6 echo those of Experiment 1, in that the CDI’s valence did not modulate the AB’s magnitude. Experiment 6 also showed that the CDI’s valence did not modulate the AB’s duration. Therefore, the conclusion from Experiments 1–5 stands: emotional stimuli must be highly conspicuous to modulate reports of T2, which is, to our knowledge, the only index of surviving the AB yet proposed that is not confounded with top-down attention to the CDI.
Comparisons of effects across experiments
Additional exploratory analyses were conducted to compare the effects of CDI manipulations across Experiments 2–5, though we note that a main effect of report task confounds comparisons between Experiments 2–3 and Experiments 4–5. Setting aside this confound, these experiments all included image CDIs; thus, these experiments form a 2 (CDI size: small in Experiments 2 and 4 and large in Experiments 3 and 5) × 2 (modality switch between CDI and remainder of RSVP stream: present in Experiments 2 and 3, absent in Experiments 4 and 5) × 3 (valence: neutral, positive, negative) × 3 (T1–T2 lag: 2, 4, or 6 items) mixed factorial design, with the first two factors manipulated between subjects and the remaining factors manipulated within subjects. Thus, the between-subjects factors were included in an ANOVA with primary interest directed toward any interactions between one of the between-subject factors and the within-subjects Lag × Valence interaction. Because power analysis is difficult for the interactions of interest, we rely primarily on the Bayes factor analysis for cross-experiment effects; we also present a null hypothesis testing analysis for completeness. Under either analysis framework, it should also be noted that an effect of modality switch would require careful interpretation because this factor is confounded with report demands: open-ended report of word targets versus forced-choice report of image orientations. The results did not yield a significant four-way interaction, F(4, 628) = 1.15, p = .33, ηp2 = .007, nor a significant Size × Lag × Valence interaction, F(4, 628) = .58, p = .68, ηp2 = .004. Bayes factors strongly favored not including these effects; specifically, Bayes factors for inclusion were vanishingly small (3.90 × 10-9:1 and 6.20 × 10-4:1, respectively). The results did yield a small but significant Modality Switch × Lag × Valence interaction, F(4, 628) = 4.05, p = .003, ηp2 = .025. However, as for the other interactions, the Bayes factor did not favor including this effect (Bayes factor for inclusion, 2.70 × 10-4:1). Full results of the ANOVA and Bayesian analyses are presented in Table 2. Collectively, these results suggest that the modality switch from an RSVP stream of words to image CDIs could explain the effects of CDI valence on AB modulation, though it is logically possible that this effect is driven by the change in target report demands (open-ended vs. forced-choice) rather than the modality switch per se. More importantly, the small effect size of the Modality Switch × Lag × Valence interaction and the Bayesian analysis suggest that it may be preferable to favor the explanation derived from analysis of individual experiments: that both a modality switch and a large, conspicuous CDI were necessary for emotional valence to modulate the AB.
General discussion
Extensive research has been conducted to examine the effects emotional stimuli have on a momentary lapse in temporal attention, or the AB. Previous studies suggest that emotional stimuli can interrupt top-down goals (target templates) to increase (emotional T1—Ihssen & Keil, 2009; MacLeod et al., 2017; Mathewson et al., 2008; Milders et al., 2006), break through (emotional T2—Anderson, 2005; Keil & Ihssen, 2004; Most et al., 2005), or evoke (EAB—Arnell et al., 2007; Ciesielski et al., 2010; Kennedy & Most, 2015a, 2015b; MacLeod et al., 2017; Mathewson et al., 2008; Most et al., 2005) the AB effect. However, these studies do not pit emotional capture against the AB itself, only against top-down target specification. The present study is the first to examine the strength of purely bottom-up attentional capture by emotional stimuli in the AB using a novel RSVP task that included task-irrelevant emotional CDIs presented within the two-target AB. The present research had two possible outcomes: The valence of the task-irrelevant CDIs either could or could not modulate the AB. AB modulation could be interpreted to mean that the CDI was processed despite its temporal position within the AB. This would be consistent with a strong attentional capture by emotional stimuli, as predicted based on EAB studies in which a task-irrelevant CDI interrupts the top-down attentional set for targets and evokes an AB-like effect (Arnell et al., 2007; Ciesielski et al., 2010; Kennedy & Most, 2015a, 2015b; MacLeod et al., 2017; Mathewson et al., 2008; Most et al., 2005). A lack of emotional modulation, as observed throughout this study, could lead to two possible interpretations: either that CDIs do not, in fact, survive the AB (which could be reconciled with previous research by the fact that previous studies included goal-driven motivation to attend emotional items), or that CDIs are not sufficiently processed to magnify or prolong an ongoing AB. Either interpretation of the absence of emotional modulation is consistent with a strong AB that suppresses even CDIs that are similar to those used in EAB studies.
Through six experiments, the current study tested these possibilities by decoupling emotional stimuli from targets in the two-target AB paradigm, using an RSVP stream with two neutral targets and an inter-target CDI that was either pleasant, neutral, or unpleasant. Experiment 1 used an RSVP stream of words serving as the targets, neutral distractors, and CDIs and revealed no AB modulation by emotional CDIs, suggesting that bottom-up attentional capture by emotional stimuli was not strong enough to lead to sufficient processing of the CDI content to survive and modulate the AB. Experiment 2 used the same RSVP targets and fillers, but with comparably sized emotional images as CDIs to make them more visually distinct than the surrounding stimuli, similar to EAB studies (e.g., Ciesielski et al., 2010; Most et al., 2005). The CDIs in Experiment 2 were still unable to be processed sufficiently to modulate the AB, suggesting that participants were still able to suppress the valence of the CDIs, even when they were more conspicuous images. Experiment 3 further increased the conspicuity of the CDIs by making them very large images among the same surrounding word stimuli. Here, the CDIs did yield AB modulation, where emotional (pleasant and unpleasant) CDIs resulted in poorer T2 report accuracy than neutral CDIs. The results from Experiments 1–3 suggest that to-be-ignored emotional CDIs must be highly conspicuous and vastly distinct from surrounding stimuli in order to create a strong enough bottom-up attentional capture to survive the AB in the classic, two-target AB paradigm. Results from Experiment 6 showed that emotional stimuli also do not modulate the AB’s duration.
To ensure that the modality shift from neutral word distractors and targets to image CDIs did not aid in the suppression of the CDIs’ valences in Experiment 2, Experiment 4 used an RSVP stream with images that acted as the fillers, targets, and CDIs. Experiment 4 showed no AB modulation by CDI valence, ruling out that possibility. In order to evaluate the possibility that the CDI valences were processed in Experiment 3 simply because they were large enough to be seen, Experiment 5 replicated Experiment 4, but with an RSVP stream of all very large images and still showed no AB modulation by CDI emotional valence.
It is worth discussing further the necessary conditions for emotional modulation of the AB by a task-irrelevant CDI (Experiment 3). Given that the CDI must be an image (compare Experiment 3 vs. 1), large (compare Experiment 3 vs. 2), and distinct from the other RSVP items (compare Experiment 3 vs. 1, 4, and 5), it seems reasonable to conclude that the large and distinct nature of the CDI, rather than its emotional content, gives rise to the attentional capture that breaks through the AB. However, this cannot fully explain the results of Experiment 3 because the valence of the CDI interacted with lag. Thus, it seems likely that both CDI conspicuity and valence play critical roles in whether or how a CDI modulates the AB. Additionally, the overall higher performance in Experiment 3 could suggest that the highly conspicuous image CDIs lead to a decreased AB effect, but less so when they were emotional, rather than the emotional CDIs leading to an increased AB effect, compared with neutral CDIs. In any case, the larger point remains that the emotional information of distractors can only be fully processed during the AB if the distractors are extremely conspicuous, while much weaker stimuli are unable to be processed sufficiently to disrupt a top-down target template/search set.
A limitation of the current study stems from the base AB paradigm from which each experiment derived. Specifically, the AB task required participants to select targets on the basis of a feature that was semantically and emotionally unrelated to the target (the color green among white). This paradigm was chosen because of its widespread prior use (e.g., Ihssen & Keil, 2009; Keil & Ihssen, 2004; Petro & Keil, 2015) and its specific use in studies of emotional modulation of the AB (Ihssen & Keil, 2009; Keil & Ihssen, 2004). As the primary goal of this study was to examine the relative strength of bottom-up emotional capture when pitted against the AB, the chosen paradigm has an advantage over paradigms in which item content identifies each item as a target versus a filler. Alternative paradigms that use selection of items based on their content run the risk of incentivizing top-down attention to all items in the RSVP stream, including the CDI, because content does not “pop out” similarly to a low-level feature distinction like color. Here, it was critical that the CDI represent pure bottom-up attentional capture, ruling out these alternative paradigms. Nonetheless, the chosen design might have made it easier for participants to suppress both fillers and CDIs, because they were only looking for the color green. Specific to Experiments 4 and 5 (with an RSVP stream of all images), one could make the case that the green border used as the target-defining feature could draw attention away from semantic meaning of the images themselves. However, because participants were required to report the orientation of the target images, there was also incentive to attend to the image itself. Additionally, we chose to use the colored frame approach to keep the target-defining feature consistent across experiments. Nevertheless, we acknowledge that it is possible that this could impact the results. Thus, future research could be conducted using a paradigm that requires participants to semantically process each RSVP item in order to select targets. While the results of the present research showed that CDIs have to be extremely conspicuous (very large images among words) to modulate the AB, it is possible that less conspicuous-CDIs could modulate the AB if each item in the RSVP stream had to be semantically processed to select the target items.
The current study shows that when task-irrelevant emotional stimuli are embedded in a two-target AB paradigm, they are normally unable to create a strong enough bottom-up attentional capture in order for their valences to modulate the AB. This suggests that, unlike in EAB studies that show how emotional CDIs create an AB-like effect on a single target, emotional CDIs only modulate the classic, two-target AB paradigm when they are highly conspicuous and vastly distinct from their surrounding RSVP items. These results lead to a better understanding of how and when emotional stimuli and their bottom-up attentional capture can affect already-limited temporal attention, such as in the AB.
Notes
Data for Experiment 1 were collected at both the University of Houston and the University of Florida. An earlier publication (Petro & Keil, 2015) included data from the 18 participants at the University of Florida, but did not focus on the emotional valence of the distractor items and did not fully report statistics for the current study’s comparison of interest. It was reported, however, that “Neither the main effect of valence nor the lag by valence interaction reached significance, indicating that the valence of the distractor immediately following T1 had no effect on T2 report. As a consequence, this factor is not considered in the remainder of this report.” (Petro & Keil, 2015; page 3586, paragraph 1) Because of the concern that this subset may not have been sufficiently sensitive due to its relatively small sample size, the present authors chose to collect an additional sample of the same size and pool it with the earlier sample to maximize sensitivity (see Sample Size Justification section). Pooling new data with an existing sample entails having “peeked” at the existing sample; thus, this paper relies mainly on the Bayesian analysis for this experiment, for which “optional stopping” is not problematic (Rouder, 2014; Wagenmakers, Marsman, et al., 2018a). It should be noted that the traditional null hypothesis testing and Bayesian approaches lead to concurring conclusions for this experiment.
To ensure that the new data were not systematically different from the existing data, in addition to the initial 3 (valence; pleasant, neutral, unpleasant) × 3 (lag; 2, 4, 6) ANOVA, a separate ANOVA was run with study location as a between-subjects factor to test the possibility of study location effecting this experiment’s results. The ANOVA revealed no interactions between study location and CDI valence, F(2, 74) = .50, p = .61, ηp2 = .013); lag, F(2, 74) = .15, p = .87, ηp2 = .004; or CDI valence and lag, F(4, 148) = .78, p = .78, ηp2 = .012.
Data for Experiment 2 were collected at both the University of Houston and the University of Florida; no data from Experiment 2 were previously published. In addition to the initial 3 (valence; pleasant, neutral, unpleasant) × 3 (lag; 2, 4, 6) ANOVA, a separate ANOVA was run with study location as a between-subjects factor to test the possibility of study location effecting this experiment’s results. The ANOVA revealed no interaction between study location and CDI valence, F(2, 86) = .45, p = .64, ηp2 = .010, but did show a significant interaction with lag, F(2, 86) = 49.09, p < .001, ηp2 = .533, where the University of Florida participants performed worse at Lag 2. Most importantly to the current study, there was no Study Location × CDI Valence × Lag interaction, F(4, 172) = .16, p = .96, ηp2 = .004, meaning that study location did not affect AB modulation by CDI valence and thus does not affect the overall outcome of this study.
References
Anderson, A. K. (2005). Affective influences on the attentional dynamics supporting awareness. Journal of Experimental Psychology. General, 134(2), 258–281. https://doi.org/10.1037/0096-3445.134.2.258
Arnell, K. M., Killman, K. V., & Fijavz, D. (2007). Blinded by emotion: target misses follow attention capture by arousing distractors in RSVP. Emotion (Washington, D.C.), 7(3), 465–477. https://doi.org/10.1037/1528-3542.7.3.465
Bradley, M. M., & Lang, P. J. (1994). Measuring emotion: The self-assessment manikin and the semantic differential. Journal of Behavior Therapy and Experimental Psychiatry, 25(1), 49–59. https://doi.org/10.1016/0005-7916(94)90063-9
Bradley, M. M., Lang, P. J., Bradley, M. M., & Lang, P. J. (1999). Affective Norms for English Words (ANEW): Instruction manual and affective ratings. https://www.uvm.edu/pdodds/teaching/courses/2009-08UVM-300/docs/others/everything/bradley1999a.pdf
Brainard, D. H. (1997). The Psychophysics Toolbox. Spatial Vision, 10(4), 433–436. https://doi.org/10.1163/156856897X00357
Chan, M., & Singhal, A. (2013). The emotional side of cognitive distraction: Implications for road safety. Accident Analysis & Prevention, 50, 147–154. https://doi.org/10.1016/j.aap.2012.04.004
Ciesielski, B. G., Armstrong, T., Zald, D. H., & Olatunji, B. O. (2010). Emotion Modulation of Visual Attention: Categorical and Temporal Characteristics. PLoS ONE, 5(11). https://doi.org/10.1371/journal.pone.0013860
Faul, F., Erdfelder, E., Lang, A.-G., & Buchner, A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175–191. https://doi.org/10.3758/BF03193146
Folk, C. L., & Remington, R. W. (2015). Unexpected abrupt onsets can override a top-down set for color. Journal of Experimental Psychology: Human Perception and Performance, 41(4), 1153–1165. https://doi.org/10.1037/xhp0000084
Greenberg, S. N., Tokarev, J., & Estes, Z. (2012). Affective Orientation Influences Memory for Emotional and Neutral Words. The American Journal of Psychology, 125(1), 71–80. JSTOR. https://doi.org/10.5406/amerjpsyc.125.1.0071
Hajcak, G., MacNamara, A., Foti, D., Ferri, J., & Keil, A. (2013). The dynamic allocation of attention to emotion: Simultaneous and independent evidence from the late positive potential and steady state visual evoked potentials. Biological Psychology, 92(3), 447–455. https://doi.org/10.1016/j.biopsycho.2011.11.012
Han, S. W., & Marois, R. (2014). Functional Fractionation of the Stimulus-Driven Attention Network. Journal of Neuroscience, 34(20), 6958–6969. https://doi.org/10.1523/JNEUROSCI.4975-13.2014
Houwer, J. D., & Hermans, D. (1994). Differences in the affective processing of words and pictures. Cognition and Emotion, 8(1), 1–20. https://doi.org/10.1080/02699939408408925
Huang, Y.-M., Baddeley, A., & Young, A. W. (2008). Attentional capture by emotional stimuli is modulated by semantic processing. Journal of Experimental Psychology. Human Perception and Performance, 34(2), 328–339. https://doi.org/10.1037/0096-1523.34.2.328
Ihssen, N., & Keil, A. (2009). The costs and benefits of processing emotional stimuli during rapid serial visual presentation. Cognition and Emotion, 23(2), 296–326. https://doi.org/10.1080/02699930801987504
JASP Team. (2018). JASP (Version 0.9) [Computer software]. https://jasp-stats.org/
Kanske, P., Schönfelder, S., & Wessa, M. (2013). Emotional modulation of the attentional blink and the relation to interpersonal reactivity. Frontiers in Human Neuroscience, 7. https://doi.org/10.3389/fnhum.2013.00641
Kawahara, J.-I., Zuvic, S. M., Enns, J. T., & Di Lollo, V. (2003). Task switching mediates the attentional blink even without backward masking. Perception & Psychophysics, 65(3), 339–351. https://doi.org/10.3758/BF03194565
Keil, A., Gruber, T., Müller, M. M., Moratti, S., Stolarova, M., Bradley, M. M., & Lang, P. J. (2003). Early modulation of visual perception by emotional arousal: evidence from steady-state visual evoked brain potentials. Cognitive, Affective & Behavioral Neuroscience, 3(3), 195–206.
Keil, A., & Ihssen, N. (2004). Identification facilitation for emotionally arousing verbs during the attentional blink. Emotion (Washington, D.C.), 4(1), 23–35. https://doi.org/10.1037/1528-3542.4.1.23
Keil, A., Moratti, S., Sabatinelli, D., Bradley, M. M., & Lang, P. J. (2005). Additive effects of emotional content and spatial selective attention on electrocortical facilitation. Cerebral Cortex, 15(8), 1187–1197. https://doi.org/10.1093/cercor/bhi001
Kennedy, B. L., & Most, S. B. (2015a). Affective stimuli capture attention regardless of categorical distinctiveness: An emotion-induced blindness study. Visual Cognition, 23(1/2), 105–117. https://doi.org/10.1080/13506285.2015.1024300
Kennedy, B. L., & Most, S. B. (2015b). The rapid perceptual impact of emotional distractors. PLOS ONE, 10(6), Article e0129320. https://doi.org/10.1371/journal.pone.0129320
Kennedy, B. L., Pearson, D., Sutton, D. J., Beesley, T., & Most, S. B. (2018). Spatiotemporal competition and task-relevance shape the spatial distribution of emotional interference during rapid visual processing: Evidence from gaze-contingent eye-tracking. Attention, Perception, & Psychophysics, 80(2), 426–438. https://doi.org/10.3758/s13414-017-1448-9
Kennedy, B. L., Rawding, J., Most, S. B., & Hoffman, J. E. (2014). Emotion-induced blindness reflects competition at early and late processing stages: An ERP study. Cognitive, Affective, & Behavioral Neuroscience, 14(4), 1485–1498. https://doi.org/10.3758/s13415-014-0303-x
Kensinger, E. A., & Schacter, D. L. (2006). Processing emotional pictures and words: Effects of valence and arousal. Cognitive, Affective, & Behavioral Neuroscience, 6(2), 110–126. https://doi.org/10.3758/CABN.6.2.110
Kleiner, M., Brainard, D., Pelli, D., Ingling, A., Murray, R., & Broussard, C. (2007). What’s new in psychtoolbox-3. Perception, 36(14), 1–16.
Lang, P. J., Bradley, M. M., & Cuthbert, B. N. (1997). Motivated attention: Affect, activation, and action. In P. J. Lang, R. F. Simons, & M. T. Balaban (Eds.), Attention and orienting: Sensory and motivational processes (pp. 97–135). Erlbaum.
Lang, P. J., Bradley, M. M., & Cuthbert, B. N. (2008). International affective picture system (IAPS): Affective ratings of pictures and instruction manual. https://ci.nii.ac.jp/naid/20001061266/
Lichtenstein-Vidne, L., Henik, A., & Safadi, Z. (2012). Task relevance modulates processing of distracting emotional stimuli. Cognition and Emotion, 26(1), 42–52. https://doi.org/10.1080/02699931.2011.567055
MacLeod, J., Stewart, B. M., Newman, A. J., & Arnell, K. M. (2017). Do emotion-induced blindness and the attentional blink share underlying mechanisms? An event-related potential study of emotionally-arousing words. Cognitive, Affective & Behavioral Neuroscience, 17(3), 592–611. https://doi.org/10.3758/s13415-017-0499-7
Maki, W. S., Frigen, K., & Paulson, K. (1997). Associative priming by targets and distractors during rapid serial visual presentation: Does word meaning survive the attentional blink? Journal of Experimental Psychology: Human Perception and Performance, 23(4), 1014–1034. https://doi.org/10.1037/0096-1523.23.4.1014
Mathewson, K. J., Arnell, K. M., & Mansfield, C. A. (2008). Capturing and holding attention: The impact of emotional words in rapid serial visual presentation. Memory & Cognition, 36(1), 182–200. https://doi.org/10.3758/MC.36.1.182
McHugo, M., Olatunji, B. O., & Zald, D. H. (2013). The emotional attentional blink: What we know so far. Frontiers in Human Neuroscience, 7. https://doi.org/10.3389/fnhum.2013.00151
Milders, M., Sahraie, A., Logan, S., & Donnellon, N. (2006). Awareness of faces is modulated by their emotional meaning. Emotion, 6(1), 10–17. https://doi.org/10.1037/1528-3542.6.1.10
Most, S. B., Chun, M. M., Widders, D. M., & Zald, D. H. (2005). Attentional rubbernecking: Cognitive control and personality in emotion-induced blindness. Psychonomic Bulletin & Review, 12(4), 654–661. https://doi.org/10.3758/BF03196754
Most, S. B., & Jungé, J. A. (2008). Don’t look back: Retroactive, dynamic costs and benefits of emotional capture. Visual Cognition, 16(2–3), 262–278. https://doi.org/10.1080/13506280701490062
Nieuwenstein, M. R., Potter, M. C., & Theeuwes, J. (2009). Unmasking the attentional blink. Journal of Experimental Psychology: Human Perception and Performance, 35(1), 159–169. https://doi.org/10.1037/0096-1523.35.1.159
Norman, D. A., & Bobrow, D. G. (1975). On data-limited and resource-limited processes. Cognitive Psychology, 7(1), 44–64. https://doi.org/10.1016/0010-0285(75)90004-3
Peirce, J., Gray, J. R., Simpson, S., MacAskill, M., Höchenberger, R., Sogo, H., Kastman, E., & Lindeløv, J. K. (2019). PsychoPy2: Experiments in behavior made easy. Behavior Research Methods, 51(1), 195–203. https://doi.org/10.3758/s13428-018-01193-y
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: transforming numbers into movies. Spatial Vision, 10(4), 437–442.
Petro, N. M., & Keil, A. (2015). Pre-target oscillatory brain activity and the attentional blink. Experimental Brain Research, 233(12), 3583–3595. https://doi.org/10.1007/s00221-015-4418-2
Petrucci, M., & Pecchinenda, A. (2018). Sparing and impairing: Emotion modulation of the attentional blink and the spread of sparing in a 3-target RSVP task. Attention, Perception, & Psychophysics, 80(2), 439–452. https://doi.org/10.3758/s13414-017-1470-y
Raymond, J. E., Shapiro, K. L., & Arnell, K. M. (1992). Temporary suppression of visual processing in an RSVP task: An attentional blink? Journal of Experimental Psychology: Human Perception and Performance, 18(3), 849–860. https://doi.org/10.1037/0096-1523.18.3.849
Rouder, J. N. (2014). Optional stopping: No problem for Bayesians. Psychonomic Bulletin & Review, 21(2), 301–308. https://doi.org/10.3758/s13423-014-0595-4
Schimmack, U., & Derryberry, D. (2005). Attentional Interference Effects of Emotional Pictures: Threat, Negativity, or Arousal? Emotion, 5(1), 55–66. https://doi.org/10.1037/1528-3542.5.1.55
Simons, D. J. (2000). Attentional capture and inattentional blindness. Trends in Cognitive Sciences, 4(4), 147–155. https://doi.org/10.1016/S1364-6613(00)01455-8
Spielberger, D., Gorsuch, R., Lushene, R., Vagg, P., & Jacobs, G. (1983). State-Trait Anxiety Inventory for Adults. Mind Garden.
Theeuwes, J., Kramer, A. F., Hahn, S., & Irwin, D. E. (1998). our eyes do not always go where we want them to go: Capture of the eyes by new objects. Psychological Science, 9(5), 379–385. https://doi.org/10.1111/1467-9280.00071
Todd, R. M., Taylor, M. J., Robertson, A., Cassel, D. B., Doesburg, S. M., Doesberg, S. M., Lee, D. H., Shek, P. N., & Pang, E. W. (2014). Temporal-spatial neural activation patterns linked to perceptual encoding of emotional salience. PLOS ONE, 9(4), Article e93753. https://doi.org/10.1371/journal.pone.0093753
van Doorn, J., van den Bergh, D., Bohm, U., Dablander, F., Derks, K., Draws, T., Evans, N. J., Gronau, Q. F., Hinne, M., Kucharský, Š., Ly, A., Marsman, M., Matzke, D., Raj, A., Sarafoglou, A., Stefan, A., Voelkel, J. G., & Wagenmakers, E.-J. (2019). The JASP Guidelines for Conducting and Reporting a Bayesian Analysis [Preprint]. PsyArXiv. https://doi.org/10.31234/osf.io/yqxfr
Verbruggen, F., & Houwer, J. D. (2007). Do emotional stimuli interfere with response inhibition? Evidence from the stop signal paradigm. Cognition and Emotion, 21(2), 391–403. https://doi.org/10.1080/02699930600625081
Vinson, D., Ponari, M., & Vigliocco, G. (2014). How does emotional content affect lexical processing? Cognition and Emotion, 28(4), 737–746. https://doi.org/10.1080/02699931.2013.851068
Wagenmakers, E.-J., Marsman, M., Jamil, T., Ly, A., Verhagen, J., Love, J., Selker, R., Gronau, Q. F., Šmíra, M., Epskamp, S., Matzke, D., Rouder, J. N., & Morey, R. D. (2018a). Bayesian inference for psychology. Part I: Theoretical advantages and practical ramifications. Psychonomic Bulletin & Review, 25(1), 35–57. https://doi.org/10.3758/s13423-017-1343-3
Wagenmakers, E.-J., Love, J., Marsman, M., Jamil, T., Ly, A., Verhagen, J., Selker, R., Gronau, Q.-F., Dropmann, D., Boutin, B., Meerhoff, F., Knight, P., Raj, A., van Kesteren, E.-J., van Doorn, J., Šmíra, M., Epskamp, S., Etz, A., Matzke, D., de Jong, T., van den Bergh, D., Sarafoglou, A., Steingroever, H., Derks, K., Rouder, J.-N., & Morey, R.-D. (2018b) Bayesian inference for psychology. Part II: Example applications with JASP. Psychonomic Bulletin & Review 25(1):58–76
Zinchenko, A., Geyer, T., Müller, H. J., & Conci, M. (2019). Affective modulation of memory-based guidance in visual search: Dissociative role of positive and negative emotions. Emotion. https://doi.org/10.1037/emo0000602
Acknowledgments
A subset of the data from the first experiment was published as part of a separate study (Petro, & Keil, 2015, Pre-target oscillatory brain activity and the attentional blink. Experimental Brain Research, 233[12], 3583–3595. https://doi.org/10.1007/s00221-015-4418-2). We thank Andreas Keil for his assistance in the early phases of this study and Christopher Walker and Apurva Swami for their help with data collection.
Open practices statement
The raw data (devoid of personal identifiers) from Experiments 3–6 (and the portions of Experiments 1 and 2’s data collected at the University of Houston) have been made available on the Open Science Framework (https://osf.io/7ntjc/). Full experimental data and analysis code will be available upon request.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Significance statement
Because of both daily experience and past research, one might believe that emotional events can capture attention away from important tasks—such as “rubbernecking” attention toward a car accident while driving. However, the current study suggests that when an emotional event is not also related to current goals, these effects are much weaker than previously thought and typically fail to capture attention.
Rights and permissions
About this article

Cite this article
Santacroce, L.A., Carlos, B.J., Petro, N. et al. Nontarget emotional stimuli must be highly conspicuous to modulate the attentional blink. Atten Percept Psychophys 83, 1971–1991 (2021). https://doi.org/10.3758/s13414-021-02260-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-021-02260-x