
Abstract
In this paper, relations between some kinds of cumulative entropies and moments of order statistics are established. By using some characterizations and the symmetry of a non-negative and absolutely continuous random variable X, lower and upper bounds for entropies are obtained and illustrative examples are given. By the relations with the moments of order statistics, a method is shown to compute an estimate of cumulative entropies and an application to testing whether data are exponentially distributed is outlined.
Similar content being viewed by others

1 Introduction
In reliability theory, to describe and study the information associated with a non-negative absolutely continuous random variable X, we use the Shannon entropy, or differential entropy of X, defined by Shannon (1948)
where \(\log \) is the natural logarithm and f is the probability density function (pdf) of X. In the following, we use F and \(\overline F\) to indicate the cumulative distribution function (cdf) and the survival function (sf) of X, respectively.
In the literature, there are several different versions of entropy, each one suitable for a specific situation. In Rao et al. (2004) introduced the Cumulative Residual Entropy (CRE) of X as
Di Crescenzo and Longobardi (2009) introduced the Cumulative Entropy (CE) of X as
If the random variable X is a lifetime of a system, this information measure is suitable when uncertainty is related to the past. It is a concept dual to the cumulative residual entropy which relates uncertainty on the future lifetime of the system.
Mirali et al. (2016) introduced the Weighted Cumulative Residual Entropy (WCRE) of X as
Mirali and Baratpour (2017) introduced the Weighted Cumulative Entropy (WCE) of X as
It should be mentioned that the above measures can also be defined for random variables X with support over the entire real line provided the involved integrals exist (as in some examples discussed in later sections).
Recently, various authors have discussed different versions of entropy and their applications (see, for instance, Cali et al. 2017, 2019, 2020; Longobardi 2014).
The paper is organized as follows. In Section 2, we study relationships between some kinds of entropies and moments of order statistics and present various illustrative examples. In Section 3, bounds are given by using some characterizations and properties (as the symmetry) of the random variable X, and some examples and bounds for a few well-known distributions are also presented. In Section 4, we present a method based on moments of order statistics to estimate the cumulative entropies and an application to testing exponentiality of data is also outlined.
2 Relationships Between Entropies and Order Statistics
We recall that, if we have n i.i.d. random variables \(X_{1},\dots ,X_{n}\), we can introduce the order statistics Xk:n, \(k=1,\dots ,n\). The k-th order statistic is equal to the k-th smallest value from the sample. We know that the cdf of Xk:n can be given in terms of the cdf of the parent distribution as
while the pdf of Xk:n is
Choosing k = 1 and k = n, we get the smallest and largest order statistics, respectively. Their cdf and pdf are given by
In the following, we denote by μ and μk:n the expectation or mean of X and the mean of the k-th order statistic in a sample of size n with parent distribution as that of X, respectively, i.e., \(\mu =\mathbb E(X)\) and \(\mu _{k:n}=\mathbb E(X_{k:n})\). Moreover, we denote by μ(2) and \(\mu ^{(2)}_{k:n}\) the second moment of X and the second moment of k-th order statistic in a sample of size n with parent distribution as that of X, respectively, i.e., \(\mu ^{(2)}=\mathbb E(X^{2})\) and \(\mu ^{(2)}_{k:n}=\mathbb E(X_{k:n}^{2})\). We recall that if X is a random variable with finite expectation μ, then the first moment of all order statistics is finite, and if the second moment of X is finite, then the second moment of all order statistics is also finite; see David and Nagaraja (2003) for further details.
2.1 Cumulative Residual Entropy
Let X be a random variable with finite expectation μ. The Cumulative Residual Entropy (CRE) of X can also be written in terms of order statistics as follows:
provided that \(\lim _{x\to +\infty }-x(1-F(x))\log (1-F(x))\) exists and CRE is finite. In this case, the previous limit is equal to 0. We note that Eq. 2 can be rewritten as
Remark 1
We want to emphasize that, under the assumptions made, the steps in Eq. 2 are correct. The improper integral can be written as
Hence, we observe that the sequence \(S_{N}(x)={\sum }_{n=1}^{N} \frac {F(x)^{n}}{n}\) is increasing and converges pointwise to the continuous function \(-\log (1-F(x))\) for each x ∈ [0,t] and, by applying Dini’s theorem for uniform convergence (Bartle and Sherbert 2000), the convergence is uniform. Then, Eq. 4 can be written as
In order to apply Moore–Osgood theorem for the iterated limit (Taylor 2010), we have to show that
converges pointwise for each fixed N, and this is satisfied if X has finite mean. Hence, by applying Moore–Osgood theorem for the iterated limit, Eq. 5 can be written as
In the following examples, we use Eq. 3 to evaluate the CRE for the standard exponential and uniform distributions.
Example 1
Consider the standard exponential distribution with pdf f(x) = e−x, x > 0. Then, it is known that
see Arnold and Balakrishnan (1989) for further details. Then, from Eq. 3, we readily have
Example 2
Consider the standard uniform distribution with pdf f(x) = 1, 0 < x < 1. Then, it is known that
So, from Eq. 2, we readily find
2.2 Cumulative Entropy
Let X be a random variable with finite expectation μ. The Cumulative Entropy (CE) of X can also be rewritten in terms of the mean of the minimum order statistic; in fact, from Eq. 1, we easily obtain
provided that \(\lim _{x\to +\infty }-xF(x)\log F(x)\) exists and CE is finite. We note that Eq. 6 can be rewritten as
In the following examples, we give an application of Eq. 7 to the standard exponential and uniform distributions.
Example 3
For the standard exponential distribution, it is known that
and so from Eq. 7, we readily have
by the use of Euler’s identity.
Example 4
For the standard uniform distribution, using the fact that
we obtain from Eq. 6 that
by the use of Euler’s identity.
Remark 2
If the random variable X has finite mean μ and is symmetrically distributed about μ, then it is known that
and so the equality \(\mathcal {E}(X)=\mathcal {CE}(X)\) readily follows.
2.3 Weighted Cumulative Entropies
In a similar manner, the Weighted Cumulative Residual Entropy (WCRE) of X, with finite second moment, can be expressed as
provided that \(\lim _{x\to +\infty }-\frac {x^{2}}{2}(1-F(x))\log (1-F(x))\) exists and WCRE is finite.
In the following example, we use Eq. 8 to evaluate the WCRE for the standard uniform distribution.
Example 5
For the standard uniform distribution, using the fact that
we obtain from Eq. 8 that
Moreover, we can derive the Weighted Cumulative Entropy (WCE) of X in terms of the second moment of the minimum order statistic as follows:
provided that \(\lim _{x\to +\infty }-\frac {x^{2}}{2}F(x)\log F(x)\) exists and WCE is finite.
3 Bounds
In the following, we use Z to denote the standard version of the random variable X, i.e.,
where σ is the standard deviation of X. By construction, the relation between a variable and its standard version holds for order statistics and so we have
for \(k=1,\dots ,n\). Hence, the mean of Xk:n and the mean of Zk:n are directly related and, in particular, for the largest order statistic, we have
We remark that this formula also holds by considering a generalization of the random variable Z with an arbitrary location parameter μ in place of the mean, and an arbitrary scale parameter σ in place of the standard deviation.
Let us consider a sample with parent distribution Z such that \(\mathbb E(Z)=0\) and \(\mathbb E(Z^{2})=1\). Hartley and David (1954) and Gumbel (1954) have then shown that
Using the Hartley-David-Gumbel bound for a parent distribution with mean μ and variance σ2, we get
Theorem 1
Let X be a random variable with mean μ and variance σ2. Then, we obtain an upper bound for the CRE of X as
Proof
which is the upper bound given in Eq. 11. □
Remark 3
If X is a non-negative random variable, we have μn+ 1:n+ 1 ≥ 0, for all \(n\in \mathbb N\). For this reason, using finite series approximations in Eq. 2, we get lower bounds for \(\mathcal E(X)\) as
for all \(m\in \mathbb N\).
Remark 4
If X is a non-negative random variable, we have μ1:n+ 1 ≥ 0, for all \(n\in \mathbb N\). For this reason, using finite series approximations in Eq. 6, we get upper bounds for \(\mathcal {CE}(X)\) as
for all \(m\in \mathbb N\).
In the following theorem, we consider a decreasing failure rate distribution (DFR). We recall that the failure rate, or hazard rate, function of X, r(x), is defined as
where the last equality occurs under the assumption of absolute continuity. Then, the random variable X is said to be DFR when the function r(x) is decreasing in x; see Barlow and Proschan (1996) for further details on hazard rate functions and DFR distributions.
Theorem 2
Let X be DFR. Then, we have the following lower bound for \(\mathcal {CE}(X)\):
Proof
Let X be DFR. From Theorem 12 of Rychlik (2001), it is known that for a sample of size n, if
then
For j = 1, we have \(\delta _{1,n}=\frac {1}{n}\leq 2\) for all \(n\in \mathbb N\), so that
Then, from Eq. 6, we get the following lower bound for \(\mathcal {CE}(X)\):
Remark 5
We note that we can not provide an analogous bound for \(\mathcal E(X)\) because δn,n ≤ 2 is not fulfilled for n ≥ 4.
From Eqs. 2 and 6, we get the following expression for the sum of the cumulative residual entropy and the cumulative entropy:
Calì et al. (2017) have shown a connection between (14) and the partition entropy studied by Bowden (2007).
Theorem 3
We have the following bound for the sum of the CRE and the CE:
Proof
From Theorem 3.24 of Arnold and Balakrishnan (1989), it is known that the bound for the difference between the expectations of the largest and smallest order statistics from a sample of size n + 1 is
and so using Eq. 16 in Eq. 14, we get the following bound for the sum of the CRE and the CE:
as required.
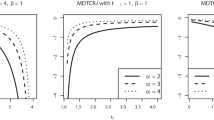
In Table 1, we present some of the bounds obtained in this section for a few know distributions.
3.1 Symmetric Distributions
In this subsection, we obtain bounds for a symmetric parent distribution. David and Nagaraja (2003) have stated that if we have a sample \(Z_{1},\dots ,Z_{n}\) with parent distribution Z symmetric about 0 and with variance 1, then
where
Using the bound in Eq. 17 for a random variable X symmetric about mean μ and with variance σ2, we have
Remark 6
It is clear that a non-negative random variable X that is symmetric about the mean has a bounded support.
Theorem 4
Let X be a symmetric random variable with mean μ and variance σ2. Then, an upper bound for the CRE of X is given by
Proof
which is the upper bound given in Eq. 19. □
The bound in Eq. 17 is equivalent to (see Arnold and Balakrishnan 1989)
where B(n,n) is the complete beta function defined as
where α,β > 0 (see Abramowitz and Stegun (1964) for further details). In fact
Then, the bound in Eq. 18 is equivalent to
Hence, we have the following theorem which is equivalent to Theorem 4.
Theorem 5
Let X be a symmetric random variable with mean μ and variance σ2. Then, an upper bound for the CRE of X is
Example 6
Let us consider a sample with parent distribution for \(X\sim N(0,1)\). From Harter (1961), we have the values of means of largest order statistics for samples of size up to 100. Hence, we compare the finite series approximations of Eqs. 2 and 22 and we expect the same result as the true value because truncated terms are negligible. We thus get the following result:
computed by truncating the series in Theorem 5.
For a symmetric distribution, Arnold and Balakrishnan (1989) have stated that if we have a sample \(Z_{1},\dots ,Z_{n}\) from a parent distribution symmetric about mean μ and with variance 1, then
where B(n,n) is the complete beta function.
Using the bound in Eq. 23 for a parent distribution symmetric about mean μ and with variance σ2, we have
Theorem 6
Let X be a symmetric random variable with mean μ and variance σ2. Then, an upper bound for the sum of the CRE and the CE of X is given by
Proof
which is the upper bound given in Eq. 25. □
4 Computation and Application
4.1 Numerical Evaluation
In this subsection, we present a method for the evaluation of an estimate of cumulative entropies based on the relationships with moments of order statistics derived in Section 2. The method is based on finite series approximations. About the CRE, we will use the result shown in Eq. 12:
where the difference between LHS and RHS is infinitesimal for \(m\to +\infty \). Starting from a sample \(\underline X=(X_{1},\dots ,X_{N})\), we estimate the CRE by
where \(\hat {\mu }\) is the arithmetic mean of the realization of the sample and \(\hat {\mu }_{n+1:n+1}\) is an estimate for the mean of largest order statistic in a sample of size n + 1. In order to obtain an estimate of the mean of largest order statistic in a sample of size n + 1, we generate several simple random samples starting from \(\underline X\) of size n + 1, for example, by using the function randsample of MATLAB. Then, we consider the maximum of each sample and by the mean we obtain \(\hat {\mu }_{n+1:n+1}\). Specifically, for a fixed \(n\in \{1,\dots ,m\}\), starting from \(\underline X\), we generate K simple random samples of size n + 1, \((X_{1,k},\dots ,X_{n+1,k})\), \(k=1,\dots ,K\). For each of them, we can consider the maximum, i.e., Xn+ 1:n+ 1,k, \(k=1,\dots ,K\). Then, we take as estimate of the mean of the maximum order statistic in a sample of size n + 1 from \(\underline X\) by
Using similar techniques, we can get estimates for the second moment of the largest order statistic and the first and second moments of the smallest order statistic and, in analogy with Eq. 26, we obtain estimates for the other cumulative entropies, \(\hat {\mathcal {CE}}(X),\hat {\mathcal E}^{w}(X), \hat {\mathcal {CE}}^{w}(X)\).
Example 7
By using the function exprnd of MATLAB, we generated a sample of size N = 1000 values from an exponential distribution with parameter 1. We obtain estimates for cumulative entropies stopping the sum at m = 100. For each sample size n from 2 to 101 we generate K = 100 random samples of size n by the function randsample. In Table 2, we compare these results with the corresponding theoretical results.
4.2 Application to Test for Exponentiality
We recall a result proved in Rao et al. (2004) about the maximum cumulative residual entropy for fixed moments of the first and second order.
Theorem 7
Let X be a non-negative random variable. Then,
where X(μ) is an exponentially distributed random variable with mean \(\mu =\mathbb E(X^{2})/2\mathbb E(X)\).
There are many situations in which we have a sample and we want to investigate about the underlying distribution, and in some of these situations, it may be of interest to test if the data are distributed according to an exponential distribution. In the literature, there are several papers about testing exponentiality of data; see, for example, Balakrishnan et al. (2007).
From Theorem 7, we know that the CRE of X is lower than \(\mathbb E(X^{2})/2\mathbb E(X)\) because, for an exponential random variable Y, we have \(\mathcal E(Y)=\mathbb E(Y)\). If we have the realization of a sample \(\underline X=(X_{1},\dots ,X_{N})\), we can consider the difference between the estimate of CRE, given in Eq. 26, and \(\hat \mu ^{(2)}/2\hat \mu \), where \(\hat \mu \) and \(\hat \mu ^{(2)}\) are given by the arithmetic means of \(X_{1},\dots ,X_{N}\) and \({X_{1}^{2}},\dots ,{X_{N}^{2}}\), respectively. If this difference is small enough in absolute value, we may suppose that the data are exponentially distributed and, as the difference increases, it becomes less plausible that the sample is exponentially distributed.
We fixed as threshold values 0.1 and 0.25 and we tested data generated in MATLAB from different distributions. For each distribution, we generated K = 1000 samples of size N = 1000, Xk, and the obtained results are presented in Table 3, where the success with threshold α, S(α), is given by
It will, of course, be of interest to develop a formal testing procedure along these lines.
Change history
13 May 2021
Springer Nature’s version of this paper was updated to add the OA funding note.
References
Abramowitz M, Stegun I (1964) Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables. Dover, New York
Arnold BC, Balakrishnan N (1989) Relations, Bounds and Approximations for Order Statistics. Springer, New York
Balakrishnan N, Habibi Rad A, Arghami NR (2007) Testing exponentiality based on Kullback-Leibler information with progressively Type-II censored data. IEEE Trans Reliab 56:301–307
Barlow RE, Proschan FJ (1996) Mathematical Theory of Reliability. Society for Industrial and Applied Mathematics, Philadelphia
Bartle RG, Sherbert DR (2000) Introduction to Real Analysis, 3rd edn. Wiley, New York
Bowden R (2007) Information, measure shifts and distribution diagnostics. Statistics 46(2):249–262
Calì C, Longobardi M, Ahmadi J (2017) Some properties of cumulative Tsallis entropy. Physica A 486:1012–1021
Calì C, Longobardi M, Psarrakos G (2019) A family of weighted distributions based on the mean inactivity time and cumulative past entropies. Ricerche Mat. (in press). https://doi.org/10.1007/s11587-019-00475-7
Calì C, Longobardi M, Navarro J (2020) Properties for generalized cumulative past measures of information. Probab Eng Inform Sci 34:92–111
David HA, Nagaraja HN (2003) Order Statistics, 3rd edn. Wiley, Hoboken
Di Crescenzo A, Longobardi M (2009) On cumulative entropies. J Stat Plann Inference 139:4072–4087
Gumbel EJ (1954) The maxima of the mean largest value and of the range. Ann Math Stat 25:76–84
Harter HL (1961) Expected values of normal order statistics. Biometrika 48(1):151–165
Hartley HO, David HA (1954) Universal bounds for mean range and extreme observation. Ann Math Stat 25:85–99
Longobardi M (2014) Cumulative measures of information and stochastic orders. Ricerche Mat 63:209–223
Mirali M, Baratpour S, Fakoor V (2016) On weighted cumulative residual entropy. Commun Stat - Theory Methods 46(6):2857–2869
Mirali M, Baratpour S (2017) Some results on weighted cumulative entropy. J Iran Stat Soc 16(2):21–32
Rao M, Chen Y, Vemuri B, Wang F (2004) Cumulative residual entropy: A new measure of information. IEEE Trans Inf Theory 50:1220–1228
Rychlik T (2001) Projecting Statistical Functionals. Springer, New York
Shannon CE (1948) A mathematical theory of communication. Bell Syst Tech J 27:379–423
Taylor AE (2010) General Theory of Functions and Integration. Dover Publications, Mineola
Acknowledgements
Francesco Buono and Maria Longobardi are partially supported by the GNAMPA research group of INdAM (Istituto Nazionale di Alta Matematica) and MIUR-PRIN 2017, Project “Stochastic Models for Complex Systems” (No. 2017 JFFHSH). The first author thanks the Natural Sciences and Engineering Research Council of Canada for funding this research through an Individual Discovery Grant.
Funding
Open access funding provided by Università degli Studi di Napoli Federico II within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no conflict of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Balakrishnan, N., Buono, F. & Longobardi, M. On Cumulative Entropies in Terms of Moments of Order Statistics. Methodol Comput Appl Probab 24, 345–359 (2022). https://doi.org/10.1007/s11009-021-09850-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11009-021-09850-0