
Predicting the Appearance of Hypotension during Hemodialysis Sessions Using Machine Learning Classifiers

 ,
,  , , and
, , and
Abstract
:1. Background and Objectives
1.1. Clinical Consequences of Hemodynamic Changes in Hemodialysis Patients
1.2. Evidence Supporting the Use of Massive Data Analysis in Healthcare
1.2.1. Present Status of Massive Data Analysis and Pattern Recognition in Health
1.2.2. Previous Experiences of Massive Data Analysis and Pattern Recognition in Healthcare
1.2.3. Techniques Massive Data Analysis and Its Applicability to the Field of Hemodialysis
1.3. Hypothesis and Objectives
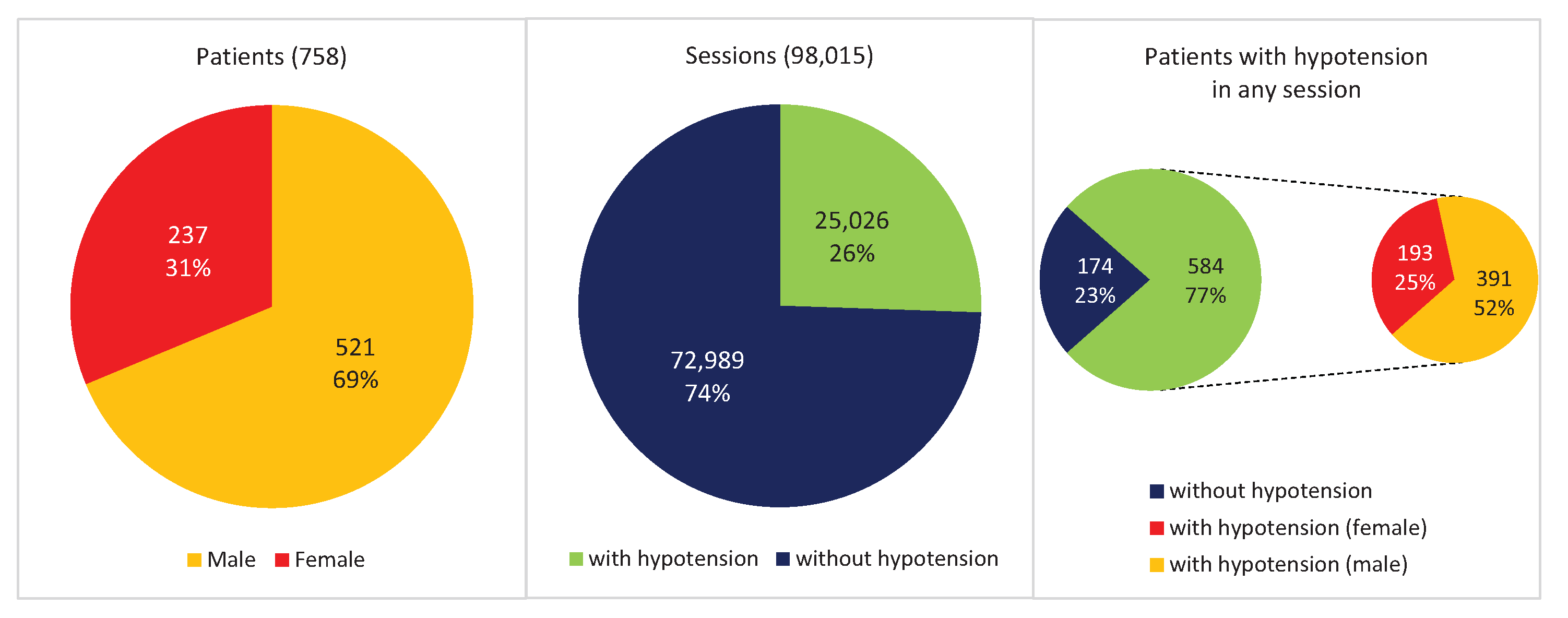
1.4. Hemodialysis Database
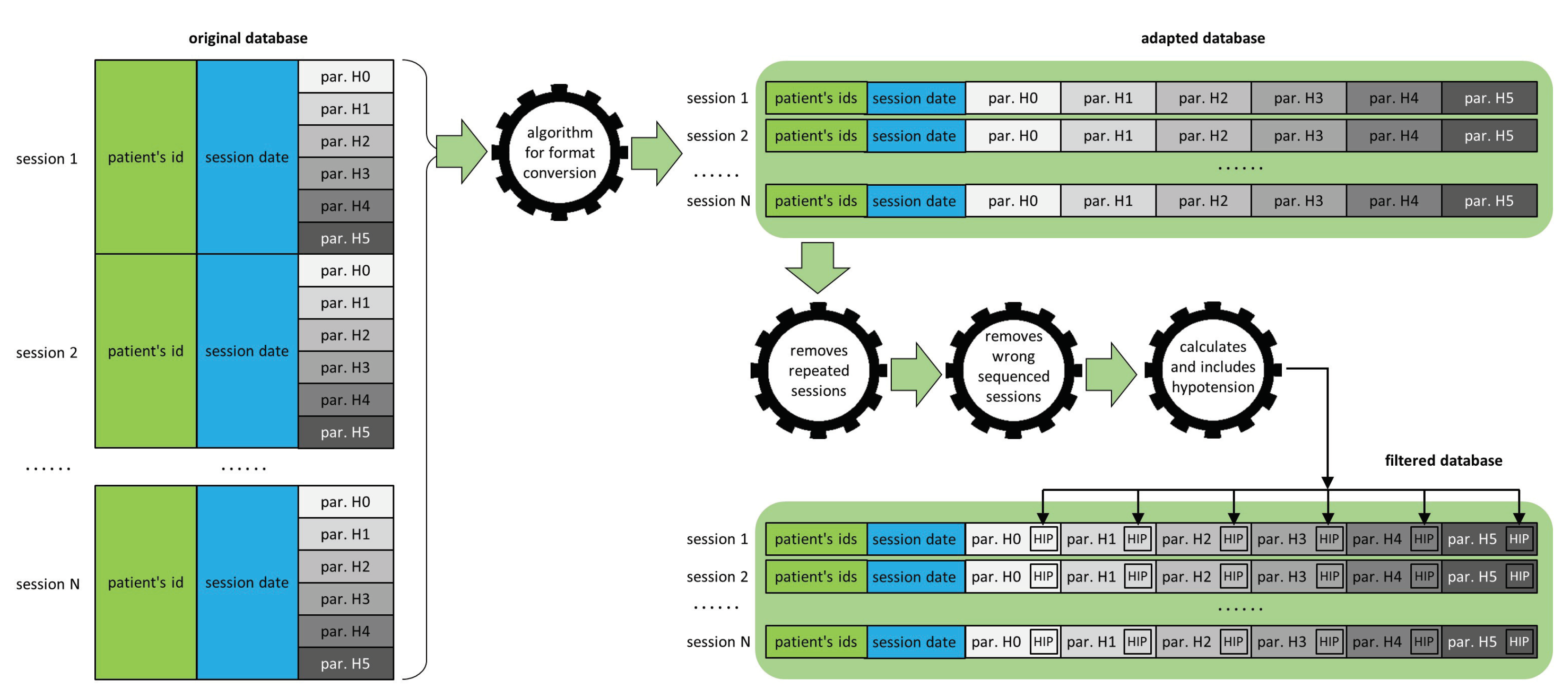
1.4.1. Database Debugging
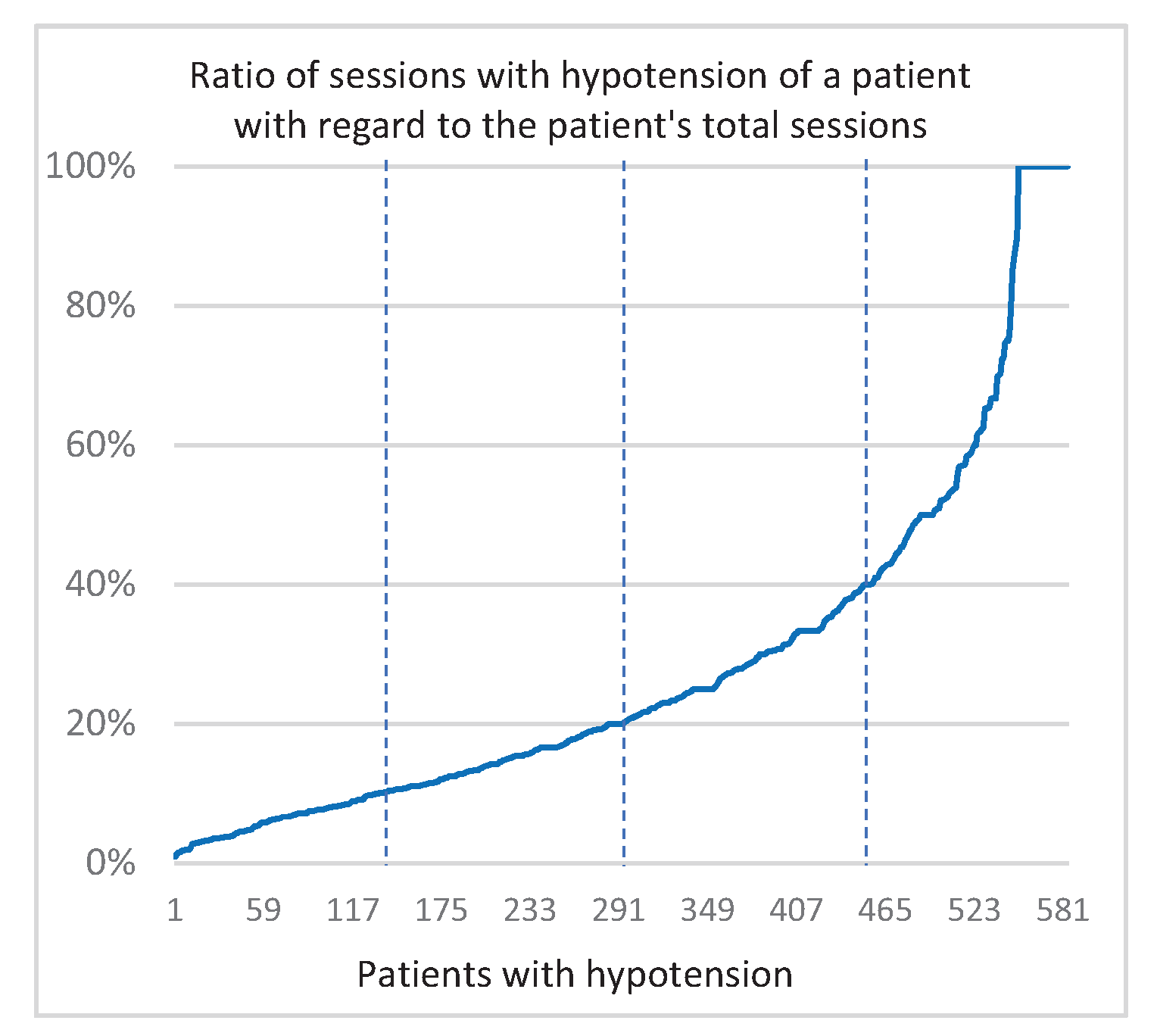
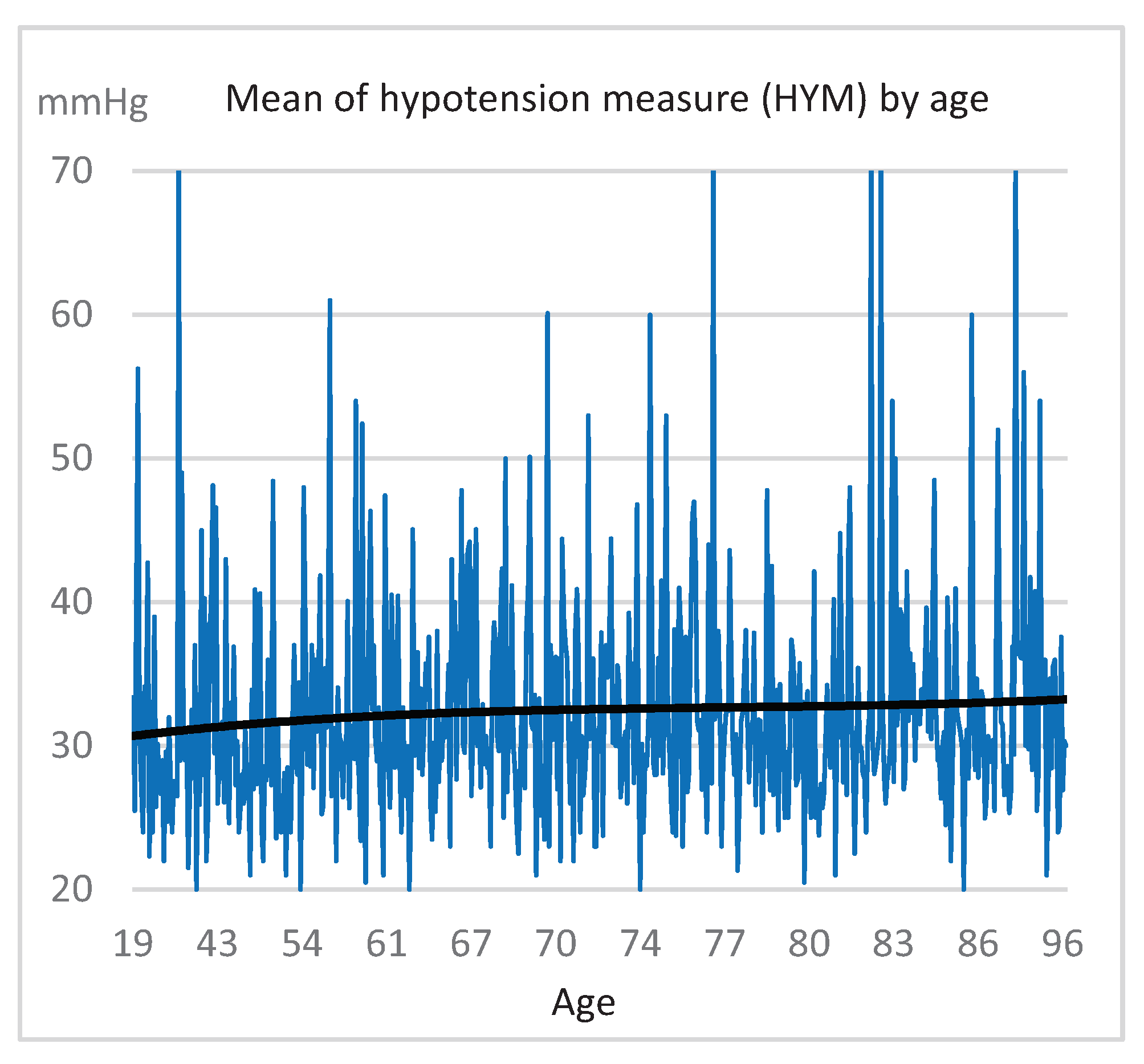
1.4.2. Hypotension Calculus
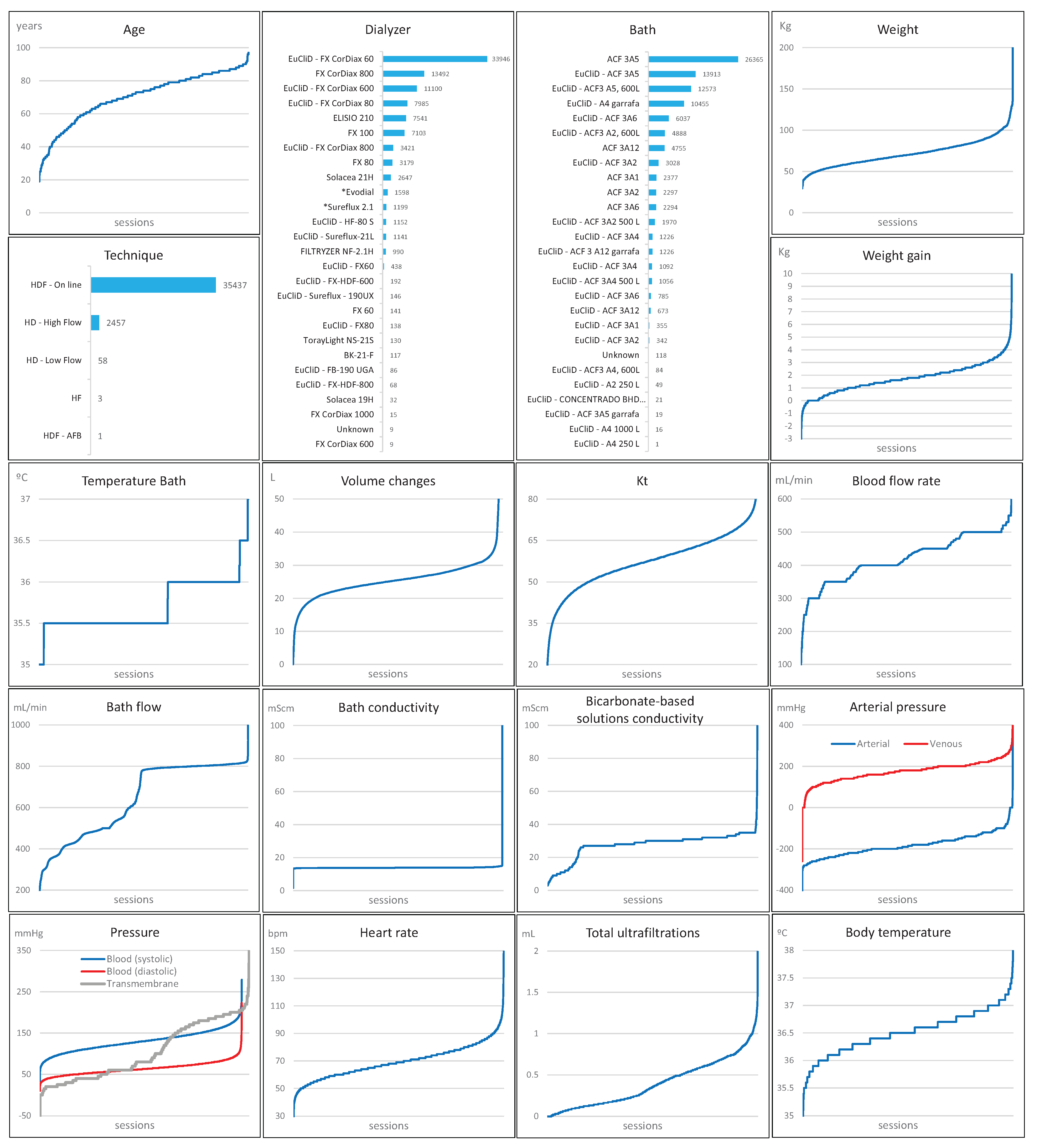
1.4.3. Clinical Parameters
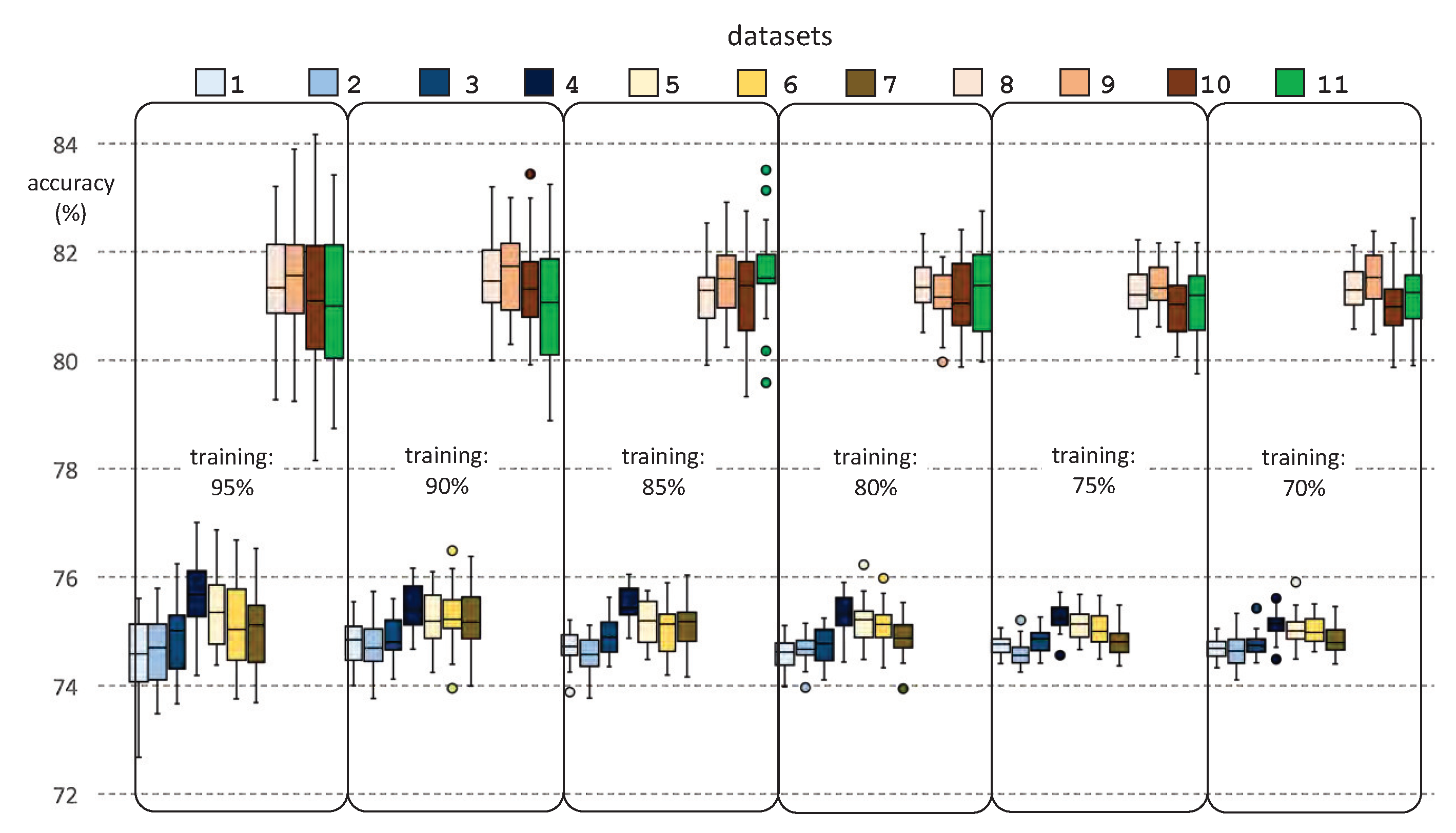
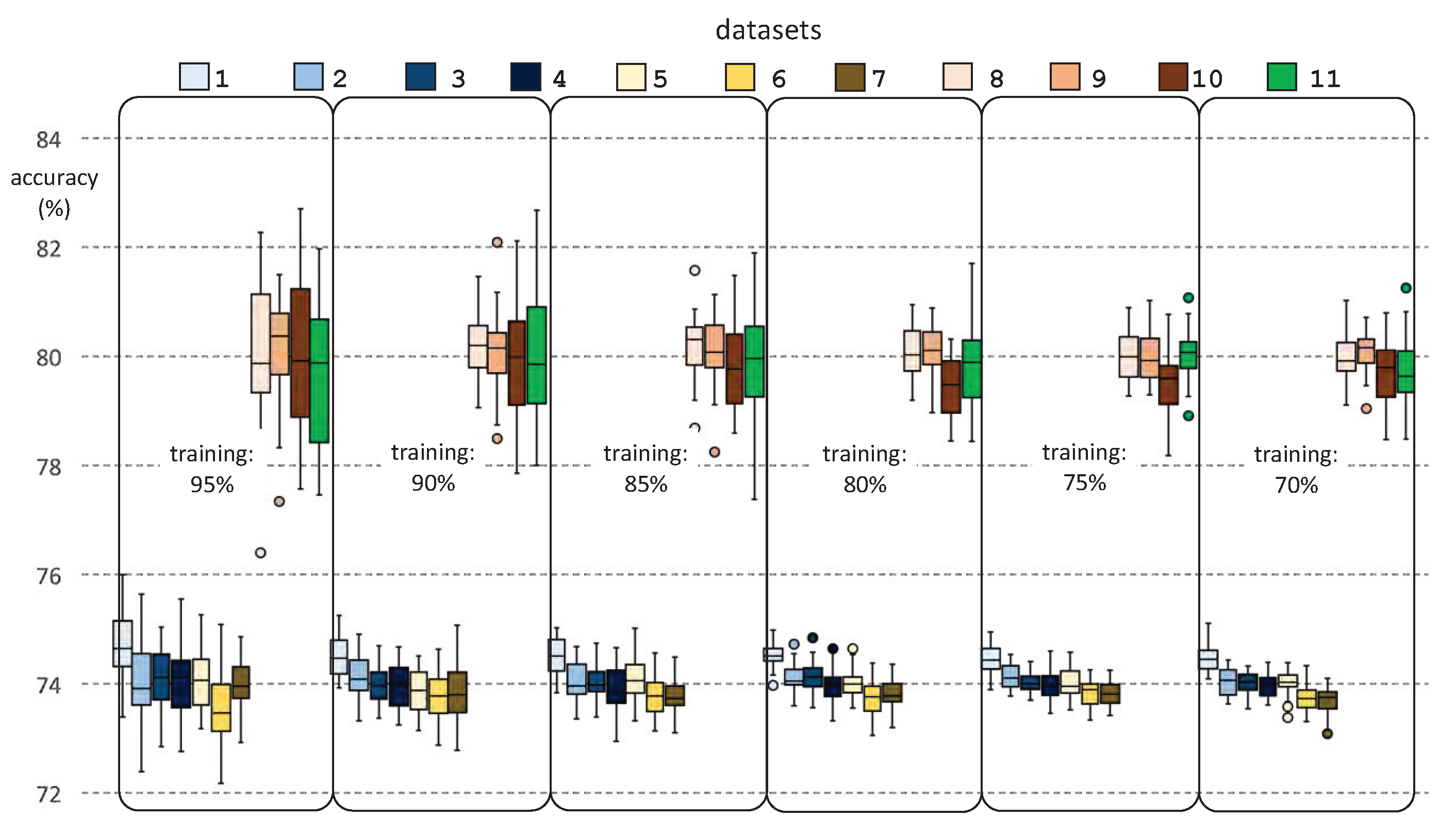
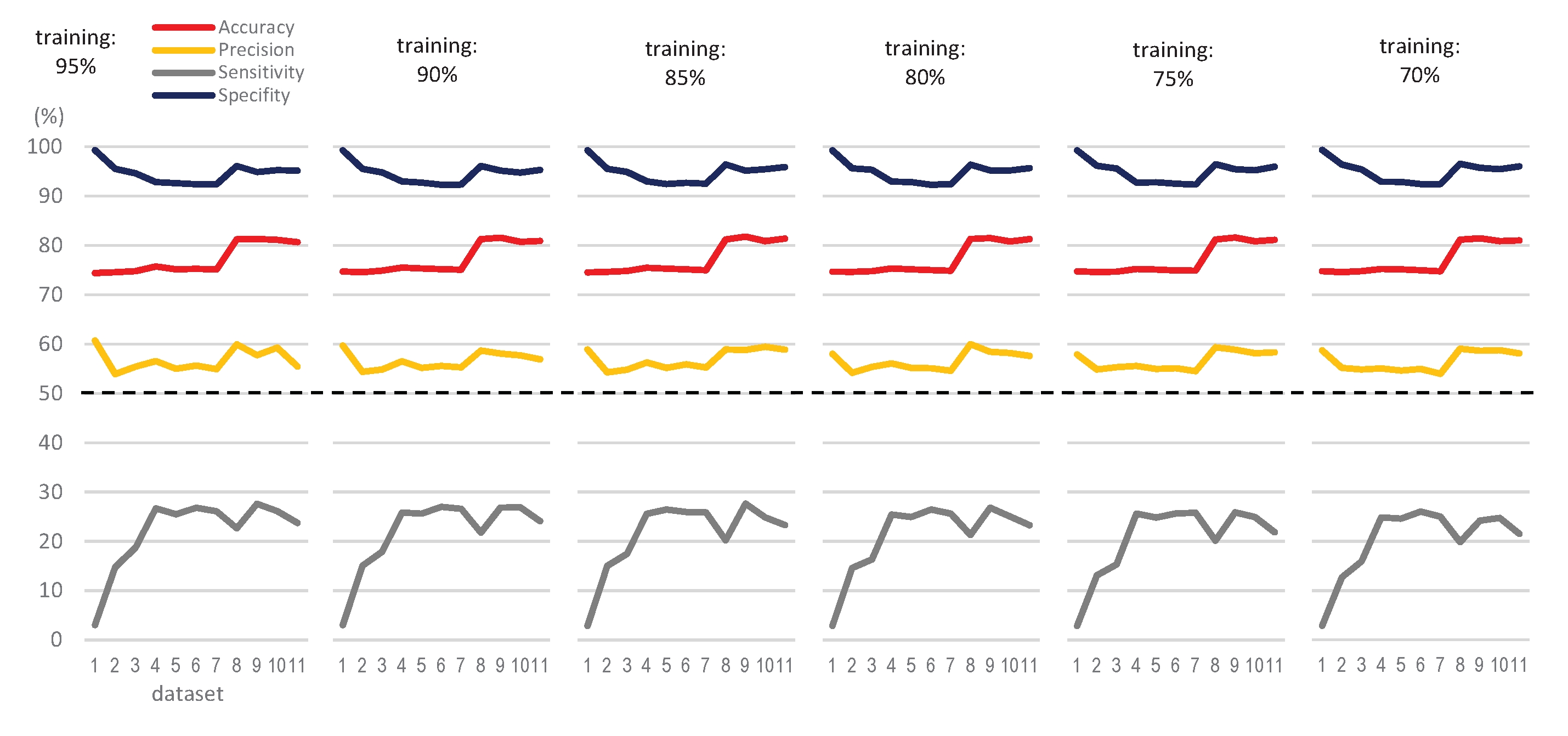
2. Results
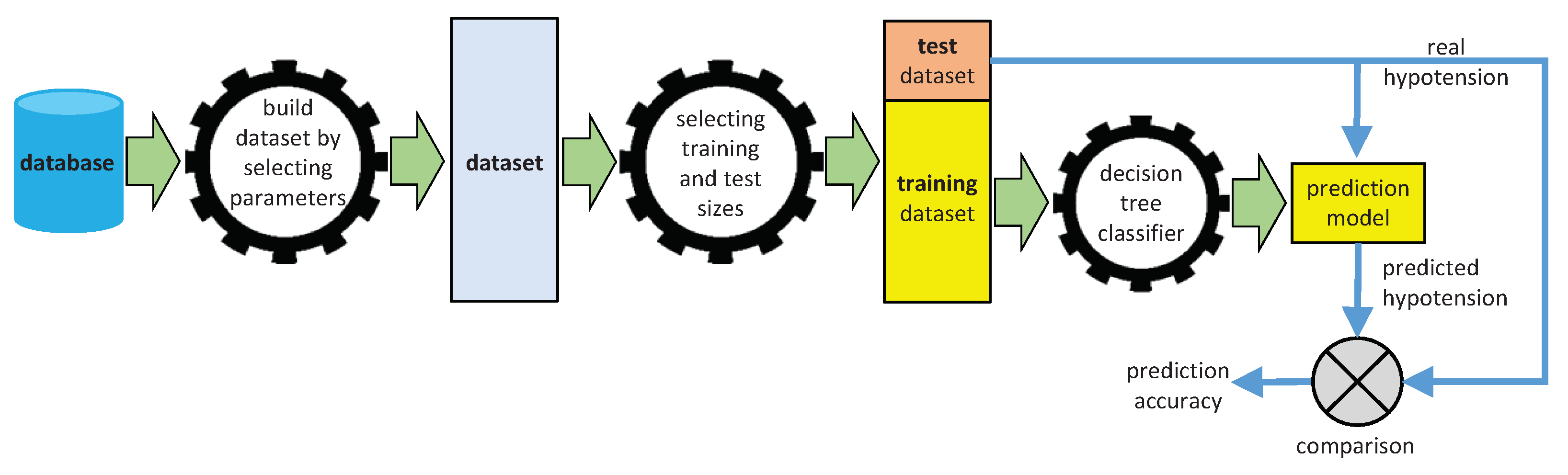
2.1. Generating Predictive Models from Machine Learning Classifiers
2.1.1. Decision Trees
2.1.2. Support Vector Machines
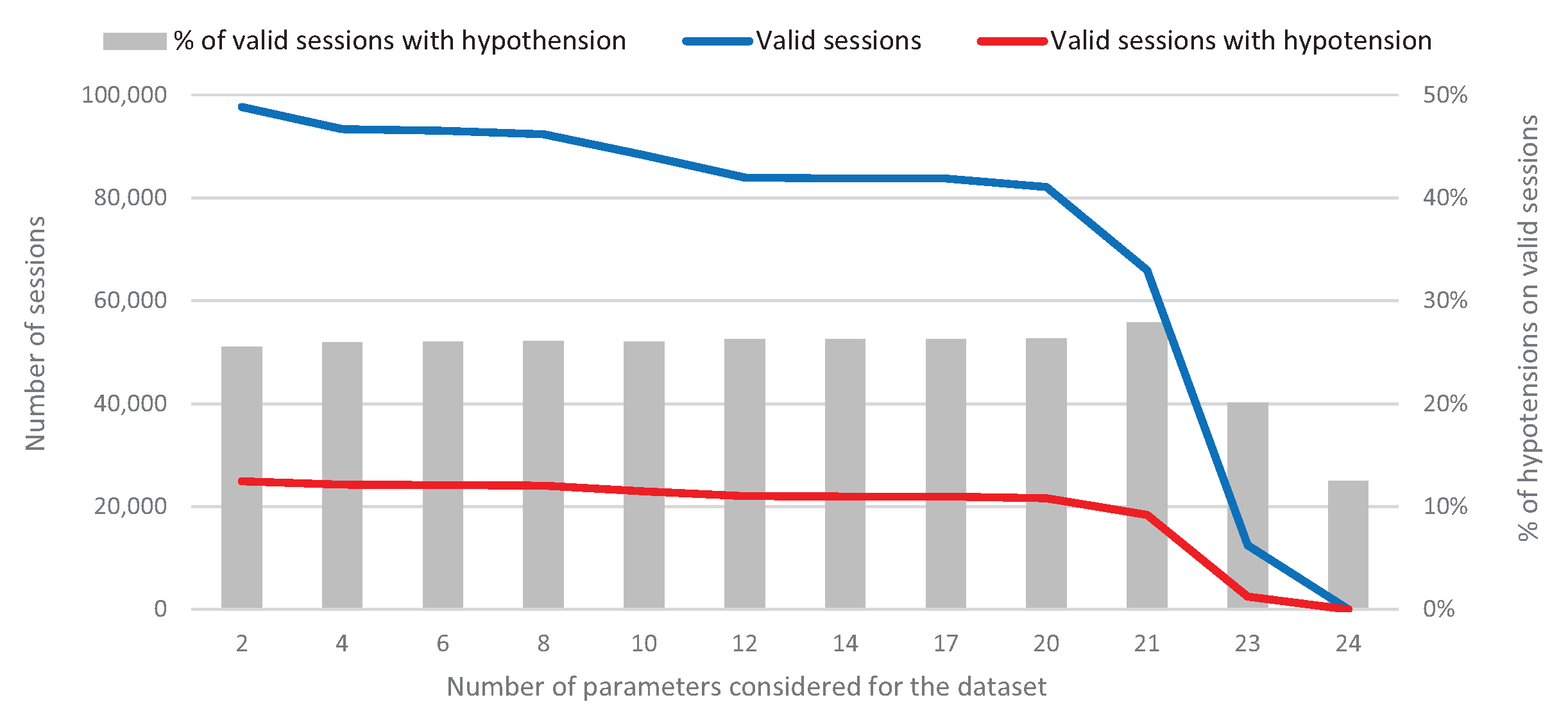
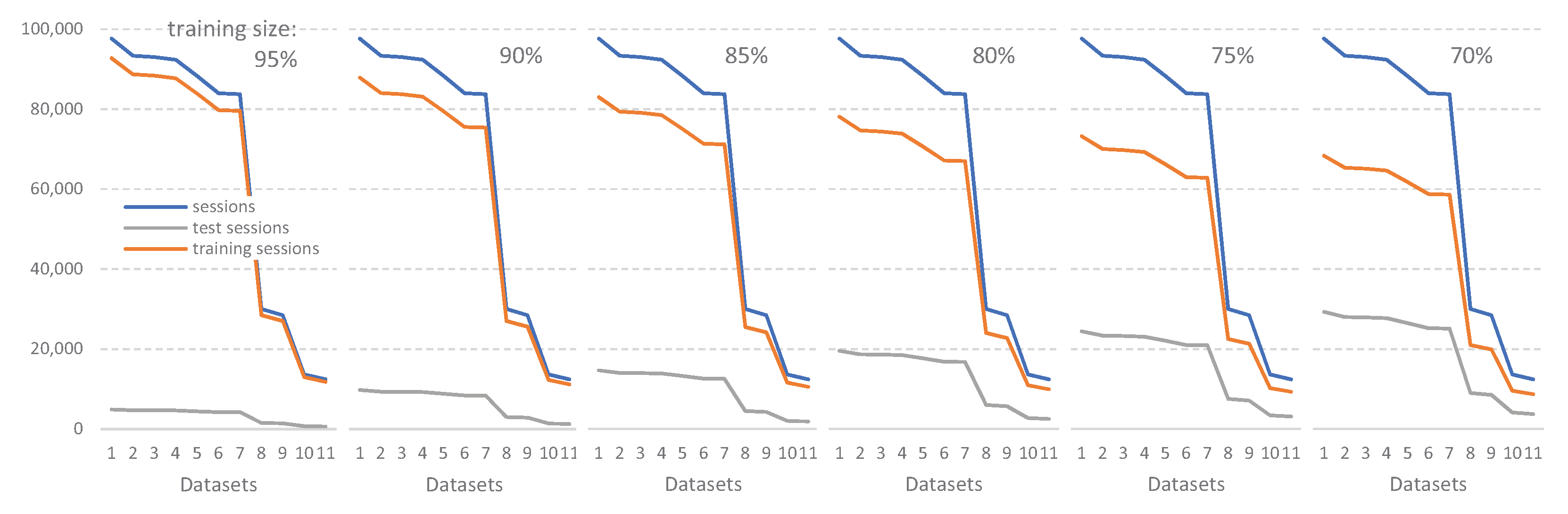
2.2. Datasets
2.3. Experimental Procedure
3. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AGE | Age |
| APR | Arterial pressure |
| BAT | Bath |
| BFR | Blood flow rate |
| BOT | Body temperature |
| BSC | Bicarbonate-based solutions conductivity |
| DBP | Diastolic Blood Pressure |
| DIA | Dialyzer |
| DT | Decision Tree |
| EHR | Electronic Health Record |
| ERC | Chronic Renal Disease |
| HBC | Hemodialysis bath conductivity |
| HBF | Hemodialysis bath flow |
| HBT | Hemodialysis bath temperature |
| HCO | Health Care Output |
| HD | Hemodialysis |
| HRA | Heart rate |
| HYM | Hypotension measure |
| IWG | Interdialytic weight gain |
| KT | Urea clearance |
| ML | Machine Learning |
| SBP | Systolic Blood Pressure |
| SEAIC | Spanish Society of Allergology and Clinical Immunology |
| SEX | Sex |
| SVM | Support Vector Machine |
| TBI | Traumatic Brain Injury |
| TEC | Type of dialysis technique |
| TMP | Transmembrane pressure |
| TUF | Total ultrafiltrations |
| VOL | Volume changes |
| VPR | Venous pressure |
| WDR | Weight (dry) |
| WPO | Weight (post) |
| WPR | Weight (pre) |
References
- Arrieta, J.; Rodríguez-Carmona, A.; Remon, C.; Pérez-Fontán, M.; Ortega, F.; Sánchez-Tomero, J.; Selgas, R. Cost comparison between hemodialysis and peritoneal dialysis outsourcing agreements. Nefrología 2012, 32, 247–248. [Google Scholar] [CrossRef] [PubMed]
- Hegbrant, J.; Gentile, G.; Strippoli, G. The Quest to Standardize Hemodialysis Care. Contrib. Nephrol. 2011, 171, 39–49. [Google Scholar] [CrossRef]
- Mavrakanas, T.; Charytan, D. Cardiovascular complications in chronic dialysis patients. Curr. Opin. Nephrol. Hypertens. 2016, 25, 1. [Google Scholar] [CrossRef]
- Turner, J.; Peixoto, A. Blood pressure targets for hemodialysis patients. Kidney Int. 2017, 92, 816–823. [Google Scholar] [CrossRef]
- Chou, J.; Kalantar-Zadeh, K. Volume Balance and Intradialytic Ultrafiltration Rate in the Hemodialysis Patient. Curr. Heart Fail. Rep. 2017, 14. [Google Scholar] [CrossRef]
- Khan, A.; Khan, A.; Adnan, A.; Sulaiman, S.; Gan, S.; Khan, I. Management of Patient Care in Hemodialysis While Focusing on Cardiovascular Disease Events and the Atypical Role of Hyper- and/or Hypotension: A Systematic Review. Biomed Res. Int. 2016, 2016, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Patel, S.; Raimann, J.; Kotanko, P. The impact of dialysis modality and membrane characteristics on intradialytic hypotension. Semin. Dial. 2017, 30. [Google Scholar] [CrossRef]
- Locatelli, F.; Karaboyas, A.; Pisoni, R.; Robinson, B.; Fort, J.; Vanholder, R.; Rayner, H.; Kleophas, W.; Jacobson, S.; Combe, C.; et al. Mortality risk in patients on hemodiafiltration versus hemodialysis: A ’real-world’ comparison from the DOPPS. Nephrol. Dial. Transplant. Off. Publ. Eur. Dial. Transpl. Assoc. Eur. Ren. Assoc. 2017, 33. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, X.; Gao, X.; Zhang, Y.; Zhou, Z.; Liu, Z.; Fu, B.; Hu, F.; Zhang, Z. (Eds.) Intelligence Science and Big Data Engineering. Image and Video Data Engineering—5th International Conference, IScIDE 2015, Suzhou, China, 14–16 June 2015, Revised Selected Papers, Part I; Volume 9242, Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar] [CrossRef]
- Ali, F.; El-Sappagh, S.; Islam, S.M.R.; Kwak, D.; Ali, A.; Imran, M.; Kwak, K. A Smart Healthcare Monitoring System for Heart Disease Prediction Based On Ensemble Deep Learning and Feature Fusion. Inf. Fusion 2020, 63. [Google Scholar] [CrossRef]
- Alsinglawi, B.; Alnajjar, F.; Mubin, O.; Novoa, M.; Alorjani, M.; Karajeh, O.; Darwish, O. Predicting Length of Stay for Cardiovascular Hospitalizations in the Intensive Care Unit: Machine Learning Approach. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; Volume 2020, pp. 5442–5445. [Google Scholar] [CrossRef]
- Ijaz, M.F.; Attique, M.; Son, Y. Data-Driven Cervical Cancer Prediction Model with Outlier Detection and Over-Sampling Methods. Sensors 2020, 20, 2809. [Google Scholar] [CrossRef]
- Hows, D.; Membrey, P.; Plugge, E.; Hawkins, T. The Definitive Guide to MongoDB; Apress: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Rajkumar, A.; Reena, M. Diagnosis Of Heart Disease Using Datamining Algorithm. Glob. J. Comput. Sci. Technol. 2009, 10, 38–43. [Google Scholar]
- Bertone, P.; Gerstein, M. Integrative data mining: The new direction in bioinformatics. IEEE Eng. Med. Biol. Mag. Q. Mag. Eng. Med. Biol. Soc. 2001, 20, 33–40. [Google Scholar] [CrossRef]
- Palaniappan, S.; Awang, R. Intelligent heart disease prediction system using data mining techniques. In Proceedings of the 2008 IEEE/ACS International Conference on Computer Systems and Applications, Doha, Qatar, 1–4 April 2008; pp. 108–115. [Google Scholar] [CrossRef] [Green Version]
- Oh, C.; Zak, S. Large-Scale Pattern Storage and Retrieval Using Generalized Brain-State-in-a-Box Neural Networks. IEEE Trans. Neural Netw./A Publ. IEEE Neural Netw. Counc. 2010, 21, 633–643. [Google Scholar] [CrossRef]
- Patil, V. Mining Web Graphs for query Recommendations. Int. J. Emerg. Trends Tech Comput. Sci. 2013, 2, 316–320. [Google Scholar]
- Borhani, Y.; Fleming, S.; Clifton, D.; Sutherland, S.; Hills, L.; Meredith, D.; Pugh, C.; Tarassenko, L. Towards a data fusion model for predicting deterioration in dialysis patients. In Proceedings of the 2010 Computing in Cardiology, Belfast, UK, 26–29 September 2010; Volume 37, pp. 967–970. [Google Scholar]
- Daugirdas, J.T.; Blake, P.G.; Ing, T.S. Handbook of Dialysis, 5th ed.; Wolters Kluwer Health: Alphen aan den Rijn, PA, USA, 2015. [Google Scholar]
- Lakshmi, K.R.; Nagesh, Y.; Krishna, M.V. Performance comparison of three data mining techniques for predicting kidney dialysis survivability. Int. J. Adv. Eng. Technol. 2014, 7, 242–254. [Google Scholar]
- Poldermans, D.; Veld, A.; Rambaldi, R.; van den Meiracker, A.; Dorpel, M.; Rocchi, G.; Boersma, E.; Bax, J.; Weimar, W.; Roelandt, J.; et al. Cardiac evaluation in hypotension-prone and hypotension-resistant hemodialysis patients. Kidney Int. 1999, 56, 1905–1911. [Google Scholar] [CrossRef] [Green Version]
- Rostoker, G.; Griuncelli, M.; Loridon, C.; Magna, T.; Janklewicz, P.; Drahi, G.; Dahan, H.; Cohen, Y. Maximal Standard Dose of Parenteral Iron for Hemodialysis Patients: An MRI-Based Decision Tree Learning Analysis. PLoS ONE 2014, 9, e115096. [Google Scholar] [CrossRef]
- Khavanin Zadeh, M.; Rezapour, M.; Sepehri, M.M. Data Mining Performance in Identifying the Risk Factors of Early Arteriovenous Fistula Failure in Hemodialysis Patients. Int. J. Hosp. Res. 2013, 2, 49–54. [Google Scholar]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Kononenko, I. Machine learning for medical diagnosis: History, state of the art and perspective. Artif. Intell. Med. 2001, 23, 89–109. [Google Scholar] [CrossRef]
- Sriram, T.V.S.; Rao, M.V.; Narayana, G.V.S.; Kaladhar, D.S.V.G.K. A Comparison And Prediction Analysis For The Diagnosis Of Parkinson Disease Using Data Mining Techniques On Voice Datasets. Int. J. Appl. Eng. Res. 2016, 11, 6355–6360. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 2015, 13, 8–17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Classification and Regression Trees; Routledge: Boca Raton, FL, USA, 2017; pp. 1–358. [Google Scholar] [CrossRef]
- Serrano, K.J.; Yu, M.; Coa, K.I.; Collins, L.M.; Atienza, A.A. Mining health app data to find more and less successful weight loss subgroups. J. Med. Internet Res. 2016, 18. [Google Scholar] [CrossRef] [PubMed]
- Shmilovici, A. Support Vector Machines. Data Mining and Knowledge Discovery Handbook; Springer Science+Business Media, LLC.: Berlin, Germany, 2010; p. 231. ISBN 978-0-387-09822-7. [Google Scholar] [CrossRef]
- Wu, Z.L.; Li, C.H. On improving sequential minimal optimization. In Proceedings of the 2004 International Conference on Machine Learning and Cybernetics (IEEE Cat. No.04EX826), Shanghai, China, 26–29 August 2004; Volume 7, pp. 4308–4313. [Google Scholar] [CrossRef]
- Kecman, V.; Huang, T.M.; Vogt, M. Iterative Single Data Algorithm for Training Kernel Machines from Huge Data Sets: Theory and Performance. In Support vector machines: Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2005; Volume 177, p. 605. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initials | Parameter | Units | Initials | Parameter | Units |
|---|---|---|---|---|---|
| SEX | Sex | ‘Male’ or ‘Female’ | BFR | Blood flow rate | mL/min |
| AGE | Age | years | HBF | Hemodialysis bath flow | mL/min |
| DIA | Dialyzer | dimensionless | HBC | Hemodialysis bath conductivity | mScm |
| BAT | Bath | dimensionless | BSC | Bicarbonate-based solutions conductivity | mScm |
| TEC | Type of technique | dimensionless | APR | Arterial pressure | mmHg |
| WDR | Weight (dry) | Kg | VPR | Venous pressure | mmHg |
| WPR | Weight (pre) | Kg | TMP | Transmembrane pressure | mmHg |
| WPO | Weight (post) | Kg | SBP | Systolic Blood Pressure | mmHg |
| IWG | Interdialytic weight gain | Kg | DBP | Diastolic Blood Pressure | mmHg |
| HBT | Hemodialysis bath temperature | °C | HRA | Heart rate | bpm |
| VOL | Volume changes | L | TUF | Total ultrafiltrations | mL |
| KT | Urea clearance | L | BOT | Body temperature | °C |
| Experiment/Dataset | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Valid Sessions | 97,640 | 93,355 | 93,013 | 92,351 | 88,265 | 83,949 | 83,745 | 83,745 | 82,097 | 65,938 | 12,469 | 32 |
| Valid Sessions with Hypotension | 24,912 | 24,242 | 24,168 | 24,050 | 22,953 | 22,025 | 21,969 | 21,969 | 21,612 | 18,397 | 2504 | 4 |
| % of These Sessions | 25.5% | 26.0% | 26.0% | 26.0% | 26.0% | 26.2% | 26.2% | 26.2% | 26.3% | 27.9% | 20.1% | 12.5% |
| Parameters | 2 | 4 | 6 | 8 | 10 | 12 | 14 | 17 | 20 | 21 | 23 | 24 |
| SEX | x | x | x | x | x | x | x | x | x | x | x | x |
| AGE | x | x | x | x | x | x | x | x | x | x | x | x |
| DIA | x | x | x | x | x | |||||||
| BAT | x | x | x | x | x | |||||||
| TEC | x | x | x | x | x | |||||||
| WDR | x | x | x | x | ||||||||
| WPR | x | x | x | x | ||||||||
| WPO | x | x | x | x | ||||||||
| IWG | x | x | x | x | x | x | ||||||
| HBT | x | x | x | |||||||||
| VOL | x | x | x | x | x | x | x | |||||
| KTV | x | x | x | x | x | x | x | x | ||||
| BFR | x | x | x | x | x | x | x | x | ||||
| HBF | x | x | ||||||||||
| HBC | x | x | x | x | x | x | x | |||||
| BSC | x | |||||||||||
| APR | x | x | x | x | x | x | x | x | x | x | ||
| VPR | x | x | x | x | x | x | x | x | x | x | ||
| TMP | x | x | x | x | x | x | ||||||
| SBP | x | x | x | x | x | x | x | x | x | x | x | |
| DBP | x | x | x | x | x | x | x | x | x | x | x | |
| HRA | x | x | x | x | x | x | x | x | x | |||
| TUF | x | x | x | x | x | x | x | x | x | |||
| BOT | x | x |
| Parameter | Meaning | |
|---|---|---|
| True positive | TP | Hypotension predicted, which is correct |
| False positive | FP | Hypotension predicted, which is not correct |
| False negative | FN | No-hypotension predicted, which is not correct |
| True negative | TN | No-hypotension predicted, which is correct |
| Accuracy | Rate of correct predictions over total | |
| Precision | Rate of positive identifications actually correct | |
| Sensitivity | Rate of positives correctly predicted | |
| Specificity | Rate of negatives misclassified |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gómez-Pulido, J.A.; Gómez-Pulido, J.M.; Rodríguez-Puyol, D.; Polo-Luque, M.-L.; Vargas-Lombardo, M. Predicting the Appearance of Hypotension during Hemodialysis Sessions Using Machine Learning Classifiers. Int. J. Environ. Res. Public Health 2021, 18, 2364. https://doi.org/10.3390/ijerph18052364
Gómez-Pulido JA, Gómez-Pulido JM, Rodríguez-Puyol D, Polo-Luque M-L, Vargas-Lombardo M. Predicting the Appearance of Hypotension during Hemodialysis Sessions Using Machine Learning Classifiers. International Journal of Environmental Research and Public Health. 2021; 18(5):2364. https://doi.org/10.3390/ijerph18052364
Chicago/Turabian StyleGómez-Pulido, Juan A., José M. Gómez-Pulido, Diego Rodríguez-Puyol, María-Luz Polo-Luque, and Miguel Vargas-Lombardo. 2021. "Predicting the Appearance of Hypotension during Hemodialysis Sessions Using Machine Learning Classifiers" International Journal of Environmental Research and Public Health 18, no. 5: 2364. https://doi.org/10.3390/ijerph18052364