



Over the past 40 years, many studies have investigated the nature of visual word recognition and have tried to understand how morphologically complex words like allowable are processed. A number of processes such as morphological decomposition, letter position encoding, and the retrieval of whole-word semantics have been identified as important factors in the process (Amenta & Crepaldi, Reference Amenta and Crepaldi2012). However, no consensus has been reached on how exactly such factors work and interact and whether native (L1) and nonnative (L2) speakers rely on the same fundamental mechanisms while processing morphologically complex words.
L1 Morphological Processing and the Transposed-Letter Effect
Studies seeking to disentangle the mechanism(s) responsible for L1 morphological processing have been largely dominated by discussions around the cross-linguistic validity of models positing single versus dual mechanisms. Though there is a large number of studies that advocate some type of dual-route hypothesis, which essentially holds that two mechanisms are at work in the L1 processing of complex words (Diependaele, Sandera, & Grainger, 2009; Krkc & Clahsen, Reference Kırkıcı and Clahsen2013; Silva & Clahsen, Reference Silva and Clahsen2008), there is also research that supports the purely morphological parsing approach (Gor & Cook, Reference Gor and Cook2010; Morris & Stockall, Reference Morris and Stockall2012).
More recently, the literature has witnessed discussions regarding the potential influence of semantic information on the morphological decomposition process. These are essentially based on whether, how, and when morpho-semantic information is available during the processing of morphologically complex words. The predominant experimental paradigm used in such studies has been masked priming, which is known to tap into a very early, automatic, and prelexical level of processing (Marslen-Wilson, Reference Marslen-Wilson and Gaskel2007). Rastle, Davis, and New (Reference Rastle, Davis and New2004), for example, investigated the priming patterns of semantically transparent morphological pairs (cleaner–CLEAN), semantically opaque morphological pairs (corner–CORN) and non-morphological form prime–target pairs (brothel–BROTH). The results reported in Rastle et al. and a number of subsequent studies displayed greater magnitudes of priming for conditions where the prime and the target had an apparent morphological relationship (cleaner–CLEAN and corner–CORN) compared to a non-morphological condition (brothel–BROTH). This is taken as the manifestation of rapid morphological decomposition at a very early, orthographical stage of visual work recognition, independent of semantic constraints.
Such findings indicating that morphological decomposition is a process that takes place at very early, prelexical stages of visual word recognition have led to the question whether this process co-occurs with other early, low-level processes such as letter position coding and whether the recognition of morphologically complex words interacts with orthographical effects like the transposed-letter (TL) effect (Duñabeitia, Perea, & Carreiras, Reference Duñabeitia, Perea and Carreiras2007, Reference Duñabeitia, Perea and Carreiras2014). The TL effect occurs when a prime that involves two adjacent, transposed letters (the TL condition, as in jmup–JUMP) is significantly less disruptive than a prime where the same two letters are replaced by other letters (the substituted letter [SL] condition, as in jrap–JUMP). The presence of TL effects demonstrates that letter position is flexible, and speaks against slot-coding models, which hypothesize location-specific processing of letters where each letter in a word is absolutely assigned to a single position (Coltheart, Rastle, Perry, Langdon, & Ziegler, Reference Coltheart, Rastle, Perry, Langdon and Ziegler2001; Rumelhart & McClelland, Reference Rumelhart and McClelland1982). Such models would predict that TL nonwords like allwo, allve, and alliz would all facilitate the recognition of the target word allow to the same extent as the same number of letters is in the correct letter positions. However, a substantial number of studies have reported that TL nonwords (e.g., jmup, the transposed-letter version of JUMP) are harder to reject in a lexical decision task than substituted-letter nonwords (e.g., jrap, the substituted-letter version). Such results have been taken to indicate that the lexical representation of JUMP is identified although two of its letters have been transposed (Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2009; Lee & Taft, Reference Lee and Taft2009; Lupker, Perea, & Davis, Reference Lupker, Perea and Davis2008; Perea & Lupker, Reference Perea and Lupker2003). A number of available models are actually flexible enough to accommodate the imprecisions in letter position that lead to TL effects (Luke, Reference Luke2011; Perea & Lupker, Reference Perea and Lupker2003). Some of these are models hypothesizing bigram encoding like the SERIOL model (Whitney, Reference Whitney2001), where the word BIG would activate the bigrams BI, IG, and BG, models suggesting that letter position is encoded by the varying activation levels of each letter like the SOLAR model (Davis, Reference Davis1999, Reference Davis2010) and the overlap model, which assumes that letters in the visual input display distributions over positions to facilitate the extension of the representation of a letter into adjacent letter positions (Gomez, Ratcliff, & Perea, Reference Gomez, Ratcliff and Perea2008).
In the case of morphologically complex words, TL primes can be either intra-morphemic, that is, can take place within the morpheme boundary, as in govenrment–GOVERN, or cross-morphemic, that is, can cut across the morpheme boundary, as in govermnent–GOVERN. As a relatively higher level of position-specificity is required in the decoding of affixes, TLs would be expected to be more disruptive for morphemes and morpheme boundaries than for word internal letters. Morphological TL effects have been examined in many L1 masked TL priming studies (Christianson, Johnson, & Rayner, Reference Christianson, Johnson and Rayner2005; Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2007, Perea & Carreiras, Reference Perea and Carreiras2006; Rueckl & Rimzhim, Reference Rueckl and Rimzhim2011; Taft & Nillsen, Reference Taft and Nillsen2013). The results have mostly favored the obligatory decomposition theory as cross-morphemic transpositions were found to be more disruptive than intra-morphemic transpositions. It has been argued that the disturbance of the affix in the cross-morphemic transposition condition impedes the prelexical parsing process, which, in turn, prevents the processing of a complex word through morpho-orthographic parsing. If morphological decomposition takes place at the same early stage as orthographic processing, letter transpositions that straddle morpheme boundaries should impede word recognition more than letter transpositions that do not (Beyersmann, Castles, & Coltheart, Reference Beyersmann, Castles and Coltheart2011). Obtaining morphological priming effects in spite of certain positional alterations and disruptions to semantic interpretability could be taken as evidence for the positional uncertainty of morphemic segmentation. The findings obtained from available L1 TL priming studies are still far from being clear-cut and point to different patterns of morphological processing. While some studies have reported the TL priming effect only for conditions that involve intra-morphemic transposition (Christianson et al., Reference Christianson, Johnson and Rayner2005; Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2007), others have concluded that the magnitude of priming does not depend on the locus of the transpositions (Rueckl & Rimzhim, Reference Rueckl and Rimzhim2011).
L2 Morphological Processing
More recently, studies investigating the processing of morphologically complex words have expanded their scope to include (predominantly inflectional) L2 processes. L2 derivational processing studies have been relatively sparse and have produced conflicting results. Krkc and Clahsen (Reference Kırkıcı and Clahsen2013), for example, used masked priming experiments to test L2 speakers of Turkish and found that derived word forms yielded significant masked priming effects comparable to those observed with L1 Turkish speakers. Similar findings were obtained in masked and cross-modal morphological priming experiments testing other L1–L2 language-pairs like Spanish–English and Dutch–English (Diependaele, Duñabeitia, Morris, & Keuleers, Reference Diependaele, Duñabeitia, Morris and Keuleers2011), English–Arabic (Freynik, Gor, & O’Rourke, Reference Freynik, Gor and O’Rourke2017) and Italian–English (Viviani & Crepaldi, Reference Viviani and Crepaldi2019).
Conversely, other studies employing comparable experimental paradigms reported results indicative of L1–L2 processing differences as L2 processing has been found to display a lower level of sensitivity to morphological structure and to rely more on other types of information (Song, Do, Thompson, Waegemaekers, & Lee, Reference Song, Do, Thompson, Waegemaekers and Lee2020). Silva and Clahsen (Reference Silva and Clahsen2008), for example, used masked priming experiments to test the L2 processing of English deadjectival nominalizations with –ness and –ity and obtained only limited priming effects. It was concluded that the L2 processing of morphologically complex words is less affected by their internal combinatorial structure (Clahsen, Felser, Neubauer, Saro, & Silva, Reference Clahsen, Felser, Neubauer, Sato and Silva2010). Similarly, Heyer and Clahsen (Reference Heyer and Clahsen2015) compared orthographically related (e.g., freeze–FREE) and derived (e.g., bluntness–BLUNT) prime–target pairs in L1 German–L2 English speakers. While L1 speakers displayed morphological but not orthographic priming, the two prime types yielded the same magnitudes of facilitation for L2 speakers. Heyer and Clahsen concluded that L2 speakers were heavily influenced by word orthography, suggesting a greater reliance on form-processing in L2. Comparable findings were reported for further L1–L2 language pairs like Polish–German (Clahsen & Neubauer, Reference Clahsen and Neubauer2010) and Russian–German. (Jacob et al., Reference Jacob, Heyer and Veríssimo2018).
An Exploration of Individual Differences Modulation in Masked Morphological Priming
Given these conflicting findings regarding L2 morphological processing, testing for L2 TL-effects may offer new insights. Available accounts of (morphological) TL priming effects are largely based on data from L1 speakers. It is difficult to apply these readily to L2 speakers as L2 lexical access involves the parallel activation of lexical representations across languages, which may affect orthographic coding for L2 speakers (Lin, Bangert, & Schwartz, Reference Lin, Bangert and Schwartz2015; Schwartz & Kroll, Reference Schwartz, Kroll, Traxler and Gernsbacher2006). In addition, there are many potentially important factors in L2 processing that do not straightforwardly apply to L1 contexts such as the level of L2 proficiency, prior reading experiences with different types of text direction, L1–L2 differences in orthographic neighborhood size, and L1–L2 differences in orthographic similarity (Lin & Lin, Reference Lin and Lin2016).
Another potential factor that needs to be considered with L2 speakers is individual differences. L2 speakers are known to display variability in many individual-level factors that impact the learning and processing of an L2 (Tanner, Inoue, & Osterhout, Reference Tanner, Inoue and Osterhout2014). To avoid the prevailing “uniformity assumption” in experimental psycholinguistic studies that it is possible to draw inferences about lexical processing on the basis of averaged data (Andrews, Reference Andrews2012), the present study explores individual differences as potential explanatory factors. Individual differences in lexical processing are well captured in the lexical quality hypothesis (Perfetti Reference Perfetti, Gough, Ehri and Treiman1992, Reference Perfetti2007), which claims that variability in the quality of lexical representations is a crucial determinant of tasks that require word recognition. High-quality representations of words constitute a significant precondition of skilled reading comprehension, and differences between skilled and poor readers can be attributed to variation in these representations because reading is mostly about words. Word recognition studies make mostly use of lexical decision tasks, and as participants in such tasks are required to respond to visual stimuli (i.e., words) by reading them first, differences among the responses of participants could be attributed to the quality of the lexical representations of the words that they need to respond to.
Andrews and Lo (Reference Andrews and Lo2013) investigated the impact of individual differences in spelling and vocabulary scores on the L1 processing of morphologically complex English words. The averaged results for the whole sample showed larger priming effects for transparent-related pairs compared to opaque and form-related pairs. However, when individual performances on vocabulary and spelling tests were considered, readers with better vocabulary than spelling skills showed larger priming effects for transparent than for opaque and form-related primes. Conversely, readers with better spelling than vocabulary skills showed comparable priming effects for opaque and transparent pairs. In addition, compatible with earlier evidence that reading skills modulate unique variance in masked form priming (Andrews & Hersch, Reference Andrews and Hersch2010), Andrews and Lo (2012) reported that relative to spelling, vocabulary, and reading, skilled readers were associated with a distinct priming profile indexed by stronger inhibition from TL primes and stronger priming from neighbor primes.
Medeiros and Duñabeitia (Reference Medeiros and Duñabeitia2016) investigated the impact of individual differences in reading speed on morphological processing. It was found that masked suffix priming (e.g., darkness–TOUGHNESS) effects were greater only for slow readers while negligible masked suffix priming effects were obtained for faster readers. Similarly, Beyersmann, Cavalli, Casalis, and Colé (Reference Beyersmann, Cavalli, Casalis and Colé2016) analyzed the impact of individual differences in reading speed based on performance in a lexical decision task on embedded stem priming (e.g., amouresse [lovedom]–AMOUR [LOVE]) effects. Their results showed that priming effects increased with increasing reading proficiency (i.e., faster reaction times) and that low-proficient readers had robust priming effects only in the affixed condition (i.e., preamour [prelove]–amouresse [lovedom]), indicating that they were more dependent upon morpho-orthographic decomposition mechanisms. In contrast, high-proficient readers could map input letter strings onto whole-word representations, suggesting that they activated embedded stems even in the absence of a real affix. Likewise, Duñabeitia et al. (Reference Duñabeitia, Perea and Carreiras2014) explored whether reading speed modulated the magnitude of within- (e.g., vioilnista–VIOLINISTA) versus between-morphemes TL priming (e.g., violiinsta–VIOLINISTA) effects. Greater transposed-letter priming was observed for intra-transpositions than inter-transpositions with faster but not with slower readers. It was suggested that faster readers use fast-acting, automatic morphological segmentation mechanisms.
In addition to reading speed, reading, and spelling scores have also been used as measures of individual differences. Perea, Marcet, and Gómez (Reference Perea, Marcet and Gómez2016), for example, reported a smaller transposed-letter effect in competitive Scrabble players compared to nonplayers. Beyersmann, Casalis, Grainger, and Ziegler (Reference Beyersmann, Casalis, Grainger and Ziegler2015) tested the effects of individual differences in spelling and vocabulary measures and found that participants with higher language proficiency displayed greater nonsuffixed nonword priming (e.g., tristald [sadald]– TRISTE [SAD]) compared to lower proficient users. Finally, Tan and Yap (Reference Tan and Yap2016) investigated the extent to which masked repetition priming (e.g., touch–TOUCH) and semantic priming (e.g., feel–TOUCH) effects were moderated by individual differences and found that the magnitude of priming was predicted by vocabulary and spelling ability.
To our knowledge, there is only one, fairly recent, study that investigated whether L2 masked priming effects are mediated by individual differences. Viviani and Crepaldi (Reference Viviani and Crepaldi2019) examined masked priming effects for morphologically transparent (e.g., employer–EMPLOY), morphologically opaque (e.g., corner–CORN), and purely orthographic (e.g., brothel–BROTH) prime–target pairs with L1 Italian–L2 English speakers. The results demonstrated that while transparent priming was consistent across the whole phonemic fluency spectrum, opaque and orthographic priming shrank with growing fluency.
The Present Study
Against this background, the aim of the present study is two-fold. First, it seeks to explain the workings of L2 morphological processing using confirmatory data-analytic techniques. Though morphological TL priming paradigm could offer new insights into the L2 processing system, it has not received enough attention in the L2 literature. Distinctions between the native and L2 orthographic systems, coupled with typically lower L2 proficiency levels may lead to a comparatively less refined, and therefore less precise, L2 orthographic processing system. Furthermore, a number of studies have suggested that L2 speakers process morphologically complex words holistically (for a discussion, see Marslen-Wilson, Reference Marslen-Wilson and Gaskel2007), which would imply a higher level of uncertainty for letter positions at morpheme boundaries. To this end, the current study constitutes one of the very first attempts to investigate L2 morphological TL effects with the purpose of clarifying the relationship between L2 letter position coding and morphological processing.
On the basis of earlier findings, we hypothesized that a briefly presented morphologically related word (e.g., allowable–ALLOW) would be decomposed during word recognition in line with its morphological structure ([allow][–able]). It was difficult to predict the direction and magnitude of L2 TL priming effects as previous studies had almost exclusively relied on L1 speakers. Following results obtained from L1 readers, if TL effects are impacted by the position of the transposed letters, we predicted less priming in the condition where transpositions straddled the morpheme. In contrast, if disrupting morpheme boundaries does not modulate TL effects, we expected to obtain similar priming across two conditions.
The second aim of the study was to further explore the possibility that individual differences moderate L2 processing. Given the variability in terms of approaches and measures (e.g., Andrews & Lo, Reference Andrews and Lo2013; Beyersmann et. al., Reference Beyersmann, Casalis, Grainger and Ziegler2015) as well as the inconsistent results across individual difference studies, this section of the study makes an exploratory attempt to develop an understanding of the modulation of L2 priming effects by various proficiency measures. To this end, a broad assessment of participants’ reading skills through nine reading-proficiency-related measures (see below) was used to understand their potential moderation of morphological priming and transposed-letter priming effects.
Method
Participants
A sample size of 29 students at Middle East Technical University (22 females; age: mean = 26.14, SD = 3.16, min = 20, max = 32) volunteered to participate. All participants reported Turkish as their L1 and English as a L2 language. They had all learned English through formal instruction after the age of 10 (mean length of English instruction = 16.3 years, SD = 3.23). All reported normal or corrected-to-normal vision.
Materials
Stimuli
For the masked priming experiment, a set of 58 English words was selected as targets (see Table 1 for characteristics). All targets were the monomorphemic stem forms (e.g., ALLOW) of derived words to ensure priming effects (if any) are particularly associated with morphological rather than orthographic similarity. Each target was preceded by six prime types: morphological (allowable), TL-within (allwoable), SL-within (allveable), TL-across (alloawble), SL-across (alloimble), and unrelated (believable). Related and unrelated primes were matched on stem length, stem frequency, stem bigram frequency, stem orthographic neighborhood, word length, frequency, bigram frequency, and orthographic neighborhood. To control for the potential effect of the suffix, the related and the unrelated primes for a given target word were constructed using the same suffix (e.g., allowable and believable). Letter transpositions always included a vowel and a consonant (Lupker et al., Reference Lupker, Perea and Davis2008), and none of the transpositions led to the formation of a real word. The SL-control primes were formed by replacing the two TLs with new letters of similar resemblance and height (e.g., allowable and allveable). TL and SL primes were matched on length, bigram frequency, and orthographic neighborhood.
Table 1. Mean word and stem bigram frequency, length, frequency, and orthographic neighborhood (SDs) for the stimuli

Note: Counts of word frequency were extracted from the SUBTLEX-UK database (van Heuven et al., Reference van Heuven, Mandera, Keuleers and Brysbaert2014) using the log transformation of word frequency, also referred to as the Zipf values (log10 occurrences per billion).
For the lexical decision task, the 58 target words were mixed with 42 real-word and 100 orthographically legal and pronounceable nonword filler targets. The nonwords were formed by changing the first and last letters of a real word (e.g., frinp from bring). Each nonword target was preceded by an unrelated word, and all nonwords were matched with the word targets on length, position-specific bigram frequency, and position-specific trigram frequency, and Coltheart’s N. 12 experimental lists were formed, so each target appeared once in each list in a different priming condition and in a different order using Latin-square design. Participants were randomly assigned to each list.
Procedure
Each participant was tested individually in a quiet room. The stimuli were presented in randomized order using E-Prime (Schneider, Eschman, & Zuccolotto, Reference Schneider, Eschman and Zuccolotto2002). Each trial consisted of the presentation of a forward mask of hash marks for 500 ms, followed by the prime in lowercase letters for 50 ms, which was immediately followed by the target stimulus in uppercase letters. The target remained onscreen until the participant responded or for a maximum of 2500 ms. The participants were asked to decide as quickly and accurately as possible whether the visual targets were real English words and to respond through the use of a gamepad. The whole lexical decision task lasted for approximately 8 min.
Reading skills test battery
To measure individual differences, a reading skills test battery was designed and administered in paper-and-pencil format. The battery consisted of nine tests that tapped into various aspects of reading skills in English. These measures were selected or adapted to assess the contribution of different skills to the modulation of priming effects in L2 word recognition. Author 1 and a further expert in linguistics scored the answers in the nonword spelling, reading nonwords, and word identification tests (interrater reliability coefficients: α = 0.99, 0.97, and 0.99, respectively). The listening, vocabulary, and reading comprehension tests were scored by two experts in language teaching (interrater reliability coefficients: α = 0.98, 0.98, and 0.94, respectively).
Test I: Word identification
Participants read out loud 16 words in isolation (e.g., volcanologists). The items were of increasing difficulty and were presented in list format without context. All answers were transcribed and scored as either correct or incorrect.
Test II: Reading fluency
Participants read a text for meaning in 1 min. To ensure comprehension of the passage, at intervals of approximately 60 words, participants selected one out of three words coherent with the passage or indicated if a given statement was true or false. Scores were calculated by counting the number of words read and subtracting 50 words for every incorrect selection.
Test III: Spelling
Spelling ability was assessed through dictation and spelling recognition tests (44 items each). The score for the spelling dictation test was calculated by counting the total number of words spelled correctly; for the spelling dictation test, the score was calculated based on the number of correct answers.
Test IV: Reading comprehension
Two passages were used to assess reading proficiency. The first was an informative text and tested reading comprehension skills such as the recognition of the discourse structure of the text, identification of the main idea and explicit details, drawing conclusions, and making inferences. The second included gaps that the participants had to fill with appropriate words. For the two tests, participants were required to answer as many reading comprehension questions as possible in 20 min. Total reading comprehension scores were calculated by subtracting the number of incorrect responses from the number of correctly answered questions.
Test V: Reading nonwords
This test required participants to decode, pronounce, and understand unfamiliar words. The participants pronounced 20 nonwords, through which their knowledge of over 20 sound-letter-rules was assessed. Responses were voice-recorded and were considered correct if they matched the pronunciation printed on the scoring sheet. The participant was not penalized for variations in pronunciation due to speech impediments or regional accent variation.
Test VI: Listening comprehension
This test consisted of 17 thematically unrelated sentences that were factual statements and did not require a subjective evaluation by the participants. Each sentence contained a sentence-final gap, for which the participants had to supply an appropriate word. An example item is provided below:
Participants hear: An omnivore is an animal, which has a digestive system designed such that it can eat both plants and __________.
Participants write: meat(s)
Test VII: Vocabulary knowledge
Vocabulary knowledge was assessed through tests of Similar and Opposite Meanings and Word Associations. The vocabulary test was productive in nature and required participants to provide synonyms and antonyms of words in a specific context. In these tests, participants were presented with 48 words in sentence contexts and were asked to write 1 word that has a similar or opposite meaning in the same context and a word that it is often used in collocation with.
Test VIII: Reading span
As a measure of the efficiency of verbal working memory, the reading span test developed by Oswald, McAbee, Redick, and Hambrick (Reference Oswald, McAbee, Redick and Hambrick2015) was used. This test involved sets of letters (ranging from 2 to 6) that the participants memorized while reading and judging sentences for plausibility.
Test IX: Nonword spelling
This test measured knowledge of sound–letter correspondences and of typical spelling patterns. Participants listened to and spelled 23 nonwords (all adopted from Kohnen & Nickels, Reference Kohnen and Nickels2010).
Results
Incorrect trials were excluded from the reaction time (RT) analyses (0.03 % of all data). One target word (i.e., DEMURE), which was responded to correctly in less than 40% of instances and individual data points below 350 ms or above 2500 ms were removed (0.007% of the total data). The clean data set consisted of 1,615 data points for the analysis. The overall mean RT and accuracy rate for the lexical decision task were 623 ms and 97% for the word data, and 760 ms and 94% for the nonword data, respectively. Table 2 shows mean RTs across conditions.
Table 2. RTs averaged across items and conditions

Note: Standard deviations are in parentheses. Significant priming effects were only obtained in the morphological condition. TL-priming effects were absent irrespective of whether the transpositions cross morphemic boundaries. RT, reaction time, ER%, error rate.
RTs were inverse transformed (–1000/RT), and linear mixed-effect modeling model was used to fit RTs within the R environment (Version 1.2.1335, R Development Core Team, 2008) through the lmerTest package (Kuznetsova, Bruun Brockoff, & Haubo Bojesen Christensen, Reference Kuznetsova, Bruun Brockhoff and Haubo Bojesen Christensen2017). The model contained prime type (morphological, TL-within, SL-within, TL-across, SL-across, and unrelated) as a fixed effect and subjects and items as random effects factors (random intercepts). Though the data were originally modeled in a maximal random slope structure (Barr, Levy, Scheepers, & Tily, Reference Barr, Levy, Scheepers and Tily2013), due to the complexity of the model, the inclusion of random slopes for each fixed factor and their interactions resulted in a convergence failure. Therefore, they were removed from the structure.
The pairwise comparisons between conditions (i.e., unrelated vs. morphological; SL-within vs TL-within; SL-across vs TL-across), and interaction between within-morpheme manipulations and across-morpheme manipulations were computed using the emmeans (Lenth, Reference Lenth2019) package in R. The number of languages participants could speak as their native and foreign language, and their age were also added to the model as fixed effects. However, these were removed from the model as they did not significantly improve the model’s goodness-of-fit using the stepwise selection procedure. Finally, the model was refitted after data points were removed that deviated from their corresponding predicted value by more than 2.5 SD.
The model for the bilingual data revealed a significant main effect of prime type, F (5, 1487.2) = 5.32, p < .0001.1 As can be seen in the model summary in Table 3, with the unrelated condition as the baseline, there was a significant priming effect for the morphological condition, t (1488) = –4.376, p < .0001, for the TL across condition, t (1487) = –2.136, p = .03, and for the SL across condition, t (1486) = –2.791, p < .001.
Table 3. Fixed effects in the final model on reaction times

SE, standard error. *** p < 0.0001, ** p < 0.001, * p < 0.01.
Pairwise comparisons between experimental and control conditions for correct responses are presented in Table 4. In terms of RTs, the table reveals that words preceded by morphologically related primes (e.g., allowable–ALLOW) were responded to significantly faster than words preceded by unrelated primes (e.g., believable–ALLOW), reflecting a 26-ms morphological priming effect, t (1488) = –4.375, p < .0001.
Table 4. Pairwise comparisons between conditions

SE, standard error. *** p ≤ 0.0001, * p < 0.01.
The TL-within condition did not differ statistically from the SL-within condition, t (1487) = 0.52, p = .60. Similarly, there was no statistically significant difference between the TL-across and SL-across conditions, t (1488) = 0.661, p = .51. Of note, response latencies were faster to SL-primes than to the TL primes. In addition, a direct investigation was made within the same model regarding the interaction between intra-transpositions (e.g., allwoable, and allveable) and inter-transpositions (e.g., alloawble and alloimble), which yielded no significant two-way interaction, t (1488) = –0.101, p = .92. RT analyses revealed a statistically significant difference between the SL-across condition and the unrelated condition, t (1488) = –2.791, p = .005). The SL-across primes were responded to significantly faster than the primes in the unrelated condition by 23 ms. However, there was no meaningful difference between the SL-within condition and unrelated condition, t (1489) = –1.007, p = .32. There was a statistical difference between the conditions of non-transposed morphologically related primes (e.g., allowable) and of TL-within primes (e.g., allwoable), t (1488) = –3.871, p = .0001. The estimated RTs for each condition are plotted in Figure 1.

Figure 1. Model-based estimates of response times per condition. Error bars are 95% confidence intervals. Unr, unrelated. Morph, morphological, SL_Acr, SL-across. TL_Acr, TL-across. SL_With, SL-within. TL_With, TL-within conditions.
Reading skills and priming modulation
The distribution of each reading skills test is illustrated in Figure 7 (see Appendix). A broad range of score distribution was achieved using distinct measures that tap into different facets of reading skills. For the individual differences measures in the battery, each test score was added to the model2 one at a time using the stepwise selection procedure to calculate whether each proficiency score contributed significantly to producing a better fitting model. Later, a direct analysis into the interaction of each proficiency test with morphological priming (i.e., unrelated condition versus morphological condition), TL-within priming (i.e., SL-within condition vs. TL-within condition), and TL-across priming (i.e., SL-across condition vs. TL-across condition) was conducted using contrasts in the emmeans package in R. Significant results regarding the interaction between each priming type and each individual differences measure are reported in Table 5 through estimates for each contrast, standard error, t ratio and p values across low proficiency, medium proficiency, and high proficiency levels (see Figures 8–11 in Appendix B for scatterplots of real priming effects with overlaid trend lines from the predicted model in proficiency measures).
Table 5. Contrasts for proficiency levels for morphological priming, TL-within priming, and TL-across priming

Note: Low, medium, and high refers to the low proficiency, medium proficiency, and high proficiency levels.
Morphological priming modulation
As can be seen in Table 5, the interaction between morphological priming and the Vocabulary Knowledge test was significant, t (1516) = 2.107, p = .03. Even though morphological priming effects were observed across the whole proficiency spectrum, the magnitude of effects shrank as the knowledge of vocabulary expanded (also see Figure 2 for a visual representation of the model-based estimates).

Figure 2. Vocabulary test.
Transposed-letter priming within morpheme boundaries modulation
RT analyses of TL-within priming condition revealed a significant interaction of Reading Nonwords, t (1503) = 3.335, p = .001, and the reading comprehension, t (1508) = –2.061, p = .04, tests with respect to the different proficiency profiles (see Table 5), suggesting that while TL-within priming effects were absent in the average data, those effects were observed when individual differences measures were introduced into the model. The impact of proficiency levels on priming is shown in Figures 3 and 4.

Figure 3. Reading comprehension.

Figure 4. Reading nonwords.
As the figures suggest, while TL-within priming effects were prominent in better readers, those effects only emerged in less skilled nonword readers. The magnitude of priming effects was also larger when nonword reading skills were considered (29 ms) compared to reading comprehension skills (17 ms).
Transposed-letter priming across morpheme boundaries modulation
A significant interaction between the magnitude of TL-across priming effects and word identification, t (1515) = 2.215, p = .03, and reading nonwords, t (1503) = 2.142 p = .03, tests emerged (see Table 5). As displayed in Figures 5 and 6, TL-across priming effects were present in the less skilled word and the nonword reader group.
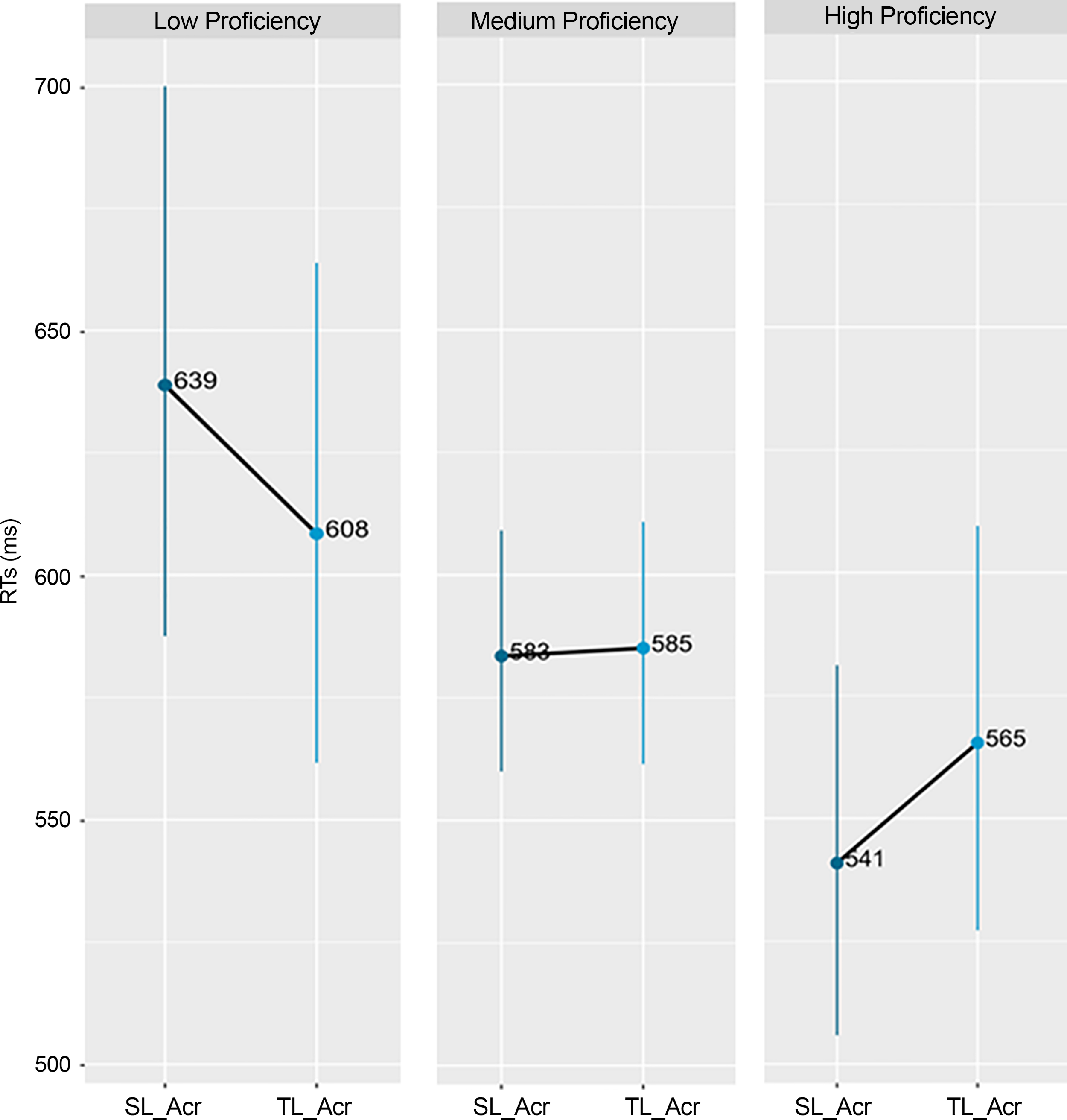
Figure 5. Word identification test.

Figure 6. Reading nonwords.
Discussion
The overall goal of this study was to investigate the early automatic processes involved in the L2 processing of morphologically complex words. Using a masked priming lexical decision experiment, we reported the commonly recognized pattern whereby the prior presentation of a morphologically related prime (e.g., allowable–ALLOW) facilitates the recognition of a target word. Consistent with the majority of earlier studies, results based on averaged RT data demonstrated that the morphological parsing of the root is a required process (Rastle, Davis, Tyler, & Marslen-Wilson, Reference Rastle, Davis, Tyler and Marslen-Wilson2000; Taft, Sonny, & Beyersmann, Reference Taft, Li and Beyersmann2018).
Across the whole sample group, the results failed to replicate the TL-priming effects reported earlier for L1 participants (intra-morphemic: 13 ms, inter-morphemic: 10 ms priming effects for Spanish in Duñabeitia et. al., Reference Duñabeitia, Perea and Carreiras2014; 14 ms for TL-within priming effects for English in Rueckl & Rimzhim, Reference Rueckl and Rimzhim2011) as no significant priming was obtained in the intra-morphemic or inter-morphemic TL conditions. It is likely that our results diverge from the generally observed pattern for the following two reasons. First, in the current study, TL-effects were investigated in L2 speakers, which has to date been extremely limited. In this sense, the findings of the present study need to be evaluated together with those of a restricted number of attempts to test TL effects in L2 speakers and, hence, require further elaboration with other L2 samples. Second, many of the TL effects reported in the literature come from studies in which Indo-European languages such as English, German, and Spanish were tested. In the current study, in contrast, all participants were L2 English speakers with an L1 Turkish background. Turkish is a typologically different, non-Indo-European language with largely agglutinative morphology. As indicated at the outset of the present study, L2 lexical access involves the activation of lexical representations across languages (Schwartz & Kroll, Reference Schwartz, Kroll, Traxler and Gernsbacher2006) and L1–L2 differences may lead to differences in orthographic coding for L2 speakers (Lin et al., Reference Lin, Bangert and Schwartz2015). The lack of TL-priming effects may be a manifestation of such differences, though there have been reports of masked transposed-letter priming effects in agglutinative non-Indo-European languages such as Basque (Perea & Carreiras, Reference Perea and Carreiras2006) and Uyghur (Yakup, Abliz, Sereno, & Perea, Reference Yakup, Abliz, Sereno and Perea2015).
Our general analysis on the TL prime data at the group-level showed that there is a statistical difference between the nontransposed morphologically related (allowable) and TL-within (allwoable) conditions compared to the unrelated condition (believable). These differences may be taken as support for postlexical accounts of morphological processing with less positional uncertainty that suggest morphologically complex words are initially mapped onto whole-word representations and are only decomposed after access to the lexicon has been achieved (Diependaele et al., Reference Diependaele, Sandra and Grainger2009; Giraudo & Grainger, Reference Giraudo and Grainger2001).
It was found that targets followed by TL primes were responded to significantly slower than targets preceded by letter substitutions. These findings are in line with those of Duñabeitia et al. (Reference Duñabeitia, Perea and Carreiras2007), who reported no TL-priming effect across morpheme boundaries for suffixed (–14 ms in Experiment I) and prefixed words (–8 ms in Experiment II), and also with those of Perea and Carreiras (Reference Perea and Carreiras2008; –6 ms in Experiment I). In addition, the absence of a transposed-letter priming effect in the current study, when the RT data were averaged, also implies that decomposition occurs only when there is a semantic relationship between the target and prime because the use of TLs minimizes the prime’s resemblance to a real word and disrupts its semantic interpretability. Earlier TL experiments probably recruited participants with mixed levels of reading proficiency. Hence, following the argument of Beyersmann, McCormick, and Rastle (2016), TL priming effects might have been inhibited by the presence of participants with higher levels of proficiency as TL-priming is more prominent in participants with lower proficiency levels. A statistically significant difference between the unrelated and the SL-across condition was obtained, shedding doubt on some of the findings of studies that have used the unrelated condition as the baseline to obtain TL priming effects, and those that have used the SL condition as the baseline to get morphological priming effects (as in Experiment 2 in Diependaele, Morris, Serota, Bertrand, & Graunger, 2013; Experiments 3–5 in Rueckl & Rimzhim, Reference Rueckl and Rimzhim2011; Perea & Carreiras, Reference Perea and Carreiras2008).3
Our findings are consistent with a body of studies reporting that processing differences might be related to reading skills (Andrews & Lo, Reference Andrews and Lo2013; Ashby, Rayner, & Clifton, Reference Ashby, Rayner and Clifton2005; Beyersmann, Ziegler, et al., Reference Beyersmann, Ziegler, Castles, Coltheart, Kezilas and Grainger2016; Yap, Tse, & Balota, Reference Yap, Tse and Balota2009). Individual differences in reading skills, in our case vocabulary, word identification, reading comprehension, and reading nonwords, might predict masked morphological and TL-within and TL-across priming effects (as in Andrews & Lo, Reference Andrews and Lo2013; Beyersmann et al., Reference Beyersmann, Casalis, Grainger and Ziegler2015, Duñabeitia et. al., Reference Duñabeitia, Perea and Carreiras2014).
Even though morphological priming was stable across the whole reading-proficiency spectrum, the effect gradually diminished as readers became more proficient in their vocabulary knowledge, and this difference was most pronounced between the low-proficiency and high-proficiency groups. Different magnitudes of morphological priming observed in readers that have low versus high vocabulary knowledge support theories advocating that whole-word processing and morphological processing are carried out simultaneously as distinct routes (Beyersmann et al., Reference Beyersmann, McCormick and Rastle2013; Schreuder & Baayen, Reference Schreuder, Baayen and Feldman1995). While the group with low proficiency vocabulary skills showed more morphological priming through fast and automatic morpho-orthographic segmentation (e.g., Rastle & Davis, Reference Rastle and Davis2008), there was less priming in the high proficiency group, where the whole-word mapping route apparently “won the race.” Therefore, our observation supports the view that the morphological segmentation route is only one of the pathways in a dual-route model of morphological processing (Diependaele et al., Reference Diependaele, Sandra and Grainger2009; Morris, Porter, Grainger, & Holcomb, Reference Morris, Porter, Grainger and Holcomb2011). Such an approach also corroborates the lexical quality account of skilled reading (Perfetti, Reference Perfetti, Gough, Ehri and Treiman1992, Reference Perfetti2007), which associates skilled reading with the high quality of lexical representations, leading the reader to get the exact word rather than some part of it. This minimizes confusion about the meaning and the form of a word because precise representations are fully specified, and the features of the input govern which representation will be activated so that one correct representation can be activated.
With regard to the possible modulation of TL-priming effects by reading skills, the results of our exploratory analyses suggest that TL-within and TL-across priming effects were observed only in the case of nonword reading skills. Whether the TLs straddle a morphemic boundary appeared to have little impact on the magnitude of facilitation. TL-priming effects were greater for within-morpheme transpositions than for between-morpheme transpositions for less skilled nonword readers. This is in line with Duñabeitia et al. (Reference Duñabeitia, Perea and Carreiras2014), who found greater priming for within-morpheme transpositions with faster readers. However, no such difference was observed for the high-proficiency readers of nonwords in the present study. Hence, the decrease in the magnitude of priming effects when letter transpositions crossed morpheme boundaries in participants with lower nonword reading skills may speak in favor of accounts suggesting that prelexical morphological decomposition occurs at early stages of visual word recognition, and that orthography and morphology belong to the same stages (Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2007) in the context of nonword reading.
The opposite pattern of facilitation was observed for participants with high reading comprehension skills. Skilled readers could extract morphological information from TL-within primes but not from TL-across primes, possibly because morphological information was blocked when the transposition crossed a morphemic boundary. This might imply that morphological decomposition occurs very early in word recognition and is prelexical in nature for efficient readers. The disturbance of the affix in the cross-morphemic transposition condition appears to obstruct the prelexical parsing process, which, in turn, prevents the activation of allowable through morpho-orthographic parsing and leads to the dissipation of morphological boundary effects.
It is noteworthy that TL-across priming effects, but not TL-within priming effects, were robust in participants with low word-identification skills. The reason for this finding could be that TL-across primes still share a greater number of letters in the exact position with their prime words compared to TL-within primes (e.g., four vs. three letters in alloawble vs. allwoable–ALLOW, respectively). Considering that the recognition of visual word-forms and phonological access to pronunciations associated with visual word-forms are cognitive processes necessary for good word identification skills, it seems probable that participants with lower skills in word recognition displayed cross-morphemic priming effects while the higher proficiency group did not. Similarly, different levels of proficiency may have created the stark difference between participants with high- versus low-proficiency L2 word-identification skills. While the high-proficiency group displayed faster reaction times to SL-primes in the SL-across condition (alloimble), the low-proficiency participants produced slower reaction times to SL primes, leading to TL-priming effects.
The findings also imply that lower proficiency readers are more sensitive to morpho-orthographic interactions, pointing to the existence of a morpho-orthographic route at lower levels of proficiency. The results of the present study may also have implications for the effect of semantics on morphological TL-priming effects through the transposition of letters in real words, which were converted into nonexisting words (e.g., allwoable and alloawble). The absence of TL-priming effects in poor readers and highly proficient nonword readers is in keeping with Beyersmann, Ziegler, et al. (Reference Beyersmann, Ziegler, Castles, Coltheart, Kezilas and Grainger2016), who provided evidence in support of morpho-orthographic segmentation processes operating independent of semantics. However, the presence of TL-across priming effects in low-proficient nonword and real-word readers supports the dual-pathways theory (Diependaele et al., Reference Diependaele, Morris, Serota, Bertrand and Grainger2013) as the presentation of the masked prime alloawble facilitated the recognition of the target word ALLOW. As the disturbance of the affix hinders the morpho-orthographic parsing of the morphologically complex word, activation can only arise through the whole-word activation of the word form, which was suggested to be the case.
It is important to note that these results were exploratory in nature and can, in their present form, not be generalized to the general population. We suggest that future research follow up on the individual difference measures used in the present study with a larger cohort to investigate mechanisms that might modulate L2 priming.
The results of the current study also have implications for the time-course of morphological decomposition and letter position assignment. The absence of TL-across priming effects with competent readers, and relatively weak TL-across priming effects obtained for low-proficient nonword readers show that letter position assignment and morphological decomposition could probably co-occur for these particular groups of participants (Taft et al., Reference Taft, Li and Beyersmann2018).
As a final point, we would like to point out that these results should be considered together with a limitation of the present study. We acknowledge that the number of observations is somewhat below the recommendations for an ideally powered study with repeated measures design (Brysbaert & Stevens, Reference Brysbaert and Stevens2018). The present study nevertheless contributes to recent efforts in gaining a better understanding of the potential effects of individual differences on L2 morphological processing, particularly through the use of a comprehensive assessment of reading skills that goes beyond the comparatively limited, receptive test measures employed in earlier studies to assess individual differences in reading skills.
Conclusion
In conclusion, our results indicate that morphologically complex words are decomposed into their roots and affixes in the very early stages of L2 processing and that TL manipulations are associated with longer RTs than SL manipulations, leading to the absence of TL-priming effects. However, the results of the exploratory analysis into individual variabilities suggest that they might be modulating the masked morphological TL-priming effects. These findings, hence, point to a methodological stance that requires a shift from group-level design toward individual-level characteristics.
The present data also show that the process of letter position coding is dependent upon the context in which the manipulations take place, and that bilinguals are found to be more sensitive to cross-morphemic transpositions than they are to within-morphemic transpositions, though both types of transpositions occur string-internally. This points to the need for models of L2 visual word recognition to be able to provide an account for why intra-morphemic and cross-morphemic letter positions are not equal and for the role of individual differences in reading skills.
Acknowledgments
We are grateful to the Jorge González Alonso, Margaret Sönmez, Leo Gough, Joshua Bear, Martina Gračanin-Yüksek, Burak Aydn, Havva Öztürk, Nur Gedik-Bal, Enis Uğuz, and our reviewers for their contributions. We thank Serje Robidoux for very helpful statistics support. This research was supported by a PhD scholarship to Hasibe Kahraman by TÜBİTAK (the Scientific and Technological Research Council of Turkey) within the 2211–A National PhD Fellowship Programme and the 2214-A International Research Fellowship Programme.
Appendix A

Figure 7. Proficiency scores across Reading Skills battery.
Appendix B

Figure 8. Scatterplot of real priming effects with overlaid trend lines from the predicted model in vocabulary. The “observed values” that make up the scatterplot are provided in raw RT scores, but the models are fitting “–1000/RT.” Black line represents morphological priming, while the dark gray line and light gray line shows TL-within priming and TL-across priming, respectively. Thicker line represents the significant interaction.

Figure 9. Scatterplot of real priming effects with overlaid trend lines from the predicted model in reading comprehension. Black line: morphological priming. Dark gray line: significant TL-within priming. Light gray line: TL-across priming.

Figure 10. Scatterplot of real priming effects with overlaid trend lines from the predicted model in reading nonwords. Black line represents morphological priming, while dark gray line and light gray lines shows significant TL-within priming and TL-across priming, respectively.

Figure 11. Scatterplot of real priming effects with overlaid trend lines from the predicted model in word identification. Black line: morphological priming. Dark gray line: TL-within priming. Light gray line: significant TL-across priming.
Supplementary files for this article are available at the Open Science Framework (Appendix C and D).
Appendix C
Stimuli: https://osf.io/ahmg8/
Appendix D
The Reading Skills Battery on https://osf.io/rxm2e/

















 Open access
Open access