
Abstract
This work proposes stochastic genetic algorithm-assisted Fuzzy Q-Learning-based robotic manipulator control. Specifically, the aim is to redefine the action choosing mechanism in Fuzzy Q-Learning for robotic manipulator control. Conventionally, a Fuzzy Q-Learning-based controller selects a deterministic action from available actions using fuzzy Q values. This deterministic Fuzzy Q-Learning is not an efficient approach, especially in dealing with highly coupled nonlinear systems such as robotic manipulators. Restricting the search for optimal action to the agent’s action set or a restricted set of Q values (deterministic) is a myopic idea. Herein, the proposal is to employ genetic algorithm as stochastic optimizer for action selection at each stage of Fuzzy Q-Learning-based controller. This turns out to be a highly effective way for robotic manipulator control rather than choosing an algebraic minimal action. As case studies, present work implements the proposed approach on two manipulators: (a) two-link arm manipulator and (b) selective compliance assembly robotic arm. Scheme is compared with baseline Fuzzy Q-Learning controller, Lyapunov Markov game-based controller and Linguistic Lyapunov Reinforcement Learning controller. Simulation results show that our stochastic genetic algorithm-assisted Fuzzy Q-Learning controller outperforms the above-mentioned controllers in terms of tracking errors along with lower torque requirements.















Similar content being viewed by others


References
Gao, H., et al.: Neural network control of a two-link flexible robotic manipulator using assumed mode method. IEEE Trans. Ind. Inf. 15(2), 755–765 (2018)
Jin, L.; et al.: Robot manipulator control using neural networks: a survey. Neurocomputing 285, 23–34 (2018)
Radac, M.B.; et al.: Model-free control performance improvement using virtual reference feedback tuning and reinforcement Q-learning. Int. J. Syst. Sci. 48(5), 1071–1083 (2017)
Luo, B.; et al.: Model-free optimal tracking control via critic-only Q-learning. IEEE Trans. Neural Netw. Learn. Syst. 27(10), 2134–2144 (2016)
Kumar, A.; Sharma, R.: Fuzzy lyapunov reinforcement learning for nonlinear systems. ISA Trans. 67, 151–159 (2017)
Wen, S.; Hu, X.; Li, Z.; Lam, H.K.; Sun, F.; Fang, B.: NAO robot obstacle avoidance based on fuzzy Q-learning. Ind. Robot. 47(6), 801–811 (2019). https://doi.org/10.1108/IR-01-2019-0002
He, W.; et al.: Admittance-based controller design for physical human-robot interaction in the constrained task space. IEEE Trans. Autom. Sci. Eng. 17, 1937–1949 (2020)
Roveda, L.; Maskani, J.; Franceschi, P.; Abdi, A.; Braghin, F.; Tosatti, L.M.; Pedrocchi, N.: Model-based reinforcement learning variable impedance control for human-robot collaboration. J. Intell. Robot. Syst. 100, 417–433 (2020)
Yu, X.; He, W.; Li, H.; Sun, J.: Adaptive fuzzy full-state and output-feedback control for uncertain robots with output constraint. IEEE Trans. Syst. Man Cybern. Syst. (2020). https://doi.org/10.1109/TSMC.2019.2963072
Kumar, A., et al.: Lyapunov fuzzy Markov game controller for two link robotic manipulator. J. Intell. Fuzzy Syst. 34(3), 1479–1490 (2018)
Kumar, A., et al.: Linguistic lyapunov reinforcement learning control for robotic manipulators. Neurocomputing 272, 84–95 (2018)
Daneshfar, F.; Bevrani, H.: Load–frequency control: a GA-based multi-agent reinforcement learning. IET Gener. Transm. Distrib. 4(1), 13–26 (2010)
Martínez-Tenor, A., et al.: Towards a common implementation of reinforcement learning for multiple robotic tasks. Expert Syst. Appl. 100, 246–259 (2018)
Berkenkamp, F.; Turchetta, M.; Schoellig, A.; Krause, A.: Safe model-based reinforcement learning with stability guarantees. Adv. Neural Inf. Process. Syst. 2, 908–918 (2017)
Kukker, A.; Sharma, R.: Genetic algorithm-optimized fuzzy lyapunov reinforcement learning for nonlinear systems. Arab J. Sci. Eng. 45, 1–10 (2019)
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
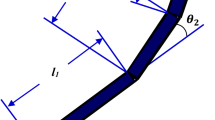
1.1 Two-Link Robot Arm
Figure

Two-link robot manipulator
16 shows two-link arm manipulator model.
-
Manipulator dynamics:
$$ \begin{array}{l} \left[ \begin{array}{l} \beta + \alpha + 2\eta \cos \phi (2) \, \alpha + \eta \cos \phi (2) \hfill \\ \alpha + \eta \cos \phi (2) \, \alpha \hfill \\ \end{array} \right]\left[ \begin{array}{l} {\mathop{\phi}\limits^{ \cdot\cdot}} (1) \hfill \\ {\mathop \phi \limits^{ \cdot\cdot }} (2) \hfill \\ \end{array} \right] + \left[ \begin{array}{l} - \eta \left( {2{\mathop \phi \limits^{ \cdot }} (1){\mathop \phi \limits^{ \cdot }} (2) + {\mathop \phi \limits^{ \cdot }}{2} (2)} \right)\sin \phi (2) \hfill \\ \, \eta {\mathop \phi \limits^{ \cdot }}{2} (1)\sin \phi (2) \hfill \\ \end{array} \right] \hfill \\ + \left[ \begin{array}{l} \beta \ell_{1} \cos \phi (1) + \eta \ell_{1} \cos \left( {\phi (1) + \phi (2)} \right) \hfill \\ \, \eta \ell_{1} \cos \left( {\phi (1) + \phi (2)} \right) \hfill \\ \end{array} \right] = \left[ \begin{array}{l} \tau (1) \hfill \\ \tau (2) \hfill \\ \end{array} \right] \hfill \\ \end{array} $$(18)$$ \beta = \left( {m_{1} + m_{2} } \right)b_{1}^{2} {, }\,\alpha { = }m_{2} b_{2}^{2} , \, \eta = m_{2} b_{1} b_{2} , \, \ell_{1} = {\raise0.7ex\hbox{$g$} \!\mathord{\left/ {\vphantom {g {b_{1} }}}\right.\kern-\nulldelimiterspace} \!\lower0.7ex\hbox{${b_{1} }$}} $$(19)$$ b_{1} = b_{2} = 1{\text{ m, }}m_{1} = m_{2} = 1{\text{ kg}}{.} $$-
Required Path: \(\phi_{d} \left( 1 \right) = \sin (t), \, \phi_{d} \left( 2 \right) = \cos (t)\).
-
State variable:\(x(k) = \left( {\phi (1),\phi (2),\mathop \phi \limits^{ \bullet } (1),\mathop \phi \limits^{ \bullet } (2)} \right)\).
-
1.2 SCARA Robot
Figure

2 DOF SCARA
17 gives model of the 2-degree-of-freedom (DOF) SCARA used in the present work.
-
Dynamical Model and Parameters:
$$ \begin{gathered} \left[ \begin{gathered} p_{1} + p_{2} \cos \left( {\phi (2)} \right) \, p_{3} + 0.5p_{2} \cos \left( {\phi (2)} \right) \hfill \\ p_{3} + 0.5p_{2} \cos \left( {\phi (2)} \right) \, p_{3} \hfill \\ \end{gathered} \right]\left[ \begin{gathered} \mathop \phi \limits^{ \bullet \bullet } (1) \hfill \\ \mathop \phi \limits^{ \bullet \bullet } (2) \hfill \\ \end{gathered} \right] + \hfill \\ \left[ \begin{gathered} \left( {p_{4} - p_{2} \sin \left( {\phi (2)} \right)\mathop \phi \limits^{ \bullet } (2)} \right)\mathop \phi \limits^{ \bullet } (2) - 0.5p_{2} \sin \left( {\phi (2)} \right)\mathop \phi \limits^{ \bullet } (2) \hfill \\ \, 0.5p_{2} \sin \left( {\phi (2)} \right)\mathop \phi \limits^{ \bullet } (1) + p_{5} \mathop \phi \limits^{ \bullet } (2) \hfill \\ \end{gathered} \right] = \left[ \begin{gathered} \tau (1) \hfill \\ \tau (2) \hfill \\ \end{gathered} \right] \hfill \\ \end{gathered} $$(20)$$ p_{1} = 5.0,p_{2} = 0.9,p_{3} = 0.3,p_{4} = 3.0,p_{5} = 0.6 $$(21)-
Desired trajectory:
$$ \begin{gathered} \phi_{d} (1) = 0.5 + 0.2\left( {\sin t + \sin 2t} \right) \, rad. \hfill \\ \phi_{d} (2) = 0.13 - 0.1\left( {\sin t + \sin 2t} \right) \, rad. \hfill \\ \end{gathered} $$
-
For both manipulators, the task is to follow desired trajectory \(\phi_{d} = \left[ {\phi_{d} (1) \, \phi_{d} (2)} \right]\) by applying torques \(\tau = \left[ {\tau (1) \, \tau (2)} \right]\) at each joint.
Rights and permissions
About this article

Cite this article
Kukker, A., Sharma, R. Stochastic Genetic Algorithm-Assisted Fuzzy Q-Learning for Robotic Manipulators. Arab J Sci Eng 46, 9527–9539 (2021). https://doi.org/10.1007/s13369-021-05379-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13369-021-05379-z