
Abstract
We extend the ability of an unitary quantum circuit by interfacing it with a classical autoregressive neural network. The combined model parametrizes a variational density matrix as a classical mixture of quantum pure states, where the autoregressive network generates bitstring samples as input states to the quantum circuit. We devise an efficient variational algorithm to jointly optimize the classical neural network and the quantum circuit to solve quantum statistical mechanics problems. One can obtain thermal observables such as the variational free energy, entropy, and specific heat. As a byproduct, the algorithm also gives access to low energy excitation states. We demonstrate applications of the approach to thermal properties and excitation spectra of the quantum Ising model with resources that are feasible on near-term quantum computers.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Quantum statistical mechanics concerns the physical properties of quantum systems at non zero temperatures. These problems pose two sets of challenges to classical computational approaches. First of all, classical algorithms generally encounter the difficulties of diagonalizing exponentially large Hamiltonians or the sign problem originating from the quantum nature of the problem. Moreover, even on the eigenbasis of the Hamiltonian one still faces the problem of the intractable partition function, which involves summation of an exponentially large number of terms.
A straightforward way to address these difficulties is to directly implement the physical Hamiltonian on analog quantum devices and study the system at thermal equilibrium; for example, see references [1, 2]. On the other hand, a potentially more general approach would be to study problems in quantum statistical mechanics with a universal gate model quantum computer. However, this strategy still calls for algorithmic innovations to prepare thermal quantum states given the unitary nature of quantum circuits. There have been quantum algorithms to prepare thermal Gibbs states on quantum computers [3–7]. Unfortunately, these approaches may not be feasible on near-term noisy quantum computers with limited circuit depth. While variational quantum algorithm for preparing thermofield double states [8, 9] requires additional quantum resources such as ancilla qubits, as well as measuring and extrapolating Renyi entropies. The quantum imaginary-time evolution [10] relies on exponentially difficult tomography on a growing number of qubits and synthesize of general multi-qubit unitaries.
Recently, references [11, 12] proposed practical approaches to prepare the thermal density matrix as a classical probabilistic mixture of quantum pure states in the eigenbasis of the density matrix. In these proposals, the classical part is either assumed to be a factorized probability distribution or as an energy-based model [13]. However, the factorized distribution is generally a crude approximation for the Gibbs distribution in the eigenbasis. While the energy-based model still faces the problem of the intractable partition function, which inhibits efficient and unbiased sampling, learning, or even evaluating the model likelihood.
Modern probabilistic generative models offer solutions to these problems about expressibility and tractability [15] since the goals of generative modeling are exactly to represent, learn and sample from complex high-dimensional probability distributions efficiently. Popular generative models include autoregressive models [14, 16, 17], variational autoencoders [18], generative adversarial networks [19], and flow-based models [20]. For the purpose of this study, the autoregressive models stand out since they support unbiased gradient estimator for discrete variables, direct sampling, and tractable likelihood at the same time. The autoregressive models have reached state-of-the-art performance in modeling realistic data and found real-world applications in synthesizing natural speech and images [16, 17]. Variational optimization of the autoregressive network has been used for classical statistical physics problems [21, 22]. Quantum generalization of the network was also employed for the ground state of quantum many-body systems [23].
In this paper, we combine quantum circuits with autoregressive probabilistic models to study thermal properties of quantum systems at finite temperature. The resulting model allows one to perform variational free energy calculation over density matrices efficiently. We demonstrate applications of the approach to quantum Ising model on a square lattice, where we obtain its variational free energy, thermal entropy, specific heat and excitation energies.
By leveraging the recent advances in deep probabilistic generative models, the proposed approach extends the variational quantum eigensolver (VQE) [24] to thermal quantum states with essentially no overhead. Thus, the present algorithm is also feasible for near-term quantum computers [25–31]. The only practical difference to the ground state VQE is that one needs to sample input states to the quantum circuit from a classical distribution, and one has an additional term in the objective function to account for the entropy of the input distribution.
For the classical simulation of the proposed algorithm, we use Yao.jl, an extensible and efficient framework for quantum algorithm design [32]. Yao.jl's batched quantum register and automatic differentiation via reversible computing [33] makes it an ideal tool for differentiable programming models which combine classical neural networks and quantum circuits. Our code implementation can be found at [34].
2. Model architecture, objective function, and optimization scheme
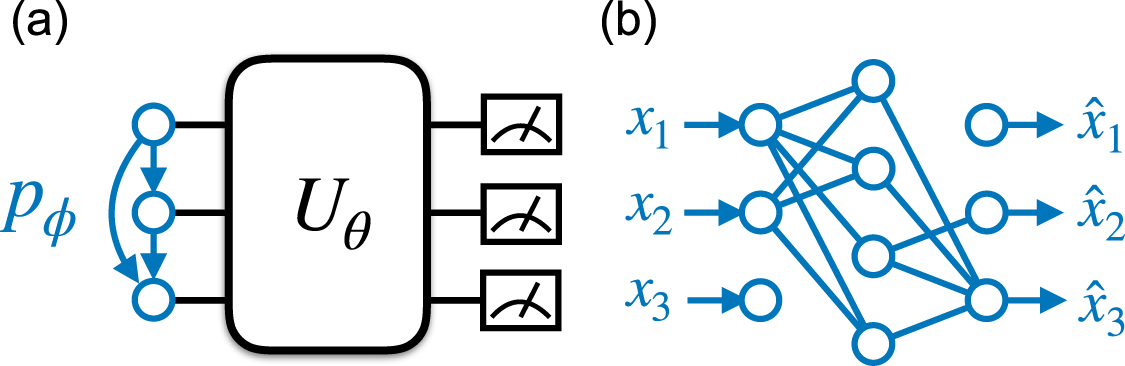
Figure 1(a) shows the architecture of the variational ansatz. A classical probabilistic model generates binary random variables x according to a classical distribution  , where φ are the network parameters. It is straightforward to prepare qubits to the classical product state
, where φ are the network parameters. It is straightforward to prepare qubits to the classical product state  . Then, a parametrized quantum circuit performs unitary transformation to the input states
. Then, a parametrized quantum circuit performs unitary transformation to the input states  , where the circuit parameters θ do not depend on the inputs. Overall, the model produces a classical mixture of quantum states. The density matrix of the ensemble reads [11, 12]
, where the circuit parameters θ do not depend on the inputs. Overall, the model produces a classical mixture of quantum states. The density matrix of the ensemble reads [11, 12]

The density matrix is hermitian and positive definite. Moreover, given a normalized classical probability, one has  . The density matrix depends both on parameters φ and θ. We omit the explicit dependence in the notation to avoid cluttering in the notations.
. The density matrix depends both on parameters φ and θ. We omit the explicit dependence in the notation to avoid cluttering in the notations.

Figure 1. (a) The autoregressive network shown in blue is a classical probabilistic model that parametrizes a joint distribution in the form of equation (2). The model generates bit string as easy to prepare input product states to the quantum circuit. The neural network and the circuit produce a parametrized density matrix equation (1). (b) An implementation of the autoregressive model  using the masked autoencoder [14]. The neural network maps bit strings to real-valued outputs which parametrizes the conditional probabilities in equation (2).
using the masked autoencoder [14]. The neural network maps bit strings to real-valued outputs which parametrizes the conditional probabilities in equation (2).
Download figure:
Standard image High-resolution imageThe parametrized quantum circuit performs a unitary transformation to the diagonal density matrix  , whose diagonal elements are parametrized by a neural network. Using a quantum circuit for the unitary transformation [35] is more general than the classical flow model [36]. Moreover, it automatically ensures physical constraints such as the orthogonality of the eigenstates. The classical distribution
, whose diagonal elements are parametrized by a neural network. Using a quantum circuit for the unitary transformation [35] is more general than the classical flow model [36]. Moreover, it automatically ensures physical constraints such as the orthogonality of the eigenstates. The classical distribution  is in general nontrivial since it is not necessarily factorized for each dimension of x [11, 12]. Thus, exact representation of the classical distribution on the eigenbasis
is in general nontrivial since it is not necessarily factorized for each dimension of x [11, 12]. Thus, exact representation of the classical distribution on the eigenbasis  may also incur exponential resources. Parametrizing the probability distribution using a classical Boltzmann distribution has the problem of intractable partition functions. Hence, we employ an autoregressive network to produce the input states of the quantum circuit.
may also incur exponential resources. Parametrizing the probability distribution using a classical Boltzmann distribution has the problem of intractable partition functions. Hence, we employ an autoregressive network to produce the input states of the quantum circuit.
The autoregressive network models the joint probability distribution as a product of conditional probabilities

where one has assumed an order of each dimension of the variables.  denotes the set of variables that are before xi
. The autoregressive network is a special form of Bayesian network, which models conditional dependence of random variables as a directed acyclic graph shown in figure 1(a). The model can capture high-dimensional multimode distribution with complex correlations. One can also directly draw uncorrelated samples from the joint distribution via ancestral sampling, which follows the order of the conditional probabilities.
denotes the set of variables that are before xi
. The autoregressive network is a special form of Bayesian network, which models conditional dependence of random variables as a directed acyclic graph shown in figure 1(a). The model can capture high-dimensional multimode distribution with complex correlations. One can also directly draw uncorrelated samples from the joint distribution via ancestral sampling, which follows the order of the conditional probabilities.
The practical implementation of the autoregressive networks largely benefits from rapid development of deep learning architectures such as the recurrent or convolutional neural networks [16, 17] and autoencoders [14]. In this paper, we employ the masked autoencoder shown in figure 1(b). The autoencoder network transforms bit string x to real-valued vector  of the same dimension, where each element satisfies
of the same dimension, where each element satisfies  , e.g. outputs of sigmoid activation functions [13]. We mask out some connections in the autoencoder network so the connectivity ensures that
, e.g. outputs of sigmoid activation functions [13]. We mask out some connections in the autoencoder network so the connectivity ensures that  only depends on the binary variable
only depends on the binary variable  . Thus, each element of the output defines a conditional Bernoulli distribution
. Thus, each element of the output defines a conditional Bernoulli distribution  for the binary variable xi
. In this way, the joint probability for all binary variables satisfies the autoregressive property equation (2). Since each conditional probability is normalized
for the binary variable xi
. In this way, the joint probability for all binary variables satisfies the autoregressive property equation (2). Since each conditional probability is normalized  , the joint distribution is normalized by construction. The probability distribution is parameterized by the network parameters φ. In a simple limit where the network is disconnected,
, the joint distribution is normalized by construction. The probability distribution is parameterized by the network parameters φ. In a simple limit where the network is disconnected,  and one restores the product state ansatz considered in references [11, 12].
and one restores the product state ansatz considered in references [11, 12].
Given a Hamiltonian H at inverse temperature β, the density matrix  plays a central role in the quantum statistical mechanics problem, where
plays a central role in the quantum statistical mechanics problem, where  is an intractable partition function. One can perform the variational calculation over the parametrized density matrix equation (1) by minimizing the objective function
is an intractable partition function. One can perform the variational calculation over the parametrized density matrix equation (1) by minimizing the objective function

which follows the Gibbs–Delbrück–Molière variational principle of quantum statistical mechanics [37]. The two terms of equation (3) correspond to the entropy and the expected energy of the variational density matrix respectively. The objective function is related to the quantum relative entropy  between the variational and the target density matrices. Since the relative entropy is non-negative [38], one has
between the variational and the target density matrices. Since the relative entropy is non-negative [38], one has  , i.e. the loss function is lower bounded by the physical free energy. The equality is reached only when the variational density matrix reaches the physical one ρ = σ.
, i.e. the loss function is lower bounded by the physical free energy. The equality is reached only when the variational density matrix reaches the physical one ρ = σ.
To estimate the objective function equation (3), one can sample a batch of input states  from the autoregressive network, then apply the parametrized circuit and measure the following estimator:
from the autoregressive network, then apply the parametrized circuit and measure the following estimator:

The first term depends solely on the classical probabilistic model, which can be directly computed via equation (2) on the samples. Note that the entropy of the autoregressive model is known exactly rather than being intractable in the energy-based models [12]. Moreover, having direct access to the entropy avoids the difficulties of extrapolating the Renyi entropies measured on the quantum processor [8, 9]. The second term of equation (4) involves the expected energy of Hamiltonian operators  , where we denote
, where we denote ![$\langle O \rangle = \mathbb{E}_{x\sim p_\phi(x)} \left[ \left\langle x\left|U_{\theta}^{\dagger} O U_{\theta}\right| x \right\rangle \right]$](https://content.cld.iop.org/journals/2632-2153/2/2/025011/revision3/mlstaba19dieqn23.gif) . The classical neural network and the quantum circuit perform classical and quantum average respectively. The equation (4) shows zeros variance property, i.e. when the variational density matrix exactly reaches to the physical one, the variance of the estimator equation (4) reduces to zero. This can be used as a self-verification of the variational ansatz and minimization procedure [30].
. The classical neural network and the quantum circuit perform classical and quantum average respectively. The equation (4) shows zeros variance property, i.e. when the variational density matrix exactly reaches to the physical one, the variance of the estimator equation (4) reduces to zero. This can be used as a self-verification of the variational ansatz and minimization procedure [30].
We would like to utilize the gradient information to train the hybrid model which consists of neural networks and quantum circuits efficiently. Moreover, random sampling of the autoregressive net and the quantum circuit suggest that one should employ stochastic optimization with noisy gradient estimators [13]. First, the gradient with respect to the circuit parameters reads

The term inside the square bracket is a gradient of a quantum expected value. To evaluate the expectation on an actual quantum device, one can employ the parameter shift rule of [39–42]. These approaches estimate the gradient of each circuit parameter using the difference of two sets of measurement on the quantum circuit with the same architecture. While in the classical simulation of the quantum algorithm one can employ the automatic differentiation [43] to evaluate the gradient efficiently.
Next, the gradients of the neural network parameters can be evaluated using the REINFORCE algorithm [45]

where the term  , known as the score-function gradient in the machine learning literature [46], can be efficiently evaluated via backpropagation through the probabilistic model equation (2) [43]. In this regard,
, known as the score-function gradient in the machine learning literature [46], can be efficiently evaluated via backpropagation through the probabilistic model equation (2) [43]. In this regard,  can be viewed as the 'reward signal' given the policy
can be viewed as the 'reward signal' given the policy  for generating bit string samples. We have introduced the baseline
for generating bit string samples. We have introduced the baseline ![$b = \mathbb{E}_{x \sim p_{\phi}} \left[f(x)\right]$](https://content.cld.iop.org/journals/2632-2153/2/2/025011/revision3/mlstaba19dieqn27.gif) which does not affect the expectation of equation (6) since
which does not affect the expectation of equation (6) since ![$\mathbb{E}_{x \sim p_{\phi}} \left[ \nabla_\phi \ln p_\phi(x) \right] = 0$](https://content.cld.iop.org/journals/2632-2153/2/2/025011/revision3/mlstaba19dieqn28.gif) . However, the baseline helps to reduce the variance of the gradient estimator [47].
. However, the baseline helps to reduce the variance of the gradient estimator [47].
Given the gradient information we train the autoregressive network and the quantum circuit jointly with the stochastic gradient descend method. The training procedure finds out the circuit  which approximately diagonalizes the density matrix and brings the negative log-likelihood
which approximately diagonalizes the density matrix and brings the negative log-likelihood  closer to the energy spectrum of the system. In principle, the same circui can diagonalize the density matrices at all temperatures if
closer to the energy spectrum of the system. In principle, the same circui can diagonalize the density matrices at all temperatures if  fully diagonalize the Hamiltonian. However, in the practical variational calculation, this does not need to be the case to achieve good variational free energy since the temperature selects the relevant low-energy spectra which contributes mostly to the objective function.
fully diagonalize the Hamiltonian. However, in the practical variational calculation, this does not need to be the case to achieve good variational free energy since the temperature selects the relevant low-energy spectra which contributes mostly to the objective function.
After training, one can sample a batch of input states  and treat them as approximations of the eigenstates of the system. Since the unitary circuit preserves orthogonality of the input states, the sampled quantum states span a low energy subspace of the Hamiltonian. For example, measuring the expected energy
and treat them as approximations of the eigenstates of the system. Since the unitary circuit preserves orthogonality of the input states, the sampled quantum states span a low energy subspace of the Hamiltonian. For example, measuring the expected energy  reveals the excitation energies of the system. In this respect, the objective function equation (3) is related to the weighted subspace-search VQE algorithm for the excited states [48]. Different from the weighted subspace-search VQE, a single physical parameter inverse temperature β controls the relative weights on the input states. Adaptive sampling of the autoregressive model provides the correct weights that spans the relevant low energy space. Due to its close connection to the original VQE algorithm [24], we denote the present approach as the β-VQE algorithm. While suppose the Hamiltonian is diagonal in the computational basis, i.e. a classical Hamiltonian, one can leave out the quantum circuit and the approach falls back to the variational autoregressive network approach of reference [21]. In the classical limit it is also obvious that the autoregressive ansatz is advantageous than a simple product ansatz.
reveals the excitation energies of the system. In this respect, the objective function equation (3) is related to the weighted subspace-search VQE algorithm for the excited states [48]. Different from the weighted subspace-search VQE, a single physical parameter inverse temperature β controls the relative weights on the input states. Adaptive sampling of the autoregressive model provides the correct weights that spans the relevant low energy space. Due to its close connection to the original VQE algorithm [24], we denote the present approach as the β-VQE algorithm. While suppose the Hamiltonian is diagonal in the computational basis, i.e. a classical Hamiltonian, one can leave out the quantum circuit and the approach falls back to the variational autoregressive network approach of reference [21]. In the classical limit it is also obvious that the autoregressive ansatz is advantageous than a simple product ansatz.
3. Numerical simulations
We demonstrate application of β-VQE to thermal properties of quantum lattice problems. Despite that most of the efforts on VQE have been devoted to quantum chemistry problems [25–29], quantum lattice problems are more native applications on near-term quantum computers for two reasons. First, typical problems with local interaction one does not suffer from unfavorable scaling of a large number of Hamiltonian terms. Second, quantum lattice models that only involve spins and bosons do not invoke the overhead of mapping from fermion to qubits. Therefore, it is anticipated that near-term devices should already produce valuable results for quantum lattice problems before they are impactful for quantum chemistry problems [49].
We consider the prototypical transverse field Ising model on a square lattice with open boundary conditions:

where Zi
and Xi
are Pauli operators acting on the lattice sites. The model exhibits a quantum critical point at zero temperature at Γc
= 3.044 38(2). While for  the model exhibits a thermal phase transition from a ferromagnetic phase to a disordered phase. All of these rich physics can be studied unbiasedly with sign-problem free quantum Monte Carlo approach, e.g. see [50]. Having abundant established knowledge makes the problem equation (7) an ideal benchmark problem for the β-VQE algorithm on near-term quantum computers.
the model exhibits a thermal phase transition from a ferromagnetic phase to a disordered phase. All of these rich physics can be studied unbiasedly with sign-problem free quantum Monte Carlo approach, e.g. see [50]. Having abundant established knowledge makes the problem equation (7) an ideal benchmark problem for the β-VQE algorithm on near-term quantum computers.
For the autoregressive network equation (2) we employ the masked autoencoder architecture [14] shown in figure 1(b). We arrange the qubits on the two dimensional grid following the typewriter order. The autoencoder has a single hidden layer of 500 hidden neurons with rectified linear unit activation. For the variational quantum circuit, we employ the setup shown in figure 2, which arranges the qubits on a two dimensional grid [51] and apply general two qubit gates [44] on the neighboring sites in each layer. The general gate consists of 15 single-qubit gates and three CNOT gates. Each two qubit unitary is parametrized by 15 parameters in the rotational gates, which parametrizes the SU(4) group. The circuit architecture enjoys a balanced expressibility and hardware efficiency. We repeat the pattern for d times, which we denote as the depth d of the variational quantum circuit. Therefore, for the 3 × 3 system considered in figure 2(a) with d = 5, there are 15 × 12 × 5 = 900 circuit parameters. Initially we set all the circuit parameters to be zero. We estimate the gradients equations (5) and (6) on batch of 1000 samples, and we use the Adam algorithms [13] to optimize the parameters φ and θ jointly.

Figure 2. (a) Layout of the two qubit unitaries in the variational circuit  . In each step one applies two-qubit gates to adjacent qubits. (b) The two-qubit SU(4) gate consists of three CNOT and 15 single qubit rotation gates. Each single-qubit gate contains a learnable parameter [44].
. In each step one applies two-qubit gates to adjacent qubits. (b) The two-qubit SU(4) gate consists of three CNOT and 15 single qubit rotation gates. Each single-qubit gate contains a learnable parameter [44].
Download figure:
Standard image High-resolution imageFigure 3 shows that the objective function decreases towards the exact values as a function of training epochs. We measure physical observables on the trained model and compare them with exact results. For example, figures 4(a) and (b) show the expected energy  and the specific heat
and the specific heat  computed by measuring Hamiltonian expectation and its variance. Moreover, one sees in figure 4(c) that the entropy
computed by measuring Hamiltonian expectation and its variance. Moreover, one sees in figure 4(c) that the entropy ![$\mathbb{E}_{x\sim p_\phi(x)} \left[ -\ln p_{\phi}(x) \right]$](https://content.cld.iop.org/journals/2632-2153/2/2/025011/revision3/mlstaba19dieqn38.gif) changes from ln2 per site in the high temperature limit towards zero at zero temperature. While the purity of the system
changes from ln2 per site in the high temperature limit towards zero at zero temperature. While the purity of the system ![$\operatorname{\textrm{Tr}}(\rho^2) = \mathbb{E}_{x\sim p_\phi(x)} \left[ p_{\phi}(x) \right]$](https://content.cld.iop.org/journals/2632-2153/2/2/025011/revision3/mlstaba19dieqn39.gif) shown in figure 4(d) increases from zero towards one as the temperature decreases. All these observables can be directly measured on an actual quantum device. Overall, one sees the autoregressive model equation (2) combined with variational quantum circuit yields accurate results over all temperatures. Note that in both the simulation and the actual experiment there will be statistical error bars due to random sampling of the autoregressive model. However, given the Hilbert space size (29 = 512) and the batch size used in the calculation (1000), the remaining deviation from the exact results is due to limits of representability and optimization, but not the statistical noises.
shown in figure 4(d) increases from zero towards one as the temperature decreases. All these observables can be directly measured on an actual quantum device. Overall, one sees the autoregressive model equation (2) combined with variational quantum circuit yields accurate results over all temperatures. Note that in both the simulation and the actual experiment there will be statistical error bars due to random sampling of the autoregressive model. However, given the Hilbert space size (29 = 512) and the batch size used in the calculation (1000), the remaining deviation from the exact results is due to limits of representability and optimization, but not the statistical noises.

Figure 3. The variational loss equation (4) approaches to the exact free energies (black solid lines) of the 3 × 3 quantum Ising model equation (7) at β = 1.
Download figure:
Standard image High-resolution image
Figure 4. Physical quantities obtained via the β-VQE algorithm for the 3 × 3 quantum Ising model equation (7) at Γ = 3. The black solid lines are exact solutions.
Download figure:
Standard image High-resolution imageFigure 5 shows the low energy spectrum of the quantum Ising model obtained from β-VQE at β = 0.5. One sees that the approach provides low energy spectrum of the problem at various strength of the transverse field. The approach works nicely even when the first excited state becomes nearly degenerated with the ground state.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 5. Low energy excitation spectra of 3 × 3 quantum Ising model. The symbols denote energy expectations  measured on the samples of the autoregressive model trained at inverse temperature β = 0.5. The solid lines are exact solutions.
measured on the samples of the autoregressive model trained at inverse temperature β = 0.5. The solid lines are exact solutions.
Download figure:
Standard image High-resolution image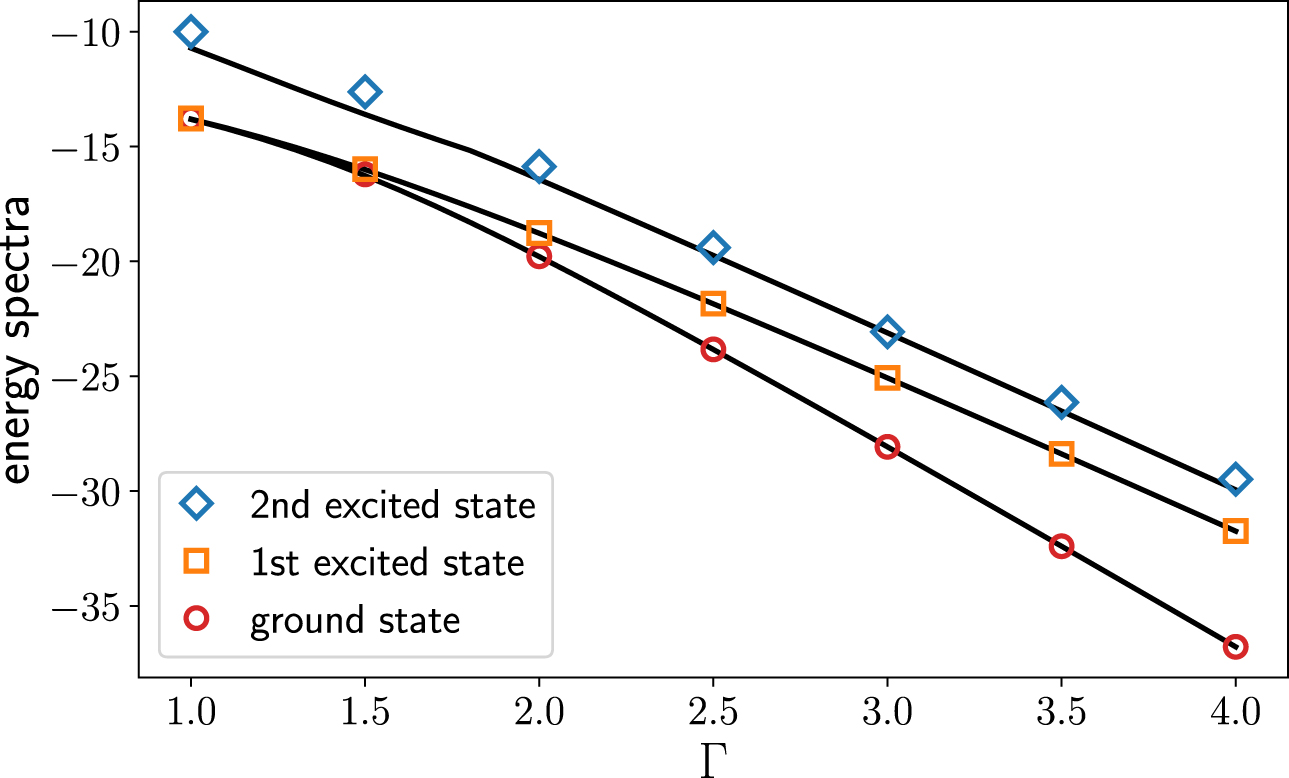{kind=link}
4. Outlooks
The present approach would be most useful for studying the thermal properties of frustrated quantum systems which are prevented by the sign problem [52]. Moreover, one can further employ the qubit efficient VQE scheme [53, 54], where one can study the thermal properties of quantum many-body systems on a quantum computer with the number of qubits smaller than problem size. In that scenario, the ansatz for the density matrix is a classical mixture of matrix product states. The variational ansatz for density matrix can also be used in a quantum algorithm for non-equilibrium dynamics [55] and steady states [56].
The quantum circuit also acts as a canonical transformation that brings the density matrix to a diagonal representation. Combined with the fact that one can obtain the marginal likelihood of the leading bits in the autoregressive models, the setup may be useful for deriving effective models with less degrees of freedom similar to the classical case [57]. Therefore, one can envision using the present setup to derive effective models by using a quantum circuit for renormalization group transformation. Moreover, since the circuit approximately diagonalizes the density matrix, one also can make use of it for later purposes, such as accelerated time evolution [58].
Regarding further improvements of the algorithm, one may consider using tensor network probabilistic models [59, 60] instead of the autoregressive network to represent the classical distribution in the eigenbasis. Both models have the shortcoming that the sampling approach produces the bits sequentially. To address this issue, one may consider employing the recently proposed flow models for discrete variables [61, 62]. While to further improve the optimization efficiency, one may consider using the improved gradient estimator with even lower variances [63, 64]. To this end, differentiable programming of neural networks and quantum circuits shares a unified computational framework. Therefore, a seamless integration of models and techniques will enjoy advances of both worlds.
Acknowledgment
We thank useful discussion with Nobuyuki Yoshioka and Yuya O Nakagawa. We thank Xiu-Zhe Luo for contribution to Yao.jl [32] and Dian Wu for collaboration in reference [21]. The authors are supported by the National Natural Science Foundation of China under Grant No. 11774398. P Z is supported by the Key Research Program of Frontier Sciences, CAS, Grant No. QYZDB-SSW-SYS032, and Project Nos. 11 747 601 and 11 975 294 of National Natural Science Foundation of China.
All data that support the findings of this study are included within the article (and any supplementary information files).