
Abstract
The coronavirus COVID-19 pandemic is today’s major public health crisis, we have faced since the Second World War. The pandemic is spreading around the globe like a wave, and according to the World Health Organization’s recent report, the number of confirmed cases and deaths are rising rapidly. COVID-19 pandemic has created severe social, economic, and political crises, which in turn will leave long-lasting scars. One of the countermeasures against controlling coronavirus outbreak is specific, accurate, reliable, and rapid detection technique to identify infected patients. The availability and affordability of RT-PCR kits remains a major bottleneck in many countries, while handling COVID-19 outbreak effectively. Recent findings indicate that chest radiography anomalies can characterize patients with COVID-19 infection. In this study, Corona-Nidaan, a lightweight deep convolutional neural network (DCNN), is proposed to detect COVID-19, Pneumonia, and Normal cases from chest X-ray image analysis; without any human intervention. We introduce a simple minority class oversampling method for dealing with imbalanced dataset problem. The impact of transfer learning with pre-trained CNNs on chest X-ray based COVID-19 infection detection is also investigated. Experimental analysis shows that Corona-Nidaan model outperforms prior works and other pre-trained CNN based models. The model achieved 95% accuracy for three-class classification with 94% precision and recall for COVID-19 cases. While studying the performance of various pre-trained models, it is also found that VGG19 outperforms other pre-trained CNN models by achieving 93% accuracy with 87% recall and 93% precision for COVID-19 infection detection. The model is evaluated by screening the COVID-19 infected Indian Patient chest X-ray dataset with good accuracy.
Similar content being viewed by others

1 Introduction
The outbreak of coronavirus occurred in December 2019, where China reported a cluster of unknown causes of pneumonia cases in the city of Wuhan, Hubei province to the World Health Organisation(WHO) [14, 30, 38]. This SARS-CoV-2 or COVID-19 disease spread rapidly around the world [30, 33] and considering severity, WHO announced COVID-19 as a pandemic. Till date (5th June 2020), a total of 6,675,011 cases of COVID-19 have been reported, including total 391,848 deaths worldwide [10]. Inhaling infected droplets may spread the disease, with an incubation period of between two and fourteen days [29]. People with cough, shortness of breath or difficulty breathing, fever, chills, muscle pain, loss of taste or smell, and sore throat symptoms may have COVID-19 [9, 29]. Other less common symptoms have been reported, such as nausea, vomiting, or diarrhea etc. [9]. Dr. Mike Ryan, Executive Director, WHO Health emergencies said, ”It is important to put this on the table: this virus may become just another endemic virus in our communities, and this virus may never go away” on 14th May 2020 at the Geneva Virtual Press Conference [3]. WHO suggested that rapid testing is one of the effective measures to control the spread of SARS-CoV-2 infection [37]. Currently, Real-time reverse transcription-polymerase chain reaction (RT-PCR) testing technique is used for laboratory diagnosis of COVID-19 [6, 34]; however it suffers with following three issues:
-
1.
Shortage of RT-PCR kits.
-
2.
Non-urban community hospitals lack the PCR infrastructure to support high sample throughput.
-
3.
RT-PCR depends on the existence of detectable SARS-CoV-2 in the collected samples. [34].
Alternatively, it is found that Chest radiography examination can also be used for COVID-19 screening; where X-ray images or computed tomography (CT) images are examined by radiologists to search for visual markers linked with SARS-CoV-2 infection. The major hallmarks of SARS-CoV-2 infection on chest radiography imaging are consolidative pulmonary opacities with more tendency to involve lower lobe(s); bilateral and peripheral ground glass appearance [5]. Pleural effusion is rare in case of COVID infections. Due to low RT-PCR sensitivity (60%-70%), even though negative results found, symptoms can be identified by an analysis of CT images [16]. Use of CT images as a diagnostic modality has following issues:
-
1.
CT imaging devices are costly and require high level of expertise in handling.
-
2.
CT imaging devices are not portable; thus, there are higher chances of human to human transmission during patient transport due to lack of personal protective equipment (PPE) kits available with medical staffs [26].
-
3.
CT imaging takes more time for processing than that of X-ray imaging.
-
4.
High-quality CT imaging devices may not be available in many hospitals or clinics in non-urban areas, making timely screening of COVID-19 infections difficult.
X-rays, on the other hand, are the most common and easily accessible radiographic examination techniques in the clinical practices and is of great use for low cost and faster screening of COVID-19 infections in the current epidemic situation [25, 36].
In response to the growing coronavirus pandemic situation and the shortage of expert radiologists, an artificial intelligence (AI) based COVID-19 diagnostic system with high sensitivity and specificity; without human intervention is highly desirable for the analysis of radiography imaging features. These AI-powered COVID-19 diagnostic systems can make COVID-19 screening tests cheaper and real-time mass testing effectively. Also, the chances of transmission to the involved technicians will be reduced and the burden on the existing limited health experts or radiologists will also be reduced.
Considering the limitations of the existing RT-PCR and CT based COVID-19 diagnostic techniques, in this work, we propose a low cost, realtime, faster, scalable DCNN model, called Corona-Nidaan for COVID-19 patient screening using chest X-ray samples. The proposed model is end-to-end trained with 20,907 chest X-ray images (including synthetic images) which are collected from the three different open-source datasets [7, 8, 20]. In our proposed model, we use Depth-wise separable convolutional layers instead of traditional 2D convolutional layers in order to make our model lightweight and to reduce the computational complexity. In case of embedded and mobile vision applications with the constrained computational resource requirements, light-weight deep learning models with fewer parameters plays an important role. Our proposed model consists of total of 4.022 million parameters, which is lower than that of 1.0 MobileNet-224 (4.2 million parameters) [13]. This makes our model suitable in case of on-device DNN implementation for COVID-19 screening.
In this research, we also want to answer the following questions: 1) How effective is the transfer-learning with existing pre-trained DCNN models for detecting COVID-19 infection?; 2) Given the X-Ray image of the chest, what is the best way to extract features related to the hallmarks of COVID-19 disease? To find the answers to these questions, we evaluate the performance of five different well-known pre-trained CNN models along with the proposed Corona-Nidaan model. It is found that Corona-Nidaan model outperforms over the transfer-learning models and other state of art works mentioned in recent literature. Proposed Corona-Nidaan model and other implemented transfer-learning based pre-trained models are publicly available at https://github.com/mainak15/Corona-Nidaan.
To summarize, this work has four major contributions:
-
1.
A novel light weight DCNN model titled Corona-Nidaan is proposed that can learn the hallmarks of SARS-CoV-2 infection from chest X-ray samples and then detect COVID-19 cases within a second, without human intervention.
-
2.
The efficacy of transfer learning using pre-trained CNNs is investigated on the chest X-ray images for COVID-19 infection detection.
-
3.
A simple oversampling technique is suggested to overcome the imbalance classification problem.
-
4.
The efficacy of the Corona-Nidaan model is also validated against the screening of COVID-19 infected Indian Patient chest X-ray dataset.
The remaining paper organized as follows: In Section 2, we review the related work on chest X-Ray based COVID-19 infection detection. In Section 3, we introduce the proposed Corona-Nidaan deep neural network architecture and its design principles along with new minority class oversampling approach. In Section 4, we present the experimental setup, the formation of the ChestX dataset, implementation details, detailed analysis of implemented models, comparison of Corona-Nidaan with other approaches, along with the performance of Corona-Nidaan against Indian COVID-19 patients dataset. Section 5 states the conclusions of this work along with the future work to be established in these directions.
2 Related work
Recent advancements in the deep learning techniques and the availability of large open-source medical image datasets has enabled creation of deep neural networks to deliver promising results without human intervention in a wide range of medical imaging tasks, such as lung diseases diagnosis from chest X-ray images [25, 36], breast cancer detection [4], pulmonary tuberculosis classification [18], diabetic retinopathy detection [11] and arrhythmia detection [24]. Wang et al. [36] released a new front-view chest X-ray dataset consisting of 108,948 images of 32,717 patients with 8 disease labels. The authors used transfer learning with ImageNet pre-trained CNNs (ResNet-50, GoogLeNet, AlexNet, and VGGNet-16) to detect 8 lung diseases, including pneumonia. Rajpurkar et al. [25] utilized CheXNet for pneumonia detection using the ChestX-ray14 dataset. The dataset contains 112,120 frontal chest X-ray images. The authors achieved the F1 score of value 0.435 which is slightly more than the F1 score value (0.387) which is achieved by using radiologist’s consultation.
Recently, several deep learning approaches are suggested by researchers to screen and diagnose coronavirus-infected patients using chest X-ray images. Wang and Lin et al. [35] proposed COVID-Net, a deep learning model, and trained the model with the COVIDx dataset consisting of 13,800 frontal-view chest X-ray images, extracted from total 13,725 patient cases. The dataset consists of 183 COVID-19 samples, 8,066 normal samples, and 5,538 pneumonia samples are obtained from the three different open-access datasets. Although the authors achieved 92.6% test accuracy in three-class classification, it is found that the model exhibits high false negative rate for COVID-19 class and large number of trainable parameters. Hemdan et al. [12] employed transfer learning with ImageNet pre-trained CNNs for COVID-19 detection and reported good performance of VGG19 and DenseNet121 compared to other pre-trained CNN models. However, we found that these CNN models are fine-tuned with only 25 COVID-19 and 25 normal X-ray samples. Ozturk et al. [22] proposed DarkCovidNet model based on DarkNet architecture, and achieved 87.02% test accuracy in the three-class classification. DarkCovidNet model consists of 17 convolutional layers, and the model is trained on minimal COVID-19 samples. Due to the use of under-sampling techniques, it is quite possible that the DarkCovidNet model miss the important signatures of normal and pneumonia class. Mangal et al. [19] presented the CovidAID model that achieves 90.5% accuracy with a 100% recall for COVID-19 screening. To tackle the imbalanced classification problem due to limited COVID samples, the authors considered a random subset of pneumonia data in each batch, while training the model. However, the model suffers with many false negative cases for the normal class. Apostolopoulos et al. [1] analyzed the performance of the transfer learning with pre-trained CNNs. The authors achieved 93.48% and 98.75% classification accuracy in three and two class classifications, respectively, against a dataset consisting of 700 pneumonia, 224 Covid-19, and 504 normal chest X-ray samples. Basu et al. [2] introduced the domain extension transfer learning with a 12 layered CNN model to achieve 95.3% accuracy supporting four-class classification into categories, Covid-19, normal, other diseases, and pneumonia using limited number of samples from each class. Using fixed size filter may not capture multilevel features from the X-ray images; which is essential for generalization capability of any CNN model. Also, detecting COVID-19 becomes a complex learning problem as in many cases COVID patterns may mimic non-COVID pneumonia cases; and hence, end to end training systems can solve such complex problems better than suggested Domain Extension Transfer Learning (DETL) in their paper. Oh et al. [21] employed FC-DenseNet103 to extract the lung segments from the pre-processed X-ray images. From the extracted lung contour, the authors generated random patches. Each patch is fed into ResNet-18 CNN (which is pre-trained on ImageNet) to train and classify Tuberculosis, Normal, Bacterial Pneumonia, Viral Pneumonia, and COVID-19 infections. This model with 11.6 million trainable parameters has achieved 91.9% accuracy. However, the authors trained the model with a minimal number of samples. Khan et al. [17] used 284 COVID-19, 310 Normal, 330 Bacterial Pneumonia, 327 Viral Pneumonia X-ray samples to train the model namely CoroNet (Xception) and achieved 89.6% accuracy for three-class classification. The computational complexity of the model is high, and it is found that the model some times mis-classifies Pneumonia cases as Normal. Perumal et al. [23] utilized the extracted Haralick features from both X-ray and CT images to trained VGG-16 CNN, and obtained 93% accuracy. The model sometimes mis-classifies COVID-19 as viral pneumonia, viral pneumonia as COVID-19, and Normal as Bacterial Pneumonia. Although the authors claimed it easy to use pre-defined CNN models to solve COVID-19 detection problem, such predefined model suffers with large number of trainable parameters. Also, the suggested model by the authors requires manual pre-processing and feature generation from input X-ray images before feeding it to the CNN model.
Many of these works achieved promising results in the detection of COVID-19 infected patients using chest X-ray images. However, most of these models are trained with a limited number of samples (pneumonia and normal X-ray images) to overcome the class balancing problem of the dataset, which results in loss of essential information of the majority classes (pneumonia and normal X-ray images). Also, the total number of trainable parameters of the stated models is too large to use in the embedded and mobile vision applications. On-device DNN implementation for COVID-19 screening may reduce diagnosis cost and time.
In this work, we propose Corona-Nidaan DNN model for COVID-19 patient screening using chest X-ray image analysis along with a new minority class oversampling approach to deal with imbalance classification problem. A detailed experiment with five different pre-trained CNNs is carried out to compare the performance of our model. We analysed that both approaches can achieve comparable performance, but the performance of the Corona-Nidaan model is better in terms of accuracy and model complexity. We trained and tested our model with 245 COVID-19, 8,066 Normal, 5,551 Pneumonia Chest X-ray images, and validated our findings by medical experts of Sardar Vallabhbhai Patel COVID Hospital, New Delhi, India. Corona-Nidaan model can be used as an on-device DNN for COVID-19 screening due to it’s lower complexity than that of 1.0 MobileNet-224. Through the empirical study, we found that our model does not suffer from too many false positive and false negative results.
3 Proposed approach
In this section, we explain the architecture of proposed Corona-Nidaan Model along with the Minority Class Oversampling Approach.
3.1 Proposed Corona-Nidaan model architecture
Here, we propose Corona-Nidaan, a novel lightweight deep neural network architecture, mainly inspired by the architectural designs of InceptionV3, InceptionResNetV2, and MobileNetV2. The overall architecture of the model shown in Fig. 1.

The overall architecture of the proposed model
The following design principles are taken into account in designing proposed model.
-
1.
DP1: In a CNN model, the application of multiple different sized convolution filters to the same input can extract multi-level feature representations at the same time and hence, improves the overall performance of the model, minimizing over-fitting and computational costs.
-
2.
DP2: The introduction of residual connection in the model reduces the Vanishing Gradient effect and accelerates the model’s training speed.
-
3.
DP3: Introduction of Depth-wise separable convolutions significantly reduces model parameters and extra computation overhead.
-
4.
DP4: Addition of batch normalization layers to the network has benefits, such as speed up network training, reduce the difficulty of initial starting weights, and introduce additional network regularization.
-
5.
DP5: The use of Global Average Pooling before the softmax layer is better than the fully connected layer as it reduces the number of trainable parameters from the network.
The proposed model consists of total 91 layers, with forty-one depth-wise separable convolutional layers, thirty-two batch normalization layers, five max-pooling layers, three concatenate layers, three add layers, three activation layers, one global average pooling layer, one dropout layer, one input, and one softmax layer. Instead of the traditional 2D convolutional layer, we used the deep-wise separable convolutional layer in our network, driven by the MobileNetV2 philosophy (refer design principle: DP3). We used ReLU activation and the same padding in all depth-wise separable convolutional layers. Batch normalization is used after activation in the depth-wise separable convolutional layer to accelerate training and improve the generalization error of our model as opposed to the InceptionResNetV2, which use batch normalization before activation in each convolutional layer. The first convolutional layer applies 64 kernels of size (7 × 7) with stride 2 to the input image of dimension (256 × 256 × 3). The output of this convolutional layer is given to the first batch normalization layer and the first max pooling layer with pool size (3 × 3) and stride 2. The second convolutional layer consists of 192 kernels of size (3 × 3) and stride 1 connected to the first max-pooling layer’s output. The second batch normalization layer and the second max pooling layer with pool size (3 × 3) and stride 2 take the second convolutional layer’s output. The output of the second max-pooling layer is given to the next stage of network, which is made up of three consecutive I-blocks, as in Fig. 1. Each I-block follows the five design principles stated earlier in order to improve performance of the final model. The detailed architectural design of a single I-block is as shown in Fig. 2.

I-blocks of the proposed model
The I-block consists of thirteen depth-wise separable convolutional layers, ten batch normalization layers, one max-pooling layer, one concatenate layer, one add layer, and one activation layer. This block has five parallel paths, acting as multiple convolution kernels applied with some pooling to the output of the previous layer or activation at the same time (refer design principle: DP1, DP2 and DP4). Third and fourth paths perform (1 × 1) convolution at the initial stage to reduce dimension and computational costs, before some costly convolutions. The initial (1 × 1) convolution in the second path and the (3 × 3) convolutions in the third and fourth paths extract multi-level representations of features (as in design principle: DP1). All paths, except the first path, use the last (1 × 1) convolution for dimension expansion. As a result, we get the same feature map dimension as the output dimension of the previous layer or the activation. The max-pooling layer of the fifth layer helps to extract low-level features from the input. The output feature maps of the second, third, fourth, and fifth paths are then concatenated. The concatenate layer output is then fed to a convolutional layer with kernel size (1 × 1) for feature dimension reduction. The path one acts as a shortcut connection in the I-block, i.e., the output of the previous layer added to the stacked layers’ output, which enables residual learning (refer design principle: DP2). We use a (1 × 1) convolutional layer in path one to match with the output dimension of the convolutional layer after the concatenate layer. Finally, the path one convolutional layer output added to the output of the convolutional layer after the concatenate layer. ReLU activation is used in the final activation layer of our I-block. The architecture of each I-block can be represented as in (1).
Where, \(f^{P_{1}}\), \(f^{P_{2}}\), \(f^{P_{3}}\), \(f^{P_{4}}\) and \(f^{P_{5}}\) denotes five parallel paths of the I-block; whereas i, x, b, w represents convolutional layer’s index, input feature map, biases and weights respectively. The depth-wise separable convolutional layer, max-pooling layer, concatenate layer, add layer, batch normalization, feature map addition, feature map concatenation and ReLU are indicated using fC, fm, fCon, fA, fb, ⊕, ⊗ and σ respectively.
The global average pooling layer takes the output of the third I-block as input (as in design principle: DP5). After the global average pooling layer, we used a dropout layer to avoid overfitting. The dropout layer’s output is then fed to the three-way softmax layer to produce a probability distribution of three class labels. Our proposed model consists of a total of 4,021,974 parameters.
3.2 Proposed minority class oversampling approach
In most of the published dataset, it is found that the COVID-19 class has a deficient number of samples compared to the other two classes. This type of problem with the distribution of training data is known as the imbalanced class distribution. It is difficult for any machine learning or deep learning model to obtain optimized results using imbalanced training data. The model will not be capable of learning the characteristics of the minority class because the number of observations is deficient. Three of the most popular approaches to address this problem are 1) undersampling, 2) oversampling, and 3) synthetic sampling. Through experimental analysis using approach one and two, we observed that the random deletion of samples from the majority class loses essential information and, on the other hand, random over-sampling for the minority class (copies of samples already available) leads to overfitting. Using synthetic images from existing samples of the minority class as well as standard image data augmentation techniques did not improve proposed model’s performance. So, we come up with a two-phase oversampling approach. In Phase one, we generated five images (blur, sharp, blue channel, green channel and red channel) using the Algorithm 1 for each sample of the minority class (i.e. COVID-19).

Figure 3 shows the distribution and statistical parameters of original and over-sampled COVID-19 images. It can be seen that, generated over-sampled images using Algorithm 1 follows the same distribution characteristics as that of original COVID-19 images and hence capable of handling dataset imbalance problem effectively.

Distribution of means of original and over-sampled COVID-19 images
In phase two, standard data augmentation techniques applied to each sample generated by the Algorithm 1 to generate more sample representations for minority class i.e. COVID cases.
4 Experiments and results
The experiments are carried out on a laptop running Windows 10 with Intel Core i5-8300H CPU 2.30 GHz, 8 GB memory, NVIDIA GeForce GTX 1050 Ti, Dedicated GPU memory 4.0 GB, CUDA v10.0.130 Tool kit and CuDNN v7.6.5.
4.1 Dataset
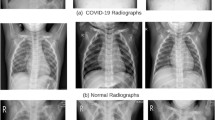
We trained, validated, and tested the proposed Corona-Nidaan model on the ChestX dataset. The dataset is formed by combining the three different open access chest X-ray datasets 1) RSNA Pneumonia Detection Challenge dataset [20], 2) Fig. 1 COVID-19 Chest X-ray Dataset Initiative [7] and 3) COVID-19 Image Data Collection [8] . There are currently 218 COVID-19 and 33 pneumonia samples in the COVID-19 Image Data Collection dataset, and 27 COVID-19 samples are in Fig. 1 COVID-19 Chest X-ray Dataset Initiative. The RSNA Pneumonia Detection Challenge dataset comprises 8,066 normal samples and 5,518 pneumonia samples. After combining all the samples from the three different datasets, our ChestX dataset consisted of 13,862 samples of which 245 samples belong to the COVID-19 class, 5,551 samples belong to the pneumonia class, and 8,066 samples belong to the normal class (examples of x-ray samples are shown in Fig. 4).

Examples of Chest X-ray samples taken from ChestX dataset.
The sample distribution shows that the COVID-19 class has a deficient number of samples compared to the other two classes. Hence, two-phase oversampling approach is used. In Phase one, we generated five images (blur, sharp, blue channel, green channel and red channel) using the Algorithm 1 for each sample of the minority class (i.e. COVID-19).
In phase two, standard data augmentation techniques applied to each sample generated by the Algorithm 1 with parameters set as: horizontal flip=True, rotation range= 10, zoom range= 0.2, height shift range= 0.1, brightness range=(0.9, 1.1) and width shift range= 0.1. The total number of training samples for the minority class (COVID-19) become 7,490 after the two-phase oversampling, in which 1,070 and 6,420 (214 × 5 × 6) samples are produced by phase one and two respectively. The distribution of the final chest X-ray image for training and testing summarized in Table 1.
4.2 Implementation details
Proposed Corona-Nidaan DNN is trained end to end using the ChestX dataset. We conducted a detailed experiment with five different pre-trained CNNs to ensure the usefulness of transfer learning for COVID-19 cases detection from the chest X-ray images. We implemented Corona-Nidaan model and other transfer learning models using Python 3.7.7, OpenCV 4.1.1, and the Keras 2.2.4 API, TensorFlow-GPU v1.14.0 backend. We have set the weights for equally penalized under or over-represented classes in training sets in order to overcome the imbalanced classification problem. The implementation details of both Corona-Nidaan model as well as other transfer learning models (based on five different pre-trained CNNs) are explained as:
4.2.1 Corona-Nidaan model
The proposed Corona-Nidaan model is end to end trained on the ChestX dataset and optimized using Adam optimizer. The X-ray images of the ChestX dataset are resized to (256 × 256 × 3). Each pixel value of the images is rescaled with a 1./255 factor. We used depth-wise separable convolutional instead of traditional 2D convolutional to reduce the number of multiplications. In our proposed model, all the convolutional layers activated by ReLU activation, and the final prediction layer activated by softmax activation. We employed glorot uniform kernel initializer, same padding, and bias initialized with a constant value of 0.2 for all depth-wise separable convolutional layers.
In this study, the hyperparameters (shown in Table 2) of the model are tuned using a manual search technique. We performed experimental analysis using different optimization algorithms such as Adam, AdaGrad, Stochastic Gradient Descent with Momentum, and RMSProp. We found that our proposed model with Adam Optimizer performs well on the train and test sets. We used 0.001 as an initial learning rate, 300 epochs, and eight batch size during training. If no improvement is observed in validation accuracy for two consecutive epochs, then the learning rate is reduced by 0.5 factors by our algorithm. To reduce overfitting, 40% dropout is applied to the dropout layer after the global average pooling layer, and we adopted an early stop. For multi-class classification, the categorical cross-entropy loss function enhanced during training.
4.2.2 Transfer learning based models
The implemented transfer learning models, are divided into two parts 1) Convolutional base and 2) Classifier. The convolutional base is used as a spatial feature extractor and classifier predicts the class label based on features extracted by CNN. The overall architecture of these models is shown as in Fig. 5.

The overall architecture of the transfer learning model
In this experiment, DenseNet201 [15], InceptionResNetV2 [32], MobileNetV2 [27], VGG19 [28] and InceptionV3 [31] are employed as convolutional base of the model. All the CNNs are pre-trained on ImageNet. The final softmax layer is removed from all the pre-trained CNNs as we want to extract features, and not predictions. The ChestX dataset is small and different from the pre-trained model’s dataset; in this scenario, freezing the lower level layers and training the higher-level layer technique works well. The non-trainable layers and the input X-ray image dimensions of the respective pre-trained CNNs shown in Table 3.
The classifier consists of a global average pooling and a fully connected layer with the ReLU activation function, followed by a softmax layer. The manual search method is employed to find the model’s hyperparameters and the most efficient optimization algorithm. Table 3 illustrates the model’s hyperparameter and optimization algorithm based on the pre-trained CNNs. The fully connected layer and the softmax layer consists of 1024 and 3 neurons, respectively. We adopted he-uniform kernel initializer at the fully connected layer. We set the learning rate to 0.0001 value and the batch size to the value of 32 during the training phase of the pre-trained VGG19 and InceptionResNetV2 model. In case of other pre-trained CNNs, we set an initial learning rate to 0.001 value and then reduced it by 0.5 factor, if the validation accuracy does not improve after two epochs. The batch size of the model is set to 8 in case of pre-trained DenseNet201 model, otherwise it is set to 32 for pre-trained MobileNetV2 and InceptionV3 models. The maximum epoch set at 300 for training the model. To overcome overfitting problem, 1) A dropout layer with a dropout rate of 0.4 is added after the global average pooling layer; 2) An early stop with 10 epochs; and 3) The L2 kernel and the bias regularizer is applied in a fully connected layer with a weight decay of 0.001. For disease prediction from X-ray samples, the categorical cross-entropy loss function is enhanced. The model is optimized by using SGD Optimizer in case of pre-trained VGG19 and InceptionResNetV2 models. Adam Optimizer is used in case of other pre-trained CNNs during training.
4.3 Detailed analysis of implemented models
In this section, we present results and analysis of the both methods, 1) transfer learning with pre-trained CNNs and; 2) End to end trained Corona-Nidaan model on the ChestX dataset. To investigate the performance of any model, we computed the f1-score, recall (sensitivity), and precision (positive predictive value) for each class on the test dataset. In the case of an imbalanced dataset, only the accuracy metric does not reflect the model’s performance. For example, if the majority class has 98 samples, then the model achieves 98% accuracy. However, the model is not able to detect 2% of minority class samples. To evaluate the overall efficiency of any model, we calculated the accuracy, the macro average, and the weighted average. To visualize the performance of these models, we plotted the confusion matrix.
4.3.1 Transfer learning based models
In this section, we present our results and analysis for the implemented transfer learning based pre-trained models on the ChestX test dataset.
MobileNetV2:
The performance of pre-trained MobileNetV2 (Fig. 5) on the ChestX test dataset is shown in Table 4 and the confusion matrix in Fig. 6. It can be observed that the model achieved 85% on the test dataset, but the recall value for COVID-19 class is only 32%, which means that the model is very picky. The model mis-classifies many COVID-19 cases as normal or pneumonia cases. The line plots of categorical cross-entropy loss and accuracy over training epochs of the model have shown in Fig. 7. The loss plot shows that the training loss remains flat after the 10th epoch, regardless of training, means under-fitting condition, and the model is unable to learn the training dataset well.

Confusion matrix of the model (Fig. 5) using pre-trained MobileNetV2

Line plots of categorical cross-entropy loss and accuracy over training epochs of the model (Fig. 5) using pre-trained MobileNetV2
VGG19:
Table 5 shows the performance of pre-trained VGG19 model (Fig. 5) on the ChestX dataset and Fig. 8 represents the confusion matrix of the model. It is clear from the experimental results that the overall performance of the model is good. The model obtained a test accuracy of 93%, and the train and validation loss and accuracy are very close to each other, showing that the model is not over-fitted (see Fig. 9). The recall and precision values of all three classes are quite impressive, which means low false negative, and positive prediction rates. In this model, the COVID-19 class achieves a precision and recall value of 93% and 87%, respectively. From the confusion matrix, it is clear that the model mis-classifies very few samples. The model correctly predicts 27 samples as COVID-19, 96 as Normal, and 91 as Pneumonia.

Confusion matrix of the model (Fig. 5) using pre-trained VGG19

Line plots of categorical cross-entropy loss and accuracy over training epochs of the model (Fig. 5) using pre-trained VGG19
InceptionResNetV2
The pre-trained InceptionResNetV2 model (Fig. 5) achieved 80% test accuracy with 39% and 55% recall and precision, respectively, for the COVID-19 class, as shown in Table 6 along with low recall (79%) rate for Pneumonia class. The model predicts around 10 false-positive and 19 false-negative cases for the COVID-19 class (Refer: Fig. 10). It can be observed from the loss and accuracy plots of the model as in Fig. 11, that there is no indication of over-fitting or under-fitting.

Confusion matrix of the model (Fig. 5) using pre-trained InceptionResNetV2

Line plots of categorical cross-entropy loss and accuracy over training epochs of the model (Fig. 5) using pre-trained InceptionResNetV2
InceptionV3
Model performance (Fig. 5) using pre-trained InceptionV3 is summarized in Table 7. This model achieves an accuracy of 77% on the test dataset. From Table 7, it can be seen that the model mis-classifies almost 35% of Pneumonia cases during testing. The precision value of the COVID-19 class is only 48%. The confusion matrix (Fig. 12) shows that Pneumonia and the COVID-19 classifications suffer from high false-negative and false-positive results. The loss and accuracy plots of the model is shown in Fig. 13. The loss plot tells that the validation accuracy curve is decreased to the 2nd epoch and then start to increase again, which means that the model is over-fitted on the training data.

Confusion matrix of the model (Fig. 5) using pre-trained InceptionV3

Line plots of categorical cross-entropy loss and accuracy over training epochs of the model (Fig. 5) using pre-trained InceptionV3
DenseNet201
Pretrained DenseNet201 model (Fig. 5) achieved an overall test accuracy of 84% as shown in Table 8.The recall value of the COVID-19 class is very low, i.e., only 42%. We can notice that a lot of COVID-19 cases are misclassified as Normal or Pneumonia, as shown in the confusion matrix in Fig. 14. The model exhibits large false-negative results in case of COVID-19 class. The loss and accuracy plots shown in Fig. 15 reflects the overfitting condition against training data.

Confusion matrix of the model (Fig. 5) using pre-trained DenseNet201

Line plots of categorical cross-entropy loss and accuracy over training epochs of the model (Fig. 5) using pre-trained DenseNet201
4.3.2 Corona-Nidaan model
Here, we present the results and analysis of the Corona-Nidaan model on the ChestX test dataset. The f1-score, precision, and recall for each class and the overall test accuracy is shown in Table 9. Corona-Nidaan achieved 1) 95% overall test accuracy; 2) 94% precision and recall value for the COVID-19 class classification; 3) 93% precision and 98% recall for the Normal class classification; and 4) 97% precision and 92% recall for the Pneumonia class classification. The confusion matrix in Fig. 16 shows that the model does not suffer from too many false-negative and false-positive results. That is an excellent indication because high false-negative and false-positive results increase the burden on public health services due to the requirement for additional PCR testing. The loss and accuracy plots indicate that the training process converged well as in Fig. 17.

Confusion matrix for Corona-Nidaan on the ChestX test dataset

Line plots of categorical cross-entropy loss and accuracy over training epochs of the Corona-Nidaan model
4.4 Comparison of Corona-Nidaan with the transfer learning models
It can be seen from the results (Refer Table 10) that the performance of the Corona-Nidaan is always better than that of other pre-trained models. During experimentation, it is found that pre-trained VGG19 model outperformed other pre-trained CNNs. Hence, in case if the dataset is small, pre-trained VGG19 model can be used instead of other pre-trained models.
4.5 Comparison of Corona-Nidaan with other published approaches
In this section, we compared the Corona-Nidaan model with other published approaches (shown in Table 11). The proposed Corona-Nidaan model achieves 95% accuracy on the ChestX dataset and outperforms other previously published approaches. The dataset comprised of total 13862 chest X-ray images which are collected from the three different open-source image repository [7, 8, 20]. The studies mentioned in this section have used the same COVID-19 samples from COVID-19 Image Data Collection [8]. Wang and Lin et al. [35] proposed the COVID-Net deep learning model and achieved 92.6% test accuracy in three-class classifications. Their model is trained and tested with the same number of samples collected from the same data sources. The overall performance of the model is good. However, COVID-Net suffers from false-negative results for the COVID-19 class. The COVID-Net consists of 117.4 million parameters, which is 29 times larger than that of Corona-Nidaan model. The precision and recall value of COVID-Net for each class type is lower than that of our proposed model. Hemdan et al. [12] achieved 90% accuracy by utilizing transfer learning with seven pre-trained CNNs. The authors claimed that VGG19 and DenseNet201 performed well compared to the other five pre-trained models. However, in case of these CNN models, the f1-score for COVID-19 and Normal class calculated is 91% and 89% respectively, where it is 94% and 96% respectively in case of our model. Ozturk et al. [22] used a deep convolutional neural network, DarkCovidNet, and achieved 87.02% test accuracy in three-class classifications. The model is trained using 500 pneumonia, 500 normal, and 125 COVID-19 chest X-ray samples. The sensitivity, precision, and f1-score of DarkCovidNet model stated for three-class classifications are 85.35%, 89.96%, and 87.37%, respectively, which are lower than that of Corona-Nidaan model (shown in Table 9).
From the confusion matrix for three class classifications, it is clear that the DarkCovidNet model suffers from false-positive and false-negative results. DarkCovidNet used only 500 samples for each pneumonia and normal class, using under-sampling technique to avoid the problem of imbalanced classification, however, such random deletion of samples from the majority class loses important class information. For COVID-19 screening, Mangal et al. [19] used transfer learning and obtained 90.5% accuracy. They used 115 COVID-19, 1,341 normal, and 3,867 pneumonia chest X-ray samples to train the CovidAID model. The model’s overall performance is impressive, especially for COVID-19 cases with a sensitivity of 100 %. However, the model suffers with the same problem of getting many false-negative cases for the normal class. It is important to minimize false negative and false positive rates for initial screening techniques. Apostolopoulos et al. [1] adopted the same transfer learning technique as Hemdan et al. [12] and also observed that the performance of VGG19 is better than other pre-trained CNNs. They achieved 93.48% three-class classification accuracy on the test dataset. Basu et al. [2] achieved 95.3% using 12 layers of CNN against a dataset consisting of 225 COVID-19, 50 Other-disease, 322 Pneumonia, and 350 Normal samples. It is found that the authors used five-fold cross-validation to measure the performance of their model, and the model is trained on minimal Normal and Pneumonia samples. Oh et al. [21] used 57 Tuberculosis, 191 Normal, 54 Bacterial Pneumonia, 20 Viral Pneumonia, and 180 COVID-19 X-ray images to train proposed patch-based CNN. The authors stated 91.9% test accuracy when tested on the same samples, however, the model suffers from false positive and negative results. The number of trainable parameters in their model is as twice as that of our model. The precision value of COVID-19 (76.9%), Pneumonia (90.3%) infections, and the sensitivity of Normal class (90%) is lower. Khan et al. [17] used a limited number of training samples to train CoroNet (Xception pre-trained on ImageNet) and achieved 89.6% three-class classification accuracy. The number of trainable parameters of their model is eight times larger compared to Corona-Nidaan and the model also mis-classifies many Pneumonia cases as Normal cases. Perumal et al. [23] used 205 COVID-19 (X-ray), 1,349 Normal, 2,538 Bacterial Pneumonia, 202 COVID-19(CT) and 1,345 Viral pneumonia samples to train VGG-16 CNN and achieved 93% accuracy. The model sometimes misclassifies COVID-19 as viral pneumonia, viral pneumonia as COVID-19, and Normal as Bacterial Pneumonia. The computational complexity of the proposed model is also enormous.
4.6 Study of Corona-Nidaan performance against Indian COVID-19 patient dataset
In this study, we tested the performance of Corona-Nidaan on Indian patient chest X-ray samples. We consulted medical experts from the Pune region, India, and Sardar Vallabhbhai Patel COVID Hospital, New Delhi, India and validated the performance of our model against almost 1000 X-ray samples belonging to two different classes (Normal, COVID-19). These chest X-ray images’ assessment results by Corona-Nidaan model against confirmed COVID-19 cases is shown in Fig 18. The model is validated for the screening of COVID-19 infected patients by the medical experts. The remarks of the end-users (Medical Experts) on the performance of Corona-Nidaan model are as under:
-
1.
The overall performance of the model on Indian patient’s chest X-ray images is good, and the prediction results are convincing, especially in the present pandemic.
-
2.
This low-cost tool can differentiate COVID-19 infection, Pneumonia, and Normal cases from chest X-ray images without human intervention.
-
3.
In exceptional cases with the early-stage symptoms, COVID-19 X-ray images may be misclassified by the model as Pneumonia or Normal. The early features of COVID-19 infection may mimick other non-COVID pneumonia features. Hence, to overcome this problem, the model needs to train with more samples of Chest X-ray images.
-
4.
The model does not suffer from high false negative and positive results, which indicates the suitability of the model for medical imaging classification tasks. This is in alignment with aim of this model, wherein we do not want to miss any COVID case in the current CORONA pandemic.
-
5.
The information generated as a result of the X-ray image analysis can be used as a screening test for rapid and mass testing.

Chest X-ray images diagnosis by the proposed Corona-Nidaan model against confirmed COVID-19 cases
5 Conclusion
In this study, Corona-Nidaan, a lightweight deep convolutional neural network, is introduced for COVID-19 cases screening using the chest X-ray samples. A simple oversampling method to tackle the imbalance classification problem is also suggested in this work. The following conclusions can be drawn based on the results of this study: (1) Our proposed Corona-Nidaan model achieved 95% test accuracy with 94% recall and precision value for multi-class classification. (2) The Corona-Nidaan model does not suffer from too many false positive and false negative results, which is an excellent indicator because it reflects our model’s reliability. (3) Three stacked I-blocks are capable of capturing critical COVID-19 features for better classification. (4) Transfer learning can be used for medical imaging tasks when the data set is small, and it found that VGG19 outperformed other pre-trained CNNs.
In our future work, the proposed model will be enhanced to perform severity level analysis by collecting serial X-ray images of COVID-19 infected with local radiologists and hospitals’ help, as the major drawback in such research work is the availability of minimal open-source COVID-19 chest X-ray samples.
Code Availability
References
Apostolopoulos ID, Mpesiana TA (2020) Covid-19: automatic detection from x-ray images utilizing transfer learning with convolutional neural networks. Phys Eng Sci Med, p 1
Basu S, Mitra S (2020) Deep learning for screening covid-19 using chest x-ray images. arXiv:200410507
BBC (2020) Coronavirus may never go away, world health organization warns. https://www.bbc.com/news/world-52643682
Bejnordi BE, Veta M, Van Diest PJ, Van Ginneken B, Karssemeijer N, Litjens G, Van Der Laak JA, Hermsen M, Manson QF, Balkenhol M, et al. (2017) Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer. Jama 318(22):2199–2210
Bernheim A, Mei X, Huang M, Yang Y, Fayad ZA, Zhang N, Diao K, Lin B, Zhu X, Li K, et al (2020) Chest ct findings in coronavirus disease-19 (covid-19): relationship to duration of infection. Radiology p 200463
Chan JFW, Yip CCY, To KKW, Tang THC, Wong SCY, Leung KH, Fung AYF, Ng ACK, Zou Z, Tsoi HW, et al. (2020) Improved molecular diagnosis of covid-19 by the novel, highly sensitive and specific covid-19-rdrp/hel real-time reverse transcription-pcr assay validated in vitro and with clinical specimens. J Clin Microbiol 58(5)
Chung A (2020) Figure 1 COVID-19 chest x-ray data initiative
Cohen JP, Morrison P, Dao L (2020) Covid-19 image data collection. arXiv:200311597https://github.com/ieee8023/covid-chestxray-dataset
For Disease Control C Prevention (2020) Symptoms of coronavirus. https://www.cdc.gov/coronavirus/2019-ncov/symptoms-testing/symptoms.html
Dong E, Du H, Gardner L (2020) An interactive web-based dashboard to track covid-19 in real time. The Lancet infectious diseases
Gulshan V, Peng L, Coram M, Stumpe MC, Wu D, Narayanaswamy A, Venugopalan S, Widner K, Madams T, Cuadros J, et al. (2016) Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. Jama 316(22):2402–2410
Hemdan EED, Shouman MA, Karar ME (2020) Covidx-net: a framework of deep learning classifiers to diagnose covid-19 in x-ray images. arXiv:200311055
Howard AG, Zhu M, Chen B, Kalenichenko D, Wang W, Weyand T, Andreetto M, Adam H (2017) Mobilenets: efficient convolutional neural networks for mobile vision applications. arXiv:170404861
Huang C, Wang Y, Li X, Ren L, Zhao J, Hu Y, Zhang L, Fan G, Xu J, Gu X, et al. (2020) Clinical features of patients infected with 2019 novel coronavirus in wuhan, china. Lancet 395 (10223):497–506
Huang G, Liu Z, Van Der Maaten L, Weinberger KQ (2017) Densely connected convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4700–4708
Kanne JP, Little BP, Chung JH, Elicker BM, Ketai LH (2020) Essentials for radiologists on covid-19: an update—radiology scientific expert panel
Khan AI, Shah JL, Bhat MM (2020) Coronet: a deep neural network for detection and diagnosis of covid-19 from chest x-ray images. Comput Meth Prog Biomed p 105581
Lakhani P, Sundaram B (2017) Deep learning at chest radiography: automated classification of pulmonary tuberculosis by using convolutional neural networks. Radiology 284(2):574–582
Mangal A, Kalia S, Rajgopal H, Rangarajan K, Namboodiri V, Banerjee S, Arora C (2020) Covidaid: Covid-19 detection using chest x-ray. arXiv:200409803
Of North America RS (2019) Rsna pneumonia detection challenge dataset. https://www.kaggle.com/c/rsna-pneumonia-detection-challenge/data
Oh Y, Park S, Ye JC (2020) Deep learning covid-19 features on cxr using limited training data sets. IEEE Trans Med Imaging
Ozturk T, Talo M, Yildirim EA, Baloglu UB, Yildirim O, Acharya UR (2020) Automated detection of covid-19 cases using deep neural networks with x-ray images. Comput Biol Med p 103792
Perumal V, Narayanan V, Rajasekar SJS (2020) Detection of COVID-19 using CXR and CT images using Transfer Learning and Haralick features. Appl Intell pp 1–18, https://doi.org/10.1007/s10489-020-01831-z
Rajpurkar P, Hannun AY, Haghpanahi M, Bourn C, Ng AY (2017a) Cardiologist-level arrhythmia detection with convolutional neural networks. arXiv:170701836
Rajpurkar P, Irvin J, Zhu K, Yang B, Mehta H, Duan T, Ding D, Bagul A, Langlotz C, Shpanskaya K, et al. (2017b) Chexnet: radiologist-level pneumonia detection on chest x-rays with deep learning. arXiv:171105225
Rubin GD, Ryerson CJ, Haramati LB, Sverzellati N, Kanne JP, Raoof S, Schluger NW, Volpi A, Yim JJ, Martin IB, et al. (2020) The role of chest imaging in patient management during the covid-19 pandemic: a multinational consensus statement from the fleischner society. Chest
Sandler M, Howard A, Zhu M, Zhmoginov A, Chen LC (2018) Mobilenetv2: Inverted residuals and linear bottlenecks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4510–4520
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv:14091556
Singhal T (2020) A review of coronavirus disease-2019 (covid-19). The Indian Journal of Pediatrics pp 1–6
Sohrabi C, Alsafi Z, O’Neill N, Khan M, Kerwan A, Al-Jabir A, Iosifidis C, Agha R (2020) World health organization declares global emergency: A review of the 2019 novel coronavirus (covid-19). Int J Surg
Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z (2016) Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2818–2826
Szegedy C, Ioffe S, Vanhoucke V, Alemi AA (2017) Inception-v4 inception-resnet and the impact of residual connections on learning. In: Thirty-First AAAI conference on artificial intelligence
Tandon PN, et al. (2020) Covid-19: impact on health of people & wealth of nations. Indian J Med Res 151(2):121
Udugama B, Kadhiresan P, Kozlowski HN, Malekjahani A, Osborne M, Li VY, Chen H, Mubareka S, Gubbay J, Chan WC (2020) Diagnosing covid-19: the disease and tools for detection. ACS nano
Wang L, Wong A (2020) Covid-net: a tailored deep convolutional neural network design for detection of covid-19 cases from chest radiography images. arXiv:200309871
Wang X, Peng Y, Lu L, Lu Z, Bagheri M, Summers RM (2017) Chestx-ray8: hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2097–2106
WHO (2020) Who director-general’s opening remarks at the media briefing on covid-19 - 16 march 2020 https://www.who.int/dg/speeches/detail/who-director-general-s-opening-remarks-at-the-media-briefing-on-covid-19---16-march-2020
Wu F, Zhao S, Yu B, Chen YM, Wang W, Song ZG, Hu Y, Tao ZW, Tian JH, Pei YY, et al. (2020) A new coronavirus associated with human respiratory disease in china. Nature 579 (7798):265–269
Acknowledgements
This research is supported by the Defence Institute of Advanced Technology, DRDO Lab, Ministry of Defence, India, and the Indian National Academy of Engineering. The authors would like to thank Sardar Vallabhbhai Patel COVID Hospital, New Delhi, India, to facilitate validation of Corona-Nidaan against the Indian Patient X-Ray samples. The authors would like to thank NVIDIA for the GPU grant for carrying out deep learning based research work.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interests
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article belongs to the Topical Collection: Artificial Intelligence Applications for COVID-19, Detection, Control, Prediction, and Diagnosis
Rights and permissions
About this article

Cite this article
Chakraborty, M., Dhavale, S.V. & Ingole, J. Corona-Nidaan: lightweight deep convolutional neural network for chest X-Ray based COVID-19 infection detection. Appl Intell 51, 3026–3043 (2021). https://doi.org/10.1007/s10489-020-01978-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-020-01978-9