
Fuzzy Interpolation with Extensional Fuzzy Numbers



CE IT4Innovations–IRAFM, University of Ostrava, 70103 Ostrava, Czech Republic
*
Author to whom correspondence should be addressed.
Symmetry 2021, 13(2), 170; https://doi.org/10.3390/sym13020170
Submission received: 27 December 2020
/
Revised: 16 January 2021
/
Accepted: 20 January 2021
/
Published: 22 January 2021
(This article belongs to the Special Issue Computational Intelligence and Soft Computing: Recent Applications)
Abstract
:The article develops further directions stemming from the arithmetic of extensional fuzzy numbers. It presents the existing knowledge of the relationship between the arithmetic and the proposed orderings of extensional fuzzy numbers—so-called -orderings—and investigates distinct properties of such orderings. The desirable investigation of the -orderings of extensional fuzzy numbers is directly used in the concept of -function—a natural extension of the notion of a function that, in its arguments as well as results, uses extensional fuzzy numbers. One of the immediate subsequent applications is fuzzy interpolation. The article provides readers with the basic fuzzy interpolation method, investigation of its properties and an illustrative experimental example on real data. The goal of the paper is, however, much deeper than presenting a single fuzzy interpolation method. It determines direction to a wide variety of fuzzy interpolation as well as other analytical methods stemming from the concept of -function and from the arithmetic of extensional fuzzy numbers in general.
1. Introduction
Fuzzy interpolation is a generally well-established area with crucial results. Indeed, it is a natural area that has a deep connection to distinct areas. We can consider, e.g., the interpolation of fuzzy rule bases with logical motivations stemming from approximate reasoning where the pairs of antecedent and consequent fuzzy sets of a fuzzy rule base establish “pairs of fuzzy points” and the task is to infer an appropriate output fuzzy set for an input fuzzy sets lying in between of the antecedents. In this logical setting, such an interpolation task leads to the solvability of fuzzy relational equations—an area initiated by Sanchez [1] and followed by many others, see [2,3,4,5]. The interest of the community in this area does not seem to disappear [1] as it moves to the investigation of distinct extensions [6,7,8].
Another direction of fuzzy interpolation was rather geometrically motivated although the connection to fuzzy rule-based systems was declared too. The geometrical approaches often stem from usual interpolations (linear [9] or spline [10]) extended to fuzzy numbers and allow the interpolation of sparse rule bases [11,12]. Due to the importance of the interpolation for the approximate reasoning, decision-making or optimization, we may observe the interest of the community into this direction too [13]. For the comparison of some fundamentals, we refer readers to [14] and we also highlight a work that up to some degree combines both approaches and serves us one of our motivations [15].
Our work follows this attempt of joining both views. It works with pairs of fuzzy numbers representing ague quantities [16] and interpolates even a sparse case. However, the fuzzy numbers as well as the manipulation with them will be deeply stemming from fuzzy relational calculus [17], similarity relations, extensional hulls and other concepts related to the approximate reasoning [18].
In particular, we will deal with the MI-algebra-based arithmetics based on extensional fuzzy numbers, i.e., extensional hulls of crisp numbers constructed with respect to some similarity relations [19]. Such arithmetic serves as an alternative to other technical approaches [20,21] allowing the formalization of the ideas of Mareš [22] in a way that splits the often time-consuming process of calculating operations on fuzzy numbers into a two-step procedure: one calculating the standard operation on crisp points, the other one on processing the similarity relations forming fuzzy numbers around the crisp points. Indeed, as the extensional fuzzy numbers are nothing else but extensional hulls of crisp numbers, we get genuine representations of vague quantities—collections of points similar to the given crisp point. And operations on such objects, e.g., when summing up “about 3” and “about 5”, are intuitively performed by a human brain by adding the crisp numbers 3 and 5 to a partial result 8 which is later viewed with a tolerance measure respecting that both entries were imprecise. This tolerance measure is nothing else but a similarity relation that is a result of the operation on similarities used in the construction of both extensional fuzzy numbers.
The difference in the used arithmetic, of course, also changes the interpolation method and its results. Any classical interpolation can be extended to a fuzzy interpolation method, assuming that the used arithmetic is functional and equipped with all the necessary operations. Apart from the arithmetical operations, also other fundamental mathematical concepts, such as ordering of fuzzy numbers, must be developed. Thus, we adopt the orderings of extensional fuzzy numbers introduced in [23] and studied in [24]. It is important to note that such an ordering is tightly connected to the arithmetic itself, which we find essential.
The structure of the article is as follows. Section 2 recalls the basic preliminaries about the arithmetics of extensional fuzzy numbers. Section 3 recalls the approach to the orderings of extensional fuzzy numbers and Section 4 sets up their crucial properties. Section 5 leads the investigation towards fuzzy interpolation that is, later, in Section 6 experimentally demonstrated on an illustrative example from the real practice. Section 7 closes the article with a brief discussion.
2. Preliminaries—Arithmetical Operations on Extensional Fuzzy Numbers
2.1. Motivation and the Main Concepts
The arithmetic of extensional fuzzy numbers has been originally proposed in [25,26] as an alternative to other functional arithmetics that are often stemming from Zadeh’s extension principle. Such arithmetics often consider the -cut calculus and they are more technically oriented based on distinct parametric representations of fuzzy numbers [21,27,28].
The proposed alternative (detail description in [19]), was motivated from the non-preservation of some algebraic properties by the existing approaches, especially the non-existence of inverse elements. This is nothing surprising as the models of vague quantities provided by fuzzy numbers are rather fuzzy intervals than fuzzy numbers, and the absence of an inverse element is a feature of the interval calculus, see [29]. However, as pointed out by Mareš [16], instead of considering only a single crisp neutral element, we may observe infinitely many “neutral-like” elements so, when solving equations with vague quantities, we get the equality of both sides up to “nearly zero”. Therefore, there is no absence of the inverse, the operations on inverses only do not lead to the genuine neutral (identity) element but to any of the identity-like elements. This idea of Mareš is then developed in [19] and it leads to the MI-algebras (MI stands for many identities). Algebraically, it drops the standard field structure of real numbers however, it does not harm its ideas, just incorporates them with a certain vagueness.
Above-recalled alternative approach [29] correctly stems from the fact that the lack of the preserved algebraic properties is caused by the interval character of fuzzy numbers and the non-preservation inherited from interval calculus, is “healed” by using the concept of gradual numbers that are conceptually sort of inverse to the usual fuzzy numbers (intervals). Indeed, a gradual fuzzy number is a mapping from the interval to the real line and the (crisp) real number a is its special case such that for arbitrary . Then the arithmetic operating on such functions preserves the algebraic properties such as existence of an inverse to any element. Note that the concept is so general that it does not assume any restriction on the “shape” (e.g., on monotonicity or continuity) which is, on one hand, an advantage, on the other hand, it allows dealing with or obtaining functions hardly interpreting any vaguely given quantity.
The arithmetic of extensional fuzzy numbers stemmed from a natural model of a vague quantity and formalized human-style calculus with them. It models a vaguely given quantity “about a” as an extensional hull of the crisp value (singleton) a with respect to a given similarity relation. Thus, it has a genuine construction determining a fuzzy set of values similar to a. On one hand, as we stated, it is a fuzzy set of elements so, it leads to a set-like concept that will never possess the arithmetical properties of numbers however, it was not constructed as an (fuzzy) interval and the generating crisp number is available for further purposes including the calculus.
The price we pay for such a restriction to extensional hulls of crisp numbers is not high as we do not see other than technical reasons stemming from the usual arithmetics themselves (e.g., results of limits) to consider technical definitions allowing dealing with e.g., upper semi-continuous fuzzy sets as models of fuzzy numbers. In our opinion, the restriction pays off in the subsequent advantages.
Let us fix the notation for a set of fuzzy sets defined on a universe X: ; and of the support of a fuzzy set A: . Now, we recall the well-known fundamental definitions adopted to the universe of real numbers.
Definition 1.
[30,31] Let ⊗ be a left-continuous t-norm. A binary fuzzy relation is called ⊗-similarity if the following holds
- (i)
- (ii)
- (iii)
for all .
Definition 2.
[19] Let S be a ⊗-similarity relation. It is called separable if implies that .
Definition 3.
[19] Let S be a ⊗-similarity relation. It is called shift-invariant if for any .
Convention 1.
Due to the practical importance of the separability property, we assume that all ⊗-similarity relations considered in this paper are separable.
Definition 4.
Example 1.
Binary fuzzy relations on given by
are the shift-invariant ⊗-similarity relations where ⊗ is the ukasiewicz t-norm.
Example 2.
Binary fuzzy relations on given by
are the shift-invariant ⊗-similarity relations where ⊗ is the product t-norm.
Remark 1.
The shift-invariance is a useful property for connecting similarities and arithmetics, see Proposition 6. An example of similarity relation that is not shift-invariant can be found in Remark 2.2 in [19].
An extensional hull of a fuzzy set A is the least fuzzy superset of A that is extensional.
Theorem 1.
[31] Let S be a ⊗-similarity relation and let . The extensional hull of A, denoted by , is given by
If we consider a singleton representation of a real number that is a fuzzy set such that , and for any we can construct an extensional hull of a real number. Such an object is called extensional fuzzy number or a fuzzy point, see [18,31,32].
Definition 5.
A correct version of Formula (4) would consider the extensional hull of the singleton but as there is no danger of confusion, we will neglect the difference between a and and stick to the simpler denotation. The extensional fuzzy number may be easily calculated by a simple substitution.
Lemma 1.
[19] Let and let S be a ⊗-similarity. Then , for any .
Convention 2.
We restrict our choice of similarities to those ensuring that the fuzzy numbers are formed by -cuts that are closed intervals in .
2.2. Arithmetic of Extensional Fuzzy Numbers
The construction as well as the denotation of the extensional fuzzy number emphasizes its semantics—number a with close numbers around it—where the closeness is determined by similarity S. Such a restriction to a subclass of fuzzy numbers is reasonable and justified by the most natural representation of a vague quantity reflecting the semantics already in its construction. Furthermore, the construction allows the derivation of appropriate models of the arithmetic [25,26]—algebraically leading to MI-algebraic structures. We avoid going into algebraic details and only refer interested readers to the relevant sources, mainly to [19] and furthermore, to [33,34] for the quotient MI-groups, and to [35] for the topological MI-groups. Here, we continue only with the computational part of the arithmetic of extensional fuzzy numbers.
Consider a system of nested ⊗-similarities with the bottom element and the set of all fuzzy numbers that are extensional with respect to a similarity from the given system:
preserving the Convention 2. Then the arithmetic operations on are given as
with the maximum operating on the set of similarities is defined via the inclusion:
The operations given by (5) are motivated by calculus performed by humans. Indeed, when one is asked to sum up “about 20” and “about 30”, she or he ends up with “about 50” without any technical (-cut-based) calculus simply by summing up 20 and 30 to 50, and by adding some neighborhood. The arithmetic (5) acts analogously, it sums up a and b to in the first phase, and, in the second phase, performs some operation on similarities to determine what are the acceptably close numbers. This approach is very fast, and it does not result inevitably wide fuzzy numbers after a few operations.
Remark 2.
The proposed calculus that does not widen the resulting fuzzy sets may be for some readers unusual, yet we do not view it unintuitive. Let us recall the argumentation used in [36] cit. “Suppose that we have two factors that affect the accuracy of a measuring instrument. One factor leads to errors ±—meaning that the resulting error component can take any value from − to . The second factor leads to errors of ±. What is the overall error? From the purely mathematical viewpoint, the largest possible error is 10.1%. However, from the common sense viewpoint, an engineer would say: 10%.” These arguments in favor of common-sense in summing up errors (in our case similarities) are not left only on the motivation level but elaborated also mathematically based on the Hurwicz criterion [37], for details see [36].
The bottom element (the “narrowest” similarity) is used in the construction of the so-called strong identity elements for the arithmetic operations, in particular:
Inverses are obtained using the arithmetic operations, i.e., and , where the division by “zero” must be omitted. The (non-strong) identities (pseudoidentities) are elements of obtained as results of operations applied to elements and their inverses:
Example 3.
Remark 3.
As the classical equality “=” is a ⊗-similarity for arbitrary t-norm ⊗, we can consider the systems of similarities from Example 3 with the parametrization and additionally defined as the crisp equality. Then by adding this element to , we obtain a system allowing us to deal with crisp numbers as well. The bottom element will be then formed by the crisp equality .
Let us fix the denotation for a system containing the crisp equality and let us call them systems of nested similarities with the crisp bottom element.
For the purposes of our work, it is sufficient to recall a single particular structure with properties sufficient for the further studies. It is an MI-prefield preserving: the existence of the sets of pseudoidentities and ; associativity and commutativity of both arithmetic operations; closeness of the sets of pseudoidentitites with respect to the arithmetic operations (e.g., for any ); existence of inverse elements; and the distributive law:
As the MI-prefield structure possess most of the appropriate properties, though we often do not need such a rich structure in the subsequent sections of the article, we will always assume we are given an MI-prefield. This assumption will help the brevity and readability of the article.
3. Orderings of Extensional Fuzzy Numbers
3.1. Motivation
The necessity of defining the ordering (also ranking) of fuzzy numbers (or generally even fuzzy sets) has been pointed out already by Zadeh [38] and then in many other works, e.g., in [39,40,41] leading to distinct applications [42]. Moreover, the ordering is essential for defining monotonous fuzzy rule bases [43,44,45] and reasoning with them which is a topic extremely closely connected to the area of fuzzy interpolation [7,8].
The simplest yet maybe most natural example of an ordering is the ordering of intervals
applied to all -cuts of the fuzzy numbers:
In the following lemma, we show two equivalent definition of the ordering of fuzzy numbers using the orderings of their -cuts.
Lemma 2.
Let be fuzzy numbers. Then the following statements are equivalent.
- (1)
- ,
- (2)
- for any and , there exists such that , and vice versa, for any , there exists such that .
- (3)
- for any , there exists such that and , and vice versa, for any , there exists such that and .
Proof.
Let . Assume that . Since , it is sufficient to put , and we obtain that such that . Similarly, if , from , it is sufficient to put , and we obtain that such that .
Let . If , then it is sufficient to consider any such that . Assume that . By (2), there exists such that and holds. Let . Again, if , then it is sufficient to consider any such that . If , then by (2), we find that there exists such that and holds.
Let , and consider and . By (3), for , there exists such that and . Since , we find that . Similarly, for , there exists such that and . Since , we find that . Hence, we obtain that . □
This approach, however, does not preserve any information about the vagueness so, we will not apply it to extensional fuzzy numbers . Indeed, general fuzzy sets or technically defined fuzzy numbers do not necessarily encode the information on the position and the neighborhood unlike the extensional numbers that are generically created from these two sources of the information.
Another flaw of the -cut-based ordering is that it is not a total ordering and, for example, two fuzzy numbers depicted in Figure 1 are not comparable. The totality in the strict sense, as with the one we know from classical mathematics, is not an unavoidable property. However, cases such as the one in Figure 1 are so intuitive that anyone would expect that A is smaller than B. Incidentally, appropriate arithmetic confirms this intuition as it leads to a positive result of the difference .
There are different approaches attempting to avoid the problem of the missing totality, mostly they consist of determining a certain ranking index (a crisp number representing the fuzzy number). On the other hand, this leads to a reduction of information. One of the exceptions that we found very elegant and formally founded was defined by Bodenhofer in [46,47]. It works with extending the original fuzzy numbers by constructing their extensional hulls up to the situation when the extended fuzzy numbers can be already ordered regarding their -cuts. Naturally, this approach is very closely connected to the arithmetic of extensional fuzzy numbers and thus, it served for us a motivation, yet our approach comes from a bit more abstract setting and then lands to a particular type of Bodenhofer’s ordering.
3.2. Definitions and Examples
With the goal to encode the necessary vagueness and preserve it as an essential property over the whole computational process, we extend the standard binary ordering relation (between crisp numbers) to a ternary relation ≤ operating on the Cartesian product . As there is never a danger of confusion between the order operating on real numbers and the newly defined order operating on extensional fuzzy sets, the difference will be always clear from the context, we will use the same symbol ≤.
Definition 6.
Let be an MI-prefield of extensional fuzzy numbers with respect to a system of nested ⊗-similarities on . A ternary relation ≤ on is called an-ordering on provided that
- (O1)
- , (reflexivity)
- (O2)
- (O3)
holds for any and for any .
Notation 1.
For the case of brevity and clarity, let us introduce the following notation denoting the fact that . Furthermore, let denotes the fact that there exists some such that . This second notation losses the information on which particular must be used to obtain a triplet however, in certain situations, such a Boolean information about the order of two fuzzy numbers will be sufficient.
Using Notation 1, the axioms of the -ordering on can be rewritten to a very convenient form:
- (O1)
- , (reflexivity)
- (O2)
- (O3)
- .
Example 4.
Let be an MI-prefield. Then defined as
is an -ordering on .
The simple denotation of the fact is according to Notation 1 very convenient, in particular, we may write or in general .
Relation demonstrates an -ordering reflecting the arithmetic operations: the width of the result of the arithmetic operations determines also the “width of the fuzzy truth” of the proposition stating that is smaller or equal to that is encoded in the third component of the triplet . If we mirror this idea into particular arithmetics from Example 3, we get the following ternary relation:
where and is given by (1). The demonstration of such an ordering is visualized in Figure 2.
Let us present another example of an -ordering. It assumes that set of similarities has the greatest element.
Example 5.
Let be the greatest element of , i.e., for all . Then the ternary relation given by:
is an -ordering.
The order orders two fuzzy numbers if there exists a similarity such that the extensional hulls of both fuzzy numbers with respect to this similarity are -cut ordered. Here we see a direct link to the works of Bodenhofer [46,47] that will not be here commented more detail but will turn to be very important in the subsequent sections.
Remark 4.
Note that the particular similarity relation R that was used to order the extensional hulls of two fuzzy numbers via their α-cuts is not mirrored in the information . This feature, which is not present here, will also turn to be important in the subsequent sections. It actually tells us that is not that appropriate -ordering as it does not provide meaningful all three components of the triplet. But it is important to mention that even such structures meet the axiomatic definition of the -ordering.
Let us consider, e.g., the product t-norm and
The ordering can be visually demonstrated by Figure 3 where one can see two extensional fuzzy numbers and (displayed by solid lines) and their extensional hulls (left dashed fuzzy set) and (right dashed fuzzy set) that due to their interval-ordering allow the ordering of the original fuzzy numbers .
Let us equip the system of similarities with its bottom element . Then, as is the system of nested similarities, it has all infima, i.e., exists for any subset . Then, we can define the ordering that determines the third component of the triplet (the tolerance added to the ordering) as the “narrowest” similarity relation that is sufficient to get ordered -cut of extensional hulls (with respect to this similarity) of the given fuzzy numbers. Mathematically, such a -ordering will be given by the intersection of all such similarities that lead to the interval-ordering of -cuts of the extensional hulls:
The visualization of the ordering is provided in Figure 4.
Let us now come back to the properties of the that were foreshadowed above. In particular, we will recall the so-called pre-order compatibility [23,24] and the real-order compatibility [24].
Definition 7.
Let ≤ be an -ordering on an MI-prefield . Then ≤ is called pre-order compatible if for any and ,
The name of the pre-order compatibility comes from the close connection to the works of Bodenhofer where the author dealt with pre-orderings of fuzzy sets, see [46,47]. The nature of the property is indeed such that it puts the given -ordering into the perspective of the above-mentioned pre-orderings. In other words, an -ordering that is pre-order compatible reflects in the third component of the triplet the width (similarity) of the extension that is necessary to obtain -cut ordered extensional hulls of given fuzzy numbers.
The provided examples of -orderings and are examples of pre-order compatible orderings. Now, we will show how easy it is to construct -orderings that will meet the axioms of Definition 6 but will not be pre-order compatible. There will be two such examples, each of them harming the pre-order compatibility from a different perspective. The first example harms the reflection of the necessary extension.
Example 6.
Let be equipped with the bottom element . Then the ternary relation given by
is an -ordering that is not pre-order compatible.
The construction of focuses only on the core elements—crisp numbers and ignores the widths of the extensional fuzzy numbers constructed above them. In other words, the fuzzy truth (similarity, tolerance) of the proposition is smaller or equal to is thus meaningless, it does not store any information and we get only binary information on the mutual position of a and b.
The other way how the pre-order compatibility can be easily harmed is presented in the following example that reverses the linear order on .
Example 7.
The ternary relation defined as follows
is an -ordering that is not pre-order compatible.
Unlike the -ordering , the construction of reflects the necessary extension and the third component of the triplet would not be meaningful; however, it reverses the order. Thus, we get the information that “about 4” below “about 2”. Please note that reversed order is still order so, nothing wrong in a sense that would harm Definition 6.
Let us present a lemma which demonstrates the practical impact of the pre-order compatibility as the crucial property of -orderings.
Lemma 3.
Let ≤ be a pre-order compatible -ordering on an MI-prefield . If for certain then .
Proof.
Let ≤ be pre-order compatible. Then (according to Notation 1) means that there exists such that . Let us expand the formula for the extensional hull of
and let us determine its core, i.e., let us put it equal to 1:
Due to the separability property assumed in Convention 1, we get if and only if . Thus, the sought core (-cut for ) is . Analogously, we get . Finally, can be directly rewritten as , which concludes the proof. □
Example 8.
Let us demonstrate Lemma 3 on examples. Consider the case depicted in Figure 2. For the pre-order compatible -ordering , the assumptions of the lemma are met, and it can be seen that as well as holds. For the -ordering the assumption on the pre-order compatibility is dropped and from we cannot deduce that as the opposite is true.
However, Lemma 3 claims only one direction implication, not the equivalence, and so, it does not exclude the possibility of a pre-order -ordering that would preserve the implication. Indeed, consider that is defined in such a way that from we can easily deduce .
Naturally, one may revisit the pre-order compatibility defining Formula (7) and consider it with the equivalence instead of the implication. However, such a condition would be too restrictive and the only order that would in general meet such a requirement would be . However, we can weaken the opposite implication and require only weaken version that ensures some dependence on the order of the real line but without reflecting the particular similarity. The reflection of the necessarily used similarity mirrored only in one of the implications—the one in Formula (7)—will turn to be sufficient, see Section 4.
Definition 8.
Let ≤ be an -ordering on an MI-prefield . Then ≤ is called real-order compatible if for any and the following holds
The -orderings , , and presented above are real-order compatible however, for example, is not real-order compatible. Can we construct an -ordering that is unlike pre-order compatible however, it is not real-order compatible? Indeed, the following example focusing only on the left points of the supports provides such an example.
Example 9.
The ternary relation defined as follows
is an -ordering that is pre-order compatible but it is not real-order compatible.
Now, putting both compatibilities together gives us an -ordering with properties sufficient for proving further results.
Definition 9.
If an -ordering is pre-order compatible and real-order compatible, it is said to be strongly compatible.
Remark 5.
The -orderings , and presented above are strongly compatible.
Another crucial property is the linearity or totality of the order. Naturally, also this property deserves to be incorporated into the context of -orderings.
Definition 10.
Consider an MI-prefield and an -ordering ≤ on . Then ≤ is called total if the following holds for arbitrary :
Let us focus on the relationship of the real-order compatibility and the totality.
Proposition 1.
Let be an MI-prefield and let ≤ be an -ordering on . If ≤ is real-order compatible then it is also total.
Proof.
We prove the proposition by contradiction. Let us assume that for some it holds that .
The assumption means that there does not exist any such that . Indeed, if it existed, the real-order compatibility would lead to the contradiction with the assumption. As for any , the -cuts and are of the same width and holds then necessarily which, due to the real-order compatibility, means that . □
4. Properties of -Orderings
4.1. Wang–Kerre Properties of Orderings of Fuzzy Numbers
As the orderings and rankings of fuzzy numbers attracted significant interest of the researcher, it is not surprising that some of them aimed at their properties. Many ordering techniques rely on comparing certain crisp numbers (indices or representative numbers) instead of comparing the original fuzzy numbers [49]. The natural consequence is a partiality of such orderings that is viewed as a problem by some authors. This is sometimes heuristically overcome by using multiple indices. This article does not focus on an exhaustive survey of all such methods and we are convinced that every single approach has its motivation justifying its existence. However, if we intend to apply the proposed arithmetic of extensional fuzzy numbers to the problem of fuzzy interpolation where orderings of fuzzy numbers play a crucial role, we need to know more about it. In particular, we should investigate under which conditions our approach preserves the most natural properties.
We have adopted the investigations of Wang and Kerre [49,50] as the starting point. This step is rather natural as the authors set up the most intuitive properties of orderings of fuzzy numbers and our goal is not to mimic such works but to investigate our technique in such a generally accepted framework.
Remark 6.
No matter if using indices or not, several techniques for ordering/ranking of fuzzy numbers operate on a finite subset of (reference) fuzzy numbers to which the ordering can be applied. Therefore, the ordering of two fuzzy numbers compares both to the reference set first. This fact is mirrored in the Wang–Kerre properties (axioms) recalled below. When mimicking the properties in our formalism of extensional fuzzy numbers, the properties will need to be slightly modified to drop the reference set(s), one of the properties will become totally redundant without considering the reference set.
Wang–Kerre properties: Let us consider and let and be arbitrary finite subsets of (the reference sets). Furthermore, let . Then
- A1:
- , for ;
- A2:
- , for ;
- A3:
- , for ;
- A4:
- , for ;
- A5:
- Let . Then ;
- A6:
- Let . Then ;
- A7:
- Let and .Then .
For the sake of brevity, when recalling the Wang–Kerre properties A1–A7, we dared to relax the precise definitions of the used symbols ⪯ and ∼ as the main motivation is to provide the readers with the ideas that must be accommodated to a different formalism in the framework of extensional fuzzy numbers anyhow.
4.2. Wang–Kerre Properties for -Orderings and Their Preservation
The implementation of the above-recalled Wang–Kerre properties to the framework of -orderings and extensional fuzzy numbers requires some modifications, for example, any use of reference sets is meaningless, -orderings of not use them to order objects from at all. Consequently, axiom A5 is omitted from our consideration as whenever no reference set is used, it is always automatically fulfilled. Otherwise, one can see that the modification is only formal and preserving the same ideas and motivations.
Let and let . Then the modified Wang–Kerre properties are given as follows:
- A1’:
- ;
- A2’:
- ;
- A3’:
- ;
- A4’:
- ;
- A6’:
- ;
- A7’:
- and ;
The goal of the subsequent parts of the article is to investigate under which conditions an -ordering preserves the properties A1’–A7’.
Proposition 2.
Let ≤ be an -ordering. Then it preserves properties A1’, A2’, and A3’.
Proof.
Using the reflexivity axiom (O1) from Definition 6, for any there must exist such that which implies . It suffices to put to complete the proof of A1’.
The anti-symmetry axiom (O2) from Definition 6 states that and implies . As it holds for any for any , we directly obtain the proof of A2’.
Finally, the transitivity axiom (O3) from Definition 6 states that and implies for some . As it holds for any for any , we directly obtain the proof of A3’. □
The preservation of A4’ is not as automatic as the preservation of A1’-A3’ that stemmed directly from the axioms (O1)-(O3). An additional property must be assumed.
Proposition 3.
Let ≤ be a real-order compatible -ordering. Then it preserves the property A4’.
Proof.
If holds, we immediately get the interval-ordering for all -cuts of both fuzzy numbers: or equivalently by Lemma 1. Put . Recall that the composition of similarities U and V is defined as . Obviously, we have and , where . Indeed, assume that . Then follows immediately from the transitivity of S. In addition, we have
therefore, . On the other side, from and the transitivity of T, we have
therefore, , and hence, we obtain . Similarly, one can show the equalities for . Since , using the previous equalities, we simply find that which jointly with the real-order compatibility leads to . □
Example 10.
Let us again demonstrate Proposition 3 on examples. Let us consider two (disjoint) extensional fuzzy numbers such that . For the real-order compatible -ordering , we easily obtain . However, for the -ordering that is not real-order compatible, we get the opposite, in particular .
The real-order compatibility turned to be useful in proving the preservation of A4’ however, it is not sufficient to prove the preservation of A5’. As it will be shown, we will need to use “the other direction” encoded in the pre-order compatibility and thus, the strong compatibility will be assumed.
Proposition 4.
Let ≤ be a strongly compatible -ordering, and let any similarity from be shift-invariant. Then it preserves the property A6’.
Proof.
Let and let where ≤ is strongly compatible. Put . From the reflexivity axiom (O1) we have and for certain similarities , i.e., and , and by the transitivity axiom (O3), we find that for a certain similarity , i.e., . In what follows, for simplicity, we do not mention the existence of similarities P and Q in , and we will directly write -ordering. Since ≤ is strong compatible, there exists such that . We show that also holds. By Lemma 2, one can simply check that for any , there exists such that and
and vice versa, for any , there exists such that and
Hence, and using the shift-invariance of U and W, e.g., or , if , then there exists such that and (9) holds, which implies
Similarly, if , then there exists such that and (10) holds, which implies
By Lemma 2, we find that , and using the real-order compatibility, we obtain . Using reflexivity (O1), it holds that and , and by transitivity (O3), we obtain . □
Example 11.
Let us demonstrate Proposition 4 on some examples. Let us again consider the case depicted in Figure 2 with and that are shift-invariant. Furthermore, let us consider such that z is an arbitrary number from and (i.e., ).
If we consider a strongly compatible -ordering then we have and easily, we can check that also holds, where the left-hand side is equal to and the right-hand side is equal to .
Now, let us consider the -ordering and that is not strongly compatible, see Example 9. Due to the position of the left-hand sides of the supports, the following holds. However, and so, we get two extensional fuzzy number of the same width and as , also the left-hand sides of the supports are ordered in this way. Consequently, which harms the property A6’.
Again, note that the proposition states only one implication but the opposite implication does not hold. Therefore, if we consider the -ordering that reverses the order , we get as well as and thus, A6’ is preserved even though is not strongly compatible.
The last axiom that must be checked will be preserved again under the assumption of the strong compatibility. Additionally, the presence of the crisp bottom element in the considered MI-pregroup will be assumed.
Proposition 5.
Let ≤ be a strongly compatible -ordering on an MI-prefield with the crisp bottom element. Then it preserves the property A7’.
Proof.
As contains the crisp bottom element (classical equality), we may incorporate the representation of the scalar multiplication in :
If and ≤ is pre-order compatible, then and necessarily for any . Since and for any , we find that , which implies as a consequence of the real-order compatibility. Using the reflexivity axiom (O1), we obtain and , and from the transitivity axiom (O3), we find that . □
Corollary 1.
Let ≤ be a strongly compatible -ordering on an MI-prefield with the crisp bottom element. Then it simultaneously preserves axioms A1’-A4’ and A6’-A7.
Proof.
We have to prove that A6’ remains true if the shift-invariance is omitted in (cf. Proposition 4). Let . As with the proof of Proposition 5, if and ≤ is pre-order compatible, then and necessarily . Since , we find that because of the real-order compatibility. Using the reflexivity axiom (O1), we obtain and , and from the transitivity axiom (O3), we obtain . □
Corollary 1 directly gathers the results from Propositions 2–5 and shows an elegant and safe way how to construct a system of similarities and an -ordering that is safe in the sense of meeting all the preferable properties. Indeed, the list of assumptions may seem high, but it is not restrictive at all. As we showed above, the most natural and intuitive -orderings are strongly compatible and analogously, including the crisp equality as the crisp bottom element to the system of nested similarities is more natural than starting from a wider bottom element.
Definition 11.
Let be an MI-prefield, and let ≤ be an -ordering on . The structure will be called an-ordered MI-prefield provided that for any and , it holds that
- (P1)
- ,
- (P2)
- and .
The following statement shows that the shift-invariance of similarities and strong compatibility of -ordering are sufficient conditions to get a -ordered MI-prefield.
Proposition 6.
Let be an MI-prefield such that any similarity from is shift-invariant, and let ≤ be a strongly compatible -ordering on . Then is an -ordered MI-prefield.
Proof.
(P1) follows from Proposition 4. Let and for and . According to reflexivity of -ordering, we obtain and , and by transitivity, we find that and . Denote . Then we have and . We will show that . Since ≤ is strongly compatible, as a consequence of the real-order compatibility, it is sufficient to show that there exists such that
By Lemma 2, we will show that for any there exists such that and
and vice versa, for any there exists such that and
Let be an arbitrary similarity. Since R and W are shift-invariant, for any , we obtain
where we put . Since R is strongly compatible, by Lemma 3 we find that and , which implies . Similarly, for any , we obtain
where we put , and thus . By Lemma 2, we obtain (11) and thus , which concludes the proof of (P2). □
Example 12.
Let be the MI-prefield with , where is given by (1) for any and is the crisp equality (see, Remark 3), which is enriched by a strong compatible -ordering ≤. Since any similarity from is shift-invariant (see, Example 1), by the previous proposition, is an ordered MI-prefield.
Since -ordering on an MI-prefield is determined by the set of similarities that is referred in the index of the MI-prefield, for convenience, we will omit in “-ordered MI-prefield” and write only “ordered MI-prefield”. In the following definition, we introduce the isomorphism of ordered MI-prefields which is used in our demonstration of fuzzy interpolation. As with algebraic literature, for convenience, we do not distinguish the operations and orderings of ordered MI-prefields using indexes if no confusion can appear.
Definition 12.
Let and be ordered MI-prefields. A map is a homomorphism of ordered MI-prefields provided that
- (H1)
- , and for any ;
- (H2)
- , and for any ;
- (H3)
- for any .
A homomorphism h of ordered MI-prefields is called an isomorphism provided that h is a bijective map.
In the following example we show an isomorphism using the ordered MI-prefield from Example 12.
Example 13.
Let be an ordered MI-prefield with a strong compatible -ordering ≤. Let such that . The the map given by for any is an isomorphism of ordered MI-prefields. It is easy to see that is a bijective map, since for is a bijection from onto , where we naturally define . Let us show that satisfies (H1) and (H2). Since the proofs are analogous for + and ·, we verify only (H1). For any , we have
For the zero element in , we obtain , where we use . Finally, for any , we have . Now, we show that (H3) also holds. Let such that . Since ≤ is strong compatible, to prove that , it is sufficient to show that there exists such that ; the desired inequality is a straightforward consequence of the real-order compatibility of ≤. Recall that whenever or equivalently (see the proof of Proposition 3). Since and ≤ is pre-order compatible, we find that according to Lemma 3. Put . Then we obtain and . Indeed, for any , we have
where ⊗ is the ukasiewicz multiplication, and similarly for the second equality. Now, for any , we can simply calculate that
which implies that as a consequence of .
5. Application to Fuzzy Interpolation
5.1. The Concept of -Function
We will approach fuzzy interpolation from the analytical perspective rather than from the logical one. Therefore, we will always have in mind some function that is partially given (in a finite number of points) and our goal is to complete it to a total mapping that assigns an output to an arbitrary input. Therefore, first, we must start from defining such fundamental objects as a function operating on extensional fuzzy numbers.
Remark 7.
Deliberately, we avoid the notion of a fuzzy function as it has been used by many authors for distinct objects with distinct definitions. Usually, the ideas and motivations are similar, but the technical aspects differ. As the natural name involving the “extensional fuzzy numbers” might be too long, for the sake of brevity we adopt the name -function.
Definition 13.
Let ≤ be an -ordering on an MI-prefield and let D be a non-empty subset of . A mapping is an-function if there exists a function such that
Equation (15) states that each -function is determined by a real-valued function. This allows the introduction of fundamental properties known from mathematical analysis, such as monotonicity, injectivity, or surjectivity of functions, in an analogous way.
For example, an -function is called increasing if
Analogously, we could define monotonically decreasing -function and of course, also strictly increasing and strictly decreasing -function. Note the importance of the choice of the -ordering and the fact that the same ordering is used on both sides of the definition. Indeed, for distinct choices of the -ordering, the given -function may be or must not be monotonous. The generalization of the definition that would allow the use of different ordering on the left-hand side than the one used on the right-hand side is technically possible yet, would need to be strongly motivated by the modeled problem.
Using the concept of -function, we can very naturally define extensions of classical functions using the arithmetic operations, for example:
is a linear -function;
is a polynomial -function (of the n-th order).
Moreover, we can define natural extensions of other fundamental functions, for example
is an exponential (logarithm) -function;
is a sine (cosine) -function.
The crucial for transferring the vagueness will be the choice and appropriateness of the mapping h. The most trivial would be to put h equal to the identity mapping however, such a choice would not be probably adequate for managing the uncertainty.
5.2. -interpolation
The fuzzy interpolation task can be in general formally define as follows. Let us be given two finite equal sized sets of fuzzy sets and on the universe (or its non-empty subsets). We search for a mapping such that the condition holds for any . Let us reformulate the problem into the formalism of -functions.
Definition 14.
Let be an MI-prefield and let ≤ be an -ordering on . Let for and let such that for any . We say that an -function f-interpolates above-given pairs of extensional fuzzy numbers if
Naturally, we may mimic the classical interpolation methods that are well-founded. For example, the linear -interpolation will be defined for an arbitrary such that as follows:
Remark 8.
The linear interpolation in the crisp sense can be computed by several formulas that are equivalent. Therefore, a natural question is whether this would hold also for the case of -interpolations stemming from these crisp equivalent formulas. The answer is positive. Due to the particular used arithmetic, the computation runs over the “centers” and the similarities are, in the second phase, calculated over their maximum. Therefore, as long as we use extensions of formulas that are equivalent in the crisp case, and the inputs are the same, the results of the extended formulas must be equal too. However, note that if we use another type of MI-algebra with different calculus over the similarities (see [19] for some examples), the results could differ.
We will present a short lemma that will be used in the latter. The basically states that if an input is between two input nodes, the output obtained by Formula (17) is between the respective output nodes.
Lemma 4.
Let be an MI-prefield such that any similarity from is shift-invariant and let ≤ be a strongly compatible -ordering on . Let for and let such that for any . For and for the -function f given by (17) it holds that:
Proof.
Using the fact that and Lemma 3 we obtain . Using Formula (17), we obtain such that
and . Hence, we find that . We show that . Put . Since T is shift-invariant, for any , we obtain , where , and vice versa, for any , we obtain , where . By Lemma 9, we find that . Similarly, one can show that . Since and and from the transitivity of similarities, we have , and as has been verified in the proof of Proposition 3. Hence, we have , , and , which implies , and due to the real-order compatibility of ≤, we obtain . □
There are two important observations coming from the definition of the -interpolation and the formula for the linear -interpolation.
First, the choice -ordering is absolutely crucial as the technique assumes all fuzzy points in the input space to be linearly ordered and moreover, every input needs to lie in between of two neighboring fuzzy points. Thus, the totality of the -ordering seems to be a natural requirement of the highest importance.
Secondly, the technique may determine reliably a unique solution for an extensional fuzzy number that possesses the following position however, if the input point is one of the given points, say, then there are two approaches leading to two results that need not be equal. In particular, the first approach (interpolation from the right) considers to lie between and :
while the other approach (interpolation from the left) considers to be positioned between and :
Moreover, none of the two results is necessarily equal to which means that the interpolation condition would not be met. This problem is not critical at all as then word interpolation actually assumes that it focuses on points between the given nodes so, nothing prevents us from defining the outputs for the given nodes .
However, the problem arises when the input is not equivalent to the node only due to a different width, i.e., we consider such that . In such a case, the interpolation from the right would give us while the interpolation from the left would lead to . As it is not clear which result should be adopted and both “directions” can be justified, we can choose the one that lowers the uncertainty by picking
However, we should check whether if we impose some reasonable properties, the proposed approach meets them. The most natural property one would expect is the monotonicity with respect to the uncertainty, i.e., less uncertain inputs cannot lead to more uncertain outputs:
It is easy to assume conditions to preserve the uncertainty monotonicity condition (19) for any , but its preservation for must be ensured. Indeed, Formula (18) can easily lead to although . Therefore, let us introduce a linear -interpolation that meets the constraint.
Definition 15.
Let and be MI-pregroups and let ≤ be an -ordering on that is strongly compatible. Let for and let such that for any . The linear -interpolation of the given pairs of extensional fuzzy numbers is an -function , where such that , i.e., for any given as follows:
Remark 9.
Let us note that as the basis for the above-introduced -interpolation, we have chosen the simplest crisp interpolation—the linear one. However, the concept of -function allows much more, basically, any standard interpolation method can be extended in this way, for example, Lagrange polynomial interpolation or Newton polynomial interpolation. On the other hand, one must take into account that such interpolations do not consider only neighboring points but basically all nodes which, using the arithmetic, causes inevitable widening of the results, which is exactly the problem that was aimed when introducing the arithmetic of extensional fuzzy numbers.
Indeed, when calculating with two extensional fuzzy numbers, the result does not get wider than the widest one which is a positive aspect compared to arithmetics using Zadeh’s extension principle. On the other hand, if we consider all nodes, the result will always be as wide as the widest one, which is a positive result when the used similarities are more or less of the same widths. But it is not very positive when we deal with significantly different values (e.g., daily COVID-19 increases in a particular country ranging from individuals to thousands per day) and the interpolation between two vaguely defined small (and thus also narrow) quantities would result into something as wide as the width of the highest values in the set of nodes. Such cases must be treated by special similarity transformation techniques or by using “relative” similarities flexibly changing the widths of the fuzzy numbers.
5.3. Properties
Proposition 7.
The linear -interpolation:
- (a)
- -interpolates the given pairs of extensional fuzzy numbers;
- (b)
- preserves uncertainty monotonicity condition (19).
Proof.
The proof is constructed directly. Let then (20) directly assigns which meets the interpolation conditions and thus, a) holds.
Let us consider and such that and let us split the situation. First, let . If both S and R are narrower than then the result is and the monotonicity condition is preserved. If and then according to (18):
and clearly, which again preserves the monotonicity.
Finally, we investigate another important property of the interpolating -function that is, the preservation of the monotonicity with respect to the inputs. This property, naturally, makes sense only if the described dependency that is being modeled is assumed to be monotone. This assumption, though might be viewed as too restrictive, belongs to crucial and very usual properties. In the context of the approximate reasoning, the first studies on monotonicity of fuzzy rule bases were introduced by Van Broekhoven and De Baets [44,51,52]. Later, the original studies focusing mainly (not exclusively) on Mamdani–Assilian type of fuzzy rules, were followed by works aiming at the preservation of the monotonicity of implicative fuzzy rules [45,53,54]. Such research starts always by assuming that the given fuzzy rule base is monotone, i.e., abstracting from the mathematical formalism, considering any two antecedents, the bigger one is connected to a bigger consequent. Interestingly, the resulting function after applying the defuzzification is not always preserving the monotonicity, see [43]. Therefore, the other works aimed at determining the conditions under which the monotonicity is preserved.
Other two approximate reasoning tasks related to the above-given monotonicity problem are: preservation of the interpolation condition and monotonicity regarding fuzzy inputs.
The very first one became a natural consequence of the works [7,8] that, in order to preserve the monotonicity of the resulting function, modifies the original fuzzy rule base by specific at-least and at-most modifiers [55,56]. Then naturally, one must ask whether an input equivalent with one of the original antecedents still leads to the derived output equivalent to the original consequent, although the fuzzy rule base used for the inference contains already modified antecedents as well as consequents. The solution presented in [7,8] investigated the conditions under which the interpolativity remains preserved.
The other problem arises whenever we do not intend to involve a defuzzification and the inputs are fuzzy as well. Then the monotonicity preservation is investigated on a higher layer, in particular, assuming that we are given a partial mapping from fuzzy sets to fuzzy sets, e.g., by a fuzzy rule base, such that for any two fuzzy inputs (antecedents) that are ordered, the respective fuzzy outputs (consequents) reflect the order. Moreover, as in the above cases, the fuzzy inputs (are supposed to be ordered) and thus, the monotonic description is provided, although in a discrete form. Now, the task is to complete this partial mapping from fuzzy sets to fuzzy sets to a total one, but preserving the monotonicity. Therefore, if two order fuzzy inputs are processed, the generated fuzzy outputs must preserve the same order. Following the previous works, the whole description of the monotonicity is provided for the increasing case as the decreasing case is directly obtained by inverse steps.
This naturally leads to the investigation of the monotonicity of the -interpolation. Let us assume that the nodes are ordered and the respective consequents are reflecting the order, i.e., let , for any . Let us apply the linear -interpolation. Do we obtain a monotone -function f? The following proposition provides us with the answer.
Proposition 8.
Let be an MI-prefield such that any similarity from is shift-invariant and let ≤ be a strongly compatible -ordering on . Let such that and for any and let f be given by the linear -interpolation of the given pairs of extensional fuzzy numbers. Then f is increasing.
Proof.
As the -order is strongly compatible, it is also total and thus, the problem is correctly defined. Let us consider inputs such that . The situation splits into several cases.
First, let us assume that both inputs are indistinguishable from the nodes up to a certain similarity, i.e., and for some i and some k such that . Then necessarily and and the respective outputs and for some . Due to the assumption of the theorem, we know that . Put . Since and , we obtain and as has been verified in the proof of Proposition 3. As with the proof of Lemma 4, from the shift-invariance of U, we simply obtain , and hence, . Due to the real-order compatibility we get that is .
Second, let us consider such that they lie in different “intervals”, i.e., let and let for some such that and . Then using Formula (20) for the -interpolation and Lemma 4 we obtain and which, using the transitivity axiom (O3), proves that .
Finally, we assume that both inputs belong to the same “interval”, i.e., . Using an analogous technique, we used in the second case, we obtain and such that . Then, we proceed analogously to the first case and we obtain that jointly with the pre-order compatibility leads to the desirable conclusion that . □
Proposition 7 jointly with Proposition 8 provides us with the crucial answers. In particular, they confirm that the proposed linear -interpolation interpolates the given pairs of extensional fuzzy numbers and moreover, it is monotone in “both directions”, with respect to the uncertainty as well as with respect to the ordering of vague quantities. Especially the latter has a strong impact on modeling the approximate reasoning in distinct schemes, namely when fuzzy interpolating a sparse fuzzy rule base.
6. Experimental Demonstration
The purpose of this experiment is not to demonstrate an exhaustive comparison of the suggested approach with the existing ones. First, such a comparison would need to have given a justified cost function on which we could evaluate some fair score. And the fairness of such a cost function would be a nutshell from the objectivity point of view. Indeed, for any interpolation function, there might be a cost function on which the particular method is optimal; however, this only creates biased information that we want to avoid deliberately. Secondly, the aim of this article is not centrally focused on the fuzzy interpolation problem. It provides a very general concept coming from the arithmetics of extensional fuzzy numbers and allowing the construction of concepts such as -ordering, -function, and/or -interpolation that can be either directly used or further extended to additional concepts known from the classical mathematical analysis. It is clear that a particular comparison would rather give information on the particular setting. Not only parametric but mainly conceptual, see Section 7.
However, for the sake of clarity, comprehensibility, and mainly for demonstrative purposes, we find the experimental example as a crucial part of the work. Below, we provide one such example that comes from the real-world problem, in particular, from our long-term grant supported co-operation with economists.
6.1. Ice-Cream Sales Modeling
The world ice-cream market is dominated by several well-established players who saturate a large market share. Their products are very similar and often differ only in marketing and seasonal innovations. The market basically consists of three types of products, namely artisanal ice-cream, pulse ice-cream, and take-home ice-cream, where the latter dominates the global market, with hypermarkets and supermarkets being the leading distribution channel. The largest market in terms of revenues is the US market, although the highest growth rate is currently observed in Asia–Pacific market.
The experimental demonstration is focused on the Czech Republic with the average per capital consumption close to 5 kg with low but stable annual growth of about 2% over the last decade and the high sensitivity to weather conditions leading to large differences between summer and winter sales, which is a feature observed in all countries outside the (sub)tropics. Analysis of ice-cream market data (see e.g., www.statista.com) shows that atypical weather conditions in seasons such as warm winter and early spring or colder summer can cause a drop in the ice-cream market revenue growth. Therefore, it is desirable to model the relationship between weather conditions in individual seasons and ice-cream sales, which will be used to predict the ice-cream market revenue growth when weather conditions are estimated.
For this purpose, we use dataset that consists of adjusted and normalized quarterly sales in the Ice category (various kinds of, mostly, take-home ice-cream) of one of the largest market players over 2008–2014, i.e., 28 observations are available, in the Czech Republic. It should be noted that only quarterly sales data are available; however, the production process cannot be rescheduled every day and the product has a relatively long use, allowing it to be stored relatively long in shops and households; therefore, the quarterly sales prediction appears to be sufficient to optimize the production process. To illustrate the -interpolation also for quarterly ice-cream sales that are inaccurate for some reason, we extend the crisp sales to extensional fuzzy numbers by adding a randomly determined standard deviation to each sale (see, Table 1). The quarterly sale expressed as an extension fuzzy number is then determined by the parameters and described as a fuzzy number , where the similarity of the relation T on is given (1) in Example 1, i.e.,
and . Unlike the quarterly ice-cream sale s expressed by a crisp number, the extensional fuzzy number models the fact that the quarterly sale is “about s”; for example, we have “about 1.53” in spring 2010 as could be seen in Figure 5a.
To express weather conditions, for demonstration purposes, we will use the daily average temperatures (in degree Celsius) at Václav Havel Airport in Prague. Because each quarter contains approximately 90 records of temperature, and similarly to ice-cream sales, we summarize the temperature into an extensional fuzzy number determined by two parameters, namely the average temperature and the standard deviation in the quarter (see Table 2), which contains more information than only average temperature. Please note that the standard modeling of the relationship between temperatures and ice-cream sales (e.g., based on the interpolation or regression) use the average temperature in the quarters, while the random fluctuation of temperatures in the quarters expressed by the standard deviation is not considered (cf. [57]).
An extensional fuzzy number expressing the temperature in a quarter and determined by parameters is the fuzzy set , which is defined in the same way as the similarity R for the quarterly sales. An example of the extensional fuzzy number expressing the temperature “about ” in spring 2010, which is determined by parameters in Table 2, is displayed in Figure 5b.
In the following subsection we will describe the procedure how to -interpolate extensional fuzzy numbers expressing temperatures and ice-cream sales in quarters in the years 2008–2014.
6.2. General Description of -Interpolation Procedure
Let be pairs of extensional fuzzy numbers such that for any . We call these pairs of extensional fuzzy numbers as extensional fuzzy data. In contrast to the interpolation of real data, we must be more careful in the direct use of Formula (20) for extensional fuzzy data. The reason is that the fuzziness of extensional fuzzy numbers on input, which is expressed by a similarity relationship, is distributed through Formula (20) to another fuzziness specifying the similarity relation of extensional fuzzy number on the output of -interpolation. Since the input and output of extensional fuzzy data are in practice obtained by the measurement on different scales, the meanings of fuzziness are different for input and output fuzzy data, which leads to incorrect results by direct application of (20). In other words, unless the same measurement scale is used to determine the input and output fuzzy data, we cannot assume that extensional fuzzy data can be handled in one ordered MI-prefield, and the -interpolation introduced in Definition 14 cannot be applied for them. This problem can be overcome by a normalization procedure, which ensures that the normalized extensional fuzzy numbers will belong to the same ordered MI-prefield.
In what follows, we assume that extensional fuzzy data generally belong to , where and are ordered MI-prefields with a strongly compatible -ordering and a strongly compatible -ordering . respectively. We use I and O in the indexes to refer to the input and output, respectively. Let be an ordered MI-prefield with a strongly compatible -orderings ≤, and let and be isomorphisms of ordered MI-prefields. We say that a pair of isomorphisms is a normalization of extensional fuzzy numbers if the composition and introduce natural correspondences between the ordered MI-prefields and , i.e., is a natural image of in and vice versa is a natural image of in . Please note that the decision if the compositions and are natural correspondences between the ordered MI-prefields and depends on the user. If , i.e., , the pair given by , where is the identity map on , defines the trivial normalization of extensional fuzzy numbers, nevertheless, the user must agree that extensional fuzzy data are determined by the measurement on the same scale and thus can be processed in the same ordered MI-prefield . Now, we can introduce the procedure of -interpolation of extensional fuzzy data.
Let be extensional fuzzy data, and let and define a normalization of extensional fuzzy numbers. We put and similarly . The procedure of linear -interpolation of extensional fuzzy data with respect to the normalization given by is as follows:
- Input:
- extensional fuzzy number from
- Step 1:
- normalize with respect to to get
- Step 2:
- find such that
- Step 3:
- compute from and by Formula (20)
- Step 4:
- compute (a denormalization procedure)
- Output:
- extensional fuzzy number from
It is easy to see that if and the input and output extensional fuzzy numbers were determined by the measurement on the same scale, one can set as the trivial normalization, and the output extensional fuzzy number coincides with the extensional fuzzy number obtained directly by Formula (20).
6.3. Experimental Results
Our extensional fuzzy data consist of 32 pairs , where we put for winter 2008, for spring 2008, etc. Recall that each input extensional fuzzy number is determined by parameters displayed in Table 2, where is the average temperature, the standard deviation in the i-th quarter and is given by (21). For the output values, we will consider two situations:
- (a)
- the ice-cream sales are crisp fuzzy numbers, i.e., extensional fuzzy numbers , where is the equality relation and only the first parameter in each pair is considered in Table 1;
- (b)
The first situation is very common in practice and occurs when output data (ice-cream sales) are available as real numbers, and we have no further information. The second situation requires additional information, for example, quarterly sales are average ice-cream sales that are calculated from weekly sales in quarters, where the standard deviation provides additional information, or the expert expresses an inaccuracy in the total sale in the quarter.
Let be the ordered MI-prefield introduced in Example 12. Obviously, our extensional fuzzy data belong to , where is the inverse element to the standard deviation , i.e., , but the input and output extensional fuzzy numbers cannot be reasonably processed in this ordered MI-prefield without normalization. Indeed, the scale for measuring temperature is different from the scale used for sales of ice-cream, and even scales within different quarters are different as could be seen from Table 3, where we display the standard deviations for the temperatures and ice-cream sales.
In contrast to the standard deviations of temperature in quarters (the standard deviation for all temperatures in 2008–2014 is ), which are almost the same, there are large differences between the standard deviations of ice-cream sales in quarters (the standard deviation for all sales in 2008–2014 is ). The variability of the standard deviations of ice-cream sales forces us to model the relationship between temperature and ice-cream sales in each quarter separately, otherwise the resulting sales uncertainty may be affected by inaccurate normalization. This would certainly happen if we applied overall normalization to all sales. Therefore, before we use the linear -interpolation procedure introduced in the previous subsection, we normalize the standard deviations with respect to the standard deviations of the temperatures and the sales in the respective quarters of the years 2008–2014, see Table 3. Please note that the normalized values (i.e., standard deviations) are measured in the unit of the standard deviation.
For any extensional fuzzy number expressing a temperature in a quarter (, we define with , where is the standard deviation of temperatures in . Similarly, for any extensional fuzzy number expressing an ice-cream sale in a quarter , we define with , where is the standard deviation of sales in . For , we put , hence, and . Please note that (and similarly ) is derived from the following formula
where represents a standard deviation for p and a standard deviation for , and thus the standard deviation is a normalization of the standard deviation with respect to . According to Example 13, the maps and are isomorphisms from onto . In addition, we agree that these isomorphisms are appropriately selected for normalization, where we do not measure in the original units, which are clearly different, but in the units of standard deviations in quarters, which are abstract and the same for input and output.
Unlike the standard linear interpolation, we cannot display the linear -interpolation in a clear way, because we have infinitely many extensional fuzzy numbers for any real number. On Figure 6, we illustrate the linear -interpolation on extensional fuzzy data observed in summer that are crisp and fuzzy, and we show separately the use of each rule of Formula (20) from Definition 15, where the computational algorithm is designed according to the procedure established in the previous subsection. In Figure 6a-left, the temperature measured as “about 17.7” and expressed by the extensional fuzzy number with and (or ) gives the estimation of ice-cream sale with and (or ). Since the sales of ice-cream in output data are crisp numbers, the uncertainty of the estimated sale is only affected by the uncertainty of the input data temperatures and the uncertainty of the temperature for which the sale is estimated. The standard deviation for normalization and for denormalization are used in our procedure to get an appropriate estimation of the uncertainty of the ice-cream sale. In Figure 6a-right, we consider the same input data as above, but the sales of ice-cream in output data are “true” extensional fuzzy numbers. It can be seen that in both situations the same estimate of ice-cream sales is obtained, which indicates a dominant similarity among the used temperatures. In other words, the uncertainty present in the sales nodes is lower than the uncertainty present in a used temperature. In Figure 6b-left, the input temperature determined as “about ” and expressed by with and (or ) gives the estimation of ice-cream sale that coincides with the crisp sale output for the temperature node with and (or . The reason is that and simultaneously (i.e., ), and due to the uncertainty monotonicity condition (19), the uncertainty of ice-cream sale corresponding to temperature cannot be higher than the uncertainty of output corresponding to temperature node . Similarly, in Figure 6b-right, the estimation of ice-cream sale coincides with the sale output with and (or ). On the other side, in Figure 6c-left, the input temperature determined as “about 17.4” and expressed by with and (or ) gives the estimation of ice-cream sale with and (or ). The reason is that and simultaneously and therefore, the uncertainty of ice-cream sale output corresponding to temperature can be higher than the uncertain of output corresponding to temperature node (i.e., ), which results in the application of Formula (18). In Figure 6c-right, we display the resulting estimation of ice-cream sale in the situation when the input data are the same as above and the ice-cream sales in the output data are expressed by extensional fuzzy numbers. One can see that the estimation is the same as for sales expressed in real numbers, which indicates a dominant similarity among the used temperatures similarly as in Figure 6a.
In Figure 7, we illustrate the linear -interpolation between three pairs of temperatures and ice-cream sales observed in winter, where sales are expressed by extensional fuzzy numbers, and show the estimation of ice-cream sales for three selected temperatures. Two of them, namely “about 1.7” () and “about 3.3” (), lie between temperature nodes and “about 1.16” () coincides with the first node up to similarity with a higher similarity. The estimation of ice-cream sales is “about 0.257” (), “about 0.277” () and “about 0.266” ().
It should be noted that in practice it is very difficult to predict the average temperature in the coming quarter as a single number and it is more appropriate to use a confidence interval or an extensional fuzzy number as in our case. The linear -interpolation can be then used to predict ice-cream sales in the coming quarter, providing important information for production planning.
6.4. Comparing with Other Approaches—Discussion
As stated in the Introduction, fuzzy interpolation is a rather old problem with many well-developed techniques, no matter we talk about the geometrically motivated or rather logically motivated approaches. Thus, the formal apparatus designed in this article should naturally face some comparison with them. In data sciences (e.g., in pattern recognition or classification), we usually encounter an exhaustive experimental comparison with some objective evaluation on a given cost function. However, up to our best knowledge, there is no generally accepted quality criterion determining for fuzzy interpolation tasks. Indeed, there is always a way to define such a criterion, but it would be purely subjectively designed.
In such a case, we opt for a demonstrative comparison on the above-presented ice-cream sales data with two prototypical representatives of existing methods employing different paradigms. The first one that stems from the geometric motivation is the well-known Kóczy–Hirota (abbr. KH) methods introduced in [9]. Although this method is rather old and several improvements have been employed soon after its publication, it is a fundamental basis for many other geometrically oriented techniques, see [58]. Moreover, this method possesses the advantage of low computational costs and it is driven by the same crisp technique—the classical linear interpolation. For observing the differences, we find this choice very appropriate.
The second method stems from the logical (approximate reasoning) motivation and it is the standard fuzzy relational inference. Such method models the existing rules by a fuzzy relation that is either conjunctive (often called Mamdani–Assilian [59]) or implicative [60] and connects the fuzzy relation to a composition-based inference, i.e., to an appropriate image of a fuzzy set under the fuzzy relation. For more details on the distinct types of rules, their properties and the connection to the compositions/images as inference mechanisms, we refer to [61,62]. Briefly, the appropriate combinations are: (1) the implicative fuzzy rule base (antecedents and consequents are connected via a residated implication, rules are aggregated with help of the minimum) together with the basic composition, which is the well-known Compositional Rule of Inference (CRI); and (2) the conjunctive fuzzy rule base (antecedents and consequents are connected via a t-norm, rules are aggregated with help of the maximum) together with the Bandler–Kohout subproduct. The opposite combinations may cause complications, see [63].
Remark 10.
Many articles use the combination of the (Mamdani–Assilian) conjunctive fuzzy rules base and the CRI. This is often totally correct as the vast majority of cases deals with crisp inputs while the danger appears in the case of fuzzy inputs. Indeed, in the case of crisp inputs, no matter we deal with CRI or the Bandler–Kohout subproduct, the inference degenerates into a simple substitution of the crisp input into the given fuzzy relation so, we even cannot distinguish between these two compositional inferences, they coincide. But for the fuzzy interpolation task with fuzzy inputs, the choice of the combination is essential.
Now, let us focus on several examples from the above elaborated ice-cream sales dataset. The first example considers “the simplest” case when the antecedents as well as consequents are ordered with respect to the interval-ordering of -cuts and the fuzzy input lies “between” the antecedents, and the antecedents as well as consequents are overlapping. This case is demonstrated on a part of the autumn data from the ice-cream sales problem, see Figure 8. As we can see, the KH method and the proposed -interpolation method provides very comparable results. The proposed method generated a bit narrower output however, this advantage is caused by a well-chosen relativization determined by the standard deviation transformation caused and indeed, it could be easily lost. Therefore, we do not dare to claim it as a generally valid principle. The third method determined by fuzzy relational inference determined something that is logically correct however, not meeting the expectations of the analytical interpolation that is used under the implicit assumption of the satisfaction of the functionality axiom. Please note that the choice of the algebra has no significant influence, for example, using the Łukasiewicz implications would lead to a higher output fuzzy set but still reaching values around 0.6 at maximum and moreover, with an unlimited support. Here, we would like to emphasize that this is nothing against fuzzy relational inference. The problem lies in the fact that the antecedents are closer to each other than the consequents and thus, the fuzzy rule base is not coherent [64] which is a sort of consistency (non-conflictness) of the fuzzy rules. In other words, this means nothing wrong about fuzzy relational inference but rather about its non-applicability on such interpolative setting. Finally, the use of the other preferred combination (Mamdani–Assilian rules with Bandler–Kohout subproduct) would lead to a subnormal and non-convex output fuzzy set—again not meeting the implicit functionality axiom.
Now, let us consider the cases depicted on the right-hand side of Figure 6a. There, the antecedents are not ordered with respect to the interval-ordering of -cuts which makes impossible to use the KH method (at least in its original form) while the proposed -interpolation works well due to the robustness of the -ordering. The fuzzy relational inference here can easily infer the outputs too as the ordering of antecedents does not play any role. However, the consequent part makes the inferred outputs inappropriate, in particular, the disjointness of the consequents is an extreme version of the incoherence and thus, the implicative rules would infer a fuzzy set equal to zero on the whole universe. For the completeness, let us mention that the Mamdani–Assilian rules would result again subnormal and non-convex outputs without any functional meaning.
Another similar example is depicted on the right-hand side of Figure 6b. It is the same situation as in the previous case with the only difference that the fuzzy input is located in one of the nodes for the antecedents; however, the input is narrower than the antecedent. The figure shows how the proposed -interpolation generates the outputs while up to our best knowledge, KH method would not be applicable. But again, after some adjustments, KH method would deal with this input too and infer some reasonable output. The fuzzy relational inference would lead to the same as in the previous case.
The last case we consider is the situation of a sparse rule base where fuzzy relational inference would not again meet the expectations imposed by the assumed functionality axiom. In particular, if we were given two disjoint antecedents and the fuzzy input would be placed in between of them in such a way it would be disjoint with both, the inferred output would be equal to 1 on the whole output universe (or to 0, in the case of the Mamdani–Assilian rules with the Bandler–Kohout subproduct). Here, we would like to again emphasize that this not wrong at all from the logical perspective. If the rules are logical constraints stating that the consequent should be inferred under the assumption that the antecedent holds, and none of the antecedent is met by the input, we may deduce nothing, which is mirrored by the outputs 1 or 0, depending on the semantics of the rules. This is only again a case where, without further improvement like the one proposed in [15], relational inference is not appropriate for approximate reasoning schemes of this type of sparse cases. Here, the KH method performs a practical advantage as it is deliberately designed for the sparse rule bases. This case is not demonstrated on the real data as such a case has not occurred in the ice-cream sales dataset at all. However, from the principal point of view, the results obtained from the KH method and from the proposed -interpolation would be very comparable—mimicking the cases depicted in Figure 8.
7. Conclusions and Future Work
The presented approach stemmed from the particular fuzzy arithmetic, namely from the arithmetic of extensional fuzzy numbers [19,25]. The first steps from the arithmetic towards the ordering were published in [23,24] with the aim to construct metrics of fuzzy numbers [48]. The original motivation came from the need for modeling the triangle inequality in the metric-like structures. However, it is clear that the importance of -orderings is much only higher and mainly more general. Apart from the clear directions coming from the mathematical analysis based on the extensional fuzzy numbers (fuzzy approximation, mathematical analysis, construction of limits, convergences), already [24] mentioned approximate reasoning as one of the related areas where this research can have an importance.
Indeed, the fuzzy interpolation is one of the crucial problems in approximate reasoning and it is not possible to study it from the analytical point of view if we cannot order the used fuzzy sets (fuzzy numbers) in such a way to be able to state that an input lies “between two given fuzzy nodes”. This article copes with this topic and incorporates the technique of the -interpolation generically from the formal roots (arithmetic, ordering, -functions) to the problem formalization (-interpolation, uncertainty monotonicity, and standard monotonicity) towards the practical implementation and the demonstrative example. It is clear that the proposed calculation is just one of the rich pool of possibilities and as mentioned in Remark 9 other techniques can be introduced analogously. The remark also contains a discussion pointing the potential drawbacks of more sophisticated approaches as well as the direction towards their elimination.
One can view the proposed approach as a single instance of more general classes of -interpolations not only form the linear, polynomial or other basis point of view, but also form the point of view of processing the vagueness. Indeed, following the arithmetic of extensional fuzzy numbers, also the -interpolation is a sort of two-step procedure. In the first one, the “crisp” part of the task is solved using the standard technique. In the second one, the resulting vagueness (uncertainty, tolerance, etc.) is calculated as a result of the computation with the similarities entering the interpolation problem. And as one can modify the first step of the procedure and consider, e.g., polynomial interpolations, the second step can be modified as well, and the resulting similarity may be deduced differently. So far, the procedure coming from the arithmetic of extensional numbers was naturally inherited as the linear -interpolation is derived from the arithmetic operations. However, considering the definition of the -function that is more general and the above-introduced examples (exponential, logarithmic, trigonometric), we are equipped with tools that allow modeling of the spreading of the vagueness in distinct ways according to the application or theoretical needs.
In our future research we plan to continue in the development of -interpolation for other types of functions and using metrics introduced in [48] we want to design more advanced interpolation approaches. For example, motivated by the Gaussian process regression (kriging) that has become popular in Machine Learning [65], where the interpolated values are modeled by Gaussian processes and are basically obtained as weighted averages of known neighbor nodes (see, e.g., [66]). In addition, it is a very challenging task to design an interpolation (regression) model that together admits probability and fuzziness of the data. The proposed theory seems to provide promising tools for successful solutions of this task.
Author Contributions
The conceptualization was contributed mainly by M.H. and M.Š.; methodology was mainly done by M.H.; software implementation was done by N.Š.; experimental design was proposed by M.H. and contributed by the other two authors as well; formal analysis was mainly done by M.Š. and contributed by the other authors as well; writing was done mainly by M.Š. and reviewed by the other two co-authors; visualization was done by N.Š. and reviewed by M.H.; the piloting ideas were created in joint brainstormings and discussions as a joint work. All authors have read and agreed to the published version of the manuscript.
Funding
The 1-st author announces support of Czech Science Foundation through the grant 18-13951S. The 2-nd author acknowledges funding from the project “Support of talented PhD students at the University of Ostrava” from the program RRC/10/2018 “Support for Science and Research in the Moravian-Silesian Region 2018”. The 3-rd author announces support of Czech Science Foundation through the grant 20-07851S.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors would like to express their thanks to László T. Kóczy, Kaoru Hirota, and Ulrich Bodenhofer for their inspiring works that brought our attention to this field. Furthermore, we would like to express our thanks to the anonymous reviewers who helped to improve our article and directed our future research.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Perfilieva, I. Finitary Solvability Conditions for Systems of Fuzzy Relation Equations. Inf. Sci. 2013, 234, 29–43. [Google Scholar] [CrossRef]
- Di Nola, A.; Sessa, S.; Pedrycz, W.; Sanchez, E. Fuzzy Relation Equations and Their Applications to Knowledge Engineering; Kluwer: Boston, MA, USA, 1989. [Google Scholar]
- Pedrycz, W. Applications of fuzzy relational equations for methods of reasoning in presence of fuzzy data. Fuzzy Sets Syst. 1985, 16, 163–175. [Google Scholar] [CrossRef]
- De Baets, B. Analytical solution methods for fuzzy relational equations. In The Handbook of Fuzzy Set Series Vol. 1; Dubois, D., Prade, H., Eds.; Academic Kluwer Publ.: Boston, MA, USA, 2000; pp. 291–340. [Google Scholar]
- Perfilieva, I.; Lehmke, S. Correct models of fuzzy IF-THEN rules are continuous. Fuzzy Sets Syst. 2006, 157, 3188–3197. [Google Scholar] [CrossRef]
- Cornejo, M.E.; Lobo, D.; Medina, J. On the solvability of bipolar max-product fuzzy relation equations with the product negation. J. Comput. Appl. Math. 2018, 354, 520–532. [Google Scholar] [CrossRef]
- Štěpnička, M.; De Baets, B. Interpolativity of at-least and at-most models of monotone single-input single-output fuzzy rule bases. Inf. Sci. 2013, 234, 16–28. [Google Scholar] [CrossRef]
- Štěpnička, M.; Jayaram, B. Interpolativity of at-least and at-most models of monotone fuzzy rule bases with multiple antecedent variables. Fuzzy Sets Syst. 2016, 297, 26–45. [Google Scholar] [CrossRef]
- Kóczy, L.; Hirota, K. Approximate reasoning by linear rule interpolation and general approximation. Int. J. Approx. Reason. 1993, 9, 197–225. [Google Scholar] [CrossRef] [Green Version]
- Vetterlein, T.; Štěpnička, M. Completing fuzzy if-then rule bases by means of smoothing. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2006, 14, 235–244. [Google Scholar] [CrossRef] [Green Version]
- Kóczy, L.; Hirota, K. Interpolative reasoning with insufficient evidence in sparse fuzzy rule bases. Inf. Sci. 1993, 71, 169–201. [Google Scholar] [CrossRef]
- Baranyi, P.; Kóczy, L.; Gedeon, T. A generalized concept for fuzzy rule interpolation. IEEE Trans. Fuzzy Syst. 2004, 12, 820–837. [Google Scholar] [CrossRef]
- Li, F.; Shang, C.; Li, Y.; Yang, J.; Shen, Q. Interpolation with Just Two Nearest Neighboring Weighted Fuzzy Rules. IEEE Trans. Fuzzy Syst. 2020, 28, 2255–2262. [Google Scholar] [CrossRef] [Green Version]
- Bouchon-Meunier, B.; Dubois, D.; Marsala, C.; Prade, H.; Ughetto, L. A comparative view of interpolation methods between sparse fuzzy rules. In Proceedings of the Annual Conference of the North American Fuzzy Information Processing Society-NAFIPS, Vancouver, BC, Canada, 25–28 July 2001; Volume 5, pp. 2499–2504. [Google Scholar]
- Perfilieva, I.; Dubois, D.; Prade, H.; Esteva, F.; Godo, L.; Hoďáková, P. Interpolation of fuzzy data: Analytical approach and overview. Fuzzy Sets Syst. 2012, 192, 134–158. [Google Scholar] [CrossRef]
- Mareš, M. Computation over Fuzzy Quantities; CRC Press: Boca Raton, FL, USA, 1994. [Google Scholar]
- Bělohlávek, R. Fuzzy Relational Systems: Foundations and Principles; Kluwer Academic, Plenum Press: Dordrecht, the Netherlands; New York, NY, USA, 2002. [Google Scholar]
- Klawonn, F. Fuzzy Points, Fuzzy Relations and Fuzzy Functions. In Discovering the World with Fuzzy Logic; Novák, V., Perfilieva, I., Eds.; Springer: Berlin, Germany, 2000; pp. 431–453. [Google Scholar]
- Holčapek, M.; Štěpnička, M. MI-algebras: A new framework for arithmetics of (extensional) fuzzy numbers. Fuzzy Sets Syst. 2014, 257, 102–131. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H. Operations on fuzzy numbers. Int. J. Syst. Sci. 1978, 9, 613–626. [Google Scholar] [CrossRef]
- Stefanini, L.; Sorini, L.; Guerra, M. Parametric representation of fuzzy numbers and application to fuzzy calculus. Fuzzy Sets Syst. 2006, 157, 2423–2455. [Google Scholar] [CrossRef]
- Mareš, M. Weak arithmetics of fuzzy numbers. Fuzzy Sets Syst. 1997, 91, 143–153. [Google Scholar] [CrossRef]
- Štěpnička, M.; Holčapek, M.; Škorupová, N. Orderings of Extensional Fuzzy Numbers. In Proceedings of the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) 2019, New Orleans, LA, USA, 23–26 June 2019. [Google Scholar]
- Štěpnička, M.; Škorupová, N.; Holčapek, M. On the properties of orderings of extensional fuzzy numbers. In Proceedings of the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) 2020, Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Holčapek, M.; Štěpnička, M. Arithmetics of extensional fuzzy numbers–part I: Introduction. In Proceedings of the IEEE International Conference on Fuzzy Systems, Brisbane, Australia, 10–15 June 2012. [Google Scholar]
- Holčapek, M.; Štěpnička, M. Arithmetics of extensional fuzzy numbers–part II: Algebraic framework. In Proceedings of the IEEE International Conference on Fuzzy Systems, Brisbane, Australia, 10–15 June 2012. [Google Scholar]
- Ma, M.; Friedman, M.; Kandel, A. A new fuzzy arithmetic. Fuzzy Sets Syst. 1999, 108, 83–90. [Google Scholar] [CrossRef]
- Stefanini, L.; Sorini, L.; Guerra, M. Simulation of fuzzy dynamical systems using the LU-representation of fuzzy numbers. Chaos Solitons Fractals 2006, 29, 638–652. [Google Scholar] [CrossRef]
- Fortin, J.; Dubois, D.; Fargier, H. Gradual Numbers and Their Application to Fuzzy Interval Analysis. IEEE Trans. Fuzzy Syst. 2008, 16, 388–402. [Google Scholar] [CrossRef] [Green Version]
- Boixader, D.; Jacas, J. Extensionality based approximate reasoning. Int. J. Approx. Reason. 1998, 19, 221–230. [Google Scholar] [CrossRef]
- Klawonn, F.; Castro, J.L. Similarity in Fuzzy Reasoning. Mathw. Soft Comput. 1995, 2, 197–228. [Google Scholar]
- Klawonn, F.; Kruse, R. Equality relations as a basis for fuzzy control. Fuzzy Sets Syst. 1993, 54, 147–156. [Google Scholar] [CrossRef]
- Holčapek, M.; Wrublová, M.; Bacovský, M. Quotient MI-groups. Fuzzy Sets Syst. 2016, 283, 1–25. [Google Scholar] [CrossRef]
- Holčapek, M. On generalized quotient MI-groups. Fuzzy Sets Syst. 2017, 326, 3–23. [Google Scholar] [CrossRef]
- Holčapek, M.; Škorupová, N. Topological MI-Groups: Initial Study. In IPMU 2018: Information Processing and Management of Uncertainty in Knowledge-Based Systems, Proceedings of the Applications-17th International Conference, Cádiz, Spain, 11–15 June 2018; Proceedings, Part III; Medina, J., Ojeda-Aciego, M., Galdeano, J.L.V., Perfilieva, I., Bouchon-Meunier, B., Yager, R.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 855, Communications in Computer and Information Science; pp. 603–615. [Google Scholar]
- Aryal, B.; Bokati, L.; Godinez, K.; Ibarra, S.; Liu, H.; Wang, B.; Kreinovich, V. Common Sense Addition Explained by Hurwicz Optimism-Pessimism Criterion. J. Uncertain Syst. 2019, 13, 171–174. [Google Scholar]
- Hurwicz, L. Optimality Criteria for Decision Making Under Ignorance; Cowles Commission Discussion Paper, Statistics; Yale University: New Haven, CT, USA, 1951; pp. 171–174. [Google Scholar]
- Zadeh, L. Similarity relations and fuzzy orderings. Inf. Sci. 1971, 3, 177–200. [Google Scholar] [CrossRef]
- Bodenhofer, U. A Similarity-Based Generalization of Fuzzy Orderings Preserving the Classical Axioms. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2000, 8, 593–610. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Wang, Z. Total orderings defined on the set of all fuzzy numbers. Fuzzy Sets Syst. 2014, 243, 131–141. [Google Scholar] [CrossRef]
- Asady, B.; Zendehnam, A. Ranking fuzzy numbers by distance minimization. Appl. Math. Model. 2007, 31, 2589–2598. [Google Scholar] [CrossRef]
- De Hierro, A.F.R.L.; Roldán, C.; Herrera, F. On a new methodology for ranking fuzzy numbers and its application to real economic data. Fuzzy Sets Syst. 2018, 353, 86–110. [Google Scholar] [CrossRef]
- Van Broekhoven, E.; De Baets, B. A linguistic fuzzy model with a monotone rule base is not always monotone. In Proceedings of the EUSFLAT-LFA’05, Barcelona, Spain, 7–9 September 2005; pp. 530–535. [Google Scholar]
- Van Broekhoven, E.; De Baets, B. On the monotonicity of Mamdani-Assilian models with two input variables. In Proceedings of the NAFIPS’06, Montreal, QC, Canada, 3–6 June 2006; pp. 102–107. [Google Scholar]
- Štěpnička, M.; De Baets, B. Implication-based models of monotone fuzzy rule bases. Fuzzy Sets Syst. 2013, 232, 134–155. [Google Scholar] [CrossRef]
- Bodenhofer, U. Orderings of Fuzzy Sets Based on Fuzzy Orderings Part I: The Basic Approach. Mathw. Soft Comput. 2008, 15, 201–218. [Google Scholar]
- Bodenhofer, U. Orderings of Fuzzy Sets Based on Fuzzy Orderings Part II: Generalizations. Mathw. Soft Comput. 2008, 15, 219–249. [Google Scholar]
- Štěpnička, M.; Škorupová, N.; Holčapek, M. From arithmetics of extensional fuzzy numbers to their distances. In Proceedings of the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) 2020, Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Wang, X.; Kerre, E.E. Reasonable properties for the ordering of fuzzy quantities (I). Fuzzy Sets Syst. 2001, 118, 375–385. [Google Scholar] [CrossRef]
- Wang, X.; Kerre, E.E. Reasonable properties for the ordering of fuzzy quantities (II). Fuzzy Sets Syst. 2001, 118, 387–405. [Google Scholar] [CrossRef]
- Van Broekhoven, E.; De Baets, B. Monotone Mamdani-Assilian models under mean of maxima defuzzification. Fuzzy Sets Syst. 2008, 159, 2819–2844. [Google Scholar] [CrossRef]
- Van Broekhoven, E.; De Baets, B. Only smooth rule bases can generate monotone Mamdani-Assilian models under Center-of-gravity defuzzification. IEEE Trans. Fuzzy Syst. 2009, 17, 1157–1174. [Google Scholar] [CrossRef]
- Štěpnička, M.; De Baets, B. Monotonicity of implicative fuzzy models. In Proceedings of the FUZZ-IEEE 2010, Barcelona, Spain, 18–23 July 2010; pp. 2334–2340. [Google Scholar]
- Mandal, S.; Jayaram, B. Monotonicity of SISO Fuzzy Relational Inference With an Implicative Rule Base. IEEE Trans. Fuzzy Syst. 2016, 24, 1475–1487. [Google Scholar] [CrossRef]
- Bodenhofer, U.; De Cock, M.; Kerre, E.E. Openings and closures of fuzzy preorderings: Theoretical basics and applications to fuzzy rule-based systems. Int. J. Gen. Syst. 2003, 32, 343–360. [Google Scholar] [CrossRef]
- Bodenhofer, U.; Bauer, P. Interpretability of Linguistic Variables: A Formal Account. Kybernetika 2005, 41, 227–248. [Google Scholar]
- Dvořáčková, H.; A., K.; Tichý, T. Sales Prediction in the Ice Category Applying Fuzzy Sets Theory. Ekon. Rev. Cent. Eur. Rev. Econ. Issues 2018, 21, 35–41. [Google Scholar]
- Das, S.; Chakraborty, D.; Kóczy, L. Linear fuzzy rule base interpolation using fuzzy geometry. Int. J. Approx. Reason. 2019, 112, 105–118. [Google Scholar] [CrossRef]
- Mamdani, E.H.; Assilian, S. An experiment in linguistic synthesis with a fuzzy logic controller. Int. J. Man-Mach. Stud. 1975, 7, 1–13. [Google Scholar] [CrossRef]
- Jones, H.; Charnomordic, B.; Dubois, D.; Guillaume, S. Practical inference with systems of gradual implicative rules. IEEE Trans. Fuzzy Syst. 2009, 17, 61–78. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H. What are fuzzy rules and how to use them. Fuzzy Sets Syst. 1996, 84, 169–185. [Google Scholar] [CrossRef]
- Štěpnička, M.; Mandal, S. Fuzzy inference systems preserving Moser–Navara axioms. Fuzzy Sets Syst. 2018, 338, 97–116. [Google Scholar] [CrossRef]
- Štěpnička, M.; Jayaram, B.; Su, Y. A short note on fuzzy relational inference systems. Fuzzy Sets Syst. 2018, 338, 90–96. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H.; Ughetto, L. Checking the Coherence and Redundancy of Fuzzy Knowledge Bases. IEEE Trans. Fuzzy Syst. 1997, 5, 398–417. [Google Scholar] [CrossRef]
- Rasmussen, C.; Williams, C. Gaussian Processes for Machine Learning; The MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Le, N.D.; Zidek, J.V. Statistical Analysis of Environmental Space-Time Processes; Springer: New York, NY, USA, 2006. [Google Scholar]
Figure 1.
Fuzzy numbers modeling the vague quantity “about 3” (A), and the vague quantity “about 5” (B).
Figure 1.
Fuzzy numbers modeling the vague quantity “about 3” (A), and the vague quantity “about 5” (B).

Figure 2.
Fuzzy numbers and determined by the ukasiewicz similarities from Example 3 based on values and (“left” solid fuzzy set), and (“right” solid fuzzy set). Fuzzy sets and cannot be ordered by of -cuts however, if we use , we obtain the dashed fuzzy sets and , respectively, and thus .
Figure 2.
Fuzzy numbers and determined by the ukasiewicz similarities from Example 3 based on values and (“left” solid fuzzy set), and (“right” solid fuzzy set). Fuzzy sets and cannot be ordered by of -cuts however, if we use , we obtain the dashed fuzzy sets and , respectively, and thus .

Figure 3.
Demonstration of the -ordering .

Figure 4.
Example of applied to fuzzy sets from Figure 2.
Figure 4.
Example of applied to fuzzy sets from Figure 2.

Figure 5.
Extensional fuzzy numbers expressing the ice-cream sale “about ” and temperature “about ” in spring 2010.
Figure 5.
Extensional fuzzy numbers expressing the ice-cream sale “about ” and temperature “about ” in spring 2010.

Figure 6.
Estimation of ice-cream sales based on the linear -interpolation for selected temperatures in summer, where sale data are crisp (left) and fuzzy (right); temperature and ice-cream sale nodes are colored red, the selected (input) temperature and estimated (output) sale blue.
Figure 6.
Estimation of ice-cream sales based on the linear -interpolation for selected temperatures in summer, where sale data are crisp (left) and fuzzy (right); temperature and ice-cream sale nodes are colored red, the selected (input) temperature and estimated (output) sale blue.

Figure 7.
Estimation of ice-cream sales based on the linear -interpolation for selected temperatures in winter.
Figure 7.
Estimation of ice-cream sales based on the linear -interpolation for selected temperatures in winter.

Figure 8.
Comparison of our method with two fundamental interpolation techniques on particular part of autumn ice-cream sales.
Figure 8.
Comparison of our method with two fundamental interpolation techniques on particular part of autumn ice-cream sales.


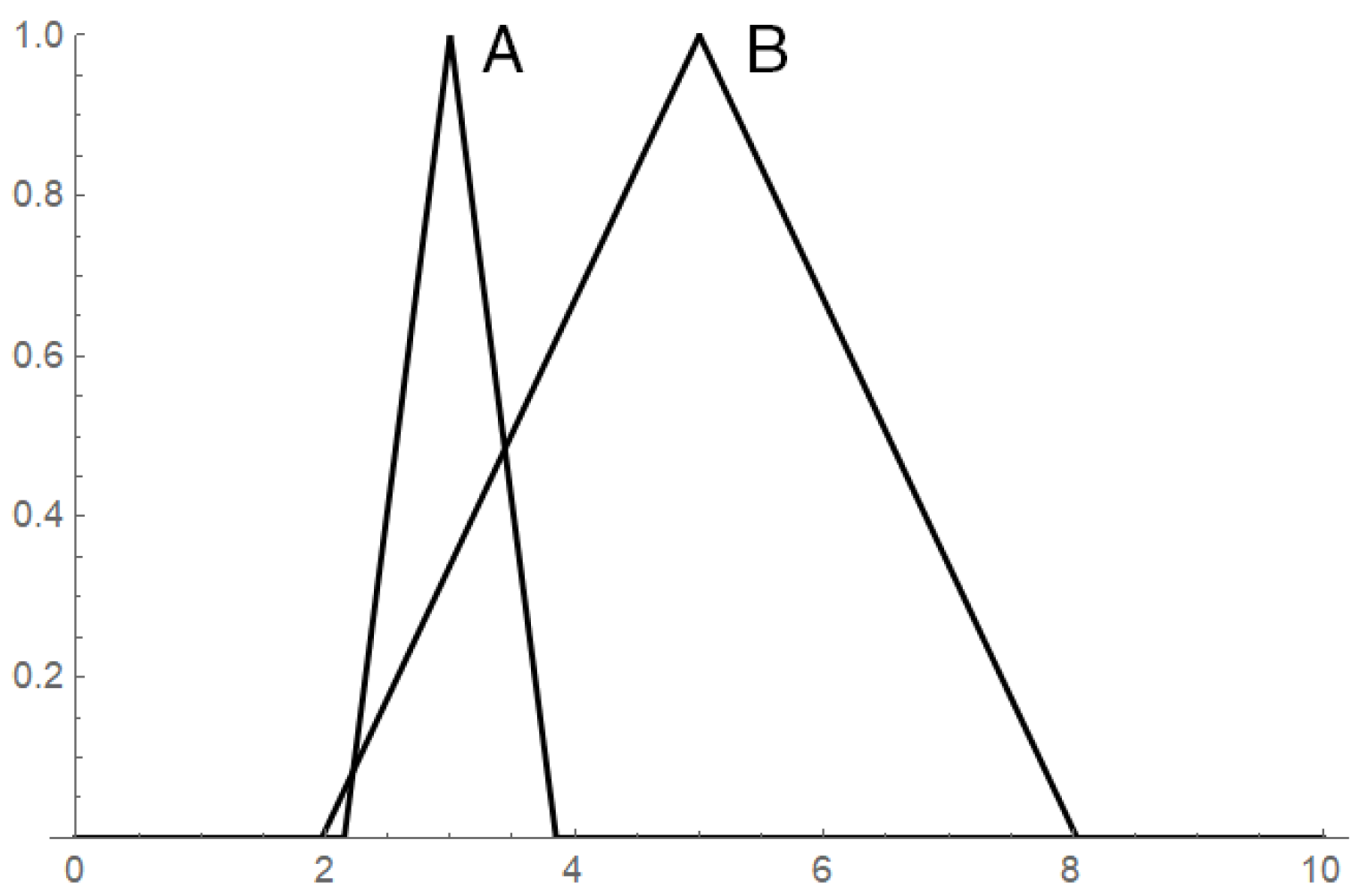{kind=link}
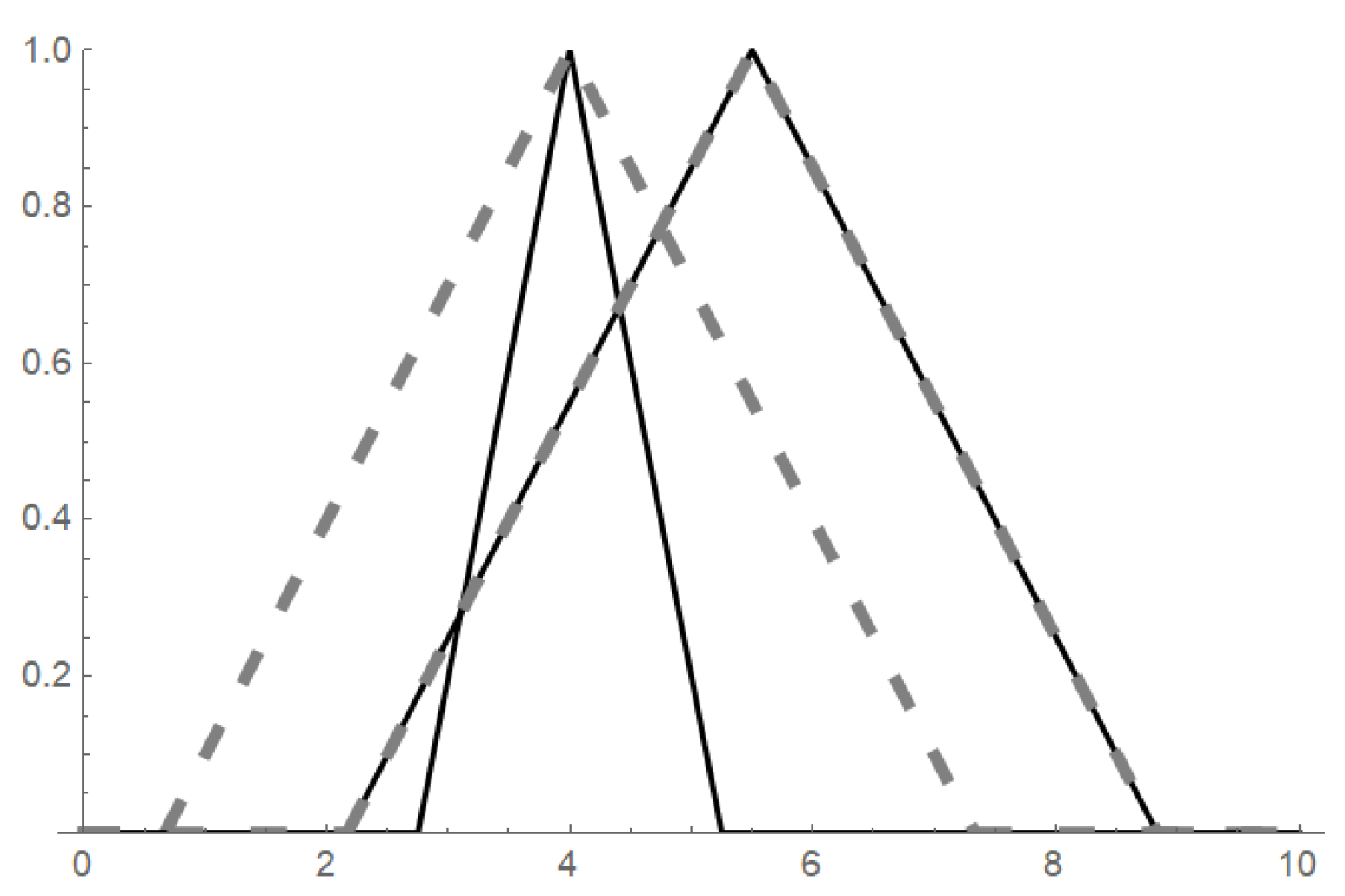{kind=link}
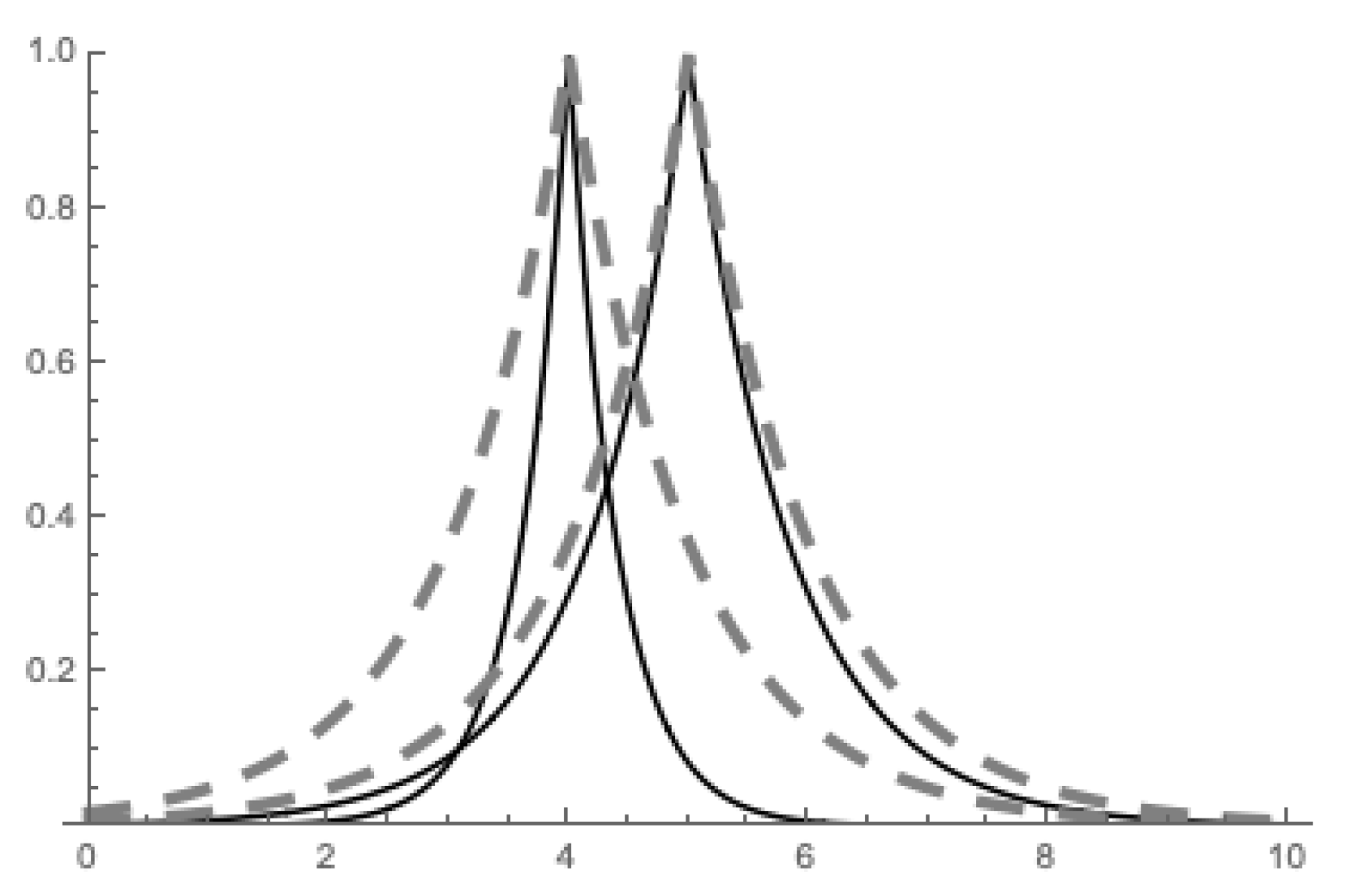{kind=link}
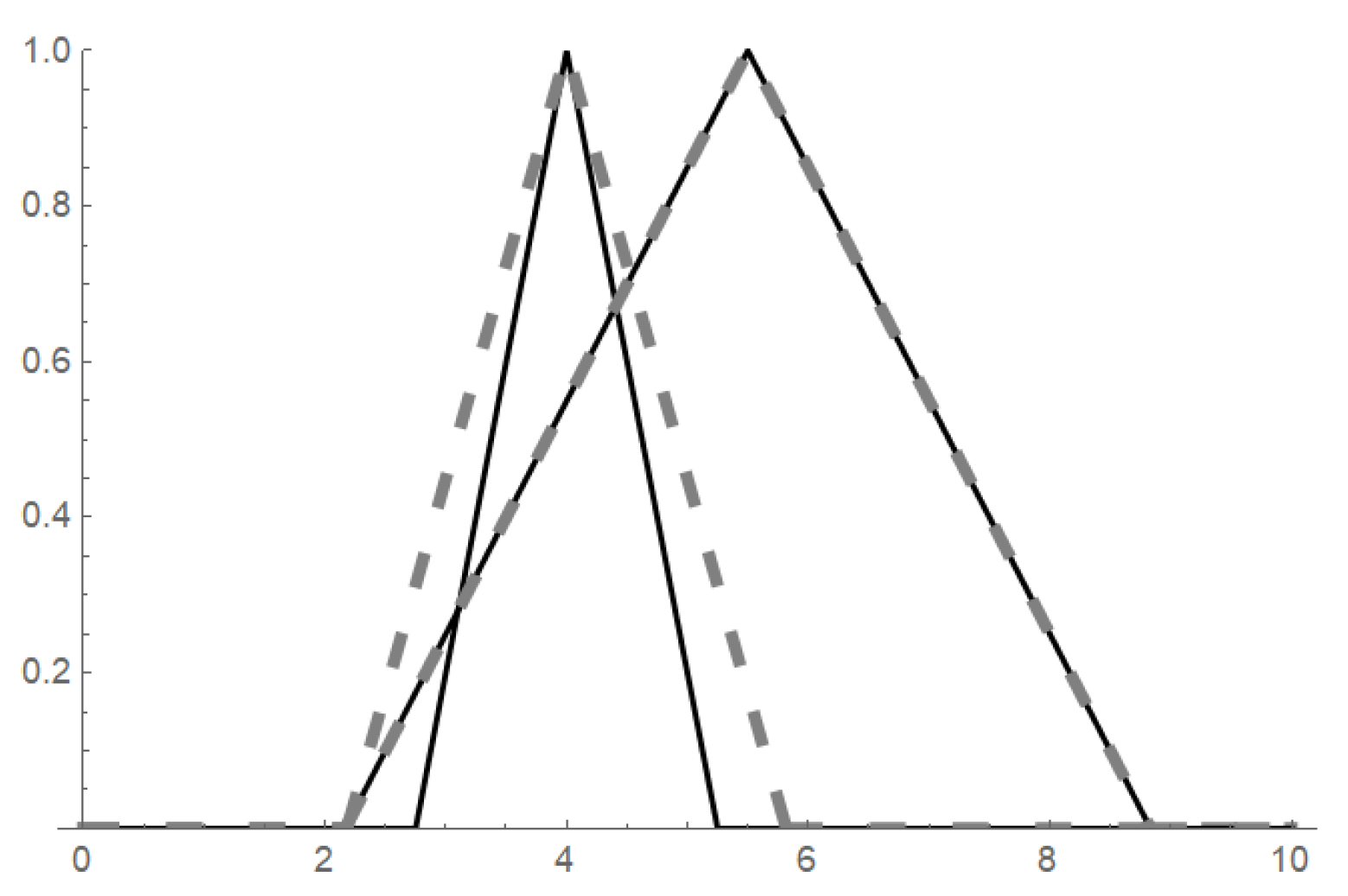{kind=link}
{kind=link}
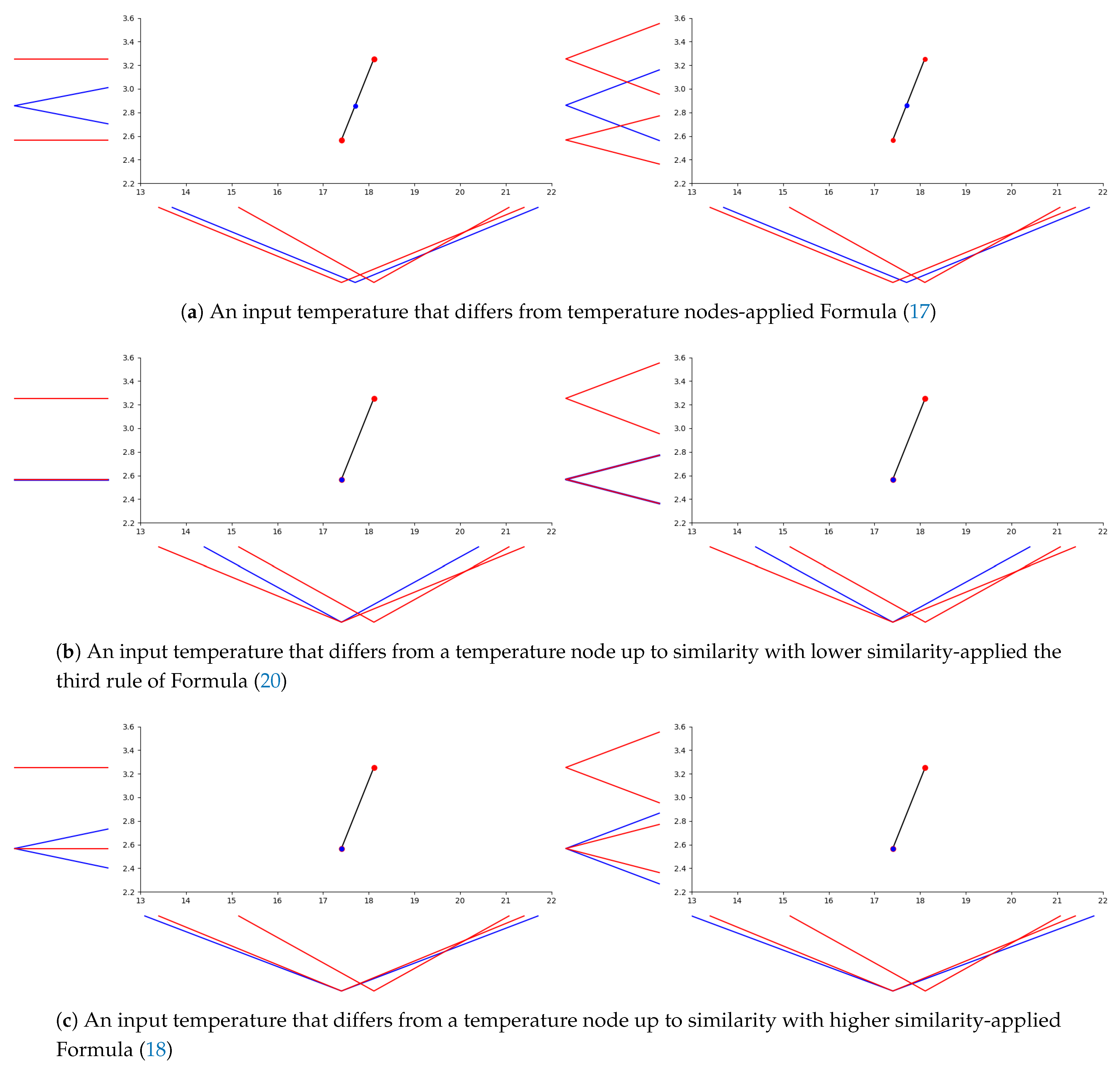{kind=link}
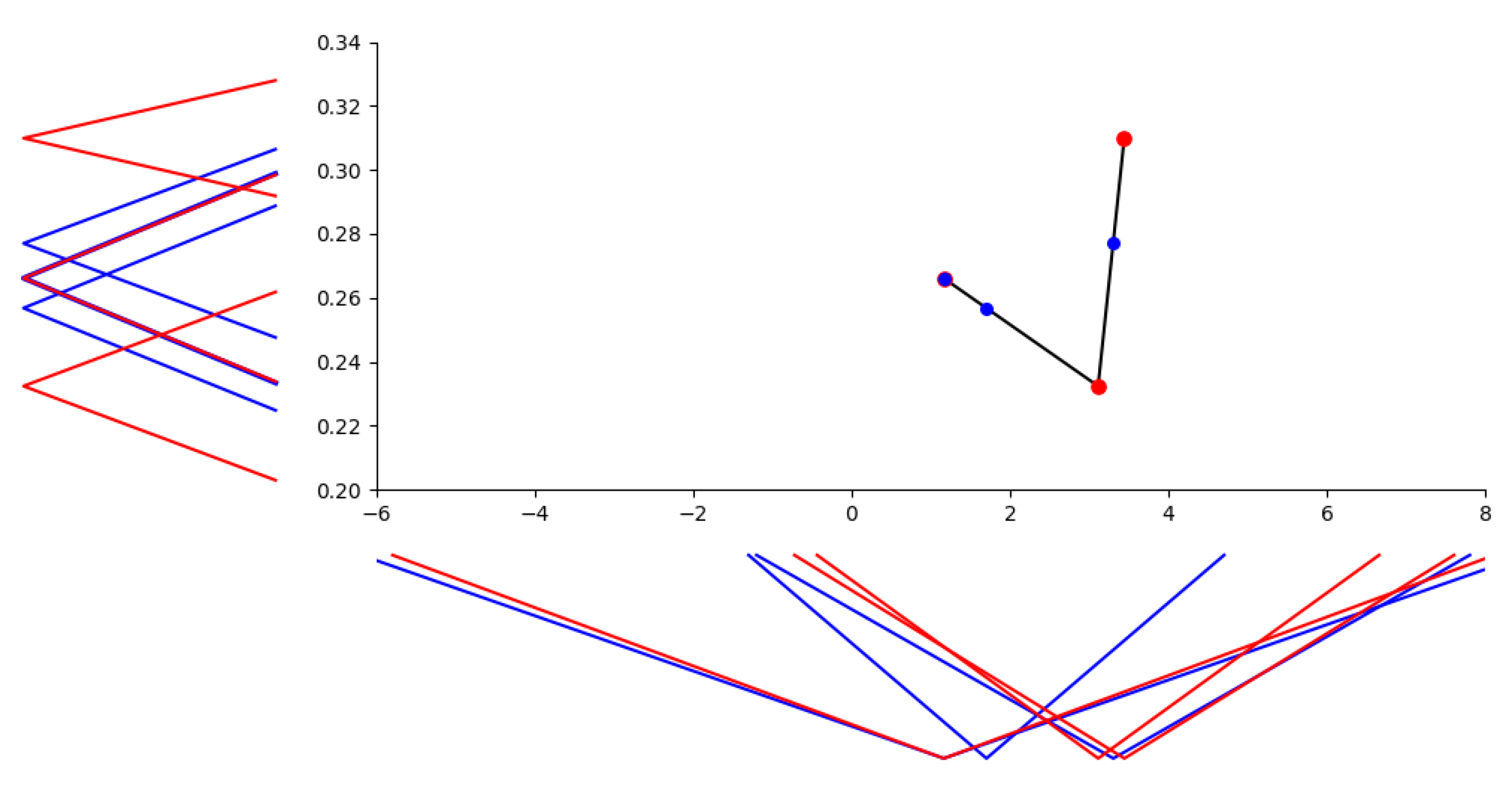{kind=link}
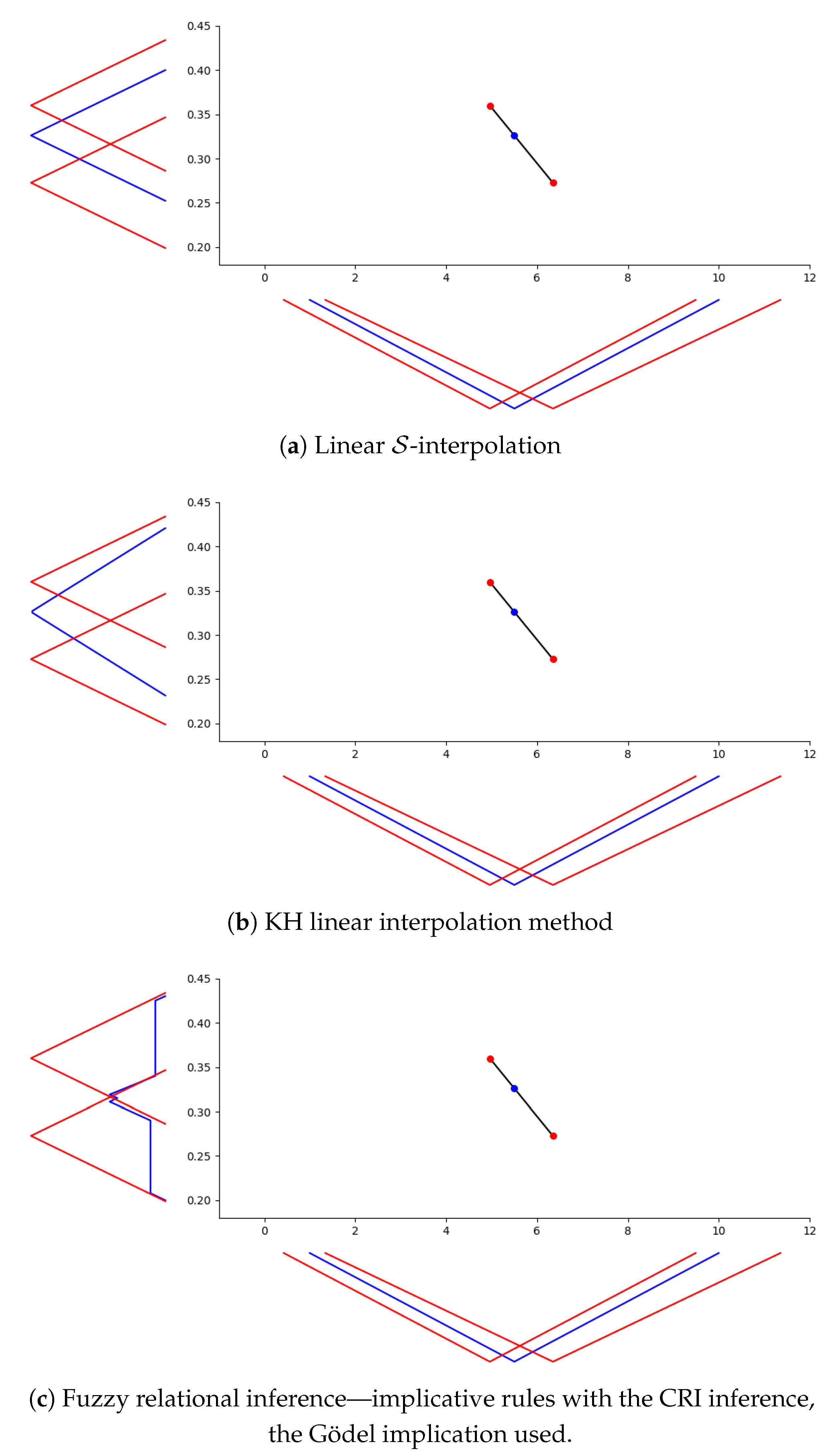{kind=link}
Table 1.
Quarterly sales of ice-cream rounded to two decimals and standard deviations rounded to three decimals over 2008–2014 (, , , ).
Table 1.
Quarterly sales of ice-cream rounded to two decimals and standard deviations rounded to three decimals over 2008–2014 (, , , ).
| 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | |
|---|---|---|---|---|---|---|---|
| (0.23, 0.029) | (0.24, 0.053) | (0.25, 0.030) | (0.24, 0.048) | (0.27, 0.032) | (0.19, 0.047) | (0.31, 0.18) | |
| (1.54, 0.091) | (1.77, 0.094) | (1.53, 0.072) | (1.72, 0.082) | (1.66, 0.101) | (1.51, 0.118) | (1.60, 0.073) | |
| (2.53, 0.171) | (3.25, 0.299) | (2.59, 0.260) | (2.62, 0.433) | (2.57, 0.204) | (2.50, 0.399) | (2.22, 0.244) | |
| (0.32, 0.072) | (0.17, 0.106) | (0.35, 0.042) | (0.35, 0.075) | (0.22, 0.087) | (0.36, 0.064) | (0.27, 0.079) |
Table 2.
Quarterly temperatures and standard deviations rounded to two decimals over 2008–2014.
| 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | |
|---|---|---|---|---|---|---|---|
| (3.11, 3.55) | (0.09, 4.44) | (−0.75, 5.63) | (0.94, 5.30) | (1.16, 6.95) | (−0.97, 4.04) | (3.44, 4.16) | |
| (13.37, 5.09) | (14.09, 3.22) | (12.70, 4.74) | (14.46, 4.37) | (13.94, 5.95) | (12.32, 5.59) | (13.19, 4.34) | |
| (16.53, 4.60) | (18.12, 2.96) | (17.02, 4.85) | (17.05, 3.26) | (17.40, 3.99) | (17.02, 4.64) | (17.05, 3.60) | |
| (4.75, 4.68) | (4.53, 8.81) | (2.13, 6.67) | (4.84, 4.54) | (3.96, 4.80) | (4.96, 4.53) | (6.35, 5.01) |
Table 3.
Data for normalization computed in quarters 2008–2017.
| Quarters | Temperature st. Deviation | Ice-Cream Sale st. Deviation |
|---|---|---|
| 8.110 | 0.036 | |
| 8.063 | 0.010 | |
| 8.161 | 0.313 | |
| 8.034 | 0.072 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Holčapek, M.; Škorupová, N.; Štěpnička, M. Fuzzy Interpolation with Extensional Fuzzy Numbers. Symmetry 2021, 13, 170. https://doi.org/10.3390/sym13020170
AMA Style
Holčapek M, Škorupová N, Štěpnička M. Fuzzy Interpolation with Extensional Fuzzy Numbers. Symmetry. 2021; 13(2):170. https://doi.org/10.3390/sym13020170
Chicago/Turabian StyleHolčapek, Michal, Nicole Škorupová, and Martin Štěpnička. 2021. "Fuzzy Interpolation with Extensional Fuzzy Numbers" Symmetry 13, no. 2: 170. https://doi.org/10.3390/sym13020170
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.