
MooFuzz: Many-Objective Optimization Seed Schedule for Fuzzer


College of Information Science and Engineering, Ocean University of China, Qingdao 266100, China
*
Author to whom correspondence should be addressed.
Mathematics 2021, 9(3), 205; https://doi.org/10.3390/math9030205
Submission received: 22 December 2020
/
Revised: 15 January 2021
/
Accepted: 16 January 2021
/
Published: 20 January 2021
(This article belongs to the Special Issue Evolutionary Computation 2020)
Abstract
:Coverage-based Greybox Fuzzing (CGF) is a practical and effective solution for finding bugs and vulnerabilities in software. A key challenge of CGF is how to select conducive seeds and allocate accurate energy. To address this problem, we propose a novel many-objective optimization solution, MooFuzz, which can identify different states of the seed pool and continuously gather different information about seeds to guide seed schedule and energy allocation. First, MooFuzz conducts risk marking in dangerous positions of the source code. Second, it can automatically update the collected information, including the path risk, the path frequency, and the mutation information. Next, MooFuzz classifies seed pool into three states and adopts different objectives to select seeds. Finally, we design an energy recovery mechanism to monitor energy usage in the fuzzing process and reduce energy consumption. We implement our fuzzing framework and evaluate it on seven real-world programs. The experimental results show that MooFuzz outperforms other state-of-the-art fuzzers, including AFL, AFLFast, FairFuzz, and PerfFuzz, in terms of path discovery and bug detection.
1. Introduction
Fuzzing is a popular and effective software testing technology for detecting bugs and vulnerabilities. In the past few years, it has gained widespread usage in mainstream software companies (such as Google [1,2,3], Microsoft [4], and Adobe [5]) and has found thousands of vulnerabilities.
Coverage-based Greybox Fuzzing (CGF) [6,7] is one of the most popular methods of fuzzing. It is based on the guidance that increasing code coverage usually leads to better crash detection. By using lightweight instrumentation, CGF automatically generates a large number of inputs to feed target programs, and continuously collects coverage information as feedback to guide fuzzing.
Inspired by the impressive achievements of CGF, many researchers have conducted studies and developed their own fuzzers from different perspectives [8,9,10]. AFLFast [11] assigns more energy to the low-frequency paths based on the Markov chain model. AFLGo [12], a directed grey-box fuzzer, is implemented to generate inputs to reach given sets of target program locations. FairFuzz [13] identifies rare branches in the program and adjusts mutation strategies to increase coverage. MOPT [14] leverages a mutation schedule based on particle swarm optimization (PSO) to accelerate the convergence speed. EcoFuzz [15] improves the power schedule for discovering new paths using a variant of the adversarial multi-armed bandit model. PerfFuzz [16] generates pathological inputs to detect algorithm complexity vulnerabilities. MemLock [17] utilizes memory consumption information to guide seed selection to trigger the weakness of memory corruption.
However, most previous approaches mainly leverage a single selection criterion to select seeds. While these approaches are simple and easy to use in solving specific problems, they are still inadequate to reach effective coverage and detect bugs within a reasonable amount of time. Cerebro [18] uses many objectives as the seed selection criteria, but it cannot dynamically adjust the seed selection strategy according to the fuzzing process. As a result, much useful information is ignored, affecting the discovery of bugs and paths.
In this paper, we propose a many-objective optimization seed schedule model, named MooFuzz, which is aimed at speeding up bug discovery and improving code coverage. MooFuzz performs static analysis on the code and marks the risky locations in order to collect edge risk information. In the fuzzing process, a novel measurement method is used to update useful information including the path risk, the path frequency, and the mutation information. According to the fuzzing process, MooFuzz divides the seed pool state into three categories: Exploration State, Search State, and Assessment State. In Exploration State, the fuzzer emphasizes the exploration of high-risk locations in the program. In Search State, the fuzzer spends more energy to find the new path. In Assessment State, the fuzzer aims to select and evaluate promising seeds. MooFuzz collects different information to measure the priority of seeds in each state and builds a many-objective optimization model to select optimal seed set using a non-dominated sorting algorithm [19]. Beside, we also observe that many studies have improved power schedule method, but they have not performed energy monitoring in power schedule. Therefore, MooFuzz uses multiple information to set the energy for selected seeds and monitors energy usage.
We design and implement our prototype by extending American Fuzzy Lop (AFL) [7], and evaluate it against for popular fuzzers AFL, AFLFast, FairFuzz, and PerfFuzz in terms of path discovery and bug detection. We conduct our evaluation on seven real-world applications. The experimental results demonstrate that MooFuzz performs better than others. Compared with AFL, AFLFast, Fairfuzz, and PerfFuzz, it triggers 46%, 32%, 34%, and 153% more crashes with almost the same execution time, respectively. Furthermore, we run cases and analyze the discovery of vulnerabilities. MooFuzz is able to trigger stack overflow, heap overflow, null pointer dereference, and memory leaks related vulnerabilities.
The contributions of this paper are as follows.
- We propose the path risk measurement method to assist seed schedule in Exploration State.
- We use many-objective optimization to model CGF and classify three different states of seed pool and put forth different selection criteria that enhance the fuzzer performance.
- We propose an energy allocation and monitor mechanism to improve the power schedule.
- We implement our framework as MooFuzz and evaluate its effectiveness on a series of popular real-world applications. MooFuzz substantially outperforms the other fuzzers.
2. Background and Related Work
In this section, we introduce the background of many-objective optimization and CGF and discuss related work.
2.1. Many-Objective Optimization
Multi-objective optimization [20,21,22,23] falls into the field of multiple criteria decision-making. It optimizes all goals at the same time to get the optimal solution. Therefore, multi-objective optimization problems (MOPs) get a set of solutions. Generally, a MOP is an optimization problem with two or three objectives. A many-objective optimization problem (MaOP) is an optimization problem [24,25,26,27] with four or more objectives. In recent years, many researchers have used multi-objective optimization methods to solve practical problems [28,29,30,31], such as scheduling [32,33], planning [34,35,36], fault diagnosis [37,38,39], classification [40,41], test-sheet composition [42], object extraction [43], variable reduction [44], and virtual machine placement [45]. Multi-objective evolutionary algorithms (MOEAs), such as non-dominated sorting GA [46], multi-objective particle swarm optimization (MOPSO) [47,48,49], NSGA-II [50], NSGA-III [51,52], decomposition-based MOEA [53] and corresponding improved versions [54,55,56], are the most used solutions.
In many-objective optimization problems, minimization problems simultaneously optimize minimize objectives to obtain the maximum benefit. Within the scope of mathematics, minimization problems are embodied in the minimization of objective functions (that is, to minimize all objective values of objective functions as far as possible). In this paper, we use the minimum optimization model to carry out seed schedule. The definition of minimum optimization problems is given below.
where is the objective vector, is the i-th objective to be minimized, is a vector of n decision variables, X is an n-dimensional decision space, and m denotes the number of objectives to be optimized.
Definition 1
(Pareto Dominance [57]). Given any two decision vectors x, y with M objectives for the minimization optimization. , if there is for all then x dominates y, which is denoted as x ≺ y.
Definition 2
(Pareto Optimal [57]). Assuming that , if there is no solution satisfying x ≺ , then is the Pareto optimal solution.
Definition 3
(Pareto Optimal Set [57]). All the Pareto optimal solutions constitute the Pareto optimal set (PS).
Definition 4
(Pareto Front [57]). All the objective vectors of the solutions in Pareto optimal set constitute the Pareto front (PF).
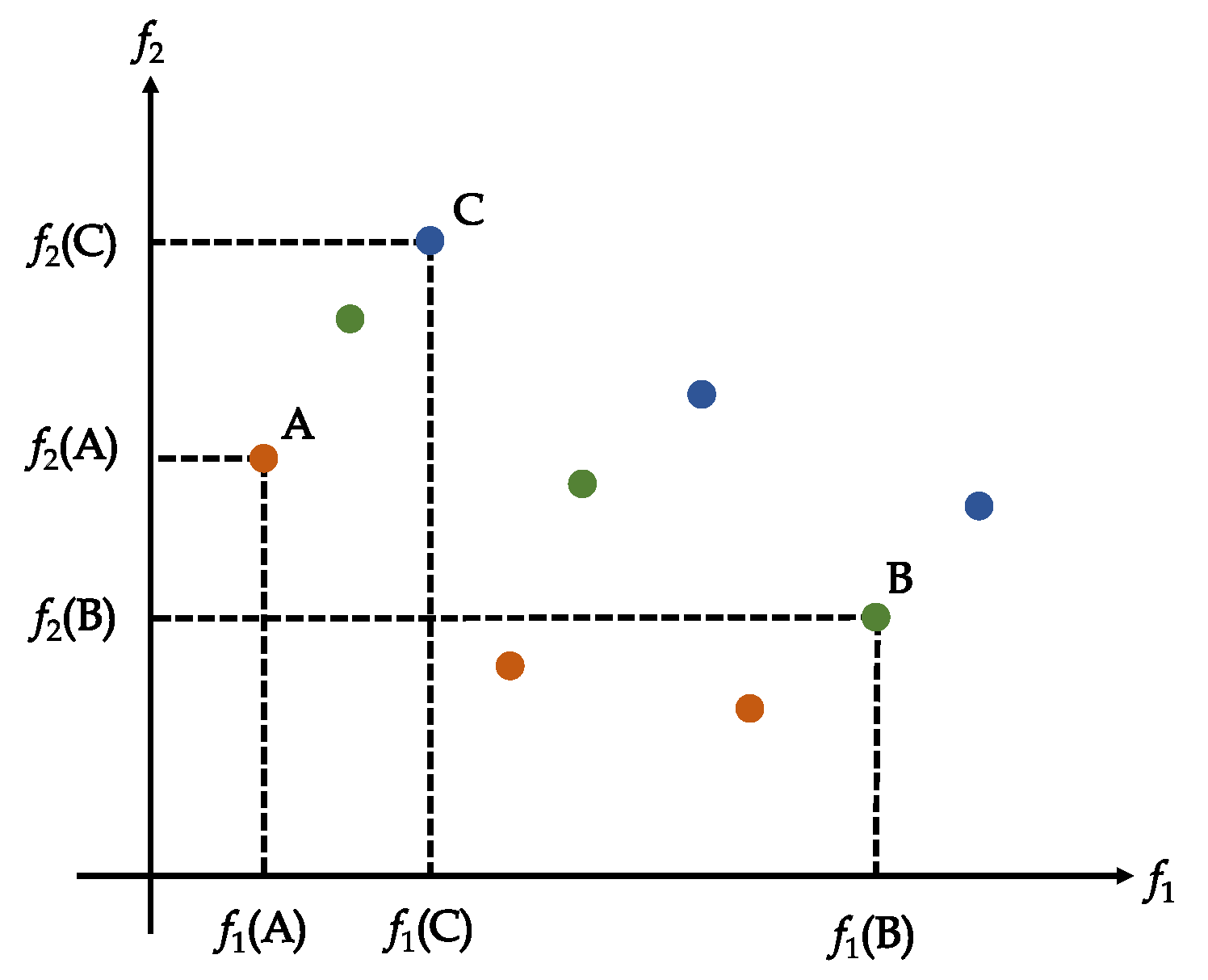
Figure 1 is a solution distribution under two-dimensional objective space, where all points represent solutions. For a minimal optimization problem, it can be seen that the point A is smaller than the point C under the two-dimensional objective space, that is, there is a dominance relationship between the point A and the point C, and the point C is dominated the point A. For the points A and B in Figure 1, we can see that the point A is greater than the point B on the axis, but the point A is less than B on the axis, so there is not a dominance relationship between the point A and the point B.
2.2. Coverage-Based Greybox Fuzzing
CGF is an evolutionary algorithm that includes two stages: the static analysis stage and the fuzzing loop stage. In the static analysis stage, it executes compile-time or dynamic binary instrumentation to obtain the instrumented target program. In the fuzzing loop stage, CGF uses a series of initial seeds provided by the user as inputs and maintains a seed queue stored in the seed pool. CGF first selects a saved seed input from the seed queue and mutates it to generate the new input by using mutation strategies. Next, the target program is executed with the new input. Then, lightweight instrumentation technique is used to gather coverage information, if the new input causes a crash, it will be marked and added to the crash set. If the new input leads to new coverage, CGF will judge that the new input is interesting and add it to the seed pool. Algorithm 1 shows the workflow of CGF in the fuzzing loop stage.
| Algorithm 1: Coverage-based Greybox Fuzzing |
 |
2.2.1. Code Instrumentation
Code instrumentation aims to insert code fragments at compile-time, which is useful for path tracing and testing during the fuzzing process. AFL [7] is a greybox fuzzer using edge (branch) coverage as feedback. Before the fuzzing loop stage, AFL first uses afl-gcc or afl-clang as instrumentation commands to trace edge coverage. AFL preserves a 64KB shared bitmap to record edge coverage information including whether the edge has been visited, and the count of hits. AFL assigns a random number to represent each basic block in the program and uses the XOR and right shift operation for the current basic block and the previous basic block to mark each edge. Each edge is used as an offset of and the value is the count of hits.
2.2.2. Seed Schedule
Seed schedule refers to select seeds from the seed pool for future mutation. A perfect seed schedule scheme is conducive to speeding up path discovery and bug detection. AFL [7] gives priority to seeds that are unfuzzed (not selected for mutation) and favored (among all seeds passing through the edge, the seed with the smallest product of seed length and execution time). AFLGo [12] preferentially selects seeds closer to the target location for directed fuzzing. VUzzer [8] prioritizes seeds of deeper paths, it may detect bugs deep in the code. SlowFuzz [58] preferentially selects seeds that generate more resource consumption to trigger algorithm complexity vulnerabilities. In order to discover memory consumption bugs, MemLock [17] preferentially selects seed inputs that generate more memory consumption. UAFL [59] preferentially selects seeds that execute the operation sequence violating typestate properties to uncover use-after-free (UAF) vulnerabilities.
2.2.3. Mutation Strategy
The mutation strategy determines where and how to mutate the selected seed. Different fuzzers use different mutation strategies. AFL has two mutation stages: the deterministic stage and the indeterministic stage.
The deterministic stage. The deterministic stage is used when the first time fuzzing seed. This stage includes mutation operators, bitflip, byteflip, arithmetic addition/subtraction, interesting values, and dictionary.
The indeterministic stage. After completing the deterministic stage, seeds will enter the indeterministic stage, in which AFL includes havoc and splice. In this stage, AFL randomly selects a sequences of mutation operators and assigns random location to mutate the seed.
There are many studies on mutation strategies for fuzzer. VUzzer [8] leverages data flow and control flow features to infer the critical regions of the input for mutation. GREYONE [60] uses a fuzzing-driven taint inference to infer taint variables for mutation. Superion [61] deploys mutation strategies to fuzz programs that process structured inputs. MOPT [14] uses particle swarm optimization algorithm to optimize mutation operators.
2.2.4. Power Schedule
Power schedule aims to allocate energy to each seed during the fuzzing process, which determines the number of seed mutations. Reasonable energy allocation can effectively improve the discovery of new paths. If the energy of a seed is over allocated, other seeds mutation will be affected. Conversely, if the energy of one seed is under allocated, it will be detrimental to new path discovery and potential bug detection.
AFL has two power schedule methods based on different mutation stages. In the deterministic stage, the energy of a seed is related to its length. The longer seed length, the more energy will be consumed. In the indeterministic stage, the energy allocation depends on the running time, the number of edges, the average size of the file, the number of cycles, and others.
Recent research shows that power schedule is very critical for fuzzer. AFLFast [11] allocates more energy to the low-frequency path to explore more paths. EcoFuzz [15] uses reinforcement learning to model power schedule as the adversarial multi-armed bandit model that enables adaptive energy saving. However, they did not consider the path risk and the effectiveness of energy allocation.
3. The Design of MooFuzz
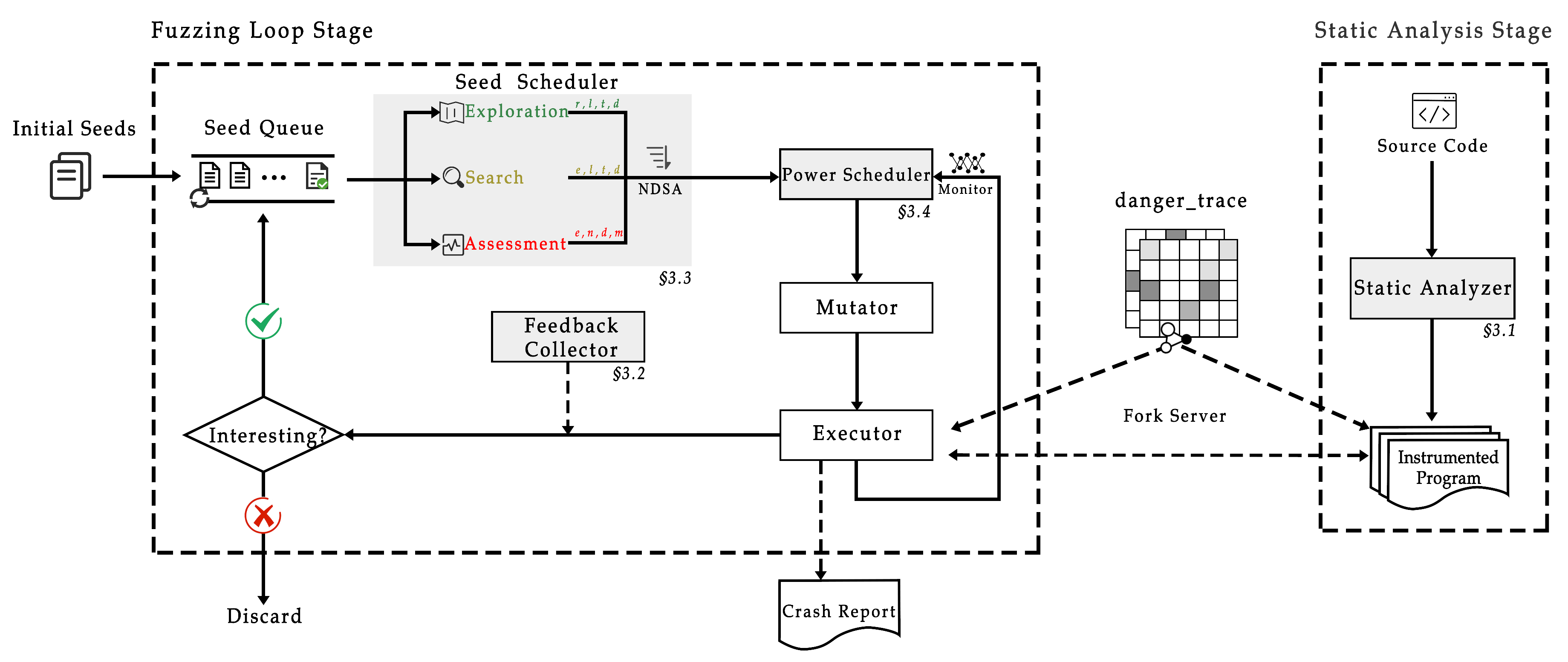
To address problems mentioned in the previous sections, we propose a many-objective optimization fuzzer MooFuzz, as shown in Figure 2. The main components of MooFuzz contain static analyzer, feedback collector, seed scheduler, and power scheduler. In MooFuzz, static analyzer marks the risk edge and records the risk value for each edge by scanning the source code and then inserts code fragments to update the edge risk value in running program. Feedback collector is used to record and update related information to guide the seed schedule after the program execution. Seed scheduler adopts different many-objective optimization schedules based on different states of the seed pool to select seeds. Power scheduler assigns energy based on feedback information and monitors energy usage.
3.1. Static Analyzer
A common idea is that the place has dangerous functions may trigger vulnerabilities. For example, the function is used to dynamically allocate memory in C language. Although it can automatically allocate memory space, if used improperly, it may cause problems such as overflow, heap exhaustion, and use-after-free. The function shall attempt to write n bytes from the buffer pointed to by into the file associated with the open file descriptor. However, if programmer cannot control the size of the bytes written to , it will cause the risk of out-of-bounds read of the memory. Therefore, MooFuzz identifies potentially dangerous functions as risk edges to label in static analyzer. In this paper, MooFuzz uses functions in Table 1 as dangerous functions [62], including memory allocation, memory recovery, memory operation, string operation, and file I/O operation. At the same time, users can also customize dangerous functions and add them to static analyzer for fuzzing.
Algorithm 2 shows the basic idea of MooFuzz instrumentation. Before the static analysis, there are well-known potentially dangerous functions. The static analyzer can identify them by traversing the source code and perform source code instrumentation at the corresponding edge position without running the program. MooFuzz uses a pointer to record the hit-counts of the risk edge in shared memory after running program every time. Specifically, MooFuzz first obtains each basic block information of the program, then identifies each call instruction and judges whether someone is dangerous (Lines 1–7). If any exists, the hit-counts will be updated and stored in the memory pointed to by (Lines 8–11).
| Algorithm 2: Code instrumentation |
 |
3.2. Feedback Collector
The feedback collector is mainly used to continuously update seed information to assist seed schedule. For the running of the instrumented program, a series of running information would be updated for seeds. Algorithm 3 shows the process of information updating by feedback collector. It takes the seed queue Q and the pointer variable as inputs, and output is the seed queue with new information. The new information includes the number of times the seed has been selected, the path frequency, the path risk, and the mutation information. Specifically, MooFuzz selects a seed s by using seed scheduler (see Section 3.3) and updates the number of times it has been selected (Lines 1–3). Then, it uses a mutation strategy to generate a new test case and executes the target program by using test case (Lines 4–5). Next, two pointer variables and are used to update the edge risk (Line 6). Here, is obtained with the pointer variable . The records the risk of each edge. At the beginning, the edge corresponding to dangerous function has a maximum value, while those of the other edges are zero. Next, if the mutated test case produces new coverage, MooFuzz will calculate path risk value (Lines 7–8). Next, MooFuzz traverses each seed in the seed pool and determine whether its path is the same as the current path. If so, the frequency information of the seeds in seed pools will be updated (Lines 9–11). Finally, if the path of s is identical to the path of , the mutation information will be updated (Lines 12–13).
We discuss how to update different information separately as follows.
The path risk mainly refers to the ability of seeds to detect dangerous locations, which determines the number and speed of bug discovery. Before discussing the path risk, we first give the definition of edge risk update and then that of path risk update.
The edge risk update. Given an edge and the corresponding hit-count , the edge risk is updated as follows.
where is the set of edges corresponding to dangerous function.
| Algorithm 3: Information update |
 |
The path risk update. Given a seed s and the risk values of all edges covered by the seed s, the path risk of seed s, is calculated as follows.
The path frequency indicates the ability of the seed to discover a new path. As time goes by, there are high-frequency paths and low-frequency paths in the program. Generally, those seeds that cover low-frequency paths have a higher probability of discovering new paths than those that cover high-frequency paths (the larger the value, the higher the path frequency) after the program running for a while.
The path frequency update. Given a seed and its path , if there is a seed s in the seed pool and its path , and is the same as . We add one to the path frequency of seed s, that is,
The mutation information indicates the mutation ability of a seed. For each seed that has not been fuzzed, its mutation effectiveness is set to 0, indicating that the seed has the best mutation validity. Among the seeds being fuzzed, the mutation ability of the seeds will be continuously evaluated, and individuals with high mutation ability (the smaller the value, the better) will obtain priority.
The mutation information update. Given a seed s and its mutation strategy M, if the path of seed s is the same as that of seed generated by seed mutation upon s, the mutation information of seed s, is calculated as follows.
3.3. Seed Scheduler
Seed scheduler is mainly used for seeds selection. In order to effectively prioritize seeds, we propose a many-objective optimization seed schedule scheme.
Before seed schedule, MooFuzz divides the seed pool into three states according to seed attributes.
Exploration State. Exploration State refers to the existence of unfuzzed and favored seeds in the seed pool. Exploration State represents that the current seed pool state is an excellent state and it maintains the diversity of seeds.
Search State. In this state, the favored seeds have been fuzzed, but there are still unfuzzed seeds. Search State represents that there is a risk that the seed pool is completely fuzzed, and it is necessary to concentrate on finding more paths.
Assessment State. In this state, all the seeds are all fuzzed. It is very difficult to find a priority seed, but the fuzzed seeds produce a lot of information that can serve as a reference. Besides, MooFuzz performs state monitoring in the assessment state. Once the state changes, the seed set of the current state will be discarded to perform seed schedule in other states.
For these three states, MooFuzz uses different selection criteria based on bug detection, path discovery, and seed evaluation. MooFuzz constructs different objective functions based on different states.
In the previous discussion, MooFuzz has obtained the risk value of the seed before it is added to the seed pool, indicating the path risk. Based on previous research [8], seeds with deeper executing paths may be more capable of detecting bugs. Therefore, MooFuzz uses path risk r and path depth d as objectives for seed selection. To reduce the energy consumption of seeds and speed up the discovery of bugs, MooFuzz also takes the length l of the seed data and the execution time t of the seed as objectives. In Exploration State, MooFuzz uses the following objective functions to select the seeds that have not been fuzzed and favored.
Search State indicates that all the favored seeds in current seed pool have been fuzzed and there are unfuzzed seeds. At this time, MooFuzz’s selection of seeds will mainly focus on the path discovery. The frequency information of the seeds will increase with the running time changes. In this state, those seeds that pass the low-frequency path will have greater potential to discover new paths. MooFuzz regards path frequency e and path depth d as criteria for seeds selection. Meanwhile, MooFuzz uses l and t described above to balance energy consumption. In Search State, MooFuzz uses the following objective functions to select the seeds that have not been fuzzed.
Assessment State means that all seeds in the current seed pool have been fuzzed. MooFuzz will obtain the information of the seed including the path frequency e, the number of times that the seed has been selected n, the seed path depth d, and the mutation information m, and then add them to the objective functions as mutation criterion. Note that the current state does not choose the length and execution time of the seed as criteria to balance energy consumption, because the current state is very difficult to generate new seeds. Besides, once new seeds are generated in this state, Assessment State will be terminated and enter other state. In Assessment State, MooFuzz uses the following objective functions to select the seeds from the seed pool.
MooFuzz selects the optimal seed set after establishing objective functions for different seed pool states and models seed schedule as a minimization problem. Algorithm 4 mainly completes the seed schedule by using non-dominated sorting [19]. The seed set S that satisfies state conditions will be selected as the input. A set that is used to store the optimal seed set. Initially, is an empty set, and in seed set S was added to . For each seed from the seed set S and seeds in finish the dominance comparisons (Lines 1–9). If dominates (each attribute value of is less than ), the next seed comparison will be performed. If dominates , remove from . After the comparison between the seed and , if there is not a dominance relationship between and all the seeds in , will be added to (Lines 10–11). After the above cycle is completed, the optimal seed set is stored in , and MooFuzz extracts each seed inside for fuzzing (Lines 12–13).
| Algorithm 4: Seed schedule |
 |
3.4. Power Scheduler
The purpose of power schedule is assigning reasonable energy for each seed involved in mutation. A high quality seed has more chances to mutation and should be assigned with more energy in fuzzing process.
Existing coverage-based fuzzers (such as AFL [7]) usually calculate the energy for the selected seeds as follows [18],
where i is the seed and is the quality of the seed, depending on the execution time, branch edge coverage, creation time, and so on.
Algorithm 5 is the seed power schedule algorithm. MooFuzz considers different seed pool states to set up different energy distribution methods. Meanwhile, it also uses an energy monitoring mechanism, which has the ability to monitor the execution of target programs and reduce unnecessary energy consumption.
After many experiments, we find that the amount of energy in the deterministic stage is mainly related to the length of the seed, which is a relatively fine-grained mutation, but as the number of candidate seeds in the seed pool increases, it will affect the path discovery. Thus, in Algorithm 5 we open the deterministic stage to seeds that cause crashes after mutation (Lines 1–2). In the indeterministic stage, MooFuzz judges the state of the current seed. If it belongs to Search State, MooFuzz uses the frequency information to set the energy. If it belongs to Assessment State, both the frequency and the mutation information will be comprehensively considered to set the energy (Lines 3–6).
After energy allocation, we set up a monitoring mechanism to monitor the mutation of seeds (Lines 7–14). When each seed consumes 75% of the allocated energy, MooFuzz monitors the mutation of the current seed, and records the ratio of the average energy consumption of the current seed covering a new path and that of all seeds covering a new path. If its ratio is lower than , MooFuzz will withdraw the energy, if its ratio is higher than , the mutation information will be updated. Here, is equal to 0.9 and is equal to 1.3.
| Algorithm 5: Power schedule |
 |
4. Evaluation
MooFuzz is built on top of AFL-2.52b [7]. The implementation adds C/C++ code to the AFL. The instrumentation components are implemented to mark danger edges based on the LLVM framework [63] in static analysis. Through these experiments, the following research questions are tackled:
- RQ1:
- How capable is MooFuzz in crash detection?
- RQ2:
- How effective is the code coverage of MooFuzz?
- RQ3:
- How capable is MooFuzz in identifying real-world vulnerabilities?
4.1. Experimental Settings
Baseline Fuzzer. We compare MooFuzz with existing state-of-the-art tools AFL [7], AFLFast [11], FairFuzz [13], and PerfFuzz [16]. The selection of baseline fuzzer is mainly based on the following considerations:
- AFL is currently one of the most common coverage-based greybox fuzzer in community.
- AFLFast is a variant of AFL with better power schedule.
- FairFuzz is also an extending fuzzer of AFL. It optimizes inputs that hit rare branches.
- PerfFuzz improves the instrumented components to generate pathological inputs.
Benchmark. To evaluate MooFuzz, we choose seven real-world open source Linux applications as the benchmark to conduct experiments. Jasper [64] is a software tool kit for processing image data that provides a way to represent images and facilitates the manipulation of image data. LibSass [65] is a C/C++ port of the Sass engine. Exiv2 [66] is a C++ library and a command line utility to read, write, delete, and modify Exif, IPTC, XMP, and ICC image metadata. Libming [67] is a library for generating Macromedia Flash files, written in C, and includes useful utilities for working with Flash files. OpenJPEG [68] is an open source JPEG 2000 codec written in C language. Bento4 [69] is a C++ class library that is designed to read and write ISO-MP4 files. The GUN Binutils [70] is a collection of binary tools. Table 2 shows target applications and their fuzzing configure.
Performance Metrics. Crashes, paths, and vulnerabilities are chosen as metrics in this section. In code coverage metrics, we use the number of seeds in the queue as an indicator and use tool Afl-cov [71] to measure code line coverage and function coverage. In vulnerability detection, we directly use AddressSanitizer [72] to detect it.
Experiment Environment. All experiments are conducted on a server configured with two Xeon E5-2680 v4 processors (56 logical cores in total) and 32 GB RAM. The server installed Ubuntu 18.04 system. For the same application, the initial seed set is the same. We fuzz each application for 24 h (on a single logical core) and repeat 5 times to reduce randomness. In all implementations, we use 42 logical cores, and we leave 14 logical cores for other processes to keep the workload stable.
4.2. Unique Crashes Evaluation (RQ1)
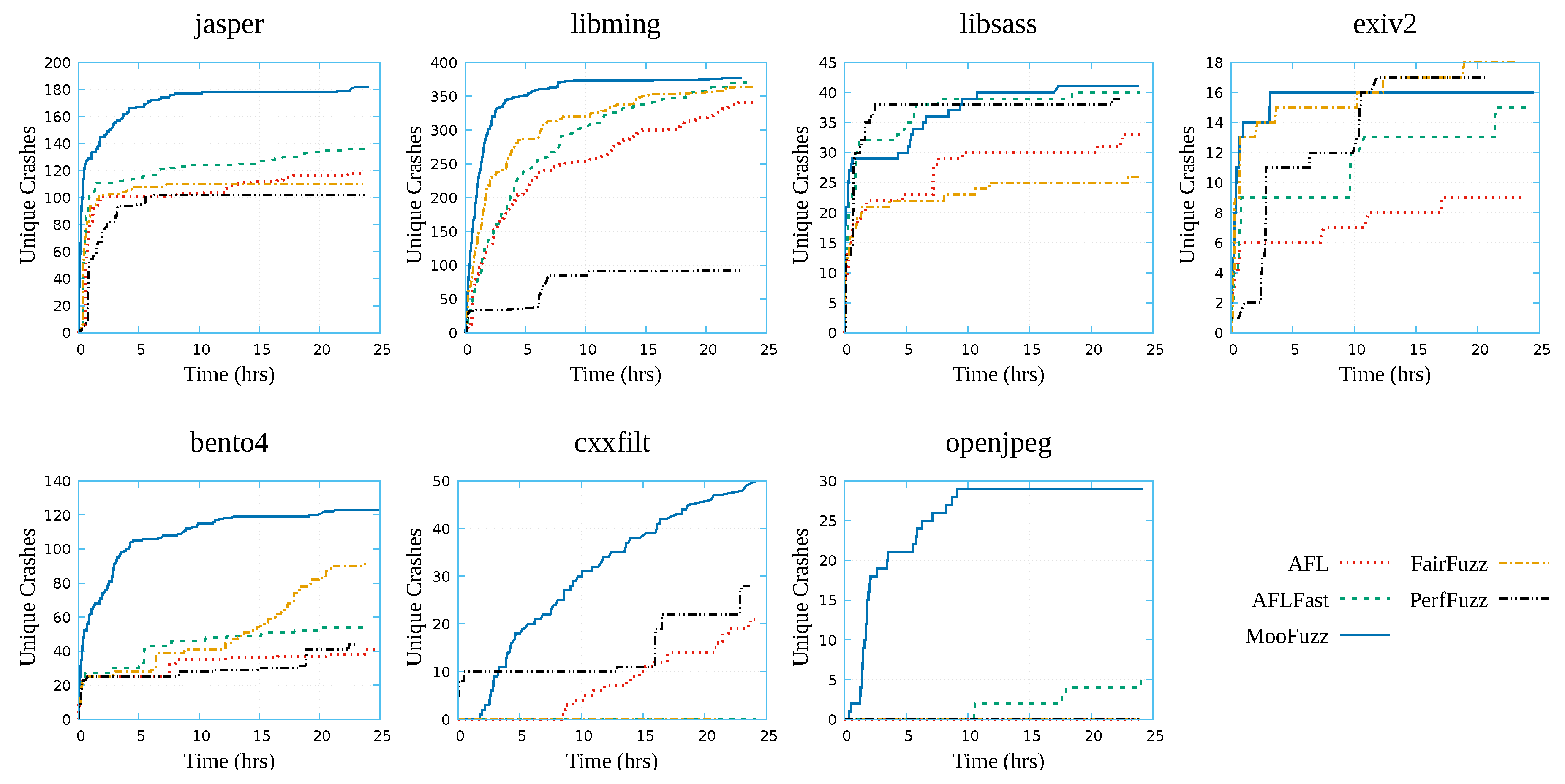
In order to evaluate the effectiveness of MooFuzz, a direct method is to evaluate the number of crashes and the speed at which they are triggered. It is believed that more crashes may trigger more bugs. We fuzz each application to run on 5 different fuzzers to compare the number of unique crashes and the speed of discovery. Figure 3 shows the growth trends of unique crashes discovery in different fuzzers. From these results, we can make the follow observations.
First, different fuzzers have different capability in fuzzing different application programs. For example, PerfFuzz has zero crash in fuzzing openjpeg within 24 h, but it can trigger most crashes in fuzzing exiv2 among other fuzzers. This shows that the different criteria of the seed selection affect the number of crashes.
Second, seed schedule and power schedule affect the efficiency of crashes discovery. The experimental results show that MooFuzz outperforms AFL in the speed of crashes discovery and just takes about 10 h to trigger most of the unique crashes. There is no path risk measurement and energy monitoring in AFL, leading to a lot of time spent on invalid mutation operators.
Third, MooFuzz is able to find more crashes than other state-of-the-art fuzzers. The static results are shown in Table 3. We count the number of crashes found in applications by different fuzzers within 24 h, and count the total number of crashes found by each fuzzer. Table 3 shows that except for exiv2, MooFuzz triggers more crashes than other fuzzers, among which jasper triggers 182 crashes within 24 h and AFL only triggers 118 crashes. In total, MooFuzz triggers 818 crashes in benchmark application programs, improving by 46%, 32%, 34%, and 153%, respectively, compared with state-of-the-art fuzzers AFL [7], AFLFast [11], FairFuzz [13], and PerfFuzz [16].
Overall, MooFuzz significantly outperforms other fuzzers in terms of speed and number of unique crashes.
4.3. Coverage Evaluation (RQ2)
Code coverage is an effective way to evaluate fuzzers. The experiment measures coverage from source code line, function, and path. Table 4 shows the line and function covered by different fuzzers. In total, MooFuzz’s line coverage and function coverage are better than AFL, AFLFast, FairFuzz, and PerfFuzz.
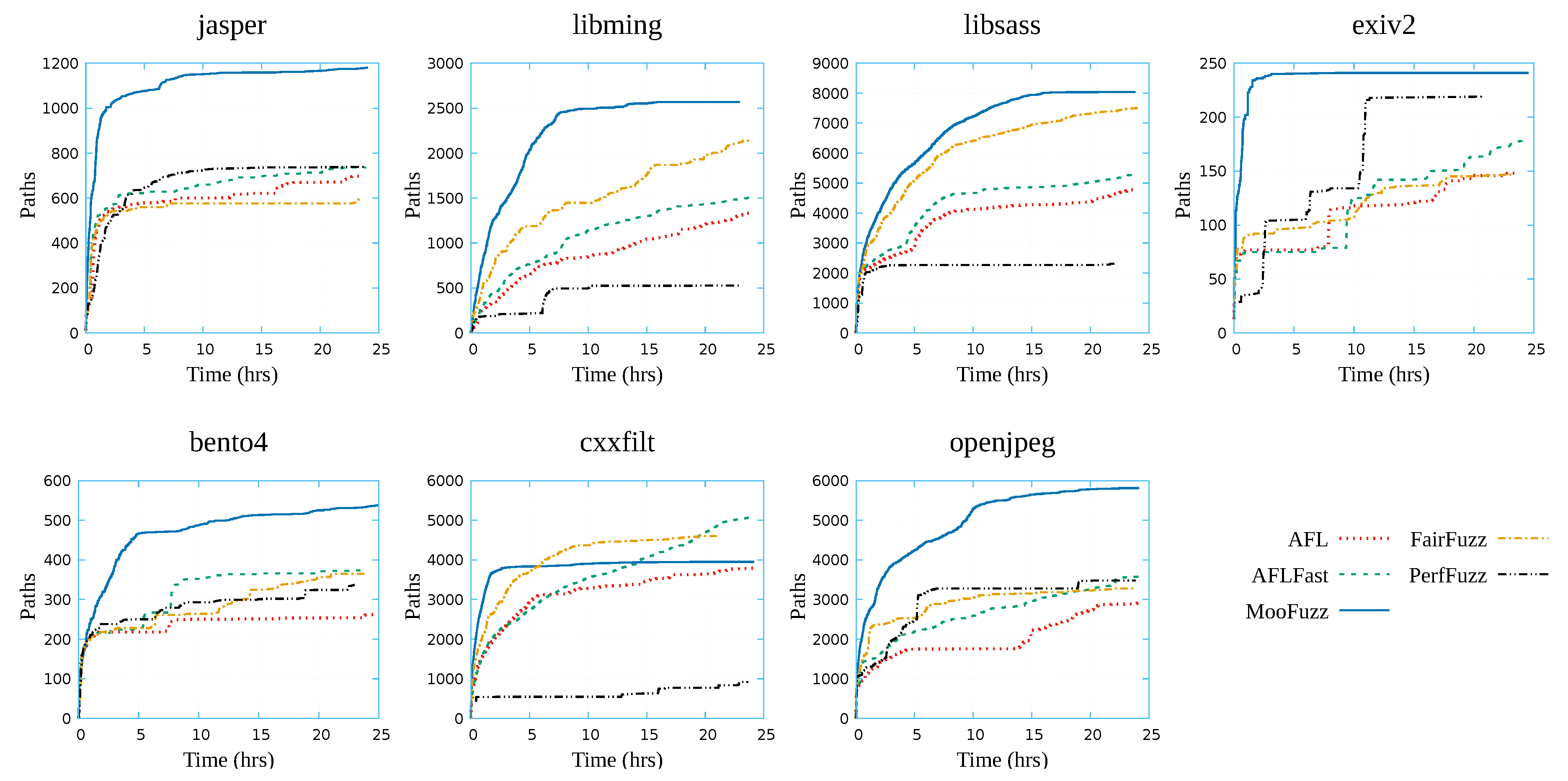
Figure 4 shows the growth trends of paths discovery in five different fuzzers after fuzzing applications for 24 h. We can clearly observe that except for cxxfilt, MooFuzz ranks first among all fuzzers from the perspective of the number of path discovery. Among them, it can find about 6000 paths in fuzzing openjpeg, and the other four fuzzers can only find about 3600 paths. It can find about 1200 paths after fuzzing jasper for 24 h, while other fuzzers can only find about 500 to 700 paths. Although the number of paths discovered by MooFuzz is lower than FairFuzz and AFLFast in fuzzing cxxfilt, it can trigger the most crashes compared with other fuzzers. From the speed of path discovery, MooFuzz is significantly higher than other fuzzers.
Overall, MooFuzz outperforms other fuzzers in terms of line, function, and path coverage.
4.4. Vulnerability Evaluation (RQ3)
MooFuzz tests old version of the applications and analyzes related vulnerabilities to evaluate the ability in vulnerability detection. Table 5 shows the real vulnerabilities combination with its IDs identified by MooFuzz. MooFuzz is able to find stack overflow, heap overflow, null pointer dereference, and memory leaks related vulnerabilities.
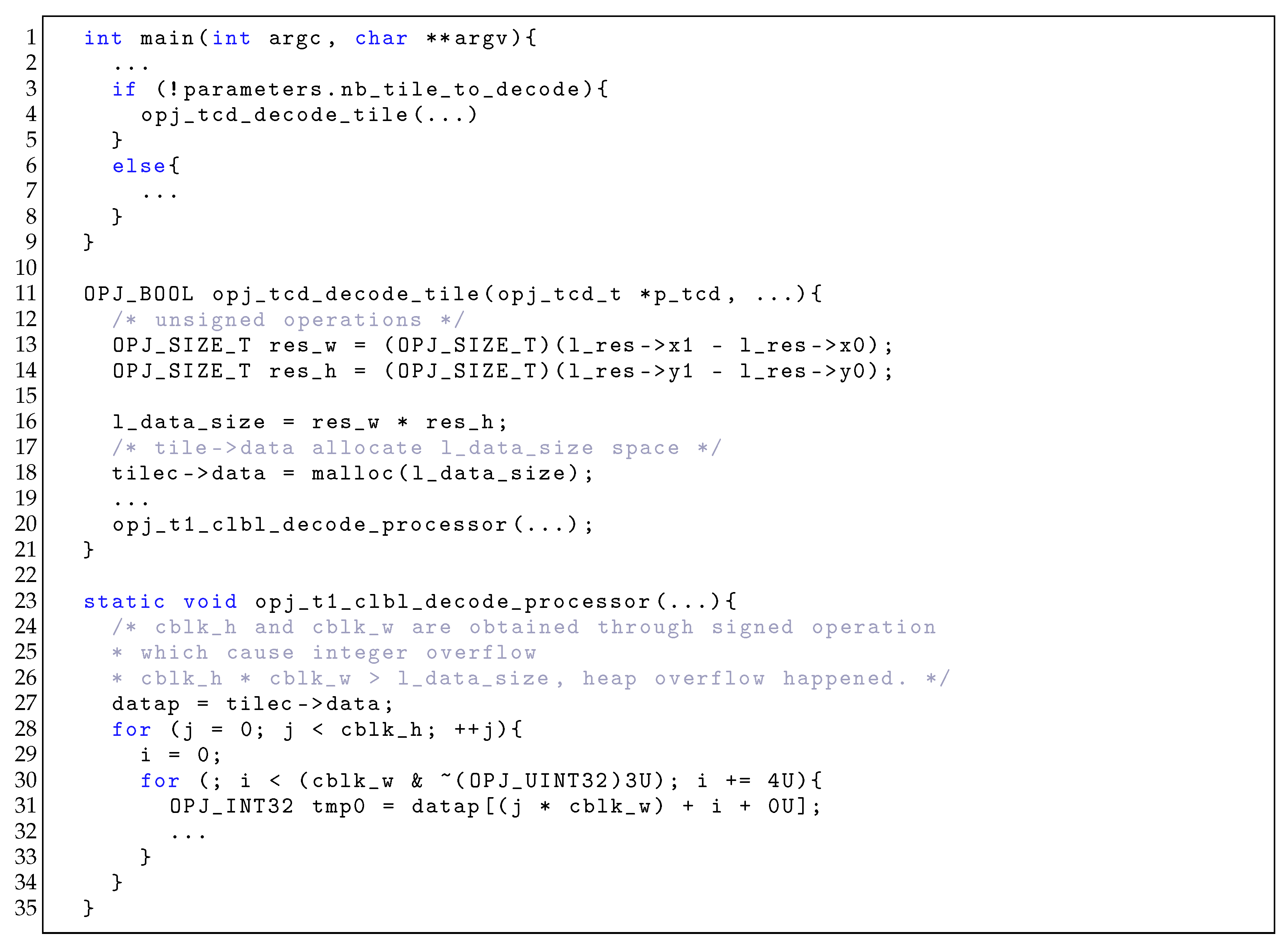
Vulnerability analysis. We use a real-world application program vulnerability to analyze the effectiveness of our approach, as shown in Figure 5. This is a code snippet from openjpeg [68] which contains a heap-buffer-overflow vulnerability (i.e., CVE-2020-8112).
In Figure 5, the main function contains a conditional statement (Lines 1–9). In MooFuzz, the seed satisfies the judgment condition and enters the true branch to execute function . Moreover, the seed enters the false branch to execute other codes that do not contain dangerous functions. As is a dangerous function which is used in , risks might emerge when this function is used. Therefore, MooFuzz preferentially selects seed for mutation. In this case, is called and comes from an unsigned operation in the function . Then, the function will be called in the following program flow, where the allocated memory will be modify through two variables and . All of these two variables are obtained through signed operation, which causes an integer overflow making , and MooFuzz easily satisfies the above conditions through mutation, so the heap-buffer-overflow happened.
4.5. Discussion
We enhance fuzzing from the perspectives of vulnerabilities and coverage. Although more coverage may trigger more vulnerabilities, not all coverage is equal [62]. Based on our observation of the fuzzing process, we define the path risk and prioritize seeds that consume less energy while executing high risks, to maximize the improvement of fuzzing. Meanwhile, we use different objectives for seed optimization and energy allocation. It can improve the efficiency of fuzzing in a limited time.
In the algorithm design of the power schedule, we use two thresholds to judge the current seed energy usage. There is still an opportunity to adaptively adjust these two thresholds instead of the fixed thresholds. For example, these thresholds can be dynamically adjusted according to the fuzzing process. In our evaluation, our method can improve the probability of triggering vulnerabilities, but it may not be effective for triggering vulnerabilities that require complex conditions, such as deeply nested conditions. Although we use a variety of open source benchmarks to evaluation MooFuzz, it may not be effective for programs that require specific grammatical conditions for inputs (such as XML). However, the prototype we develop, MooFuzz, is a completely dynamic prototype. It can integrate static analysis techniques like symbolic execution to generate test cases that satisfy specific conditions to improve fuzzing.
5. Conclusions and Further Work
In this paper, a many-objective optimization model is built for seed schedule. Considering the three states of the seed pool, we use different objective functions to select seeds from the perspectives of bug detection, path discovery, and seed evaluation. At the same time, an energy recovery mechanism is designed to monitor energy usage during the fuzzing process. We implement a prototype MooFuzz on top of AFL and evaluate it on seven real-world programs. The experiment results show that MooFuzz behaves more effectively than state-of-the-art fuzzers in path discovery and bug detection.
In the future, we plan to use MooFuzz to fuzz the latest version of the applications to assist testers in testing. In next study, we will consider optimizing power schedule through multi-information feedback on the basis of MooFuzz, so that it can monitor energy consumption according to the current program running progress, and automatically set and adjust energy. We also consider starting from the seed mutation, and propose a new decision model to determine effective region of the seed and select the effective mutation strategy.
Author Contributions
Conceptualization, X.Z. and H.Q.; methodology, X.Z. and H.Q.; software, W.L. and X.Z.; validation, W.L., S.L., and X.Z.; formal analysis, H.Q.; investigation, X.Z. and S.L.; resources, J.X.; data curation, W.L.; writing—original draft preparation, X.Z.; writing—review and editing, X.Z. and J.X.; visualization, W.L. and S.L.; supervision, H.Q.; project administration, X.Z.; funding acquisition, H.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China grant number 61827810.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The test results data presented in this study are available on request. The data set can be found in public web sites.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Arya, A.; Neckar, C. Fuzzing for Security. Available online: https://blog.chromium.org/2012/04/fuzzing-for-security.html (accessed on 30 November 2020).
- Evans, C.; Moore, M.; Ormandy, T. Fuzzing at Scale. Available online: https://security.googleblog.com/2011/08/fuzzing-at-scale.html (accessed on 30 November 2020).
- Moroz, M.; Serebryany, K. Guided in-Process Fuzzing of Chrome Components. Available online: https://security.googleblog.com/2016/08/guided-in-process-fuzzing-of-chrome.html (accessed on 30 November 2020).
- Godefroid, P.; Kiezun, A.; Levin, M.Y. Grammar-based whitebox fuzzing. In Proceedings of the 29th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI 2008), Tucson, AZ, USA, 21–25 June 2008; pp. 206–215. [Google Scholar]
- Arkin, B. Adobe Reader and Acrobat Security Initiative. Available online: https://blogs.adobe.com/security/2009/05/adobe_reader_and_acrobat_secur.html (accessed on 30 November 2020).
- Serebryany, K. Continuous fuzzing with libFuzzer and AddressSanitizer. In Proceedings of the 2016 IEEE Cybersecurity Development (SecDev 2016), Boston, MA, USA, 3–4 November 2016; p. 157. [Google Scholar]
- Zlewski, C. American Fuzzy Lop. Available online: http://lcamtuf.coredump.cx/afl (accessed on 1 September 2020).
- Rawat, S.; Jain, V.; Kumar, A.; Cojocar, L.; Giuffrida, C.; Bos, H. VUzzer: Application-aware evolutionary fuzzing. In Proceedings of the 24th Annual Network and Distributed System Security Symposium (NDSS 2017), San Diego, CA, USA, 26 February–1 March 2017; pp. 1–14. [Google Scholar]
- Gan, S.; Zhang, C.; Qin, X.; Tu, X.; Li, K.; Pei, Z.; Chen, Z. Collafl: Path sensitive fuzzing. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (S&P 2018), San Francisco, CA, USA, 21–23 May 2018; pp. 679–696. [Google Scholar]
- Sun, L.; Li, X.; Qu, H.; Zhang, X. AFLTurbo: Speed up path discovery for greybox fuzzing. In Proceedings of the 2020 IEEE 31st International Symposium on Software Reliability Engineering (ISSRE 2020), Coimbra, Portugal, 12–15 October 2020; pp. 81–91. [Google Scholar]
- Böhme, M.; Pham, V.; Roychoudhury, A. Coverage-based greybox fuzzing as markov chain. IEEE Trans. Softw. Eng. 2019, 45, 489–506. [Google Scholar] [CrossRef]
- Böhme, M.; Pham, V.T.; Nguyen, M.D.; Roychoudhury, A. Directed greybox fuzzing. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS 2017), Dallas, TX, USA, 30 October–3 November 2017; pp. 2329–2344. [Google Scholar]
- Lemieux, C.; Sen, K. Fairfuzz: A targeted mutation strategy for increasing greybox fuzz testing coverage. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering (ASE 2018), Montpellier, France, 3–7 September 2018; pp. 475–485. [Google Scholar]
- Lyu, C.; Ji, S.; Zhang, C.; Li, Y.; Lee, W.H.; Song, Y.; Beyah, R. MOPT: Optimized mutation scheduling for fuzzers. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 2019), Santa Clara, CA, USA, 14–16 August 2019; pp. 1949–1966. [Google Scholar]
- Yue, T.; Wang, P.; Tang, Y.; Wang, E.; Yu, B.; Lu, K.; Zhou, X. EcoFuzz: Adaptive energy-saving greybox fuzzing as a variant of the adversarial multi-armed bandit. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 2020), Vancouver, BC, Canada, 12–14 August 2020; pp. 2307–2324. [Google Scholar]
- Lemieux, C.; Padhye, R.; Sen, K.; Song, D. PerfFuzz: Automatically generating pathological inputs. In Proceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA 2018), Amsterdam, The Netherlands, 16–21 July 2018; pp. 254–265. [Google Scholar]
- Wen, C.; Wang, H.; Li, Y.; Qin, S.; Liu, Y.; Xu, Z.; Chen, H.; Xie, X.; Pu, G.; Liu, T. Memlock: Memory usage guided fuzzing. In Proceedings of the 42nd International Conference on Software Engineering (ICSE 2020), Han River, Seoul, Korea, 6–11 July 2020; pp. 765–777. [Google Scholar]
- Li, Y.; Xue, Y.; Chen, H.; Wu, X.; Zhang, C.; Xie, X.; Wang, H.; Liu, Y. Cerebro: Context-aware adaptive fuzzing for effective vulnerability detection. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (FSE 2019), Tallinn, Estonia, 26–30 August 2019; pp. 533–544. [Google Scholar]
- Yuan, Y.; Xu, H.; Wang, B. An improved NSGA-III procedure for evolutionary many-objective optimization. In Proceedings of the 2014 Annual Conference on Genetic and Evolutionary Computation (GECCO 2014), Vancouver, BC, Canada, 12–16 July 2014; pp. 661–668. [Google Scholar]
- Rizk-Allah, R.M.; El-Sehiemy, R.A.; Deb, S.; Wang, G.G. A novel fruit fly framework for multi-objective shape design of tubular linear synchronous motor. J. Supercomput. 2017, 73, 1235–1256. [Google Scholar] [CrossRef]
- Li, J.; Lei, H.; Alavi, A.H.; Wang, G.G. Elephant herding optimization: Variants, hybrids, and applications. Mathematics 2020, 8, 1415. [Google Scholar] [CrossRef]
- Sun, J.; Miao, Z.; Gong, D.; Zeng, X.J.; Li, J.; Wang, G. Interval multiobjective optimization with memetic algorithms. IEEE Trans. Cybern. 2020, 50, 3444–3457. [Google Scholar] [CrossRef]
- Wang, F.; Li, Y.; Liao, F.; Yan, H. An ensemble learning based prediction strategy for dynamic multi-objective optimization. Appl. Soft Comput. 2020, 96, 106592. [Google Scholar] [CrossRef]
- Feng, Y.; Wang, G.G.; Li, W.; Li, N. Multi-strategy monarch butterfly optimization algorithm for discounted {0-1} knapsack problem. Neural Comput. Appl. 2018, 30, 3019–3036. [Google Scholar] [CrossRef]
- Srikanth, K.; Panwar, L.K.; Panigrahi, B.K.; Herrera-Viedma, E.; Sangaiah, A.K.; Wang, G.G. Meta-heuristic framework: Quantum inspired binary grey wolf optimizer for unit commitment problem. Comput. Electr. Eng. 2018, 70, 243–260. [Google Scholar] [CrossRef]
- Feng, Y.; Deb, S.; Wang, G.G.; Alavi, A.H. Monarch butterfly optimization: A comprehensive review. Expert Syst. Appl. 2021, 168, 114418. [Google Scholar] [CrossRef]
- Pan, Q.K.; Sang, H.Y.; Duan, J.H.; Gao, L. An improved fruit fly optimization algorithm for continuous function optimization problems. Knowl.-Based Syst. 2014, 62, 69–83. [Google Scholar] [CrossRef]
- Sang, H.Y.; Pan, Q.K.; Duan, P.y. Self-adaptive fruit fly optimizer for global optimization. Nat. Comput. 2019, 18, 785–813. [Google Scholar] [CrossRef]
- Wang, F.; Li, Y.; Zhou, A.; Tang, K. An estimation of distribution algorithm for mixed-variable newsvendor problems. IEEE Trans. Evol. Comput. 2020, 24, 479–493. [Google Scholar] [CrossRef]
- Wang, G.G.; Guo, L.; Gandomi, A.H.; Hao, G.S.; Wang, H. Chaotic krill herd algorithm. Inf. Sci. 2014, 274, 17–34. [Google Scholar] [CrossRef]
- Wang, G.G.; Deb, S.; Cui, Z. Monarch butterfly optimization. Neural Comput. Appl. 2019, 31, 1995–2014. [Google Scholar] [CrossRef] [Green Version]
- Gao, D.; Wang, G.G.; Pedrycz, W. Solving fuzzy job-shop scheduling problem using DE algorithm improved by a selection mechanism. IEEE Trans. Fuzzy Syst. 2020, 28, 3265–3275. [Google Scholar] [CrossRef]
- Sang, H.Y.; Pan, Q.K.; Duan, P.Y.; Li, J.Q. An effective discrete invasive weed optimization algorithm for lot-streaming flowshop scheduling problems. J. Intell. Manuf. 2018, 29, 1337–1349. [Google Scholar] [CrossRef]
- Wu, G.; Pedrycz, W.; Li, H.; Ma, M.; Liu, J. Coordinated planning of heterogeneous earth observation resources. IEEE Trans. Syst. Man, Cybern. Syst. 2015, 46, 109–125. [Google Scholar] [CrossRef]
- Wang, G.G.; Gandomi, A.H.; Yang, X.S.; Alavi, A.H. A new hybrid method based on krill herd and cuckoo search for global optimisation tasks. Int. J. Bio-Inspired Comput. 2016, 8, 286–299. [Google Scholar] [CrossRef]
- Wang, G.G.; Guo, L.; Duan, H.; Liu, L.; Wang, H.; Shao, M. Path planning for uninhabited combat aerial vehicle using hybrid meta-heuristic DE/BBO algorithm. Adv. Sci. Eng. Med. 2012, 4, 550–564. [Google Scholar] [CrossRef]
- Yi, J.H.; Wang, J.; Wang, G.G. Improved probabilistic neural networks with self-adaptive strategies for transformer fault diagnosis problem. Adv. Mech. Eng. 2016, 8, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Mao, W.; He, J.; Li, Y.; Yan, Y. Bearing fault diagnosis with auto-encoder extreme learning machine: A comparative study. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2017, 231, 1560–1578. [Google Scholar] [CrossRef]
- Mao, W.; Feng, W.; Liang, X. A novel deep output kernel learning method for bearing fault structural diagnosis. Mech. Syst. Signal Process. 2019, 117, 293–318. [Google Scholar] [CrossRef]
- Wang, G.G.; Lu, M.; Dong, Y.Q.; Zhao, X.J. Self-adaptive extreme learning machine. Neural Comput. Appl. 2016, 27, 291–303. [Google Scholar] [CrossRef]
- Mao, W.; Zheng, Y.; Mu, X.; Zhao, J. Uncertainty evaluation and model selection of extreme learning machine based on Riemannian metric. Neural Comput. Appl. 2014, 24, 1613–1625. [Google Scholar] [CrossRef]
- Duan, H.; Zhao, W.; Wang, G.G.; Feng, X.H. Test-sheet composition using analytic hierarchy process and hybrid metaheuristic algorithm TS/BBO. Math. Probl. Eng. 2012, 2012, 1239–1257. [Google Scholar] [CrossRef]
- Liu, G.; Zou, J. Level set evolution with sparsity constraint for object extraction. IET Image Process. 2018, 12, 1413–1422. [Google Scholar] [CrossRef]
- Wu, G.; Pedrycz, W.; Suganthan, P.N.; Li, H. Using variable reduction strategy to accelerate evolutionary optimization. Appl. Soft Comput. 2017, 61, 283–293. [Google Scholar] [CrossRef]
- Li, R.; Zheng, Q.; Li, X.; Yan, Z. Multi-objective optimization for rebalancing virtual machine placement. Future Gener. Comput. Syst. 2020, 105, 824–842. [Google Scholar] [CrossRef]
- Srinivas, N.; Deb, K. Muiltiobjective optimization using nondominated sorting in genetic algorithms. Evol. Comput. 1994, 2, 221–248. [Google Scholar] [CrossRef]
- Coello, C.A.C.; Pulido, G.T.; Lechuga, M.S. Handling multiple objectives with particle swarm optimization. IEEE Trans. Evol. Comput. 2004, 8, 256–279. [Google Scholar] [CrossRef]
- Felde, I.; Szénási, S. Estimation of temporospatial boundary conditions using a particle swarm optimisation technique. Int. J. Microstruct. Mater. Prop. 2016, 11, 288–300. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, H.; Zhou, A. A particle swarm optimization algorithm for mixed-variable optimization problems. Swarm Evol. Comput. 2021, 60, 100808. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Yi, J.H.; Deb, S.; Dong, J.; Alavi, A.H.; Wang, G.G. An improved NSGA-III algorithm with adaptive mutation operator for Big Data optimization problems. Future Gener. Comput. Syst. 2018, 88, 571–585. [Google Scholar] [CrossRef]
- Yi, J.H.; Xing, L.N.; Wang, G.G.; Dong, J.; Vasilakos, A.V.; Alavi, A.H.; Wang, L. Behavior of crossover operators in NSGA-III for large-scale optimization problems. Inf. Sci. 2020, 509, 470–487. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H. MOEA/D: A multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, Q.; Zhang, T. Decomposition-based algorithms using pareto adaptive scalarizing methods. IEEE Trans. Evol. Comput. 2016, 20, 821–837. [Google Scholar] [CrossRef]
- Wang, R.; Zhou, Z.; Ishibuchi, H.; Liao, T.; Zhang, T. Localized weighted sum method for many-objective optimization. IEEE Trans. Evol. Comput. 2018, 22, 3–18. [Google Scholar] [CrossRef]
- Wang, G.G.; Tan, Y. Improving metaheuristic algorithms with information feedback models. IEEE Trans. Cybern. 2017, 49, 542–555. [Google Scholar] [CrossRef]
- Ishibuchi, H.; Tsukamoto, N.; Nojima, Y. Evolutionary many-objective optimization: A short review. In Proceedings of the 2008 IEEE Congress on Evolutionary Computation (CEC 2008), Hong Kong, China, 1–6 June 2008; pp. 2419–2426. [Google Scholar]
- Petsios, T.; Zhao, J.; Keromytis, A.D.; Jana, S. Slowfuzz: Automated domain-independent detection of algorithmic complexity vulnerabilities. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS 2017), Dallas, TX, USA, 30 October–3 November 2017; pp. 2155–2168. [Google Scholar]
- Wang, H.; Xie, X.; Li, Y.; Wen, C.; Li, Y.; Liu, Y.; Qin, S.; Chen, H.; Sui, Y. Typestate-guided fuzzer for discovering use-after-free vulnerabilities. In Proceedings of the 42nd International Conference on Software Engineering (ICSE 2020), Han River, Seoul, Korea, 6–11 July 2020; pp. 999–1010. [Google Scholar]
- Gan, S.; Zhang, C.; Chen, P.; Zhao, B.; Qin, X.; Wu, D.; Chen, Z. GREYONE: Data flow sensitive fuzzing. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 2020), Boston, MA, USA, 12–14 August 2020; pp. 2577–2594. [Google Scholar]
- Wang, J.; Chen, B.; Wei, L.; Liu, Y. Superion: Grammar-aware greybox fuzzing. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE 2019), Montreal, QC, Canada, 25–31 May 2019; pp. 724–735. [Google Scholar]
- Wang, Y.; Jia, X.; Liu, Y.; Zeng, K.; Bao, T.; Wu, D.; Su, P. Not all coverage measurements are equal: Fuzzing by coverage accounting for input prioritization. In Proceedings of the 27th Annual Network and Distributed System Security Symposium (NDSS 2020), San Diego, CA, USA, 23–26 February 2020; pp. 1–17. [Google Scholar]
- Lattner, C.; Adve, V. LLVM: A compilation framework for lifelong program analysis & transformation. In Proceedings of the International Symposium on Code Generation and Optimization (CGO 2004), Palo Alto, CA, USA, 20–24 March 2004; pp. 75–86. [Google Scholar]
- Jasper. Available online: https://www.ece.uvic.ca/~frodo/jasper/ (accessed on 23 September 2020).
- Libsass. Available online: https://sass-lang.com/libsass (accessed on 23 September 2020).
- Exiv2. Available online: https://exiv2.org/ (accessed on 23 September 2020).
- Ming. Available online: https://github.com/libming/libming (accessed on 23 September 2020).
- Openjpeg. Available online: https://www.openjpeg.org/ (accessed on 23 September 2020).
- Bento4. Available online: https://www.bento4.com/ (accessed on 23 September 2020).
- Binutils. Available online: https://www.gnu.org/software/binutils/ (accessed on 23 September 2020).
- Afl-cov. Available online: https://github.com/soh0ro0t/afl-cov (accessed on 23 September 2020).
- Serebryany, K.; Bruening, D.; Potapenko, A.; Vyukov, D. AddressSanitizer: A fast address sanity checker. In Proceedings of the 2012 USENIX Annual Technical Conference (USENIX ATC 2012), Boston, MA, USA, 13–15 June 2012; pp. 309–318. [Google Scholar]
Figure 1.
Solutions in a two-dimensional objective space.

Figure 2.
A high-level overview of MooFuzz.

Figure 3.
The growth trends of unique crashes discovery in different fuzzers within 24 h.

Figure 4.
The growth trends of paths discovery in different fuzzers within 24 h.

Figure 5.
An example from openjpeg (CVE-2020-8112).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Dangerous functions.
| Class | Description | Function Name |
|---|---|---|
| memory | memory allocation | |
| memory recovery | ||
| memory operation | ||
| string | string operation | |
| others | file I/O |
Table 2.
Target applications and their fuzzing configure.
| Program | Command Line | Project Version |
|---|---|---|
| jasper | jasper - -input @@ - -output t.bmp | Jasper 2.0.14 |
| libsass | tester @@ | LibSass 3.5.4 |
| exiv2 | exiv2 -pX @@ | Exiv2 0.26 |
| libming | listswf @@ | Libming 0.4.8 |
| openjpeg | opj_decompress -i @@ -o t.png | OpenJPEG 0.26 |
| cxxfilt | c++filt -t | GUN Binutils 2.31 |
| bento4 | mp42hls @@ | Bento4 1.5.1 |
Table 3.
Number of unique crashes found in real-world programs by various fuzzers.
| Program | MooFuzz | AFL | AFLFast | FairFuzz | PerfFuzz |
|---|---|---|---|---|---|
| jasper | 182 | 118 | 136 | 110 | 102 |
| libming | 377 | 341 | 371 | 364 | 92 |
| libsass | 41 | 33 | 40 | 26 | 39 |
| exiv2 | 16 | 9 | 15 | 18 | 17 |
| bento4 | 123 | 40 | 54 | 91 | 44 |
| cxxfilt | 50 | 21 | 0 | 0 | 29 |
| openjpeg | 29 | 0 | 5 | 0 | 0 |
| total | 818 | 562 | 621 | 609 | 323 |
Table 4.
Line and function covered by fuzzers.
| Program | MooFuzz | AFL | AFLFast | FairFuzz | PerfFuzz | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Line | Func | Line | Func | Line | Func | Line | Func | Line | Func | |
| jasper | 32.8% | 47.5% | 32.1% | 46.4% | 32.2% | 46.7% | 31.4% | 45.8% | 32.2% | 46.7% |
| libming | 15.5% | 16.8% | 13.6% | 14.8% | 13.0% | 14.3% | 16.1% | 17.3% | 6.0% | 7.4% |
| libsass | 52.2% | 35.0% | 51.1% | 35.1% | 50.2% | 34.5% | 52.2% | 35.3% | 45.3% | 32.8% |
| exiv2 | 5.0% | 9.0% | 4.9% | 8.8% | 4.9% | 8.9% | 4.9% | 8.8% | 4.9% | 8.8% |
| bento4 | 12.1% | 12.6% | 11.4% | 11.5% | 11.4% | 11.5% | 11.5% | 11.7% | 11.5% | 11.7% |
| cxxfilt | 2.5% | 3.0% | 2.5% | 3.0% | 2.7% | 3.1% | 2.8% | 3.1% | 1.5% | 2.5% |
| openjpeg | 31.2% | 41.4% | 29.2% | 33.5% | 31.7% | 41.3% | 33.2% | 41.9% | 29.5% | 39.0% |
Table 5.
Real-world vulnerabilities found by MooFuzz.
| Program | CVE | Vulnerability |
|---|---|---|
| cxxfilt | CVE-2018-9138 | stack overflow |
| cxxfilt | CVE-2018-17985 | stack overflow |
| jasper | CVE-2018-19543 | out-of-bounds read |
| jasper | CVE-2018-19542 | null pointer dereference |
| jasper | CVE-2018-19541 | out-of-bounds read |
| libsass | CVE-2018-19837 | stack overflow |
| libsass | CVE-2018-20821 | stack overflow |
| libsass | CVE-2018-20822 | stack overflow |
| exiv2 | CVE-2018-16336 | heap-buffer-overflow |
| exiv2 | CVE-2018-17229 | heap-buffer-overflow |
| exiv2 | CVE-2018-17230 | heap-buffer-overflow |
| exiv2 | CVE-2017-14861 | stack-buffer-overflow |
| libming | CVE-2018-13066 | memory leaks |
| libming | CVE-2020-6628 | heap-buffer-overflow |
| openjpeg | CVE-2020-8112 | heap-buffer-overflow |
| bento4 | CVE-2019-15050 | out-of-bounds read |
| bento4 | CVE-2019-15048 | heap-buffer-overflow |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhao, X.; Qu, H.; Lv, W.; Li, S.; Xu, J. MooFuzz: Many-Objective Optimization Seed Schedule for Fuzzer. Mathematics 2021, 9, 205. https://doi.org/10.3390/math9030205
AMA Style
Zhao X, Qu H, Lv W, Li S, Xu J. MooFuzz: Many-Objective Optimization Seed Schedule for Fuzzer. Mathematics. 2021; 9(3):205. https://doi.org/10.3390/math9030205
Chicago/Turabian StyleZhao, Xiaoqi, Haipeng Qu, Wenjie Lv, Shuo Li, and Jianliang Xu. 2021. "MooFuzz: Many-Objective Optimization Seed Schedule for Fuzzer" Mathematics 9, no. 3: 205. https://doi.org/10.3390/math9030205
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.