No Statistical-Computational Gap in Spiked Matrix Models with Generative Network Priors †


1
Department of Mathematics, Northeastern University, Boston, MA 02115, USA
2
Khoury College of Computer Sciences, Northeastern University, Boston, MA 02115, USA
3
Helm.ai, Menlo Park, CA 94025, USA
*
Author to whom correspondence should be addressed.
†
This paper is an extended version of our paper published in NeurIPS 2020.
Entropy 2021, 23(1), 115; https://doi.org/10.3390/e23010115
Submission received: 1 December 2020
/
Revised: 30 December 2020
/
Accepted: 8 January 2021
/
Published: 16 January 2021
(This article belongs to the Special Issue The Role of Signal Processing and Information Theory in Modern Machine Learning)
{kind=link}
{kind=link}
Abstract
:We provide a non-asymptotic analysis of the spiked Wishart and Wigner matrix models with a generative neural network prior. Spiked random matrices have the form of a rank-one signal plus noise and have been used as models for high dimensional Principal Component Analysis (PCA), community detection and synchronization over groups. Depending on the prior imposed on the spike, these models can display a statistical-computational gap between the information theoretically optimal reconstruction error that can be achieved with unbounded computational resources and the sub-optimal performances of currently known polynomial time algorithms. These gaps are believed to be fundamental, as in the emblematic case of Sparse PCA. In stark contrast to such cases, we show that there is no statistical-computational gap under a generative network prior, in which the spike lies on the range of a generative neural network. Specifically, we analyze a gradient descent method for minimizing a nonlinear least squares objective over the range of an expansive-Gaussian neural network and show that it can recover in polynomial time an estimate of the underlying spike with a rate-optimal sample complexity and dependence on the noise level.
1. Introduction
One of the fundamental problems in statistical inference and signal processing is the estimation of a signal given noisy high dimensional data. A prototypical example is provided by spiked matrix models where a signal is to be estimated from a matrix Y taking one of the following forms:
- Spiked Wishart Model in which is given by:where , , are i.i.d. from , and u and Z are independent;
- Spiked Wigner Model in which is given by:where , is drawn from a Gaussian Orthogonal Ensemble GOE, that is, for all and for .
In the last 20 years, spiked random matrices have been extensively studied, as they serve as a mathematical model for many signal recovery problems such as PCA [1,2,3,4], synchronization over graphs [5,6,7] and community detection [8,9,10]. Furthermore, these models are archetypal examples of the trade-off between statistical accuracy and computational efficiency. From a statistical perspective, the objective is to understand how the choice of the prior on determines the critical signal-to-noise ratio (SNR) and number of measurements above which it becomes information-theoretically possible to estimate the signal. From a computational perspective, the objective is to design efficient algorithms that leverage such prior information. A recent and vast body of literature has shown that depending on the chosen prior, gaps can arise between the minimum SNR required to solve the problem and the one above which known polynomial-time algorithms succeed. An emblematic example is provided the Sparse PCA problem where the signal in (1) is taken to be s-sparse. In this case number of samples are sufficient for estimating [2,4], while the best known efficient algorithms require [3,11,12]. This gap is believed to be fundamental. This “statistical-computational gap” has been observed also for Spiked Wigner models (2) and, in general, for other structured signal recovery problems where the prior imposed has a combinatorial flavor (see the next section and [13,14] for surveys).
Motivated by the recent advances of deep generative networks in learning complex data structures, in this paper we study the spiked random matrix models (1) and (2), where the planted signal has a generative network prior. We assume that a generative neural network with , has been trained on a data set of spikes, and the unknown spike lies on the range of G, that is, we can write for some . As a mathematical model for the trained G, we consider a network of the form:
with weight matrices and is applied entrywise. We furthermore assume that the network is expansive, that is, , and the weights have Gaussian entries. These modeling assumptions and their variants were used in [15,16,17,18,19,20].
Enforcing generative network priors has led to substantially fewer measurements needed for signal recovery than with traditional sparsity priors for a variety of signal recovery problems [17,21,22]. In the case of phase retrieval, [17,23] have shown that under the generative prior (3), efficient compressive phase retrieval is possible with sample complexity proportional (up to log factors) to the underlying signal dimensionality k. In contrast, for a sparsity-based prior, the best known polynomial time algorithms (convex methods [24,25,26], iterative thresholding [27,28,29], etc.) require a sample complexity proportional to the square of the sparsity level for stable recovery. Given that generative priors lead to no computational-statistical gap with compressive phase retrieval, one might anticipate that they will close other computational-statistical gaps as well. Indeed, [30] analyzed the spiked models (1) and (2) under a generative network prior similar to (3) and observed no computational-statistical gap in the asymptotic limit with and . For more details on this work and on the comparison of sparsity and generative priors, see Section 2.2.
Our Contribution
In this paper we analyze the spiked matrix models (1) and (2) under a generative network prior in the nonasymptotic, finite data regime. We consider a d-layer feedforward generative network with architecture (3). We furthermore assume that the planted spike lies on the range of G, that is, there exists a latent vector such that .
To estimate , we first find an estimate of the latent vector and then use to estimate . We thus consider the following minimization problem (under the conditions on the generative network specified below, it was shown in [15] that G is invertible and there exists a unique that satisfies :
where:
- for the Wishart model (1) we take with
- for the Wigner model (2) we take .
Despite the non-convexity and non-smoothness of the problem, our preliminary work in [31] shows that when the generative network G is expansive and has Gaussian weights, (4) enjoys a favorable optimization geometry. Specifically, every nonzero point outside two small neighborhoods around and a negative multiple of it, has a descent direction which is given a.e. by the gradient of f. Furthermore, in [31] it is shown that the the global minimum of f lies in the neighborhoods around and has optimal reconstruction error. This result suggests that a first order optimization algorithm can succeed in efficiently solving (4), and no statistical-computational gap is present for the spiked matrix models with a (random) generative network prior in the finite data regime. In the current paper, we prove this conjecture by providing a polynomial-time subgradient method that minimizes the non-convex problem (4) and obtains information-theoretically optimal error rates.
Our main contribution can be summarized as follows. We analyze a subgradient method (Algorithm 1) for the minimization of (4) and show that after a polynomial number of steps and up to polynomials factors in the depth d of the network, the iterate satisfies the following reconstruction errors:
- in the Spiked Wishart Model:in the regime ;
- in the Spiked Wigner Model:
We notice that these bounds are information-theoretically optimal up to the log factors in n, and correspond to the best achievable in the case of a k-dimensional subspace prior. In particular, they imply that efficient recovery in the Wishart model is possible with a number of samples N proportional to the intrinsic dimension of the signal . Similarly, the bound in the Spiked Wigner Model implies that imposing a generative network prior leads to a reduction of the noise by a factor of .
| Algorithm 1: Subgradient method for the minizimization problem (4) |
 |
2. Related Work
2.1. Sparse PCA and Other Computational-Statistical Gaps
A canonical problem in Statistics is finding the directions that explain most of the variance in a given cloud of data, and it is classically solved by Principal Component Analysis. Spiked covariance models were introduced in [1] to study the statistical performance of this algorithm in the high dimensional regime. Under a spiked covariance model it is assumed that the data are of the form:
where , and are independent and identically distributed, and is the unit-norm planted spike. Each is an i.i.d. sample from a centered Gaussian with spiked covariance matrix given by , with being the direction that explains most of the variance. The estimate of provided by PCA is then given by the leading eigenvector of the empirical covariance matrix , and standard techniques from high dimensional probability can be used to show that (we write if for some constant that might depend and . Similarly for as long as ,
with overwhelming probability. Note incidentally that the data matrix with rows can be written as (1).
Bounds of the form (8), however, become uninformative in modern high dimensional regimes where the ambient dimension of the data n is much larger than, or on the order of, the number of samples N. Even worse, in the asymptotic regime and for large enough, the spike and the estimate become orthogonal [32], and minimax techniques show that no other estimators based solely on the data (7), can achieve better overlap with [33].
In order to obtain consistent estimates and lower the sample complexity of the problem, therefore, additional prior information on the spike has to be enforced. For this reason, in recent years various priors have been analyzed such as positivity [34], cone constraints [35] and sparsity [32,36]. In the latter case is assumed to be s-sparse, and it can be shown (e.g., [33]) that for and , the s-sparse largest eigenvector of
Satisfies with high probability the condition:
This implies, in particular, that the signal can be estimated with a number of samples that scales linearly with its intrinsic dimension s. These rates are also minimax optimal; see for example [4] for the mean squared error and [2] for the support recovery. Despite these encouraging results, no currently known polynomial time algorithm achieves such optimal error rates and, for example, the covariance thresholding algorithm of [37] requires samples in order to obtain exact support recovery or estimation rate
as shown in [3]. In summary, only computationally intractable algorithms are known to reach the statistical limit for Sparse PCA, while polynomial time methods are only sub-optimal, requiring . Notably, [38] provided a reduction of Sparse PCA to the planted clique problem which is conjectured to be computationally hard.
Further strong evidence for the hardness of sparse PCA have been given in a series of recent works [39,40,41,42,43]. Other computational-statistical gaps have also been found and studied in a variety of other contexts such as sparse Gaussian mixture models [44], tensor principal component analysis [45], community detection [46] and synchronization over groups [47]. These works fit in the growing and important body of literature aiming at understanding the trade-offs between statistical accuracy and computational efficiency in statistical inverse problems.
We finally note that many of the above mentioned problems can be phrased as recovery of a spike vector from a spiked random matrix. The difficulty can be viewed as arising from simultaneously imposing low-rankness and additional prior information on the signal (sparsity in case of Sparse PCA). This difficulty can be found in sparse phase retrieval as well. For example, [25] has shown that number of quadratic measurements are sufficient to ensure well-posedness of the estimation of an s-sparse signal of dimension n lifted to a rank-one matrix, while measurements are necessary for the success of natural convex relaxations of the problem. Similarly, [48] studied the recovery of simultaneously low-rank and sparse matrices, showing the existence of a gap between what can be achieved with convex and tractable relaxations and nonconvex and intractable methods.
2.2. Inverse Problems with Generative Network Priors
Recently, in the wake of successes of deep learning, generative networks have gained popularity as a novel approach for encoding and enforcing priors in signal recovery problems. In one deep-learning-based approach, a dataset of “natural signals” is used to train a generative network in an unsupervised manner. The range of this network defines a low-dimensional set which, if successfully trained, contains or approximately contains, target signals of interest [19,21]. Non-convex optimization methods are then used for recovery by optimizing over the range of the network. We notice that allowing the algorithms the complete knowledge of the generative network architecture and of the learned weights is roughtly analogous to allowing sparsity-based algorithms the knowledge of the basis or frame in which the signal is modeled as sparse.
The use of generative network for signal recovery has been successfully demonstrated in a variety of settings such as compressed sensing [21,49,50], denoising [16,51], blind deconvolution [22], inpainting [52] and many more [53,54,55,56]. In these papers, generative networks significantly outperform sparsity based priors at signal reconstruction in the low-measurement regime. This fundamentally leverages the fact that a natural signal can be represented more concisely by a generative network than by a sparsity prior under an appropriate basis. This characteristic has been observed even in untrained generative networks where the prior information is encoded only in the network architecture and has been used to devise state-of-the-art signal recovery methods [57,58,59].
Parallel to these empirical successes, a recent line of works have investigated theoretical guarantees for various statistical estimation tasks with generative network priors. Following the work of [15,21] gave global guarantees for compressed sensing, followed then by many others for various inverse problems [19,20,50,51,55]. In particular, in [17] the authors have shown that number of measurements are sufficient to recover a signal from random phaseless observations, assuming that the signal lies on the range of a generative network with latent dimension k. The same authors have then provided in [23] a polynomial time algorithm for recovery under the previous settings. Note that, contrary to the sparse phase retrieval problem, generative priors for phase retrieval allow for efficient algorithms with optimal sample complexity, up to logarithmic factors, with respect to the intrinsic dimension of the signal.
Further theoretical advances in signal recovery with generative network priors have been spurred by using techniques from statistical physics. Recently, [30] analyzed the spiked matrix models (1) and (2) with in the range of a generative network with random weights, in the asymptotic limit with and . The analysis is carried out mainly for networks with sign or linear activation functions in the Bayesian setting where the latent vector is drawn from a separable distribution. The authors of [30] provide an Approximate Message Passing and a spectral algorithm, and they numerically observe no statistical-computational gap as these polynomial time methods are able to asymptotically match the information-theoretic optimum. In this asymptotic regime, [60] further provided precise statistical and algorithmic thresholds for compressed sensing and phase retrieval.
3. Algorithm and Main Result
In this section we present an efficient and statistically-optimal algorithm for the estimation of the signal given a spiked matrix Y of the form (1) or (2). The recovery method is detailed in Algorithm 1, and it is based on the direct optimization of the nonlinear least squares problem (4).
Applied in [16] for denoising and compressed sensing under generative network priors, and later used in [23] for phase retrieval, the first order optimization method described in Algorithm 1 leverages the theory of Clarke subdifferentials (the reader is referred to [61] for more details). As the objective function f is continuous and piecewise smooth, at every point it has a Clarke subdifferential given by
where conv denotes the convex hull of the vectors , which are respectively the gradient of the T smooth functions adjoint at x. The vectors are the subgradients of f at x, and at a point x where f is differentiable it holds that .
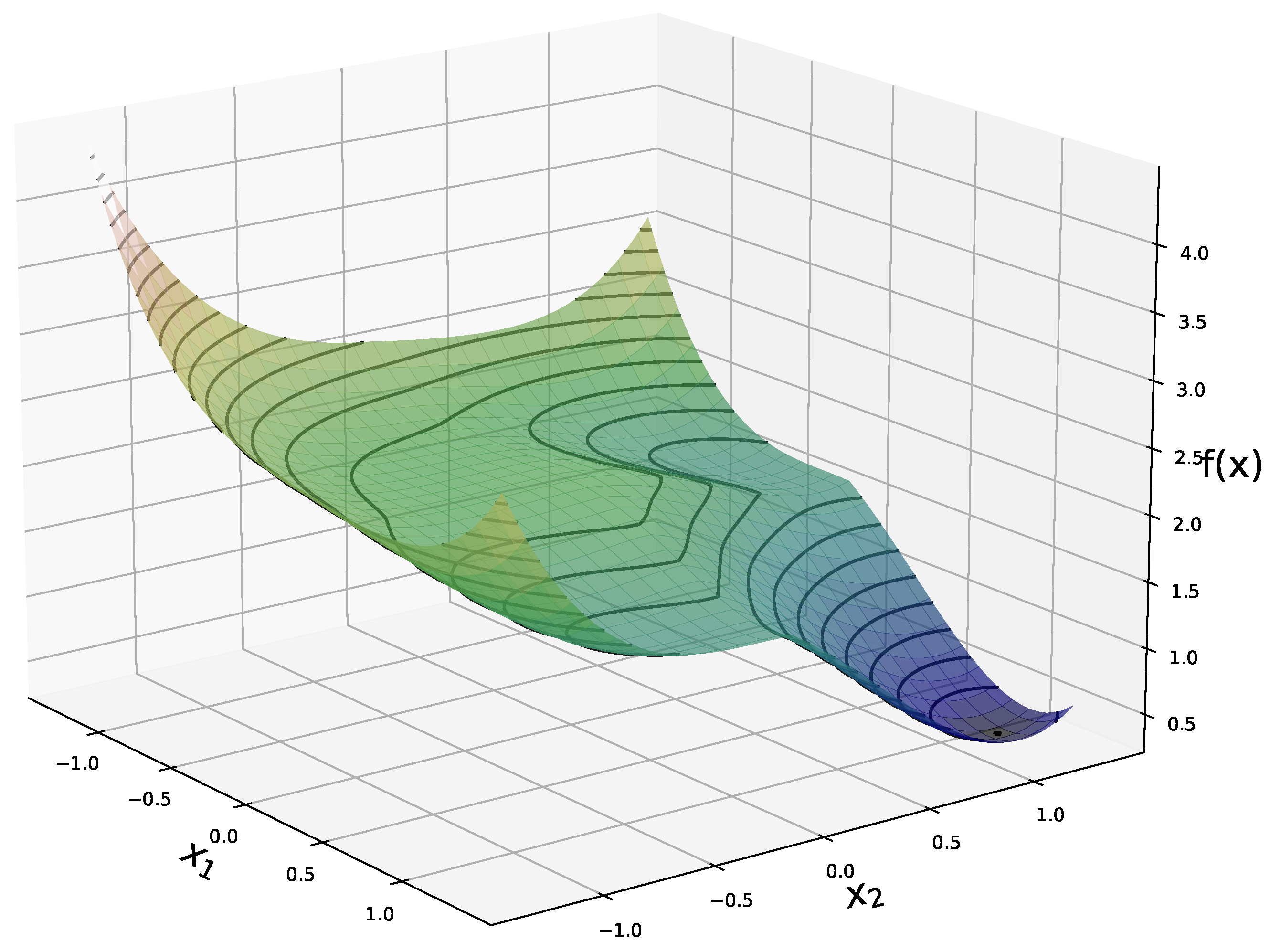
The reconstruction method presented in Algorithm 1 is motivated by the landscape analysis of the minimization problem (4) for a network G with sufficiently-expansive Gaussian weights matrices. Under this assumption, we showed in [31] that (4) has a benign optimization geometry and in particular that for any nonzero point outside a neighborhood of and a negative multiple of it, any subgradient of f is a direction of strict descent. Furthermore we showed that the points in the vicinity of the spurious negative multiple of have function values strictly larger than those close to . Figure 1 shows the expected value of f in the noiseless case, and , for a generative network with latent dimension . This plot highlights the global minimimum at , and the flat region in near a negative multiple of .
At each step, the subgradient method in Algorithm 1 checks if the current iterate has a larger loss value than its negative multiple, and if so negates . As we show in the proof of our main result, this step will ensure that the algorithm will avoid the neighborhood around the spurious negative multiple of and will converge to the neighborhood around in a polynomial number of steps.
Below we make the following assumptions on the weight matrices of G.
Assumption 1.
The generative network G defined in (3), has weights with i.i.d. entries from and satisfying the expansivity condition with constant :
for all i and a universal constant .
We note that in [31] the expansivity condition was more stringent, requiring an additional log factor. Since the publication of our paper, [62] has shown that the more relaxed assumption (10) suffices for ensuring a benign optimization geometry. Under Assumption 1, our main theorem below shows that the subgradient method in Algorithm 1 can estimate the spike with optimal sample complexity and in a polynomial number of steps.
Theorem 1.
Let nonzero and where G is a generative network satisfying Assumption 1 with . Consider the minimization problem (4) and assume that the noise level ω satisfies where:
- for theSpiked Wishart Model(1) take , and
- for theSpiked Wigner Model(2) take , and
Consider Algorithm 1 with nonzero and where , and stepsize . Then with probability at least , for any , there exists an integer such that for any :
where , , and are universal constants.
Note that the quantity in the hypotheses and conclusions of the theorem is an artifact of the scaling of the network and it should not be taken as requiring exponentially small noise or number of steps. Indeed under Assumption 1, the ReLU activation zeros out roughly half of the entries of its argument leading to an “effective” operator norm of approximately . We furthermore notice that the dependence of the depth d is likely quite conservative and it was not optimized in the proof as the main objective was to obtain tight dependence on the intrinsic dimension of the signal k. As shown in the numerical experiments, the actual dependence on the depth is much better in practice. Finally, observe that despite the nonconvex nature of the objective function in (4) we obtain a rate of convergence which is not directly dependent on the dimension of the signal, reminiscent of what happens in the convex case.
The quantity in Theorem 1 can be interpreted as the intrinsic noise level of the problem (inverse SNR). The theorem guarantees that in a polynomial number of steps the iterates of the subgradient method will converge to up to . For large enough will satisfy the rate-optimal error bounds (5) and (6).
Numerical Experiments
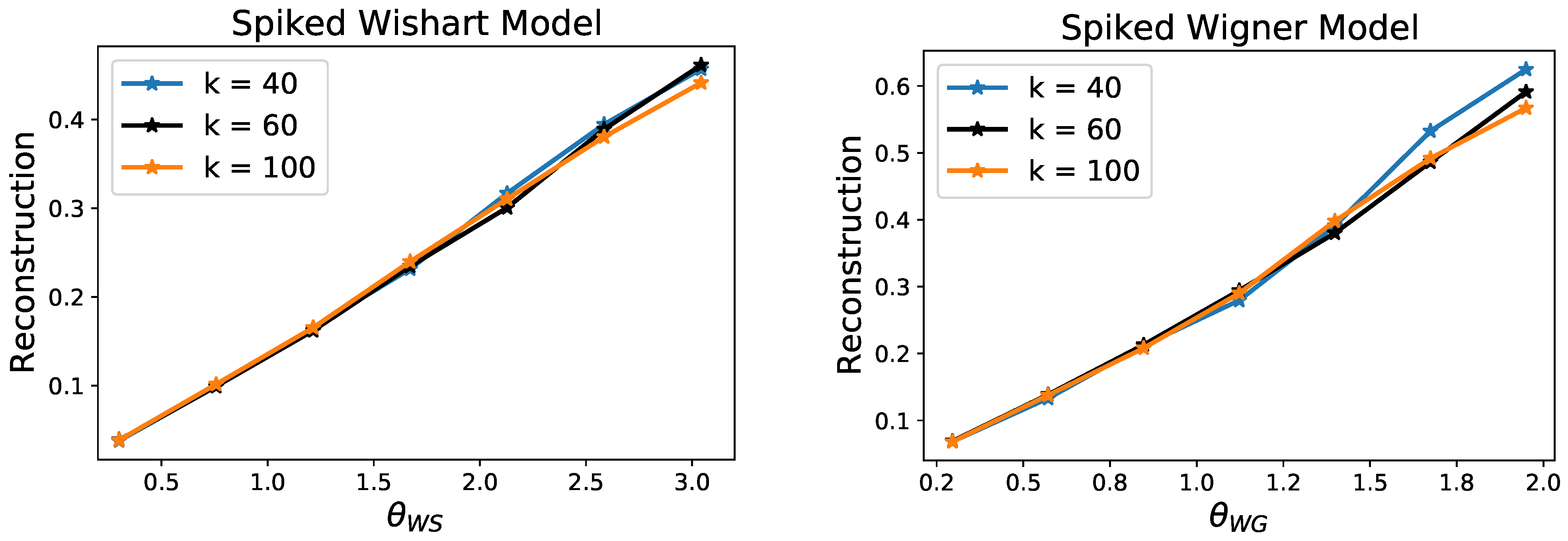
We illustrate the predictions of our theory by providing results of Algorithm 1 on a set of synthetic experiments. We consider 2-layer generative networks with ReLU activation functions, hidden layer of dimension , output dimension and varying number of latent dimension . We randomly sample the weights of the matrix independently from (this scaling removes that dependence in Theorem 1). We then consider data Y according the spiked models (1) and (2), where is chosen so that has unit norm. For the Wishart model, we vary the number of samples N; and for the Wigner model, we vary the noise level so that the following quantities remain constant for the different networks with latent dimension k:
In Figure 2 we plot the reconstruction error given by against and . As predicted by Theorem 1, the errors scale linearly with respect to these control parameters, and moreover the overlap of these plots confirms that these rates are tight with respect to the order of k.
4. Recovery Under Deterministic Conditions
We will derive Theorem 1 from Theorem 3, below, which is based on a set of deterministic conditions on the weights of the matrix and the noise. Specifically, we consider the minimization problem (4) with
for an unknown symmetric matrix , nonzero , and a given d-layer feed forward generative network G as in (3).
In order to describe the main deterministic conditions on the generative network G, we begin by introducing some notation. For and , we define the operator such that . Moreover, we let , and for we define recursively
where . Finally we let and note that . With this notation we next recall the following deterministic condition on the layers of the generative network.
Definition 2
(Weight Distribution Condition [15]). We say that satisfies the Weight Distribution Condition (WDC) with constant if for all nonzero :
where
and , , , is the identity matrix and is the matrix that sends , , and with kernel span .
Note that is the expected value of when W has rows , and if then is an isometry up to the scaling factor . Below we will say that a d-layer generative network G of the form (3), satisfies the WDC with constant if every weight matrix has the WDC with constant for all .
The WDC was originally introduced in [15], and ensures that the angle between two vectors in the latent space is approximately preserved at the output layer and, in turn, it guarantees the invertibility of the network. Assumption 1 will guarantees that the generative network G satisfies the WDC with high probability.
We are now able to state our recovery guarantees for a spike under deterministic conditions on the network G and noise H.
Theorem 3.
Let and assume the generative network (3) has weights satisfying the WDC with constant . Consider Algorithm 1 with , and H a symmetric matrix satisfying:
Take nonzero and with where , . Then the iterates generated by the Algorithm 1 satisfy and obey to the following:
- (A)
- there exists an integer such that
- (B)
- for any :where , and are universal constants.
Theorem 1 follows then from Theorem 3 after proving that with high probability the spectral norm of , where , can be upper bounded by , and the weights of the network G satisfy with high probability the WDC.
In the rest of this section section we will describe the main steps and tools needed to prove Theorem 3.
4.1. Technical Tools and Outline of the Proofs
Our proof strategy for Theorem 3 can be summarized as follows:
- In Proposition A1 (Appendix A.3) we show that the iterates of the Algorithm 1 stay inside the Euclidean ball of radius and remain nonzero for all .
- We then identify two small Euclidean balls and around respectively and , where only depends on the depth of the network. In Proposition A2 we show that after a polynomial number of steps, the iterates of the Algorithm 1 enter the region (Appendix A.4).
- We show, in Proposition A3, that the negation step causes the iterates of the algorithm to avoid the spurious point and actually enter within a polynomial number of steps (Appendix A.5).
- We finally show in Proposition A4, that in the loss function f enjoys a favorable convexity-like property, which implies that the iterates will remain in and eventually converge to up to the noise level (Appendix A.6).
One of the main difficulties in the analysis of a subgradient method in Algorithm 1 is the lack of smoothness of the loss function f. We show that the WDC allows us to overcome this issue by showing that the subgradients of f are uniformly close, up to the noise level, to the vector field :
where is continuous for nonzero x (see Appendix A.2). We show furthermore that is locally Lipschitz, which allows us to conclude that the gradient method decreases the value of the loss function until eventually reaching (Appendix A.4).
Using the WDC, we show that the loss function f is uniformly close to
A direct analysis of reveals that its values inside are strictly larger then those inside . This property extends to f as well, and guarantees that the gradient method will not converge to the spurious point (Appendix A.5).
Author Contributions
Conceptualization, P.H. and V.V.; Formal analysis, J.C., Writing—original draft, J.C.; Writing - review & editing J.C. and P.H.; Supervision P.H. and V.V. All authors have read and agreed to the published version of the manuscript.
Funding
PH was partially supported by NSF CAREER Grant DMS-1848087 and NSF Grant DMS-2022205.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Supporting Lemmas and Proof of Theorem 3
The proof of Theorem 3 is provided in Appendix A.7. We begin this section with a set of preliminary results and supporting lemmas.
Appendix A.1. Notation
We collect the notation that is used throughout the paper. For any real number a, let and for any vector , denote the entrywise application of relu as . Let be the diagonal matrix with i-th diagonal element equal to 1 if and 0 otherwise. For any vector x we denote with its Euclidean norm and for any matrix A we denote with its spectral norm and with its Frobenius norm. The euclidean inner product between two vectors a and b is , while for two matrices A and B their Frobenius inner product will be denoted by . For any nonzero vector , let . For a set S we will write for its cardinality and for its complement. Let be the Euclidean ball of radius r centered at x, and be the unit sphere in . Let and for let where g is defined in (A1). We will write to mean that there exists a positive constant C such that and similarly if . Additionally we will use when , where the norm is understood to be the absolute value for scalars, the Euclidean norm for vectors and the spectral norm for matrices.
Appendix A.2. Preliminaries
For later convenience we will define the following vectors:
Note then that when f is differentiable at x, then and in particular when then we have .
The following function controls how the angles are contracted by a ReLU layer:
As we mentioned in Section 4.1, our analysis is based on showing that the subgradients of f are uniformly close to the vector field given by
where
and for g given by (A1) and .
Lemma A1
Proof.
The first two bounds can be found in [15] (Lemma 8). The third bound follows by noticing that the WDC implies:
where we used and for all . □
The next lemma shows that the noiseless gradient concentrates around .
Lemma A2.
Suppose and the WDC holds with , then for all nonzero :
We now use the characterization of the Clarke subdifferential given in (9) to derive a bound on the concentration of around up to the noise level.
Lemma A3.
Under the assumptions of Lemma A2, and assuming , for any :
From the above and the bound on the noise level we can bound the norm of the step in the Algorithm 1.
Lemma A4.
Under the assumptions of Lemma A3, and assuming that ω satisfies (13), for any :
Appendix A.3. Iterates Stay Bounded
In this section we prove that all the iterates generated by Algorithm 1 remain inside the Euclidean ball where and .
Lemma A5.
Let the assumptions of Lemma A4 be satisfied, with . Then for any with and any , it holds that .
From the previous lemma we can now derive the boundedness of the iterates of the Algorithm 1.
Proposition A1.
Under the assumptions of Theorem 3, if it follows that . Furthermore if , the iterates of the Algorithm 1 satisfy for all and .
Proof.
Assume , then the conclusions follows from Lemma A5. Assuming instead that , note that
using Lemma A4, and the assumptions on and . Finally observe that if then the same holds for .
Finally if for some it was the case that , then this would imply that which cannot happen because by Lemma A4 and the choice of the step size it holds that . □
Appendix A.4. Convergence to
We define the set outside which we can lower bound the norm of as
where we take
Outside the set the sub-gradients of f are bounded below and the landscape has favorable optimization geometry.
Lemma A6.
Let , then for all
Moreover let and then
for all and .
Based on the previous lemma we can prove the main result of this section.
Proposition A2.
Under the assumptions of Theorem 3, if then
for some numerical constant . Moreover there exists an integer such .
Proof.
Let and assume that , then . By the mean value theorem for Clarke subdifferentials [61] (Theorem 8.13), there exists such that for and a it holds that
where the first inequality follows from the triangle inequality and the second from Equation (A9). Next observe that by (A8)
which together with the definition of and (A11) gives (A10).
Next take and assume , so that . Observe that
we obtain then (A10) proceeding as before.
Finally the claim on the maximum number of iterations directly follows by a telescopic sum on (A10) and . □
Appendix A.5. Convergence to a Neighborhood Around
In the previous section we have shown that after a finite number of steps the iterates of the Algorithm 1 will enter in the region . In this section we show that, thanks to the negation step in the descent algorithm, they will eventually be confined in a neighborhood of .
The following lemma shows that is contained inside two balls around and .
Lemma A7.
Suppose , then we have where
where are numerical constants and such that as .
We furthermore observe that the ball around has values strictly higher that the one around .
Lemma A8.
Suppose that , the WDC holds with and H satisfies (13). Then for any , it holds that
for all and where is a universal constant.
The main result of this section is about the convergence to a neighborhood of of the iterates .
Proposition A3.
Under the assumptions of Theorem 3, if , then there exists a finite number of steps such that . In particular it holds that
Proof.
Either or by Proposition A2 there exist such that . By the choice of , the definition of in (A7), and the assumption on the noise level (13), it follows that the hypotheses of Lemma A7 are satisfied. We therefore define the two neighborhoods and and conclude that that either or .
We next notice that and . We can then use Lemma A8 to conclude that by the negation step, if then , otherwise we will have .
We now analyze the case . Applying again Proposition A2, we have that there exists and integer such that . Furthermore Proposition A2 implies that , while from Lemma A8 we know that for all . We conclude therefore that must be in .
In summary we obtained that there exists an integer such that . Finally Equation (A13) follows from the definition of in (A7) and . □
Appendix A.6. Convergence to up to Noise
Lemma A9.
Suppose the WDC holds with , then for all and , it holds that
where , and .
Based on the previous condition on the direction of the sub-gradients we can then prove that the iterates of the algorithm converge to up to noise.
Proposition A4.
Under the assumptions of Theorem (3), if then for any it holds that and furthermore
where and are numerical constants.
Proof.
If , by Proposition A2, it follows that . Furthermore, the assumptions of Lemma A9 are satisfied and we can write:
Next recall that satisfies (13), and , then
Therefore for and small enough we obtain that and by induction this holds for all . Finally we obtain (A14) by letting and in (A15). □
Appendix A.7. Proof of Theorem 3
We begin recalling the following fact on the local Lipschitz property of the generative network G under the WDC.
Lemma A10
We then conclude the proof of Theorem 3 by using the above lemma and the results in the previous sections.
- (I)
- By assumption so that according to Proposition A1 for any it holds that .
- (II)
- By Proposition A3, there exists an integer T such that and therefore it satisfies the conclusions of Theorem 3.A
- (III)
- Once in the iterates of Algorithm 1 converge to up to the noise level, as shown by Proposition A4 and Equation (A14)which corresponds to (11) in Theorem 3.B.
- (IV)
- The reconstruction error (12) in Theorem 3.B, follows then from (11) by applying Lemma A10 and the lower bound (A4).
Appendix B. Supplementary Proofs
Appendix B.1. Supplementary Proofs for Appendix A.2
Below we prove Lemma A2 on the concentration of the gradient of f at a differentiable point.
Proof of Lemma A2.
We begin by noticing that:
Below we show that:
and
from which the thesis follows.
Regarding Equation (A16) observe that:
where in the first inequality we used and in the second we used Equations (A5) and (A6) of Lemma A1.
Next note that:
where in the second inequality we have the bound (A6) and the definition of . Equation (A17) is then found by appealing to Equation (A5) in Lemma A1. □
The previous lemma is now used to control the concentration of the subgradients of f around .
Proof of Lemma A3.
When f is differentiable at x, , so that by Lemma A2 and the assumption on the noise:
Observe, now, that by (9), for any , conv, and therefore for some , . Moreover for each there exist a such that . Therefore using Equation (A18), the continuity of with respect to nonzero x and :
□
The above results are now used to bound the norm of .
Proof of Lemma A4.
Since observe that , therefore by the assumption on the noise level and Lemma A3 it follows that for any and
Next observe that that since , we have:
and from we obtain the thesis. □
Appendix B.2. Supplementary Proofs for Appendix A.3
In this section we prove Lemma A5 which implies that the norm of the iterates does not increase in the region .
Proof of Lemma A5.
Note that the thesis is equivalent to . Next recall that by the WDC for any and :
At a nonzero differentiable point with , then
Next, by Lemma A4, the definition of the step length and , we have:
which, using , gives
We can then conclude by observing that by the assumptions and for small enough constants .
At a non-differentiable point x, by the characterization of the Clarke subdifferential, we can write where then
which implies that the lower bound (A19) also holds for . Similarly Lemma A4 leads to the upper bound (A20) also for , which then leads to the thesis . □
Appendix B.3. Supplementary Proofs for Appendix A.4
In the next lemmas we show that is locally Lipschitz.
Lemma A11.
For all
Proof.
Note that where and are defined in (A23). Then observe that by (A28) and (A29) it follows that . Furthermore by [16] (Lemma 18) for any nonzero we have
Next notice that
where by triangle inequality the first term on the left hand side can be bounded as
Finally note that by from the bound (A21) we obtain:
where we used
□
Based on the previous lemma we can now prove that is locally Lipschitz.
Lemma A12.
Let , , with and , then for it holds that:
Proof.
Consider and observe that by Lemma A4, and the choice of , for any and any we have . It follows that
and in particular
Therefore by Lemma A11 we deduce that
where in the second inequality we used by Proposition A1. The thesis is obtained by substituting the definition of and using . □
Based on the previous result we can now prove Lemma A6.
Proof of Lemma A6.
Let ,
where we used the definition in Equation (A7) and Lemma A3.
Next take and with . Then for any
where in the first inequality we used Lemma A3 and Lemma A12, in the second inequality (A22) and in the last one (A8). □
Appendix B.4. Supplementary Proofs for Appendix A.5
Below we prove that the region of where we cannot control the norm of the vector field is contained in two balls around and .
We prove Lemma A7 by showing the following.
Lemma A13.
Suppose . Define:
where and . If , then we have either:
or
In particular, we have:
where are numerical constants and as .
Proof of Lemma A13.
Without loss of generality, let and , for some , and . Recall that we call and . We then introduce the following notation:
where with g as in (A1), and observe that . Let , then we can write:
Using the definition of and we obtain:
and conclude that since , then:
We now list some bounds that will be useful in the subsequent analysis. We have:
The identities (A26) through (A34) can be found in Lemma 16 of [16], while the identity (A35) follows by noticing that and using (A27) together with .
Bound on R.
We now show that if , then and therefore .
If , then the claim is trivial. Take , then note that either or must hold. If then from (A25) it follows that which implies:
using (A29) and (A35) in the second inequality and in the third. Next take , then (A24) implies which in turn results in:
using (A28), (A29), (A35) and . In conclusion if then .
Bounds on .
We proceed by showing that we only have to analyze the small angle case and the large angle case .
At least one of the following three cases must hold:
- (1)
- : Then we have or as .
- (2)
- : Then (A24), (A35) and yield . Using (A30), we then get .
- (3)
- and : Then (A27) gives which used with (A24) leads to:Then using (A35), the assumption on and we obtain . The latter together with (A30) leads to . Finally as then (A25) leads to . Therefore as and , we can conclude that .
Inspecting the three cases, and recalling that , we can see that it suffices to analyze the small angle case and the large angle case .
Small angle case.
We assume with and show that .
We begin collecting some bounds. Since , then assuming , which holds true since . Moreover from (A29) we have . Finally observe that for . We then have so that and . We can therefore rewrite (A24) as:
Using the bound and the definition of , we obtain:
Large angle case.
Here we assume with and show that it must be .
From (A33) we know that , while from (A34) we know that as long as . Moreover for large angles and , it holds . These bounds lead to:
and using :
Then recall that (A24) is equivalent to , that is:
and in particular:
where we used , the definition of and .
Controlling the distance.
We have shown that it is either and or and . We can therefore conclude that it must be either or .
Observe that if a two dimensional point is known to have magnitude within of some r and is known to be within an angle from 0, then its Euclidean distance to the point of coordinates is no more that . Similarly we can write:
In the small angle case, by (A36), (A38), and , we have:
Next we notice that and as follows from the definition and (A31), (A32). Then considering the large angle case and using (A37) we have:
The latter, together with (A38), yields:
where in the second inequality we have used and in the third .
We conclude by noticing that as as shown in [16] (Lemma 16). □
We next will show that the values of the loss function in a neighborhood of are strictly smaller that those in a neighborhood of .
Recall that , we next define the following loss functions:
In particular notice that . Below we show that assuming the WDC is satisfied, concentrates around .
Lemma A14.
Suppose that and the WDC holds with , then for all nonzero
Proof.
Observe that:
We analyze each term separately. The first term can be bounded as:
where in the first inequality we used (A6) and in the second inequality (A5). Similarly we can bound the second term:
We next note that and therefore from (A6) and we obtain:
We can then conclude that:
□
We next consider the loss and show that in a neighborhood , this loss function has larger values than in a neighborhood of .
Lemma A15.
Fix and then:
Proof.
Let then observe that and . Then observe that:
using and as long as . We can therefore write:
where in the second inequality we used for all . We then observe that:
where in the second inequality we have used and in the last one and . We can then conclude that:
We next take which implies and . We then note that for and as defined in (A23) we have:
where the second inequality is due to (A33) and (A34), the rest from , and . Finally using , we can then conclude that:
□
The above two lemmas are now used to prove Lemma A8.
Proof of Proposition A8.
Let for a that will be specified below, and observe that by the assumptions on the noise:
and therefore by Lemma A14:
We next take and , so that by Lemma A15 and the assumption , we have:
Similarly if , and we obtain:
In order to guarantee that , it suffices to have:
with , that is to require:
Finally notice that by Lemma 17 in [16] it holds that for some numerical constant K, we therefore choose for some small enough. □
Appendix B.5. Supplementary Proofs for Appendix A.6
In this section we use strong convexity and smoothness to prove convergence to up to the noise variance . The idea is to show that every vector in the subgradient points in the direction . Recall that the gradient in the noiseless case was:
We show that by continuity of , when x is close to , then it is close to:
which in turn concentrates around:
by the WDC.
We begin by recalling the following result which can be found in the proof of Lemma 22 of [16].
Lemma A16.
Suppose and the WDC holds with . Then it holds that:
We now prove that for x close to .
Lemma A17.
Suppose and the WDC holds with . Then it holds that:
Proof.
Let and . Then observe that:
where the second inequality follows from Lemma A1, and the third from Lemma A16. □
We next prove that by the WDC .
Lemma A18.
Suppose the WDC holds with . Then for all nonzero :
Proof.
For notational convenience we define the scaled identity in , and . Next observe that:
where the second inequality follows from Lemma A1 and the third from (17) in [15]. We conclude by noticing that . □
Next consider the quartic function and observe that:
Following [63] we show that is -smooth and strongly convex, in turn deriving the result in Lemma A19.
Lemma A19.
Assume with . Take , then:
where .
Proof.
Let with , then:
since satisfies . Using (A40) we then obtain
We therefore have:
where in the second line we have used (A39) and in the third .
Next notice that using (A39) we have
and therefore, for all
The above bounds imply in particular that for all the gradient of satisfies the regularity condition (see [63]):
where and . By (A41) we can then conclude that for :
Finally letting , , and by the assumptions on and the thesis follows. □
We finally can prove Lemma A9.
Proof of Lemma A9.
Let , then and since we have from Lemma A17 and Lemma A18
If is a differentiable point of f, then by Lemma A19 and the assumption (13) on the noise H, it holds that:
where , and .
In general, if and , by the characterization of Clarke subdifferential (9) and the previous results:
We finally obtain the thesis by noting that by the assumptions on it holds that and taking , and . □
Appendix C. Proof of Theorem 1
By Theorem 3 it suffices to show that with high probability the weight matrices satisfy the WDC, and that upper bounds the spectral norm of the noise term where
- in the Spiked Wishart Model where and the ;
- in the Spiked Wigner Model where .
Regarding the Weight Distribution Condition (WDC), we observe that it was initially proposed in [15], where it was shown to hold with high probability for networks with random Gaussian weights under an expansivity condition on their dimensions. It was later shown in [62] that a less restrictive expansivity rate is sufficient.
Lemma A20
(Theorem 3.2 in [62]). There are constants with the following property. Let and suppose has entries. Suppose that . Then with probability at least , W satisfies the WDC with constant ϵ.
By a union bound over all layers, using the above result we can conclude that the WDC holds simultaneously for all layers of the network with probability at least Note in particular that this argument does not requires the independence of the weight matrices .
By Lemma A20, with high probability the random generative network G satisfies the WDC. Therefore if we can guarantee that the assumptions on the noise term H are satisfied, then the proof of the main Theorem 1 follows from the deterministic Theorem 3 and Lemma A20.
Before turning to the bounds of the noise terms in the spiked models, we recall the following lemma which bounds the number of possible for . Note that this is related to the number of possible regions defined by a deep ReLU network.
Lemma A21.
Consider a network G as defined in (3) with , weight matrices with i.i.d. entries . Then, with probability one, for any the number of different matrices is
Proof.
The first inequality follows from Lemma 16 and the proof of Lemma 17 in [15]. For the second inequality notice that as , and it follows that □
In the next section we use this lemma to control the noise term on the event where the WDC holds.
Appendix C.1. Spiked Wigner Model
Recall that in the Wigner model and the symmetric noise matrix follows a Gaussian Orthogonal Ensemble GOE, that is for all and for . Our goal is to bound uniformly over x with high probability.
Fix , and let be a -net on the sphere such that (see for example [64]) and
Observe next that for any by the definition of GOE(n) it holds that
Therefore for any let , then . In particular by (A6), the quadratic form is sub-Gaussian with parameter given by
Then for fixed , standard sub-Gaussian tail bounds (e.g., [64]) and a union bound over give for any
Lemma A21, then ensures that the number of possible is at most , so a union bound over this set allows us to conclude that
Choosing then and substituting the definition of , we obtain
which implies the thesis as and .
Appendix C.2. Spiked Wishart Model
Each row of the matrix Y in (1) can be seen as i.i.d. samples from where . In the minimization problem (4) we take where is the empirical covariance matrix . The symmetric noise matrix H is then given by and by the Law of Large Numbers as . We bound with high probability uniformly over .
Fix , let be a -net on the sphere such that , and notice that:
By a union bound on we obtain for any fixed :
Let and , so that we can write
and in particular
Observe then that with . It follows for by the small deviation bound for random variables (e.g., [33] (Example 2.11))
Recall now that , then proceeding as for the Wigner case by a union bound over all possible :
Substituting we find that:
since .
Similarly if by large deviation bounds for sub-exponential variables
Substituting we find that:
Finally observe that using (A6) for bounding (by the WDC) and for bounding , we have
which combined with (A42) and (A43) implies the thesis.
References
- Johnstone, I.M. On the distribution of the largest eigenvalue in principal components analysis. Ann. Stat. 2001, 29, 295–327. [Google Scholar] [CrossRef]
- Amini, A.A.; Wainwright, M.J. High-dimensional analysis of semidefinite relaxations for sparse principal components. In Proceedings of the 2008 IEEE International Symposium on Information Theory, Toronto, ON, Canada, 6–11 July 2008; pp. 2454–2458. [Google Scholar]
- Deshpande, Y.; Montanari, A. Sparse PCA via covariance thresholding. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014; pp. 334–342. [Google Scholar]
- Vu, V.; Lei, J. Minimax rates of estimation for sparse PCA in high dimensions. In Proceedings of the 15th International Conference on Artificial Intelligence and Statistics, La Palma, Canary Islands, Spain, 21–23 April 2012; pp. 1278–1286. [Google Scholar]
- Abbe, E.; Bandeira, A.S.; Bracher, A.; Singer, A. Decoding binary node labels from censored edge measurements: Phase transition and efficient recovery. IEEE Trans. Netw. Sci. Eng. 2014, 1, 10–22. [Google Scholar] [CrossRef] [Green Version]
- Bandeira, A.S.; Chen, Y.; Lederman, R.R.; Singer, A. Non-unique games over compact groups and orientation estimation in cryo-EM. Inverse Probl. 2020, 36, 064002. [Google Scholar] [CrossRef] [Green Version]
- Javanmard, A.; Montanari, A.; Ricci-Tersenghi, F. Phase transitions in semidefinite relaxations. Proc. Natl. Acad. Sci. USA 2016, 113, E2218–E2223. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McSherry, F. Spectral partitioning of random graphs. In Proceedings of the 42nd IEEE Symposium on Foundations of Computer Science, Newport Beach, CA, USA, 8–11 October 2001; pp. 529–537. [Google Scholar]
- Deshpande, Y.; Abbe, E.; Montanari, A. Asymptotic mutual information for the binary stochastic block model. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 185–189. [Google Scholar]
- Moore, C. The computer science and physics of community detection: Landscapes, phase transitions, and hardness. arXiv 2017, arXiv:1702.00467. [Google Scholar]
- D’Aspremont, A.; Ghaoui, L.; Jordan, M.; Lanckriet, G. A direct formulation for sparse PCA using semidefinite programming. Adv. Neural Inf. Process. Syst. 2004, 17, 41–48. [Google Scholar] [CrossRef] [Green Version]
- Berthet, Q.; Rigollet, P. Optimal detection of sparse principal components in high dimension. Ann. Stat. 2013, 41, 1780–1815. [Google Scholar] [CrossRef] [Green Version]
- Bandeira, A.S.; Perry, A.; Wein, A.S. Notes on computational-to-statistical gaps: Predictions using statistical physics. arXiv 2018, arXiv:1803.11132. [Google Scholar] [CrossRef] [Green Version]
- Kunisky, D.; Wein, A.S.; Bandeira, A.S. Notes on computational hardness of hypothesis testing: Predictions using the low-degree likelihood ratio. arXiv 2019, arXiv:1907.11636. [Google Scholar]
- Hand, P.; Voroninski, V. Global guarantees for enforcing deep generative priors by empirical risk. IEEE Trans. Inf. Theory 2019, 66, 401–418. [Google Scholar] [CrossRef] [Green Version]
- Heckel, R.; Huang, W.; Hand, P.; Voroninski, V. Rate-optimal denoising with deep neural networks. arXiv 2018, arXiv:1805.08855. [Google Scholar]
- Hand, P.; Leong, O.; Voroninski, V. Phase retrieval under a generative prior. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 9136–9146. [Google Scholar]
- Ma, F.; Ayaz, U.; Karaman, S. Invertibility of convolutional generative networks from partial measurements. Adv. Neural Inf. Process. Syst. 2018, 31, 9628–9637. [Google Scholar]
- Hand, P.; Joshi, B. Global Guarantees for Blind Demodulation with Generative Priors. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 11535–11543. [Google Scholar]
- Song, G.; Fan, Z.; Lafferty, J. Surfing: Iterative optimization over incrementally trained deep networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 15034–15043. [Google Scholar]
- Bora, A.; Jalal, A.; Price, E.; Dimakis, A.G. Compressed sensing using generative models. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 537–546. [Google Scholar]
- Asim, M.; Shamshad, F.; Ahmed, A. Blind Image Deconvolution using Deep Generative Priors. arXiv 2019, arXiv:cs.CV/1802.04073. [Google Scholar] [CrossRef]
- Hand, P.; Leong, O.; Voroninski, V. Compressive Phase Retrieval: Optimal Sample Complexity with Deep Generative Priors. arXiv 2020, arXiv:2008.10579. [Google Scholar]
- Hand, P.; Voroninski, V. Compressed sensing from phaseless gaussian measurements via linear programming in the natural parameter space. arXiv 2016, arXiv:1611.05985. [Google Scholar]
- Li, X.; Voroninski, V. Sparse signal recovery from quadratic measurements via convex programming. SIAM J. Math. Anal. 2013, 45, 3019–3033. [Google Scholar] [CrossRef]
- Ohlsson, H.; Yang, A.Y.; Dong, R.; Sastry, S.S. Compressive phase retrieval from squared output measurements via semidefinite programming. arXiv 2011, arXiv:1111.6323. [Google Scholar] [CrossRef] [Green Version]
- Cai, T.; Li, X.; Ma, Z. Optimal rates of convergence for noisy sparse phase retrieval via thresholded Wirtinger flow. Ann. Stat. 2016, 44, 2221–2251. [Google Scholar] [CrossRef]
- Wang, G.; Zhang, L.; Giannakis, G.B.; Akçakaya, M.; Chen, J. Sparse phase retrieval via truncated amplitude flow. IEEE Trans. Signal Process. 2017, 66, 479–491. [Google Scholar] [CrossRef]
- Yuan, Z.; Wang, H.; Wang, Q. Phase retrieval via sparse wirtinger flow. J. Comput. Appl. Math. 2019, 355, 162–173. [Google Scholar] [CrossRef] [Green Version]
- Aubin, B.; Loureiro, B.; Maillard, A.; Krzakala, F.; Zdeborová, L. The spiked matrix model with generative priors. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8366–8377. [Google Scholar]
- Cocola, J.; Hand, P.; Voroninski, V. Nonasymptotic Guarantees for Spiked Matrix Recovery with Generative Priors. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 11 December 2020; Volume 33. [Google Scholar]
- Johnstone, I.M.; Lu, A.Y. On consistency and sparsity for principal components analysis in high dimensions. J. Am. Stat. Assoc. 2009, 104, 682–693. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wainwright, M.J. High-Dimensional Statistics: A Non-Asymptotic Viewpoint; Cambridge University Press: Cambridge, UK, 2019; Volume 48. [Google Scholar]
- Montanari, A.; Richard, E. Non-negative principal component analysis: Message passing algorithms and sharp asymptotics. IEEE Trans. Inf. Theory 2015, 62, 1458–1484. [Google Scholar] [CrossRef] [Green Version]
- Deshpande, Y.; Montanari, A.; Richard, E. Cone-constrained principal component analysis. Adv. Neural Inf. Process. Syst. 2014, 27, 2717–2725. [Google Scholar]
- Zou, H.; Hastie, T.; Tibshirani, R. Sparse principal component analysis. J. Comput. Graph. Stat. 2006, 15, 265–286. [Google Scholar] [CrossRef] [Green Version]
- Krauthgamer, R.; Nadler, B.; Vilenchik, D.; others. Do semidefinite relaxations solve sparse PCA up to the information limit? Ann. Stat. 2015, 43, 1300–1322. [Google Scholar] [CrossRef]
- Berthet, Q.; Rigollet, P. Computational lower bounds for Sparse PCA. arXiv 2013, arXiv:1304.0828. [Google Scholar]
- Cai, T.; Ma, Z.; Wu, Y. Sparse PCA: Optimal rates and adaptive estimation. Ann. Stat. 2013, 41, 3074–3110. [Google Scholar] [CrossRef]
- Ma, T.; Wigderson, A. Sum-of-squares lower bounds for sparse PCA. Adv. Neural Inf. Process. Syst. 2015, 28, 1612–1620. [Google Scholar]
- Lesieur, T.; Krzakala, F.; Zdeborová, L. Phase transitions in sparse PCA. In Proceedings of the 2015 IEEE International Symposium on Information Theory (ISIT), Hong Kong, China, 14–19 June 2015; pp. 1635–1639. [Google Scholar]
- Brennan, M.; Bresler, G. Optimal average-case reductions to sparse pca: From weak assumptions to strong hardness. arXiv 2019, arXiv:1902.07380. [Google Scholar]
- Arous, G.B.; Wein, A.S.; Zadik, I. Free energy wells and overlap gap property in sparse PCA. In Proceedings of the Conference on Learning Theory, PMLR, Graz, Austria, 9–12 July 2020; pp. 479–482. [Google Scholar]
- Fan, J.; Liu, H.; Wang, Z.; Yang, Z. Curse of heterogeneity: Computational barriers in sparse mixture models and phase retrieval. arXiv 2018, arXiv:1808.06996. [Google Scholar]
- Richard, E.; Montanari, A. A statistical model for tensor PCA. Adv. Neural Inf. Process. Syst. 2014, 27, 2897–2905. [Google Scholar]
- Decelle, A.; Krzakala, F.; Moore, C.; Zdeborová, L. Asymptotic analysis of the stochastic block model for modular networks and its algorithmic applications. Phys. Rev. E 2011, 84, 066106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Perry, A.; Wein, A.S.; Bandeira, A.S.; Moitra, A. Message-Passing Algorithms for Synchronization Problems over Compact Groups. Commun. Pure Appl. Math. 2018, 71, 2275–2322. [Google Scholar] [CrossRef] [Green Version]
- Oymak, S.; Jalali, A.; Fazel, M.; Eldar, Y.C.; Hassibi, B. Simultaneously structured models with application to sparse and low-rank matrices. IEEE Trans. Inf. Theory 2015, 61, 2886–2908. [Google Scholar] [CrossRef] [Green Version]
- Dhar, M.; Grover, A.; Ermon, S. Modeling sparse deviations for compressed sensing using generative models. arXiv 2018, arXiv:1807.01442. [Google Scholar]
- Shah, V.; Hegde, C. Solving linear inverse problems using gan priors: An algorithm with provable guarantees. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4609–4613. [Google Scholar]
- Mixon, D.G.; Villar, S. Sunlayer: Stable denoising with generative networks. arXiv 2018, arXiv:1803.09319. [Google Scholar]
- Yeh, R.A.; Chen, C.; Lim, T.Y.; Schwing, A.G.; Hasegawa-Johnson, M.; Do, M.N. Semantic image inpainting with deep generative models. arXiv 2016, arXiv:1607.07539. [Google Scholar]
- Sønderby, C.K.; Caballero, J.; Theis, L.; Shi, W.; Huszár, F. Amortised map inference for image super-resolution. arXiv 2016, arXiv:1610.04490. [Google Scholar]
- Yang, G.; Yu, S.; Dong, H.; Slabaugh, G.; Dragotti, P.L.; Ye, X.; Liu, F.; Arridge, S.; Keegan, J.; Guo, Y.; et al. DAGAN: Deep de-aliasing generative adversarial networks for fast compressed sensing MRI reconstruction. IEEE Trans. Med. Imaging 2017, 37, 1310–1321. [Google Scholar] [CrossRef] [Green Version]
- Qiu, S.; Wei, X.; Yang, Z. Robust One-Bit Recovery via ReLU Generative Networks: Improved Statistical Rates and Global Landscape Analysis. arXiv 2019, arXiv:1908.05368. [Google Scholar]
- Xue, Y.; Xu, T.; Zhang, H.; Long, L.R.; Huang, X. Segan: Adversarial network with multi-scale l 1 loss for medical image segmentation. Neuroinformatics 2018, 16, 383–392. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Heckel, R.; Hand, P. Deep Decoder: Concise Image Representations from Untrained Non-convolutional Networks. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Heckel, R.; Soltanolkotabi, M. Denoising and regularization via exploiting the structural bias of convolutional generators. arXiv 2019, arXiv:1910.14634. [Google Scholar]
- Heckel, R.; Soltanolkotabi, M. Compressive sensing with un-trained neural networks: Gradient descent finds the smoothest approximation. arXiv 2020, arXiv:2005.03991. [Google Scholar]
- Aubin, B.; Loureiro, B.; Baker, A.; Krzakala, F.; Zdeborová, L. Exact asymptotics for phase retrieval and compressed sensing with random generative priors. In Proceedings of the First Mathematical and Scientific Machine Learning Conference, PMLR, Princeton, NJ, USA, 20–24 July 2020; pp. 55–73. [Google Scholar]
- Clason, C. Nonsmooth Analysis and Optimization. arXiv 2017, arXiv:1708.04180. [Google Scholar]
- Daskalakis, C.; Rohatgi, D.; Zampetakis, M. Constant-Expansion Suffices for Compressed Sensing with Generative Priors. arXiv 2020, arXiv:2006.04237. [Google Scholar]
- Chi, Y.; Lu, Y.M.; Chen, Y. Nonconvex optimization meets low-rank matrix factorization: An overview. IEEE Trans. Signal Process. 2019, 67, 5239–5269. [Google Scholar] [CrossRef] [Green Version]
- Vershynin, R. High-Dimensional Probability: An Introduction with Applications in Data Science; Cambridge University Press: Cambridge, UK, 2018; Volume 47. [Google Scholar]
Figure 1.
Expected value, with respect to the weights, of the objective function f in (4) in the noiseless case (see (16) for explicit formula), for a network with latent dimension and .
Figure 1.
Expected value, with respect to the weights, of the objective function f in (4) in the noiseless case (see (16) for explicit formula), for a network with latent dimension and .

Figure 2.
Reconstruction error for the recovery of a spike in the Wishart and Wigner models with random generative network priors. Each point corresponds to the average over 50 random drawing of the network weights and samples. These plots demonstrate that the reconstruction errors follow the scalings established by Theorem 1.
Figure 2.
Reconstruction error for the recovery of a spike in the Wishart and Wigner models with random generative network priors. Each point corresponds to the average over 50 random drawing of the network weights and samples. These plots demonstrate that the reconstruction errors follow the scalings established by Theorem 1.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Cocola, J.; Hand, P.; Voroninski, V. No Statistical-Computational Gap in Spiked Matrix Models with Generative Network Priors. Entropy 2021, 23, 115. https://doi.org/10.3390/e23010115
AMA Style
Cocola J, Hand P, Voroninski V. No Statistical-Computational Gap in Spiked Matrix Models with Generative Network Priors. Entropy. 2021; 23(1):115. https://doi.org/10.3390/e23010115
Chicago/Turabian StyleCocola, Jorio, Paul Hand, and Vladislav Voroninski. 2021. "No Statistical-Computational Gap in Spiked Matrix Models with Generative Network Priors" Entropy 23, no. 1: 115. https://doi.org/10.3390/e23010115
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.