Improving the Accuracy of the Fast Inverse Square Root by Modifying Newton–Raphson Corrections


1
Wydział Fizyki, Uniwersytet w Białymstoku, ul. Ciołkowskiego 1L, 15-245 Białystok, Poland
2
Department of Security Information and Technology, Lviv Polytechnic National University, st. Kn. Romana 1/3, 79000 Lviv, Ukraine
*
Author to whom correspondence should be addressed.
Entropy 2021, 23(1), 86; https://doi.org/10.3390/e23010086
Submission received: 29 November 2020
/
Revised: 31 December 2020
/
Accepted: 6 January 2021
/
Published: 9 January 2021
(This article belongs to the Special Issue Distributed Signal Processing for Coding and Information Theory)
Abstract
:Direct computation of functions using low-complexity algorithms can be applied both for hardware constraints and in systems where storage capacity is a challenge for processing a large volume of data. We present improved algorithms for fast calculation of the inverse square root function for single-precision and double-precision floating-point numbers. Higher precision is also discussed. Our approach consists in minimizing maximal errors by finding optimal magic constants and modifying the Newton–Raphson coefficients. The obtained algorithms are much more accurate than the original fast inverse square root algorithm and have similar very low computational costs.
1. Introduction
Efficient performance of algebraic operations in the framework of floating-point arithmetic is a subject of considerable importance [1,2,3,4,5,6]. Approximations of elementary functions are crucial in scientific computing, computer graphics, signal processing, and other fields of engineering and science [7,8,9,10]. Our aim is to compute elementary functions at a very low computational cost without using memory resources. Direct evaluation of functions could be of interest in any systems where storage capabilities challenge the processing of a large volume of data. This problem is crucial, for instance, in high-energy physics experiments [11,12,13].
In this paper, we consider approximation and fast computation of the inverse square root function, which has numerous applications (see [8,10,14,15,16,17]), especially in 3D computer graphics, where it is needed for normalization of vectors [4,18,19]. The proposed algorithms are aimed primarily at floating-point platforms with limited hardware resources, such as microcontrollers, some field-programmable gate arrays (FPGAs), and graphics processing units (GPUs) that cannot use fast look-up table (LUT)-based hardware instructions, such as SSE (i.e., Streaming SIMD (single instruction, multiple data) Extensions) or Advanced Vector Extensions (AVX). We mean here devices and chips containing floating-point multipliers, adders–subtractors, and fused-multiply adders. Therefore, our algorithms can easily be implemented on such a platform. We also offer them as an alternative to library functions that provide full precision, but are very time consuming. This was the motivation for considering the cases of higher precision in Section 3.2. By selecting the precision and number of iterations, the desired accuracy can be obtained. We propose the use of our codes as direct insertions into more general algorithms without referring to the corresponding library of mathematical functions. In the double-precision mode, most modern processors do not have SSE instructions like rsqrt (such instructions appeared only in AVX-512, which is supported only by the latest processor models). In such cases, one can use our algorithms (with the appropriate number of iterations) as a fast alternative to the library function 1/sqrt(x).
In most cases, the initial seed needed to start the approximation is taken from a memory-consuming look-up table (LUT), although the so-called “bipartite table methods” (actually used on many current processors) make it possible to considerably lower the table sizes [20,21]. The “fast inverse square root” code works in a different way. It produces the initial seed in a cheap and effective way using the so-called magic constant [4,19,22,23,24,25]. We point out that this algorithm is still useful in numerous software applications and hardware implementations (see, e.g., [17,26,27,28,29,30]). Recently, we presented a new approach to the fast inverse square root code InvSqrt, presenting a rigorous derivation of the well-known code [31]. Then, this approach was used to construct a more accurate modification (called InvSqrt1) of the fast inverse square root (see [32]). It will be developed and generalized in the next sections, where we will show how to increase the accuracy of the InvSqrt code without losing its advantages, including the low computational cost. We will construct and test two new algorithms, InvSqrt2 and InvSqrt3.
The main idea of the algorithm InvSqrt consists in interpreting bits of the input floating-point number as an integer [31]. In this paper, we consider positive floating-point normal numbers
and, in Section 3.1, we also consider subnormal numbers. We use the standard IEEE-754, where single-precision floating-point numbers are encoded with 32 bits. For positive numbers, the first bit is zero. The next eight bits encode , and the remaining 23 bits represent the mantissa . The same 32 bits can be treated as an integer :
where and . In this case is a natural number not exceeding 254. The case of higher precision is analogous (see Section 3.2).
The crucial step of the algorithm InvSqrt consists in shifting all bits to the right by one bit and subtracting the result of this operation from a “magic constant” R (and the optimum value of R has to be guessed or determined). In other words,
Originally, R was proposed as (see [19,23]). Interpreted in terms of floating-point numbers, approximates the inverse square root function surprisingly well (). This trick works because (3) is close to dividing the floating-point exponent by . The number R is needed because the floating-point exponents are biased (see (2)).
The magic constant R is usually given as a hexadecimal integer. The same bits encode the floating-point number with an exponent and mantissa . According to (1), . In [31], we have shown that if (e.g., in the 32-bit case), then the function (3) (defined on integers) is equivalent to the following piece-wise linear function (when interpreted in terms of corresponding floating-point numbers):
where
is the mantissa of R (i.e., ), and, finally, or depending on the parity of the last digit of the mantissa of .
The function is two-valued, so a given parameter t may correspond to either two values of R or one value of R (when the term containing has no influence on the bits of the mantissa ). The function , the function (3), and all Newton–Raphson corrections considered below are invariant under the scaling and for any integer n. Therefore, we can confine ourselves to numbers from the interval . Here and in the following, the tilde always denotes quantities defined on the interval .
In this paper, we focus on the Newton–Raphson corrections, which form the second part of the InvSqrt code. Following and developing ideas presented in our recent papers [31,32], we propose modifications of the Newton–Raphson formulas, which result in algorithms that have the same or similar computational cost as/to InvSqrt, but improve the accuracy of the original code, even by several times. The modifications consist in changing both the Newton–Raphson coefficients and the magic constant. Moreover, we extend our approach to subnormal numbers and to higher-precision cases.
2. Modified Newton–Raphson Formulas
The standard Newton–Raphson corrections and for the zeroth approximation given by (4) are given by the following formulas:
(analogous formulas hold for the next corrections as well; see [31]). The relative error functions (where ) can be expressed as:
The function , which is very important for the further analysis, is thoroughly described and discussed in [31]. Using (7), we substitute (for ) into (6), cancels out, and the formulas (6) assume the following form:
where . We immediately see that every correction increases the accuracy, even by several orders of magnitude (due to the factor ). Thus, a very small number of corrections is sufficient to reach the machine precision (see the end of Section 4).
The above approximations depend on the parameter t (which can be expressed by the magic constant R, see (5)). The best approximation is obtained for minimizing , i.e.,
In this paper we confine ourselves to the case (i.e., we assume ) because the more general case (where the magic constant is also optimized with respect to the assumed number of iterations) is much more cumbersome, and the related increase in accuracy is negligible. Then, we get
for details, see [31]. The theoretical relative errors are given by
The superscript indicates values corresponding to the algorithm InvSqrt (other superscripts will denote modifications of this algorithm).
The idea of increasing the accuracy by a modification of the Newton–Raphson formulas is motivated by the fact that for any (see [31,32]). Therefore, we can try to shift the graph of upwards (making it more symmetric with respect to the horizontal axis). Then, the errors of the first correction are expected to decrease twice and the errors of the second correction are expected to decrease by about eight times (for more details, see [32]). Indeed, according to (8), reducing the first correction by a factor of 2 will reduce the second correction by a factor of 4. The second correction is also non-positive, so we may shift the graph of , once more improving the accuracy by the factor of 2. This procedure can be formalized by postulating the following modification of the Newton–Raphson formulas (6):
where for . Thus, we have four independent parameters (, , , and ) to be determined. In other words,
where four coefficients can be expressed by the four coefficients and :
We point out that the Newton–Raphson corrections and any of their modifications of the form (13) are obviously invariant with respect to the scaling mentioned at the end of Section 1. Therefore, we can continue to confine our analysis to the interval .
Below, we present three different algorithms (InvSqrt1, InvSqrt2, InvSqrt3) constructed along the above principles (the last two of them are first introduced in this paper). They will be denoted by superscripts in parentheses, e.g., means the kth modified Newton–Raphson correction to the algorithm InvSqrt N. We always assume that the zeroth approximation is given by (4), i.e.,
and relative error functions, , are expressed as
We point out that the coefficients of our algorithms are obtained without taking rounding errors into account. This issue will be shortly discussed at the end of Section 4.
2.1. Algorithm InvSqrt1
Assuming and , we transform (12) into
Therefore, and depend on , t, , and . Parameters and are determined by minimization of . Then, the parameter is determined by minimization of (for details, see [32]). As a result, we get:
and (see (10)). Therefore, , i.e., InvSqrt1 has the same magic constant as InvSqrt. The theoretical relative errors are given by
Taking into account numerical values for and , we obtain the following values of the parameters :
This large number of digits, which is much higher than that needed for the single-precision computations, will be useful later in the case of higher precision.
Thus, finally, we obtained a new algorithm InvSqrt1 that has the same structure as InvSqrt, but with different values of numerical coefficients (see [32]). In the case of two iterations, the code has more algebraic operations (one additional multiplication) in comparison to InvSqrt.
2.2. InvSqrt2 Algorithm
Parameters and are determined by the minimization of . Then, the parameter is determined by the minimization of (see Appendix A.1 for details). As a result, we get:
and
The theoretical relative errors are given by
The coefficients in (13) are given by
Taking into account the numerical values for and (see (23)), we obtain the following values of the parameters :
where the large number of digits will be useful later in the case of higher precision. Thus, we completed the derivation of the code :
1. floatInvSqrt2(float x){
2. float halfx = 0.5f*x;
3. int i = *(int*) &x;
4. i = 0x5F376908 - (i1);
5. float y = *(float*) &i;
6. y* = 1.50087896f - halfx*y*y;
7. y* = 1.50000057f - halfx*y*y;
8. return y;
9. }
The code InvSqrt2 contains a new magic constant () and has two lines (6 and 7) that were modified in comparison with the code . We point out that has the same number of algebraic operations as .
2.3. InvSqrt3 Algorithm
Now, we consider the algorithm (13) in its most general form:
where , , , and are constant. In Appendix A.2, we determine parameters , , and by minimization of . Then, the parameters and are determined by minimization of . As a result, we get:
and
The theoretical relative errors are given by
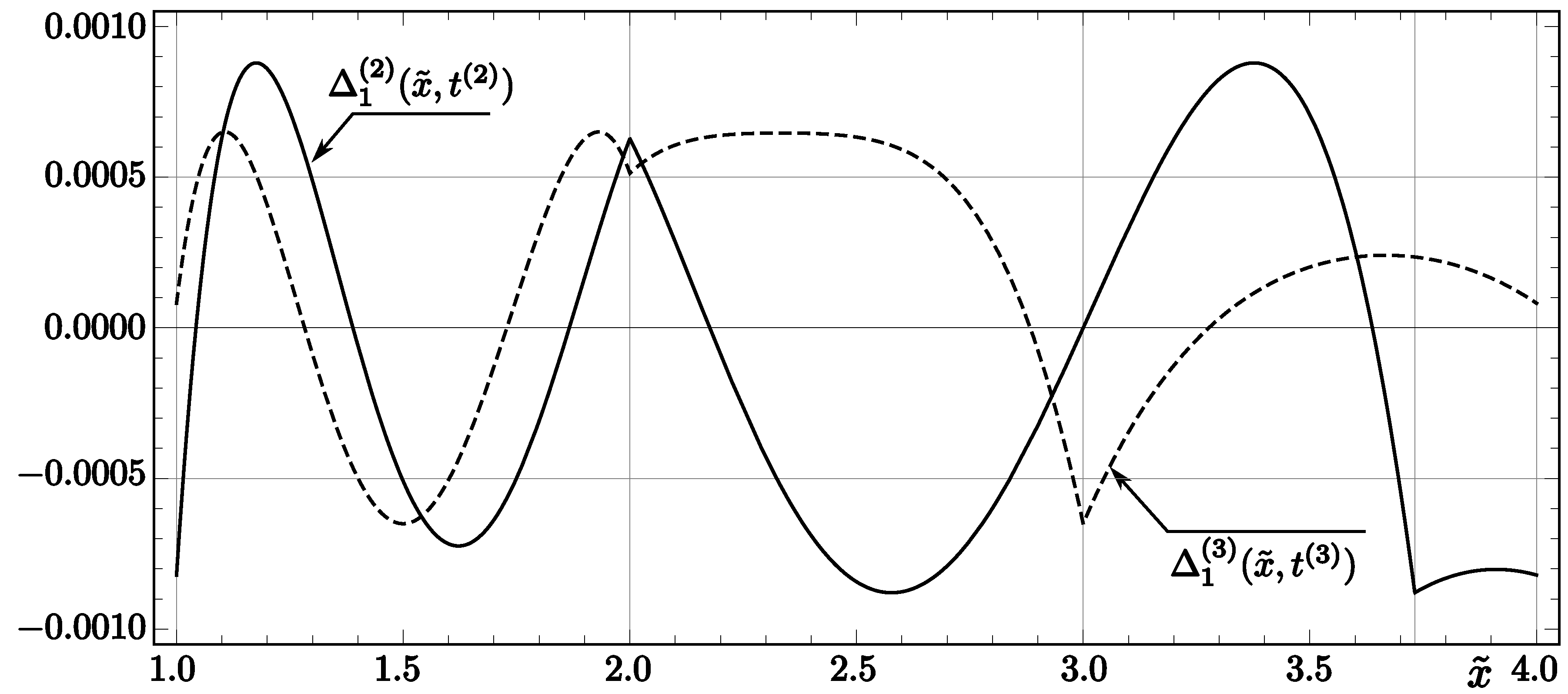
They are significantly smaller (by and , respectively) than the analogous errors for InvSqrt1 and InvSqrt2 (see (19) and (25)). The comparison of error functions for InvSqrt2 and InvSqrt3 (in the case of one correction) is presented in Figure 1.
The numerical values of coefficients (compare with (13)) are given by:
Thus, we obtained the following code, called InvSqrt3:
1. floatInvSqrt3(float x){
2. int i = *(int*) &x;
3. i = 0x5F200000 - (i1);
4. float y = *(float*) &i;
5. y* = 1.68191391f - 0.703952009f*x*y*y;
6. y* = 1.50000036f - 0.500000053f*x*y*y;
7. return y;
8. }
The code InvSqrt3 has the same number of multiplications as InvSqrt1, which means that it is slightly more expensive than InvSqrt and InvSqrt2.
3. Generalizations
The codes presented in Section 2 can only be applied to normal numbers (1) of the type float. In this section, we show how to extend these results to subnormal numbers and to higher-precision formats.
3.1. Subnormal Numbers
Subnormal numbers are smaller than any normal number of the form of (1). In the single-precision case, positive subnormals can be represented as , where . They can also be characterized by nine first bits equal to zero (which also includes the case where ). In order to identify subnormals, we will make a bitwise conjunction (AND) of a given number with the integer , which has all eight exponent bits equal to 1 and all 23 mantissa bits equal to 0. This bitwise conjunction is zero if and only if the given number is subnormal (including 0).
In the case of the single precision, the multiplication by transforms any subnormal number into a normal number. Therefore, we make this transformation; then, we apply one of our algorithms and, finally, make the inverse transformation (i.e., multiplying the result by ). Thus, we get an approximated value of the inverse square root of the subnormal number. Note that is the smallest power of 2 with an even exponent that transforms all subnormals into normal numbers.
In the case of InvSqrt3, the procedure described above can be written in the form of the following code.
1. floatInvSqrt3s(float x){
2. int i = *(int*) &x;
3. int k = i & 0x7f800000;
4. if (k==0) {
5. x = 16777216.f*x; //16777216.f=pow(2.0f, 24)
6. i = *(int*) &x;
7. }
8. i = 0x5F200000 - (i1);
9. float y = *(float*) &i;
10. y* = 1.68191391f - 0.703952009f*x*y*y;
11. y* = 1.50000036f - 0.500000053f*x*y*y;
12. if (k==0) return 4096.f*y; //4096.f=pow(2.0f, 12)
13. return y;
14. }
3.2. Higher Precision
The above analysis was confined to the single-precision floating-point format. This is sufficient for many applications (especially microcontrollers), although the double-precision format is more popular. A trade-off between accuracy, computational cost, and memory usage is welcome [33]. In this subsection, we extend our analysis to double- and higher-precision formats. The calculations are almost the same. We just have to compute all involved constants with an appropriate accuracy. Low-bit arithmetic cases could be treated in exactly the same way. In this paper, however, we are focused on increasing the accuracy and on possible applications in distributed systems, so only the cases of higher precision are explicitly presented.
We present detailed results for double precision and some results (magic constants) for quadruple precision. Performing computations in C, we use the GCC Quad-Precision Math Library (working with numbers of type _float128). The crucial point is to express the magic constant R through the corresponding parameter t, which can be done with the formula:
where , t depends on the considered algorithm and and B depend on the precision format used. Namely,
In the case of the zeroth approximation (without Newton–Raphson corrections), the parameter t is given by:
which can be compared with [31]. The corresponding magic constants computed from the formula (33) read:
In this paper, we focus on the case of Newton–Raphson corrections, where the value of the parameter t may depend on the algorithm. For InvSqrt and InvSqrt1, we have:
(see (Section 2.1); compare with [31,32]). Then, (33) yields the following magic constants:
Actually, the above value of R in the 64-bit case (i.e., ) corresponds to (the same value of R was obtained by Robertson for InvSqrt[24] with a different method). For , we got an R greater by 1 (other results reported in this section do not depend on ). In the 128-bit case, Robertson obtained an R that was 1 less than our value (i.e., ).
The parameters of the modified Newton–Raphson corrections for the higher-precision codes can be computed from the theoretical formulas used in the single-precision cases, taking into account an appropriate number of significant digits. In numerical experiments, we tested the algorithms InvSqrt1D, InvSqrt2D, and InvSqrt3D with the magic constants , , and , respectively, and the following coefficients in the modified Newton–Raphson iterations (compare with (21), (27), and (32), respectively):
The algorithm InvSqrt and its improved versions are usually implemented in the single-precision case with no more than two Newton–Raphson corrections. However, in the case of higher precision, higher accuracy of the result is welcome. Then, a higher number of modified Newton–Raphson iterations could be considered. As an example, we present the algorithm InvSqrt2D with four iterations:
1. doubleInvSqrt2D(double x){
2. double halfx=0.5*x;
3. long long i=*(long long*) &x;
4. i=0x5FE6ED2102DCBFDA - (i1);
5. double y =*(double*) &i;
6. y* = 1.50087895511633457 - halfx*y*y;
7. y* = 1.50000057967625766 - halfx*y*y;
8. y* = 1.5000000000002520 - halfx*y*y;
9. y* = 1.5000000000000000 - halfx*y*y;
10. return y;
11. }
4. Numerical Experiments
The numerical tests for the codes derived and presented in this paper were performed on an Intel Core i5-3470 processor using the TDM-GCC 4.9.2 32-bit compiler (when repeating these tests on the Intel i7-5700 processor, we obtained the same results, and comparisons with some other processors and compilers are given in Appendix B). In this section, we discuss round-off errors for the algorithms InvSqrt2 and InvSqrt3 (the case of single precision and two Newton–Raphson iterations) and then present the final results of analogous analysis for other codes described in this paper.
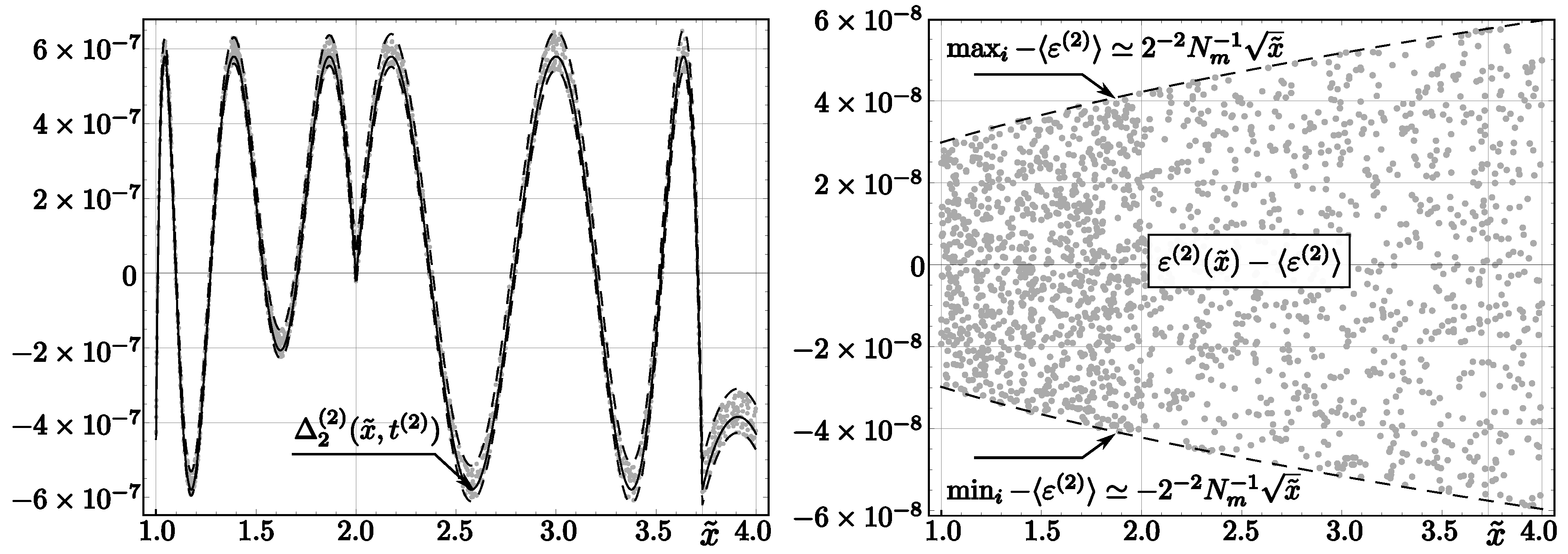
Applying algorithms InvSqrt2 and InvSqrt3, we obtain relative errors that differ slightly, due to round-off errors, from their analytical values (see Figure 2 and Figure 3; compare with [32] for an analogous discussion concerning InvSqrt1). Although we present only randomly chosen values in the figures, calculations were done for all float numbers x such that .
The errors of numerical values returned by
belong (for ) to the interval . For , we get a wider interval: . These errors differ from the errors of , which were determined analytically (compare (25)). We define:
This function, representing the observed blur of the float approximation of the InvSqrt2 output, is symmetric with respect to its mean value
(see the right part of Figure 2), and covers the following range of values:
Analogous results for the code InvSqrt3 read:
The results produced by the same hardware with a 64-bit compiler have a greater amplitude of the error oscillations as compared with the 32-bit case (also compare Appendix B).
The maximum errors for the code InvSqrt and all codes presented in the previous sections are given in Table 2 (for codes with just one Newton–Raphson iteration) and Table 3 (the same codes but with two iterations).
Looking at the last column of Table 2 (this is the case of one iteration), we see that the code InvSqrt1 is slightly more accurate than InvSqrt2, and both are roughly almost two times more accurate than InvSqrt. However, it is the code InvSqrt3 that has the best accuracy. The computational costs of all these codes are practically the same (four multiplications in every case).
In the case of two iterations (Table 3), the code InvSqrt3 is the most accurate as well. Compared with InvSqrt, its accuracy is 12 times higher for single precision and 14.5 times higher for double precision. However, the computational costs of InvSqrt1 and InvSqrt3 (eight multiplications) are higher than the cost of InvSqrt (seven multiplications). Therefore, the code InvSqrt2 has some advantage, as it is less accurate than InvSqrt3 but cheaper. In the single-precision case the code InvSqrt2 is 6.8 times more accurate than InvSqrt.
We point out that the round-off errors in the single-precision case significantly decrease the gain of the accuracy of the new algorithms as compared with the theoretical values, especially in the case of two Newton–Raphson corrections (compare the third and the last column of Table 3).
The range of errors in the case of subnormal numbers (using the codes described in Section 3.1) is shown in Table 1. One can easily see that the relative errors are similar—in fact, even slightly lower—than in the case of normal numbers.
Although the original InvSqrt code used only one Newton–Raphson iteration, and in this paper, we focus mostly on two iterations, it is worthwhile to also briefly consider the case of more iterations. Then, the increased computational cost is accompanied by increased accuracy. We confine ourselves to the code InvSqrt2 (see the end of Section 3.2), which is less expensive than InvSqrt3 (and the advantage of InvSqrt2 increases with the number of iterations). In the double-precision case, the maximum error for three Newton–Raphson corrections is much lower, and the fourth correction yields the best possible accuracy.
In the case of single precision, we already get the best possible accuracy for the third correction, given by adding the line y* = 1.5f - halfx*y*y as Line 8 in the code InvSqrt2 (see Section 2.2).
The derivation of all numerical codes presented in this paper did not take rounding errors into account. Therefore, the best floating-point parameters can be slightly different from the rounding of the best real parameters, all the more so since the distribution of the errors is still not exactly symmetric (compare fourth and fifth columns in Table 2 and Table 3). The full analysis of this problem is much more difficult than the analogous analysis for the original InvSqrt code because we now have several parameters to be optimized instead of a single magic constant. At the same time, the increase in accuracy is negligible. Actually, much greater differences in the accuracy appear in numerical experiments as a result of using different devices (see Appendix B).
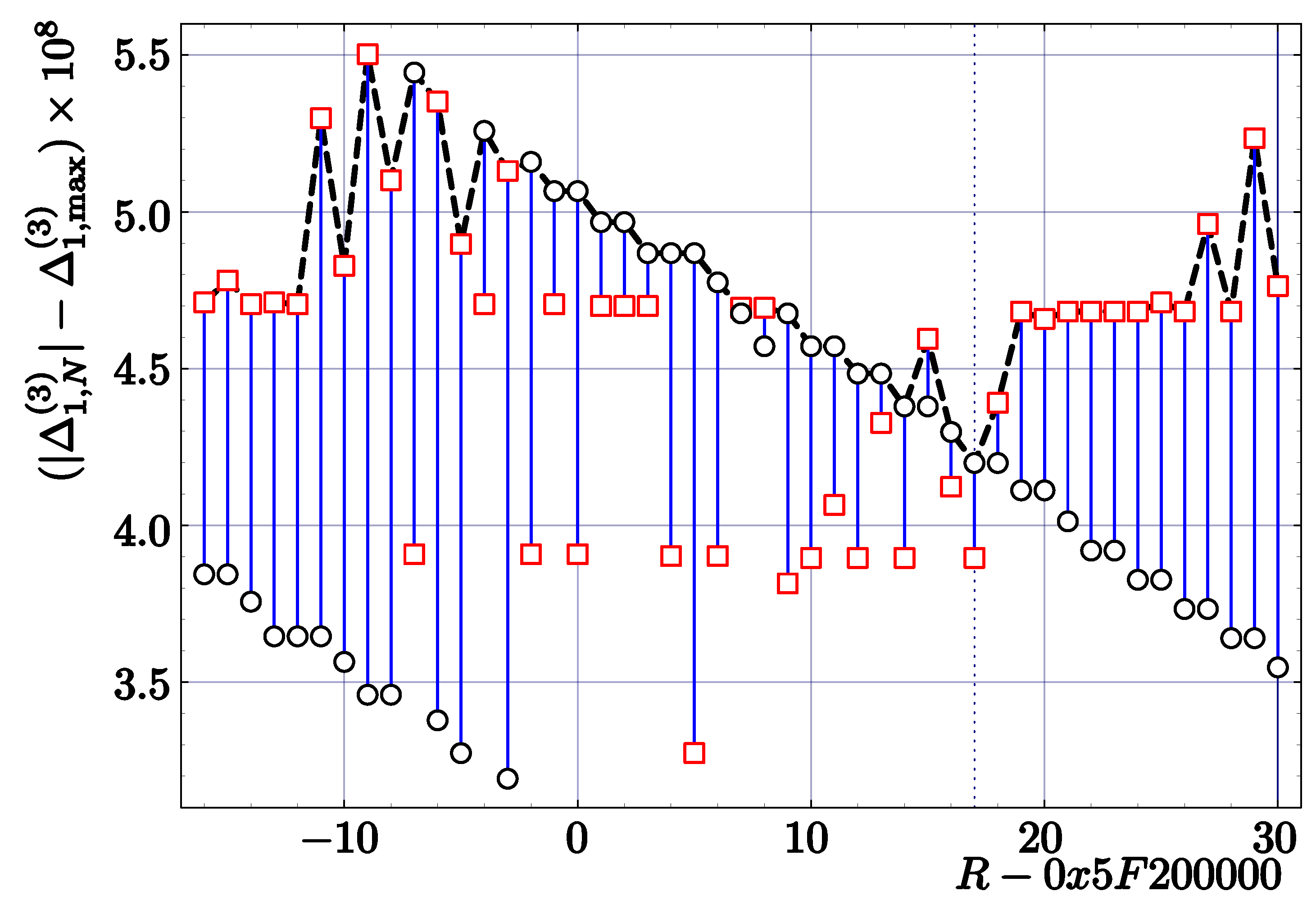
As an example, we present the results of an experimental search in the case of the code InvSqrt3 with one Newton–Raphson correction (three parameters to be optimized). The modified Newton–Raphson coefficients are found to be
Figure 4 summarizes the last step of this analysis. The dependence of maximum errors on R shows clearly that the optimum value for the magic constant is slightly shifted as compared to the theoretical (real) value:
The corresponding errors given by
are nearly symmetric. They are smaller than the maximum error corresponding to our theoretical values, but only by about (see Table 2).
5. Conclusions
We presented two new modifications (InvSqrt2 and ) of the fast inverse square root code in single-, double-, and higher-precision versions. Each code has its own magic constant. All new algorithms are much more accurate than the original code InvSqrt. One of the new algorithms, InvSqrt2, has the same computational cost as InvSqrt in the case of any precision. Another code, InvSqrt3, has the best accuracy, but is more expensive if the number of Newton–Raphson corrections is greater than 1. However, its gain in accuracy is very high, even by more than 12 times for two iterations (see Table 3 in Section 4).
Our approach was to modify the Newton–Raphson method by introducing arbitrary parameters, which are then determined by minimizing the maximum relative error. It is expected that such modifications will provide a significant increase in accuracy, especially in the case of asymmetric error distribution for Newton–Raphson corrections (and this is the case with the inverse square root function when these corrections are non-positive). One has to remember that due to rounding errors, our theoretical results may differ from the best floating-point parameters, but the difference is negligible (see the end of Section 4). In fact, parameters (magic constants and modified Newton–Raphson coefficients) from a certain range near the values obtained in this article seem equally good for all practical purposes.
Concerning potential applications, we have to acknowledge that for general-purpose computing, the SSE and AVX reciprocal square root instructions are faster and more accurate. We hope, however, that the proposed algorithms can be applied in embedded systems and microcontrollers without a hardware floating-point divider, and potentially in FPGAs. Moreover, in contrast to the SSE and AVX instructions, our approach can be easily extended to computational platforms of high precision, like 256-bit or 512-bit platforms.
Author Contributions
Conceptualization, L.V.M.; Formal analysis, C.J.W.; Investigation, C.J.W., L.V.M., and J.L.C.; Methodology, C.J.W. and L.V.M.; Visualization, C.J.W.; Writing—original draft, J.L.C.; Writing—review and editing, J.L.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Data is contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Analytical Derivation of Modified Newton–Raphson Coefficients
Appendix A.1. Algorithm InvSqrt2
We will determine the parameters and in formulas (22) that minimize the maximum error. Substituting (16) (with ) into (22), we get:
where and is the relative error of the zeroth approximation (the function is presented and discussed in [31,32]).
First, we are going to determine the t and that minimize the maximum absolute value of the relative error of the first correction. We have to solve the following equation:
Its solution
corresponds to the value
which is a maximum of because its second derivative with respect to , i.e.,
is negative. In order to determine the dependence of on the parameter t, we solve the equation
which (for some ) equates the maximum value of error with the modulus of the minimum value of error. Thus, we obtain the following relations:
where
The last step consists in equating the minimum boundary value of the error of analyzed correction with its smallest local minimum:
where (see [31]). Solving the Equation (A10) numerically, we obtain the following value of t:
which corresponds to the following magic constant:
In the case of the second correction, we keep the obtained value and determine the parameter , which equates the maximum value of the error with the modulus of its global minimum. is increasing (decreasing) with respect to negative (positive) and has local minima that come only from positive maxima and negative minima. Therefore, the global minimum should correspond to the global minimum or to the global maximum . Substituting these values into Equation (A2) in the place of , we obtain that deeper minima of come from the global minimum of the first correction:
and the maximum, by analogy to the first correction, corresponds to the following value of :
Solving the equation
we get
Appendix A.2. Algorithm InvSqrt3
Parameters , and in the formula (28) will be determined by minimization of the maximum error. The relative error functions for (28) are given by:
where . Substituting (A19) into (28), we obtain:
where and is the relative error of the zeroth approximation (see [31,32]).
We are going to find parameters t and k such that the error functions take extreme values. We begin with .
Therefore, the local extremes of can be located either at the same points as the extremes of or at the satisfying the equation:
where
The extremes corresponding to are global maxima equal to
The two extremes of , located at and (see [31]), can correspond either to minima or to maxima of (depending on parameters t, , and ). If , we have a maximum. The case corresponds to a minimum.
Global extremes of can be either local extremes or boundary values (which, in turn, correspond to global extremes of ). We recall that the global minimum of is at and the global maximum is at or [31]. Therefore, in order to find the parameters and that minimize the maximal value of , we have to solve two equations:
where for and for . Note that and is a minimum of .
Thus, , given by (A24), is a function of one variable t, and we can easily find its minimum value. It is enough to compute
In order to find the parameters and that minimize the maximal relative error of the second correction, we fix . Then, we have to solve the following Equations (obtained in the same way as Equations (A25) and (A26)):
where
corresponds to satisfying:
Solving the system (A32), we get:
One can easily see that the obtained error is only about half () of the error .
Appendix B. Numerical Experiments Using Different Processors and Compilers
The accuracy of our codes depends, to some extent, on the devices used for testing. In Section 4, we limited ourselves to the Intel Core i5 with the 32-bit compiler. In this Appendix, we present, for comparison, data from other devices (Table A1 and Table A2). All data are for the type float (single precision).
The first two columns with data correspond to the Intel Core i5 with the 32-bit compiler (described, in more detail, in Section 4), the next two columns correspond to the same processor, but with the 64-bit compiler. Then, we have results (the same) for three microcontrollers: STM32L432KC and TM4C123GH6PM (ARM Cortex-M4), as well as STM32F767ZIT6 (ARM Cortex-M7). The last two columns contain results for the ESP32-D0WDQ5 system with two Xtensa LX6 microprocessors.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table A1.
The range of numerical errors for the first correction depending on the CPU used.
| Code | Intel Core i5 (32-bit) | Intel Core i5 (64-bit) | ARM Cortex M4-7 | ESP32 | ||||
|---|---|---|---|---|---|---|---|---|
| InvSqrt1 | ||||||||
| InvSqrt2 | ||||||||
| InvSqrt3 | ||||||||
Table A2.
The range of numerical errors for the second correction depending on the processor used.
| Code | Intel Core i5 (32-bit) | Intel Core i5 (64-bit) | ARM Cortex M4-7 | ESP32 | ||||
|---|---|---|---|---|---|---|---|---|
| InvSqrt1 | ||||||||
| InvSqrt2 | ||||||||
| InvSqrt3 | ||||||||
References
- Ercegovac, M.D.; Lang, T. Digital Arithmetic; Morgan Kaufmann: San Francisco, CA, USA, 2003. [Google Scholar]
- Parhami, B. Computer Arithmetic: Algorithms and Hardware Designs, 2nd ed.; Oxford University Press: New York, NY, USA, 2010. [Google Scholar]
- Muller, J.-M.; Brunie, N.; Dinechin, F.; Jeannerod, C.-P.; Joldes, M.; Lefèvre, V.; Melquiond, G.; Revol, N.; Torres, S. Handbook of Floating-Point Arithmetic, 2nd ed.; Birkhäuser: Basel, Switzerland, 2018. [Google Scholar]
- Eberly, D.H. GPGPU Programming for Games and Science; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Beebe, N.H.F. The Mathematical-Function Computation Handbook: Programming Using the MathCW Portable Software Library; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Blanchard, P.; Higham, N.J.; Mary, T. A class of fast and accurate summation algorithms. SIAM J. Sci. Comput. 2020, 42, A1541–A1557. [Google Scholar] [CrossRef]
- Moroz, L.; Samotyy, W. Efficient floating-point division for digital signal processing application. IEEE Signal Process. Mag. 2019, 36, 159–163. [Google Scholar] [CrossRef]
- Liu, W.; Nannarelli, A. Power Efficient Division and Square root Unit. IEEE Trans. Comp. 2012, 61, 1059–1070. [Google Scholar] [CrossRef]
- Viitanen, T.; Jääskeläinen, P.; Esko, O.; Takala, J. Simplified floating-point division and square root. In Proceedings of the IEEE International Conference Acoustics Speech and Signal Process, Vancouver, BC, Canada, 26–31 May 2013; pp. 2707–2711. [Google Scholar]
- Cornea, M. Intel® AVX-512 Instructions and Their Use in the Implementation of Math Functions; Intel Corporation: Santa Clara, CA, USA, 2015. [Google Scholar]
- Ivanchenko, V.N.; Apostolakis, J.; Bagulya, A.; Bogdanov, A.; Grichine, V.; Incerti, S.; Ivantchenko, A.; Maire, M.; Pandola, L.; Pokorski, W.; et al. Geant4 Electromagnetic Physics for LHC Upgrade. J. Phys. Conf. Seriies 2014, 513, 022015. [Google Scholar] [CrossRef]
- Piparo, D.; Innocente, V.; Hauth, T. Speeding up HEP experiment software with a library of fast and auto-vectorisable mathematical functions. J. Phys. Conf. Seriies 2014, 513, 052027. [Google Scholar] [CrossRef] [Green Version]
- Faerber, C. Acceleration of Cherenkov angle reconstruction with the new Intel Xeon/FPGA compute platform for the particle identification in the LHCb Upgrade. J. Phys. Conf. Seriies 2017, 898, 032044. [Google Scholar] [CrossRef] [Green Version]
- Ercegovac, M.D.; Lang, T. Division and Square Root: Digit Recurrence Algorithms and Implementations; Kluwer Academic Publishers: Boston, MA, USA, 1994. [Google Scholar]
- Kwon, T.J.; Draper, J. Floating-point Division and Square root Implementation using a Taylor-Series Expansion Algorithm with Reduced Look-Up Table. In Proceedings of the 51st Midwest Symposium on Circuits and Systems, Knoxville, TN, USA, 10–13 August 2008. [Google Scholar]
- Aguilera-Galicia, C.R. Design and Implementation of Reciprocal Square Root Units on Digital ASIC Technology for Low Power Embedded Applications. Ph.D. Thesis, ITESO, Tlaquepaque, Jalisco, Mexico, 2019. [Google Scholar]
- Lemaitre, F. Tracking Haute Frequence Pour Architectures SIMD: Optimization de la Reconstruction LHCb. Ph.D. Thesis, Paris University IV (Sorbonne), Paris, France, 2019. (CERN-THESIS-2019-014). [Google Scholar]
- Oberman, S.; Favor, G.; Weber, F. AMD 3DNow! technology: Architecture and implementations. IEEE Micro 1999, 19, 37–48. [Google Scholar] [CrossRef]
- id software, quake3-1.32b/code/game/q_math.c, Quake III Arena. 1999. Available online: https://github.com/id-Software/Quake-III-Arena/blob/master/code/game/q_math.c (accessed on 8 January 2021).
- Sarma, D.D.; Matula, D.W. Faithful bipartite ROM reciprocal tables. In Proceedings of the 12th IEEE Symposium on Computer Arithmetic, Bath, UK, 19–21 July 1995; pp. 17–29. [Google Scholar]
- Stine, J.E.; Schulte, M.J. The symmetric table addition method for accurate function approximation. J. VLSI Signal Process. 1999, 11, 1–12. [Google Scholar]
- Blinn, J. Floating-point tricks. IEEE Comput. Graph. Appl. 1997, 17, 80–84. [Google Scholar] [CrossRef]
- Lomont, C. Fast Inverse Square Root, Purdue University, Technical Report. 2003. Available online: http://www.lomont.org/papers/2003/InvSqrt.pdf (accessed on 8 January 2021).
- Robertson, M. A Brief History of InvSqrt. Bachelor’s Thesis, University of New Brunswick, Fredericton, NB, Canada, 2012. [Google Scholar]
- Warren, H.S. Hacker’s Delight, 2nd ed.; Pearson Education: Upper Saddle River, NJ, USA, 2013. [Google Scholar]
- Hänninen, T.; Janhunen, J.; Juntti, M. Novel detector implementations for 3G LTE downlink and uplink. Analog. Integr. Circ. Sig. Process. 2014, 78, 645–655. [Google Scholar] [CrossRef]
- Hsu, C.J.; Chen, J.L.; Chen, L.G. An Efficient Hardware Implementation of HON4D Feature Extraction for Real-time Action Recognition. In Proceedings of the 2015 IEEE International Symposium on Consumer Electronics (ISCE), Madrid, Spain, 17 June 2015. [Google Scholar]
- Hsieh, C.H.; Chiu, Y.F.; Shen, Y.H.; Chu, T.S.; Huang, Y.H. A UWB Radar Signal Processing Platform for Real-Time Human Respiratory Feature Extraction Based on Four-Segment Linear Waveform Model. IEEE Trans. Biomed. Circ. Syst. 2016, 10, 219–230. [Google Scholar] [CrossRef] [PubMed]
- Sangeetha, D.; Deepa, P. Efficient Scale Invariant Human Detection using Histogram of Oriented Gradients for IoT Services. In 2017 30th International Conference on VLSI Design and 2017 16th International Conference on Embedded Systems; IEEE: Piscataway, NJ, USA, 2016; pp. 61–66. [Google Scholar]
- Hasnat, A.; Bhattacharyya, T.; Dey, A.; Halder, S.; Bhattacharjee, D. A fast FPGA based architecture for computation of square root and Inverse Square Root. In Proceedings of the 2nd International Conference on Devices for Integrated Circuit, DevIC 2017, Kalyani, Nadia, India, 23–24 March 2017; pp. 383–387. [Google Scholar]
- Moroz, L.; Walczyk, C.J.; Hrynchyshyn, A.; Holimath, V.; Cieśliński, J.L. Fast calculation of inverse square root with the use of magic constant – analytical approach. Appl. Math. Comput. 2018, 316, 245–255. [Google Scholar] [CrossRef] [Green Version]
- Walczyk, C.J.; Moroz, L.V.; Cieśliński, J.L. A Modification of the Fast Inverse Square Root Algorithm. Computation 2019, 7, 41. [Google Scholar] [CrossRef] [Green Version]
- Graillat, S.; Jézéquel, F.; Picot, R.; Févotte, F.; Lathuilière, B. Auto-tuning for floating-point precision with Discrete Stochastic Arithmetic. J. Comput. Sci. 2019, 36, 101017. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Theoretical relative errors of the first correction for the codes InvSqrt2 and InvSqrt3. The solid line represents the function , while the dashed line represents .
Figure 1.
Theoretical relative errors of the first correction for the codes InvSqrt2 and InvSqrt3. The solid line represents the function , while the dashed line represents .

Figure 2.
Theoretical and rounding errors of the code InvSqrt2 (with two Newton–Raphson corrections). Left: The solid line represents , dashed lines correspond to , and dots represent errors for 4000 floating-point numbers x randomly chosen from the interval . Right: relative error (see (47)). Dashed lines correspond to the minimum and maximum values of these errors, and dots denote errors for 2000 values randomly chosen from the interval .
Figure 2.
Theoretical and rounding errors of the code InvSqrt2 (with two Newton–Raphson corrections). Left: The solid line represents , dashed lines correspond to , and dots represent errors for 4000 floating-point numbers x randomly chosen from the interval . Right: relative error (see (47)). Dashed lines correspond to the minimum and maximum values of these errors, and dots denote errors for 2000 values randomly chosen from the interval .

Figure 3.
Theoretical and rounding errors of the code InvSqrt3 (with two Newton–Raphson corrections). Left: The solid line represents , dashed lines correspond to , and dots represent errors for 4000 floating-point numbers x randomly chosen from the interval . Right: relative error . Dashed lines correspond to minimum and maximum values of these errors, and dots denote errors for 2000 values randomly chosen from the interval .
Figure 3.
Theoretical and rounding errors of the code InvSqrt3 (with two Newton–Raphson corrections). Left: The solid line represents , dashed lines correspond to , and dots represent errors for 4000 floating-point numbers x randomly chosen from the interval . Right: relative error . Dashed lines correspond to minimum and maximum values of these errors, and dots denote errors for 2000 values randomly chosen from the interval .

Figure 4.
Maximum relative errors for the first Newton–Raphson correction in the code InvSqrt3 as a function of R in the case of and . Circles denote maximum errors (), while squares denote minimum errors (). The maximum error (shown by the dashed line) was determined by minimizing the maximum error for all floating-point numbers from .
Figure 4.
Maximum relative errors for the first Newton–Raphson correction in the code InvSqrt3 as a function of R in the case of and . Circles denote maximum errors (), while squares denote minimum errors (). The maximum error (shown by the dashed line) was determined by minimizing the maximum error for all floating-point numbers from .

Table 1.
Relative numerical errors for the first and second corrections in the case of the type float (compiler 32-bit) for subnormal numbers.
Table 1.
Relative numerical errors for the first and second corrections in the case of the type float (compiler 32-bit) for subnormal numbers.
| Algorithm | ||||
|---|---|---|---|---|
| InvSqrt1 | ||||
| InvSqrt2 | ||||
| InvSqrt3 |
Table 2.
Relative numerical errors for the first correction in the case of type float (compiler 32-bit). In the case of type double, the errors are equal to theoretical errors up to the accuracy given in the table.
Table 2.
Relative numerical errors for the first correction in the case of type float (compiler 32-bit). In the case of type double, the errors are equal to theoretical errors up to the accuracy given in the table.
| Algorithm | i | ||||
|---|---|---|---|---|---|
| InvSqrt | 0 | ||||
| InvSqrt1 | 1 | ||||
| InvSqrt2 | 2 | ||||
| InvSqrt3 | 3 |
Table 3.
Relative numerical errors for the second correction in the case of type float (compiler 32-bit). In the case of type double, the errors are equal to theoretical errors up to the accuracy given in the table.
Table 3.
Relative numerical errors for the second correction in the case of type float (compiler 32-bit). In the case of type double, the errors are equal to theoretical errors up to the accuracy given in the table.
| Algorithm | i | ||||
|---|---|---|---|---|---|
| InvSqrt | 0 | ||||
| InvSqrt1 | 1 | ||||
| InvSqrt2 | 2 | ||||
| InvSqrt3 | 3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Walczyk, C.J.; Moroz, L.V.; Cieśliński, J.L. Improving the Accuracy of the Fast Inverse Square Root by Modifying Newton–Raphson Corrections. Entropy 2021, 23, 86. https://doi.org/10.3390/e23010086
AMA Style
Walczyk CJ, Moroz LV, Cieśliński JL. Improving the Accuracy of the Fast Inverse Square Root by Modifying Newton–Raphson Corrections. Entropy. 2021; 23(1):86. https://doi.org/10.3390/e23010086
Chicago/Turabian StyleWalczyk, Cezary J., Leonid V. Moroz, and Jan L. Cieśliński. 2021. "Improving the Accuracy of the Fast Inverse Square Root by Modifying Newton–Raphson Corrections" Entropy 23, no. 1: 86. https://doi.org/10.3390/e23010086
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.